This is a Python toolbox that implements the training and testing of the approach described in our papers:
Fine-tuning CNN Image Retrieval with No Human Annotation,
Radenović F., Tolias G., Chum O.,
TPAMI 2018 [arXiv]
CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples,
Radenović F., Tolias G., Chum O.,
ECCV 2016 [arXiv]
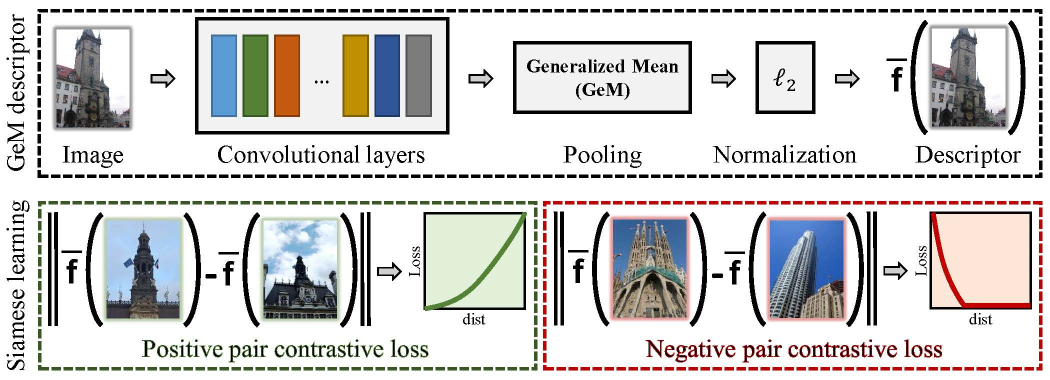
This code implements:
- Training (fine-tuning) CNN for image retrieval
- Learning supervised whitening, as post-processing, for global image descriptors
- Testing CNN image retrieval on Oxford and Paris datasets
In order to run this toolbox you will need:
- Python3 (tested with Python 3.7.0 on Debian 8.1)
- PyTorch deep learning framework (tested with version 1.0.0)
- All the rest (data + networks) is automatically downloaded with our scripts
Navigate (cd) to the root of the toolbox [YOUR_CIRTORCH_ROOT].
You can install package with pip3 install . if you need.
Make sure to have desired PyTorch and torchvision packages installed.
Training
Example training script is located in YOUR_CIRTORCH_ROOT/cirtorch/examples/train.py
python3 -m cirtorch.examples.train [-h] [--training-dataset DATASET] [--no-val]
[--test-datasets DATASETS] [--test-whiten DATASET]
[--test-freq N] [--arch ARCH] [--pool POOL]
[--local-whitening] [--regional] [--whitening]
[--not-pretrained] [--loss LOSS] [--loss-margin LM]
[--image-size N] [--neg-num N] [--query-size N]
[--pool-size N] [--gpu-id N] [--workers N] [--epochs N]
[--batch-size N] [--optimizer OPTIMIZER] [--lr LR]
[--momentum M] [--weight-decay W] [--print-freq N]
[--resume FILENAME]
EXPORT_DIR
For detailed explanation of the options run:
python3 -m cirtorch.examples.train -h
Note: Data and networks used for training and testing are automatically downloaded when using the example script.
Testing
Example testing script is located in YOUR_CIRTORCH_ROOT/cirtorch/examples/test.py
python3 -m cirtorch.examples.test [-h] (--network-path NETWORK | --network-offtheshelf NETWORK)
[--datasets DATASETS] [--image-size N]
[--multiscale MULTISCALE] [--whitening WHITENING] [--gpu-id N]
For detailed explanation of the options run:
python3 -m cirtorch.examples.test -h
Note: Data used for testing are automatically downloaded when using the example script.
Training
For example, to train our best network described in the TPAMI 2018 paper run the following command. After each epoch, the fine-tuned network will be tested on the revisited Oxford and Paris benchmarks:
python3 -m cirtorch.examples.train YOUR_EXPORT_DIR --gpu-id '0' --training-dataset 'retrieval-SfM-120k'
--test-datasets 'roxford5k,rparis6k' --arch 'resnet101' --pool 'gem' --loss 'contrastive'
--loss-margin 0.85 --optimizer 'adam' --lr 5e-7 --neg-num 5 --query-size=2000
--pool-size=22000 --batch-size 5 --image-size 362
Networks can be evaluated with learned whitening after each epoch (whitening is estimated at the end of the epoch). To achieve this run the following command. Note that this will significantly slow down the entire training procedure, and you can evaluate networks with learned whitening later on using the example test script.
python3 -m cirtorch.examples.train YOUR_EXPORT_DIR --gpu-id '0' --training-dataset 'retrieval-SfM-120k'
--test-datasets 'roxford5k,rparis6k' --test-whiten 'retrieval-SfM-30k'
--arch 'resnet101' --pool 'gem' --loss 'contrastive' --loss-margin 0.85
--optimizer 'adam' --lr 5e-7 --neg-num 5 --query-size=2000 --pool-size=22000
--batch-size 5 --image-size 362
Note: Adjusted (lower) learning rate is set to achieve similar performance as with MatConvNet and PyTorch-0.3.0 implementation of the training.
Testing our pretrained networks
Pretrained networks trained using the same parameters as in our TPAMI 2018 paper are provided, with precomputed post-processing whitening step. To evaluate them run:
python3 -m cirtorch.examples.test --gpu-id '0' --network-path 'retrievalSfM120k-resnet101-gem'
--datasets 'oxford5k,paris6k,roxford5k,rparis6k'
--whitening 'retrieval-SfM-120k'
--multiscale '[1, 1/2**(1/2), 1/2]'
or
python3 -m cirtorch.examples.test --gpu-id '0' --network-path 'retrievalSfM120k-vgg16-gem'
--datasets 'oxford5k,paris6k,roxford5k,rparis6k'
--whitening 'retrieval-SfM-120k'
--multiscale '[1, 1/2**(1/2), 1/2]'
The table below shows the performance comparison of networks trained with this framework and the networks used in the paper which were trained with our CNN Image Retrieval in MatConvNet:
| Model | Oxford | Paris | ROxf (M) | RPar (M) | ROxf (H) | RPar (H) |
|---|---|---|---|---|---|---|
| VGG16-GeM (MatConvNet) | 87.9 | 87.7 | 61.9 | 69.3 | 33.7 | 44.3 |
| VGG16-GeM (PyTorch) | 87.3 | 87.8 | 60.9 | 69.3 | 32.9 | 44.2 |
| ResNet101-GeM (MatConvNet) | 87.8 | 92.7 | 64.7 | 77.2 | 38.5 | 56.3 |
| ResNet101-GeM (PyTorch) | 88.2 | 92.5 | 65.4 | 76.7 | 40.1 | 55.2 |
Note (June 2022): We updated download files for Oxford 5k and Paris 6k images to use images with blurred faces as suggested by the original dataset owners. Bear in mind, "experiments have shown that one can use the face-blurred version for benchmarking image retrieval with negligible loss of accuracy".
Testing your trained networks
To evaluate your trained network using single scale and without learning whitening:
python3 -m cirtorch.examples.test --gpu-id '0' --network-path YOUR_NETWORK_PATH
--datasets 'oxford5k,paris6k,roxford5k,rparis6k'
To evaluate trained network using multi scale evaluation and with learned whitening as post-processing:
python3 -m cirtorch.examples.test --gpu-id '0' --network-path YOUR_NETWORK_PATH
--datasets 'oxford5k,paris6k,roxford5k,rparis6k'
--whitening 'retrieval-SfM-120k'
--multiscale '[1, 1/2**(1/2), 1/2]'
Testing off-the-shelf networks
Off-the-shelf networks can be evaluated as well, for example:
python3 -m cirtorch.examples.test --gpu-id '0' --network-offtheshelf 'resnet101-gem'
--datasets 'oxford5k,paris6k,roxford5k,rparis6k'
--whitening 'retrieval-SfM-120k'
--multiscale '[1, 1/2**(1/2), 1/2]'
Training
An alternative architecture includes a learnable FC (projection) layer after the global pooling. It is important to initialize the parameters of this layer with the result of learned whitening.
To train such a setup you should run the following commands (the performance will be evaluated every 5 epochs on roxford5k and rparis6k):
python3 -m cirtorch.examples.train YOUR_EXPORT_DIR --gpu-id '0' --training-dataset 'retrieval-SfM-120k'
--loss 'triplet' --loss-margin 0.5 --optimizer 'adam' --lr 1e-6
--arch 'resnet50' --pool 'gem' --whitening
--neg-num 5 --query-size=2000 --pool-size=20000
--batch-size 5 --image-size 1024 --epochs 100
--test-datasets 'roxford5k,rparis6k' --test-freq 5
or
python3 -m cirtorch.examples.train YOUR_EXPORT_DIR --gpu-id '0' --training-dataset 'retrieval-SfM-120k'
--loss 'triplet' --loss-margin 0.5 --optimizer 'adam' --lr 5e-7
--arch 'resnet101' --pool 'gem' --whitening
--neg-num 4 --query-size=2000 --pool-size=20000
--batch-size 5 --image-size 1024 --epochs 100
--test-datasets 'roxford5k,rparis6k' --test-freq 5
or
python3 -m cirtorch.examples.train YOUR_EXPORT_DIR --gpu-id '0' --training-dataset 'retrieval-SfM-120k'
--loss 'triplet' --loss-margin 0.5 --optimizer 'adam' --lr 5e-7
--arch 'resnet152' --pool 'gem' --whitening
--neg-num 3 --query-size=2000 --pool-size=20000
--batch-size 5 --image-size 900 --epochs 100
--test-datasets 'roxford5k,rparis6k' --test-freq 5
for ResNet50, ResNet101, or ResNet152, respectively.
Implementation details:
- The FC layer is initialized with the result of whitening learned in a supervised manner using our training data and off-the-shelf features.
- The whitening for this FC layer is precomputed for popular architectures and pooling methods, see imageretrievalnet.py#L50 for the full list of precomputed FC layers.
- When this FC layer is added in the fine-tuning procedure, the performance is highest if the images are with a similar high-resolution at train and test time.
- When this FC layer is added, the distribution of pairwise distances changes significantly, so roughly twice larger margin should be used for contrastive loss. In this scenario, triplet loss performs slightly better.
- Additional tunning of hyper-parameters can be performed to achieve higher performance or faster training. Note that, in this example,
--neg-numand--image-sizehyper-parameters are chosen such that the training can be performed on a single GPU with16 GBof memory.
Testing our pretrained networks with projection layer
Pretrained networks with projection layer are provided, trained both on retrieval-SfM-120k (rSfM120k) and google-landmarks-2018 (gl18) train datasets.
For this architecture, there is no need to compute whitening as post-processing step (typically the performance boost is insignificant), although one can do that, as well.
For example, multi-scale evaluation of ResNet101 with GeM with projection layer trained on google-landmarks-2018 (gl18) dataset using high-resolution images and a triplet loss, is performed with the following script:
python3 -m cirtorch.examples.test_e2e --gpu-id '0' --network 'gl18-tl-resnet101-gem-w'
--datasets 'roxford5k,rparis6k' --multiscale '[1, 2**(1/2), 1/2**(1/2)]'
Multi-scale performance of all available pre-trained networks is given in the following table:
| Model | ROxf (M) | RPar (M) | ROxf (H) | RPar (H) |
|---|---|---|---|---|
| rSfM120k-tl-resnet50-gem-w | 64.7 | 76.3 | 39.0 | 54.9 |
| rSfM120k-tl-resnet101-gem-w | 67.8 | 77.6 | 41.7 | 56.3 |
| rSfM120k-tl-resnet152-gem-w | 68.8 | 78.0 | 41.3 | 57.2 |
| gl18-tl-resnet50-gem-w | 63.6 | 78.0 | 40.9 | 57.5 |
| gl18-tl-resnet101-gem-w | 67.3 | 80.6 | 44.3 | 61.5 |
| gl18-tl-resnet152-gem-w | 68.7 | 79.7 | 44.2 | 60.3 |
Note (June 2022): We updated download files for Oxford 5k and Paris 6k images to use images with blurred faces as suggested by the original dataset owners. Bear in mind, "experiments have shown that one can use the face-blurred version for benchmarking image retrieval with negligible loss of accuracy".
Training (fine-tuning) convolutional neural networks
@article{RTC18,
title = {Fine-tuning {CNN} Image Retrieval with No Human Annotation},
author = {Radenovi{\'c}, F. and Tolias, G. and Chum, O.}
journal = {TPAMI},
year = {2018}
}
@inproceedings{RTC16,
title = {{CNN} Image Retrieval Learns from {BoW}: Unsupervised Fine-Tuning with Hard Examples},
author = {Radenovi{\'c}, F. and Tolias, G. and Chum, O.},
booktitle = {ECCV},
year = {2016}
}
Revisited benchmarks for Oxford and Paris ('roxford5k' and 'rparis6k')
@inproceedings{RITAC18,
author = {Radenovi{\'c}, F. and Iscen, A. and Tolias, G. and Avrithis, Y. and Chum, O.},
title = {Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking},
booktitle = {CVPR},
year = {2018}
}
master (devolopment)
master (development)
v1.2 (07 Dec 2020)
v1.2 (07 Dec 2020)
- Added example script for descriptor extraction with different publicly available models
- Added the MIT license
- Added mutli-scale performance on
roxford5kandrparis6kfor new pre-trained networks with projection, trained on bothretrieval-SfM-120andgoogle-landmarks-2018train datasets - Added a new example test script without post-processing, for networks that include projection layer
- Added few things in train example: GeMmp pooling, triplet loss, small trick to handle really large batches
- Added more pre-computed whitening options in imageretrievalnet
- Added triplet loss
- Added GeM pooling with multiple parameters (one p per channel/dimensionality)
- Added script to enable download on Windows 10 as explained in Issue #39, courtesy of SongZRui
- Fixed cropping of down-sampled query image
v1.1 (12 Jun 2019)
v1.1 (12 Jun 2019)
- Migrated code to PyTorch 1.0.0, removed Variable, added torch.no_grad for more speed and less memory at evaluation
- Added rigid grid regional pooling that can be combined with any global pooling method (R-MAC, R-SPoC, R-GeM)
- Added PowerLaw normalization layer
- Added multi-scale testing with any given set of scales, in example test script
- Fix related to precision errors of covariance matrix estimation during whitening learning
- Fixed minor bugs











































































































































