-
电影信息包括电影id、图片链接、名称、导演名称、编剧名称、主演名称、类型、制片国家、语言、上映日期、片长、季数、集数、其他名称、剧情简介、评分、评分人数,共67245条数据信息。虽说是电影信息,但其中也包括电视剧、综艺、动漫、纪录片、短片。
-
电影演员信息包括演员id、姓名、图片链接、性别、星座、出生日期、出生地、职业、更多中文名、更多外文名、家庭成员、简介,共89592条数据信息。这里所指的演员包括电影演员、编剧、导演。
-
书籍信息包括书籍id、图片链接、姓名、子标题、原作名称、作者、译者、出版社、出版年份、页数、价格、内容简介、目录简介、评分、评分人数,共64321条数据信息。
-
书籍作者信息包括作者id,姓名、图片链接、性别、出生日期、国家、更多中文名、更多外文名、简介,共6231条数据信息。这里作者包括书籍作者和译者。
-
系统环境:ubuntu 18.04
-
python环境:python3.6
-
python依赖包:requests, bs4, redis, yaml, multiprocessing
进入电影分类界面后,找到开发者工具,找到NetWork->XHR,我们能够看到Request URL为https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=剧情。
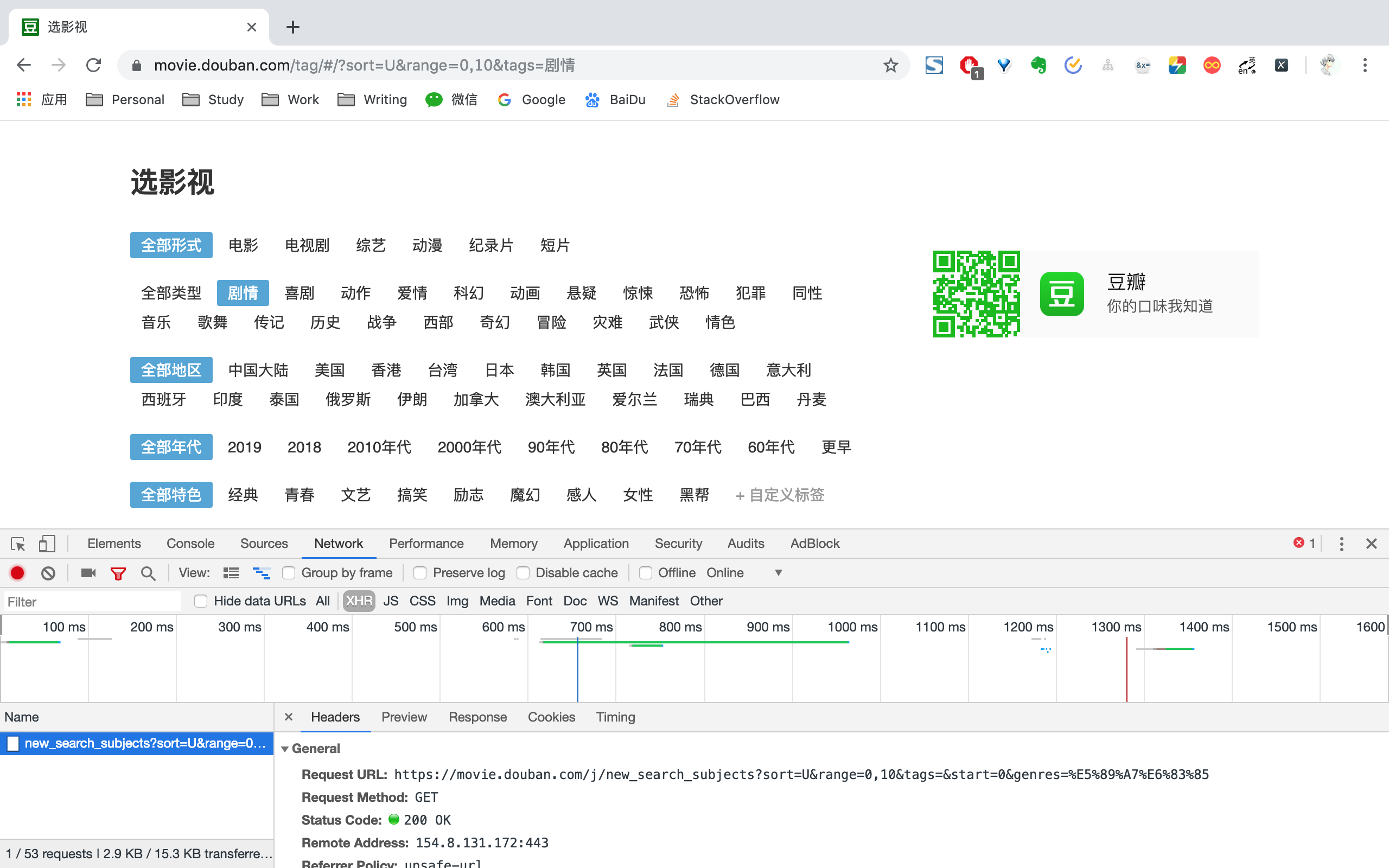
打开上述Request URL,能够看到一系列电影信息,我们只需要拿到其中的id即可。为了确保不重复爬取相同的电影,每拿到一个id之后,都存到redis已爬取队列之中。如果下次再遇到相同的id,则跳过不进行爬取。
另外,再次观察上面URL,发现只要改变start和genres,便能够拿到所有电影id。
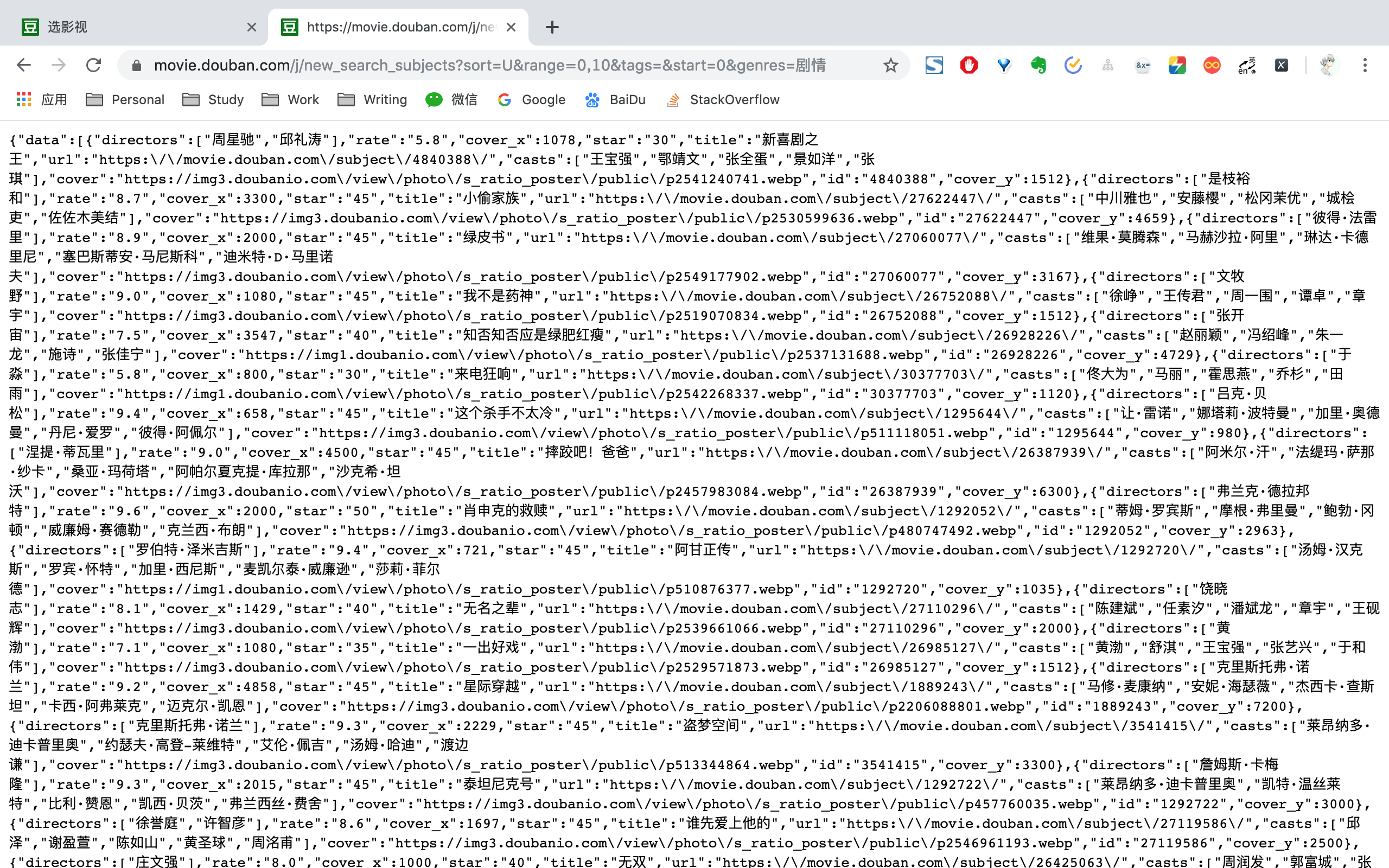
以新喜剧之王id 4840388为例,拼接https://movie.douban.com/subject后得到Movie URL为https://movie.douban.com/subject/4840388。请求Movie URL,便能得到电影信息。
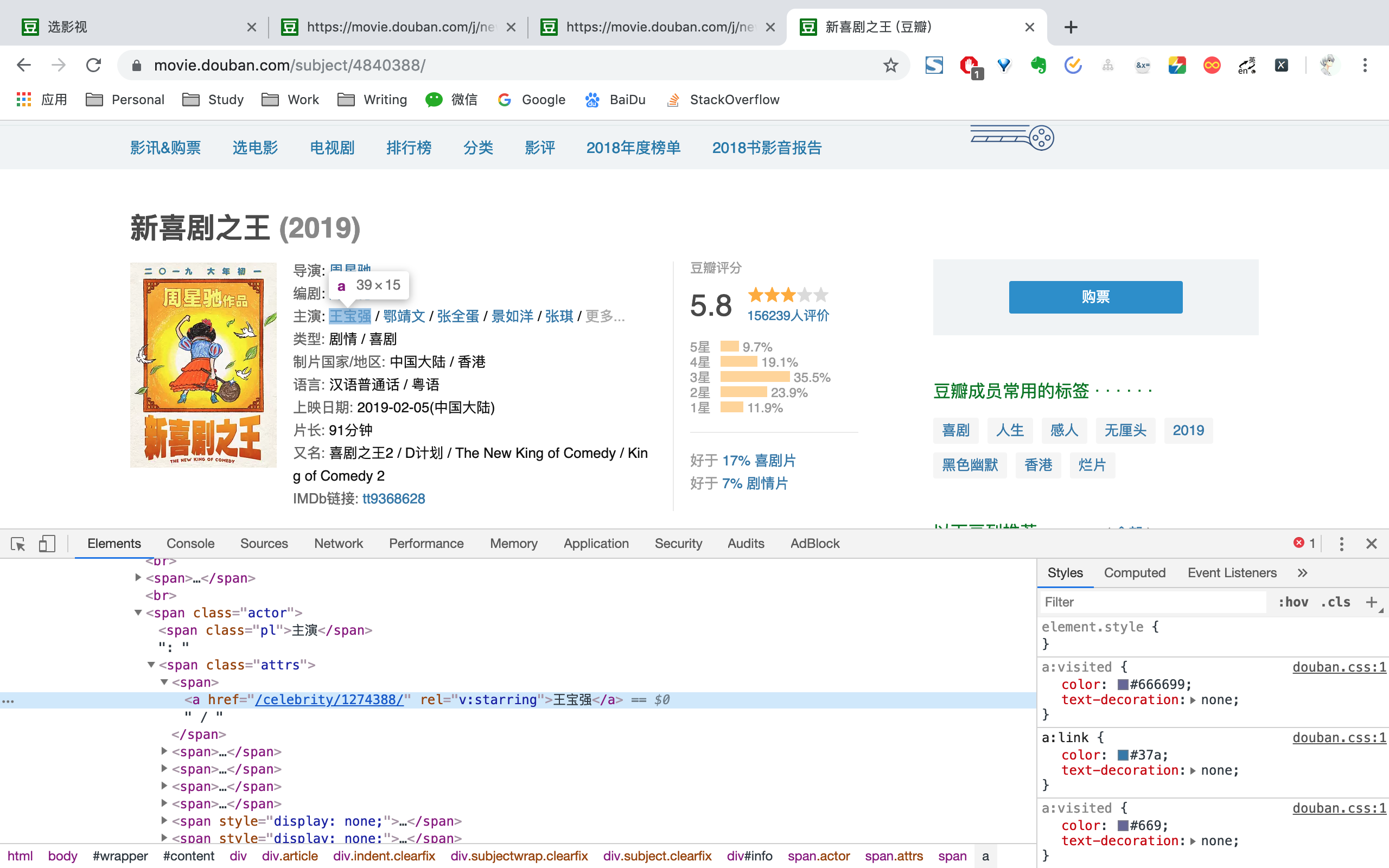
通过BeautifulSoup选取相应标签,便能够拿到电影id、图片链接、名称、导演名称、编剧名称、主演名称、类型、制片国家、语言、上映日期、片长、季数、集数、其他名称、剧情简介、评分、评分人数信息。
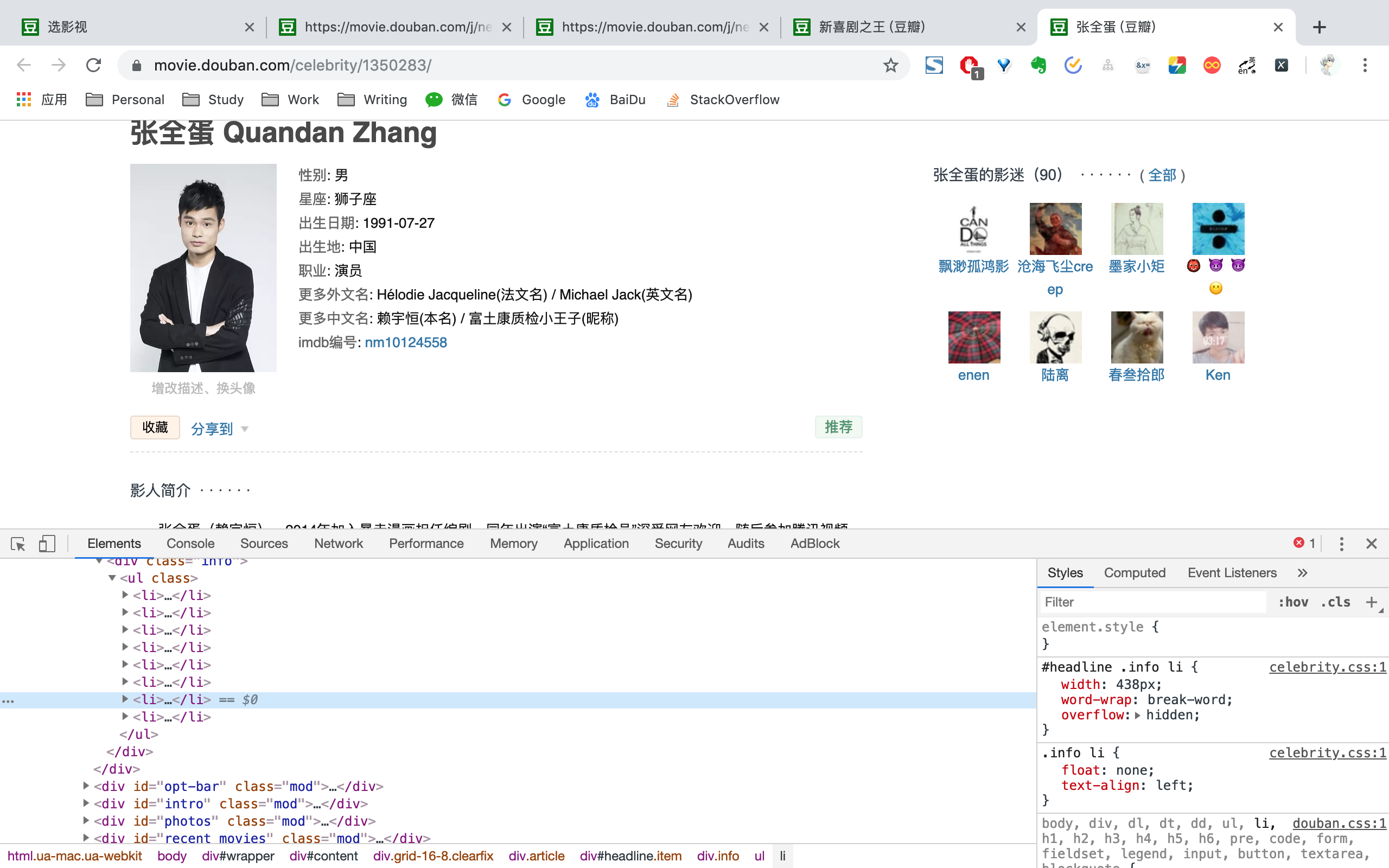
爬取电影信息结束之后,将演员id单独进行提取出来。同样为了保证不重复爬取,每得到一个演员id,都存放到redis已爬取队列之中。
以张全蛋id /celberity/1350283为例,拼接https://movie.douban.com,便能得到演员URF为https://movie.douban.com/celebrity/1350283/。然后请求演员URL,利用BeautifulSoup选取相应标签,便能拿到演员id、姓名、图片链接、性别、星座、出生日期、出生地、职业、更多中文名、更多外文名、家庭成员、简介信息。
总结一下,获取电影信息和电影演员信息流程为
-
获取https://movie.douban.com/tag/#/界面所有电影类别genres,循环电影类别genres。
-
请求https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=剧情网址,每次返回20个电影id。如果返回为空,更换电影类别genres。
-
对返回的20个电影id存放到redis已爬取队列之中,返回去重后的电影id list。
-
多线程爬取电影id list之中的电影信息。
-
获取电影演员id,存到到redis已爬取队列之中,返回去重后的演员id list。
-
多线程爬取演员id list之中的电影信息。
-
start加20循环2-7步骤。
进入豆瓣图书标签页面,请求https://book.douban.com/tag/?view=type&icn=index-sorttags-all,利用BeautifulSoup得到所有图书标签。
以小说标签为例,URL为https://book.douban.com/tag/小说?start=0&type=T,请求URL之后,利用BeautifulSoup选取相应标签,便能够拿到当前页面所有书籍id。为了确保不重复爬取相同的书籍,每拿到一个id之后,都存到redis已爬取队列之中。如果下次再遇到相同的id,则跳过不进行爬取。
同样,观察上述URL,我们只需要通过遍历start和tag便能够拿到所有书籍id。
以解忧杂货店id 25862578为例,拼接https://book.douban.com/subject/后便能得到书籍URL为https://book.douban.com/subject/25862578/。然后请求书籍URL页面,通过BeautifulSoup选取相应标签,便能够拿到书籍id、图片链接、姓名、子标题、原作名称、作者、译者、出版社、出版年份、页数、价格、内容简介、目录简介、评分、评分人数信息。
爬取书籍信息结束之中,将作者id单独提取出来。同样为了保证不重复爬取,每得到一个作者id,都存放到redis已爬取队列之中。
以东野圭吾为例,获取作者id 4537266,拼接https://book.douban.com/author/之后,便能得到作者URL为https://book.douban.com/author/4537266/。然后请求作者URL,利用BeautifulSoup选取相应标签,便能拿到作者id,姓名、图片链接、性别、出生日期、国家、更多中文名、更多外文名、简介信息。
总结一下,获取书籍信息和书籍作者流程为
-
请求https://book.douban.com/tag/?view=type&icn=index-sorttags-all界面,利用BeautifulSoup获取图书所有标签。
-
请求https://book.douban.com/tag/小说?start=0&type=T,利用BeautifulSoup获取20个书籍ID。如果为空,则更换书籍标签tag。
-
对返回的20个书籍id存放到redis已爬取队列之中,返回去重后的书籍id list。
-
多线程爬取书籍id list之中的书籍信息。
-
获取书籍作者id,存放到redis已爬取队列之中,返回去重后的作者id list。
-
多线程爬取演员id list之中的作者信息。
-
start加20循环2-7步骤。
├── book
│ ├── __init__.py
│ ├── book_crawl.py
│ ├── book_page_parse.py
│ ├── book_person_page_parse.py
│ └── book_spider_config.yaml
├── log
│ ├── book_log_config.yaml
│ └── movie_log_config.yaml
├── movie
│ ├── __init__.py
│ ├── movie_crawl.py
│ ├── movie_page_parse.py
│ ├── movie_person_page_parse.py
│ └── movie_spider_config.yaml
└── proxy
├── get_ip.py
├── ip_list.txt
└── ua_list.txt爬取之前,需要先启动redis server,然后再配置proxy中的get_ip。爬取过程中为了省事,我用的是收费的ip代理池,蘑菇代理,每三分钟请求10个ip。如果你要使用的话,可以找一些免费的ip代理工具,成功之后,将有效ip写入到ip_list之中即可。方便一点的话,可以直接购买ip代理池,同样成功后将ip写入到ip_list即可。
movie_spider_config.yaml和book_spider_config用于配制一些爬虫信息,比如超时时间和redis信息。
movie_log_config.yaml和book_log_config.yaml用于配制log信息,比如log地址和写文件格式信息。
如果你想爬取一些电影或书籍的其他信息,比如电影评论等,可以根据需求更改movie_page_parse, movie_person_page_parse, book_page_parse, book_person_page_parse的代码。
最后,配置好redis和ip代理池之后,分别启动movie_crawl和book_crawl即可。
如果需要豆瓣电影和书籍的数据,欢迎关注公众号谓之小一,回复豆瓣数据获取下载链接。配置过程中有任何问题,欢迎在公众号后台提问,随时回答,内容转载请注明出处。


