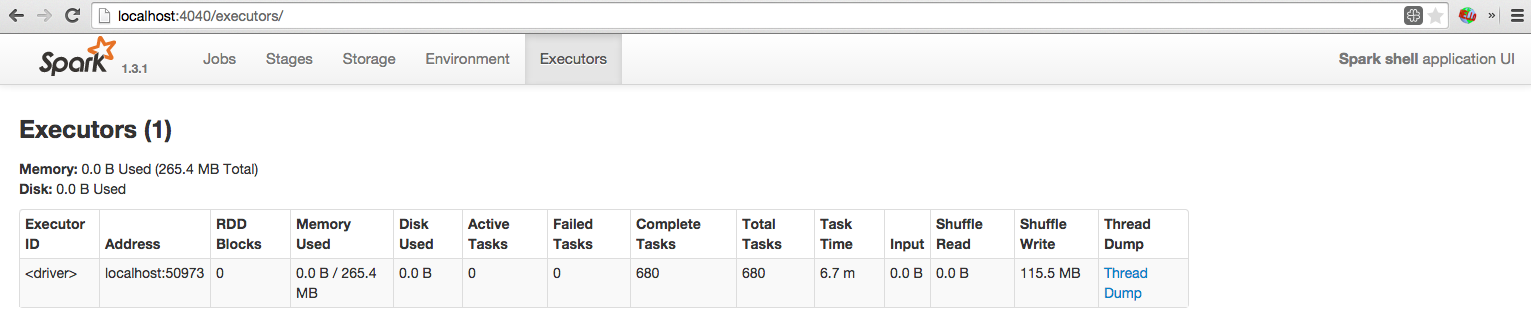
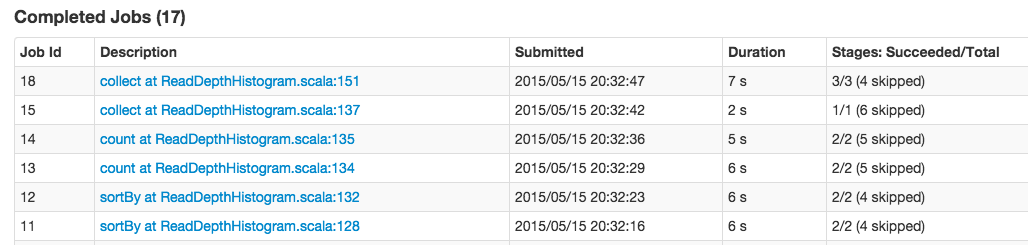
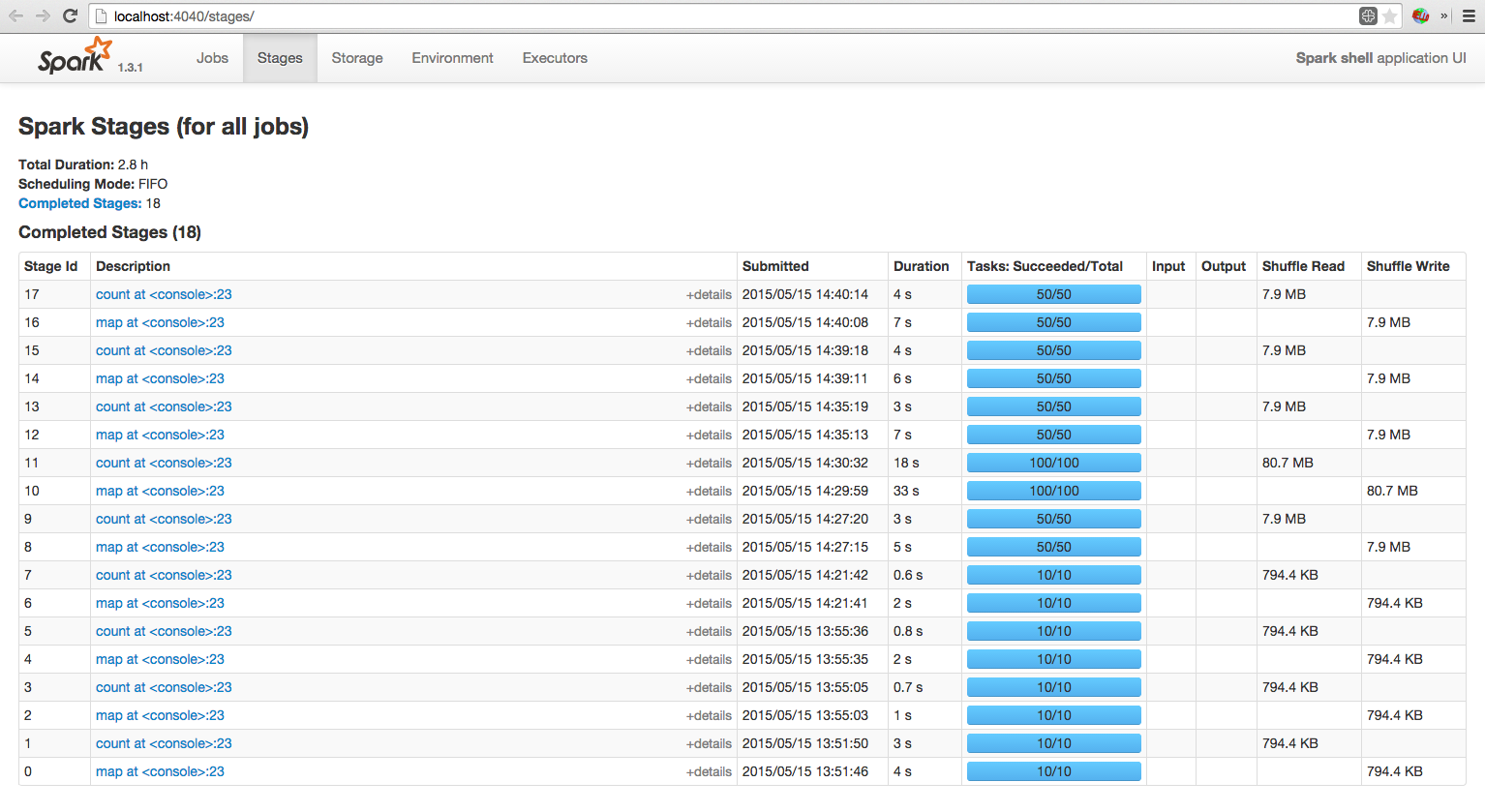
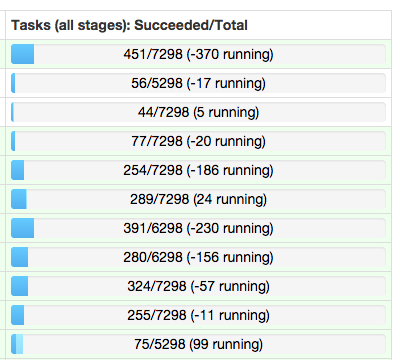
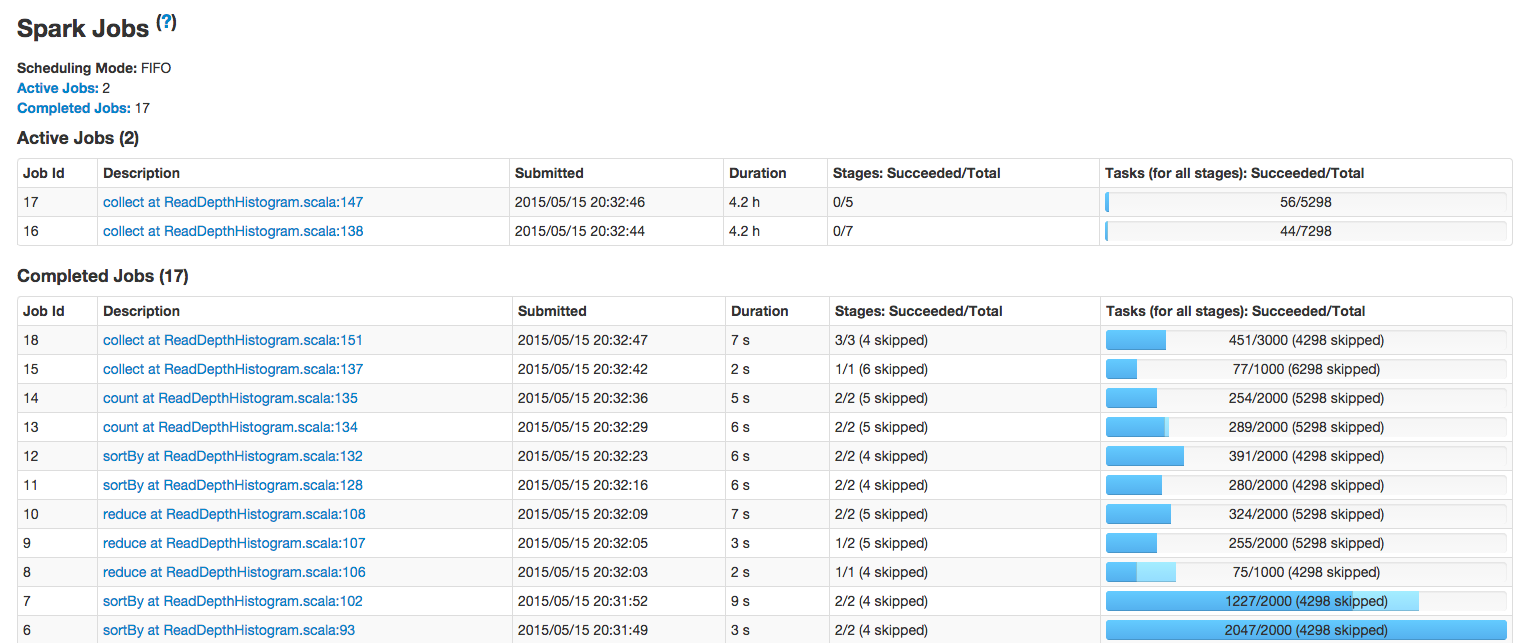
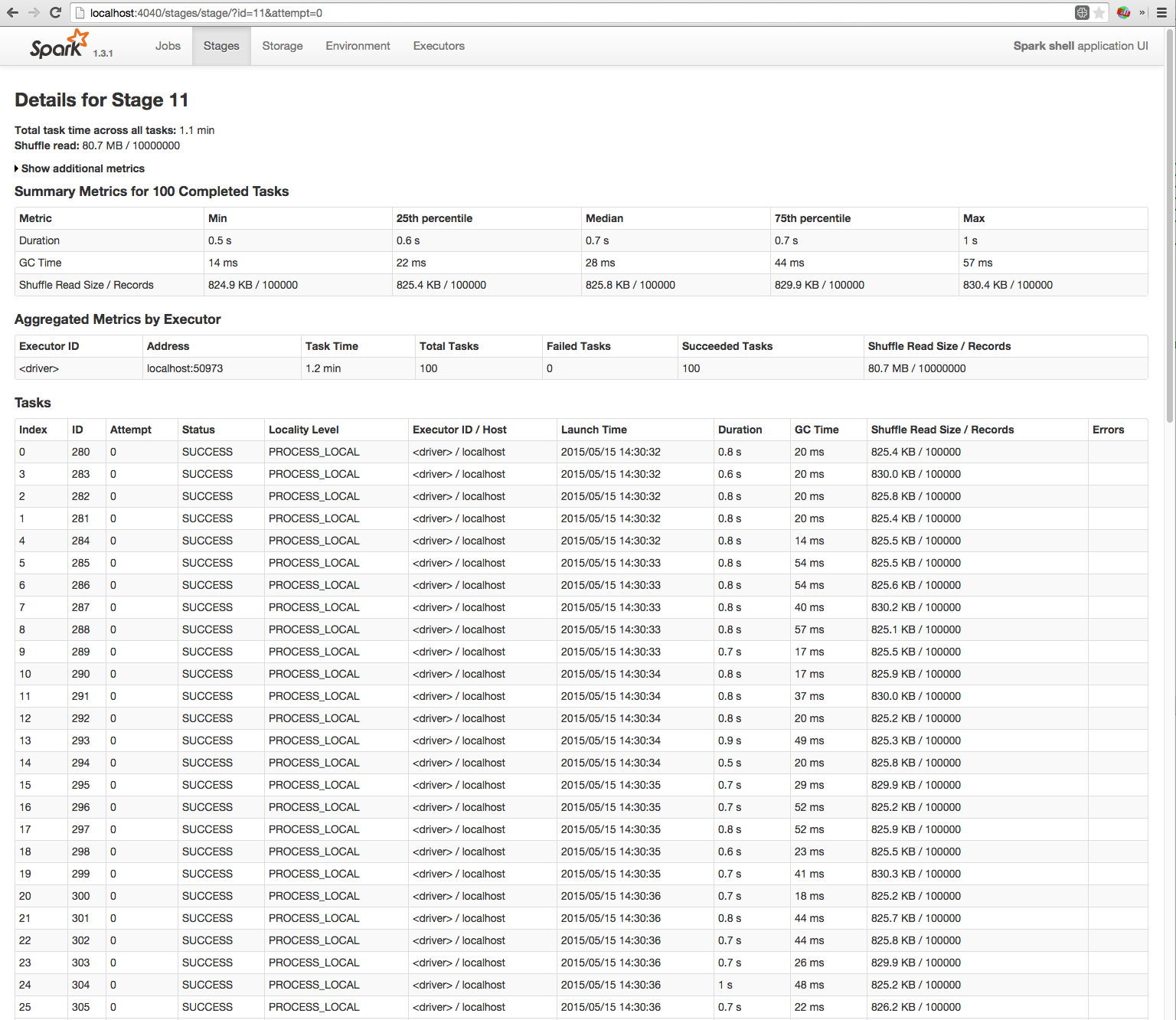
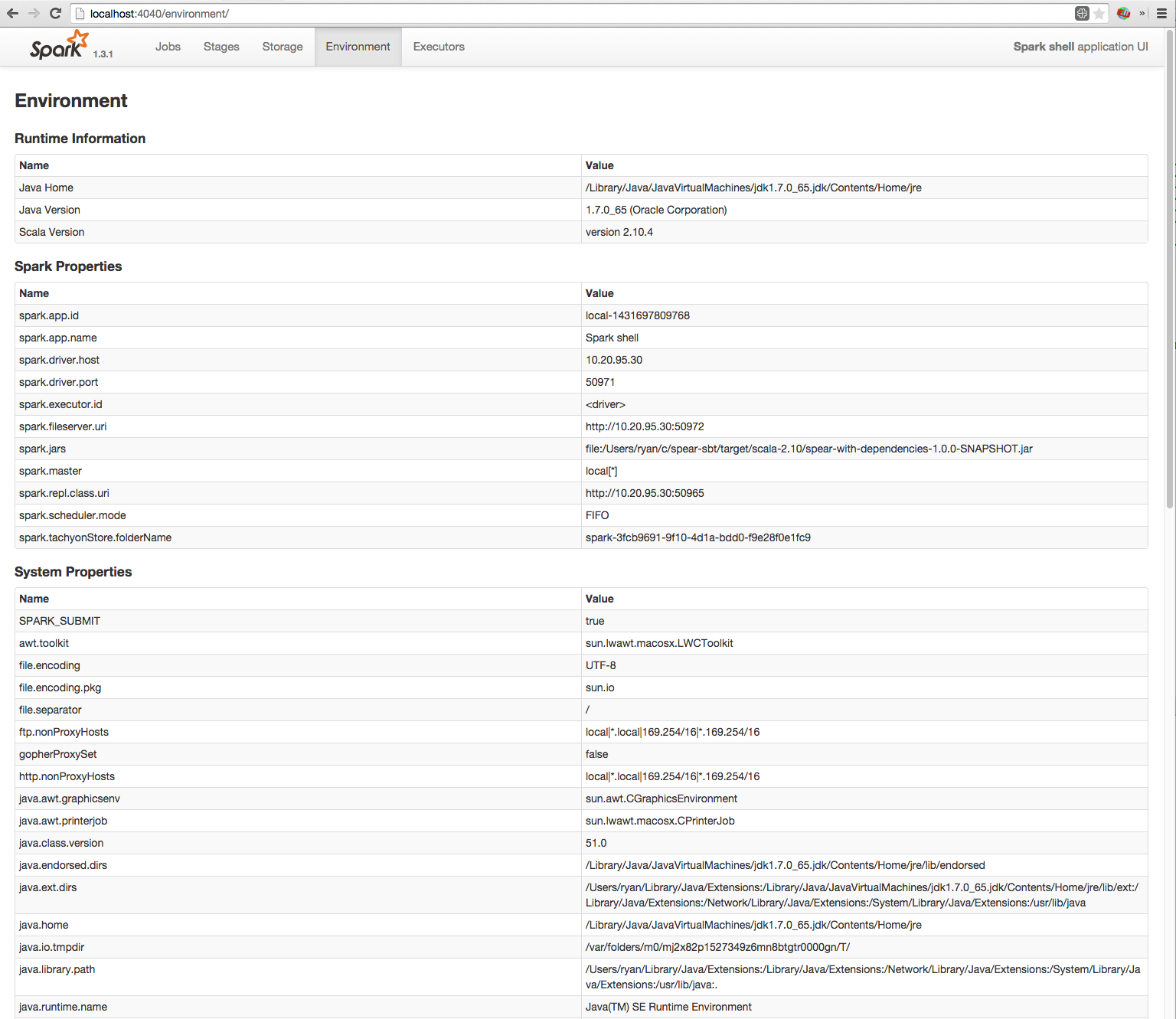
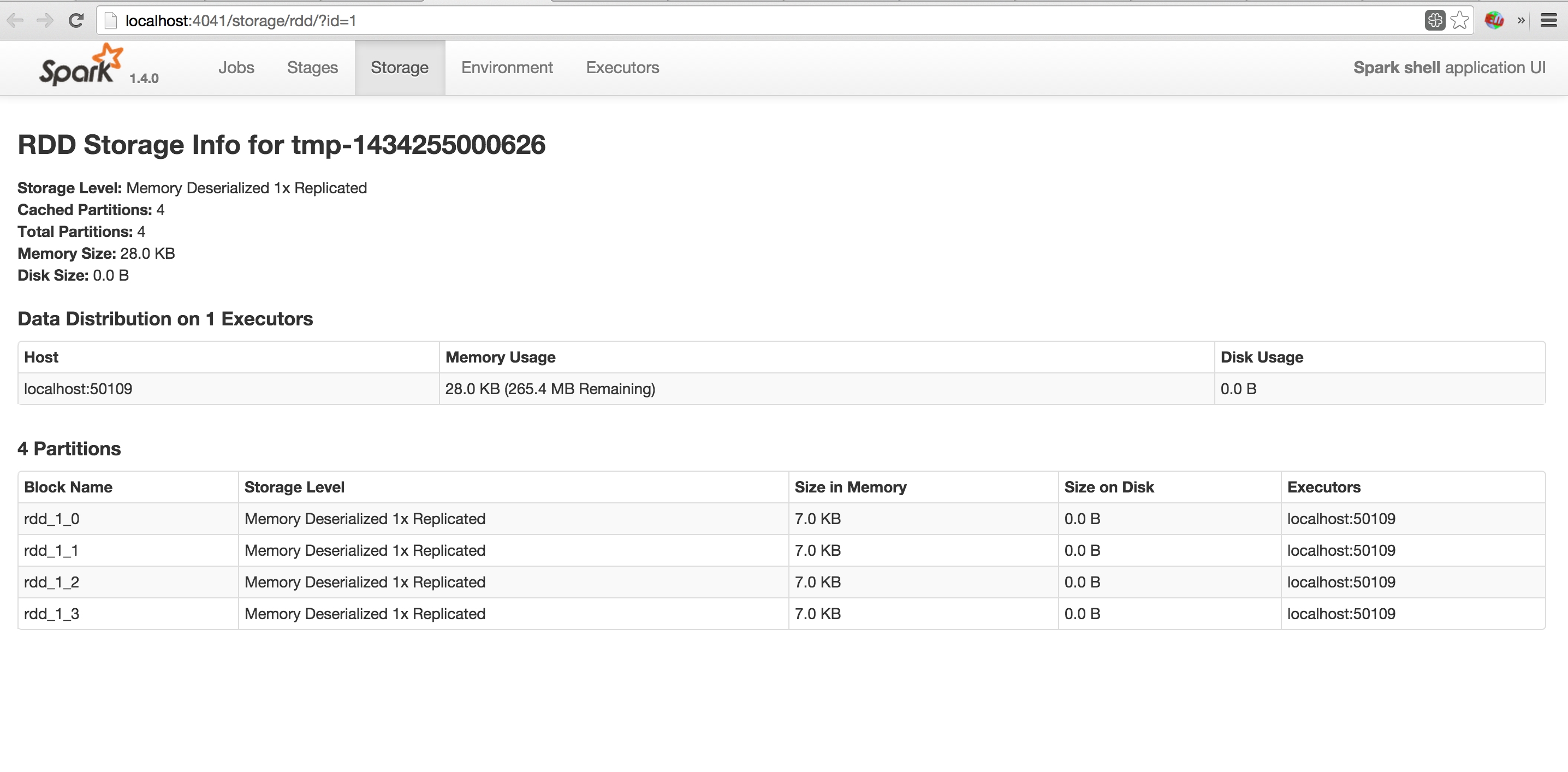
Spree is a live-updating web UI for Spark built with Meteor and React.

Left: Spree pages showing all jobs and stages, updating in real-time; right: a spark-shell running a simple job; see the Screencast gallery in this repo for more examples.
Spree is a complete rewrite of Spark's web UI, providing several notable benefits…
All data on all pages updates in real-time, thanks to Meteor magic.
Spree offers a unified interface to past- and currently-running Spark applications, combining functionality that is currently spread across Spark's web UI and "history server".
It persists all information about Spark applications to MongoDB, allowing for archival storage that is easily query-able and solves various Spark-history-server issues, e.g. slow load-times, caching problems, etc.
Pagination and sorting are delegated to Mongo for graceful handling of arbitrarily large stages, RDDs, etc., which makes for a cleaner scalability story than Spark's current usage of textual event-log files and in-memory maps on the driver as ad-hoc databases.
Spree includes several usability improvements, including:
All tables allow easy customization of displayed columns:
Additionally, whole tables can be collapsed/uncollapsed for easy access to content that would otherwise be "below the fold":

Finally, all client-side state is stored in cookies for persistence across refreshes / sessions, including:
- sort-column and direction,
- table collapsed/uncollapsed status,
- table columns' shown/hidden status,
- pages' displaying one table with "all" records vs. separate tables for "running", "succeeded", "failed" records, etc.
Spree is easy to fork/customize without worrying about changing everyones' Spark UI experience, managing custom Spark builds with bespoke UI changes, etc.
It also includes two useful standalone modules for exporting/persisting data from Spark applications:
- The
json-relaymodule broadcasts all Spark events over a network socket. - The
slimmodule aggregates stats about running Spark jobs and persists them to indexed Mongo collections.
These offer potentially-useful alternatives to Spark's EventLoggingListener and event-log files, respectively (Spark's extant tools for exporting and persisting historical data about past and current Spark applications).
Spree has three components, each in its own subdirectory:
ui: a web-app that displays the contents of a Mongo database populated with information about running Spark applications.slim: a Node server that receives events about running Spark applications, aggregates statistics about them, and writes them to Mongo for Spree'suiabove to read/display.json-relay: aSparkListenerthat serializesSparkListenerEvents to JSON and sends them to a listeningslimprocess.
The latter two are linked in this repo as git submodules, so you'll want to have cloned with git clone --recursive (or run git submodule update) in order for them to be present.
Following are instructions for configuring/running them:
First, run a Spree app using Meteor:
git clone --recursive https://github.com/hammerlab/spree.git
cd spree/ui # the Spree Meteor app lives in ui/ in this repo.
meteor # run it
You can now see your (presumably empty) Spree dashboard at http://localhost:3000:

If you don't have meteor installed, see "Installing Meteor" below.
Next, install and run slim:
npm install -g slim.js
slim
If you have an older unsupported version of npm installed you may get error messages from the above command that contain message failed to fetch from registry. If so, upgrade the version of node and npm and try again.
slim is a Node server that receives events from JsonRelay and writes them to the Mongo instance that Spree is watching.
By default, slim listens for events on localhost:8123 and writes to a Mongo at localhost:3001, which is the default Mongo URL for a Spree started as above.
Run Spark with JsonRelay
If using Spark ≥ 1.5.0, simply pass the following flags to spark-{shell,submit}:
--packages org.hammerlab:spark-json-relay:2.0.0
--conf spark.extraListeners=org.apache.spark.JsonRelay
Otherwise, download a JsonRelay JAR:
wget https://repo1.maven.org/maven2/org/hammerlab/spark-json-relay/2.0.0/spark-json-relay-2.0.0.jar
…then tell Spark to send events to it by passing the following arguments to spark-{shell,submit}:
# Include JsonRelay on the driver's classpath
--driver-class-path /path/to/json-relay-2.0.0.jar
# Register your JsonRelay as a SparkListener
--conf spark.extraListeners=org.apache.spark.JsonRelay
# Point it at your `slim` instance; default: localhost:8123
--conf spark.slim.host=…
--conf spark.slim.port=…
Below is a journey through Spark JIRAs past, present, and future, comparing the current state of Spree with Spark's web UI.
I believe the following are resolved or worked around by Spree:
- Live updating: SPARK-5106.
- Scalability / Pagination: SPARK-2015, SPARK-2016, SPARK-2017, SPARK-4598.
- Customizability / Usability: SPARK-1301, SPARK-4024, SPARK-6541.
- Other: SPARK-9195.
Functionality known to be present in the existing Spark web UI / history server and missing from Spree:
- Most viz covered by SPARK-6942, including:
- RDD DAG viz (SPARK-6943).
- Event timeline viz (jobs: SPARK-3468, stages: SPARK-7296).
- Executor thread-dumps.
- Streaming UI.
A motley collection of open Spark-UI JIRAs that might be well-suited for fixing in Spree:
- SPARK-1622: expose input splits
- SPARK-1832: better use of warning colors
- SPARK-2533: summary stats about locality-levels
- SPARK-3682: call out anomalous/concerning/spiking stats, e.g. heavy spilling.
- SPARK-3957: distinguish/separate RDD- vs. non-RDD-storage.
- SPARK-4072: better support for streaming blocks.
- Control spark application / driver from Spree:
- SPARK-4411: Job kill links
- SPARK-4906: unpersist applications in
slimthat haven't been heard from in a while. - SPARK-7729: display executors' killed/active status.
- SPARK-8469: page-able viz?
- Various duration-confusion clarification/bug-fixing:
- SPARK-8950: "scheduler delay time"-calculation bug
- SPARK-8778: "scheduler delay" mismatch between event timeline, task list.
- SPARK-4800: preview/sample RDD elements.
If you see errors like this when starting slim:
/usr/local/lib/node_modules/slim.js/node_modules/mongodb/lib/server.js:228
process.nextTick(function() { throw err; })
^
AssertionError: null == { [MongoError: connect ECONNREFUSED 127.0.0.1:3001]
name: 'MongoError',
message: 'connect ECONNREFUSED 127.0.0.1:3001' }
it's likely because you need to start Spree first (by running meteor from the ui subdirectory of this repo).
slim expects to connect to a MongoDB that Spree starts (at localhost:3001 by default).
Meteor (hence Spree) spins up its own Mongo instance by default, typically at port 3001.
For a variety of reasons, you may want to point Spree and Slim at a different Mongo instance. The handy ui/start script makes this easy:
$ ui/start -h <mongo host> -p <mongo port> -d <mongo db> --port <meteor port>
Either way, Meteor will print out the URL of the Mongo instance it's using when it starts up, and display it in the top right of all pages, e.g.:

Important: for Spree to update in real-time, your Mongo instance needs to have a "replica set" initialized, per this Meteor forum thread.
Meteor's default mongo instance will do this, but otherwise you'll need to set it up yourself. It should be as simple as:
- adding the
--replSet=rs0flag to yourmongodcommand (wherers0is a dummy name for the replica set), and - running
rs.initialize()from a mongo shell connected to thatmongodserver.
Now your Spark jobs will write events to the Mongo instance of your choosing, and Spree will display them to you in real-time!
Meteor can be installed, per their docs, by running:
curl https://install.meteor.com/ | sh
By default, Meteor will install itself in ~/.meteor and attempt to put an additional helper script at /usr/local/bin/meteor.
It's ok to skip the latter if/when it prompts you for your root password by ^Cing out of the script.
npm install -g slim.js may require superuser privileges; if this is a problem, you can either:
- Install locally with
npm, e.g. in your home directory:cd ~ npm install slim.js cd ~/node_modules/slim.js ./slim - Run
slimfrom the sources in this repository:cd slim # from the root of this repository; make sure you `git clone --recursive` npm install ./slim
See the screencast gallery in this repo for more GIFs showing Spree in action!
Spree has been tested pretty heavily against Spark 1.4.1. It's been tested less heavily, but should Just Work™, on Sparks from 1.3.0, when the spark.extraListeners conf option was added, which JsonRelay uses to register itself with the driver.
Please file issues if you have any trouble using Spree or its sub-components or have any questions!
See slim's documentation for info about ways to report issues with it.