Tartalom:
- Példakód
- A nyelv definíciója
- Lexikális elemző ~ 1. beadandó
- Szintaktikus elemző ~ 2. beadandó
- Szemantikus ellenörző ~ 3. beadandó
- Kódgenerálás ~ 4. beadandó
- Nyelv kiegészítése (vizsgafeladatok)
- Irodalom, jegyzetek, példák, előadás anyag, könyvek
- Szoftverkörnyezet
Példaprogram:
# A legkisebb valodi oszto meghatarozasa.
PROGRAM oszto
VALTOZOK:
EGESZ a
EGESZ i
EGESZ oszto
LOGIKAI vanoszto
UTASITASOK:
BE: a
vanoszto := HAMIS
i := 2
CIKLUS AMIG NEM vanoszto ES i < a
HA a % i = 0 AKKOR
vanoszto := IGAZ
oszto := i
HA_VEGE
i := i+1
CIKLUS_VEGE
HA vanoszto AKKOR
KI: vanoszto
KI: oszto
KULONBEN
KI: vanoszto
HA_VEGE
PROGRAM_VEGE
Még több példa a tesztfájlokban
eredeti leírás és bővebben: https://deva.web.elte.hu/pubwiki/doku.php?id=fordprog:plang2019
a PLanG nyelvről bővebben: http://digitus.itk.ppke.hu/~flugi/bevprog_1415/plang.html
A forrásfájlok a következő ASCII karaktereket tartalmazhatják:
- az angol abc kis és nagybetűi
- számjegyek (0-9)
():+-*/%<>=_#- szóköz, tab, sorvége
- megjegyzések belsejében pedig tetszőleges karakterek állhatnak Minden más karakter esetén hibajelzést kell adnia a fordítónak. A nyelv case-sensitive, azaz számít a kis és nagybetűk közötti különbség.
A nyelv kulcsszavai a következők: PROGRAM, PROGRAM_VEGE, VALTOZOK:, UTASITASOK:, EGESZ, LOGIKAI, IGAZ, HAMIS, ES, VAGY, NEM, SKIP, HA, AKKOR, KULONBEN, HA_VEGE, CIKLUS, AMIG, CIKLUS_VEGE, KI:, BE:
A változók nevei, illetve a program neve kis- és nagybetűkből, _ jelből és számjegyekből állhatnak, de nem kezdődhetnek számjeggyel, és nem ütközhetnek egyik kulcsszóval sem.
EGESZ: négy bájtos, előjel nélküli egészként kell megvalósítani; konstansai számjegyekből állnak, és nincs előttük előjelLOGIKAI: egy bájton kell ábrázolni, értékei:HAMIS,IGAZ
A # karakteretől a sor végéig. Megjegyzések a program tetszőleges pontján előfordulhatnak, a fordítást és a keletkező programkódot nem befolyásolják.
A PROGRAM kulcsszóval kezdődik (amit egy tetszőleges azonosító, a program neve követ) és a PROGRAM_VEGE kulcsszóval fejeződik be. (Ezek előtt illetve után csak megjegyzések állhatnak.) A változódeklarációk a program elején találhatóak, és a VALTOZOK: szöveg vezeti be őket. A deklarációs rész opcionális, de ha a VALTOZOK: szöveg megjelenik, akkor legalább egy változót deklarálni kell. A deklarációk után a program utasításai következnek, ezt a részt az UTASITASOK: szöveg vezeti be, és legalább egy utasítást tartalmaznia kell.
Minden változót a típusának és nevének megadásával kell deklarálni, több azonos típusú változó esetén mindegyikhez külön ki kell írni a típust.
EGESZtípusú kifejezések: számkonstansok,EGESZtípusú változók és az ezekből a+(összedás),-(kivonás),*(szorzás),/(egészosztás),%(maradékképzés) infix operátorokkal és zárójelekkel a szokásos módon felépített kifejezések.LOGIKAItípusú kifejezések: azIGAZésHAMISliterálok,LOGIKAItípusú változók, kétEGESZtípusú kifejezésből az=(egyenlőség),<(kisebb),>(nagyobb),<=(kisebbegyenlő),>=(nagyobbegyenlő) infix operátorokkal előállított, valamint az ezekbőlES(konjunkció),VAGY(diszjunkció),=(egyenlőség) infix és aNEM(negáció) prefix operátorral és zárójelekkel a szokásos módon felépített kifejezések.- Az infix operátorok mind balasszociatívak és a precedenciájuk növevő sorrendben a következő:
VAGYES=< > <= >=+ -* / %
SKIPutasítás: a változók értékeinek megváltoztatása nélküli továbblépés.- Értékadás: az
:=operátorral. Baloldalán egy változó, jobboldalán egy - a változóéval megegyező típusú - kifejezés állhat. - Olvasás: A
BE:utasítás a megadott változóba olvas be egy megfelelő típusú értéket a standard bementeről. (Megvalósítása: meg kell hívni a be eljárást, amit a negyedik beadandó kiírásához mellékelt C fájl tartalmaz. A beolvasott értékEGESZtípus esetén az eax,LOGIKAItípus esetén az al regiszterben lesz.) - Írás: A
KI:utasítás a megadott kifejezés értékét a standard kimenetre írja (és egy sortöréssel fejezi be). (Megvalósítása: meg kell hívni aki_egesz(vagy aki_logikai) eljárást, amit a 4. beadandó leírásához mellékelt C fájl tartalmaz. Paraméterként a kiírandó értéket (mindkét esetben 4 bájtot) kell a verembe tenni.) - Ciklus:
CIKLUS AMIG feltétel utasítások CIKLUS_VEGEalakú. A feltétel logikai kifejezés. A ciklus utasításlistája nem lehet üres. A megszokott módon, elöltesztelős ciklusként működik. - Elágazás:
HA feltétel AKKOR utasítások HA_VEGEvagyHA feltétel AKKOR utasításokKULONBEN utasitasok HA_VEGEalakú. A feltétel logikai kifejezés. Az egyes ágak utasításlistái nem lehetnek üresek. A megszokott módon működik.
Feladat:
Lexikális hiba észlelése esetén hibajelzést kell adni, ami tartalmazza a hiba sorának számát; ezután a program befejeződhet, nem kell folytatni az elemzést.
a megoldáshoz szükséges egy
flexés egyC++fájl
Fájlok: saját megoldás illetve múlt félévből valamint a hivatalos példaprogram, hivatalos, tanári megoldás, régebbi WHILE feladatra adott megoldás
Flex tutorial kifejtve futtatható példaprogramokkal itt
Teszteléshez a hivatalos tesztfájlokat érdemes lehet kiegészíteni még pár fájllal
- futtassuk:
flex flex1.l - keletkezik egy
lex.yy.ccfájl benneC++kóddal - fordítsuk:
g++ -o flex1 lex.yy.cc - a fordítás eredménye
flex1futtatható állomány - futtassuk paraméterezve
input.txt:ekkor azinput.txttartalma jelenik meg standar kimeneten
Ezekhez a formákhoz igen hasznosak a Flex regexei.
A legegyszerűbb, legelemibb elemeket megadjuk makrónak
DIGIT [0-9]
WS [ \t\n]
CHAR [a-zA-Z]
UNDERSCORE "_"
A kulcsszavakat, kifejezéseket, típusokat stb, egyéb a nyelvben konkrétan szereplő szavakat lekezeljük az alábbi módon:
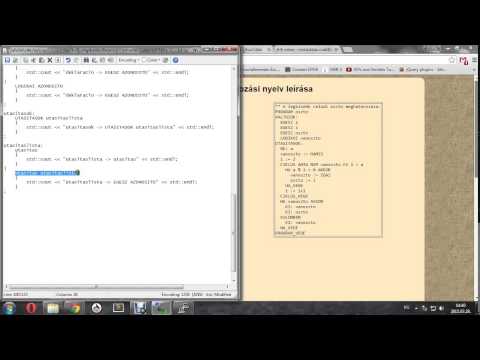
PROGRAM_VEGE std::cout << "kulcsszo: PROGRAM_VEGE" << std::endl;
VALTOZOK: std::cout << "kulcsszo: VALTOZOK:" << std::endl;
UTASITASOK: std::cout << "kulcsszo: UTASITASOK:" << std::endl;
Reguláris kifejezésekkel megadhatjuk a komplexebb konstrukciókat, pl: a karakterek formáit, vagy a whitespacek kezelését, illetve a megjegyzéseket
{DIGIT}+ std::cout << "karakter(ek): " << YYText()<< std::endl;
{WS}+ std::cout << "ureskarakter(ek): " << YYText()<< std::endl;
"#"+.*+\n std::cout << "megjegyzes: " << YYText()<< std::endl;
ugyanígy megadhatjuk az azonosítókat is
({CHAR}|{UNDERSCORE})+({CHAR}|{DIGIT}|{UNDERSCORE})* std::cout << "azonosito: " << YYText() << std::endl;
Regexekről bővebben: részletes regex magyarázat, illetve aalborgi egyetemi anyag
Fontosabb regexek:
\- escape operátor, a rákövetkezőt semlegesíti
.- bármi kivéve új sor
[abc]- bármiylen karakter ezek között, megfelel ennek:[a-c]
(r)-rre illeszkedik a precedencia felülírásával
a?- 0 vagy 1a
a+- 1 vagy többa
a*- 0 vagy többa
^a-akarakter a sor elején
a$-akarkater a sor végén
a/b-ade csak habköveti
a sorrendben a legelső illeszkedő mintát fogja figyelembe venni. hasonló Stackowerflow kérdés
Feladat:
a programnak parancssori paraméterben lehessen megadni az elemzendő fájl nevét
a program minden alkalmazott szabályhoz egy sort írjon a képernyőre, például
a tesztfájlok közül a
lexikalis_hibasésszintaktikus_hibaskiterjesztésű fájlokra kell hibát jelezni, a többit el kell fogadni.
A PLanG nyelv összes szükséges szabályátirata: http://digitus.itk.ppke.hu/~flugi/bevprog_1415/atiras.html
Fájlok: saját megoldás, mintaprogram, amiből érdemes kiindulni, hivatalos tanári megoldás, illetve korábbi félév anyagai, régebbi WHILE feladatra adott megoldás
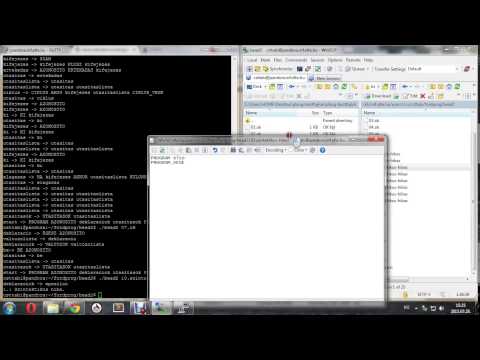
Fordítás:
flex calculate.l
bisonc++ calculate.y
ekkkor keletkezik: Parserbase.h, Parser.ih, Parser.h,parse.cc
a Parser.ih, Parser.h nem kerül felülírásra legközelbb, így futtatható
g++ -ocalculate calculate.cc parse.cc lex.yy.cc
Futtatás:
./calculate example.calculate
A folyamat során
C++ scannerek generálódnak, erről bővebben itt: dinosaur.compilertools.net
Gyakori hibaüzenetek kifejtése korábbról
az
yfájlban figyeljünk a%lezárásokra stackowerflow
ha több parserünk van akkor külön kell őket elneveznünk. Stackowerflow válasz
van korábban illeszkedő minta a mintánkra az
lfájlban , pl: kulcsszavak előtt változónév, sorrendmegfordítás megoldja. Bővebben kifejtve
korábban illeszkedő minta a szabályok között az
yfájlban. Bővebben kifejtve
Többféle úton jut el ugyanahhoz a terminálishoz, bővebben kifejtve
Továbbá érdemes odafigyelni, hogy a megfelelő header fájlokat használjuk.
Hasznos linkek: http://www.jonathanbeard.io/tutorials/FlexBisonC++
Fordítóprogramok bisonc++ szintaktikus-hiba 10. (nyelv kiegészítése egyéb pár szabályal, típussal, stb)
Feladat:
A kód szemantikai ellenőrzése
Fájlok: példakód, régebbi WHILE feldatra adott megoldás, előző félév anyaga, mintamegoldás, saját megoldás
forrás: deva.web.elte.hu/szemantikus.hu.html eredeti tutorial fájlok és teszteseteik: tutorial
Ebben a tananyagban egy olyan nyelvet fogunk használni, amelynek alapelemei a nemnegatív egész számok, a logikai literálok és változók. A változókat a program elején kell deklarálni. A deklarációk után értékadások sorozata következik. Ezek bal oldalán egy változó, jobb oldalán egy változó vagy egy literál szerepel. Egy példaprogram:
natural n
natural m
boolean b
n := 0
b := true
m := n
- Töltsd le a nyelv lexikális és szintaktikus elemzőjét valamint a tesztfájlokat!
- Nézd át a flex forrást (assign.l) és a bisonc++ forrást (assign.y)!
- A Parser.h és Parser.ih fejállományokat a bisonc++ generálta az első futtatásakor, de ezekbe beleírhatunk.
- A Parser.h fejállományba felvettük a lexikális elemzőt adattagként, és hozzáadtunk egy konstruktort, ami inicializálja azt.
- A Parser.ih implementációs fejállományban implementáltuk a lex függvényt, ami továbbítja lexikális elemző által felismert tokeneket a szintaktikus elemzőnek, és beállítja a szintaktikus elemző
d_loc__mezőjét arra pozícióra, ahol az elemzés éppen tart a forrásszövegben! Ugyanebben a forrásfájlban a hibakezelést végzőerrorfüggvényt is módosítottuk. - Fordítsd le a projektet a
makeparanccsal (vagy "kézzel", a flex, bisonc++ és g++ segítségével)! - Futtasd a programot a helyes, a lexikális hibás és a szintaktikus hibás példákra!
- Figyeld meg, hogy a program nem jelez hibát a szemantikus hibás példákra! Ennek a feladatsornak az a célja, hogy kiszűrjük ezeket a hibákat.
Szimbólumtáblát szeretnénk létrehozni. Az egyszerűség kedvéért ezt a C++ standard könyvtárának map adattípusával fogjuk megvalósítani. A map kulcsa a változó neve (string) lesz, a hozzárendelt érték pedig tartalmazni fogja a változó típusát és a deklarációjának sorát. A szükséges C++ kódot egy új fejállományba, a semantics.h fájlba írjuk.
- A semantics.h fájlban include-old az
iostream,stringésmapstandard fejállományokat! - Hozz létre ugyanitt egy felsorolási típust a programnyelvben előforduló két típus reprezentálásához!
enum type { natural, boolean }; - Készíts egy
var_datanevű rekord típust, amit az egyes változókhoz hozzárendelt adatok tárolására fogunk használni. Két mezője legyen:decl_rowazt fogja tárolni, hogy az adott változó a program hányadik sorában volt deklarálva.var_typea változó típusát tárolja. Ez a mező az imént definiált type típusú legyen!
- Írj a
var_datarekordhoz egy két paraméteres konstruktort is, hogy könnyen lehessen inicializálni az ilyen típusú objektumokat létrehozásukkor. Legyen továbbá egy nulla paraméteres (üres törzsű) konstruktor is, mert erre majd szükség lesz akkor, amikor ilyen típusú elemeket akarunk egymap-ben tárolni! - A Parser.h fejállományban add hozzá a Parser osztály privát adattagjai közé a szimbólumtáblát:
std::map<std::string,var_data> szimbolumtabla; - Az assign.y fájl elején cseréld le a
%baseclass-preincludedirektívában az<iostream>fejállományt"semantics.h"-ra, hogy az imént készített fejállomány része legyen a projektnek! Próbáld lefordítani a projektet, és javítsd az esetleges hibákat!
Az assign.y fájlban a deklarációk szintaxisát leíró szabályhoz szeretnénk majd egy olyan akciót írni, ami az adott változót beszúrja az adataival együtt a szimbólumtáblába. Ehhez a következőkre van szükség:
- A deklaráció sorának száma: ez a
d_loc__.first_lineérték lesz, amit alexfüggvény állít be. (Lásd az 1. lépést!) - A változó típusa: ez onnan derül ki, hogy éppen melyik szabály-alternatíva az aktív (
NATURAL IDENTvagyBOOLEAN IDENT). - A változó neve: ezt csak a lexikális elemző tudja! El kell érnünk, hogy ez továbbításra kerüljön a szintaktikus elemzőhöz. A bisonc++ megengedi, hogy tetszőleges (terminális vagy nemterminális) szimbólum mellé egy ún. szemantikus értéket (lásd az előadás anyagában: attribútum) rendeljünk. Mivel különböző szimbólumokhoz különböző típusú szemantikus érték rendelhető, ezért létre kell hoznunk egy unió típust ezekhez. Erre a bisonc++ külön szintaxist biztosít, amiből majd egy valódi C++ unió típust fog generálni. Ennek most egyetlen sora lesz, hiszen kezdetben csak a változókhoz szeretnénk szemantikus információként hozzárendelni a nevüket.
- Az assign.y fájlhoz az első
%tokendeklaráció elé add hozzá a következőt:
%union
{
std::string *szoveg;
}
- Ennek az uniónak a mezőneveit használhatjuk arra, hogy meghatározzuk az egyes szimbólumokhoz rendelt szemantikus értékek típusát. Egészítsd ki az azonosító tokent így:
%token <szoveg> IDENT; - Az azonosító tokeneknek most már lehet szemantikus értéke (string), de ezt be is kell állítanunk valahol. A terminálisok szemantikus értékét a lex függvény tudja beállítani. (Lásd az előadás anyagában: kitüntetett szintetizált attribútum.) Egészítsd ki a lex függvényt (még a return előtt) a következő sorokkal:
if( ret == IDENT )
{
d_val__.szoveg = new std::string(lexer.YYText());
}
(Az YYText() függvénnyel lehet elkérni a flex-től a felismert token szövegét. Ebből létrehozunk egy string-et. A Parser osztály d_val__ adattagja olyan unió típusú, amit az imént az assign.y fájlba írtunk. Ennek a szoveg mezőjébe írhatjuk a szöveget.)
Most már elérjük az assign.y fájlban a szabályok mögé írható akciók belsejében az azonosítókhoz tartozó szövegeket. Az a: A B C szabály esetén az A szimbólum szemantikus értékére $1, a B szimbóluméra $2, a C szimbóluméra $3 hivatkozik. Ezek típusának megállapításához meg kell néznünk, hogy az unió típusnak melyik mezőjét rendeltük hozzá az adott szimbólumhoz. Ennek a mezőnek a típusa lesz a szemantikus érték típusa. (Esetünkben string*.)
- A deklarációkra vonatkozó szabályalternatívákat egészítsd ki úgy, hogy kiírják a standard kimenetre az éppen deklarált változó nevét!
NATURAL IDENT
{
std::cout << *$2 << std::endl;
}
- Futtasd a helyes példára a programot!
Ahelyett, hogy a standard kimenetre írnánk a deklarált változók nevét, most betesszük az adataikat a szimbólumtáblába. A map adattípusnak van [] operátora, ennek segítségével lehet beállítani és lekérdezni az adott kulcshoz tartozó értéket.
- Írd át a deklarációkhoz tartozó szabályalternatívák programját úgy, hogy a változót és adatait szúrja be a szimbólumtáblába!
NATURAL IDENT
{
szimbolumtabla[*$2] = var_data( d_loc__.first_line, natural );
}
- Ellenőrizzük le a beszúrás előtt, hogy nem volt-e már ugyanezzel a névvel korábban deklaráció! A map adattípus
countfüggvénye megadja, hogy egy adott kulcshoz hány elem van a map-ben (0vagy1).
if( szimbolumtabla.count(*$2) > 0 )
{
std::stringstream ss;
ss << "Ujradeklaralt valtozo: " << *$2 << ".\n"
<< "Korabbi deklaracio sora: " << szimbolumtabla[*$2].decl_row << std::endl;
error( ss.str().c_str() );
}
A hibaüzenet szövegének összegyűjtéséhez és a korábbi deklaráció sorának szöveggé konvertálásához a stringstream osztályt használtuk. Ehhez be kell include-olni a semantics.h fájlba a sstream standard fejállományt!
A stringstream típusú ss-ből a str() tagfüggvénnyel lehet lekérni a benne összegyűlt string-et. Mivel az error függvény (lásd a Parser.ih-ban!) string helyett C stílusú karakterláncot vár paraméterként, ezért a c_str() függvény segítségével konvertálunk.
- Töltsd ki hasonlóan a logikai változók deklarációjához tartozó szabályalternatívát is, de ott a szimbólumtáblába logikai változót szúrj be!
- A programnak most már a 4.szemantikus-hibas fájlra hibát kell jeleznie.
Azt is szeretnénk ellenőrizni, hogy az értékadásokban használt változók deklarálva vannak-e.
- Egészítsd ki az értékadásokat és a kifejezéseket leíró szabályoknak az
IDENT-et tartalmazó alternatíváit úgy, hogy hibaüzenetet kapjunk nem deklarált változók esetén! - Ellenőrizd, hogy az 5. és 6. szemantikus hibás tesztfájlra valóban hibaüzenetet ad-e a fordító!
Az értékadások típushelyességének ellenőrzéséhez szükséges, hogy szemantikus értéket adjunk a kifejezésekhez. A konkrét esetben ez lehet a korábban definiált type felsorolási típusú érték. A kifejezéseket leíró szabályokban be fogjuk állítani a kifejezés szemantikus értékét (a kifejezés típusát) a szabály jobboldala alapján (lásd az előadás anyagában: szintetizált attribútum). A szabály baloldalának szemantikus értékére a $$ jelöléssel hivatkozhatunk az akciókban. Ha nemterminálisokhoz szeretnénk szemantikus értéket hozzárendelni, akkor ezt is fel kell tüntetni a fájl elején. Mivel ez már nem token, ezért a %type <unió_megfelelő_mezője> nemterminális_neve szintaxist kell használni.
- Egészítsd ki az assign.y fájlban korábban definiált uniót egy
type*típusú mezővel, és tüntesd fel azexprnemterminálishoz rendelt szemantikus érték típusát az unióban létrehozott új mezőnév segítségével! - Egészítsd ki a kifejezéseket leíró négy szabályalternatíva akcióit olyan utasításokkal, amelyek beállítják a szabály baloldalának szemantikus értékét (a kifejezés típusát)!
Például az
IDENTalternatíva esetén a szimbólumtáblából kérhetjük le az azonosító típusát:
$$ = new type(szimbolumtabla[*$1].var_type);
A TRUE alternatíva még egyszerűbb:
$$ = new type(boolean);
Használd fel az expr nemterminálisokhoz most beállított szemantikus értékeket az értékadásra vonatkozó szabályban: ellenőrizd, hogy az értékadás két oldala azonos típusú-e!
if( szimbolumtabla[*$1].var_type != *$3 )
{
error( "Tipushibas ertekadas.\n" );
}
- Most már valamennyi szemantikus hibás példára hibát kell jeleznie a programnak.
- Az
IDENTésexprszimbólumok szemantikus értékeit minden esetben (a lex függvényben és a szabályokhoz csatolt akciókban is) a new kulcsszó segítségével, dinamikus memóriafoglalással hoztuk létre. Azokban az akciókban, ahol ezek a szimbólumok a szabály jobb oldalán állnak, felhasználtuk az értékeket. A program memóriahatékonyságának érdekében azonban a felhasználás után fel kell szabadítani a lefoglalt memóriát, hogy elkerüljük a memóriaszivárgást. Nézd végig az összes szabályt, és ahol a jobb oldalonIDENTvagyexpráll, ott az akció végére írd be a következő utasítást:delete $i(aholiazIDENTvagyexprsorszáma).
A lexikális elemző és szintaktikus ellenörző nélkül nem működőképes rendszer, így előbb annak kell működnie.
- A
Parser.hban egymapformájában létrehozzuk a szimbólumtáblát. - A
semantics.hban meghatározzuk a használt típusokat egyenumban ezt követően, meghatározzuk a használt kifejezésmintákat és azok típusait, meghatározásaitstructokban.- itt mindig meg kell adni a sor számát (
decl_row), amiint. - és meg kell adjuk az adott kifejezés típusát is (
var_type)
- itt mindig meg kell adni a sor számát (
- Először biztosítanunk kell, hogy lássuk a yacc fájlban ezeket, így egy
unionként meghatározzuk az előbb megadott mintákat, majd azokat később a kifejezésekhez társítjuk, még a program legeljén - fontos, hogy a sorokat olvasó, Parser.ih-ban található
lexfüggvényünk visszadja nekünk a sorok tartalmát, méghozzá feldarabolva:d_val__.szoveg = new std::string(lexer.YYText()); - ezután már tudunk a darabokra egyenként hivatkozni és azokat lekezelhetjük, azaz, ha a kapott forma
A B C Dakkor hivatkoznk rá$1 $2 $3 $4formában, illetve mostmár leérhető ad_loc__.first_lineis, amivel visszadhatjuk a sort amit épp vizsgálunk
Mindez mit sem ér ha nem tesszük be az egészet a szimbolóumtáblába, például így: szimbolumtabla [*$i] = var_data(d_loc__.first_line, típus)
Ezek után a típusok helyességét kell ellenőriznünk, hogy megfelelően van-e megadva pl egy matematikai művelet és nem pl egy logikai értékhez szeretnénk hozzáadni valamit. A szabályok baloldalának szemantikai értékét a $$al érjük el, a nemterminálist (kifejezés, stb) az unionon keresztül érjük el, ahogy azt fent megadtuk.
Fájlok:régebbi WHILE feladatra adott megoldás, előző félév anyaga, mintaprogram, amiből érdemes kiindulni, tanári mintamegoldás
Egészítsük ki
Stringtípussal és hozzá egy++(konkatenáció) művelettel és egy hosszúság lekérdezéssel,hossz.Mintakód:
PROGRAM pelda VALTOZOK: STRING s UTASITASOK: s := "com" KI: hossz(s ++ "piler") PROGRAM_VEGE
fájlok: calculate.l, calculate.y
Lexikális kiegészítés
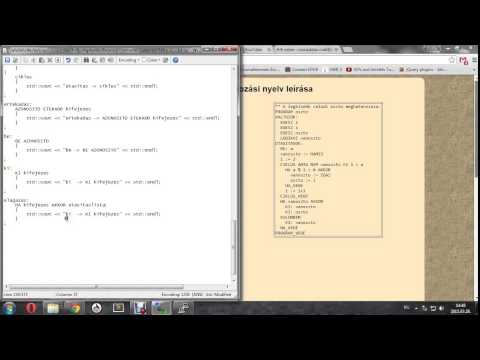
"++" return Parser::CONCAT;"hossz" return Parser::HOSSZ;STRING return Parser::STRING;\"([^\n"])*\" { return Parser::STRINGCONST; }
szintaktikai kiegészítés
%token STRING %token STRINGCONST %token HOSSZ%left CONCATTípusokhoz (
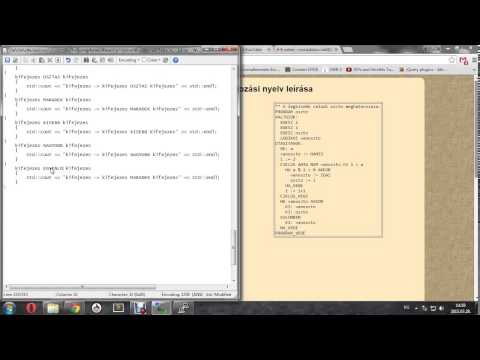
type)STRING { std::cout << "type -> STRING" << std::endl; }fuggveny: HOSSZ OPEN kifejezes CLOSE { std::cout << "fuggveny -> HOSSZ OPEN kifejezes CLOSE" << std::endl; } ;Kifejezésekhez (
kifejezes)fuggveny { std::cout << "kifejezes -> fuggveny" << std::endl; } | kifejezes CONCAT kifejezes { std::cout << "kifejezes -> kifejezes CONCAT kifejezes" << std::endl; } | STRINGCONST { std::cout << "kifejezes -> STRINGCONST" << std::endl; }
- Lex, Yacc, Flex, Bison manual
- Előadás anyaga eredeti
- Előadás anyag itt
- Fordítóprogramok és formális nyelvek - Király Roland 2007
- Assembly programozás - Kitlei Róbert 2007
- egybefűzve az előadás, a tesztkérdések és gyakorlófeladatok
- feladatmegoldások ~ Nagy Krisztián
- Language-Parametric Methods for Developing Interactive Programming Systems



