![]()
CARLA is a python library to benchmark counterfactual explanation and recourse models. It comes out-of-the box with commonly used datasets and various machine learning models. Designed with extensibility in mind: Easily include your own counterfactual methods, new machine learning models or other datasets. Find extensive documentation here! Our arXiv paper can be found here.
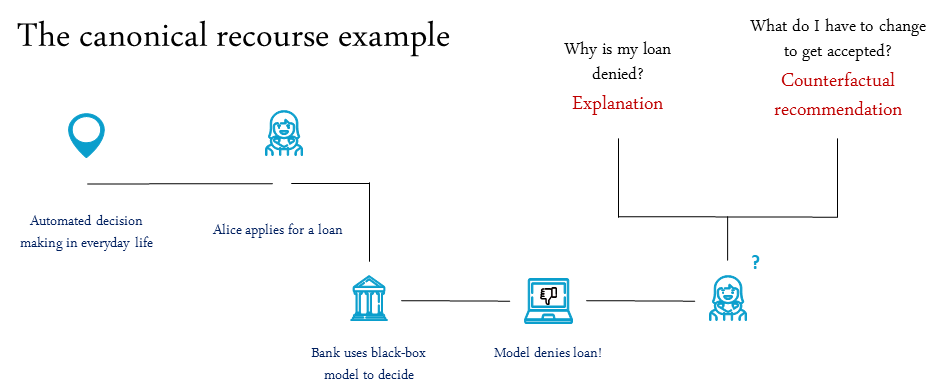
What is algorithmic recourse? As machine learning (ML) models are increasingly being deployed in high-stakes applications, there has been growing interest in providing recourse to individuals adversely impacted by model predictions (e.g., below we depict the canonical recourse example for an applicant whose loan has been denied). This library provides a starting point for researchers and practitioners alike, who wish to understand the inner workings of various counterfactual explanation and recourse methods and their underlying assumptions that went into the design of these methods.
- Getting Started (notebook): Source
- Causal Recourse (notebook): Source
- Plotting (notebook): Source
- Benchmarking (notebook): Source
- Adding your own Data: Source
- Adding your own ML-Model: Source
- Adding your own Recourse Method: Source
| Name | Source |
|---|---|
| Adult | Source |
| COMPAS | Source |
| Give Me Some Credit | Source |
| HELOC | Source |
| Model | Description | Tensorflow | Pytorch | Sklearn | XGBoost |
|---|---|---|---|---|---|
| ANN | Artificial Neural Network with 2 hidden layers and ReLU activation function. | X | X | ||
| LR | Linear Model with no hidden layer and no activation function. | X | X | ||
| RandomForest | Tree Ensemble Model. | X | |||
| XGBoost | Gradient boosting. | X |
The framework a counterfactual method currently works with is dependent on its underlying implementation. It is planned to make all recourse methods available for all ML frameworks . The latest state can be found here:
| Recourse Method | Paper | Tensorflow | Pytorch | SKlearn | XGBoost |
|---|---|---|---|---|---|
| Actionable Recourse (AR) | Source | X | X | ||
| Causal Recourse | Source | X | X | ||
| CCHVAE | Source | X | |||
| Contrastive Explanations Method (CEM) | Source | X | |||
| Counterfactual Latent Uncertainty Explanations (CLUE) | Source | X | |||
| CRUDS | Source | X | |||
| Diverse Counterfactual Explanations (DiCE) | Source | X | X | ||
| Feasible and Actionable Counterfactual Explanations (FACE) | Source | X | X | ||
| FeatureTweak | Source | X | X | ||
| FOCUS | Source | X | X | ||
| Growing Spheres (GS) | Source | X | X | ||
| Revise | Source | X | |||
| Wachter | Source | X |
python3.7pip
pip install carla-recoursefrom carla import OnlineCatalog, MLModelCatalog
from carla.recourse_methods import GrowingSpheres
# load a catalog dataset
data_name = "adult"
dataset = OnlineCatalog(data_name)
# load artificial neural network from catalog
model = MLModelCatalog(dataset, "ann")
# get factuals from the data to generate counterfactual examples
factuals = dataset.raw.iloc[:10]
# load a recourse model and pass black box model
gs = GrowingSpheres(model)
# generate counterfactual examples
counterfactuals = gs.get_counterfactuals(factuals)python3.7-venv(when not already shipped with python3.7)- Recommended: GNU Make
Using make:
make requirementsUsing python directly or within activated virtual environment:
pip install -U pip setuptools wheel
pip install -e .Using make:
make testUsing python directly or within activated virtual environment:
pip install -r requirements-dev.txt
python -m pytest test/*We use pre-commit hooks within our build pipelines to enforce:
Install pre-commit with:
make install-devUsing python directly or within activated virtual environment:
pip install -r requirements-dev.txt
pre-commit installcarla is under the MIT Licence. See the LICENCE for more details.
This project was recently accepted to NeurIPS 2021 (Benchmark & Data Sets Track). If you use this codebase, please cite:
@misc{pawelczyk2021carla,
title={CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms},
author={Martin Pawelczyk and Sascha Bielawski and Johannes van den Heuvel and Tobias Richter and Gjergji Kasneci},
year={2021},
eprint={2108.00783},
archivePrefix={arXiv},
primaryClass={cs.LG}
}Please also cite the original authors' work.













































































































