huggingface / blog Goto Github PK
View Code? Open in Web Editor NEWPublic repo for HF blog posts
Home Page: https://hf.co/blog
Public repo for HF blog posts
Home Page: https://hf.co/blog









































































































































































































Hi @julien-c ,
BERT is a mask language model which will mask the tokens at about 15% while training to train model how to predict the masked tokens, right?
But in the tutorial 'How to train a new language model from scratch using Transformers and Tokenizers', I don't see anywhere to put the token for training, or at least specify the rate of tokens if the model already do that inside
https://github.com/huggingface/blog/blob/master/how-to-train.md
Can you help me to point this out?
Thank you very much!
@patrickvonplaten
I have been trying to achieve a bleu score of 31.7 (as reported in the blog and paper for WMT en->de evaluation) using hugging-face model google/bert2bert_L-24_wmt_en_de but I could only achieve 23.77 on newstest2014 test set . I have kept the beam search config as mentioned in the paper that is num_beams = 4 and length penalty = 0.6 , fixed the max length = 128 as was done during training in paper. I have also used the bleu script mentioned in the footnotes .
Can you please tell what could be missing in this whole process and how can I achieve the similar scores?
Thanks for great blog posts!
I was reading this post and faced some errors while integrating ray and huggingface transformers.
It seems n_jobs, n_samples in hyperparameter_search function doesn't exist anymore.
Even removing these two arguments, I still get TypeError: can't pickle _thread.RLock objects.
Can you help me on that? Thanks
Traceback (most recent call last):
File "mask_ins.py", line 237, in <module>
backend="ray",)
File "/home/yeoun/.local/lib/python3.6/site-packages/transformers/trainer.py", line 1459, in hyperparameter_search
best_run = run_hp_search(self, n_trials, direction, **kwargs)
File "/home/yeoun/.local/lib/python3.6/site-packages/transformers/integrations.py", line 235, in run_hp_search_ray
**kwargs,
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/tune/tune.py", line 297, in run
_ray_auto_init()
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/tune/tune.py", line 664, in _ray_auto_init
ray.init()
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/_private/client_mode_hook.py", line 47, in wrapper
return func(*args, **kwargs)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/worker.py", line 771, in init
hook()
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/tune/registry.py", line 171, in flush
self.references[k] = ray.put(v)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/_private/client_mode_hook.py", line 47, in wrapper
return func(*args, **kwargs)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/worker.py", line 1514, in put
object_ref = worker.put_object(value)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/worker.py", line 261, in put_object
serialized_value = self.get_serialization_context().serialize(value)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/serialization.py", line 324, in serialize
return self._serialize_to_msgpack(value)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/serialization.py", line 304, in _serialize_to_msgpack
self._serialize_to_pickle5(metadata, python_objects)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/serialization.py", line 264, in _serialize_to_pickle5
raise e
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/serialization.py", line 261, in _serialize_to_pickle5
value, protocol=5, buffer_callback=writer.buffer_callback)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/cloudpickle/cloudpickle_fast.py", line 73, in dumps
cp.dump(obj)
File "/home/yeoun/.local/lib/python3.6/site-packages/ray/cloudpickle/cloudpickle_fast.py", line 580, in dump
return Pickler.dump(self, obj)
TypeError: can't pickle _thread.RLock objects
inputs = tokenizer("Mi estas Julien.", return_tensors="pt")
outputs = model(**inputs)
outputs.logits.shape
=> torch.Size([1,12,52000])
I am quite a beginner in this area, please correct me if I misunderstood.
For your reference, I tries to pull out the embedding vector of each token to do cosine similarity.
Thanks.
https://huggingface.co/blog/how-to-generate#beam-search
Original paragraph:
At time step 1, besides the most likely hypothesis \text{"The", "woman"}"The", "woman", beam search also keeps track of the second most likely one \text{"The", "dog"}"The", "dog".
"The" "woman" should be changed to "The" "nice".
As at time step 1, the possible words after "The" are "dog", "nice" and "car".
This is a very helpful tutorial! Unfortunately there are a couple things missing that would help the clarity a lot.
Thanks again!
Hi, @patrickvonplaten, in the Leveraging Pre-trained Language Model Checkpoints for Encoder-Decoder Models blog post. https://huggingface.co/blog/warm-starting-encoder-decoder
Some of the links to the additional notebooks seem to redirect me to the same master blog post. Is this expected?
for BERT2BERT on CNN/Dailymail (a condensed version of this notebook), click here.
for RoBERTaShare on BBC XSum, click here.
for BERT2Rnd on WMT14 En to→ De, click here.
for RoBERTa2GPT2 on DiscoFuse, click here.
Please add a note for "Fit More and Train Faster With ZeRO via DeepSpeed and FairScale" that deepspeed or parallel training is not easy/possible on Windows (10 for me) as nccl is not supported (directly) on windows yet..
After all steps likely you will get this error:
RuntimeError: Distributed package doesn't have NCCL built in
You can install it somehow via https://github.com/MyCaffe/NCCL but I did not try it as I doubt it will work.
Also torch indicates nccl is not supported on Windows too.
https://pytorch.org/docs/stable/distributed.html
As of PyTorch v1.8, Windows supports all collective communications backend but NCCL
Thanks I am switching to Ubuntu to fit 10GB model to a 8GB GPU RAM..
P.S. I was not able to make it working Colab Free version either as it is limited on RAM, did not try smaller model though.
Hi,
Since you are the blog entry author I reference you @patrickvonplaten in this issue.
With great interest I read the blog entry on the Reformer model (https://huggingface.co/blog/reformer). In Section 3 you describe the reversible residual layer mechanism to drastically save memory and allow the training of very deep architectures. The explanation and visuals have helped me a lot to better grasp the concept. However, I think there is a mistake in the formulas depicting how to reconstruct X^1 and X^2.
You write:
X^1 = F(Y^1) - Y^1
and
X^2 = Y^1 - G(X^1)
Imho the correct formulas should be:
X^1 = Y^1 - F(Y^2)
and
X^2 = Y^2 - G(X^1)
Best regards
Lars
Hi,
When I try to run this notebook on my laptop, I got several errors like this: ImportError: cannot import name 'LineByLineTextDataset' from 'transformers', but same code running fine on the collab. Is that because the "LineByLineTextDataset" is deprecated?
The issue concerns the blog post "Deep Learning over the Internet: Training Language Models Collaboratively" https://hf.co/blog/collaborative-training.
There are two videos - youtube embeddings - in this blog post that integrate well with the blog post when we read it on a computer but display poorly when on mobile.
On computer, the video is well aligned with the text:

On mobile, the video is out of frame:
@patrickvonplaten ,please, take a look at the code:
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoded_output_vectors, None, None, None, return_dict=True).last_hidden_state
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids, encoded_output_vectors, None, None, None, return_dict=True).last_hidden_state
You pass decoder_input_ids in both cases, it's exactly the same computation. If I pass decoder_input_ids_perturbed in the second case, then torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3) is not True anymore.
And do they really have to be the same? Decoder also uses cross-attention on top of unidirectional attention. And in cross-attention ich will have access to encoded and processed es or das and it may cause difference in the last hidden state of ich. Is this right?
Both lm_logits and lm_logits_perturbed predict correctly next word as Auto.
I'm really interested in your opinion.
The article itself is really great, thank you.
Hi,
I was reading this post and faced some errors while trying to train the model using amazon sagemaker. Using the following code in the blog:
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='run_summarization.py', # script
source_dir='./examples/seq2seq', # relative path to example
git_config=git_config,
instance_type='ml.p3.16xlarge', # in the blog instance_type is ml.p3dn.24xlarge
instance_count=2,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
role=role,
hyperparameters = hyperparameters,
distribution = distribution
)
# starting the training job
huggingface_estimator.fit()
Eveything is the same, except the instance_type I used is 'ml.p3.16xlarge', not 'ml.p3dn.24xlarge'. Because my aws account does not have permission to use this instance.
The code was run on an aws sagemaker notebook instance.
Below is the log output detail:
[1,0]<stderr>:Using amp fp16 backend
[1,0]<stderr>:***** Running training *****
[1,0]<stderr>: Num examples = 14732
[1,0]<stderr>: Num Epochs = 3
[1,0]<stderr>: Instantaneous batch size per device = 4
[1,0]<stderr>: Total train batch size (w. parallel, distributed & accumulation) = 64
[1,0]<stderr>: Gradient Accumulation steps = 1
[1,0]<stderr>: Total optimization steps = 693
[1,0]<stderr>:#015 0%| | 0/693 [00:00<?, ?it/s][1,8]<stderr>:***** Running training *****
[1,8]<stderr>: Num examples = 14732
[1,8]<stderr>: Num Epochs = 3
[1,8]<stderr>: Instantaneous batch size per device = 4
[1,8]<stderr>: Total train batch size (w. parallel, distributed & accumulation) = 64
[1,8]<stderr>: Gradient Accumulation steps = 1
[1,8]<stderr>: Total optimization steps = 693
[1,8]<stderr>:#015 0%| | 0/693 [00:00<?, ?it/s][1,9]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,9]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,10]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,10]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,8]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,8]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,12]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,12]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,13]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,13]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,14]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,14]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,11]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,11]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,8]<stderr>:#015 0%| | 1/693 [00:04<56:06, 4.87s/it][1,15]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,15]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,2]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,2]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,0]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,0]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,1]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,1]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,4]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,4]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,6]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,6]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,5]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,5]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,0]<stderr>:#015 0%| | 1/693 [00:04<56:43, 4.92s/it][1,3]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,3]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,7]<stderr>:/opt/conda/lib/python3.6/site-packages/torch/optim/lr_scheduler.py:123: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[1,7]<stderr>: "https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
[1,8]<stderr>:#015 0%| | 2/693 [00:06<45:28, 3.95s/it][1,0]<stderr>:#015 0%| | 2/693 [00:06<45:50, 3.98s/it][1,8]<stderr>:#015 0%| | 3/693 [00:07<34:56, 3.04s/it][1,0]<stderr>:#015 0%| | 3/693 [00:07<35:17, 3.07s/it][1,0]<stderr>:#015 1%| | 4/693 [00:08<28:02, 2.44s/it][1,8]<stderr>:#015 1%| | 4/693 [00:08<27:55, 2.43s/it][1,8]<stderr>:#015 1%| | 5/693 [00:09<22:20, 1.95s/it][1,0]<stderr>:#015 1%| | 5/693 [00:09<22:26, 1.96s/it][1,0]<stderr>:#015 1%| | 6/693 [00:10<18:21, 1.60s/it][1,8]<stderr>:#015 1%| | 6/693 [00:10<18:20, 1.60s/it][1,8]<stderr>:#015 1%| | 7/693 [00:11<15:38, 1.37s/it][1,0]<stderr>:#015 1%| | 7/693 [00:11<15:43, 1.38s/it][1,8]<stderr>:#015 1%| | 8/693 [00:11<13:48, 1.21s/it][1,0]<stderr>:#015 1%| | 8/693 [00:11<13:50, 1.21s/it][1,8]<stderr>:#015 1%|� | 9/693 [00:12<12:32, 1.10s/it][1,0]<stderr>:#015 1%|� | 9/693 [00:12<12:35, 1.10s/it]--------------------------------------------------------------------------
MPI_ABORT was invoked on rank 0 in communicator MPI COMMUNICATOR 5 DUP FROM 0
with errorcode 1.
NOTE: invoking MPI_ABORT causes Open MPI to kill all MPI processes.
You may or may not see output from other processes, depending on
exactly when Open MPI kills them.
--------------------------------------------------------------------------
--------------------------------------------------------------------------
An MPI communication peer process has unexpectedly disconnected. This
usually indicates a failure in the peer process (e.g., a crash or
otherwise exiting without calling MPI_FINALIZE first).
Although this local MPI process will likely now behave unpredictably
(it may even hang or crash), the root cause of this problem is the
failure of the peer -- that is what you need to investigate. For
example, there may be a core file that you can examine. More
generally: such peer hangups are frequently caused by application bugs
or other external events.
Local host: algo-2
Local PID: 62
Peer host: algo-1
--------------------------------------------------------------------------
2021-05-28 09:03:30 Uploading - Uploading generated training model
2021-05-28 09:03:30 Failed - Training job failed
---------------------------------------------------------------------------
UnexpectedStatusException Traceback (most recent call last)
<ipython-input-46-8f7fac035eb7> in <module>
1 # starting the training job
----> 2 huggingface_estimator.fit()
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/sagemaker/estimator.py in fit(self, inputs, wait, logs, job_name, experiment_config)
680 self.jobs.append(self.latest_training_job)
681 if wait:
--> 682 self.latest_training_job.wait(logs=logs)
683
684 def _compilation_job_name(self):
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/sagemaker/estimator.py in wait(self, logs)
1623 # If logs are requested, call logs_for_jobs.
1624 if logs != "None":
-> 1625 self.sagemaker_session.logs_for_job(self.job_name, wait=True, log_type=logs)
1626 else:
1627 self.sagemaker_session.wait_for_job(self.job_name)
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/sagemaker/session.py in logs_for_job(self, job_name, wait, poll, log_type)
3679
3680 if wait:
-> 3681 self._check_job_status(job_name, description, "TrainingJobStatus")
3682 if dot:
3683 print()
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/sagemaker/session.py in _check_job_status(self, job, desc, status_key_name)
3243 ),
3244 allowed_statuses=["Completed", "Stopped"],
-> 3245 actual_status=status,
3246 )
3247
UnexpectedStatusException: Error for Training job huggingface-pytorch-training-2021-05-28-08-55-04-013: Failed. Reason: AlgorithmError: ExecuteUserScriptError:
Command "mpirun --host algo-1:8,algo-2:8 -np 16 --allow-run-as-root --tag-output --oversubscribe -mca btl_tcp_if_include eth0 -mca oob_tcp_if_include eth0 -mca plm_rsh_no_tree_spawn 1 -mca pml ob1 -mca btl ^openib -mca orte_abort_on_non_zero_status 1 -mca btl_vader_single_copy_mechanism none -mca plm_rsh_num_concurrent 2 -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH -x SMDATAPARALLEL_USE_HOMOGENEOUS=1 -x FI_PROVIDER=sockets -x RDMAV_FORK_SAFE=1 -x LD_PRELOAD=/opt/conda/lib/python3.6/site-packages/gethostname.cpython-36m-x86_64-linux-gnu.so -x SMDATAPARALLEL_SERVER_ADDR=algo-1 -x SMDATAPARALLEL_SERVER_PORT=7592 -x SAGEMAKER_INSTANCE_TYPE=ml.p3.16xlarge smddprun /opt/conda/bin/python3.6 -m mpi4py run_summarization.py --dataset_name samsum --do_predict True --do_train True --fp16 True --learning_rate 5e-05 --model_name_or_path facebook/bart-large-cnn --num_train_epochs 3 --output_dir /opt/ml/model --per_device_eval_batch_size 4 --per_device_train_batch_size 4 --pre
Can someone help me on this? Thanks.
The code for the hyperparameter search shared on https://github.com/huggingface/blog/blob/master/ray-tune.md does not work anymore.
I tried the code on Colab Notebook.
Error with Ray backend:
<Crop some error code that is identical to the part below>
== Status ==
Memory usage on this node: 2.7/12.7 GiB
Using FIFO scheduling algorithm.
Resources requested: 1.0/2 CPUs, 0/0 GPUs, 0.0/7.36 GiB heap, 0.0/3.68 GiB objects
Result logdir: /root/ray_results/_objective_2021-10-05_11-51-07
Number of trials: 10/10 (9 ERROR, 1 RUNNING)
+------------------------+----------+-------+-----------------+--------------------+-------------------------------+----------+
| Trial name | status | loc | learning_rate | num_train_epochs | per_device_train_batch_size | seed |
|------------------------+----------+-------+-----------------+--------------------+-------------------------------+----------|
| _objective_86e23_00009 | RUNNING | | 7.96157e-06 | 2 | 32 | 38.0065 |
| _objective_86e23_00000 | ERROR | | 5.61152e-06 | 5 | 64 | 8.15396 |
| _objective_86e23_00001 | ERROR | | 1.56207e-05 | 2 | 16 | 7.08379 |
| _objective_86e23_00002 | ERROR | | 8.28892e-06 | 5 | 16 | 24.4435 |
| _objective_86e23_00003 | ERROR | | 1.09943e-06 | 2 | 8 | 29.158 |
| _objective_86e23_00004 | ERROR | | 2.3102e-06 | 5 | 8 | 25.0818 |
| _objective_86e23_00005 | ERROR | | 1.12076e-05 | 4 | 16 | 1.89943 |
| _objective_86e23_00006 | ERROR | | 1.67381e-05 | 2 | 32 | 2.81996 |
| _objective_86e23_00007 | ERROR | | 5.4041e-06 | 3 | 32 | 15.916 |
| _objective_86e23_00008 | ERROR | | 1.53049e-05 | 3 | 64 | 34.5377 |
+------------------------+----------+-------+-----------------+--------------------+-------------------------------+----------+
Number of errored trials: 9
+------------------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Trial name | # failures | error file |
|------------------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| _objective_86e23_00000 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00000_0_learning_rate=5.6115e-06,num_train_epochs=5,per_device_train_batch_size=64,seed=8.154_2021-10-05_11-51-07/error.txt |
| _objective_86e23_00001 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00001_1_learning_rate=1.5621e-05,num_train_epochs=2,per_device_train_batch_size=16,seed=7.0838_2021-10-05_11-51-08/error.txt |
| _objective_86e23_00002 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00002_2_learning_rate=8.2889e-06,num_train_epochs=5,per_device_train_batch_size=16,seed=24.443_2021-10-05_11-51-09/error.txt |
| _objective_86e23_00003 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00003_3_learning_rate=1.0994e-06,num_train_epochs=2,per_device_train_batch_size=8,seed=29.158_2021-10-05_11-51-17/error.txt |
| _objective_86e23_00004 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00004_4_learning_rate=2.3102e-06,num_train_epochs=5,per_device_train_batch_size=8,seed=25.082_2021-10-05_11-51-17/error.txt |
| _objective_86e23_00005 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00005_5_learning_rate=1.1208e-05,num_train_epochs=4,per_device_train_batch_size=16,seed=1.8994_2021-10-05_11-51-25/error.txt |
| _objective_86e23_00006 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00006_6_learning_rate=1.6738e-05,num_train_epochs=2,per_device_train_batch_size=32,seed=2.82_2021-10-05_11-51-26/error.txt |
| _objective_86e23_00007 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00007_7_learning_rate=5.4041e-06,num_train_epochs=3,per_device_train_batch_size=32,seed=15.916_2021-10-05_11-51-34/error.txt |
| _objective_86e23_00008 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00008_8_learning_rate=1.5305e-05,num_train_epochs=3,per_device_train_batch_size=64,seed=34.538_2021-10-05_11-51-35/error.txt |
+------------------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2021-10-05 11:51:52,275 ERROR trial_runner.py:773 -- Trial _objective_86e23_00009: Error processing event.
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/ray/tune/trial_runner.py", line 739, in _process_trial
results = self.trial_executor.fetch_result(trial)
File "/usr/local/lib/python3.7/dist-packages/ray/tune/ray_trial_executor.py", line 746, in fetch_result
result = ray.get(trial_future[0], timeout=DEFAULT_GET_TIMEOUT)
File "/usr/local/lib/python3.7/dist-packages/ray/_private/client_mode_hook.py", line 82, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/ray/worker.py", line 1621, in get
raise value.as_instanceof_cause()
ray.exceptions.RayTaskError(TuneError): ray::ImplicitFunc.train_buffered() (pid=823, ip=172.28.0.2, repr=<ray.tune.function_runner.ImplicitFunc object at 0x7f6b715d4990>)
File "/usr/local/lib/python3.7/dist-packages/ray/tune/trainable.py", line 178, in train_buffered
result = self.train()
File "/usr/local/lib/python3.7/dist-packages/ray/tune/trainable.py", line 237, in train
result = self.step()
File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 379, in step
self._report_thread_runner_error(block=True)
File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 527, in _report_thread_runner_error
("Trial raised an exception. Traceback:\n{}".format(err_tb_str)
ray.tune.error.TuneError: Trial raised an exception. Traceback:
ray::ImplicitFunc.train_buffered() (pid=823, ip=172.28.0.2, repr=<ray.tune.function_runner.ImplicitFunc object at 0x7f6b715d4990>)
File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 260, in run
self._entrypoint()
File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 329, in entrypoint
self._status_reporter.get_checkpoint())
File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 594, in _trainable_func
output = fn()
File "/usr/local/lib/python3.7/dist-packages/transformers/integrations.py", line 282, in dynamic_modules_import_trainable
return trainable(*args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/ray/tune/utils/trainable.py", line 344, in inner
trainable(config, **fn_kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/integrations.py", line 183, in _objective
local_trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
File "/usr/local/lib/python3.7/dist-packages/transformers/trainer.py", line 1241, in train
self.state.trial_params = hp_params(trial.assignments) if trial is not None else None
AttributeError: 'dict' object has no attribute 'assignments'
Result for _objective_86e23_00009:
{}
== Status ==
Memory usage on this node: 2.2/12.7 GiB
Using FIFO scheduling algorithm.
Resources requested: 0/2 CPUs, 0/0 GPUs, 0.0/7.36 GiB heap, 0.0/3.68 GiB objects
Result logdir: /root/ray_results/_objective_2021-10-05_11-51-07
Number of trials: 10/10 (10 ERROR)
+------------------------+----------+-------+-----------------+--------------------+-------------------------------+----------+
| Trial name | status | loc | learning_rate | num_train_epochs | per_device_train_batch_size | seed |
|------------------------+----------+-------+-----------------+--------------------+-------------------------------+----------|
| _objective_86e23_00000 | ERROR | | 5.61152e-06 | 5 | 64 | 8.15396 |
| _objective_86e23_00001 | ERROR | | 1.56207e-05 | 2 | 16 | 7.08379 |
| _objective_86e23_00002 | ERROR | | 8.28892e-06 | 5 | 16 | 24.4435 |
| _objective_86e23_00003 | ERROR | | 1.09943e-06 | 2 | 8 | 29.158 |
| _objective_86e23_00004 | ERROR | | 2.3102e-06 | 5 | 8 | 25.0818 |
| _objective_86e23_00005 | ERROR | | 1.12076e-05 | 4 | 16 | 1.89943 |
| _objective_86e23_00006 | ERROR | | 1.67381e-05 | 2 | 32 | 2.81996 |
| _objective_86e23_00007 | ERROR | | 5.4041e-06 | 3 | 32 | 15.916 |
| _objective_86e23_00008 | ERROR | | 1.53049e-05 | 3 | 64 | 34.5377 |
| _objective_86e23_00009 | ERROR | | 7.96157e-06 | 2 | 32 | 38.0065 |
+------------------------+----------+-------+-----------------+--------------------+-------------------------------+----------+
Number of errored trials: 10
+------------------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Trial name | # failures | error file |
|------------------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| _objective_86e23_00000 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00000_0_learning_rate=5.6115e-06,num_train_epochs=5,per_device_train_batch_size=64,seed=8.154_2021-10-05_11-51-07/error.txt |
| _objective_86e23_00001 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00001_1_learning_rate=1.5621e-05,num_train_epochs=2,per_device_train_batch_size=16,seed=7.0838_2021-10-05_11-51-08/error.txt |
| _objective_86e23_00002 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00002_2_learning_rate=8.2889e-06,num_train_epochs=5,per_device_train_batch_size=16,seed=24.443_2021-10-05_11-51-09/error.txt |
| _objective_86e23_00003 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00003_3_learning_rate=1.0994e-06,num_train_epochs=2,per_device_train_batch_size=8,seed=29.158_2021-10-05_11-51-17/error.txt |
| _objective_86e23_00004 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00004_4_learning_rate=2.3102e-06,num_train_epochs=5,per_device_train_batch_size=8,seed=25.082_2021-10-05_11-51-17/error.txt |
| _objective_86e23_00005 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00005_5_learning_rate=1.1208e-05,num_train_epochs=4,per_device_train_batch_size=16,seed=1.8994_2021-10-05_11-51-25/error.txt |
| _objective_86e23_00006 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00006_6_learning_rate=1.6738e-05,num_train_epochs=2,per_device_train_batch_size=32,seed=2.82_2021-10-05_11-51-26/error.txt |
| _objective_86e23_00007 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00007_7_learning_rate=5.4041e-06,num_train_epochs=3,per_device_train_batch_size=32,seed=15.916_2021-10-05_11-51-34/error.txt |
| _objective_86e23_00008 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00008_8_learning_rate=1.5305e-05,num_train_epochs=3,per_device_train_batch_size=64,seed=34.538_2021-10-05_11-51-35/error.txt |
| _objective_86e23_00009 | 1 | /root/ray_results/_objective_2021-10-05_11-51-07/_objective_86e23_00009_9_learning_rate=7.9616e-06,num_train_epochs=2,per_device_train_batch_size=32,seed=38.007_2021-10-05_11-51-43/error.txt |
+------------------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
(pid=823) Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertForSequenceClassification: ['vocab_transform.weight', 'vocab_layer_norm.weight', 'vocab_transform.bias', 'vocab_projector.weight', 'vocab_layer_norm.bias', 'vocab_projector.bias']
(pid=823) - This IS expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
(pid=823) - This IS NOT expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
(pid=823) Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'pre_classifier.weight', 'classifier.weight', 'pre_classifier.bias']
(pid=823) You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
(pid=823) 2021-10-05 11:51:52,224 ERROR function_runner.py:266 -- Runner Thread raised error.
(pid=823) Traceback (most recent call last):
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 260, in run
(pid=823) self._entrypoint()
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 329, in entrypoint
(pid=823) self._status_reporter.get_checkpoint())
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 594, in _trainable_func
(pid=823) output = fn()
(pid=823) File "/usr/local/lib/python3.7/dist-packages/transformers/integrations.py", line 282, in dynamic_modules_import_trainable
(pid=823) return trainable(*args, **kwargs)
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/utils/trainable.py", line 344, in inner
(pid=823) trainable(config, **fn_kwargs)
(pid=823) File "/usr/local/lib/python3.7/dist-packages/transformers/integrations.py", line 183, in _objective
(pid=823) local_trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
(pid=823) File "/usr/local/lib/python3.7/dist-packages/transformers/trainer.py", line 1241, in train
(pid=823) self.state.trial_params = hp_params(trial.assignments) if trial is not None else None
(pid=823) AttributeError: 'dict' object has no attribute 'assignments'
(pid=823) Exception in thread Thread-2:
(pid=823) Traceback (most recent call last):
(pid=823) File "/usr/lib/python3.7/threading.py", line 926, in _bootstrap_inner
(pid=823) self.run()
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 279, in run
(pid=823) raise e
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 260, in run
(pid=823) self._entrypoint()
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 329, in entrypoint
(pid=823) self._status_reporter.get_checkpoint())
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/function_runner.py", line 594, in _trainable_func
(pid=823) output = fn()
(pid=823) File "/usr/local/lib/python3.7/dist-packages/transformers/integrations.py", line 282, in dynamic_modules_import_trainable
(pid=823) return trainable(*args, **kwargs)
(pid=823) File "/usr/local/lib/python3.7/dist-packages/ray/tune/utils/trainable.py", line 344, in inner
(pid=823) trainable(config, **fn_kwargs)
(pid=823) File "/usr/local/lib/python3.7/dist-packages/transformers/integrations.py", line 183, in _objective
(pid=823) local_trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
(pid=823) File "/usr/local/lib/python3.7/dist-packages/transformers/trainer.py", line 1241, in train
(pid=823) self.state.trial_params = hp_params(trial.assignments) if trial is not None else None
(pid=823) AttributeError: 'dict' object has no attribute 'assignments'
(pid=823)
---------------------------------------------------------------------------
TuneError Traceback (most recent call last)
<ipython-input-9-1f1a81b84f40> in <module>()
42 direction="maximize",
43 backend="ray",
---> 44 n_trials=10 # number of trials
45 )
2 frames
/usr/local/lib/python3.7/dist-packages/ray/tune/tune.py in run(run_or_experiment, name, metric, mode, stop, time_budget_s, config, resources_per_trial, num_samples, local_dir, search_alg, scheduler, keep_checkpoints_num, checkpoint_score_attr, checkpoint_freq, checkpoint_at_end, verbose, progress_reporter, log_to_file, trial_name_creator, trial_dirname_creator, sync_config, export_formats, max_failures, fail_fast, restore, server_port, resume, queue_trials, reuse_actors, trial_executor, raise_on_failed_trial, callbacks, loggers, ray_auto_init, run_errored_only, global_checkpoint_period, with_server, upload_dir, sync_to_cloud, sync_to_driver, sync_on_checkpoint, _remote)
553 if incomplete_trials:
554 if raise_on_failed_trial and not state[signal.SIGINT]:
--> 555 raise TuneError("Trials did not complete", incomplete_trials)
556 else:
557 logger.error("Trials did not complete: %s", incomplete_trials)
TuneError: ('Trials did not complete', [_objective_86e23_00000, _objective_86e23_00001, _objective_86e23_00002, _objective_86e23_00003, _objective_86e23_00004, _objective_86e23_00005, _objective_86e23_00006, _objective_86e23_00007, _objective_86e23_00008, _objective_86e23_00009])
And this is the error I get when I switched Ray backend to Optuna:
loading configuration file https://huggingface.co/distilbert-base-uncased/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/23454919702d26495337f3da04d1655c7ee010d5ec9d77bdb9e399e00302c0a1.91b885ab15d631bf9cee9dc9d25ece0afd932f2f5130eba28f2055b2220c0333
Model config DistilBertConfig {
"activation": "gelu",
"architectures": [
"DistilBertForMaskedLM"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"transformers_version": "4.11.2",
"vocab_size": 30522
}
loading file https://huggingface.co/distilbert-base-uncased/resolve/main/vocab.txt from cache at /root/.cache/huggingface/transformers/0e1bbfda7f63a99bb52e3915dcf10c3c92122b827d92eb2d34ce94ee79ba486c.d789d64ebfe299b0e416afc4a169632f903f693095b4629a7ea271d5a0cf2c99
loading file https://huggingface.co/distilbert-base-uncased/resolve/main/tokenizer.json from cache at /root/.cache/huggingface/transformers/75abb59d7a06f4f640158a9bfcde005264e59e8d566781ab1415b139d2e4c603.7f2721073f19841be16f41b0a70b600ca6b880c8f3df6f3535cbc704371bdfa4
loading file https://huggingface.co/distilbert-base-uncased/resolve/main/added_tokens.json from cache at None
loading file https://huggingface.co/distilbert-base-uncased/resolve/main/special_tokens_map.json from cache at None
loading file https://huggingface.co/distilbert-base-uncased/resolve/main/tokenizer_config.json from cache at /root/.cache/huggingface/transformers/8c8624b8ac8aa99c60c912161f8332de003484428c47906d7ff7eb7f73eecdbb.20430bd8e10ef77a7d2977accefe796051e01bc2fc4aa146bc862997a1a15e79
loading configuration file https://huggingface.co/distilbert-base-uncased/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/23454919702d26495337f3da04d1655c7ee010d5ec9d77bdb9e399e00302c0a1.91b885ab15d631bf9cee9dc9d25ece0afd932f2f5130eba28f2055b2220c0333
Model config DistilBertConfig {
"activation": "gelu",
"architectures": [
"DistilBertForMaskedLM"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"transformers_version": "4.11.2",
"vocab_size": 30522
}
Reusing dataset glue (/root/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%
3/3 [00:00<00:00, 47.70it/s]
Loading cached processed dataset at /root/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-6be500ff95cfa94a.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/glue/mrpc/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad/cache-0208e5893d9737cc.arrow
100%
2/2 [00:00<00:00, 6.15ba/s]
PyTorch: setting up devices
The default value for the training argument `--report_to` will change in v5 (from all installed integrations to none). In v5, you will need to use `--report_to all` to get the same behavior as now. You should start updating your code and make this info disappear :-).
loading configuration file https://huggingface.co/distilbert-base-uncased/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/23454919702d26495337f3da04d1655c7ee010d5ec9d77bdb9e399e00302c0a1.91b885ab15d631bf9cee9dc9d25ece0afd932f2f5130eba28f2055b2220c0333
Model config DistilBertConfig {
"activation": "gelu",
"architectures": [
"DistilBertForMaskedLM"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"transformers_version": "4.11.2",
"vocab_size": 30522
}
loading weights file https://huggingface.co/distilbert-base-uncased/resolve/main/pytorch_model.bin from cache at /root/.cache/huggingface/transformers/9c169103d7e5a73936dd2b627e42851bec0831212b677c637033ee4bce9ab5ee.126183e36667471617ae2f0835fab707baa54b731f991507ebbb55ea85adb12a
Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertForSequenceClassification: ['vocab_transform.bias', 'vocab_transform.weight', 'vocab_projector.weight', 'vocab_layer_norm.weight', 'vocab_layer_norm.bias', 'vocab_projector.bias']
- This IS expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight', 'pre_classifier.bias', 'pre_classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
[I 2021-10-05 11:57:53,131] A new study created in memory with name: no-name-b8bec492-da86-496a-8dc9-889c57c2949a
Trial:
loading configuration file https://huggingface.co/distilbert-base-uncased/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/23454919702d26495337f3da04d1655c7ee010d5ec9d77bdb9e399e00302c0a1.91b885ab15d631bf9cee9dc9d25ece0afd932f2f5130eba28f2055b2220c0333
Model config DistilBertConfig {
"activation": "gelu",
"architectures": [
"DistilBertForMaskedLM"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"transformers_version": "4.11.2",
"vocab_size": 30522
}
loading weights file https://huggingface.co/distilbert-base-uncased/resolve/main/pytorch_model.bin from cache at /root/.cache/huggingface/transformers/9c169103d7e5a73936dd2b627e42851bec0831212b677c637033ee4bce9ab5ee.126183e36667471617ae2f0835fab707baa54b731f991507ebbb55ea85adb12a
Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertForSequenceClassification: ['vocab_transform.bias', 'vocab_transform.weight', 'vocab_projector.weight', 'vocab_layer_norm.weight', 'vocab_layer_norm.bias', 'vocab_projector.bias']
- This IS expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight', 'pre_classifier.bias', 'pre_classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
***** Running training *****
Num examples = 3668
Num Epochs = 2
Instantaneous batch size per device = 64
Total train batch size (w. parallel, distributed & accumulation) = 64
Gradient Accumulation steps = 1
Total optimization steps = 116
[W 2021-10-05 11:57:54,441] Trial 0 failed because of the following error: AttributeError("'Trial' object has no attribute 'assignments'")
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/optuna/study/_optimize.py", line 213, in _run_trial
value_or_values = func(trial)
File "/usr/local/lib/python3.7/dist-packages/transformers/integrations.py", line 150, in _objective
trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
File "/usr/local/lib/python3.7/dist-packages/transformers/trainer.py", line 1241, in train
self.state.trial_params = hp_params(trial.assignments) if trial is not None else None
AttributeError: 'Trial' object has no attribute 'assignments'
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-10-ec85f0236770> in <module>()
42 direction="maximize",
43 backend="optuna",
---> 44 n_trials=10 # number of trials
45 )
8 frames
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1239 self.callback_handler.train_dataloader = train_dataloader
1240 self.state.trial_name = self.hp_name(trial) if self.hp_name is not None else None
-> 1241 self.state.trial_params = hp_params(trial.assignments) if trial is not None else None
1242 # This should be the same if the state has been saved but in case the training arguments changed, it's safer
1243 # to set this after the load.
AttributeError: 'Trial' object has no attribute 'assignments'
def extract_all_chars(batch):
all_text = " ".join(batch["text"])
vocab = list(set(all_text))
return {"vocab" : [vocab], "all_text" : [all_text]}
vocabs = timit.map(extract_all_chars, batched = True, batch_size=-1, keep_in_memory=True, remove_columns=timit.column_names["train"])
I can't get the meaning of 'remove_columns=timit.column_names["train"]'.
Looks like it is removing training dataset, but output var 'vocabs' also have both 'train' and 'data' keys.
Result lookssame with 'remove_columns=timit.column_names["test"]'.
Newbie looking for a help.
Thank you
Hello,
I want to generate text with GPT-2 and I read the post
How to generate text: using different decoding methods for language generation with Transformers
which provides different decoding methods to experiment with.
In the post, the method that generates texts is the generate() method of the model object which is a TFGPT2LMHeadModel.
Instead of TensorFlow I use PyTorch and looking at the documentation of GPT-2 in Hugging Face docs, and in particular the documentation of GPT2LMHeadModel I cannot find the generate() method used in the post, to see how it works, its parameters, etc.
Where can I find details about the generate() method?
Thank you in advance.
I tried adding validation data by just copying:
validation_dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path="./DeveloperGuides.txt",
block_size=128,
)
and then adding it to the Trainer like this:
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=validation_dataset
)
UPDATE: Fixed by adding evaluation_strategy = "epoch" to the trainer argument
Hello Patrick @patrickvonplaten
Thanks for the nice post on how to finetune wav2vec2. It was quite intuitive and simple.
I had been trying to fine tune "facebook/wav2vec2-large-xlsr-53" and also "facebook/wav2vec2-base" for my own Somali dataset which I had used previously in my research [The best WER obtained was approximately 50 using a combination of CNN-LSTM system]. The dataset contains extremely low amounts of data for finetuning (approximately maybe an hour of data). In terms of utterances, I have approximately 500 odd utterance and this is after cleaning and getting utterances whose length is > 4s. Tried fine tuning in the way described in your post but unfortunately the best WER I could obtain is 76 [my hmm-gmm systems was giving me a WER of approximately 63 with the same dataset where I have included all the sentences and not just the ones > 4s]. Something else which I noticed was that the validation loss decreases to a certain point and then starts increasing but the WER does not seem to increase reflecting the increase in validation loss. Not able to comprehend what is going on. Would you be able to comment on what is going on and am I overlooking anything here which is important. I was interested in wav2vec2 as there were claims that it could fine tune with as little as 10m of data.
Thanks in advance
Regards,
Raghav
Thank you for your "How to generate text" blog post a couple of years ago. I'm not sure if there are any recent posts for text generation, but I noticed the TF version is outdated (TF 2.1) which results in the error below.
Upgrading to 2.3 works fine for me.
I also noticed in the README.md it's classified as a PyTorch example and not TF. Is this intentional?
AttributeError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/transformers/file_utils.py in _get_module(self, module_name)
2464 try:
-> 2465 return importlib.import_module("." + module_name, self.__name__)
2466 except Exception as e:
13 frames
AttributeError: module 'tensorflow_core.python.keras.api._v2.keras.activations' has no attribute 'swish'
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/transformers/file_utils.py in _get_module(self, module_name)
2467 raise RuntimeError(
2468 f"Failed to import {self.__name__}.{module_name} because of the following error (look up to see its traceback):\n{e}"
-> 2469 ) from e
2470
2471 def __reduce__(self):
RuntimeError: Failed to import transformers.models.gpt2.modeling_tf_gpt2 because of the following error (look up to see its traceback):
module 'tensorflow_core.python.keras.api._v2.keras.activations' has no attribute 'swish'
I have seeming people do this in GPT, such as on Shakespeare's poem, but I don't know how to train it and load the pre-train with hugging face. Any suggestions on how and which model to pick?
Thank You🤗
I don't see it on the doc, blog, or notebooks.
I'm following the guide here (https://github.com/huggingface/blog/blob/master/how-to-train.md, https://huggingface.co/blog/how-to-train) to train a RoBERTa-like model from scratch. (With my own tokenizer and dataset)
However, when I run run_mlm.py (https://github.com/huggingface/transformers/blob/master/examples/pytorch/language-modeling/run_mlm.py) to train my model with masking task, the following messages appear:
All model checkpoint weights were used when initializing RobertaForMaskedLM.
All the weights of RobertaForMaskedLM were initialized from the model checkpoint at roberta-base.
If your task is similar to the task the model of the checkpoint was trained on, you can already use RobertaForMaskedLM for predictions without further training.
And here's my content of config.json:
{
"_name_or_path": "roberta-base",
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"classifier_dropout": null,
"eos_token_id": 2,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.12.0.dev0",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 50265
}
I'm wondering does it mean that I'm training from scratch with "the pretrained weight" of RoBERTa? And if it's training from the pretrained weights, is there a way to use randomly initiated weights rather than the pretrained ones?
Thanks a lot.
I was coding along with the how to train language model from scratch blog & notebook and I had a question.
Why do we first create, train and save a tokenizer from tokenizers.ByteLevelBPETokenizer() and then use it to create another ByteLevelBPETokenizer from tokenizers.implementations? Are these the same? If not, what is the difference? Could we have just used the same tokenizer object we initially trained to then to postprocessing and truncation etc.?
It may help to explain this in the blog if others are confused like I was.

Within this formula,

should we change 𝐱′1 to 𝐱′2?
Thanks.
i was wondering about how to train this notebook: "01_how_to_train.ipynb" on TPU (GCS or colab) ?
I'm following the "01_how_to_train.ipynb" notebook to build my own model on the "multi_news" dataset and have ran into this error after running the following portion of the code:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="/Users/username/.cache/huggingface/datasets/multi_news/default/1.0.0/465b14e19b4d6a55c9bb9131ca1de642175872143c9b231bee1dce789311b449",
overwrite_output_dir=True,
num_train_epochs=1,
per_gpu_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
prediction_loss_only=True,
)
The exact error reads
TypeError Traceback (most recent call last)
in
11 )
12
---> 13 trainer = Trainer(
14 model=model,
15 args=training_args,
TypeError: init() got an unexpected keyword argument 'prediction_loss_only'
How would you suggest fixing this issue?
when !pip install -q git+https://github.com/huggingface/transformers.git
ERROR: transformers 2.11.0 has requirement tokenizers==0.7.0, but you'll have tokenizers 0.8.0rc3 which is incompatible.
how to solve ,thanks
Good morning/evening?
Thanks for the amazing blog posts and the amazing huggingface package!
I am using tensorflow and I realized the nice colab notebook on training a language model from scratch is only available in pytorch... https://github.com/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb
Is there a tensorflow version somewhere? That would be amazing!
Thanks!
Link to blog post: How to train a new language model from scratch using Transformers and Tokenizers
In section 3 of the article:
We will now train our language model using the run_language_modeling.py script from transformers....
That link is dead.
run_language_modeling.py file was moved from its previous location (which was at examples/language-modeling/run_language_modeling.py) to the new location at examples/contrib/legacy/language-modeling/run_language_modeling.py (link) in this commit in Oct 2020. However it looks like the file was deleted from the second location too.examples/legacy/run_language_modeling.py in this commit in Dec 2020.It would be nice if: (1) this blog post was either marked as legacy/out of date, or (2) the link is updated to this, assuming support for this still exists.
I am using custom data on the fine-tuning wav2vec for English ASR , after training the model I am having trouble loading it.This is what i get :
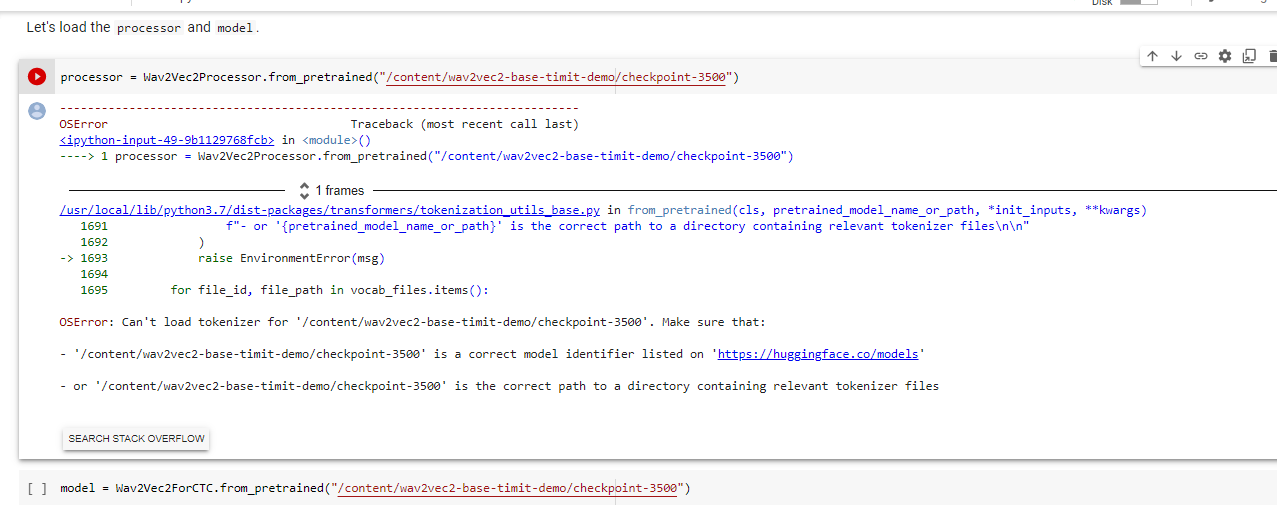
it only happens for the processor , works fine for the model
Thank you for your latest blogpost on boosting Wav2Vec2 with n-grams. I'm having trouble there with the processor.batch_decode step, since I get a KeyError in the pyctcdecode/decoder.py module when running the Wav2Vec2ProcessorWithLM model and processor.
I am using python 3.8.2, pyctcdecode==0.3.0, and transformers==4.15.0.
Below is the traceback:
Traceback (most recent call last):
File "/Users/gfigueroa/.pyenv/versions/3.8.2/lib/python3.8/multiprocessing/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/Users/gfigueroa/.pyenv/versions/3.8.2/lib/python3.8/multiprocessing/pool.py", line 48, in mapstar
return list(map(*args))
File "/Users/gfigueroa/.pyenv/versions/3.8.2/lib/python3.8/site-packages/pyctcdecode/decoder.py", line 547, in _decode_beams_mp_safe
decoded_beams = self.decode_beams(
File "/Users/gfigueroa/.pyenv/versions/3.8.2/lib/python3.8/site-packages/pyctcdecode/decoder.py", line 525, in decode_beams
decoded_beams = self._decode_logits(
File "/Users/gfigueroa/.pyenv/versions/3.8.2/lib/python3.8/site-packages/pyctcdecode/decoder.py", line 329, in _decode_logits
language_model = BeamSearchDecoderCTC.model_container[self._model_key]
KeyError: b'\xab\x94\xb9\xb0I\xc0\x1b\xf93\xa9\xa6\x1c]\t\xf6\x86'
Hello, I am trying to follow the tutorial on how to train a language model from scratch found here: https://github.com/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb. However, I get stuck at building the training dataset, because I have multiple text files, whereas the example states "Here, as we only have one text file, we don't even need to customize our Dataset. We'll just use the LineByLineDataset out-of-the-box."
How do I go about "customizing my Dataset" since I have multiple text files to use for the trainer in the following steps?
What is the license of these blog articles? Could I e.g., translate them into a different language for personal or commercial purposes?
Hi @patrickvonplaten,
could please you add info abut the resources you are using it the colab?
Like:
!nvidia-smi
from multiprocessing import cpu_count print("CPU count: ", cpu_count())
or some info from W&B about the training would be nice (on your profile aren't any public).
Thank you
When I train the tokenizer on an Arabic data from https://wortschatz.uni-leipzig.de/en/download/arabic , I get this shape of Arabic letters. I tried changing the files encoding but nothing changed.

In the tutorial
'how to train a language model.ipynb'
after trainer.train(), it print the loss of each step,but when I try the same code in my jupyter notebook , there are only 2 progress bars , one for epochs the other for batches.
So I wonder if I can print loss as it was shown in the notebook ?
help~~~
here is the code:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./EsperBERTo",
overwrite_output_dir=True,
num_train_epochs=1,
per_gpu_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
prediction_loss_only=True,
)
and here is the output after trainer.train()
HBox(children=(FloatProgress(value=0.0, description='Epoch', max=1.0, style=ProgressStyle(description_width='i…
HBox(children=(FloatProgress(value=0.0, description='Iteration', max=15228.0, style=ProgressStyle(description_…
{"loss": 7.152712148666382, "learning_rate": 4.8358287365379566e-05, "epoch": 0.03283425269240872, "step": 500}
{"loss": 6.928811420440674, "learning_rate": 4.671657473075913e-05, "epoch": 0.06566850538481744, "step": 1000}
{"loss": 6.789419063568115, "learning_rate": 4.5074862096138694e-05, "epoch": 0.09850275807722617, "step": 1500}
{"loss": 6.688932447433472, "learning_rate": 4.343314946151826e-05, "epoch": 0.1313370107696349, "step": 2000}
{"loss": 6.595982004165649, "learning_rate": 4.179143682689782e-05, "epoch": 0.1641712634620436, "step": 2500}
{"loss": 6.545944199562073, "learning_rate": 4.0149724192277385e-05, "epoch": 0.19700551615445233, "step": 3000}
{"loss": 6.4864857263565066, "learning_rate": 3.850801155765695e-05, "epoch": 0.22983976884686105, "step": 3500}
{"loss": 6.412427802085876, "learning_rate": 3.686629892303651e-05, "epoch": 0.2626740215392698, "step": 4000}
{"loss": 6.363630670547486, "learning_rate": 3.522458628841608e-05, "epoch": 0.29550827423167847, "step": 4500}
{"loss": 6.273832890510559, "learning_rate": 3.358287365379564e-05, "epoch": 0.3283425269240872, "step": 5000}
{"loss": 6.197585330963134, "learning_rate": 3.1941161019175205e-05, "epoch": 0.3611767796164959, "step": 5500}
{"loss": 6.097779376983643, "learning_rate": 3.029944838455477e-05, "epoch": 0.39401103230890466, "step": 6000}
{"loss": 5.985456382751464, "learning_rate": 2.8657735749934332e-05, "epoch": 0.42684528500131336, "step": 6500}
{"loss": 5.8448616371154785, "learning_rate": 2.70160231153139e-05, "epoch": 0.4596795376937221, "step": 7000}
{"loss": 5.692522863388062, "learning_rate": 2.5374310480693457e-05, "epoch": 0.4925137903861308, "step": 7500}
{"loss": 5.562082152366639, "learning_rate": 2.3732597846073024e-05, "epoch": 0.5253480430785396, "step": 8000}
{"loss": 5.457240365982056, "learning_rate": 2.2090885211452588e-05, "epoch": 0.5581822957709482, "step": 8500}
{"loss": 5.376953645706177, "learning_rate": 2.0449172576832152e-05, "epoch": 0.5910165484633569, "step": 9000}
{"loss": 5.298609251022339, "learning_rate": 1.8807459942211716e-05, "epoch": 0.6238508011557657, "step": 9500}
{"loss": 5.225468152046203, "learning_rate": 1.716574730759128e-05, "epoch": 0.6566850538481744, "step": 10000}
{"loss": 5.174519973754883, "learning_rate": 1.5524034672970843e-05, "epoch": 0.6895193065405831, "step": 10500}
{"loss": 5.113943946838379, "learning_rate": 1.3882322038350407e-05, "epoch": 0.7223535592329918, "step": 11000}
{"loss": 5.08140989112854, "learning_rate": 1.2240609403729971e-05, "epoch": 0.7551878119254006, "step": 11500}
{"loss": 5.072491912841797, "learning_rate": 1.0598896769109535e-05, "epoch": 0.7880220646178093, "step": 12000}
{"loss": 5.012459496498108, "learning_rate": 8.957184134489099e-06, "epoch": 0.820856317310218, "step": 12500}
{"loss": 4.999591351509094, "learning_rate": 7.315471499868663e-06, "epoch": 0.8536905700026267, "step": 13000}
{"loss": 4.994838352203369, "learning_rate": 5.673758865248227e-06, "epoch": 0.8865248226950354, "step": 13500}
{"loss": 4.955870885848999, "learning_rate": 4.032046230627791e-06, "epoch": 0.9193590753874442, "step": 14000}
{"loss": 4.941655583381653, "learning_rate": 2.390333596007355e-06, "epoch": 0.9521933280798529, "step": 14500}
{"loss": 4.931783639907837, "learning_rate": 7.486209613869189e-07, "epoch": 0.9850275807722616, "step": 15000}
I have voice recordings of the names of the cities in my country I want to build dataset and convert it to speech recognition model for my century cities
I am follow you , please help me with this
I don't know if I should go to Mars I can't find the answer
Please, help me
Hi guys,
I tried following this article in order to train a BERT model from scratch on a corpus of the Hebrew Bible transliteration(for example, see the right column of the table on this page). I used the ByteLevelBPETokenizer. After training the model with the same configuration as you used for EsperBERTo (1 epoch etc.), I tried performing the "fill-mask" task on an arbitrary sentence from the corpus. Unfortunately the completions I got were weird - single characters, mainly the apostrophe and the hyphen(that are indeed widely used by the transliteration not as separate words but rather as signs for specific Hebrew consonants). Can you point out what I did wrong or alternatively what I can do to prevent this behavior?
P.S. running the same process on the original(not transliterated) Hebrew text of the Bible, despite the morphological complexity of Hebrew(written without vowels and thus every word might have many valid reading options depending on the context), has yielded much better results. The masks have been filled by valid Hebrew words, even though not necessarily matching the semantic context.
Here is my notebook.
Here is the disappointing screenshot:

Thank you in advance,
Moshe.
Hi,
I am unable to recreate the results reported in your blogpost https://huggingface.co/blog/fine-tune-wav2vec2-english on the timit dataset. I just ran the notebook as it is on google-colab, but got very different results. I am attaching a screenshot of the training and validation results. The results are completely different from the ones reported in the blog post. Can u please let m know the issue here? and how we can recreate the results?
Thanks

Hi!
I just discovered this blog and would like to follow it. I usually do that with a rss reader, but I couldn't find any feed on the website. Am I missing it or is it just not there?
The quotation marks in the how-to-generate article are wrong.
Would be nice to have them fixed.
Tried out correct latex style `` '' but that breaks the markdown.
' ' '' does not work either.
Katex compiles the latex code -> other ideas are welcome :-)
Thanks for pointing out @sheikheddy
Hi,
I found that there were multiple issues such as BPE tokenizers not being found,
Problems loading the tokenizer among others.
I'd suggest redoing the blog code to work with the current deployment and make the same publicly available.
Thanks
SPECS:
OS: Windows 10
CUDA: 10.1
GPU: RTX 2060 6G VRAM (x2)
RAM: 32GB
Hello I am trying to train my own language model and I have had some memory issues. I have tried to run some of this code in Pycharm on my computer and then trying to replicate in my Collab Pro Notebook.
from transformers import RobertaConfig, RobertaTokenizerFast, RobertaForMaskedLM, LineByLineTextDataset
from transformers import DataCollatorForLanguageModeling, Trainer, TrainingArguments
config = RobertaConfig(vocab_size=60000, max_position_embeddings=514, num_attention_heads=12, num_hidden_layers=6,
type_vocab_size=1)
tokenizer = RobertaTokenizerFast.from_pretrained("./MODEL DIRECTORY", max_len=512)
model = RobertaForMaskedLM(config=config)
print("making dataset")
dataset = LineByLineTextDataset(tokenizer=tokenizer, file_path="./total_text.txt", block_size=128)
print("making c")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
training_args = TrainingArguments(output_dir="./MODEL DIRECTORY", overwrite_output_dir=True, num_train_epochs=1,
per_gpu_train_batch_size=64, save_steps=10000, save_total_limit=2)
print("Building trainer")
trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=dataset,
prediction_loss_only=True)
trainer.train()
trainer.save_model("./MODEL DIRECTORY")
"./total_text.txt" being a 1.7GB text file.
This code on pycharm builds the dataset and then would throw an error saying that my preferred gpu was running out of memory, and that Torch was already using 3.7GiB of memory.
I tried:
os.environ["CUDA_VISIBLE_OBJECTS"] ="" so that torch would have to use my CPU and not my GPU. Still threw same gpu memory error...So succumbing to the fact that torch, for the time being, was forcing itself to use my gpu, I decided to go to Collab.
Collab has different issues with my code. It does not have the memory to build the dataset, and crashes due to RAM shortages. I purchased a Pro account and then increased the usable RAM to 25GB, still memory shortages.
Cheers!
Hi
@patrickvonplaten
I encountered some error while following this blog to fine tune a Chinese dataset.
After I solved the last problem (RuntimeError:element 0 of tensor does not require grad and does not have a grad_fn),
I encountered this problem,as follows:
I don't know how to solve it
Traceback (most recent call last):
File "/media/xzw/WORK/fairseq/work/3.py", line 220, in
trainer.train()
File "/home/xzw/anaconda3/envs/work/lib/python3.7/site-packages/transformers/trainer.py", line 1092, in train
self.scaler.step(self.optimizer)
File "/home/xzw/anaconda3/envs/work/lib/python3.7/site-packages/torch/cuda/amp/grad_scaler.py", line 318, in step
assert len(optimizer_state["found_inf_per_device"]) > 0, "No inf checks were recorded for this optimizer."
AssertionError: No inf checks were recorded for this optimizer.
0%| | 0/112620 [00:02<?, ?it/s]
Best regards
xiao
Hi! I hope this is the right place to ask this, if not please advise.
We wrote a post using transformers a while back and I would like to know the process of getting it cross-posted here.
cc @srush!
Using a dataset of annotated Esperanto POS tags formatted in the CoNLL-2003 format
Where is this dataset?
Thanks!
while training my own tamil language data set it will create vocab.json and merge.txt... the problem is tamil vocabulary is not properly shown... it will show like below
#version: 0.2 - Trained by huggingface/tokenizers
à ®
à ¯
௠į
Ġ à®
௠ģ
à® ķ
à® ¿
à® ¤
à® ¾
à® °
à® Ł
à® ©
à® ª
à® ®
à® ²
à® ±
௠Ī
my data set available in oscar data set...language tamil...it is in proper utf-8 format... what is the issue?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.