Stroke adalah sebuah penyakit yang telah menjadi momok bagi masyarakat luas. Meskipun stroke sudah lama dikenal oleh masyarakat tetapi kita masih susah dalam mengetahui kapan dan di mana kita akan mendapati penyakit stroke. Menurut Organisasi Kesehatan Dunia (WHO) stroke adalah penyebab kematian ke-2 secara global dan bertanggung jawab atas sekitar 11% dari total kematian tersebut.
Dengan adanya machine learning ini, diharapkan kita dapat mengetahui apakah kita mendapati penyakit tersebut atau tidak. Dengan memasukkan beberapa parameter seperti gender, usia, penyakit, dll.
Stroke sering kali melanda manusia kapan pun dan di mana pun. Stroke sendiri adalah penyakit yang sulit kali untuk diprediksi oleh manusia. Apakah dengan bantuan machine learning, kita bisa memprediksi adanya penyakit stroke tersebut?
Tujuan dari projek ini adalah untuk memprediksi apakah pasien tersebut mendapati penyakit stroke atau tidak dengan dengan memasukkan beberapa parameter yang sudah tersedia.
Solusi kali ini adalah dengan menggunakan machine learning, diharapkan manusia dapat mengetahui apakah dia sedang terjangkit stroke atau tidak. Saya akan menggunakan lima metode machine learning yaitu:
-
Support Vector Machine
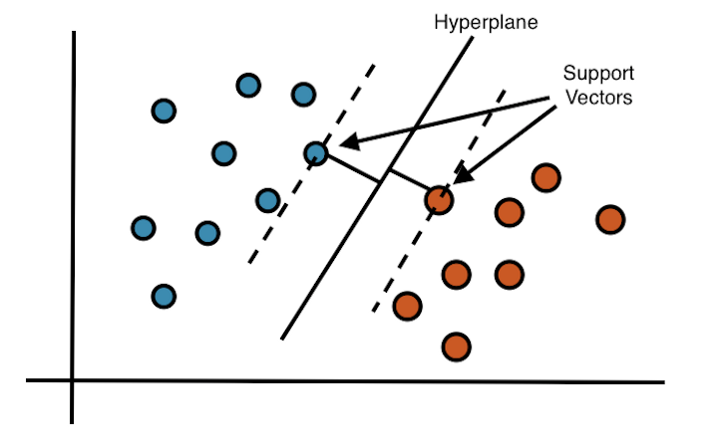
Support Vector Machine adalah algoritma machine learning yang memungkinkan kita memprediksi suatu masukkan dengan cara dengan memasukkan konsep kernel pada ruang berdimensi tinggi. Kernel disini maksudnya layaknya membagi setiap koloni dengan menarik garis pemisah antara kelas satu dan kelas lainnya. -
Naive Baiyes
Naive Baiyes adalah algoritma machine learning yang memungkinkan kita memprediksi suatu masukkan dengan cara dengan menghitung peluang dari satu kelas dari masing-masing kelompok atribut yang ada dan memntukan kelas mana yang paling optimal. -
Decision Tree
Decision Tree adalah algoritma machine learning yang memungkinkan kita memprediksi suatu masukkan dengan cara dimulai dengan satu node kemudian node tersebut bercabang untuk menyatakan pilihan-pilihan yang ada. -
Logistic Regression
Logistic Regression adalah algoritma machine learning yang memungkinkan kita memprediksi suatu masukkan dengan cara mencari hubungan antara fitur (input) diskrit dengan probabilitas hasil output diskrit tertentu. -
Random Forest
Random Forest adalah algoritma machine learning yang memungkinkan kita memprediksi suatu masukkan dengan cara dengan berawal dari memecah data sampel yang ada kedalam decision tree secara acak.



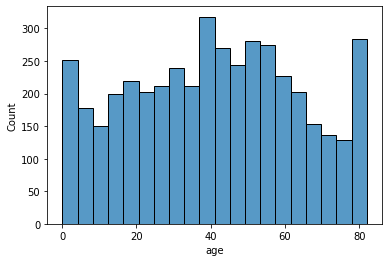
Dataset ini saya ambil dari situs kaggle yang berjudul Stroke Predicition Dataset. Dataset ini dibuat oleh seseorang dengan nama fedesoriano dan sudah diunggah ke situs kaggle mulai bulan februari 2021. Dalam dataset tersebut terdapat beberapa fitur, diantaranya adalah:
-
id: Untuk identifikasi setiap pasien.
-
gender: Kelamin dari pasien yaitu "Male", "Female" atau "Other".
-
age: Umur dari pasien.
-
hypertension: 0 jika pasien tidak punya hipertensi, 1 jika pasien punya hipertensi.
-
heart_disease: 0 jika pasien tidak punya serangan jantung, 1 jika pasien punya serangan jantung.
-
ever_married: Apakah pasien sudah menikah? "No" atau "Yes".
-
work_type: Tipe pekerjaan pasien yaitu "children", "Govt_jov", "Never_worked", "Private" atau "Self-employed".
-
Residence_type: Tempat tinggal pasien yaitu "Rural" atau "Urban".
-
avg_glucose_level: rata-rata nilai gula dalam darah.
-
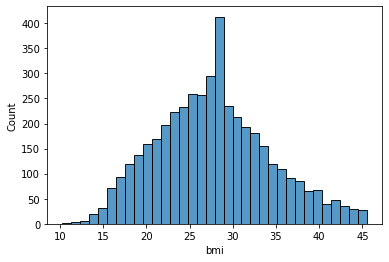
bmi: Index massa tubuh.
-
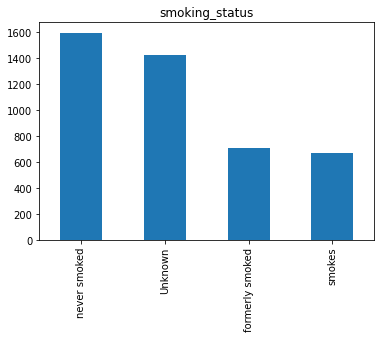
smoking_status: Status merokoknya yaitu "formerly smoked", "never smoked", "smokes" atau "Unknown".
Note: Unknown disini data tersebut tidak tersedia pada pasien
-
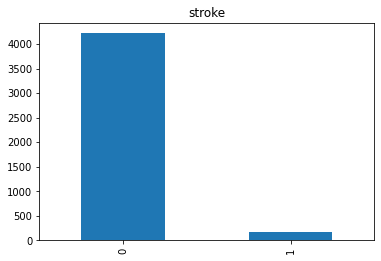
stroke: 1 jika pasien punya stroke atau 0 jika pasien tidak punya stroke.


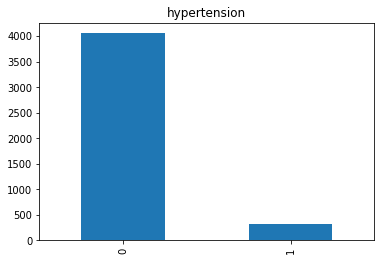

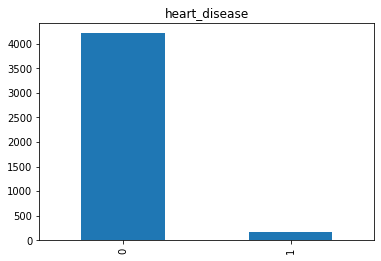
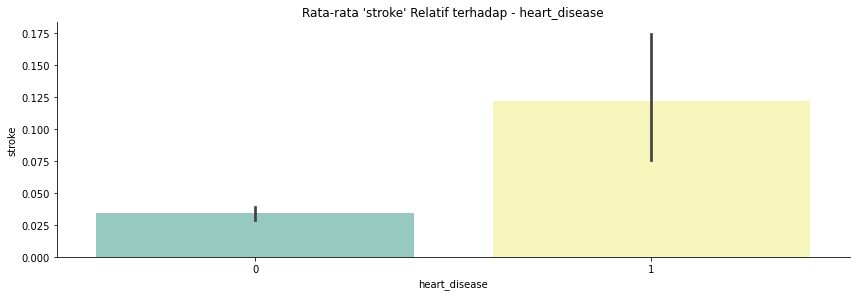
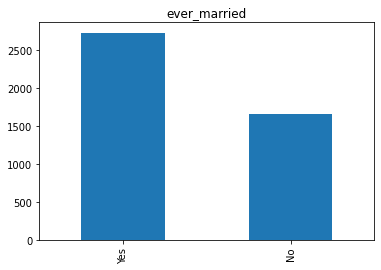
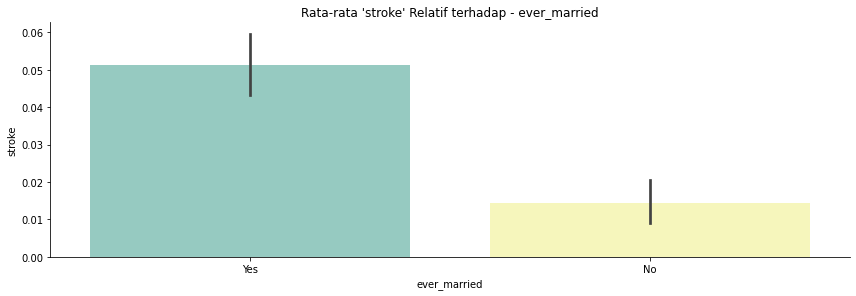
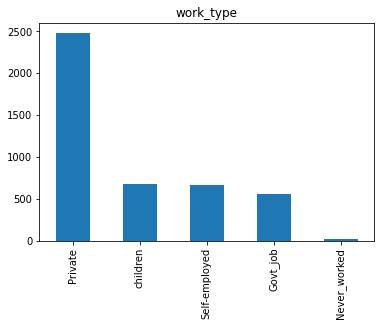
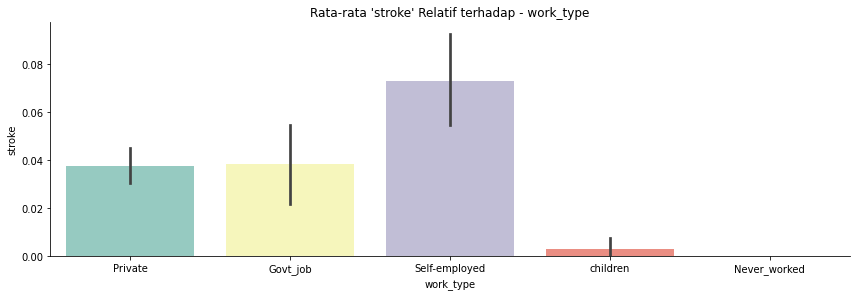
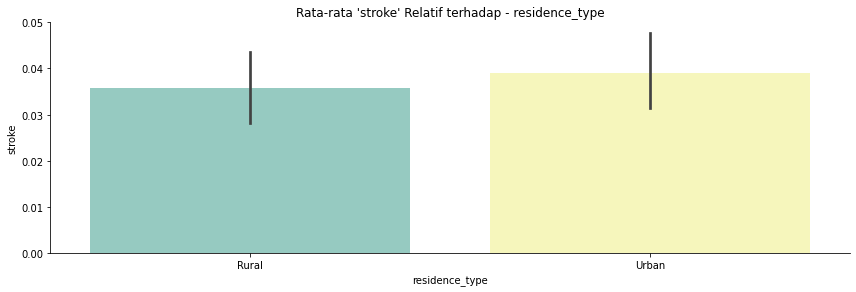


- Pertama saya rubah semua nama kolom menjadi huruf kecil untuk mempermudah dalam pengerjaan.
- Setelah itu, saya hapus daya yang sama dan saya ganti semua kolom data yang kosong dengan rata-rata nilai dari kolom tersebut.
- Selanjutnya, saya lakukan adalah menghapus beberapa kolom yang tidak dibutuhkan yaitu id dam avg_glucose_level. Karena kedua tersebut, sangatlah tidak berkorelasi terhadap kolom yang lain.
- Setelah itu, saya menghapus outliers data karena outliers data dapat menganggung performa model kita nanti. Karena data tersebut berbeda dari yang lain.
- Kita rubah semua kolom kategorikal menjadi kolom numerik, karena model machine learning hanya menerima numerik sebagai masukkan.
- Kita standarisasi data tersebut, supaya perbandingan jarak antar kolom satu dengan yang lain tidaklah jauh. Saya menggunakan StandardScaler pada scikit-learn yang memungkinkan standarisasi fitur dengan menghilangkan rata-rata dan penskalaan ke varians unit.
- Kita split data kita menjadi data latih dan data tes, supaya model machine learning kita dapat mempelajari data baru yaitu tes, bukan hanya berkutat pada data latih.
Disini saya membuat lima model machine learning, yaitu Support Vector Machine, Decision Tree, Naive Baiyes, Logistic Regression, dan Random Forest. Saya menggunakan Support Vector Machine karena model ini seringkali digunakan dalam banyak klasifikasi. Saya menggunakan Naive Baiyes karena model ini dapat menghitung sebuah peluang antara kelas satu dan lainnya, itu dapat memudahkan kita untuk mengetahui komposisinya. Saya menggunakan Logistic Regression karena model ini simpel dan cepat dalam penerapannya tetapi untuk performa modelnya terbilang bagus. Saya menggunakan Random Forest karena model tersebut gabungan dari Decision Tree yang dapat menghilangkan kecenderungan memahami data latih.
Metrik evaluasi adalah sebuah pengukur performa dari model tersebut bagus atau tidaknya. Disini saya menggunakan metrik evaluasi Akurasi, karena metrik tersebut sangatlah cocok dengan permasalahan kali ini. Akurasi adalah metrik yang biasa digunakan untuk model machine learning. Berikut adalah evaluasi model yang telah saya buat.
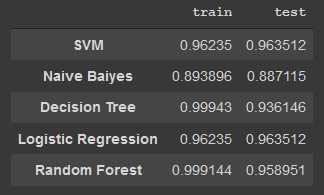


Bisa dilihat dari diagram diatas, bahwasanya Logistic Regression dan Support Vector Machine memiliki performa yang hampir mirip dalam memprediksi penyakit stroke. Setiap model juga berhasil memprediksi dengan baik.





