Some combinations of filters, e.g. ({'species': ['Gentoo'], 'Island': ['Torgersen'], sex: []}), leads to the following error being raised:
2021-10-01 01:00:30,708 Exception in callback functools.partial(<bound method IOLoop._discard_future_result of <tornado.platform.asyncio.AsyncIOMainLoop object at 0x7fd118426bd0>>, <Task finished coro=<_needs_document_lock.<locals>._needs_document_lock_wrapper() done, defined at /Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/bokeh/server/session.py:51> exception=AttributeError("'int' object has no attribute 'dtype'")>)
Traceback (most recent call last):
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/tornado/ioloop.py", line 741, in _run_callback
ret = callback()
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/tornado/ioloop.py", line 765, in _discard_future_result
future.result()
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/bokeh/server/session.py", line 71, in _needs_document_lock_wrapper
result = await result
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/tornado/gen.py", line 216, in wrapper
result = ctx_run(func, *args, **kwargs)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/panel/reactive.py", line 278, in _change_coroutine
self._change_event(doc)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/panel/reactive.py", line 288, in _change_event
self._process_events(events)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/panel/reactive.py", line 262, in _process_events
self.param.set_param(**self_events)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 1526, in set_param
self_._batch_call_watchers()
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 1665, in _batch_call_watchers
self_._execute_watcher(watcher, events)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 1627, in _execute_watcher
watcher.fn(*args, **kwargs)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/panel/reactive.py", line 394, in reverse_link
setattr(self, reverse_links[event.name], event.new)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 316, in _f
instance_param.__set__(obj, val)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 318, in _f
return f(self, obj, val)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 984, in __set__
obj.param._call_watcher(watcher, event)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 1645, in _call_watcher
self_._execute_watcher(watcher, (event,))
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 1627, in _execute_watcher
watcher.fn(*args, **kwargs)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/panel/reactive.py", line 379, in link
setattr(target, links[event.name], event.new)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 318, in _f
return f(self, obj, val)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 984, in __set__
obj.param._call_watcher(watcher, event)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 1645, in _call_watcher
self_._execute_watcher(watcher, (event,))
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/param/parameterized.py", line 1627, in _execute_watcher
watcher.fn(*args, **kwargs)
File "/Users/mliquet/WORK/DEV/lumen/lumen/target.py", line 434, in _rerender
self._update_views(invalidate_cache, update_views, events=events)
File "/Users/mliquet/WORK/DEV/lumen/lumen/target.py", line 402, in _update_views
events=events
File "/Users/mliquet/WORK/DEV/lumen/lumen/target.py", line 325, in _get_card
view_stale = view.update(*events, invalidate_cache=invalidate_cache)
File "/Users/mliquet/WORK/DEV/lumen/lumen/views/base.py", line 506, in update
return self._update_panel()
File "/Users/mliquet/WORK/DEV/lumen/lumen/views/base.py", line 196, in _update_panel
self._updates = self._get_params()
File "/Users/mliquet/WORK/DEV/lumen/lumen/views/base.py", line 474, in _get_params
return dict(object=self.get_plot(df))
File "/Users/mliquet/WORK/DEV/lumen/lumen/views/base.py", line 437, in get_plot
kind=self.kind, x=self.x, y=self.y, **processed
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/hvplot/plotting/core.py", line 79, in __call__
return self._get_converter(x, y, kind, **kwds)(kind, x, y)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/hvplot/plotting/core.py", line 87, in _get_converter
self._data, x, y, kind=kind, **params
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/hvplot/converter.py", line 506, in __init__
symmetric = self._process_symmetric(symmetric, clim, check_symmetric_max)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/hvplot/converter.py", line 561, in _process_symmetric
cmin = np.nanquantile(data, 0.05)
File "<__array_function__ internals>", line 6, in nanquantile
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/numpy/lib/nanfunctions.py", line 1357, in nanquantile
a, q, axis, out, overwrite_input, interpolation, keepdims)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/numpy/lib/nanfunctions.py", line 1366, in _nanquantile_unchecked
return np.nanmean(a, axis, out=out, keepdims=keepdims)
File "<__array_function__ internals>", line 6, in nanmean
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/numpy/lib/nanfunctions.py", line 950, in nanmean
avg = _divide_by_count(tot, cnt, out=out)
File "/Users/mliquet/miniconda3/envs/lumen-dev37/lib/python3.7/site-packages/numpy/lib/nanfunctions.py", line 217, in _divide_by_count
return a.dtype.type(a / b)
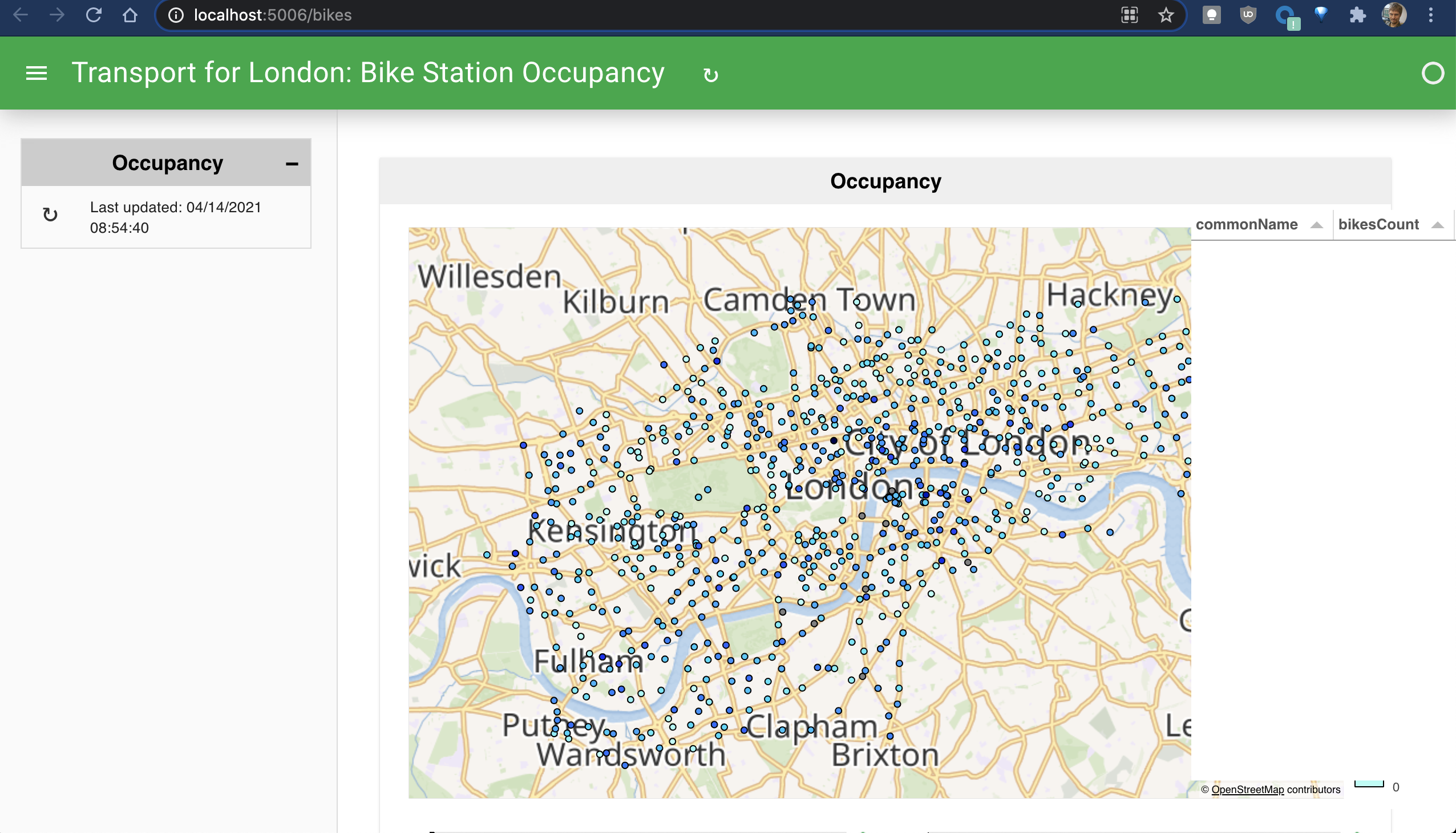
AttributeError: 'int' object has no attribute 'dtype'The app is still running but fails at updating the plots for that combination of filters. What happened is that in that case the filtered dataframe is empty (there are no Gentoo penguins from the Torgersen island apparently in the dataset). df.hvplot() of that data seems to fail because color is specified, indeed, the dashboard is set to group the data by species in the scatter plot.
I'm opening this issue specifically here since running directly the following snippet in a notebook just raises a warning and displays an empty plot (with a colormap).
An issue could probably be opened in hvplot too.














































































































































{kind=link}