LSTM Autencoders are seq2seq encoders, consisting of an encoder LSTM and a decoder LSTM. The encoder LSTM takes in a sequence of values, outputting only the hidden (latent) vector. The decoder LSTM takes in this hidden (latent) vector and reconstructs the sequence as its output, hench the input and output lengths are the same. Note that seq2seq is a form of many-to-many RNNs and its structure can be seen below.
The objective is to minimize reconstructions loss, in this case the L1Loss (Mean Absolute Error) performs better than the L2Loss (Mean Squared Error). The Autoencoder architecture uses only a 1-layer LSTM for Encoder and also Decoder, this is because the dataset is too small for a more complex model.

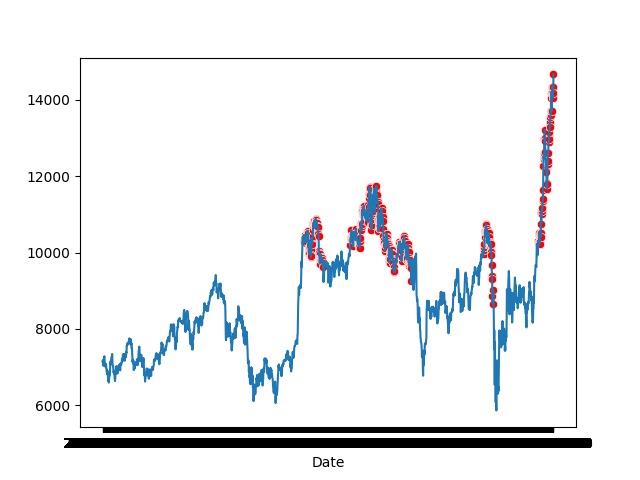
To detect an anomoly we look at the distribution of the reconstruction loss set a cutoff threshold to classify outliers. In the validation dataset we observe how points beyond this cutoff threshold are classified as anomolies.
The dataset is comprised of Goldman Sachs data from 1999-2021 and split at 2013 into train and validation sets. Dates beyond 2021 present very anomolous stock behaviour due to complex world events. To be able to train a model capable of accurately detecting finer anomolies here, the model would need many more parameters (depth), a longer sequence length and trained on many more data points. Nevertheless, the model could predict anomolies in the validation.