This is a WIP port of Shivam Shriao's Diffusers Repo, which is a modified version of the default Huggingface Diffusers Repo optimized for better performance on lower-VRAM GPUs.
It also adds several other features, including training multiple concepts simultaneously, and (Coming soon) Inpainting training.
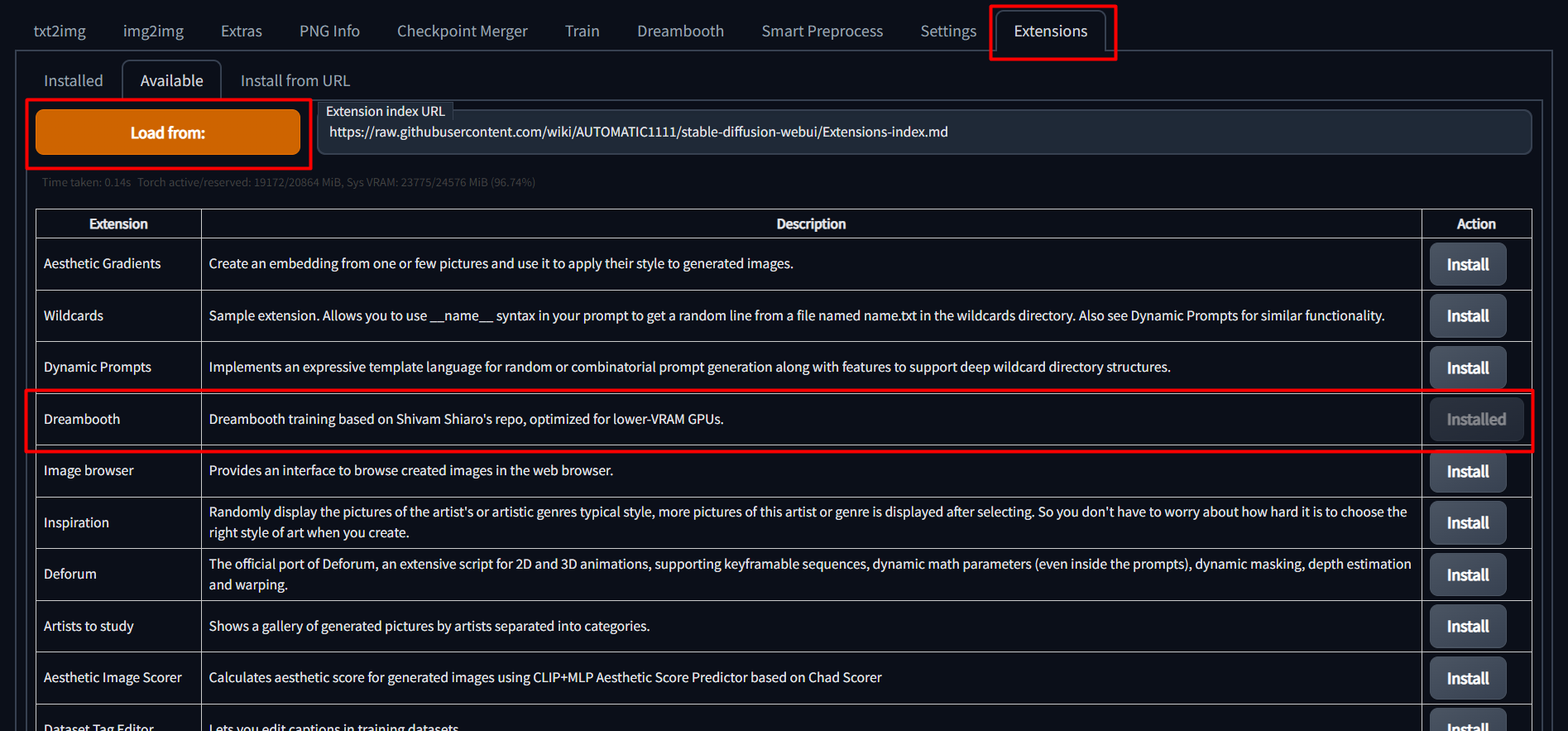
To install, simply go to the "Extensions" tab in the SD Web UI, select the "Available" sub-tab, pick "Load from:" to load the list of extensions, and finally, click "install" next to the Dreambooth entry.
For 8bit adam to run properly, it may be necessary to install the CU116 version of torch and torchvision, which can be accomplished below:
Edit your webui-user.bat file, add this line after 'set COMMANDLINE_ARGS=':
set TORCH_COMMAND="pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116"
Once installed, restart the SD-WebUI entirely, not just the UI. This will ensure all the necessary requirements are installed.
- Go to the Dreambooth tab.
- Under the "Create Model" sub-tab, enter a new model name and select the source checkpoint to train from. The source checkpoint will be extracted to models\dreambooth\MODELNAME\working - the original will not be touched.
- Click "Create". This will take a minute or two, but when done, the UI should indicate that a new model directory has been set up.
- After creating a new model, select the new model name from the "Model" dropdown at the very top.
- Select the "Train Model" sub-tab.
- Fill in the paramters as described below:
Concepts List - The path to a JSON file or a JSON string containing multiple concepts. See here for an example.
If a concepts list is specified, then the instance prompt, class prompt, instance data dir, and class data dir fields will be ignored.
Instance Prompt - A short descriptor of your subject using a UNIQUE keyword and a classifier word. If training a dog, your instance prompt could be "photo of zkz dog". The key here is that "zkz" is not a word that might overlap with something in the real world "fluff", and "dog" is a generic word to describe your subject. This is only necessary if using prior preservation.
Class Prompt - A keyword indicating what type of "thing" your subject is. If your instance prompt is "photo of zkz dog", your class prompt would be "photo of a dog". Leave this blank to disable prior preservation training.
Dataset Directory - The path to the directory where the images described in Instance Prompt are kept. REQUIRED
Classification dataset directory - The path to the directory where the images described in Class Prompt are kept. If a class prompt is specified and this is left blank, images will be generated to /models/dreambooth/MODELNAME/classifiers/
Total number of classification images to use - Leave at 0 to disable prior preservation. For best results you want ~n*10 classification images - so if you have 40 training photos, then set this to 400. This is just a guess.
Batch size - How many training steps to process simultaneously. You probably want to leave this at 1.
Class batch size - How many classification images to generate simultaneously. Set this to whatever you can safely process at once using Txt2Image, or just leave it alone.
Learning rate - You probably don't want to touch this.
Resolution - The resolution to train images at. You probably want to keep this number at 512 or lower unless your GPU is insane. Lowering this (and the resolution of training images) may help with lower-VRAM GPUs.
Save a checkpoint every N steps - How frequently to save a checkpoint from the trained data. I should probably change the default of this to 1000.
Generate a preview image every N steps - How frequently will an image be generated as an example of training progress.
Preview image prompt - The prompt to use to generate preview image. Leave blank to use the instance prompt.
Preview image negative prompt - Like above, but negative. Leave blank to do nothing. :P
Number of samples to generate - Self explainatory?
Sample guidance scale - Like CFG Scale in Txt2Image/Img2Img, used for generating preview.
Sample steps - Same as sample guidance scale, but the number of steps to run to generate preview. According to (this guide)[https://github.com/nitrosocke/dreambooth-training-guide], you should train for appx 100 steps per sample image. So, if you have 40 instance/sample images, you would train for 4k steps. This is, of course, a rough approximation, and other values will have an effect on final output fidelity.
Use CPU Only - As indicated, this is more of a last resort if you can't get it to train with any other settings. Also, as indicated, it will be abysmally slow. Also, you cannot use 8Bit-Adam with CPU Training, or you'll have a bad time.
Don't Cache Latents - Enabling will save a bit of VRAM at the cost of a bit of speed.
Train Text Encoder - Not required, but recommended. Enabling this will probably cost a bit more VRAM, but also purportedly increase output image fidelity.
Use 8Bit Adam - Enable this to save VRAM. Should now work on both windows and Linux without needing WSL.
Center Crop - Crop images if they aren't the right dimensions? I don't use this, and I recommend you just crop your images "right".
Gradient Checkpointing - Enable this to save VRAM at the cost of a bit of speed.
Scale Learning Rate - I don't use this, not sure what impact it has on performance or output quality.
Mixed Precision - Set to 'fp16' to save VRAM at the cost of speed.
Everything after 'Mixed Precision' - Adjust at your own risk. Performance/quality benefits from changing these remain to be tested.
The next two were added after I wrote the above bit, so just ignore me being a big liar.
Pad Tokens - Pads the text tokens to a longer length for some reason.
Apply Horizontal Flip - "Apply horizontal flip augmentation". Flips images horizontally at random, which can potentially offer better editability?
Once a model has been trained for any number of steps, a config file is saved which contains all of the parameters from the UI.
If you wish to continue training a model, you can simply select the model name from the dropdown and then click the blue button next to the model name dropdown to load previous parameters.