A linguagem SQL foi desenvolvida no começo dos anos 70, na cidade de São José, Califórnia, em um projeto chamado System R da IBM, do inglês International Business Machines, cujo objetivo era comprovar a viabilidade da implementação de um modelo relacional, que um estudioso chamado Codd estava propondo.

Esse estudioso elaborou uma forma estruturada de realizar consultas nos bancos de dados que estavam surgindo, chamados “bancos de dados relacionais”.
Naquela época, os bancos de dados ainda não possuíam relacionamento entre as tabelas nas quais os dados eram armazenados. Era a categoria de banco de dados mais antigo, a sequencial, que efetuava a consulta dos registros de maneira sequencial, ou seja, um após o outro.
Com o surgimento dos bancos de dados relacionais (ou DBMS, do inglês, Data Base Management System, “Sistema de Gerenciamento de Banco de Dados), Codd considerou criar uma linguagem que facilitasse a extração e manipulação de dados, além da manipulação das estruturas desse banco aproveitando a característica de relacionamento entre eles.
Então, foi criada a linguagem SQL, do inglês Structured English Query Language, que traduzindo seria algo como “linguagem de consulta estruturada em inglês”. No inglês, geralmente, é pronunciado SEQUEL e não SQL, soletrando as letras - diferentemente do português, em que normalmente lemos como “ésse quê éle”.
O principal objetivo da linguagem SQL é padronizar a maneira como os registros são consultados nos bancos de dados relacionais. Atualmente, os bancos relacionais aderem ao padrão SQL, que vai além das consultas: é usado também, na criação, alteração, estruturação e manipulação do banco de dados, além da maneira como banco de dados interage com a segurança, entre outros usos.
-
Essa padronização utilizando a linguagem SQL tem um custo reduzido do aprendizado. Por exemplo, o profissional com conhecimento sobre o SQL da Oracle conseguirá manipular facilmente o MySQL ou SQL Server da Microsoft. Por mais que existam diferenças (principalmente na parte de funções), a adaptação do profissional não é uma questão complicada.
-
A portabilidade. Por exemplo, é mais simples migrar sistemas que usam Oracle para SQL Server ou para MySQL, ou vice-versa. Lembrando que quanto mais for utilizado o SQL Standard definido pelo ANSI, mais fácil será essa portabilidade no futuro. Então, é útil evitar as funções específicas do banco de dados e permitir que o programa realize essa tarefa.
-
A longevidade é a garantia de que os seus relatórios ou processos utilizando o SQL irão funcionar por um longo período, já que estarão sempre adaptados ao padrão ANSI. Ou seja, ao efetuar um upgrade de banco de dados o seu sistema não ficará fora de serviço.
-
A comunicação. O fato da maioria utilizar SQL permite a facilidade de comunicação entre os sistemas. Como, por exemplo, processos de ETL, (extract, transform and load), ou de integração entre sistemas que ficam mais simples de serem desenvolvidos, já que ambos utilizam o SQL padrão.
-
Liberdade de escolha. Por existir um padrão de linguagem, se a empresa for optar pelo uso de um banco de dados relacional não ficará presa à linguagem de comunicação, por exemplo, já que são bem semelhantes. Ao tomar essa decisão, a corporação irá utilizar outros critérios de escolha, como performance, hardware, custo, entre outros.
- A privação da criatividade. O SQL possui limitações que podem não atender às novas demandas no mercado na linguagem SQL, principalmente com o surgimento das redes sociais e dos enormes volumes de dados, o chamado big data. Ou seja, há uma carência nas coletas de dados que estão trafegando na internet.
Para tal, estão surgindo outros bancos que usam padrões diferentes dos bancos de dados relacionais, o chamado NoSQL. Estes atendem de forma mais eficiente as demandas de tabelas de big data , como no caso das redes sociais. Lembrando que estamos nos referindo a estruturas que escapam do padrão ANSI e que, por isso, exigem um aprendizado mais específico.
- A escassez de estruturação da linguagem SQL, já que ela não possui if, for e when, isto é, comandos condicionais como as demais linguagens de programação.
Para conseguir suprir essa carência da estruturação, os bancos de dados relacionais da Oracle, SQL e MySQL criaram suas linguagens próprias internas que realizam esse conjunto de estruturação usando a linguagem SQL, mas que acaba se afastando um pouco do padrão ANSI.
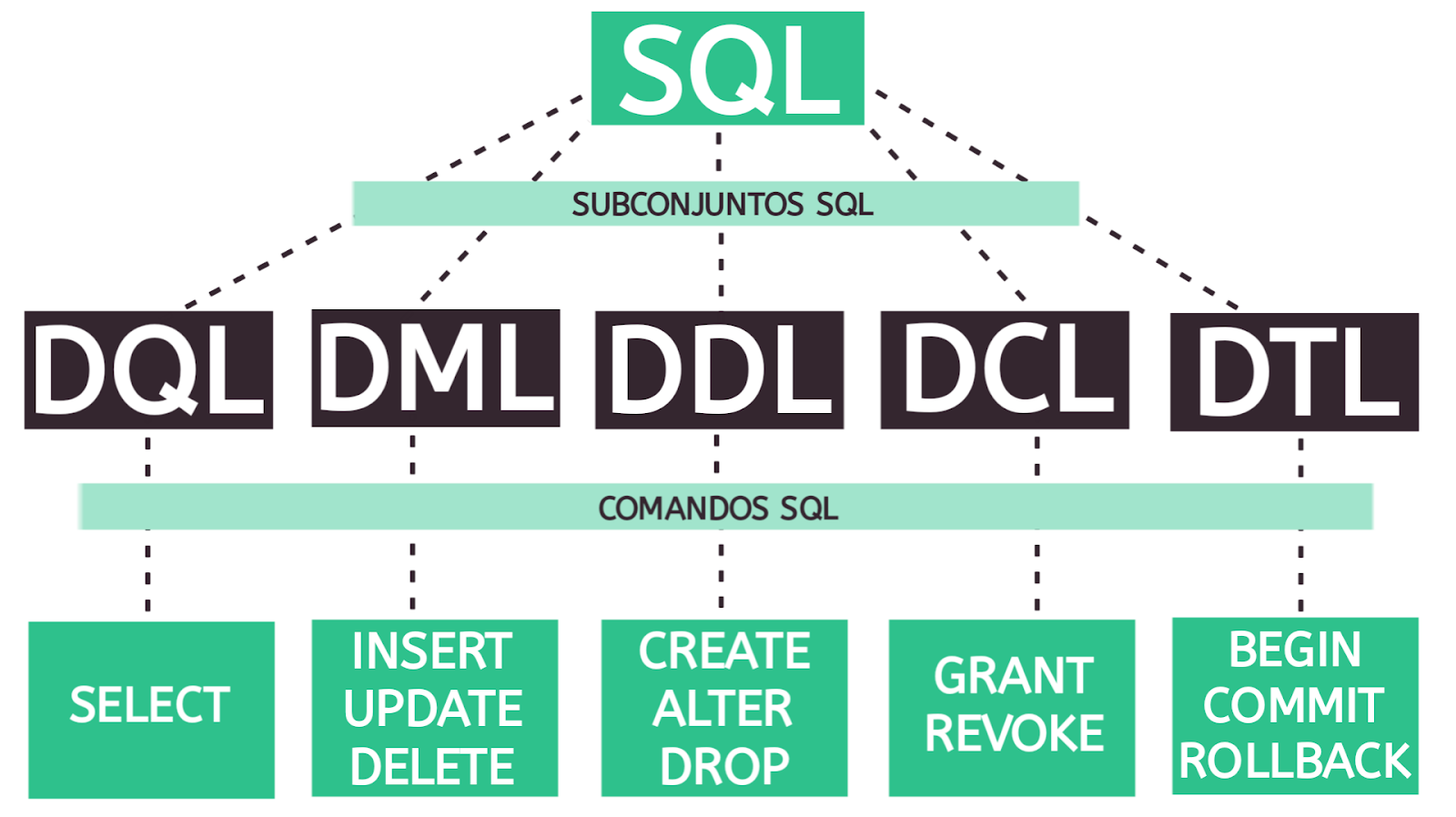
Falando um pouco sobre o padrão ANSI, este possui três grupos de comandos. O primeiro, é o DDLs, ou Data Definition Language (linguagem de definição de dados). Os DDLs são a parte da linguagem SQL que permite a manipulação das estruturas do banco de dados. Como, por exemplo, criar um banco, tabelas, índices, apagar as tabelas e alterar a política de crescimento de índice. Ou seja, os comandos que envolvem a estrutura do banco de dados relacionais são os comandos do tipo DDL.
O segundo grupo de comandos são os chamados DML, ou Data Manipulation Language (linguagem de manipulação de dados). Esse grupo visa gerenciar os dados: incluindo, alterando e excluindo informações nas estruturas do banco, como as tabelas. Além disso, realizam as consultas, buscam as informações das estruturas e exibiremos para o usuário.
Finalmente, chegamos nos comandos DCL, ou Data Control Language ("linguagem de controle de dados"). Este grupo nos permite administrar o banco de dados como, por exemplo, o controle de acesso, o gerenciamento do usuário, gerenciar o que cada usuário(a) pode ou não visualizar, gerenciar o banco ao nível de estrutura (como a política de crescimento, como e onde será armazenado no disco), administrar os processos, saber quantos processos estão sendo executados, controle de log e assim por diante.

- Para selecionar tudo de qualquer tabela use:
SELECT * FROM tabela_de_clientes;
- Para selecionar campos específicos:
SELECT CPF, NOME FROM tabela_de_clientes;- Em consultas SQL, existe a opção do uso de alias, que funciona como um apelido que atribuímos a determinado campo. Isso é feito com o uso de as:
SELECT CPF as IDENTIFICADOR, NOME as CLIENTE FROM tabela_de_clientes;Nesse caso, "identificador" representa o CPF e "cliente" representa o NOME. Assim, quando o script for executado, notaremos que as colunas do resultado são os aliases e não os nomes originais dos campos (CPF e NOME).

SELECT * FROM tabela_de_produtos;
SELECT * FROM tabela_de_produtos WHERE CODIGO_DO_PRODUTO ="1000889";
Essa consulta retorna apenas um produto, pois somente um suco tem sabor uva. Trocando o valor "uva" por "limão", nenhum produto será mostrado, pois não há sucos com esse sabor. Já ao escrever "laranja", são cinco os produtos que atendem a essa condição.
Mas qual é a grande diferença interna na execução da consulta com WHERE CODIGO_DO_PRODUTO = '1000889' e da consulta com WHERE SABOR = 'Uva'? A resposta está na performance!
Buscas com condições de filtro que possuem chaves primárias (como "CODIGO_DO_PRODUTO") são mais rápidas, pois chaves primárias têm índices que facilitam muito esse processo. "SABOR", por outro lado, não é uma chave primária nem estrangeira, logo não tem índice e consequentemente resulta numa busca um pouco mais lenta.
Como nosso banco de dados atual é relativamente pequeno, essa lentidão não é perceptível, porém essa diferença de performance pode ser problemática em bancos mais volumosos. Uma forma de solucionar esse problema é atribuindo um índice à coluna, algo que aprenderemos mais para frente, em outro curso de MySQL.
- Seguindo com as consultas, agora vamos fazer um filtro referente à embalagem:
SELECT * FROM tabela_de_produtos WHERE EMBALAGEM = 'PET';
Ao executar esse script, note que na tabela o valor "PET" está escrito com letras maiúsculas. O que será que acontece se eu fizer a consulta usando letras minúsculas?
SELECT * FROM tabela_de_produtos WHERE EMBALAGEM = 'pet';O resultado é o mesmo! Como vimos anteriormente, o MySQL não distingue entre letras maiúsculas e minúsculas, ele fará a busca da mesma forma.
- Também podemos fazer seleções usando valores como critérios. Na nossa base, temos o produto "Videira do Campo - 1,5 Litros - Melancia" cujo "PRECO_DE_LISTA" é 19.51. Vamos criar um filtro usando esse valor como critério:
SELECT * FROM tabela_de_produtos WHERE PRECO_DE_LISTA = 19.51Ao rodar essa consulta, o MySQL retorna vazio. Mas por que isso acontece, se vimos que existe um produto que corresponde a esse filtro? Ao verificar mais detalhes sobre "PRECO_DE_LISTA", vê-se que é um dado do tipo float. Isso significa que é um ponto flutuante, ou seja, não é exatamente 19.51 mas, sim, um número com muitas casas decimais além das que estamos vendo. Em outras palavras, não corresponde completamente à condição que descrevemos.
- Para solucionar esse problema e filtrar um valor cravado, bem específico, podemos usar os operadores BETWEEN (entre) e AND (e):
SELECT * FROM tabela_de_produtos WHERE PRECO_DE_LISTA BETWEEN 19.50 AND 19.52;SELECT * FROM tabela_de_produtos WHERE SABOR = 'Manga';Ao executar o script, você pode verificar na coluna "SABOR" que todos os registros encontrados têm valor "manga". Então, vamos incrementar nossa consulta, adicionando mais uma expressão à condição:
SELECT * FROM tabela_de_produtos WHERE SABOR = 'Manga' OR TAMANHO = '470 ml';
Com essa seleção, vamos filtrar apenas os registros que tenham sabor manga ou tamanho de 470 ml (ou até mesmo os dois). Executando o script, podemos reparar que o primeiro item do resultado atende às duas expressões; os quatro produtos seguintes têm sabor manga, porém tamanhos diferentes de 470 ml; e o último registro tem 470 ml, no entanto, é sabor laranja.
- A seguir, criaremos uma consulta com AND:
SELECT * FROM tabela_de_produtos WHERE SABOR = 'Manga' AND TAMANHO = '470 ml';Nesse caso, como usamos o AND, o retorno terá apenas um registro - nessa tabela, é o único produto cujo sabor é manga E** o tamanho é igual a 470 ml **ao mesmo tempo.
- Agora, vamos inserir o NOT, para fazer a seleção inversa: uma consulta de todos os registros exceto os que têm sabor manga e** tamanho 470 ml **ao mesmo tempo:
SELECT * FROM tabela_de_produtos WHERE NOT (SABOR = 'Manga' AND TAMANHO = '470 ml');- Já se colocarmos o NOT em combinação com OR, o retorno não será tão abrangente:
SELECT * FROM tabela_de_produtos WHERE NOT (SABOR = 'Manga' OR TAMANHO = '470 ml');Desse script resulta uma seleção em que não veremos nenhum registro com sabor manga e nenhum registro com tamanho 470 ml.
- Há ainda outras formas de usar o NOT. Podemos, por exemplo, inseri-lo na frente de apenas uma das expressões:
SELECT * FROM tabela_de_produtos WHERE SABOR = 'Manga' AND NOT (TAMANHO = '470 ml');Nesse caso, procuraremos itens que tenham sabor manga E** que o tamanho **não seja 470 ml. Isso é, ao rodar o script, na tabela resultante você encontrará todos os produtos com sabor manga exceto os que tem tamanho 470 ml - qualquer outro tamanho será apresentado.
- Existem mais condições lógicas além das que expliquei no vídeo anterior. Uma delas é o IN, que pode ser interpretado como "contido":
SELECT * FROM tabela_de_produtos WHERE SABOR IN ('Laranja', 'Manga');
Rodando esse script, teremos como resultado uma tabela com todos os clientes cuja cidade consta como Rio de Janeiro ou como São Paulo, e cuja idade seja maior ou igual a 20.
- Ademais, há sempre a possibilidade de criar consultas mais complexas:
SELECT * FROM tabela_de_clientes WHERE CIDADE IN ('Rio de Janeiro', 'São Paulo') AND (IDADE >= 20 AND IDADE <= 22);
Vamos aprender mais um comando que filtra informações de uma seleção: o operador LIKE. Normalmente, ele é usado assim:
SELECT * FROM tab WHERE campo LIKE '<condição>';COPIAR CÓDIGONesse exemplo, "tab" refere-se a uma tabela, e "campo" é a coluna que se está consultando. Após o LIKE, escrevemos o critério de busca entre aspas simples. Esse critério deve ser um texto e pode vir acompanhado do símbolo de porcentagem, também chamado de percent (%).
O % é usado para representar qualquer registro genérico que venha antes ou depois do texto que estamos procurando. Ele é como um caractere curinga em determinado trecho de uma string, equivalente ao * quando manipulamos arquivos.
Vamos ver na prática para ficar mais claro:
SELECT * FROM tabela_de_produtos WHERE SABOR LIKE '%Maça%';
Perceba que usamos um percent antes e outro depois do texto que vamos buscar. Ao executar o script, podemos verificar que a seleção retorna produtos com dois sabores diferentes: Maçã e Cereja/Maçã. Este último está presente no resultado por causa do primeiro % que colocamos na consulta: há outros caracteres antes, mas contém "Maça", que era o nosso critério de busca.
- Vale lembrar que o LIKE pode ser uma parcela de uma expressão mais complexa, é possível combiná-lo com outros operadores, por exemplo:
SELECT * FROM tabela_de_produtos WHERE SABOR LIKE '%Maça%' AND
EMBALAGEM = 'PET';
Ou seja, buscaremos todos os produtos que contêm "Maça" no campo "SABOR" E cuja embalagem é PET.
O comando que vamos aprender é o DISTINCT, que pode ser traduzido como "distinto, diferente". Ele retornará somente linhas com valores diferentes e vamos usá-lo depois do SELECT e antes da exibição dos campos.
- Vamos ao MySQL Workbench para testar esse comando na nossa tabela "sucos_vendas". Criaremos um novo script SQL e começaremos com uma seleção sem o DISTINCT:
SELECT EMBALAGEM, TAMANHO FROM tabela_de_produtos;
Essa consulta trata uma série de linhas e num instante é possível perceber que há registros que se repetem. Por exemplo, a combinação Garrafa com 700ml (linhas 1 e 3) ou a combinação PET com 2 Litros (linhas 6, 7 e 8).
- No entanto, temos a opção de incluir o DISTINCT para mudar essa situação:
SELECT DISTINCT EMBALAGEM, TAMANHO FROM tabela_de_produtos;
Desse modo, o retorno será bem mais reduzido, porque mostrará apenas as combinações que não se repetem.
- Vale lembrar que podemos aplicar junto com DISTINCTtodas aquelas condições de filtro que aprendemos anteriormente, por exemplo:
SELECT DISTINCT EMBALAGEM, TAMANHO FROM tabela_de_produtos WHERE SABOR = 'Laranja';Essa consulta seria útil se, por exemplo, um cliente dessa empresa de sucos perguntasse: "Quais são as embalagens e os tamanhos disponíveis para o suco de frutas do sabor laranja?"
Examinando o resultado, poderíamos responder: "O suco de laranja é oferecido em PET de 2 litros, garrafa de 470 ml, PET de 1 litro, lata de 350 ml e PET de 1,5 litro."
- Vamos ver um último exemplo, incluindo mais um campo à seleção:
SELECT DISTINCT EMBALAGEM, TAMANHO, SABOR FROM tabela_de_produtos;Nesse caso, obteremos mais registros do que na consulta anterior, pois com uma coluna a mais ("SABOR") o número de combinações aumenta. Observe que as cinco linhas que apareceram na penúltima seleção também estão presentes nessa última consulta, já que continuam a atender as condições.
Às vezes, criamos seleções que retornam 1 milhão de registros, mas estamos na fase de desenvolvimento de um projeto e não queremos, de fato, ver 1 milhão de linhas, o objetivo era saber se a consulta funcionaria e se ela traria os dados esperados. Nesses casos, podemos limitar a saída de dados usando o comando LIMIT, que no caso do MySQL estará sempre no final da query, por exemplo:
SELECT * FROM tabela_de_produtos LIMIT 5;
- Já se nosso objetivo for selecionar três linhas a partir do código 1002767, que é o terceiro registro da tabela, faremos:
SELECT * FROM tabela_de_produtos LIMIT 2,3;
- Vale lembrar que o MySQL considera a primeira linha como linha 0, portanto se vamos começar a seleção na linha 3, por isso, o primeiro número após o LIMIT será 2. Da mesma forma, se queremos que a seleção se inicie na primeira linha, podemos escrever o seguinte:
SELECT * FROM tabela_de_produtos LIMIT 0, 2;
Quando fazemos uma seleção de dados num banco, eles são exibidos na ordem natural que a informação está armazenada na tabela. Mas nós podemos, através do comando ORDER BY, fazer com que o resultado da consulta venha ordenado por determinados critérios. Basta especificar o campo pelo qual se deseja organizar os dados, por exemplo:
SELECT * FROM tabela_de_produtos ORDER BY PRECO_DE_LISTA; Verificando o resultado, notaremos que os registros estão ordenados conforme a ordem crescente da coluna "PRECO_DE_LISTA", começando no valor R$2,808 e indo até R$38,012.
Verificando o resultado, notaremos que os registros estão ordenados conforme a ordem crescente da coluna "PRECO_DE_LISTA", começando no valor R$2,808 e indo até R$38,012.
- Para mudar a direção da ordenação, vamos inserir o comando DESC na nossa consulta, depois do nome do campo:
SELECT * FROM tabela_de_produtos ORDER BY PRECO_DE_LISTA DESC;Dessa vez, os registros aparecerão de acordo com a ordem descendente da coluna "PRECO_DE_LISTA", do R$38,012 ao R$2,808.
- A seguir, faremos uma seleção nessa mesma tabela, porém ordenando pelo campo "NOME_DO_PRODUTO", que tem dados em formato de texto:
SELECT * FROM tabela_de_produtos ORDER BY NOME_DO_PRODUTO;
O resultado estará ordenado pela ordem alfabética dos nomes dos produtos.
- Caso nosso objetivo seja ver na ordem contrária, precisaremos acrescentar o comando DESC:
SELECT * FROM tabela_de_produtos ORDER BY NOME_DO_PRODUTO DESC;- Por fim, vamos fazer um teste usando um critério composto:
SELECT * FROM tabela_de_produtos ORDER BY EMBALAGEM, NOME_DO_PRODUTO;
Sabemos que existem três tipos de embalagem no nosso banco: garrafa, lata e PET. Executando a consulta, obteremos um resultado que primeiramente respeitará à ordem crescente (alfabética) do campo "EMBALAGEM", começando portanto por "GARRAFA". Dentre os registros cuja embalagem é garrafa, teremos a ordem crescente pelo campo "NOME_DO_PRODUTO" (nosso segundo critério). Só depois poderemos ver registros com embalagem "LATA" (também em ordem alfabética dos nomes dos produtos) e, em seguida, "PET".
- É possível deixar essa consulta ainda mais específica, acrescentando a direção da ordenação que queremos para cada um dos campos:
SELECT * FROM tabela_de_produtos ORDER BY EMBALAGEM DESC, NOME_DO_PRODUTO ASC;
Dessa vez, porque usamos DESC para o primeiro critério, a ordem das embalagens começará do maior para o menor (no caso, de "PET" a "GARRAFA") e, dentre os itens de cada tipo de embalagem, os nomes dos produtos estarão organizados em ordem alfabética, pois usamos o ASC para o segundo critério, "NOME_DO_PRODUTO".
No vídeo anterior, aprendemos como ordenar resultados. Agora, vamos estudar como agrupá-los. Agrupar é juntar campos que são repetidos e, nos casos de campos numéricos, em meio a essa junção temos a opção de aplicar fórmulas matemáticas, que podem ser de soma, de média, de máximo ou mínimo valor, entre outros.
- Então, vamos ao MySQL Workbench criar alguns exemplos na base "sucos_vendas". Criaremos um novo script e começaremos consultando toda a tabela de clientes:
SELECT * FROM tabela_de_clientes;- Em seguida, vamos restringir um pouco essa consulta, selecionando apenas o estado e o limite de crédito na tabela
SELECT ESTADO, LIMITE_DE_CREDITO FROM tabela_de_clientes;Ao fazer essa consulta, veremos uma lista em que cada linha mostra o estado e o limite de crédito de um cliente.
- Se nosso objetivo for saber o total de limite de crédito de cada estado, usaremos o GROUP BY:
SELECT ESTADO, SUM(LIMITE_DE_CREDITO) as LIMITE_TOTAL FROM tabela_de_clientes GROUP BY ESTADO;
Sempre que uma fórmula for usada, é necessário usar um alias ("apelido") para o campo. No nosso caso, definimos "LIMITE_TOTAL" como alias da soma dos limites de crédito.
O retorno mostrará os limites de crédito somados agrupados por estado: em São Paulo, o limite total é R$810.000,00 e, no Rio de Janeiro, é R$995.000,00.
- Faremos, agora, uma consulta relativa às embalagens e aos preços de lista presentes na tabela de produtos:
SELECT EMBALAGEM, PRECO_DE_LISTA FROM tabela_de_produtos;- Vamos supor que precisamos descobrir qual é o preço mais caro de cada tipo de embalagem (PET, garrafa e lata):
SELECT EMBALAGEM, MAX(PRECO_DE_LISTA) as MAIOR_PRECO FROM tabela_de_produtos GROUP BY EMBALAGEM;
Com essa consulta, constatamos que o produto mais caro que vem em garrafas tem o valor de R$13,312. O mais caro com embalagem PET é R$38,012. E o de lata custa R$4,56.
- Além disso, é possível criar seleções com o comando COUNT:
SELECT EMBALAGEM, COUNT(*) as CONTADOR FROM tabela_de_produtos GROUP BY EMBALAGEM;
O retorno nos mostrará a quantidade de produtos que existem com cada tipo de embalagem: 11 tem embalagem garrafa, 15 vem em PET e 5 em lata.
- Vale lembrar que podemos aplicar critérios de filtro juntamente do ORDER BYe do GROUP BY. Como exemplo, primeiramente vamos selecionar os limites de crédito agrupados por bairro:
SELECT BAIRRO, SUM(LIMITE_DE_CREDITO) as LIMITE FROM tabela_de_clientes GROUP BY BAIRRO;
- E, para filtrar a consulta, usaremos uma cláusula WHERE para ver apenas os limites de crédito dos bairros da cidade do Rio de Janeiro:
SELECT BAIRRO, SUM(LIMITE_DE_CREDITO) as LIMITE FROM tabela_de_clientes WHERE CIDADE = 'Rio de Janeiro' GROUP BY BAIRRO;
- Ademais, é possível usar mais de um campo no GROUP BY:
SELECT ESTADO, BAIRRO, SUM(LIMITE_DE_CREDITO) as LIMITE FROM tabela_de_clientes GROUP BY ESTADO, BAIRRO;
Note que adicionamos o campo "ESTADO" no início da seleção (SELECT ESTADO) e também no fim, depois de GROUP BY. Na primeira ocorrência, estamos determinando como exibiremos os dados, já na segunda indicamos como queremos que sejam agrupados.
- Em seguida, aplicaremos um filtro que irá restringir a consulta somente à cidade do Rio de Janeiro:
SELECT ESTADO, BAIRRO, SUM(LIMITE_DE_CREDITO) as LIMITE FROM tabela_de_clientes WHERE CIDADE = 'Rio de Janeiro' GROUP BY ESTADO, BAIRRO;
Ou seja, estamos selecionando estado, bairro e a soma dos limites de crédito somente da cidade do Rio de Janeiro, agrupando esses dados por estado e bairro.
- E, por fim, se nossa meta for visualizar esse resultado de forma ordenada, podemos ainda incluir o ORDER BY:
SELECT ESTADO, BAIRRO, SUM(LIMITE_DE_CREDITO) as LIMITE FROM tabela_de_clientes
WHERE CIDADE = 'Rio de Janeiro'
GROUP BY ESTADO, BAIRRO
ORDER BY BAIRRO;
Dessa forma, veremos que o retorno respeitará a ordem alfabética dos bairros, começando por Água Santa, Barra da Tijuca, Cidade Nova e assim por diante. Essa última consulta é mais complexa, pois estamos agrupando, filtrando e ordenando dados em uma única seleção.
SELECT ESTADO, SUM(LIMITE_DE_CREDITO) as SOMA_LIMITE FROM tabela_de_clientes
GROUP BY ESTADO;
O retorno mostrará que, no estado de São Paulo, temos o total de limite de crédito de R$810.000,00 e, no estado do Rio de Janeiro, R$995.000,00.
- Agora, se nosso objetivo for listar apenas os estados cuja soma do limite de crédito for maior que R$900.000,00, parece natural que usemos a cláusula WHERE:
SELECT ESTADO, SUM(LIMITE_DE_CREDITO) as SOMA_LIMITE FROM tabela_de_clientes
WHERE SOMA_LIMITE > 900000
GROUP BY ESTADO;No entanto, ao tentar rodar essa consulta, obteremos um erro! O problema é que, quando o WHERE é aplicado, o agrupamento ainda não ocorreu.
- A solução será usar o HAVING, que virá depois do GROUP BY:
SELECT ESTADO, SUM(LIMITE_DE_CREDITO) as SOMA_LIMITE FROM tabela_de_clientes
GROUP BY ESTADO
HAVING SUM(LIMITE_DE_CREDITO) > 900000;
Ou seja, primeiro agrupamos e depois aplicamos a condição. Dessa vez, nossa consulta retornará com sucesso.
Nesse último caso, usamos SUM(LIMITE_DE_CREDITO) tanto no SELECT quanto no HAVING, entretanto não há necessidade de sempre usar o mesmo critério.
- Para exemplificar, primeiro vamos selecionar as embalagens, o maior preço e o menor preço, agrupando-os pelo tipo de embalagem:
SELECT EMBALAGEM, MAX(PRECO_DE_LISTA) as MAIOR_PRECO,
MIN(PRECO_DE_LISTA) as MENOR_PRECO FROM tabela_de_produtos
GROUP BY EMBALAGEM;
- E, com o intuito de usar o HAVING, filtraremos esse resultado, buscando apenas os produtos cuja soma dos preços de lista seja menor ou igual a R$80,00:
SELECT EMBALAGEM, MAX(PRECO_DE_LISTA) as MAIOR_PRECO,
MIN(PRECO_DE_LISTA) as MENOR_PRECO FROM tabela_de_produtos
GROUP BY EMBALAGEM
HAVING SUM(PRECO_DE_LISTA) <= 80;
No SELECT utilizamos MAXe MIN, enquanto no HAVING usamos o SUM - essa consulta ilustra que não há necessidade de escolher os mesmos critérios. No retorno, veremos que a embalagem PET não aparece mais, pois não satisfaz a nova condição que impomos (SUM(PRECO_DE_LISTA) <=80).
- Para finalizar, vale lembrar que temos a opção de acrescentar mais condições ao HAVING, criando um filtro composto com os operadores OR e AND, por exemplo:
SELECT EMBALAGEM, MAX(PRECO_DE_LISTA) as MAIOR_PRECO,
MIN(PRECO_DE_LISTA) as MENOR_PRECO FROM tabela_de_produtos
GROUP BY EMBALAGEM
HAVING SUM(PRECO_DE_LISTA) <= 80 AND MAX(PRECO_DE_LISTA) >= 5;
Com essa nova condição (MAX(PRECO_DE_LISTA) >= 5), vamos notar que a embalagem "lata" também não aparecerá mais, já que seu valor máximo do preço de lista é R$4,56.
A seguir, aprenderemos sobre a expressão CASE (em português, "caso"). Esse comando serve para se fazer testes em um ou mais campos e, quando determinada condição for atendida, então seguiremos por um caminho, senão continuamos por outro.
O CASE vem acompanhado dos termos WHEN (quando), THEN (então), ELSE (senão) e END (fim). Veja a seguir um exemplo da estrutura desse comando:
- Digamos que nossa intenção é classificar os produtos entre "baratos", "em conta" ou "caros". Faremos uma consulta usando o comando CASE e o campo "PRECO_DE_LISTA":
SELECT NOME_DO_PRODUTO, PRECO_DE_LISTA,
CASE
WHEN PRECO_DE_LISTA >= 12 THEN 'PRODUTO CARO'
WHEN PRECO_DE_LISTA >= 7 AND PRECO_DE_LISTA < 12 THEN 'PRODUTO EM CONTA'
ELSE 'PRODUTO BARATO'
END AS STATUS_PRECO
FROM tabela_de_produtos;
Ao final da seleção, coloca-se o END para encerrar o CASE e cria-se um alias. Ao rodar a consulta, teremos um retorno com as colunas "NOME_DO_PRODUTO", "PRECO_DE_LISTA" e "STATUS_PRECO", com uma relação de quais produtos estão baratos, quais estão em conta e quais estão caros.
- Aplicando uma das fórmulas que aprendemos na aula anterior, podemos fazer, por exemplo, uma seleção que apresenta a média (average) de preços de produtos baratos, em conta ou caros, agrupados por tipo de embalagem:
SELECT EMBALAGEM,
CASE
WHEN PRECO_DE_LISTA >= 12 THEN 'PRODUTO CARO'
WHEN PRECO_DE_LISTA >= 7 AND PRECO_DE_LISTA < 12 THEN 'PRODUTO EM CONTA'
ELSE 'PRODUTO BARATO'
END AS STATUS_PRECO, AVG(PRECO_DE_LISTA) AS PRECO_MEDIO
FROM tabela_de_produtos
GROUP BY EMBALAGEM,
CASE
WHEN PRECO_DE_LISTA >= 12 THEN 'PRODUTO CARO'
WHEN PRECO_DE_LISTA >= 7 AND PRECO_DE_LISTA < 12 THEN 'PRODUTO EM CONTA'
ELSE 'PRODUTO BARATO'
END
Note que o CASE completo precisa ser inserido no GROUP BY.
Ao analisar o retorno, podemos ver no primeiro registro que os sucos em garrafa que custam menos de R$7 (barato) tem uma média de preço de R$5,23. No segundo registro, notamos que os PETs em conta tem uma média de preço de R$9,10, e assim por diante.
Assim, notamos que é possível misturar vários tipos de comandos em um única seleção. Cabe ainda nessa consulta inserirmos um ORDER BY EMBALAGEM ao final do script e o resultado será a mesma lista, porém respeitando a ordem alfabética dos tipos de embalagem. Com essa nova organização, ficará mais fácil de verificar, por exemplo, que não existem embalagens PET baratas e que todos os sucos em lata custam menos de R$7 (baratos).
- É possível até incluir uma cláusula WHERE para filtrar somente os produtos com sabor de manga. Veja como fica a consulta completa:
SELECT EMBALAGEM,
CASE
WHEN PRECO_DE_LISTA >= 12 THEN 'PRODUTO CARO'
WHEN PRECO_DE_LISTA >= 7 AND PRECO_DE_LISTA < 12 THEN 'PRODUTO EM CONTA'
ELSE 'PRODUTO BARATO'
END AS STATUS_PRECO, AVG(PRECO_DE_LISTA) AS PRECO_MEDIO
FROM tabela_de_produtos
WHERE sabor = 'Manga'
GROUP BY EMBALAGEM,
CASE
WHEN PRECO_DE_LISTA >= 12 THEN 'PRODUTO CARO'
WHEN PRECO_DE_LISTA >= 7 AND PRECO_DE_LISTA < 12 THEN 'PRODUTO EM CONTA'
ELSE 'PRODUTO BARATO'
END
ORDER BY EMBALAGEM;
Nesse caso, podemos observar na primeira linha do resultado, por exemplo, que a média de preços de sucos de manga baratos vendidos em garrafas é de R$5,17. Mesclando tudo que já estudamos nesse curso, já somos capazes de criar consultas bastante específicas e complexas.
Até agora, somente realizamos seleções de uma tabela por vez, no entanto, haverá ocasiões em que será necessário consultar informações que estão separadas, parte em uma tabela e parte em outra. Nesses contextos, aplicaremos os JOINs.
A seguir, veremos alguns exemplos, usando duas tabelas:
SELECT * FROM tabela_de_vendedores A
INNER JOIN notas_fiscais B
ON A.MATRICULA = B.MATRICULA;
Os campos em comum usados no JOIN não precisam ter o mesmo nome. O importante é que tenham o mesmo conteúdo para que a relação entre tabelas seja viável.
O retorno mostrará todos os campos da tabela A e todos os campos da tabela B, unidos em um só resultado. Será possível ver os dados de cada nota fiscal emitida, junto das informações do vendedor associado a ela.
- Com essas duas tabelas, também podemos usar outros comandos com o JOIN, como o GROUP BY. Por exemplo, se nossa meta for descobrir quantas notas fiscais cada vendedor emitiu:
SELECT A.MATRICULA, A.NOME, COUNT(*) FROM
tabela_de_vendedores A
INNER JOIN notas_fiscais B
ON A.MATRICULA = B.MATRICULA
GROUP BY A.MATRICULA, A.NOME;
- O mesmo resultado será obtido se fizéssemos um CROSS JOIN entre essas tabelas e filtrássemos (com WHERE) apenas os registros que têm correspondência no número da matrícula:
SELECT A.MATRICULA, A.NOME, COUNT(*) FROM
tabela_de_vendedores A, notas_fiscais B
WHERE A.MATRICULA = B.MATRICULA
GROUP BY A.MATRICULA, A.NOME;
Entre essas duas opções, recomendo o uso da primeira, porque com o INNER JOIN é mais fácil de compreender as junções (principalmente quando ficam complexas) e também por ser a forma mais moderna. A segunda opção era comum há uns 20 anos, quando estruturas como INNER JOIN, LEFT JOIN e RIGHT JOIN ainda não existiam, e há quem ainda opte por ela, mas eu particularmente prefiro o INNER JOIN.
Vamos abrir o MySQL Workbench, criar um novo script e começar com uma seleção que trará a contagem de clientes cadastrados:
SELECT COUNT(*) FROM tabela_de_clientes;
Lembrete: quando omitimos os campos selecionados e somente usamos uma fórmula, não há necessidade de usar o GROUP BY. É o que acabamos de fazer com a fórmula COUNT.
O retorno revela que existem 15 clientes cadastrados.
- Em seguida, vamos consultar para quantas pessoas foram emitidas notas fiscais, verificando a quantidade de CPFs diferentes que aparecem na tabela de notas fiscais:
SELECT CPF, COUNT(*) FROM notas_fiscais GROUP BY CPF;
Ao contar os registros, saberemos que apenas 14 clientes receberam nota fiscal. Ou seja, dos 15 cadastrados, 1 deles nunca comprou suco de frutas na nossa empresa.
- Para descobrir quem é esse cliente, primeiro vamos rodar uma consulta com INNER JOIN para descobrir quais registros apresentam correspondências no campo "CPF":
SELECT DISTINCT A.CPF, A.NOME, B.CPF FROM tabela_de_clientes A
INNER JOIN notas_fiscais B ON A.CPF = B.CPF;
Ou seja, o retorno mostrará os CPFs e os nomes dos clientes para os quais foram emitidas notas - são as 14 pessoas que vimos anteriormente.
- No entanto, substituindo o INNER JOIN pelo LEFT JOIN, o resultado será diferente:
SELECT DISTINCT A.CPF, A.NOME, B.CPF FROM tabela_de_clientes A
LEFT JOIN notas_fiscais B ON A.CPF = B.CPF;
Agora, veremos todos os elementos da tabela de clientes e apenas os correspondentes da tabela de notas fiscais. Analisando o resultado, encontraremos o cliente Fábio Carvalho que tem um campo nulo, ou seja, que nunca comprou na empresa, então nunca recebeu nota fiscal e, consequentemente, seu CPF não tem consta na tabela de notas fiscais.
- Desse modo, se o gerente da empresa de sucos nos pedisse para investigar quais clientes cadastrados nunca realizaram uma compra, uma maneira de encontrar a resposta é filtrar os registros que apresentam o campo B.CPF nulo (no caso, apenas o Fábio):
SELECT DISTINCT A.CPF, A.NOME, B.CPF FROM tabela_de_clientes A
LEFT JOIN notas_fiscais B ON A.CPF = B.CPF
WHERE B.CPF IS NULL;
IS, em inglês, significa "é/está". Logo, no comando WHERE B.CPF IS NULL, buscamos campos que têm valor null.
- Lembrando que sempre temos a opção de incrementar nossos filtros. Um exemplo seria refinar a busca pelo ano da data da venda, que é uma informação que encontramos na tabela de notas fiscais:
SELECT DISTINCT A.CPF, A.NOME, B.CPF FROM tabela_de_clientes A
LEFT JOIN notas_fiscais B ON A.CPF = B.CPF
WHERE B.CPF IS NULL AND YEAR(B.DATA_VENDA) = 2015;
Nesse caso, utilizamos o operador AND, então nosso retorno será vazio, porque não há registros que atendam às duas condições ao mesmo tempo.
- Quanto ao RIGHT JOIN, sabemos que ele tem quase a mesma mecânica do LEFT JOIN, exceto que trará todos os elementos da tabela à direita do comando JOIN e somente os correspondentes da outra tabela. Para fazer uma demonstração, podemos realizar a mesma consulta que fizemos anteriormente, invertendo os nomes das tabelas:
SELECT DISTINCT A.CPF, A.NOME, B.CPF FROM notas_fiscais B
RIGHT JOIN tabela_de_clientes A ON A.CPF = B.CPF;
Apesar da consulta ligeiramente diferente, como invertemos as tabelas, o resultado é o mesmo que obtivemos com o LEFT JOIN.
No exercício anterior, por exemplo, apelidamos a tabela de clientes de "A" e a tabela de notas fiscais de "B" e, para nos referir aos seus respectivos campos, usamos essas letras como prefixos (A.NOMEe B.CPF). Agora, veremos que também é possível usar os próprios nomes das tabelas.
Quanto aos prefixos e sufixos, notaremos que eles são obrigatórios somente quando lidamos com campos em comum nas tabelas. Costumamos usá-los porque, em geral, não sabemos de antemão se os campos se repetem, porém por vezes os prefixos são opcionais e vamos demonstrar isso.
Então, começaremos abrindo um novo script no MySQL Workbench e selecionando a tabela de vendedores:
Então, começaremos abrindo um novo script no MySQL Workbench e selecionando a tabela de vendedores:
SELECT * FROM tabela_de_vendedores;Uma das colunas do resultado é "BAIRRO", referente ao local onde o vendedor possui escritório. Consultando a tabela de clientes, veremos que ela também contém esse campo:
SELECT * FROM tabela_de_clientes;Sabendo dessa relação entre as tabelas, criaremos uma seleção com JOIN:
SELECT * FROM tabela_de_vendedores INNER JOIN tabela_de_clientes
ON tabela_de_vendedores.BAIRRO = tabela_de_clientes.BAIRRO;

Note que nessa seleção não usamos alias! Em vez disso, utilizamos os próprios nomes das tabelas como prefixo, como em tabela_de_vendedores.
BAIRRO. Inclusive, quando digitamos o ponto depois do nome da tabela, o MySql Workbench até mostra algumas sugestões de preenchimento para agilizar
o processo.
O retorno mostrará os clientes que estão em bairros onde há escritórios da empresa de sucos. Nessa consulta, obtemos somente 7 registros, o que significa que 8 clientes estão em bairros que não têm escritório, pois no vídeo anterior descobrimos que são 15 clientes cadastrados no total.
- No momento, essa seleção traz todos os campos das duas tabelas, então vamos melhorar essa organização e trazer somente os quatro campos que nos interessam:
SELECT tabela_de_vendedores.BAIRRO,
tabela_de_vendedores.NOME,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.NOME FROM tabela_de_vendedores INNER JOIN tabela_de_clientes
ON tabela_de_vendedores.BAIRRO = tabela_de_clientes.BAIRRO;
- Para demonstrar um ponto interessante sobre os prefixos, acrescentaremos também a coluna "DE_FERIAS", da tabela de vendedores:
SELECT tabela_de_vendedores.BAIRRO,
tabela_de_vendedores.NOME,
tabela_de_vendedores.DE_FERIAS,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.NOME FROM tabela_de_vendedores INNER JOIN tabela_de_clientes
ON tabela_de_vendedores.BAIRRO = tabela_de_clientes.BAIRRO;
- A coluna "DE_FERIAS" não existe na tabela de clientes, ela está presente apenas na de vendedores. Isso nos permite omitir o prefixo, pois o MySQL consegue deduzir e localizar sozinho o campo a que nos referimos, já que ele só existe em uma tabela. No caso de "BAIRRO" e "NOME", por exemplo, o prefixo é obrigatório para se fazer a distinção, pois são campos em comum nas duas tabelas que estamos usando:
SELECT tabela_de_vendedores.BAIRRO,
tabela_de_vendedores.NOME,DE_FERIAS,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.NOME FROM tabela_de_vendedores INNER JOIN tabela_de_clientes
ON tabela_de_vendedores.BAIRRO = tabela_de_clientes.BAIRRO;
- A seguir, vamos rodar a consulta com LEFT JOIN:
SELECT tabela_de_vendedores.BAIRRO,
tabela_de_vendedores.NOME,
DE_FERIAS,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.NOME FROM tabela_de_vendedores LEFT JOIN tabela_de_clientes
ON tabela_de_vendedores.BAIRRO = tabela_de_clientes.BAIRRO;
Essa seleção retornará todos os vendedores e apenas os clientes correspondentes. Encontraremos, por exemplo, o registro da vendedora Roberta Martins, cujo bairro (Copacabana) não tem correspondência na tabela de clientes. Chegamos a essa conclusão porque a terceira e a quarta coluna estão com valor null. Ou seja, o seu escritório não está em um lugar estratégico, pois não há clientes cadastrados que comprem sucos nesse bairro.
Substituindo o comando por RIGHT JOIN, o MySQL trará todos os clientes e apenas os vendedores correspondentes. Com esse resultado, é possível verificar vários compradores que moram em bairros em que não há escritórios da empresa de sucos, como Água Santa e Brás - os três primeiros campos são nulos. Esse tipo de análise seria interessante, por exemplo, para investigar onde há mais demanda para abrir um novo escritório.
- Podemos ver todas essas informações ao mesmo tempo usando o FULL JOIN - todos os vendedores, inclusive os que tem escritórios nos bairros onde não há compradores; e todos os clientes, inclusive os que moram em bairros em que não há escritórios da empresa de sucos:
SELECT tabela_de_vendedores.BAIRRO,
tabela_de_vendedores.NOME,
DE_FERIAS,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.NOME FROM tabela_de_vendedores FULL JOIN tabela_de_clientes
ON tabela_de_vendedores.BAIRRO = tabela_de_clientes.BAIRRO;Ao executar essa consulta, o programa vai alegar um erro. Como foi explicado no começo do curso, a linguagem SQL segue o padrão ANSI, que respeita uma série de regras, mas nem todo gerenciador de banco de dados realiza 100% do que esse padrão especifica. O FULL JOIN está contido no padrão ANSI, porém o MySQL não suporta esse comando. Ou seja, não conseguiremos fazer o FULL JOIN no MySQL Workbench. Existe, no entanto, uma alternativa para o FULL JOIN que é fazer o LEFT JOIN e o RIGHT JOIN simultaneamente. Nesse momento, ainda não aprendemos como fazer essa união de consultas, então vamos reservar esse erro e, mais adiante, quando estudarmos mais sobre o assunto, voltaremos a ele.
- Para finalizar esse vídeo, vamos criar um exemplo com CROSS JOIN, lembrando que esse comando não requer que seja especificado o campo em comum nem que seja escrito o termo CROSS JOIN:
SELECT tabela_de_vendedores.BAIRRO,
tabela_de_vendedores.NOME,
DE_FERIAS,
tabela_de_clientes.BAIRRO,
tabela_de_clientes.NOME FROM tabela_de_vendedores, tabela_de_clientes;


