
You can also find all 45 answers here 👉 Devinterview.io - Naive Bayes
The Naive Bayes classifier is a simple yet powerful probabilistic algorithm that's popular for text classification tasks like spam filtering and sentiment analysis.
Naive Bayes leverages Bayes' Theorem:
Here's what the terms represent:
-
$P(A|B)$ : The probability of "A" given "B". -
$P(B|A)$ : The probability of "B" given "A". -
$P(A)$ and$P(B)$ : The marginal probabilities of "A" and "B", respectively.
The classifier calculates the posterior probability,
Here is the Python code:
def bayes_theorem(prior_A, prob_B_given_A, prob_B_given_not_A):
marginal_B = (prob_B_given_A * prior_A) + (prob_B_given_not_A * (1 - prior_A))
posterior_A = (prob_B_given_A * prior_A) / marginal_B
return posterior_A- Assumption: Naive Bayes assumes independence between features. This simplifies calculations, though may not always hold in real-world data.
- Laplace Smoothing: To address zero frequencies and improve generalization, Laplace smoothing is used.
- Handling Continuous Values: For features with continuous values, Gaussian Naive Bayes and other methods can be applied.
Here is the Python code:
def laplace_smoothing(prior_A, prob_B_given_A, prob_B_given_not_A, k=1):
marginal_B = (prob_B_given_A * prior_A + k) + (prob_B_given_not_A * (1 - prior_A) + k)
posterior_A = ((prob_B_given_A * prior_A) + k) / marginal_B
return posterior_A- Multinomial: Often used for text classification with term frequencies.
- Bernoulli: Suited for binary (presence/absence) features.
- Gaussian: Appropriate for features with continuous values that approximate a Gaussian distribution.
- Efficient and Scalable: Training and predictions are fast.
- Effective with High-Dimensional Data: Performs well, even with many features.
- Simplicity: User-friendly for beginners and a good initial baseline for many tasks.
- Assumption of Feature Independence: May not hold in real-world data.
- Sensitivity to Data Quality: Outliers and irrelevant features can impact performance.
- Can Face the "Zero Frequency" Issue: Occurs when a categorical variable in the test data set was not observed during training.
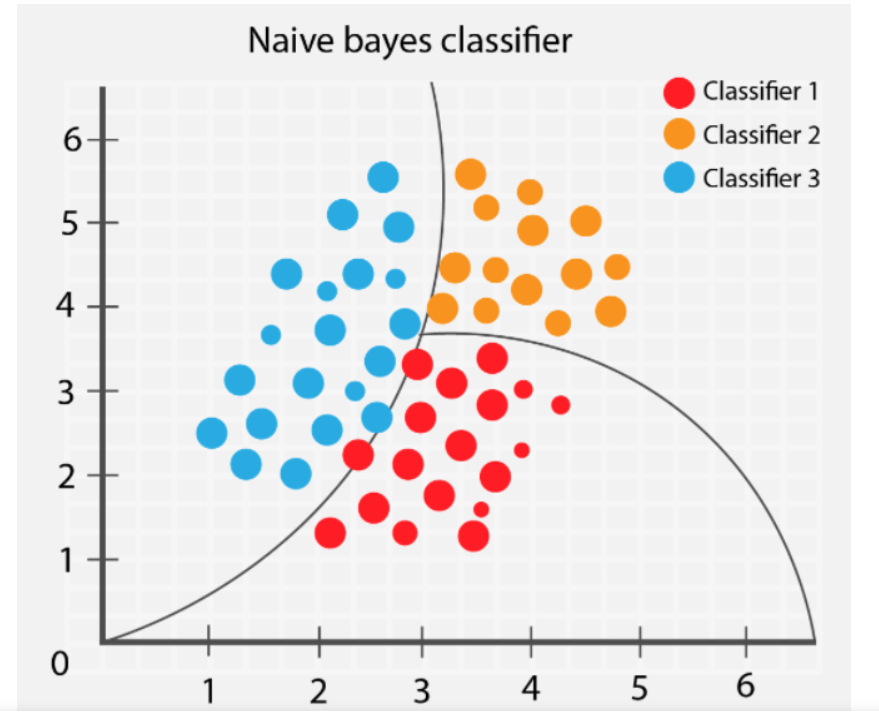
Naive Bayes is particularly useful when tackling multi-class categorization tasks, making it a popular choice for text-based applications.
Bayes' Theorem forms the foundational theory behind Naive Bayes, a classification algorithm used in supervised machine learning. The algorithm is particularly popular in text and sentiment analysis, spam filtering, and recommendation systems due to its efficiency and ability to handle large datasets with many attributes known as "High-Dimensional Data".
Bayes' Theorem, named after Reverend Thomas Bayes, describes the probability of an event, based on prior knowledge of conditions that might be related to the event.
It is expressed mathematically as:
Where:
-
$P(A|B)$ is the conditional probability of event A occurring, given that B has occurred -
$P(B|A)$ is the conditional probability of event B occurring, given that A has occurred -
$P(A)$ and$P(B)$ are the probabilities of A and B independently
In the context of classification problems, this can be interpreted as:
-
$P(A|B)$ is the probability that an instance will belong to a class A, given the evidence B -
$P(A)$ , the prior probability, is the likelihood of an instance belonging to class A without considering the evidence B -
$P(B|A)$ , also known as the likelihood, is the probability of observing the evidence B given that the instance belongs to class A -
$P(B)$ is the probability of observing the evidence B, and in the context of the Naive Bayes algorithm, it's a scaling factor that can be ignored.
-
Divisive Training:
- The algorithm breaks the dataset into training and test sets.
- It then identifies the likelihood of each class based on the training set.
-
Assumption of Independence:
- Naive Bayes assumes that all features in the dataset are independent of each other. This allows for a simplified version of Bayes' Theorem, which is computationally less expensive.
Mathematically, this simplifies the conditional probability to be the product of individual feature probabilities, given the class label:
-
Posterior Probability Calculation:
- The algorithm then leverages Bayes' Theorem to calculate the posterior probability of each class given the input features.
- The class with the highest posterior probability is chosen as the predicted class.
-
Evaluating Model Performance:
- The accuracy of the model is assessed using a test set to measure how well it classifies instances that it has not seen during training.
-
Laplace (Add-One) Smoothing (Optional):
- This technique is used to address the issue of zero probabilities in the data. It adds a small value to all probabilities to prevent the certainty of zero probabilities.
Naive Bayes is a powerful yet simple algorithm that works efficiently on various types of classification problems, especially in situations with a high number of features.
Naive Bayes (NB) is a family of straightforward, yet powerful, probabilistic classifiers notable for their simplicity, speed, and usefulness in text-related tasks, such as spam filtering and sentiment analysis. The "naive" in Naive Bayes refers to the assumption of independence between features, a simplification that makes the algorithm efficient.
The Multinomial Naive Bayes model is grounded in the assumption that the features are categorical. It is particularly useful for representing word counts in document classification tasks, such as emails or news articles.
MultinomialNB from the sklearn library
Here is the Python code:
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(X_train, y_train)Gaussian Naive Bayes is tailored for features whose distribution can be represented by a Gaussian (normal) distribution; in other words, it is suitable for continuous features. It calculates probabilities using the mean and variance of each class label.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)The key assumption in Bernoulli Naive Bayes is that all features are binary variables, taking values such as 0 or 1. This makes it well-suited for working with features that are the result of Bernoulli trials, i.e., experiments with two distinct outcomes.
from sklearn.naive_bayes import BernoulliNB
model = BernoulliNB()
model.fit(X_train, y_train)Depending on the nature of the features and the data distribution, it is sometimes beneficial to use customized or hybrid variants. For example, the Complement Naive Bayes model, which is akin to Multinomial but tuned for imbalanced datasets, provides a tailored approach in such situations. For multi-modal data distributions, like text corpora with positive and negative ratings, the Categorical Naive Bayes implemented in the scikit-learn library provides a fitting choice.
The naive assumption in the Naive Bayes classifier is that all features are independent of each other given the class label.
This makes the model computationally efficient but can lead to reduced accuracy when the assumption doesn't hold.
The probability of a class given a set of features can be calculated using Bayes' theorem:
Where:
-
$P(y | x_1, x_2, \ldots, x_n)$ is the posterior probability: Probability of the class given the features. -
$P(y)$ is the prior probability: Probability of the class before considering the features. -
$P(x_1, x_2, \ldots, x_n | y)$ is the likelihood: Probability of observing the features given the class. -
$P(x_1, x_2, \ldots, x_n)$ is the evidence: Probability of observing the features.
With the naive assumption, the equation reduces to:
Here, the denominator can be ignored as it's simply a scaling factor, and the final decision is based on the numerator.
Consider classifying a fruit based on its features: color (C), shape (S), and taste (T). Let's say we have two classes: "Apple" and "Orange". The naive assumption implies independence between these features:
Notice the product expression that simplifies the calculation.
While Naive Bayes classifiers traditionally excel with categorical data, they can also handle numerical features using various probability density functions (PDFs).
For categorical features in the data, Naive Bayes uses the likelihood probabilities.
Consider an email classification task. A feature might be the word "FREE," which can either be present or absent in an email. If we're targeting spam (S) or non-spam (NS) classification:
-
$P(FREE|S)$ is the probability that a spam email contains the word "FREE." -
$P(FREE|NS)$ is the probability that a non-spam email contains the word "FREE."
Handling numerical features is often accomplished through binning and using PDFs that fit the data distribution best, such as the normal (Gaussian) distribution or the multinomial distribution.
In the case of Gaussian Naive Bayes, which assumes a normal distribution for the numerical features:
- For a feature such as "length of the email," we'll estimate mean and standard deviation for spam and non-spam emails.
- Then, we'll use the Gaussian PDF to calculate the probability of a given length, given the class (spam or non-spam).
Another approach is Multinomial Naive Bayes for discrete-count data, such as word occurrences. However, in the strict sense, it's optimized for count data rather than continuous numerical values.
For datasets with both numerical and categorical features, it's often recommended to convert numerical data into categorical bins, enabling a more unified Naive Bayes approach.
Alternatively, one can consider using Gaussian Naive Bayes solely for numerical features and Multinomial/other Naive Bayes variants for categorical features.
The Naive Bayes (NB) classifier is particularly well-suited to text classification tasks for a number of reasons.
-
Efficiency: NB is computationally light and quick to train, making it especially beneficial for large text datasets. It's often the initial model of choice before evaluating more complex algorithms.
-
Independence of Features Assumption: NB treats the presence of words in a document as independent events, a simplification known as the "bag of words" approach. This assumption often holds in text processing and doesn't significantly impact classification accuracy.
-
Nominal and Binary Data Handling: NB can efficiently work with binary features (e.g., "word present" or "word absent") and nominal ones (categorical variables such as part-of-speech tags or word stems).
-
Language-Agnostic: As NB takes a statistical approach, it's not dependent on language-specific parsing or relationship structures. This makes it versatile across different languages.
-
Outlier Robustness: NB is less influenced by rare, specific, or even erroneous word features since it ignores feature dependencies and treats each feature individually. This quality is particularly useful in text processing, where these anomalies can be prevalent.
-
Class Probability Estimation: NB provides direct class probability estimates, which finds application in tasks like spam filtering that rely on probability thresholds for decision-making.
-
Stream Compatibility: The Naive Bayes model is well-suited to streaming applications or real-time inference systems, where it updates parameters on the fly as data streams in.
While NB initially works with raw word frequencies, using Term Frequency-Inverse Document Frequency (TF-IDF) for feature extraction can further enhance model performance.
-
Feature Selection: TF-IDF highlights important terms by assigning higher scores to those that are frequent within a document but rare across the entire corpus. This way, the model can focus on discriminative terms, potentially improving classification effectiveness.
-
Sparse Data Handling: Matrices created using TF-IDF are typically sparse, which means most of the cells have a value of zero. NB can efficiently work with this kind of data, especially using sparse matrix representations that save memory and, ultimately, computation time.
-
Multinomial Naive Bayes for TF-IDF: While Gaussian or Bernoulli NB variants suit binary or normally distributed data, Multinomial NB is tailored for the non-negative, integer-valued features derived from TF-IDF.
Using TF-IDF in conjunction with NB is a way to best capture the strengths both mechanisms offer for text classification tasks.
In Naive Bayes (NB), the assumption of class-conditional independence is foundational to its operation. It simplifies the inference, especially when working with textual or high-dimensional data.
NB's name "naive" denotes its elementary nature, forming the simplest form of a Bayesian model. It starts with Bayes' theorem:
where:
-
$P(\text{{class}}|\text{{features}})$ is the posterior probability of the class given observed features. -
$P(\text{{class}})$ is the prior probability of that class. -
$P(\text{{features}}|\text{{class}})$ is the likelihood. -
$P(\text{{features}})$ serves as a normalization factor.
Conceptually, it means that the presence of a particular feature does not influence the likelihood of the presence of another feature within the same class.
Mathematically, instead of considering the joint probability of all features given the class
where:
-
$P(\text{{feature}}_i|\text{{class}})$ is the probability of the$i$ -th feature given the class$\text{{class}}$ .
Thus, the full NB equation becomes:
In text classification with Naive Bayes, unique words serve as features. The class-conditional assumption means that the presence or absence of a word within a document is independent from the presence or absence of other words in that document, given its class. This is a significant simplification and, despite its apparent naivety, often yields robust results.
If the independence assumption doesn't hold, Naive Bayes can yield biased results. Such dependencies are termed "Bayesian networks", represented through directed, acyclic graphs, and are outside the scope of NB.
In practice, the NB's independence assumption is quite liberal. It can handle some degree of correlation between features without significantly degrading performance, making it a powerful and computationally efficient model, especially in tasks like text classification.
Naive Bayes (NB) classifiers are efficient, assumption-based models with unique strengths and limitations.
- Simple & Fast: Computationally efficient and easy to implement.
- Works with Small Data: Effective even when you're working with limited training data.
- Handles Irrelevant Features: Can disregard irrelevant or redundant features, reducing the risk of overfitting or unnecessary computations.
- Multiclass Classification Support: Well-suited for both binary and multi-class classification tasks.
- Independence Assumption: The model assumes that features are independent, which may not hold true in many real-world scenarios. This can often affect its predictive performance.
- Sensitivity to Data Quality: If the assumption of data distribution is violated, the model's accuracy may suffer.
- Weak Probabilistic Outputs: The model sometimes generates unreliable probability estimates, making them less suitable for tasks that require well-calibrated probabilities, such as risk assessments.
Multinomial Naive Bayes (MNB) and Gaussian Naive Bayes (GNB) are variations of the Naive Bayes classifier, optimized for specific types of data. Let's take a closer look at these two variations and their unique characteristics.
- Multinomial NB: Assumes features come from a multinomial distribution. This distribution is most suitable for text classification tasks.
- Gaussian NB: Assumes features have a Gaussian (normal) distribution. This model is well-matched to continuous, real-valued features.
- Multinomial NB: Designed for discrete (count-based) features.
- Gaussian NB: Tailored for continuous numerical features.
- Multinomial NB: Typically uses term frequencies or TF-IDF scores for text.
- Gaussian NB: Often requires feature normalization (standardization) to ensure feature attributes are on the same scale.
- Multinomial NB: Tends to perform better with smaller datasets, making it a suitable choice for text data.
- Gaussian NB: Usually more effective with larger datasets, where the Gaussian assumption can better model the feature distributions.
-
Multinomial NB: Utilizes the multinomial distribution in its probability calculations. This distribution is well-suited for count-based or frequency-based feature representations, such as bag-of-words models in text analytics.
- In a text classification context, for instance, this model examines the likelihood of a word (feature) occurring in a document belonging to a particular class.
-
Gaussian NB: Leverages the Gaussian (normal) distribution for probability estimations. It assumes continuous features have a normal distribution within each class.
- Mathematically, the formula involves mean and variance of feature values within each class, where those are estimated using mean and standard deviation of the training data.
- Multinomial NB: Best suited for tasks like document classification (e.g., spam filtering). It performs well with text data, especially after representing it as a bag-of-words or TF-IDF matrix.
- Gaussian NB: Ideal for datasets with continuous features, making it a good fit for tasks like medical diagnosis systems or finance-related classifications.
Here is the Python code:
from sklearn.naive_bayes import GaussianNB, MultinomialNB
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Instantiate and train both classifiers
gnb = GaussianNB()
gnb.fit(X_train, y_train)
mnb = MultinomialNB()
mnb.fit(X_train, y_train)
# Compare accuracy
gnb_accuracy = accuracy_score(y_test, gnb.predict(X_test))
mnb_accuracy = accuracy_score(y_test, mnb.predict(X_test))
print(f"Gaussian NB Accuracy: {gnb_accuracy}")
print(f"Multinomial NB Accuracy: {mnb_accuracy}")
# Output:
# Gaussian NB Accuracy: 1.0
# Multinomial NB Accuracy: 0.6While Naive Bayes classifies data using standard probabilities, it's common to convert these to log-probabilities for computational efficiency.
-
Numerical Stability: Multiplying many small probabilities can lead to vanishing precision. Taking the log, transforming multiplications into additions, counteracts this issue.
-
Simplicity in Addition: Adding small probabilities in log-space simplifies computations, particularly if underflow is a concern.
-
Computational Speed: Calculating logs is quicker than computing exponentials, especially where multiple probabilities are involved.
In the context of Naive Bayes, log-probabilities streamline the computation of the posterior probability which governs the classification outcome.
For an observation
By substituting log-probabilities, this equation simplifies to a sum of terms — a more computationally efficient form.
In practice, software packages often manage this behind the scenes for a seamless and efficient user experience.
Naive Bayes classifiers, despite their simplicity, are powerful tools for tackling text classification problems.
Text classification is the task of automatically sorting unstructured text into categories. This technique is widely used in spam detection.
Naive Bayes operates under the presumptions of:
- Feature Independence: Each feature (word) is assumed to be independent of the others.
- Equal Feature Importance: All features contribute equally to the classification.
While these assumptions might not be strictly true for text data, Naive Bayes often still offers accurate predictions.
Before feeding the data into the Naive Bayes classifier, it needs to be preprocessed. This includes:
- Tokenization: Breaking the text into individual words or tokens.
- Lowercasing: Converting all text to lowercase to ensure "Free" and "free" are treated as the same word.
- Stop Words Removal: Eliminating common words like "and," "the," etc., that carry little or no information for classification.
- Stemming/Lemmatization: Reducing inflected words to their word stem or root form.
For spam detection, the email’s content serves as input for the algorithm, and words act as features. The presence or absence of specific words, in the email's body or subject line, dictates the classification decision.
These words are sometimes referred to as spam indicators.
Consider a few feature sets:
- Binary: Records the presence or absence of a word.
- Frequency: Incorporates the frequency of a word's occurrence in an email.
- Prior Probability: It is the probability of an incoming email being spam or non-spam, without considering any word occurrences.
- Posterior Probability: Reflects the updated probability of a new email being spam or non-spam after factoring in the words in that email.
- Data Collection: Gather a labeled dataset comprising emails tagged as spam or non-spam.
- Text Preprocessing: Clean the text data.
- Feature Extraction: Build the feature set, considering, for example, word presence and absence.
- Model Training: Use the feature set to calculate conditional probabilities for a message being spam or non-spam, given word presence or absence.
- Prediction: For a new email, compute the derived probabilities using Bayes' theorem and classify the email based on the higher probability.
Here is the Python code:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
# Load the dataset
emails = pd.read_csv('email_data.csv')
# Preprocess the text
# Feature Extraction using Count Vectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails['text'])
y = emails['spam']
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the Naive Bayes model
nb_model = MultinomialNB()
nb_model.fit(X_train, y_train)
# Make predictions
predictions = nb_model.predict(X_test)
# Evaluate the model
print(metrics.confusion_matrix(y_test, predictions))
print(metrics.classification_report(y_test, predictions))In this example:
- 'text' is the column containing the email content.
- 'spam' is the column denoting whether the email is spam or not.
- The
CountVectorizeris used to convert text data into a feature vector. - The
MultinomialNBNaive Bayes model is chosen, as it's suitable for discrete features, like word counts.
- Accuracy: The proportion of correctly classified emails.
- Precision: The fraction of emails flagged as spam that are genuinely spam.
- Recall: The percentage of actual spam emails identified as such.
- Language Use: Works best with well-structured languages but may struggle with nuanced texts or misspellings.
- Assumption Violation: Text does not strictly adhere to Naive Bayes' independence assumptions.
- Data Imbalance: In real-world scenarios, the data may overwhelmingly favor non-spam examples, leading to less accurate predictions for spam emails.
In the context of Naive Bayes, handling missing values can be challenging. This is because the algorithm fundamentally relies on having complete data for its probabilistic computations.
- Deletion: Remove samples or features with missing values. However, this can lead to a significant loss of data.
- Imputation: Estimate missing values based on available data, using techniques such as mean, median, or mode for continuous data, or probability estimations for categorical data.
- Prediction Models: Use machine learning models to predict missing values, which can be followed by imputation.
While Naive Bayes is robust and capable of performing well even with incomplete datasets, missing values are still a concern.
- If a particular record has a missing value in a feature, that record would be ignored entirely during likelihood computations. This can lead to information loss.
- The conditional probabilities for a feature given a class may be inaccurately estimated when missing values are present. This can skew the predictions.
Here's the Python code:
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
# Generating dummy data
# Assume col_1 and col_2 are our features and target is our target variable
data = np.array([[1, 2, 'A'], [3, np.nan, 'B'], [5, 6, 'A']])
X, y = data[:, :-1], data[:, -1]
# Split data for imputation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Impute missing values in the training and testing datasets
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
X_train_imputed = imputer.fit_transform(X_train)
X_test_imputed = imputer.transform(X_test)
# Train Naive Bayes on full data and imputed data, compare results
gnb_full_data = GaussianNB().fit(X, y)
gnb_imputed_data = GaussianNB().fit(X_train_imputed, y_train)
# Evaluate the models on the testing dataset
accuracy_full_data = gnb_full_data.score(X_test, y_test)
accuracy_imputed_data = gnb_imputed_data.score(X_test_imputed, y_test)
print("Accuracy on data with missing values (before imputation): {:.2f}".format(accuracy_full_data))
print("Accuracy on imputed data: {:.2f}".format(accuracy_imputed_data))Laplace Smoothing, also known as Additive Smoothing, is a technique primarily employed in Naive Bayes Classification to address the immense imbalance between the number of training instances for various class–feature combinations.
The naive assumption that individual features are independent of each other condenses the classification process into evaluating each feature in isolation. Consequently, the probability of conjunctions of multiple features (especially when rare) often reduces to zero.
This "zero probability dilemma" commonly arises when:
- The dataset is limited, failing to cover all possible feature combinations.
- The training set contains several classes and features, yet some unique combinations only manifest in the test data.
In either case, traditional Naive Bayes would give such instances a probability of zero, adversely affecting their classification.
Laplace Smoothing mitigates the zero probability issue by assigning a small but non-zero probability to unseen features or unobserved feature-class combinations.
Its methodical inclusion of pseudocounts is defined by:
where the fixed pseudocount (typically 1) is distributed uniformly.
This ensures that every class–feature pairing, regardless of the presence or absence of training instances, mulls over each potential vocabulary or value the feature might assume.
Naive Bayes is primarily a classification algorithm, but it's not designed for regression tasks. Here are the mathematical and practical reasons why this is the case.
- Regression metrics like Mean Squared Error (MSE) or Mean Absolute Error (MAE) measure the closeness of predicted and actual numerical values.
- Classification accuracy, which Naive Bayes optimizes, indicates the percentage of accurate predictions, not the degree of deviation.
- Naive Bayes calculates the probability of a data point belonging to different classes, using the chosen class with the highest probability as the prediction.
- This probabilistic approach isn't suitable for predicting continuous target variables.
- One of the fundamental assumptions in Naive Bayes is the conditional independence of features, meaning that the presence of one feature doesn't influence the presence of another, given the class label.
- For regression tasks, predicting a target variable often requires assessing how different features collectively influence the outcome; this goes against the independence assumption.
- Although Naive Bayes isn't naturally designed for regression, it can offer approximate results in some cases, especially when features and target variables are normally distributed.
- By assuming a Gaussian distribution for features within each class, the algorithm can estimate essential parameters like means and variances, potentially allowing for a form of regression prediction.
- Naive Bayes algorithms, including the Gaussian variant, are predominantly used for categorical and discrete data, primarily in classification tasks.
- There are better-suited algorithms for regression, such as linear regression, decision trees, and ensemble methods like Random Forest and Gradient Boosting, which are optimized for continuous target variables.
Here is Python code:
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load and split the diabetes dataset
X, y = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and fit Gaussian Naive Bayes model
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# Make predictions and calculate MSE
y_pred = gnb.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse:.2f}")While Naive Bayes is highly interpretable, it trades off some predictive power, especially in complex, high-dimensional data sets.
-
Interpretability: Naive Bayes is constructed from straightforward conditional probability calculus, making feature influence and class probability transparent.
-
Data Requirements: Efficient with small data sets, Naive Bayes is reliable for quick predictions but can struggle with larger, diverse data.
-
Overfitting: It's less prone to overfitting than models like Decision Trees, often achieving generalizability similar to more complex counterparts.
-
Speed and Efficiency: Naive Bayes's simplicity results in swift training and prediction times, making it ideal for real-time, resource-limited applications.
-
Assumption of Independence: The model may inaccurately learn from correlated attributes due to this assumption.
-
Adaptability: Once trained, a Naive Bayes model struggles to accommodate new features or discriminative patterns, unlike ensemble methods or deep learning architectures.
-
Accuracy and Performance: In many cases, Naive Bayes may not match the precision of leading classifiers like Random Forest or Gradient Boosting Machines, particularly with larger, more diverse data sets.
Explore all 45 answers here 👉 Devinterview.io - Naive Bayes

