This is my and Ian Pan's solution.
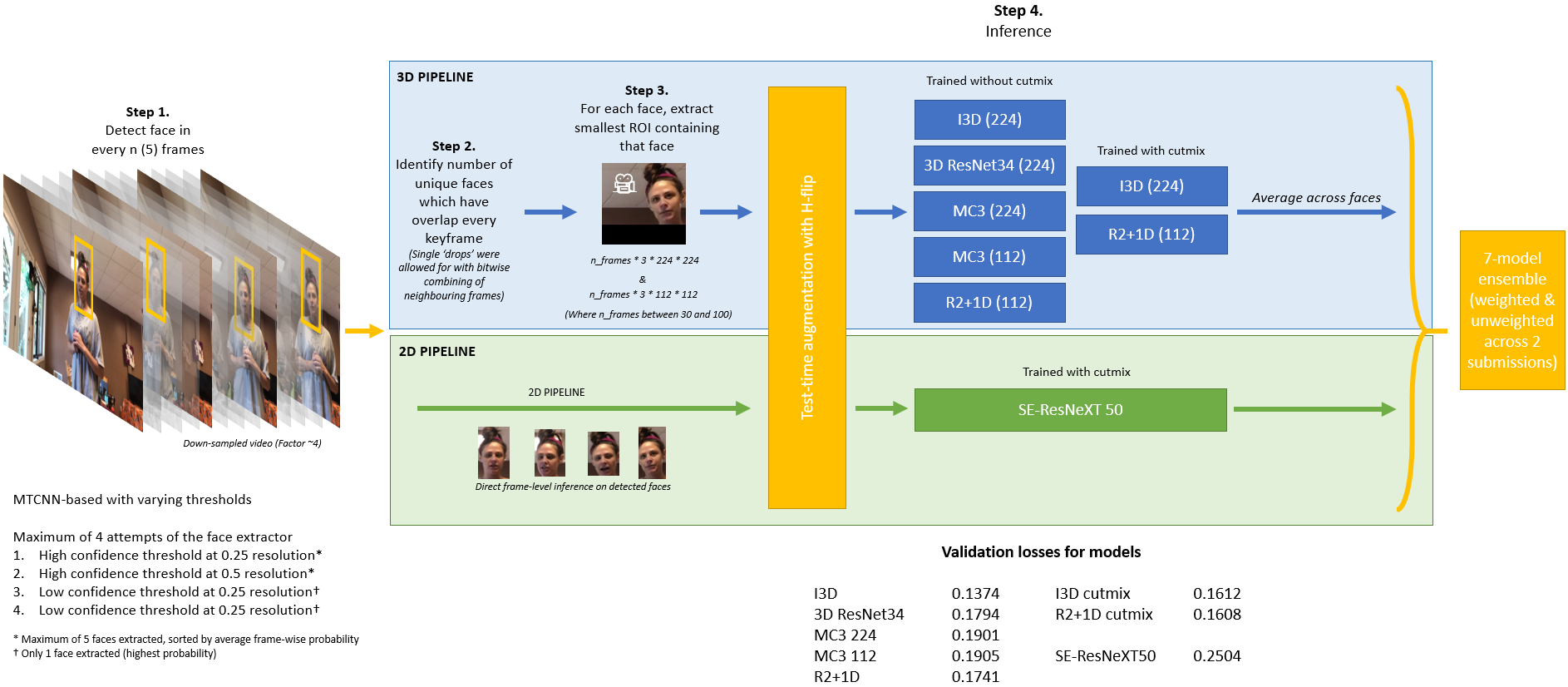
Our solution is largely based around 3D CNNs which we felt would generalise well to 'different' methods of deepfakes. Instead of focusing on specific pixel patterns in frames, we hope they might identify temporal problems like the often tried-and-failed 2D CNN->RNN models, but with a much lower tendency to overfit. The 3D models have similar numbers of parameters to 2D models, and yet also the kernels have a 'depth', so they are relatively modest in their ability to fit in the 2D plane.
The basis of the pipeline is the face extractor. This was written within the first week of the competition and since then it's undergone only minor tweaks. In summary, every nth frame (we settled on 10) is passed through MTCNN. The bounding box co-ordinates are then used to set a mask in a 3D array. Faces which are contiguous (overlapping) in 3D are assumed to be a single person's face moving through face and time. We then extract a bounding box which includes this entire face over time and create a video from this region of interest, including every frame (not just every 10th).
One nice thing about this method, even ignoring the video aspect, is it greatly reduced false positives, because the 'face' had to be present for a long period of time of the video to count as a face.
Separately, we use the bounding boxes of MTCNN for a traditional 2D CNN inference.
We trained 7 different 3D CNNs across 4 different architectures (I3D, 3D ResNet34, MC3 & R2+1D) and 2 different resolutions (224 x 224 & 112 x 112). The validation losses of the 3D CNNs ranged between 0.1374 and 0.1905. I initially struggled to fit models with spatial-level augmentation, finding they were so disruptive that the model struggled to tell real apart from fake. I had therefore only been using only pixel-level augmentation such as brightness (and Hflip) and some random cropping. However, Ian developed what we hope is a very successful 3D cutmix approach which led to models with good CV scores to be trained and were added to the ensemble.
To put the benefits of ensembling with these models into context, when we last tried the I3D model (lowest validation loss) alone we ended up with a public LB score of 0.341. With ensembling we’ve improved to 0.253.
Both these networks and the 2D CNNs, these were trained with AdamW (or sometimes Ranger) with a 1-cycle learning rate scheduler.
We ended up including a single 2D CNN in the ensemble in the end. It was trained with quite aggressive augmentation. Ian settled on SE-ResNeXT50 for the final model, though we tried multiple others including Xceptions and EfficientNets.
-
Using a series of PNGs for videos instead of MP4s. I think this is interesting. We trained these models by generating videos using an identical face extraction pipeline and saving the faces as MP4s (~216,000 fake faces, ~42,000 real, 17Gb of video). Towards the end we wondered if saving the faces as MP4s led to a loss of fidelity and so we saved every frame of these videos as a PNG and tried retraining the networks that way. This took almost a week, resulted in over 500 Gb of data, and resulted in the 3D CNNs overfitting even with reference to the validation data very early. It was a very time-consuming experiment that we still find surprising, given the PNG data is more like what the feature extractor is seeing at test time.
-
Using fewer frames. This might seem obvious but it's a bit more nuanced. We only used faces for videos if they were contiguous over at least 30 frames, up to a maximum of 100. That 100 was set by time constraints. However, using fewer frames would also mean a face is able to move around less. We found in some videos someone would walk across the entire screen in a second. This meant that the face only took up a tiny proportion of the entire region of interest. We therefore tested reducing the maximum frame number to, say, 64 ensure we still got a couple of seconds of video (we trained on chunks of 64 frames) but faces moved around less. However, this gave a worse LB score. We also tried more intelligent methods, such as using at least 30 frames, but then ‘stopping’ as soon as a face had moved > 1 face diameter away from its start point. Again, this was worse (this was particularly surprising). It probably shows that deepfakes are more and less detectable through different stages of the video, and so more frames is always better.
-
CNN -> RNNs did work a little, but not enough to use. Before Ian joined and we became a team, my pipeline did include one of these, but with his better models we dropped it. This seems in contrast to a lot of people who seemed to have 0 success. I suspect this is because we trained these models with the MP4 files rather than image files (see the previous point).
-
A segmentation network to identify altered pixels. Ian developed masked by 'diffing' the real and fake videos and trained a network to identify altered pixels. It had some success, but overfitting meant it had an LB score of ~0.5 and wasn't enough to provide benefit in ensembling.
-
Skipping alternate frames as a form of test-time-augmentation to amplify deltas between frames certainly didn't help, and possibly hindered.
-
Training a fused 3D/2D model which allowed the ensemble weighting to be 'learned' on validation videos did worse than a simple 50:50 pooling.
-
Using more complicated methods of pooling predictions across faces than taking a mean. I previously thought the 'fakest' value should be used, for example, if we were using very high thresholds for detection.
-
Some 3D models. For example, architectures such as 'slowfast' were very easy to train but overfitted profoundly, akin to a 2D CNN. Other networks such as MiCT we struggled to fit at all!
We hope this code is clear. As we are doctors without formal training in programming our systems are probably a little bit idiosyncratic but hopefully they are clear.
We worked on the 2 different pipelines used by our system separately.
The 3D CNN pathway (the top blue pathway on the figure) is trained using the system outlined in the cnn3d folder.
- Training of the different models was performed across two machines using Pytorch which are evident based on whether the model uses a DataParellel sturcture or not, and whether the paths to the data are in Linux or Windows formatting.
- A Windows machine with a single NVidia RTX Titan
- A Linux machine with two NVidia RTX Titans
- Dependencies for training these networks are as follows (all were install via
conda, except albumentations which caused issues with the most recent conda release).- tqdm (https://pypi.org/project/tqdm/)
- facenet_pytorch (https://pypi.org/project/facenet-pytorch/)
- scikit-video (https://pypi.org/project/scikit-video/)
- scikit-image (https://pypi.org/project/scikit-image/)
- PIL/pillow (https://pypi.org/project/Pillow/2.2.1/)
- numpy (https://pypi.org/project/numpy/)
- opencv & opencv-python >2 (https://anaconda.org/conda-forge/opencv)
- pandas (https://pypi.org/project/pandas/)
- pytorch (https://pytorch.org/)
- albumentations (https://pypi.org/project/albumentations/)
- Detailed instructions on how to train these models are in the
README.mdfile within thecnn3ddirectory.
The 2D CNN pathway (the bottom green pathway on the figure) is trained using the system outlines in the cnn2d folder.
- Models were trained on a Red Hat Enterprise Linux Server (7.7) which contained 4 NVidia RTX 2080 Ti (11GB) GPUs. Only single-GPU training was performed.
- Dependencies can be found and installed using
cnn2d/skp/setup.sh
To make predictions on a new test set, we advise using our public notebook, which we have made public, along with all of the attached datasets:
https://www.kaggle.com/vaillant/dfdc-3d-2d-inc-cutmix-with-3d-model-fix

