codelittleprince / blog Goto Github PK
View Code? Open in Web Editor NEWA front-end blog | 前端博客
A front-end blog | 前端博客

























































































































跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF, 是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。
简单的说,就是利用游览器对用户的信任,比如,用户已经登录了ww.aaa.com,自然aaa这个网站就会将用户的登录状态session存在cookie中;
然后,aaa.com这个网页有一个对作品点赞的功能,点赞提交地址为aaa.com/api.like?id=777;
这时,另外一个叫www.bbb.com的网站,放了这样一个元素<img src="aaa.com/api.like?id=888">,我们知道,请求静态资源用的是get方法,这样的话,一旦用户进入这个bbb.com页面,就会请求aaa.com这个网站的点赞接口,而且点赞的用户对象是888;
最后因为用户的登录信息尚未过期,那就等于给id为888这个作品点赞了,然而,用户并不知情。
有两种方法:
使用iframe会引出一些不安全的问题,比如绕过referer验证,比如资源盗用等,所以,很多网站会设置X-Frame-Options 为 DENY,这也是一个安全的补充点。
问:既然请求静态资源都是get请求,那么要是后端把点赞接口改为post的方式也可以吧?
答:不可以。因为,bbb.com网站完全可以设置一个form表单,action为bbb.com,method为post,接着input的name为id,value为888,然后,script代码直接submit表单。为了页面不重定向,还可以在form外层加一个iframe。由于form表单其实是直接跳转,所以不存在跨域的问题。
防止CSRF的最好方法还是带token吧~
有时候,市面上的webpack loader并不完全符合我们的需求,所以,我们不得不自己从0开始写一个,或者是在别人写的loader基础之上进行修改。
无论哪种,都需要我们对webpack加载loader的方式有所了解。
出招吧~
1、git clone项目到本地
2、初始化npm
npm init填写完npm init的一路提示下来以后,我们看下文件结构:
.
├── README.md
└── package.json3、安装webpack
npm i -D webpack4、设置一下package.json里的scripts命令:
"scripts": {
"dev": "webpack"
},这样的话,基本的工具就准备完毕了。
1、创建webpack.config.js
.
├── README.md
├── node_modules
├── package-lock.json
├── package.json
└── webpack.config.js2、编辑webpack.config.js
const path = require('path')
module.exports = {
entry: {
app: path.resolve('demo/index.js')
},
output: {
path: path.resolve('dist'),
filename: 'index.js'
},
module: {
rules: [
{
test: /\.js$/,
loader: path.resolve('src/loader-test.js'),
options: {
speak: 'wang~',
}
}
]
}
}因为我们是从0开始编写的,所以不得不先从简单到复杂。
所以,如上,我们通过path引用的方式来使用loader。并且,我们配置了option,作为参数。
index则是需要处理的文件。
const cat = 'kitty'
console.log(cat)// loader-utils作为工具类引入(作为webpack依赖,所以在安装webpack时候就带上了)
const loaderUtils = require('loader-utils')
// loader调用的时候,会将源数据和sourcemap作为参数传入函数
module.exports = function(source, inputSourceMap) {
const code = source
const map = inputSourceMap
// loaderUtils.getOptions 可以获取到设置loader时候设置的options
// 当然loaderUtils还有很多其他有用的方法,详情可以看 https://github.com/webpack/loader-utils
const loaderOptions = loaderUtils.getOptions(this) || {};
console.log(source)
console.log(loaderOptions)
// loader需要将自己的值传给下一个loader,并且,loader不免会有异步操作
// 因此需要回调来证明自己已经处理结束了
this.callback(null, code, map)
}先看下目录结构,为了不影响视觉,我忽略了node_module文件:
.
├── README.md
├── demo
│ └── index.js
├── package-lock.json
├── package.json
├── src
│ └── loader-test.js
└── webpack.config.js好,让我们运行一下webpack,看一下效果:
npm run dev
...
const cat = 'kitty'
console.log(cat)
{ speak: 'wang~' }
...正如我们写的loader,打印出了index.js的源码,以及,webpack.config.js配置loader时候的options。
是不是有点儿小兴奋?

虽然说是教程,但是这样的小例子的确有点太过简单了,我们可以做点有意义点的功能。
比如,我们想把js中px全部替换成vw,比例就按照1vw = 10px吧。
(我相信很多朋友会觉得为啥替换js,而不是css或者scss。因为,会涉及更多的webapck配置,比较无聊和对本章内容没什么作用,所以,我觉得还是越简单越好,就拿js举例子吧)
好,计划有了,开始行动吧!
const parentStyle = `
background: #fdc;
width: 1200px;
height: 600px;
box-sizing: border-box;
padding: 150px 300px;
`
const childStyle = `
background: #cdf;
width: 600px;
height: 300px;
`
const parent = document.getElementById('parent')
const child = document.getElementById('child')
parent.style.cssText = parentStyle
child.style.cssText = childStyle<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
* {padding: 0; margin: 0;}
</style>
</head>
<body>
<div id="parent">
<div id="child"></div>
</div>
</body>
</html>一不做二不休,为了更顺畅的看效果,我们加个webpack-dev-server自动启动吧。同时,顺带着,将html-webpack-plugin和clean-webpack-plugin也都加上。
关于写demo,我觉得,是写npm modules必须要有的东西,如果没有demo,没有顺畅的启动demo操作。别说别人懒得看,自己都懒得启动了。
好,我们再看下现在的webpack配置:
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const CleanWebpackPlugin = require('clean-webpack-plugin')
module.exports = {
entry: {
app: path.resolve('demo/index.js')
},
output: {
path: path.resolve('dist'),
filename: 'index.js'
},
module: {
rules: [
{
test: /\.js$/,
loader: path.resolve('src/loader-test.js')
}
]
},
plugins: [
// 清理dist
new CleanWebpackPlugin('dist'),
// 将js打入html
new HtmlWebpackPlugin({
filename: 'index.html',
template: path.resolve('demo/index.html'),
chunks: ['app'] // 因为只有一个页面,这行不写也可以
})
]
}修改下package.json里的scripts命令:
"scripts": {
"dev": "webpack-dev-server --open"
},然后,启动实验一下,npm run dev。
看下效果:
没问题,进入下一步~
让我们重新编辑loader-test.js吧:
...
// 替换px
const regex = /(\d+?)px/g
code = code.replace(regex, function(match, p1) {
return p1/10 + 'vw'
})
...
}然后,再重新启动一下,我们会发现,px都被替换成了vw了,而且比例为1vw = 10px,成功!
当然,有同学肯定会想到,要是这个比例可以自己设置那就更好了。实现方式当然也很简单啊,还记得我们之前是怎么获取loader中options配置的speak吗?我相信同学完全可以独立完成了。
这个的话,其实是我之前已经写过这样的文章了,同学们可以转到npm-从0开始写一个npm module
最后,希望喜欢的同学能给star哦
说点题外话,不知道为什么webpack官网对loader的介绍那么简短,很难单单根据文档就写出loader来。所以还建议看些别人写的loader,如babel-loader等。
上一篇我们遇到'少年,是不是忘了npm run mock?'的警告,这一篇我们就来解决这个问题。
安装koa和一系列的包(我们用的是koa v2):
koa
koa-bodyparser
koa-router
boom
nodemon
mockjs解释说明一下(知道的同学可以忽略):
| 名称 | 作用 |
|---|---|
| koa | 我们都知道Node.js有HTTP模块,来处理HTTP请求,koa基于Node做了很多方便的接口让我们更顺畅地处理HTTP,比如,接收、解析、响应。 |
| koa-router | 方便的路由方式获取get/post、以及参数 |
| koa-bodyparser | koa插件之一,方便解析get/post的参数 |
| boom | 友好的HTTP错误对象 |
| nodemon | 为了在启动koa服务以后,修改了koa相关的node代码会自动重载更新,无需手动关闭再重启 |
| mockjs | 模拟数据用 |
结构:
mock
├── home // 和views文件夹对应
│ └── hello.js // home页面需要的hello模拟数据
├── public // 公共的接口模拟数据
└── server.js // node代码先上一盘server.js代码:
const Koa = require('koa')
// 使用router
const Router = require('koa-router')
const Boom = require('boom')
const bodyParser = require('koa-bodyparser')
const app = new Koa()
const router = new Router()
// https://github.com/alexmingoia/koa-router
app.use(router.routes())
app.use(router.allowedMethods({
throw: true,
notImplemented: () => new Boom.notImplemented(),
methodNotAllowed: () => new Boom.methodNotAllowed()
}))
// 使用bodyparser 解析get,post的参数
app.use(bodyParser())
// 模拟数据返回
/* 首页 */
// 获取hello数据
const helloData = require('./home/hello.js')
router.get('/api/home/hello', async(ctx, next) => {
ctx.body = helloData
await next()
})
// log error
app.on('error', (err, ctx) => {
console.log('server error', err, ctx)
})
// 注意:这里的端口要和webpack里devServer的端口对应
app.listen(7777)再来一盘hello.js代码:
// 引入mockjs来模拟数据
// https://github.com/nuysoft/Mock/wiki/Getting-Started
const Mock = require('mockjs')
const data = Mock.mock({
'list|1-10': [{
'id|+1': 1
}]
})
const img = Mock.Random.image('200x100')
module.exports = {
msg: 'mock hello api works',
data: data,
imgUrl: img
}在package.json里scripts里加上:
"mock": "nodemon ./mock/server.js"
这样的话,我们只需要npm run mock就启动了本地的模拟数据接口功能了。
回到之前我们下的完整项目,先启动mock,然后npm run dev,我们就可以发现报错不见啦。
通过koa v2实现前后端分离,并且使用mockjs来更方便的模拟数据。
下一篇,我们创建发布环境下的webpack配置文件,并且看看怎么优化产出的代码的 - 从零开始做Vue前端架构(5)
npm 自从v7开始,引入了一个十分强大的功能,那就是workspaces。另外,yarn和pnpm也拥有workspaces的能力。不过,从用法上来说,几乎是一模一样的。所以,学会了npm workspaces的话,自然而然也就学会了yarn和pnpm的了。
本文会分四个部分进行介绍:
顾名思义,workspaces就是多空间的概念,在npm中可以理解为多包。它的初衷是为了用来进行多包管理的,它可以让多个npm包在同一个项目中进行开发和管理变得非常方便:
这个设计模式最初来自于Lerna,但Lerna对于多包管理,有着更强的能力,而且最新版的Lerna可以完全兼容npm或yarn的workspaces模式。不过因为本文讲的是workspaces,所以,对于Lerna有兴趣的同学,可以自行去Lerna官网学习。
多包管理上面已经说过它相对单包单独管理的好处。所以,我们通过实例的例子来让同学们感受一下workspaces为什么被我吹的这么牛批。
项目地址我挂在github上了,有兴趣的同学可以自行查看源码。
npm i -g npm@latestmkdir demo-workspaces-multi-packagesnpm init -y
.
└── package.jsonpackage.json新增配置:
"private":"true",
"workspaces": [
"packages/*"
],这里的packages/*表示我们的子包都在packages文件夹下。(对于workspaces的细节和更多用法本文不会一一介绍,文档非常清楚,本文讲究实战)
m1创建子包m1:
npm init -w packages/m1 -y
.
├── package.json
└── packages
└── m1
└── package.json创建m1的主文件index.js:
echo "exports.name = 'kitty'" >> packages/m1/index.js
.
├── package.json
└── packages
└── m1
├── index.js
└── package.jsonm2同样的方式,创建子包m2:
npm init -w packages/m2 -y
.
├── package.json
└── packages
├── m1
│ ├── index.js
│ └── package.json
└── m2
└── package.json创建m2的主文件index.js:
echo "const { name } = require('m1')\nexports.name = name" >> packages/m2/index.js
.
├── package.json
└── packages
├── m1
│ ├── index.js
│ └── package.json
└── m2
├── index.js
└── package.json因为这里require('m1'),所以需要添加m1依赖到m2的package.json中:
npm i -S m1 --workspace=m2demo为了方便我们看到效果,再创建一个demo文件夹(多包管理推荐搞个demo子包进行整体效果测试):
npm init -w packages/demo -y
echo "const { name } = require('m2')\nconsole.log(name)" >> packages/demo/index.js
.
├── package.json
└── packages
├── demo
│ ├── index.js
│ └── package.json
├── m1
│ ├── index.js
│ └── package.json
└── m2
├── index.js
└── package.json额外的,这个demo包,我们并不像他进行发布,为了防止不小心发布,我们在demo的package.json中新增:
"private":"true",因为这里require('m2'),所以需要添加m2依赖到demo的package.json中:
npm i -S m2 --workspace=demo我们看看这时候项目根目录的node_modules吧:

是不是很有意思?全是软链接,链接的指向就是packages文件夹下的各子包。
OK,搞了半天,我们运行demo看下效果吧:
node packages/demo/index.js
# 输出:
kitty通过上面的例子,我们可以看出,workspaces对于本地子包之间的依赖处理的非常巧妙,也让开发者更加方便,尤其是多人开发的时候。另一个人在拉取完项目以后,只需要运行npm install,即可进行开发,软链接会自动建立好。
接下来,我们看workspaces项目中如果安装三方包的情况。
npm i -S vue@2 --workspace=m1
npm i -S vue@3 --workspace=m2例子中,我们想看看,因为我们的包都会被提升到根目录进行安装,那么不同版本的vue它会怎么处理呢?难道只会安装vue3的包吗?
结果:

这样,我们就无需担心版本冲突的问题了,workspaces显然已经很好地解决了。
--workspace在workspaces项目中,一个很核心的参数就是--workspace,因为从前文的安装包到子包的命令可以发现,和传统的安装包一样,都是使用npm i -S 包名或者npm i -D 包名,不同的仅仅是末尾加了--workspace。
那是不是对于其它的命令,比如run、version、publish等也是样的使用方式呢?答案是:Yes!
另外,如果我们子包的package.json中scprits全都有一个叫test的命令,我们想一次性运行所有子包的这个命令,可以使用npm run test --workspaces即可。
这样的话,对于我们的Lint校验或是单测都是非常方便的。
到此,workspaces在多包管理中启到的作用就基本介绍完了。值得一提的是,多包管理,实际项目中还是推荐使用Lerna,它对于版本依赖自动升级、发包提示、自动生成Log(Change Log / Release Note)、CI等都具有一套十分成熟的流程机制了。
目前的npmworkspaces,个人认为是非常适合用来做多项目的整合(Monorepo)管理的 。
项目地址我挂在github上了,有兴趣的同学可以自行查看源码。
mkdir demo-workspaces-multi-projectnpm init -y
.
└── package.jsonpackage.json新增配置:
"private":"true",
"workspaces": [
"projects/*"
],zoo创建子项目zoo:
npm init -w projects/zoo -y
.
├── package.json
└── packages
└── zoo
└── package.json创建模板文件index.html,主内容为:
<!-- projects/zoo/index.html -->
<body>
<h1>Welcome to Zoo!</h1>
<div id="app"></div>
</body>创建项目入口js文件index.js,内容为:
console.log('Zoo')安装项目构建依赖包:
npm i -S webpack webpack-cli webpack-dev-server html-webpack-plugin webpack-merge --workspace=zoo
# projects/zoo/package.json
"private":"true",
"dependencies": {
"html-webpack-plugin": "^5.5.0",
"webpack": "^5.65.0",
"webpack-cli": "^4.9.1",
"webpack-dev-server": "^4.7.2"
}创建webpack配置:
// projects/zoo/webpack/base.config.js
const HtmlWebpackPlugin = require('html-webpack-plugin')
const path = require('path')
function resolve(dir) {
return path.join(__dirname, '../' + dir)
}
exports.config = {
entry: resolve('src/index.js'),
plugins: [
new HtmlWebpackPlugin({
title: 'Zoo',
filename: 'index.html',
template: resolve('src/index.html')
})
],
}
exports.resolve = resolve// projects/zoo/webpack/dev.config.js
const { config, resolve } = require('./base.config')
const { merge } = require('webpack-merge')
exports.default = merge(config, {
mode: 'development',
output: {
filename: 'bundle.js',
},
})// projects/zoo/webpack/prod.config.js
const { config, resolve } = require('./base.config')
const { merge } = require('webpack-merge')
exports.default = merge(config, {
mode: 'production',
output: {
filename: 'bundle.js',
},
})zoo下的package.json新增命令:
"scripts": {
"dev": "webpack-dev-server --config webpack/dev.config.js --open",
"prod": "webpack --config webpack/prod.config.js"
},接下来就可以运行了,只需要在项目根目录使用:
npm run dev --workspace=zoo即可进行本地开发。
效果:

运行prod同理。
shop创建子项目shop:
npm init -w projects/shop -y其余步骤同初始化子项目zoo几乎一模一样,所以不再赘述。
最后的目录结构:

对于Monorepo,共享是最重要的一个优势。所以,我们来做一些共享的事情。
share空间,作为共享资源空间,并创建共享文件Fish.js:npm init -w projects/share -y
mkdir projects/share/js
touch projects/share/js/Fish.js// projects/share/js/Fish.js
class Fish {
constructor(name, age) {
this.name = name
this.age = age
}
swim() {
console.log('swim~')
}
print() {
return '🐟 '
}
}
module.exports = Fish子项目zoo的入口文件改为:
// projects/zoo/src/index.js
const Fish = require('share/js/Fish')
const fish = new Fish()
document.getElementById('app').textContent = fish.print()运行zoo的dev看效果:

修改子项目shop的入口文件后,会出现同样的效果。
workspaces做集合项目,用传统方式不行吗?传统方式:
package.json只有一份,在根目录,所有项目中的npm包都安装到根目录,在根目录的package.json中定义开发和部署子项目的命令;package.json,但基础的构建工具在根目录进行安装,比如上面提到的webpack、webpack-cli、webpack-dev-server、html-webpack-plugin、webpack-merge,全都在根目录进行安装,和业务相关的npm包都安装到各自子项目中;package.json,根目录无package.json;方式1 —— 缺点:
方式2 —— 缺点:
方式3 —— 缺点:
那使用workspaces就很好的解决了上面的所有问题!
另外,对于已经存在的项目而言,比如我今年所接手的项目,一个是Web的,一个是Wap的,然后发现,因为他们属于同一个业务,所以有大量的代码可以复用,又因为只涉及这两个项目而已,把公共代码做成npm包又有点太杀鸡用牛刀,所以,过去一直采用的是复制、粘贴的模式。这显然是非常低效的。另外就是,mock服务也是个字项目单独一套,但是大多数接口的数据都是可以公用的,只是url前缀不同。最离谱的就是几百个银行图标都一模一样。所以,我打算将它俩合并成一个项目。而workspaces对于我来说,是一个对原项目改动量最小的方案。
我们想要在构建机上只部署项目zoo,应该怎么做?
npm install --production --workspace=zoo 这样的话,构建机上就只会安装zoo项目下的依赖包了。
npm run prod --workspace=zoo 这样的话,就构建成功了!🎉
npm的workspaces其实有隐藏的坑,所以我也罗列下。
npm v7开始,install会默认安装依赖包中的peerDependencies声明的包。新项目可能影响不大,但是,如果你是改造现有的项目。因为用了统一管理的方式,所以一般都会把子项目中的lock文件删掉,在根目录用统一的lock管理。然后,当你这么做了以后,可能坑爹的事情就出现了。
场景:我的子项目中用的是webpack4,然后,我们的构建相关的工具(webpack、babel、postcss、eslint、stylint等)都会封装到基础包中。这些包的依赖包中有一个包,在package.json声明中使用这样写:
"peerDependencies": {
"webpack": "^5.1.0"
},然后,在根目录中npm install,然后再跑子项目发现项目跑不起来了。原因就是,项目居然安装的是webpack5的版本!
package.json中显示声明用的webpack版本;webpack4也兼容webpack5,应该写成,把声明改为: "webpack": "^4.0.0 || ^5.0.0"npm install --legacy-peer-deps个人真的觉得这是npm作者脑袋被驴踢了。对于yarn或者pnpm,他们的workspaces都不会用这种默认安装peerDependencies的模式。
作者原本是想,因为如果npm包的开发者声明了peerDependencies,如果我们使用过程中没有安装匹配的版本的包就可能导致项目跑不了,为了方便使用,他就采用了默认安装的模式。
但是,这种做法会导致那些peerDependencies不符合书写规范的包,在项目中配合使用出现问题。而且,即使新的包中包作者们开始注意书写规范,但是无法处理那些已经发布出去的老包,总不可能全都回收,然后一个个版本重新再发布一遍吧!
这其实是个人粗心导致的。
举个例子:zoo使用命令npm i -S @vue2.2.1引入vue,shop使用命令npm i -S @vue2.2.2引入vue。那么,项目会有两个版本的vue吗?不会。
原因我们可以看zoo项目下的package.json:
"dependencies": {
"html-webpack-plugin": "^5.5.0",
"vue": "^2.2.1",
"webpack": "^5.65.0",
"webpack-cli": "^4.9.1",
"webpack-dev-server": "^4.7.2",
"webpack-merge": "^5.8.0"
}恍然大悟。
^即可;npm i --save-exact [email protected] --workspace=zoo本文,利用了workspaces来做多包管理,以及多项目管理,体现出了workspaces的强大。因为我个人负责的项目一直以来都是使用npm来管理的,所以想要迁移到yarn或者pnpm存在未知的风险,而且,也尝试过,因为一些老包yarn2和pnpm都跑不起来。对于新的项目,个人也更推荐yarn2或者pnpm进行管理,它们比npm更加强大。
本原文来自于个人github博客,觉得好的小伙伴可以点个赞哈~
<( ̄▽ ̄)/
文中多包管理和多项目管理的源码分别在:
有兴趣的同学可以自行下载学习。
相信很多网站都会遇到也不知道是谁,毫无目的刷网站的接口的事情。
尤其是短信接口,好像所有网站都会被人刷接口,十有八九都是短信接口的提供商找人干的。。。
其次,登录接口也是经常被刷地方,因为可以被破坏者用来爆破用户的密码。
然后,注册接口也是,不过因为国家强制要求手机号注册的原因,现在还好刷注册接口很难了。
1、监控异常ip,发现异常ip,直接封ip(这种方法要是遇到使用肉鸡刷的人就没什么办法了)
2、使用验证码(这种方法缺点就是降低用户体验)
在实际项目中,这两种防御方式会一起使用。
这两种防御方式同样应用在爬虫的防御上。
由于验证码这东西市面上有很多种,而好的交互和用户的体验息息相关,那么,现在有哪些种类的验证码呢,我们又该怎么选择呢?

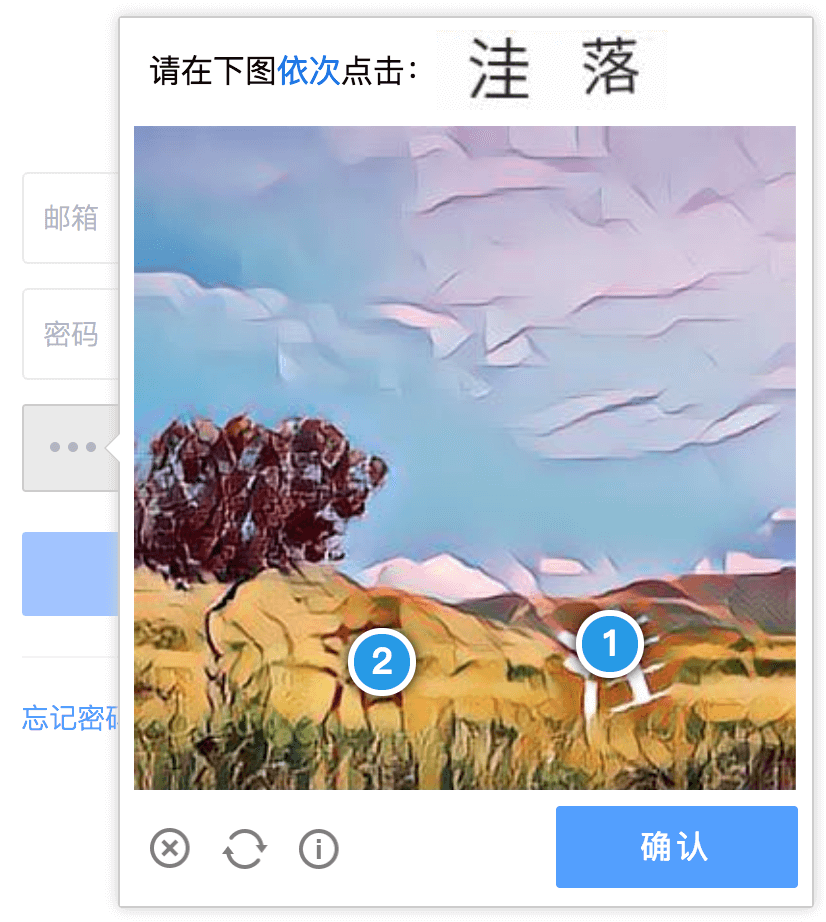
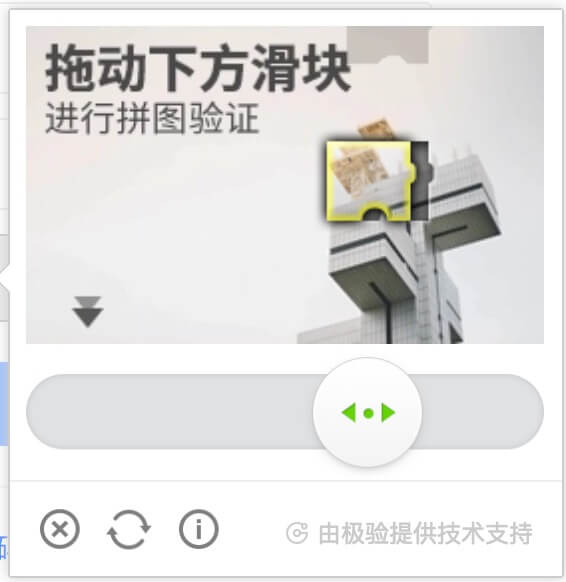
无感知验证码可以说是目前最好的验证码解决方案了。
然而很多公司还是停留在图形验证码的阶段 ╮(╯_╰)╭
koa-mock-swich是一个前端mock数据、并可以管理返回数据的server。
为什么需要koa-mock-switch。
目前开发过程中的mock数据方式,主流来说分为:
即,局域环境有一个专门模拟数据用的数据库,然后,后端开发完接口以后,和线上一样地进行增删改查,最后返回给前端数据。
缺点:
时间上,前端在需要数据接口的时候,不得不等后端开发完接口以后,才能进行下一步开发。
职责上,即使前端开发页面的效率很高,但是因为最后完成的时间肯定是在后端之后的,如果一个项目进度耽误了,前端的锅是背定了。
我们前端,一般都会自己用express或者koa搭建自己的本地前端mock数据服务,市面上也有很多现成的npm可以使用。
优点:
前后端并行开发。前后端只需要在开发之前,一起定义好接口规范即可。之后前端按照api文档模拟mock数据,自己可以躲在小黑屋独自开发,直到最后的联调。
通过对比,我们发现前端搭建mock数据服务的方式无疑是前端开发的首选。
但是,对于传统的前端mock服务,我们做的仅仅只有,前端页面发起请求,mock服务接收请求,根据请求路径寻找对应的mock文件,最后返回给前端。
相信大多公司也是这么干的。
考虑一下以下场景:
如果我们想要返回不同的mock数据,开发者不得不手动的修改mock数据源文件,每次注释,解注释。
状态少还可以,比如一个接口,成功或失败,在界面的显示需要不同,因此,我们就需要写完两组模拟数据,并注释一组比如失败,等到需要用失败的时候,解注释失败,注释成功。
如果状态多呢?比如一个用户信息接口,用户分为企业用户和个人用户,然后,企业用户有四种状态:未实名、实名中、已实名、实名失败。默认模拟数据为企业用户->已实名,这个时候,我们想要测测所有的情况,那就得做7次注释加解注释的操作。
版本迭代了,已实名还有分:初级会员、中级会员、高级会员、超级会员。我们以后每次改相关代码,为了避免出bug被测试看不起,就不得不所有的情况全都再测一遍。

如果状态更多呢?

有同学说,我三年的注释解注释工作经验,怕这百把十个操作?我就喜欢每次改完代码就一顿注释解注释操作,让老板看到,我工作是有多么饱和。

我相信有些很有毅力的同学,会觉得这都不是事儿。但是,这么做的话,我们能保证我们不会漏掉任何一个有多个状态的接口吗?
又有同学说:恩,这个不难,在每个有多个状态的mock文件中加个标记,比如本王宇宙最牛逼这行注释,然后全局搜索,就能知道哪些mock文件会有多状态了。
那我们能保证我们不会把状态拼接错乱吗?比如,明明是个人用户,却不小心解注释了企业用户的某些状态。
有同学说:小意思,写注释就好,想要多少写多少,下次一行行看注释就好了,吐了算我输。
恩~~~对于这样的杠精,我只能说:

回归正题,为了解决这些问题,koa-mock-switch诞生了。
那么,怎么设计koa-mock-switch这个server呢?
首先,先说一下我们的期望,我们期望:
1、有一个涉及多状态mock数据的管理页面,方便查看
2、通过UI界面的操作就可以控制返回对应状态的mock数据
其实这个方案并不是我首创的,最开始接触这个方案,是从我们部门同事那,原始版叫做mock-middleware。我先解释一下他的实现原理。
前端项目browser -> node 算法:
其实就是在express或者koa的node服务中,维护一个全局变量,我们叫$config,数据类型为对象,key为api的地址,value为返回的模拟数据。如果node端接收到浏览器的请求的话,先在$config中查找,看看是否存在当前api,有的话直接返回,没有的话,就寻找对应的mock文件,返回数据。同时,将api作为key,返回数据作为value存入$config。
mock管理界面browser -> node 算法:
为了达到通过UI界面的操作就可以控制返回对应状态的mock数据的效果,会有一个和项目无关的,专门用来管理mock返回数据的页面,我们就叫做mock-management-page吧,如图:

这个页面的列表渲染,依赖与事先创建的mockSwitchMap。

渲染完以后,只要切换状态,就会想node服务发起ajax请求,参数为api的地址以及对应的status(如成功或失败)。node端接收到后,读取该api的mock文件,根据需要的状态,更新$config。
如此一来,我们就可以通过mock-management-page,在开发的时候,简单的点击一下按钮,就达到了切换返回数据的目的。
然而,还是会遇到问题,从算法可以看出,mock-management-page可以发起ajax对应的status是单一的,会遇到什么问题呢?

缺点很明显:
1、不得在每次的返回函数中,根据key(即之前说的各种状态)进行人工处理。
2、我们看到有段注释// 'bankCardType': 'ENTERPRISE',,我们依然用了传统的注释,解注释方式来切换返回数据。因为,我们之前说过mock-management-page可以发起ajax对应的status是单一的。如果我们一定要把它变为可切换方式,我们不得不这么写:

我们发现,处理状态的过程又多了,最终导致该接口状态越多,处理逻辑约繁重,想想都觉得好心疼,做了这么多,回报却不是很大。
但是,细心的同学可以发现,我们根据key(即之前说的各种状态)的名字规定,可以做些不同的处理,所以是不是存在某种方式,可以通过一个通用的数据处理方法,自动地根据key(即之前说的各种状态)的规则,处理后得到最终理想的数据呢?
当然可以!最后,我们的任务就是:制定key规则;编写一个通用数据处理函数。
我们通过事先约定来规定mockSwitchMap的value,为了便于理解,我们回到Hello Kitty的例子,我们重新构造mockSwitchMap的value:

我们[]代表数据的层级,用@代表状态,@作为状态选项,经过处理以后,会向上提升一层。
/api/kitty的mock数据文件:

如此,我们就可以非常灵活地管理我们想要返回的mock数据,并且,对于哪些mock接口具有多种状态一目了然。此外,如果不需要多状态的mock数据和传统mock文件一样,不需要做任何额外的处理,比如Tom的mock文件:

npm install -D koa-mock-switchconst path = require('path')
// mock文件的根目录
const mockRoot = path.join(__dirname, './mock')
// require koa-mock-switch
const KoaMockSwitch = require('koa-mock-switch')
// mock管理列表
const mockSwitchMap = require('./mockSwitchMap.js')
/**
* KoaMockSwitch(mockRoot, mockSwitchMap, apiSuffix)
* @param mockRoot mock文件的根目录
* @param mockSwitchMap mock管理列表
* @param apiSuffix 客户端请求api的后缀,比如'/api/kitty.json',apiSuffix就是'.json'
*/
const mock = new KoaMockSwitch(mockRoot, mockSwitchMap, '.htm')
// 启动mock服务
mock.start(7878)还是对使用方法疑惑的同学,可以参考demo。
项目中有demo演示,同学们可以自己clone后体验下。
地址:koa-mock-switch
安装
npm install第一个窗口shell
npm run mock第二个窗口shell
npm run demo不知道有没有同学和我一样,在网上看https的资料总是觉得好像讲的不详细或者经不起推敲,甚至在书本中,也看的云里雾里,稍微到了关键的地方,就被跳过不介绍了。自己好像懂了,诶,好像又没懂。
反正我当初是憋了好一段时间 (〒︿〒)
因此,为了避免新手别像本王一样走弯,本王放弃了看动漫的时间,下定决心写一篇关于https的文章。
https在MDN上的定义:
HTTPS (安全的HTTP)是 HTTP 协议的加密版本。它通常使用 SSL 或者 TLS 来加密客户端和服务器之前所有的通信 。这安全的链接允许客户端与服务器安全地交换敏感的数据,例如网上银行或者在线商城等涉及金钱的操作。
SSL和TLS的区别:

大体上说白了,没什么区别。就是TLS是IETF的标准化,SSL不是,而且会被历史给能慢慢淘汰。
值得一提的是SSL 3.0开始,便引入了前向安全性,为了不一开始就让各位困扰,前向安全会在后面介绍。
那为什么要是用https呢?
自然因为安全啦。
那http怎么就不安全了呢?
接下来就让我们一起来看看吧:
小灰是客户端,小灰的同事小红是服务端,有一天小灰试图给小红发送请求。

但是,由于传输信息是明文,这个信息有可能被某个中间人恶意截获甚至篡改。这种行为叫做中间人攻击。



如何进行加密呢?
小灰和小红可以事先约定一种对称加密方式,并且约定一个随机生成的密钥。后续的通信中,信息发送方都使用密钥对信息加密,而信息接收方通过同样的密钥对信息解密。


这样做是不是就绝对安全了呢?并不是。
虽然我们在后续的通信中对明文进行了加密,但是第一次约定加密方式和密钥的通信仍然是明文,如果第一次通信就已经被拦截了,那么密钥就会泄露给中间人,中间人仍然可以解密后续所有的通信内容。

这可怎么办呢?别担心,我们可以使用非对称加密,为密钥的传输做一层额外的保护。非对称加密的一组秘钥对中,包含一个公钥和一个私钥。明文既可以用公钥加密,用私钥解密;也可以用私钥加密,用公钥解密。
在小灰和小红建立通信的时候,小红首先把自己的公钥Key1发给小灰:

收到小红的公钥以后,小灰自己生成一个用于对称加密的密钥Key2,并且用刚才接收的公钥Key1对Key2进行加密,发送给小红:

小红利用自己非对称加密的私钥,解开了公钥Key1的加密,获得了Key2的内容。从此以后,两人就可以利用Key2进行对称加密的通信了。

在通信过程中,即使中间人在一开始就截获了公钥Key1,由于不知道私钥是什么,也无从解密。
那这样做是不是就绝对安全了呢?同样不是。
中间人虽然不知道小红的私钥是什么,但是在截获了小红的公钥Key1之后,却可以偷天换日,自己另外生成一对公钥私钥,把自己的公钥Key3发送给小灰。

小灰不知道公钥被偷偷换过,以为Key3就是小红的公钥。于是按照先前的流程,用Key3加密了自己生成的对称加密密钥Key2,发送给小红。
这一次通信再次被中间人截获,中间人先用自己的私钥解开了Key3的加密,获得Key2,然后再用当初小红发来的Key1重新加密,再发给小红。


那怎么办呢?难道再把公钥进行一次加密吗?这样只会陷入鸡生蛋蛋生鸡,永无止境的困局。
这时候,我们有必要引入第三方,一个权威的证书颁发机构(CA)来解决。
接下来,也是开始正真的进入https的详解了。
权威的证书颁发机构(CA)是做什么的?
简单的说,就是发安全证书的,而且受全世界认可,相信它绝不造假,安全可靠。用户通过申请,填写相关资料,然后花点钱,就能获得CA下发的安全证书。
我们介绍下具体的流程:
openssl genrsa -out www.example.com.key 2048openssl req -new -sha256 -key www.example.com.key -out www.example.com.csrYou are about to be asked to enter information that will be incorporated
into your certificate request
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:CA
State or Province Name (full name) [Some-State]:California
Locality Name (for example, city) []:Mountain View
Organization Name (for example, company) [Internet Widgits Pty Ltd]:Example, Inc.
Organizational Unit Name (for example, section) []:Webmaster Help Center Example
Team
Common Name (e.g. server FQDN or YOUR name) []:www.example.com
Email Address []:[email protected]
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:对于为您的公钥进行证实的服务,不同 CA 的收费将有所不同。
还可以选择将密钥映射到多个 DNS 名称,包括多个独立名称(例如 example.com、www.example.com、example.net 和 www.example.net 的全部)或“通配符”名称(例如 *.example.com)。
例如,某个 CA 目前提供以下价格:
标准:16 美元/年,适用于 example.com 和 www.example.com。
通配符:150 美元/年,适用于 example.com 和 *.example.com。
证书包含如下信息:

对于已经双方都有私钥以后的事情,想必同学们都已经经过之前的训练非常清楚了。
所以我们只需要重点介绍服务端和客户端进行对称加密的时候的密钥是怎么生成就可以了。
我们来看看整个用https信息交互的流程:


图中生成对称密钥的流程已经很清楚了。
回过头来,有个问题是,为什么有两种方式?
这就得提到之前说过的前向安全性了。
它们主要的区别就是生成对称密钥的算法,图1是RSA,图2则是DH。
C随机选取一个master key(即对称加密的密钥) ,用S 的公钥加密,S解密,得到明文的master key,剩下过程和DH算法类似!
S为server端,C为client端:
S 筛选出自己的素数对 S1、S2;
C 筛选出自己的素数对 C1、C2;
S与C交换各自的S2、C2;
S拥有了S1、C2,DH可以算出一个master key;
C拥有了C1、S2,DH可以算出一个master key;
两个master key 完全一样。
这就是神奇的DH算法!
任何第三方都无法根据截获的S2、C2算出master key。
最终,我们通过http中遇到的种种问题,到一步步的想办法解决,再到后来的走投无路,最终引入了https。然后又学习了https加密的整个过程,以及https早期的前向安全问题的解决方案。
想必,同学们已经对https有了更深入的了解了。

HTTPS可以防止中间人篡改内容吗?
在服务器上启用 HTTPS
TLS/SSL 高级进阶
漫画:什么是 HTTPS 协议?
dynamic import不知道为什么有很多叫法,什么按需加载,懒加载,Code Splitting,代码分页等。
总之,就是在SPA,把JS代码分成N个页面份数的文件,不在用户刚进来就全部引入,而是等用户跳转路由的时候,再加载对应的JS文件。
这样做的好处就是加速首屏显示速度,同时也减少了资源的浪费。
这个一个完整的项目,这节相关的内容可在router/routerMap.jsx中找到。
babel用的是babel-env,使用方法可以去babel官方学习,实践可看我项目的源代码。
npm i -D babel-plugin-syntax-dynamic-import 以后, 在.babelrc文件的plungins中加上"syntax-dynamic-import"。
npm i -S react-loadable 以后,我们就能愉快得做dynamic import了。
import React from 'react';
import { HashRouter as Router, Route, Switch } from 'react-router-dom';
import createHistory from 'history/createBrowserHistory';
const history = createHistory();
import App from 'containers';
// 按路由拆分代码
import Loadable from 'react-loadable';
const MyLoadingComponent = ({ isLoading, error }) => {
// Handle the loading state
if (isLoading) {
return <div>Loading...</div>;
}
// Handle the error state
else if (error) {
return <div>Sorry, there was a problem loading the page.</div>;
}
else {
return null;
}
};
const AsyncHome = Loadable({
loader: () => import('../containers/Home'),
loading: MyLoadingComponent
});
const AsyncCity = Loadable({
loader: () => import('../containers/City'),
loading: MyLoadingComponent
});
const AsyncDetail = Loadable({
loader: () => import('../containers/Detail'),
loading: MyLoadingComponent
});
const AsyncSearch = Loadable({
loader: () => import('../containers/Search'),
loading: MyLoadingComponent
});
const AsyncUser = Loadable({
loader: () => import('../containers/User'),
loading: MyLoadingComponent
});
const AsyncNotFound = Loadable({
loader: () => import('../containers/404'),
loading: MyLoadingComponent
});
// 路由配置
class RouteMap extends React.Component {
render() {
return (
<Router history={history}>
<App>
<Switch>
<Route path="/" exact component={AsyncHome} />
<Route path="/city" component={AsyncCity} />
<Route path="/search/:category/:keywords?" component={AsyncSearch} />
<Route path="/detail/:id" component={AsyncDetail} />
<Route path="/user" component={AsyncUser} />
<Route path="/empty" component={null} key="empty" />
<Route component={AsyncNotFound} />
</Switch>
</App>
</Router>
);
// 说明
// empty Route
// https://github.com/ReactTraining/react-router/issues/1982 解决人:PFight
// 解决react-router v4改变查询参数并不会刷新或者说重载组件的问题
}
}
export default RouteMap;
我们可以运行webpack,然后就能看到效果(图仅为dev环境,build才会再打包一个vendor.js,为什么要有vendor.js,请见devDependencies和dependencies的区别 >>)
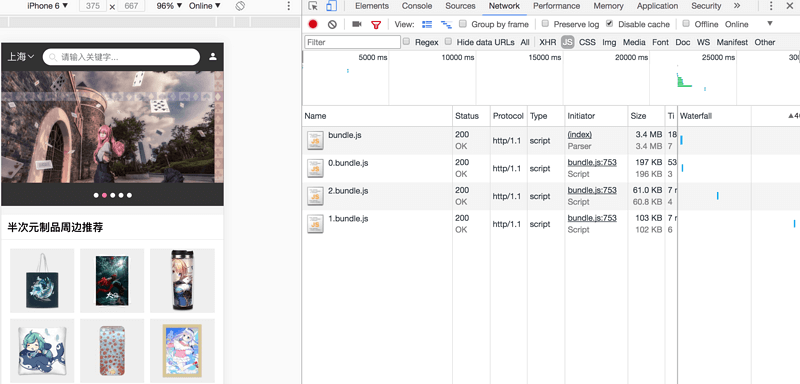
Code Splitting in Create React App
有同学表示,我的方法做页面分离并没有什么好处,因为每个页面都依赖了三方库的代码,所以其实页面有很多冗余代码,能想到这点很棒,已经开始有架构思维了。不过,注意这个想法在dev环境下,这个同学是对的。
那到了build环境,或者说到了发布环境,又是怎么样的呢?的确,这篇文章我没有提到,请见我的另一篇文章devDependencies和dependencies的区别。这篇文章主要解释了npm的package.json中devDependencies和dependencies区别是什么。
看完以后,我们就可以知道,为什么我之前说“注意这个想法在dev环境下,这个同学是对的”了。因为,我们npm run build以后,webpack会把三方包打包到vendor.js文件,页面逻辑代码不会牵涉其中,每个页面都会引用vendor.js这个文件,这样的话,就不会出现重复引入冗余代码的情况了。
去年在公司内部做了一次canvas的分享,或者说canvas总结会更为贴切,但由于一直都因为公事或者私事,一直没有把东西总结成文章分享给大家,实在抱歉~
分享这篇文章的目的是为了让同学们对canvas有一个全面的认识,废话不多说,开拔!
Canvas是一个可以使用脚本(通常为Javascript,其它比如 Java Applets or JavaFX/JavaFX Script)来绘制图形,默认大小为300像素×150像素的HTML元素。
<canvas style="background: purple;"></canvas>
<!-- canvas -->
<canvas id="canvas"></canvas>
<!-- javascript -->
<script>
const canvas = document.getElementById('canvas')
const ctx = canvas.getContext('2d')
ctx.fillStyle = 'purple'
ctx.fillRect(0, 0, 300, 150)
</script>
经过了以上地狱般的学习,我相信同学们现在已精通canvas。
接下来,我将介绍很多案例,把自己能想到的都列举出来,并且,结合其原理,为同学们一一介绍。
案例如下:
该方法告诉浏览器您希望执行动画并请求浏览器在下一次重绘之前调用指定的函数来更新动画。
该方法使用一个回调函数作为参数,这个回调函数会在浏览器重绘之前调用。
1.避免掉帧
完全依赖浏览器的绘制频率,从而避免过度绘制,影响电池寿命。
2.提升性能
当Tab或隐藏的iframe里,暂停调用。
方块移动
<!-- canvas -->
<canvas id="canvas" width="600" height="600"></canvas>
<!-- javascript -->
<script>
const canvas = document.getElementById('canvas')
const ctx = canvas.getContext('2d')
ctx.fillStyle = 'purple'
const step = 1 // 每步的长度
let xPosition = 0 // x坐标
move() // call move
function move() {
ctx.clearRect(0, 0, 600, 600)
ctx.fillRect(xPosition, 0, 300, 150)
xPosition += step
if (xPosition <= 300) {
requestAnimationFrame(() => {
move()
})
}
}
</script>
个人做游戏总结的三要素:
对象抽象:即对游戏中角色的抽象,面向对象的思维在游戏中非常地普遍。举个例子,我们来抽象一个《勇者斗恶龙》里的史莱姆:
class Slime {
constructor(hp, mp, level, attack, defence) {
this.hp = hp
this.mp = mp
this.level = level
this.attack = attack
this.defence = defence
}
bite() {
return this.attack
}
fire() {
return this.attack * 2
}
}requestAnimationFrame:之前我们已经接触过这个API了,结合上面动画的例子,我们很容易自然的就能想到,游戏动起来的原理了。
缓动函数:我们知道,匀速运动的动画会显得非常不自然,要变得自然就得时而加速,时而减速,那样动画就会变得更加灵活,不再生硬。

有兴趣的同学可以看我以前写的小游戏。
项目地址:github.com/CodeLittlePrince/FishHeart
绘制图像方法。
方法返回一个包含图片展示的 data URI 。可以使用 type 参数其类型,默认为 PNG 格式。图片的分辨率为96dpi。
注意:


把canvas元素比作画框:
canvas.width则是控制画框尺寸的方式。
canvas.style.width则是控制在画框中的画尺寸的方式。
核心代码
const captureResultBox = document.getElementById('captureResultBox')
const captureRect = document.getElementById('captureRect')
const style = window.getComputedStyle(captureRect)
// 设置canvas画布大小
canvas.width = parseInt(style.width)
canvas.height = parseInt(style.height)
// 画图
const x = parseInt(style.left)
const y = parseInt(style.top)
const w = parseInt(img.width)
const h = parseInt(img.height)
ctx.drawImage(img, x, y, w, h, 0, 0, w, h)
// 将图片append到html中
const resultImg = document.createElement('img')
// toDataURL必须在http服务中
resultImg.src = canvas.toDataURL('image/png', 0.92)
回看之前的例子,我们知道了drawImage可以自己画图画,也可以画图片。canvas完全就是个画板,可任由我们发挥。
合成的思路其实就是把多张图片都画在同一个画布(cavans)里。是不是一下子就知道接下来怎么做啦?
核心代码
// 设置画布大小
canvas.width = bg.width
canvas.height = bg.height
// 画背景
ctx.drawImage(bg, 0, 0)
// 画第一个角色
ctx.drawImage(
character1, 100, 200,
character1.width / 2,
character1.height / 2
)
// 画第二个角色
ctx.drawImage(
character2, 500, 200,
character2.width / 2,
character2.height / 2
)
拿比较出名的html2canvas为例,实现方式就是遍历整个dom,然后挨个拉取样式,在canvas上一个个地画出来。

返回一个ImageData对象,用来描述canvas区域隐含的像素数据,这个区域通过矩形表示,起始点为(sx, sy)、宽为sw、高为sh。
看段代码:
const img = document.createElement('img')
img.src = './filter.jpg'
img.addEventListener('load', () => {
canvas.width = img.width
canvas.height = img.height
ctx.drawImage(img, 0, 0)
console.log(ctx.getImageData(0, 0, canvas.width, canvas.height))
})它会打印出如下数据:

有点迷?不慌,接下去看。
8位无符号整型固定数组) 类型化数组表示一个由值固定在0-255区间的8位无符号整型组成的数组;如果你指定一个在 [0,255] 区间外的值,它将被替换为0或255;如果你指定一个非整数,那么它将被设置为最接近它的整数。(数组)内容被初始化为0。一旦(数组)被创建,你可以使用对象的方法引用数组里的元素,或使用标准的数组索引语法(即使用方括号标记)。
回看这张图:
data里其实就是像素,按每4个为一组成为一个像素。
4个一组,难道是rgba?
(o゜▽゜)o☆[BINGO!]
这样的话,图片的宽x高x4(w * h * 4 )就是所有像素的总和,刚好就死data的length。
已知:924160 = 640 x 316 x 4

可知:数组的长度为length = canvas.width x canvas.height x 4
知道了这种关系,我们不妨把这个一维数组想象成二维数组,想象它是一个平面图,如图:

一个格子代表一个像素
w = 图像宽度
h = 图像高度
这样,我们可以很容易得到点(x, y)在一维数组中对应的位置。我们想一想,点(1, 1)坐标对应的是数组下标为0,点(2, 1)对应的是数组下标4,假设图像宽度为2*2,那么点(1,2)对应下标就是index=((2 - 1)*w + (1 - 1))*4 = 8。
推导出公式:index = [(y - 1) * w + (x - 1) ] * 4
createImageData是在canvas在取渲染上下文为2D(即canvas.getContext(‘2d'))的时候提供的接口。作用是创建一个新的、空的、特定尺寸的ImageData对象。其中所有的像素点初始都为黑色透明。并返回该ImageData对象。
putImageData方法作为canvas 2D API 以给定的ImageData对象绘制数据进位图。如果提供了脏矩形,将只有矩形的像素会被绘制。这个方法不会影响canvas的形变矩阵。
这小节我们学了好几个新API,然后重新理了理数学知识。同学们好好消化完以后,就进Demo阶段吧。
核心代码:

最终效果:

对于纯背景抠图,其实还是比较简单的。上面我们已经说过,我们可以拿到整个canvas的每个像素点的值了。所以,只需要把纯色的色值转为透明就好了。
但这种场景不多,因为,背景很少有纯色的情况,而且即使背景纯色,不保证被扣对象的身上没有和背景同色值的情况。
所以,如果要处理复杂的情况,还是建议后端来做比较好,后端早已有了成熟的图像处理解决方案,比如opencv等。像美图的话,有专门的图像算法团队,天天研究这方面。
接下来,我将介绍下美图人像抠图的思路。
控制drawImage的绘制图层先后顺序。

我们将使用souce-in这个属性。如上图所示,这个属性的作用是,两图叠加,只取叠加的部分。
为什么这样搞?不是说好了,美图是让后端算法大佬们处理吗?
因为,为了人像抠图适应更多的场景,算法大佬们只会把人物图像处理成一个蒙版图并返给前端,之后让前端自己处理。
我们看下原图:

再看下后端返给的蒙版图:

得到以上的蒙版图以后,先把黑色处理成透明;
先在canvas上draw原图;
再把globalCompositeOperation 设置为 'source-in';
然后再draw处理后的蒙版图;
得到的就是最后的抠图啦!
这个方案是咨询前美图大佬@xd-tayde的,感谢~
处理结果:

对于旋转、缩放、位移、形变,canvas的上下文ctx有对应的API可以调用,也可以用martrix方式做更高级的变化。因为涉及的内容很多,如果全写这的话,篇幅太大。
所以,我这里直接推荐一篇文章给同学们学习 ——《canvas 图像旋转与翻转姿势解锁》
之前我们就知道了,我们可以获取canvas上的每个像素点。
所谓的粒子,其实算是对一个像素的抽象。它具有自己坐标,自己的色值,可以通过改变自身的属性“动”起来。
因此我们不妨将粒子作为一个对象来看待,它有坐标和色值,如:
let particle = {
x: 0,
y: 0,
rgba: '(1, 1, 1, 1)'
}我将把一张网易支付的logo图,用散落的粒子重新画出来。
核心代码:
// 获取像素颜色信息
const originImageData = ctx.getImageData(0, 0, canvas.width, canvas.height)
const originImageDataValue = originImageData.data
const w = canvas.width
const h = canvas.height
let colors = []
let index = 0
for (let y = 1; y <= h; y++) {
for (let x = 1; x <= w ; x++) {
const r = originImageDataValue[index]
const g = originImageDataValue[index + 1]
const b = originImageDataValue[index + 2]
const a = originImageDataValue[index + 3]
index += 4
// 将像素位置打乱,保存进返回数据中
colors.push({
x: x + getRandomArbitrary(-OFFSET, OFFSET),
y: y + getRandomArbitrary(-OFFSET, OFFSET),
color: `rgba(${r}, ${g}, ${b}, ${a})`
})
}效果:

粒子对象化已经介绍过了。
缓动函数,在之前的游戏也提及过,是为了让动画更加的自然生动。
性能是一个很需要关注的问题。因为比如一张500x500的图片,那数据量就是500x500x4=1000000。动画借助了requestAnimationFrame,正常的情况下一般刷新频率在60HZ,能展现非常流畅的动画。但现在要处理这么大的数据量,浏览器抗不过来了,自然造成了降频,导致动画卡帧严重。
为了性能,粒子动画往往采用选择性的选取像素用来绘制。比如,只绘制原图x坐标为偶数,或能被4等整除的像素。比如,只绘制原图对应像素r色值为155以上的像素。
结合上面的思路,就可以做出各种强大的粒子动画啦。

github.com/CodeLittlePrince/canvas-tutorial
记得前两年,nightmare还是很火的。所以,我在自己的前端脚手架也集成了它。不过,过去了那么久,不知道现在的形式如何。
因为最近发现面向的跨境项目业务越来越复杂,每个组员都负责着多个项目,一下做做A,一下做做B,然后有档期就会被安排做做跨境。因此,因为注意力不能集中,再加上对业务的不了解,就时不时会写一些影响到以前逻辑的bug。
这不得不让我们去规划做自动化回归测试的事情,虽然网站业务繁琐,但至少得保证每次组员的修改,不会影响主流程。
首先,我先罗列出我调研的e2e框架或库,让大家有个大体的认识。

NightmareJS好像难产了,核心代码的更新是在一年多前,而且daydream的插件安装页面也404中。果断抛弃。NightmareJS一样,也提供了自动生成代码的Chrome插件-puppeteer-recorder。所以它完全可以替代NightmareJS,或者说就是NightmareJS凉了的原因吧。
puppeteer和puppeteer-core,区别可参阅 puppeteer-vs-puppeteer-core。const webdriver = require('selenium-webdriver');
const chrome = require('selenium-webdriver/chrome');
const firefox = require('selenium-webdriver/firefox');
let driver = new webdriver.Builder()
.forBrowser('firefox')
.setChromeOptions(/* ... */)
.setFirefoxOptions(/* ... */)
.build();Geckodriver (Firefox):
Geckodriver is the WebDriver service used to drive the Mozilla Firefox Browser.
$ npm install geckodriver --save-dev
Chromedriver:
Chromedriver is the WebDriver service used to drive the Google Chrome Browser.
$ npm install chromedriver --save-dev说到对比,就得先分类,先搞清服务的维度。

如图,我将这些测试库或框架,以底层实现的方式分为三类:
Webdriver类,之前也说过,不局限某个特定浏览器,只要想测的浏览器有Webdriver能力就都可以跑自动化。

devtools-protocol类,和Webdriver类类似,也是不局限某个特定浏览器,只要想测的浏览器有devtools-protocol能力就都可以跑自动化。

图片来源WICG/devtools-protocol
其他类,比如Phantom,Nightmare这种,没有跨浏览器能力。
Protractor太针对Angular了,所以就不加入对比:
| 名称 | 接口易用 | 框架 | 跨浏览器 | 自动生成代码插件 | 社区活跃 |
|---|---|---|---|---|---|
| PhantomJS | yes | ||||
| NightmareJS | yes | yes | |||
| Puppeteer | yes | yes | yes | yes | |
| Selenium | yes | yes | yes | ||
| Nightwatch | yes | yes | yes | yes |
所以,比对下来的结论就是:
在调研的过程中,还发现了一款挺有意思的e2e测试框架——cypress。
酷

启动它后,它会有一个可视化界面提供给用户进行操作,而且,操作的过程和结果都体现在了web页面上,整个测试过程高端大气上档次。
方便
因为是框架,所以基础的东西都已经集成处理好了:

不跨浏览器
当我看到它文档的Unsupported-Browsers,我就觉得不香了;
没有自动生成代码的插件
之前我们也看到了,非Webdriver虽然不能跨浏览器,但是毕竟是提供自动生成代码的插件,还是很方便的。所以,我就觉得它也不酷了,啥花里胡哨的东西。
重要的话说两遍:
公司大了,团队大了以后,自然会出各种产品,即各种项目。而我们知道,每个项目其实都有很多共同的代码可以复用。复制粘贴这种重复劳动当然每个人都很讨厌,而且还有操作失误的情况。因此,往往,比如常用函数封装、正则、组件等,都可以做成npm module发布到npm上,方便所有的项目使用。
基础的命令和操作就不介绍了,资料太多,当然还是最推荐官方的教程,教程地址戳我>>。然后,我发现掘金的一篇文章作为补充也不错,npm - 参考手册>>。
在做自己的module之前,不得不说说怎么管理module这个项目。npm本身并没有版本管理的能力,我们publish什么,npm上就是什么。因此,很显然,我们需要Git来管理我们的npm module。
团队合作的时候,如果是多人维护一个npm module,npm publish的权限建议只能是一个人,比如是创建这个module的人,我们暂且叫他Tom。其他人,包括Tom,对module的所有修改,先push到Git上,然后由Tom做code review。当Tom觉得OK、没问题了以后,合并代码,然后npm publish到npm。
总结一下,我们通过这两点来管理:
接下来,我们从0开始,一步步地实现属于我们的npm module,过程中,我们会遇到webpack的配置,读者可以不用太理解webpack部分,应该更多关注npm方面,不过如果对webpack配置有兴趣或者疑问,可以评论留言哦。OK,让我们开始吧~
这里我们选用github,首先创建项目:

然后本地clone代码。

npm init依次输入package name,version,description,git repository等。
有两个需要注意:
@开头,然后跟上公司名或者团队名,再用/分割,最后接模块名字,比如@xkeshi/utils,然后只有加入这个私有项目的成员才有权限npm安装@xkeshi/utils这个包。其实关于public和private,即共有和私有的区别,文章开头的“基础”部分推荐的教程里也讲的很清楚了。package.json生成,里面就是我们刚才填写的信息。在npm init的时候,在填entry point的时候,我们如果选择默认的话就是index.js。那就在根目录创建一个index.js吧。
首先创建一个文件夹加src,然后里面创建两个文件夹,第一个就叫mathematic,里面封装一些数学函数;第二个叫regex,里面就是一些常用的正则。目录结构为:
├── README.md
├── index.js
├── package.json
└── src
├── mathematic
│ ├── README.md
│ └── index.js
└── regex
├── README.md
└── index.js具体的math和regex代码我就不介绍了,文章最后会附上项目地址,读者可以自己查看。
我们怎么知道自己写的东西是不是有问题呢?或者,怎么才能让使用者知道他正准备用的东西能不能达到他的预期呢?所以,examples不可少。具体的代码就忽略了,可以看文章最后的项目地址。
问题又来了,其实,我们编写的util都是用es6甚至es7的语法,游览器并不能执行。所以我们不得不用babel编译,又因为js模块化的需要,因此,webapck自然加了进来。
webpack和babel的配置就不多说了。
我们的npm包有webpack配置文件,有examples,有node_modules,这些其实我们并不想要,因此,我们可以通过.npmignore来在npm publish的时候,忽略自己不想要的文件。
代码都写好,运行测试没问题以后,push到GitHub。
在这之前,你得去npm注册过,然后npm login,最后发布npm publish就哦了。
文章中项目github地址戳这里:
https://github.com/CodeLittlePrince/kuro-util
文章中项目npm地址戳这里:
https://www.npmjs.com/package/kuro-util
想想也已经做过不少架构的项目了,有基于vue,基于react,基于thinkPHP,基于laravel的。
做多了,也就对现有的架构有各种想法,有好的,有坏的,总之,用起来还是不爽。vue-cli虽然可以很快地构建并使用,尤其是vue-cli v3.0,把webpack都封进@vue/cli的sdk里了,用起来更加干净、简洁。
但是,对于爱折腾的我们,好吧,开个玩笑。重来,但是,对于页面的优化,还有项目的架构,我们不得不做多多少少的修改。
好了,介绍完毕,接下来,我就从零开始,一步一步建起前后端完全分离的前端架构了。
由于要介绍的很多,全写在一篇里,有些太长了。
所以,我会分为:
创建开发环境下的webpack配置文件
配置eslint、babel、postcss
创建项目文件、目录架构
通过koa实现本地数据接口模拟
创建发布环境下的webpack配置文件
创建测试环境下的webpack配置文件、以及测试用例 (TODO)
自动初始化构建项目(TODO)
这七篇来分别介绍。
创建项目文件夹
我们就叫vue-construct吧
初始化git
git init
初始化npm
npm init
创建项目文件
为了能让webpack跑起来,而不是一口气只讲配置而不运行一下,那样未免有些空洞,所以我们先创建一点项目文件和目录。
在这之前我们先安装两个包:vue、vue-router, npm i -S vue vue-router。
我们将项目代码相关文件都放在名为app的文件夹下。我先都创建完,然后一个个介绍。
├── app
│ ├── app.vue
│ ├── common
│ │ ├── img
│ │ ├── js
│ │ └── scss
│ ├── index.html
│ ├── index.js
│ ├── router
│ │ └── index.js
│ └── views
│ └── home
│ └── index.vue
├── .gitignore
├── package-lock.json
├── package.json
└── webpack.config.jsnode_modules的话就忽略了。
| 文件/文件夹 | 用途 |
|---|---|
| app.vue | 作为vue的主文件 |
| common | 里面放公共的代码 |
| index.html | 页面模板文件 |
| index.js | 项目主入口文件 |
| router | 放vue对应的router文件 |
| views | 放视图文件 |
| .gitignore | 忽略node_module |
咱们暂且不关系这些文件里的具体代码是什么,等webpack配置完再说。
webpack
webpack-dev-server为了处理vue单页文件,安装:
vue-loader为了处理scss文件并从js中抽离,安装:
node-sass
style-loader
css-loader
sass-loader
vue-style-loader
postcss
postcss-loader
autoprefixer
extract-text-webpack-plugin为了处理图片和字体文件,安装:
file-loader
url-loader为了支持高级语法-babel,安装:
babel
babel-loader
babel-plugin-syntax-dynamic-import
babel-plugin-transform-object-rest-spread
babel-polyfill
babel-preset-env为了验证代码格式-eslint,安装:
eslint
eslint-loader
eslint-plugin-html
babel-eslintconst webpack = require('webpack')
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const FriendlyErrorsPlugin = require('friendly-errors-webpack-plugin')
// 为了抽离出两份CSS,创建两份ExtractTextPlugin
// base作为基础的css,基本不变,所以,可以抽离出来充分利用浏览器缓存
// app作为迭代的css,会经常改变
const isProduction = process.env.NODE_ENV === 'production'
const ExtractTextPlugin = require('extract-text-webpack-plugin')
const extractBaseCSS =
new ExtractTextPlugin(
{
filename:'static/css/base.[chunkhash:8].css',
allChunks: true,
disable: !isProduction // 开发环境下不抽离css
}
)
const extractAppCSS
= new ExtractTextPlugin(
{
filename:'static/css/app.[chunkhash:8].css',
allChunks: true,
disable: !isProduction // 开发环境下不抽离css
}
)
// 减少路径书写
function resolve(dir) {
return path.join(__dirname, dir)
}
// 网站图标配置
const favicon = resolve('favicon.ico')
// __dirname: 总是返回被执行的 js 所在文件夹的绝对路径
// __filename: 总是返回被执行的 js 的绝对路径
// process.cwd(): 总是返回运行 node 命令时所在的文件夹的绝对路径
const config = {
// sourcemap 模式
devtool: 'cheap-module-eval-source-map',
// 入口
entry: {
app: resolve('app/index.js')
},
// 输出
output: {
path: resolve('dev'),
filename: 'index.bundle.js'
},
resolve: {
// 扩展名,比如import 'app.vue',扩展后只需要写成import 'app'就可以了
extensions: ['.js', '.vue', '.scss', '.css'],
// 取路径别名,方便在业务代码中import
alias: {
api: resolve('app/api/'),
common: resolve('app/common/'),
views: resolve('app/views/'),
components: resolve('app/components/'),
componentsBase: resolve('app/componentsBase/'),
directives: resolve('app/directives/'),
filters: resolve('app/filters/'),
mixins: resolve('app/mixins/')
}
},
// loaders处理
module: {
rules: [
{
test: /\.js$/,
include: [resolve('app')],
loader: [
'babel-loader',
'eslint-loader'
]
},
{
test: /\.vue$/,
exclude: /node_modules/,
loader: 'vue-loader',
options: {
extractCSS: true,
loaders: {
scss: extractAppCSS.extract({
fallback: 'vue-style-loader',
use: [
{
loader: 'css-loader',
options: {
sourceMap: true
}
},
{
loader: 'postcss-loader',
options: {
sourceMap: true
}
},
{
loader: 'sass-loader',
options: {
sourceMap: true
}
}
]
})
}
}
},
{
test: /\.(css|scss)$/,
use: extractBaseCSS.extract({
fallback: 'style-loader',
use: [
{
loader: 'css-loader',
options: {
sourceMap: true
}
},
{
loader: 'postcss-loader',
options: {
sourceMap: true
}
},
{
loader: 'sass-loader',
options: {
sourceMap: true
}
}
]
})
},
{
test: /\.(png|jpe?g|gif|svg|ico)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 8192,
name: isProduction
? 'static/img/[name].[hash:8].[ext]'
: 'static/img/[name].[ext]'
}
},
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 8192,
name: isProduction
? 'static/font/[name].[hash:8].[ext]'
: 'static/font/[name].[ext]'
}
}
]
},
plugins: [
// html 模板插件
new HtmlWebpackPlugin({
favicon,
filename: 'index.html',
template: resolve('app/index.html')
}),
// 抽离出css
extractBaseCSS,
extractAppCSS,
// 热替换插件
new webpack.HotModuleReplacementPlugin(),
// 更友好地输出错误信息
new FriendlyErrorsPlugin()
],
devServer: {
proxy: {
// 凡是 `/api` 开头的 http 请求,都会被代理到 localhost:7777 上,由 koa 提供 mock 数据。
// koa 代码在 ./mock 目录中,启动命令为 npm run mock。
'/api': {
target: 'http://localhost:7777', // 如果说联调了,将地址换成后端环境的地址就哦了
secure: false
}
},
host: '0.0.0.0',
port: '9999',
disableHostCheck: true, // 为了手机可以访问
contentBase: resolve('dev'), // 本地服务器所加载的页面所在的目录
// historyApiFallback: true, // 为了SPA应用服务
inline: true, //实时刷新
hot: true // 使用热加载插件 HotModuleReplacementPlugin
}
}
module.exports = {
config: config,
extractBaseCSS: extractBaseCSS,
extractAppCSS: extractAppCSS
}这一篇主要就做了三件事:
下一篇我们将配置eslint、babel、postcss - 从零开始做Vue前端架构(2)
这一篇,我们将接着上篇来完成创建项目文件、目录结构。
先回顾一下现在项目有哪些东西了:
.
├── app
│ ├── app.vue
│ ├── common
│ │ ├── img
│ │ ├── js
│ │ └── scss
│ ├── index.html
│ ├── index.js
│ ├── router
│ │ └── index.js
│ └── views
│ └── home
│ └── index.vue
├── .babelrc
├── .eslintrc.js
├── .gitignore
├── package-lock.json
├── package.json
├── postcss.config.js
└── webpack.config.js总体看一下创建了哪些东西:
.
├── app
│ ├── api // 放get/post接口
│ ├── app.vue // vue主文件
│ ├── common // 放公共静态资源
│ ├── components // 该项目都通用的公用组件
│ ├── componentsBase // 所有项目都通用的公用组件,之后可以做成npm
│ ├── directives // Vue的directives
│ ├── filters // Vue的filters
│ ├── index.html // 模板文件
│ ├── index.js // 入口文件
│ ├── mixins // Vue的mixins
│ ├── router // Vue的路由配置文件夹
│ ├── store // vue-redux的文件夹,暂时不用,因为并不是所有项目都需要redux的
│ └── views // 视图
├── .babelrc
├── .eslintrc.js
├── .gitignore
├── package-lock.json
├── package.json
├── postcss.config.js
└── webpack.config.js这节要是一个一个放代码和步骤,会非常枯燥,所以我们可以直接看完整版的项目,代码非常简单,一眼扫完的那种,所以直接看项目比我这里详细地写会快很多很多,地址:戳这里>>
几乎所有的文件夹我都有建markdown文档,方便大家理解。另外,我也是建议,每个文件夹都配一份markdown说明文档,这真的很重要!!!
如果有什么问题可以评论,我看到会第一时间回复的。
这篇主要是文件和目录架构的东西,读者务必运行一下完整的项目。
运行开发环境npm run dev的过程中,我们在调试器中会发现有一个接口错误,并带有'少年,是不是忘了npm run mock? '的警告。这是因为在首页,我们会有一个ajax请求,但我们这时候还没创建本地请求模拟数据接口的服务,所以报错了。
因此,下一篇,我们将通过koa实现本地数据接口模拟 - 从零开始做Vue前端架构(4)
这一篇,我们将接着上篇来完成配置eslint、babel、postcss。
我们采用eslint --init的方式来创建eslintrc.js。
对了,前提我们需要全局安装eslint:npm i -g eslint。
安装完全局eslint以后,我们在项目根目录使用eslint --init,我选择自定义的方式来规定eslint规则:
➜ vue-construct git:(master) ✗ eslint --init
? How would you like to configure ESLint? Answer questions about your style
? Are you using ECMAScript 6 features? Yes
? Are you using ES6 modules? Yes
? Where will your code run? Browser, Node
? Do you use CommonJS? Yes
? Do you use JSX? No
? What style of indentation do you use? Spaces
? What quotes do you use for strings? Single
? What line endings do you use? Unix
? Do you require semicolons? No
? What format do you want your config file to be in? (Use arrow keys)
❯ JavaScript当然,你可以按照自己喜欢,选择自己想要的方式,比如How would you like to configure ESLint? 这个问题的时候,可以选择popular的规则,有Google、standard等规则,选择你想要的就好。
我po下我的配置吧:
// 创建这个文件的话,本王推荐用eslint --init创建
module.exports = {
"env": {
"browser": true,
"node": true
},
// https://stackoverflow.com/questions/38296761/how-to-support-es7-in-eslint
// 为了让eslint支持es7或更高的语法
"parser": 'babel-eslint',
"extends": "eslint:recommended",
"parserOptions": {
"sourceType": "module"
},
"plugins": [
// https://github.com/BenoitZugmeyer/eslint-plugin-html
// 支持 *.vue lint
"html"
],
// https://eslint.org/docs/rules/
"rules": {
"indent": [
"error",
2
],
"linebreak-style": [
"error",
"unix"
],
"quotes": [
"error",
"single"
],
"semi": [
"error",
"never"
],
// https://eslint.org/docs/user-guide/configuring#using-configuration-files
// "off" or 0 - turn the rule off
// "warn" or 1 - turn the rule on as a warning (doesn’t affect exit code)
// "error" or 2 - turn the rule on as an error (exit code is 1 when triggered)
'no-debugger': process.env.NODE_ENV === 'production' ? 2 : 0,
'no-console': 0,
}
};创建.babelrc文件,直接上配置:
{
"presets": [
[
"env",
{
"targets": {
"browsers": [
"> 1%",
"last 2 versions",
"ie >= 10"
]
},
"modules": false,
"useBuiltIns": true
}
]
],
"plugins": [
"transform-object-rest-spread",
"syntax-dynamic-import"
]
}配合webpack配置:
{
test: /\.js$/,
include: [resolve('app')],
use: [
'babel-loader',
'eslint-loader'
]
},我们使用的是babel-preset-env,我们知道,babel只是转译了高级语法,比如lambda,class,async等,并不会支持高级的api,所以需要babel-polyfill的帮忙。方便的是,我们只需要"useBuiltIns": true,然后npm安装babel-polyfill,再在webpack配置中的entry带上babel-polyfill就好了。
babel-preset-env的优点:
targets来决定支持到那个哪些版本的语法就够了,不会过渡转译,可控性强useBuiltIns来支持babel-polyfill的按需加载,而不是一口气把整个包打入,因为其实我们只用到了很小一部分transform-object-rest-spread是为了支持const a = {name: kitty, age: 7}; const b = { ...a }这种es7语法。
syntax-dynamic-import是为了支持const Home = () => import('../views/home')这种语法,达到按需分割、加载的目的。
创建postcss.config.js文件,上配置:
module.exports = {
plugins: [
require('autoprefixer')
],
// 配置autoprefix
browsers: [
"> 1%",
"last 2 versions",
"ie >= 10"
]
}这篇不多,就做了三件事,eslint、babel、postcss。
下一篇我们将创建项目文件、目录架构 - 从零开始做Vue前端架构(3)
接触canvas应该是在去年半次元做制品计划吧,想想也好久了,不过,那会儿每天累得和狗一样,周末还要上课。经验总结也基本都记录在OneNote,思维跳跃性的记录也就不适合作为博客发布。
现在来了新公司,一段时间忙,一段时间闲成狗,所以就会再重新总结,写写博客。
引用自MDN:
是 HTML5 新增的元素,可用于通过使用JavaScript中的脚本来绘制图形。例如,它可以用于绘制图形,制作照片,创建动画,甚至可以进行实时视频处理或渲染。
我认为canvas最好的教程就是MDN的,canvas基础补充请戳这里>>
我们可以将已经加载好的图片画到canvas上。
绘制图片的api接口:
drawImage(image, x, y, width, height)
其中 image 是 image 或者 canvas 对象,x 和 y 是其在目标 canvas 里的起始坐标。width 和 height,这两个参数用来控制 当像canvas画入时应该缩放的大小。
drawImage其实还有四个额外参数,一般用来做截图,这里因为文章不涉及就不赘述了。有兴趣的小伙伴可以戳这里>>
getImageData是canvas提供的一个非常强大的接口,它可以获取canvas的所有的像素点的值。不过,值的展现形式和一般的rgba或rgb等属性不同,所有的值会被记录在一个Uint8ClampedArray的一维数组里面。
The Uint8ClampedArray typed array represents an array of 8-bit unsigned integers clamped to 0-255; if you specified a value that is out of the range of [0,255], 0 or 255 will be set instead; if you specify a non-integer, the nearest integer will be set. The contents are initialized to 0.
翻译一下:
Uint8ClampedArray类型数组表示一个8-bit无符号整数,即0-255区间;如果你设了一个的值超出了[0, 255]的范围,他们会被0或者255代替(小于0代替为0,大于255替代为255);如果你设了一个非整数,会被替代为这个小数最接近的整数。所有的初始值为0;
见图:

如果,canvas将每个像素点的值按照rgba这样的顺序一个一个的存入Unit8ClampedArray里面。
因此,数组的长度为length = canvas.width * canvas.height * 4。
知道了这种关系,我们不妨把这个一维数组想象成二维数组,想象它是一个平面图,如图:
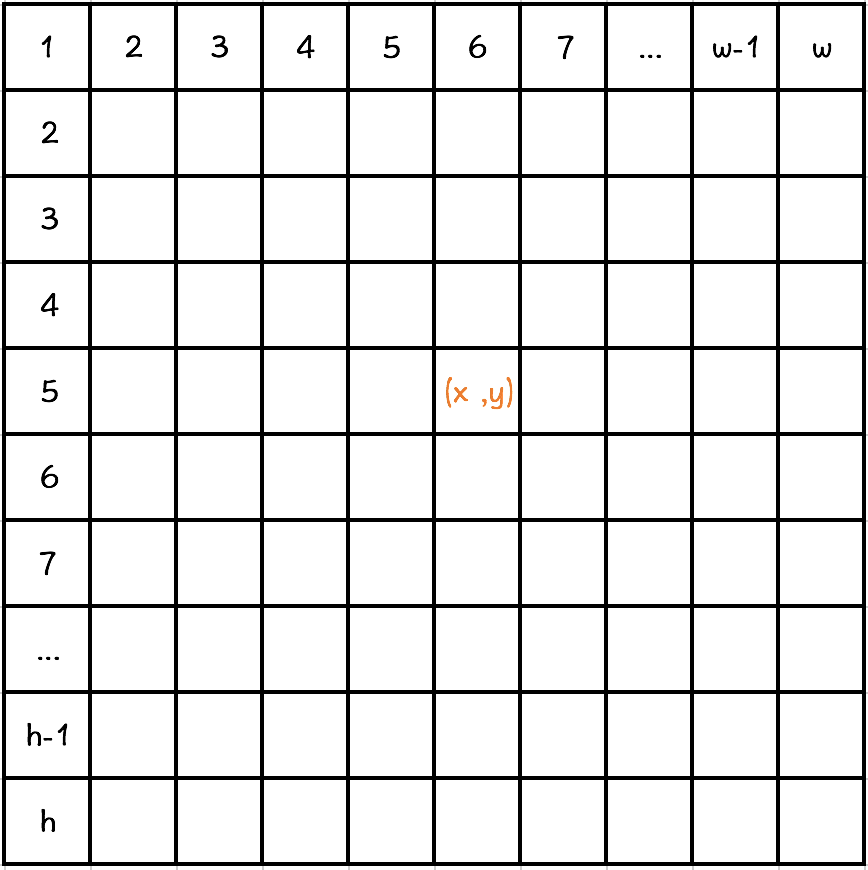
一个格子代表一个像素
w = 图像宽度
h = 图像高度
这样,我们可以很容易得到点(x, y)在一维数组中对应的位置。我们想一想,点(1, 1)坐标对应的是数组下标为0,点(2, 1)对应的是数组下标4,假设图像宽度为2*2,那么点(1,2)对应下标就是index=((2 - 1)*w + (1 - 1))*4 = 8。
推导出公式:index = [(y - 1) * w + (x - 1) ] * 4
我们既然已经能够拿到图像的每一个像素点,那么我们就可以为所欲为啦!

不过客官别急,我们还有点小知识要补充,避免代码实现的过程陷入迷茫~
The CanvasRenderingContext2.createImageData() method of the Canvas 2D API creates a new, blank ImageData object with the specified dimensions. All of the pixels in the new object are transparent black.
翻译(非直译):
createImageData是在canvas在取渲染上下文为2D(即
canvas.getContext('2d'))的时候提供的接口。作用是创建一个新的、空的、特定尺寸的ImageData对象。其中所有的像素点初始都为黑色透明。
我们会用到ctx.createImageData(width, height)这个接口,width和height是新ImageData对象的初始长宽。
ImageData是一个对象,其实我们在canvas.getImageData拿到的对象就是ImageData,它内部由width,height,Uint8ClampedArray组成,
如:{data: Uint8ClampedArray(958400), width: 400, height: 599}
The CanvasRenderingContext2D.putImageData() method of the Canvas 2D API paints data from the given ImageData object onto the bitmap. If a dirty rectangle is provided, only the pixels from that rectangle are painted. This method is not affected by the canvas transformation matrix.
翻译:
CanvasRenderingContext2D.putImageData() 方法作为canvas 2D API 以给定的ImageData对象绘制数据进位图。如果提供了脏矩形,将只有矩形的像素会被绘制。这个方法不会影响canvas的形变矩阵。
看上去有点迷糊,矩阵都出来了。不过不用担心,我们只关注第一句就好,忽略“如果“之后的文字。
我们将会用到ctx.putImageData(imagedata, dx, dy)接口,imageData就是用户提供的ImageData对象,dx和dy分别是canvas坐标系的x点和y点,将从这个(dx,dy)开始输入数据。
终于迎来了最后的阶段!
直接上代码:
html:
<div class="box">
<img id="img" src="index.png">
</div>
<canvas id="canvas"></canvas>
js
draw()
function draw() {
const canvas = document.getElementById('canvas')
const ctx = canvas.getContext('2d')
const img = document.getElementById('img')
// 等图片加载完以后才能获取图片信息
img.onload = function() {
const style = window.getComputedStyle(img)
const w = style.width
const h = style.height
const ws = w.replace(/px/, '')
const hs = h.replace(/px/, '')
canvas.width = ws
canvas.height = hs
ctx.drawImage(img, 0, 0, canvas.width, canvas.height)
// 修改颜色准备
const originColor = ctx.getImageData(0, 0, ws, hs)
// 保存ImageData里的Uint8ClampedArray数据
const originColorData = originColor.data
// 创建一个空的图像,这时canvas里其实已经没原来的图像了
const output = ctx.createImageData(ws, hs)
const outputData = output.data
// 诡异画风按钮绑定
const weirdBtn = document.getElementById('weird')
weirdBtn.addEventListener('click', function() {
// 诡异画风数据处理(我们可以用各种处理方法处理图像数据,达到想要的效果)
weird(originColorData, outputData, ws, hs)
ctx.putImageData(output, 0, 0)
})
}
}
// 诡异
function weird(originColorData, outputData, ws, hs) {
let random
let randomData
let index;
let r, g, b;
// 逐行扫描
for (let y = 1; y <= hs; y++) {
// 逐列扫描
for (let x = 1; x <= ws; x++) {
// rgb处理
for (let c = 0; c < 3; c++) {
random = Math.random(0, 255) * 100
randomData = Math.abs(random - originColorData[index])
index = ((y-1) * ws + (x-1)) * 4 + c
outputData[index] = randomData
}
// alpha处理,我们就让透明度一直未1就好了
outputData[index + 3] = 255;
}
}
}
通过对imageData的处理,我们可以控制每个像素点,然后你想处理出不同的效果,只需要改写weird方法就可以了。我写了5种滤镜效果,效果如下gif图:

1.html引入requirejs和主js:
<script src="/require.js"></script>
<script src="/index.js"></script>主js:
// index.js
console.log('index')
// 加载入口模块
requirejs(['a'], function(a) {
console.log('index call')
a.speak()
});模块a:
// a.js
console.log('a')
define(function(require, factory) {
console.log('a call')
var b = require('b')
var c = require('c')
return {
speak: b.speak,
say: c.say
}
});模块b:
// b.js
define(function () {
console.log('b')
return {
speak: function () {
console.log('Hello World')
}
};
});模块c:
// c.js
console.log('c')
define(function () {
console.log('c call')
return {
say: function () {
console.log('Wow')
}
};
});最终,浏览器Console会打印出:
index
a
b
b call
c
c call
a call
index call
Hello Worldscript标签加载require.js。
script标签加载index.js。
index.js中通过requirejs函数定义该文件为入口文件。所有子模块(a、b、c)加载方式其实是在<head>里append对应的js,并且带async属性。
js按照
index.js=>a.js=>b.js
=>c.js
这样的顺序加载执行。所以,自然的先打印出index、a。又因为,b和c都是a所依赖的模块,所以b、c同时异步加载,谁加载完即先执行谁,因为两文件大小几乎一样,并且本地测试网络延迟可以忽略原因,先require谁就会先执行谁,并且,因为b、c都是最后一项被依赖的模块,所以回调就会被调用,因此打印出b、b call、c、c call。
a中的依赖逻辑处理完之后,才轮到a除了require之外的逻辑处理,所以继续打印出a call。
(因为它的实现可以看define的实现,其实是将define回调里的函数变为字符串,然后通过正则cjsRequireRegExp获取到所有的模块名,加入依赖队列;接着,去请求js资源执行,同样,如果被依赖的js文件还有依赖模块,则加入依赖队列,没有则执行define里的回调函数;另外顺便说下,回调的返回值会被defined对象收集,实现可见localRequire实现,所以,如b=require('b')得到的值即是b.js的define回调的返回值)
index中的依赖逻辑处理完之后,才轮到index除了require之外的逻辑处理,所以继续打印出index call。
提升页面响应速度:js文件异步加载;
模块化成本低:只需要引入require.js就可以实现模块化;
代码执行顺序不按书写顺序:从文件a.js可以看出,require的模块执行顺序是在console.log('a call')之前,并不是按照书写的顺序那样;
无法按需加载:比如:if(false){ require('a') },这样的写法并不会就不去加载a.js的文件了,照样会加载;另外,像上面说到的,b、c可能因为文件大小或者网络原因,执行的顺序有可能不会像require的顺序一样。
1.html引入seajs和主js:
<script src="/seajs.js"></script>
<script src="/index.js"></script>主js:
// index.js
console.log('index')
// 加载入口模块
seajs.use(['a'], function(a) {
console.log('index call')
a.speak()
});模块a:
// a.js
console.log('a')
define(function(require, factory) {
console.log('a call')
var b = require('b')
var c = require('c')
// var flag = false
// if (flag) {
// var c = require.async('c')
// c.say()
// }
return {
speak: b.speak,
say: c.say
}
});模块b:
// b.js
define(function () {
console.log('b')
return {
speak: function () {
console.log('Hello World')
}
};
});模块c:
// c.js
console.log('c')
define(function () {
console.log('c call')
return {
say: function () {
console.log('Wow')
}
};
});最终,浏览器Console会打印出:
index
a
b
c
a call
b call
c call
index call
Hello Worldscript标签加载sea.js。
script标签加载index.js。
index.js中通过seajs.use函数定义该文件为入口文件。所有子模块(a、b、c)加载方式其实是在<head>里append对应的js,并且带async属性。不过和requirejs不一样的是,seajs会用完后,把script给移除掉,为了减少内存占用。
js按照
index.js=>a.js=>b.js
=>c.js
这样的顺序加载执行。所以,自然的先打印出index、a。又因为,b和c都是a所依赖的模块,所以b、c同时异步加载,谁加载完即先执行谁,因为两文件大小几乎一样,并且本地测试网络延迟可以忽略原因,先require谁就会先执行谁。
和requirejs不一样的是,seajs不会加载完就立刻去执行define里的回调,而是等到父模块require的时候才去执行,所以我们看到,打印出的是a、b、c、a call、b call、c call。(上面说到,因为网络原因,c可能先于b加载完,那样的话打印出的就是a、c、b、a call、b call、c call)
index中的依赖逻辑处理完之后,才轮到index除了require之外的逻辑处理,所以继续打印出index call。
提升页面响应速度:js文件异步加载;
模块化成本低:只需要引入require.js就可以实现模块化;
按需执行:比如:if(false){ require('c') },这样的写法虽然还是会就去加载c.js的文件,但是不会执行c模块里的define回调,从而提升代码执行性能;
按需加载:比如:if(false){ require.async('a') },这样的写法就不去加载c.js的文件了;
1.因为commonjs是node的模块化方式,我们我们直接在控制台用:
node index.js主js:
// index.js
console.log('index')
// 加载入口模块
var a = require('./a')
console.log('index call')
a.speak()模块a:
// a.js
console.log('a')
var b = require('./b')
var c = require('./c')
// var flag = false
// if (flag) {
// var c = require('./c')
// c.say()
// }
console.log('a call')
module.exports = {
speak: b.speak,
say: c.say
}模块b:
// b.js
console.log('b')
module.exports = {
speak: function () {
console.log('Hello World')
}
};模块c:
// c.js
console.log('c')
module.exports = {
say: function () {
console.log('Wow')
}
};最终,控制台会打印出:
index
a
b
c
a call
index call
Hello World1.html引入主js:
<script type="module" src="/ES6-import/index.js"></script>主js:
// index.js
console.log('index')
// 加载入口模块
import a from './a.js'
console.log('index call')
a.speak()模块a:
// a.js
console.log('a')
import b from './b.js'
import c from './c.js'
// var flag = true
// if (flag) {
// import('./c.js')
// .then(c => {
// c.default.say()
// });
// }
console.log('a call')
export default {
speak: b.speak,
say: c.say
}模块b:
// b.js
console.log('b')
module.exports = {
speak: function () {
console.log('Hello World')
}
};模块c:
// c.js
console.log('c')
module.exports = {
say: function () {
console.log('Wow')
}
};最终,浏览器Console会打印出:
b
c
a
a call
index
index call
Hello World提升页面响应速度:js文件异步加载;
模块化成本低:原生支持;
按需加载:比如:if(false){ import('a.js') },这样的写法就不去加载c.js的文件了;
引入模块代码按顺序执行:虽然还是不能解决:虽然console.log('a')在import之前,但执行却晚于这两个模块执行,但是,至少不会因为b、c可能因为文件大小或者网络原因,导致这两个文件执行顺序有有变化。
简单地说,就是因为es6虽然有import的能力了,但是因为兼容性不好,所以,目前市面上,都会选择用webpack来做js的模块化,这样对开发者来说,就可以愉快的使用import了。
1.html引入主js:
<script src="/ES6-import-webpack/index.js"></script>主js:
// index.js
console.log('index')
// 加载入口模块
import a from './a.js'
console.log('index call')
a.speak()模块a:
// a.js
console.log('a')
import b from './b.js'
import c from './c.js'
// var flag = true
// if (flag) {
// import('./c.js')
// .then(c => {
// c.default.say()
// });
// }
console.log('a call')
export default {
speak: b.speak,
say: c.say
}模块b:
// b.js
console.log('b')
module.exports = {
speak: function () {
console.log('Hello World')
}
};模块c:
// c.js
console.log('c')
module.exports = {
say: function () {
console.log('Wow')
}
};可以自行全局安装,或者局部安装webpack、webpack-cli。然后以index.js作为入口文件,编辑生成代码。
这里,我就直接生成了,文件为dist/main.js。
我们看下打包后的文件:
(() => {
"use strict";
console.log("b");
const o = {
speak: function () {
console.log("Hello World")
}
};
console.log("c");
const l = {
say: function () {
console.log("Wow")
}
};
console.log("a"), console.log("a call");
const s = {
speak: o.speak,
say: l.say
};
console.log("index"), console.log("index call"), s.speak()
})();最终,浏览器Console会打印出:
b
c
a
a call
index
index call
Hello World其实是和es6 import一模一样的。
兼容性:可认为除杠精浏览器外的所有版本浏览器;
零语法学习成本:和es6的模块化方式一模一样,没有语法上的学习成本;
按需加载:比如:if(false){ import('a.js') },这样的写法就不去加载c.js的文件了;
引入模块代码按顺序执行:虽然还是不能解决:虽然console.log('a')在import之前,但执行却晚于这两个模块执行,但是,至少不会因为b、c可能因为文件大小或者网络原因,导致这两个文件执行顺序有有变化。
毕竟node也是JavaScript,浏览器都支持import了,作为后端语言,不支持也不好意思吧。
当然,为了大一统,也是毕竟要做的一件事。
emmm,不过这个import真正被引入进Node其实挺晚的,实在v13才开始,以下是overflow里的引用。
Node.js >= v13
It's very simple in Node.js 13 and above. You need to either:
Save the file with .mjs extension, or
Add { "type": "module" } in the nearest package.json.
You only need to do one of the above to be able to use ECMAScript modules.Node.js <= v12
If you are using Node.js version 8-12, save the file with ES6 modules with .mjs extension and run it like:
node --experimental-modules my-app.mjs
1.我们我们直接在控制台用(如果node版本为13及以上,可以不用参数):
node --experimental-modules index.mjs主js:
// index.js
console.log('index')
// 加载入口模块
import a from './a.js'
console.log('index call')
a.speak()模块a:
// a.js
console.log('a')
import b from './b.js'
import c from './c.js'
console.log('a call')
export default {
speak: b.speak,
say: c.say
}模块b:
// b.js
console.log('b')
export default {
speak: function () {
console.log('Hello World')
}
};模块c:
// c.js
console.log('c')
export default {
say: function () {
console.log('Wow')
}
};最终,浏览器Console会打印出:
b
c
a
a call
index
index call
Hello World并不像commonjs,这里的结果和浏览器端的表现一模一样。
UMD在我看来只是一种打包模式,做的是模块兼容的事情,所以不做具体例子。
使用的场景就是做npm包的时候,因为并不知道会被使用者用什么模块化方式引入,所以兼容了AMD、CommonJS的引入方式。
文中的所有demo地址都在:https://github.com/CodeLittlePrince/js-modules
有兴趣的小伙伴可以下载运行帮助理解。
首先,先说明下该文章是译文,原文出自《AST for JavaScript developers》。很少花时间特地翻译一篇文章,咬文嚼字是件很累的事情,实在是这篇写的太棒了,所以忍不住想和大家一起分享。
OK,我们直接进入正题。
如果你查看目前任何主流的项目中的devDependencies,会发现前些年的不计其数的插件诞生。我们归纳一下有:javascript转译、代码压缩、css预处理器、elint、pretiier,等。有很多js模块我们不会在生产环境用到,但是它们在我们的开发过程中充当着重要的角色。所有的上述工具,不管怎样,都建立在了AST这个巨人的肩膀上。

所有的上述工具,不管怎样,都建立在了AST这个巨人的肩膀上
我们定一个小目标,从解释什么是AST开始,然后到怎么从一般代码开始去构建它。我们将简单地接触在AST处理基础上,一些最流行的使用例子和工具。并且,我计划谈下我的js2flowchart项目,它是一个不错的利用AST的demo。OK,让我们开始吧。

什么是AST(抽象语法树)?
It is a hierarchical program representation that presents source code structure according to the grammar of a programming language, each AST node corresponds to an item of a source code.

估计很多同学会和图中的喵一样,看完这段官方的定义一脸懵逼。OK,我们来看例子:

这很简化
实际上,真正AST每个节点会有更多的信息。但是,这是大体**。从纯文本中,我们将得到树形结构的数据。每个条目和树中的节点一一对应。
那怎么从纯文本中得到AST呢?哇哦,我们知道当下的编译器都做了这件事情。那我们就看看一般的编译器怎么做的就可以了。
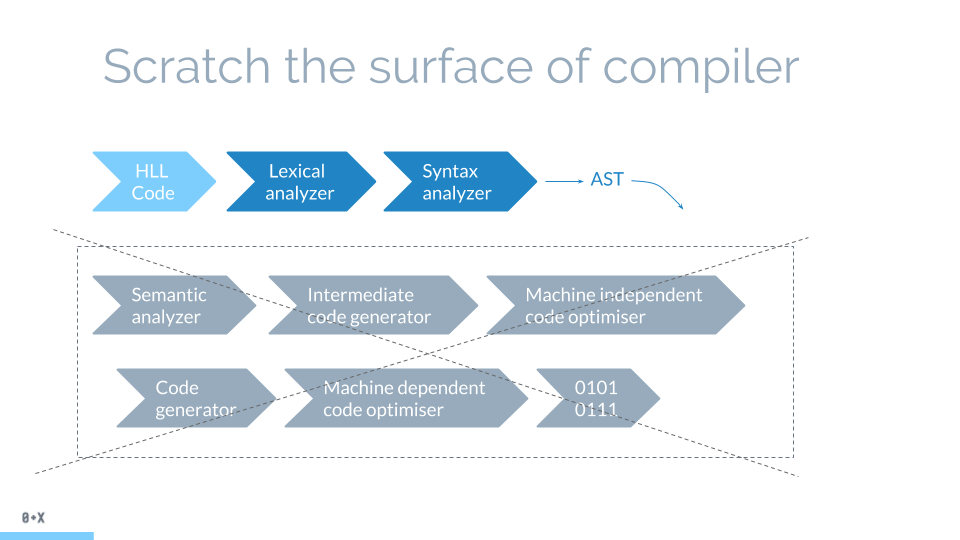
想做一款编译器是个比较消耗发量的事情,但幸运的是,我们无需贯穿编译器的所有知识点,最后将高级语言转译为二进制代码。我们只需要关注词法分析和语法分析。这两步是从代码中生成AST的关键所在。
第一步,词法分析,也叫做扫描scanner。它读取我们的代码,然后把它们按照预定的规则合并成一个个的标识tokens。同时,它会移除空白符,注释,等。最后,整个代码将被分割进一个tokens列表(或者说一维数组)。

当词法分析源代码的时候,它会一个一个字母地读取代码,所以很形象地称之为扫描-scans;当它遇到空格,操作符,或者特殊符号的时候,它会认为一个话已经完成了。
第二步,语法分析,也解析器。它会将词法分析出来的数组转化成树形的表达形式。同时,验证语法,语法如果有错的话,抛出语法错误。

当生成树的时候,解析器会删除一些没必要的标识tokens(比如不完整的括号),因此AST不是100%与源码匹配的,但是已经能让我们知道如何处理了。说个题外话,解析器100%覆盖所有代码结构生成树叫做CST(具体语法树)

我们最终得到的
想要学习更多关于编译器的知识?
the-super-tiny-compiler,一个贼好的项目。大概200来行代码,几乎每行都有注释。

想要自己创建门编程语言?
LangSandbox,一个更好的项目。它演示了如何创造一门编程语言。当然,设计编程语言这样的书市面上也一坨坨。所以,这项目上一个相比更加深入,与the-super-tiny-compiler的项目将Lisp转为C语言不同,这个项目你可以写一个你自己的语言,并且将它编译成C语言或者机器语言,最后运行它。
我能直接用三方库来生成AST吗?
当然可以!有一坨坨的三方库可以用。你可以访问astexplorer,然后挑你喜欢的库。astexplorer是一个很棒的网站,你可以在线玩转AST,而且除了js,还有很多其它语言的AST库。

我不得不强调一款我觉得很棒的三方库,叫做babylon。

它被用在大名鼎鼎的babel中,也许这也是它之所以这么火的原因。因为有babel项目的支持,我们可以意料到它将与时俱进,一直支持最新的JS特性,因此可以放心大胆地用,不怕以后JS又出新版导致代码的大规模重构。另外,它的API也非常的简单,容易使用。
Ok,现在你知道怎么将代码生成AST了,让我们继续,来看看现实中的用例。
第一个用例,我想谈谈代码转化,没错,就是那个货,babel。
Babel is not a ‘tool for having ES6 support’. Well, it is, but it is far not only what it is about.
经常把beble和支持es6/7/8联系起来,实际上,这也是我们经常用它的原因。但是,它仅仅是一组插件。我们也可以使用它来压缩代码,react相关语法转译(如jsx),flow插件等。

babel是一个javascript编译器。宏观来说,它分3个阶段运行代码:解析(parsing),转译(transforming),生成(generation)。我们可以给babel 一些javascript代码,它修改代码然后生成新的代码返回。那它是怎样修改代码的呢?没错!它创建了AST,遍历树,修改tokens,最后从AST中生成新的代码。
我们来从下面的demo中看下这个过程:

像我之前提到的,babel使用babylon,所以,首先,我们解析代码成AST,然后遍历AST,再反转所有的变量名,最后生成代码。完成!正如我们看到的,第一步(解析)和第三步(生成)看起来很常规,我们每次都会做这两步。所以,babel接管处理了它俩。最后,我们最为关心的,那就是AST转译这一步了。
当我们开发babel-plugin的时候,我们只需要描述转化你AST的节点“visitors”就可以了。

将它加入你的babel插件列表中,设置你webpack的babel-loader配置或者.babelrc中的plugins即可
如果你想要学习怎么创建你的第一个babel-plugin,可以查看Babel-handbook

让我们继续,下一个用例,我想提到的是自动代码重构工具,以及神器JSCodeshift。
比如说你想要替换掉所有的老掉牙的匿名函数,把他们变成Lambda表达式(箭头函数)。

你的代码编辑器很可能没法这么做,因为这并不是简单地查找替换操作。这时候jscodeshift就登场了。
如果你听过jscodeshift,你很可能也听过codemods,一开始挺这两个词可能很困惑,不过没关系,接下来就解释。jscodeshift是一个跑codemods的工具。codemod是一段描述AST要转化成什么样的代码,这**和babel的插件如出一辙。
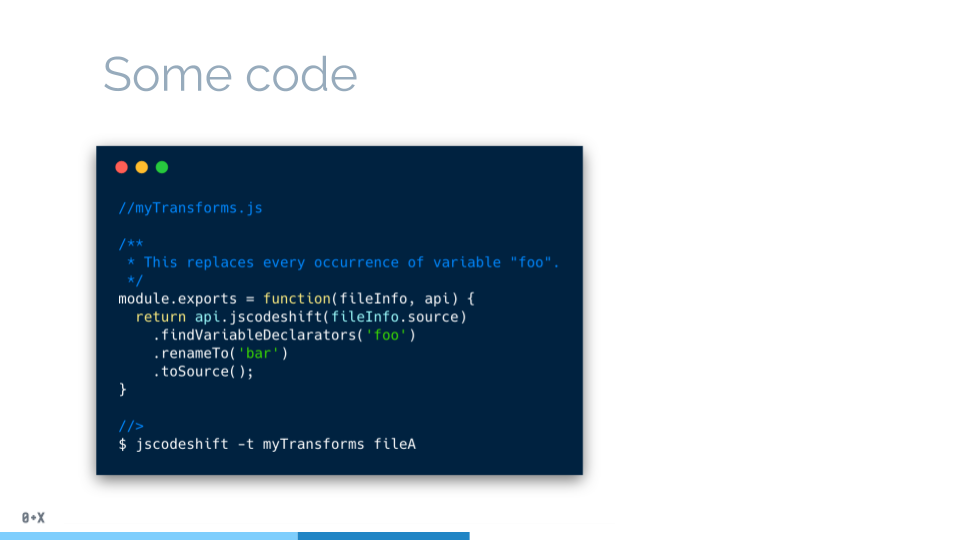
所以,如果你想创建自动把你的代码从旧的框架迁移到新的框架,这就是一种很乃思的方式。举个例子,react 16的prop-types重构。
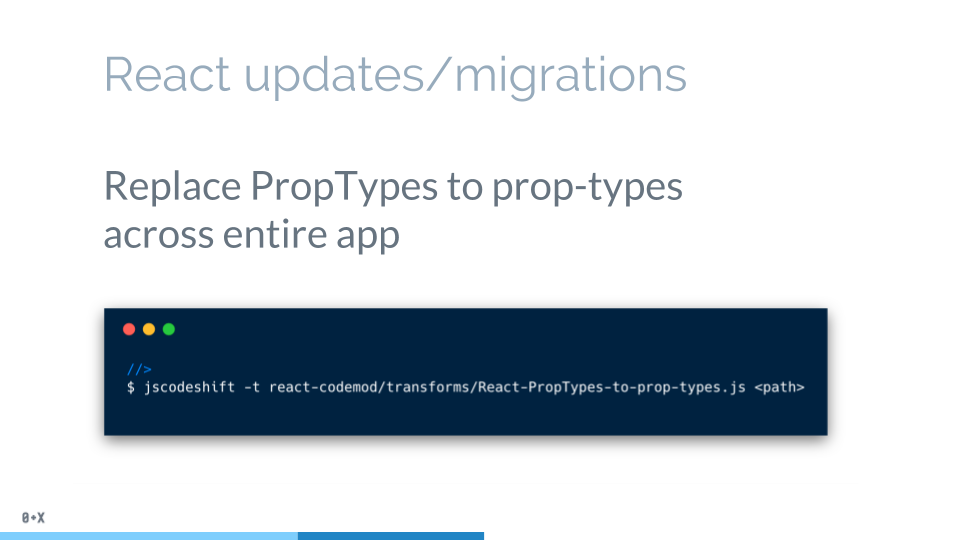
有很多不同的codemodes已经创建了,你可以保存你需要的,以免手动的修改一坨坨代码,拿去挥霍吧:
https://github.com/facebook/jscodeshift
https://github.com/reactjs/react-codemod

最后一个用例,我想要提到Prettier,因为可能每个码农都在日常工作中用到它。

Prettier 格式化我们的代码。它调整长句,整理空格,括号等。所以它将代码作为输入,修改后的代码作为输出。听起来很熟悉是吗?当然!

思路还是一样。首先,将代码生成AST。之后依然是处理AST,最后生成代码。但是,中间过程其实并不像它看起来那么简单。
同样,如果你想学习更多在美化打印背后理论,这里有一本你可以深入的书 《A prettier printer》。

文章迎来尾声,我们继续,今天最后一件事,我想提及的就是我的库,叫做js2flowchart(4.5 k stars 在 Github)。

顾名思义,它将js代码转化生成svg流程图
这是一个很好的例子,因为它向你展现了你,当你拥有AST时,可以做任何你想要做的事。把AST转回成字符串代码并不是必要的,你可以通过它画一个流程图,或者其它你想要的东西。
js2flowchart使用场景是什么呢?通过流程图,你可以解释你的代码,或者给你代码写文档;通过可视化的解释学习其他人的代码;通过简单的js语法,为每个处理过程简单的描述创建流程图。
马上用最简单的方式尝试一下吧,去线上编辑看看 js-code-to-svg-flowchart
你也可以在代码中使用它,或者通过CLI,你只需要指向你想生成SVG的文件就行。而且,还有VS Code插件(链接在项目readme中)
那么,它还能做什么呢?哇哦,我这里就不废话了,大家有兴趣直接看这个项目的文档吧。
OK,那它是如何工作的呢?

首先,解析代码成AST,然后,我们遍历AST并且生成另一颗树,我称之为工作流树。它删除很多不重要的额tokens,但是将关键块放在一起,如函数、循环、条件等。再之后,我们遍历工作流树并且创建形状树。每个形状树的节点包含可视化类型、位置、在树中的连接等信息。最后一步,我们遍历所有的形状,生成对应的SVG,合并所有的SVG到一个文件中。
寻找和筛选资料着实辛苦,希望同学们可以多多支持!
之前因为上家公司的经营出了问题,年前的大裁员,过了一个漫长的春节。
之后加入了新公司,然后正好赶上一个很紧急的项目,忙成狗,因此好久没更新文章了。
不过,我又回来啦!
自动化测试,我们将使用karma和nightmare,内容会包括:
npm install karma --save-dev
npm install karma-jasmine karma-chrome-launcher jasmine-core --save-dev在package.json的scripts配置
"test": "karma start"
$ karma init my.conf.js
Which testing framework do you want to use?
Press tab to list possible options. Enter to move to the next question.
> mocha
Do you want to use Require.js?
This will add Require.js plugin.
Press tab to list possible options. Enter to move to the next question.
> no
Do you want to capture a browser automatically?
Press tab to list possible options. Enter empty string to move to the next question.
> Chrome
>
What is the location of your source and test files?
You can use glob patterns, eg. "js/*.js" or "test/**/*Spec.js".
Press Enter to move to the next question.
> test/**/*.js
>
Should any of the files included by the previous patterns be excluded?
You can use glob patterns, eg. "**/*.swp".
Press Enter to move to the next question.
>
Do you want Karma to watch all the files and run the tests on change?
Press tab to list possible options.
> yes初始成功以后,会生成一份karma.conf.js配置文件。
顺便,在根目录创建一个test的文件夹,在这文件夹中创建一份index.js,内容为:
describe('A spec suite', function() {
it('contains a passing spec', function() {
console.log('Hello Karma')
})
})运行一下:
npm run test
我们会看到程序会自动打开chrome浏览器,然后显示测试结果。
.
└── unit
├── index.js
├── karma.conf.js
└── specs
└── dom.spec.js因为我们还要做e2e测试,所以,在test下,用各个文件夹区分,unit下就是单元测试的内容了。
karma-webpack
karma-sourcemap-loader
karma-coverage
chai
sinon
sinon-chai
karma-sinon-chai
karma-mocha-reporterkarma-webpack:因为我们的项目代码是用es6或者es7写的,所以webpack编译是必须的
karma-sourcemap-loader:sourcemap明显是必要的
karma-coverage:做代码覆盖率的时候需要用
chai:搭配mocha断言
sinon:搭配mocha做spy、stub、mock
sinon-chai:用chai来做sinon的断言,可以说是扩展
karma-sinon-chai:方便在测试代码中的调用,直接就能用expect、sinon.spy等,不需要每个文件都import
karma-mocha-reporter:mocha测试完的报告
像karma、mocha、chai、sinon这种测试工具,我不会很详细的介绍,全部都介绍的话内容实在有点多,而且也比较枯燥。想要学习可以看我的参考资料,是我花了大把时间筛选整理出来的。
const webpackConfig = require('../../webpack.config.test.js')
module.exports = function(config) {
config.set({
// base path that will be used to resolve all patterns (eg. files, exclude)
basePath: '',
// frameworks to use
// available frameworks: https://npmjs.org/browse/keyword/karma-adapter
frameworks: ['mocha', 'sinon-chai'],
// list of files / patterns to load in the browser
files: [
'./index.js'
],
// list of files / patterns to exclude
exclude: [
],
// preprocess matching files before serving them to the browser
// available preprocessors: https://npmjs.org/browse/keyword/karma-preprocessor
preprocessors: {
'./index.js': ['webpack', 'sourcemap', 'coverage']
},
// test results reporter to use
// possible values: 'dots', 'progress'
// available reporters: https://npmjs.org/browse/keyword/karma-reporter
reporters: ['mocha', 'coverage'],
coverageReporter: {
dir: './coverage',
reporters: [
{ type: 'lcov', subdir: '.' },
{ type: 'text-summary' }
]
},
.
.
.
// Continuous Integration mode
// if true, Karma captures browsers, runs the tests and exits
singleRun: true,
// Concurrency level
// how many browser should be started simultaneous
concurrency: Infinity,
webpack: webpackConfig,
webpackMiddleware: {
stats: 'errors-only'
}
})
}karma原本在根目录,我们直接移过来就好了。然后修改的不多,我稍微解释一下:
stats: 'errors-only'我们让webpack的编译过程不显示出来,除非编译报错const webpackConfigBase = require('./webpack.config.base.js')
const config = Object.assign(webpackConfigBase.config, {
// sourcemap 模式
devtool: '#inline-source-map',
module: {
rules: [
{
test: /\.js$/,
loader: 'babel-loader',
exclude: /node_modules/
}
]
},
})
module.exports = config
``
#### 编辑index.js入口文件
这个文件是为了配合`karma-webpack`的,详情见[Alternative Usage](https://github.com/webpack-contrib/karma-webpack#alternative-usage)
```js
// require all test files (files that ends with .spec.js)
// 语法说明:https://doc.webpack-china.org/guides/dependency-management/#require-context
const testsContext = require.context('./specs', true, /\.spec$/)
testsContext.keys().forEach(testsContext)
// require all src files which in the app/common/js for coverage.
// you can also change this to match only the subset of files that
// you want coverage for.
const srcContext = require.context('../../app/common/js/', true, /\.js$/)
srcContext.keys().forEach(srcContext)测试代码放在./specs文件夹下,被测试原文件在../../app/common/js/下。这里我只测试一些公共的js文件,如果你需要测试其它,可自行修改。比如一些基于vue的UI组件库,你想要测试所有组件代码,还需要做些配置上的修改,这方面可以参考滴滴的cube-ui项目,挺完整的,覆盖率也很高。
编辑dom.spec.js文件:
/**
* 测试common/utils/dom.js
*/
import * as dom from 'common/js/utils/dom.js'
// const expect = require('chai').expect 装过sinon-chai就不需要这句了;sinon同理
describe('utils/dom', () => {
// 测试hasClass
it('hasClass', () => {
const ele = document.createElement('div')
ele.className = 'base kitty'
// 是否含有base
expect(dom.hasClass(ele, 'base')).to.be.equal(true)
// 是否含有kitty
expect(dom.hasClass(ele, 'kitty')).to.be.equal(true)
// 是否含有tom
expect(dom.hasClass(ele, 'tom')).to.be.equal(false)
// 无参数
expect(dom.hasClass()).to.be.equal(false)
})
// 测试addClass
it('addClass', () => {
const ele = document.createElement('div')
ele.className = 'base'
// 增加类名kitty
dom.addClass(ele, 'kitty')
expect(ele.className).to.be.equal('base kitty')
// 再增加类名kitty,希望并不会有重复类名
dom.addClass(ele, 'kitty')
expect(ele.className).to.be.equal('base kitty')
})
// 测试removeClass
it('removeClass', () => {
const ele = document.createElement('div')
ele.className = 'base kitty'
// 删除类名kitty
dom.removeClass(ele, 'kitty')
expect(ele.className).to.be.equal('base')
// 删除不存在的类名
dom.removeClass(ele, 'tom')
expect(ele.className).to.be.equal('base')
})
// 测试noce
it('once', () => {
const ele = document.createElement('div')
const callback = sinon.spy()
dom.once(ele, 'click', callback)
// 点击一次
ele.click()
expect(callback).to.have.been.calledOnce
// 再点击一次,预期应该是不调用callback的,所以依然为calledOnce
ele.click()
expect(callback).to.have.been.calledOnce
})
})代码注释已经很清楚啦~
先修改下package.json配置:"test:unit": "karma start test/unit/karma.conf.js"
运行:
➜ construct git:(master) npm run test:unit
> [email protected] test:unit /Users/Terry/WFE/vue-study/construct
> karma start test/unit/karma.conf.js
START:
ℹ 「wdm」:
ℹ 「wdm」: Compiled successfully.
ℹ 「wdm」: Compiling...
ℹ 「wdm」:
ℹ 「wdm」: Compiled successfully.
23 04 2018 01:25:39.438:INFO [karma]: Karma v2.0.0 server started at http://0.0.0.0:9876/
23 04 2018 01:25:39.440:INFO [launcher]: Launching browser Chrome with unlimited concurrency
23 04 2018 01:25:39.448:INFO [launcher]: Starting browser Chrome
23 04 2018 01:25:41.778:INFO [Chrome 66.0.3359 (Mac OS X 10.13.2)]: Connected on socket A9ZeKTNtnUU9MAceAAAA with id 51610088
utils/dom
✔ hasClass
✔ addClass
✔ removeClass
✔ once
Finished in 0.008 secs / 0.004 secs @ 01:25:41 GMT+0800 (CST)
SUMMARY:
✔ 4 tests completed
=============================== Coverage summary ===============================
Statements : 87.12% ( 142/163 ), 14 ignored
Branches : 61.25% ( 49/80 ), 22 ignored
Functions : 86.11% ( 31/36 ), 5 ignored
Lines : 90.79% ( 138/152 )
================================================================================karma 测试框架的前世今生
karma thesis
karma 官网
前端自动化测试工具overview
前端自动化测试解决方案探析
mocha官网
代码测试覆盖率分析
聊一聊前端自动化测试
Sinon指南: 使用Mocks, Spies 和 Stubs编写JavaScript测试
sinon-chai github
论文是个很有意思的东西,看多了你会惊人地发现,很多大厂有深度的文章其实都是对论文的纯翻译~
另外还参考了vue和滴滴的cube-ui的项目测试部分。
无论是Laravel还是ThinkPHP,都会用后端模板,Laravel是Blade,TinkPHP则是类Smarty。
中小型公司,为了快速开发,Laravel真的是利器了。
初始化
git init克隆项目
git clone长期保存密码
git config --global credential.helperstore获取分支
git fetch origin合并分支
git merge获取并且合并分支
git pull origin切换分支
git checkout新建并切换到分支
git checkout -b删除分支
git branch -d查看修改状态
git status查看所有的修改内容
git diff查看指定文件修改内容
git diff <file>添加指定文件到暂存区
git add添加所有文件到暂存区
git add all查看已经在提交区(即已经add了的)所有修改内容
git diff --cached提交暂存区修改到本地
git commit -m ""修改刚才提交的描述
git commit --amend -m ""提交本地版本到远端
git push origin其他分支有紧急问题,需要马上切过去处理,但当前分支又只改了一半,又不想commit
git stash处理完其他分支的紧急问题以后,回到原先分支继续修改
git stash pop清除所有没有add了的修改
git checkout .清除指定没有add了的文件的修改
git checkout清除untracked的文件
git clean -fd清除 - git ignore了的文件
git clean -xcommit了修改到本地,想放弃这个commit
git reset HEAD~commit了修改到本地,想放弃这个commit,并清空修改
git reset --hard HEAD~commit了修改到本地,想恢复特定文件成指定的历史版本
git checkout --打标签
git tag -a v1.0 -m "somthing message"删除标签
git tag -d v1.0列出所有标签
git tag推送特定标签到远端
git push origin v1.0推送所有标签到远端
git push origin --tags删除远端tag
git push origin -d tag v1.0维基百科:
跨站脚本(英语:Cross-site scripting,通常简称为:XSS)是一种网站应用程序的安全漏洞攻击,是代码注入的一种。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。
比如,一个网站的评论区,用户可以输入<script>标签,如图:

点击submit发送内容,如果前端后端都没有做任何处理的话,这段评论在提交以后就会原封不动地展示在html上。而这个时候,script里的代码执行了,导致所有访问这个页面的用户的cookie都发送到了黑客指定的API。
前端对于这种情况好像在发送到后端的过程中无能为力,即使在流程中加上前端转译,黑客也可以通过直接在控制台执行js的方式来提交评论。
前端倒是在渲染的时候可以做相应的处理,比如可以用以下方法处理:
processedContent(comment) {
return comment
.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, """)
.replace(/'/g, "'")
}
这样就能处理掉非法符号了(代码仅列举了部分符号)。
& < >这些字符叫做字符实体因为比如< >这样的字符游览器会认为是标签,所以,如果想正常显示< >,那么就得转成字符实体,而游览器默认也认识这些字符,在展示的时候,还是展示成字符实体对应的符号。
对于渲染阶段,像react,vue这样的库,又或者是juicer,ejs这样的前端模板,都会默认处理非法符号为字符实体。
字符实体详解可以看这里>>
后端在收到前端的提交以后,直接存起来就好。
这里的渲染指的是后端模板渲染,渲染模板可能是smarty,可能是laravel的blade,可能是node做中间层用的ejs,亦可能是vue或react的SSR。这些后端模板都自己内部会做转义。
转义的实现方法也无非是通过正则匹配,然后进行替换。
在遇到富文本编辑器的时候,处理方法就不同了。因为,在前端展示的时候,我们自然是有什么标签就展示什么标签,而不是转为字符实体,不然得到的不都是文本了嘛。
这种情况的话,就需要后端进行非法字符过滤了,把比如script这种标签给过滤掉,或者转义掉。当然,其实富文本还有很多过滤条件,比如,非本站的网页地址过滤,非法字符过滤等。
总之,无论是后端模板还是前端模板,其实都是前端的范畴。
上面也说了,现在的前端库、前端模板、后端模板,都已经内部做了转译了,开发者愉快的使用就好了。
所以,其实除了遇到富文本编辑器的情况(工作量在后端),我们几乎不用做任何额外的工作。但是,还是理解内部机制比较好。
相信很多人都用过vue-cli或create-react-app或者类似的脚手架。
脚手架方便我们复制,粘贴,或者clone代码库,而且还可以更具用户的选择,引入用户所需要的插件。
脚手架往往搭配着早已设计好了架构的项目,然后按需进行拷贝。
官网介绍: The web's scaffolding tool for modern webapps.
yeoman是一款来做脚手架的工具,我们借助它,就能很容易地开发出自己的脚手架了。
yeoman具体的使用,本文不会介绍太多,官网的文档差不多就够了,我也会在文章末尾放上自己搜集的一些参考资料,同学们自己看看就好了。
安装yeoman: npm install -g yo
generator其实就是一个node module,即npm。yeoman根据我们写的generator来执行我们写的构建代码。(对怎么自己选一个npm包不熟悉的同学,可以戳这里>>)
generator文件夹必须以generator-开头,然后之后跟上自定义的脚手架名字,比如generator-zx-vue,将它做成npm包以后,上传到npm官网,只有在电脑上全局安装,然后用yoman运行就好了,之后会详细介绍。
除了手动创建自己的generator项目,我们还可以通过别人已经做好的脚手架来创建。
安装generator-generator: npm install -g generator-generator
然后,运行脚手架: yo generator
之后,我们就可以看到一系列的提示,按照提示输入完信息以后,我们就有了一份编写自己的generator的模板项目了。
其实,这个generator脚手架生成的很多文件我们都不需要管,我们只需要把注意力放在generator/app这个文件夹下的内容就好了。
templates文件是用来作为仓库,我们在编写脚本的时候,如果需要哪些文件,就直接去这个仓库里copy出来就好了。
因为我们自己做的generator是一个npm包,我们自然希望对其进行版本管理,用上git,方便今后的迭代。
templates其实也是一个独立的项目,我们之前说了,它是一个早已完成了的项目架子,我们是从gitlab或者github上copy过来的而已。那该怎么管理这两个不同的项目呢?
git用的6的同学肯定一下子就想到git子模块的知识了。
不熟悉的同学可以戳 git文档-子模块>>
因此,我们不是把项目copy进templates,也不是git clone进templates,而是先删除app文件夹下的templates,然后:
git submodule add https://github.com/CodeLittlePrince/vue-construct-for-zx-vue.git templates
这样的话,我们就可以更新自己的仓库项目(vue-construct-for-zx-vue),generator项目的话,pull子模块就好了。两者保持独立,方便迭代和维护。
实际运用submodule后发现,其实真的很难让作为模板的项目独立运行,而且它的.git也会影响实际项目的git配置,所以不再采用submodule。
接下来,我们就可以来编写app文件夹下的index.js文件了:
const Generator = require('yeoman-generator')
const chalk = require('chalk')
const yosay = require('yosay')
const path = require('path')
const fs = require('fs')
module.exports = class extends Generator {
initializing() {
// 打印欢迎语
this.log(
yosay(`Welcome to the shining ${chalk.cyan('generator-zx-vue')} generator!`)
)
}
prompting() {
// 让用户选择是否需要包含vuex
const prompts = [
{
type: 'input',
name: 'name',
message: 'Name of project:',
default: path.basename(process.cwd())
},
{
type: 'input',
name: 'description',
message: 'Description:',
default: '',
},
// {
// type: 'confirm',
// name: 'includeVuex',
// message: 'Would you like to include Vuex in your project?',
// default: false,
// }
]
return this.prompt(prompts).then(answers => {
this.name = answers.name
this.description = answers.description
// this.includeVuex = answers.includeVuex
this.log(chalk.green('name: ', this.name))
this.log(chalk.green('description: ', this.description))
// this.log(chalk.green('includeVuex: ', this.includeVuex))
})
}
writing() {
// 复制普通文件
// https://github.com/sboudrias/mem-fs-editor
this.fs.copyTpl(
this.templatePath(),
this.destinationPath(),
{
name: this.name
},
{},
{ globOptions:
{
dot: true
}
}
)
// 根据用户选择,决定是否安装vuex
if (this.includeVuex) {
const pkgJson = {
name: this.name,
description: this.description,
// dependencies: {
// vuex: '^3.0.1'
// }
}
// Extend or create package.json file in destination path
this.fs.extendJSON(this.destinationPath('package.json'), pkgJson)
}
}
install() {
this.npmInstall()
}
end() {
this.log(chalk.green('Construction completed!'))
}
}语法很简单,具体可以自己看yeoman官方文档,我简单的介绍一下几个比较常用的函数,或者说生命周期:
| 函数名 | 我用来做什么 |
|---|---|
| initializing | 我用来写一些欢迎语 |
| prompting | 与用户的交互,比如input、checkbox、confirm等 |
| writing | 拷贝和编辑文件 |
| install | 安装依赖,如npm install |
| end | 写一些如goodbye的结束语 |
没发布上线的npm包,本地测试只需要link一下就好了,到generator根目录,然后运行npm link,这样我们就可以使用我们的generator了,比如,到一个新的空文件夹下运行:yo zx-vue,就可以看到项目开始自动构建了。
测试完成后,就可以发布到npm官网了,发布流程可参考我另一篇文章npm-从0开始写一个npm module
zx-vue是一个以vue-construct作为模板仓库的脚手架,为了方便新项目构建,也为了今后的新项目能够统一。
首先,安装全局yeomman和generator-zx-vue:
npm install -g yo
npm install -g generator-zx-vue
然后找一个空的文件夹执行:
yo zx-vue
生成项目以后的操作可以参考vue-construct
最后,generator-zx-vue的地址是generator-zx-vue
我之前原本打算把vuex作为一个可选项,让用户选择是否引入这个库。
但是,做下来以后发现,因为用到了ejs模板去做这个事情,然后,最终输出的文件会因为<% if (condition) { %>这种ejs语法导致换行,或者缩进不符合eslint。当然,我也可以把项目弄的更空一点,把所有vuex的使用清掉,但这样也不是很好,因为我又想让用户跑起来这个项目就能看到整个全家桶的效果在页面上使用到。
其实还有另外一种比较暴力的方法就是,我弄一个有vuex的项目,一个没有vuex的项目,然后选择copy哪份,,太暴力。
憋了好久也没想到什么很好接受的方法,所以就暂且把vuex也直接带上。
最后,也希望有想法的同学还有大佬多多留言,给点建议^_^
====== 2018.5.24
最终,我还是选择了算是暴力的模式把,将用vuex和不用vuex的分为两个代码仓库,详细可以参见子咻的vue脚手架——zx-vue
e2e测试在前端测试中,也许是最不被看重的一项吧。
小公司就不说了,即使是大厂,也极少有e2e测试。因为它需要花费的精力,相比得到的回报而言,可以说是相差悬殊,说白了,就是吃力不讨好- -||
e2e测试其实就是模拟用户行为,我们得根据业务写各种各样的不同操作。而几乎所有的项目,业务都是会变的。所以,因为业务变了,模拟用户行为也会随之改变。最后,就各种改,即改业务代码,又改测试代码,结果,无端端多出一大堆工作量,而且,很大的可能,下一轮迭代还得改,我上次就是这么死的。
但并不是所有的项目都不适合e2e测试的。比如,一个大项目,已经上线多年了,需求内容等基本都成形了。这种情况,就比较适合上e2e了。
项目大的缺点就是,修改的时候,一不小心就会牵一发而动全身。当年刚初来乍到的时候,就经常不小心改了公共样式,或者公共js,然后导致多个页面发生了变化,从而产生bug。因此,这种时候就很需要e2e测试了。
总的来说,e2e的运用场景就是:上线久、业务稳、体量大的项目啦~(千万不要在刚启动或迭代很快的项目上e2e,切记,切记)
nightmare是高阶浏览器自动测试库。
nightmare相比phantom而言,api更加简洁方便,比如引用的比较多的就是,同样是实现一个向yahoo自动提交关键词并搜索的功能:
phantom.create(function (ph) {
ph.createPage(function (page) {
page.open('http://yahoo.com', function (status) {
page.evaluate(function () {
var el =
document.querySelector('input[title="Search"]');
el.value = 'github nightmare';
}, function (result) {
page.evaluate(function () {
var el = document.querySelector('.searchsubmit');
var event = document.createEvent('MouseEvent');
event.initEvent('click', true, false);
el.dispatchEvent(event);
}, function (result) {
ph.exit();
});
});
});
});
});yield Nightmare()
.goto('http://yahoo.com')
.type('input[title="Search"]', 'github nightmare')
.click('.searchsubmit');是不是感觉世界突然变得很美好?
另外,官方文档还推荐了两个很棒的工具:
npm i -D nightmare因为nightmare是基于electron的,安装的时候还会安装electron相关的东西,所以安装会比较慢,这个时候,可以打开网易云音乐来首歌。
我们先用其他网站来做个小测试,比如github。
在test文件夹中,和unit文件夹同级,新建一个e2e文件夹,然后在e2e文件夹下新建一个叫test.js的文件,内容为:
const Nightmare = require('nightmare')
const chai = require('chai')
const expect = chai.expect
describe('test CodeLittlePrince results', () => {
it('should find the CodeLittlePrince\'s blog github link first', function(done) {
// 设定整个模拟的时长,超过则GG
this.timeout('60s')
const nightmare = Nightmare({
show: true
})
nightmare
.goto('https://github.com/login')
.wait('input[name="login"]')
.type('input[name="login"]', '[email protected]')
.type('input[name="password"]', '******') // 用户名和密码自行修改
.click('input[name="commit"]')
.wait('input[placeholder="Search GitHub"]')
.type('input[placeholder="Search GitHub"]', 'CodeLittlePrince/blog \u000d')
.wait('a[href="/CodeLittlePrince/blog"]')
.click('a[href="/CodeLittlePrince/blog"]')
// .evaluate(() => document.querySelector('#links .result__a').href)
// evaluate的作用就是将值return,给expect用
.evaluate(() => location.href)
.end()
.then(link => {
expect(link).to.equal('https://github.com/CodeLittlePrince/blog')
done()
})
})
})然后修改package.json的scripts:
"test:e2e": "mocha ./test/e2e/test.js"最后运行看效果:

感觉棒棒的~
因为运行过我的项目的同学知道,我只有三个页面,所以,可交互太少,所以我牛刀小试让同学们可以更加直观的感受到nightmare的方便。
接下来我们就来正式地配置吧。
还是刚才的test/e2e文件夹下,删除text.js文件,创建index.js作为入口文件:
/**
* e2e测试文件的入口文件
*/
// 测试页面的路由和文案是否正确
require('./specs/page.spec.js')然后,创建specs文件夹,然后在该文件夹下创建文件page.spec.js:
const Nightmare = require('nightmare')
const chai = require('chai')
const expect = chai.expect
const nightmare = Nightmare({
show: true
})
describe('pages', () => {
it('page ', function(done) {
// 设定整个模拟的时长,超过则GG
this.timeout('30s')
nightmare
.viewport(1200, 600)
.goto('http://0.0.0.0:9999')
.wait('h1')
.click('a[href="#/pageA"]')
.wait(() => {
return location.hash === '#/pageA'
})
.click('a[href="#/pageB"]')
.wait(() => {
return location.hash === '#/pageB'
})
.evaluate(() => location.hash)
.end()
.then(hash => {
expect(hash).to.equal('#/pageB')
done()
})
})
})修改下package.json的scripts:
"test:e2e": "mocha ./test/e2e/index.js"npm run devnpm run test:e2e➜ construct git:(master) ✗ npm run test:e2e
> [email protected] test:e2e /Users/Terry/WFE/vue-study/construct
> mocha ./test/e2e/index.js
pages
✓ page (1431ms)
1 passing (1s)
感觉测试流程,这样有点鸡肋,因为得先run dev,说不定有需要还需要run mock,最后再run test:e2e,略繁琐。当然,这些都可以被优化成一步。
不过,个人感觉,e2e在联调以后,进入开发环境,或者测试环境以后测也可以。或者说,在测试环境测就好了,测试环境和线上环境比较接近,效果更好。本身e2e测试就是测试开发工程师写的,所以,在测试环境测也合理。不然,本地要测一遍,开发环境又测,测试环境又测,多累呐。
最后,也希望各位有什么好的意见或者建议,可以在评论区留言,讨论讨论呐~
有同学反应我的vue项目没有加入vuex,额,好吧,下一篇我们加一下vuex,也出一篇文章,以免我自己偷偷加,发生断片,让同学们迷糊。
再之后呢,我们就会把这个项目利用yeoman做成脚手架啦!
vuex想必不需要我介绍很多了,这一节主要是为了填补项目没有引入vuex的问题,之后做完脚手架可以选择是否使用vuex。
因为vuex用的实在是很普遍,就不介绍细节了,我们直接搭项目。
在app目录新建文件夹store:
app/store
├── README.md
├── actions.js
├── getters.js
├── index.js
├── mutation-types.js
├── mutations.js
└── state.js不多说,直接上代码吧。
actions.js:
import * as types from './mutation-types'
/* 增加年龄 */
export const ageIncrease = function ({commit}) {
setTimeout(() => {
commit(types.AGE_INCREASE)
}, 3000)
}getters.js:
// 获取名字
export const name = state => state.nameindex.js:
import Vue from 'vue'
import Vuex from 'vuex'
import * as actions from './actions'
import * as getters from './getters'
import state from './state'
import mutations from './mutations'
import createLogger from 'vuex/dist/logger'
Vue.use(Vuex)
const debug = process.env.NODE_ENV !== 'production'
export default new Vuex.Store({
actions,
getters,
state,
mutations,
strict: debug,
plugins: debug ? [createLogger()] : []
})mutation-types.js:
export const AGE_INCREASE = 'AGE_INCREASE'mutations.js:
import * as types from './mutation-types'
const mutations = {
/* 增加年龄 */
[types.AGE_INCREASE](state) {
state.age ++
}
}
export default mutationsstate.js:
const state = {
name: '子咻',
age: 18
}
export default state最后我们将vuex引入app下的index.js就好了。
如果项目非常大,还需要module来管理的话,可以按照当前规则,进行改造即可。
到现在,我们就将整个项目的骨架搭好了,下一章,我们将正式开始做脚手架。
弄完了前后端分离,我们自然想打包发布项目了。
不多说,就让我们来看看吧。
直接上代码:
const webpack = require('webpack')
const path = require('path')
const ExtractTextPlugin = require('extract-text-webpack-plugin')
const webpackConfigBase = require('./webpack.config.js')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const CleanWebpackPlugin = require('clean-webpack-plugin')
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin
const exec = require('child_process').execSync
const pkg = require('./package.json')
// 为了抽离出两份CSS,创建两份ExtractTextPlugin
// base作为基础的css,基本不变,所以,可以抽离出来充分利用浏览器缓存
// app作为迭代的css,会经常改变
const extractBaseCSS = new ExtractTextPlugin({filename:'static/css/base.[chunkhash:8].css', allChunks: true})
const extractAppCSS = new ExtractTextPlugin({filename:'static/css/app.[chunkhash:8].css', allChunks: true})
// 减少路径书写
function resolve(dir) {
return path.join(__dirname, dir)
}
// 网站图标配置
const favicon = resolve('favicon.ico')
// 网站版本号设置
let appVersion = ''
try {
appVersion = exec('git rev-parse --short HEAD').toString().replace(/\n/, '')
} catch (e) {
console.warn('Getting revision FAILED. Maybe this is not a git project.')
}
const config = Object.assign(webpackConfigBase, {
// You should configure your server to disallow access to the Source Map file for normal users!
devtool: 'source-map',
entry: {
app: resolve('app/index.js'),
// 将第三方依赖(node_modules)的库打包,从而充分利用浏览器缓存
vendor: Object.keys(pkg.dependencies)
},
output: {
path: resolve('dist'),
// publicPath: 'https://cdn.self.com'
publicPath: resolve('dist/'),
filename: 'static/js/[name].[chunkhash:8].js'
},
module: {
rules: [
{
test: /\.js$/,
include: [resolve('app')],
loader: 'babel-loader'
},
{
test: /\.vue$/,
exclude: /node_modules/,
loader: 'vue-loader',
options: {
extractCSS: true,
loaders: {
scss: extractAppCSS.extract({
fallback: 'vue-style-loader',
use: [
{
loader: 'css-loader',
options: {
sourceMap: true
}
},
{
loader: 'postcss-loader',
options: {
sourceMap: true
}
},
{
loader: 'sass-loader',
options: {
sourceMap: true
}
}
]
})
}
}
},
{
test: /\.(css|scss)$/,
use: extractBaseCSS.extract({
fallback: 'style-loader',
use: [
{
loader: 'css-loader',
options: {
sourceMap: true
}
},
{
loader: 'postcss-loader',
options: {
sourceMap: true
}
},
{
loader: 'sass-loader',
options: {
sourceMap: true
}
}
]
})
},
{
test: /\.(png|jpe?g|gif|svg|ico)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 8192,
name: 'static/img/[name].[hash:8].[ext]'
}
},
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 8192,
name: 'static/font/[name].[hash:8].[ext]'
}
}
]
},
plugins: [
// Scope hosting
new webpack.optimize.ModuleConcatenationPlugin(),
// 删除build文件夹
new CleanWebpackPlugin(
resolve('dist')
),
// 抽离出css
extractBaseCSS,
extractAppCSS,
// 提供公共代码vendor
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
filename: 'static/js/[name].[chunkhash:8].js'
}),
// html 模板插件
new HtmlWebpackPlugin({
appVersion,
favicon,
filename: 'index.html',
template: resolve('app/index.html'),
minify: {
removeComments: true,
collapseWhitespace: false
}
}),
// 定义全局常量
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: '"production"'
}
}),
// 可视化分析
new BundleAnalyzerPlugin(),
// 加署名
new webpack.BannerPlugin('Copyright by 子咻 https://github.com/CodeLittlePrince/blog'),
]
})
module.exports = config代码几乎全都有注释,有不懂的可以在评论去留言。
虽然代码写好了,但是我们不禁发出一声“卧槽”,好多和webpack.config.js一样的代码啊,要是改了一样的代码部分,我还得同时改两份,而且,这么多的冗余代码对于一个优秀的程序员来讲,是不可容忍的。
那我们改怎么呢?
我们就叫webapck.config.base.js吧:
const path = require('path')
// 为了抽离出两份CSS,创建两份ExtractTextPlugin
// base作为基础的css,基本不变,所以,可以抽离出来充分利用浏览器缓存
// app作为迭代的css,会经常改变
const isProduction = process.env.NODE_ENV === 'production'
const ExtractTextPlugin = require('extract-text-webpack-plugin')
const extractBaseCSS =
new ExtractTextPlugin(
{
filename:'static/css/base.[chunkhash:8].css',
allChunks: true,
disable: !isProduction // 开发环境下不抽离css
}
)
const extractAppCSS
= new ExtractTextPlugin(
{
filename:'static/css/app.[chunkhash:8].css',
allChunks: true,
disable: !isProduction // 开发环境下不抽离css
}
)
// 减少路径书写
function resolve(dir) {
return path.join(__dirname, dir)
}
// 网站图标配置
const favicon = resolve('favicon.ico')
// __dirname: 总是返回被执行的 js 所在文件夹的绝对路径
// __filename: 总是返回被执行的 js 的绝对路径
// process.cwd(): 总是返回运行 node 命令时所在的文件夹的绝对路径
const config = {
resolve: {
// 扩展名,比如import 'app.vue',扩展后只需要写成import 'app'就可以了
extensions: ['.js', '.vue', '.scss', '.css'],
// 取路径别名,方便在业务代码中import
alias: {
api: resolve('app/api/'),
common: resolve('app/common/'),
views: resolve('app/views/'),
components: resolve('app/components/'),
componentsBase: resolve('app/componentsBase/'),
directives: resolve('app/directives/'),
filters: resolve('app/filters/'),
mixins: resolve('app/mixins/')
}
},
// loaders处理
module: {
rules: [
{
test: /\.js$/,
include: [resolve('app')],
loader: [
'babel-loader',
'eslint-loader'
]
},
{
test: /\.vue$/,
exclude: /node_modules/,
loader: 'vue-loader',
options: {
extractCSS: true,
loaders: {
scss: extractAppCSS.extract({
fallback: 'vue-style-loader',
use: [
{
loader: 'css-loader',
options: {
sourceMap: true
}
},
{
loader: 'postcss-loader',
options: {
sourceMap: true
}
},
{
loader: 'sass-loader',
options: {
sourceMap: true
}
}
]
})
}
}
},
{
test: /\.(css|scss)$/,
use: extractBaseCSS.extract({
fallback: 'style-loader',
use: [
{
loader: 'css-loader',
options: {
sourceMap: true
}
},
{
loader: 'postcss-loader',
options: {
sourceMap: true
}
},
{
loader: 'sass-loader',
options: {
sourceMap: true
}
}
]
})
},
{
test: /\.(png|jpe?g|gif|svg|ico)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 8192,
name: isProduction
? 'static/img/[name].[hash:8].[ext]'
: 'static/img/[name].[ext]'
}
},
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 8192,
name: isProduction
? 'static/font/[name].[hash:8].[ext]'
: 'static/font/[name].[ext]'
}
}
]
}
}
module.exports = {
config,
favicon,
resolve,
extractBaseCSS,
extractAppCSS
}const webpack = require('webpack')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const FriendlyErrorsPlugin = require('friendly-errors-webpack-plugin')
const webpackConfigBase = require('./webpack.config.base.js')
const config = Object.assign(webpackConfigBase.config, {
// sourcemap 模式
devtool: 'cheap-module-eval-source-map',
// 入口
entry: {
app: webpackConfigBase.resolve('app/index.js')
},
// 输出
output: {
path: webpackConfigBase.resolve('dev'),
filename: 'index.bundle.js'
},
plugins: [
// html 模板插件
new HtmlWebpackPlugin({
favicon: webpackConfigBase.favicon,
filename: 'index.html',
template: webpackConfigBase.resolve('app/index.html')
}),
// 抽离出css,开发环境其实不抽离,但是为了配合extract-text-webpack-plugin插件,需要做个样子
webpackConfigBase.extractAppCSS,
webpackConfigBase.extractBaseCSS,
// 热替换插件
new webpack.HotModuleReplacementPlugin(),
// 更友好地输出错误信息
new FriendlyErrorsPlugin()
],
devServer: {
proxy: {
// 凡是 `/api` 开头的 http 请求,都会被代理到 localhost:7777 上,由 koa 提供 mock 数据。
// koa 代码在 ./mock 目录中,启动命令为 npm run mock。
'/api': {
target: 'http://localhost:7777', // 如果说联调了,将地址换成后端环境的地址就哦了
secure: false
}
},
host: '0.0.0.0',
port: '9999',
disableHostCheck: true, // 为了手机可以访问
contentBase: webpackConfigBase.resolve('dev'), // 本地服务器所加载的页面所在的目录
// historyApiFallback: true, // 为了SPA应用服务
inline: true, //实时刷新
hot: true // 使用热加载插件 HotModuleReplacementPlugin
}
})
module.exports = configconst webpack = require('webpack')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const CleanWebpackPlugin = require('clean-webpack-plugin')
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin
const exec = require('child_process').execSync
const webpackConfigBase = require('./webpack.config.base.js')
const pkg = require('./package.json')
// 网站版本号设置
let appVersion = ''
try {
appVersion = exec('git rev-parse --short HEAD').toString().replace(/\n/, '')
} catch (e) {
console.warn('Getting revision FAILED. Maybe this is not a git project.')
}
const config = Object.assign(webpackConfigBase.config, {
// You should configure your server to disallow access to the Source Map file for normal users!
devtool: 'source-map',
entry: {
app: webpackConfigBase.resolve('app/index.js'),
// 将第三方依赖(node_modules)的库打包,从而充分利用浏览器缓存
vendor: Object.keys(pkg.dependencies)
},
output: {
path: webpackConfigBase.resolve('dist'),
// publicPath: 'https://cdn.self.com'
publicPath: webpackConfigBase.resolve('dist/'),
filename: 'static/js/[name].[chunkhash:8].js'
},
plugins: [
// Scope hosting
new webpack.optimize.ModuleConcatenationPlugin(),
// 删除build文件夹
new CleanWebpackPlugin(
webpackConfigBase.resolve('dist')
),
// 抽离出css
webpackConfigBase.extractAppCSS,
webpackConfigBase.extractBaseCSS,
// 提取公共代码vendor
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
filename: 'static/js/[name].[chunkhash:8].js'
}),
// html 模板插件
new HtmlWebpackPlugin({
appVersion,
favicon: webpackConfigBase.favicon,
filename: 'index.html',
template: webpackConfigBase.resolve('app/index.html'),
minify: {
removeComments: true,
collapseWhitespace: false
}
}),
// 定义全局常量
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: '"production"'
}
}),
// 可视化分析
new BundleAnalyzerPlugin(),
// 加署名
new webpack.BannerPlugin('Copyright by 子咻 https://github.com/CodeLittlePrince/blog'),
]
})
module.exports = config代码瞬间变得清晰、精简、高大上有没有?!(^-^)V
看一下打包处理后代码情况(兼容IE10及以上):

这一篇我们编写了开发环境用的webpack配置文件,然后发现代码的冗余从而重构了开发和发布环境的webpack配置。
之后,我们还需要能够自动测试我们写的业务代码,避免人工手动各种戳页面(虽然大部分公司都是这么干的,即使是大公司会腾出时间和人手写测试用例的部门也不多),不过架构还是要做的。
下篇我们会来完成测试的流程 - 从零开始做Vue前端架构(6)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.