bismuth-consultancy-bv / mlops Goto Github PK
View Code? Open in Web Editor NEWMachine Learning Toolset for Houdini
License: BSD 3-Clause "New" or "Revised" License
Machine Learning Toolset for Houdini
License: BSD 3-Clause "New" or "Revised" License

























































































































It's just after release, so everyone is on the same version but in future it could be quite big problem where dependencies of dependencies could make impact. I would suggest to have locked requirements file for each version release
Different dependencies use different data for loading, it would be convenient to have a module that facilitates their loading. In particular, Transformers - CLIPSeg have a Processor that is not downloaded using the same rules as models.
Unfortunately, there is no hotkey to interrupt the download of these large models. Killing the process through the task manager is an option, but not a convenient one. Additionally, if the download is interrupted due to a connection failure or other issue, it's not clear if the download can be resumed from where it left off or it will be started from the beginning next time.
SD COP2 Processor
This node contains COP2 subnetwork for image manipulations and outputs colored points.
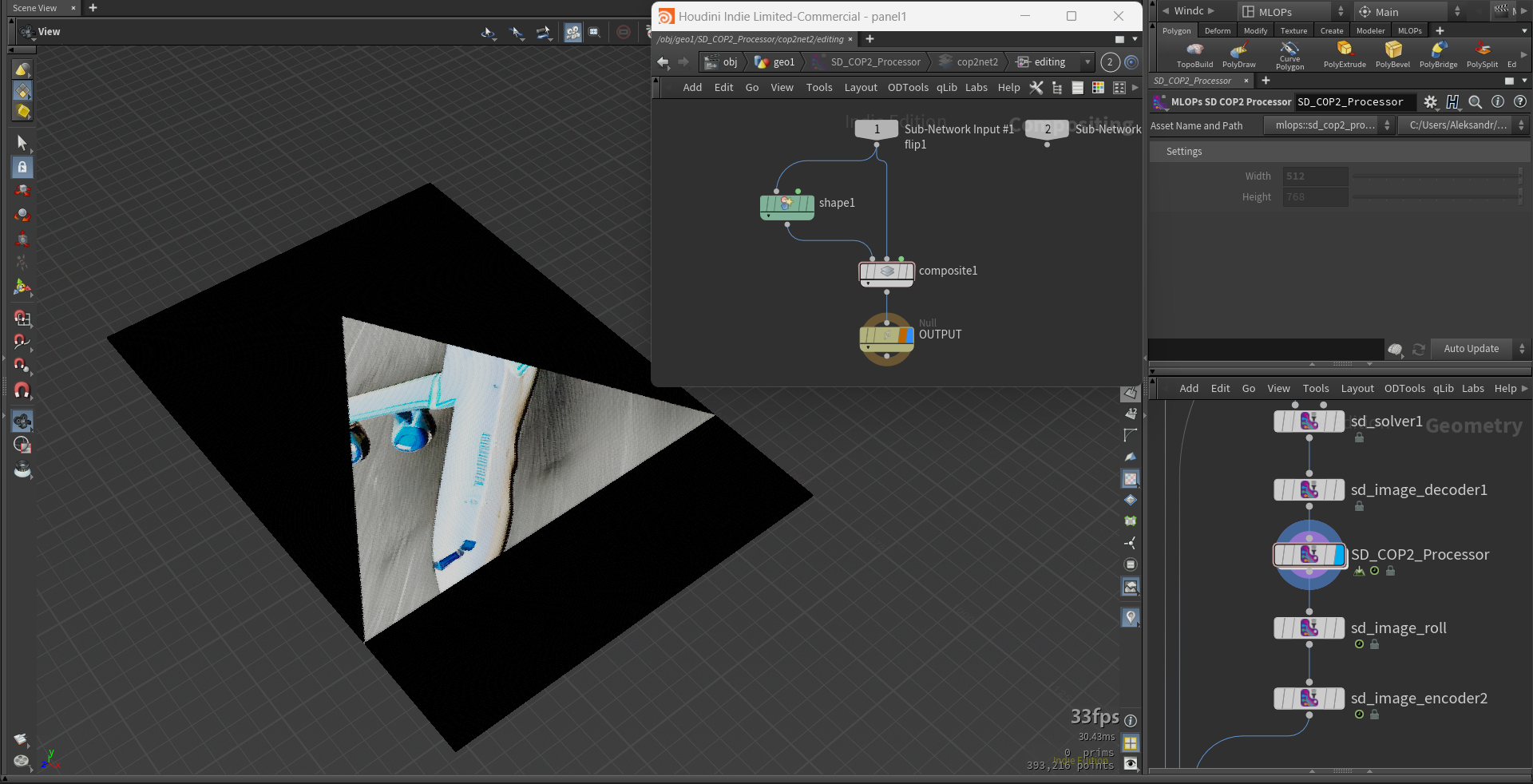
"Image heigt". Expected: "Image height"

When starting Houdini with MLOPs installed I get this:
C:\Users/Mo/Documents/houdini19.5/scripts/python\transformers\modeling_utils.py:402: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
with safe_open(checkpoint_file, framework="pt") as f:
C:\Users/Mo/Documents/houdini19.5/scripts/python\torch_utils.py:776: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.get(instance, owner)()
C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\storage.py:899: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
storage = cls(wrap_storage=untyped_storage)
C:\Users/Mo/Documents/houdini19.5/scripts/python\safetensors\torch.py:99: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
with safe_open(filename, framework="pt", device=device) as f:
MLOPs utility function which checks if specific dependency is installed and returns two variables True/False and string "$Dependency_name dependency is installed" or "$Dependency_name dependecy installation is required"
To put as label parameter on custom nodes for example
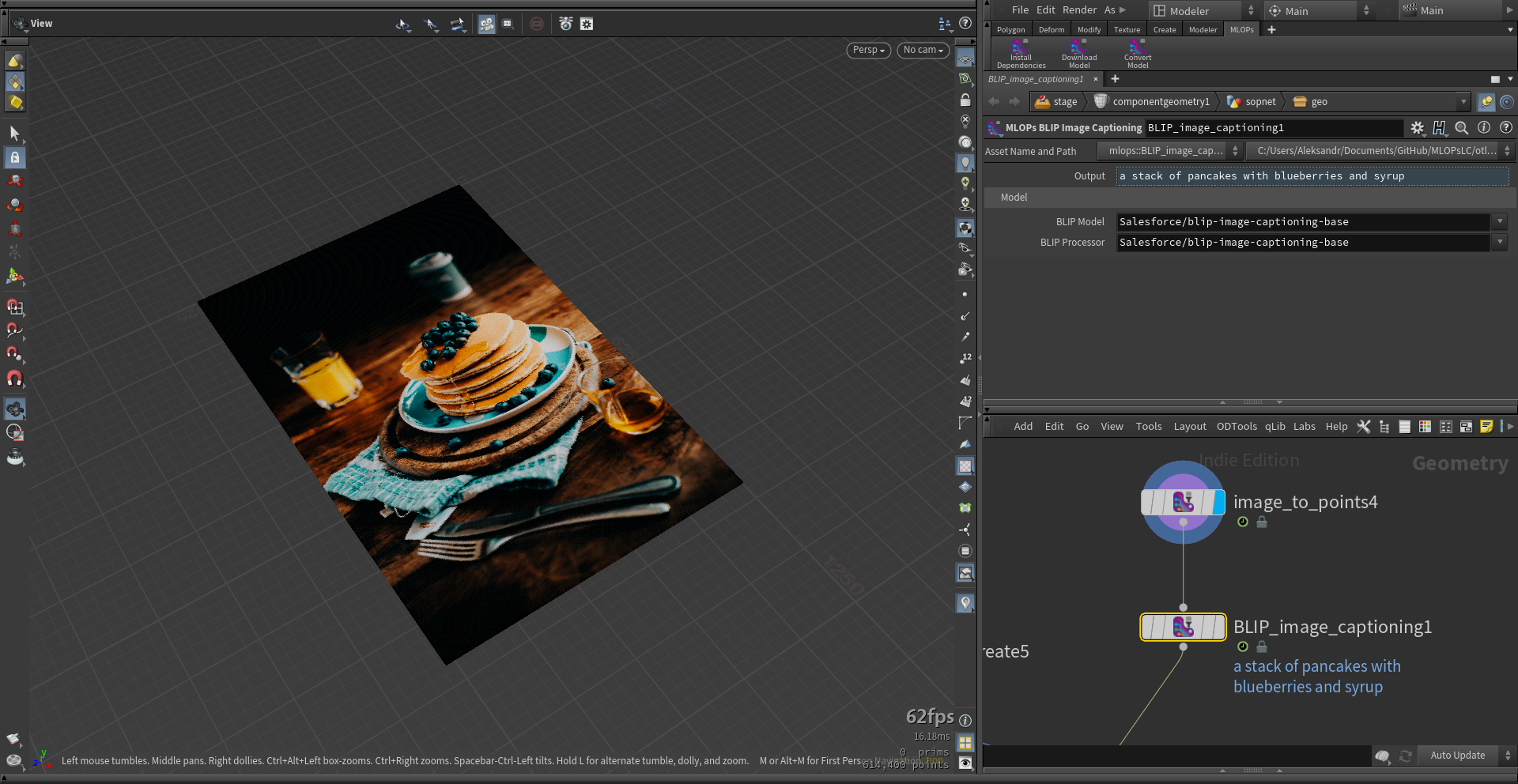
mlops.BLIP_image_captioning.1.0.hdalc
This experimental node converts an image represented as colored points into a textual description of its content. The description is stored as a point attribute called 'prompt' and is based on a machine learning model trained on image-caption pairs.
Getting an image of normals is already implemented in "camera to points" sop, but the controlnet create with normal set mangles the results. Currently no idea why


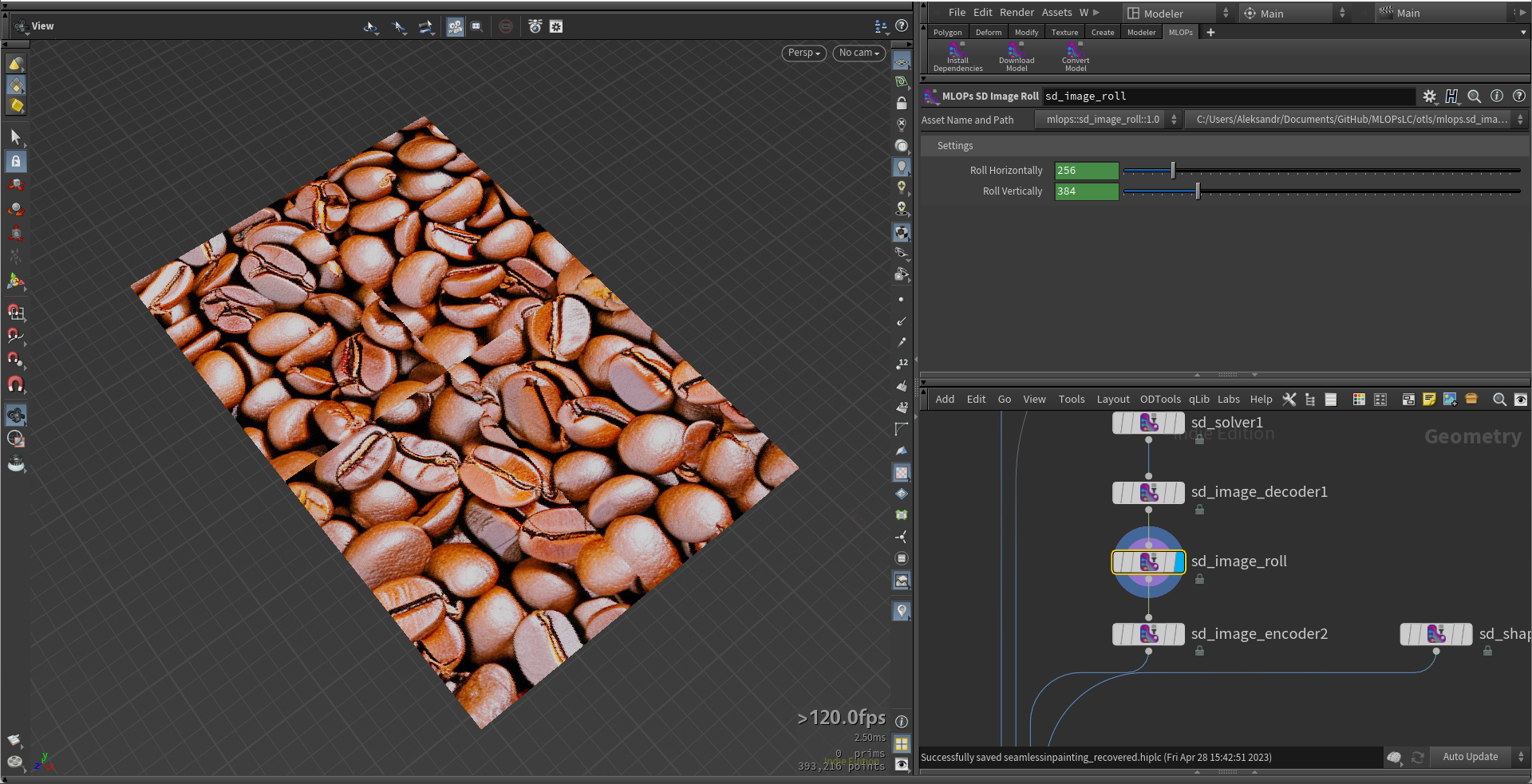
mlops.sd_image_roll.1.0.hdalc
This node shifts or offsets an input pixels along a specified axis.
If your looking for RFEs, a nice feature for the sd_export_image node would be an additional parm to allow meta tag data to be added to the generated image. The obvious text for the field would be the prompt and the model. Then you'd always have a path back to regenerate an image.
If MaterialX shaders are essentially just xml files, why not to generate them with chatgpt in conjunction with SD textures.
MTLx files
https://matlib.gpuopen.com/main/materials/all
How to load them in solaris:
https://www.sidefx.com/forum/topic/86396/#post-373528

Using prompt as a descriptive parameter is necessary to visualize text when working with multiple nodes for text generation.
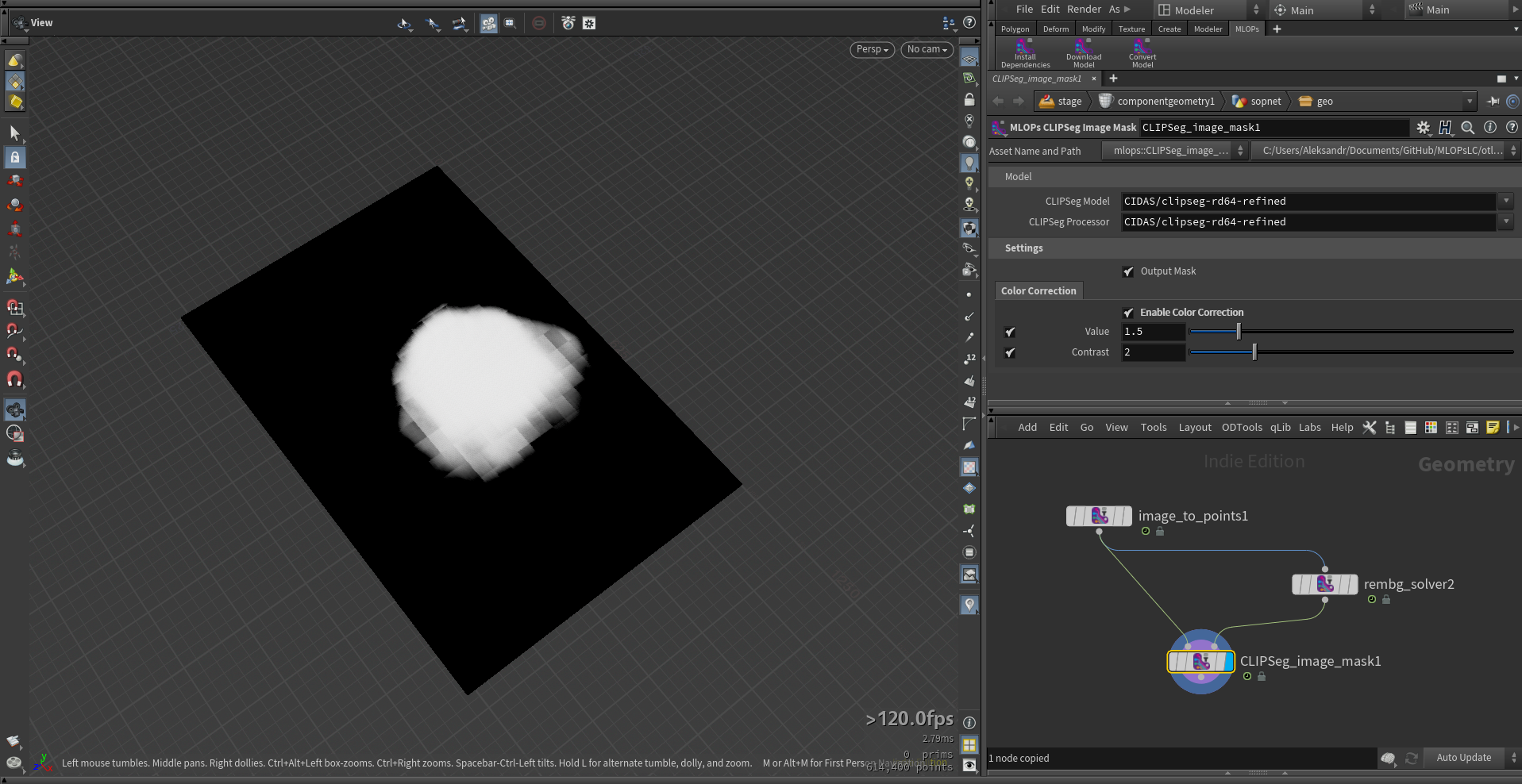
mlops.CLIPSeg_image_mask.1.1.hdalc
This node extracts low resolution mask from an input image based on another image when it is difficult to describe in text what exactly needs to be identified in the image. The mask can be used to isolate specific areas of interest for further processing downstream.
Traceback (most recent call last):
File "D:\MLOPs-main/scripts/python\mlops_utils.py", line 77, in on_accept
ensure_huggingface_model_local(model_name, download_dir)
File "D:\MLOPs-main/scripts/python\mlops_utils.py", line 34, in ensure_huggingface_model_local
from huggingface_hub import snapshot_download
File "C:\Program Files\Side Effects Software\Houdini 19.5.569\python39\lib\site-packages-forced\shiboken2\files.dir\shibokensupport\__feature__.py", line 142, in _import
return original_import(name, *args, **kwargs)
ModuleNotFoundError: No module named 'huggingface_hub'
after the install Dependences, I click the Download Model button, it raises this error.what's the problem?
not a big deal but:
height and width parameters are mixed up. height is width and width is height
same for image_to_points
mlops.sd_points_to_heightfield.1.0.hdalc
This node converts colored points channels to heightfield volumes Height and Mask.
when using txt2img, image guidance strength has an effect on the result. shouldn't.
Have a scene wide switch to change models and not have to go through individual nodes.
Support switching to .ckpt files
controlnet conditioning in MLSD mode errors out:_
Error
Invalid source /obj/Multi_ControlNet/sd_controlnet_conditioning4/python1
Error: Python error: Traceback (most recent call last):
File "", line 124, in
File "C:\PROGRA1/SIDEEF1/HOUDIN~1.569/houdini/python3.9libs\hou.py", line 38046, in setPointFloatAttribValues
return _hou.Geometry_setPointFloatAttribValues(self, name, values)
hou.OperationFailed: The attempted operation failed.
Incorrect attribute value sequence size
mlops.sd_matplotlib_python.1.0.hdalc
This node generates an image from a Matplotlib figure. You can customize the figure parameters and configure gridspec to layout plots if needed.
Based on: SD Image Python
MatPlotLib documentation: MatPlotLib
Useful article: Plot organization
Related video: SD MatPlotLib Python
Dependencies: matplotlib
!!! You have to install dependecies: Tab - MLOPs - Stable Diffusion - MLOPS SD MatPlotLib Python (Install)
Shelf tool to create obj or lop orthographic camera which looks on image.
so images look correct...
Hi there, great package. I'm really enjoying it so far.
I'm getting this error on the sd_solver node with controlnet.
Both my sd_latent_noise_generate and sd_image_to_points nodes are set to 512x512. The conditioning seems to be irrelevant as does the controlnet model. Skipping controlnet and using the image as an input for the scheduler's latents works as expected.
Happy to upload the hip if it helps.
Windows 10, Houdini 19.5
Invalid source [/obj/geo1/sd_solver1/solver](node:/obj/geo1/sd_solver1/solver)
Error: Python error: Traceback (most recent call last):
File "<stdin>", line 46, in <module>
File "C:/Users/adam.krebs/Houdini Packages/MLOPs-main/scripts/python\sdpipeline\image_solve.py", line 72, in run
down_block_res_samples, mid_block_res_sample = controlnet(latent_model_input, t.to(torch.float16), encoder_hidden_states=text_embeddings, controlnet_cond=controlnet_conditioning_image, conditioning_scale=controlnet_scale, return_dict=False,)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\diffusers\pipelines\stable_diffusion\pipeline_stable_diffusion_controlnet.py", line 134, in forward
return_dict,
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\diffusers\models\controlnet.py", line 529, in forward
cross_attention_kwargs=cross_attention_kwargs,
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\diffusers\models\unet_2d_blocks.py", line 870, in forward
cross_attention_kwargs=cross_attention_kwargs,
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\diffusers\models\transformer_2d.py", line 270, in forward
class_labels=class_labels,
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\diffusers\models\attention.py", line 316, in forward
**cross_attention_kwargs,
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\diffusers\models\attention_processor.py", line 248, in forward
**cross_attention_kwargs,
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\diffusers\models\attention_processor.py", line 375, in __call__
key = attn.to_k(encoder_hidden_states)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:/Users/ADAM~1.KRE/Dropbox/PC(2)~1/DOCUME~1/houdini19.5/scripts/python\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (154x1024 and 768x320)
.
Any advice? Thanks!
SD Shapes To Points
This node generates black and white mask from different kinds of shapes with ability to blur edges.
-have a set of quality prompts for quality (4k ,artstation,professional photography etc.) that can be enabled/disabled to add to the users prompts
-have multiple rows to be able to see all of the tags without going into the offscreen text space
Error (See HIP): Erroring .hip file
Invalid source /obj/Multi_ControlNet/sd_solver3/solver
Error: Python error: Traceback (most recent call last):
File "", line 42, in
File "C:\Users/Mo/Documents/GitHub/MLOPs/scripts/python\sdpipeline\image_solve.py", line 74, in run
noise_pred = unet(latent_model_input, t.to(torch.float16), encoder_hidden_states=text_embeddings, down_block_additional_residuals=down_block_res_samples, mid_block_additional_residual=mid_block_res_sample, ).sample
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\diffusers\models\unet_2d_condition.py", line 695, in forward
sample, res_samples = downsample_block(
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\diffusers\models\unet_2d_blocks.py", line 867, in forward
hidden_states = attn(
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\diffusers\models\transformer_2d.py", line 265, in forward
hidden_states = block(
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\diffusers\models\attention.py", line 312, in forward
attn_output = self.attn2(
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\diffusers\models\attention_processor.py", line 243, in forward
return self.processor(
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\diffusers\models\attention_processor.py", line 631, in call
key = attn.to_k(encoder_hidden_states)
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users/Mo/Documents/houdini19.5/scripts/python\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (154x768 and 1024x320)
.
{
"HOUDINI_SCRIPT_PATH": "$MLOPS/data/dependencies/"
},
{
"PYTHONPATH": "$MLOPS/data/dependencies/python"
}
To force Houdini to search dependencies in mlops before in default houdini python folder. To avoid a situation where Houdini finds old versions of dependencies that come bundled with Houdini installation, such as numpy and pillow, before new ones.
When in img2img mode, the decoded image has artifact at left and bottom edges.
Also when setting image guidance strength to 0, we get noise instead of an image (expected behaviour here: like txt2img - infer without guiding image, but infer.)
See attached screenshots



maybe some time in the future?
Hi there;
Might someone be able to elaborate on how this suite expects Python to be configured prior to installing? Does it use Houdini's Hython?
I have the automatic1111 repo set up by way of Anaconda on my Windows machine, as I'd prefer a more flexible way to manage Python that having to muck around with a system Python installation. Is it possible for this tool to be used in this setup?
I ask because I installed this just now, and am trying to follow Entagma's "my first stable diffusion setup" video, but immediately get an error with the text_encoder node about "Torch not compiled with CUDA enabled"; the troubleshooting docs seem to assume (I think) that I have previously installed a system python that's compatible with stable diffusion, but I'd like to be able to configure this to use my Anaconda python if possible.
mlops.rembg_solver.1.7.hdalc
This node extracts and replaces background of image with solid color.
Based on: KenjieDec/RemBG
Model documentation: danielgatis/rembg
Interactive page: KenjieDec/RemBG
Dependencies: rembg, rembg[gpu]
!!! Copy MLOPs_rembg.json to Packages folder in Houdini's preferences directory
!!! You have to install dependecies: Tab - MLOPs - RemBG - MLOPS RemBG Solver (Install)
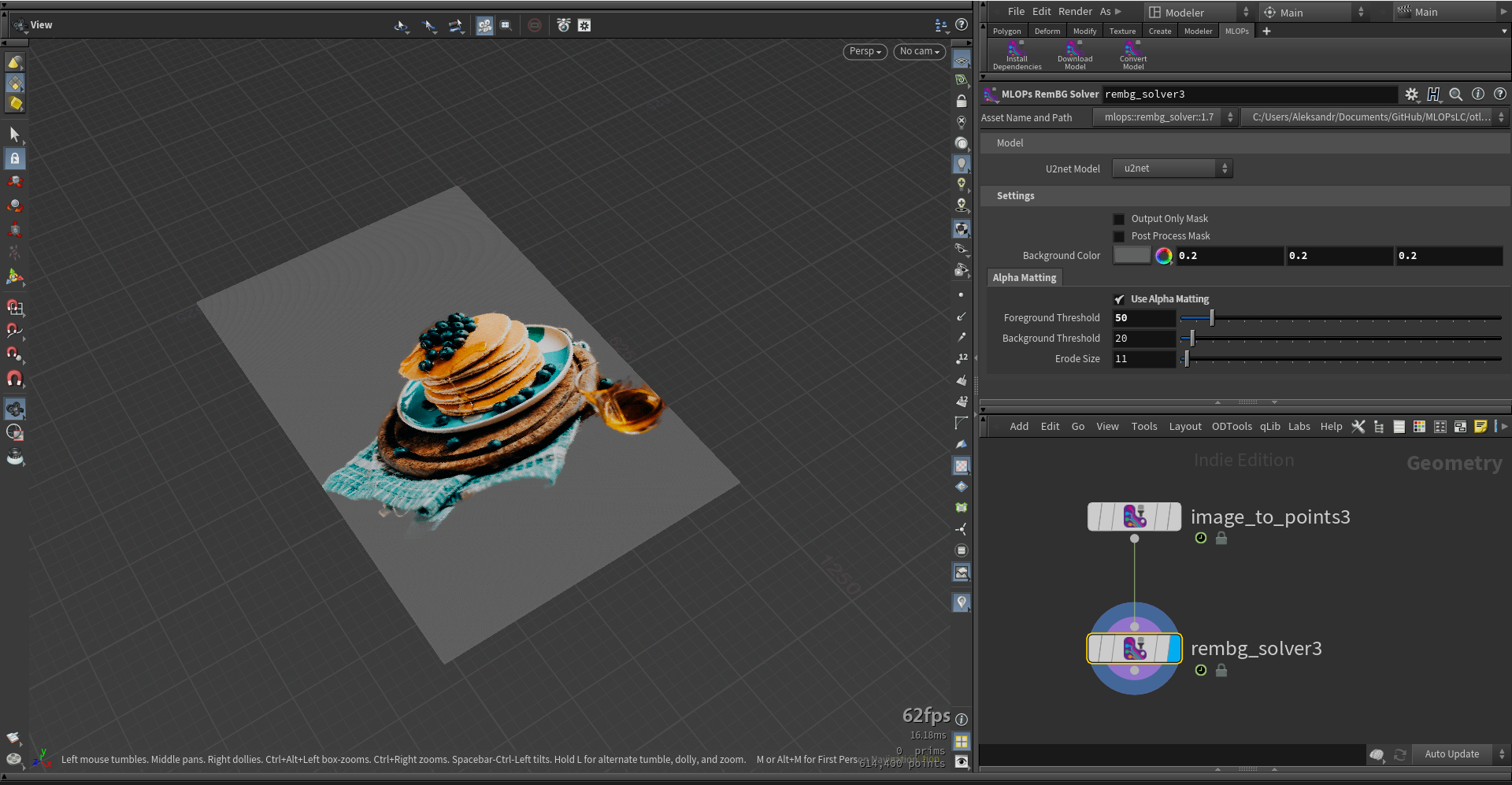
Question is: shouldn't they be identical?
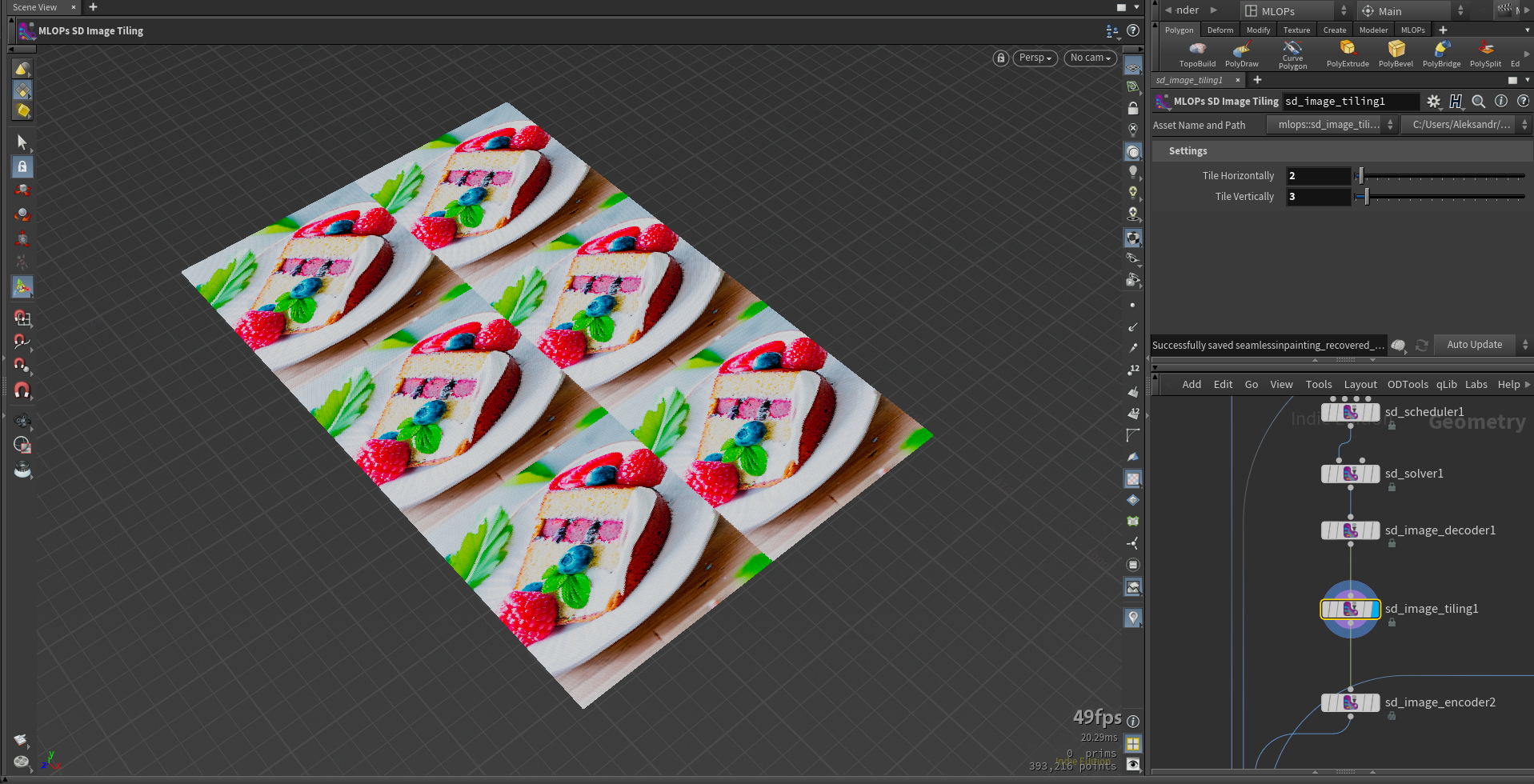
mlops.sd_image_tiling.1.0.hdalc
This node repeats images along a specified axis with preserving image dimensions.
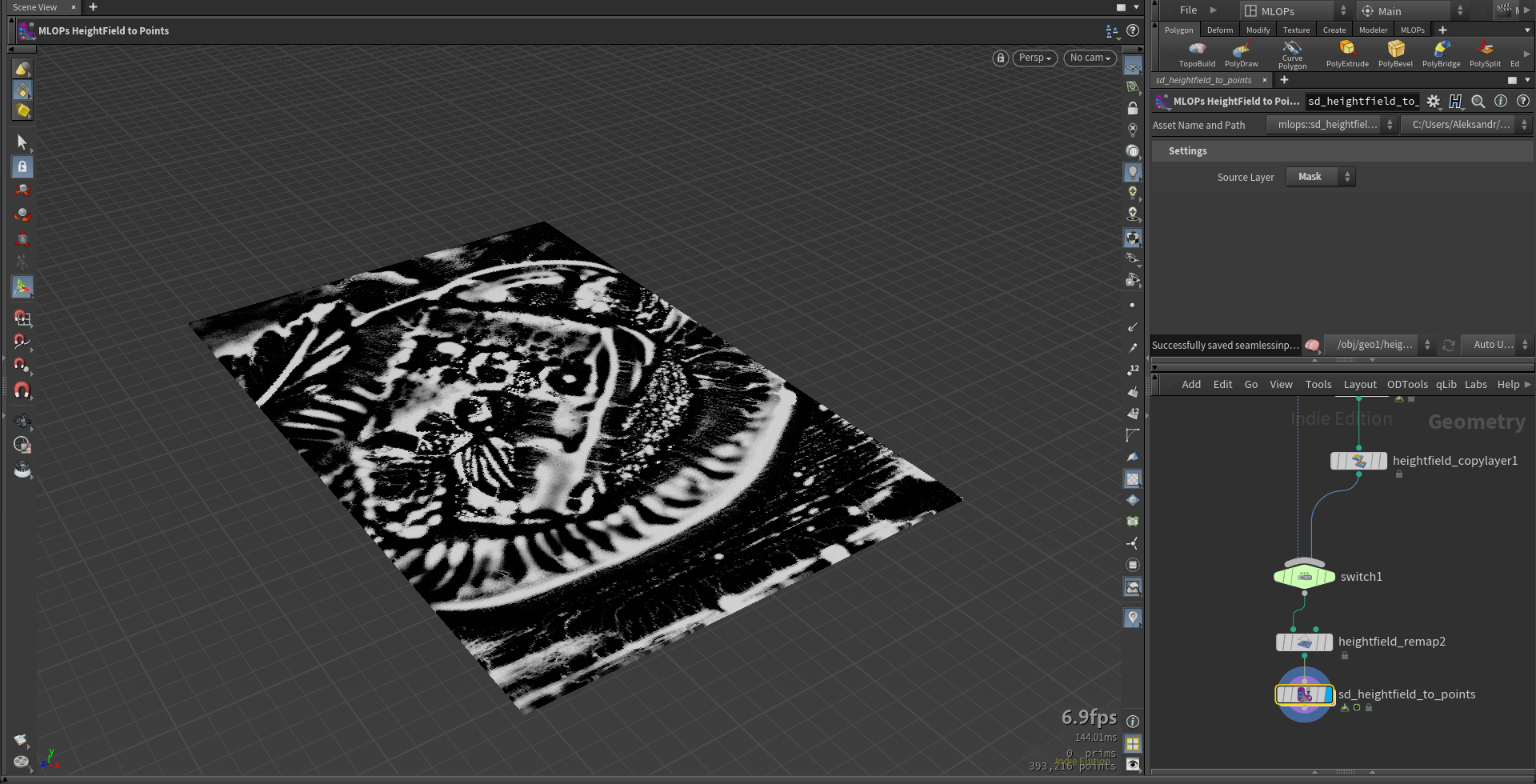
mlops.sd_heightfield_to_points.1.0.hdalc
This node converts heightfield volumes volumes Height or Mask to colored points. It also has COP2 subnetwork inside for image post-processing.
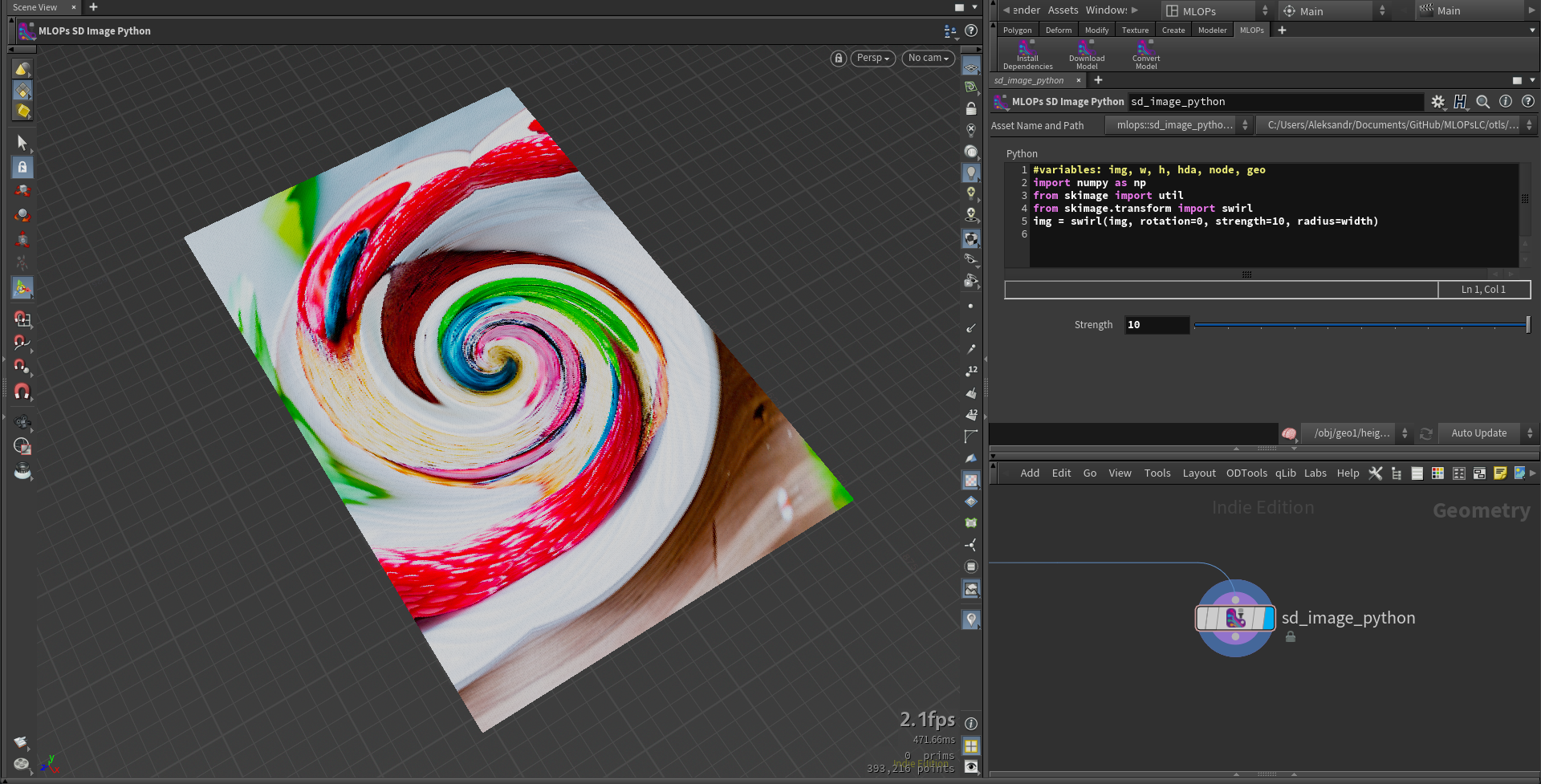
mlops.sd_image_python.1.0.hdalc
This node allows processing Colored Points by representing them as a three-dimensional numpy array in the variable "img" with a shape of (w, h, c), where w and h are the width and height in pixels, and c represents the color channels r, g, b. You can use popular image processing libraries that come with MLOPs, such as skimage. You can also use other libraries, but remember that colors in the array must be represented as float variables from 0 to 1.
Hython used in the shelf tools, actually invoke a totally different python install, namely the one in RM.
C:\Program Files\Side Effects Software\Houdini 19.5.569\bin>hython -m pip list
.....snip....
File "C:\Program Files/Pixar/RenderManProServer-25.0\lib\python3.9\Lib\site-packages\pip\_vendor\certifi\core.py", line 51, in where _CACERT_PATH = str(_CACERT_CTX.__enter__())
File "C:\PROGRA~1\SIDEEF~1\HOUDIN~1.569\python39\lib\contextlib.py", line 119, in __enter__ return next(self.gen)
File "C:\PROGRA~1\SIDEEF~1\HOUDIN~1.569\python39\lib\importlib\resources.py", line 175, in _path_from_reader opener_reader = reader.open_resource(norm_resource)
File "<frozen importlib._bootstrap_external>", line 1055, in open_resource
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Program Files/Pixar/RenderManProServer-25.0\\lib\\python3.9\\Lib\\site-packages\\pip\\_vendor\\certifi\\cacert.pem'
Because this python.exe is used instead, it constantly hits this missing file issue, and the shelf tool likely doesn't do actual work, installing 'nothing', and not reporting errors, resulting in a further failure a ModuleNotFoundError: No module named 'huggingface_hub'. when Download Models is pressed.
However, invoking the python interpreter window directly, and querying where 'os.py' exists as an example shows:
>>>os.__file__
C:\\PROGRA~1\\SIDEEF~1\\HOUDIN~1.569\\python39\\lib\\os.py
Therefore, perhaps the use of "hython" for the shelf tool is not the best approach?
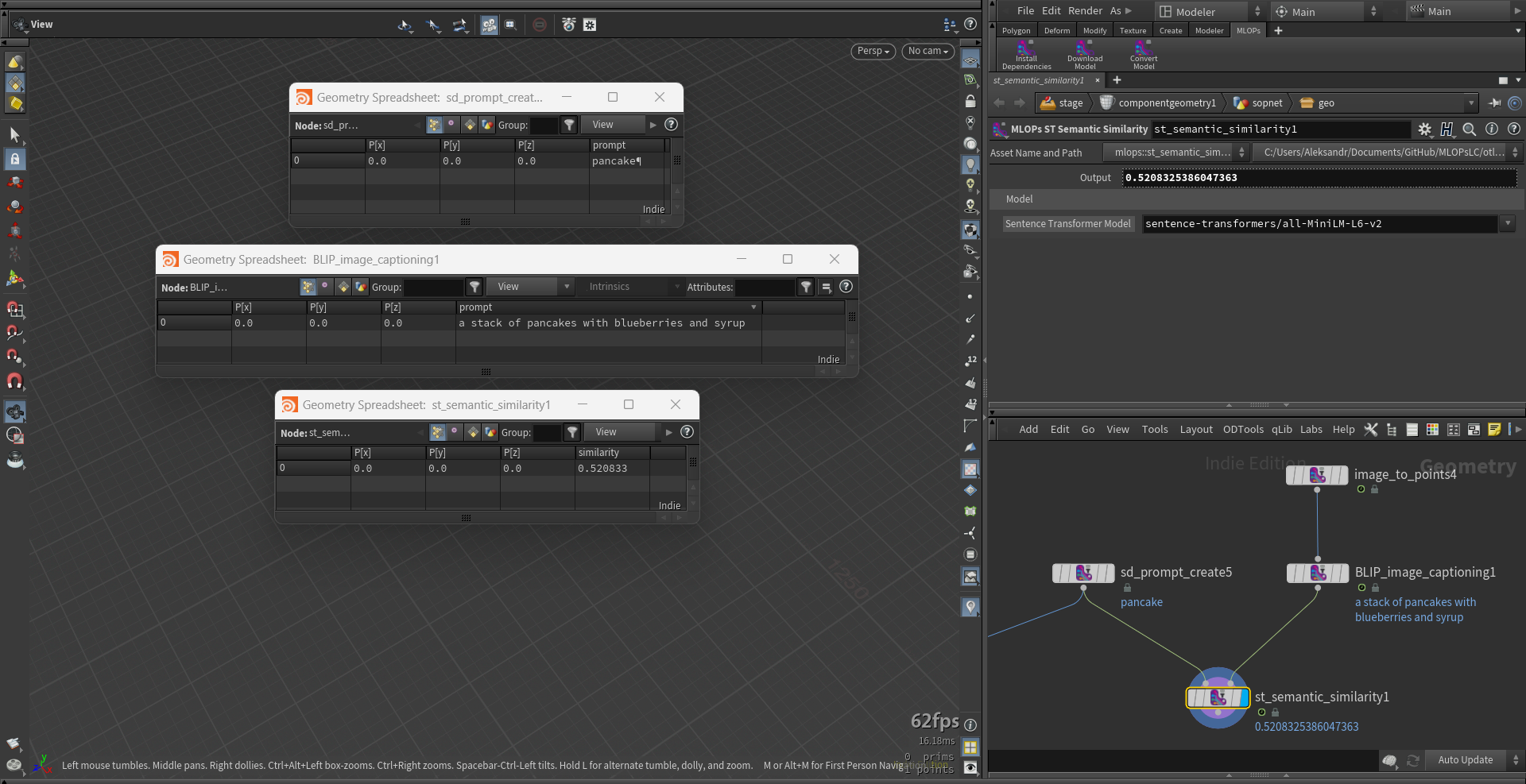
mlops.st_semantic_similarity.1.0.hdalc
This node takes two textual prompts as input and returns a Similarity attribute between 0 and 1 indicating how closely related the prompts are in meaning. The score is based on a natural language processing model that compares the semantic content of the two prompts.
Based on: tasks/sentence-similarity
Model documentation: SentenceTransformers
More models: sentence-transformers
Dependencies: sentence-transformers
!!! You have to install dependecies: Tab - MLOPs - SentenceTransformers - MLOPS Semantic Similarity (Install)
Tldr: I cannot use CUDA or CPU with MLOPs
I never had pyTorch installed but I keep getting CUDA errors
AssertionError: Torch not compiled with CUDA enabled
I've removed all my anaconda installations and installed the latest
Houdini 19.5.569
CUDA 12.1
Reinstalled dependencies but yet in Houdini Python Shell:
>>> import torch
>>> torch.cuda.is_available()
False
So I decided to just work with CPU mode. But I get
houdini19.5/scripts/python\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: "addmm_impl_cpu_" not implemented for 'Half'
Which stackoverflow tells me is because:
The error was throwing because the data type of operands was float16. Changing it back to float32 solved the problem. I guess float16 is for GPU implementation only.
So MLOPs is expecting a GPU solver, not CPU and I cannot use a GPU because CUDA cannot be found.
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:36:15_Pacific_Daylight_Time_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
Function to install specific dependency. To put as button parameter in custom nodes for example.

Decoder issue? Latents offset?
Transformer dependency is already connected to MLOPs, why not to implement CLIPseg from it to generate masks from prompts and images.
https://huggingface.co/blog/clipseg-zero-shot
Leaving this here for the future.
from multiprocessing.resource.tracker import error: "No such file or directory"
Thread Link for current discussion about feature:
https://discord.com/channels/925093472464146442/1099725981071200307
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.