funnycoderstar的个人主页
funnycoderstar / leetcode Goto Github PK
View Code? Open in Web Editor NEWLeetcode(Javascript实现)
Home Page: https://wangyaxing.cn/leetcode/
Leetcode(Javascript实现)
Home Page: https://wangyaxing.cn/leetcode/









不使用运算符 + 和 - ,计算两整数 a 、b 之和。
示例 1:
输入: a = 1, b = 2
输出: 3
示例 2:
输入: a = -2, b = 3
输出: 1
/**
* @param {number} a
* @param {number} b
* @return {number}
*/
var getSum = function(a, b) {
var temp;
while (a !== 0) {
temp = (a & b) << 1; // a & b 得到所有需要进位的地方,左移一位完成进位。
b = a ^ b; // a ^ b 得到a与b不一样的地方,即不需要进位的地方
a = temp;
}
return b;
};给定一个正整数,输出它的补数。补数是对该数的二进制表示取反。
注意:
给定的整数保证在32位带符号整数的范围内。
你可以假定二进制数不包含前导零位。
示例 1:
输入: 5
输出: 2
解释: 5的二进制表示为101(没有前导零位),其补数为010。所以你需要输出2。示例 2:
输入: 1
输出: 0
解释: 1的二进制表示为1(没有前导零位),其补数为0。所以你需要输出0。有三种思路

补充知识: javascript 进制转换(2进制、8进制、10进制、16进制之间的转换)
const x = 5;
console.log(x);
console.log(x.toString(8));
console.log(x.toString(32));
console.log(x.toString(16)); const x = 5;
console.log(parseInt(x, 2));
console.log(parseInt(x, 8));
console.log(parseInt(x, 16)); 方法一:
/**
* @param {number} num
* @return {number}
*/
var findComplement = function(num) {
const a = num.toString(2);
let result = [];
for(let i = 0;i < a.length; i++) {
if(a[i] == 0) {
result.push(1);
} else {
result.push(0);
}
}
return parseInt(result.join(''),2);
};方法二:
/**
* @param {number} num
* @return {number}
*/
var findComplement = function(num) {
return parseInt(num.toString(2).split('').map((a) => 1 ^ a).join(''), 2)
};方法三:
/**
* @param {number} num
* @return {number}
*/
var findComplement = function(num) {
const a = num.toString(2);
let result = 0;
for(let i = 0;i < a.length; i++) {
if(a[i] == 0) {
result += Math.pow(2, a.length - i - 1)
}
}
return result;
};给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
深度优先搜索
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @param {number} sum
* @return {boolean}
*/
var hasPathSum = function (root, sum) {
if (root === null) {
return false;
}
let left = root.left;
let right = root.right;
if (left === null && right === null) {
return root.val === sum;
}
return hasPathSum(left, sum - root.val) || hasPathSum(right, sum - root.val);
};每个元素由存储元素本身的节点和一个指向下一个元素的引用.
优点就是无需移动元素就可以轻松添加和移除元素.因此, 你需要添加和移除很多元素时, 最好的选择时链表, 而非数组.
function LinkedList() {
let Node = function(element) {
this.element = element;
this.next = null;
}
let length = 0;
let head = null;
// 向链表尾部追加元素
this.append = function (element) {
let node = new Node(element);
let current;
if(head === null) {
head = node;
} else {
current = head;
while(current.next) {
current = current.next;
}
current.next = node;
}
length++;
};
this.insert = function(position, element) {
if(position >= 0 && position <= length) {
let node = new Node(element);
let current = head;
let previous;
let index;
if(position === 0) {
node.next = current;
head = node;
} else {
while(index++ < position) {
previous = current;
current = current.next;
}
node.next = current;
previous.next = node;
}
length++;
return true;
} else {
return false;
}
};
// 从链表中移除元素
this.removeAt = function(position) {
if(position > -1 && position < length) {
let current = head;
let previous;
let index = 0;
if(position === 0) {
head = current.next;
} else {
while (index++ < position) {
previous = current;
current = current.next;
}
previous.next = current.next;
}
length--;
return current.element;
} else {
return null;
}
};
this.remove = function(element) {
let index = this.indexOf(length);
return this.removeAt(index);
};
this.indexOf = function(element) {
let current = head;
let index = -1;
while(current) {
if(element == current.element) {
return index;
}
index++;
current = current.next;
}
return -1;
};
this.isEmpty = function() {
return length === 0;
};
this.size = function() {
return length;
};
this.getHead = function() {
return head;
};
this.toString = function() {
let current = head;
let string = '';
while(current) {
string += current.element + (current.next ? 'n': '');
current = current.next;
}
return string;
};
this.print = function() {
};
}
let list = new LinkedList();
list.append(15);
list.append(10);function DoublyLinkedList() {
let node = function(element) {
this.element = element;
this.next = null;
this.prev = null;
}
let length = 0;
let head = null;
let tail = null;
this.insert = function(position, element) {
if(position >= 0 && position <= length) {
let node = new Node(element);
let current = head;
let previous;
let index = 0;
if(position === 0) {
if(!head) {
head = node;
tail = node;
} else {
node.next = current;
current.prev = node;
head = node;
}
} else if(position == length) {
current = tail;
current.next = node;
node.prev = current;
tail = node;
} else {
while(index++ < position) {
previous = current;
current = current.next;
}
node.next = current;
previous.next = node;
current.prev = node;
node.prev = previous;
}
length++;
return true;
}
return false;
};
this.removeAt = function(position) {
if(position >= 0 && position < length) {
let current = head;
let previous;
let index = 0;
if(position === 0) {
head = current.next;
if(length === 1) {
tail = null;
} else {
head.prev = null;
}
} else if(position === length -1) {
current = tail;
tail = current.prev;
tail.next = null;
} else {
while(index++ < position) {
previous = current;
current = current.next;
}
previous.next = current.next;
current.next.prev = previous;
}
length--;
return current.element;
} else {
return null;
}
}
}循环链表可以像链表一样只有单向引用, 也可以像双向链表一样有双向引用.循环链表与链表之前唯一的区别在于, 最后一个元素指向下一个元素的指针(tail.next)不是引用null, 而是指向第一个元素(head)
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
示例:
给定有序数组: [-10,-3,0,5,9],
一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
0
/ \
-3 9
/ /
-10 51.如果nums长度为0,返回null
2.如果nums长度为1,返回一个节点
3.如果nums长度大于1,首先以中点作为根节点,然后将两边的数组作为左右子树。
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {number[]} nums
* @return {TreeNode}
*/
var sortedArrayToBST = function(nums) {
if(nums.length === 0) {
return null;
}
if(nums.length === 1) {
return new TreeNode(nums[0]);
}
const mid = parseInt(nums.length / 2);
let root = new TreeNode(nums[mid]);
root.left = sortedArrayToBST(nums.slice(0, mid));
root.right = sortedArrayToBST(nums.slice(mid + 1));
return root;
};你有一个日志数组 logs。每条日志都是以空格分隔的字串。
对于每条日志,其第一个字为字母数字标识符。然后,要么:
标识符后面的每个字将仅由小写字母组成,或;
标识符后面的每个字将仅由数字组成。
我们将这两种日志分别称为字母日志和数字日志。保证每个日志在其标识符后面至少有一个字。
将日志重新排序,使得所有字母日志都排在数字日志之前。字母日志按字母顺序排序,忽略标识符,标识符仅用于表示关系。数字日志应该按原来的顺序排列。
返回日志的最终顺序。
示例
输入:["a1 9 2 3 1","g1 act car","zo4 4 7","ab1 off key dog","a8 act zoo"]
输出:["g1 act car","a8 act zoo","ab1 off key dog","a1 9 2 3 1","zo4 4 7"]将日志数组 logs 进行分类(对每项去掉第一个字符后进行判断), 分成数字日志numberLog和字符串日志 stringLog, 对stringLog进行排序, 然后和numberLog合并在一起
/**
* @param {string[]} logs
* @return {string[]}
*/
var reorderLogFiles = function (logs) {
const compareFn = function (s1, s2) {
const s1Content = s1.slice(s1.indexOf(' ') + 1);
const s2Content = s2.slice(s2.indexOf(' ') + 1);
return s1Content > s2Content ? 1 : -1;
};
let stringLog = [];
let numberLog = [];
for (let log of logs) {
if (log[log.indexOf(' ') + 1].charCodeAt() < 97) {
numberLog.push(log);
} else {
stringLog.push(log);
}
}
stringLog.sort(compareFn);
return stringLog.concat(numberLog);
};给定两个大小为 m 和 n 的有序数组 nums1 和 nums2。
请你找出这两个有序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。
你可以假设 nums1 和 nums2 不会同时为空。
示例 1:
nums1 = [1, 3]
nums2 = [2]
则中位数是 2.0示例 2:
nums1 = [1, 2]
nums2 = [3, 4]
则中位数是 (2 + 3)/2 = 2.5将两个数组合并成一个, 然后排序(JavaScript数组内置的sort函数), 复杂度O(nlogn), 最后根据数组的长度选择中位数
/**
* @param {number[]} nums1
* @param {number[]} nums2
* @return {number}
*/
var findMedianSortedArrays = function(nums1, nums2) {
const nums = nums1.concat(nums2);
nums.sort(function(a, b) {
return a - b;
});
let len = nums.length;
if (len % 2 === 0) {
return (nums[len / 2] + nums[len / 2 - 1]) / 2;
} else {
return nums[(len - 1) / 2];
}
};将两个有序的数组合并成一个有序的数组, 每个数组都已经是单独排过序的, 使用归并排序封装一个merge函数, 剩下思路上上述一样
/**
* @param {number[]} nums1
* @param {number[]} nums2
* @return {number}
*/
var findMedianSortedArrays = function (nums1, nums2) {
const merge = function (left, right) {
var temp = [];
while (left.length && right.length) {
if (left[0] < right[0]) {
temp.push(left.shift());
} else {
temp.push(right.shift());
}
}
return temp.concat(left, right);
};
let nums = merge(nums1, nums2);
let len = nums.length;
if (len % 2 === 0) {
return (nums[len / 2] + nums[len / 2 - 1]) / 2;
} else {
return nums[(len - 1) / 2];
}
};// 交换位置
let swap = function(index1, index2) {
[array[index1], array[index2]] = [array[index2], array[index1]]
}比较任何两个相邻的值, 如果第一个比第一个大,则交换他们;
复杂度为O(n^2)
let bubbleSort = function() {
let len = array.length;
for(let i = 0; i < len; i++) {
for(let j = 0; j < len - 1;j++ ) {
if(array[j] > array[j+1]) {
swap(j, j+1);
}
}
}
}
// 升级后的冒泡排序
let modifiedBubbleSort = function() {
let len = array.length;
for(let i = 0; i < len; i++) {
for(let j = 0; j < len - 1 - i;j++ ) {
if(array[j] > array[j+1]) {
swap(j, j+1);
}
}
}
}找到最小的值放第一位, 找到第二小的值放第二位;
复杂度为O(n^2)
// 选择排序
let selectionSort = function() {
let len = array.length;
let indexMin;
for(let i = 0; i < len -1; i++) {
let indexMin = i;
for(let j = i; j < len; j++) {
if(array[indexMin] > array[j]) {
indexMin = j;
}
}
if( i !== indexMin) {
swap(i, indexMin);
}
}
}// 插入排序
this.insertionSort = function() {
let len = array.length;
let j;
let temp;
for(let i = 0; i < length; i++) {
j = i;
temp = array[i];
while( j > 0 && array[j - 1] > temp) {
array[j] = array[j - 1];
j--;
}
array[j] = temp;
}
}let mergeSort = function() {
array = mergeSortRec(array);
}
var mergeSortRec = function(array) {
let len = array.length;
if(length === 1) {
return array;
}
var mid = Math.floor(length / 2);
var left = array.slice(0, mid);
var right = array.slice(mid, length);
return merge(mergeSortRec(left), mergeSortRec(right))
}
var merge = function(left, right) {
let result = [];
let il = 0;
let ir = 0;
while(il < left.length && ir < right.length) {
if(left[il] < right[ir]) {
result.push(left[il++])
} else {
result.push(left[ir++])
}
}
while(il < left.length) {
result.push(left[il++]);
}
while(ir < right.length) {
result.push(right[ir++]);
}
return result;
}this.quickSort = function() {
quick(array, 0, array.length - 1);
}
var quick = function(array, left, right) {
// 从数组中选择一项作为主元
var index;
if(array.length > 1) {
index = partition(array, left, right);
if(left < index - 1)) {
quick(array, left, index - 1);
}
if(index < right) {
quick(array, index, right);
}
}
}
var partition = function(array, left, right) {
// 选用中间项作为主元
var pivot = array[Math.floor(left + right) / 2]],
// left, 低,初始为数组中的第一个元素
i = left,
// right, 高, 初始为数组
j = right;
while(i <= j) {
// 移动left指针直到找到一个元素比主元大
while(array[i] < pivot) {
i++;
}
// 移动right指针直到找到一个元素比主元小
while(array[j] > pivot) {
j--;
}
// 当左指针指向的元素比主元大且右指针指向的元素比主元小, 并且左指针索引没有右指针索引大, 则交换它们, 移动两个指针
if(i <= j) {
swap(array, i , j);
i++;
j--;
}
}
return i;
}
对原数组操作,不占用额外空间;
先排一次序,找到index, index左边的都比arr[index]小,右边的都比arr[index]大
然后左右分别重复上一个排序做法
this.heapSort = function() {
var heapSize = array.length;
// 构造一个满足array[parent[i]] >= array[i]的堆结构
buildHeap(array);
while(heapSize > 1) {
heapSize--;
// 交换堆里面第一个元素(数组中较大的值)和最后一个元素的位置
swap(array, 0, heapSize);
// 再次将数组转成堆, 找到当前堆的根节点(较小的值), 重新放在底部
heapify(array, heapSize, 0);
}
}
var buildHeap = function(array) {
var heapSize = array.length;
for(var i = Math.floor(array.length / 2); i >= 0; i--) {
heapify(array, heapSize, 0);
}
}
var heapify = function(array, heapSize, i) {
var left = i * 2 + 1,
right = i * 2 + 2,
largest = i;
if(left < heapSize && array[left] > array[largest]) {
largest = left;
}
if(right < heapSize && array[right] > array[largest]) {
largest = right;
}
if(largest !== i) {
swap(array, i, largest);
heapify(array, heapSize, largest);
}
}之前介绍的排序方法都是在不借助辅助数据结构的情况下对数组进行排序
分布式排序算法是: 原始数组中的数据会分发到多个中间结构(桶), 再合起来放回原始数组
最著名的分布式算法有计数排序, 桶排序和基数排序
this.sequentialSearch = function(item) {
for(let i = 0; i < array.length; i++) {
if(item === array[i]) {
return i;
}
}
return -1;
}1.选择数组中的中间值
2.如果选中值是待搜索值, 那么算法执行完毕
3.如果待搜索值比选中值要小, 则返回步骤1并在选中值左边的子数组中寻找
4.如果待搜索值比选中值要大, 则返回步骤1并在选中值右边的子数组中寻找
this.binarySearch = function(item) {
this.quickSort();
let low = 0;
let high = nums.length - 1;
while(low <= high) {
const mid = Math.floor((low + high)/2);
const element = nums[mid];
if(element < target) {
low = mid + 1;
} else if(element > target) {
high = mid - 1;
} else {
return mid;
}
}
return -1;
}二叉树的深度,也叫二叉树的高度,二叉树的深度等于从根结点到叶子结点的最长路径加1。
用递归的观点来看,二叉树的深度,等于其最大左右子树的深度加1,而每个左子树(右子树)又可以分解为次左子树+次右子树,它们是深度也是最大子树深度加1。
二叉树的宽度:具有结点数最多的那一层的结点个数。
采用分层遍历的方法求出所有结点的层编号,然后,求出各层的结点总数,通过比较找出层结点数最多的值。
当b为空树时,叶子结点数为0;
当b的左子树和右子树都为空,b只有一个结点时,叶子结点数为1;
当b的左子树或右子树不为空时,叶子结点数=左子树叶子结点数+右子树叶子结点数。
给定一个字符串 S,返回 “反转后的” 字符串,其中不是字母的字符都保留在原地,而所有字母的位置发生反转。
示例 1:
输入:"ab-cd"
输出:"dc-ba"示例 2:
输入:"a-bC-dEf-ghIj"
输出:"j-Ih-gfE-dCba"示例 3:
输入:"Test1ng-Leet=code-Q!"
输出:"Qedo1ct-eeLg=ntse-T!"提示:
S.length <= 100
33 <= S[i].ASCIIcode <= 122
S 中不包含 \ or "
/**
* @param {string} S
* @return {string}
*/
var reverseOnlyLetters = function(S) {
const regx = /^[A-Za-z]$/;
let result = [];
for(let i = 0; i < S.length; i++) {
if(regx.test(S[i])) {
result.push(S[i]);
}
}
result.reverse();
let temp = [...S];
for(let i = 0,j = 0;i < temp.length;i++){
if(regx.test(temp[i])){
temp[i] = result[j];
j++;
}
}
return temp.join('');
};如何遍历链表呢?非常简单,你需要一个 current 指针(其实就是个变量),然后在 while 循环中执行 current = current.next 即可。
如何生成新链表?这也非常简单,你只需要一个 current 指针指向链表最后一位,然后执行 current.next = new Node(val) 即可。
了解了链表的这两个操作,然后我们对前两个链表进行遍历相加,生成新链表即可。为此,我们需要设置几个变量:
三个链表的 current 指针:current1、current2、current3。
新链表:dummyHead。
放到下一位相加的数字:carry。
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} l1
* @param {ListNode} l2
* @return {ListNode}
*/
var addTwoNumbers = function(l1, l2) {
let dummyHead = null;
let current1 = l1;
let current2 = l2;
let current3 = null;
let carry = 0; // 放到下一位相加的数字
while (current1 != null || current2 != null || carry) {
let x = (current1 != null) ? current1.val : 0;
let y = (current2 != null) ? current2.val : 0;
let sum = carry + x + y;
carry = Math.floor(sum / 10);
// 如果current3存在, 则创建一个链表赋值给current3.next, 然后将current3.next赋值给current3
if(current3) {
current3.next = new ListNode(sum % 10);
current3 = current3.next;
} else {
// 如果不存在, 则重新创建一个链表赋值给current3
dummyHead = new ListNode(sum % 10);
current3 = dummyHead;
}
if (current1 != null) {
current1 = current1.next;
}
if (current2 != null) {
current2 =current2.next;
}
}
return dummyHead;
};function minCoinChange(coins, amount) {
const cache = [];
const makeChange = (value) => {
if (!value) {
return [];
}
if (cache[value]) {
return cache[value];
}
let min = [];
let newMin;
let newAmount;
for (let i = 0; i < coins.length; i++) {
const coin = coins[i];
newAmount = value - coin;
if (newAmount >= 0) {
newMin = makeChange(newAmount);
}
if (
newAmount >= 0 &&
(newMin.length < min.length - 1 || !min.length) &&
(newMin.length || !newAmount)
) {
min = [coin].concat(newMin);
console.log('new Min ' + min + ' for ' + amount);
}
}
return (cache[value] = min);
};
return makeChange(amount);
}
console.log(minCoinChange([1, 5, 10, 25], 36)); // [1, 10, 25];
console.log(minCoinChange.makeChange(36)); // [1, 10, 25];// 找出构成解决方案的物品
function findValues(n, capacity, kS) {
let i = n;
let k = capacity;
console.log('解决方案包含以下物品');
while (i > 0 && k > 0) {
if (kS[i][k] !== kS[i - 1][k]) {
console.log('物品' + i + ',重量' + weights[i -1] + ',价值' + values[i-1]);
i--;
k -= kS[i][k];
} else {
i--;
}
}
}
function knapSack(capacity, weights, values, n) {
const kS = [];
// 初始化将用于寻找解决方案的矩阵kS[n + 1][capacity +1];
for (let i = 0; i <= n; i++) {
kS[i] = [];
}
for (let i = 0; i <= n; i++) {
for (let w = 0; w <= capacity; w++) {
// 忽略矩阵的第一列和第一行, 只处理索引不为0的列和行
if (i === 0 || w === 0) {
kS[i][w] = 0;
} else if (weights[i - 1] <= w) {
// 物品的重量必须小于约束(capacity)才有可能称为解决方案的一部分
const a = values[i - 1] + kS[i - 1][w - weights[i - 1]];
const b = kS[i - 1][w];
// 当找到可以构成解决方案的物品时, 选择价值最大的那个
kS[i][w] = a > b ? a : b; // max(a,b)
} else {
// 否则, 总重量就会超出背包能够携带的重量, 此时忽略, 用之前的值
kS[i][w] = kS[i - 1][w];
}
}
}
findValues(n, capacity, kS);
return kS[n][capacity];
}
var values = [3, 4, 5],
weights = [2, 3, 4],
capacity = 5,
n = values.length;
console.log(knapSack(capacity, weights, values, n)); // 输出7找出两个字符串序列的最长子序列(在两个字符串序列中以相同顺序出现, 但不要求连续(非字符串子串)的字符串序列)的长度
function printSolution(solution, wordX, m, n) {
let a = m;
let b = n;
let x = solution[a][b];
let answer = '';
while (x !== '0') {
if (solution[a][b] === 'diagonal') {
answer = wordX[a - 1] + answer;
a--;
b--;
} else if (solution[a][b] === 'left') {
b--;
} else if (solution[a][b] === 'top') {
a--;
}
x = solution[a][b];
}
return answer;
}
function lcs(wordX, wordY) {
const m = wordX.length;
const n = wordY.length;
const l = [];
const solution = [];
for (let i = 0; i <= m; i++) {
l[i] = [];
solution[i] = [];
for (let j = 0; j <= n; j++) {
l[i][j] = 0;
solution[i][j] = '0';
}
}
for (let i = 0; i <= m; i++) {
for (let j = 0; j <= n; j++) {
if (i === 0 || j === 0) {
l[i][j] = 0;
} else if (wordX[i - 1] === wordY[j - 1]) {
l[i][j] = l[i - 1][j - 1] + 1;
solution[i][j] = 'diagonal';
} else {
const a = l[i - 1][j];
const b = l[i][j - 1];
l[i][j] = a > b ? a : b; // max(a,b)
solution[i][j] = l[i][j] === l[i - 1][j] ? 'top' : 'left';
}
}
}
return printSolution(solution, wordX, m, n);
}你的朋友正在使用键盘输入他的名字 name。偶尔,在键入字符 c 时,按键可能会被长按,而字符可能被输入 1 次或多次。
你将会检查键盘输入的字符 typed。如果它对应的可能是你的朋友的名字(其中一些字符可能被长按),那么就返回 True。
示例 1:
输入:name = "alex", typed = "aaleex"
输出:true
解释:'alex' 中的 'a' 和 'e' 被长按。示例 2:
输入:name = "saeed", typed = "ssaaedd"
输出:false
解释:'e' 一定需要被键入两次,但在 typed 的输出中不是这样。示例 3:
输入:name = "leelee", typed = "lleeelee"
输出:true示例 4:
输入:name = "laiden", typed = "laiden"
输出:true
解释:长按名字中的字符并不是必要的。提示:
name.length <= 1000
typed.length <= 1000
name 和 typed 的字符都是小写字母。
i, j, 一个指向字符串typed, 一个指向字符串name, 如果 typed[i] === name[j], 那么移动两个指针, 否则一直移动ij到了name的结尾, 需要检查typed是否后面的字符一直相同, 即typed多出的那一部分必须和name的最后一个字符相同, 如果相同, 则匹配i到了typed的结尾, 判断是否已经到了name的结尾, 如果没有, 那么不匹配/**
* @param {string} name
* @param {string} typed
* @return {boolean}
*/
var isLongPressedName = function (name, typed) {
let j = 0;
for (let i = 0; i < typed.length; i++) {
if (j < name.length && typed[i] === name[j]) {
j++;
} else {
if (i > 0 && typed[i] === typed[i - 1]) {
continue;
} else {
return false;
}
}
}
return j === name.length;
};给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。这是一道动态规划题目
1.声明两个变量, currentString: 当前无重复字符的子串,max,无重复字符的最大子串长度
2.判断当前的最长串中是否有该字母s[i],
/**
* @param {string} s
* @return {number}
*/
var lengthOfLongestSubstring = function(s) {
let currentString = '';
let max = 0;
for(let i = 0; i < s.length; i++) {
const index = currentString.indexOf(s[i]);
// 判断当前的最长串中是否有该字母
if( index < 0) {
// 如果没有,则加上s[i]
currentString += s[i];
} else {
// 如果有,则需要从重复的位置断开,开始新的计算
currentString = currentString.substring(index + 1) + s[i];
}
max = Math.max(max, currentString.length);
}
return max;
};先进后出
调用栈
程序运行的时候需要内存空间存放数据, 一般来说系统会划分为两种不同的方式来存储数据, 一种是栈(Stack),一种是
堆(heap);
内存分配中中的堆栈
栈: 由操作系统自由分配释放,存放函数的参数值, 局部变量的值等
堆: 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收
class Stack {
constructor() {
this.items = [];
}
push(element) {
this.items.push(element)
}
pop() {
this.items.pop();
}
// 查看栈顶元素
peek() {
return this.items[this.items.length -1];
}
isEmpty() {
return this.items.length == 0;
}
size() {
return this.items.length;
}
clear() {
this.items = [];
}
print() {
console.log(this.items.toString());
}
}十进制转二进制
function divideBy2(decNumber) {
var remStack = new Stack, rem, binaryString = '';
while(decNumber > 0) {
rem = Math.floor(decNumber % 2);
remStack.push(rem);
decNumber = Math.floor(decNumber / 2);
}
while(!remStack.isEmpty()) {
binaryString += remStack.pop().toString();
}
return binaryString;
}十进制转成其他任意进制
你现在是棒球比赛记录员。
给定一个字符串列表,每个字符串可以是以下四种类型之一:
1.整数(一轮的得分):直接表示您在本轮中获得的积分数。
2. "+"(一轮的得分):表示本轮获得的得分是前两轮有效 回合得分的总和。
3. "D"(一轮的得分):表示本轮获得的得分是前一轮有效 回合得分的两倍。
4. "C"(一个操作,这不是一个回合的分数):表示您获得的最后一个有效 回合的分数是无效的,应该被移除。
每一轮的操作都是永久性的,可能会对前一轮和后一轮产生影响。
你需要返回你在所有回合中得分的总和。
示例 1:
输入: ["5","2","C","D","+"]
输出: 30
解释:
第1轮:你可以得到5分。总和是:5。
第2轮:你可以得到2分。总和是:7。
操作1:第2轮的数据无效。总和是:5。
第3轮:你可以得到10分(第2轮的数据已被删除)。总数是:15。
第4轮:你可以得到5 + 10 = 15分。总数是:30。示例2
输入: ["5","-2","4","C","D","9","+","+"]
输出: 27
解释:
第1轮:你可以得到5分。总和是:5。
第2轮:你可以得到-2分。总数是:3。
第3轮:你可以得到4分。总和是:7。
操作1:第3轮的数据无效。总数是:3。
第4轮:你可以得到-4分(第三轮的数据已被删除)。总和是:-1。
第5轮:你可以得到9分。总数是:8。
第6轮:你可以得到-4 + 9 = 5分。总数是13。
第7轮:你可以得到9 + 5 = 14分。总数是27。注意:
/**
* @param {string[]} ops
* @return {number}
*/
var calPoints = function(ops) {
let nums = [];
let regexp = /[0-9]/;
for(let op of ops) {
if(regexp.test(op)) {
nums.push(op);
} else {
switch(op) {
case 'C':
nums.pop();
break;
case 'D':
nums.push(nums[nums.length - 1] * 2);
break;
case '+':
nums.push(parseInt(nums[nums.length - 1]) + parseInt(nums[nums.length - 2]));
break;
}
}
}
let sum = 0;
for(let num of nums) {
sum += parseInt(num);
}
return sum;
};找出奇数位上和偶数和偶数位上的奇数进行交换
/**
* @param {number[]} A
* @return {number[]}
*/
var sortArrayByParityII = function(A) {
let j = 1;
for(let i = 0; i < A.length;) {
if(i % 2 == A[i] % 2 ) {
i++;
if(j === i) {
j++;
}
continue;
}
[A[i], A[j]] = [A[j], A[i]];
j++;
}
return A;
};非线性数据结构-图
一组由边连接的节点(或顶点);
一个图G=(V, E)
由一条边连接在一起的顶点称为相邻顶点;
一个顶点的度是其相邻顶点的数量;
如果一个矩阵的每一方向由左上到右下的对角线上具有相同元素,那么这个矩阵是托普利茨矩阵。
给定一个 M x N 的矩阵,当且仅当它是托普利茨矩阵时返回 True。
示例 1:
输入:
matrix = [
[1,2,3,4],
[5,1,2,3],
[9,5,1,2]
]
输出: True
解释:
在上述矩阵中, 其对角线为:
"[9]", "[5, 5]", "[1, 1, 1]", "[2, 2, 2]", "[3, 3]", "[4]"。
各条对角线上的所有元素均相同, 因此答案是True。示例 2:
输入:
matrix = [
[1,2],
[2,2]
]
输出: False
解释:
对角线"[1, 2]"上的元素不同。说明:
进阶:
基本想法就是遍历每一个元素,同时比较这个元素和它右下角元素的值是否相等,如果不相等,直接返回false,停止遍历。
/**
* @param {number[][]} matrix
* @return {boolean}
*/
var isToeplitzMatrix = function(matrix) {
for(let i = 0; i < matrix.length -1; i++) {
for(let j = 0; j < matrix[i].length -1; j++) {
if(matrix[i+1][j+1] != matrix[i][j]) {
return false;
}
}
}
return true;
};给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行。
在杨辉三角中,每个数是它左上方和右上方的数的和。
示例:
输入: 3
输出: [1,3,3,1]/**
* @param {number} rowIndex
* @return {number[]}
*/
var getRow = function (rowIndex) {
let result = [1];
for (let i = 1; i <= rowIndex; i++) {
for (let j = result.length - 1; j > 0; j--) {
result[j] = result[j] + result[j - 1];
}
result = result.concat(1);
}
return result;
};给定一个非负整数 numRows,生成杨辉三角的前 numRows 行。
在杨辉三角中,每个数是它左上方和右上方的数的和。
var generate = function (numRows) {
let arr = new Array(numRows);
for (let i = 0; i < arr.length; i++) {
arr[i] = new Array(i + 1);
}
for (let i = 0; i < arr.length; i++) {
for (let j = 0; j < arr[i].length; j++) {
if (j === 0 || j === i) {
arr[i][j] = 1;
} else {
arr[i][j] = arr[i - 1][j - 1] + arr[i - 1][j];
}
}
}
return arr;
};给定两个句子 A 和 B 。(句子是一串由空格分隔的单词。每个单词仅由小写字母组成。)
如果一个单词在其中一个句子中只出现一次,在另一个句子中却没有出现,那么这个单词就是不常见的。
返回所有不常用单词的列表。
您可以按任何顺序返回列表。
示例 1:
输入:A = "this apple is sweet", B = "this apple is sour"
输出:["sweet","sour"]示例 2:
输入:A = "apple apple", B = "banana"
输出:["banana"]仔细分析一下其实就是, 先把这两个参数转换成数组, 把这两个数组合并, 找出只出现一次的元素.
遍历转换后的数组A和数组,找出只出现一次的元素
将两个数组合并,新建一个Map, 里面的key是当前元素, value为出现的次数, 最后统计次数为1的元素
方法一
/**
* @param {string} A
* @param {string} B
* @return {string[]}
*/
function checkout(paramA, arrB, A) {
let arrA = paramA.concat();
let result = [];
for(let i = 0; i < arrA.length; i++) {
let a = arrA[i];
arrA.splice(i, 1);
if(!arrA.includes(a) && !arrB.includes(a) ) {
result.push(a);
}
arrA = paramA.concat();
}
return result;
}
var uncommonFromSentences = function(A, B) {
let arrA = A.split(' ');
let arrB = B.split(' ');
return checkout(arrA, arrB, A).concat(checkout(arrB, arrA, B));
};方法二
var uncommonFromSentences = function(A, B) {
let map = new Map();
A.split(' ').concat(B.split(' ')).forEach(item => {
if(map.has(item)) {
map.set(item, map.get(item) + 1);
} else {
map.set(item, 1);
}
});
let result = [];
map.forEach((value, key, map) => {
if(value == 1) {
result.push(key);
}
})
return result;
};给定一个大小为 n 的数组,找到其中的众数。众数是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在众数。
示例 1:
···js
输入: [3,2,3]
输出: 3
示例 2:
```js
输入: [2,2,1,1,1,2,2]
输出: 2
摩尔投票算法:每次从序列中选择两个不同的数字删除掉(活称为"抵消"),最后剩下的一个数字或几个相同的数字,就是出现次数大于总数一半的那个;
参考:如何理解摩尔投票算法
/**
* @param {number[]} nums
* @return {number}
*/
var majorityElement = function(nums) {
let count = 0;
let major = 0;
for(let num of nums) {
if(count == 0) {
major = num;
}
count+= (major === num) ? 1 : -1;
}
return major;
};let insertNode = function(node, newNode) {
if(newNode.key < node.key) {
if(node.left == null) {
node.left = newNode;
} else {
insertNode(node.left, newNode)
}
} else {
if(node.right === null) {
node.right = newNode;
} else {
insertNode(node.right, newNode)
}
}
}
function BinarySearchTree() {
let Node = function(key) {
this.key = key;
this.left = null;
this.right = null;
}
let root = null;
this.insert = function(key) {
let newNode = new Node();
if (root == null) {
root = newNode;
} else {
insertNode(root, newNode);
}
}
// 中序遍历
this.inOrderTraverse = function(callback) {
}
// 后序遍历
}给定一个整数 n,返回 n! 结果尾数中零的数量。
示例 1:
输入: 3
输出: 0
解释: 3! = 6, 尾数中没有零。
示例 2:
输入: 5
输出: 1
解释: 5! = 120, 尾数中有 1 个零.
这个问题可以用数学的方法简单分析;
10 = 2 * 5(质因数分解)
从最末尾开始连续地每出现一个0,即表示有一个 (2 * 5) 组出现。
而对于正整数 N,在[0, N]范围内,质因子中含有 2 的总是会比质因子含有 5 的要多。即如果质因子有 5 的数字总数为 a,那么质因子为2的总数 b >= a。因此,有x个质因子含有 5 的数,就有至少x个含有 2 的数。
于是,只要需要知道质因数含有 5 的数字有多少个,即可知道末尾连续出现 0 的个数有多少
/**
* @param {number} n
* @return {number}
*/
var trailingZeroes = function (n) {
let count = 0;
// 因为可能出现一个数的质因子有多个5
while (n >= 5) {
n = Math.floor(n / 5);
count += n;
}
return count;
};给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。进阶:
如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。
这是一道动态规划类的题目;
声明两个变量, currentSum: 之前连续几个值相加的和, maxSum: 当前最大的子序列和
/**
* @param {number[]} nums
* @return {number}
*/
var maxSubArray = function(nums) {
let maxSum = nums[0];
let currentSum = nums[0];
for(let i = 1; i < nums.length; i++) {
currentSum = Math.max(nums[i], currentSum+=nums[i]); // 比较当前的和跟加上nums[i]后的值, 将较大的赋值给currentSum
maxSum = Math.max(currentSum, maxSum); // 比较currentSum, maxSum, 将较大的值赋值给maxSum
}
return maxSum;
};给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
示例 1:
输入: [2,2,1]
输出: 1示例 2:
输入: [4,1,2,1,2]
输出: 4使用异或的方法: 异或要化为二进制,来对比相同位置的数 相同置为 0 不同置为1 再化为十进制数。
零和任何数异或都等于任何数, 一个数异或两次就等于0;
又因为本题中除一个之外每个元素都出现两次,所以用循环异或所有数就等于 只出现一次的那个数
/**
* @param {number[]} nums
* @return {number}
*/
var singleNumber = function(nums) {
return nums.reduce((a, b) => a ^ b, 0);
};class Set {
constructor() {
this.items = {};
}
has(value) {
return this.items.hasOwnProperty(value);
}
add(value) {
if(!this.has(value)) {
this.items[value] = value;
return true;
}
return false;
}
remove(value) {
if(this.has(value)) {
delete this.items[value];
return true;
}
return false;
}
clear() {
this.items = {};
}
size() {
return Object.keys(this.items).length;
}
values() {
let values = [];
for(let key in this.items) {
if(this.items.hasOwnProperty(key)) {
values.push(this.items[key])
}
}
return values;
}
// 并集
union(otherSet) {
let unionSet = new Set();
let values = this.values();
for(let i = 0; i < values.length; i++) {
unionSet.add(values[i]);
}
values = otherSet.values();
for(let i = 0; i < values.length; i++) {
unionSet.add(values[i]);
}
return unionSet;
}
// 交集
intersection(otherSet) {
let intersectionSet = new Set();
let values = this.values();
for(let i = 0 ; i < values.length; i++) {
if(otherSet.has(values[i])) {
intersectionSet.add(values[i]);
}
}
return intersectionSet;
}
// 差集
difference(otherSet) {
let differenceSet = new Set();
let values = this.values();
for(let i = 0; i < values.length; i++) {
if(!otherSet.has(values[i])) {
differenceSet.add(values[i]);
}
}
return differenceSet;
}
// 子集
subSet(otherSet) {
if(this.size() > otherSet.size()) {
return false;
} else {
let values = this.values();
for(let i = 0; i < values.length; i++) {
if(!otherSet.has(values[i])) {
return false;
}
}
return true;
}
}
}
let setA = new Set();
setA.add(1);
setA.add(2);
setA.add(3);
let setB = new Set();
setB.add(2);
setB.add(3);
console.log(setA.subSet(setB));
console.log(setB.subSet(setA));在 N * N 的网格上,我们放置一些 1 * 1 * 1 的立方体。
每个值 v = grid[i][j] 表示 v 个正方体叠放在单元格 (i, j) 上。
返回结果形体的总表面积。
示例 1:
输入:[[2]]
输出:10示例 2:
输入:[[1,2],[3,4]]
输出:34示例 3:
输入:[[1,0],[0,2]]
输出:16示例 4:
输入:[[1,1,1],[1,0,1],[1,1,1]]
输出:32示例 5:
输入:[[2,2,2],[2,1,2],[2,2,2]]
输出:46提示:
1 <= N <= 50
0 <= grid[i][j] <= 50/**
* @param {number[][]} grid
* @return {number}
*/
var surfaceArea = function(grid) {
let result = 0;
for (let i = 0; i < grid.length; i++)
for (let j=0; j < grid[i].length; j++) {
result += (4 * grid[i][j]);
result += (grid[i][j] > 0) ? 2 : 0;
result -= (i > 0) ? (2 * Math.min(grid[i-1][j], grid[i][j])) : 0;
result -= (j > 0) ? (2 * Math.min(grid[i][j-1], grid[i][j])) : 0;
}
return result;
};在大小为 2N 的数组 A 中有 N+1 个不同的元素,其中有一个元素重复了 N 次。
返回重复了 N 次的那个元素。
示例 1:
输入:[1,2,3,3]
输出:3示例 2:
输入:[2,1,2,5,3,2]
输出:2示例 3:
输入:[5,1,5,2,5,3,5,4]
输出:5提示:
4 <= A.length <= 10000
0 <= A[i] < 10000
A.length 为偶数
总共2N个 N+1种 有一个有N个 那么只有一个数字有复数个 所以只要找到大于1个那个数字就可以了
/**
* @param {number[]} A
* @return {number}
*/
var repeatedNTimes = function(A) {
let obj = {}
for(let i = 0; i < A.length; i++){
if(A[i] in obj) {
return A[i];
}
obj[A[i]] = 0;
}
};给定一个非负整数组成的非空数组,在该数的基础上加一,返回一个新的数组。
最高位数字存放在数组的首位, 数组中每个元素只存储一个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入: [1,2,3]
输出: [1,2,4]
解释: 输入数组表示数字 123。示例 2:
输入: [4,3,2,1]
输出: [4,3,2,2]
解释: 输入数组表示数字 4321。我们需要给这个数字加一,即在末尾数数字加一, 如果是9,则存在进位问题, 如果前面的位数是9,则需要继续向前进位
具体算法:
1.判断最后一位是否为小于9, 如果是,则加一返回;如果是9,则该位置赋值为0,再继续查找前一位, 直到查到第一位, 若第一位原本是9,加一会产生新的一位
2.查找运算完的第一位是否为0, 如果是 ,则在最前头一位加一个1
/**
* @param {number[]} digits
* @return {number[]}
*/
var plusOne = function(digits) {
const length = digits.length;
for(let i = length -1; i >=0; --i) {
if(digits[i] < 9) {
++digits[i];
return digits;
}
digits[i] = 0;
}
let res = [1];
return res.concat(digits);
};用来存储唯一值(不重复的)的数据结构
字典存储的是【键, 值】对;
创建字典
class Dictionary {
constructor() {
this.items = {};
}
has(key) {
return key in this.items;
}
set(key, value) {
this.items[key] = value;
}
delete(key, value) {
if(this.has(key)) {
delete this.items[key];
return true;
}
return false;
}
get(key) {
return this.items[key] ? this.items[key] : undefined;
}
values() {
let values = [];
for(let k in this.items) {
if(this.has(k)) {
values.push(this.items[k]);
}
}
return values;
}
clear() {
this.items = {};
}
size() {
return this.values().length;
}
keys() {
return Object.keys(this.items);
}
getItems() {
return this.items;
}
}
let dictionary = new Dictionary();
dictionary.set('aa', 'aa.com');
dictionary.set('bb', 'bb.com');
dictionary.set('cc', 'cc.com');
dictionary.delete('aa')
console.log(dictionary.keys());
console.log(dictionary.values());
console.log(dictionary.getItems());散列算法的作用是尽可能快的在数据结构中找到一个值
var loseloseHashCode = function(key) {
let hash = 0;
for(let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % 37;
}
class HashTable{
constructor() {
this.table = [];
}
put(key, value) {
let position = loseloseHashCode(key);
console.log(position + '-' + key);
this.table[position] = value;
}
get(key) {
return this.table[loseloseHashCode(key)];
}
remove(key) {
this.table[loseloseHashCode(key)] = undefined;
}
}
const hash = new HashTable();
hash.put('Gandalf', 'aa.com');
hash.put('John', 'bb.com');
hash.put('Tyrion', 'cc.com');
console.log(hash.get('Gandalf'));
console.log(hash.remove('John'));
console.log(hash.get('John'));假如列表包含n个元素,
简单查找需要检查每个元素,因此需要执行n次操作.使用大O表示法,这个运行的时间为O(n);
二分查找需要执行log 次操作。使用大O表示法,这个运行的时间为O(log n);
大O表示法让你能够比较操作数,它指出了算法运行时间的增速
加入要绘制一个包含16格的网格,且有5种不同的算法可供选择
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4新建一个链表,然后比较两个链表中的元素值,把较小的那个链到新链表中,由于两个输入链表的长度可能不同,所以最终会有一个链表先完成插入所有元素,则直接另一个未完成的链表直接链入新链表的末尾。
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} l1
* @param {ListNode} l2
* @return {ListNode}
*/
var mergeTwoLists = function(l1, l2) {
let res = new ListNode(-1);
let cur = res;
while(l1 !== null && l2 !== null) {
if (l1.val < l2.val){
cur.next = l1;
l1 = l1.next;
} else {
cur.next = l2;
l2 = l2.next;
}
cur = cur.next;
}
cur.next = (l1 === null) ? l2 : l1;
return res.next;
};给定由 N 个小写字母字符串组成的数组 A,其中每个字符串长度相等。
选取一个删除索引序列,对于 A 中的每个字符串,删除对应每个索引处的字符。 所余下的字符串行从上往下读形成列。
比如,有 A = ["abcdef", "uvwxyz"],删除索引序列 {0, 2, 3},删除后 A 为["bef", "vyz"], A 的列分别为["b","v"], ["e","y"], ["f","z"]。(形式上,第 n 列为 [A[0][n], A[1][n], ..., A[A.length-1][n]])。
假设,我们选择了一组删除索引 D,那么在执行删除操作之后,A 中所剩余的每一列都必须是 非降序 排列的,然后请你返回 D.length 的最小可能值
示例 1:
输入:["cba", "daf", "ghi"]
输出:1
解释:
当选择 D = {1},删除后 A 的列为:["c","d","g"] 和 ["a","f","i"],均为非降序排列。
若选择 D = {},那么 A 的列 ["b","a","h"] 就不是非降序排列了。示例 2:
输入:["a", "b"]
输出:0
解释:D = {}示例 3:
输入:["zyx", "wvu", "tsr"]
输出:3
解释:D = {0, 1, 2}提示:
1 <= A.length <= 100
1 <= A[i].length <= 1000
/**
* @param {string[]} A
* @return {number}
*/
var minDeletionSize = function(A) {
let strLen = A[0].length;
let min = 0;
for(let i = 0; i < strLen; i++) {
for(let j = 0; j < A.length - 1; j++) {
if(A[j].charAt(i) > A[j + 1].charAt(i)) {
min++;
break;
}
}
}
return min;
};给定一个偶数长度的数组,其中不同的数字代表着不同种类的糖果,每一个数字代表一个糖果。你需要把这些糖果平均分给一个弟弟和一个妹妹。返回妹妹可以获得的最大糖果的种类数。
示例 1:
输入: candies = [1,1,2,2,3,3]
输出: 3
解析: 一共有三种种类的糖果,每一种都有两个。
最优分配方案:妹妹获得[1,2,3],弟弟也获得[1,2,3]。这样使妹妹获得糖果的种类数最多。示例 2 :
输入: candies = [1,1,2,3]
输出: 2
解析: 妹妹获得糖果[2,3],弟弟获得糖果[1,1],妹妹有两种不同的糖果,弟弟只有一种。这样使得妹妹可以获得的糖果种类数最多。注意:
数组的长度为[2, 10,000],并且确定为偶数。
数组中数字的大小在范围[-100,000, 100,000]内。
/**
* @param {number[]} candies
* @return {number}
*/
var distributeCandies = function(candies) {
return Math.min(new Set(candies).size,candies.length / 2);
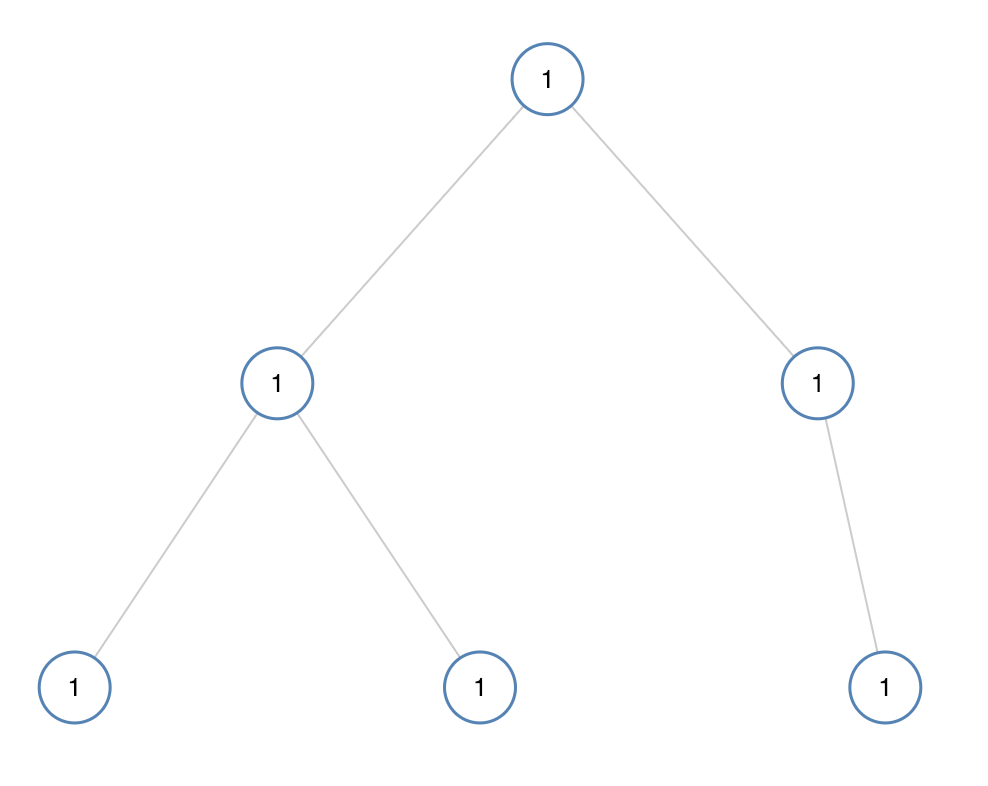
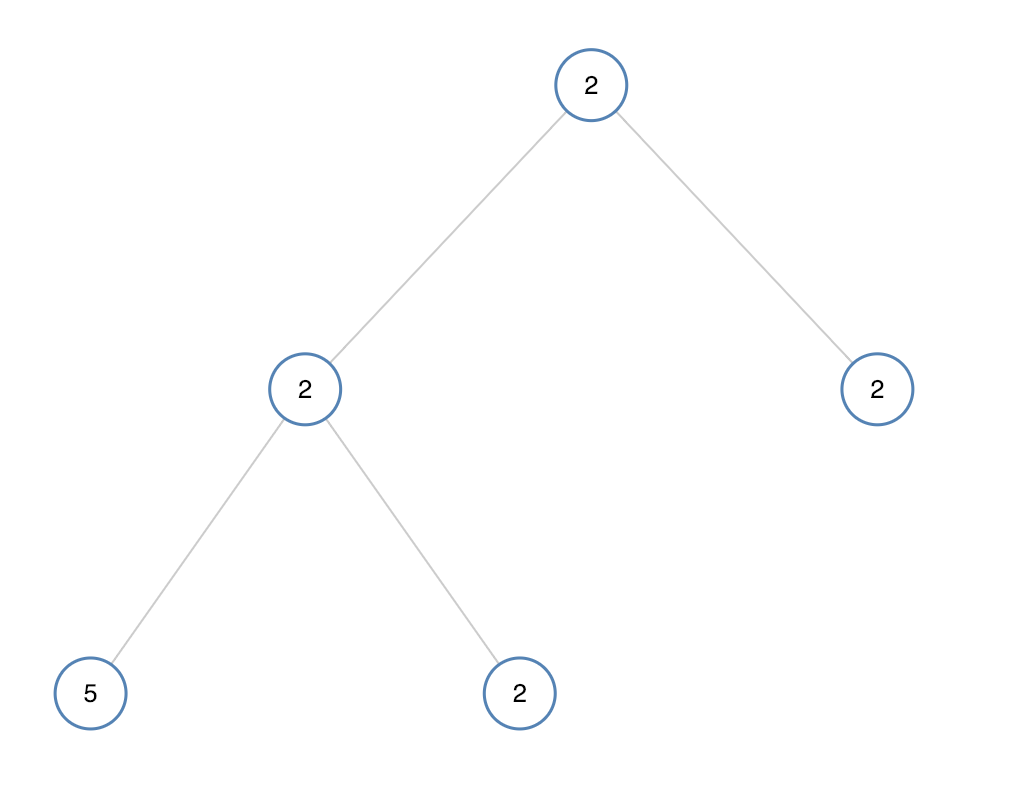
};如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
只有给定的树是单值二叉树时,才返回 true;否则返回 false。
示例 1:
输入:[1,1,1,1,1,null,1]
输出:true
示例 2:
输入:[2,2,2,5,2]
输出:false
提示:
给定树的节点数范围是 [1, 100]。
每个节点的值都是整数,范围为 [0, 99] 。
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @return {boolean}
*/
var isUnivalTree = function(root) {
return isSame(root,root.val);
function isSame(node,value){
if(node == null){
return true;
} else {
if(node.val != value){
return false;
} else {
return isSame(node.left,node.val) && isSame(node.right,node.val);
}
}
}
};斐波那契数,通常用 F(n) 表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
给定 N,计算 F(N)。
示例 1:
输入:2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1.示例 2:
输入:3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2.示例 3:
输入:4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3.提示:
0 ≤ N ≤ 30
/**
* @param {number} N
* @return {number}
*/
var fib = function(N) {
let cache = {
0: 0,
1: 1
};
return typeof cache[N] === 'number'
? cache[N]
: cache[N] = fib(N - 1) + fib(N - 2);
};https://leetcode-cn.com/problems/lru-cache/
1.使用Map记录缓存值,使用链表记录缓存操作顺序,最后操作的缓存放在链表头部,链表尾部就是最少操作的缓存
2.读取缓存时,更新缓存操作顺序,将缓存节点从链表中移除, 再将其添加到链表头部, 移除节点时要保证链表的连续性,为了在 O(1)时间完成该操作,需要使用双向链表
3.设置缓存时
class DoubleLinkList {
constructor() {
this.head = null;
this.tail = null;
this.length = 0;
}
/**
* 链表头部插入
* 1.如果头部和尾部都存在, 则直接在头部之前插入
* 修改原来head的prev指向当前node, node的next指向原先的head, node的prev设置为null修改head为当前node
* 2.如果头部或尾部不存在, 则设置当前node为head和tail
* node的next指向null, node的prev设置为nul
*/
unshift(node) {
if (this.head && this.tail) {
node.prev = null;
node.next = this.head;
this.head.prev = node;
this.head = node;
} else {
node.prev = node.next = null;
this.head = this.tail = node;
}
this.length++;
return node;
/**
* 链表尾部删除
* 1.判断tail是否存在
* 2.判断head和tail是否相等
* 相等: this.head = this.tail = null;
* 不相等: this.tail.prev.next = null; this.tail = this.tail.prev;
*/
pop() {
if (this.tail) {
const node = this.tail;
if (this.head === this.tail) {
this.head = this.tail = null;
} else {
this.tail.prev.next = null;
this.tail = this.tail.prev;
}
this.length--;
return node;
}
}
/**
* 删除具体的某个节点
* 1.node等于head
* 2.node等于tail
* 3.node即不等于head, 也不等于tail
*/
remove(node) {
if (node !== this.head && node !== this.tail) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
if (node === this.head) {
this.head = this.head.next;
}
if (node === this.tail) {
this.tail = this.tail.prev;
}
this.length--;
}
}
class LRUCache {
constructor(capacity) {
this.capacity = capacity;
this.list = new DoubleLinkList();
this.map = new Map();
}
get(key) {
let node = this.map.get(key);
if (node) {
this.list.remove(node);
this.list.unshift(node);
return node.value;
} else {
return -1;
}
}
put(key, value) {
let node = this.map.get(key);
if (node) {
node.value = value;
this.list.remove(node);
this.list.unshift(node);
} else {
node = { key, value };
this.list.unshift(node);
this.map.set(key, node);
if (this.list.length > this.capacity) {
const tail = this.list.pop();
this.map.delete(tail.key);
}
}
}
}我们称一个数 X 为好数, 如果它的每位数字逐个地被旋转 180 度后,我们仍可以得到一个有效的,且和 X 不同的数。要求每位数字都要被旋转。
如果一个数的每位数字被旋转以后仍然还是一个数字, 则这个数是有效的。0, 1, 和 8 被旋转后仍然是它们自己;2 和 5 可以互相旋转成对方;6 和 9 同理,除了这些以外其他的数字旋转以后都不再是有效的数字。
现在我们有一个正整数 N, 计算从 1 到 N 中有多少个数 X 是好数?
示例:
输入: 10
输出: 4
解释:
在[1, 10]中有四个好数: 2, 5, 6, 9。
注意 1 和 10 不是好数, 因为他们在旋转之后不变。提示:
N 的取值范围是 [1, 10000]。
/**
* @param {number} N
* @return {number}
*/
var rotatedDigits = function(N) {
let count = 0;
for(let i = 0; i <= N; i++) {
let num = i + '';
if (!/[347]/g.test(num) && /[2569]/g.test(num)) {
count++
}
}
return count;
};class Heap {
constructor() {
this.data = [];
}
build(arr) {
this.data = [];
for (let i = 0; i < arr.length; i++) {
this.insert(arr[i]);
}
}
print() {
console.log(this.data);
}
insert(value) {
// 先把当前元素加到最后一个位置
this.data.push(value);
// 获取当前元素的index
let nIndex = this.data.length - 1;
// 获取父节点
let nParentIndex = Math.floor((nIndex - 1) / 2);
while (nParentIndex >= 0) {
// 当前节点大于父节点,则交换顺序
if (this.data[nIndex] > this.data[nParentIndex]) {
[this.data[nIndex], this.data[nParentIndex]] = [
this.data[nParentIndex],
this.data[nIndex],
];
}
// 当前父元素赋值为 nIndex
nIndex = nParentIndex;
// 获取再上一个父元素的下标
nParentIndex = Math.floor((nIndex - 1) / 2);
}
}
// 删除最大节点
delete() {
if (this.data.length <= 1) {
return (this.data = []);
}
// 把最后一个节点临时补到原本堆顶的位置
// 删除第一个节点,将最后一个子节点补充到根节点
this.data[0] = this.data.pop();
let len = this.data.length;
let curIndex = 0;
// 暂时处于堆顶位置的节点和它的左右孩子节点进行比较
while (curIndex < len) {
let nLeftIndex = 2 * curIndex + 1;
let nRightIndex = 2 * curIndex + 1;
let maxLeafIndex = nLeftIndex;
// 找到左右节点中较大的一个 nSelectIndex
if (nRightIndex < len) {
maxLeafIndex =
this.data[nLeftIndex] > this.data[nRightIndex] ? nLeftIndex : nRightIndex;
}
// 判断 maxLeafIndex 如果大于 curIndex, 则交换
if (maxLeafIndex < len && this.data[maxLeafIndex] > this.data[curIndex]) {
[this.data[maxLeafIndex], this.data[curIndex]] = [
this.data[curIndex],
this.data[maxLeafIndex],
];
}
curIndex = maxLeafIndex;
}
}
}
const heap = new Heap();
heap.build([1, 3, 4, 2]);
heap.print(); // [ 4, 2, 3, 1 ]
heap.delete();
heap.print(); // [ 3, 2, 1 ]这几道题其实很相似,所以可以放在一起理解。
给定两个二叉树,编写一个函数来检验它们是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:
输入: 1 1
/ \ / \
2 3 2 3
[1,2,3], [1,2,3]
输出: true示例 2:
输入: 1 1
/ \
2 2
[1,2], [1,null,2]
输出: false示例 3:
输入: 1 1
/ \ / \
2 1 1 2
[1,2,1], [1,1,2]
输出: false使用深度优先遍历;
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} p
* @param {TreeNode} q
* @return {boolean}
*/
var isSameTree = function(p, q) {
// 两棵树的当前节点都为null时,返回true
if(p == null && q == null) {
return true;
}
// 当其中一个是null,另外一个不是 null时,返回 false
if(p == null || q == null) {
return false
}
// 当两个都不为null,但是值不相等时,返回 false
if(p.val !== q.val) {
return false;
}
// 不断递归两颗树的左右子树
return isSameTree(p.left, q.left) && isSameTree(p.right, q.right);
};给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
进阶:
你可以运用递归和迭代两种方法解决这个问题吗?
这个问题可以转化为 两个树在什么情况下互为镜像?
如果同时满足下面的条件,两个树互为镜像:
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @return {boolean}
*/
var isSymmetric = function(root) {
function isMirror(p, q) {
if(p == null && q == null) {
return true;
}
if(p == null || q == null) {
return false;
}
if(p.val !== q.val) {
return false;
}
return isMirror(p.left, q.right) && isMirror(p.right, q.left);
}
return isMirror(root, root);
};翻转一棵二叉树。
示例:
输入:
4
/ \
2 7
/ \ / \
1 3 6 9
输出:
4
/ \
7 2
/ \ / \
9 6 3 1递归的交换左右子树。
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @return {TreeNode}
*/
var invertTree = function(root) {
// 当节点为 null 的时候直接返回
if(root === null) {
return root;
}
// 如果当前结点不为null,那么先将其左右子树进行翻转,然后交换左右子树
let right = invertTree(root.right);
let left = invertTree(root.left);
root.left = right;
root.right = left;
// 返回值为完成了翻转后的当前结点
return root;
};根据每日 气温 列表,请重新生成一个列表,对应位置的输入是你需要再等待多久温度才会升高的天数。如果之后都不会升高,请输入 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的都是 [30, 100] 范围内的整数。
/**
* @param {number[]} T
* @return {number[]}
*/
var dailyTemperatures = function(T) {
let len = T.length;
let res = [];
res[len - 1] = 0;
for(let i = len - 2; i >= 0; i--) {
for(let j = i + 1; j < len; j+= res[j]) {
if(T[i] < T[j]) {
res[i] = j - i;
break;
} else if(res[j] == 0) {
res[i] = 0;
break;
}
}
}
return res;
};编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
给定 target = 5,返回 true。
给定 target = 20,返回 false。分治法
/**
* @param {number[][]} matrix
* @param {number} target
* @return {boolean}
*/
var searchMatrix = function (matrix, target) {
const m = matrix.length;
if (m === 0) {
return false;
}
const n = matrix[0].length;
if (n === 0) {
return false;
}
let i = m - 1;
let j = 0;
while (i >= 0 && j < n) {
if (matrix[i][j] === target) {
return true;
} else if (matrix[i][j] < target) {
j++;
} else {
i--;
}
}
return false;
};
队列是遵循FIFO( First In First Out, 先进先出)原则的一组有序的项
class Queue {
constructor() {
this.items = [];
}
enqueue(element) {
this.items.push(element)
}
// 从队列移除元素
dequeue() {
return this.items.shift();
}
// 查看队头元素
front() {
return this.items[0];
}
isEmpty() {
return this.items.length == 0;
}
size() {
return this.items.length;
}
clear() {
this.items = [];
}
print() {
console.log(this.items.toString());
}
}元素的添加和删除是基于优先级的.例如机场登机的顺序, 头等舱和商务舱乘客的优先级要高于经济舱.
function PriorityQueue() {
let items = [];
function QueueElement(element, priority) {
this.element = element;
this.priority = priority;
}
this.enqueue = function(element, priority) {
let queueElement = new QueueElement(element, priority);
let added = false;
for(let i = 0; i < items.length; i++) {
if(queueElement.priority < items[i].priority) {
items.splice(i, 0, queueElement);
added = true;
break;
}
}
if(!added) {
items.push(queueElement);
}
}
this.print = function() {
for(let i = 0; i < items.length; i++) {
console.log(`${items[i].element} - ${items[i].priority}`);
}
}
}
let priorityQueue = new PriorityQueue();
priorityQueue.enqueue('Join', 2);
priorityQueue.enqueue('Jack', 1);
priorityQueue.enqueue('Camila', 1);
priorityQueue.print();以上代码实现的是最小优先队列.因为优先级较小的值放在队列的最前面, 最大优先队列跟这个是相反的
function hotPotato (nameList, num) {
let queue = new Queue();
for(let i = 0; i < nameList.length; i++) {
queue.enqueue(nameList[i]);
}
let eliminated = '';
while(queue.size() > 1) {
for(let i = 0;i < num ; i++) {
queue.enqueue(queue.dequeue());
}
eliminated = queue.dequeue();
console.log(eliminated + '在击鼓传花游戏中被淘汰');
}
return queue.dequeue();
}
let names = ['John', 'Jack', 'Camia', 'Ingrid', 'Carl'];
let winner = hotPotato(names, 7);
console.log('The winner is:' + winner);需要将数据数据存储到内存时, 你请求计算机提供存储空间, 计算机给你存储地址。需要存储多项数据时, 有两种基本方式--数组和链表
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function (nums, target) {
var len = nums.length;
var numObj = {};
for (var i = 0; i < len; i++) {
var current = nums[i];
var match = target - current;
if (match in numObj) {
return [i, numObj[match]];
} else {
numObj[current] = i;
}
}
};给定一个整数数组 A,如果它是有效的山脉数组就返回 true,否则返回 false。
让我们回顾一下,如果 A 满足下述条件,那么它是一个山脉数组:
A.length >= 3
在 0 < i < A.length - 1 条件下,存在 i 使得:
A[0] < A[1] < ... A[i-1] < A[i]
A[i] > A[i+1] > ... > A[B.length - 1]示例 1:
输入:[2,1]
输出:false示例 2:
输入:[3,5,5]
输出:false示例 3:
输入:[0,3,2,1]
输出:true提示:
0 <= A.length <= 10000
0 <= A[i] <= 10000
首先解读题目中山脉数组的定义:长度大于3,且先递增后递减的数组。
具体解决思路
/**
* @param {number[]} A
* @return {boolean}
*/
var validMountainArray = function(A) {
if(A.length < 3) {
return false;
}
let max = A[0];
let maxIndex = 0;
for(let i = 1; i < A.length; i++) {
let a = A[i];
if(a > max) {
max = a;
maxIndex = i;
}
}
if(maxIndex > 0 && maxIndex < A.length - 1) {
let isIncrease = true;
let isDecrease = true;
for(let i = 0; i < maxIndex; i++) {
if(A[i] > A[i+1]) {
isIncrease = false;
break;
}
}
for(let i = maxIndex; i < A.length - 1; i++) {
if(A[i] <= A[i+1]) {
isDecrease = false;
break;
}
}
return isIncrease && isDecrease;
} else {
return false;
}
};给定只含 "I"(增大)或 "D"(减小)的字符串 S ,令 N = S.length。
返回 [0, 1, ..., N] 的任意排列 A 使得对于所有 i = 0, ..., N-1,都有:
如果 S[i] == "I",那么 A[i] < A[i+1]
如果 S[i] == "D",那么 A[i] > A[i+1]
示例 1:
输出:"IDID"
输出:[0,4,1,3,2]示例 2:
输出:"III"
输出:[0,1,2,3]示例 3:
输出:"DDI"
输出:[3,2,0,1]提示:
1 <= S.length <= 1000
S 只包含字符 "I" 或 "D"。
利用双指针来添加,当遇到"I":将左指针指向的值添加到数组中并右移(用当前双指针范围的最小值添加,是最安全的);当遇到"D":将右指针指向的值添加到数组中并左移(用当前双指针范围的最大值添加,是最安全的),最后把左右指针同时指向的值添加进去即为最后结果。
/**
* @param {string} S
* @return {number[]}
*/
var diStringMatch = function(S) {
let m = S.length;
let n = 0;
let result = [];
for(let i = 0; i < S.length; i++) {
if(S[i] == 'I') {
result.push(n++);
} else {
result.push(m--);
}
}
result.push(m);
return result;
};给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]遍历每一个元素, 并查找是否存在一个值与target - X 相等的目标元素
var twoSum = function (nums, target) {
for (let i = 0; i < nums.length; i++) {
for (let j = i + 1; j < nums.length; j++) {
const sum = nums[i] + nums[j];
if (sum === target) {
return [i, j];
}
}
}
};复杂度分析
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.