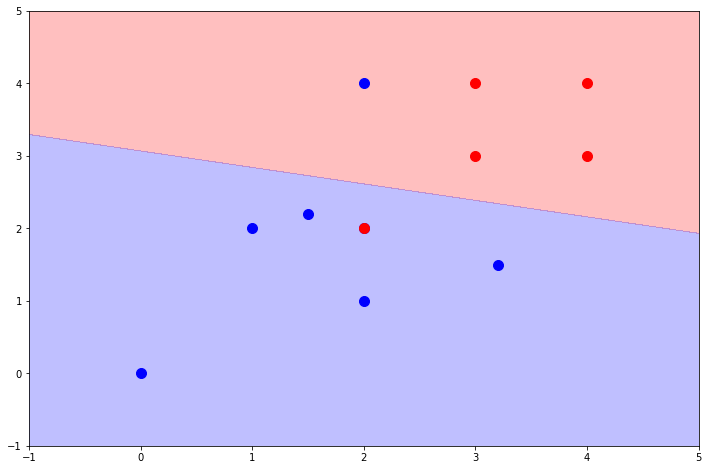
This is an implementation of a training algorithm for a linear classifier.
The training algorithm is based on the Gauss-Seidel method for solving systems of linear equations. Some adjustments had to be made to apply the method to a linear classifier:
- w*x+b > 0 inequality for positive samples is converted to w*x+b = 1
- w*x+b < 0 inequality for negative samples is converted to w*x+b = -1
- If the A matrix has zeros on the main diagonal, some weights won't be updated for that iteration
- The training data is tiled to form problems with a square A matrix
It is possible for the problem to converge even in linearly inseparable problems, in which case we
hope to minimize the empirical risk according to the hinge-loss function.
- numpy
- python 3.6
- jupyter (to try the notebook)
- matplotlib (to plot the resulting hyperplane)