Latest
-
Status: beta. Most of the functionality is in place, more tests needed
-
Milestone 0.1 reached. Available here
-
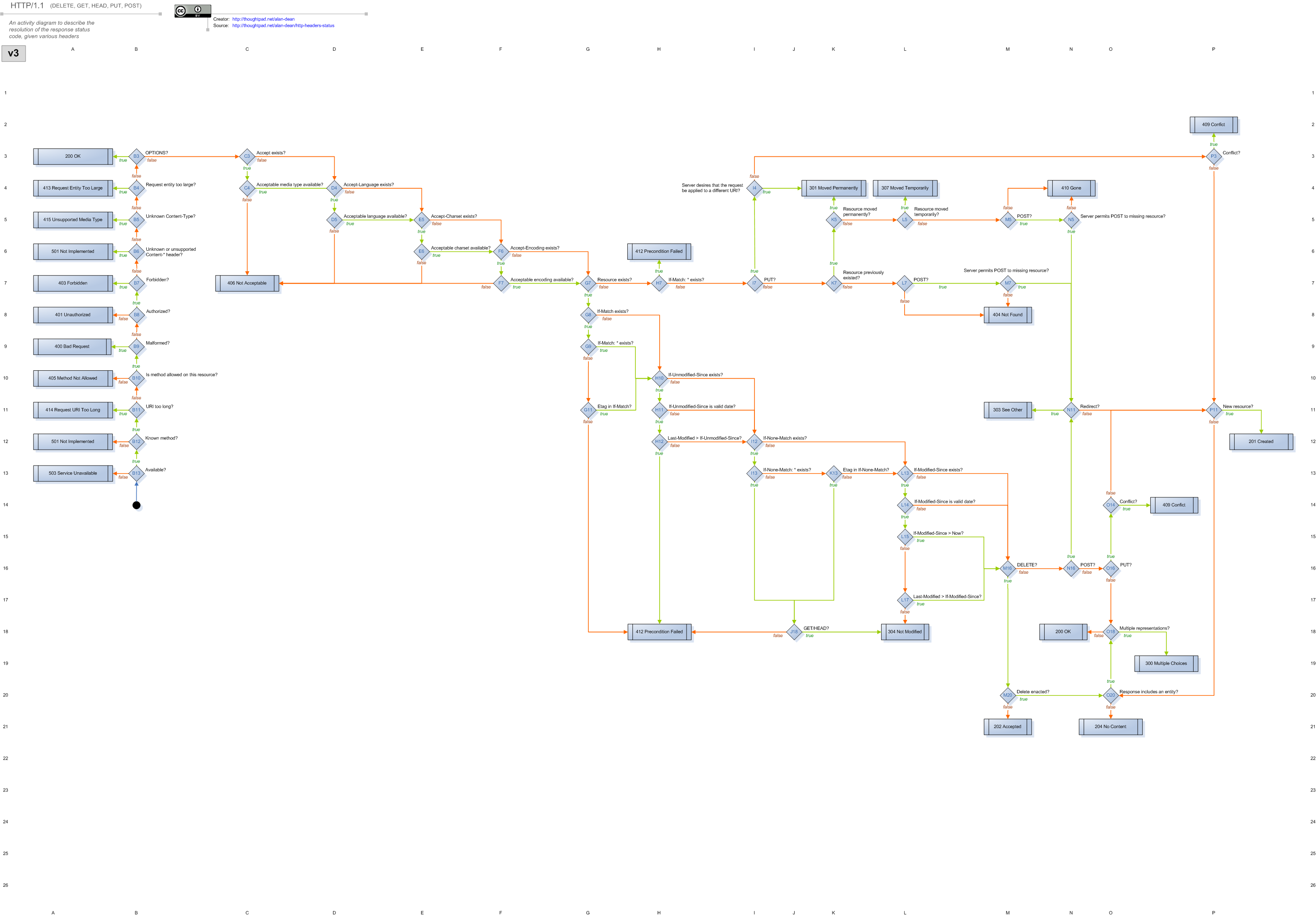
Webmachine flow for Milestone 0.2 is completed. Consult
priv/webmachine.yml -
Note: master is kept stable (though might not point to a release). If you want latest and greatest, grab the in-progress branch

What?
Are you stuck with implementing the same functions over and over again for Webmachine and can't find a flow for PATCH on their diagram? Do you want to implement Andrei Neculau's H^2 (Huge HTTP) Diagram over Cowboy's REST handler but can't wrap your head around and can't extend it's execution flow?
Don't fret, unrest is here to rescue you.
unrest allows you to define your own execution flows, tailored to your needs. If you're smart or lucky enough, you'll be able to control and change the behaviour of your entire application just by moving lines around in a config file.
- use
priv/config.ymlas a starting point for your own configs priv/webmachine.ymlprovides a drop-in replacement for webmachine. Consult the file for more details
Gimme quickstart
- Get rebar
clone https://github.com/dmitriid/unrest && cd unrestrebar get-depsrebar compile./start.shor./start-debug.sh- Go to http://localhost:8080/ and see the debug messages scroll by in the shell :)
The flows are defined in priv/config.yml. A dummy handler for these flows is implemented in src/unrest_service.erl
Can I use it from my app?
Yes. Include unrest in your app and call one of
unrest:start(path_to_config_file).unrest:start([a, list, of, paths, to, config, files]).unrest:start(hostname, path_to_config_file)unrest:start(hostname, [a, list, of, paths, to, config, files])unrest:start([{hostname1, path_to_config_file}, {hostname2, [a, list, of, paths, to, config, files]}]).
You're set and ready to go.
What's a config file? Read on :)
Full story
Flows
The main concept behind unrest is flows. A flow is just a chain of functions that unrest calls one by one and expects a certain kind of response before proceeding to the next one.
This is a flow:
%% A flow is [{M::atom(), F::atom()} | fun()]
[ {my_module, a_function_in_my_module}
, fun some_module:some_fun/1
, {my_module, some_other_fun}
, fun(Ctx) -> {ok, Ctx} end
]You can use unrest_flow:run/1,2 to run such a flow from within your code.
Note that each function in the flow will be called with exactly one parameter, an unrest context.
unrest context
An unrest context is the only way to interact between the functions in your flow. You save your data to and retrieve it from the unrest context. See unrest_context.erl to see what operations on the context are available to you.
Besides data unrest context also stores the callstack of functions the flow has executed, the errors that may have been generated during the run, etc. Let's see now how all this comes together with the flow.
Flow + context
As I mentioned above, the flow expects each function to return a specific response and/or the updated context. These are the responses a function can return:
-
{ok, unrest_context:context()}This means that the function completed succesfully. The context it returned will be passed in to the next function.
-
{error, unrest_context:context(), ErrorData:any()}Function generated a non-critical error. The next function in chain will still be called. However, errors will be accumulated and will be accessible via:
unrest_context:is_error_state/1will return trueunrest_context:errors/1will return the error list
This is useful when you run a chain of validating functions and you want to accumulate the list of errors
-
{stop_flow, unrest_context:context()}Interrupt the flow without generating an error. Context returned from this function will be treated as the final value of the entire flow call
-
{stop_flow, unrest_context:context(), ErrorData:any()}Interrupt the flow and generate the error. Context returned from this function will be treated as the final value of the entire flow call.
unrest_context:is_error_state/1will return trueunrest_context:errors/1will return the error list
-
{flow, FlowName:binary(), unrest_context:context()}Run the named flow specified by the FlowName. A field named flows must exist in the context and FlowName must exist in this proplist.
Named flows are discussed below
-
{respond, Req::cowboy_req::req()}Interrupt the flow and return response to the client. Use cowboy_req:reply/2,3,4 to produce Req.
Normally, the last function in the flow would return this
Routes and flows
Now that we have a way to define flows and know what returns o expect, we can mix functions to create different flows for our web-application.
To do so we will use YAML, Cowboy's matching syntax and unrest's flows.
On startup unrest requires a configuration file that will define flows for all the routes that exist in your application. Here's a simple example:
/:
GET:
__flow__:
root_module: init
root_module: get
root_module: outputThis snippet reads as follows: Once we receive a GET request on /, call
init, get and output from root_module. root_module:output/1 must
return {respond, Req}, and Req will be sent to the browser.
Easy, is it not? Let's change this a little. The output function is usually a libarary function that does conversion to JSON, for example. It would also be nice if we could skip writing the name of the module all the time.
/:
GET:
__flow__:
root_module:
- init
- check_headers
- get
output_module: to_json
POST:
__flow__:
root_module:
- init
- check_headers
- post
output_module: to_jsonLooks easy, doesn't it? We call three functions in root_module, then call
output_module. We also extended our config to include support for POST.
This, however, introduced a problem. We have to type the same init and
check_headers twice, once each for GET and POST. Since this is a common
part of the flow, can these be moved away in a flow of their own? Of course,
they can:
/:
GET:
__flow__:
__flow__: common_flow
__flow__: auth_flow
root_module:
- get
output_module: to_json
POST:
__flow__:
__flow__:
- common_flow
- auth_flow
root_module:
- post
output_module: to_json
__flows__:
common_flow:
root_module:
- init
common_lib:
- check_content_type
- check_accept
- check_language
auth_flow:
auth_lib:
- check_cookie
- check_oauth2Woah there, mister! What's going on?
Let's break this apart.
First, let's start with the __flows__. This configuration parameter defines
flows that can later be refered to by a name. In our case we define two flows:
-
common_flowwill callroot_module:init/1andcommon_lib:check_*functions -
auth_flowwill callauth_lib:check_*functions
The syntax for defining flows is the same as in the routing section above.
Now we need a way to call/include our flows. This is easy. Instead of specifying
a module: function call, you specify a __flow__: flow_name. So, in our case:
- When a call comes to
/, and it's aGET, what is our flow?- call functions defined in
common_flow - call functions defined in
auth_flow - call
root_module:get/1 - call
output_module:to_json/1
- call functions defined in
- When a call comes to
/, and it's aPOST, what is our flow? - call functions defined in
common_flow - call functions defined in
auth_flow - call
root_module:post/1 - call
output_module:to_json/1
See, easy as pie.
So, instead of writing 6 functions defined in common_flow and auth_flow
every time we need them, we write only two flows. But still... It means that we
have to write the same two flows each time we need them. Is there a way to make
a single flow that will call these two flows? Of course!
/:
GET:
__flow__:
__flow__: common_flow
root_module: get
output_module: to_json
POST:
__flow__:
__flow__: common_flow
root_module: post
output_module: to_json
__flows__:
common_flow:
root_module:
- init
__flow__:
- check_headers
- check_auth
check_headers:
common_lib:
- check_content_type
- check_accept
- check_language
check_auth:
auth_lib:
- check_cookie
- check_oauth2This should be very easy by now. Using the same syntax as for routing, we just
include other flows in the definition of flows. So, common_flow will call all
the functions of check_headers flow and then all the functions of check_auth
flow.
And, of course, you can use check_headers and check_auth flows directly in
routing or in other flows as well.
This all leaves us with a small problem. We are going to call a check_headers
function, but how will it know what headers to check against? Well, besides
flows you can include other useful configuration parameters that will be passed
along to your function in the context:
/:
GET:
headers:
accept: application/json
__flow__:
__flow__: common_flow
root_module: get
output_module: to_json
POST:
headers:
accept: application/json
content-type: application/json
__flow__:
__flow__: common_flow
root_module: post
output_module: to_json
__flows__:
common_flow:
root_module:
- init
__flow__:
- check_headers
- check_auth
check_headers:
common_lib:
- check_content_type
- check_accept
- check_language
check_auth:
auth_lib:
- check_cookie
- check_oauth2And then in your function:
check_headers(Context) ->
Headers = unrest_context:get("headers", Context),
Accept = proplists:get("accept", Headers)...It's that easy!
Two things left to show though.
First: what if you want to skip all the flows and deal with Cowboy's requests directly?
Easy! Just specify a module name instead of any config values:
/:
GET: index_handlerindex_handler module will be responsible for providing all the callbacks
Cowboy requires.
Second: What about other routes?
Easy! Since unrest runs on top of Cowboy, it lets you specify whatever routes Cowboy accepts:
/path/:with/[:optional/and/named/[:params]]:
GET: index_handler
POST:
__flow__: common_flow
root_module: post
output_module:
- to_json
- add_headers
- outputRefer to Cowboy documentation for more info.
Technicalities
unrest creates a dynamic dispatch for Cowboy that it generates from the config
file. The request passes through unrest_middleware which looks for
corresponding flows and runs them.
Given the following config:
unrest configuration file
---
/:
GET:
headers:
accept: application/json
__flow__:
__flow__: common_flow
root_module: get
output_module: to_json
POST:
headers:
accept: application/json
content-type: application/json
__flow__:
__flow__: common_flow
root_module: post
output_module: to_json
__flows__:
common_flow:
root_module:
- init
__flow__:
- check_headers
- check_auth
check_headers:
common_lib:
- check_content_type
- check_accept
- check_language
check_auth:
auth_lib:
- check_cookie
- check_oauth2Cowboy will receive the following dispatch:
[{'_',[{"/",unrest_handler,
[{config,[{<<"GET">>,
[{"headers",[{"accept","application/json"}]},
{<<"__flow__">>,
[{root_module,init},
{common_lib,check_content_type},
{common_lib,check_accept},
{common_lib,check_language},
{auth_lib,check_cookie},
{auth_lib,check_oauth2},
{root_module,get},
{output_module,to_json}]}]},
{<<"POST">>,
[{"headers",
[{"accept","application/json"},
{"content-type","application/json"}]},
{<<"__flow__">>,
[{root_module,init},
{common_lib,check_content_type},
{common_lib,check_accept},
{common_lib,check_language},
{auth_lib,check_cookie},
{auth_lib,check_oauth2},
{root_module,post},
{output_module,to_json}]}]}]},
{flows,[{<<"common_flow">>,
[{root_module,init},
{common_lib,check_content_type},
{common_lib,check_accept},
{common_lib,check_language},
{auth_lib,check_cookie},
{auth_lib,check_oauth2}]},
{<<"check_headers">>,
[{common_lib,check_content_type},
{common_lib,check_accept},
{common_lib,check_language}]},
{<<"check_auth">>,
[{auth_lib,check_cookie},{auth_lib,check_oauth2}]}]}]}]}]






{kind=link}
{kind=link}