This repository contains code for the final N-gram model for my Coursera Data Science Capstone project. The goal is to take a dataset provided by SwiftKey and create an NLP (natural language processing) model that is able to predict subsequent words.
- N-gram model with "Stupid Backoff" (Brants et al 2007)
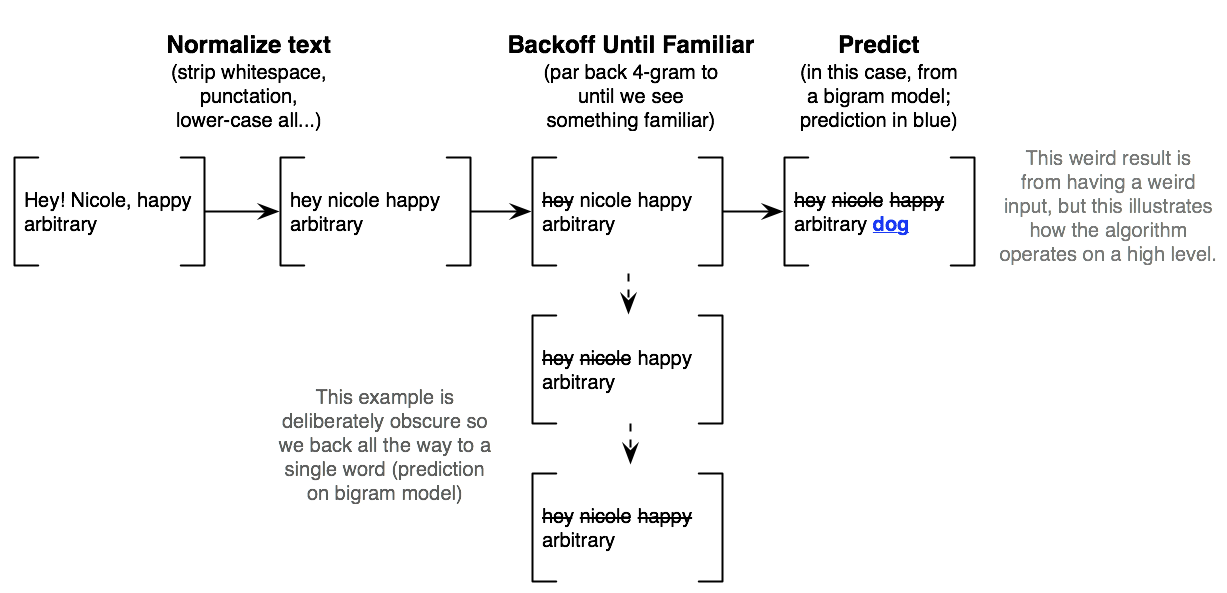
- Checks if highest-order (in this case, n=4) n-gram has been seen. If not "degrades" to a lower-order model (n=3, 2); we would use even higher orders, but ShinyApps caps app size at 100mb
- A simplified view of it is below
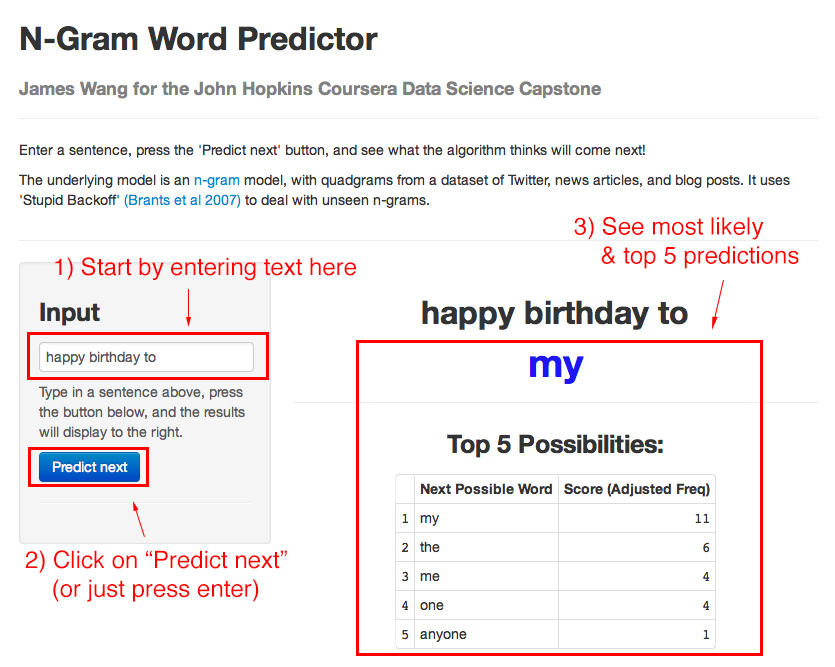
If you haven't tried out the app, go here to try it.
- Predicts next word
- Shows you top 5 other possibilities
- Can be used to string together continuous, sensible sentences (even with the limited amount of data it's using now)
- The underlying code stores the n-gram and frequency tables in an SQLite database. N-gram queries use SQL, which is optimized for this type of table retrieval/lookup (can also be adapted for even larger production-scale databases like PostgreSQL)
- "Stupid Backoff" is designed for scale. We're restricted to 100mb on ShinyApps, but the original paper trained on 2 trillion tokens
- Stupid Backoff performance approaches more sophisticated models like Kneser-Ney as we increase amount of data
- Here, we merely use 1.4% of the data provided by SwiftKey and Coursera to fit into the 100mb limit
- The code (for processing into a database and prediction) is available on GitHub
- Further work can expand the main weakness of this approach: long-range context
- Current algorithm discards contextual information past 4-grams
- We can incorporate this into future work through clustering underlying training corpus/data and predicting what cluster the entire sentence would fall into
- This allows us to predict using ONLY the data subset that fits the long-range context of the sentence, while still preserving the performance characteristics of an n-gram and Stupid Backoff model

