george-es / blog Goto Github PK
View Code? Open in Web Editor NEWMy Blog
My Blog


在开发过程种,我们对复杂数据类型使用 useState 去更新,发现并没有重新渲染,于是手动设计一个刷新函数。
const [refresh, setRefresh] = useState(false);
useEffect(() => {
refresh && setTimeout(() => setRefresh(false))
}, [refresh])
const doRefresh = () => setRefresh(true)
doRefresh()
在开发过程中,我们会遇到这样一种场景,需要在 props 变化时更新 state,state 内有自己的逻辑。
举个反面例子说明下场景
class EmailInput extends Component {
state = { email: this.props.email }; // 为了满之单一来源值,email 需要根据外部值来初始化
render() {
return <input onChange={this.handleChange} value={this.state.email} />;
}
handleChange = event => {
this.setState({ email: event.target.value }); // 但是在实操中也需要改变相应的值
};
}
首先,我们了解下受控组件和非受控组件:
受控组件:用 props 传入数据的话,组件可以被认为是受控(因为组件被父级传入的 props 控制)。
非受控组件:数据只保存在组件内部的 state 的话,是非受控组件(因为外部没办法直接控制 state)。
其次,再说明下错误案例
直接复制(unconditionally)props 到 state 是不安全的。这样做会导致 state 后没有正确渲染。
class EmailInput extends Component {
state = { email: this.props.email };
}
可见直接复制 prop 到 state 是一个非常糟糕的想法,任何数据,都要保证只有一个数据来源,而且避免直接复制它。
为了解决这个问题,提出了 3 种方案
1、完全可控的组件
从组件里删除 state。如果 prop 里包含了 email,我们就没必要担心它和 state 冲突。我们甚至可以把 EmailInput 转换成一个轻量的函数组件:
function EmailInput(props) {
return <input onChange={props.onChange} value={props.email} />;
}
这样,所有的数据都在顶层出来,这样就不会出现直接复制 prop 到 state。
2、有 key 的非可控组件
让组件自己存储临时的 email state。在这种情况下,组件仍然可以从 prop 接收“初始值”,但是更改之后的值就和 prop 没关系了:
class EmailInput extends Component {
state = { email: this.props.defaultEmail };
handleChange = event => {
this.setState({ email: event.target.value });
};
render() {
return <input onChange={this.handleChange} value={this.state.email} />;
}
}
<EmailInput
defaultEmail={this.props.user.email}
key={this.props.user.id}
/>
通过 Key 这个特殊的 React 属性,当 key 发生变化时,React 会创建一个新的而不是更新一个既有的组件。
每次 ID 更改,都会重新创建 EmailInput ,并将其状态重置为最新的 defaultEmail 值。
大部分情况下,这是处理重置 state 的最好的办法。
3、用 prop 的 ID 重置非受控组件
如果某些情况下 key 不起作用(可能是组件初始化的开销太大),一个麻烦但是可行的方案是通过 getDerivedStateFromProps 监听数据的变化:
class EmailInput extends Component {
state = {
email: this.props.defaultEmail,
prevPropsUserID: this.props.userID
};
static getDerivedStateFromProps(props, state) {
// 只要当前 user 变化,
// 重置所有跟 user 相关的状态。
// 这个例子中,只有 email 和 user 相关。
if (props.userID !== state.prevPropsUserID) {
return {
prevPropsUserID: props.userID,
email: props.defaultEmail
};
}
return null;
}
// ...
}
如果props中的值更新了,那么更新state,否则不更新 state
在开发过程中,遇到屏幕适配问题,经常会用到 % 单位,宽度一般都没问题,很好实现 100%,但是在计算高度时候我们就会发现 height: 100% 是无效的。让我们来了解下
Web 浏览器在计算有效宽度时会考虑浏览器窗口的打开宽度。如果不给宽度设置任何缺省值,那浏览器会自动将页面平铺填满整个横向宽度。即我们不设置宽,也会自动填满整个横向宽度。
但是对于高度,浏览器根本就不会计算内容高度,除非内容超出可视范围(导致滚动条的出现)或者你给整个页面设置一个绝对高度。否则,在正常情况下,内容会无限向下堆砌,页面高度根本无需考虑。
对于高度的计算,子元素的高度百分比是相对于父元素的高度而言的,由于页面并没有缺省的高度值,所以我们在一个元素中设置高度百分比时,若父级高度又是缺省值,这样就无法算出自己的高度。
默认情况下高度默认值是 auto,它是一个缺省值,我们设置height: 100%时,是要求浏览器根据这样一个缺省值来计算百分比高度时,只能得到 undefined 的结果。也就是一个 null 值,浏览器不会对这个值有任何的反应。
知道了高度的计算方式,我们要想要子元素的 height: 100% 生效,那么父级,祖父级都要设置 height:100%,中间不能有空缺。
// style
html, body {
height: 100%;
}
.test1, .test2 {
height: 100%;
}
// html
<html>
<body>
<div class="test1">
<div class="test2">
我是子元素 高度要 100% 哟,
若 test1 没有设置 100%,就算 body 设置了 100%
那么我就无法 100%
</div>
</div>
</body>
</html>
要通过这种方式设置高度 100% 一定要包括 html 层,若 html 没有设置 height: 100%,也是无效的
高度百分百那么麻烦呀,如果某个 div 突然要它里面的元素相对于它高度 100%,逐个设置多复杂呀,有没有简单方法呢?
肯定有啦,看我的,安排
我们可以通过绝对定位(absolute)实现
<!DOCTYPE html>
<html lang="en">
<head>
<style>
html, body {
/* height: 100%; */
}
.test1 {
position: absolute;
height:100%;
}
.test2 {
height: 100%;
background-color: green;
}
</style>
</head>
<body>
<div class="test1">
<div class="test2">
height: 100%
</div>
</div>
</body>
</html>
可以看出 test2 的高度只受 test1 影响,与 html,body 无关
圣杯模型和双飞翼模型都是为了实现三列的布局的,中间内容宽度自适应,两边内容宽度固定。
很好理解呀,想象一下,圣杯,就是奖杯,两边两个耳朵,中间可大可小,但是两边是不变的;双飞翼,想象成鸟,鸟的翅膀是不变的,鸟吃的多,肚子就胖了。


这两个模型都是一样的只是叫法不同罢了,它的布局要求有几点:
三列布局,中间宽度自适应,两边定宽
中间栏要在浏览器中优先展示渲染
允许任意列的高度最高
实现代码
<!DOCTYPE html>
<html lang="en">
<head>
<style>
.header {
background-color: red;
}
.container {
overflow: hidden;
padding:0 200px 0 200px;
}
.main {
float: left;
position: relative;
background-color: orange;
width: 100%;
}
.left {
margin-left: -100%;
float: left;
position: relative;
left: -200px;
background-color: green;
width: 200px;
}
.right {
margin-left: -200px;
float: left;
position: relative;
right: -200px;
background-color: yellow;
width: 200px;
}
.footer {
position: relative;
background-color: blue;
clear: both;
}
</style>
</head>
<body>
<div class="header">
header
</div>
<div class="container">
<div class="main">main</div>
<div class="left">left</div>
<div class="right">right</div>
</div>
<div class="footer">
footer
</div>
</body>
</html>
这里主要说几个技术点
html 布局方式上(header)中(container)下(footer),container 中呈现圣杯式布局方案 main,left,right
main 放第一位的主要原因是为了实现中间栏要在浏览器中优先展示渲染这个需求。
container 中的元素均采用浮动方式,让元素左对齐 float: left。

由于 container 中元素都浮动了,这会导致 footer 元素也跟着到了第二行,为了解决这个问题,我们要用到清除浮动*操作 clear:both。

解决完清除浮动,在 container 中设置边框会发现,出现了高度塌陷问题,如紫色部分。

为了解决这一问题,我们要给 container 加上 overflow: hidden,触发 BFC 闭合浮动

由于我们的前提是左右固定,中间自适应,因此在宽度属性上,左右 200px,中间 100%,因此中间宽度 100% 后两边会撑下去。

为了解决这个问题,我们要用到 margin 负值大法,左边元素 margin-left: -100%;,右边元素 margin-left: -200px; 此时的 main 在最底下。

为了让 main 出现,我们通过调整 container 的 padding 实现

最后,通过 relative 调整元素位置,实现圣杯模型布局

实现代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
.header {
background-color: red;
}
.container {
overflow: hidden;
}
.main {
float: left;
width: 100%;
}
.content {
background-color: blue;
margin: 0 200px 0 200px;
}
.left {
float: left;
margin-left: -100%;
width: 200px;
background-color: green;
}
.right {
float: left;
margin-left: -200px;
width: 200px;
background-color: yellow;
}
.footer {
background-color: violet;
clear: both;
}
</style>
</head>
<body>
<div class="header">
header
</div>
<div class="container">
<div class="main">
<div class="content">
main
</div>
</div>
<div class="left">left</div>
<div class="right">right</div>
</div>
<div class="footer">footer</div>
</body>
</html>
圣杯模型和双飞翼布局大部分实现**是相同,也都是三栏全部 float 浮动,左右两栏加上负 margin 让其跟中间栏 div 并排,实现三栏布局。他们的唯一区别在于解决中间栏 div 内容不被遮挡问题的思路不一样。
圣杯布局的中间栏是通过设置 container 的内边距和相对定位来解决覆盖问题。而双飞翼中,我们是在 main 中加一个 content 来显示内容,然后设置 margin 为左右栏 div 留出位置。
相对于圣杯模型,双飞翼多使用了一个 div,却少了 4 个 css 属性(圣杯布局 container 的 padding-left 和padding-right 这2个属性,加上左右两个 div 用相对布局 position: relative 及对应的 right 和 left 共 4 个属性)而双飞翼布局子 div 里用 margin-left 和 margin-right 共 2 个属性,比圣杯布局思路更直接和简洁一点。
function func(...arg) {
console.log(arg) // 此时是数组类型,将参数值封装成数组
console.log(...arg) // 通过 ... 可以将数组解构
}
func(1,2,3);
output
[1,2,3]
1 2 3
原理:执行上下文也就是执行环境,每个函数都有自己的执行环境,当执行流进入一个函数时,函数的环境会被推入到一个环境栈中,而在函数执行之后,栈将其环境弹出,把控制权返回给之前的执行环境。
js 中执行环境分三种:
变量提升一个原则,赋值点不变,不会被忽略,提升的只是定义,只不过函数声明会提升后立刻运行
最后取得什么值只和它代码的书写顺序有关,赋值永远不会被提升,函数声明除外
console.log(a) // function a() {}
function a() {}
var a = 1
console.log(a) // 1
// 经过预解析后的顺序是这样的
var a;
function a() {}
console.log(a); // function a() {}
a = 1
console.log(a) // 1
变量的提升是分段(script标签)的,也就是说提升只会提升到所在 script 标签的最顶端,不会跨 script 标签提升。
条件式函数声明的只会提升函数名字,不会提升函数。
console.log(a) // undefined
if (true) {
function a() {}
}
关于函数形参相关的提升,如果有形参传入,那么形参赋值是在变量提升之前。
function func(a) {
console.log(a)
var a = 2
}
func(1)
// 等价于
function func() {
var a = 1;
var a;
console.log(a)
a = 2
}
执行环境只针对函数而言,当执行流进入一个函数时,函数的环境会被推入一个环境栈中。
执行上下文的建立分为两个过程
关于 this 的指向问题
函数中 this 取何值,是在函数真正被调用执行的时候确定下来的,函数定义的时候确定不了。
this 的取值是属于执行上下文的一部分,每次调用函数,都会产生一个新的执行上下文环境。当代码中使用了 this,这个 this 的值就直接从执行的上下文中获取了,而不会从作用域链中搜寻。
有 7 种情况
① 全局 & 调用普通函数
在全局环境中,this 永远指向 window
普通函数在调用的时候,无论普通函数内嵌套多少个普通函数,this 依旧指向 window
② 构造函数
在构造函数中,this 代表的是 new 出来的对象,也就是构造函数
function Func() {
this.x = 1
console.log(this) // Func { x: 1 }
}
let func = new Func()
③ 对象方法
如果函数作为对象方法时,方法中的 this 指向该对象,但是,如果在对象方法中定义函数,那情况就不同了
var obj = {
x: 10,
foo: function () {
function f(){
console.log(this); //Window
console.log(this.x); //undefined
}
f();
}
}
obj.foo();
可以这么理解:函数 f 虽然是在 obj.foo 内部定义的,但它仍然属于一个普通函数,this 仍指向 window。
但如果函数不作为对象方法被调用时
var obj = {
x: 10,
foo: function () {
console.log(this); //Window
console.log(this.x); //undefined
}
};
var fn = obj.foo;
fn();
obj.foo 被赋值给一个全局变量,并没有作为 obj 的一个属性被调用,那么此时 this 的值是 window。
④ 构造函数 prototype 属性
构造函数中,this 指向的是 new 出来的对象,在整个原型链中,任何一个地方调用 this,依旧指的是 new 出来的对象
⑤ 函数用 call,apply 或者 bind 调用
当一个函数被 call、apply 或者 bind 调用时,this 的值就取传入对象的值
⑥ DOM event this
在一个 HTML DOM 事件处理程序里,this 始终指向这个处理程序所绑定的 HTML DOM 节点
⑦ 箭头函数中的 this
箭头函数内部的 this 是词法作用域,由上下文确定,也就是说,箭头函数其实是没有 this 的,箭头函数中的 this 只取决包裹箭头函数的第一个普通函数的 this。由于 this 在箭头函数中已经按照词法作用域绑定了,所以,用 call()或者 apply()调用箭头函数时,无法对 this 进行绑定,即传入的第一个参数被忽略。
如果对一个函数j进行多次bind,那么上下文会是什么呢?
let a = {}
let fn = function () { console.log(this) }
fn.bind().bind(a)() // => ?
// fn.bind().bind(a) 等于
let fn2 = function fn1() {
return function() {
return fn.apply()
}.apply(a)
}
fn2()
如果你说是 a 就错了,不管我们给函数 bind 几次,fn 中的 this 永远由第一次 bind 决定,所以结果永远是 window。
⑧ 延迟函数 setTimeout & setInterval
非箭头函数情况下,延迟函数中的 this 是指向 window 的,箭头函数情况下,如果有外层包裹延迟函数,则箭头函数中 this 指向外层函数,若没有,指向 window。
在浏览 customize-cra 的源码时候,找到了 override 的实现方式
export const override = (...plugins) => flow(...plugins.filter(f => f));
在 flow 函数中,一开始以为是先执行 ... 解构操作,但怎么想都觉得不对,后来翻看了 js 运算符优先级发现,... 展开运算符的优先级是很低的,只有 1,因此这条语句的解读方式是,plugins 是个数组,进行 filter 语句后,返回一个数组,再执行展开运算符将数组解构传入到 flow 函数中
举个例子
function test() {
let arr = [1, 2, 3, 4]
console.log(arr.map(f => f + 1)) // [ 2, 3, 4, 5 ]
console.log(...arr.map(f => f + 1)) // 2, 3, 4, 5
}
test()
从上面可以看出,... 确实是最后才执行的
在 CSS 世界中,元素有三种形式
1)若是行内元素,父级又是块级元素,直接在父级设置 test-align: center 可实现水平居中
<div class="level_01">
<span>我要居中</span>
</div>
<style>
.level_01{
text-align: center;
border: 1px solid red;
}
</style>
2)使用 margin: 0 auto 要注意,设定宽度。
<div class="level_02">
<span>使用 margin: 0 auto; 记得设置宽度</span>
</div>
<style>
.level_02{
border: 1px solid red;
margin: 0 auto;
width: fit-content;
}
</style>
3)子元素 float 情况下,父元素使用 width: fit-content 和 margin: 0 auto 可实现水平居中
<div class="level_03">
<div style="float: left">
子元素用 float 情况下的水平居中
</div>
</div>
<style>
.level_03 {
border: 1px solid red;
margin: 0 auto;
width: fit-content;
}
</style>
4)使用 flex 布局,可以轻松实现水平居中
<div class="level_04">
<span>
flex 布局
</span>
</div>
<style>
.level_04 {
border: 1px solid red;
display: flex;
justify-content: center;
}
</style>
5)使用 absolute + transform 属性
<div class="level_05">
<span>
absolute + transform 属性
</span>
</div>
<style>
.level_05 {
position: absolute;
left: 50%;
transform: translateX(-50%);
}
</style>
6)需要居中的元素, 通过 margin-left, 和 width 实现, 这个有固定宽度需求
<div class="level_06">
<span>
需要居中的元素, 通过 margin-left, 和 width 实现, 这个有固定宽度需求
</span>
</div>
<style>
.level_06 {
width: 600px;
margin-left: -300px;
position: absolute;
left: 50%;
}
</style>
7)使用绝对定位方式, 以及left:0; right:0; margin:0 auto;
<div class="level_07">
<span>
需要居中的元素, 通过 margin 和 absolute 实现, 这个有固定宽度需求
</span>
</div>
<style>
.level_07 {
width: 600px;
position: absolute;
left: 0;
right: 0;
margin: 0 auto;
}
</style>
1)单行文本可通过 line-height 实现
<div class="vertical_01">
单行文本可通过 line-height 实现
</div>
<style>
.vertical_01 {
border: 1px solid red;
height: 100px;
line-height: 100px;
}
</style>
2)若元素是行内块级元素, 基本**是使用 display: inline-block, vertical-align: middle 和一个伪元素让内容块处于容器**.
<div class="vertical_02">
<div class="son">
通过伪元素实现,
</div>
</div>
<style>
.vertical_02::after {
content: '';
height: 300px;
}
.vertical_02::after,
.son {
display: inline-block;
vertical-align: middle;
}
</style>
3)可用 vertical-align 属性, 而 vertical-align 只有在父层为 td 或者 th 时, 才会生效, 对于其他块级元素, 例如 div、p 等, 默认情况是不支持的. 为了使用 vertical-align , 我们需要设置父元素display:table, 子元素 display:table-cell;vertical-align:middle; 优点:元素高度可以动态改变, 不需再CSS中定义, 如果父元素没有足够空间时, 该元素内容也不会被截断
<div class="vertical_03">
<div class="son">
通过 table vertical-align 属性实现
</div>
</div>
<style>
.vertical_03 {
display: table;
height: 300px;
}
.vertical_03 .son {
display: table-cell;
vertical-align: middle
}
</style>
4)flex 布局
<div class="vertical_04">
通过 flex 实现垂直居中
</div>
<style>
.vertical_04 {
display: flex;
align-items: center;
height: 300px;
}
</style>
5)通过 transform 实现垂直居中
<div class="vertical_05">
<div class="son">
通过 transform 实现垂直居中
</div>
</div>
<style>
.vertical_05 {
position: relative;
height: 300px;
}
.vertical_05 .son {
position: absolute;
top:50%;
transform: translateY(-50%);
}
</style>
6)设置父元素相对定位(position:relative),通过 margin-top 实现垂直居中。缺点:父元素空间不够时, 子元素可能不可见(当浏览器窗口缩小时,滚动条不出现时).如果子元素设置了overflow:auto, 则高度不够时, 会出现滚动条。
<div class="vertical_06">
<div class="son">
通过 margin-top 实现垂直居中
</div>
</div>
<style>
.vertical_06 {
position: relative;
}
.vertical_06 .son {
position: absolute;
height: 300px;
margin-top: 150px;
}
</style>
买了服务器就要用嘛,我的第一个数据请求,这里记录一下前端发起请求到后端接口收到数据的过程。
环境需求
node
n 模块
postman:用于发生 api 请求
nodemon:通过 node 运行 js 脚本
首先要打通的一步是,数据传输问题,在 ubuntu 上写代码效率太低了,这里我想到在 window 上开发,服务器上运行,这里我选用了 github 作为中转传输代码。
简要概述下思路
① 服务器上新建 git 密钥,并加到 github 中。
② 将 github 上仓库分别下载到 window 和 ubuntu 中
③ window 上编写代码,推上去,到 ubuntu 上下载
提示下,服务器上安装 oh-my-zsh,可以显示 github 分支
解决完数据传输问题后,我们通过 n 模块安装 node,并安装 nodemon
nodemon 是一个工具,它可以监听代码文件的变动,当代码改变之后,自动重启
npm install -g nodemon
下面我们在服务器上编写一个接口程序
要用到 express 框架
首先创建一个文件夹 api
mkdir api
初始化 package.json
npm init
安装 express 框架
npm install express --save
新建 api.js 文件,并注入代码
var express = require('express');
var app = express();
app.all('*', function(req, res, next) { //设置跨域访问
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header("Access-Control-Allow-Methods","PUT,POST,GET,DELETE,OPTIONS");
res.header("X-Powered-By",' 3.2.1');
res.header("Content-Type", "application/json;charset=utf-8");
next();
});
var infor = [ //传前端的数据
{
name:'jay',
age:20,
sex:'男',
hobby:'basketball'
},
{
name:'贼好玩',
age:23,
sex:'女',
hobby:'shopping'
},
{
name:'高渐离',
age:24,
sex:'男',
hobby:'music'
},
{
name:'小红',
age:28,
sex:'男',
hobby:'game'
},
{
name:'Tony',
age:24,
sex:'男',
hobby:'no'
},
]
app.get('/api',function(req,res){ //配置接口api
res.status(200),
res.json(infor)
})
//配置服务端口
var server = app.listen(3002,function(){
var host = server.address().address;
var port = server.address().port;
console.log('listen at http://%s:%s',host,port)
})
运行后端代码
nodemon api.js
然后在 postman 里面访问,就能获取到后端接口数据了。
JS 有 5 种判断数据类型的方法
typeof 的返回值有 7 种,string,number,boolean,undefined,null,object,function
规则如下:
instanceof 用于处理对象类型的,它要求开发者明确地确认对象为某个特定类型,它检测的是原型。它是根据原型链去查找的。
它的公式关系是
a 是 A 的实例,即(a instanceof A),则返回 true,否则返回 false,这里要注意一下,A 是所属原型链上的构造函数,例如 A -> B -> C 构成一条原型链,那么 a instanceof B 等于 true,a instaceof C 也等于 true, 也就是说 instanceof 会沿着原型链去寻找。
通常来讲,使用 instanceof 就是判断一个实例是否属于某种类型。
instanceof 只能用来判断对象类型,而不能用来判断原始类型,并且所有对象类型 instanceof Object 都是 true
funciton Foo() {}
var foo = new Foo()
console.log(foo instanceof Foo) // true
更重要的一点是 instanceof 可以在继承关系中用来判断一个实例是否属于它的父类型
// 判断 foo 是否是 Foo 类的实例 , 并且是否是其父类型的实例
function Aoo(){}
function Foo(){}
Foo.prototype = new Aoo();//JavaScript 原型继承
var foo = new Foo();
console.log(foo instanceof Foo)//true
console.log(foo instanceof Aoo)//true
因此使用 instanceof 时要注意的一点是,如果该类型从属一个原型链上,那么通过 instanceof 来判断就不准了,因此instanceof 只能用来判断两个对象是否属于实例关系, 而不能判断一个对象实例具体属于哪种类型。
举个例子:
[], Array, Object
[] instanceof Array; // true
{} instanceof Object;// true
new Date() instanceof Date;// true
function Person(){};
new Person() instanceof Person;
[] instanceof Object; // true
new Date() instanceof Object;// true
new Person instanceof Object;// true
我们发现,虽然 instanceof 能够判断出 [] 是Array的实例,但它认为 [] 也是Object的实例,为什么呢?
我们来分析一下 []、Array、Object 三者之间的关系:
从 instanceof 能够判断出 [].proto 指向 Array.prototype,而 Array.prototype.proto 又指向了Object.prototype,最终 Object.prototype.proto 指向了null,标志着原型链的结束。因此,[]、Array、Object 就在内部形成了一条原型链
instanceof内部原理
// JavaScript instanceof 运算符代码
function instance_of(L, R) {//L 表示左表达式,R 表示右表达式
var O = R.prototype;// 取 R 的显示原型
L = L.__proto__;// 取 L 的隐式原型
while (true) {
if (L === null)
return false;
if (O === L)// 这里重点:当 O 严格等于 L 时,返回 true
return true;
L = L.__proto__;
}
}
我们通过一个函数 F 来说明
当一个函数 F 被定义时,JS 引擎会为 F 添加 prototype 原型,然后在 prototype 上添加一个 constructor 属性,并让其指向F的引用,当执行 var f = new F() 时,F 被当成了构造函数,f 是 F 的实例对象,此时 F 原型上的 constructor 传递到了 f 上,因此 f.constructor === F。因此 F 利用原型对象上的constructor 引用了自身,当 F 作为构造函数来创建对象时,原型上的 constructor 就被传递到了新创建的对象上,从原型链角度讲,构造函数 F 就是新对象的类型。这样做的意义是,让新对象在诞生以后,就具有可追溯的数据类型。
因此通过 constructor 可以判断实例的数据类型,它和 instanceof 的其中一个不同点在于不会沿着原型链查找
注意点
① null 和 undefined 是无效的对象,因此是不会有 constructor 存在的,这两种类型的数据需要通过其他方式来判断。
② 函数的 constructor 是不稳定的,这个主要体现在自定义对象上,当开发者重写 prototype 后,原有的 constructor 引用会丢失,constructor 会默认为 Object
function F(){}
F.prototype = { a: 'xxx' }
var f = new F()
f.constructor == F // false
f.constructor // Object
prototype 被重新赋值的是一个 { }, { } 是 new Object() 的字面量,因此 new Object() 会将 Object 原型上的 constructor 传递给 { },也就是 Object 本身。
因此,为了规范开发,在重写对象原型时一般都需要重新给 constructor 赋值,以保证对象实例的类型不被篡改。
toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格式为 [object Xxx] ,其中 Xxx 就是对象的类型。
对于 Object 对象,直接调用 toString() 就能返回 [object Object] 。而对于其他对象,则需要通过 call / apply 来调用才能返回正确的类型信息。
公式
Object.prototype.toString.call(xxx)
Object.prototype.toString.call('') // [object String] Object.prototype.toString.call(123) // [object Number]toString 方法对于所有基本的数据类型都能进行判断,即使是 null 和 undefined,但是它无法获取到实例是属于那个构造函数的。
返回值有 String,Number,Symbol,Null,undefined,Undefined,Function,Object,Array
Object.prototype.toString.call() 常用于判断浏览器内置对象。
所以说 typeof 和 toString 检测的是实例与数据类型的关系,instanceof 和 constructor 检测的是实例与构造函数之间的关系
该函数的作用是用来判断对象是否为数组
当检测Array实例时,Array.isArray 优于 instanceof ,因为 Array.isArray 可以检测出 iframes
var iframe = document.createElement('iframe');
document.body.appendChild(iframe);
xArray = window.frames[window.frames.length-1].Array;
var arr = new xArray(1,2,3); // [1,2,3]
// Correctly checking for Array
Array.isArray(arr); // true
Object.prototype.toString.call(arr); // true
// Considered harmful, because doesn't work though iframes
arr instanceof Array; // false
Array.isArray() 是ES5新增的方法,当不存在 Array.isArray() ,可以用 Object.prototype.toString.call() 实现。
if (!Array.isArray) {
Array.isArray = function(arg) {
return Object.prototype.toString.call(arg) === '[object Array]';
};
}
函数的参数若是复杂数据类型,会随着外界的变化而变化吗?
SSH 登录时出现如下错误:Permission denied, please try again
解决方案如下
我们用 ssh 登录时候一定要记得看用户名,有几次登录不成功都是因为用户名搞错了,在服务器登录界面会显示的

然后就可以在本地愉快玩耍服务器了
同步:程序会发生阻塞,方法调用一旦开始,必须要等到改函数调用返回后,才能继续后续的行为。如alert
异步:程序不会发生阻塞,方法返回时,调用者还不能够得到预期结果,而是需要在将来通过一定手段(如:回调函数)得到,如setTimeout
异步发展历程:callback -> Promise -> Generator -> async/await
JS 是通过事件循环来实现异步的
| 优点 | 缺点 |
|---|---|
| 方便,简单 | 大量的回调嵌套会导致代码难以维护,不方便统一处理错误 容易产生回调地狱 不易于异常捕获 try...catch |
Promise 的诞生解决了回调地狱问题
| 优点 | 缺点 |
|---|---|
| 三种状态 pending,fulfilled,rejected 对象状态不受外界影响 一旦状态改变,就不会再变 |
无法中途取消,一旦新建就会立即执行 如果不设置回调函数,promise内部错误不会反应到外部 当处于pending状态时,无法得知目前进展到哪一个阶段 |
Promise 构造函数接收一个回调函数,该回调函数包含两个参数,分别是resolve, reject,这两个参数作用都是改变状态的,前者将状态从 "未完成" 变成 "成功",后者将状态从 "未完成" 变成 "失败",这两个参数都可将接收到的参数值作为 then 函数的参数值。
Promise 新建后会立刻执行,then 方法输出的是它的结果,所以异步是发生在 then 中的,Promise中的是同步。
它的作用是为 Promise 实例添加状态改变时的回调函数,可接收两个参数(require,reject),该方法返回一个新的 Promise 实例,因此可以采用链式调用,即
new Promise().then().then()
该方法是 .then(undefined, rejected) 或 .then(null, rejected)的别名,用于指定发生错误时的回调函数,返回一个新的 Promise 对象。
new Promise().then().then().catch()
也就是说,catch 前只要有任意一个地方发生错误,都会直接被 catch 捕获到,触发 catch 中的回调。
如果没用使用 catch 方法指定错误处理的函数,又没有写 rejected 显示抛出错误,那么 Promise 对象抛出的错误不会传递到外层代码,即不会有任何反应,也就是说,在 Promise 中发生的错误不会阻塞代码的运行。如果没有显示抛出,又没有 catch 语句捕获,Promise 就会 "吃掉" 错误。
catch 方法只会捕获它前面发生的错误,后面产生的错误,是捕获不了的,解决方法是再加一个 catch。
catch 内部也可以产生错误,而产生的错误,需要下一个 catch 才能捕获到。
该方法用于指定不管 Promise 对象最后状态如何,都会执行操作
该方法不接受任何参数
实现原理
Promise.prototype.finally = function (callback) {
let P = this.constructor
return this.then(
value => P.resolve(callback()).then(() => value),
reason => P.resolve(callback()).then(() => { throw reason })
)
}
该方法接收一个Iterator接口(例如:数组)作为参数,将多个 Promise 实例包装成一个新的 Promise 实例,只有参数中所有 promise 元素的值为都变成 fulfilled,改方法才为 fulfilled,此时,这些元素的返回值会组成一个数组作为该方法的返回值,传递给 then(回调函数),若有一个元素值为rejected,则返回第一个实例为 rejected 返回值给 then(回调函数)。
如果参数不是 Promise 实例,就会调用 Promise.resolve 方法,将参数转为 Promise 实例。
如果作为参数的 Promise 实例,自己定义了 catch 方法,那么它一旦被rejected,并不会触发 Promise.all() 的 catch 方法,反之,若没定义,就会调用该方法上的 catch 方法。
该方法和 all 方法基本一样, 唯一的区别是会优先捕获最先变为 fulfilled 的实例。
该方法作用将对象转为 Promise 对象,实例状态为 resolve。
Promise.resolve().then()
该方法的参数有四种情况
该方法作用将对象转为 Promise 对象,实例状态为 rejected。
Promise.reject().then()
也是立即执行的,它会原封不动的将参数作为后续方法的参数传入,这点就是它和 Promise.reslove() 方法不一致的地方。
该方法是一种异步编程的解决方案
可以理解为一种状态机,封装了多个内部状态,返回一个遍历器对象(Iterator)。
两个特征
调用 Generator 函数后,该函数并不执行,返回的也不是函数运行结果,而是一个指向内部状态的指针对象(遍历器对象)。
必须使用 next 方法才能够改变状态,每一个 yield 表达式就是一个状态。
每次调用 next 方法都会返回一个有着 value 和 done 两个属性的对象,value 属性表示当前的内部状态的值,是 yield 表达式后面那个表达式的值,done 属性是一个布尔值,表示是否遍历结束。
next 的运行逻辑
注意点
由于 Generator 函数就是遍历器生成函数,因此可以把 Generator 赋值给对象的 Symbol.iterator 属性,从而使得该对象具有 Iterator 接口。
yield 表达式本身没有返回值,或者说总是返回 undefined。next 方法可以带一个参数,该参数就会被当作上一个 yield 表达式的返回值。
也就是说,每调用一次 next 方法会执行 yield 右边的表达式,然后暂停,再遇到下一个 next,会将其中的参数作为上一个 yield 的值。
这些方法都可以自动遍历 Generator 函数运行时生成的 Iterator 对象,且此时不再需要调用 next 方法, 并将 next 返回的 value 属性值提取出来.
该方法可以在函数体外抛出错误,然后在 Generator 函数体内捕获,它可以接收一个参数,该参数会被catch语句接收,建议抛出Error对象的实例。
Generator 内部定义了 try...catch 如果需要抛出错误,必须使用遍历器对象的 throw 方法才可以,如果用全局 throw 方法, 只能被函数体外 try...catch 捕获。
该方法可以终结遍历 Generator 函数。
调用该方法后,返回值的 done 属性为 true,以后再调用 next 方法,done 属性总是返回 true。
如果 return 方法调用时,不提供参数,则返回值的 value 属性为 undefined。
如果 Generator 函数内部有 try...finally 代码块,且正在执行 try 代码块,那么 return 方法会推迟到 finally 代码块执行完再执行。
next()、throw()、return() 这三个方法本质上是同一件事,可以放在一起理解。它们的作用都是让 Generator 函数恢复执行,并且使用不同的语句替换 yield 表达式。
该表达式用于解决一个 Generator 函数里面执行另一个 Generator 函数.
从语法角度看,如果yield表达式后面跟的是一个遍历器对象,需要在yield表达式后面加上星号,表明它返回的是一个遍历器对象。这被称为yield*表达式。
任何数据结构, 只要有 Iterator 接口, 就可以被 yield* 遍历.
async 函数是 Generator 函数的语法糖, 它就是将 Generator 函数的星号(*) 替换成 async, 将 yield 替换成 await, 仅此而已.
async 对 Generator 的改进体现以下四点:
或者说 async 函数完全可以看作多个异步操作, 包装成一个 Promise 对象, 而 await 命令就是内部 then 命令的语法糖.
async 函数返回一个 Promise 对象,可以使用 then 方法添加回调函数。当函数执行的时候,一旦遇到 await 就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
async 一定是紧跟着函数在一起的。
async 是 Generator 的语法糖, 不过它返回的是 Promise 对象, 这个函数 return 语句的返回值, 会成为 then 方法回调函数的参数, 而里面抛出的错误, 会导致返回的 Promise 对象变为 reject 状态, 抛出的错误对象会被 catch 方法回调函数接收到.
async function f() {
return 'hello world';
}
f().then(v => console.log(v))
// "hello world"
async 函数返回的 Promise 对象, 必须等到内部所有 await 命令后面的 Promise 对象执行完, 才会发生状态变化, 除非遇到 return 语句或抛出错误. 也就是说, 只有 async 函数内部的异步操作执行完, 才会执行 then 方法指定的回调函数.
await 命令后面是一个 Promise 对象, 返回该对象的结果, 如果不是 Promise 对象, 就直接返回对应的值.
要执行完 await 后函数才会让出线程
async function f() {
// 等同于
// return 123;
return await 123;
}
f().then(v => console.log(v))
// 123
还有一种情况, await 后面是一个 thenable 对象 (即定义 then 方法的对象), 那么 await 会将其等同于 Promise 对象, await 命令后面的 Promise 对象如果变为 reject 状态, 则 reject 的参数会被 catch 方法的回调函数接收到.
async function f() {
await Promise.reject('出错了');
}
f()
.then(v => console.log(v))
.catch(e => console.log(e))
// 出错了
任何一个 await 语句后面的 Promise 对象变为 reject 状态,那么整个 async 函数都会中断执行。如果希望前一个 await 失败也不会影响到整个 async
async function f() {
await Promise.reject('出错了');
await Promise.resolve('hello world'); // 不会执行
}
async function main() {
try {
const val1 = await firstStep();
const val2 = await secondStep(val1);
const val3 = await thirdStep(val1, val2);
console.log('Final: ', val3);
}
catch (err) {
console.error(err);
}
}
// 写法一
let [foo, bar] = await Promise.all([getFoo(), getBar()]);
// 写法二
let fooPromise = getFoo();
let barPromise = getBar();
let foo = await fooPromise;
let bar = await barPromise;
将 Generator 函数和自动执行器, 包装在一个函数里.
function spawn(genF) {
return new Promise(function(resolve, reject) {
const gen = genF();
function step(nextF) {
let next;
try {
next = nextF();
} catch(e) {
return reject(e);
}
if(next.done) {
return resolve(next.value);
}
Promise.resolve(next.value).then(function(v) {
step(function() { return gen.next(v); });
}, function(e) {
step(function() { return gen.throw(e); });
});
}
step(function() { return gen.next(undefined); });
});
}
事件流描述的是从页面中接收事件的顺序,IE 提出冒泡流,Netscape 提出捕获流
一个事件的触发会经历三个阶段捕获阶段,目标阶段,冒泡阶段。
事件捕获:由外向内,指从 window -> document -> html -> body -> ... -> 目标
目标阶段:到达目标事件位置(事发地),触发事件
事件冒泡:由内向外,指从 目标 -> ... -> body -> html -> document -> window

但是要注意,如果给一个 body 中的子节点同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行。如果不是同一节点上同时注册的,就会按照先捕获后冒泡顺序执行
也就是说
// 以下会先打印冒泡然后是捕获
node.addEventListener(
'click',
event => {
console.log('冒泡')
},
false
)
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)
指将一个函数赋值给一个事件处理程序属性,它有两个优势,①简单,②可跨浏览器,要使用它必须获得 DOM 对象的引用。
每个元素(包括 window 和 document)都有自己的事件处理程序属性,这些属性通常全部小写,例如 onclick,为这些属性的值设置一个函数,就可以指定事件处理程序
var btn = document.getElementById("myBtn");
btn.onclick = function() {
alert("clicked")
console.log(this)
}
使用 DOM0 级方法指定的事件处理程序被认为是元素的方法。因此,这时候的事件处理程序是在元素的作用域中运行,换句话说,程序中的 this 引用当前元素。
删除通过 DOM0级方法指定的事件处理程序
只要将属性值设为 null 即可
btn.onclick = null // 删除事件处理程序
将事件处理程序设置为 null 之后,再单击按钮将不会有任何动作发生。
"DOM2 级事件" 定义了两个方法,用于处理指定和删除事件处理程序的操作
DOM 操作中通过 addEventListener() 进行事件监听,它有三个参数,其中第三个参数控制捕获还是冒泡,true 事件捕获 false 事件冒泡,第三参数还可以是对象。
el.addEventListener(type, listener, {
capture: false // 布尔值,和 useCapture 作用一样,是否是捕获型, 默认 false(冒泡)
once: false, // 值为 true 表示该回调只会调用一次,调用后会移除监听
passive: false, // 布尔值,是否让阻止默认行为preventDefault()失效
})
通过 DOM2 级方法可以添加多个事件处理程序,这两个事件处理程序会按照他们的顺序触发
let btn = document.getElementById('app')
btn.addEventListener('click', () => {
console.log('test1')
})
btn.addEventListener('click', () => {
console.log('test2')
})
removeEventListener() 用于删除事件,但是它只能移除通过 addEventListener() 添加的事件,移除时传入的参数与添加处理程序时使用的参数相同,这也意味着通过 addEventListener() 添加的匿名函数将无法移除。
var btn = document.getElementById('btn')
btn.addEventLinstener("click", () => {
console.log('click')
})
btn.removeEventListener("click", () => { // 匿名函数,删除不成功
console.log('click')
})
function handleC() {
console.log('handleC')
}
btn.addEventLinstener("click", handleC)
btn.removeEventListener("click", handleC) // 删除成功
**为了最大限度地兼容各种浏览器,大多数情况下,都是将事件处理程序添加到事件流的冒泡阶段。**最好只在需要事件到达目标之前截获它的才添加到捕获阶段。
低版本使用 attachEvent() 和 detachEvent() 来进行事件绑定和事件移除,由于 IE8 以前,之支持事件冒泡,所以通过 attachEvent() 添加的事件处理都会被添加到冒泡阶段。
了解就好了,现在基本不用 IE 了。
核心**:封装个方法,去识别这个浏览器是否支持 addEventListener()(DOM2),否则,则使用 attachEvent()(IE),若都不支持,则使用 DOM0 级方法
var EventUtil = {
addHandle: function(element, type, handler) {
if(element.addEventListener) {
element.addEventListener(type, handle, false)
} else if(element.attachEvent) {
element.attachEvent("on" + type, handler)
} else {
element["on" + type] = handler
}
},
removeHandler: function(element, type, handler) {
if(element.removeEventListener) {
element.removeEventListener(type, handle, false)
} else if (element.detachEvent) {
element.detachEvent("on" + type, handler)
} else {
element["on" + type] = null
}
}
}
触发 Dom 上的某个事件,会产生一个事件对象 event ,这个对象中包含着所有与事件有关的信息。
常见的对象属性
| 属性 | 类型 | 说明 |
|---|---|---|
| bubbles | Boolean | 表明事件是否冒泡 |
| cancelable | Boolean | 表明是否可以取消事件的默认行为 |
| currentTarget | Element | 其事件处理程序当前正在处理事件的那个元素 |
| defaultPrevented | Boolean | 为 true 表示已经调用了 preventDefault() |
| detail | Integer | 与事件相关的细节信息 |
| eventPhase | Integer | 调用事件处理程序的阶段:1表示捕获阶段,2表示"处于目标",3表示冒泡 |
| preventDefault() | Function | 取消事件的默认行为。如果 cancelable 是 true,则可以使用这个方法 |
| stopImmediatePropagation() | Function | 取消事件的进一步捕获或冒泡,同时阻止任何事件处理程序被调用 |
| stopPropagation() | Function | 取消事件进一步捕获或冒泡。如果 bubbles 为 true,则可以使用这个方法。 |
| target | Element | 事件的目标 |
| trusted | Boolean | 为 true 表示事件是浏览器生成的,为 false 表示事件是由开发人员通过 Javascript 创建的 |
| type | String | 被触发事件的类型 |
| view | AbstractView | 与事件关联的抽象视图,等同于发生事件的 window 对象 |
在事件处理程序内部,对象 this 始终等于 currentTarget 的值,而 target 则只包含事件的实际目标,如果直接将事件处理程序指定给了目标元素,则 this,currentTarget 和 target 包含相同的值
var btn = document.getElementById("myBtn")
btn.onclick = function(event) {
alert(event.currentTarget === this) // true
alert(event.target === this) // true
}
这个例子检测了 currentTarget 和 target 与 this 的值。由于 click 事件的目标是按钮,因此这三个值是相等的。如果事件处理程序存在于按钮的父节点中(例如 document.body),那么这些值是不相同的
document.body.onclick = function(event) {
alert(event.currentTarget === document.body) // true
alert(this === document.body) // true
alert(event.target === document.getElementById("myBtn")) // true
}
要**阻止特定事件的默认行为,可以使用 preventDefault() **方法。例如,连接的默认行为就是在被单击时会导航到其 href 特性指定的 URL。如果你想阻止链接导航这一默认行为,那么通过链接的 onclick 事件处理程序可以取消它。
let link = document.getElementById("myLink")
link.onclick = function(event) {
if(event.cancelable) {
event.preventDefault()
}
}
只有 cancelable 属性设置为 true 的事件,才可以使用 preventDefault() 来取消其默认行为。
要停止特定事件在 DOM 层次中的传播,可以使用 stopPropagation() 方法,它可以同时取消捕获或者冒泡。该方法可以进一步取消事件捕获或冒泡。例如,直接添加到一个按钮的事件处理程序可以调用 stopPropagation(),从而避免触发注册在 document.body 上面的事件处理程序
var btn = document.getElementById("myBtn")
btn.onclick = function(event) {
alert("clicked")
event.stopPropagation()
}
document.body.onclick = function(event) { // 这个不会被触发
alert("Body clicked")
}
event 对象中将 cancelBubble 值设置为 true,可以取消事件冒泡,它和 stopPropagation() 方法作用相同,都是用来停止事件冒泡的,由于 IE 不支持事件捕获,因此只能取消事件冒泡
通过 eventPhase 属性,我们可以用来确定事件正位于事件流的哪个阶段,
只有在事件处理程序执行期间,event 对象才会存在,一旦事件处理程序执行完成,event 对象就会被销毁。
在 IE 中 event 对象有几种不同的方式,DOM0 级方法添加事件处理程序时,event 对象作为 window 对象的一个属性存在。即 event = window.event
因此要兼容不同浏览器中间的事件对象,我们需要封装一个函数
let EventUtil = {
getEvent: function(event) {
return event ? event : window.event; // 兼容不同浏览器中的事件对象
},
getTarget: function(event) {
return event.target || event.srcElement; // 兼容不同浏览器的事件目标
},
stopPropagation: function(event) { // 兼容不同浏览器的阻止事件传播
if(event.stopPropagation) {
event.stopPropagation()
} else {
event.cancelButtle = true;
}
},
preventDefault: function(event) { // 兼容不同浏览器的阻止默认事件
if(event.preventDefault) {
event.preventDefault()
} else {
event.returnValue = false;
}
}
}
每个函数都是对象,对象就会占用内存,内存中对象越多,效率越差,其次,必须事先指定所有事件处理程序而导致的 DOM 访问次数,会延迟整个页面的交互就绪时间。因此可以通过以下方案进行优化
事件代理也叫事件委托,它原理是利用事件冒泡,指定一个事件处理程序,就可以管理某一类型的所有事件。举个例子,click 事件会一直冒泡到 document 层次,也就是说,我们可以为整个页面指定一个 onclick 事件处理程序,而不必给每个可单击的元素分别添加事件处理程序。
解决方案:通过冒泡方式,我们在使用事件代理时候,只需在 DOM 树中尽量最高的层次上添加一个事件处理程序。
<ul id="myLinks">
<li>somewhere</li>
<li>something</li>
<li>hi</li>
</ul>
例如,在这里,无需在每个 li 中注册事件,只需要在 ul 中注册即可,因为 li 被点击后会冒泡到 ul 中统一处理。
如果可行的话,也可以考虑为 document 对象添加一个事件处理程序,用以处理页面上发生的某种特定类型的事件,这样做与采取传统的做法相比具有如下优点。
最适合采用事件委托技术的事件包括 click,mousedown,mouseup,keydown,keyup 和 keypress。
在事件中,如果我们需要删除某个节点,不是单纯的去修改 dom 就行了,若该节点绑定了某个事件,需要将它的方法置为 null,不然,虽然通过 inner HTML 修改了节点内容,但是节点上绑定的事件依旧存在的,这样垃圾回收无法正确识别,导致内存泄漏。
<div id="myDiv">
<input type="button" value="click me" id="myBtn">
</div>
<script type="text/javascript">
var btn = document.getElementById("myBtn")
btn.onclick = function() {
btn.onclick = null // 移除事件处理程序
document.getElementById("myDiv").innerHTML = "Provessing..."
}
</script>
此时,我们在设置 <div> 的 innerHTML 属性之前,先移除了按钮的事件处理程序,这样就确保了内存可以被再次利用,而从 DOM 中移除按钮也做到了干净利落。
移除事件处理程序方法就是将他置为 null
原文作者:Mikey Stecky-Efantis
原文地址:5 Easy Steps to Understanding JSON Web Tokens(JWT)
在本文中, 将解释JSON Web Tokens(JWT)的基本原理以及使用他们的原因。JWT 是确保你应用程序信任和安全的重要部分。JWT 允许以安全的方式来声明,例如用户数据。
为了解释JWT如何工作,让我们从一个抽象的定义开始。
一个 JSON Web Token(JWT)是一个 JSON 对象,在 RFC7519 中定义为表示两方之间的一组信息的安全方式。该令牌由标头,有效负载和签名组成。
简单来说,JWT 只是一个具有以下格式的字符串
header.payload.signature
应该注意的是,双引号字符串实际上被视为有效的 JSON 对象。
下面将展示实际使用 JWT 的方式和原因,我们将使用一个简单的例子(如下图所示),这个例子中的实体是用户,应用服务器,和认证服务器。认证服务器将提供 JWT 给用户,通过 JWT,用户可以安全的和应用服务器间进行通讯。
在这个例子中,用户第一次进入认证服务器并使用认证服务器登陆系统(例:在 Facebook 和 Google 中通过用户名和密码登陆,等)。认证服务器创建JWT并且发生给用户,当用户对应用程序进行 API 调用时,JWT将随着API一并传递。在此配置中,应用程序服务器将会进行认证配置,用于验证传入的JWT是否是由身份服务器创建的(稍后将详细解释验证过程)。因此,当用户使用带有JWT的API去发起调用请求时,该应用能够使用JWT去认证这个API是否来自被认证的用户。
现在,将更深入地研究JWT本身及其构建和认证的方式。
##Step1. 创建令牌头
JWT 的头部包含有关如何计算 JWT 签名的信息,其标头是以下格式的 JSON 对象
{
"typ": "JWT",
"alg": "HS256"
}
在上述 JSON 中,"typ" 键值指定了 JWT 对象,"alg"键值指定使用哪种散列算法来创建 JWT 签名组件。在这个例子中,我们使用 HMAC-SHA256 算法(一种使用密钥的散列算法)来计算签名(在步骤 3 中更详细地讨论)。
##Step2. 创建 PayLoad
PayLoad是存储在 JWT 里的内部数据(该数据也称为 JWT 的 “声明”)。在这个例子中,认证服务器创建一个JWT 用于存储用户信息,特别是用户ID。
{
"userId": "b08f86af-35da-48f2-8fab-cef3904660bd"
}
在这个例子中,我们只将一个声明放入 payload 中,你也可以根据需要添加任意数量的声明。JWT关键信息(payload)有几种不同的标准声明,例如 "iss" 表示 issuer,"sub" 表示 subject还有 "exp" 表示expiration time。创建 JWT 时,这些字段非常有用,但是他们是可选的,想了解更多有关 JWT 标准字段的详细信息,请参阅 JWT 上的维基百科页面。
请记住,数据的大小会影响 JWT 的整体大小,通常这不是问题,但是,JWT 太大可能会对性能产生负面影响并导致延迟。
##Step3. 创建签名
签名的计算方式通过以下的伪代码进行表述
// signature algorithm
data = base64urlEncode( header ) + “.” + base64urlEncode( payload )
hashedData = hash( data, secret )
signature = base64urlEncode( hashedData )
该算法的作用是通过 base64url 对步骤1和步骤2中创建的头和关键信息(payload)进行编码。然后通过点(.)来连接两个编码字符串,构成数据 data 。在 JWT 头部使用指定的散列算法对数据字符串使用密钥进行散列,并将生成的散列数据分配给 hashedData。然后对该散列数据进行 base64url 编码以产生 JWT 签名。
在该例子中,头部和关键信息(payload)都是 base64url 编码的
// header
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
// payload
eyJ1c2VySWQiOiJiMDhmODZhZi0zNWRhLTQ4ZjItOGZhYi1jZWYzOTA0NjYwYmQifQ
然后,在编码头和编码关键负载(payload)中周期的加入携带密钥的应用指定签名算法,于是,我们得到签名所需的散列数据。在该例子中,这意味着应用HS256算法,并将密钥设置为字符串 "secret",在数据字符串上获取 hashedDate 字符串,之后,通过 base64url 编码 hashedData 字符串,我们得到以下 JWT 签名
// signature
-xN_h82PHVTCMA9vdoHrcZxH-x5mb11y1537t3rGzcM
##Step4. 将 JWT 的所有组件(3个)组合在一起
我们已经创建了所有的组件(3个),现在我们可以通过它们来创建 JWT了。请记住 JWT 的结构 header.payload.signature ,我们使用通过 base64url 编码的 header 和 payload,以及步骤 3 中签署的签名,只需要组合这些组件并通过句号(.)分隔它们。
// JWT Token
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VySWQiOiJiMDhmODZhZi0zNWRhLTQ4ZjItOGZhYi1jZWYzOTA0NjYwYmQifQ.-xN_h82PHVTCMA9vdoHrcZxH-x5mb11y1537t3rGzcM
通过浏览器,在jwt.io上你可以尝试创建属于自己的 JWT。
回到这个例子,现在该认证服务器能够发送 JWT 给用户了。
###JWT 如何保护我们的数据?
要理解使用 JWT 的目的,并而不是通过任何的方式手段去隐藏或者模糊数据。使用 JWT 的原因是为了证明发送的数据实际上是由真实的源创建的。
如上述步骤所示,JWT 内的数据经过编码和签名而不是加密的。编码数据的目的是转换数据的结构。一方面签名数据允许数据接收器验证数据源的真实性。因此,编码和签名数据不会保护数据。另一方面,加密的主要目的是保护数据并防止未经授权的访问。有关编码和加密之间差异的详细说明,以及有关散列如何工作的更多信息,请参阅此文章
由于 JWT 仅被签名和编码,并且由于 JWT 未加密,因此 JWT 不保证敏感数据的任何安全性。
##Step5. JWT 验证
在第三个例子中,我们使用由 HS256 算法签名的 JWT,其中只有身份验证服务器和应用服务器知道密钥。当应用程序设置其身份认证的时候,应用服务器从身份验证服务器接收密钥。由于应用程序知道密钥,因此当用户对应用程序调用JWT 连接的 API 时,应用程序可以在 JWT 上执行与步骤 3 相同的签名算法。然后该应用程序能够验证自身通过哈希操作获得的签名与 JWT 本身得到的签名是否匹配(即,它与由认证服务器创建的 JWT 签名匹配)。如果签名匹配,这意味着 JWT 有效,表示 API 的调用是来自认证服务器的。除此之外,如果签名不匹配,则表示收到的 JWT 无效,这意味着你的应用程序正受到潜在的攻击。因此,通过验证 JWT ,应用程序在自身和用户之间添加了一层信任。
##结论
我们了解了 JWT 是什么,如何创建和验证它们,以及如何使用它们来确保应用程序与其用户之间的信任关系。这是了解 JWT 的基础和起点。在确保应用程序中的信任和安全性难题中,JWT 只是其中之一。
应该注意的是,本文中描述的 JWT 认证设置使用的是对称密钥算法(HS256),你也可以以类似的方式设置 JWT 身份验证,除非你使用非对称算法(例如:RS256)这类算法的身份验证服务器具有密钥,并且应用程序服务器具有公钥。查看此 Stack Overflow 问题了解对称和非对称算法的差异性及其详细分类。
还应该注意,JWT 应该通过 HTTPS(而不是 HTTP)连接。HTTPS 可以有效的防止未经授权的用户通过拦截服务器和用户之间通讯的方式来发送 JWT。
此外,如果你的 JWT 关键信息(payload)有一部分过期了,那么整个 JWT 将被视为无效,不能再使用了。
为了让自己更全面发展,买了个云服务器,学习下后端知识
服务器到位,激动的心,颤动的手,重置完密码直接开搞
由于选的是 ubuntu 环境,第一步安装 nginx,在工作中经常听到反向代理,也打算玩玩
sudo apt-get install nginx
打开网站配置文件
cat /etc/nginx/sites-available/default
我们可以看到
server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html;
}
root 是我们的访问网站,也就是说在浏览器访问 nginx 地址时,会打开 root 指定的文件,80 就是 nginx 服务器端口
后续,把我们前端 build 的文件放到 root 指定的目录即可
执行 sudo service nginx stop | start | restart 代表停止 | 启动 | 重启 服务器
启动 nginx 服务器后,在浏览器访问 http:// + 服务器地址
呈现

我们都知道 create-react-app 是将 webpack 配置文件隐藏起来的,但在项目过程中,我们需要修改配置文件,这里提供两个方法
npm run eject
npm install react-app-rewired --save-dec
"scripts": {
"start": "react-app-rewired start",
"build": "react-app-rewired build",
"test": "react-app-rewired test",
"eject": "react-app-rewired eject"
}
要对 webpack 配置,还需要安装 customize-cra 包
npm install customize-cra --save-dev
customize-cra 利用 react-app-rewired 和 config-overrides.js 文件。通过导入customize-cra 函数并导出包装在我们的 override 函数中的一些函数调用,您可以轻松地修改构成 create-react-app 的基础配置对象(webpack,webpack-dev-server,babel等)。
JS 的数据类型分两大类
基本数据类型也就值类型,值类型里面存储的都是值,没有函数可调用
譬如 undefined.toString() 会报错的,这时你会奇怪 '1'.toString() 又可以,是的,没错,但此时的 '1' 已经被强制转换为 String 对象类型了,注意哟,这是大写的 String。
其实你用 typeof 就可以看出小写和大写的区别了,小写表示值类型
typeof('1') // string
在基本类型中还需要注意的是 null 类型,该类型通过 typeof 去判断会输出 object,因为 JS 的最初版本中使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,然而 null 表示为全零,所以将它错误的判断为 object 。
复杂数据类型叫引用类型,常见的有对象,数组和函数,它存储的是地址(指针)。当你创建一个对象类型的时候,计算机会在内存中开辟一个空间来存放值。
对于基本数据类型而言,由于值在内存中占据固定大小的空间,因此保存在栈内存中,而对象类型在栈内存中存储的只是该值的地址的指针,值存储于堆内存中。
栈(stack)和堆(heap)的知识
系统会划分出两张不同的内存空间,栈(stack)和堆(heap),Stack 是一种存放数据的内存区域
stack(栈)是有结构的(后进先出,从下到上)每个区域都按照一定次序存放,可以明确每个区块的大小。heap 没有结构,数据可以任意存放,因此 stack 的寻址速度要快于 heap。
一般来说,每个线程分配一个stack(栈)每个进程分配一个heap(堆)。就是说 stack 独占线程,heap 是共享线程。
所以,数据存放的规则是,只要是局部的,占用空间确定的数据,一般都存放在stack里面。否则就放在heap里面。局部变量一旦运行结束,就会 GC 回收,而heap的那个对象实例直到系统的GC将这里的内存回收,因此一般内存泄漏都发生在 heap 。
作用域也就是定义变量的区域,它确定了当前执行代码对变量的访问权限。
JS 只有函数作用域,没有块级作用域,块级作用域是 ES6 以后出现的,let,count 会产生块级作用域。
JS 采用的是词法作用域,也就是静态作用域
这里补充一个知识,静态作用域和动态作用域
静态作用域,指函数的作用域在函数定义的时候就决定了,它是基于函数创建的位置
动态作用域,指函数的作用域在函数调用的时候才决定的
js没有动态作用域
var value = 1; function foo() { console.log(value); } function bar() { var value = 2; foo(); } bar(); // 1如果采用静态作用域,结果是1,动态作用域,结果是2
动态作用域的语言,bash
变量对象(VO):变量对象是执行上下文对应的概念,定义执行上下文中的所有变量,函数以及当前执行上下文函数的参数列表。
变量对象的内部顺序是参数列表 -> 内部函数 -> 内部变量
变量对象的创建过程
① 检查当前执行环境的参数列表,建立 Arguments 对象。
② 检查当前执行环境上的 function 函数声明,每检查到一个函数声明,就在变量对象中以函数名建立一个属性,属性值则指向函数所在的内存地址。
③ 检查当前执行环境上的所有 var 变量声明,每检查到一个 var 声明,如果 VO(变量对象)中已存在 function 属性名,则跳过,不存在就在变量对象中以变量名建立一个属性,属性值 undefined
变量对象是在函数被调用,但是函数尚未执行的时刻被创建的,这个创建变量对象的过程实际就是函数内数据(函数参数,内部变量,内部函数)初始化的过程。
未进入执行阶段之前,变量对象中的属性都不能访问,但是进入执行阶段之后,变量对象转变为了活动对象,里面的属性都能被访问了,然后开始进行执行阶段的操作。所以活动对象实际就是变量对象在真正执行时的另一种形式。
作用域链可以理解为一组对象列表,包含父级和自身的变量对象,因此我们便能通过作用域链访问到父级里声明的变量或者函数。
由两部分组成
引入一个思考题
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();
//
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();
上述都会输出 local scope,因为 JS 采用的是词法作用域,函数的作用域基于函数创建的位置。JavaScript 函数的执行用到了作用域链,这个作用域链是在函数定义的时候创建的。嵌套的函数 f() 定义在这个作用域链里,其中的变量 scope 一定是局部变量,不管何时何地执行函数 f(),这种绑定在执行 f() 时依然有效。
JavaScript 引擎并非一行一行地分析和执行程序,而是一段一段地分析执行。当执行一段代码的时候,会进行一个“准备工作”,例如变量提升,或者函数提升,我们要理解的是:
在 JS 世界里,**可执行代码**分三类,全局代码,函数代码,eval代码
当执行到一个函数时,就会进行准备工作,这里的准备工作就叫执行上下文。
js 有个执行栈,它会将**可执行代码**压入栈中,后进先出
function fun1() {let t = 1;fun2()}
function fun2() {fun3()}
function fun3() {}
fun1()
// 伪代码
// fun1()
ECStack.push(<fun1> functionContext);
// fun1中竟然调用了fun2,还要创建fun2的执行上下文
ECStack.push(<fun2> functionContext);
// 擦,fun2还调用了fun3!
ECStack.push(<fun3> functionContext);
// fun3执行完毕
ECStack.pop();
// fun2执行完毕
ECStack.pop();
// fun1执行完毕
ECStack.pop();
// javascript接着执行下面的代码,但是ECStack底层永远有个globalContext
当前作用域没有定义的变量,叫"自由变量"
自由变量会根据作用域链去查找对应的定义
let a = 100
function fn() {
let b = 20
console.log(a) // 100 此时 a 是自由变量
console.log(b) // 20
}
fn()
闭包的本质是个函数,它是函数和该函数作用域的组合,所以可以理解为,在 js 中,所有函数都是闭包(函数都是对象并且函数都有和他们相关联的作用域链 scope chain)。
大多数函数被调用时(invoked),使用的作用域和他们被定义时(defined)使用的作用域是同一个作用域,这种情况下,闭包神马的,无关紧要。但是,当他们被 invoked 的时候,使用的作用域不同于他们定义时使用的作用域的时候,闭包就会变的非常有趣,并且开始有了很多使用场景,这就是你之所以要掌握闭包的原因了。
OK,我们知道原因后,要去探索下闭包了
① 嵌套函数词法作用域规则
② 闭包的使用场景
该方法是数组的方法, 为数组每个元素提供一次执行操作
array.forEach(callback, thisArg)
callback 接受三个参数
thisArg: 可选参数。当执行回调函数时用作 this 的值(参考对象)。
需要注意的是在使用 thisArg 时, callback 不能使用箭头函数形式, 因为箭头函数下, thisArg 参数会被忽略,因为箭头函数在词法上绑定了 this 值。
let arr = [1,2,3]
let this_arg = {
name: 'george'
}
arr.forEach(() => {
console.log(this) // undefined
}, this_arg)
arr.forEach(function() {
console.log(this) // {name: 'george'}
}, this_arg)
forEach 遍历范围在第一次调用 callback 前就会确定, 调用 forEach 后添加到数组的项不会被 callback 访问到. 但是已经存在的值被改变, 则传递给 callback 的值是 forEach 遍历到他们那一刻的值. 已经删除的项不会被遍历到, 如果已访问的元素在迭代时被删除了, 之后的元素将被跳过.
一句话口诀, forEach 定最大量不定值, 下标最大就终止, 下标不变其他变。
定最大量: 指定最大长度, forEach 不会因在遍历过程中动态增加了数组长度, 而增加遍历次数.
不定值: 指当前遍历的值是不确定的, 会随着遍历过程中的改变而改变.
下标最大就终止, 下标不变其他变: forEach 的在遍历过程中, 当前值可以变, 数组长度可以变, 唯一不变的就是当前下标, 每遍历一次就加1, 当前下标等于当前数组长度时, 停止遍历. 说明 forEach 的遍历次数是 <= 第一次遍历时最大长度.
没有办法终止或者跳出 forEach 循环, 除非抛出一个异常, 但是如果你的需求就是要中途终止, 那么使用 forEach() 方法是错误的.
解决方案:
这些数组方法可以对数组元素判断,以便确定是否需要继续遍历:every(),some(),find(),findIndex()
若条件允许,也可以使用 filter() 提前过滤出需要遍历的部分,再用 forEach() 处理。
forEach 会跳过空项, 例如 ['a', 'b', '', 'd'] forEach打印结果
| currentValue | index |
|---|---|
| 'a' | 0 |
| 'b' | 1 |
| 'd' | 2 |
特点
该方法创建一个新数组, 新数组的元素是, 每个元素都调用一个提供的函数后返回的结果
参数和 forEach 一样, callback 和 thisArg, 注意点也是一样的, callback 箭头函数会忽略 thisArg
array.map(callback, thisArg)
返回值: 一个新数组, 每个元素都是回调函数的结果
特性和 forEach 一样, 原数组都会被修改.
一句话口诀: map 定最大量不定值, 下标最大就终止, 下标不变其他变, 返回结果创数组
方法技巧
// 数组类型转换
['1', '2', '3'].map(Number); // [1, 2, 3]
map 和 forEach 大体一样, 有个需要注意的细节是, 当数组中元素是值类型,forEach绝对不会改变数组;当是引用类型,则可以改变数组
let arr1 = [{
name: 'George'
}, {
name: 'Jue'
}]
let arr2 = ['George', 'Jue']
arr1.forEach(v => {
v.name = 'Peter'
})
console.log(arr1) // [{name: 'Peter'}, {name: 'Peter'}]
arr2.forEach(v => {
v = 'Peter'
})
console.log(arr2) // ['George', 'Jue']
特点
filter() 方法创建一个新数组, 其包含通过所提供函数实现的测试的所有元素
参数值和 forEach 一样
区别在于只返回结果是 Boolean 类型且为 true 的值, 并组成一个数组
一句话口诀: filter 定最大量不定值, 下标最大就终止, 下标不变其他变, 返回结果创数组
特性
用原地算法对数组进行排序, 并返回数组
array.sort()
不传参情况下, 默认按字母升序(更准确点是根据字符串Unicode码点)
参数只有一个callback, 包含两个值, 分别是两个比较元素
返回值 大于0 升序, 小于0 降序, 等于0 不变
技巧
// 对一个纯数字的数组进行排序
let arr = [1,23,4,5,45,9,7]
arr.sort((a, b) => a - b)
console.log(arr) // [1, 4, 5, 7, 9, 23, 45]
// 以数组对象中某个值大小进行排序
var items = [
{ name: 'Edward', value: 21 },
{ name: 'Sharpe', value: 37 },
{ name: 'And', value: 45 },
{ name: 'The', value: -12 },
{ name: 'Magnetic' },
{ name: 'Zeros', value: 37 }
];
// sort by value
items.sort(function (a, b) {
return (a.value - b.value)
});
特点
some 检查数组中是否有符合条件的测试
array.some(callback, thisArg)
参数和 forEach 一样
返回值为 Boolean 类型
some 循环中, callback 值只要有一个为 truthy值, 就返回 true, 否则 false
let arr = [1,2,3]
console.log(arr.some(v => v > 2)) // true
every 和 some 一样的, 唯一的区别在于, every 是所有都符合条件测试才返回 true
如果说 some 是 ||, 那么every 就是 &&
let arr = [1,2,3]
console.log(arr.every(v => v > 2)) // false
for 循环是我们最常用的循环之一,基本每个语法都有它的身影,它的基本语法是
for(初始条件;循环条件;变化规则) {}
它的三个条件都是可以省略,但是如果循环条件省略的话,代码块中必须有 break 退出 for 循环语句,不然它就是一个死循环
for(;;){} // 死循环
// 这样就不会构成死循环
let x = 0;
for(;;) {
if(x > 10) {
break;
}
}
for ([initialExpression]; [condition]; [incrementExpression]) {
statement
}
for 语句的循环范围是动态变化的,也就是说,若在循环过程中,condition 部分的每循环一次都会取最新的值,举个例子
let arr = [1,2,3]
for(let i = 0; i < arr.length; i++) {
arr.push(i + 4)
}
问,会执行几次循环?
答案是,这段代码会出现死循环,因为每循环一次,arr 中就增加一个新元素,每次 condition 都会重新计算 arr 的长度,因此是死循环。
如果想要一开始就定长,可以用 forEach,forEach 的循环次数是在首次循环前就确定的,不会动态变化。
| command | describe | other |
|---|---|---|
| git init | git 初始化 | |
| git remote add origin 地址 | 设置远端地址 | |
| git push -u origin master | 提交新分支并与远端分支关联,这样每次push都不会出现关联提示 | |
| git reset --hard commit_id | 回退到指定commit_id中 | |
| git reset --hard | 撤销当前 add 提交并将文件内容回滚到 add 之前 | |
| git reset --hard~1 | 回滚到当前 hard 的前一个 hard commit | |
| git commit -m "xxx" | 提交commit | |
| git pull | 获取当前分支的远端分支版本与本地分支合并 | |
| git pull origin master | 获取远端指定分支(master)中的内容与本地分支合并 | git pull = git fetch + git merge |
| git fetch | 从远程获取最新版本到本地, 不会自动merge | |
| git reset HEAD . | 撤销本地所有add 提交 | |
| git stash | 存入缓存区 | |
| git stash pop | 从缓存区恢复 | |
| git stash list | 查看缓存区列表 | |
| git stash drop 缓存号 | 移除缓存区列表中某个缓存 | |
| git stash clear | 清除缓存区 | |
| git config -list | 查看当前全部配置 | |
| git config --global user.name "xxx" | 设置全局用户名 | |
| git config --global user.email "xxx" | 设置全局邮箱 | |
| git config user.name "xxx" | 设置仓库级的用户名 | |
| git config user.email "xxx" | 设置仓库级的邮箱 | |
| git checkout -b XXX origin/XXX | 从远端拉取新分支到本地 | |
| git show 历史记录中的hash码 | 从历史记录中查看修改 | |
| git clone 路径 | 从github上下载代码 | |
| git remote -v | 查看远程仓库 | |
| git branch -a | 查看所有分支 | |
| git merge 分支名 | 合并分支 | |
| git fetch --all | 下载远程仓库最新内容,不做合并 | |
| git reset --hard origin/master | 把HEAD指向master最新版本也就是强制覆盖 | |
| git log --oneline --graph --decorate --all | 用 git 代替 gitk 查看节点树 | |
| git reflog | 展示出所有你之前的 git 操作,你以前所有的操作都被git记录了下来 | |
| git cherry-pick commit_id | 拣选 —— 拣选会提取某次提交的补丁,之后尝试将其重新应用到当前分支上。这种方式在你只想引入特性分支中的某个提交时很有用 | |
| git commit --no-verify -m "xxx" | 当你在终端输入git commit -m"XXX",提交代码的时候,pre-commit(客户端)钩子,它会在Git键入提交信息前运行做代码风格检查,如果代码不符合相应规则,则报错。而这行命令可以绕过 pre-commit 检查钩子,实现代码提交。 | |
| history | 查看历史输入命令 | |
| git push origin --delete xxx | 删除远端 xxx 分支 | |
| git branch -D xxx | 强制删除本地分支 | |
useEffect(() => {
console.log(1)
return () => {
console.log('clear1')
}
}, [count])
useEffect(() => {
console.log(2)
return () => {
console.log('clear2')
}
}, [count])
若监听了相同的值,会按照代码的编写顺序依次执行
React 将按照 effect 声明的顺序依次调用组件中的每一个effect
clear1
clear2
1
2
注意,useEffect 中的 return 返回一个函数,该函数是一个清除操作,effect 在每次渲染的时候都会执行。React 会在执行当前 effect 之前对上一个 effect 进行清除。所以在上述输出列表中,会发现,count 改变后,先打印 clear1 和 clear2,再打印相应的 effect。
工作也好几年了,辗转于各大平台写博客,最后还是 Github 是我的最爱
要通过 issues 写技术博客,需要以下几个步骤
这步就不多说了,有 Github 账号的应该都会创建吧
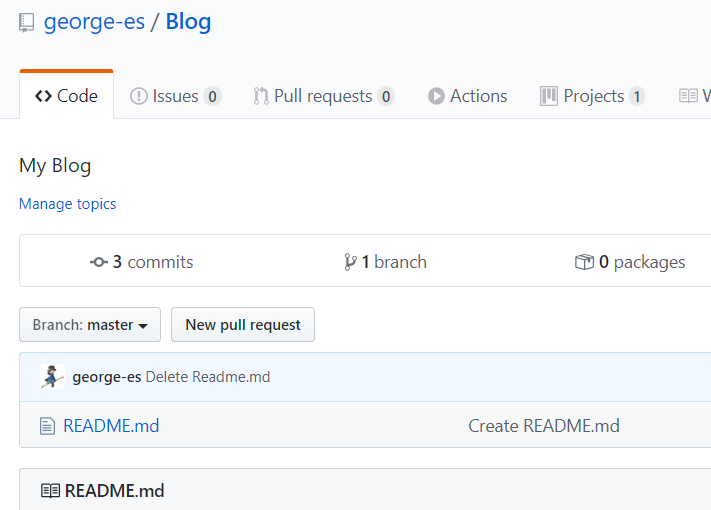
Projects 可以理解为一个一个组,写好的 issues 可以存放到相应的组中
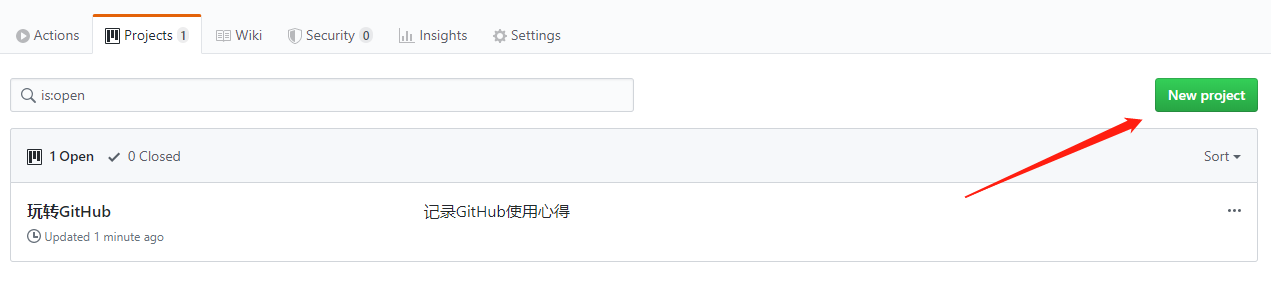
在项目的 issues 下有个 Labels 功能,通过它,你可以创建相应的 Labels,Labels 可以理解为 Blog 中的一个个标签,通过标签,可以搜索分类你的内容.
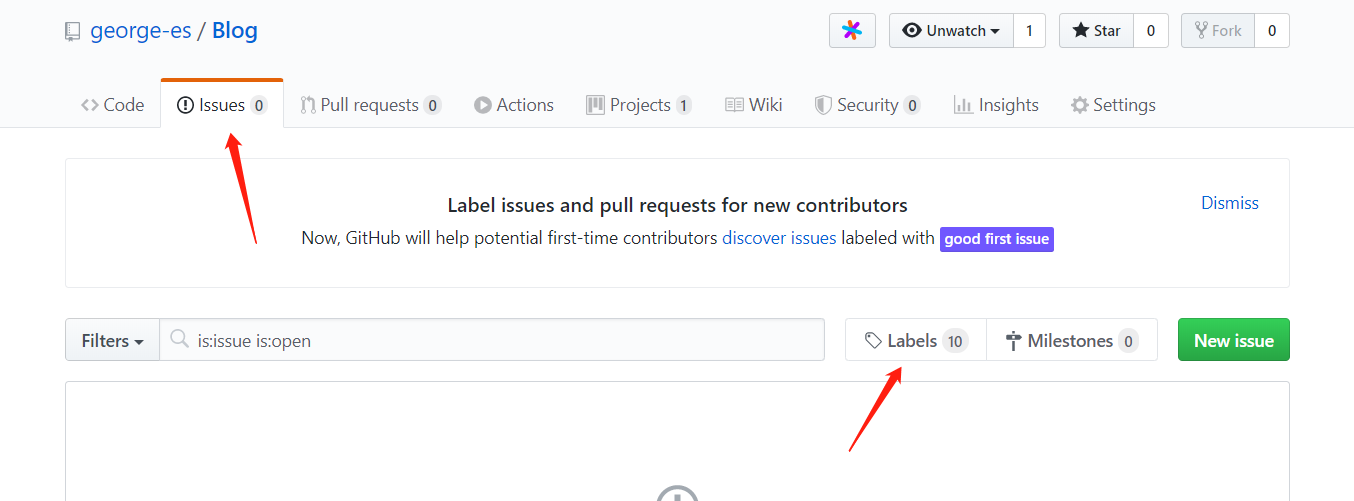

issues 就是我们博客的内容了,new issues 开启我们的博客编写页面

在 issues 里,可以做相应配置,选择一个project,提交后这个issue就会分类到这个project下面
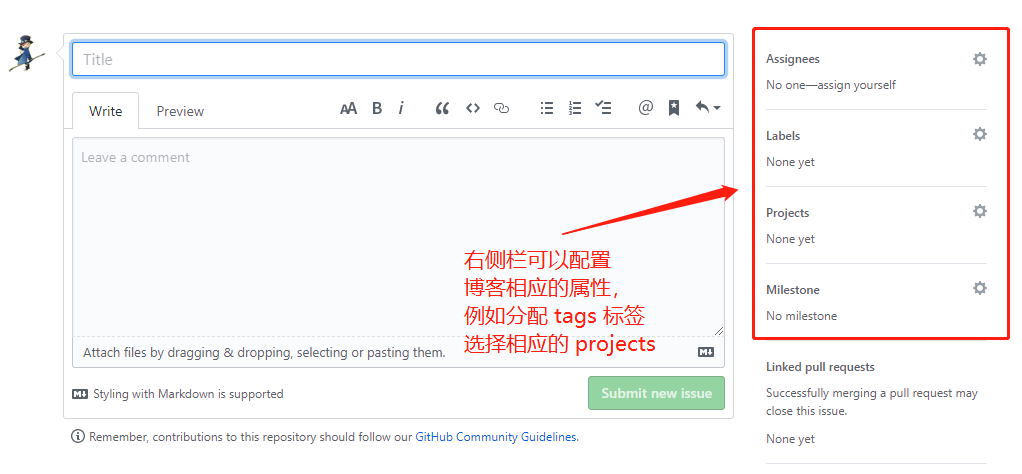
进入需要关联的 Projects 后,创建子分组,例如我这里创建一个 Blog
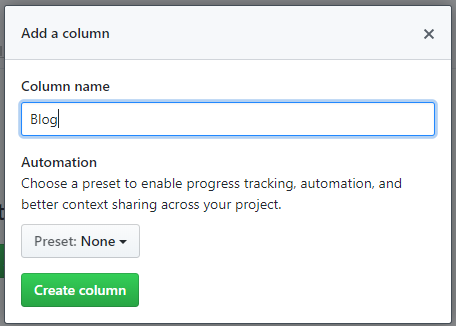
然后点击 add card 在里面可以找到刚刚编写的 issues
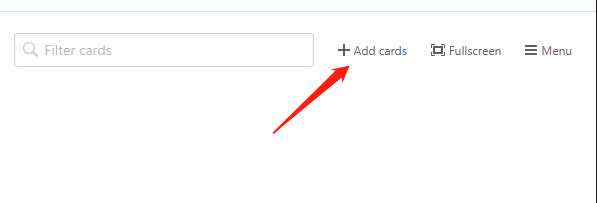
最后将 issues 拖入到子分组中

以上就完成了博客的开发功能了
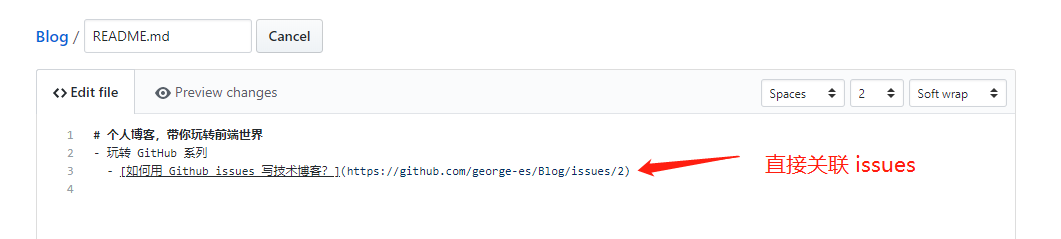
博客编写好了,在 README 上配置相应的入口,这样就完成了呢

这样我们就可以在主页上快速找到 Blog 了

说了半天,有的小伙伴觉得,这样也太复杂了吧,又点这又点那,还要配置关联 projects,那么有没有像其他平台一样,分类 + 文章呢? of course,安排!
最快速的方法就是在 issues 编写,然后在首页 README 中建立相应连接即可
设计**:在 useEffect 中,测试解构的方式和非解构方式是否可以触发监听
结论:是一样的,双方效果一致
const { name } = props
useEffect(() => {}, [name])
// 等价于
useEffect(() => {}, [props.name])
在工作中,看到 flow 函数,一开始不是很理解,文档的解释是
创建一个函数。 返回的结果是调用提供函数的结果,
this会绑定到创建函数。 每一个连续调用,传入的参数都是前一个函数返回的结果。
还不是很懂,然后就搜索了一下源码
function flow(...funcs) {
const length = funcs.length
let index = length
while (index--) {
if (typeof funcs[index] !== 'function') {
throw new TypeError('Expected a function')
}
}
return function(...args) {
let index = 0
let result = length ? funcs[index].apply(this, args) : args[0]
while (++index < length) {
result = funcs[index].call(this, result)
}
return result
}
}
它的写法很有意思,看返回值,它返回的是一个函数,函数中又有参数,而官方示例是
function square(n) {
return n * n;
}
var addSquare = _.flow([_.add, square]);
addSquare(1, 2); // 9
实际上 flow 返回一个函数,因此可以使用 addSquare(1, 2) 写法,需要注意的是 1,2 是传入 flow 返回函数的参数,而不是传给 flow 作为参数,flow 的参数是 [_.add, square]
在前端开发中,console.log 是最频繁使用的调试工具了,但除此之外,你还了解他其他的伙伴吗?
该命令可用于打印各种调试信息,它还支持格式化打印,常见的操作符有
const string = 'Glory of Kings';
const number = 100;
const float = 9.5;
const obj = {name: 'daji'};
%s 字符串占位符
console.log('I do like %s', string);
%d 整数占位符
console.log('I won %d times', number);
%f 浮点数占位符
console.log('My highest score is %f', float);
%o 对象占位符
console.log('My favorite hero is %o', obj);
%c CSS样式占位符
console.log('I do like %c%s', 'padding: 2px 4px;background: orange;color: white;border-radius: 2px;', string);
console.warn 和 console.log 效果一样,区别是隶属的级别不同,console.warn 隶属告警级别,在 try...catch 中建议使用,相比于普通信息,警告信息会出现在上图左侧的warning面板中,而不是info面板中,这样也有助于我们在一堆打印信息中快速筛选出警告信息,方便查看。
大体和 console.log 一样,区别较大的地方是当我们打印 HTML 文档的节点时,它可以打印出 DOM 节点下的所有属性信息,去看看效果吧。
console.log(document.body)
console.dir(document.body)
该方法可以用于格式化表格输出,传入对象数组即可。
const response = [
{
id: 1,
name: 'Marry',
age: 18,
sex: 0
},
{
id: 2,
name: 'John',
age: 20,
sex: 1
}
];
console.table(response)
它还有第二个参数,用于筛选表格需要显示的列,默认为全部列都显示。
console.table(response, ['id', 'name', 'age'])
assert 是断言的意思,该方法接收多个参数,其中第一个参数为输入的表达式,只有在该表达式的值为false时,才会将剩余的参数输出到控制台中。
const arr = [1, 2, 3, 4, 5];
console.assert(arr.length === 5, `this will not execute`);
console.assert(arr.length > 5, `arr.length is $(arr.length)`);
上图中的第二行因为arr.length > 5值为false,因此打印出后面的信息。如果在某些场景下你需要评估当前的数据是否满足某个条件,那么不妨使用console.assert()方法来在控制台中查看断言信息。
该方法用于在控制台中显示当前代码在堆栈中的调用路径,通过这个调用路径我们可以很容易地在发生错误时找到原始错误点
function foo(data) {
if (data === null) {
console.trace();
return [];
}
return [data.a, data.b];
}
function bar1(data) {
return foo(data);
}
function bar2(data) {
return foo(data);
}
bar1({a: 1, b: 2});
bar2(null);
可以看到自下而上的一条调用路径,并可以快速判定是在bar2函数中传入了不合适的参数null而导致出错,方便我们跟踪发生错误的原始位置。
该方法相当于一个计数器,用于记录调用次数,并将记录结果打印到控制台中。其接收一个可选参数console.count(label),label表示指定标签,该标签会在调用次数之前显示,示例如下:
for (let i = 1;i <= 5;i++) {
if (!(i % 2)) {
console.count('even');
} else {
console.count('odd');
}
}
这两个方法一般配合使用,是JavaScript中用于跟踪程序执行时间的专用函数,console.time方法是作为计算的起始时间,console.timeEnd是作为计算的结束时间,并将执行时长显示在控制台。如果一个页面有多个地方需要使用到计算器,则可以为方法传入一个可选参数label来指定标签,该标签会在执行时间之前显示。
console.time('sum');
let sum = 0;
for(let i = 0;i < 100000;i++) {
sum += i;
}
console.timeEnd('sum');
对数据信息进行分组,其中console.group()方法用于设置分组信息的起始位置,该位置之后的所有信息将写入分组,console.groupEnd()方法用于结束当前的分组。
class MyClass {
constructor() {
console.group('Constructor');
console.log('Constructor executed');
this.init();
console.groupEnd();
}
init() {
console.group('init');
console.log('init executed');
console.groupEnd();
}
}
const myClass = new MyClass();
该方法的作用主要是让我们在控制台打印的日志更加清晰可读。
在大部分情况下,我们在浏览器中调试DOM结构或者编辑一些文本时,会在Chrome Developer Tools的Elements选项中对DOM节点进行编辑,但是一旦节点过多,会很容易增加调试过程的困难,这里我们可以使用一种方式来将浏览器直接转换为编辑器模式
document.body.contentEditable = true;
打开路径C:\Windows\System32\drivers\etc下的hosts文件
# GitHub Start
192.30.253.112 github.com
192.30.253.119 gist.github.com
151.101.184.133 assets-cdn.github.com
151.101.184.133 raw.githubusercontent.com
151.101.184.133 gist.githubusercontent.com
151.101.184.133 cloud.githubusercontent.com
151.101.184.133 camo.githubusercontent.com
151.101.184.133 avatars0.githubusercontent.com
151.101.184.133 avatars1.githubusercontent.com
151.101.184.133 avatars2.githubusercontent.com
151.101.184.133 avatars3.githubusercontent.com
151.101.184.133 avatars4.githubusercontent.com
151.101.184.133 avatars5.githubusercontent.com
151.101.184.133 avatars6.githubusercontent.com
151.101.184.133 avatars7.githubusercontent.com
151.101.184.133 avatars8.githubusercontent.com
# GitHub End
在网上,关于防抖和节流的实现方式已经很多了,这里也就不在依依列举,只是说说这两种**方式,要注意,函数防抖和节流只是一种解决问题的设计**罢了。
在浏览器中,频繁的操作 DOM 是非常消耗内存和 CPU 时间,在我们项目开发过程中,或多或少会绑定一些持续触发的事件,如 resize,scroll,mousemove 以及移动端 touchmove 等。同一个事件在同一刻产生大量的事件函数,若处理不当,轻则导致浏览器卡顿,重则导致浏览器崩溃,无论出现哪种情况,都不是我们所期望的,此时,函数防抖 (debounce) 和节流 (throttle) 的**应运而生。
函数防抖和节流就是为了处理同一时刻事件的触发频率和事件函数的执行频率这两者关系的。
我们知道 DOM 事件的触发频率是不可控的,因此我们只能控制事件函数的执行频率,只要是没有达到条件要求的事件,都不触发事件函数,通过这一手段,可以极大的优化浏览器的性能。
函数防抖是指某事件被频繁的触发,在延迟一定的时间内,若该事件没有继续被触发,则执行事件函数,在整个过程中,事件函数只会被触发一次。
应用场景:在事件连续触发过程中,你期望事件函数只执行一次,例如:Ajax实时搜索(keydown)。
举个例子,我们在浏览页面内容的时候经常会使用到滚动条,若此时我们绑定了一个滚动条事件,但是,并没有加任何的防抖保护,这意味着用户只要触动了滚动条,就会产生成百上千条滚动事件,进而触发成百上千次事件函数,若每条事件函数的时间复杂度为O(n²),后果可想而知,直接把浏览器搞崩了,这样的产品,还没开始,已经结束了。
此时,若加上防抖,效果就大大的不同了,我们虽然无法阻止事件的触发频率,但是可以控制事件函数的执行频率,无论你触发了多少次事件,只要在保护时间内有触发,就不执行事件函数,反之,执行。
没有什么能比图片更形象的了👇
function debounce(func, wait) {
let timeout = null;
return function() {
let _this = this;
let args = arguments;
if (timeout) {
clearTimeout(timeout)
}
timeout = setTimeout(() => {
func.apply(_this, args)
), wait)
}
}
防抖的核心就是通过定时器来延迟事件函数的执行,在未达到定时器时间情况下,依旧产生了触发事件,就将上一个定时器删除。
函数节流是指某事件被频繁的触发,在事件触发期间,它会周期的执行事件函数。
举个例子,水滴的下落,我们将水喉拨到一个角度,水滴会周期性一滴一滴的滴落。
应用场景:在事件连续触发过程中,你期望周期性的间隔一定时间来调用回调函数,例如:计算鼠标移动的距离(mousemove)
function (func, wait) {
let time = null;
return function() {
let _this = this;
let args = arguments;
if (!timer) {
timer = setTimeout(function() {
func.apply(_this, args)
timer = null
}, delay)
}
}
}
对象序列化指将对象状态转换成字符串,也可将字符串还原为对象,ESMAScript 提供了内置函数 JSON.stringify() 和 JSON.parse() 用来序列化和反序列化(还原 JavaScript 对象)。
序列化 JSON.stringify() 对象转字符串
反序列化 JSON.parse() 字符串还原成对象
o = {x:1, y:{z:[false, null, ""]}}
s = JSON.stringify(o) // {"x":1,"y":{"z":[false,null,""]}}
p = JSON.parse(s) // {x:1, y:{z:[false, null, ""]}}
通过序列化和反序列化操作,可以实现一个对象的深拷贝,此时 p 就是深拷贝。
JSON 序列化解析规则
对象、数组、字符串,无穷大数字、true、false 和 null,他们可以序列化和还原。
NaN、Infinity 和 -Infinity 序列化的结果是 null。
let o = {x: NaN, y:[Infinity, -Infinity, ""]}
let s = JSON.stringify(o) // {"x":null,"y":[null,null,""]}
let p = JSON.parse(s) // { x: null, y: [ null, null, '' ] }
日期对象序列化会调用了 toJSON() 将其转换为了 string 字符串(同Date.toISOString()),因此会被当做字符串处理。反序列化时,依旧保留它们的字符串形态,不会将它们还原为原始日期对象。
let o = {x: new Date()}
let s = JSON.stringify(o) // {"x":"2020-05-26T03:07:19.385Z"}
let p = JSON.parse(s) // { x: '2020-05-26T03:07:19.385Z' }
函数、RegExp、Error对象和 undefined 值不能序列化和还原。
let o = {x: function() {}, y: new Error(), z: undefined, a:1}
let s = JSON.stringify(o) // {"y":{},"a":1}
let p = JSON.parse(s) // { y: {}, a: 1 }
JSON.stringify() 只能序列化对象可枚举的自有属性,对于一个不能序列化的属性来说,在序列化后的输出字符串中会将这个属性忽略掉。
JSON.stringify() 和 JSON.parse() 接收第二个可选参数,可以理解为过滤,如果该参数是一个函数,则在序列化过程中,被序列化的值的每个属性都会经过该函数的转换和处理;如果该参数是一个数组,则只有包含在这个数组中的属性名才会被序列化到最终的 JSON 字符串中;如果该参数为 null 或者未提供,则对象所有的属性都会被序列化;
作为函数
作为函数,它有两个参数,键(key)和值(value),它们都会被序列化。
开始时,函数会被传入一个空字符串作为 key 值,代表着要被 stringify 的这个对象。随后每个对象或数组上的属性会被依次传入。
函数应当返回JSON字符串中的value,规则如下
作为数组
let o = {x: 1,y: 0}
let s = JSON.stringify(o, ['x']) // {"x":1}
let p = JSON.parse(s) // { x: 1 }
异步是通过事件循环实现的 Event Loop
步骤
那么我们怎么知道什么时候主线程是空的呢?
js引擎存在monitoring process进程,会持续不断的检查主线程执行栈是否为空,一旦为空,就会去Event Queue那里检查是否有等待被调用的函数。
异步操作会将相关回调添加到任务队列中,不同的异步操作添加到任务队列的时间不一样,这些异步操作是由浏览器内核的 webcore 来执行的,webcore 包含上图中的3种 webAPI,分别是 DOM Binding、network、timer模块。
任务队列是在事件循环之上的,事件循环每次 tick 后会查看 ES6 的任务队列中是否有任务要执行,也就是 ES6 的任务队列比事件循环中的任务(事件)队列优先级更高。如 Promise 就使用了 ES6 的任务队列特性。
一个函数如果加上了 async,那么该函数就会返回一个 Promise,await实际上是一个让出线程的标志。await后面的表达式会先执行一遍,将await后面的代码加入到microtask中,然后就会跳出整个async函数来执行后面的代码
因为async await 本身就是promise+generator的语法糖。所以await后面的代码是microtask。
Event Loop 有两个队列,宏任务(macrotask)队列和 微任务(microtask)队列
宏任务(macrotask):也就是常说的任务队列,macrotask是由宿主环境分发的异步任务,事件轮询的时候总是一个一个任务队列去查看执行的,"任务队列"是一个先进先出的数据结构,排在前面的事件,优先被主线程读取。
script(整体代码)
setTimeout
setInterval
setImmediate
I/O
UI rendering
微任务(microtask):是由 js 引擎分发的任务,总是添加到当前任务队列末尾执行,如果在处理 microtask 期间,如果有新添加的 microtasks,也会被添加到队列的末尾并执行。
宏任务和微任务执行顺序,先执行一个宏任务,然后会执行所有的微任务,此时微任务执行完,若突然插入新的微任务,那么还是执行微任务。值到没检测出微任务,才会执行宏任务,如此就是 Event Loop 运行原理。
一句话表述,主任务事件,先微后宏,一次可以执行多个微,只能一个宏
在代码中会出现 async,我们知道当 await 后面的表达式是一个 Promise 时,它的返回值实际上是 Promise 的回调函数 resolve 的参数
来个经典面试题
async function async1(){
console.log('async1 start')
await async2() // 理解为 promise
console.log('async1 end')
}
async function async2(){
console.log('async2')
}
console.log('script start')
setTimeout(function(){
console.log('setTimeout')
},0)
async1();
new Promise(function(resolve){
console.log('promise1')
resolve();
}).then(function(){
console.log('promise2')
})
console.log('script end')
/*
代码从上到下执行,先执行主任务
打印 'script start'
然后遇到 setTimeout,由于是宏任务,扔到 Event Loop 的宏任务事件中
执行 async1(),打印主任务 'async1 start'
遇到 async 执行后面内容,async2(),打印 'async2'
后面事件,由于 await 语句结束后返回一个 promise,因此将 console.log('async1 end') 放到微任务中
接下来执行 new Promise 语句,打印 'promise1',遇到 then 后面的放到微任务中
然后执行 'script end' 结束主任务。
下面按照顺序执行微任务
'async1 end'
'promise2'
微任务全部执行完,开始执行宏任务
'setTimeout'
输出
'script start'
'async1 start'
'async2'
'promise1'
'script end'
'async1 end'
'promise2'
'setTimeout'
*/
根据以上分析,再来两个,就很容易理解了,总之一句话,主任务,后先微后宏
console.log('1');
async function async1() {
console.log('2');
await async2();
console.log('3');
}
async function async2() {
console.log('4');
}
process.nextTick(function() {
console.log('5');
})
setTimeout(function() {
console.log('6');
process.nextTick(function() {
console.log('7');
})
new Promise(function(resolve) {
console.log('8');
resolve();
}).then(function() {
console.log('9')
})
})
async1();
new Promise(function(resolve) {
console.log('10');
resolve();
}).then(function() {
console.log('11');
});
console.log('12');
// 1 2 4 10 12 5 3 11 6 8 7 9
关于隐藏元素,我们从两个维度去衡量,能隐藏是前提,隐藏后,是否占据空间,隐藏后(部分)能否触发点击事件?
overflow: hidden
受 width 和 height 影响,用来隐藏元素溢出来部分,隐藏后不占据空间,隐藏部分无法触发点击事件。
.hide {
overflow: hidden;
}
opacity: 0
该属性是用来设置元素的透明度的,虽然元素透明度为 0 了,可它依旧在那里,点击该元素是可以触发事件的。filter 同理,只不过它兼容性不好。
.hide {
opacity: 0;
}
.hide1 {
filter:opacity(0);
}
visibility: hidden
该属性设置后,元素存在,占据空间,点击该元素无法触发事件。
.hide {
visibility: hidden;
}
display: none
该属性是彻底移除元素,不占空间,也无法触发元素上的事件。
.hide {
display: none;
}
position
通过相对和绝对定位的方式隐藏元素的思路就是将他们移出可视范围,我们知道 absolute 是可以将元素脱离文档流的,因此值为 absolute 时候,不占据空间,由于元素也被移不见了,因此也无法点击,relative 却有所不同,它依旧占着位置,也是无法点击
.hide {
position:absolute;
left:-99999px;
top:-90999px;/* 不占据空间,无法点击 */
}
.hide1 {
position:relative;
left:-99999px;
top:-99999px;/* 占据空间,无法点击 */
}
z-index: -1000
通过绝对定位的方式,在层级维度上将其隐藏,不占空间,且无法点击。
.hide {
position: absolute;
z-index: -1000;
}
transform: scaleY(0)
通过修改元素大小(缩放)的方式隐藏元素,占据空间,无法点击。
.hide {
transform: scale(0, 0);
}
clip(clip-path): rect()/inset()/polygon()
通过剪裁方式去实现,占据空间,无法点击。
.hide {
clip-path: polygon(0px 0px,0px 0px,0px 0px,0px 0px);
}
小结一下,我们一共有 8 种方法去隐藏一个元素,唯一在隐藏后还能触发事件的只有一种(opacity),不占空间有四种(z-index、position:absolute、display,overflow),占据空间的有 5 种(clip、transform、position: relative、visibility、opacity)
这就要涉及到 React 的合成事件了
React并不是将click事件直接绑定在dom上面,而是采用事件冒泡的形式冒泡到document上面,然后React将事件封装给正式的函数处理运行和处理。
如果DOM上绑定了过多的事件处理函数,整个页面响应以及内存占用可能都会受到影响。React为了避免这类DOM事件滥用,同时屏蔽底层不同浏览器之间的事件系统差异,实现了一个中间层——SyntheticEvent。
原生事件的绑定会快于合成事件,注意不要将原生事件(addEventListener)和React合成事件一起混合使用,这两个机制是不一样的。
理解了合成事件,现在回到 event.persist(),该方法是用于清除合成事件的
如果你想异步访问(如在setTimeout内)事件属性,你需在事件上调用 event.persist(),此方法会从池中移除合成事件,允许用户代码保留对事件的引用。
因此解决方案
onClick={e => {
e.persist() // 加入这个方法
setTimeout(() => {
this.filterContent(e.target.value)
}, 200)
}}
replace + 正则可以便捷的去替换文本
将 aaabbbccc 变成
<span class="aaa">aaa</span>
<a class="bbb">bbb</a>
<div class="ccc">ccc</div>
const str = 'aaabbbccc'
const aaa_reg = /aaa/g
const bbb_reg = /bbb/g
const ccc_reg = /ccc/g
str
.replace(aaa_reg, '<span class="aaa">$&</span>')
.replace(bbb_reg, '<a class="bbb">$&</a>')
.replace(ccc_reg, '<div class="ccc">$&</div>')
$& 表示插入匹配的子串,replace 虽然链式调用,但要知道的是,它每次修改的都是基于最原始的 str
也可以理解为
str.replace(aaa_reg, '<span class="aaa">$&</span>')
str.replace(bbb_reg, '<a class="bbb">$&</a>')
str.replace(ccc_reg, '<div class="ccc">$&</div>')
而每次的 $& 或 $1 都是针对当前的 str
用 1 代表父,2 代表子
创建时:1 constructor -> 1 getDerivedStateFromProps -> 1 render -> 2 constructor -> 2 getDerivedStateFromProps -> 2 render -> 2 componentDidMount -> 1 componentDidMount
更新时:1 getDerivedStateFromProps -> 1 shouldComponentUpdate -> 1 render -> 2 getDerivedStateFromProps -> 2 shouldComponentUpdate -> 2 render -> 2 getSnapshotBeforeUpdate -> 1 getSnapshotBeforeUpdate -> 2 componentDidUpdate -> 1 componentDidUpdate
卸载时:1 getDerivedStateFromProps -> 1 shouldComponentUpdate -> 1 render -> 1 getSnapshotBeforeUpdate -> 2 componentWillUnmount -> 1 componentDidUpdate
**注意:在卸载组件时,father -> child -> grandson,生命周期中是先执行 child 的 componentWillUnmount 再执行 grandson 的 componentWillUnmount **
什么是单线程?
即可一次只做一件事情
console.log(1);
console.log(2);
console.log(3);
JS 为什么单线程
为了利用多核 CPU 的计算能力,HTML5 提出 Web Worker,它允许 JS 脚本创建多个线程,子线程完全受主线程控制,且不得操作 DOM。
const Demo = () => {
const [data, updata] = useState('hello')
console.log(1)
useEffect(() => {
console.log(2)
updata('hi')
// updata('hello') // 此时不会触发渲染,因为 data 值没变
}, [data])
}
// output
1
2
1
只要 useEffect 内部有触发 state 的变化都会触发渲染,划重点,data 必须要变化。
一个 useEffect 中若有多个 state 变化,也只会触发一次渲染,若有多个 useEffect ,那么每个 useEffect 内部 state 的变化都会触发新的一次渲染
console.log(1)
useEffect(() => {
console.log(2)
updateCurrent(SETP_TWO)
updateData([2])
}, [sqlData, repoData])
useEffect(() => {
console.log(3)
updateCurrent(SETP_ONE)
}, [data])
// output
1
2
3
1
3
1
在阅读 React 的 webpack.config.js 时,看到一种写法
entry: [
isEnvDevelopment && require.resolve('react-dev-utils/webpackHotDevClient'),
paths.appIndexJs,
].filter(Boolean)
前面好理解,就在 filter 发现用的太妙了,filter(Boolean) 的目的是移除所有的 ”false“ 类型元素 (false, null, undefined, 0, NaN or an empty string):
实际上,这是一种简写方式
b = a.filter(Boolean)
// 它等价于
b = a.filter(function(x) { return Boolean(x)})
有四种引入 CSS 的方式
内联样式:直接在 HTML 标签中添加 style 样式
优点:简洁高效,除了 !important 优先级最高
缺点:无法复用,难以维护
<div style="color: blue">george</div>
嵌入样式:在 head 中嵌入 style 代码
优点:清晰明了,在单页 html 中可实现复用
缺点:只在当前页面可以,无法实现多个页面共用
<head>
<style>
.block {
border: 1px solid red;
}
</style>
</head>
link:引入外部 CSS
优点:可实现多页复用,易维护,目前最常用,最推荐的 CSS 引入方式,CSS 代码只会在第一次加载时引入,以后切换页面时只需加载 HTML 文件即可。
<head>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
import:导入方式,即使用 CSS 语法规则,引入外部 CSS 文件
<style>
@import url(style.css);
</style>
或者在 css 样式中
@import url(style.css);
.george { color:#999;}
<link rel="canonical" href="https://blog.csdn.net/u013778905/article/details/52885924">,@import 属于 CSS 范畴,只能加载 CSS@import ‘style.css’ //Windows IE4/ NS4, Mac OS X IE5, Macintosh IE4/IE5/NS4不识别
@import “style.css” //Windows IE4/ NS4, Macintosh IE4/NS4不识别
@import url(style.css) //Windows NS4, Macintosh NS4不识别
@import url(‘style.css’) //Windows NS4, Mac OS X IE5, Macintosh IE4/IE5/NS4不识别
@import url(“style.css”) //Windows NS4, Macintosh NS4不识别
由上分析知道,@import url(style.css) 和@import url(“style.css”)是最优的选择,兼容的浏览器最多。从字节优化的角度来看@import url(style.css)最值得推荐。
注意:@import url(xxx.css); 有最大次数的限制,经测试IE6的最大次数是31次,第32个import及以后的都不能生效。虽然最多只能import 31次,但不会影响css里面的其他规则,如body{}的定义还能正常显示。
Firefox 没有发现有import的最大值。 另外,既然纵向import有最大次数限制,却可以通过横向import来继续扩展。
若你想并行加载使页面更快,可通过 link 代替 @import
事情是这样的,某天,和往常一样上班,突然接到密令,做个拖拽需求,也就是一个面板上有几个 block ,你可以随意拖动它位置,并且它的 x 轴可以无限延长,block 之间可以自由拖动和换位,x 轴滚动条要隐藏。
收到密令后,藐视一番,so easy,以前玩过,就是 mouse 事件嘛,这次唯一的区别也就是多了个 drag 事件。
理清思路后,唰唰唰就开始了
在 React 上开发,就记录下核心代码
useEffect(() => { // 一开始就绑定 mousedown,mousemove,mouseup 事件
const blockDom = containerRef.current;
if(blockDom) {
const blockStart = (e) => {
if (e.button === 0) { // 判断是不是鼠标左键
gapX = e.clientX;
startX = blockDom.scrollLeft;
blockDom.addEventListener("mousemove", blockMove);
blockDom.addEventListener("mouseup", blockStop);
}
};
const blockMove = (e) => {
blockDom.scrollLeft = startX - (e.clientX - gapX);
};
const blockStop = (e) => {
blockDom.removeEventListener("mousemove", blockMove);
blockDom.removeEventListener("mouseup", blockStop);
};
blockDom.addEventListener("mousedown", blockStart);
return () => blockDom.removeEventListener("mousedown", blockStart); // 组件销毁后别忘了删除事件监听
}
}, [])
<div ref={containerRef}>
<Block>block</Block>
</div>
这就完成了面板的拖拽,接着写 block 上的事件
// block.tsx
const Block = (props) => {
...
return (
<div
draggable={true} // 这个属性是设置是否能拖拽
onDragStart={handleDragStart}
onDragEnd={handleDragEnd}
onDragEnter={handleDragEnter}
onDragOver={(e) => e.preventDefault()}
onDrop={handleDrop}
>
{props.children}
</div>
)
}
撸完后,进入调试环节,一切都是按期望进行, mousedown,mousemove,mouseup 可以按期望去进行拖拽,drag 可以进行交换操作。但是却发现一个问题,mouseup 事件会丢失,这样就导致在松开鼠标时候依旧执行 mousemove。
细细捋了下,这是由于执行 mousemove 事件的时候,又执行了 drag 事件,这样就导致了mouseup 事件丢失。
事件触发过程是这样的,拖拽 block 后,mousedown -> mousemove -> dragStart ...
挣扎了很久,想尽办法看能不能先执行 dragStart,发现是不行的。转换思路,既然每次都要执行 mouse 事件,能不能从 mouse 事件下手呢?翻阅资料后,发现,mouse 事件还有 mouseover 事件
当使用定点设备(例如鼠标或触控板)将光标移动到元素或其子元素之一时,将在元素上触发 mouseover 事件。
有了这个,问题就好解决了,添加一个 mouseover 事件,在事件中执行 removeEventListener 函数删除 mousemove 和 mouseup
const blockOver = (e) => {
e.stopPropagation();
e.preventDefault();
blockDom.removeEventListener("mousemove", blockMove); // 清除事件
blockDom.removeEventListener("mouseover", blockOver);
blockDom.removeEventListener("mouseup", blockStop);
};
const blockStart = (e) => {
if (e.button === 0) {
gapX = e.clientX;
startX = blockDom.scrollLeft;
blockDom.addEventListener("mousemove", blockMove);
blockDom.addEventListener("mouseover", blockOver); // 添加 mouseover 事件监听函数
blockDom.addEventListener("mouseup", blockStop);
}
};
因为我们在 drag 事件时候是不需要执行 mouse 事件的,因此在这里清除掉
| 命令 | 描述 | 详细解释 |
|---|---|---|
| npm install moduleName | 安装模块到项目目录下 | 1. 安装模块到项目node_modules目录下。 2. 不会将模块依赖写入devDependencies或dependencies 节点。 3. 运行 npm install 初始化项目时不会下载模块。 |
| npm install -g moduleName | -g 的意思是将模块安装到全局,具体安装到磁盘哪个位置,要看 npm config prefix 的位置。 | 1. 安装模块到全局,不会在项目node_modules目录中保存模块包。 2. 不会将模块依赖写入devDependencies或dependencies 节点。 3. 运行 npm install 初始化项目时不会下载模块。 |
| npm install --save moduleName | -save 的意思是将模块安装到项目目录下,并在package文件的dependencies节点写入依赖。 缩写 -S |
1. 安装模块到项目node_modules目录下。 2. 会将模块依赖写入dependencies 节点。 3. 运行 npm install 初始化项目时,会将模块下载到项目目录下。 4. 运行npm install --production或者注明NODE_ENV变量值为production时,会自动下载模块到node_modules目录中。 |
| npm install --save-dev moduleName | -save-dev 的意思是将模块安装到项目目录下,并在package文件的devDependencies节点写入依赖。 缩写 -D |
1. 安装模块到项目node_modules目录下。 2. 会将模块依赖写入devDependencies 节点。 3. 运行 npm install 初始化项目时,会将模块下载到项目目录下。 4. 运行npm install --production或者注明NODE_ENV变量值为production时,不会自动下载模块到node_modules目录中。 |
| npm install --save-optional moduleName | --save-optional 表示将安装的包写入 package.json 里面的 optionalDependencies 缩写 -O |
|
结论:
devDependencies 节点下的模块是我们在开发时需要用的,比如项目中使用的 gulp ,压缩css、js的模块。这些模块在我们的项目部署后是不需要的,所以我们可以使用 -save-dev 的形式安装。像 express 这些模块是项目运行必备的,应该安装在 dependencies 节点下,所以我们应该使用 -save 的形式安装。
解析 package.json
scripts: 声明 npm 脚本指令, 在启动项目时, 通过 npm run 可调用相应的指令
dependencies: 项目在生产环境中的依赖包, 版本有 ^ 表示向上兼容, 例如 "3.3.5^"
devDependencies: 项目在开发和测试环境中的依赖包
engines: 声明项目需要的 node 和 npm 版本范围
browserslist: 浏览器版本
原文地址:13 Noteworthy Points from Google’s JavaScript Style Guide
原文作者:Daniel Simmons
对编码风格不熟悉的人而言,Google 推出一套用于编写 JavaScript 代码的样式指南, 并指出(谷歌认为)编写清晰易懂的代码最佳风格。
首先声明一点,以下规则并不是编写 Javascript 代码的硬性要求,仅是为了维持项目代码的一致性,Javascript 是一种灵活而宽松的语言,它允许各种风格。
Google 和 Airbnb 都推出了各自的编码风格指南,且是比较受欢迎的,如果你的项目中需要编写大量的JS代码,我绝对建议你阅读。
以下列出了在 Google JS 风格指南中我认为比较有趣且实用的 13 条规则
Google对编码中的每个细节点都进行了争议(标签, 空格,以及分号的使用)还有一些模糊的规范, 无疑, 这套风格肯定会改变我写JS的方式。
对每一条规则,我都会列出规范的摘要部分,然后是样式指南中的支持引用和详细描述规则,在恰当的情况下,我将举例说明,并与之和不遵循规则的代码进行对比。
推荐使用空格, 而不是tab键
除了行终止符以外,ASCII 中的水平空格字符 (0x20) 是唯一一个表示空格的空白字符,这意味着 Tab 键并不适用于缩进。
// bad
function foo() {
∙∙∙∙let name;
}
// bad
function bar() {
∙let name;
}
// good
function baz() {
∙∙let name;
}
推荐使用分号, 而不是将其省略
每条语句结束后必须带有分号,严禁依赖编译器自动插入分号。
虽然我无法想象为什么有人会反对这个想法,但是 JS 中一贯使用分号将成为新 "spaces versus tabs" 争论,Google 表示坚持分号的使用。
// bad
let luke = {}
let leia = {}
[luke, leia].forEach(jedi => jedi.father = 'vader')
// good
let luke = {};
let leia = {};
[luke, leia].forEach((jedi) => {
jedi.father = 'vader';
});
不要使用 ES6 模块
不要使用 ES6 模块(即 export 和 import 关键词),因为它们的语义尚未最终确定,注意,一旦语义完全标准化,将重新审视这条规则。
// 现在先不要这样用:
//------ lib.js ------
export function square(x) {
return x * x;
}
export function diag(x, y) {
return sqrt(square(x) + square(y));
}
//------ main.js ------
import { square, diag } from 'lib';
不推荐水平对齐(但不禁止)
首先水平对齐这种做法是允许的,但是在 Google 风格中并不推荐这种用法。甚至不需要在已使用过的地方保持水平对齐。
水平对齐即在代码中添加空格,使每一列对齐。
// bad
{
tiny: 42,
longer: 435,
};
// good
{
tiny: 42,
longer: 435,
};
不要再使用var
使用 const 或 let 声明所有局部变量,除非需要重新分配变量,否则默认使用 const,不推荐使用 var 关键词。
我仍然看见人们在 StackOverflow 和其他地方使用 var 代码示例。可能有人会为此反对,或者说这是一种旧习惯,要改变,比较困难。
// bad
var example = 42;
// good
let example = 42;
首选箭头函数
箭头函数提供一个简洁的句法,并解决了许多困难,首选箭头函数而不是函数关键词,尤其是嵌套函数
说句真心话,我认为箭头函数非常棒,因为他们更加简洁,更好看,事实证明,他们也有很重要的作用。
// bad
[1, 2, 3].map(function (x) {
const y = x + 1;
return x * y;
});
// good
[1, 2, 3].map((x) => {
const y = x + 1;
return x * y;
});
使用模板字符串代替连接符
在复杂字符串上使用模板字符串 (``) 而是不是连接符 (+) ,特别是涉及多个字符串文字的情况下,模板字符串可以跨行
// bad
function sayHi(name) {
return 'How are you, ' + name + '?';
}
// bad
function sayHi(name) {
return ['How are you, ', name, '?'].join();
}
// bad
function sayHi(name) {
return `How are you, ${ name }?`;
}
// good
function sayHi(name) {
return `How are you, ${name}?`;
}
对长字符串不要使用行连续符
不要在普通字符串或模板字符串中使用行连续(即, 通过反斜杠结束字符串文字内的一行)尽管 ES5 允许这样做,如果有空格尾随在后面,它将会导致棘手的错误,并且对读者来说不那么明显。
有趣的是,Google 和 Airbnb 都不赞同这种做法这又Airbnb规范
谷歌的建议是通过连接符来拆分长字符串(如下所示),而 Airbnb 则建议写成一行,允许出现长字符串(如果需要的话)
// bad (sorry, this doesn't show up well on mobile)
const longString = 'This is a very long string that \
far exceeds the 80 column limit. It unfortunately \
contains long stretches of spaces due to how the \
continued lines are indented.';
// good
const longString = 'This is a very long string that ' +
'far exceeds the 80 column limit. It does not contain ' +
'long stretches of spaces since the concatenated ' +
'strings are cleaner.';
for...of是for循环首选
ES6 提供了三种不同的 for 循环。三个可用情况下,如果可以, 推荐优先使用 for-of 循环
包括我在内, 也觉得这条规则有点奇怪,但是谷歌认为它作为 for 循环的首选将会非常优雅
我认为,for...in 循环更适合对象,而 for...of 更适合数组
虽然 Google 的规范并不一定能和我们想法相吻合, 但是它依旧觉得这种做法相当优雅
不要使用eval()
不要使用 eval 或 Function(...String) 构造函数(代码加载器除外),这些功能具有潜在风险,并且在 CSP 环境中无法正常工作。
对于 eval() 而言,在 MDN 页面甚至专门有一页去呼吁不要使用 eval()
// bad
let obj = { a: 20, b: 30 };
let propName = getPropName(); // returns "a" or "b"
eval( 'var result = obj.' + propName );
// good
let obj = { a: 20, b: 30 };
let propName = getPropName(); // returns "a" or "b"
let result = obj[ propName ]; // obj[ "a" ] is the same as obj.a
常量应该用大写字母和下划线表示
常量名称使用 CONSTANT_CASE: 全部为大写字母,单词用下划线分割。
如果你能确保一个变量不会再改变,你可以通过大写常量的名称来表明这一点,这使得常量的不变性在整个代码的使用中显而易见。
这个规则有个值得注意的例外是,如果常量是属于函数范围的,在这种情况下,应该将其用驼峰命名法来表示。
// bad
const number = 5;
// good
const NUMBER = 5;
每次只声明一个变量
每个局部声明只声明一个变量,例如 let a = 1, b = 2 是不被允许的。
// bad
let a = 1, b = 2, c = 3;
// good
let a = 1;
let b = 2;
let c = 3;
使用单引号而不是双引号
普通的字符文本使用单引号(')来分割,而不是双引号(")
Tip: 如果一个字符串文本中包含单引号字符,请考虑使用模板字符串,而避免使用转义符号。
// bad
let directive = "No identification of self or mission."
// bad
let saying = 'Say it ain\u0027t so.';
// good
let directive = 'No identification of self or mission.';
// good
let saying = `Say it ain't so`;
最后一点
正如我一开始说的那样,以上这些规则并不是强制性的,Google 只是众多科技巨头中的一员,这些只是建议。
也就是说,看看像谷歌这样的公司提出的风格建议很有意思,它聘请了许多精彩的人,他们花了很多时间去编写优秀的代码。
如果你想遵循 “ Google 标准源码 ” 指南,你可以遵循这些规则,当然,很多人不同意,你可以部分遵循,甚至不遵循也可以。
我个人认为,很多情况下 Airbnb 比 Google 的规范更具吸引力,无论在何种情况下,一定要牢记,整个项目的编码风格要保持统一。
js 对象有三个属性,原型属性,类属性和可扩展性
原型(prototype): 一个简单的对象,用于实现对象的属性继承。可以简单的理解成对象的爹。在 Firefox 和 Chrome 中,每个JavaScript对象中都包含一个__proto__ (非标准)的属性指向它爹(该对象的原型),可用 obj.__ proto __ 进行访问。
函数的原型是 Function.prototype
function A() {}
A.__proto__ === Funtion.property
Object.__proto__ === Function.property
5 条原型规则
函数即可定义方法也可以用来创建对象,当一个函数用于创建对象时,我们就说这个函数是构造函数。
与 new 关键词在一起,并生成对象的函数,称为构造函数。
构造函数中的 this 永远指向函数自身
function Func() {}
let func = new Func() // 这个时候,Func 就是构造函数
let a = {} 其实是 let a = new Object() 的语法糖
let a = [] 其实是 let a = new Array() 的语法糖
function Foo() {...} 其实是 let Foo = new Function(...)
一般情况下,我们可以通过 instanceof 来确定变量与构造函数之间的关系,缺点是 instanceof 会沿着原型链查找,这样结果会出现偏差。
构造函数中的返回值问题
如果不用 new 操作符而直接调用函数,那么构造函数的执行对象就是 window,即 this 指向了 window。现在用new 操作符后,this 就指向了新生成的对象。
通过构造函数和new创建出来的对象,便是实例。 实例通过**__ proto __**指向原型,通过constructor指向构造函数。
实例.__ proto __ === 原型
原型.constructor === 构造函数
构造函数.prototype === 原型
实例.constructor === 构造函数

// new 运算符实现机制
var new = function(func) {
var o = Object.create(func.prototype)
var k = func.call(o)
if (typeof k === 'object') {
return k;
} else {
return o
}
}
new 后面必须跟构造函数,否则会报错,在不需要参数情况下,构造函数的括号可以省略
也就是说 new 后面必须跟 typeof(x) === 'function' 的变量
new 带参数优先级 > 无参优先级
原型链的顶端是 null
原型链是由原型对象组成,每个对象都有 __ proto __ 属性,指向了创建该对象的构造函数原型,__ proto __ 将对象连接起来组成了原型链。是一个用来实现继承和共享属性的有限的对象链。
即 a.__ proto __ -> A.原型, A.原型.__ proto __ -> B.原型 层层相扣,组成原型链

属性查找机制: 当查找对象的属性时,如果实例对象自身不存在该属性,则沿着原型链往上一级查找,找到时则输出,不存在时,则继续沿着原型链往上一级查找,直至最顶级的原型对象Object.prototype,如还是没找到,则输出 undefined;
属性修改机制: 只会修改实例对象本身的属性,如果不存在,则进行添加该属性,如果需要修改原型的属性时,则可以用: b.prototype.x = 2;但是这样会造成所有继承于该对象的实例的属性发生改变。
对象的类属性是一个字符串,用以表示对象的类型信息。ECMA Script 都未提供设置这个属性的方法,只能通过间接方法 —— toString() 去查询,toString() 继承自 Object.prototype,返回如下这种格式的字符串
[object class]
因此要获得对象的类型,可调用 toString() 方法去实现,如果直接调用可能存在被篡改的风险,因此一般我们间接调用 Function.call() 方法
Object.prototype.toString.call()
需要注意一点是,这个方法查询无法查询自定义类,因为,通过对象直接量,Object.create,自定义构造函数创建的对象,它们查出来结果都是 Object,
对象的可扩展性用以表示是否可以给对象添加新属性。
涉及到下面几个函数
Object.preventExtensions():不可扩展一个对象,该对象不可添加新属性。但是可删除和修改。该方法仅阻止添加自身的属性。但其对象类型的原型依然可以添加新的属性。
Object.seal():密封一个对象,该对象不可添加和删除,但是可修改。
Object.freeze():冻结一个对象,该对象不可添加,删除和修改。
Object.isExtensible():判断对象是否可扩展(是否可以在它上面添加新的属性)。
Object.isSealed():判断对象是否被密封。
Object.isFrozen():判断对象是否被冻结。
其中冻结是最严格的,禁止一切*操作。
" | " 位运算符
位运算符:两个位只要有一个为1,那么结果都为1,否则就为0。
通过它可以进行取整操作
8.2 | 0 = 8 // 8 的二进制为 1000,0 的二进制为 0,1000 | 0 = 1000 为 8
2.4 | 0 = 2 // 2 的二进制为 10,0 的二进制为 0,10 | 0 = 10 为 2
工欲善其事,必先利其器
TS 是 JS 超集,在工作中,我们也逐渐从 JS 转变到了 TS 中,今天主要梳理以下几个知识点
在 TS 世界里,数据类型分以下几类,除了我们在 js 中见过面的 boolean,number,string,null,undefined,object,还有数组,元组(Tuple),枚举,any,void,never,注意,在 TS 中的数据类型都是小写的,这点和 JS 略有不同
可以将 TS 理解为强类型语言,数据类型是要明确表示出来的,下面介绍下各类型的表示方法吧
let isBoolean: boolean = true;
let n: number = 6
let f: number = Oxf00d
let s: string = "a"
let t: string = 'b'
let r: string = `a${t}c`
[],表示由此类型元素组成的一个数组:
let lists: number[] = [1,2,3]
Array<元素类型>
let lists: Array[number] = [1,2,3]
const x: [string, number] = ['str', 1] // true
const x: [string, number] = [1, 'str'] // error
enum XXX {}
enum Day {a, b, c}
console.log(Day.a, Day.b, Day.c) // 0, 1, 2
enum Day { a = 5, b, c }
console.log(Day.a, Day.b, Day.c) // 5, 6, 7
enum Day { a = 5, b, c }
console.log(Day[5]) // a
null 和 undefined 是所有类型的子类型。因此只能给它赋予 undefined 和 null。可以理解为 void 为 null 和 undefined 的集合。
function test(): void { // 由于函数默认返回 undefined,所以此处可以使用 void
console.log('void')
}
undefined 和 null 两者各自有自己的类型分别叫做 undefined 和 null,默认情况下 null 和 undefined 是所有类型的子类型,在开发过程中,我们经常查看某个变量时候,会发现 num :number | undefined,如果你指定了 --strictNullChecks 标记,null 和 undefined 只能赋值给 void 和它们各自。never 类型,当它们被永不为真的类型保护所约束时。never 类型是任何类型的子类型,也可以赋值给任何类型;然而,没有类型是 never 的子类型或可以赋值给 never 类型(除了 never 本身之外)。 即使 any 也不可以赋值给 never // 返回 never的函数必须存在无法到达的终点
function error(message: string): never {
throw new Error(message);
}
function infiniteLoop(): never {
while (true) { // while 一直循环,所以无法到达终点
}
}
number,string,boolean,symbol,null 或 undefined 之外的类型。可以理解为复杂数据类型的集合,当你不知道对象中会存在什么数据时候,可以用 object 暂时表示
let obj: object = { props: 0 }
Object 类型的变量只是允许你给它赋任意值 - 但是却不能够在它上面调用任意的方法,即便它真的有这些方法
let notSure: any = 4
notSure.ifItExists(); // okey
notSure.toFixed();
let prettySure: Object = 4;
prettySure.toFixed(); // error
与数据类型最紧密相关,也是贯穿整个 TS 的就是接口了,因为 TypeScript 的核心原则之一是对值所具有的结构进行类型检查,在 TS 中,接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约。
所谓的接口,就是一个数据结构,有时候你传入的数据可能有很多属性,但是编译器只会检测那些必要的属性是否存在。
类型检查器不会去检查属性的顺序,只要相应的属性存在并且类型也是对的就可以。
interface ILabel {
name: string
age: number
}
let test = {name: 'george', age: 18, address: 'china'}
const printLabel = (p: ILabel) => {
console.log(p)
}
printLabel(test)
// 注意,如果在赋值过程中,属性不对应会报错的,但是函数传值就不会
let test1: ILabel = {name: 'george', age: 18, address: 'china'} // error
某些情况下,有的属性并不一定存在,譬如在 A 接口和 B 接口中的属性 99% 都是相同的,只是 B 接口多了一个属性,这时候,我们就要用到可选属性。
可选属性用 ? 表示
interface IPerson {
name: string
age?: number
}
let person: IPerson = {name: 'george'}
可选属性的好处有两点
虽然我们可以通过 const 来定义常量,但有时候也需要告诉编译器,某个数据结构的某个属性是只读的,此时,就要用到只读属性。
只读属性用 readonly 表示
interface IPerson {
readonly name: string;
readonly age: number;
}
let person: IPerson = { name: "george", age: 18 }
person.name = "Go" // error
TS 具有 ReadonlyArray 类型,它与 Array 相似,只是把所有可变方法去掉了,因此可以确保数组创建后再也不能被修改
最简单判断该用 readonly 还是 const 的方法是看要把它做为变量使用还是做为一个属性。 做为变量使用的话用 const,若做为属性则使用 readonly。
Q&A
DOM 是那种基本数据结构?
DOM 的本质是什么?
获取 DOM 树节点的方法?
获取节点的方法有四种,分别是通过 ID,name 属性,标签名和类名
querySelector 和 querySelectorAll 是静态选取,也就是说第一次获取到某个节点数是3,就算后面不获取直接调用该变量,获取的节点数仍然是3,而getElement这种的获取方法是动态查找,一开始获取的节点数是3,追加节点后,不获取直接调用先前变量,节点数会改变。
DOM 中 Property 和 Attribute 区别
我们可以在 DOM 上创建自定义属性,每一个 DOM 对象都会有它默认的基本属性,而在创建的时候,它只会创建这些基本属性,我们在 TAG 标签中自定义的属性是不会直接放到 DOM 中的,因此我们通过获取 DOM 树节点的方法是无法直接获取到自定义属性的,而 DOM 上的所有属性(包括自定义属性)会被保存到 DOM 的 attribute 属性上
节点操作
会报错的,被解构的,一定是复杂数据类型,解构值可以为 undefined,但被解构一定不行
const obj = undefined
const { a, b } = obj // obj 为 undefined 报错
//
const obj = {}
const { a, b } = obj // obj 为 {},未找到 a, b,因此 a, b 值为 undefined
只有三种转换为数字,字符串,布尔类型
将一个值转换为数值的方式有三种:Number()、parseFloat()、parseInt()
Number() 适用于任何数据类型
① 如果是 Boolean 类型,true 和 false 将分别转换为 1 和 0
② 如果是数字值,只是简单的传入和返回
③ 如果是 null,返回 0
④ 如果是 undefined, 返回 NaN
⑤ 如果是字符串,遵循以下规则
⑥ 如果是对象,则调用对象的 valueOf 方法,然后依照前面的规则转换返回的值。如果转换的结果是 NaN,则调用对象的 toString() 方法,然后再次依照前面的规则转换返回的字符串值。
⑦ 如果是数组,会返回数组长度
⑧ 如果是 Symbol 则报错
由于 Number() 函数在转换字符串时比较复杂而且不够合理,因此推荐 parseInt() 和 parseFloat() 来处理字符串类型
parseInt()
parseInt() 函数在转换字符串时,更多的时看其是否符合数值模式。该函数会忽略字符串前面的空格,直到找到第一个非空格字符串。如果第一个字符不是数字字符或者负号,则会返回NaN,也就是说如果是空字符串会返回 NaN,如果第一个字符是数字会继续解析第二个字符,直到解析完所有后续的字符或者遇到了一个非数字字符才结束。
parseInt() 还有第二个参数,转换时使用的基数(即多少进制),默认是 10 进制。
parseInt() 是向下取整的
parseFloat()
parseFloat() 和 parseInt() 类似,唯一的区别就是保留浮点数。而 parseInt() 会将浮点数省略。
将一个值转换为字符串的方式有两种:toString()、String()
toString()
除了 null 和 undefined,几乎每个值都有该方法,该方法唯一要做的就是返回相应的字符串表现。通常情况下,toString() 方法不必传递参数,但是它可以接收一个参数,输出数值的基数,默认情况下,toString() 方法以十进制格式返回数值的字符串表示。
String()
该方法能够处理任何类型的值,包括 null 和 undefined。但要注意的是在处理对象时会默认调用 toString() 方法
let obj = {a:1}
console.log(String(obj)) // [object Object]
let obj1 = {b:2,toString: function() {return 3}}
console.log(String(obj1)) // 3
显示转换布尔类型的函数只有一种 Boolean()
| 类型 | true | false |
|---|---|---|
| Boolean | true | false |
| String | 任何非空字符串 | ""(空字符串) |
| Number | 任何非零数字值(包括无穷大) | 0 和 NaN |
| Object | 任何对象 | null |
| Undefined | n/a | undefined |
| Function | true | n/a |
n/a :表示不存在这种情况
① 值类型之间的数据类型转换
数字和字符串使用 + 运算符:会将数字先转换为字符串,然后进行字符串连接操作
布尔参与的 + 运算符:首先会将布尔值转换为对应的数字或者字符串,然后再进行相应的字符串连接或者算数运算。
Null 和 Undefined 参与的 + 运算符操作:
减法操作: 如果一个操作数为string,boolean,null,undefined,则在后台调用 Number(),将其转换成数值,再进行操作。
== 等性运算:undefined 和 null 比较特殊,它们两个使用 == 运算符返回值是 true,其他值类型(Number,Null,Undefined)进行比较的时候都会将运算数转换为数字,NaN 和 NaN 是不相等的(这是由于浮点数的精度决定的)
虽然,JavaScript 提供了 isNaN 来检测某个值是否为 NaN,但是,这也不太精确的,因为,在调用 isNaN 函数之前,本身就存在了一个隐式转换的过程,它会把那些原本不是 NaN 的值转换成 NaN 的,如下:
isNaN("foo"); // true
isNaN(undefined); // true
isNaN({}); // true
isNaN({ valueOf: "foo" }); // true
幸运的是,有一种可靠的并且准确的方法可以检测NaN。我们都知道,只有NaN是自己不等自己的,那么,我们就以使用不等于号 (!==) 来判断一个数是否等于自身,从而,可以检测到 NaN 了
我们也可以把这种模式定义成一个函数,如下:
function isReallyNaN(x) { return x !== x; } // 只适用于判断基本类型,因为对象也不等于对象 即 {} !== {}
② 引用类型转值类型
对象是可以转换成原始值的,最简单方法就是把它转换成字符串
对象转换成字符串是调用了它的 toString 函数,即 obj.toString()
类似,对象也可以转换成数字的,它是通过 valueOf 函数实现的,当然你也可以自定义 toString 和 valueOf 函数
如果,一个对象同时存在 valueOf 方法和 toString 方法,那么 valueOf 方法总是会被优先调用
注意:具有valueOf的对象,应该定义一个相应的toString方法,用来返回相等的数字的字符串形式。
③ 真值运算
比如 if,||,&&,如果它们的操作数不是布尔类型,JS 会通过简单的转换规则,将一些非布尔类型的值转换成布尔类型的,大多数的值都会转换成 true,只有少数的是 false,它们分别是 false,0,-0,"",NaN,null,undefined,因为存在数字和字符串以及对象的值为 false,所以,直接用真值转换来判断一个函数的参数是否传进来了,这是不太安全的。
检测 undefined 的更加准确的方法是用 typeof 操作
注意:检测一些未定义的变量时,应该使用typeOf或者undefined作比较,而不应该直接用真值运算。
=== 可以理解绝对比较,不会类型相同,值相同才相等,不多说
下面讲解下 == 比较规则
== 比较规则:相同类型比较数据,不同类型才会发生类型转换
对于 == 来说,如果双方的类型不一样就会发生类型转换。
比较规则如下:
现在有两个值 x,y
先比较 x 和 y 的类型是否相同,类型相同情况下
反之,类型不同
如果 x 等于 null 并且 y 等于 undefined 返回 true
如果 x 等于 undefined 并且 y 等于 null 返回 ture
如果 x 的类型为 Number,y 的类型为 String,则会将 y 转换为 Number 类型后再比较
如果 x 的类型为 String,y 的类型为 Number,则会将 x 转换为 Number 类型后再比较
如果 x 的类型为 Boolean,则将 x 的类型转换为 Number 类型后再比较
如果 y 的类型为 Boolean,则将 y 的类型转换为 Number 类型后再比较
如果 x 的类型为 String 或者 Number,y 的类型为 Object,则将 y 转换成原始类型后再与 x 比较
如果 y 的类型为 String 或者 Number,x 的类型为 Object,则将 x 转换成原始类型后再与 y 比较
否则返回 false
上面提到了,类型是对象的基本类型比较时的情况,这里特别说明下,对象到数字的转换过程
首先,你要转换的对象必须有 valueOf 或 toString 方法,如果没有,则无法转换,直接返回 false,若对象具有valueOf()方法,它会调用该方法,得到一个返回值是原始类型的结果(注意,调用方法返回的结果应该是原始类型值才行,若不是,则会调用下一个方法(toString)),再将该值与另一个比较值比较,否则,会去找toString()方法,比较原理和 valueOf 一样。
一句话总结,三元运算符先“分清是非”,再决定今后该走哪条路,“==”运算符比较“喜欢”Number类型。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.


