Comments (13)
 JasonJPu
commented on May 13, 2024
1
JasonJPu
commented on May 13, 2024
1
@webstruck inference is pretty slow, and depends on if you use TPU or GPU
from bert.
 jacobdevlin-google
commented on May 13, 2024
jacobdevlin-google
commented on May 13, 2024
Hmm, I'm guessing the problem is that I do:
d = tf.data.Dataset.from_tensor_slices(feature_map)
To avoid having to write out data files, and this creates very large allocations that may or may not fail depending on exactly how tensorflow/python was compiled (e.g., what version of the C++ standard library its using).
I don't think that Dataset.from_generator() will work on the TPU because it implemented with a pyfunc, which weren't supported on TPU last time I checked (even for CPU data-processing). So I may have to change this to write to intermediate files.
from bert.
jacobdevlin-google
commented on May 13, 2024
To check whether this is the issue, can you add a quick change where you truncate the SQuAD training data and if the bad alloc goes away.
def read_squad_examples(input_file, is_training):
...
# Add this right before return statement to only train on 10k examples
if is_training:
examples = examples[0:10000]
return examples
from bert.
JasonJPu
commented on May 13, 2024
It works when I truncate the training data!
from bert.
JasonJPu
commented on May 13, 2024
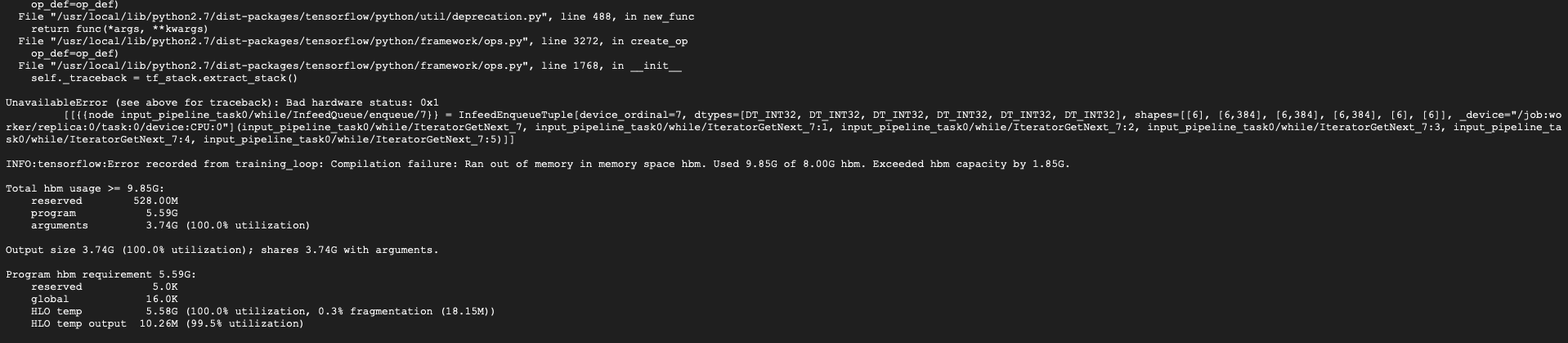
Getting another error for memory during training after enqueuing and dequeuing batches of data from infeed and outfeed.
from bert.
jacobdevlin-google
commented on May 13, 2024
I'll work on a fix for the first issue. Actually I just realized that I can just write the TF record files to output_dir so I don't need to change the interface.
For the second issue, can you try reducing the batch size to 32? On our internal version of TF using a batch size of 48 only uses 7.48 GB of memory but things might be different between versions and that's cutting it close anyways. I may need to find a better learning rate and num_epochs for batch size 32, but it should work as well as 48 in terms of final accuracy.
from bert.
JasonJPu
commented on May 13, 2024
A batch size of 32 still results in being 200 mb over the memory capacity. Using 24 works for now, not sure how this will impact performance yet.
from bert.
jacobdevlin-google
commented on May 13, 2024
That's a pretty huge difference, I'll coordinate with the TPU team here to figure out what's causing the mismatch.
from bert.
jacobdevlin-google
commented on May 13, 2024
Jason,
I just checked in a (hopeful) fix for the first issue. It might be a little slower to start because it has to write out a TFRecord file to output_dir, then read it back in. But at most a few minutes to start. Can you try it without truncation (but batch size 24) to see if it fixes the bad_alloc and can train all the way through for you?
from bert.
jacobdevlin-google
commented on May 13, 2024
For the memory issue, I just confirmed that the TPU memory usage different is in fact due to improvements that have been made to the TPU compiler since TF 1.11.0 was released. So with TF 1.11.0 it seems like 24 is the max batch size, and in the next upcoming version it will be 48. (I'm assuming you're using 1.11.0, since that's what the README said to use).
from bert.
jacobdevlin-google
commented on May 13, 2024
I confirmed that fine-tuning BERT-Large using batch size of 24 with a learning rate of 3e-5 and a 2.0 epochs consistently gets 90.7% F1, the same as the paper. I updated the README to reflect this.
Thanks for bringing up this issue!
Please let me know if your bad_alloc issue goes away and if you're able to obtain 90.5%+ on SQuAD dev with a Cloud TPU.
from bert.
JasonJPu
commented on May 13, 2024
Thanks so much Jacob! I'm no longer getting the bad_alloc issue, and I'm able to run BERT-Large with those parameters and I was able to get that F1 score.
I also tried using a TPU v3.0 with the parameters you originally gave (batch size of 48) and ran it with no issues, and got a F1 score of 90.9!
Amazing work!
from bert.
 webstruck
commented on May 13, 2024
webstruck
commented on May 13, 2024
@JasonJPu Can you please comment on inference performance? Is it comparable to QANet?
from bert.
Related Issues (20)
- sussy baka HOT 1
- Data source you used for training the wordpiece model in your original paper HOT 2
- Notas
- Bert:tensorflow:Error recorded from training_loop: Read less bytes than requested HOT 2
- load_model
- My Gmail account password recovery HOT 1
- Hi HOT 1
- bert loading
- Reproducing Experiment Results for Data Augmentation with TriviaQA
- Sentence Splitting Approach in BERT Preprocessing
- Forget password Gmail account HOT 1
- Awesomeness 👌
- Extraction of context Embeddings
- bert中文交流群,交流应用和训练心得 HOT 2
- raise SSLError(e, request=request)
- ValueError: A KerasTensor is symbolic: it's a placeholder for a shape an a dtype. It doesn't have any actual numerical value. You cannot convert it to a NumPy array. HOT 3
- The MRPC dataset downloaded from the script is missing the train.tsv file HOT 1
- Language Translation for classification
- MRPC and CoLA Dataset UnicodeDecodeError
- Internal: Blas GEMM launch failed when running classifier for URLs
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from bert.