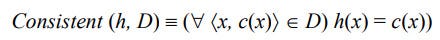
A training example x is said to satisfy hypothesis h when h(x) = 1, regardless of whether x is a positive or negative example of the target concept. An example x is said to consistent with hypothesis h iff h(x) = c(x)
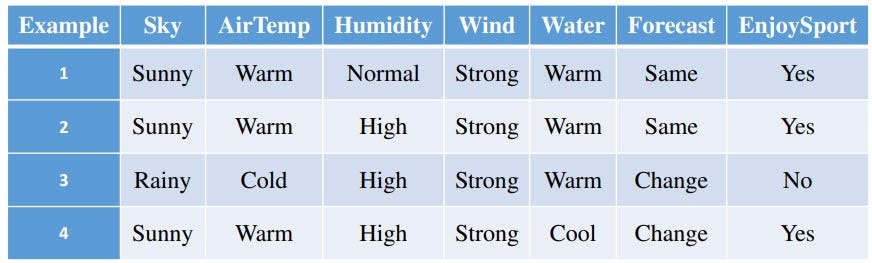
The set of training examples D are below:
The hypothesis h = < Sunny, Warm, ?, Strong, ?, ?>. Now for each example (x, c(x)) in D, we will evaluate h(x) equals c(x).
- (<Sunny, Warm, Normal, Strong, Warm, Same>, yes) → h(x)=c(x)
- (<Sunny, Warm, High, Strong, Warm, Same>, yes) → h(x)=c(x)
- (<Rainy, Cold, High, Strong, Warm, Change>, No) → h(x)=c(x)
- (<Sunny, Warm, High, Strong, Cool, Change>, yes) → h(x)=c(x)
Now we can say, hypothesis h is consistent with a set of training examples D Lets say, we have a hypothesis h1=< ?, ?, ?, Strong, ?, ?>, is this hypothesis consistent with set of training example D ?
In case of training example (3), h(x) != c(x). So hypothesis h1 is not consistent with D.
Lets say, we have a hypothesis h2 = < ?, Warm, ?, Strong, ?, ?>, is this hypothesis consistent with set of training example D ? All the training examples hold h(x) = c(x). So hypothesis h2 is consistent with D.
The version space, denoted VS_H,D with respect to hypothesis space H and training examples D, is the subset of hypotheses from H consistent with the training examples in D.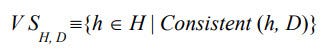

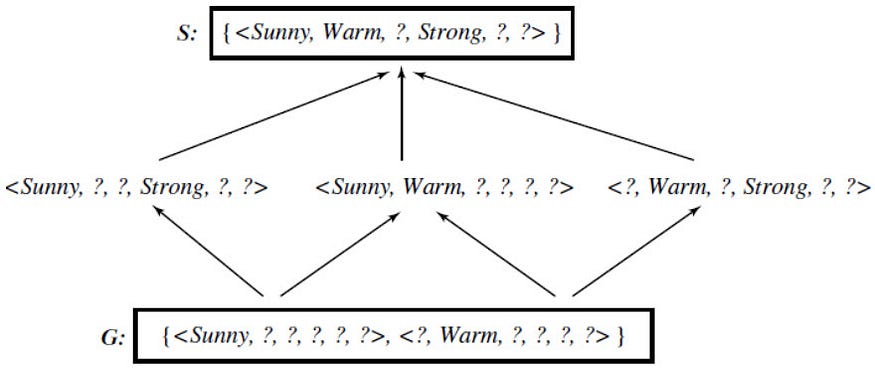
we can represent the version space in terms of its most specific and most general members. For the above enjoysport training examples D, we can output the below list of hypothesis which are consistent with D. In other words, the below list of hypothesis is a version space.
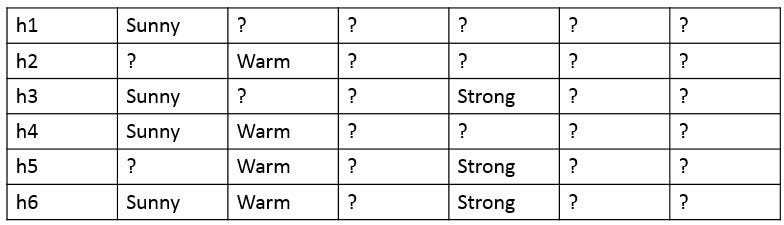
The general boundary G, with respect to hypothesis space H and training data D, is the set of maximally general members of H consistent with D. The specific boundary S, with respect to hypothesis space H and training data D, is the set of minimally general (i.e., maximally specific) members of H consistent with D. Let X be an arbitrary set of instances and Let H be a set of Boolean-valued hypotheses defined over X. Let c: X →{O, 1} be an arbitrary target concept defined over X, and let D be an arbitrary set of training examples {(x, c(x))). For all X, H, c, and D such that S and G are well defined,
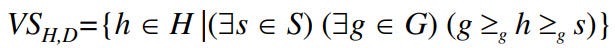
The below figure shows the version space for enjoysport concept learning including both general and specific boundary sets.