- I’m currently working on mpd-web-api and mpd-web-ui
hexh250786313 / blog Goto Github PK
View Code? Open in Web Editor NEWhexh 的博客
Home Page: https://github.com/hexh250786313/blog/issues
hexh 的博客
Home Page: https://github.com/hexh250786313/blog/issues








































博文标题图片
博文置顶图片
![]()
博文置顶说明
新版的 KDE 和 Gnome 都有类 i3 的窗口管理功能或者插件. 而 Xfce4 的 Xfwm 比较遗憾, 还没有这种类 i3 功能或插件, 本文将介绍如何用 i3wm 替换 Xfwm, 从而实现在 xfce4 环境下使用 i3wm
yay -S i3-gaps-next-git
sudo pacman --remove xfdesktop
xfconf-query -c xfce4-session -p /sessions/Failsafe/Client0_Command -t string -sa i3sudo pacman -S xfdesktop
yay --remove i3-gaps-next-git
xfconf-query -c xfce4-session -p /sessions/Failsafe/Client0_Command -t string -sa xfwm$mod 键和 $sup 键被覆盖, 如果读者心里有数, 一个不删也可以操作完成后 xfwm 的合成器 (用于实现过渡动画 / 透明效果的软件) 和桌面 xfdesktop (背景墙纸) 当然是不生效了, 那么这时候就推荐 picom 合成器和 feh 墙纸等软件和 i3 配套, 这里不提
xfce4-i3-workspaces-plugin 是个可以在 xfce4-panel 上显示当前的 i3 workspace 的插件, 其实还挺有必要的
但这插件的问题在于会有严重的 bug, 就是会在刷新 i3 ($mod + shift + r) 的时候有时会断开与 i3wm 的连接, 于是会不断尝试重连, 又不断失败, 无限循环, 这过程中会不断对 ~/.xsession-errors 写入错误日志, 导致日志文件无限增加导致电脑硬盘容量爆满, 这个 bug 作者至今未修复, 十分让人蛋疼
不过也有个粗暴的解决方案, 就是在刷新 i3 时同时重启整个 xfce4-panel 的容器插件, 只需要在 ~/.config/i3/config 加入以下行即可 (注意 wrapper 的位置, 未必和我的位置一样, 具体以每个人的配置为准, 可以通过 htop 找到这个 wrapper 的位置):
exec_always --no-startup-id killall /usr/lib/xfce4/panel/wrapper-2.0博文置顶说明
前段时间知道了 Proton 这个神器, 心想怎么把吃灰的 Pro 手柄利用起来, 因为默认情况下 Pro 手柄蓝牙连接 Linux 后不能正确识别, 于是有了这篇文章
Linux 平台上的 Steam 原本就可以有线识别 Pro 手柄, 所以如果不是为了用蓝牙连接或者玩 Cemu Hook 模拟器 的话, 没有必要使用本文教程, 因为弄了本教程后, Steam 就没法把 Pro 手柄识别为 Pro 手柄了, 而是识别成 Xbox360 手柄, 也就是无法使用体感
但我还是建议你食用本教程, 因为 Steam 上的游戏本来也对 Xbox360 手柄支持度更好, 而且用 joycond 模拟成 Xbox360 手柄后, 除了无法用体感外, 其他例如震动功能都是正常的, 而且 Steam 也支持改键, 更方便. 再说蓝牙连接比有线连接体验感高不少
本人 PC 平台, Manjaro 平台, 内核 5.15.16-1-MANJARO, 不过 5.10 和 5.13 的内核本人亲测都是有效的, 大胆推测以下应该是个通用的方法
先装个 dkms 适配内核模块的更新, 下面是 Arch 的安装, 其他发行版都有对应的指令, 自行 Google
sudo pacman -Syu base-devel --needed
mhwd-kernel -li # 查看当前内核版本, 例如:linux513
sudo pacman -Syu $KERNELXYY-headers dkms # $KERNELXYY 就是上面那个内核, 所以是 linux513-headersyay -S hid-nintendo-dkmsyay -S joycond-gitsudo systemctl enable --now joycond至此已经完成了所有安装工作, 已经可以正确地蓝牙连接 Pro 手柄
博文置顶说明
试下只用 fugitive 的 Vim 是怎样的。没什么技术含量,都是最简单的实现,注重提供思路。
Vim 装了一堆插件也比不上 VSC 对 JS 的支持(个人主观暴论),没必要折腾了,就只留个 fugitive 和外观主题,用来做一些简单的编辑工作吧。下面会探讨下怎样实现一些简单的文件导航功能 without plugin!
说是全局,其实指的还是 git 管理的项目文件夹内部,会借助到 git 插件(所以我说老折腾 Vim 其实没什么必要,不如多学习怎么利用好 git,虽说也不是非要用 git 来实现全局搜索就是了)
字符串查询。Ggrep 是 fugitive 的指令,其实就是 git grep 只不过他帮你把结果输出到 Quickfix 窗口中而已,-i 是忽略大小写,个人感觉最常用,其他的 options 依需求自己加
文件查询。很遗憾,git 并不支持文件查询,点这里可以看到各种搜索插件的功能对比,git-grep 在 File finding 类别中全是空白的(真惨),说明他并不支持文件查询。那么换个思路,把项目底下的文件全部列出来后用 grep 直接查好了(没错 Linux 自带的那个 grep)
git ls-files 列出全部文件然后用 grep 找出目标文件(老实说这样挺蠢的,建议直接装个 ag 或者 rg 插件即可实现了,但是我想尽量用最少的插件来实现嘛,理解理解)<C-w>gf 或者 gf 或者 <C-w>f 即可进入对应的文件。其实也可以把结果输出到 Quickfix 中的(了解下 Vim 的 makeprg),但我不想折腾了:Ggrep -i "<regex>" # 字符串查询
:tabnew
:r! git ls-files | grep -i "<regex>" # 文件查询以前我跳转窗口都是直接把上下左右跳转的组合键 map 到了 <C-h/j/k/l> 上,但是后来感觉最好还是不要动原生的快捷键,于是就把窗口跳转绑定到了 <Leader> 上,我 <Leader> 用的是空格键(修改 .vimrc)。这样就能通过按空格 + 数字的组合跳到任意的窗口中(顺便我把 <C-^> map 到了 <Space><Tab> 上,这个组合真的很顺手)
let mapleader=" "
nnoremap <SPACE> <Nop>
let i = 1
while i <= 9
execute 'nnoremap <Leader>' . i . ' :' . i . 'wincmd w<CR>'
let i = i + 1
endwhile跳转:跳转到特定的 buffer,最简单的做法是 :b 之后按 Tab 来选择要去的文件。如果要在两个 buffers 之间反复横跳,用 <C-^> 就行
删除:删掉特定的 buffer 是用 :%bd <number-of-buffer>,但是一般要删都是全删或者保留当前窗口的,所以我用的方法是
o 插入一行):%bd 删除全部 buffers,这时候有更改但是没有保存的文件就会被保留下来,也就是我新插入行的那个文件没有从 buffers 移除,也就达到了仅保留当前 buffer 的目的单行 I// (假设 // 是注释);多行 <C-v>jjjI//
取消注释:单行 ^dw;多行 <C-v>jjjllld
:split
:lcd %:h | explorer.exe .指的是用系统解析器打开当前文件夹,lcd 可以单独对某个窗口执行 cd,也就是把某路径设置为工作路径。所以这一段的意思就是把当前文件所在路径设置为工作路径,然后用文件浏览器打开(因为我用的是 wsl,所以直接就是 explorer.exe . 打开了,另外其实 wsl 也提供了 explorer.exe 的直接打开某目录的指令::!explorer.exe `wslpath -w "%:p:h"` )
其实可以通过 Vim 的路径获取指令来做很多事情。例如 :!prettier --write %:p 或者 !standard --parser babel-eslint --fix %:p 来对当前文件执行格式化
也就这些了,没什么好整的了,高级点的自动补全、定义跳转这些已经是 IDE 的范围了,非要用 Vim 开发的话也只能上 CoC 这些 Vim 的语言服务了,但是我就是因为用多了插件觉得用 Vim 都没了那个轻灵的感觉了才毅然决然把插件都删掉的,开发还是交给 VSC 这些专门软件吧
博文置顶说明
Win10 默认的可修改的按键延迟即使调到最高,键间延迟依然很高,对于 Vim 用户来说实在慢得受不了,其实通过修改注册表就可以非常简单地增加按键重复速度和减少按键延迟
Increase keyboard repeat rate beyond control panel limits in Windows 10
控制面板 - 键盘 - 速度:
这是默认方法,但是即使调到最高,键间延迟依然很高
HKEY_CURRENT_USER\Control Panel\Accessibility\Keyboard Response"AutoRepeatDelay"="200"
"AutoRepeatRate"="6"
"DelayBeforeAcceptance"="0"
"Flags"="59"
"BounceTime"="0"这个是我自己的设置,每个人根据自己习惯自行调整,其中最影响重复延迟和按键速度的是 AutoRepeatDelay、AutoRepeatRate 和 DelayBeforeAcceptance
博文置顶说明
一个可以同时运行多个 "gh repo sync owner/cli-fork" 命令的命令行工具, 以帮助同步所有 fork 的 GitHub 仓库
确保环境中已经安装了 github-cli 并且已经登录了 github 帐号
注意是 gh-repo-sync-cli, 而不是 gh-repo-cli!!! 因为已经有另一个名为 gh-repo-sync 的库了 🤷♀
npm install -g gh-repo-sync-cligh-repo-sync --help该工具有两种方法来传递仓库名参数给 gh repo sync
gh-repo-sync owner/repo1 owner/repo2配置文件位置: ~/.config/gh-repo-sync/config.json
{
"repos": [
"owner/repo1",
"owner/repo2"
]
}配置完后执行 gh-repo-sync 就会同步所有 repos 数组中的仓库
如果同步过程中有源仓库发生了变化需要进行 PR, 那么工具就会抛出错误

博文标题图片
博文置顶图片
![]()
博文置顶说明
用 React.js 做的仿微信/小程序 Emoji 表情组件
yarn add react-wechat-emoji
import React, { useState } from 'react'
import { Emoji, ContentWithEmoji, parseEmoji } from 'react-wechat-emoji'
function App () {
const [text, setText] = useState('')
const testText = '你好,世界[微笑]'
const contents = parseEmoji(testText)
console.log(contents)
/** 打印结果:
* contents = [
* { type: 1, content: "你好,世界", imageClass: "" },
* { type: 2, content: "[微笑]", imageClass: "smiley_0" },
* ];
* */
return (
<div>
输入一些东西并点击下方表情窗口的任意表情:
<input
type='text'
value={text}
onChange={(e) => setText(e.target.value)}
/>
<div>
<Emoji
recentUsed={[
{
cn: '[鸡]',
code: '',
hk: '[小雞]',
id: 214,
style: 'e2_14',
us: '[Chick]',
web_code: ''
}
]}
source='https://dev.azure.com/hexuhua/f6126346-6e87-4d62-aa80-ff9b88293af0/_apis/git/repositories/ebd79495-5cbb-4565-8573-fa73ee451b5e/items?path=/github.com/hexh250786313/blog/14/xuebi.png&versionDescriptor%5BversionOptions%5D=0&versionDescriptor%5BversionType%5D=0&versionDescriptor%5Bversion%5D=main&resolveLfs=true&%24format=octetStream&api-version=5.0'
height={300}
insertEmoji={(emojiText, recentUsed) => {
setText(text + emojiText)
console.log({ recentUsed })
}}
/>
</div>
<p style={{ margin: '20px 0 0 0' }}>将会显示你的输入值和解析表情图片:</p>
<div style={{ backgroundColor: '#eee', padding: 10 }}>
<ContentWithEmoji
source='https://dev.azure.com/hexuhua/f6126346-6e87-4d62-aa80-ff9b88293af0/_apis/git/repositories/ebd79495-5cbb-4565-8573-fa73ee451b5e/items?path=/github.com/hexh250786313/blog/14/xuebi.png&versionDescriptor%5BversionOptions%5D=0&versionDescriptor%5BversionType%5D=0&versionDescriptor%5Bversion%5D=main&resolveLfs=true&%24format=octetStream&api-version=5.0'
emojiScale={0.5}
content={text}
/>
</div>
</div>
)
}
export default Appconst textType = {
normal: 1,
emoji: 2
}
const emoji = {
id: 0,
cn: "[微笑]",
hk: "[微笑]",
us: "[Smile]",
code: "/::)",
web_code: "/微笑",
style: "smiley_0",
};
type EmojiContentType = {
type: typeof textType.normal | typeof textType.emoji;
content: string;
imageClass: string;
};| prop | default | type | description |
|---|---|---|---|
| height | 300 |
number |
Emoji 面板高度 |
| insertEmoji | none | (emojiText: string, recentUsed?: Array<typeof emoji>) => void |
点击表情的回调,参数一是点击的 emoji text,参数二是最近使用表情(如果有开启最近使用功能的话) |
| source | bilibili 图床地址 | string |
Emoji 雪碧图地址,强烈建议使用自己的 CDN 地址,默认是 bilibili 图床地址,稳定性未知 |
| recentUsed | none | Array<typeof emoji> |
最近使用表情,参数仅用作初始化,无初始值传空数组;想关闭此功能则不传此参数 |
| prop | default | type | description |
|---|---|---|---|
| content | none | string | Array<EmojiContentType> |
内容 |
| bodyStyle | none | React.CSSProperties |
外层样式 |
| textStyle | none | React.CSSProperties |
文本样式 |
| emojiScale | 0.5 |
number |
表情的显示大小 |
| source | bilibili 图床地址 | string |
Emoji 雪碧图地址,强烈建议使用自己的 CDN 地址,默认是 bilibili 图床地址,稳定性未知 |
强烈建议使用自己的 CDN 地址,默认是 Azure Git 地址,稳定性未知。右键保存下方的图片到你的 CDN,组件的 source 填上你的 CDN 地址
function parseEmoji(content: string): EmojiContentType[];git clone https://github.com/hexh250786313/react-wechat-emoji.git
cd react-wechat-emoji
yarn && yarn start
MIT
博文置顶说明
本文介绍 wsl2 的端口转发、网络代理等问题,不会或者少量涉及 wsl2 的安装部署,因为安装教程很容易能找到。这里着重于端口转发、网络代理等容易遇到的坑
上述问题,可以通过端口转发的方式,让 windows 把 wsl2 的端口转发暴露给局域网,因此需要搞定三件事情:
以上三个问题的对应方案如下:
============================
※ 注意,本第三节已经废弃,不再需要使用这种迂回的方式来映射子系统的 ip
※
※ 对于获取子系统 ip 不感兴趣的可以直接跳到文章第 2.2.2 小节端口转发
※
※ 本节不删除只用作存档,修改时间:2024/1/20
============================
.\wsl2host.exe install192.168.82.59 ubuntu.wsl # managed by wsl2-hostubuntu.wsl 来获取到子系统的虚拟 ip.bat 文件并以管理员权限打开):
pushd "%~dp0"
dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientExtensions-Package~3*.mum >List.txt
dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientTools-Package~3*.mum >>List.txt
for /f %%i in ('findstr /i . List.txt 2^>nul') do dism /online /norestart /add-package:"C:\Windows\servicing\Packages\%%i".\wsl2host.exe debug 指令, 这样也可以手动给 hosts 添加上新的 ip, 这样需要每次开机都手动调下指令 (原因是每次开机宿主机 ip 都不一样), 挺麻烦的pwsh 中执行:notepad $profile 打开 pwsh 的配置文件,接下来要写两段脚本
在配置文件中添加如下代码并保存。另外下面的脚本中有 sudo 指令,这个要求你的 pwsh 要事先安装了 sudo 插件,这个是用来获取管理员权限的,请自行搜索安装方法。对于脚本里面的 192.168.10.68 就是你需要映射的端口,一般就是你的宿主机的内网 ip,自行修改,下面是代码:
function setWslNetsh {
param (
$Port
)
sudo netsh interface portproxy add v4tov4 listenport=$Port connectaddress=localhost connectport=$Port listenaddress=192.168.10.68 protocol=tcp
Write-Output "✔ Port($Port) now is out!"
}
function unsetWslNetsh {
param (
$Port
)
sudo netsh interface portproxy delete v4tov4 listenport=$Port listenaddress=192.168.10.68 protocol=tcp
Write-Output "✔ Port($Port) now is not out!"
}
Set-Alias wsl-netsh-set setWslNetsh
Set-Alias wsl-netsh-unset unsetWslNetsh上面这段代码就是实现端口转发的主要脚本,这时候在 pwsh 中执行:wsl-netsh-set <port> 就能让 windows 把子系统的端口转发出去。例如:wsl-netsh-set 8000 就能把子系统中端口号为 8000 的进程转发出去
同样的 wsl-netsh-unset <port> 则是取消转发
另外还可以在子系统中去执行这个指令:pwsh wsl-netsh-set <port> 或 pwsh wsl-netsh-unset <port>
原理补充:wsl2 的流量转发原理就是会把 wsl2 中的使用到的端口通过 localhost 转发的宿主机,例如你在子系统起了一个 http://localhost:8000 的服务,那么你不需要做任何事情,就可以在宿主机通过 http://localhost:8000 访问到这个服务,而这个脚本就是基于这个原理,通过 netsh 进行流量转发,把特定的 <ip>:<port> 的访问流量转发到 localhost:<port>,这样就能把子系统的端口暴露给局域网了
ipv6 说明,上面的脚本是针对使用了 ipv4 的服务的,从 v4tov4 你就可以看出来,如果你子系统使用的是 ivp6 服务,那么你也可以这样来设置转发和取消转发,你可以自行调整 v4tov6 这一处,看你的宿主机是想用什么 ip 协议来访问这个子系统端口
sudo netsh interface portproxy delete v4tov6 listenport=8000 listenaddress=192.168.10.68
sudo netsh interface portproxy add v4tov6 listenport=8000 listenaddress=192.168.10.68 connectport=8000 connectaddress=::1
每次宿主机开机以后你会发现明明上一次开机已经进行过端口映射了,但是为什么这次开机后不生效,这是预料之中的事情,你只需要每次开机完毕后都用 wsl-netsh-unset <port> 取消转发,然后再重新设置一下转发就行了,你可以通过 netsh interface portproxy show all 看到当前有哪些进行了流量转发的地址和端口
最简单的做法其实就是在防火墙中添加出站和入站规则,添加一下需要暴露到局域网的端口即可。当然也可以把这个写成脚本,需要暴露什么端口直接执行脚本就行,同样在 pwsh 的配置文件中添加代码:
function setFWPort {
param (
$Port
)
$Port4WSL = "Port4WSL-" + $Port
$NetFirewallRule = Get-NetFirewallRule
if (-not $NetFirewallRule.DisplayName.Contains($Port4WSL)) {
# sudo Remove-NetFireWallRule -DisplayName $Port4WSL
sudo New-NetFireWallRule -DisplayName $Port4WSL -Direction Outbound -LocalPort $Port -Action Allow -Protocol TCP
sudo New-NetFireWallRule -DisplayName $Port4WSL -Direction Inbound -LocalPort $Port -Action Allow -Protocol TCP
Write-Output "✔ New rule for WSL(Port: $Port)!"
}
else {
Write-Output "✔ Rule for WSL(Port: $Port) exists!"
}
}
function unsetFWPort {
param (
$Port
)
$Port4WSL = "Port4WSL-" + $Port
$NetFirewallRule = Get-NetFirewallRule
if (-not $NetFirewallRule.DisplayName.Contains($Port4WSL)) {
Write-Output "✔ Rule for WSL(Port: $Port) not exists!"
}
else {
sudo Remove-NetFireWallRule -DisplayName $Port4WSL
Write-Output "✔ Rule for WSL(Port: $Port) removed!"
}
}
Set-Alias fw-port-set setFWPort
Set-Alias fw-port-unset unsetFWPort然后就能用 fw-port-set <port> 来创建新的出入站规则,用 fw-port-unset <port> 移除规则。规则名称定为了 Port4WSL-<port>,可以自行修改
完成上述步骤,就可以把子系统的进程端口暴露到局域网了,例如我在子系统起了一个服务,端口为 8000,windows 在局域网的地址为 192.168.1.215,那么局域网下的其他设备就能通过访问 http://192.168.1.215:8000 访问我子系统下的服务
博文置顶说明
关于我和这个博客
博文置顶说明
又造了个 coc 玩具,大概的作用同 coc-list files,但是没有输入值时展示的是 mru 列表。但是使用这个插件需要 hack coc 的编译文件。
在 hack 过的 coc.nvim 上运行的文件查找器插件。您可以打开一个和 coc-list files 一样的文件查找器,但如果没有输入值,它将显示默认的 mru 列表。
它依赖于支持动态切换列表数据的 coc.nvim 客户端。这意味着你必须手动修改 coc 的编译文件。
不优雅但有用。
您需要安装 coc.nvim 才能使用此扩展。然后运行:
:CocInstall @hexuhua/coc-list-files-mru同时,因为coc不支持动态切换列表数据,你必须进行以下修改来 hack coc.nvim。
找到您的 coc.nvim 安装路径并在 /path/to/your/coc.nvim/build/index.js 中进行以下更改:

或者,如果您使用 sd,您可以执行这些命令来达到相同的结果:
sd '}\n.*set loading\(loading\)' ' this.mruFlag = true; } set loading(loading)' /path/to/your/coc.nvim/build/index.js
sd 'async drawItems\(\) \{' 'async drawItems(context) { var _a2; if (((_a2 = this.list) == null ? void 0 : _a2.name) === "filesMru") { if ((context == null ? void 0 : context.input.length) > 0 && this.mruFlag === true) { this.mruFlag = false; await this.loadItems(context); await this.drawItems(context); return; } if ((context == null ? void 0 : context.input.length) === 0 && this.mruFlag === false) { this.mruFlag = true; await this.loadItems(context); await this.drawItems(context); return; } }' /path/to/your/coc.nvim/build/index.js
sd 'void this.worker.drawItems\(\);' 'void this.worker.drawItems(this.context);' /path/to/your/coc.nvim/build/index.js:CocList filesMru这插件会读取 coc-list files 和 mru 的配置。
博文标题图片
博文置顶图片
![]()
博文置顶说明
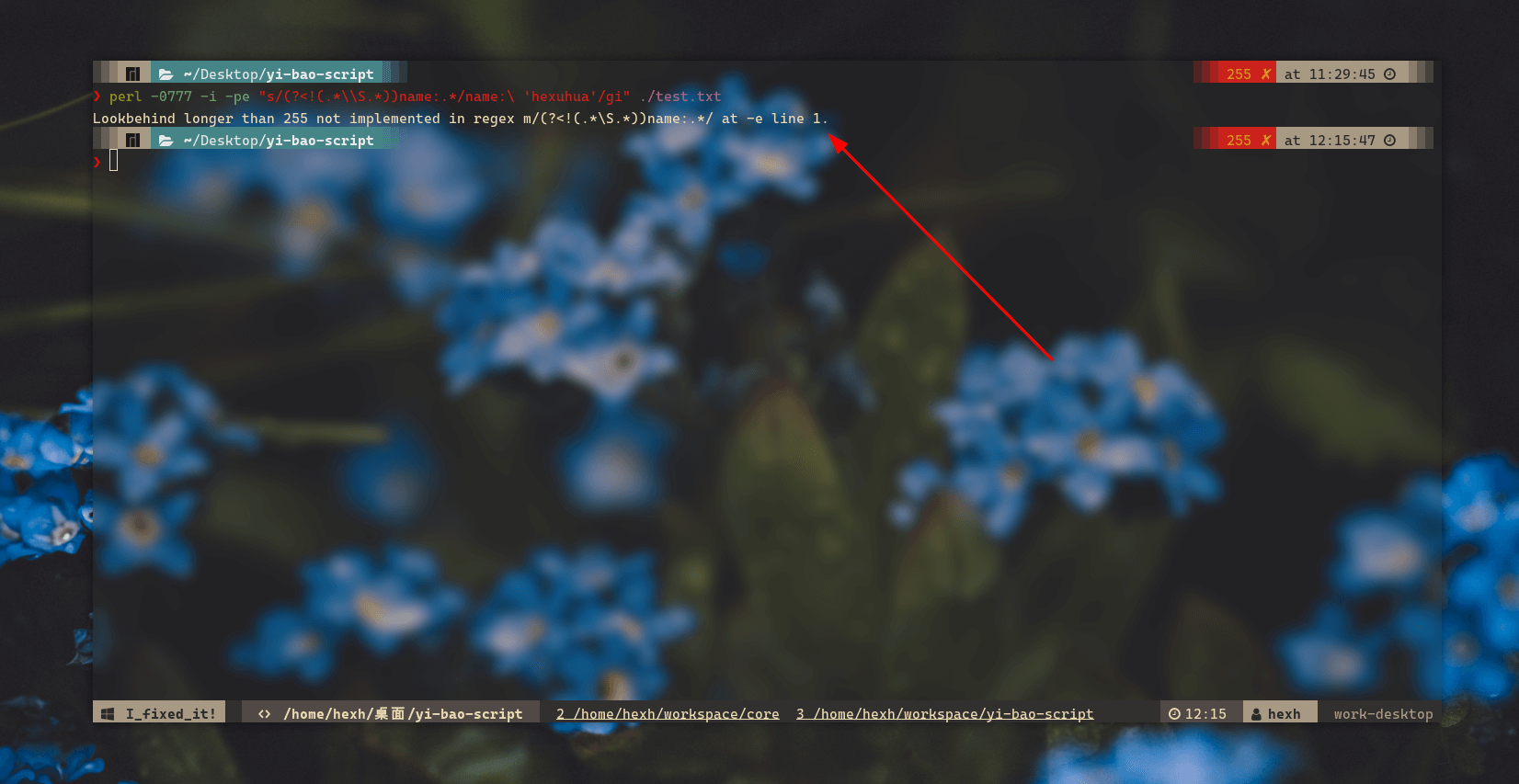
最近写一些文本处理脚本的时候遇到了使用 perl 提示 "Lookbehind longer than 255 not implemented in regex" 这样的错误, 不是什么大问题, StackOverflow 里也能找到答案, 但是中文互联网上却没有相关的条目, 于是这里稍微记录下
我的脚本调用了 perl 来做文本处理, 里面有一个正则用到了后置约束:
perl -0777 -i -pe "s/(?<!(.*\\S.*))name:.*/name:\ 'hexh'/gi" ./test.txt目的是把不带任何非空前缀的 name 值改为 hexh, 例如:
// source:
name: 'hexuhua'
fullname: 'hexuhua'
// expected:
name: 'hexh'
fullname: 'hexuhua'但是却报错了:
Lookbehind longer than 255 not implemented in regex m/(?<!(.*\S.*))name:.*/ at -e line 1.根据这篇博客: http://blogs.perl.org/users/tom_wyant/2019/03/native-variable-length-lookbehind.html
Now, there is at least one restriction. No lookbehind assertion can be more than 255 characters long. This limit has been around, as nearly as I can tell, ever since lookaround assertions were introduced in 5.005. But it has been lightly documented until now. This restriction means you can not use quantifiers * or +. But bracketed quantifiers are OK, as is ?.
大概翻译下: 任何 lookbehind 断言的长度都不能超过 255 个字符, 自从 5.005 版引入 lookbehind 断言以来, 这个限制就一直存在, 这个限制意味着你不能使用 .* 或者 .+ 这样的贪婪匹配, 而用非贪婪匹配如: 大括号限制 255 字符内或者 .? 的形式则是没问题的
那么也就是说对于上述正则: s/(?<!(.*\\S.*))name:.*/name:\ 'hexh'/gi 的问题就出在了后置约束 ?<!(.*\\S.*) 中, perl 要求约束中的字符不能用贪婪匹配且少于 255 个字符
由此分析, 可以改成类似这样的形式: ?<!({0,127}\\S.{0,127}), 保证括弧内的字符数量少于等于 255 个即可
最终命令如下:
perl -0777 -i -pe "s/(?<!(.{0,127}\\S.{0,127}))name:.*/name:\ 'hexh'/gi" ./test.txt值得一提的是, 后置约束对于 perl 来说依然属于实验性功能, 每次用后置断言后它都会有这样的提示:
Variable length negative lookbehind with capturing is experimental in regex;
博文置顶说明
本文主要说明对博客项目进行 SEO 优化,让其可以出现在 Google Search 的搜索结果中,并且让网站能够通过 sitemap 测试,使所有的网页都可以被爬取出来。最后谈谈 Google Search 的收录机制
Google Search Console 是 Google 提供的网站收录和管理服务的控制台,在这里可以验证你需要让 Google 收录的网址并管理查看点击率和访问流量等信息
以本博客为例子,来操作如何让 Google Search 收录网站。首先在在网址前缀那一边输入要验证的网站的网址
等待验证之后会出现下面的步骤
这里一共有5种验证方式,我用的是第一种文件验证。先把这个 html 文件下载下来,之后丢到本项目下的 📂 public 文件夹即可。然后再点击上图的验证,片刻后会出现验证成功
这时候没有意外的话等待 Google 去爬取下来就行,体感在1天多之后就可以在 Google Search 上搜索到了,在输入框中输入 site:<YOUR SITE> 即可看到出现在搜索结果中
接着可以回到 Google Search Console 中点击左上角的搜索资源,再点击刚验证网站
就可以进入网站管理,如下图
其中比较值得注意的是覆盖率,刚收录的网站一般没那么快记录得到覆盖率,需要过一段时间让 Google Search 完全爬取你的网站后,这里才会显示相关数据。当然在此之前我们可以手动上传 sitemap 地图,增强 Google Search 爬取网站的效率
所谓站点地图就是标识了你的网站中能够被爬取到的网站,你需要给你网站的每一个页面提供引荐来源,才能让爬虫顺利进入对应的网页,最简单的做法就是使用 a 标签。例如下图,如果你想让你的这些被圈出来的页面被爬取到,你就需要在这些地方使用 a 标签来处理这些链接
然后我们可以对进行 sitemap 测试,用这个网站,把 url 输入进去等待片刻就能生成你的网站的 sitemap,可以查看到结果,结果列表显示了你的网站里能被正常爬取到的网站,如果没出现在上面,你可能需要对网站作进一步的优化,例如把所有的跳转链接都加上 a 标签
可以看到 sitemap 文件其实是一个 xml 格式的文件,sitemap.xml:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<!-- created with Free Online Sitemap Generator www.xml-sitemaps.com -->
<url>
<loc>https://blog-front-git-dev.hexuhua.now.sh/</loc>
<lastmod>2020-10-24T16:26:23+00:00</lastmod>
<priority>1.00</priority>
</url>
<url>
<loc>https://blog-front-git-dev.hexuhua.now.sh/post/list?page=1</loc>
<lastmod>2020-10-24T16:26:23+00:00</lastmod>
<priority>0.80</priority>
</url>
</urlset>其中 priority 是指这个网页对于网站的重要性,但是事实上这个值完全不会影响 Google Search 的搜索排名,所以不需要管
接着同样把你生成的 sitemap.xml 扔进项目的根目录(本项目为 📂 public 文件夹),然后在 Google Search Console 的站点地图中输入你的站点地图文件即可
上面提到,想要让 Google Search 爬取到你的每一个网页,那就要使用 a 标签来给你的网页添加引荐来源,所以我只需要把本项目使用 Router.push() 地方改造成用 <Link><a>链接</a></Link> 的形式即可,包括 antd 的分页器的点击事件也要改造成这个形式,幸好 antd 早就预料到此处的 SEO 优化的坑,所以是支持开发者自己重新渲染分页器的组件的,改变 Pagination 组件的 itemRender 即可:
import Link from 'next/link'
const itemRender = (current, type, originalElement) => {
if (type === `page`) {
return (
<Link href={`/post/list?page=${current}`}>
<a target="_self">{current}</a>
</Link>
)
}
return originalElement
}而这里其实我遇到了另一个坑,涉及到服务端渲染的
NextJS 的特性是可以在初始化页面时在服务端完成数据的获取,直接把渲染完成后的页面丢到浏览器,这跟目前主流的 Ajax 页面的渲染局部——再获取数据——再渲染剩下的部分的做法不一样。当然 NextJS 项目在浏览器以后其渲染行为也是采用 Ajax 的方式的,区别在于第一次渲染是服务端渲染而已
实现这一点用到了 NextJS 的 getInitialProps 方法
Home.getInitialProps = async props => {
const { isServer, store } = props.ctx
if (isServer) { // 可以根据这个值判断 process 是否处在服务端,是的话请求数据并渲染,不然的话说明处在客户端,此时交给 React 的生命周期组件来实现请求数据的逻辑
// fetch data
}
return { isServer }
}而坑点就出在了 props.ctx 上,这个对象可以获得当前页面的 url 和 search 等属性或者 redux 的 store 状态方法等,但是偏偏不能获得当前页面的 hash 值。所以就跟上一篇提到的用 hash 值来获取当前页数的做法就失效了,这时候就相当于无法在服务端得知当前列表页的页数,就失去了客户端渲染的意义了,无法得到正确页面数据,也就失去 SEO 优化的意义
其实解决办法也很简单,虽然无法获取 hash 值,但是 props.ctx 中依然能正确获得网址的 search 值,也就是网址上 ? 参数后的值,所以根据上一篇的内容,只需要稍作修改,把 hashChangeComplete 改成 routeChangeComplete ,然后把路由字符串中用到了#的地方换成 ? 即可
在我把 sitemap 完成并上传后,理论上 Google Search 就会去爬取我的网页,但是事实上并不是所有的网页都被收录了,在覆盖率那里可以看到,我的有效网页只有首页和列表页,我的所有文章详情页都标识为已排除,实际搜索中也只有首页和列表页出现在了搜索结果中
这是很奇怪的事情,而且当我在控制台上方输入某个文章详情页的地址进行检查的时候,他会显示尚未收录,但是也没有提示是什么原因
后来我找了一些资料,发现了以下内容
根据 “SEO 学” 学家 Brian Dean 的说法(来自 Google Search Console):
“Crawled – currently not indexed”
Hmmm…These are pages that Google has crawled, but (for some reason) are not indexed.
Google doesn’t give you the exact reason they won’t index the page.
But from my experience, this error means: the page isn’t good enough to warrant a spot in the search results.
So, what should you do to fix this?
My advice: work on improving the quality of any pages listed.
For example, if it’s a category page, add some content that describes that category. If the page has lots of duplicate content, make it unique. If the page doesn’t have much content on it, beef it up.
Basically, make the page worthy of Google’s index.
翻译一下:
“已抓取,尚未收录”
嗯...
有些页面会被 Google 抓取,但因为某些原因没有被收录
Google 并没有给出明确的说明为何他们不收录这些页面
但是根据我的经验,问题可能出在了:这些页面的质量不足以在搜索结果中占有一席之地
所以,改怎么解决这个问题呢?
我的建议是:致力于提高你的这些网页的质量
例如,如果有一个目录页面,你可以添加一些内容来描述这个目录;如果一个页面有大量的重复内容,你可以删掉重复的部分;如果页面的内容不够丰富,那就丰富他
结论就是,让你的页面有足以让 Google 去收录的价值
结合我那几个被收录和没被收录的来看一下吧:
/、/post/list/post/6、/post/7、/about| 页面地址 | 说明 |
|---|---|
/ |
主页面,内容是我当前所有文章(共3篇)的标题 + 描述 + 描述图片 |
/page/list |
列表页面,内容是当前带有 post (共2篇)标签的文章的标题 + 描述+ 描述图片 |
/about |
博客说明页面,大约60个字 |
/post/6 |
自用软件清单,大约50个字 |
/post/7 |
测试页面,几张图 + 几个字 |
我不是很确定为什么主页面和列表页这种目录索引页也能收录进去,但是剩下那三个页面确实是没什么质量的页面,不收录也是情理之中
所以以上就是我本次博客开发的所有体验,收获还是不少的,希望也能给正在浏览的同学提供一点帮助
博文置顶说明
deb 包是由软件 apt 包管理系统管理的的包, 常用于 Debian 系统的软件安装, pacman 系的系统无法直接安装 deb 包软件. 一般而言, 可以借助 debtap 这类工具来二次打包为 tar.zst 包, 再由 pacman 进行安装. 但是这种二次打包的方式并不为人所推荐, 即使是 debtap 的作者也不推荐利用这种方式来转包. 本文记录了笔者的一次转包过程 ( 结果是失败了 ), 探讨了这种转包方式的: 原理 / 可能遇到的问题 / 兼容性的处理
aTrust 是深信服的一款产品, 主要用于在电脑中建立公司的工作环境网络, 类似 openvpn, Linux 版本只提供了 deb 包
我的需求是在我的工作环境 Manjaro 系统中装上该软件
上图 ( 来源 ) 可见, 官方支持的 Linux 系统只有 UOS 和 麒麟, 而 UOS 来自于 deepin 魔改, 可见 deepin 也支持
// sudo dpkg --install foo.deb
// foo.deb 解包后:
deb
├── DEBIAN
│ ├── control
│ ├── postinst
│ ├── postrm
│ ├── preinst
│ └── prerm
└── (others)
DEBIAN 文件夹就是存放安装信息和安装脚本的地方
control 记录了包信息postinst / postrm 等顾名思义是 hook, 里面是具体的脚本代码DEBIAN 文件夹里可以放置自定义 sh 脚本文件, 供给 hook 调用(others) 指待安装到系统的文件如 /opt/Something / /usr/bin/MyApp 等// sudo pacman -U foo.tar.zst
// foo.tar.zst 解包后:
tar.zst
├── .INSTALL
├── .MTREE
├── .PKGINFO
└── (others)
tar.zst: 该包
.PKGINFO 是存放安装信息
.MTREE 我也不太理解, 请看这里
.INSTALL 同样是脚本, 里面的代码结构描述了和上面 deb 包的 hook 脚本一样的钩子
post_install() {
echo "do something" # 此处的代码理论上与 deb 中的 postinst 一致
}
pre_remove() {
echo "do something" # 此处的代码理论上与 deb 中的 postrm 一致
}(others) 指待安装到系统的文件如 /opt/Something / /usr/bin/MyApp 等
由上文可得知, 虽然两种打包系统的安装包文件结构不同, 但是总体的安装包的设计思路还是十分类似的:
debtap 可以帮我们直接把 deb 包转成一个模板化的 tar.zst 包, 即:
postins 脚本的代码注入进 .INSTALL 的 post_install 函数中 )这种方法的坑点如下:
DEBIAN 中的内置脚本. 例如有一种情况: DEBIAN 中写有自定义脚本 helpers.sh, 钩子脚本 post_install 会调用这个 helpers.sh 来帮忙安装. 那么 debtap 在转的时候会无视这些自定义脚本, 统统不会打包进 tar.zst因此只要先用 debtap 把 deb 包初步转成 tar.zst 包, 再根据需求修改里面的 .INSTALL 代码, 理论上可以实现本次需求
这一步主要是查看源 deb 的打包脚本和取得 debtap 不会帮忙打包的冗余文件
mkdir -p extract/DEBIAN && dpkg -X aTrust.deb ./extract && dpkg -e aTrust.deb ./extract/DEBIAN然后获得文件夹 extract, 里面就是源 deb 包的安装文件和脚本
利用 debtap 初步转包
sudo debtap -u # 更新库
debtap aTrust.deb过程中要求输入包名
debtap 会帮你分析出哪个依赖包你当前的系统不满足, 然后要求你编辑依赖信息, 你可以根据自己的需求进行删除
例如 aTrust 要求一个 deepin 的环境监测包 deepin-elf-verify, 根据博文 deepin-elf-verify 究竟是何物? 可知 deepin-elf-verify 为空包, 于是直接从依赖中删掉
最终得到 tar.zst 包 aTrust.pkg.tar.zst
然后解开他: mkdir pkg && cp aTrust.tar.zst ./pkg && cd ./pkg && tar -I zstd -xvf aTrust.pkg.tar.zst
得到 tar.zst 的所有文件和脚本
分别对比 deb 包里和 tar.zst 包里的钩子脚本
首先发现 deb 的脚本中大量存在参数的获取, 例如脚本路径
SCRIPT_PATH=$(dirname "$0")但是 pacman 的安装是没有参数传递的, 因此需要改造, 这里我直接写死了路径:
SCRIPT_PATH=/home/MyPath同理, 所有的需要参数的地方都被我写死为具体的值
同时也发现了 deb 包中有几个 sh 脚本未被 debtap 打包进 tar.zst 中, 于是观察这些脚本被调用的方式, 发现是钩子直接调用了同级目录的脚本: sh -c ./xxx.sh, 于是我把这些类似的调用都改成了 sh -c ~/Desktop/aTrust/sh/xxx.sh 这样的形式, 也就是固定他的调用路径, 然后把这些脚本放到桌面中: ~/Desktop/aTrust/sh/, 然后给执行权限: chmod +x ~/Desktop/aTrust/sh/
重新打包 deb 包得到 atrust2.deb
dpkg -b ./extract aTrust2.deb再次转包
debtap aTrust2.deb然后同样和上面一样也是删掉依赖: deepin-elf-verify, 然后得到 aTrust2.pkg.tar.zst, 安装:
sudo pacman -U aTrust2.pkg.tar.zst结果和一开始相比果然有了变化:
但是从本质上来说, 和一开始比也没有不同: 同样无法启动代理. 这一点我看 aTrust 的日志以后, 发现直接原因是有一个 (登录) 服务没法启动, 这点与我在 Ubuntu22 上的实验结果完全一样 (Ubuntu22 上也没成功, 但 Ubuntu20 成功了)
最后推测原因可能有两个:
deepin-elf-verify 被删除了, Ubuntu22 也是装不上这个包, 原因是 openssl 的版本问题不过这些都是主观猜测, 没有任何证据
最后起了一个 Ubuntu20 的虚拟机, 在虚拟机上启动 aTrust 后, 利用 tinyproxy + microsocks 给 host 机输出一个代理端口
博文置顶说明
本文主要介绍如何取消 Win10 的文件共享,让 WSL 或 WSL2 的 Samba 共享服务代替 Win10 的共享,让局域网可以访问 WSL 中的共享文件
Linux 中的 Samba 服务主要用到 139 和 445 这两个端口,因此首先要取消在 Win10 中的这两个端口
Server 服务 - 启动类型禁用 - 重启sudo apt-get install sambasudo vi /etc/samba/smb.conf在最末尾添加类似如下的代码(share 是共享文件夹的名字,path 是路径,自行替换):
[share]
path = /home/me/share
available = yes
browseable = yes
writable = yes
public = yes
sudo service smbd restart把上述的 139 和 445 端口暴露出去并创建防火墙规则,具体做法参考这篇:一口气搞定 WSL2 的网络问题
chmod 777 /YourShare,但是需要在其更高级别的权限上设置,例如: 要分享 /home/my/Desktop 这个文件夹,需要执行 chmod 777 /home/my 保证其上级文件夹 /my 的权限(当然 Desktop 也有可能权限不够,可能还需要再执行一遍 chmod 777 /home/my/Desktop),结论是需要保证每一级的文件夹访问权限都是可访问的smbclient //localhost/<SharedDirName> 指令来进入分享目录测试 smb 是否已经成功,需要输入访问密码,如果设置了 public = yes,此处可以不输入密码直接回车进入目录smbclient //localhost/<SharedDirName> 后进入分享目录,可以通过 ls 测试是否可以访问目录,如果有如下提示说明权限设置不足:
NT_STATUS_ACCESS_DENIED
博文置顶说明
Sentry 在 web 端的主要应用集中在错误捕获和性能数据上报。本文旨在总结如何优化 Sentry 的上报方式,以实现更丰富的信息收集和减少接口请求量。本文将分享一些个人经验,以规范上报格式并提供实用的优化方案。请将本文视为一篇启发性的文章,希望能为你提供有价值的参考。
Sentry 的搭建可以参考这个文章:一口气完成 Sentry Docker 部署,本文不会赘述
本文针对的是 Sentry 在 React 端的上报优化,对于 web 端的上报同样具有一定的参考意义,主要总结的是以下内容:
根据 Sentry 的官方的使用例子,Sentry 会以同步的方式在程序启动时进行初始化。那么为了防止 Sentry 的初始化会堵塞进程或者 Sentry 加载过程中自身发生了错误导致程序初始化失败,那么我们可以把它变为了异步加载,如下:
async function runSentry() {
const Sentry = await import("@sentry/react");
Sentry.init(sentryOptions);
// 给全局加上 Sengtry 实例,方便用于手动上报
window.Sentry = Sentry;
}
runSentry();异步加载 Sentry 会带来另一个问题,那就是如果程序初始化时的同步任务发生了错误,这些错误就会丢失在 Sentry 初始化前。
为了解决这一点,可以在程序初始化的最开始先注册一个全局的错误监听,收集这些没被 Sentry 捕获的错误,然后在 Sentry 初始化完成后统一上报,如下:
const unhandledErrors: Error[] = [];
function addUnhandledErrors(e) {
if (!window.Sentry) {
unhandledErrors.push(e.error);
}
}
window.addEventListener("error", addUnhandledErrors);
function reportUnhandledErrors() {
if (unhandledErrors.length !== 0 && window.Sentry) {
unhandledErrors.forEach((error) => {
// 手动上报这些错误
window.Sentry.captureException(error);
});
}
// 上报结束后取消这个全局监听
window.removeEventListener("error", addUnhandledErrors);
}
function runSentry() {
const Sentry = await import("@sentry/react");
Sentry.init(sentryOptions);
window.Sentry = Sentry;
// Sentry 初始化完成后消化未被捕获的错误
reportUnhandledErrors();
}
runSentry();还有一种情况就是在 runSentry 之前已经发生了会导致系统崩溃的错误(例如 SyntaxError),让整个程序停止执行,这时候连 Sentry 都不会被初始化。遇到这种情况,我们依然希望 Sentry 能被初始化,然后上报这个致命错误。
这种情况下因为无法判断 Sentry 完成加载的时机,因此可以增加一个倒计时来触发 Sentry 的初始化,在出现错误之后的 n(ms) 后如果 Sentry 还没有初始化完毕,则自动触发 runSentry。
注:上方的 n(ms) 可以是任意值,只要你觉得正常情况下你的网站中 Sentry 可以在这个时间内完成加载即可。这里建议可以设置为正常情况下你的 web 程序的首屏渲染结束的平均时间(这需要你自己进行统计),可以使用 LCP 或 FCP 的平均时间。
下方是示例:
const unhandledErrors: Error[] = [];
function createCountdown(
countdownDuration: number,
callback: () => void
): () => void {
let timer: NodeJS.Timeout | null = null;
return function startCountdown(): void {
// 不允许重复生成倒计时
if (timer) {
return;
}
timer = setTimeout(() => {
callback();
timer = null;
}, countdownDuration);
};
}
// 15000 为一个月里统计的线上 web 程序的 lcp 平均时长
// 视你的 web 程序的实际情况而定
const sentryCountdown = createCountdown(15000, () => {
if (unhandledErrors.length !== 0 && !window.Sentry) {
runSentry();
}
});
function addUnhandledErrors(e) {
if (!window.Sentry) {
unhandledErrors.push(e.error);
// 出错后启动倒计时
sentryCountdown();
}
}
window.addEventListener("error", addUnhandledErrors);
function runSentry() {
const Sentry = await import("@sentry/react");
Sentry.init(sentryOptions);
window.Sentry = Sentry;
reportUnhandledErrors();
}
runSentry();Sentry 收集的 web 程序性能信息主要是通过插件 BrowserTracing 实现的,基本使用如下:
Sentry.init({
...sentryOptions,
integrations: [...otherIntegrations, new BrowserTracing()],
});这样使用的话,Sentry 会在首屏加载结束(记为 pageload 事件)和路由跳转事件(记为 navigation 事件)都会进行采集相应的性能数据,并上报。
而考虑到路由切换会比较频繁,并且性能数据量会较多(10kb ~ 30kb),所以可以选择关闭路由跳转的性能上报:
Sentry.init({
...sentryOptions,
integrations: [
...otherIntegrations,
new BrowserTracing({
/** 文档说明:
* Flag to enable/disable creation of `navigation` transaction on history changes.
*
* Default: true
*/
startTransactionOnLocationChange: false,
}),
],
});或者
Sentry.init({
...sentryOptions,
integrations: [
...otherIntegrations,
new BrowserTracing({
// 只触发 pageload 事件
beforeNavigate: (context) => {
if (context.op === "pageload") {
return context;
}
},
}),
],
});不过关闭 navigation 事件的性能上报并不是绝对的,任何时候你都要考虑项目的需求,如果你需要记录路由跳转性能,自然是不用关闭的。
LCP (Large Content Print)事件是评估 web 性能的一个重要标准,即首屏最大元素的渲染时间,但是它的记录时间很特殊,并不是在最大元素的渲染完成的时机,而是用户第一次操作(如点击页面)时才会正式记录下来,例如 LCP 时间为 15000ms,但是 web 性能监控并不会在 15000ms 时存储这个时间,而是在用户第一次操作页面后才会存下这个 15000ms。
这就导致了 Sentry 一般无法在首屏性能上报之前获得 LCP 时间(除非用户在上报前操作了页面),所以大多数情况下看 Sentry 后台的性能数据中都是没有 LCP 的。对于旧版本的 Sentry,一般会延长上报等待时间 idleTimeout 来延迟上报尽可能在用户操作后进行性能上报:
Sentry.init({
...sentryOptions,
integrations: [
...otherIntegrations,
new BrowserTracing({
/** 文档说明:
* The time to wait in ms until the transaction will be finished during an idle state. An idle state is defined
* by a moment where there are no in-progress spans.
*
* The transaction will use the end timestamp of the last finished span as the endtime for the transaction.
* If there are still active spans when this the `idleTimeout` is set, the `idleTimeout` will get reset.
* Time is in ms.
*
* Default: 1000
*/
idleTimeout: 50000,
}),
],
});但是这种方法依然无法百分百保证 LCP 能被收集到,因为总是存在用户一直不操作页面的可能性。但是在 Sentry 7.42.0 以及之后版本,Sentry 进行了调整,它会模拟一次页面操作,从而让浏览器产生 LCP 记录。所以请尽可能使用 7.42.0 或更高版本的 Sentry。
Sentry 在上报任何信息(错误日志、性能日志等)时都会携带这次事件的上下文,这些上下文包括打印信息、接口调用等,如果你的 web 程序没有对打印日志进行处理,例如在生产环境中也产生打印信息(console.log),那么就会导致 Sentry 的上报请求体积过大。
为了解决这个问题,可以使用 Sentry 的钩子 beforeBreadcrumb,对上下文信息进行过滤处理,以下是一个简单的示例:
Sentry.init({
...sentryOptions,
beforeBreadcrumb: (breadcrumb) => {
// 过滤 console.log 和 console.warning
if (
breadcrumb.category === "console" &&
["log", "warning"].includes(breadcrumb.level!)
) {
return null;
}
return breadcrumb;
},
});注:这样的过滤同样不是必须的,如果你需要这些信息进行 debug,那么你就不需要过滤。但是保持 web 程序在线上环境的 console 的干净是一个好的规范。
为了对上报信息进行好的分类、增强 Sentry 后台上报信息的可读性,可以在 Sentry 上报前统一对这些信息进行处理、规范上报的格式。为了实现这一点,可以利用 Sentry 钩子 beforeSend:
Sentry.init({
...sentryOptions,
beforeSend: (event, hint) => {
// hint.originalException 为捕获到的原始异常实例
// 可以通过自定义通用的 handleError 来判断此次异常的各种数据
// 从而修改上报事件的属性,提供更多有效信息
const { tags, extra, level } = handleError(hint.originalException as any);
event.tags = tags; // 定义这次上报的 tags
event.extra = extra; // 添加附加信息
event.level = level; // 定义上报级别
return event;
},
});可以留意到,上面的示例中我们修改了 tags、extra、level 这几个值,下面会说明为什么本文会建议修改这几个。
这几个变量在 sentry 后台中的呈现分别为:
tags:标签(tags: Record<string, string>)
extra:附加信息(extra: any)
level:严重程度(level: "debug" | "error" | "fatal" | "log" | "info" | "warning")

其中 tags、extra、level 均可以通过上面 beforeSend 的第一个参数 event 直接进行修改,而【错误类型】和【错误值】则建议使用下文要讲的自定义异常类型的方式进行自定义(即使这两个也可以直接修改 event 进行自定义)
对于可控的异常,例如可以被拦截器捕获的网络错误、手动上报的业务埋点等异常,建议自行封装异常类型,并配合统一的 handleError 函数来规范上报格式,以下是一个网络错误的例子:
// 一、首先,axios 的网络拦截器捕获到了网络错误
axiosInstance.interceptors.response.use(
(obj: AxiosResponse) => {
// do something...
},
(obj: AxiosResponse) => {
// 构造一个 NetworkError 实例,进行手动上报
window.Sentry.captureException(new NetworkError(obj);
}
);
// 二、构造函数 NetworkError 会根据 axios 的响应实例构造 Sentry 需要的异常信息
export class NetworkError extends Error {
/** 附加值 */
extra: any;
/** tag */
type: string = 'error.network';
/** 错误等级 */
level: string = 'error';
constructor(response: AxiosResponse) {
// 构造参数为【错误值】
super(`${response.request.responseURL}`);
// name 为【错误类型】
this.name = `Network Error ${response.data.code}`;
// 处理附加信息,getExtra 中可以任意取需要的值进行返回
this.extra = getExtra(response);
}
}
// 三、异常进入 beforeSend 进行统一处理
Sentry.init({
...sentryOptions,
beforeSend: (event, hint) => {
// hint.originalException 就是捕获的 NetworkError 实例
const { tags, extra, level } = handleError(hint.originalException as any);
event.tags = tags; // 定义这次上报的 tags
event.extra = extra; // 添加附加信息
event.level = level; // 定义上报级别
return event;
},
});
// 处理错误信息
const handleError = (error: NetworkError) => {
const info: SentryInfo = {
extra: undefined,
tags: {},
report: true,
level: 'error',
};
if (error.extra) {
info.extra = error.extra;
}
if (error.type) {
info.tags.type = error.type;
}
if (error.level) {
info.level = error.level || 'error';
}
return info;
};经过上述封装,上报后的异常信息就会在 Sentry 后台中展示出有序分类、可读性强异常信息,从而提升排查故障的效率。
以上是本文总结的一些 Sentry 上报优化的优化方案,从 Sentry 初始化、性能日志优化、上报信息优化三个方面提出了优化方案,可以为 React 端或 web 端的 Sentry 上报制定规范提供参考。
博文标题图片
博文置顶说明
工作上遇到了一个需求, 有一个接口因为 body 量相当大, 很容易请求失败, 加上是个静默接口用户不会有任何感知, 不会手动重新发起请求. 于是就需要我们从 nginx 日志上根据收集的参数信息进行接口请求恢复, 本文即记录做该需求中遇到的若干问题和解决方案
由于需要恢复请求, 所以使用脚本, 考虑到后续维护, 用 node 脚本进行开发, 脚本功能如下:
开发中遇到的问题:
http_proxy 和 https_proxy 但 node 脚本却无法发出这个请求根据 nodejs/node#1490 得知 node 原生不实现代理功能, 也不读取 http_proxy 变量, 原因是加入 proxy 的话 node 开发团队就需要考虑安全 / SOCKS / 证书等等一系列问题, 于是不做
但是依然可以通过很多库实现这个功能, 例如: node-global-proxy
import proxy from "node-global-proxy";
export function setupProxy(address: string) {
proxy.setConfig({ http: address, https: address });
proxy.start();
}
setupProxy(proxyAddress); // 程序初始化时设置代理
// ...其他代码下面的字符串 "x\xC2\x9C\xC3", 只是一个代指, 不是一个有意义的值, 只是为了方便解释
这个问题就比较复杂了, 主要体现在两个地方:
const body = "x\xC2\x9C\xC3" 再使用这个 body 是能成功发出请求的, js 自动完成了转码, 其参数和客户端的请求参数完全一样readline 解析出字符串 "x\xC2\x9C\xC3" 再赋值给 body, 却没有自动转码, 传的参数是 "x\xC2\x9C\xC3" 这个字符串而不是转码后的字符串encodeURIComponent 转义再发请求, 原因这里不提, 问题在于这次使用 decodeURIComponent 后居然无法正确恢复解析转义先说第二个问题, 直接使用 decodeURIComponent("x\xC2\x9C\xC3") 无效 (报错了), 那么也就意味着 decodeURIComponent 对这些初始 utf-16 编码的字符串依然无法正确解析
然后通过搜索找到了另一个函数: querystring.escape, 有效, 但是不是完全有效, 我发现这个函数只对部分的 utf-16 有用, 有的就无效, 这就有点奇怪了, 再仔细找原因, 发现了 node:querystring 文档里就有提到: https://nodejs.org/api/querystring.html#querystringunescapestr
By default, the querystring.unescape() method will attempt to use the JavaScript built-in decodeURIComponent() method to decode. If that fails, a safer equivalent that does not throw on malformed URLs will be used.
大概翻译下:
默认情况下 querystring.unescape() 方法会尝试用decodeURIComponent()进行转义, 如果失败了, 那么使用更安全的方法来解决那些长得不像 url 的字符串
也就是 pass 掉
使用 decodeURIComponent(escape(s)) 即可, 原来是还需要用 escape 先做一层转换呀, 不过值得一提的是 escape 函数已经被标记 deprecated 了
上面提到过, js 是 utf-16 编码的, 理论上直接支持来自 nginx 的日志参数, 直接赋值也证明了这一点 (下面 nextFetch 会直接使用 body 发出 fetch 请求)
const body = "x\xC2\x9C\xC3";
console.log(body); // 被转码的字符串
nextFetch(body); // 成功然而如果是用 node:readline 读文件中的 'x\xC2\x9C\xC3' 却无法直接使用:
// nginx-log.csv
x\xC2\x9C\xC3
let body = "";
const fileStream = createReadStream("./nginx-log.csv");
const rl = createInterface({
input: fileStream,
crlfDelay: Infinity,
});
rl.on("line", function (line) {
body = line;
});
rl.on("close", function () {
console.log(body); // 没有被转码的字符串 "x\xC2\x9C\xC3"
nextFetch(body); // 失败
});造成这个结果的原因其实是, js 代码编译过程中其实已经把第一种情况的字符串转码了, 到 runtime 时使用的已经是转码后的字符串
而第二种情况是此时 js 程序已经是 runtime 了, 此时得到的 line 自然不是代码的一部分, 就没有经过编译这个过程而未被转码, 只得到了原始的字符串
那么我们直接转码即可, 参考: https://gist.github.com/kiinlam/176ce20707336fa8278726e869e59cb1
export function decodeUtf16(s: string) {
return s.replace(/\\x(\w{2})/g, function (_, $1) {
return String.fromCharCode(parseInt($1, 16));
});
}博文置顶说明
一个既能利用 GitHub Issues 作为后台进行十分方便的文章发布和管理,也能尽可能利用 NextJS 的特性,让博客有单页面 web 程序的客户端体验同时能进行 SEO 优化的博客方案。还能获得一个免费域名。最大的缺点是不支持 IE 浏览器。
用 GitHub Issues 来写博客并不是什么新鲜事,它的优点很明显,GitHub Issues 的发布和管理是十分优秀的,尤其是利用标签和状态对 Issues 的管理满足了我们对博客的归档和分类的需求,而且也直接支持 Markdown 格式和文件上传。最重要的是 GitHub 提供了一套相对完备的 Api,让我们可以应用到开发中。
谈到博客,相信大部分想要建立博客的朋友不免都想分享自己的文章,希望让更多人能看到自己的想法,这时候搜索引擎的搜索结果就扮演了十分重要的角色,针对搜索引擎的 SEO 优化直接影响了一个博客能否被更多的人看到。
而 NextJS,一个基于 React 的、提供开箱即用的服务端渲染功能的开发框架就能满足我们对一个优秀博客的想象——既有单页面程序的客户端体验、也能利用服务端渲染的特性进行 SEO 搜索优化。
对于前端来说,一个好用的用于构建和测试前端项目的 Serverless 云平台可以让我们不再关心后端和服务器的事情,从而提高我们的开发效率。目前市面上的 Serverless 平台有不少,国内外都有,而这次会选用 Vercel 原因也很简单,因为 NextJS 目前就是由 Vercel 维护的,NextJS 项目可以不需要复杂的配置即可直接在 Vercel 平台上发布,而且还像 GitHub Page 那样白送一个域名。
设计大致上参考了猿料论坛的布局
网页方面定为主页、文章列表页、文章详情页、介绍页和搜索页
post 标签的文章,这些文章主要是想要被搜索引擎搜索到的文章,也就是需要做 SEO 优化的主要页面about 标签的那一篇,以文章详情页的样式进行展示这次我就直接找到了 luffyZh 的
next-antd-scaffold,试了一下,除了不支持 IE 外,各方面都还不错,就直接应用起来了。
[app]
├── 📄 .babelrc
├── 📄 .eslintrc
├── 📄 .gitignore
├── 📄 next.config.js
├── 📄 package.json
├── 📄 server.js
├── 📄 pm2.config.js
├── 📂 assets
├── 📂 docs
├── 📂 public
│ ├── 📄 favicon.ico
│ └── 📂 static
└── 📂 src
├── 📂 components
├── 📂 constants
│ ├── 📄 ActionsTypes.js
│ └── 📄 ApiUrlForBE.js
├── 📂 containers
├── 📂 core
│ ├── 📄 util.js
│ └── 📄 nextFetch.js
├── 📂 middlewares
│ ├── 📂 client
│ └── 📂 server
├── 📂 pages
└── 📂 redux
├── 📄 store.js
├── 📂 actions
├── 📂 reducers
└── 📂 sagas
GitHub 的 api 文档可以看这里,这次我基本上只用到了 issues 相关和 search 相关的接口,具体如下:
| api | 类型 | 主要参数 | 返回值 | 说明 |
|---|---|---|---|---|
https://api.github.com/repos/{owner}/{repo}/issues |
GET |
labels creator per_page page sort direction state |
Array |
获取某个仓库的 issues 列表 |
https://api.github.com/repos/{owner}/{repo}/issues/{number} |
GET |
不需要 | 一个带有某 issue 全部信息的对象 | 获取某个 issues 的全部信息 |
https://api.github.com/repos/{owner}/{repo} |
GET |
不需要 | 一个带有仓库全部信息的对象 | 获取某个仓库的基本信息 |
https://api.github.com/search/issues |
GET |
order page per_page q sort |
{ items: <Array>, incomplete_results: <bool>, total_count: <number> } |
对整个 Github 进行搜索 |
根据这些接口获得的数据,就能拿到博客需要的数据了
首先是根据我要做的页面来确定一下需要哪些数据
| 页面 | 需要的数据 |
|---|---|
| 主页时间轴 | 因为要进行分页,所以需要知道全部的文章的数量;然后就是根据页码请求到每个页的文章列表 |
| 文章列表页 | 同上,不过是带有 post 文章 |
| 文章详情页 | 某篇文章的数据 |
| 介绍页 | 带有 about 标签的文章的数据 |
| 搜索页 | 搜索的文章列表 |
所以根据这些信息,在测试过这些接口后确定了以下方案:
https://api.github.com/repos/{owner}/{repo} 获得,文章列表由 https://api.github.com/repos/{owner}/{repo}/issues 获得post 标签的文章列表由 https://api.github.com/repos/{owner}/{repo}/issues 获得,labels 参数改为 post 即可;至于文章列表,我决定用搜索的接口 https://api.github.com/search/issues 来请求,因为这个接口会提供 total_counthttps://api.github.com/repos/{owner}/{repo}/issues/{number} 即可https://api.github.com/search/issues 即可以上就是初步的构思,然后就根据这些实施方案即可。在接下来的第二部分主要讲讲遇到的一些坑
sudo systemctl enable vmtoolsd.service && sudo systemctl restart vmtoolsd.servicemkdir -p /home/hexh/desktopgit clone https://github.com/hexh250786313/hexh.config /home/hexh/desktop/hexh.configecho "185.199.108.133 raw.githubusercontent.com" | sudo tee -a /etc/hostssource ~/.bashrcnvm install v16.10.0npm install -g yarncd /home/hexh/desktop/hexh.configyarn && npm linkhexh-config manjaro proxysource ~/.bashrcclashfirefoxhexh-config manjaro basic resetPacmanKeyhexh-config manjaro basic neededyay -Syu --develhexh-config manjaro basic dkmshexh-config manjaro gitssh -T [email protected]: input yeshexh-config manjaro git lnhexh-config manjaro basic dotfileshexh-config manjaro zshsh -c "$(curl -fsSL https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"hexh-config manjaro zsh lnhexh-config manjaro zsh colorlszshrbenv shell 3.1.0 && rbenv global 3.1.0 && rbenv local 3.1.0gem install colorlshexh-config manjaro zsh fzf: ~/.fzf/installhexh-config manjaro proxy lnsudo systemctl restart vmtoolsd.servicecurl www.google.com.hkhexh-config manjaro nodenpm list -g --depth=0hexh-config manjaro editorhexh-config manjaro editor lnhexh-config manjaro hostsnvim: :TSInstall css scss json lua tsx javascript dot bash yaml vim markdown regex html jsdoc vue rust typescript pythonnvim ~/.desktop/test.md: :CocCommand markdown-preview-enhanced.openKaTeXConfig, hexh-config manjaro editor latexConfig:Copilot setuphexh-config manjaro pamac confighexh-config manjaro pamac flatpakflatpak updatehexh-config manjaro pamac snaphexh-config manjaro nutstore 登录, ~/桌面/sharehexh-config manjaro nutstore confighexh-config manjaro nutstore clipman: 同步路径 ~/.cache/xfce4/clipmanhexh-config manjaro inputMethodhexh-config manjaro tmuxhexh-config manjaro basic softwarehexh-config manjaro system confighexh-config manjaro system inithexh-config manjaro basic vmwareEnable Monkey Patchhexh-config manjaro howdysrc/env/manjaro/modules/howdy/config.ts 改变设备路径, 然后hexh-config manjaro howdy confighexh-config manjaro asus: https://github.com/mohamed-badaoui/asus-touchpad-numpad-driverconst tree = [ { name: "one", id: "1", list: [ { name: "oneOne", id: "11", list: [{ name: "oneOneOne", id: "111" }] }, { name: "oneTwo", id: "12", list: [ { name: "oneTwoOne", id: "121" }, { name: "oneTwoTwo", id: "122" }, { name: "oneTwoThree", id: "123" }, ], }, ], }, { name: "two", id: "2", list: [ { name: "twoOne", id: "21", list: [{ name: "twoOneOne", id: "211" }] }, { name: "twoTwo", id: "22", list: [ { name: "twoTwoOne", id: "221" }, { name: "twoTwoTwo", id: "222" }, ], }, ], }, ];
const flatten = (
children: any[],
parentId?: string | number,
parentName?: string,
level = 1,
parentNodes?: any[]
) =>
Array.prototype.concat.apply(
children.map((x) => ({
// ...x,
name: x.name,
id: x.id,
parentId,
parentName,
level,
parentNodes: JSON.parse(JSON.stringify(parentNodes || [])),
})),
children.map((x) =>
flatten(
x.list || [],
x.id,
x.name,
(level || 1) + 1,
Array.isArray(parentNodes)
? [...parentNodes, { id: x.id, name: x.name }]
: x.id !== undefined
? [{ id: x.id, name: x.name }]
: []
)
)
);
const flat = flatten(tree);
console.log(flat);const flat = [ { name: "one", id: "1", parentId: undefined, parentName: undefined, }, { name: "two", id: "2", parentId: undefined, parentName: undefined, }, { name: "oneOne", id: "11", parentId: "1", parentName: "one", }, { name: "oneTwo", id: "12", parentId: "1", parentName: "one", }, { name: "oneOneOne", id: "111", parentId: "11", parentName: "oneOne", }, { name: "oneTwoOne", id: "121", parentId: "12", parentName: "oneTwo", }, { name: "oneTwoTwo", id: "122", parentId: "12", parentName: "oneTwo", }, { name: "oneTwoThree", id: "123", parentId: "12", parentName: "oneTwo", }, { name: "twoOne", id: "21", parentId: "2", parentName: "two", }, { name: "twoTwo", id: "22", parentId: "2", parentName: "two", }, { name: "twoOneOne", id: "211", parentId: "21", parentName: "twoOne", }, { name: "twoTwoOne", id: "221", parentId: "22", parentName: "twoTwo", }, { name: "twoTwoTwo", id: "222", parentId: "22", parentName: "twoTwo", }, ];
const buildTree = (data: typeof flat) =>
data
.reduce(
(m, { id, name, parentId }) => (
m.get(parentId)!.push({ id, name, list: m.set(id, []).get(id) }), m
),
new Map<string | undefined, any[]>([[undefined, []]])
)
.get(undefined);
const tree = buildTree(flat);
console.log(tree);博文置顶说明
最近折腾 Mnajro, 这篇文章主要介绍如何在 Linux 环境下格式化 U 盘以及制作一个系统启动盘 (不限制于 Mnajaro)
sudo fdisk -l or lsblk, 找到对应的 U 盘路径sudo fdisk <U 盘路径>
m: 获取帮助命令d: 删除分区n: 新建分区p: 打印分区表t: 更改分区类型w: 写入操作并退出d 指令, 删除所有分区, 最后 w 退出即可sudo mkfs.fat -F 32 <U 盘路径>
fat 为要更换的格式 (这里查看可选的格式)-F 32 说明要格式化成 fat32, 不加这个参数则格式化为 fatn, 分区类型选择 e, 即从分区 ( p 是主分区 ), 其余默认t, 输入 07 ( ntfs 格式 ), 再 w 即可, 但是这里选什么都无所谓, 因为下一步才是真正的格式化w 保存sudo mkfs.ntfs <U 盘路径>/<分区编号>, 完成sudo ventoy -i <U 盘路径>
umount <U 盘路径> 后再运行初始化指令sudo cp <ISO 镜像路径> <U 盘路径根目录>, 然后 ventoy 就会在复制的过程中自动运行脚本把 U 盘变为启动盘, 结束后可以看到 U 盘的名字变成了你的系统镜像名, 这说明已经制作完成了
-g 参数即可: sudo ventoy -i -g <U 盘路径>cp 指令cp 指令会自动复制到正确的分区, 所以不需要关心分区路径, 直接 cp 到 U 盘路径即可当然, ventoy 的功能远不止于此, 可以参考他们的文档
sudo cp something <U 盘路径根目录> 哦, 这其实是刻录操作, 会完全重写分区, 导致 U 盘无法使用, 正常用法:
lsblk 查看 U 盘的分区信息, 会看到分区编号后面有个运行时路径如 /run/media/<用户名>/<分区名称>, 这个才是你要复制的路径cp 也不需要 sudo: cp something /run/media/<用户名>/<分区名称>博文标题图片
博文置顶说明
本文主要内容为,介绍前端开发中使用 father 进行打包组件库、工具库时,如何预处理编译 less 文件
在前端开发中,我们经常会遇到需要对一些组件库进行二次封装的需求,特别是当我们使用阿里系的组件库,如 antd 或 antd-mobile 时。在这种情况下,我们通常会使用 father 和 dumi 这一套官方推荐的方案。然而,father 官方并没有提供处理 scss 或 less 的示例,因此我们需要自行实现 father 的样式预处理。本文将介绍如何实现这一目标。
在深入讨论如何实现样式预处理之前,我们首先需要了解一下 father 在前端打包中的工作原理。
father 不仅可以用于打包前端代码,它也可以用于打包通用的 ts/js 代码库。实际上,father 是一个集成了多个打包工具的打包工具,例如,它集成了 babel 和 esbuild 两种编译器。
当我们需要打包的代码为前端代码(如前端组件库等)时,father 会使用 babel 作为 js/ts 的编译器。当我们需要打包的代码为 node 库时,father 则会使用速度更快的 esbuild。
此外,father 还提供了一些插件功能,例如 extraBabelPlugins 和 addLoader。extraBabelPlugins 可以让我们使用 babel 插件,而 addLoader 功能则类似于 webpack 的 loaders 功能,可以用于处理非 js/ts 文件。
了解了 father 的工作原理后,我们就可以开始实现样式预处理了。我们的任务可以分为两部分:
addLoader 功能,实现一个 less 转 css 的插件。extraBabelPlugins,实现一个插件,将 js/ts 中的 .less 文件内容转为 .css。接下来,我们将详细介绍如何实现这两个任务。
这一步主要是为了把 js/ts 文件中的与 less 相关的文本替换为 css,例如:import "./index.less" 替换为 import "./index.css"。
这一步比较简单,直接实现一个 babel 插件用于进行 .less 替换为 .css 的文本操作即可,代码如下:
// .fatherrc.ts
import { defineConfig } from 'father';
export default defineConfig({
...
esm: { output: 'dist', transformer: 'babel' }, // 必须要使用 babel 模式
extraBabelPlugins: [
[
'./babel-less-to-css.js', // 把 js/ts 文件中的 '.less' 字符转为 '.css'
{
test: '\\.less',
},
],
],
...
});// babel-less-to-css.js
module.exports = function () {
return {
visitor: {
ImportDeclaration(path) {
if (/\.less$/.test(path.node.source.value)) {
path.node.source.value = path.node.source.value.replace(/\.less/, '.css');
}
},
},
};
};这一步要实现一个把 less 文件转换为 css 文件的插件,其中:
这两步本身其实已经和 father 没什么太大的关系,都是 webpack 中常用的对 less 文件的处理方法,所以这里直接给出示例代码,看代码就可以知道如何在 father 中实现这些功能:
// .fatherrc.ts
import { defineConfig } from 'father';
export default defineConfig({
...
plugins: [
'./loader.ts', // 实现 loader 功能
],
...
});// loader.ts
import type { IApi } from 'father';
import { addLoader, ILoaderItem } from 'father/dist/builder/bundless/loaders';
export default async (api: IApi) => {
const loaders: ILoaderItem[] = await api.applyPlugins({
key: 'addPostcssLoader',
initialValue: [
{
key: 'less-to-css',
test: /\.less$/,
loader: require.resolve('./loader-less-to-css'), // less 文件转 css 文件
},
],
});
loaders.forEach((loader) => addLoader(loader));
};// loader-less-to-css.js
const path = require('path');
const less = require('less');
const postcss = require('postcss');
const syntax = require('postcss-less');
const atImport = require('postcss-import');
const autoprefixer = require('autoprefixer');
const loader = function (lessContent) {
const cb = this.async();
this.setOutputOptions({
ext: '.css',
});
postcss([
autoprefixer({
// 提升兼容性
overrideBrowserslist: ['last 10 versions'],
}),
atImport({
resolve: (id) => {
const currentPath = this.resource;
if (id.startsWith('@')) {
// 处理别名路径,把 @ 替换成 src
const srcPath = path.join(__filename, './src');
const targetPath = id.replace(/^@/, srcPath);
return targetPath;
} else {
// 处理相对路径
const relativePath = id;
const targetPath = path.resolve(currentPath, '..', relativePath);
return targetPath;
}
},
}),
])
.process(lessContent, { syntax })
.then((result) => {
// less 转 css
less.render(result.content, (err, css) => {
if (err) {
console.error(err);
return;
}
cb(null, css.css);
});
})
.catch((err) => {
console.error(err);
});
};
module.exports = loader;经过上述处理,就可以实现 less 的预处理,编译为 css 文件了。
事实上 father 支持 babel、esbuild 和 SWC 三种构建方式,而本文使用的是 babel 模式。
father 的配置文档 中提到,platform 为 broswer 的时候,transformer 默认使用 babel 进行 js 的编译器,这意味着,father 官方也是推荐使用 babel 来编译前端的代码的。
即使使用 esbuild 有更快的打包速度,但是 esbuild 处理的是文件的二进制格式,很多现存的前端编译插件无法直接应用到其中;而 babel 则是生成 AST 语法树,其兼容性和拓展性也是 esbuild 和 SWC 无法比拟的。
不过最关键的还是:father 还没有实现自定义 esbuild 插件!它只提供了 babel 的自定义插件能力,这样一来其实我们别无选择。
博文标题图片
博文置顶图片
![]()
博文置顶说明
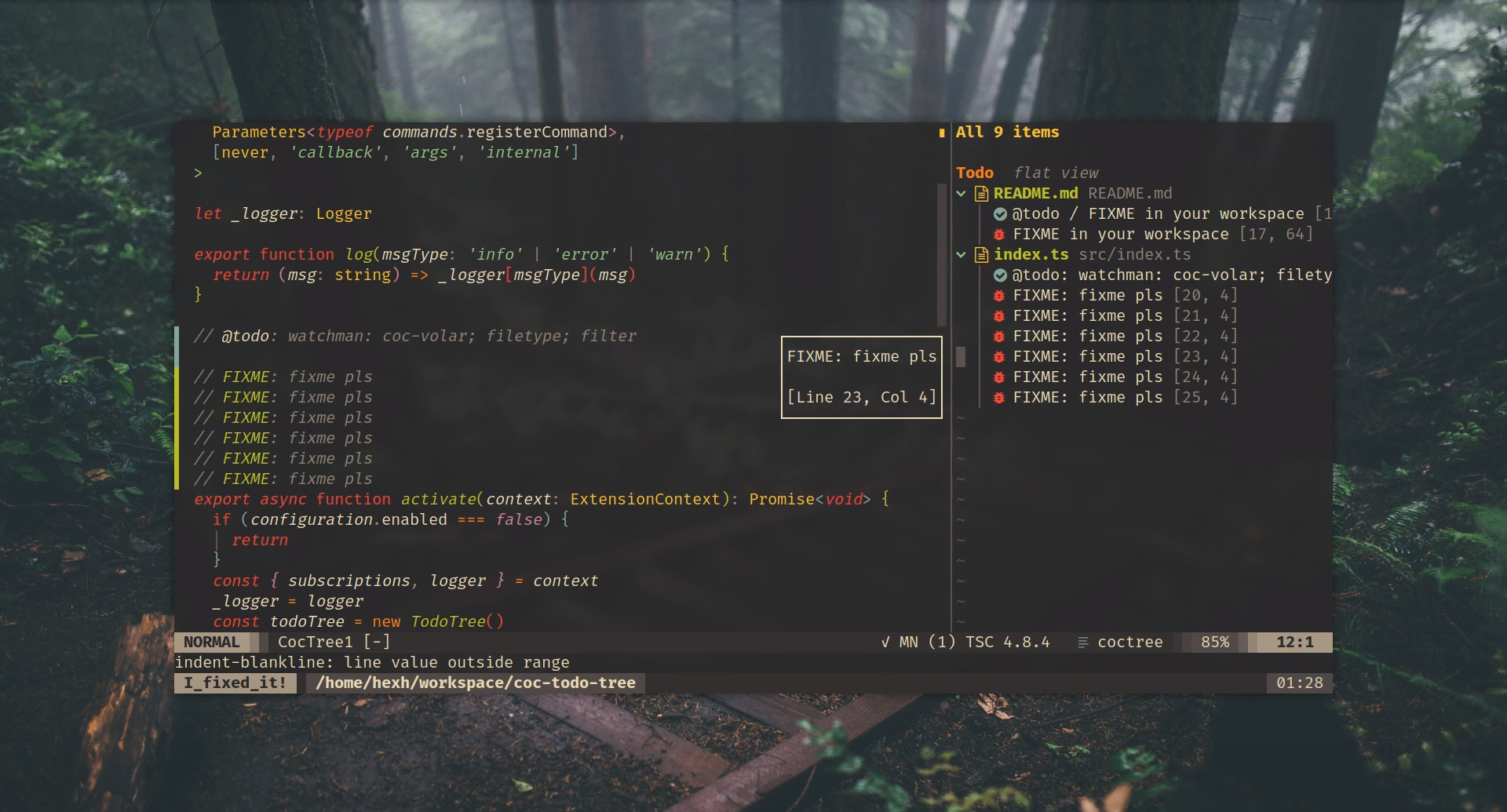
coc-todo-tree 是 vscode-todo-tree 在 coc 上的实现, 本文是简体中文说明
源码: https://github.com/hexh250786313/coc-todo-tree
coc-todo-tree 是基于 coc.nvim 的 todo tree 实现
灵感来自 vscode-todo-tree
请先确保你的 vim 已经安装了 coc, 然后执行以下指令即可安装 coc-todo-tree
:CocInstall coc-todo-tree
在 vim/neovim 中执行以下指令即可打开 todo-tree 面板:
:CocCommand coc-todo-tree.showTree
C 来在三种展示样式中切换: tags-only / flat / tree-view, 同时可以通过按小写的 c 来进行 tag group 归类所有配置: https://github.com/hexh250786313/coc-todo-tree/blob/master/.vim/coc-settings.json
博文置顶说明
本文介绍用 docker 部署 sentry 的相关步骤和一些值得注意的地方
getsentry/onpremise 这个仓库是专提供来用 docker 启动本地服务的,也就是需要首先本地环境要能运行 docker 才行。另外 sentry 也可以用 python 启动服务,这里不提
sudo apt-get install apt-utils # Debian 系统下可选,不安装也行,对结果没有影响,只影响安装交互
git clone https://github.com/getsentry/onpremisecd onpremise
chmod +x install.sh
./install.sh./install.sh 前先下载下面这两个,这是淘宝的 docker 源,能把部署 sentry 需要的大部分镜像都下载下来,这样可以减少一点安装时间,但是需要开发者账号,hkoa9dfz 就是开发者账号对应的识别码docker image pull hkoa9dfz.mirror.aliyuncs.com/getsentry/sentry
docker image pull hkoa9dfz.mirror.aliyuncs.com/viitanener/sentry-onpremise-local
📂 onpremise 中使用以下指令来拉起 sentry 服务了:docker-compose up -d # 成功后访问 http://127.0.0.1:9000 即可进入 sentry 主界面因为是通过 docker 编译出来的,因此对应的指令都要在项目文件夹 📂 onpremise 中使用 docker-compose run 来执行,如果是用 python 来构建 sentry 的话,则应该要使用 sentry 指令,python 相关自行查看文档
也就是说假设在官方文档中查询到某条指令如:sentry createuser
那么如果你是通过本文介绍的用 docker 的方法来启动 sentry 服务的话,则应该要在项目文件夹 📂 onpremise 中使用:docker-compose run createuser 来替换上述指令
本文剩余章节的相关指令同样是通过这种 docker-compose 指令来使用的,注意要在 📂 onpremise 目录底下执行
--superuser 则为普通用户,--force-update 可以用来覆盖已经存在的相同账号)docker-compose run --rm web createuser --superuser --force-update 补充:如果进入页面登录时提示网络 CSRF 相关的报错,可能和这个 issue 有关:getsentry/self-hosted#2751 。解决办法是在 sentry/config.yml 中添加:
system.url-prefix: http://127.0.0.1:9000docker-compose down// == app.js ==
import * as Sentry from '@sentry/react';
Sentry.init({
dsn: "<dsn>",
environment: "<ENV>",
release: "<VERSION>"
});参数说明:(更多参数应自行查看官方文档)
dsn:错误上报的目标接口,也就是 sentry 服务部署的地方,如果是正式生产环境用了 nginx 等工具转发了部署项目的所在 ip 到具体域名,记得要把这里的地址也修改一下environment:环境,不配置的话默认为 "production"release:版本,通常是用 "<ENV>@1.0.1" 这样的形式,理论上是唯一值,同一个项目中不会同时存在两个相同的版本,会和下方上传代码地图的 release 对应,详情在下面章节会说明一旦有错误上报成功,就会在对应的项目、环境的对应版本下生成 issue 及其详情,可以到 sentry 主界面自行查看
主动错误上报可以调用这个方法,更多 api 应自行查看官方文档
import * as Sentry from '@sentry/react';
Sentry.captureException(error);这一步的目的是让你的 sentry 账号和你的本地环境绑定,从而实现各种功能,例如下面章节会介绍的上传 source map 到 sentry 服务器从而实现抛错处的精确定位(但是要实现上传 source map 其实未必需要把账号和本地绑定,这点下面也会介绍)
npm i -g @sentry/cli因为安装过程需要运行脚本,可能会提示权限不够,那样的话用下面这个指令来安装
npm install -g --unsafe-perm=true --allow-root @sentry/cli执行以下指令开始绑定账号:
sentry-cli --url http://127.0.0.1:9000 login📂 ~)下生成 📄 .sentryclirc 配置文件--url 指定到本地的 sentry 上,可以通过 📄 .sentryclirc 配置文件进行修改默认服务器,具体配置下面的章节会说明📄 .sentryclirc 上进行配置。如果信息没问题,则说明 sentry 账号已经成功绑定到本地)sentry-cli --url http://127.0.0.1:9000 infosentry 的配置文件就是上一步生成的 📄 .sentryclirc 文件,这个文件默认情况下存在于用户目录 📂 ~ 中,表示本地账户的登录信息和配置
但是这个文件并非一定要放在 📂 ~ 下,就像上面章节提到的,要使用 sentry 的登录功能不需要本地环境也配置 📄 .sentryclirc,你可以把这个文件放在任何前端项目的目录里,从而对不同的项目实现不同的 sentry 配置
提到这个也要说明一下 sentry-cli 这个指令会优先读取指令执行目录底下的 📄 .sentryclirc,只有当当前目录下没有 📄 .sentryclirc 才会去读取用户目录 📂 ~ 下的 📄 .sentryclirc
根据 📄 .sentryclirc 的这些特点,就可以很灵活地为不同的前端项目配置不同的 sentry 配置
下面就是一份比较典型的 📄 .sentryclirc 的配置,更多属性应自行查阅文档
[auth]
token=<account token>
[defaults]
url=<server>
org=<org name>
project=<project name>token:就是认证 tokenurl:部署 sentry 的服务器地址,默认为 https://sentry.ioorg:登录 sentry 主界面可以看到你自己的团队,选择你要设置的默认团队,注意名字没有井号,默认为 “sentry”project: 设置默认项目代码地图在 sentry 中的作用是在上报的 issue 中显示报错代码对应的准确位置(精确到行列),有两种方式上传代码地图到 sentry
假设已经编译好了项目并存在 📂 .dist 文件夹,执行如下指令即可上传到对应的项目:
📄 .sentryclirc 中配置好了 url org 和 project,则可以省去 --url -o -p 这几个参数<VERSION> 对应的是上面前端上报初始化对象里的 release,说明这里上传的 source map 对应的是和 release 一样的版本--url-prefix 是项目前缀,默认是"~/" 也就是根目录,如果项目不是部署在域名的根目录,则可以用这个参数自行调整sentry-cli --url <server> -o <org name> -p <project name> releases files "<VERSION>" upload-sourcemaps --url-prefix '~/' './dist'sentry-cli releases files "<VERSION>" delete --allrm -rf ./dist/*.map📄 .sentryclirc 文件直接放到要执行命令的前端项目的根目录的话,那么 sentry-cli 就会优先使用本地的配置。而也因此,可以针对不同的项目使用不同的 sentry 配置,这一点,对于接下来要说明的使用 webpack 上传 source map 的方法同样适用。如果是用这种方式的话就可以省去 sentry 和本地环境绑定的步骤,十分灵活yarn add @sentry/webpack-plugin --dev配置完成后会在每次 build 项目的时候,source map 文件自动上传到对应的 sentry 服务。注意要开启生成源码,建议为 devtool: "source-map"
// webpack 配置文件 webpack.config.js
const SentryCliPlugin = require('@sentry/webpack-plugin');
const config = {
plugins: [
new SentryCliPlugin({
include: "./dist",
ignore: ["node_modules", "webpack.config.js"],
release: "<VERSION>",
urlPrefix: "~/",
configFile: ".sentryclirc"
}),
],
};属性说明:(访问官方文档查看更多属性)
include:上传的目标文件夹,也可以指定 "." 上传整个根目录ignore:上传时要忽略的文件夹或文件类型release:和上述章节里介绍的 sentry 初始化对象中的 release 对应urlPrefix:和上述章节里介绍的 --prefix-url 对应,默认为 "~/"configFile:如果不配置的话默认使用环境中的配置,也就是 📄 ~/.sentryclirc,也可以像这样把 📄 .sentryclirc 文件放进前端项目的根目录中然后配置成 ".sentryclirc" 来使用项目自己的配置📄 .sentryclirc 配置,也就是用不同的 .sentryclirc 单独放到不同的项目根目录下,各个项目有各自的配置,这一点在上面的章节有说明。甚至可以利用 fs.existsSync() 方法判断到项目下有没有 .sentryclirc 文件,从而控制在什么环境下需要上传 source map以上就是在部署配置 sentry 的一些基础步骤和一些小提示,更多的内容应该要到 sentry 官方文档去了解,尤其是前端配置的部分有很多值得研究的 api
博文置顶说明
这里主要记录开发本博客过程中的一些坑
根据 luffyZh 的文章,对项目进行了简单的部署后,到 Vercel 上 build 的时候却出现了报错,经过测试发现在本地的时候 build 也会出现问题,如下图所示出现了报错:
可见是 terser plugin 出现了问题,GitHub 寻找 issue 发现了有人提出来:luffyZh/next-antd-scaffold#12 ,根据 solution,作出以下修改即可:
根据 Vecel 的控制台信息的提示,说是找不到 document 对象,而总所周知 document 对象是浏览器的一个对象不可能不存在。说明这里是服务端渲染时报的错,如下图:
可以看到引用了 document 的地方是 /node_modules/rc-notification/lib/Notification.js:216:13,但是我根本没有用 rc-notification 啊,很可能是被 antd 的组件封装了起来,最大的嫌疑是 antd/message 组件。然后就把项目中引用了 antd/message 的地方全部注释掉了,果然,这时候报错没了,也能成功进入主页了
但是这个组件被我用在了 redux-sagas 中间件中,用来提示报错的,还是很有必要保留下来的。于是加了如下的判断,当处在服务端的时候就用 console.log() 打印错误信息,处在客户端也就是浏览器时就使用 message.error():
export default () => next => action => {
const ret = next(action)
switch (action.type) {
case REQUEST_FAIL: {
if (!!process.browser) { // 判断当前环境
message.error(action.payload || ERROR_TEXT)
} else {
console.log(action.payload || ERROR_TEXT)
}
break
}
default:
}
return ret
}在开发的过程中,发现接口动不动就报错,返回的信息提示 github api rate limit,说明请求接口次数有限制,Google 了一下发现了:
For unauthenticated requests, the rate limit allows for up to 60 requests per hour. Unauthenticated requests are associated with the originating IP address, and not the user making requests.
对于没有认证的请求,GitHub Api 的每小时次数限制是60次,并且非认证请求根据的是当前请求的 IP 地址进行限制,而不是根据用户账号来限制
也就是说肯定是存在认证请求:
For API requests using Basic Authentication or OAuth, you can make up to 5000 requests per hour. Authenticated requests are associated with the authenticated user, regardless of whether Basic Authentication or an OAuth token was used.
你可以通过 Basic Authentication 或者 OAuth 让请求次数提升到每小时5000次,不管是 Basic Authentication 还是 OAuth 的请求认证都是根据认证用户进行次数限制
另外我还查到了搜索接口是每分钟15次,认证请求后会提升到每分钟30次
2021.02.14 更新:上面的描述 github 已经从文档中删除,认证方式也从 Basic Auth 和 OAuth 两种变成了 github apps、oauth apps 和 personal access tokens 三种,上面提到的 oauth 实际上变成了 person access tokens,下面提到的 token 方式其实指的也是 personal access tokens 的认证方式(今天发现博客上的接口全挂了才发现 gh 更新了这一部分,不过幸好没什么特别大的变动,重新进行下 personal access tokens 认证即可)
所以事不宜迟我马上用自己的账号进行了认证,这里采用的是 ,参考此处,权限范围一个都不用选,默认是只读权限
于是就获得了一个 token,只要把 token 放到请求头中就能发起认证请求,提升请求次数:
const opts = {
method,
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
Accept: 'application/json',
Authorization: `token ${githubToken}` // 把 token 放到这里
},
// credentials: 'include',
timeout,
mode: 'cors',
cache: 'no-cache',
}分别调用列表接口和搜索接口测试一下:
[列表接口的 Response Header 的一部分]
X-Accepted-OAuth-Scopes: repo
X-Content-Type-Options: nosniff
X-Frame-Options: deny
X-GitHub-Media-Type: github.v3
X-GitHub-Request-Id: EDA3:179E:6D4C9F:84AEDC:5F940AEC
X-OAuth-Scopes
X-RateLimit-Limit: 5000
X-RateLimit-Remaining: 4997
X-RateLimit-Reset: 1603541229
X-RateLimit-Used: 3
X-XSS-Protection: 1; mode=block
[搜索接口的 Response Header 的一部分]
X-Accepted-OAuth-Scopes
X-Content-Type-Options: nosniff
X-Frame-Options: deny
X-GitHub-Media-Type: github.v3
X-GitHub-Request-Id: D763:5ED6:1B24C5F:2398D78:5F940C18
X-OAuth-Scopes
X-RateLimit-Limit: 30
X-RateLimit-Remaining: 29
X-RateLimit-Reset: 1603538004
X-RateLimit-Used: 1
X-XSS-Protection: 1; mode=block
上面的 X-RateLimit-Limit 表示当前最高请求次数,X-RateLimit-Remaining 为剩余次数,可以看到两个接口的次数均已经提升到 GitHub App 的最高次数(注:OAuth 认证是给 GitHub App 开发用的一种认证方式)
但是,这也出现了另一个问题,就是这样会使我的 token 暴露到接口中,我不确定这样会不会有问题,于是我仔细看了下文档:
Note: If you're building a GitHub App, you don’t need to provide scopes in your authorization request.
注意:如果你正在开发一个 GitHub App,你并不需要选择任何权限范围
事实上我也并没有选择权限范围,也就是使用默认的只读权限,但是我也并不确认只读范围有多大,万一会把我的 private 仓库暴露了就凉了,于是我就用认证请求请求了我的 private 仓库测试一下。最后发现其实并不会暴露 private 仓库,接口会直接说找不到:
所以,就可以放心使用该 token,这部分的问题也解决了
而这里事实上也有另一个坑,那就是如果你把 token 直接写死在你的代码中,那么 gh 会自动把你账户下的这个 token 给删掉,所以务必不要直接在你的代码中出现 token,有部署服务器的朋友可以通过写一个接口获取的方式来做,这里不提
core-js会提示 core-js 版本不够,直接加到依赖中即可 "core-js": "^2.6.5"
markdown-nav 这个插件可以改变当前的页面的 hash 来锚定当前所处的 markdown 的位置,但是这引发了 NextJS 的一个问题:如果 hash 不是通过 Next 的 router 或者 <Link /> 来改变的话,那么这个 hash 就不会记录到 Next 的服务中,这时候如果使用了浏览器的前进或者后退按钮返回这个带有 hash 的页面的话就会报错:Cannot read property 'indexOf' of undefined in NextJS server
而且很遗憾的是,markdown-navbar 插件无法自定义 hash 更改行为,只能调用 hash 改变时的回调,要解决这个问题只能从两个地方去改:
updateHashAuto 参数设置为 false 关闭// 在 markdown-navbar 的 onHashChange 中调用这个方法即可
const removeHash = e => {
setTimeout(() => {
window.location.replace(
window.location.href.toString().replace(window.location.hash, '') +
'#' +
e,
)
}, 100)
}一般而言在 SPA 程序中实现分页,最主要的目的有两个:一是实时改变 url,让不同的 url 对应相应的分页,程序可以直接通过 url 进来列表后根据 url 上的参数跳到对应的页面而不用用户一页一页地去翻;二是可以监听浏览器的前进后退按键来恢复页面数据。
这两点在传统的静态页面中根本不是问题,但是在单页面程序中需要一些手段去实现,最主流的做法自然是 history.pushState
无刷新更改 url + 异步请求数据 + window.onpopstate 监听浏览器前进后退,具体做法这里不多说,因为在 NextJS 有另外的实现
首先先看下 NextJS 的与之相关的 api:
| 接口 | 作用 |
|---|---|
hashChangeStart(url) hashChangeComplete(url) |
这两个接口监听 hash 的变化 |
routeChangeStart(url) routeChangeComplete(url) |
这两个接口监听 url 的变化(包括 search 的变化) |
首先先说明下在使用中这两者有什么具体差异,就像上面所说的当 hash 参数(#后的参数)改变的时候会触发 hashChangeStart hashChangeComplete 而不会触发 routeChangeStart(url) routeChangeComplete(url),而只有当 url 本身或者 search 参数(? 后的参数)改变时才会触发 routeChangeStart(url) routeChangeComplete(url)
而根据我的需求,我们只需要一种改变 url 参数和监听的手段就行,而在 NextJS 中改变 url 参数的方法只能通过路由来跳而不能用 window 的方法来改变,否则会出现上面 markdown-navbar 中的坑。也就是说 url 和 hash 都是通过路由来改变的,例如:
// 改变 url
Router.push(`/post/list?page=1`)
// 改变 hash
Router.push(`/post/list#page=1`)根据上面说的,其实无论是监听 router change 还是监听 hash change 都是可以实现分页优化的。于是我就直接采用了 hashChangeComplete 来做:
[文章列表页 src/containers/post/list.js]
import Router from 'next/router'
Router.events.on('routeChangeComplete', _handleRouteChange)然后就是分页器点击事件,调用 router 改变 hash 即可:
import Router from 'next/router'
const handleClick = (page, keyword) => {
Router.push(`/search#q=${keyword}&page=${page}`)
}于是就能实现 NextJS 中的分页监听了,下一篇会讲讲怎样对程序做 SEO 优化
博文置顶说明
最近找到了coc-yank 的替代方案 yanky.nvim,可惜他的列表实现基于 Telescope,于是参照 coc-yank 搞了个 yanky.nvim 记录的 coc list 实现,下文是中文版 README
这个插件是 yanky.nvim 的一个 coc list 实现,如果你像我一样使用 coc.nvim 和 yanky.nvim 并且不喜欢 Telescope,那你可以用这个 coc 列表插件替代 Telescope 来列出所有 yanky 历史
请安装这些插件:
在 neovim 中运行:
:CocInstall coc-list-yanky创建快捷键映射:
nnoremap <silent> <space>y :<C-u>CocList -A --normal yanky<cr>
MIT
博文标题图片
博文置顶说明
本文介绍如何在 fzf 中根据搜索输入框有无输入值来动态切换 mru(最近打开的文件列表)和 files(文件搜索),这个操作简单来说就像 VSCode 中的 ctrl-p,当没有任何输入值的时候展示的列表是最近打开的文件列表,当输入了值以后就会变成文件搜索。我们可以利用简单的 shell 脚本来在 fzf 中实现这一操作,本文会使用 neovim + coc.nvim 进行举例
※ 主角
fzf:本文的主角,具体是什么我就不多介绍了,相信点进来文章的读者都知道。
※ 辅助工具
以下是用于说明如何实现这一动态切换的辅助工具,非必须,只是为了方便说明,必须的只有 fzf。
※ mru
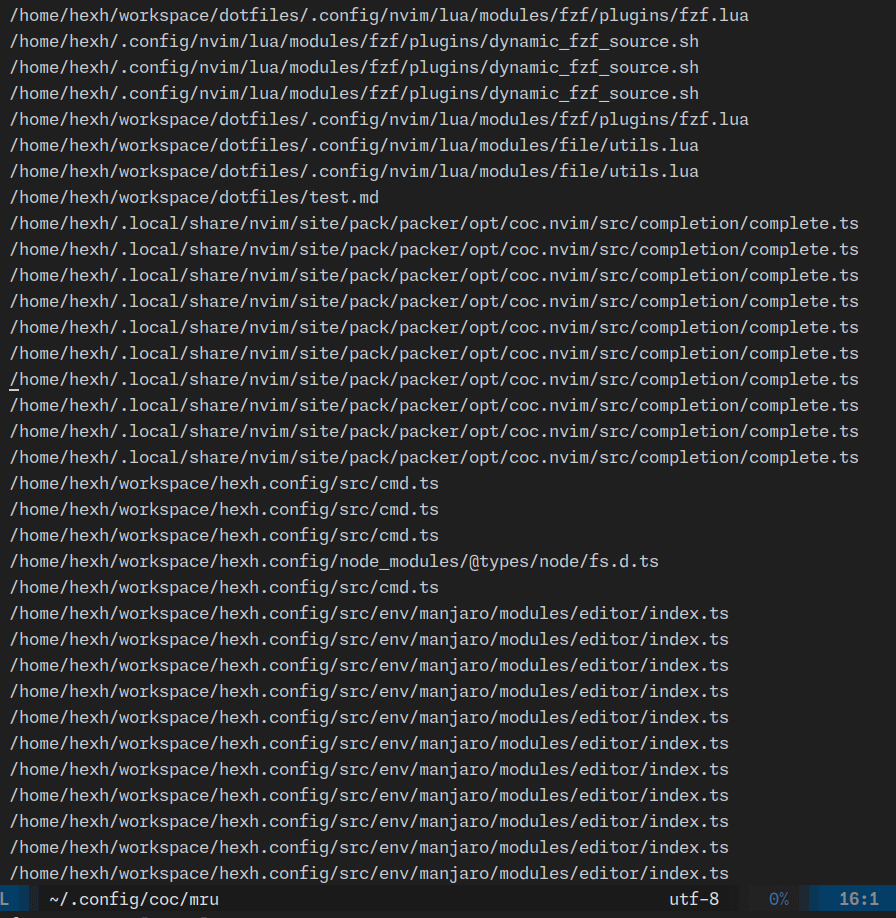
首先你需要一个保存最近打开文件列表的文件实现,例如结合 neovim 和 coc.nvim,我们可以在 neovim 中打开一个文件的时候 coc.nvim 会自动触发一个保存事件,把当前打开的文件的绝对路径保存到一个文件中,这个文件就是 mru 文件列表,格式如下:
~/.config/coc/mru 文件:
...
/home/xxx/.config/nvim/init.vim
/home/xxx/.config/nvim/coc-settings.json
/home/xxx/a.txt
/home/xxx/b.txt
/home/xxx/c.txt
...
※ files
其次你需要一个文件搜索工具,例如 fd,它可以搜索当前目录下的所有文件,然后把搜索结果输出到 stdout。例如 fd 的 fd --type f --hidden 或 find 的 find . -type f。
结合 fzf,我们可以把 fd 的搜索结果作为 fzf 的输入,然后 fzf 会把搜索结果展示到 fzf 的界面上,然后我们就可以通过 fzf 的交互来选择我们想要的文件。例如:
fd --type f --hidden | fzf
相信大家都知道如何使用这些工具,这里就不多说了。
通过 man fzf 我们可以查到和 key/event 相关的配置,其中有这么一段话:
KEY/EVENT BINDINGS
--bind option allows you to bind a key or an event to one or more actions. You can use it to customize key bindings or implement dynamic behaviors.
--bind takes a comma-separated list of binding expressions. Each binding expression is KEY:ACTION or EVENT:ACTION.
e.g.
fzf --bind=ctrl-j:accept,ctrl-k:kill-line
这段话的意思是说我们可以通过 --bind 来绑定一个 key 或者 event 到一个或者多个 action,这样我们就可以实现一些自定义的功能,比如我们可以绑定一个 key 到一个 shell 脚本,这样当我们按下这个 key 的时候就会执行这个 shell 脚本,这个 shell 脚本可以是任何我们想要执行的命令,比如打开一个文件、执行一个命令等等。
同理通过 --bind 绑定一个 event 到一个 action 也是一样的,只不过 event 是 fzf 内部的事件,比如 change 事件,当搜索输入框的值发生变化的时候就会触发这个事件,我们可以通过绑定这个事件到一个 shell 脚本来实现当搜索输入框的值发生变化的时候执行这个 shell 脚本。
而我们要实现的动态切换 mru 和 files 就是通过绑定 change 事件来实现的,当搜索输入框的值发生变化的时候,我们就会执行一个 shell 脚本,这个 shell 脚本会根据搜索输入框的值来判断是展示 mru 列表还是 files 列表。change 的文档说明是:
change
Triggered whenever the query string is changed
e.g.
# Move cursor to the first entry whenever the query is changed
fzf --bind change:first
而 action 也是指 fzf 内部的一些动作,比如 accept,当我们按下回车的时候就会触发这个 action,这个 action 会把当前选中的结果输出到 stdout,然后退出 fzf。这里我们需要用的 action 就是 reload,文档的说明是:
RELOAD INPUT
reload(...) action is used to dynamically update the input list without restarting fzf. I
takes the same command template with placeholder expressions as execute(...).
See https://github.com/junegunn/fzf/issues/1750 for more info.
e.g.
# Update the list of processes by pressing CTRL-R
ps -ef | fzf --bind 'ctrl-r:reload(ps -ef)' --header 'Press CTRL-R to reload' \
--header-lines=1 --layout=reverse
# Integration with ripgrep
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
INITIAL_QUERY="foobar"
FZF_DEFAULT_COMMAND="$RG_PREFIX '$INITIAL_QUERY'" \
fzf --bind "change:reload:$RG_PREFIX {q} || true" \
--ansi --disabled --query "$INITIAL_QUERY"
那么我们就可以通过 fzf --bind change:reload(...) 来实现当搜索输入框的值发生变化的时候重新加载输入列表,这样我们就可以在重新加载输入列表的时候根据搜索输入框的值来判断是展示 mru 列表还是 files 列表了。
首先实现一个初步的版本,只在终端中实现切换,不考虑在 neovim 中的实现,主要是为了方便说明。
※ 首先事前工作
详细的上面已经说过了,这里就不再赘述。
※ 切换脚本
~/dynamic_fzf_source.sh 切换脚本:
#!/bin/bash
input=$1 # 获取用户输入
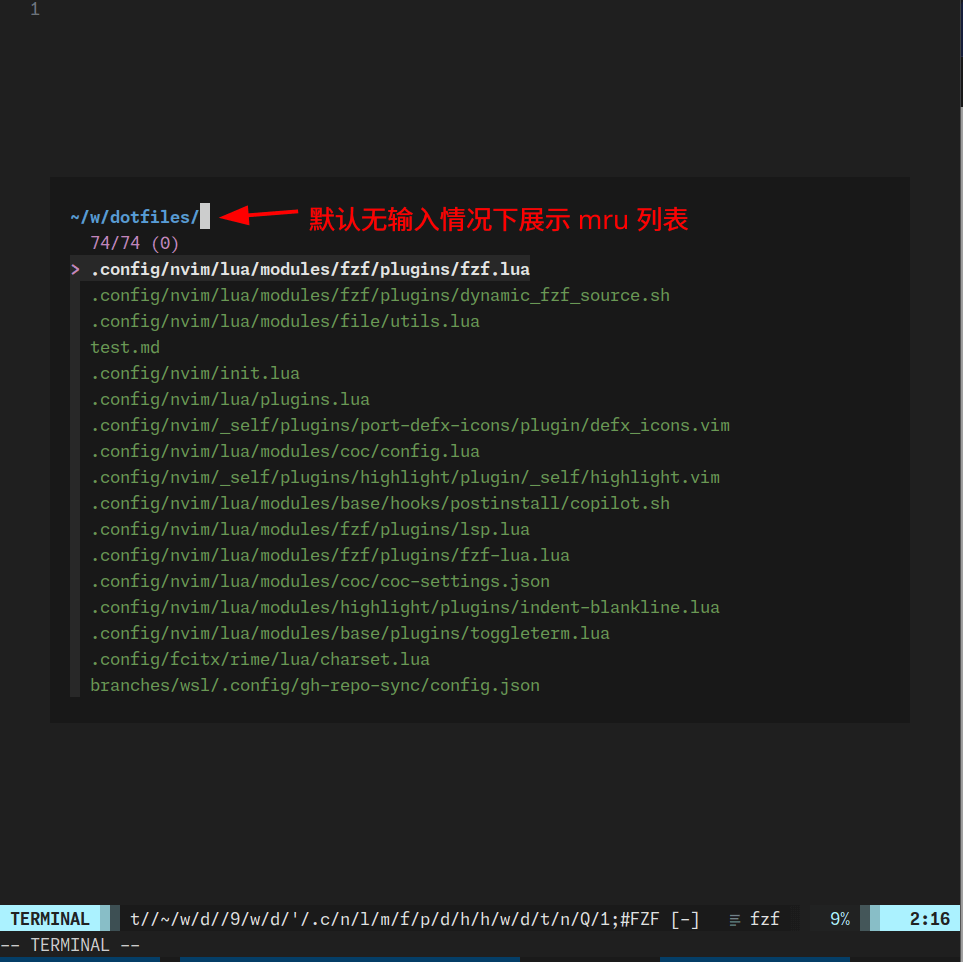
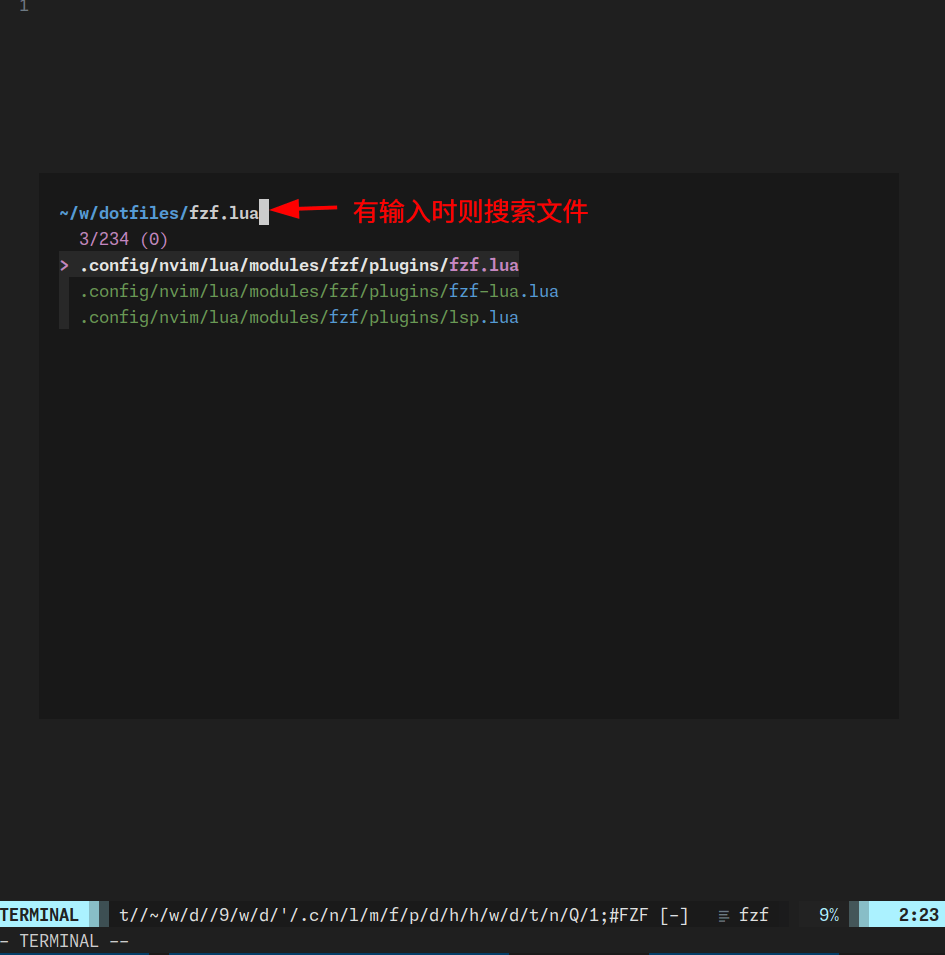
if [ -z "$input" ]; then # 检查是否有任何输入
perl -ne 'print if !$seen{$_}++' ~/.config/coc/mru # 没有输入时,显示 mru 文件内容
else
fd --type f --hidden # 有输入时,搜索当前目录
fi这段脚本的作用就是当没有任何输入的时候显示 mru 文件列表,当有输入的时候搜索当前目录下的所有文件。
而中间那一段 perl 脚本则是用于处理过滤掉 mru 文件中的重复行,因为 mru 文件中可能会有重复的行,这样就会导致 fzf 中展示的列表中有重复的行,所以我们需要过滤掉重复的行,这里使用的是 perl 脚本,当然你也可以使用其他的工具,比如 awk、sort 等等。
※ 绑定 fzf 的 change 事件
fzf --bind "change:reload($HOME/dynamic_fzf_source.sh {q})" < <($HOME/dynamic_fzf_source.sh)
这个命令意思就是当搜索输入框的值发生变化的时候重新加载输入列表,这里的输入列表就是 ~/dynamic_fzf_source.sh 脚本的输出,然后把搜索输入框的值作为参数传递给 ~/dynamic_fzf_source.sh 脚本,这样我们就可以在 ~/dynamic_fzf_source.sh 脚本中根据搜索输入框的值来判断是展示 mru 列表还是 files 列表了。
其中 {q} 是 fzf 用于获取搜索输入框的值的占位符,详细的可以查看 man fzf。
而 < <($HOME/dynamic_fzf_source.sh) 这一段则是把 ~/dynamic_fzf_source.sh 脚本的输出作为 fzf 的输入。意思就是先直接执行 ~/dynamic_fzf_source.sh 脚本(且不传任何参数),然后把它的输出作为 fzf 的输入。
※ 效果截图
当前 mru 列表文件展示:
无输入值时,fzf mru 展示:
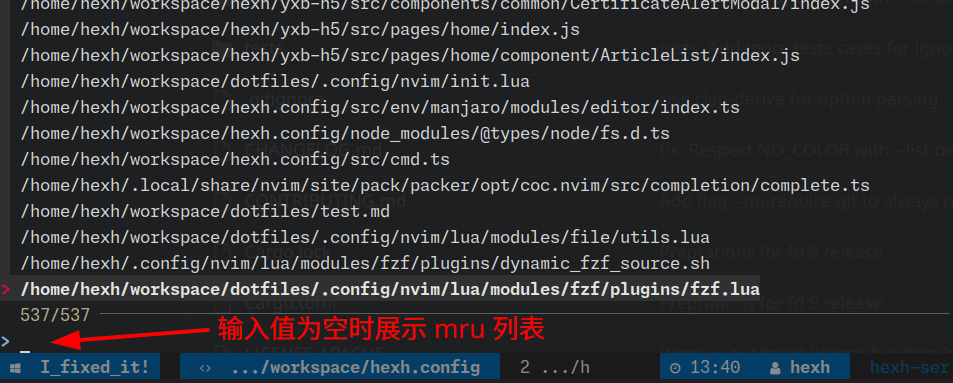
有输入值时,fzf files 展示:
※ 首先事前工作
※ 切换脚本
该脚本与上面的脚本几乎一样,但是我额外进行了对 cwd(当前工作目录)的处理,把不在当前工作目录下的文件移除掉,这样就可以使 mru 列表看起来更加简洁。
~/.vim/dynamic_fzf_source.sh 切换脚本:
#!/bin/bash
cwd=$1 # 获取传入的当前工作目录
input=$2 # 获取用户输入
if [ -z "$input" ]; then
perl -ne 'print substr($_, length("'"$cwd"'/")) if m{^'"$cwd"'/} && !$seen{$_}++' ~/.config/coc/mru
else
fd --type f --hidden
fi基本逻辑和上面的脚本一致,只多了一步对 cwd 的处理。
※ 绑定 fzf 的 change 事件
这里需要先在 neovim 中加载 fzf 插件,然后使用以下 vim 代码来构造一个 vim 方法(习惯使用 lua 的同学可以自行转换):
function! s:FZF(...)
let cwd = getcwd()
" 这一行的核心代码和上面的命令是一样的都是 `--bind change:reload(...)`
" 不过多传了一个 `cwd` 参数
let opts = fzf#wrap('FZF', { 'options': ['--bind=' . 'change:reload($HOME/.vim/dynamic_fzf_source.sh ' . cwd . ' {q})'] })
" 这一行则是用于替代上面的 `< <($HOME/dynamic_fzf_source.sh)`
" 因为 vim 中调用无法使用管道传输,所以会先构造一个初始的 source
let opts.source = "perl -ne 'print substr(\$_, length(\"" . cwd . "/\")) if m{^" . cwd . "/} && !$seen{\$_}++' ~/.config/coc/mru"
call fzf#run(opts)
endfunction
" 绑定一个快捷键
nnoremap <silent> <leader>f :call <SID>FZF()<CR>
这样我们就可以在 neovim 中使用 <leader>f 来打开 fzf mru/files 了,当然你也可以使用其他的快捷键。
※ 效果截图
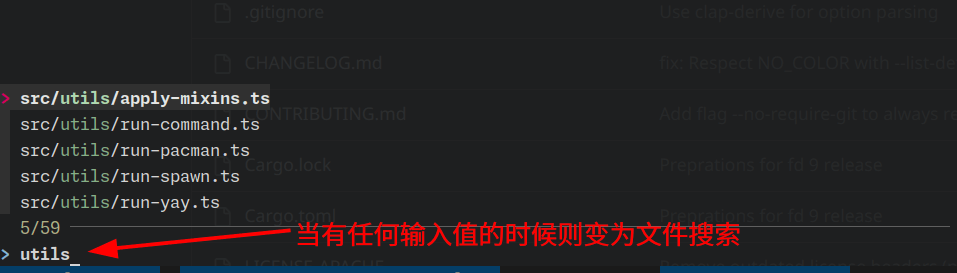
无输入值时,fzf mru 展示:
有输入值时,fzf files 展示:
上面介绍了如何在 fzf 中根据搜索输入框的值来动态切换 mru 和 files 列表,这样我们就可以在 fzf 中实现一个类似 VSCode 中的 ctrl-p 的功能了,当然这只是一个简单的实现,你可以根据自己的需求来进行扩展。
其基本原理使用了 fzf 的 --bind change:reload(...) 来实现。
以上就是本文的全部内容,希望对你有所帮助,如果有任何问题欢迎在评论区留言,我会尽快回复:)。
wd gamma-mobile && git pull && yarn gamma-build && wd bff && easy-deploy restart gammawd gamma-mobile && git pull && yarn gamma-build && wd bff && easy-deploy restart gammawd gamma-mobile && git pull && yarn gamma-build && wd bff && easy-deploy restart gammawd gamma-mobile && git pull && yarn gamma-build && wd bff && easy-deploy restart gamma
硬盘安装
首先前往 https://msdn.itellyou.cn 下载系统
直接使用已经制作好的那个硬盘,那个硬盘一般别动,然后用这个硬盘来启动。但是因为未知原因,可能会出现两个启动项,选择字儿少那个
删除分区用分盘助手,制作分区使用傲梅助手,分盘选择 GPT + UEFI
这种方式安装以后不知为何无法使用账户激活,也可能是因为用的笔记本没有上网驱动导致初始化设置的时候无法联网获取激活信息。下次用台式试验下。若无法用账户激活,请使用亦是美 http://www.yishimei.cn 另外对于笔记本,可能进去的时候无法联网,记得先装一个网卡驱动。而对于 XPS13 9350 直接用硬盘里那个来启动即可
直接安装
同上 a
直接双击安装程序即可
用户名统一使用 hexh,但是如果事先登录的账号,可能会变成 25078,所以尽量进去系统后再登录账号
hexh 里面新建一个 App 文件夹用来放所有的个人软件
开放查看隐藏文件、显示文件类型
快速访问只需要留下桌面和下载和 hexh
关闭 OneDriver
开启子系统
hexh 里面新建文件夹 Workspace,里面新建 Projects、Documents、Notes,Projects 里面建 Private 和 Work
基础软件
由另一台电脑准备好 SSR,记得使用的是便携版,然后导入账号 https://www.billtsnet.app/auth/login
然后下载 Chrome https://www.google.com/intl/zh-CN/chrome/
去 91flac 下载下载管理器 https://www.91flac.com/
AutoHotKey https://www.autohotkey.com/ 然后顺便这一步把 Something 给下载了 https://github.com/hexh250786313/Something 然后把 my-key 放进 App,运行,运行禁用 Win + I 的脚本
utools https://www.u.tools/
常用运行库 https://www.mpyit.com/?s=%E5%B8%B8%E7%94%A8%E8%BF%90%E8%A1%8C&x=0&y=0
百度下载 https://www.mpyit.com/?s=%E7%99%BE%E5%BA%A6&x=0&y=0 现在用的是亿寻
软件
DirectX https://www.mpyit.com/?s=directx&x=0&y=0 安装的时候记得关闭 VC++ 库,因为上面的常用运行库已经安装过了
迅雷 https://www.mpyit.com/?s=%E8%BF%85%E9%9B%B7&x=0&y=0 装完后记得修改下载目录,放到 Download 中去
Typora https://typora.io/
搜狗 https://www.mpyit.com/?s=%E6%90%9C%E7%8B%97&x=0&y=0 这玩儿设置有点复杂
先删除微软输入法
关闭表情
设置为竖排
在状态栏显示
关闭切换快捷键
默认设置为英文
截图工具 https://www.faststone.org/FSCaptureDownload.htm 然后设置为 Rectangle,开启开机自动启动,输出到剪贴板
Defender Control https://www.google.com/search?q=defender%20control
ThinkPad Keyboard Suite Updater https://support.lenovo.com/us/en/solutions/pd026745 然后设置首选 TP 滚动
VSCode
Windows Terminal,商店下载,下载完后配置字体和设置 JSON,然后从最近添加那里拖出一个快捷方式整到 ahk 的快速启动上
下载 Ubuntu 账户:lllk@hexh
使用 Win 上的代理更新软件和系统(如果不能连接网络则尝试 https):
sudo apt-get -o Acquire::http::proxy="http://127.0.0.1:1080" update
sudo apt-get -o Acquire::http::proxy="http://127.0.0.1:1080" -y upgradesudo apt-get -o Acquire::http::proxy="http://127.0.0.1:1080" install zshexport http_proxy=http://127.0.0.1:1080
export https_proxy=http://127.0.0.1:1080sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"然后安装 zsh-autosuggestions 和 zsh-syntax-highlighting 这两个插件:
zsh-autosuggestions https://github.com/zsh-users/zsh-autosuggestions
zsh-syntax-highlighting https://github.com/zsh-users/zsh-syntax-highlighting
如果提示权限问题尝试在 .zshrc 第一行添加:
ZSH_DISABLE_COMPFIX=true然后把 zsh 的主题设置为 muse
安装 nvm 和 npm
nvm,要把指令的 bash 改为 zsh https://github.com/nvm-sh/nvm
npm:
nvm install node安装 nvim:
下载完毕后放入 ~/app/nvim 中
然后执行:
./nvim.appimage --appimage-extractalias nvim="~/app/nvim/squashfs-root/usr/bin/nvim"设置 git https://github.com/hexh250786313/amai_mayoi.github.io/blob/bak-original/post/2017-05-15.html
为 nvim 安装 Plug https://github.com/junegunn/vim-plug
前往 ~/.config 文件夹,把我的 nvim 配置拉下来:
git clone [email protected]:hexh250786313/nvim.gitsudo apt-get -o Acquire::http::proxy="http://127.0.0.1:1080" install python3-pippip3 install pynvim
npm install -g neovim
npm install -g yarn然后就可以安装 nvim 插件了,记得开始安装前要设置代理,并且等 coc 的插件都安装完再退出(右边的窗口可以看 coc 插件的安装状态)。然后最后要检查下 MarkdownPreview 这个插件有没有问题,如果有问题要亲手前往 ~/.vim/plugged/markdown-preview.nvim 这个文件夹中 yarn 一下
安装 rg:
sudo dpkg -i <包名 1> <包名 2>tmux 相关:
git clone https://github.com/tmux/tmux.git
cd tmux
sudo apt-get -o Acquire::http::proxy="http://127.0.0.1:1080" install automake pkg-config
sh autogen.sh
sudo apt-get -o Acquire::http::proxy="http://127.0.0.1:1080" install libevent-dev ncurses-dev byacc
./configure && makecd ~ && touch ~/.tmux.conf && nvim ~/.tmux.confOpenVPN https://openvpn.net/community-downloads/ 然后把我的配置文件夹(howard 文件夹)放进 hexh/OpenVPN/config 文件夹中即可,连接时只需要打开然后在右键右下角图标连接即可。记得关掉开机自启
为 zsh 设置颜色,下载这个文件夹 https://github.com/arcticicestudio/nord-dircolors/tree/develop/src 然后改名为 .dir_colors 放到 ~,如果拉回来的 .zshrc 生效的话应该会直接生效
共享剪贴板:
安装 VcXsrv https://www.google.com/search?q=VcXsrv 一路默认。最后不选 Native opengl
安装 xclip:
sudo apt-get -o Acquire::http::proxy="http://127.0.0.1:1080" install xclip最后从 Something 文件夹把 .zshrc 配置替换到本地,source 一下,上面全部都可以生效了
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.