Text mining is a tool used for organisering text data, and displaying it in numeric data. It is used to achieve, explore, and analyze a large amounts of unstructured data which would help saving time and resources by performing. Trie data structure which also known for digital search tree structure is on of the methodologies which can be used for text mining that is based on the prefix of a string. It uses a number of nested lists that are indexed in length of the desired symbols that the text should contain. For example, the english alphabet which contains 26 letter, so the length of the trie-list would be 26 (0-26). When we insert a word, it goes through one symbol a time. When the last symbol is reached, then we can insert a numeric value.
The software starts with reading the data from Shakespeare_Complete_Works.txt file then adding the data in to a list after removing the unneeded characters. The list contains the data from the file which contains only the English alphabet a-z in lowercase, as well as apostrophe.
The software contains a “Trie” class which contains the object needed to implement a Trie, it also contains a indexOf method that takes a char in the parmeter, then it indexes it , the chat could be one of the english alphabet (a-z in to 0-25) and it also indexs the apostrophe into the number 26.
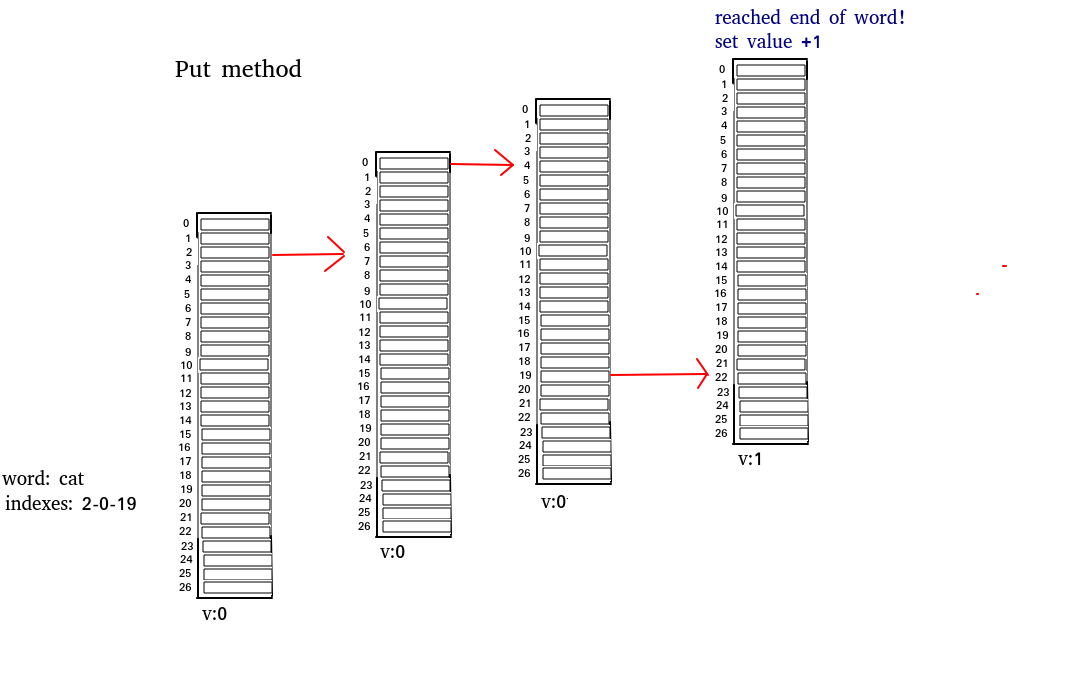
The “Trie” class contains also a “put” method which takes a String (word) in the parameter after that it takes the word to deal it into chars, after that it uses the indexOf() method to indexs the outcome chars we got from the String word, after the indexing we then find the position in the trie-list, where it put a new “Trie”, and it continues doing that until it reaches the end of the String(word). When it reaches this point it well add a value, if there is already a value in case the word has been mentioned before so it well adds 1 to the value.
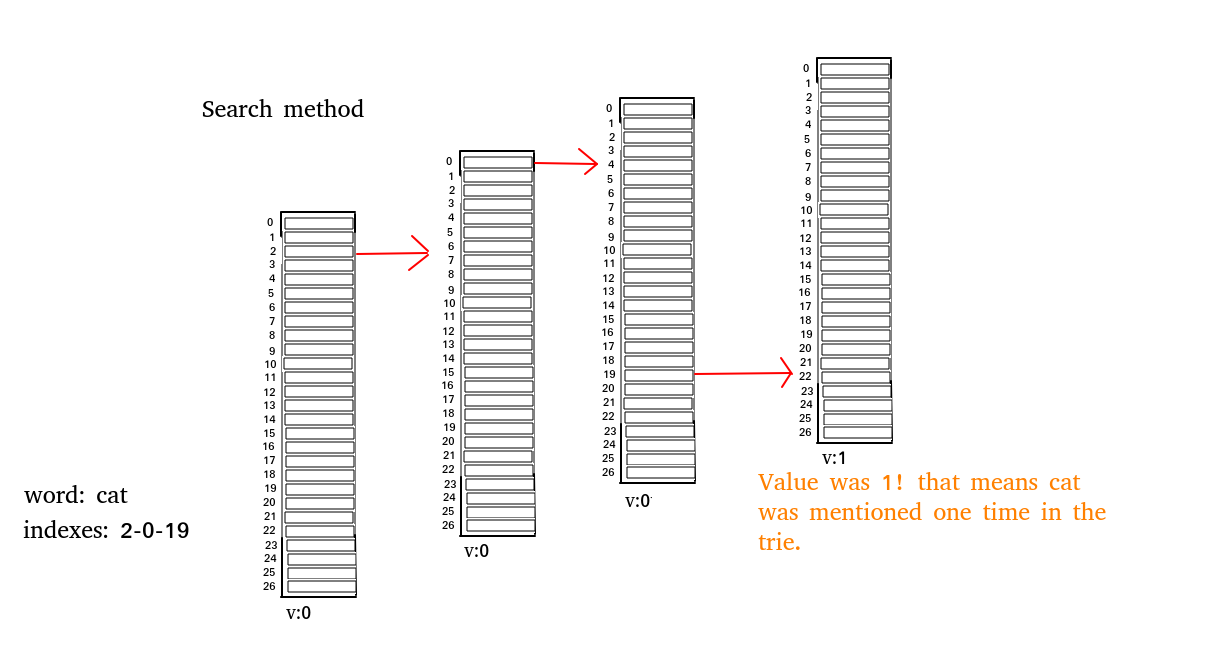
Furthermore the “Trie” class also contains a “get” method which makes it possible to search for a word in the trie, and then get the value of that word in return. The value in this case is the number of mentions it has in the complete book of Shakespeare, for example the word “be” is mentioned “7092” times in the Shakespeare_Complete_Works.txt file.
We used "StopWatch" to time out the execution, we were surprised on the results. It took 0.49 seconds to read the file, and 0.13 seconds to insert the words into our trie, and it take 0.3 secounds seraching in the trie, which is to fast.
A point of approvement worth mentioning is the usage of threads in order to optimize the speed of the process. Another point of discussion in the group was the of the library provided by the booksite, since we thought it would give us experience we wouldn’t have gotten otherwise. The last point of improvement could be alternative implementations of text mining, since it would cast a light on what else text mining could be used for, and give us an idea of its application in other problem solvings.
We would like to briefly conclude that Trie is an alternative data structure for data mining algorithms used to store strings that can be visualized like a graph, which can be useful for fast retrieval on large data sets as searching in a unorganized text data. We conclude also that Trie data structure is very similar to Binary Tree. We conclude that if we want to measure the time complexity of inserting from a trie would be depended on the length of the word a that’s well be inserted to the trie, and the number of total words, n, which would look like O(an).


