深入浅出Event Loop
我在实现Promise那篇文章中提及到了Event Loop,并且引用了其中的两种异步队列来阐述实现Promise中的一些细节。不过Event Loop可远远没有那么简单,事实上关于它有许多我们应该注意到的细节,这些细节会让我们了解到我们的代码将在何时运行,以助于我们更加有把握的让代码按照我们理想中的顺序执行。
为什么Javascript要设计成单线程?
单线程规定了js一次只能做一件事,这意味着如果前面的任务非常耗时,那么后面的任务就只能在那里干瞪着眼愣着等前面的老哥跑完。如果老哥慢是因为计算量太大,导致CPU忙不过来了,那也就算了,关键是原因往往不是这样,大部分的情况都是CPU在那里闲着,因为IO设备太慢(比如HTTP请求),不得不等拿到结果后,才向下执行,而在浏览器中,如果一旦js卡顿,页面就必须停止渲染,因为渲染引擎不知道JS代码中到底有没有对DOM的操作,强行渲染只会呈现出错误的页面,这也是为什么无限循环会阻塞一切页面操作的原因。
从上面可以看出单线程存在着非常严重的弊端,那么为什么js还要被设计成单线程语言呢?有人说是因为Eich乐意,虽然我觉得这个观点很有趣,不过我还是愿意相信更为科学一点的解释。
以下证论截自阮一峰老师的博客:
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
一句话说就是:多线程对于高交互的浏览器来说代码编写难度太不可控了。
解决方案 -- Event Loop
JavaScript语言的设计者意识到,如果是因为IO设备导致的任务阻塞,这时主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。
于是,带着这种设计理念,第一版的Event Loop问世了,它将js中的任务分为同步任务和异步任务,同步任务会在代码开始执行后被直接加入调用栈,然后排队一个一个执行。而异步任务则会被推送到对应的“执行者”那里去执行(比如浏览器中的setTimeout会将其中的回调函数推送到浏览器提供的计时器API那里去计时),并在相关任务执行完毕后(比如计时结束了),将回调函数压入一个叫做“任务队列”的列表中,这个列表会在js调用栈中所有的同步代码都执行完毕后,再开始按序一个个执行。
来看一段代码:
// 我在这段代码中挖了一个坑,不过我会在下面的文章中填上(笑)
setTimeout(() => {
console.log(1);
}, 0);
setTimeout(() => {
console.log(2);
}, 0);
console.log(3);上面这段代码执行结果为3、1、2,您可能会疑惑:我两个计时器都设置了0毫秒延迟,按道理说不应该就是没延迟的意思吗?
结合我们上面提到的关于异步任务的执行顺序,其实结果就很明朗了:之所以0毫秒延迟依然排在同步代码的后面,是因为无论传入了多长时间的延迟,异步任务在执行结束(在这里是指计时结束)后总会被压入“任务队列”,而“任务队列”必须要等到js调用栈中的代码全部执行完才可以开始执行。
如果您觉得我的文字描述不够直观,可以结合这个工具来搭配理解,它是Philip Roberts在JS2014CONF上演讲关于Event Loop时使用的工具,能够让您结合可视化更清楚的看到Event Loop的执行过程,同时我的文章也参考了Philip Robert的演讲。
如果您认为到这里就理解Event Loop了,那就大错特错了。事实上,关于Event Loop,还有许多可以探讨的点。
宏队列与微队列
您可能会发现,我在文章的最开头提到了两种异步队列,但是到目前为止只含糊的提出了一个叫“任务队列”的玩意儿。其实在前些年的浏览器中,确实只有一种“任务队列”,它其实就是现在的宏队列。而微队列是在后续的发展中更新上的,那么,为什么需要这个微队列,它与宏队列又有什么不同?
我会在下面为您一一解答,不过在那之前,我先将两种队列所包含的异步任务列举出来:
宏队列,macrotask,也叫tasks。 一些异步任务的回调会依次进入macro task queue,等待后续被调用,这些异步任务包括:
- setTimeout
- setInterval
- setImmediate (Node独有)
- requestAnimationFrame (浏览器独有,有点特殊)
- I/O
- UI rendering (浏览器独有)
微队列,microtask,也叫jobs。 另一些异步任务的回调会依次进入micro task queue,等待后续被调用,这些异步任务包括:
- process.nextTick (Node独有)
- Promise
- Object.observe
- MutationObserver(浏览器独有)
(注:这里只针对浏览器和NodeJS)
浏览器中的Event Loop
首先,展示一段代码:
document.body.appendChild(div);
div.style.display = "none";
这段代码曾经被js开发者们争议了许久,因为在它的逻辑中先为body元素增加了一个新div,同时立马又将这个div隐藏掉了。这很容易让人联想出如果浏览器卡顿的话,会不会出现这个div瞬间加入body,然后瞬间隐藏的闪烁效果。
事实上,你完全可以放心,上述的情况是一定不会发生的,因为浏览器严格规定了各部门执行任务的先后顺序,而这,全要归功于Event Loop。

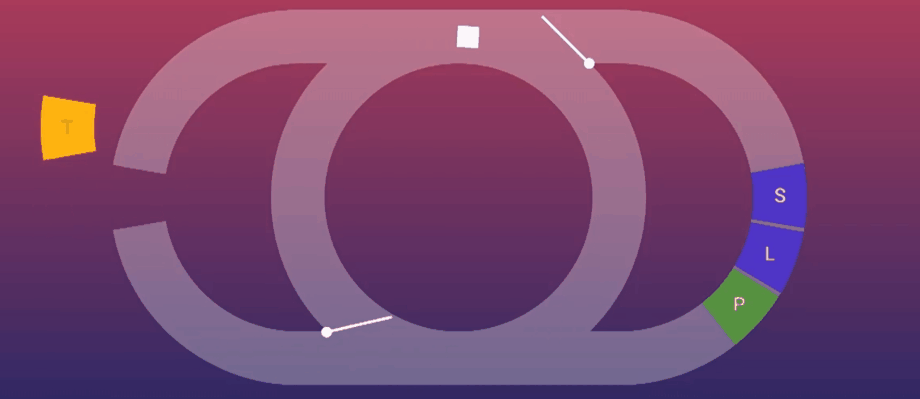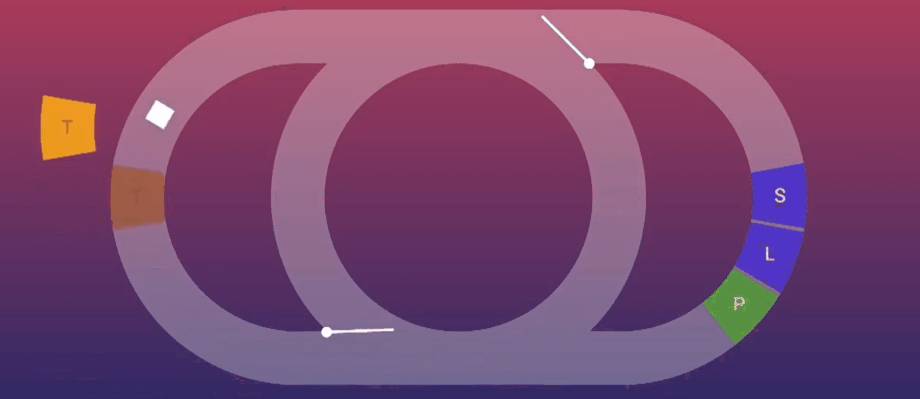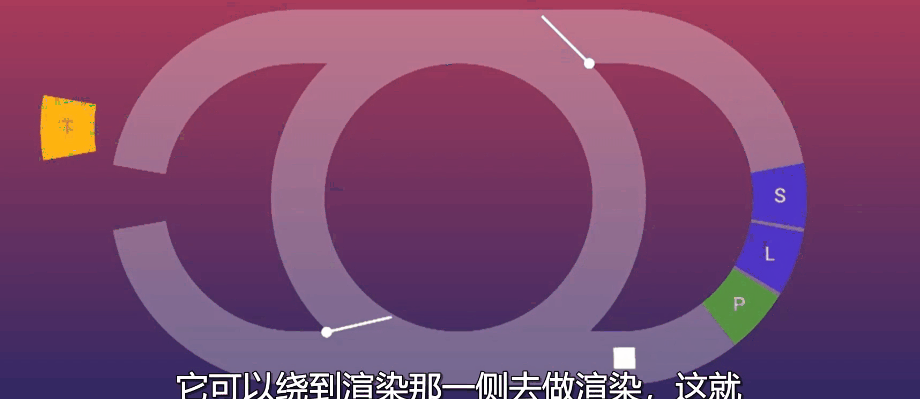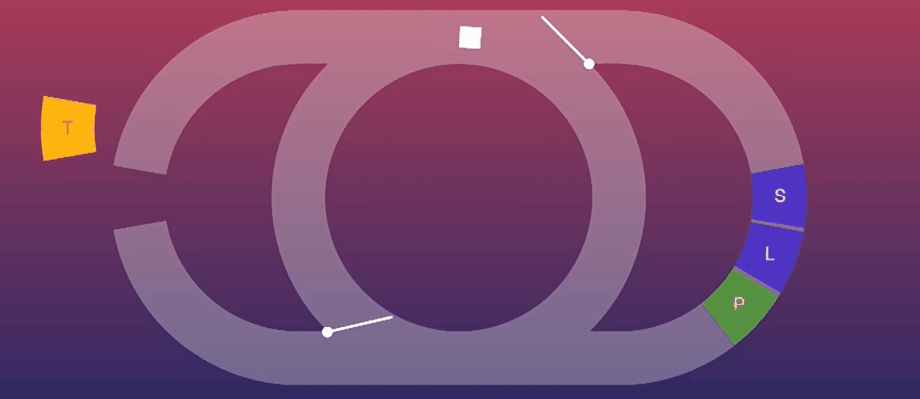
上面这个图就是Event Loop的可视化,中间的小白点是当前正在执行的任务,左侧是执行js代码的区域,右侧是关于UI渲染的阶段。默认情况下,也就是同时没有js和UI相关任务需要执行,图中的两个阀门会闭合,Event Loop会以最节省资源的方式在中间转圈,如果有需要执行的js代码,左侧的阀门就会打开并在缺口处填上需要执行的js内容,小白点就会进入到左侧的半圆中进行js相关任务的执行。
让我们将上面的两行代码带入到图中模拟执行下看看:
- Event Loop检测到有需要执行的js代码;
- 左侧的阀门打开,并将需要执行的两行js代码填充上去;
- 小白点进入左侧半圆执行相关代码;
那么请问现在页面发生变化了吗?显然是没有的,因为真正控制页面的是渲染引擎,也就是右半边的半圆,这时,因为收到了对页面进行更改的请求,右边的阀门也打开了,小白点继续前进,执行UI相关的渲染,它们分别对应:
- S:样式计算,收集所有计算应用到元素上的样式;
- L:创建一个渲染树,找出页面上的所有相关内容以及元素的位置;
- P:创建实际的像素数据,绘制内容到页面上。
那么,这个问题也就得到解决了:因为必须要等待js执行完毕并发送渲染请求后,右侧的阀门才会打开,从而将设置的全部修改渲染完毕,所以无论这两行代码如何排列,都不会影响到UI渲染的结果。不过,我建议您最好还是将display一行放到上边,因为大多数情况下,这种代码让人看着最舒服。
浏览器中的宏队列
那么宏队列在浏览器中是如何运作的呢?
在浏览器中,Event Loop一次执行(也就是转一圈)只会从宏队列中取出一个任务来执行,这是什么意思呢?
document.onclick = function () {
while (true) {};
};如果你尝试在页面中加入这种代码并且触发,随后就会理所应当得得到一个完全卡住的页面,任何的渲染,包括gif,按钮,文字选中,全部都无法进行了。
这是因为while循环是同步js代码,并且它会一直的执行下去,这样就会将小白点卡在js执行阶段,无法去执行UI渲染,所以你就会觉得页面卡住了。

那么如果是这种代码呢?
document.onclick = function () {
loop();
};
function loop() {
setTimeout(loop, 0);
};点击按钮,发现一切正常,这又是怎么回事呢?
这其实就是因为宏队列中的任务 Event Loop 一次只能拿一个出来执行,所以在执行完一个setTimeout后,小白点就会被释放,前往右半边去执行UI渲染,而下一个setTimeout就要等到小白点再从UI那里绕回来后再执行。
浏览器中的微队列
我猜您第一次听说微队列是在学习Promise的时候,我自己就是,所以我常常将Promise和微队列关联起来想。但是Promise并不是微队列推出的初衷,微队列推出的最初是为了解决DOM的变化监测问题:浏览器想要提供一种当DOM结构发生变化时所触发的事件,好让开发者能够监控到DOM的变化,于是w3c说老哥没问题,随后提供了DOM变化事件:
document.body.addEventListener("DOMNodeInserted", () => {
console.log("body里面添加了新玩意儿!")
})上面的console.log会在body的DOM结构发生改变时触发。看起来很好,对吧?但是看看下面的代码:
for (let i = 0; i < 100; i++) {
let box = document.createElement("div");
document.body.appendChild(box);
box.textContent = "hi!";
}上面的代码中,我创建了100个div,并将它们添加到了body元素中。您觉得这会产生多少个事件?1个?100个?不,都不是,正确答案是200个:100个div产生100个事件,并且还有100个事件是这行代码导致的。
为div设置文本的行为会产生事件,并且冒泡,导致这段简单的代码最终会产生200个事件。
但是我们只想被通知1次而不是200次,解决方案是使用DOM变化事件的观察者(mutationObserver),它们创建了一个新队列就叫做微任务队列,并规定微任务可以在任何一个宏任务之后执行,也就是说,每当结束一个宏任务后都会检测是否有待执行的微任务。并且会一次性执行完微任务队列里的所有微任务,如果在执行的过程中又产生了新的微队列,则继续执行新的微队列,直到队列清空。
document.onclick = function () {
loop();
};
function loop() {
Promise.resolve().then(loop);
};我们使用微任务创建一个无限循环会怎么样呢?像之前setTimeout做得一样,点击页面后我们发现,页面再一次卡住了,这样就印证了我们上面提到的,如果有不断的新微任务加入进来,js就会一直坚持将微任务执行下去,从而阻塞后面的UI渲染。
Promise与a标签
我们先来看一段代码,并且想一下它被触发后的执行顺序:
button.addEventListener("click", () => {
Promise.resolve().then(() => console.log("微任务01"));
console.log("监听器01");
});
button.addEventListener("click", () => {
Promise.resolve().then(() => console.log("微任务02"));
console.log("监听器02");
});首先,毫无疑问会先打印“监听器01”,但是接下来是什么?在JSCONF2018的演讲会上,演讲人在登台之前对这段程序做过一段调查,其中有63%的人选择了接下来会打印“监听器02”。嗯,结果很显然,这是错误的,正确的输出应该是:
- 监听器01
- 微任务01
- 监听器02
- 微任务02
这是因为,当第一个输出“监听器01”执行完毕后,第一个监听器也就执行完毕,从js执行栈中抛出了,js栈清空,所以接下来是微任务时间,下面的监听器同样道理。
上面只是在用户点击触发的情况下,那么如果使用js来触发呢?
button.addEventListener("click", () => {
Promise.resolve().then(() => console.log("微任务01"));
console.log("监听器01");
});
button.addEventListener("click", () => {
Promise.resolve().then(() => console.log("微任务02"));
console.log("监听器02");
});
button.click();我们又得到了另外一个答案:
- 监听器01
- 监听器02
- 微任务01
- 微任务02
使用js触发事件时,当第一个监听器抛出后,button.click()还没有结束,所以js调用栈没有清空,那么微任务就无法启动,只能等第二个监听器也执行完毕后,再开始执行相关的代码。
可以看出,微任务的调用和js调用栈息息相关,明白了这个道理,那么下面这段代码也就好解释了:
const nextClick = new Promise((resolve, reject) => {
link.addEventListener("click", resolve, { once: true });
});
nextClick.then(event => {
event.preventDefault();
})link是一个超链接标签,我们在一个Promise中为它注册了点击事件,并且规定当这个超链接被触发后,就立即禁用掉它的默认事件,如果您理解了上面描述的现象,这里也就很明显得分为了两种情况:
- 当用户直接点击超链接触发时,由于不会向js调用栈中压入新任务,所以导致js执行栈为空,所以微任务中禁用默认行为的逻辑会执行,导致用户第一次点击无法跳转。(后面就不行了,因为Promise只能改变一次状态);
- 而当由js来触发超链接的点击事件时,由于
nextClick.click()不会被释放,所以超链接会正常跳转。
浏览器执行顺序小结
浏览器大概的执行顺序如下:
- 执行全局Script同步代码,这些同步代码有一些是同步语句,有一些是异步语句(比如setTimeout等);
- 全局Script代码执行完毕后,调用栈Stack会清空;
- 从微队列microtask queue中取出位于队首的回调任务,放入调用栈Stack中执行,执行完后microtask queue长度减1;
- 继续取出位于队首的任务,放入调用栈Stack中执行,以此类推,直到把microtask queue中的所有任务都执行完毕。注意,如果在执行microtask的过程中,又产生了microtask,那么会加入到队列的末尾,也会在这个周期被调用执行;
- microtask queue中的所有任务都执行完毕,此时microtask queue为空队列,调用栈Stack也为空;
- 小白点跑去右边执行UI渲染,然后在跑回来继续执行js;
- 取出宏队列macrotask queue中位于队首的任务,放入Stack中执行;
- 执行完毕后,调用栈Stack为空;
- 重复第3-8个步骤;
- 重复第3-8个步骤;
- ......
可以看到,这就是浏览器的事件循环Event Loop
这里归纳3个重点:
- 宏队列macrotask一次只从队列中取一个任务执行,执行完后就去执行微任务队列中的任务;
- 微任务队列中所有的任务都会被依次取出来执行,之道microtask queue为空;
- UI渲染是在每次执行完微任务队列后,下一个宏任务之前进行执行。
requestAnimationFrame
window.requestAnimationFrame() 告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行。
在之前,我们都是使用定时器来做动画,不过定时器做出来的动画在某些低端机上会出现卡顿、抖动现象,这种现象的产生有两个原因:
- setTimeout的执行时间并不是确定的。在Javascript中, setTimeout 任务被放进了异步队列中,只有当主线程上的任务执行完以后,才会去检查该队列里的任务是否需要开始执行,因此 setTimeout 的实际执行时间一般要比其设定的时间晚一些。
- 刷新频率受屏幕分辨率和屏幕尺寸的影响,因此不同设备的屏幕刷新频率可能会不同,而 setTimeout只能设置一个固定的时间间隔,这个时间不一定和屏幕的刷新时间相同。
以上两种情况都会导致setTimeout的执行步调和屏幕的刷新步调不一致,从而引起丢帧现象。 那为什么步调不一致就会引起丢帧呢?
首先要明白,setTimeout的执行只是在内存中对图像属性进行改变,这个变化必须要等到屏幕下次刷新时才会被更新到屏幕上。如果两者的步调不一致,就可能会导致中间某一帧的操作被跨越过去,而直接更新下一帧的图像。假设屏幕每隔16.7ms刷新一次,而setTimeout每隔10ms设置图像向左移动1px, 就会出现如下绘制过程:
- 第0ms: 屏幕未刷新,等待中,setTimeout也未执行,等待中;
- 第10ms: 屏幕未刷新,等待中,setTimeout开始执行并设置图像属性left=1px;
- 第16.7ms: 屏幕开始刷新,屏幕上的图像向左移动了1px, setTimeout 未执行,继续等待中;
- 第20ms: 屏幕未刷新,等待中,setTimeout开始执行并设置left=2px;
- 第30ms: 屏幕未刷新,等待中,setTimeout开始执行并设置left=3px;
- 第33.4ms:屏幕开始刷新,屏幕上的图像向左移动了3px, setTimeout未执行,继续等待中;
- …
从上面的绘制过程中可以看出,屏幕没有更新left=2px的那一帧画面,图像直接从1px的位置跳到了3px的的位置,这就是丢帧现象,这种现象就会引起动画卡顿。

解决方法 -- requestAnimationFrame
导致问题出现的原因是我们不清楚不同设备下,浏览器会以最大多少速度的刷新率来进行UI渲染,那么requestAnimationFrame是怎么做的呢,其实很简单,浏览器在Event Loop新开辟了一段固定执行区域,用来统计本次UI渲染需要执行的DOM操作,并且会在本次UI渲染之前这些任务完成,这段区域在这:
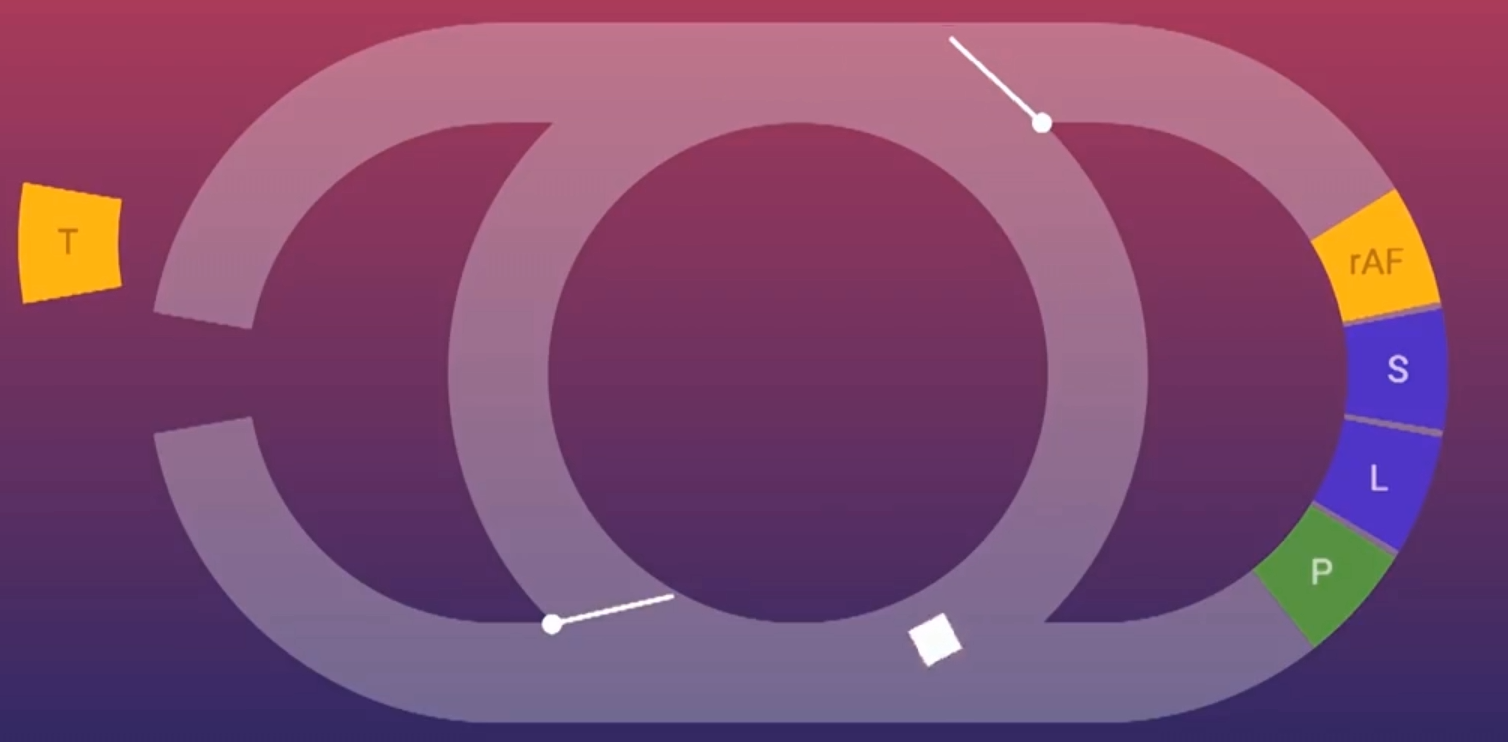
我们在上面提到过requestAnimationFrame是一种特殊的宏任务,它的特殊性主要有两点:
- 跟宏任务相比,它会在固定的时间段内将本次需要执行的任务全部执行完,而不是只取出一个;
- 跟微任务相比,如果在执行
requestAnimationFrame任务过程中,又加入了新的requestAnimationFrame任务,那么浏览器会将这些后加入的任务留到下一次再执行。
与transition造成的渲染冲突问题
在2018年的JSCONF上,一名叫jake的开发者做了关于Event Loop的分享,其中他提到了一道这样的题目:
button.addEventListener("click", () => {
box.style.transform = "translateX(1000px)";
box.style.transition = "3s";
box.style.transform = "translateX(500px)";
});jake期望box能够先移动到1000px,然后再移动到500px,然而浏览器仅仅渲染了0到500px的过程。这可能是许多js开发者都遇到过的问题,不过在学习了Event Loop的相关知识后,这道题就很容易解释了:因为UI渲染永远要等到js代码执行完毕,所以在UI渲染阶段,浏览器只会看到transition和500px两条指令,而1000px已经被覆盖了。但是问题还没有结束,如何才能实现jake期望中的效果呢?
jake本人给出了他的答案:使用requestAnimationFrame,只需要将500px的指令放到下次一UI渲染前执行,这样就不会和1000px造成冲突。嗯,听起来很完美,jake也通过他的ppt动画展示了0 --> 1000px --> 500px的过程。
但是,问题来了,我自己的尝试完全没有效果,浏览器依旧只为我展示了0 --> 500px的渲染过程,这又是怎么回事呢?
其实是jake失误了,他提供的方案确实理论上可以完成相应的操作,但是由于他的代码中出现了这句transition = "..."指令,一切都不一样了。
那么为什么transition会导致我的1000px指令“丢失”呢,我们都知道transition可以让一个属性不同值间的转变变得更顺畅,比如由1改变到10,那么如果有transition的存在,浏览器就会根据设置的速度对这个属性进行1 --> 2 --> 3 --> ... --> 10的渐进设置,那么正因如此,这一系列操作肯定不是一次UI渲染能够完成的,所以就导致了一下情况:
比如我想将一个元素的透明度由0更改到1,并为它设置了一个指定的时间,假设浏览器根据该时间计算出每次渲染要等100ms,每次渲染属性值加0.1,最终到达规定的时间,属性的值变为1,这是正常情况。但是,如果我在设置透明度的同时请求了requestAnimationFrame,并在其中将透明度更改为了0.5,猜猜会发生什么?我想您应该已经想到了:第一个100ms时间段还没到,透明度的目标值就已经在下一次的UI渲染之前被修改为了0.5,那么浏览器也就不会再执行0.5以后的操作了。
得出结论:1000px的指令之所以无法执行,是因为transition需要多次UI渲染才能完成过渡,这个过程中可能包含多次requestAnimationFrame,那么为了证明我的结论,您可以在浏览器中尝试执行以下代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
.box {
width: 300px;
height: 300px;
background-color: red;
}
</style>
</head>
<body>
<div class="box"></div>
</body>
<script>
let box = document.querySelector(".box");
document.addEventListener(
"click",
(change = () => {
box.style.transition = "3s";
box.style.width = "700px";
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
requestAnimationFrame(() => {
box.style.width = "0px";
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
});
})
);
</script>
</html>这段代码可能会让您感到不舒服,不过它确实证实了我的结论是对的:box在被点击后width属性一开始增大了,说明box.style.width = "700px";这句代码生效了,随后马上又开始缩小了,这是因为在多次requestAnimationFrame后,box.style.width = "0px";执行了,不过由于Event Loop执行速度非常快,即使我嵌套了这么多层,也只是让box.style.width = "700px";生效了一瞬间而已。
requestAnimationFrame的其他优点
最后我想跟您聊聊requestAnimationFrame的其他优点:
-
CPU节能:使用setTimeout实现的动画,当页面被隐藏或最小化时,setTimeout 仍然在后台执行动画任务,由于此时页面处于不可见或不可用状态,刷新动画是没有意义的,完全是浪费CPU资源。而requestAnimationFrame则完全不同,当页面处理未激活的状态下,该页面的屏幕刷新任务也会被系统暂停,因此跟着系统步伐走的requestAnimationFrame也会停止渲染,当页面被激活时,动画就从上次停留的地方继续执行,有效节省了CPU开销。
-
函数节流:在高频率事件(resize,scroll等)中,为了防止在一个刷新间隔内发生多次函数执行,使用requestAnimationFrame可保证每个刷新间隔内,函数只被执行一次,这样既能保证流畅性,也能更好的节省函数执行的开销。一个刷新间隔内函数执行多次时没有意义的,因为显示器每16.7ms刷新一次,多次绘制并不会在屏幕上体现出来。
Node中的Event Loop
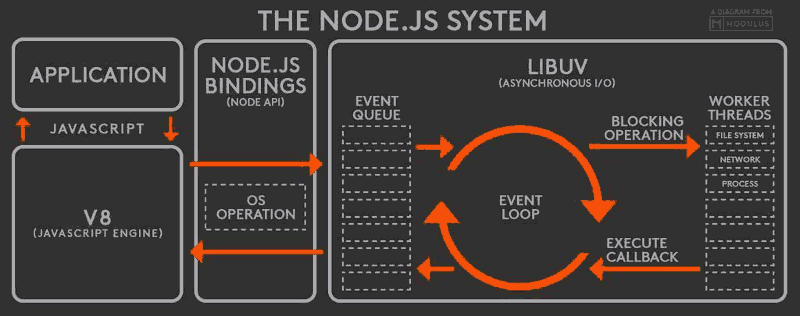
在Node中,由于和浏览器的执行环境不同,做得事情也有些不同,所以Node的Event Loop和浏览器中的Event Loop也不尽相同。
Node中的宏队列与微队列
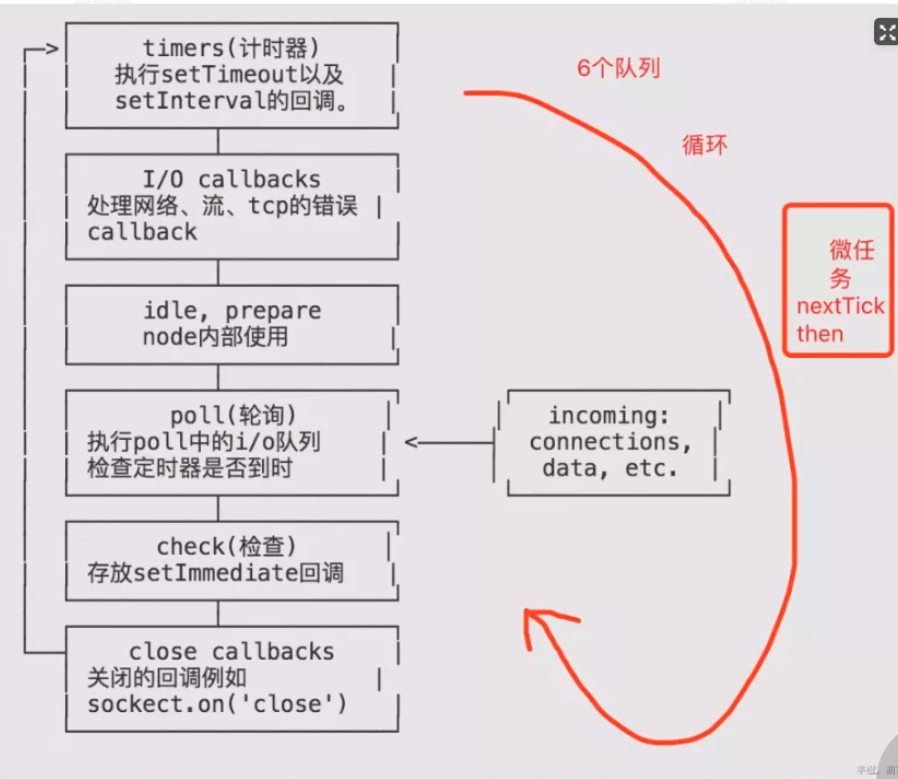
Node和浏览器不一样,浏览器只有一个宏队列,而Node有6个,它们会按照顺序不断循环执行,每个阶段的宏任务为:
- timers:执行setTimeout() 和 setInterval()中到期的callback。
- I/O callbacks:上一轮循环中有少数的I/Ocallback会被延迟到这一轮的这一阶段执行
- idle, prepare:队列的移动,仅内部使用
- poll:最为重要的阶段,执行I/O callback,在适当的条件下会阻塞在这个阶段
- check:执行setImmediate的callback
- close callbacks:执行close事件的callback,例如socket.on("close",func)
并且Node还有2个微队列:
- Next Tick Queue:是放置process.nextTick(callback)的回调任务的
- Other Micro Queue:放置其他microtask,比如Promise等
并且在Node中会一次性将一个宏队列中的所有任务执行完,然后再执行微任务,并且NextTick微队列要优先于Other微队列,这和浏览器中一次只执行一个宏任务是不一样的。
setTimeout(() => {
console.log(1);
Promise.resolve(2).then((e) => console.log(e));
}, 0);
setTimeout(() => {
console.log(3);
}, 0);上面这段代码,如果是在浏览器中执行,结果就是1、2、3,而在Node中,结果是1、3、2。
setTimeout与setImmediate
请尝试在您的Node中运行下面这段代码:
setTimeout(() => {
console.log(1);
}, 0);
setImmediate(() => {
console.log(2);
}, 0);发现什么了吗?没有?那么就请继续重复执行,慢慢的,就会发现这段代码诡异的地方:结果不确定!
上面这段代码的执行结果可能为1、2,也可能为2、1,这是为什么呢?(我要填坑了)
原因有两点:
- setTimeout第二个参数是没有0一说的,它的取值区间大概在[1, 2^31-1],如果超过这个范围,那它就为1;
- 我们知道setTimeout的回调函数在timer阶段执行,setImmediate的回调函数在check阶段执行,Event Loop开始会先检查timer阶段,但是在开始之前到timer阶段会消耗一定时间,所以就会出现两种情况:
- timer前的准备时间超过1ms,这时setTimeout已经准备完毕,所以执行setTimeout;
- timer前的准备时间小于1ms,这时setTimeout还在等待计时中,所以会跳过timer阶段执行setImmediate,等下次的timer阶段再执行setTimeout。
如果想让setTimeout百分百在setImmediate之前执行,那我们可以让timer准备的时间更充足一点,从而保证在进入timer阶段时,setTimeout能够完成计时工作:
setTimeout(() => {
console.log(1);
});
setImmediate(() => {
console.log(2);
});
// 这段代码会让程序卡住10ms,这段时间足够setTimeout完成计时
const start = Date.now();
while (Date.now() - start < 10) {}而如果想让setImmediate百分百在setTimeout之前执行,只需要给它们包裹一层环境,这个环境使得当前的Event Loop执行于timer阶段的下方,check阶段的上方即可,这样,只要Event Loop继续向下执行,那么肯定先执行到check阶段,这里我们那I/O阶段举例:
const fs = require("fs");
fs.readFile("./md/01.md", (error, data) => {
setTimeout(() => {
console.log(1);
});
setImmediate(() => {
console.log(2);
});
});Node 11.x 新变化
在Node11及以上的版本中,Event Loop的实现又开始逐渐向浏览器靠拢:微队列不再等到执行完一整个宏队列之后再执行,而是和浏览器一样,位于一个宏任务之后执行。
setTimeout(() => {
console.log(1);
Promise.resolve(2).then((e) => console.log(e));
}, 0);
setTimeout(() => {
console.log(3);
}, 0);
在Node11+的版本中,这段代码的执行结果同浏览器一样,都是1、2、3。
参考
Help, I'm stuck in an event-loop -- Philip Roberts
JavaScript 运行机制详解:再谈Event Loop
Event Loop -- JSCONF 2018
带你彻底弄懂Event Loop
通杀Event Loop面试题!
requestAnimationFrame -- MDN
MutationObserver -- MDN
深入理解 requestAnimationFrame