henryhaohao / bilibili_video_download Goto Github PK
View Code? Open in Web Editor NEW:rainbow:Bilibili_video_download-B站视频下载
Home Page: https://www.bilibili.com/
License: Apache License 2.0
:rainbow:Bilibili_video_download-B站视频下载
Home Page: https://www.bilibili.com/
License: Apache License 2.0
因为运行脚本后没有文件被下载下来,就看了一下源码,调试了一下,发现
<video>
<result>error</result>
<code>10003</code>
<message><![CDATA[Invalid appkey parameter.]]></message>
</video>
https://www.bilibili.com/video/av23585080?from=search&seid=3752882998140009579
用这个里边的视频做测试,发现总长170多分钟的视频只能下载五分钟,不知道是啥缘故
其实下载的链接就在页面中,可以查看页面源码。
😎
不过有些视频好像没有下载链接呢0.0
发生异常: urllib.error.ContentTooShortError
<urlopen error retrieval incomplete: got only 3938643 out of 14990995 bytes>
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py", line 288, in urlretrieve
% (read, size), result)
File "/Users/yongqingwang/Downloads/python-spider-master/bilibili/bilibili_video_download.py", line 135, in down_video
urllib.request.urlretrieve(url=i, filename=os.path.join(currentVideoPath, r'{}-{}.flv'.format(title, num)),reporthook=Schedule_cmd) # 写成mp4也行 title + '-' + num + '.flv'
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 869, in run
del self._target, self._args, self._kwargs
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 885, in _bootstrap
self._bootstrap_inner()
请教下,音频MP3在项目目录下面,title文件夹下生产MP4但是没有音频,不知道是什么原因
想问一下,appkey和sec是怎么获取的呢
Traceback (most recent call last):
File "bilibili_video_download-GUI.py", line 270, in
photo = PhotoImage(file='./Pic/logo.png')
File "/usr/local/Cellar/python/3.7.4/Frameworks/Python.framework/Versions/3.7/lib/python3.7/tkinter/init.py", line 3545, in init
Image.init(self, 'photo', name, cnf, master, **kw)
File "/usr/local/Cellar/python/3.7.4/Frameworks/Python.framework/Versions/3.7/lib/python3.7/tkinter/init.py", line 3501, in init
self.tk.call(('image', 'create', imgtype, name,) + options)
_tkinter.TclError: couldn't recognize data in image file "./Pic/logo.png"
是缺少什么模块吗?查了一下好像tkinter 只能用GIF?这个logo是png?
Bilibili_video_download-GUI 下载多P视频时发生socket.gaierror: [Errno 11004] getaddrinfo failed和urllib.error.URLError: <urlopen error [Errno 11004] getaddrinfo failed>
不知道哪里出了错误?是url还是服务器拒绝服务?
GUI可以下载一部分视频,但是有一部分视频没有下载成功,多次测试发现,每次下载失败的视频是随机的,成功下载的视频也是随机的。希望解决这个问题。
具体提示如下:
D:\Bilibili_video_download>"D:/Program Files/Python37/python.exe" d:/Bilibili_video_download/bilibili_video_download-GUI.py
Exception in thread Thread-74:
Traceback (most recent call last):
File "D:\Program Files\Python37\lib\urllib\request.py", line 1317, in do_open
encode_chunked=req.has_header('Transfer-encoding'))
File "D:\Program Files\Python37\lib\http\client.py", line 1229, in request
self._send_request(method, url, body, headers, encode_chunked)
File "D:\Program Files\Python37\lib\http\client.py", line 1275, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "D:\Program Files\Python37\lib\http\client.py", line 1224, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "D:\Program Files\Python37\lib\http\client.py", line 1016, in _send_output
self.send(msg)
File "D:\Program Files\Python37\lib\http\client.py", line 956, in send
self.connect()
File "D:\Program Files\Python37\lib\http\client.py", line 928, in connect
(self.host,self.port), self.timeout, self.source_address)
File "D:\Program Files\Python37\lib\socket.py", line 707, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
File "D:\Program Files\Python37\lib\socket.py", line 748, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno 11004] getaddrinfo failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Program Files\Python37\lib\threading.py", line 917, in _bootstrap_inner
self.run()
File "D:\Program Files\Python37\lib\threading.py", line 865, in run
self._target(*self._args, **self._kwargs)
File "d:/Bilibili_video_download/bilibili_video_download-GUI.py", line 147, in down_video
urllib.request.urlretrieve(url=i, filename=os.path.join(currentVideoPath, r'{}.flv'.format(title)),reporthook=Schedule_cmd) # 写成mp4也行 title + '-' + num + '.flv'
File "D:\Program Files\Python37\lib\urllib\request.py", line 247, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File "D:\Program Files\Python37\lib\urllib\request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "D:\Program Files\Python37\lib\urllib\request.py", line 525, in open
response = self._open(req, data)
File "D:\Program Files\Python37\lib\urllib\request.py", line 543, in _open
'_open', req)
File "D:\Program Files\Python37\lib\urllib\request.py", line 503, in _call_chain
result = func(*args)
File "D:\Program Files\Python37\lib\urllib\request.py", line 1345, in http_open
return self.do_open(http.client.HTTPConnection, req)
File "D:\Program Files\Python37\lib\urllib\request.py", line 1319, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [Errno 11004] getaddrinfo failed>
可能是某个软件包的版本问题,本机windows 安装python3.7, 运行pip3 list 结果如下,供排查错误参考:
$ pip3 list
Package Version
pip 19.0.3
altgraph 0.16.1
astroid 2.3.2
beautifulsoup4 4.8.1
BiliUtil 0.2.1
certifi 2019.9.11
chardet 3.0.4
Click 7.0
colorama 0.4.1
comtypes 1.1.7
decorator 4.4.0
fake-useragent 0.1.11
future 0.18.1
gql 0.1.0
graphql-core 2.2.1
graphqlclient 0.2.4
idna 2.8
imageio 2.4.1
imageio-ffmpeg 0.3.0
isort 4.3.21
lazy-object-proxy 1.4.2
lxml 4.4.1
macholib 1.11
mccabe 0.6.1
moviepy 1.0.1
numpy 1.17.3
packaging 19.2
pefile 2019.4.18
Pillow 6.2.0
pip 19.3.1
proglog 0.1.9
promise 2.2.1
PyInstaller 3.5
pylint 2.4.3
pyparsing 2.4.2
PyQt5 5.13.0
PyQt5-sip 12.7.0
pyqt5-tools 5.13.0.1.5
python-dotenv 0.10.3
pywin32 225
pywin32-ctypes 0.2.0
requests 2.22.0
Rx 1.6.1
selenium 3.141.0
setuptools 40.8.0
sgqlc 8.1
sip 5.0.0
six 1.12.0
soupsieve 1.9.4
toml 0.10.0
tqdm 4.36.1
typed-ast 1.4.0
urllib3 1.25.6
websocket-client 0.56.0
websockets 8.0.2
wrapt 1.11.2
xlwings 0.16.0
如果标题文件没有名字,在下载结束以后找不到文件位置


500m电信为何只有几十kb
得到了sessdata的值,但是怎么带入啊。是在选择清晰度的时候这样吗:”80 bd4e370a%2C1566023676%2C750e6b71” 还是要在网页上事先设置好?还有就是。。不知道为什么老闪退是操作不当吗?求大佬解答!跪谢!
bilibili_video_download_v1.py file only downloaded the first segment of the page whatever it was single page download mission or not.
大佬 你好 请问一下你获取这些视频路径的方法是啥 在bilibili_video_download_v2.py中我尝试在network中搜索访问https://api.bilibili.com/x/player/playurl的请求 却找不到 想请问一下哔哩哔哩是怎么请求视频接口
In the project, the so-called 720p video quality is not real, and may be just 360p truly.
如题,有大会员账号,可以在程序添加一个登录账号功能,然后下载1080p60的视频吗?
试了一下,按教程把自己的大会员cookie换了,结果不行,提示非大会员。后来试了一下下载非大会员的番剧,也是提示非大会员。是不是那个接口现在已经换了
程序无法运行,两个都尝试过,报错类似,如下:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/imageio/plugins/ffmpeg.py", line 82, in get_exe
auto=False)
File "/usr/local/lib/python3.7/site-packages/imageio/core/fetching.py", line 102, in get_remote_file
raise NeedDownloadError()
imageio.core.fetching.NeedDownloadError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "bilibili_video_download_v1.py", line 16, in
from moviepy.editor import *
File "/usr/local/lib/python3.7/site-packages/moviepy/editor.py", line 22, in
from .video.io.VideoFileClip import VideoFileClip
File "/usr/local/lib/python3.7/site-packages/moviepy/video/io/VideoFileClip.py", line 3, in
from moviepy.video.VideoClip import VideoClip
File "/usr/local/lib/python3.7/site-packages/moviepy/video/VideoClip.py", line 21, in
from .io.ffmpeg_writer import ffmpeg_write_image, ffmpeg_write_video
File "/usr/local/lib/python3.7/site-packages/moviepy/video/io/ffmpeg_writer.py", line 11, in
from moviepy.config import get_setting
File "/usr/local/lib/python3.7/site-packages/moviepy/config.py", line 35, in
FFMPEG_BINARY = get_exe()
File "/usr/local/lib/python3.7/site-packages/imageio/plugins/ffmpeg.py", line 86, in get_exe
raise NeedDownloadError('Need ffmpeg exe. '
imageio.core.fetching.NeedDownloadError: Need ffmpeg exe. You can download it by calling:
imageio.plugins.ffmpeg.download()
多线程并没有明显加速,是因为接口的原因吗?尝试使用cookie下载,但没有找到sessdata信息。请求帮助
File "C:\Python37-32\lib\threading.py", line 865, in run
self._target(*self._args, **self._kwargs)
File "bilibili_video_download_v3.py", line 138, in down_video
urllib.request.urlretrieve(url=i, filename=os.path.join(currentVideoPath, r'{}.flv'.format(title)),reporthook=Schedule_cmd) # 写成mp4也行 title + '-' + num + '.flv'
File "C:\Python37-32\lib\urllib\request.py", line 288, in urlretrieve
% (read, size), result)
urllib.error.ContentTooShortError: <urlopen error retrieval incomplete: got only 123141637 out of 127210381 bytes>
我发现各版本随着更新功能都互相重叠,比如V1版本似乎已经有了多线程下载之类的,以及V4基于V3,而V3为V2升级,V2需要sessdata但V4不需要。Readme中的版本描述已经不再准确,建议修改。
每次改代码贼累....直接从配置文件里读就行了
当分文件大于10个, files.sort()排序会把10排到1后面, 导致合成出来的视频是错的, 我重新做了一个排序
for i in range(len(files)):
files[i] = files[i].split('-')
files[i][2] = files[i][2].split('.')
files[i][2] = int(files[i][2][0])
files.sort()
for i in range(len(files)):
files[i][2] = str(files[i][2])
files[i] = files[i][0] + '-' + files[i][1] + '-' + files[i][2] + '.flv'
在windows下安装imageio库失败,请问怎么解决?
错误信息:
Traceback (most recent call last):
File "D:\Bilibili_video_download-master\bilibili_video_download-GUI.py", line 268, in
root.iconbitmap('./Pic/favicon.ico')
File "C:\WorkEnv\Python37\lib\tkinter_init_.py", line 1871, in wm_iconbitmap
return self.tk.call('wm', 'iconbitmap', self._w, bitmap)
_tkinter.TclError: bitmap "./Pic/favicon.ico" not defined
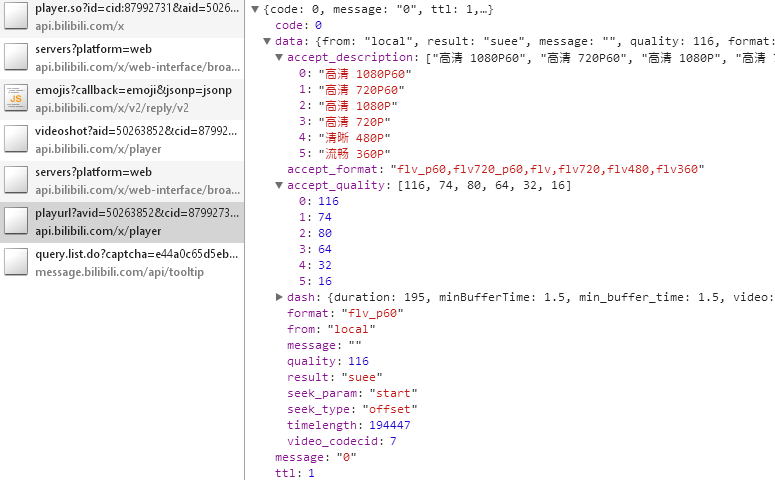
1080P60为116
720P60为74
使用 bilibili_video_download_v1.py 下载的 1080 视频下载完之后提示无法打开,我将代码里面的 flv 全部替换修改为 mp4 同样无法打开。

环境:Windows 10
Python 3.6.5
File "D:/Bilibili_video_download/bilibili_video_download_bangumi.py", line 153, in combine_video
if len(os.listdir(current_video_path)) >= 2:
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'D:\Bilibili_video_download\bilibili_video\PV '
Sometimes, the file named bilibili_video_download_v2.py will report problems as below when Merging the Segments.
'''
Traceback (most recent call last):
File "bilibili_video_download_v2.py", line 225, in
combine_video(video_list, title)
File "bilibili_video_download_v2.py", line 154, in combine_video
for file in sorted(os.listdir(root_dir), key=lambda x: int(x[x.rindex("-") + 1:x.rindex(".")])):
File "bilibili_video_download_v2.py", line 154, in
for file in sorted(os.listdir(root_dir), key=lambda x: int(x[x.rindex("-") + 1:x.rindex(".")])):
ValueError: substring not found
'''
只想下载其中的一集,starturl只能解析出av号后,要从头开始下,这时候是修改pages初始值还是修改循环?
在linux下默认的下载路径会有问题,我改成了下载在当前目录,等下好了pull request。
获取cid的api为 https://api.bilibili.com/x/web-interface/view?aid=47476691 aid后面为av号
下载链接api为 https://api.bilibili.com/x/player/playurl?cid=86427312&avid=49357810 cid为上面获取到的 avid为输入的av号
不需要什么appkey的,那些都是m端用的
如果需要大会员的传入自己登陆的cookie就行了
比如这个:https://www.bilibili.com/bangumi/play/ep173287
我修改了cookies中的SESSDATA,尝试下载1080+的视频。
程序输出错误如下:
Traceback (most recent call last):
File "bilibili_video_download_v2.py", line 209, in <module>
video_list = get_play_list(aid, cid, quality)
File "bilibili_video_download_v2.py", line 36, in get_play_list
for i in html['data']['durl']:
TypeError: 'NoneType' object is not subscriptable
貌似是play_list的获取出现了问题:
{"code":0,"message":"0","ttl":1,"data":{"aid":18679531,"videos":1,"tid":33,"tname":"连载动画","copyright":2,"pic":"http://i0.hdslb.com/bfs/archive/fcaa17b9aa60868e0e23c3b56edddee29322d32b.jpg","title":"【1月】紫罗兰永恒花园 03【独家正版】","pubdate":1516809600,"ctime":1516788526,"desc":"#03","state":0,"attribute":338688,"duration":1440,"redirect_url":"http://www.bilibili.com/bangumi/play/ep173288/","rights":{"bp":0,"elec":0,"download":0,"movie":0,"pay":1,"hd5":1,"no_reprint":0,"autoplay":0,"ugc_pay":0,"is_cooperation":0,"ugc_pay_preview":0},"owner":{"mid":928123,"name":"哔哩哔哩番剧","face":"http://i1.hdslb.com/bfs/face/60a9153609998b04301dc5b8ed44c41b537a2268.jpg"},"stat":{"aid":18679531,"view":4572327,"danmaku":211015,"reply":32609,"favorite":417,"coin":52811,"share":14008,"now_rank":0,"his_rank":0,"like":1290,"dislike":0},"dynamic":"","cid":30655086,"dimension":{"width":0,"height":0,"rotate":0},"no_cache":true,"pages":[{"cid":30655086,"page":1,"from":"vupload","part":"紫罗兰永恒花园 03","duration":1440,"vid":"","weblink":"","dimension":{"width":0,"height":0,"rotate":0}}],"subtitle":{"allow_submit":false,"list":[]}}}请求https://api.bilibili.com/x/player/playurl?cid={}&avid={}&qn={}之后的结果:
{"code":-404,"message":"啥都木有","ttl":1,"data":null}我想老哥是不是以 URL 地址为文件夹名 名字里面有 / 系统以为是说的文件夹
➜ Bilibili_video_download git:(master) python3 bilibili_video_download_v1.py
B站视频下载小助手
请输入您要下载的B站av号或者视频链接地址:av50596322
Traceback (most recent call last):
File "bilibili_video_download_v1.py", line 176, in
start_url = 'https://api.bilibili.com/x/web-interface/view?aid=' + re.search(r'/av(\d+)/*', start).group(1)
AttributeError: 'NoneType' object has no attribute 'group'
https://www.bilibili.com/video/av15057416?from=search&seid=11494394167082827401
Exception in thread Thread-1:
Traceback (most recent call last):
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python37\lib\threading.py", line 926, in _bootstrap_inner
self.run()
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python37\lib\threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File ".\bilibili_video_download-GUI.py", line 236, in do_prepare
combine_video(video_list, title)
File ".\bilibili_video_download-GUI.py", line 160, in combine_video
for file in sorted(os.listdir(root_dir), key=lambda x: int(x[x.rindex("-") + 1:x.rindex(".")])):
File ".\bilibili_video_download-GUI.py", line 160, in
for file in sorted(os.listdir(root_dir), key=lambda x: int(x[x.rindex("-") + 1:x.rindex(".")])):
ValueError: substring not found
(py3.7) ➜ Bilibili_video_download git:(master) python bilibili_video_download_bangumi.py
B站番剧视频下载小助手
[提示]: 1.如果您想下载720P60,1080p+,1080p60质量的视频,请将35行代码中的SESSDATA改成你登录大会员后得到的SESSDATA,普通用户的SESSDATA最多只能下载1080p的视频
2.若发现下载的视频质量在720p以下,请将35行代码中的SESSDATA改成你登录后得到的SESSDATA(有效期一个月),而失效的SESSDATA就只能下载480p的视频
请输入您要下载的B站番剧的完整链接地址(例如:https://www.bilibili.com/bangumi/play/ep267692):https://www.bilibili.com/video/av40280311/?p=1
请输入1或2 - 1.只下载当前一集 2.下载此番剧的全集:1
Traceback (most recent call last):
File "bilibili_video_download_bangumi.py", line 202, in
id_list.append([ep_info['epInfo']['aid'], ep_info['epInfo']['cid'],
KeyError: 'epInfo'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "bilibili_video_download_bangumi.py", line 205, in
id_list.append([ep_info['epInfo']['aid'], ep_info['epInfo']['cid'],
KeyError: 'epInfo'
输入1 2 都会报同样的错
相关依赖已经安装:
root@starx:/home/starx/Bilibili_video_download# python3 bilibili_video_download_v1.py
Traceback (most recent call last):
File "bilibili_video_download_v1.py", line 167, in
print('' * 30 + 'B\u7ad9\u89c6\u9891\u4e0b\u8f7d\u5c0f\u52a9\u624b' + '' * 30)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 31-38: ordinal not in range(128)
解决方法是运行一下
import imageio
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
imageio.plugins.ffmpeg.download()
建议处理一下
大佬,你的appkey从哪里来的啊
多P视频,下载错误后,就重新开始下了
如题
下载番剧采用的接口是什么呢,之前可以下载的番剧现在不能下了,传入大会员SESSDATA也不管用。
下载完视频之后,如果是分段视频会留下flv的片段,建议添加自动删除的功能0.0
标题遇到"/",""会出错
系统不允许文件名内存在“/”,""
可以在下载前加上
try:
title=re.sub("\","\",title,count=0)
except:
aaa=0
try:
title=re.sub("/",'/',title,count=0)
except:
aaa=0
测试视频显示下载完成 并没有进行合并 打印video_list 为1
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.