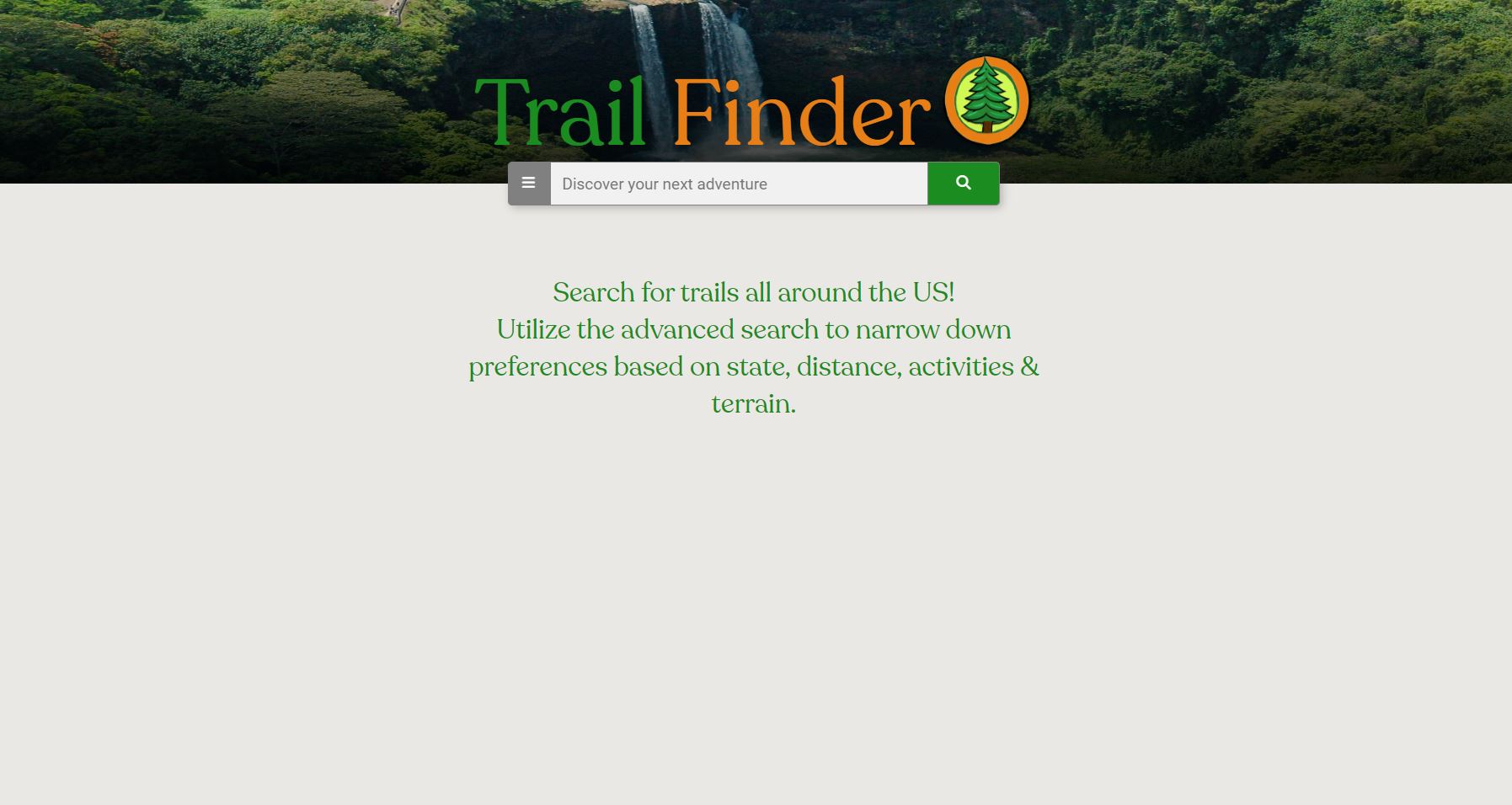
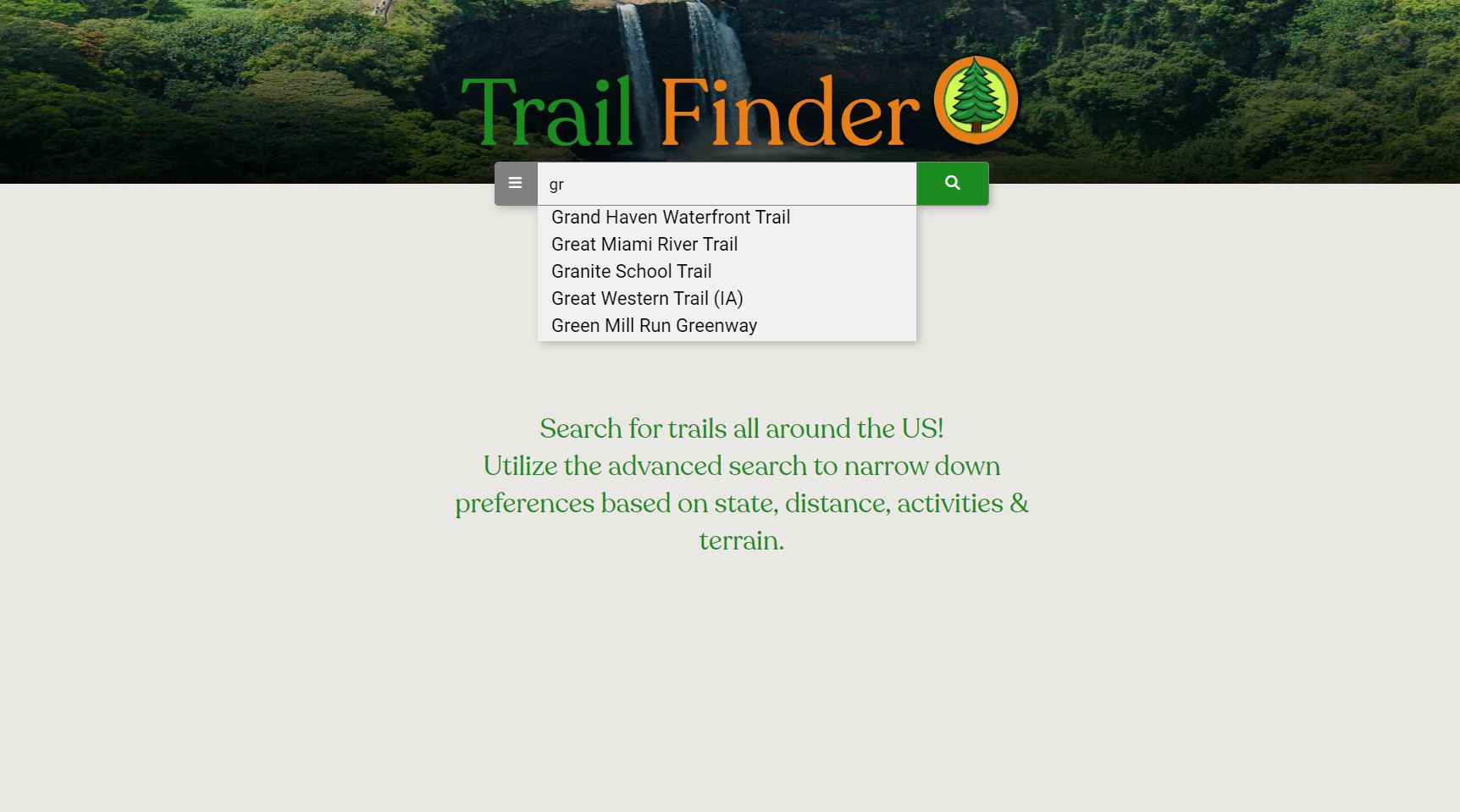


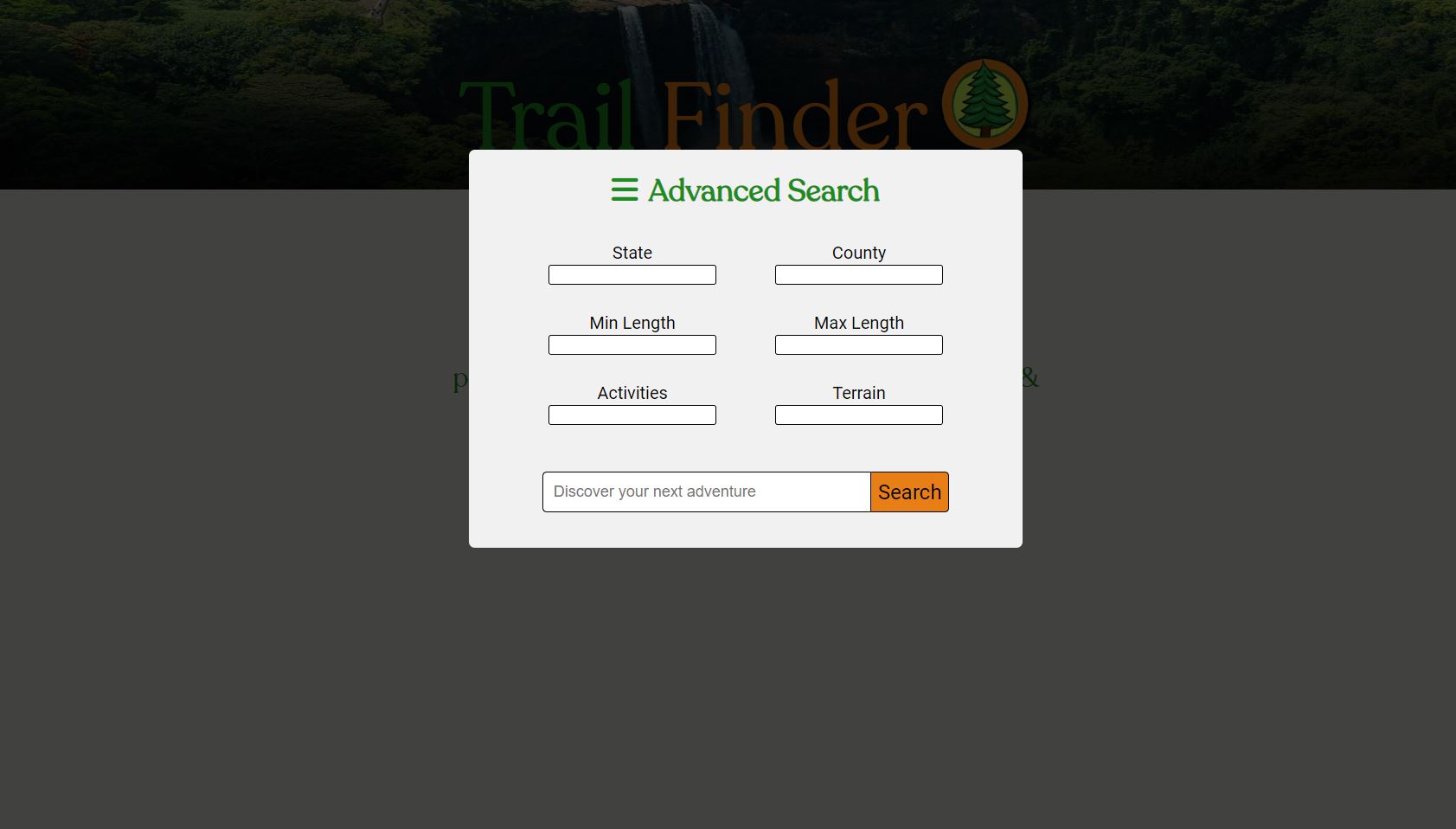
Trail cards are built using data scraped from the following sites:
- https://www.traillink.com/
- https://www.oregonhikers.org/
- https://opendata.gis.utah.gov/datasets/utah-trails-and-pathways/
- https://ct-deep-gis-open-data-website-ctdeep.hub.arcgis.com/datasets/CTDEEP::hiking-appropriate/
- https://open-data.bouldercolorado.gov/datasets/d7ad8e150c164c32ab1690658f3fa662_4/
- https://www.denvergov.org/opendata/dataset/city-and-county-of-denver-trails-and-sidewalks
- https://public-nps.opendata.arcgis.com/datasets/nps-trails-geographic-coordinate-system-1/
- Built on Flask back end
- Jinja templating
- Whoosh! for search engine
- Vanilla HTML, CSS & Javascript front end
Python 3.8 and newer required, Pip install the following modules:
- Flask
- flask-paginate
- Whoosh
- matplotlib
- pandas
- wordcloud
- Extract either samplefiles.zip or fullset.zip in the root directory so the .txt files are inside root/files/file.txt
- Indexing trail pages may take some time, there are roughly 25k pages in the fullset.zip and 10k in the samplefiles.zip
- Will also generate word cloud reviews if no matching filename for the cloud image is found.
- All crawlers can be ran separately to generate files for Whoosh
- Pagerank calculator relies on Traillink and Oregontrails being crawled at least once
- If using the existing index:
- Run 'python ./server_whoosh.py'
- If building a new index:
- Go into server_whoosh.py, comment out 'mySearcher.existing_index()'
- Uncomment 'mySearcher.build_index()'
- Run 'python ./server_whoosh.py'


