Apache Kafka distributed streaming system. kafka-python is designed to function much like the official java client, with a sprinkling of pythonic interfaces.
Background Information about Apache kafka
Apache Kafka is an open-source stream-processing software platform developed by the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a massively scalable pub/sub message queue architected as a distributed transaction log,making it highly valuable for enterprise infrastructures to process streaming data. Additionally, Kafka connects to external systems (for data import/export) via Kafka Connect and provides Kafka Streams, a Java stream processing library.
Setting Up the Environment
-
First of all you must have installed Kafka and Zookeeper on your machine.
-
Next install Kafka-Python. You can do this using pip or conda, if you’re using an Anaconda distribution.
pip install kafka-pythonconda install -c conda-forge kafka-python -
Don’t forget to start your Zookeeper server and Kafka broker before executing the example code below. In this example we assume that Zookeeper is running default on localhost:2181 and Kafka on localhost:9092.
We are also using a topic called numtest in this example, you can create a new topic by opening a new command prompt, navigating to
…/kafka/bin/windows and execute:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic numtest
Think of it is a big commit log where data is stored in sequence as it happens. The users of this log can just access and use it as per their requirement. Kafka Use Cases
Uses of Kafka are multiple. Here are a few use-cases that could help you to figure out its usage.
1 Activity Monitoring:-
Kafka can be used for activity monitoring. The activity could belong to a website or physical sensors and devices. Producers can publish raw data from data sources that later can be used to find trends and pattern.
2 Messaging:-
Kafka can be used as a message broker among services. If you are implementing a microservice architecture, you can have a microservice as a producer and another as a consumer. For instance, you have a microservice that is responsible to create new accounts and other for sending email to users about account creation.
3 Log Aggregation:-
You can use Kafka to collect logs from different systems and store in a centralized system for further processing.
4 ETL:-
Kafka has a feature of almost real-time streaming thus you can come up with an ETL based on your need.
5 Database:-
Based on things I mentioned above, you may say that Kafka also acts as a database. Not a typical databases that have a feature of querying the data as per need, what I meant that you can keep data in Kafka as long as you want without consuming it.
Kafka Concepts:
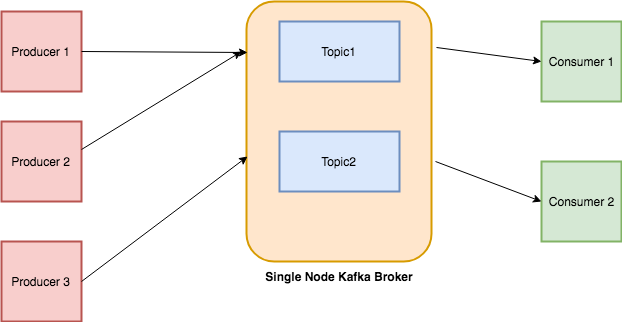
Procedure
In our example we’ll create a producer that emits numbers from 1 to 1000 and send them to our Kafka broker. Then a consumer will read the data from the broker and store them in a MongoDb collection.
***The advantage of using Kafka is that, if our consumer breaks down, the new or fixed consumer will pick up reading where the previous one stopped. This is a great way to make sure all the data is fed into the database without duplicates or missing data.
Create a new Python script named producer.py and start with importing json, time.sleep and KafkaProducer from our brand new Kafka-Python library.
from time import sleep
from json import dumps
from kafka import KafkaProducer
Then initialize a new Kafka producer. Note the following arguments:
bootstrap_servers=[‘localhost:9092’]
Sets the host and port the producer should contact to bootstrap initial cluster metadata. It is not necessary to set this here, since the default is localhost:9092. value_serializer=lambda x: dumps(x).encode(‘utf-8’): function of how the data should be serialized before sending to the broker. Here, we convert the data to a json file and encode it to utf-8.
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:
dumps(x).encode('utf-8'))
Now, we want to generate numbers from one till 1000. This can be done with a for-loop where we feed each number as the value into a dictionary with one key: number. This is not the topic key, but just a key of our data. Within the same loop we will also send our data to a broker.
This can be done by calling the send method on the producer and specifying the topic and the data. Note that our value serializer will automatically convert and encode the data. To conclude our iteration,we take a 5 second break. If you want to make sure the message is received by the broker, it’s advised to include a callback.
for e in range(1000):
data = {'number' : e}
producer.send('numtest', value=data)
sleep(5)
If you want to test the code, it’s advised to create a new topic and send the data to this new topic. This way, you’ll avoid duplicates and possible confusion in the numtest topic when we’re later testing the producer and consumer together. Consuming the data
Before we start coding our consumer, create a new file consumer.py and import json.loads, the KafkaConsumer class and MongoClient from pymongo. I won’t dig any deeper in the PyMongo code, since that’s outside the scope of this article.
Furthermore, you can replace the mongo code with any other code. This can be code to feed the data into another database, code to process the data or anything else you can think of. For more information about PyMongo and MongoDb, please consult the documentation.
from kafka import KafkaConsumer
from pymongo import MongoClient
from json import loads
The first argument is the topic, numtest in our case. bootstrap_servers=[‘localhost:9092’]: same as our producer auto_offset_reset=’earliest’: one of the most important arguments. It handles where the consumer restarts reading after breaking down or being turned off and can be set either to earliest or latest. When set to latest, the consumer starts reading at the end of the log. When set to earliest, the consumer starts reading at the latest committed offset. And that’s exactly what we want here. enable_auto_commit=True: makes sure the consumer commits its read offset every interval. auto_commit_interval_ms=1000ms: sets the interval between two commits. Since messages are coming in every five second, committing every second seems fair. group_id=’counters’: this is the consumer group to which the consumer belongs. Remember from the introduction that a consumer needs to be part of a consumer group to make the auto commit work. The value deserializer deserializes the data into a common json format, the inverse of what our value serializer was doing.
consumer = KafkaConsumer(
'numtest',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group',
value_deserializer=lambda x: loads(x.decode('utf-8')))
The code below connects to the numtest collection (a collection is similar to a table in a relational database) of our MongoDb database.
client = MongoClient('localhost:27017')
collection = client.numtest.numtest
We can extract the data from our consumer by looping through it (the consumer is an iterable). The consumer will keep listening until the broker doesn’t respond anymore. A value of a message can be accessed with the value attribute. Here, we overwrite the message with the message value.
The next line inserts the data into our database collection. The last line prints a confirmation that the message was added to our collection. Note that it is possible to add callbacks to all the actions in this loop.
for message in consumer:
message = message.value
collection.insert_one(message)
print('{} added to {}'.format(message, collection))
Let’s test our two scripts. Open a command prompt and go to the directory where you saved producer.py and consumer.py. Execute producer.py and open a new command prompt. Launch consumer.py and look how it reads all the messages, including the new ones.
Now interrupt the consumer, remember at which number it was (or check it in the database) and restart the consumer. Notice that the consumer picks up all the missed messages and then continues listening for new ones.
Note that if you turn off the consumer within 1 second after reading the message, the message will be retrieved again upon restart. Why? Because our auto_commit_interval is set to 1 second, remember that if the offset is not committed, the consumer will read the message again (if auto_offset_reset is set to earliest).



