berwin / blog Goto Github PK
View Code? Open in Web Editor NEW记录成长的过程
License: MIT License
记录成长的过程
License: MIT License








































































































































































































关于本书的任何意见和建议都可以在这里讨论~
可以在这里免费阅读本书第九章:http://www.ituring.com.cn/book/tupubarticle/25715
书中的代码:https://github.com/berwin/easy-to-understand-Vue.js-examples
也可以加入本书的微信讨论群(群已满100人,添加微信 Berwin1995 我拉进群,加我好友时建议说明自己是Vue.js读者)。
今天想谈一谈关于“需求分析”和“开发时间”这两个话题,工作这么些年还是头一次公然讨论这个话题,今天聊一下我对这两个话题的浅见。
早些年在我刚开始工作时,我认为“需求分析”就是听一听产品经理提的需求,评估下开发可行性和难度,把实现不了的需求砍掉。
这么多年过去了,我发现这是最Low Level的需求分析。
原因在于当时的我完全不知道产品经理为什么要提出这个需求,我甚至压根没有关注过这个问题,当时的我只关注这个需求如何实现,难度如何。所以我很难理解产品经理,甚至经常站在技术的角度认为产品经理提出的这个需求好SB啊,他是智障吗?
但其实产品经理和工程师不应该是敌对关系,应该是“搭档”,现在我和我们的产品经理一直是搭档关系,我们的关系很融洽,因为我们的目标是一致的:让我们的产品,满足用户的需求。
但有时候产品经理提出的需求可能不是很正确,这个时候需要工程师进行辅助。这里面有很多原因:
我们先讨论第一点:“产品经理可能对技术的边界不是很了解”。
优秀的产品经理是需要有技术广度的,他不一定要深入了解技术的原理,但一定要理解技术的边界。某个技术能做什么,不能做什么,最近是不是又有新技术了,和我的产品有关系吗?
但通常大多数产品经理都比较缺乏技术广度,所以这个时候需要工程师去补位。
但工程师去补位有一个前提,那就是工程师真的理解产品经理,理解他在想什么。这就要谈到第二点:对用户原始需求的理解很难传递。
很多时候,产品只是发了个产品文档过来,然后就拉着技术做“需求评审”,但其实这份需求文档,是产品经理对用户需求理解的二次加工。工程师在这份需求文档里是很难看清用户的原始需求的。
比如:用户需要一个消息提醒。产品经理可能是不知道有Web Push Notifications这项技术,也可能是对用户需求理解有误,总之最终提出来的需求是在网页的最顶部添加一个消息通知功能。
所以工程师应该主动去了解用户的原始需求是什么,当工程师能理解用户的原始需求是什么时,也就能理解产品经理为什么提这个需求了,就可以在这个时候成为产品经理的搭档,提醒他,有一项技术叫做Web Push Notifications,它的能力边界是什么。
一个好的需求,应该是技术深度参与,而不是产品经理单方面输出一个产品需求文档,因为产品经理有时候也会犯错,这就是我们要谈论的第三点:产品经理对用户需求的理解有误。
有时候用户反馈需求,或者产品经理在推测用户想要什么的时候,往往得到的答案是不正确的。因为有时候用户自己也不知道他需要什么。有一句名言非常有名:你如果问用户想要什么,他的回答是“一匹更快的马”,而不是汽车。
所以工程师要理解用户的原始需求,并且有自己的看法,这样不光可以给产品经理提出建设性意见,并且还可以对技术方案进行“预判”,如何设计项目的架构?最重要的就是要对产品未来的发展方向进行“预判”,一方面要对未来的改动 “做足准备”,另一方面也要避免 “过度设计”。
总之需求分析不是简单的听一听产品经理提的需求,评估下开发可行性和难度,把实现不了的需求砍掉。而是去理解用户的原始需求,和产品经理成为“搭档”,在产品经理因为缺乏技术广度或其他原因导致提出坏需求时,给出提醒并提供建设性意见。
所以你会发现我的标题叫做“需求分析”而不是“需求评审”,因为“需求评审”的潜台词是:我不知道用户需要什么,我只知道产品如果提出了SB需求我就给这个需求砍掉。
讨论完需求分析,接下来讨论下“开发时间评估”。
工作这么些年,直到今天我依然无法“准确”评估开发时间。
我认为是我的问题,是我没有掌握某些评估开发时间的方法论,为此我找了组内的技术专家和我的Leader请教他们是如何评估开发时间的。技术专家告诉我,可以用自己估算出的时间,乘以一个系数。我的Leader告诉我,可以根据以往的经验,来评估某个需求需要开发多少个“工作日”。
比如评估了5个工作日,但实际开发可能需要一个10个工作日。因为每天不一定一整天都在开发,还会去开会和处理其他杂事。
我评估的不是自然日什么时间完成,而是这个需求要多少个“有效工作日”可以完成。
评估好了有效工作日数,就可以根据工作日看需求的类型,有些需求是绝对不允许延期的,比如618,双十一这种需求都是不可能延期的,对于不可以延期的需求,如果评估出的有效工作日已经超出Deadline,那么这时候需要让产品经理把这个需求需要完成的所有功能的“重要程度”列出来,优先开发最重要的功能。如果评估后发现连最重要的功能都无法在Deadline之前完成,那么解决方案有两种,一种是寻求更多的资源,另一种是这个需求就整个砍掉。
听完之后,我学到了很多知识,“除了预估开发时间,别的我都学会了”。无论是“用评估的时间乘以一个系数”还是“根据经验评估有效工作日”,都没有正面回答如何准确预估开发时间的问题。
后来我又看了一些书,得出了一个结论:没有人可以准确估算出开发时间,准确估算开发时间是不可能的。
即使是特别简单的需求,也是无法准确评估开发时间的,例如:我可以准确的评估出我用一个工作日可以封装一个JSONP,但我无法准确评估几个小时能完成。
这不是抬杠,这是一个道理,我虽然不知道我几个小时能完成,但是我知道我一天可以完成,我虽然不知道几天可以完成,但我知道一个星期肯定可以完成。
既然结论是评估的时间根本不准,那就不评估了么?和产品经理说我不知道需要多久,开发完了我再找你?肯定不行,产品经理一定会要一个开发时间,必须得给一个,哪怕不准。
既然开发时间是无法准确评估的,而我们又必须给一个开发时间,那么我们要做的事就不再是如何评估开发时间了,而是变成了“风险管理”。
风险管理最常用的方法叫:留点余地。
这种方法的**是,我知道自己评估的工作日不准,那么为了应对各种意料之外的事发生,我需要安排一些额外的时间来以备不测。
可能遇到的风险:
用自己评估的工作日乘以一个系数,就属于这种类型。有一篇文章《我在淘宝做前端的这三年——第二年》里也介绍了一种方法也属于这种类型:
越不确定的事,未知的东西越多,风险越高,所以需要留有更多的时间以备不测。
我一般会问产品经理一个问题,我会和他说:你想要保守点的时间还是正常点的时间?保守点的是我用系数乘后的结果,正常点的是我凭经验和感觉认为多久能完成。
然后我会和他说:正常的时间,不一定准,我不能保证这个时间一定会完成,我只能尽力去完成,但保守的时间一定会完成。
通常最终商量后的结果就是把时间定到保守的时间上,然后开发尽量提前完成,但是最晚也不会超过保守的时间。
如果连不准确的开发时间都评估不出来,上面的方案不就失效了,那怎么办?
还有一个非常简单粗暴的方法:可以把需求难度分为三个等级:简单、中等、困难。
对于简单和中等难度的需求,在需求有DeadLine并且评估后发现最重要的功能也无法在Deadline之前完成,那么可以靠“堆人”来换取时间,但只适用于简单和中等难度的需求。对于复杂的需求,人员的数量根本没用,唯一可以让开发时间提前两个月以上,并且技术方案和质量都有保障的方案是:需要一个该领域的专家。
经过我自己的经验和我请教的各种专家来看,结论是:开发时间的评估完全靠感觉,感觉是不靠谱的,所以最重要的事是做风险管理。
时间好快,眨眼间,加入阿里已经一年了。这一年发生了很多事,整体上非常地充实且精彩,在一件又一件事情中,我不停地犯错,一路走来,步履蹒跚,也收获到了很多成长。每次结束一件事后,经过短暂宁静的生活便再次踏上新的征程。
之前写过一篇《我在阿里半年收获的成长》,因此文本主要讲述“后半年”收获的成长。
- Mentor:你平时周末都做些什么?
- 我:没事的时候通常会看看书,写写代码,研究一些自己感兴趣的东西
- Mentor:可以把一些平时做事的时间换成什么都不做,坐在那“思考”,想一些东西
以上对话来自一次我向导师询问的一个问题:“我应该如何再进一步,7和8的区别是什么”(大致是这个问题,原问题记不清了😿)。
7和8之间就级别本身的区别优势是 “可以调动更多资源”。之所以需要调动更多资源是因为需要做更复杂的事。复杂的事哪来? “思考得来”,当然也可以靠主管分配,但谁又能保证主管一定会把那个机遇分配给自己。
完全靠主管分配机遇,这也违背我内心一直以来所坚定的信念: “让事情因为自己而与众不同”。今天能通过面试进入到阿里巴巴的同学,能力都不差,主管把机遇分配给另一个人绝大概率拿到的结果不会比我差多少,一件事情究竟是因为我去做才拿到好结果,还是大家去做都能拿到好结果,不太好说,这达不到 “让事情因为自己而与众不同” 的标准。
只有自己凭空创造出的机遇并最终拿到了结果,才符合 “让事情因为自己而与众不同”,也更能展现出自己的水平。
所以一个更可靠的发展路径是:
这会衍生出一个新问题,“如果自己思考的项目未来发展方向和大团队方向不一致怎么办?”
其实不用担心,可以和主管多沟通对焦,如果自己思考得来的方向客观事实上是正确的方向(各方面受益都更高)或者是绝大多数人都信任是一个正确的方向,那么正确的方向一定会替换掉错误的方向。
一定要 “技术与业务两跳腿走路”。这是我主管和我导师对我的忠告,当两个经验丰厚的大佬不约而同地给了相同的建议,足以证明这句话的分量,这也引起我深思。
自从我开始工作,我都是只搞技术,我对业务其实不太感兴趣,我很崇拜那些知名的技术很强的世界顶级工程师,一直以来我的梦想都是想成为他们中的一员,想成为前端行业技术吊炸天的世界顶级工程师。
但现在我渐渐意识到,不能只搞技术,也要多思考思考自己的业务,这对自己是有好处的,对业务多思考的好处是:
让“技术”和“业务”互相成就彼此,共同成长。业务发展倒逼技术改进,技术改进成就业务,相佐相成。身为技术同学,可以基于对业务的预判用技术落地项目辅佐业务,业务的成功再反过来成就技术。
千万不要陷入到一个巨大的误区:技术的自嗨,其实并没有多大贡献。
所有伟大的技术创新,都是那些对社会有巨大贡献的技术,伟大技术的诞生,都是基于一个不被满足的“需求”,基本上伟大的技术都是这样被创造出来的(Git、React、Vue又或是支撑公司业务背后的技术体系)。
只有对业务足够了解,思考的足够深,才能知道用户需要什么,才有可能引领未来支撑业务的技术体系,才有可能创造出改变世界的伟大的技术。
一门心思只搞技术,很难做到“引领”和“创新”。大概率只能做到学习现有已被其他人创造出来的技术,学到精通,成为某领域专家,但很难引领某个技术领域。
发挥稳定型(线性增长)选手比阶段性发挥波峰波谷选手更有优势,稳定(可预测性)本身就是一种优点。发挥不稳定的选手,缺点是不可预测,换位思考如果自己是主管,有一件很重要的事,你敢交给发挥不稳定的选手么,万一碰上发挥较弱的时间段,就悲剧了。
这个道理,在电子竞技、体育竞技等领域都相通,发挥不稳定是不可能拿到冠军的。
刚进入一家公司,在一个新环境都会有点着急,急于拿到成绩得到认可,这本身其实是件好事,但不要把劲使大了,把自己变成了那个波峰波谷型选手。放轻松一点,少使点劲,让自己线性成长稳定发挥。毕竟,职业生涯本就是一场“没有终点的长跑”,大家比拼的并不是短期内谁跑的更快,而是“坚持”,在这条赛道上能跑赢的,不是那些跑得快的人,而是为数不多坚持跑的人,他们能跑赢,只是因为还在跑。
某一刻,我终于理解了这四个字,这要从一件事说起。
最开始,为了帮助团队成员“提升个人写作”、“提升表达能力”、“提升个人技术成长”,我提出了文章计划,团队成员每个人大概每5个月写一篇文章,同时发明了 “贝利体系” 作为奖惩机制,每人每月按照一定的数量自动掉贝利,贝利掉多了需要接受惩罚,发表了文章后奖励贝利,只要保证每5个月写一篇文章贝利就不会达到惩罚线,具体数值都是我计算好的,并写了段程序自动执行,拿到手里的贝利可以用来兑换一些礼物,有HHKB、AirPods等可以兑换。
后来“文章计划”受到了大家的集体挑战,觉得给大家照成了非常大的压力和负担,“文章计划”就宣告结束,不过 “贝利体系” 被我保留了下来,虽然不强制大家写文章了,但依然鼓励自愿写文章的同学,并给予贝利奖励。
这时我对贝利体系进行了一些思考,并重新定位:“衡量体系”,衡量团队成员对“团队建设”、“组织文化”、“横向贡献”的贡献值,助力团队和文化的横向建设。简单来说,就是所有对团队横向有付出的同学,我都会按照贡献的大小付出的多少来奖励贝利,且有一个排名,排名高代表横向贡献多,我会给予贡献多的一些同学发一些礼品,贝利本身也可以自行兑换礼物:HHKB、AirPods等。
我希望贝利体系和团队横向的事情,例如:团建、招聘、安全生产、写文章、技术分享、对现有产品提改进建议、组织大家健身、组织大家玩桌游等有更深度的结合。
因此,有一天,我提出一个想法:让贝利少的人举办团队的团建,并给予举办团建的人奖励贝利,主要考虑给团队横向贡献少的同学多些机会做些贡献。且在团建过程中结合贝利有一些有趣的玩法,例如可以按照贝利的多少设定初始装备(贝利高,团建玩游戏时略有优势,但又不失平衡)。
但这个提议被团队负责团建的同事拒绝(因为他认为贝利不客观公正,无法客观衡量谁贡献少)。当时我觉得这是一个对团队有帮助的好事,可能它暂时不完美,但我会持续优化,我是在“坚持做正确的事”。而且当场我问同事觉得哪里有缺陷需要改进也说不上来,再加上我觉得自己在做正确的事,在让这个团队变得更好,所以我就和同事大吵了一架,对,我又双叒叕和人吵架了,而且这次格外激烈。
我对自己进行了深度的反思,“贝利体系”打被我凭空创造出来之后,无论是面向用户,还是面向合作方,都不是很受欢迎。面向客户,团队成员觉得这是一种压力和负担。面向合作方,团队横向负责人没有与贝利体系合作的动力和需求。这件事本身不是大事,但做这件事却非常难,贝利诞生到现在一直被大家抵触,被大家无视,还有人觉得这是几个人之间的小众游戏。
但我又不想放弃,我想让我们团队因为我的存在变得不一样,而我又坚信这是正确的事,是一件好事。为此我和主管聊了两三次,学到了一些知识和做事的方法,总结提炼出精华:
贝利体系诞生以来,所有的“规则”(包括哪些贡献应该奖励,奖励多少)都是我一个人定,大家内心是“不认可”的,因此外在表现就是“你自己玩你自己的,我不参与”。换位思考,每个人都会抵触自己“不认可”的事情。
这一刻我终于体会到,也理解了什么叫 “求同尊异”,每个人都不一样,也不是所有人都和自己想法一样,要尊重不同的建议和声音。一件事,只有大家认可了才能赢得尊重和成功,要赢得客户的认可,赢得合作伙伴的认可。
后续:
这件事之后,现有的“规则”我都通过匿名调查问卷的方式投票决定,调查大家认为哪些应该奖励,应该奖励多少,哪些不应该奖励,并根据调查问卷的结果进行了修改。
所有的规则,完全由匿名投票大家共同决定,规则制度“公开透明”,由全体成员“共同参与”。并且提供了日常的“实名”和“匿名”双通道接收意见反馈,并给反馈意见的同学奖励贝利。获取贝利和消耗贝利的方式也变得更加的多样化。且这些新的多元化的获取和消耗贝利的方式都是由团队成员大家共同贡献出来的。经过一系列的调整,整体认可度相比之前有了很大的改善,贝利体系在向着更好的方向迈进。
年前也按照大家的贝利数量给大家发放了同等价值的礼品,并启动新一轮周期,大家都很开心。
这件事虽然不大,但是它教会了我 “如何推进事情”,未来我大概率会打破现有已经“成熟”甚至“固化”的技术体系,为现有技术体系做一些改进,让它变的更好,那么推进并赢得大家的“认可”和“尊重”与这件事是相同的,通过这件事,我提前得到了锻炼,这是无价的宝藏。
感谢主管的培养和信任,不止给我很多试错空间,还在我犯错后教我如何做才是正确的做法。
关于风险同步在《我在阿里半年收获的成长》有提到过,最近又有了新的感悟:不要担心“做的不好”或“不完美”而不敢同步进展和风险,因为“差的信息”比“没有信息”要好很多!
及时同步“风险”和“进展”的好处是:如果真的做错了,会得到及时的纠正和帮助,可以保证项目是安全的,项目安全永远是第一位。不要担心大家会觉得自己菜,自己菜不菜根本没人关心,大家关心是:
哪怕中途做一步错一步,也比中途“毫无音讯”强无数倍。 即便是中途做一步错一步,但由于及时同步了风险和进度,在不停地犯错中一点点把项目做好,最终大家也会看到自己的成长。会对自己很放心,下次类似的事情交给自己会让人安心,因为再差再差,自己也不会把事情搞砸。
线上出了事故后,立刻向上汇报,不要自己先闷着头去修复!避免业务方找过来时主管完全不知情,这种情况整体都会很被动!
反馈问题的方式:
当接到一个任务后,首先考虑的是 “怎样把这件事做的更好”,“谁来做更合适”,不要把自己当做唯一的资源。
合适的事让合适的人来负责,接到任务后第一个想的是如何把事做好,谁来做更合适,如果自己擅长某一块可以自己去做,如果某一块有更合适的人选,那就应该找到合适的人来做,而不是自己去做。
如果评估不准某个功能是否可以按期上线,一律按 “悲观” 态度给反馈(本质其实是:提升专业性,预判风险,做好预期管理)。新手PM都会犯一个错,那就是,虽然心里感觉大概率在Deadline前开发不完,但还是会和产品说:“我试试”。
我见过的,除了我还有新手PM也犯了这个错,那就是一句:“我试试”(觉得大概率来不及,但还是和产品说感觉来不及,但我努努力试试)。最终没有按期上线时产品就会找过来问为什么没有上线,“不认可”这个结果。
所以,如果评估不准,或感觉有风险,一律给悲观答复。如果一开始有来不及的可能,在一开始就给来不及的 “明确反馈”。
技术PM最重要的核心竞争力和职责叫做:技术判断。像双11这种级别的大促,每个功能所涉及的上下游链路都会非常复杂,横跨N多个团队,这就意味着,同一件事,可以有N种解决方案,而不同团队看待问题的视角不同,因此大家给出的方案和倾向性很多时候会有冲突,这时候技术PM要做的就是给一个技术判断,方案1、2、3、优缺点是什么,让高年级同学拍板。而不是把一个问题抛上去让高年级同学们想方案。因为信息是越底层知道的越多,越上层对细节的信息越少。
不知不觉,来阿里已经一年了。这一年是我近几年来成长最快的一年,自己的思维和想法,都有了质的提升。非常感谢舒文把我带到这个团队,以我的学历正常很难进到这个团队,经常感叹自己真的是凭运气遇到贵人。还非常感谢墨冥(我的主管),这一年来不断地言传身教并给予机会试错,这一年来的成长(可参考这两篇文章《我在阿里半年收获的成长》、《我在阿里一年收获的成长》)绝大部分来自墨冥的教导,再次感叹自己的好运气。
相信未来,我会在实战中承担更大的职责,相信未来,我会让我们团队因为我的存在变得不一样。
最后,在舒文身上学到了一个原则,特别认同:
学会坚持,“长时间的积累”永远比“为了短期高收益频繁切换”收益高,无论是“日常做事”、“投资”还是“职业规划”、“人生规划”等。
舒文经常说:“做成一件事情”有很多因素,“坚持”是成本最低的一种。
其实提升自己没有秘籍和诀窍,只要愿意花业余时间去学习,再加上长时间的坚持,就可以成为大神。
我个人比较喜欢读书,喜欢读纸质的书,记得刚开始工作的时候,很多东西都不会,只会写CSS切页面,是一名真切图仔,同时自己又特别想成为大神,然后就每天中午吃完饭在工位上看一个小时的书,下班后也会留在公司看两个小时的书再回家,就这样每天中午和晚上一边看书一边写Demo,前期的提升速度还是非常明显的,基本上每天都能感觉到自己学会了新知识。
我比较推荐多读一些技术书,特别是纸质书,熟悉我的同学都知道我有非常多的书。一本书从填选题表到最终出版,中间会经历很多步骤,出版社专业的编辑也会和作者一起反复的校验和修改好多遍,上市之后再经过读者的认可,这样一本书的内容质量是非常有保障的。根据经验图灵出版的书质量都非常高。
学习资料非常重要,要阅读高质量的第一手资料,很多时候我们学习某个技术发现怎么都学不会搞不懂时可能不一定是我们笨,也有可能是学习资料有问题。
我见过很多文章讲某个技术,即使那个技术我事先已经会了,也确实看不懂文章里在说些什么。我也见过很多文章可能作者自己也不是很懂某个技术,他只是把一些其他文章拼凑起来。
不好的学习资料通常内容晦涩难懂且没有把技术讲清楚,而高质量的学习资料通常会很清晰且精准地把一个技术讲透,因为讲解清晰明确,所以学习起来也不会太复杂枯燥。
JS框架、库、工具等,我一般会从官网和口碑较好的纸质书籍中学习。基础知识我一般通过阅读高质量的纸质书籍 + 阅读W3C的规范来学习。Web性能领域我通常在Chrome开发者官网和web.dev里的文章来学习。
具备了一定的基础知识后就可以判断出学习资料的质量,这时候就可以关注一些公众号或者明星程序员来获取一些知识。
除了学习,我还会利用业余时间写文章,做技术分享等,将自己学到的知识分享出去。切身体会,将自己学到的知识分享出去对自己的成长有很大帮助,有时候写文章的过程中会发现自己对某个知识也没有真的学透。
而且写作和分享可以让自己学会思考并锻炼思考能力,而思考能力其实很重要。
最后,坚持才是最重要的,我们的职业生涯,其实是一场没有终点的长跑比赛,很多人可能想问怎样才能跑得更快,把这场比赛跑赢。其实在这条没有终点的赛道上在短期内快一些没有任何意义。大部分人跑到中途就主动放弃了,这就是为什么大牛那么少。唯一能决定这场比赛输赢的,只有两个字叫 “坚持”。在这条赛道上跑赢的,不是那些跑得快的人,而是为数不多坚持跑的人。他们能跑赢,只是因为他们还在跑。
最后推荐一些书单,全都是我自己看过的觉得非常不错的书。
JavaScript相关的书籍:《你不知道的JavaScript》上中下共三本、《深入理解ES6》、《JavaScript高级程序设计》
CSS相关的书我都没有亲自看过,但我是看张鑫旭博客学的CSS,他出版的书我虽然没看,但凭着对作者的信任,而且作者还专门为这本书做了个官网感觉还是蛮用心的,质量应该是可以保障的:《CSS世界》。
JS框架相关的书籍,React相关我没有看过不做推荐,Vue相关的推荐一本:《深入浅出Vue.js》(真不是打广告,内容质量和深度确实是目前市面上最好的一本)。
Node.js相关的书籍,只看过一本朴灵大大写的质量还行,别的没看过,所以只推荐这本:《深入浅出Node.js》。
再分享下其他我看过的觉得不错的书:《算法4》、《Web性能权威指南》(作者是前任W3C性能工作组主席,译者是李松峰老师,虽然这本书出版快10年了,但我感觉还是值得一看的)、《重构》、《码农翻身》、《代码整洁之道》、《软技能 - 代码之外的生存指南》、《金字塔原理》。
转载文章请注明出处,谢谢 #14
文中会讲述我从0~1搭建一个前后端分离的vue项目详细过程
Feature:
前段时间我们导航在开发一款新的产品,名叫 快言,是一个主题词社区,具体这个产品是干什么的就不展开讲了,有兴趣的小伙伴可以点进去玩一玩~
这个项目的1.0乞丐版上线后,需要一个管理系统来管理这个产品,这个时候我手里快言项目的功能已经上线,暂时没有其他需要开发的功能,所以我跑去找我老大把后台这个项目给拿下了。
接到这个任务后,我首先考虑这个项目日后会变得非常复杂,功能会非常多。所以需要精心设计项目架构和开发流程,保证项目后期复杂度越来越高的时候,代码可维护性依然保持最初的状态
后台项目需要频繁的发送请求,操作dom,以及维护各种状态,所以我需要先为项目选择一款合适的mvvm框架,综合考虑最后项目框架选择使用 Vue,原因是:
所以最终选择了Vue
框架定了Vue 后,接下来我需要挑选一些vue套餐来帮助开发,我挑选的套餐有:
在开发这个项目前,我去参加了北京的首届 vueconf 大会,其中有一个主题是阴明讲的《掘金 Vue.js 2.0 后端渲染及重构实践》,讲了掘金重构后的架构设计,我觉得他们的架构设计的挺不错,所以参考掘金的架构,设计了一个更适合我们自己业务场景的架构
.
├── README.md
├── build # build 脚本
├── config # prod/dev build config 文件
├── hera # 代码发布上线
├── index.html # 最基础的网页
├── package.json
├── src # Vue.js 核心业务
│ ├── App.vue # App Root Component
│ ├── api # 接入后端服务的基础 API
│ ├── assets # 静态文件
│ ├── components # 组件
│ ├── event-bus # Event Bus 事件总线,类似 EventEmitter
│ ├── main.js # Vue 入口文件
│ ├── router # 路由
│ ├── service # 服务
│ ├── store # Vuex 状态管理
│ ├── util # 通用 utility,directive, mixin 还有绑定到 Vue.prototype 的函数
│ └── view # 各个页面
├── static # DevServer 静态文件
└── test # 测试
从目录结构上,可以发现我们的项目中没有后端代码,因为我们是纯前端工程,整个git仓库都是前端代码,包括后期发布上线都是前端项目独立上线,不依赖后端~
代码发布上线的时候会先进行编译,编译的结果是一个无任何依赖的html文件 index.html,然后把这个 index.html 发布到服务器上,在编译阶段所有的依赖,包括css,js,图片,字体等都会自动上传到cdn上,最后生成一个无任何依赖的纯html,大概是下面的样子:
<!DOCTYPE html><html><head><meta charset=utf-8><title>快言管理后台</title><link rel=icon href=https://www.360.cn/favicon.ico><link href=http://s3.qhres.com/static/***.css rel=stylesheet></head><body><div id=app></div><script type=text/javascript src=http://s2.qhres.com/static/***.js></script><script type=text/javascript src=http://s8.qhres.com/static/***.js></script><script type=text/javascript src=http://s2.qhres.com/static/***.js></script></body></html>关于这一层我想详细说一下,这一层最开始我觉得没什么用,并且这个东西很危险,新手操作不当很容易出bug,所以就没加,后来有一个需求正好用到了我才知道event-bus是用来干什么的
event-bus 我不推荐在业务中使用,在业务中使用这种全局的事件机制非常容易出bug,而且大部分需求通过vuex维护状态就能解决,那 event-bus 是用来干什么的呢?
用来处理特殊需求的,,,,那什么是特殊需求呢,我说一下我们在什么地方用到了event-bus
场景:
我们的项目是纯前端项目,又是个管理系统,所以登陆功能就比较神奇
上面是登陆的整体流程图,关于登陆前端需要做几个事情:
经过上面一系列的登陆流程,最后的结果是登陆之后会拿到一个用户信息,这个获取用户信息的操作是在router里发起的执行,那么问题就来了,router中拿到了用户信息我希望把这个用户信息放到store里,因为在router中拿不到vue实例,无法直接操作vuex的方法,这个时候如果没有 event-bus 就很难操作。
所以通常 event-bus 我们都会用在表现层下面的其他层级(没有vue实例)之间通信,而且必须要很清楚自己在做什么
为什么 event-bus 很容易出问题?好像它就是一个普通的事件机制而已,为什么那么危险?
这是个好问题,我说一下我曾经遇到的一个问题。先描述一个很简单的业务场景:“进入一个页面然后加载列表,然后点击了翻页,重新拉取一下列表”
用event-bus来写的话是这样的:
watch: {
'$route' () {
EventHub.$emit('word:refreshList')
}
},
mounted () {
EventBus.$on('word:refreshList', _ => {
this.changeLoadingState(true)
.then(this.fetchList)
.then(this.changeLoadingState.bind(this, false))
.catch(this.changeLoadingState.bind(this, false))
})
EventBus.$emit('word:refreshList')
}watch 路由,点击翻页后触发事件重新拉取一下列表,
功能写完后测试了发现功能都好使,没什么问题就上线了
然后过了几天偶然一次发现怎么 network 里这么多重复的请求?点了一次翻页怎么发了这么多个 fetchList 的请求???什么情况????
这里有一个新手很容易忽略的问题,即便是经验非常丰富的人也会在不注意的情况犯错,那就是生命周期不同步的问题,event-bus 的声明周期是全局的,只有在页面刷新的时候 event-bus 才会重置内部状态,而组件的声明周期相对来说就短了很多,所以上面的代码当我进入这个组件然后又销毁了这个组件然后又进入这个组件反复几次之后就会在 event-bus 中监听了很多个 word:refreshList 事件,每次触发事件实际都会有好多个函数在执行,所以才会在 network 中发现N多个相同的请求。
所以发现这个bug之后赶紧加了几行代码把这个问题修复了:
destroyed () {
EventHub.$off('word:refreshList')
}自从出了这个问题之后,我就像与我一同开发后台的小伙伴说了这个事,建议所有业务需求最好不要在使用event-bus了,除非很清楚的知道自己正在干什么。
项目架构搭建好了之后已经可以开始写业务了,所以我每天的白天是在开发业务功能,晚上和周末的时间用来开发编译上线的功能
前面说了我们的项目是纯前端工程,所以期望是编译出一个无任何依赖的纯html文件
在使用 vue-cli 初始化项目的时候,官方的 webpack 模板会把webpack的配置都设置好,项目生成好了之后直接运行 npm run build 就可以编译源码,但是编译出来的html中依赖的js、css是本地的,所以我现在要做的事情就是想办法把这些编译后的静态文件上传cdn,然后把html中的本地地址替换成上传cdn之后的地址
项目是通过webpack插件 HtmlWebpackPlugin 来生成html的,所以我想这个插件应该会有接口来辅助我完成任务,所以我查看了这个插件的文档,发现这个插件会触发一些事件,我感觉这些事件应该可以帮助我完成任务,所以我写了demo来尝试一下各个事件都是干什么用的以及有什么区别,经过尝试发现了一个事件名叫 html-webpack-plugin-alter-asset-tags的事件可以帮助我完成任务,所以我写了下面这样的代码:
var qcdn = require('@q/qcdn')
function CdnPlugin (options) {}
CdnPlugin.prototype.apply = function (compiler) {
compiler.plugin('compilation', function(compilation) {
compilation.plugin('html-webpack-plugin-alter-asset-tags', function(htmlPluginData, callback) {
console.log('> Static file uploading cdn...')
var bodys = htmlPluginData.body.map(upload(compilation, htmlPluginData, 'body'))
var heads = htmlPluginData.head.map(upload(compilation, htmlPluginData, 'head'))
Promise.all(heads.concat(bodys))
.then(function (result) {
console.log('> Static file upload cdn done!')
callback(null, htmlPluginData)
})
.catch(callback)
})
})
}
var extMap = {
script: {
ext: 'js',
src: 'src'
},
link: {
ext: 'css',
src: 'href'
},
}
function upload (compilation, htmlPluginData, type) {
return function (item, i) {
if (!extMap[item.tagName]) return Promise.resolve()
var source = compilation.assets[item.attributes[extMap[item.tagName].src].replace(/^(\/)*/g, '')].source()
return qcdn.content(source, extMap[item.tagName].ext)
.then(function qcdnDone(url) {
htmlPluginData[type][i].attributes[extMap[item.tagName].src] = url
return url
})
}
}
module.exports = CdnPlugin其实原理并不复杂,compilation.assets 里保存了文件内容,htmlPluginData 里保存了如何输出html, 所以从 compilation.assets 中读取到文件内容然后上传CDN,然后用上传后的CDN地址把htmlPluginData 中的本地地址替换掉就行了。
然后将这个插件添加到build/webpack.prod.conf.js配置文件中。
这里有个关键点是,html中的依赖和静态文件中的依赖是不同的处理方式。
什么意思呢,举个例子:
源码编译后生成了几个静态文件,把这些静态文件上传到cdn,然后用cdn地址替换掉html里的本地地址(就是上面CdnPlugin刚刚做的事情)
你以为完事了? No!No!No!
CdnPlugin 只是把在html中引入的编译后的js,css上传了cdn,但是js,css中引入的图片或者字体等文件并没上传cdn
如果代码中引入了本地的某个图片或字体,编译后这些地址还是本地的,此时的html是有依赖的,是不纯的,如果只把html上线了,代码中依赖的这些图片和字体在服务器上找不到文件就会有问题
所以需要先把源码中依赖的静态文件(图片,字体等)上传到cdn,然后在把编译后的静态文件(js,css)上传cdn。
代码中依赖的静态文件例如图片,怎么上传cdn呢?
答案是用 loader 来实现,webpack 中的 loader 以我的理解它是一个filter,或者是中间件,总之就是 import 一个文件的时候,这个文件先通过loader 过滤一遍,把过滤后的结果返回,过滤的过程可以是 babel 这种编译代码,当然也可以是上传cdn,所以我写了下面这样的代码:
var loaderUtils = require('loader-utils')
var qcdn = require('@q/qcdn')
module.exports = function(content) {
this.cacheable && this.cacheable()
var query = loaderUtils.getOptions(this) || {}
if (query.disable) {
var urlLoader = require('url-loader')
return urlLoader.call(this, content)
}
var callback = this.async()
var ext = loaderUtils.interpolateName(this, '[ext]', {content: content})
qcdn.content(content, ext)
.then(function upload(url) {
callback(null, 'module.exports = ' + JSON.stringify(url))
})
.catch(callback)
}
module.exports.raw = true其实就是把 content 上传CDN,然后把CDN地址抛出去
有了这个loader 之后,在 import 图片的时候,拿到的就是一个cdn的地址~
但是我不想在开发环境也上传cdn,我希望只有在生成环境才用这个loader,所以我设置了一个 disable 的选项,如果 disable 为 true,我使用 url-loader 来处理这个文件内容。
最后把loader也添加到配置文件中:
rules: [
...,
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
loader: path.join(__dirname, 'cdn-loader'),
options: {
disable: !isProduction,
limit: 10000,
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
}
]写好了 cdn-loader 和 cdn-plugin 之后,已经可以编译出一个无任何依赖的纯html,下一步就是把这个html文件发布上线
我们部门有自己的发布上线的工具叫 hera 可以把代码发布到docker机上进行编译,然后把编译后的纯html文件发布到事先配置好的服务器的指定目录中
编译的流程是先把代码发布到编译机上 -> 编译机启动 docker (docker可以保证编译环境相同) -> 在 docker 中执行 npm install 安装依赖 -> 执行 npm run build 编译 -> 把编译后的 html 发送到服务器
因为每次编译都需要安装依赖,速度非常慢,所以我们有一个 diffinstall 的逻辑,每次安装依赖都会进行一次 diff,把有缓存的直接用缓存copy到node_modules,没缓存的使用qnpm安装,之后会把这次新安装的依赖缓存一份。依赖缓存了之后每次安装依赖速度明显快了很多。
现在项目已经可以正常开发和上线啦~
虽然项目可以正常开发了,但我觉得还不够,我希望项目可以有 mock 数据的功能并且可以检查服务端返回的数据是否正确,可以避免因为接口返回数据不正确的问题debug好久。
所以我开发了一个简单的模块 api-proxy ,就是封装了一个http client,可以配置请求信息和Mock 规则,开启Mock的时候使用Mock规则生成Mock数据返回,不开启Mock的时候使用Mock规则来校验接口返回是否符合预期。
那么 api-proxy 怎样使用呢?
举个例子:
.
└── api
└── log
├── index.js
└── fetchLogs.js
/*
* /api/log/fetchLogs.js
*/
export default {
options: {
url: '/api/operatelog/list',
method: 'GET'
},
rule: {
'data': {
'list|0-20': [{
'id|3-7': '1',
'path': '/log/opreate',
'url': '/operate/log?id=3',
'user': 'berwin'
}],
'pageData|7-8': {
'cur': 1,
'first': 1,
'last': 1,
'total_pages|0-999999': 1,
'total_rows|0-999999': 1,
'size|0-999999': 1
}
},
'errno': 0,
'msg': '操作日志列表'
}
}/*
* /api/log/index.js
*/
import proxy from '../base.js'
import fetchLogs from './fetchLogs.js'
export default proxy.api({
fetchLogs
})使用:
import log from '@/api/log'
log.fetchLogs(query)
.then(...)考虑到特殊情况,也并不是强制必须这样使用,我还是抛出了一个 api方法来供开发者正常使用,例如:
// 不使用api-proxy的api
import {api} from './base'
export default {
getUserInfo (sid) {
return api.get('/api/user/getUserInfo', {
params: {
sid
}
})
}
}这个 api 就是 axios ,并没做什么特殊处理。
项目开发中会用到一些配置文件,比如开发环境需要配置一个server地址用来设置api请求的server。开发环境的配置文件每个人都不一样,所以我在 .gitignore 中把这个dev.conf 屏蔽掉,并没有入到版本库中,所以就带来了一个问题,每次有新人进入到这个项目,在第一次搭建项目的时候,总是要手动创建一个 dev.conf 文件,我希望能自动创建配置文件
正巧之前我写了一个类似于 vue-cli 的工具 speike-cli,也是通过模板生成项目的一个工具,所以这一次正好派上用场,我把配置文件定义了一个模板,然后使用 speike 来生成了一个配置文件
// package.json
{
"scripts": {
"init": "speike init ./config/init-tpl ./config/dev.conf"
}
}这次该有的都有了,可以愉快的写码了,为了以后有类似的管理系统创建项目方便,我把这次精心设计的架构,编译逻辑等定制成了模板,日后可以直接使用speike 选择这个模板来生成项目。
经过上面一系列做的事,最后整理一下项目工程化的生命周期

今天在公司内部听月影讲《如何写“好” JavaScript》,其中重点提到了函数式编程,听完之后很有感想,于是写一篇文章来谈谈我对函数式编程的理解
对前面的例子不感兴趣的同学可以直接拉到最后看结论。
聊函数式编程前,先看几个高阶函数的例子,月影的PPT中也是从高阶函数讲起的
block.onclick = function (evt) {
block.onclick = null;
evt.target.className = 'hide';
setTimeout(function () {
document.body.removeChild(block);
}, 2000);
};这样这个 block 的点击事件只能生效一次,有些同学可能还会写出下面的代码实现同样的功能
let clicked = false;
block.onclick = function (evt) {
if (clicked === false) {
clicked = true
evt.target.className = 'hide';
setTimeout(function () {
document.body.removeChild(block);
}, 2000);
}
};月影说写出这样代码的同学是要被开除的。😂😂😂
使用高阶函数实现:
function once (fn) {
return function (...args) {
if (fn) {
let ret = fn.apply(this, args);
fn = null;
return ret;
}
}
}
block.onclick = once(function (evt) {
console.log('hide');
evt.target.className = 'hide';
setTimeout(function () {
document.body.removeChild(block);
}, 2000);
});把执行一次的功能抽象成一个高阶函数 once,然后把原始功能函数传入 once 得到一个新的功能函数,新的功能函数只能执行一次。
节流的意思是不管函数调用的速度有多快,函数执行最多n毫秒执行一次(调用一次后n毫秒内不在执行)
例如用鼠标快速点击按钮:
function throttle (fn, time = 500) {
let timer;
return function (...args) {
if (timer == null) {
fn.apply(this, args);
timer = setTimeout(() => {
timer = null;
}, time)
}
}
}
btn.onclick = throttle(function (e) {
circle.innerHTML = parseInt(circle.innerHTML) + 1;
circle.className = 'fade';
setTimeout(() => circle.className = '', 250);
});可以看出 节流 和 点击一次 是同一个逻辑,将 节流 抽象成高阶函数 throttle,然后把原始功能函数传入 throttle 得到一个新的功能函数,新的功能函数具有节流的功能。
连击效果类似直播送礼物一个礼物送了多次的那个效果,查看DEMO
function consumer (fn, time) {
let tasks = [],
timer;
return function (...args) {
tasks.push(fn.bind(this, ...args));
if (timer == null) {
timer = setInterval(() => {
tasks.shift().call(this)
if (tasks.length <= 0) {
clearInterval(timer);
timer = null;
}
}, time)
}
}
}
btn.onclick = consumer((evt) => {
let t = parseInt(count.innerHTML.slice(1)) + 1;
count.innerHTML = `+${t}`;
count.className = 'hit';
let r = t * 7 % 256,
g = t * 17 % 128,
b = t * 31 % 128;
count.style.color = `rgb(${r},${g},${b})`.trim();
setTimeout(() => {
count.className = 'hide';
}, 500);
}, 800)连击 其实也是在 节流 的基础上加工一下
好了高阶函数先说到这,从上面三个例子可以看出,高阶函数就是一个函数return了另一个函数,用月影的话来说就是:它们自身输入函数或返回函数,被称为高阶函数
看完了高阶函数的几个例子后,在看几个函数式编程的例子:
switcher.onclick = function (evt) {
if (evt.target.className === 'on') {
evt.target.className = 'off';
} else {
evt.target.className = 'on';
}
}使用函数式实现:
function toggle (...actions) {
return function (...args) {
let action = actions.shift();
actions.push(action);
return action.apply(this, args);
}
}
switcher.onclick = toggle(
evt => evt.target.className = 'off',
evt => evt.target.className = 'on'
);用函数式实现后扩展性强了很多,比如说三态:
function toggle (...actions) {
return function (...args) {
let action = actions.shift();
actions.push(action);
return action.apply(this, args);
}
}
switcher.onclick = toggle(
evt => evt.target.className = 'warn',
evt => evt.target.className = 'off',
evt => evt.target.className = 'on'
);使用函数式方式实现可以实现N多态,而不需要改动代码,抽象的很完美
function batch (fn) {
return function (target, ...args) {
if (target.length >= 0) {
return Array.from(target).map(item => fn.apply(this, [item, ...args]));
} else {
return fn.apply(this, [target, ...args]);
}
}
}
function setColor (el, color) {
el.style.color = color;
}
function setFontSize (el, fontSize) {
el.style.fontSize = fontSize;
}
setColor = batch(setColor);
setFontSize = batch(setFontSize);
let items1 = document.querySelectorAll('ul > li:nth-child(2n + 1)');
let items2 = document.querySelectorAll('ul > li:nth-child(3n + 1)');
setColor(items1, 'red');
setColor(items2, 'green');
setFontSize(items2, '22px');这个例子有两个功能单一的函数 setColor 和 setFontSize,然后写了一个高阶函数 batch,将原始功能函数传入高阶函数 batch 里,然后返回一个函数可以支持批量操作的功能
基于这个例子在加工一下:
function batch (fn) {
return function (target, ...args) {
if (target.length >= 0) {
return Array.from(target).map(item => fn.apply(this, [item, ...args]));
} else {
return fn.apply(this, [target, ...args]);
}
}
}
function queriable (fn) {
return function (selector, ...args) {
if (typeof selector === 'string') {
selector = document.querySelectorAll(selector);
}
return fn.apply(this, [selector, ...args]);
}
}
function setColor (el, color) {
el.style.color = color;
}
function setFontSize (el, fontSize) {
el.style.fontSize = fontSize;
}
setColor = queriable(batch(setColor));
setFontSize = queriable(batch(setFontSize));
setColor('ul > li:nth-child(2n + 1)', 'red');
setColor('ul > li:nth-child(3n + 1)', 'green');
setFontSize('ul > li:nth-child(3n + 1)', '22px');这个例子新增了一个高阶函数 queriable,实现了查询功能。将 batch 传入 queriable 后生成一个新函数支持查询功能。
在加工一下:
function batch (fn) {
return function (target, ...args) {
if (target.length >= 0) {
return Array.from(target).map(item => fn.apply(this, [item, ...args]));
} else {
return fn.apply(this, [target, ...args]);
}
}
}
function queriable (fn) {
return function (selector, ...args) {
if (typeof selector === 'string') {
selector = document.querySelectorAll(selector);
}
return fn.apply(this, [selector, ...args]);
}
}
function pack (map) {
return function (el, obj) {
for (let key in obj) {
map[key].call(this, el, obj[key]);
}
}
}
function setColor (el, color) {
el.style.color = color;
}
function setFontSize (el, fontSize) {
el.style.fontSize = fontSize;
}
let css = pack({color: setColor, fontSize: setFontSize});
css = queriable(batch(css));
css('ul > li:nth-child(2n + 1)', {color: 'red'});
css('ul > li:nth-child(3n + 1)', {color: 'green', fontSize: '22px'});这个例子又新增了一个高阶函数 pack,将功能单一的函数通过对象的方式传入到 pack 后生成了新函数,新函数可以接受对象类型的值来设置颜色和字体大小。
最后在加工一下:
function batch (fn) {
return function (target, ...args) {
if (target.length >= 0) {
return Array.from(target).map(item => fn.apply(this, [item, ...args]));
} else {
return fn.apply(this, [target, ...args]);
}
}
}
function queriable (fn) {
return function (selector, ...args) {
if (typeof selector === 'string') {
selector = document.querySelectorAll(selector);
}
return fn.apply(this, [selector, ...args]);
}
}
function pack (map) {
return function (el, obj) {
for (let key in obj) {
map[key].call(this, el, obj[key]);
}
}
}
function methodize (fn, prop) {
return function (...args) {
fn.apply(null, [prop ? this[prop] : this, ...args]);
return this;
}
}
function setColor (el, color) {
el.style.color = color;
}
function setFontSize (el, fontSize) {
el.style.fontSize = fontSize;
}
function setText (el, text) {
el.innerHTML = text;
}
let css = pack({color: setColor, fontSize: setFontSize});
css = queriable(batch(css));
let text = queriable(batch(setText));
function E (selector) {
this._selector = selector;
}
E.prototype.css = methodize(css, '_selector');
E.prototype.text = methodize(text, '_selector');
function $(selector){
return new E(selector);
}
$('ul > li:nth-child(2n + 1)').css({color: 'red'}).text('abc');
$('ul > li:nth-child(3n + 1)').css({color: 'green', fontSize: '22px'});这个例子新增了一个高阶函数 methodize,函数中的 return this 很关键,这个函数主要的功能就是使用 return this,来实现链式调用。
前面写了那么多例子,看起来复杂,但其实我反而觉得很简单,因为在我的眼里,函数式编程其实就是无数个高阶函数组装在一起完成一个很复杂的功能。
而这些高阶函数我把它理解成下面这张图的样子:
你会发现,当滚球兽一步一步进化到战斗暴龙兽之后,它已经具备了 pack,batch,queriable,methodize 这些高阶函数所提供的所有功能。
所以简单来说,就是可以把 pack,batch,queriable,methodize 理解成类似于中间件、插件,或者 webpack中的loader(webpack 中的loader也是前一个loader的处理结果丢给下个loader继续处理),例如我手里拿着一个最原始的功能函数,比如 setColor,先丢给pack处理生成一个新函数,然后把处理后的新函数在丢给 batch 以此类推
简单说就是上一个高阶函数的输出是下一个高阶函数的输入,而这个输出和输入不仅仅是数据,也可以是函数
所以函数式编程,抽象的过程很重要,例如哪些逻辑是需要抽象成高阶函数的。还有就是玩参数,如果在自己的业务当中使用函数式编程的话,我觉得保证上一个函数的输出丢到下一个函数的输入是否能正常工作是一个需要注意的事。
理解了我说的内容,在回到文章的开头把这些例子重新看一遍,你会发现好像世界都不一样了。
我对函数式编程也不是特别的精,目前还在研究阶段,,,,,
声明:如果您觉得我理解的不对,请大佬指点~
FMP(全称“First Meaningful Paint”,翻译为“首次有效绘制”)表示页面的“主要内容”开始出现在屏幕上的时间点。它是我们测量用户加载体验的主要指标。
通常我们使用测评工具(例如:Lighthouse)就可以得到FMP值。但是这里有一个问题是:不同产品的“主要内容”是不一样的;对于博客,主要内容是文章标题+首屏文本(可见的文本)、对于搜索引擎主要内容就是搜索结果。
只有我们自己最清楚我们产品的主要内容是什么,那么测评工具是如何捕获出FMP值的?它捕获出的这个FMP准么?
本文我们将针对这两个问题进行详细的讨论。
本小节我们将介绍一种基于布局的方法来捕获FMP,它的准确率可以达到77%。
随着网页的加载与解析,浏览器会将布局对象(Layout Object)逐步添加到布局树(Layout Tree)上进行布局。
以Google搜索结果页为例,下图给出了该页面在加载时布局对象被添加到布局树中的数量和时间(横坐标为时间,纵坐标为数量)。
图1 - 布局对象
FCP(First Contentful Paint)的时间在1.577秒,此时已经有60个布局对象被添加到了布局树中,这时候页面只渲染了一个Header;在1.86秒的时候,有261个布局对象被添加到布局树中,这些对象是搜索结果,随后在1.9秒进行了一个绘制(Paint),这个绘制是FMP;随后一些剩余的页面底部等部分的布局对象被添加到布局树中并进行绘制,最终页面在2.425秒完成。
从这个例子中我们会发现,布局对象的数量与页面加载的完整性密切相关。
经过大量试验与测试,最终发现大量的新布局对象被添加到布局树中的时间,和FMP非常接近。并且在FMP这个场景下,新布局对象的数量比重新布局的布局对象数量更重要。
所以我们得出一个关于FMP的公式:
FMP = 最大布局变动之后的那个绘制(Paint)
最大布局变动指的是哪个时间点布局对象被添加到布局树中的数量是最大的。
如图1所示,最大布局变动在1.86秒,而下一个绘制时间是1.907秒,所以1.907这个时间是FMP。
通过这种方式捕获出来的FMP,精准度大概在57.1%,比单纯的FCP强很多,但是在多数情况下,它还是没有办法捕获出真正有意义的绘制。
假设我们有一个很长的页面,下图给出了这个页面的布局对象被添加到布局树中的数量和时间:
图2 - 布局对象2
在图2中,该页面最主要的内容在6.047秒被绘制出来,所以这个页面的FMP应该是6.047秒,但是如果按照我们前面的算法,则给出的FMP是24.25秒,因为23.8秒是最大布局变动,而最大布局变动的下一个绘制时间是24.25秒。
但事实是24.25秒这个绘制并不重要,因为它在屏幕之外的区域进行绘制,用户根本看不到这部分内容。
如何防止这些屏幕外的布局扰乱测量FMP的精准度?最理想的方式是计算元素是否可见,但是在布局期间进行昂贵的计算也不是一个好办法。所以解决方案是使用“权重”,当布局对象的位置超过屏幕的高度时,降级它的权重。所以现在我们使用布局的“意义”来捕获FMP,而不是布局对象的“数量”。
所以我们可以得出一个改进后的计算FMP的公式:
意义 = 当前时间布局对象的数量 / max(1, 页面高度/屏幕高度)
FMP = 意义值最大的一次布局变动之后的那个绘制(Paint)
注意:在这个公式中,页面高度 = 当前布局对象在页面中的位置
下图给出了使用该公式计算出的“布局意义”流线图:
图5 - 布局意义
现在,意义最大的一次布局变动在5.89秒,下一次绘制的时间是6.047秒,而这个时间就是FMP。通过这个算法捕获出的FMP准确率可以达到62.1%。
Web字体可以打破这个算法捕获FMP的准确率,假设某个网页的最大布局变动是在2.51秒,但是这个时候屏幕上没有任何内容,因为Web字体还在加载中。
Web字体为什么会导致这种情况以及如何优化,不在本文的讨论范围
Blink的布局层逻辑根本不关心文字是否显示,但是字体是否显示对于用户体验却至关重要,所以在计算FMP时,应该把字体的可见性也考虑进去。
当布局发生时,如果有Web字体在加载中,那么应该延迟记录布局变动,直到字体加载完毕,但是需要设置3秒钟的超时时间,不然无限制的等下去也不行。但是如果把这个规则应用于所有Web字体有些过于激进,因为有一些icon字体其实也不是很重要,它不应该影响FMP的时间,所以最终选了200多个可以阻塞记录FMP时间的字符。现在计算FMP的准确率可以达到77%。
本文介绍了基于布局的方式捕获FMP的原理,现在我们应该明白使用工具捕获出的FMP到底是什么。
本质上这个数字并不是真正的FMP,它只是通过算法来猜测某个时间点可能是FMP,而这个时间点,是依靠布局对象的数量、意义、以及Web字体推算出来的,目前准确率可以达到77%。
前段时间,我将精力专注在Web性能领域;在这个领域下有个重要的课题是如何让网页更丝滑(流畅)。
想让网页变得丝滑,首先,我们需要一个标准来判断什么样的网页是丝滑的;其次,我们要准确的测量出网页的性能数据;最后,使用有效的方法让网页变得丝滑。
本篇文章将针对这三个方面进行详细的介绍。
到底怎样的网页是丝滑的?我们需要一个标准来辅助判断我们的网页是否丝滑。
Chrome团队提出了一个以用户为中心的性能模型被称为RAIL,它为工程师提供一个目标,只要达到目标的网页,用户就会觉得很流畅;它将用户体验拆解为一些关键操作,例如:点击,加载等;并给这些操作规定一个目标,例如:点击一个按钮后,多长时间给反馈用户会觉得流畅。
RAIL将影响性能的行为划分为四个方面,分别是:Response、Animation、Idle 与Load。没错,RAIL这个名字来自于这四个单词的首字母,方便记忆。
研究表明,100ms内对用户的输入操作进行响应,通常会被人类认为是立即响应。时间再长,操作与反应之间的连接就会中断,人们就会觉得它的操作有延迟。例如:当用户点击一个按钮,如果100ms内给出响应,那么用户就会觉得响应很及时,不会察觉到丝毫延迟感。
现如今大多数设备的屏幕刷新频率是60Hz,也就是每秒钟屏幕刷新60次;因此网页动画的运行速度只要达到60FPS,我们就会觉得动画很流畅。
F P S 指的画面每秒钟传输的帧数,60FPS指的是每秒钟60帧;换算下来每一帧差不多是16毫秒。(1 秒 = 1000 毫秒) / 60 帧 = 16.66 毫秒/帧
但通常浏览器需要花费一些时间将每一帧的内容绘制到屏幕上(包括样式计算、布局、绘制、合成等工作),所以通常我们只有10毫秒来执行JS代码。
为了更好的性能,通常我们会充分利用浏览器空闲周期做一些低优先级的事情。例如:在空闲周期预请求一些接下来可能会用到的数据或上报分析数据等。
RAIL规定,空闲周期内运行的任务不得超过50ms,当然不止RAIL规定,W3C性能工作组的Longtasks标准也规定了超过50毫秒的任务属于长任务,那么50ms这个数字是怎么得来的呢?
浏览器是单线程的,这意味着同一时间主线程只能处理一个任务,如果一个任务执行时间过长,浏览器则无法执行其他任务,用户会感觉到浏览器被卡死了,因为他的输入得不到任何响应。
为了达到100ms内给出响应,将空闲周期执行的任务限制为50ms意味着,即使用户的输入行为发生在空闲任务刚开始执行,浏览器仍有剩余的50ms时间用来响应用户输入,而不会产生用户可察觉的延迟。如图1-1所示:
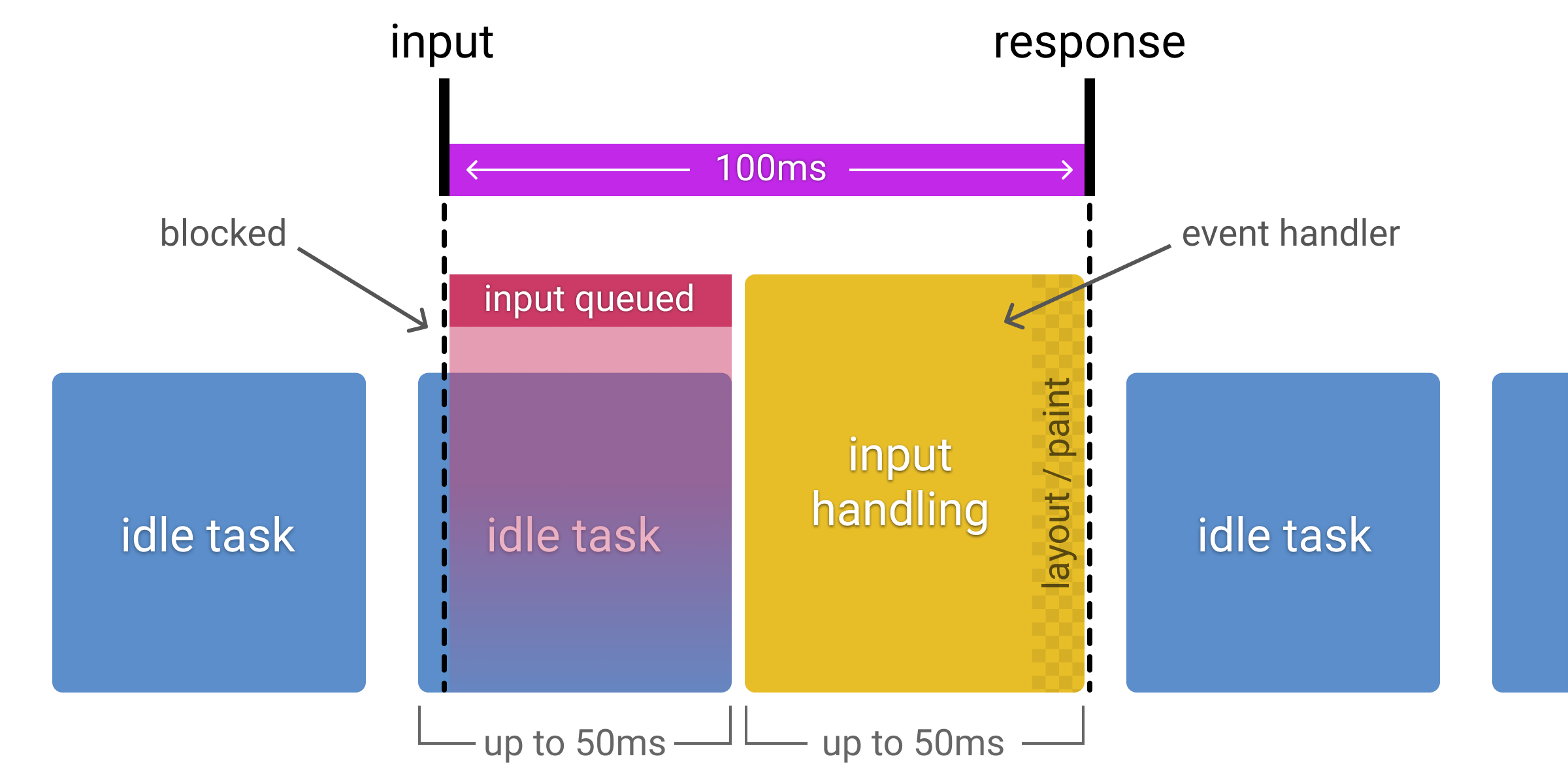
事实上,不论是空闲任务还是高优先级的其他任务,执行时间都不得超过50ms。
如果不能在1秒钟内加载网页并让用户看到内容,用户的注意力就会分散。用户会觉得他要做的事情被打断,如果10秒钟还打不开网页,用户会感到失望,会放弃他们想做的事,以后他们或许都不会再回来。
通过RAIL,我们可以判断出我们的网页是否丝滑。RAIL从用户感知角度出发规定了一些指标,只要我们的网页符合标准,则我们的网页是丝滑的,用户会觉得我们的网页很流畅。
| RAIL | 关键指标 | 用户操作 |
|---|---|---|
| 响应(Response) | 小于100ms | 点击按钮。 |
| 动画(Animation) | 小于16ms | 滚动页面,拖动手指,播放动画等。 |
| 空闲(Idle) | 小于50ms | 用户没有与页面交互,但应该保证主线程足够处理下一个用户输入。 |
| 加载(Load) | 1000ms | 用户加载页面并看到内容。 |
像素管道是制作丝滑网页的灵魂,我们后面将要介绍的技术都与它有关。
上图就是像素管道,通常我们会使用JS修改一些样式,随后浏览器会进行样式计算,然后进行布局,绘制,最后将各个图层合并在一起完成整个渲染的流程,这期间的每一步都有可能导致页面卡顿。
注意,并不是所有的样式改动都需要经历这五个步骤。举例来说:如果在JS中修改了元素的几何属性(宽度、高度等),那么浏览器需要需要将这五个步骤都走一遍。但如果您只是修改了文字的颜色,则布局(Layout)是可以跳过去的,如下图所示:
除了最后的合成,前面四个步骤在不同的场景下都可以被跳过。例如:CSS动画就可以跳过JS运算,它不需要执行JS。
css-triggers给出了不同的CSS属性被更改后会触发像素管道的哪些步骤。
简单来说,像素管道经历的步骤越多,渲染时间就越长,单个步骤内可能也会因为某种原因而变得耗时很长;所以不管是步骤多还是单个步骤耗费的时间长,最终都会导致整体渲染时间变长。整体时间越长就越有可能超出RAIL所规定的指标。
举个简单的例子:网页动画的渲染若是达到60FPS,则动画不会丢帧。假设渲染管道的布局与绘制耗费了10ms,那么加上样式计算与合成的时间,则留给JS处理动画的时间就只有几毫秒,如果JS的执行超过了几毫秒那么该动画每一帧所耗费的时间就会超过16ms,这时候动画一定会丢帧,用户用肉眼就可以看到明显的卡顿。
当然,即便能保证每一帧的总耗时小于16ms,依然无法保证不会丢帧。关于这点后面我们会详细介绍。
动画需要达到60FPS才能变得丝滑,本节我们介绍如何让动画在不丢帧的情况下稳定保持在60FPS。
在评估动画性能时,通常需要逐帧评估像素管道的开销;使用 Chrome 开发者工具可以辅助我们进行精准的测量。
在Chrome开发者工具中,点击Performance面板,然后选中Screenshots复选框,。如图3-1所示:
图3-1Chrome开发者工具Performance面板
然后点击录制按钮,录制完毕后点击停止按钮就可以捕获当前页面的性能数据。如图3-2所示:
图3-2捕获性能数据
捕获出的结果如图3-3所示:
图3-3捕获出的性能结果
我们可以放大主线程从而精准的看到每一帧浏览器都执行了哪些任务以及每个任务耗费了多长时间。如图3-4所示:
图3-4性能面板最主要的部分
从上图可以看到,浏览器每一帧渲染所执行的任务与前面我们介绍的像素管道是相同的。上图中因为是CSS动画,所以没有运行JS,但每一帧都需要计算样式、布局、绘制与合成。
JS动画是使用定时器不停的执行JS,通过在JS中修改样式完成网页动画;若想保证动画流畅,从JS的执行到最终浏览器显示出画面,每一帧总耗时最多16ms,这样动画才能达到60FPS。
如图3-4所示,即便是在不执行JS的情况下,浏览器计算样式、布局、绘制等工作也是需要时间的,所以需要给浏览器预留出 充分的时间 做这些事情,现在留给JS的执行时间就只有 10ms。
图3-5每一帧总体耗时必须小于16ms,JS运行时间小于10ms
一旦JS运行时间超过10ms,就很有可能导致这一帧的像素管道整体耗时超过16ms,从而无法达到60FPS,但你以为只要保证JS的运行时间小于10ms就一定能保证不丢帧?Naive~
requestAnimationFrame即便你能保证每一帧的总耗时都小于16ms,也无法保证一定不会出现丢帧的情况,这取决于触发JS执行的方式。
假设使用 setTimeout 或 setInterval 来触发JS执行并修改样式从而导致视觉变化;那么会有这样一种情况,因为setTimeout 或 setInterval没有办法保证回调函数什么时候执行,它可能在每一帧的中间执行,也可能在每一帧的最后执行。所以会导致即便我们能保障每一帧的总耗时小于16ms,但是执行的时机如果在每一帧的中间或最后,最后的结果依然是没有办法每隔16ms让屏幕产生一次变化。如图3-6所示:
图3-6使用定时器触发动画
也就是说,即便我们能保证每一帧总体时间小于16ms,但如果使用定时器触发动画,那么由于定时器的触发时机不确定,所以还是会导致动画丢帧。现在整个Web只有一个API可以解决这个问题,那就是requestAnimationFrame,它可以保证回调函数稳定的在每一帧最开始触发。如图3-7所示:
图3-7使用requestAnimationFrame触发动画
先执行JS,然后在JS中修改了样式从而导致样式计算,然后样式的改动触发了布局、绘制、合成。但JavaScript可以强制浏览器将布局提前执行,这就叫
F
S
L
。
图3-8强制同步布局
通常我们一不小心就造成了FSL,请看下面代码:
box.classList.add('big');
const width = box.offsetWidth;代码中通过新增class修改了元素的样式,随后使用offsetWidth读取元素的宽度。乍一看似乎没什么问题,但这段代码会导致FSL。
在 JavaScript 运行时,上一帧已经渲染好的所有布局值都是已知的,我们可以使用offsetWidth这样的语法获得值;但这一帧刚修改完的样式浏览器还没渲染呢,这时候使用offsetWidth这样的语法读取元素的宽度,那么浏览器为了告诉我们宽度值,它必须先计算该宽度,这就需要布局。如图3-8所示,布局跑到了样式计算的前面。
所以正确的做法是先获取宽度,然后再更改样式:
const width = box.offsetWidth;
box.classList.add('big');看起来,似乎即使触发了FSL也不过就是管道的顺序变了而已,影响好像并没有那么大。🤔
单个FSL对性能的影响确实不大,但如果触发了布局抖动,则影响会变得非常大。看下面代码:
const container = document.querySelector('.container');
const boxes = document.querySelectorAll('p');
for (var i = 0; i < boxes.length; i++) {
// Read a layout property
const newWidth = container.offsetWidth;
// Then invalidate layouts with writes.
boxes[i].style.width = newWidth + 'px';
}上面代码的作用是批量修改N个P元素的宽度;在循环中我们先获取容器元素的宽度,随后设置了P元素的样式。这会导致浏览器去布局,然后计算样式。每次更改样式,都会导致刚刚执行的布局失效,因为我们又改了新的样式,所以下一轮循环读取宽度时,浏览器又要执行一次布局,如此反复直到循环结束。在循环期间,浏览器不停地执行无效布局,这被称为 布局抖动;这种错误导致的性能问题非常高。
如果我们不小心触发了FSL,Chrome开发者工具会给出红色的线提示,如图3-9所示:
图3-9开发者工具提示FSL
同时任务的右上角会有红色的三角形表示,我们可以放大任务进一步查看,如图3-10所示:
图3-10开发者工具提示FSL详情
若想看Demo可以点击我,在Demo中点击按钮可以让P标签的宽度变长。
为了避免布局抖动,我们可以将读取元素宽度的代码放到循环的外面。代码如下:
const container = document.querySelector('.container');
const boxes = document.querySelectorAll('p');
// Read a layout property
const newWidth = container.offsetWidth;
for (var i = 0; i < boxes.length; i++) {
// Then invalidate layouts with writes.
boxes[i].style.width = newWidth + 'px';
}若想看Demo可以点击我,可以看到这个Demo与前一个demo一模一样,甚至我们无法用肉眼分辨出哪个更快,这是因为DOM元素少,所以总体时间都比较少,但我们可以通过Chrome开发者工具来捕获性能数据。
图3-11优化后的时间
图3-11可以看到,优化后这一帧的总时间用了4.7ms,而优化前的是101ms,如图3-12所示:
图3-12优化前的时间
优化后比优化前,每帧所耗费的时间快了21.7倍,数字非常惊人。
CSS动画通常使用@keyframe或transition结合样式的变动来实现视觉变化的效果。我们同样可以通过减少像素管道的步骤和每个步骤所耗费的时间让CSS动画更流畅。
本节介绍的CSS动画的优化方式同样适用于JS动画,但上一节介绍的JS动画优化方法不适用于CSS动画,它们是包含关系。
绘制通常需要花费很长时间,我们可以通过Chrome开发者工具来观察正在绘制的区域。打开开发者工具,按下键盘上的 Esc 键。在出现的面板中,切换到“rendering”标签,然后选中“Paint flashing”。如图3-13所示:
图3-13开启绘制闪烁
开启绘制闪烁后,每当页面发生绘制时,我们都可以在屏幕上看到绘制发生区有绿色在闪烁。如图3-14所示:
图3-14绘制区域闪烁
如图3-14所示,当我们开启了绘制闪烁,则会绘制区域出现了绿色的闪烁,可以点击我查看Demo。
当我们看到我们认为不应该绘制的区域时,我们应该进一步研究并取消绘制区域。
如何才能避免绘制的发生呢?答案是:图层。
事实上浏览器在渲染页面时,可以将页面分为很多个图层,有点类似于PhotoShop,一张图片在PotoShop中是由多个图层组合而成,而浏览器最终显示的页面实际也是由多个图层构成的。如图3-15所示:
图3-15图层
将原本不断发生变化的元素提升到单独的图层中,就不再需要绘制了,浏览器只需要将两个图层合并在一起即可,查看Demo请狠狠的点击我。
如果您点击了上面的Demo地址,并开启了绘制闪烁,您会发现没有任何闪烁发生,因为浏览器没有进行绘制。如果您查看Layers面板,你会看到这样的场景,如图3-16:
3-16图层
当我们使用Performance面板捕获性能数据时会发现绘制已经不见了。如图3-17所示:
图3-17捕获不到绘制
创建图层的最佳方式是使用will-change,但某些不支持这个属性的浏览器可以使用3D 变形(transform: translateZ(0))来强制创建一个新层。
在Chrome开发者工具“rendering”标签中,选中“Layer borders”。可以看到页面中有哪些合成层。合成层会使用橘黄色的边框,如图3-18所示:
图3-18显示合成层
为了减少绘制,可以通过新增图层,但是图层的管理也是需要成本的,所以要避免滥用,通常需要具体情况具体分析,做出合适的选择。
前面我的Demo都是修改元素的left属性让方块移动,这避免不了需要进行布局操作,最佳的方法是使用transform属性,这个属性是由合成器单独处理的,所以使用这个属性可以避免布局与绘制。
RAIL可以帮助我们判断什么样的网页是丝滑的,而开发者工具可以让我们进一步准确的捕获出网页的性能数据。
JS动画要保证预留出6ms的时间给浏览器处理像素管道,而自身执行时间应该小于10ms来保证整体运行速度小于16ms。但触发动画的时机也很重要,定时器无法稳定的触发动画,所以我们需要使用requestAnimationFrame触发JS动画。同时我们应该避免一切FSL,它对性能的影响非常大。
CSS动画我们可以通过降低绘制区域并且使transform属性来完成动画,同时我们需要管理好图层,因为绘制和图层管理都需要成本,通常我们需要根据具体情况进行权衡并做出最好的选择。

本文假设你已经对Vue的变化侦测和渲染机制有一些了解。
如果不了解请移步《深入浅出 - vue变化侦测原理》、《PPT:深入浅出Vue.js - VirtualDOM篇》
异步更新队列指的是当状态发生变化时,Vue异步执行DOM更新。
我们在项目开发中会遇到这样一种场景:当我们将状态改变之后想获取更新后的DOM,往往我们获取到的DOM是更新前的旧DOM,我们需要使用vm.$nextTick方法异步获取DOM,例如:
Vue.component('example', {
template: '<span>{{ message }}</span>',
data: function () {
return {
message: '没有更新'
}
},
methods: {
updateMessage: function () {
this.message = '更新完成'
console.log(this.$el.textContent) // => '没有更新'
this.$nextTick(function () {
console.log(this.$el.textContent) // => '更新完成'
})
}
}
})我们都知道这样做很麻烦,但为什么Vue还要这样做呢?
首先我们假设Vue是同步执行DOM更新,会有什么问题?
如果同步更新DOM将会有这样一个问题,我们在代码中同步更新数据N次,DOM也会更新N次,伪代码如下:
this.message = '更新完成' // DOM更新一次
this.message = '更新完成2' // DOM更新两次
this.message = '更新完成3' // DOM更新三次
this.message = '更新完成4' // DOM更新四次但事实上,我们真正想要的其实只是最后一次更新而已,也就是说前三次DOM更新都是可以省略的,我们只需要等所有状态都修改好了之后再进行渲染就可以减少一些无用功。
而这种无用功在Vue2.0开始变得更为重要,Vue2.0开始引入了Virtualdom,每一次状态发生变化后,状态变化的信号会发送给组件,组件内部使用VirtualDOM进行计算得出需要更新的具体的DOM节点,然后对DOM进行更新操作,每次更新状态后的渲染过程需要更多的计算,而这种无用功也将浪费更多的性能,所以异步渲染变得更加至关重要。
组件内部使用VIrtualDOM进行渲染,也就是说,组件内部其实是不关心哪个状态发生了变化,它只需要计算一次就可以得知哪些节点需要更新。也就是说,如果更改了N个状态,其实只需要发送一个信号就可以将DOM更新到最新。例如:
this.message = '更新完成'
this.age = 23
this.name = berwin代码中我们分三次修改了三种状态,但其实Vue只会渲染一次。因为VIrtualDOM只需要一次就可以将整个组件的DOM更新到最新,它根本不会关心这个更新的信号到底是从哪个具体的状态发出来的。
那如何才能将渲染操作推迟到所有状态都修改完毕呢?很简单,只需要将渲染操作推迟到本轮事件循环的最后或者下一轮事件循环。也就是说,只需要在本轮事件循环的最后,等前面更新状态的语句都执行完之后,执行一次渲染操作,它就可以无视前面各种更新状态的语法,无论前面写了多少条更新状态的语句,只在最后渲染一次就可以了。
将渲染推迟到本轮事件循环的最后执行渲染的时机会比推迟到下一轮快很多,所以Vue优先将渲染操作推迟到本轮事件循环的最后,如果执行环境不支持会降级到下一轮。
当然,Vue的变化侦测机制决定了它必然会在每次状态发生变化时都会发出渲染的信号,但Vue会在收到信号之后检查队列中是否已经存在这个任务,保证队列中不会有重复。如果队列中不存在则将渲染操作添加到队列中。
之后通过异步的方式延迟执行队列中的所有渲染的操作并清空队列,当同一轮事件循环中反复修改状态时,并不会反复向队列中添加相同的渲染操作。
所以我们在使用Vue时,修改状态后更新DOM都是异步的。
说到这里简单介绍下什么是事件循环。
JS中存在一个叫做执行栈的东西。JS的所有同步代码都在这里执行,当执行一个函数调用时,会创建一个新的执行环境并压到栈中开始执行函数中的代码,当函数中的代码执行完毕后将执行环境从栈中弹出,当栈空了,也就代表执行完毕。
这里有一个问题是代码中不只是同步代码,也会有异步代码。当一个异步任务执行完毕后会将任务添加到任务队列中。例如:
setTimeout(_=>{}, 1000)代码中setTimeout会在一秒后将回调函数添加到任务队列中。事实上异步队列也分两种类型:微任务、宏任务。
微任务和宏任务的区别是,当执行栈空了,会检查微任务队列中是否有任务,将微任务队列中的任务依次拿出来执行一遍。当微任务队列空了,从宏任务队列中拿出来一个任务去执行,执行完毕后检查微任务队列,微任务队列空了之后再从宏任务队列中拿出来一个任务执行。这样持续的交替执行任务叫做事件循环。
属于微任务(microtask)的事件有以下几种:
属于宏任务(macrotask)的事件有以下几种:
通过前面介绍的内容,我们知道Vue的更新操作默认会将执行渲染操作的函数添加到微任务队列中,而微任务的执行时机优先于宏任务。所以有一个很有意思的事情是,我们在代码中如果先使用setTimeout将函数注册到宏任务中,然后再去修改状态,在setTimeout注册的回调中依然可以获取到更新后的DOM,例如:
new Vue({
// ...
methods: {
// ...
example: function () {
// 先使用setTimeout向宏任务中注册回调
setTimeout(_ => {
// DOM现在更新了
}, 0)
// 后修改数据向微任务中注册回调
this.message = 'changed'
}
}
})之所以会出现这种现象原因前面我们也提到过,是因为修改数据默认会将更新DOM的回调添加到微任务(microtask)队列中,如果我们将获取DOM的操作放到宏任务(macrotask)中,那么注册的位置就变得不那么重要了,无论在哪里注册都是先更新DOM然后再获取DOM。因为微任务(microtask)中的任务比宏任务(macrotask)中的任务先执行。
而如果使用vm.$nextTick向微任务队列中插入任务,则代码中注册的顺序就非常重要,因为渲染操作和使用vm.$nextTick注册的回调都是向微任务队列中添加任务,那么执行回调的顺序就会按照插入队列中的循序去执行,也就是说,先插入队列的先执行。例如:
new Vue({
// ...
methods: {
// ...
example: function () {
// 先使用nextTick注册回调
this.$nextTick(function () {
// DOM没有更新
})
// 后修改数据
this.message = 'changed'
}
}
})代码中先使用vm.$nextTick注册任务,后修改数据,所以在微任务队列中它比渲染操作的位置更靠前,所以优先执行,所以在回调执行的时候页面中的DOM并没有发生变化。
必须先修改数据后使用vm.$nextTick注册回调才能获取到更新后的DOM,例如:
new Vue({
// ...
methods: {
// ...
example: function () {
// 先修改数据
this.message = 'changed'
// 后使用nextTick注册回调
this.$nextTick(function () {
// DOM已经更新
})
}
}
})代码中可以看到,先修改数据,后使用vm.$nextTick注册回调,那么在微任务队列中渲染操作比vm.$nextTick注册的回调位置更靠前,所以先执行渲染后,在执行vm.$nextTick注册的回调,所以在回调中可以获取到更新后的DOM。
两月以后,看着电脑,我回想起接到通知说要开发小程序引擎的那个下午。当时的我以为,这个小程序和其他小程序都不一样,因为它是个假的,其实是个网页。两月之后,我才发现,“噢~原来大家都是这么做的啊”。
最近一直在做小程序的底层实现,过程中磕磕绊绊也多次进行架构方向上的转型,趁着周末抽空写一篇文章记录一下开发过程中遇到的问题和一些思考与决策。
本篇文章更多的是在描述架构与技术方向层面的思考和决策,不会过多介绍具体某个问题是如何解决的,因为细节实在太多。
当时的我将我们的小程序定位成一个SPA,因为我们的小程序的宿主环境是浏览器。
它只是看起来像小程序(因为这个窗口没有地址栏什么的),但其实包括UI渲染和事件交互在内的绝大部分功能都是基于Web技术,虽然会提供Native和OS的一些能力与API,但本质上其实是个网页。又考虑到目前很多人使用第三方工具用Vue或React写小程序,我就在思考:“反正本质上就是一个网页,那为什么不原生内置Vue让用户直接用Vue的语法写小程序呢?”。
所以当时定了一个基本方向:让开发者使用Vue开发我们的小程序,开发体验完全与Web保持一致。
虽然开发体验与Web保持一致,但是Web技术实在是太开放了,开发者可以为所欲为。这种情况在小程序中是不允许的,不允许使用<iframe>、不允许<a>直接外跳到其他在线网页、不允许开发者触碰DOM、不允许使用某些未知的危险API等。
所以遇到的第一个问题是如何禁止用户在Vue的模板中使用iframe或a或其他不允许使用的东西。
若想做到这一点就不得不对Vue的渲染层进行一个托管与改造。
对Vue进行改造通常有两种方案:
polyfill的手法覆盖一些Vue原生提供的API第一个方案能力有限,有一些Vue内部的逻辑没有办法通过polyfill的形式更改。第二种方案的缺陷是如果我只想修改Vue中的某一块逻辑,其他我不修改的部分如果有Bug,Vue官方更新了版本我没有办法同步。
这两种方案都有缺陷和不足,所以我没有使用这两个其中的任何一个,我使用了另一个方案,我觉得应该是目前为止最好的一种方案。
我简单介绍一下这种方案:
node_modules里因为我需要对渲染层进行改造,所以我需要重设web这个别名,如下:
const path = require('path')
module.exports = {
'vue$': path.resolve(__dirname, '../src/web/entry-runtime-with-compiler'),
compiler: 'vue/src/compiler',
core: 'vue/src/core',
shared: 'vue/src/shared',
web: path.resolve(__dirname, '../src/web'),
weex: 'vue/src/platforms/weex',
server: 'vue/src/server',
sfc: 'vue/src/sfc'
}大致原理是:如果import了一个不需要改造的,那其实是import了node_modules里的原始Vue的文件,如果是import了需要改造的,那其实import的是我的目录,文件也是我修改后的文件。
对这方面技术有兴趣可以留言详细讨论,由于不是本文重点,不再展开。
Vue通过一系列计算之后最终产出的结果是一些指令,比如创建一个DOM元素,移除一个DOM元素,插入到某个位置等。
所以当时的做法就简单在创建DOM元素时,用tagName校验是否在黑名单中,如果在黑名单中就触发警告并怎么怎么样。
但其实这种做法只能是:防君子不防小人。
项目做到这里遇到一个问题是不论怎样,都没有办法防止开发者做一些我们想禁用的功能。因为是一个网页,开发者可以执行JS,可以操作DOM,可以操作BOM,可以做一切事情。
所以我们开始考虑将用户的代码放到一个绝对安全的沙箱中去执行。
在Web技术下,可以将用户的代码放到Web Worker中去执行,也可以放到一个隐藏的iframe中去执行,或者宿主环境提供一个环境。无论怎样,目的都是相同的,就是把用户的代码放到一个绝对安全的沙箱中执行。
由于开发者是基于Vue.js开发,用户的代码是没有办法单独放到沙箱中去执行的,所以我把Vue也放到沙箱中去执行。
这个时候技术架构和技术方向被调整成了Master-Slave的双线程模式。
沙箱中的代码我称为Master,它通过一系列计算,最终输出一些指令:创建元素、修改元素、插入元素、路由跳转、事件绑定等一些基础指令。这些指令从沙箱中通过线程间的消息机制传递到网页中,这个网页有一个模块叫做Slave,它负责监听Master发过来的指令并根据指令做指定操作。
把Vue放到Web Worker中执行需要解决非常多的问题,比如:原本Vue直接对DOM的操作需要转换成向另一个线程发送指令,还有事件绑定问题,事件的Event对象问题,事件修饰符(event.preventDefault)问题,路由控制(双向的)问题,表单元素的双向绑定问题、ref问题等。因为线程间的消息传递只能传递字符串,所以很多东西就会变得非常麻烦。
不过这些具体的技术问题都是比较容易解决的,比较难的问题是两个:“性能”和“原生能力受限”。
在这种架构下,当页面有大范围UI变化时(例如首次渲染),Logic线程需要往UI线程发送大量的指令,包括:创建DOM,插入DOM,绑定事件等,每条指令都是一个单独的跨线程的消息通信,当消息数量庞大时,性能问题就会暴露出来,而且非常明显。
如果去Chrome DevTools的Performance面板看,会发现UI线程其实很闲,但是渲染的就是很慢。因为消息传递的代价,而且每次encode与decode也都需要代价,我自己写DEMO时没发现问题,但是投放到生产环境下去渲染一个真实的组件时,就会发现性能问题非常明显。
这个架构下虽然有性能问题,但以我的能力想解决这个问题也并不是太困难。另一个问题(原生能力受限)是这个架构下永远都无法解决的一个问题。
为了安全,需要把用户的代码放到沙箱中去执行,但因为想让用户使用Vue开发,所以Vue也得放到沙箱中,这就导致了一个无法解决的问题是:我们官方提供的原生组件,也会受限。
道理很简单,假设用户在模板中使用了一个官方原生提供的组件,那么这个组件一定是需要提前注册到Vue中的,那就代表,我们官方提供的组件,也得放在沙箱中,所以把我们自己也给限制住了。
导致我们官方想提供视频组件,音频组件就很困难,因为我们官方组件也不能碰DOM和BOM,就更不用说提供其他Native能力的组件了。
当然这个问题在不改架构的情况下还是有办法强行解决的,解决方案是这样的:
官方组件先在沙箱中注册一个Vue的组件,然后这个组件不去实现具体的功能,只是接收用户传递的数据,然后把数据传递给UI线程,然后UI线程有一个这个组件对应的真实的组件去做具体的功能并最终渲染到UI上。
每一个组件都需要这样做,这对开发组件的同学非常不友好,他们需要理解这个小程序底层的架构是如何运行的,而且还会增加很多工作量。
这不是我想要的,我希望的是不管我底层是单线程还是双线程,对上层开发是无感知的。而且因为Vue.js是在沙箱中做各种操作,也不确定未来会不会有什么需求是无法满足的,技术风险太高了。
到了这一步,我已经慢慢的开始感受到,Vue已经成为瓶颈,它限制了我。
不只是因为技术原因,也因为一些其他原因,比如风险太高,时间紧,最终决定先将方案切换回单线程,这样至少说可以保证这个项目不用延期。然后另一边再去慢慢调研并研究出一个技术方案可以解决之前遇到的所有问题。
似乎又回到了起点,因为单线程有单线程的问题,那就是Web技术太开放了,我们无法做到“安全”和对开发者进行“管控”。
不过我们还是在单线程模式下找到了可以提高一定安全性的方案,方案是通过ShadowDOM的Close模式把Body锁住。这样开发者自己的代码是无法操作DOM的,因为被我锁住了,但是开发者的JavaScript是自由的。
在这个架构下,开发者可以操作DOM,可以操作BOM,可以操作Vue.js,什么都可以干,但它无法直接操作被我锁住的ShadowDOM,想操作这个ShadowDOM,必须通过合法的途径操作,而这个ShadowDOM才是小程序用于展示的主要的窗口。
然后对于BOM上的某些危险API,会被提前禁用掉。
这个方案似乎解决了所有问题,但还是为未来留下了一点隐患,只要开发者的JavaScript是自由的,你就永远无法知道他会用他的JavaScript做什么。对于某些未知的漏洞,可能非常危险,这为日后留下了一个风险,事情会变成一场官方和开发者之间持久的攻防战。
无论怎样,这个方案解决了目前遇到的所有问题,这也为我留下了非常多的时间去研究真正的小程序应该怎样做。
最终,我发现双线程才是正确的方向,只有把用户的代码放到沙箱里执行才能真正的做到:“安全”和“管控”。
不过这一次我决定不再使用Vue.js,我需要开发一个全新的框架来支持双线程这种模式。上一次的双线程之所以会失败,主要原因是上一次是UI线程比较轻,而Logic线程比较重,用户的代码,Vue.js,官方的组件都跑在Logic线程下,而这个线程只是一个JS运行时,所以我们的原生能力会受到限制。
而这一次我决定让UI重一点,Logic轻一点。只把用户的代码和框架的一部分下放到Logic线程,大部分操作和原生组件都放在UI线程下执行。
Worker线程只是做一些计算然后把数据传递到UI线程,然后大部分工作都在UI下面执行,并且官方的组件在UI这边执行。
这样可以解决之前遇到的两个问题:性能和原生能力受限。
因为线程之间的消息通道只传递数据,而数据不会像绘制UI指令数量那么多,可以说根本不在一个数量级,性能问题解决了,而且不光解决了性能问题,还顺带着提升了性能,因为无论用户代码写的执行效率再怎么低,都不会卡死UI线程。
原生能力受限的问题也解决了,因为官方提供的组件根本不在这个线程下运行,安全和管控的问题也解决了。
之前我一直以为其他小程序是Native渲染的,而我是基于Web技术实现的,但偶然有一次看到一些资料,才发现,原来大家都是基于Web技术实现的小程序,而实现方式也大致相同,遇到的问题也都一样。
可能唯一的区别是,我不需要多个webview,我只需要一个网页就够了,所以我可以把Logic线程的代码放到Web Worker里,而其他小程序是多个webview,所以他们不能用Web Worker,不过没有本质区别。
前一段时间各种小程序多端框架满天飞,准确的说,这些框架都是“翻译”器,就我个人觉得,以翻译为基础在不同小程序之间进行跨端,只能算是一种临时性技术方案。
我觉得真正的终极技术方案,有两种:
第一种,使用小程序提供的canvas的一些API实现一个渲染引擎,然后在渲染引擎上实现一些布局引擎,在此基础上提供的框架和其他能力都是统一的,不同平台之间只需要实现不同的渲染引擎即可。不过我不确定小程序提供的canvas能不能做到这一点,不过Web浏览器提供的canvas可以做到,像SpriteJS就做到了。
第二种,各大小程序厂商共同制定一套标准,按照标准实现各自的API,这种情况是比较好的,而且也不是完全没有可能。最近各大小程序厂商已经在W3C起草了小程序白皮书。
我捡重要的列一下白皮书中的内容:
.ma后缀的文件)仔细看到这里的读者应该会对我开发小程序的整个过程和一些决策有一个大致的了解。
大家对小程序的底层实现都是使用双线程模型,大家对外宣称都会说是为了:
但其实真正的原因其实是:“安全”和“管控”,其他原因都是附加上去的。
因为Web技术是非常开放的,JavaScript可以做任何事。但在小程序这个场景下,它不会给开发者那么高的权限:
当然,想解决这些问题不一定非要使用双线程模型,但双线程模型无疑是最合适的技术方案。
声明,本文仅限学习使用,最终会使用什么方案目前还无法明确表示。技术因素以及非技术因素都会影响最终技术方案的决策。
学习koa需要一些相关知识,有两个关键词
本文主要针对koa的原理进行讨论,属于深度篇,并不会对koa的使用过多介绍。
如果在阅读过程中,发现有哪些地方我写的不太清楚,不容易理解,希望能提出,我会参考建议并进行修改~~
让我们从一张图开始
上图中,详细说明了koa从启动server之前,到接受请求在到响应请求的过程中,经历了哪些步骤。
那我们按照时间线说起~
图中有三个蓝色的方块,分别代表三个静态类。
什么是静态类?这个是我自己给起的名,哈哈
静态类就是程序运行前就存在的方法集合,动态类就是通过代码生成出的方法集合。额,都是我自己起的名,概念也是我自己琢磨的,就是简单归个类。
三个静态类分别是Request,Context,Response
Request
Request中包含了一些操作 Node原生请求对象的非常有用的方法。例如获取query数据,获取请求url等,更多方法去查API
Response
Response中包含了一些用于设置状态码啦,主体数据啦,header啦,等一些用于操作响应请求的方法。更多方法去查API
Context
Context是koa中最重要的概念之一,Context字面意思是上下文,也有环境等意思,koa中的操作都是基于这个context进行的,例如
this.body = 'hello world';从前面的图中,启动前的三个蓝色方块可以看到,左边的Request和右边的Response各有一个箭头指向Context,表示Request和Response自身的方法会委托到Context中。
Context中有两部分,一部分是自身属性,主要是应用于框架内部使用,一部分是Request和Response委托的操作方法,主要为提供给用户更方便从Request获取想要的参数和更方便的设置Response内容。
下面是Context源码片段。
var delegate = require('delegates');
var proto = module.exports = {}; // 一些自身方法,被我删了
/**
* Response delegation.
*/
delegate(proto, 'response')
.method('attachment')
.method('redirect')
.method('remove')
.method('vary')
.method('set')
.method('append')
.access('status')
.access('message')
.access('body')
.access('length')
.access('type')
.access('lastModified')
.access('etag')
.getter('headerSent')
.getter('writable');
/**
* Request delegation.
*/
delegate(proto, 'request')
.method('acceptsLanguages')
.method('acceptsEncodings')
.method('acceptsCharsets')
.method('accepts')
.method('get')
.method('is')
.access('querystring')
.access('idempotent')
.access('socket')
.access('search')
.access('method')
.access('query')
.access('path')
.access('url')
.getter('origin')
.getter('href')
.getter('subdomains')
.getter('protocol')
.getter('host')
.getter('hostname')
.getter('header')
.getter('headers')
.getter('secure')
.getter('stale')
.getter('fresh')
.getter('ips')
.getter('ip');delegates是第三方npm包,功能就是把一个对象上的方法,属性委托到另一个对象上
对了,你猜对了,上面那一排方法,都是Request和Response静态类中的方法,有点看目录的感觉~
method方法是委托方法,getter方法用来委托getter,access方法委托getter+setter
下面是源码片段
function Delegator(proto, target) {
if (!(this instanceof Delegator)) return new Delegator(proto, target);
this.proto = proto;
this.target = target;
this.methods = [];
this.getters = [];
this.setters = [];
this.fluents = [];
}
Delegator.prototype.method = function(name){
var proto = this.proto;
var target = this.target;
this.methods.push(name);
proto[name] = function(){
return this[target][name].apply(this[target], arguments);
};
return this;
};从上面的代码中可以看到,它其实是在proto上新建一个与Request和Response上的方法名一样的函数,然后执行这个函数的时候,这个函数在去Request和Response上去找对应的方法并执行。
简单来个栗子
var proto = {};
var Request = {
test: function () {
console.log('test');
}
};
var name = 'test';
proto[name] = function () {
return Request[name].apply(Request, arguments);
};我们在来看看getter方法
Delegator.prototype.getter = function(name){
var proto = this.proto;
var target = this.target;
this.getters.push(name);
proto.__defineGetter__(name, function(){
return this[target][name];
});
return this;
};可以看到,在proto上绑定个getter函数,当函数被触发的时候去,会去对应的request或response中去读取对应的属性,这样request或response的getter同样会被触发~
我们在来看看access
Delegator.prototype.access = function(name){
return this.getter(name).setter(name);
};可以看到,这个方法是getter+setter,getter上面刚说过,setter与getter同理,不多说了,心好累....
应用启动前的内容到现在就说完了,接下来我们看看使用koa来启动一个app的时候,koa内部会发生什么呢?
我们使用koa来启动server的时候有两个步骤。第一步是init一个app对象,第二步是用app对象监听下端口号,一个server就启动好了。
// 第一步 - 初始化app对象
var koa = require('koa');
var app = koa();
// 第二步 - 监听端口
app.listen(1995);简单吧?
不了解内部机制的同学,通常会认为server是在koa()这个时候启动的,app.listen只是监听下端口而已~
事实上。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。并不是。
有木有被刷新三观???
我们看下源码片段
module.exports = Application;
function Application() {
if (!(this instanceof Application)) return new Application;
this.env = process.env.NODE_ENV || 'development';
this.subdomainOffset = 2;
this.middleware = [];
this.proxy = false;
this.context = Object.create(context);
this.request = Object.create(request);
this.response = Object.create(response);
}从源码中可以看到,执行koa()的时候初始化了一些很有用的东西,包括初始化一个空的中间件集合,基于Request,Response,Context为原型,生成实例等操作。
Request和Response的属性和方法委托到Context中也是在这一步进行的
并没有启动server
我们看第二步,在看一段源码
app.listen = function(){
debug('listen');
var server = http.createServer(this.callback());
return server.listen.apply(server, arguments);
};可以看到,在执行app.listen(1995)的时候,启动了一个server,并且监听端口。熟悉nodejs的同学知道http.createServer接收一个函数作为参数,每次服务器接收到请求都会执行这个函数,并传入两个参数(request和response,简称req和res),那么现在重点在this.callback这个方法上。
我们一起看一下this.callback是何方神圣
app.callback = function(){
if (this.experimental) {
console.error('Experimental ES7 Async Function support is deprecated. Please look into Koa v2 as the middleware signature has changed.')
}
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
var self = this;
if (!this.listeners('error').length) this.on('error', this.onerror);
return function(req, res){
res.statusCode = 404;
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);
}
};这个方法其实可以分成两部分,一部分是执行函数的那一瞬间所执行的代码,另一部分是接收请求的时候所执行的代码。
而前一部分就是总体流程图中,启动server这个时间段,黄色椭圆形所执行的那一部分,初始化中间件!!!
先说第一部分,很明显,这环节是在初始化中间件,那为什么要初始化中间件呢?处理后的中间件与处理之前的中间件又有什么不同呢????
童鞋,,,不要着急,听我慢慢道来~~
我们添加中间的时候使用app.use方法,其实这个方法只是把中间件push到一个数组,然后就没有然后了。。(⊙﹏⊙)
很明显,所有中间件都在数组中,那么它们之间是没有联系的,如果没有联系,就不可能实现流水线这样的功能。。。。
那么这些中间件处理之后会变成什么样的????
我们先看代码,上面的代码中用this.experimental这个属性做了一个判断。这个属性是什么鸟。
this.experimental 关于这个属性我并没有在官方文档上看到说明,但以我对koa的了解,这个方法是为了判断是否支持es7,默认是不支持的,如果想支持,需要在代码中明确指定this.experimental = true,开启这个属性之后,中间件可以传入async函数。
我想说的是,无论是否开启ES7,原理都是相同的,只是因为语法特性的不同,需要不同的处理,核心**不会因为不同的语言特性而改变,支持ES7显然处理起来更方便,因为默认不开启this.experimental,所以这里我们针对不开启的情况进行讨论~
这样一来,第一部分的代码就简化成了这样
var fn = co.wrap(compose(this.middleware));虽然只剩下一行代码,但不要小瞧它哦~~
我们先看compose(this.middleware)这部分,compose的全名叫koa-compose,他的作用是把一个个不相干的中间件串联在一起。。
例如
// 有3个中间件
this.middlewares = [function *m1() {}, function *m2() {}, function *m3() {}];
// 通过compose转换
var middleware = compose(this.middlewares);
// 转换后得到的middleware是这个样子的
function *() {
yield *m1(m2(m3(noop())))
}有木有很神奇的感觉??更神奇的是,generator函数的特性是,第一次执行并不会执行函数里的代码,而是生成一个generator对象,这个对象有next,throw等方法。
这就造成了一个现象,每个中间件都会有一个参数,这个参数就是下一个中间件执行后,生成出来的generator对象,没错,这就是大名鼎鼎的 next
那compose是如何实现这样的功能的呢??我们看一下代码
/**
* Expose compositor.
*/
module.exports = compose;
/**
* Compose `middleware` returning
* a fully valid middleware comprised
* of all those which are passed.
*
* @param {Array} middleware
* @return {Function}
* @api public
*/
function compose(middleware){
return function *(next){
if (!next) next = noop();
var i = middleware.length;
while (i--) {
next = middleware[i].call(this, next);
}
return yield *next;
}
}
/**
* Noop.
*
* @api private
*/
function *noop(){}这是这个模块的所有代码,很简单,逻辑是这样的
先把中间件从后往前依次执行,并把每一个中间件执行后得到的generator对象赋值给变量next,当下一次执行中间件的时候(也就是执行前一个中间件的时候),把next传给第一个参数。这样就保证前一个中间件的参数是下一个中间件生成的generator对象,第一次执行的时候next为noop,noop是空的generator函数。
koa的中间件必须为generator函数(就是带星号的函数),否则无法顺利的执行中间件逻辑
最后,有一个非常巧妙的地方,就是最后一行return yield *next;
这行代码可以实现把compose执行后return的函数变成第一个中间件,也就是说,执行compose之后会得到一个函数,执行这个函数就与执行第一个中间件的效果是一模一样的,这主要依赖了generator函数的yield *语句的特性。
现在中间件的状态就已经从不可用变成可用了。不可用的中间件是一个数组,可用的中间件是一个generator函数。
我们接着说刚才没说完的
var fn = co.wrap(compose(this.middleware));上面这段代码现在就可以理解成下面这样
var fn = co.wrap(function *() {yield *m1(m2(m3(noop())))});里面的函数刚刚已经说过是可用状态的中间件,那么co.wrap是干什么用的呢??
co是TJ大神基于Generator开发的一款流程控制模块,白话文就是:就是把异步变成同步的模块。。。(感觉逼格瞬间拉低了。。。)
看下源码
co.wrap = function (fn) {
createPromise.__generatorFunction__ = fn;
return createPromise;
function createPromise() {
return co.call(this, fn.apply(this, arguments));
}
};从源码中可以看到,它接收一个参数,这个参数就是可用状态下的中间件,返回一个函数createPromise,当执行createPromise这个函数的时候,调用co并传入一个参数,这个参数是中间件函数执行后生成的Generator对象。
这意味着,返回的这个函数是触发执行中间件逻辑的关键,一旦这个函数被执行,那么就会开始执行中间件逻辑
app.callback = function(){
if (this.experimental) {
console.error('Experimental ES7 Async Function support is deprecated. Please look into Koa v2 as the middleware signature has changed.')
}
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
var self = this;
if (!this.listeners('error').length) this.on('error', this.onerror);
return function(req, res){
res.statusCode = 404;
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);
}
};从源码中,可以看到这个函数赋值给fn,fn是在下面那个函数中执行的,下面那个函数是接下来要说的内容~
到现在,我们的koa已经处于一种待机状态,所有准备都以准备好(中间件和context),万事俱备,只欠东风。。。。。。
东风就是request请求~~
前面说了启动前的一些准备工作和启动时的初始化工作,现在最后一步就是接收请求的时候,koa要做的事情了,这部分也是koa中难度最大的一部分。不过认真阅读下去会有收获的。。
上面我们说this.callback这个方法有两个部分,第一个部分是初始化中间件,而另一部分就是接收请求时执行的函数啦。
简单回顾下
// 创建server并监听端口
app.listen = function(){
debug('listen');
var server = http.createServer(this.callback());
return server.listen.apply(server, arguments);
};
// 这个方法返回的函数会被传递到http.createServer中,http.createServer这个方法的作用是每当服务器接收到请求的时候,都会执行第一个参数,并且会传递request和response
app.callback = function(){
if (this.experimental) {
console.error('Experimental ES7 Async Function support is deprecated. Please look into Koa v2 as the middleware signature has changed.')
}
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
var self = this;
if (!this.listeners('error').length) this.on('error', this.onerror);
return function(req, res){
res.statusCode = 404;
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);
}
};所以第二部分的重点就是下面段代码啦~
return function(req, res){
res.statusCode = 404;
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);
}我们先看这段代码
var ctx = self.createContext(req, res);不知道各位童鞋还记不记得文章一开始的时候那个总体流程图下面的那个类似于八卦一样的东西???
这行代码就是创建一个最终可用版的context。
从上图中,可以看到分别有五个箭头指向ctx,表示ctx上包含5个属性,分别是request,response,req,res,app。request和response也分别有5个箭头指向它们,所以也是同样的逻辑。
这里需要说明下
不多说,咱们观摩下代码
app.createContext = function(req, res){
// 继承
var context = Object.create(this.context);
var request = context.request = Object.create(this.request);
var response = context.response = Object.create(this.response);
// 往context,request,response身上挂载属性
context.app = request.app = response.app = this;
context.req = request.req = response.req = req;
context.res = request.res = response.res = res;
request.ctx = response.ctx = context;
request.response = response;
response.request = request;
context.onerror = context.onerror.bind(context);
context.originalUrl = request.originalUrl = req.url;
context.cookies = new Cookies(req, res, {
keys: this.keys,
secure: request.secure
});
context.accept = request.accept = accepts(req);
context.state = {};
// 最后返回完整版context
return context;
};讲到这里其实我可以很明确的告诉大家,,,koa中的this其实就是app.createContext方法返回的完整版context
又由于这段代码的执行时间是接受请求的时候,所以表明每一次接受到请求,都会为该请求生成一个新的上下文
上下文到这里我们就说完啦。我们接着往下说,看下一行代码
onFinished(res, ctx.onerror);这行代码其实很简单,就是监听response,如果response有错误,会执行ctx.onerror中的逻辑,设置response类型,状态码和错误信息等。
源码如下:
onerror: function(err){
// don't do anything if there is no error.
// this allows you to pass `this.onerror`
// to node-style callbacks.
if (null == err) return;
if (!(err instanceof Error)) err = new Error('non-error thrown: ' + err);
// delegate
this.app.emit('error', err, this);
// nothing we can do here other
// than delegate to the app-level
// handler and log.
if (this.headerSent || !this.writable) {
err.headerSent = true;
return;
}
// unset all headers
this.res._headers = {};
// force text/plain
this.type = 'text';
// ENOENT support
if ('ENOENT' == err.code) err.status = 404;
// default to 500
if ('number' != typeof err.status || !statuses[err.status]) err.status = 500;
// respond
var code = statuses[err.status];
var msg = err.expose ? err.message : code;
this.status = err.status;
this.length = Buffer.byteLength(msg);
this.res.end(msg);
}我们接着说,还有最后一个知识点,也是本章最复杂的知识点,关于中间件的执行流程,这里会说明为什么koa的中间件可以回逆。
我们先看代码
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);co.wrap返回的那个函数总体上来说,执行fn.call(ctx)会返回promise,koa会监听执行的成功和失败,成功则执行respond.call(ctx);,失败则执行ctx.onerror,失败的回调函数刚刚已经讲过。这里先说说respond.call(ctx);。
我们在写koa的时候,会发现所有的response操作都是
this.body = xxx; this.status = xxxx;这样的语法,但如果对原生nodejs有了解的童鞋知道,nodejs的response只有一个api那就是res.end();,而设置status状态码什么的都有不同的api,那么koa是如何做到通过this.xxx = xxx来设置response的呢?
先看一张图,,我盗的图
从图中看到,request请求是以respond结束的。
是滴,所有的request请求都是以respond这个函数结束的,这个函数会读取this.body中的值根据不同的类型来决定以什么类型响应请求
我们来欣赏一下源码
function respond() {
// allow bypassing koa
if (false === this.respond) return;
var res = this.res;
if (res.headersSent || !this.writable) return;
var body = this.body;
var code = this.status;
// ignore body
if (statuses.empty[code]) {
// strip headers
this.body = null;
return res.end();
}
if ('HEAD' == this.method) {
if (isJSON(body)) this.length = Buffer.byteLength(JSON.stringify(body));
return res.end();
}
// status body
if (null == body) {
this.type = 'text';
body = this.message || String(code);
this.length = Buffer.byteLength(body);
return res.end(body);
}
// responses
if (Buffer.isBuffer(body)) return res.end(body);
if ('string' == typeof body) return res.end(body);
if (body instanceof Stream) return body.pipe(res);
// body: json
body = JSON.stringify(body);
this.length = Buffer.byteLength(body);
res.end(body);
}仔细阅读的童鞋会发现,咦,,,,为毛没有设置status和header等信息的代码逻辑?这不科学啊。我分明记得状态码是rs.statusCode = 400这样设置的,为啥代码中没有??
这就要从最开始的上下文说起了。为什么Response静态类中添加req和res属性?就是因为添加了req和res之后,response和request类就可以直接操作req和res啦。。我们看一段源码就明白了
set status(code) {
assert('number' == typeof code, 'status code must be a number');
assert(statuses[code], 'invalid status code: ' + code);
this._explicitStatus = true;
this.res.statusCode = code;
this.res.statusMessage = statuses[code];
if (this.body && statuses.empty[code]) this.body = null;
},主要是this.res.statusCode = code; this.res.statusMessage = statuses[code];这两句,statusCode和statusMessage都是nodejs原生api。有兴趣可以自行查看~
接下来我们开始说说koa的中间件为什么可以回逆,为什么koa的中间件必须使用generator,yield next又是个什么鬼?
我们看这段代码
fn.call(ctx)fn刚刚上面说过,就是co.wrap返回的那个函数,上面也说过,一旦这个函数执行,就会执行中间件逻辑,并且通过.call把ctx设为上下文,也就是this。
那中间件逻辑是什么样的呢。我们先看一下源码:
co.wrap = function (fn) {
createPromise.__generatorFunction__ = fn;
return createPromise;
function createPromise() {
return co.call(this, fn.apply(this, arguments));
}
};先回顾下,createPromise就是fn,每当执行createPromise的时候,都会执行co,中间件是基于co实现的、所以我们接下来要说的是co的实现逻辑。而执行co所传递的那个参数,我们给它起个名,就叫中间件函数吧,中间件函数也是一个generator函数,因为在执行co的时候执行了这个中间件函数,所以实际上真正传递给co的参数是一个generator对象,为了方便理解,我们先起个名叫中间件对象吧
那我们看co的源码:
function co(gen) {
var ctx = this;
var args = slice.call(arguments, 1)
// we wrap everything in a promise to avoid promise chaining,
// which leads to memory leak errors.
// see https://github.com/tj/co/issues/180
return new Promise(function(resolve, reject) {
if (typeof gen === 'function') gen = gen.apply(ctx, args);
if (!gen || typeof gen.next !== 'function') return resolve(gen);
onFulfilled();
/**
* @param {Mixed} res
* @return {Promise}
* @api private
*/
function onFulfilled(res) {
var ret;
try {
ret = gen.next(res);
} catch (e) {
return reject(e);
}
next(ret);
}
/**
* @param {Error} err
* @return {Promise}
* @api private
*/
function onRejected(err) {
var ret;
try {
ret = gen.throw(err);
} catch (e) {
return reject(e);
}
next(ret);
}
/**
* Get the next value in the generator,
* return a promise.
*
* @param {Object} ret
* @return {Promise}
* @api private
*/
function next(ret) {
if (ret.done) return resolve(ret.value);
var value = toPromise.call(ctx, ret.value);
if (value && isPromise(value)) return value.then(onFulfilled, onRejected);
return onRejected(new TypeError('You may only yield a function, promise, generator, array, or object, '
+ 'but the following object was passed: "' + String(ret.value) + '"'));
}
});
}可以看到,代码并不是很多。
首先执行co会返回一个promise,koa会对这个promise的成功和失败都准备了不同的处理,上面已经说过。
我们在看这段代码
function onFulfilled(res) {
var ret;
try {
ret = gen.next(res);
} catch (e) {
return reject(e);
}
next(ret);
}这个函数最重要的作用是运行gen.next来执行中间件中的业务逻辑。
通常在开发中间件的时候会这样写
yield next;所以ret中包含下一个中间件对象(还记得上面我们初始化中间件的时候中间件的参数是什么了吗??)
然后把下一个中间件对象传到了next(ret)这个函数里,next函数是干什么的?我们看看
function next(ret) {
if (ret.done) return resolve(ret.value);
var value = toPromise.call(ctx, ret.value);
if (value && isPromise(value)) return value.then(onFulfilled, onRejected);
return onRejected(new TypeError('You may only yield a function, promise, generator, array, or object, '
+ 'but the following object was passed: "' + String(ret.value) + '"'));
}可以看到,逻辑是这样的
如果中间件已经结束(没有yield了),那么调用promise的resolve。
否则的话把ret.value(就是下一个中间件对象),用co在包一层toPromise.call(ctx, ret.value);
if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);上面是toPromise中的一段代码
既然是用co又执行了一遍,那么co是返回promise的。所以返回的这个value就分别被监听了成功和失败的不同处理。
value.then(onFulfilled, onRejected);所以我们可以看到,如果第二个中间件里依然有yield next这样的语句,那么第三个中间件依然会被co包裹一层并运行.next方法,依次列推,这是一个递归的操作
所以我们可以肯定的是,每一个中间件都被promise包裹着,直到有一天中间件中的逻辑运行完成了,那么会调用promise的resolve来告诉程序这个中间件执行完了。
那么中间件执行完了之后,会触发onFulfilled,这个函数会执行.next方法。
所以有一个非常重要的一点需要注意,onFulfilled这个函数非常重要,重要在哪里???重要在它执行的时间上。
onFulfilled这个函数只在两种情况下被调用,一种是调用co的时候执行,还有一种是当前promise中的所有逻辑都执行完毕后执行
其实就这一句话就能说明koa的中间件为什么会回逆。
回逆其实是有一个去和一个回的操作
请求的时候经过一次中间件,响应的时候在经过一次中间件。
而onFulfilled的两种被调用的情况正好和这个回逆的过程对应上。
前方高能预警!!!
比如有3个中间件,当系统接收到请求的时候,会执行co,co会立刻执行onFulfilled来调用.next往下执行,将得到的返回结果(第二个中间件的generator对象,上面我们分析过)传到co中在执行一遍。以此类推,一直运行到最后一个yield,这个时候系统会等待中间件的执行结束,一旦最后一个中间件执行完毕,会立刻调用promise的resolve方法表示结束。(这个时候onFulfilled函数的第二个执行时机到了,这样就会出现一个现象,一个generator对象的yield只能被next一次,下次执行.next的时候从上一次停顿的yield处继续执行,所以现在当有一个中间件执行完毕后,在执行.next就会在前一个中间件的yield处继续执行)当最后一个中间件执行完毕后,触发promise的resolve,而别忘了,第二个中间件可是用then监听了成功和失败的不同处理方法,一旦第三个中间件触发成功,第二个中间件会立刻调用onFulfilled来执行.next,继续从第二个中间件上一次yield停顿处开始执行下面的代码,而第二个中间件的逻辑执行完毕后,同样会执行resolve表示成功,而这个时候第一个中间件正好也通过.then方法监听了第二个中间件的promise,也会立刻调用onFulfilled函数来执行.next方法,这样就会继续从第一个中间件上一次yield的停顿处继续执行下面的逻辑,以此类推。
这样就实现了中间件的回逆,通过递归从外到里执行一遍中间件,然后在通过promise+generator从里往外跳。
所以如果我们在一个中间件中写好多yield,就可以看出关键所在,先通过递归从外往里(从第一个中间件运行到最后一个中间件)每次遇到yield next就会进入到下一个中间件执行,当运行到最后发现没有yield的时候,会跳回上一个中间件继续执行yield后面的,结果发现又有一个yield next,它会再次进入到下一个中间件,进入到下一个中间件后发现什么都没有,因为yield的特性(一个generator对象的yield只能被next一次,下次执行.next的时候从上一次停顿的yield处继续执行),所以便又一次跳入上一个中间件来执行。以此类推。
我们试一下:
var koa = require('koa');
var app = koa();
app.use(function* f1(next) {
console.log('f1: pre next');
yield next;
console.log('f1: post next');
yield next;
console.log('f1: fuck');
});
app.use(function* f2(next) {
console.log(' f2: pre next');
yield next;
console.log(' f2: post next');
yield next;
console.log(' f2: fuck');
});
app.use(function* f3(next) {
console.log(' f3: pre next');
yield next;
console.log(' f3: post next');
yield next;
console.log(' f3: fuck');
});
app.use(function* (next) {
console.log('hello world')
this.body = 'hello world';
});
app.listen(3000);上面的代码打印的log是下面这样的
f1: pre next
f2: pre next
f3: pre next
hello world
f3: post next
f3: fuck
f2: post next
f2: fuck
f1: post next
f1: fuck如果非要画一个图的话,我脑海中大概长这样
其实刚刚那么一通复杂的逻辑下来,好多同学都会懵逼,那么我用白话文来说一下中间件的逻辑,大概是这样的
第一个中间件代码执行一半停在这了,触发了第二个中间件的执行,第二个中间件执行了一半停在这了,触发了第三个中间件的执行,然后,,,,,,第一个中间件等第二个中间件,第二个中间件等第三个中间件,,,,,,第三个中间件全部执行完毕,第二个中间件继续执行后续代码,第二个中间件代码全部执行完毕,执行第一个中间件后续代码,然后结束
用一张图表示大概是这样的。

为了方便理解,伪代码大概是下面这样
new Promise(function(resolve, reject) {
// 我是中间件1
yield new Promise(function(resolve, reject) {
// 我是中间件2
yield new Promise(function(resolve, reject) {
// 我是中间件3
yield new Promise(function(resolve, reject) {
// 我是body
});
// 我是中间件3
});
// 我是中间件2
});
// 我是中间件1
});这就是最核心的**!!!
简单总结一下,其实也很简单,只是第一次接触的同学可能暂时没有理解透彻。
其实就是通过generator来暂停函数的执行逻辑来实现等待中间件的效果,通过监听promise来触发继续执行函数逻辑,所谓的回逆也不过就是同步执行了下一个中间件罢了。
比如有几个中间件,mw1,mw2,mw3,mwn...
站在mw1的角度上看,它是不需要关系mw2里面有没有mw3,它只需要关心mw2何时执行完毕即可,当mw2执行完毕mw1继续执行yield之后的代码逻辑。其实很简单,callback也是这个原理,当mw2执行完毕执行下callback,mw1是不需要关心mw2里面究竟是怎样运行的,只要知道mw2执行完会执行回调就行了。mw2也是同样的道理不需要关心mw3。
到这里,关于koa我们就已经差不多都说完了。当然还有一些细节没有说,比如koa中的错误处理,但其实都是小问题啦,关于generator的错误处理部分弄明白了,自然就明白koa的错误处理是怎样的。这里就不在针对这些讲述了,一次写这么多确实有点累,或许后期会补充进来吧。。
最后,如果认真阅读下来的同学能感觉出来,koa中有两个最重要的地方,无论是使用上,还是**上,这两个点都非常重要,koa也只有这两个概念
最后说一些自己对koa的感觉,真他妈的是赏心悦目啊,真他妈的是优雅啊!!!每一行代码都浓缩了很多层含义,通过最少的代码实现最复杂的功能,对于我这种追求代码的极致优雅的人,看完koa之后,真的是感触良多,泪流满面啊。。。。
ppt:http://berwin.github.io/ppts/koa/
转载请注明出处


写在前面的话,最近频繁出现有人盗版我的原创文章、盗版我出版的书、抄袭我的文章、根据我的文章又写了一篇新的文章然后说是自己的研究成果、根据我的文章写了一个开源项目然后说是自己原创、根据我出版的书二次改写并开源到Github获得好几千Star等情况。
我愿意写硬核知识分享给大家是给大家学习与成长用的,也仅限于学习与学术交流使用。
我不希望我的文章以任何形式被转载、被二次改写、被盗版、被抄袭、或者根据我的文章开发了一个小程序框架开源出去骗star等侵占我版权的行为,一经发现必追究责任。
如果无法控制盗版行为,我将考虑关闭博客,开启白名单模式,只有白名单内的人可以阅读我的文章。为了帮助更多的人学习与进步,请大家拒绝盗版!
去年九月份写了篇文章 《小程序底层实现原理及一些思考》,讲述了我实现小程序的过程及一些思考,并揭露了一个事实:小程序是基于Web技术实现的。
兜兜转转尝试了很多方案,但不同的方案均存在一些问题,我试图找到完美的解决方案,功夫不负有心人,最终找到了。
在前文的最后,我提到最终还是要回到双线程,双线程才是正确的方向,现在经过验证这个方向非常正确。
但如何基于双线程实现小程序前文只是略微提及,因为当时也只是一个初步的设想,并没有实现出来。
当反复尝试了很多方案后,我开始重新思考,到底什么是小程序。
思考后得到的结论是,站在产品角度思考技术,小程序有两个特点:
小程序的定义和特点有很多,但我认为最根本的特点是以上两点
站在技术角度思考,小程序至少要保证四点:安全、稳定、性能、简单。
如果只是站在产品角度思考如何实现小程序其实非常简单。
基于宿主环境的不同可能实现方式不同
如果宿主环境是浏览器,任何一个网页都具备 “免安装” 的特点,浏览器只需提供一些拥有OS能力的API,这就是小程序了。
这和PWA区别不大,或许这也是很多人会拿小程序和PWA进行对比的原因。
如果宿主环境是一个超级APP(iOS或Android),任何一个WebView都具备免 “免安装” 的特点,超级APP只需提供一些拥有OS能力的API给WebView里面的代码用就可以了,套路都是一样的。
站在技术角度思考,为了保证安全性与稳定性问题,单线程这个方向就要完全放弃,这也是为什么上一篇文章的最后提到“双线程”是正确的方向。
事实上,双线程并不够,如果允许多个小程序同时运行,那么双线程无法解决稳定性的问题,正确的做法是使用 “多线程” ,将不同小程序的代码在不同的线程下执行。
如果同一时间只执行一个小程序,那么双线程(UI线程与逻辑线程)就可以满足“安全性”与“稳定性”的需求。但同时运行多个小程序,则需要多个逻辑线程同时执行不同小程序的逻辑,以及多个UI线程同时渲染不同小程序的UI。
多线程不只是解决多个小程序并存的问题,每个小程序还需要有自己的多个UI线程。
也就是说要完全抛弃SPA,小程序应该做成多页应用,而不是单页应用。
之所以采用多UI线程的原因是单页应用很难模拟原生应用切换页面的体验。单页应用在从A页面跳转到B页面时,其实画布还是那块画布,只是把A页面的内容擦掉把B页面的UI画上去了。这种原理在很多场景下很尴尬,举个例子:用户开发一款新闻信息流小程序,它有两个页面,A页面是新闻信息流,B页面是新闻详情页。那么当用户往下滑了很久后发现一个感兴趣的新闻,点击跳转到详情页,看完之后想回到A页面刚才的位置继续浏览。单页应用由于把A页面给擦掉了,所以这种场景下当从B回到A时,会发现A又重新刷新了一遍,体验非常糟糕。
采用多UI线程则可以解决这个问题,实现多UI线程并不复杂,如果宿主环境是浏览器,则可以在页面中使用多个iframe叠在一起,每当跳转页面时,创建一个新的iframe盖在最上面,当回退时,把最上层的iframe删除即可。如果宿主环境是手机上的超级APP,则把iframe改成WebView,套路都是一样的。
双线程的关键在于逻辑线程要尽可能的 “轻” ,并且要尽量 减少 线程间通信的 频率 ,曾经在双线程上失败主要在于逻辑线程非常重,并且线程间通信非常频繁,上一篇文章有提到。
为了做到让逻辑线程尽可能的 “轻” ,且 减少 逻辑线程与UI线程的通信 频率 ,那么逻辑线程的职责应该设计成只做两件事:
执行用户的函数是为了让开发者有能力修改状态数据,状态数据只在组件初始化以及开发者修改状态数据后发送至UI线程。其余全部逻辑均在UI线程下完成。
通过这样的方案达到了让逻辑线程尽可能的 “轻” (只是执行开发者提供的函数而已),且 减少 逻辑线程与UI线程的通信 频率 (只在初始化及状态数据发生变化时产生通信)目的。
之所以把架构设计成这样是因为如果不这样,则会有两个致命问题:“性能”和“原生能力受限”。
上一篇文章《小程序底层实现原理及一些思考》有提到另一种方案(及逻辑线程重而UI线程轻)的问题,这里简单回顾一下这个失败的方案:
UI线程只负责接收指令(创建元素、修改元素、插入元素、路由跳转、事件绑定等一些基础指令),剩余的一切都有逻辑线程执行(用开发者提供的状态数据计算应该发出哪些指令)。这个方案有两个致命问题:“性能”和“原生能力受限”。
因为逻辑线程经过计算后,若想渲染一个完整的UI页面,需要发送大量的绘制指令(创建元素、修改元素、插入元素、修改属性等),指令在线程间传输是异步的,也就导致指令信号的传输间有间隔,由于指令很小,导致间隔的时间比指令的时间还长,如下图所示:
黄色的JavaScript执行方块是指令的执行,而两个指令之间有很多空闲的时间,因为执行信号的传递需要时间。所以背后的执行过程是,接受一个指令绘制一下,然后等一会又接收一个新的指令然后再绘制下,当指令数量庞大的时候,性能问题非常明显,绘制一整个UI界面非常慢。
所以让逻辑线程尽可能的 “轻” ,且将线程间传输的“指令”改为“数据”来 减少 逻辑线程与UI线程的通信 频率 是非常重要的。
谈完了整体架构的设计和考虑,再谈谈通讯模块,顾名思义,通信模块的职责是负责不同线程之间的通信功能。
在多线程架构下,通讯模块至关重要,但通讯模块的实现并不复杂,底层依赖宿主环境提供的消息通道。例如:Master层控制iframe时底层可以使用postMessageAPI。
有一点需要注意:通信模块在通讯时,为了将信号准确地发送到指定位置,需要根据频道号发送,频道号的规范应该设置为[mid]_[pid]_[cid]。
之所以将信号规范成这样,是为了同时执行多个小程序时,信号依然可以准确地找到指定位置。
另一个需要注意的地方是,官方组件的逻辑执行环境和开发者的组件逻辑执行环境不在一个地方, 通信模块需要负责分辨并将信号发送到指定位置 。
通信的逻辑大致如下:
因为Web Worker是一个沙箱环境,能力受限,所以将用户的逻辑代码放在沙箱中执行,而官方组件的逻辑部分则需要放在拥有全部能力的UI层执行。
所以通讯模块需要分辨出信号应该发到沙箱内还是发送到UI层。
小程序的渲染流程本质上和目前市面上比较流行的前端框架(Vue.js、React)没有本质区别,小程序会让开发者写一份模板用来渲染,然后再写一份JS用于控制小程序的逻辑和更新数据。这和Vue.js和React是一样的。
UI = render(state)
更具象化一点:
UI = template(data)
在小程序中,模板是现成的,开发者写的模板框架是可以直接拿到的,而数据是在整个生命周期开始时,从逻辑层会不断的将最新的数据传输到UI层。
所以开发者编写的模板是直接在UI层加载进去,而开发者编写的JS,则加载到沙箱中执行。在整个项目的生命周期初始化时,会将数据传输到UI层,UI层拿到数据后,结合模板进行渲染,这就是首次渲染。
后面每当开发者通过JS更新状态时,均将状态传输到UI层做一次渲染。
当然,这里面会做一些优化以达到每次数据更新只修改和这次数据更新有关联的那部分UI内容,以提高性能。若想实现这一点并不难,可以使用VirtualDOM,也可以像Vue.js 1.0一样通过最细粒度的Watcher监测每一个DOM标签所绑定的数据是否有更新。
前面讲多线程时,提到小程序应该完全抛弃 SPA 做成多页应用,因为多页应用可以保留前一个页面的状态。
所以路由的内部是基于多页应用的的架构实现的,基于这个原理路由其实并不复杂。
首先,触发路由的行为可以是从UI层发出,也可以是从沙箱中发出。在UI层发出的信号可能是用户点了回退按钮,或者某种回退上一页的手势,信号由宿主环境发出。在沙箱中发出的信号是开发者通过官方提供的API发出的信号。
那么无论是UI层“用户”发出的信号,还是沙箱中“开发者”发出的信号,该信号都应该发送到Master层,由Master层统一控制路由。
路由信号有两种行为:前进、后退。
前进信号: 如果宿主环境是浏览器而承载UI页面的是iframe,那么前进信号对应的行为是创建一个新的iframe盖在前一个页面的上面,并初始化新页面的生命周期。其他宿主环境和承载UI页面的容器原理与纯Web方案一致。
后退信号: 后退信号对应的行为是从页面栈的栈顶开始删除页面(承载UI界面的载体,如:iframe、WebView等),官方提供给开发者的API可以通过参数设置回退几层,对应的行为是删除几个页面,最多删除 stack.length - 1个(最多回退到首页)。
上图给出了当开发者调用API打开新页面时,路由的内部流程图。沙箱中发出信号到Master,Master接收信号后创建iframe推入页面栈,页面在创建的时候会同时把基础JS库带进去,页面创建后JS基础库会立刻执行初始化操作,初始化完毕后会发送一个信号通知Master页面已创建并初始化完毕,随后Master会发送信号到沙箱中。之所以这样设计流程是因为有两个目的:
生命周期可以窥探到内部运行的时序,在多线程架构下,由于渲染层和逻辑层是分开执行的,所以生命周期需要依赖通讯模块传递信号来控制小程序的不同阶段。
小程序的入口是Master,Master既不属于UI层,也不属于沙箱,它是凌驾于所有的一个上帝视角。在宿主环境是浏览器的情况下,Master为 index.js,它是整个程序的入口。
在 index.js中除了做一些初始化工作,最重要的是它需要开启沙箱环境(比如:Web Worker),沙箱环境开启之后,也会做一些环境的初始化工作。相当于从index.js入口启动小程序后,Master和沙箱环境的初始化工作是第一步。
当沙箱环境初始化完毕后,它需要向Master发送一个信号,通知Master沙箱环境已经准备就绪。这时候Master会根据开发者设置的配置,创建小程序的第一个页面,也就是小程序的首页。
配置信息中包含了小程序的路由信息,当然也包括哪个是小程序的首页以及对应的组件。
当第一个页面被推到页面栈后,该页面开始进行初始化工作,这个时候UI层可以拿到该页面的组件树以及每个组件对应的模板等信息,页面会从根组件开始初始化,在UI层组件初始化的过程中,UI层的组件会发送信号到Master,通知Master组件初始化完毕,Master收到信号后需要发送一个信号到沙箱中,沙箱接收到信号后需要在沙箱环境中创建一个对应的组件用来执行开发者的JS逻辑。也就是说,同一个组件其实是被拆成两部分,分别在UI层中初始化,然后在沙箱中再初始化,在UI层中组件负责渲染以及处理UI事件等事情,而在沙箱中的组件主要负责调用开发者定义的函数,以及提供开发者一些API修改组件的状态,整个流程如下图所示:
逻辑层组件被初始化的过程中,会触发两个生命周期函数:“beforeCreate”和“created”。
当逻辑层的组件初始化完毕后,会发送一个信号到渲染层的组件中,通知渲染层的组件逻辑层组件这边已经初始化完毕,并且会将组件的状态信息发送到渲染层组件,渲染层组件收到信号后,就可以拿着数据去做首次渲染操作,如下图所示:
当首次渲染完成后,渲染层组件会发送一个信号到逻辑层组件中,逻辑层组件收到信号后触发生命周期“onReady”通知开发者已经首次渲染完毕。
后面每当开发者调用 setData 修改数据时,逻辑层组件都会将最新的数据发送到渲染层对应的组件中,该组件会用最新的状态重新走一遍渲染流程。
如果这期间用户点击了组件中的某个绑定了事件的元素,那么UI层组件会发送信号到逻辑层中对应的组件,并将一些事件信息一同发过去,逻辑层组件收到信号后调用开发者绑定的函数并将事件信息通过参数传递给开发者,整个流程结束。
前面介绍了很多底层技术原理,这套技术虽然是基于“Web环境下的小程序”发明出来的,但小程序只是这套技术的众多应用场景里的其中一个,这套技术可以支撑的应用场景还有很多。
WebIDE插件系统
WebIDE的插件系统和小程序有相同的特性,IDE插件也需要同时满足:安全、稳定、性能、简单。
区别在于,小程序的场景是在一个“环境”下只能执行一个小程序,而IDE需要在相同的“环境”下要求N个插件同时执行。
这里说的“环境”指的是:以Web环境为例,通常页面的入口文件是
index.html那么一个环境只运行一个小程序指的是这个index.html只执行与渲染一个小程序,也可以理解为浏览器一个Tab标签为一个小程序容器。一个环境运行多个插件可以理解为
index.html里同时运行大量的插件,也就是说,相同的页面下,同时运行大量的插件,这些插件在同一个页面下互相隔离运行,在这种场景下“稳定性”尤为重要,某个插件死循环或者有其他问题,整个页面不应该受到影响。而且因为在同一个页面下执行,那么插件A不应该有权限访问和修改插件B的UI也是非常重要的一个特性。
综上,本文介绍的技术原理也同样适用于WebIDE的插件体系。
Figma插件系统
Figma的插件系统与本文将的技术体系有异异曲同工之妙,本文介绍的技术原理同样适用于Figma插件系统这样的需求。
App Store
如果将一个网页当做上网的入口,或者当做操作系统,并将在这个网页中运行的小程序当做应用程序。那么使用这套技术,可以让这个网页同时运行大量的,各种类型的应用程序,从而实现将网页变成操作系统的能力。
其他场景
这套技术的适用范围远不止上面提到的案例,任何需要第三方开发者参与并最终在自己的平台上运行程序的场景,都可以使用这套技术来实现。
本文详细讨论了基于Web技术实现小程序所涉及到的方方面面,并介绍了如何让基于Web技术的小程序拥有安全、稳定、性能、简单等四个基本特性。
同时在本文的最后也提到了该技术虽然诞生于小程序这个场景,但底层技术并不只局限于小程序,在其他场景下也有很广泛的应用空间。
插播一条广告,团队之前只进P7,目前开放了几个P6+的HC,机会难得,有想法和我一起搞天猫双十一帮全国女生剁手的同学可以来一封简历:[email protected]
最近看到一篇国外的文章,说现代JS框架存在的根本原因是保持UI与状态同步、这其实与我这篇文章的**是一致的,同时也印证了我对现代前端框架的认知是正确的。
--------------------------- 我是分割线 2018年6月18 更新,下面是原文 ----------------------
现在前端界有三大框架横行,Vue,React,Angular,几乎是所有身为一名前端工程师所必备的一项技能。
但是我不知道有多少人仔细思考过为什么会这样?
现在的一些应届生和刚入行的人们,在刚一踏入前端这个行业起就会面临着是学习Vue还是学习React又或者是学习Angular等这样的选择问题。
事实上在早几年是没有这个问题的,我们不需要选择,那时候我们写前端就是jQuery一把梭,就是干,干就完了。
其实之所以现在我们需要选择框架,本质上是因为我们面临的需求变了。大家肯定都明白如果我们只写一个纯展示信息的页面,没有任何交互功能的页面,其实即便是现在,我们也是不需要选择框架的,我们只需要写几行CSS和HTML就可以完成任务。
所以是因为我们面临的需求变得复杂了,我们的应用经常需要在运行时做一些交互。
这里面有三个很重要的字我标了粗体,叫做运行时(Runtime)。现代的前端开发,我们开发的应用经常需要在运行时来做一些交互,这些交互在早期只是个幻灯片或者Tab切换下拉菜单等一些简单的交互,这些交互用jQuery实现完全没什么问题。但现代的前端我们的目标是用Web去PK原生应用,去和Native进行PK。
那这个时候我们会发现用jQuery来开发应用,我们的代码变得很难以维护,那为什么使用现代框架比如Vue,React等就变得容易维护了呢?
这里面请容我讲一个故事,一个小插曲,前几天我在一个微信群里面有人讨论,Vue和jQuery的区别是什么,有人非常强烈的说什么差别是Vue有组件,有什么这个那个的一些特性。
当时我在微信群里说了我的观点,我说Vue和jQuery之间的区别只有一点,声明式与命令式。
我们可以想一下,我们用jQuery去操作DOM的目的是什么?是为了局部更新视图,换句话说是为了局部重新渲染。
jQuery是命令式的操作DOM,命令式的局部更新视图,而现代主流框架Vue,React,Angular等都是声明式的,声明式的局部更新视图。
为什么声明式的操作DOM就可以让应用变得好维护了呢?
弄明白这个问题首先我们先简单介绍下什么是命令式,什么是声明式。
命令式,像jQuery,我们都是想干什么然后就去干就完了,例如下面的代码:
$('.box')
.append('<p>Test</p>')
.xxx()
.yyy()
.jjj()
...命令式就是想干什么就直接去调用方法直接干就完了,简单直接粗暴。
试想一个很简单的场景,比如一个toggle效果,点击一个按钮,切换颜色。
用命令式写,我们肯定是这样写,如果当前是什么颜色就让它变成另外一个颜色。
如果你仔细思考,其实这里面可以细分成两个行为,一个是对状态判断,另一个是操作DOM。
那什么是声明式??
声明式是通过描述状态与视图之间的映射关系,然后通过这样的一个映射关系来操作DOM,或者说具体点是用这样的映射关系来生成一个DOM节点插入到页面去。比如Vue中的模板。模板的作用就用是来描述状态与DOM的映射关系。
同样的场景,我们用Vue中的模板来实现,当我们用模板描述了映射关系之后,我们在点击按钮时,我们只需要对颜色这个变量进行修改就可以完成需求。
看到区别了么?
仔细思考下,用Vue来实现同样的需求,如果细分来看,我们在逻辑上只有一个行为,只有状态。而jQuery是两个行为,状态+DOM操作。
所以声明式为什么可以简化维护应用代码的复杂度?
因为它让我们可以把关注点只放在状态的维护上。这样一来当应用复杂后,其实我们的思维,我们管理代码的方式只在状态上,所有的DOM操作都不用关心了,可以说大大降低代码维护的复杂度。
我们不再需要关注怎么操作DOM,因为框架会帮我们自动去做,我们只关注状态就好了。
但是如果应用特别特别复杂,我们会发现即便是我们只关注状态的维护,依然很难,即便只维护状态也很难,所以才出现了Vuex,Redux等技术解决方案。
经过前面的介绍,你会发现其实现代主流框架要解决的最本质的问题依然是渲染,只是不同框架之间的解决方案有差异,那么什么是渲染?
现在开发前端,我们的应用在运行时需要不断的进行各种交互,现代主流框架让我们把关注点放在了状态的维护上,也就是说应用在运行时,应用内部的状态会不断的发生变化。
而将状态生成DOM插入到页面展示在用户界面上,这一套流程叫做渲染。
当应用在运行时,内部状态会不断的发生变化,这时用户页面的某个局部区域需要不停的重新渲染。
如何重新渲染?
最简单粗暴的解决方式,也是我平时在没有使用任何框架的项目里写的一些简单的功能时最常用的方式是用状态生成一份新的DOM,然后用innerHTML把旧DOM替换了。
我写的小功能块用这种方式没问题,因为功能涉及到的DOM标签少,状态变的时候,几乎就是我这个功能块的所有标签都需要变,所以即便是用innerHTML也不会有太大的性能浪费,是在可接受范围内的。
但是框架不行,框架如果用innerHTML这样去替换,那就不是局部重新渲染了,而是整个页面整体刷新,这性质就变了,那么框架如何做到局部重新渲染?
解决这个问题,需要一些技术方案来解决,可以是VirtualDOM,但并不一定必须是VirtualDOM,也可以是Angular中的脏检测的流程,也可以是细粒度的绑定,像Vue1.0就是使用细粒度的绑定来实现的。
什么是细粒度绑定?
细粒度的绑定意思是说,当某个状态,与之绑定的是页面中的某个具体的标签。就是说,如果模板中有十个标签使用了某个变量,那么与这个变量所绑定的就是10个具体的标签。
相对比较React和Angular粒度都比较粗,他们的变化侦测其实不知道具体哪个状态变量,所以需要一个暴力的比对,比对后才知道需要对视图中的哪个部分进行更新。
而Vue这种细粒度的绑定其实在状态发生变化的那一个瞬间,立刻就知道哪个状态变了,而且还知道有哪些具体的标签使用了这个状态,那么事情就变的简单的多了,直接把与这个状态所绑定的这些具体的标签进行更新就能达到局部更新的目的。
但是这样做其实也有一定的代价,因为粒度太细,会有一定的依赖追踪的开销。所以Vue2.0开始采取了一个折中的方案,就是把绑定调整为中等粒度。
一个状态对应某个组件,而不再是具体标签,这样做有一个好处是可以大大降低依赖的数量,毕竟组件的数量与DOM中的具体标签比,数量要少的多。但是这样就需要多一个操作,当状态发生变化只通知到组件,那么组件内部如何知道具体更新哪个DOM标签??
答案是VirtualDOM。
也就是说,当粒度调整为中等之后,需要多一个操作就是在组件内部使用VirtualDOM去重新渲染。
Vue很聪明地通过变化侦测+VirtualDOM这两种技术方案,提升了框架运行的性能问题。
所以说,Vue2.0引入VirtualDOM并不是因为VirtualDOM有多好,而是恰好VirtualDOM结合变化侦测可以将绑定调整成中等粒度来解决依赖追踪的开销问题。
关于变化侦测我专门写过文章来介绍Vue是如何实现变化侦测的。传送门。
所以变化侦测的方式,在一定程度上就已经决定了框架如何进行渲染。
关于VirtualDOM的实现原理我写过一个PPT,有兴趣的可以看看,传送门。
还有一个是模板编译,其实前面对于模板编译这个问题并没有说太多,模板的作用是描述状态与DOM之间的映射关系,通过模板可以编译出一个渲染函数,执行这个渲染函数可以得到VirtualDOM中所提供的VNode,事实上你看过我前面介绍VirtualDOM原理的PPT你就会知道VirtualDOM对节点进行diff其实是对VNode进行diff。关于模板编译的实现原理我专门写过一篇文章介绍过,传送门。
最后我想说的话是,现在的前端我个人感觉有点浮躁,很多人都在追新,每天关注一些今天出了一个新特性,明天出了一个新框架什么的,对于这些我是赞成的,但是我更希望在追新的同时,要看到它的本质。
所有技术解决方案的终极目标都是在解决问题,都是先有问题,然后在有解决方案,解决方案可能并不完美,可能解决方案有很多种,那么他们之间都有哪些优缺点?解决问题的同时各自都做了哪些权衡和取舍?
我们要透过现象看本质才不至于被表面所迷惑。
我们都知道对于Web应用来说性能很重要。然而性能优化相关的知识却非常的庞大并且杂乱。对于性能优化需要做些什么以及性能瓶颈是什么,通常我们并不清楚。
不包括那些对性能优化有丰富经验的高手
事实上关于Web性能有很多可以优化的点,其中涉及到的知识大致可以划分为几类:度量标准、编码优化、静态资源优化、交付优化、构建优化、性能监控。
图1. 性能优化分类
本文主要介绍性能优化需要做的事以及需要考虑的问题。目的在于给读者脑海中生成一个宏观的地图。
不会介绍每个优化项目具体如何操作。PS:后续会有系列文章针对不同优化分类下的具体优化操作进行更详细的介绍。
在进行性能优化之前,我们需要为应用选择一个正确的度量标准(性能指标)以及设定一个合理的优化目标。
并不是所有指标都同样重要,这取决于你的应用。最后根据度量标准设定一个现实的目标。
下面是一些值得考虑的指标:
FMP与英雄渲染时间非常相似,但它们不一样的地方在于FMP不区分内容是否有用,不区分渲染出的内容是否是用户关心的。
以上四种指标的设定都有据可循。详细信息请查看RAIL性能模型。
编码优化涉及到应用的运行时性能,本小节介绍几个可以提升程序运行时性能的建议。
事实上数据访问速度有快慢之分,下面列出几个影响数据访问速度的因素:
推荐的做法是缓存对象成员值。将对象成员值缓存到局部变量中会加快访问速度
应用在运行时,性能的瓶颈主要在于DOM操作的代价非常昂贵,下面列出一些关于DOM操作相关提升性能的建议:
下面列出一些流程控制相关的一些可以略微提升性能的细节,这些细节在大型开源项目中大量运用(例如Vue):
for...in(它能枚举到原型,所以很慢)if-else和switch会提升性能Web应用的运行离不开静态资源,所以对静态资源的优化至关重要。
Brotli或Zopfli进行纯文本压缩在最高级别的压缩下Brotli会非常慢(但较慢的压缩最终会得到更高的压缩率)以至于服务器在等待动态资源压缩的时间会抵消掉高压缩率带来的好处,但它非常适合静态文件压缩,因为它的解压速度很快。
使用Zopfli压缩可以比Zlib的最大压缩提升3%至8%。
尽可能通过srcset,sizes和<picture>元素使用响应式图片。还可以通过<picture>元素使用WebP格式的图像。
响应式图片可能大家未必听说过,但响应式布局大家肯定都听说过。响应式图片与响应式布局类似,它可以在不同屏幕尺寸与分辨率的设备上都能良好工作(比如自动切换图片大小、自动裁切图片等)。
当然,如果您不满足这种尺度的优化,还可以对图片进行更深层次的优化。例如:模糊图片中不重要的部分以减小文件大小、使用自动播放与循环的HTML5视频替换GIF图,因为视频比GIF文件还小(好消息是未来可以通过img标签加载视频)。
更多图片优化可以看我的另一篇文章:《图像优化原理》
交付优化指的是对页面加载资源以及用户与网页之间的交付过程进行优化。
JS的加载与执行会阻塞页面渲染,可以将Script标签放到页面的最底部。但是更好的做法是异步无阻塞加载JS。有多种无阻塞加载JS的方法:defer、async、动态创建script标签、使用XHR异步请求JS代码并注入到页面。
但更推荐的做法是使用defer或async。如果使用defer或async请将Script标签放到head标签中,以便让浏览器更早地发现资源并在后台线程中解析并开始加载JS。
Intersection Observer实现懒加载懒加载是一个比较常用的性能优化手段,下面列出了一些常用的做法:
Intersection Observer延迟加载图片、视频、广告脚本、或任何其他资源。延迟加载所有体积较大的组件、字体、JS、视频或Iframe是一个好主意
CSS资源的加载对浏览器渲染的影响很大,默认情况下浏览器只有在完成<head>标签中CSS的加载与解析之后才会渲染页面。如果CSS文件过大,用户就需要等待很长的时间才能看到渲染结果。针对这种情况可以将首屏渲染必须用到的CSS提取出来内嵌到<head>中,然后再将剩余部分的CSS用异步的方式加载。可以通过Critical做到这一点。
Resource Hints(资源提示)定义了HTML中的Link元素与dns-prefetch、preconnect、prefetch与prerender之间的关系。它可以帮助浏览器决定应该连接到哪些源,以及应该获取与预处理哪些资源来提升页面性能。
dns-prefetch可以指定一个用于获取资源所需的源(origin),并提示浏览器应该尽可能早的解析。
<link rel="dns-prefetch" href="//example.com">preconnect用于启动预链接,其中包含DNS查找,TCP握手,以及可选的TLS协议,允许浏览器减少潜在的建立连接的开销。
<link rel="preconnect" href="//example.com">
<link rel="preconnect" href="//cdn.example.com" crossorigin>Prefetch用于标识下一个导航可能需要的资源。浏览器会获取该资源,一旦将来请求该资源,浏览器可以提供更快的响应。
<link rel="prefetch" href="//example.com/next-page.html" as="html" crossorigin="use-credentials">
<link rel="prefetch" href="/library.js" as="script">浏览器不会预处理、不会自动执行、不会将其应用于当前上下文。
as与crossorigin选项都是可选的。
prerender用于标识下一个导航可能需要的资源。浏览器会获取并执行,一旦将来请求该资源,浏览器可以提供更快的响应。
<link rel="prerender" href="//example.com/next-page.html">浏览器将预加载目标页面相关的资源并执行来预处理HTML响应。
通过一个现有元素(例如:img,script,link)声明资源会将获取与执行耦合在一起。然而应用可能只是想要先获取资源,当满足某些条件时再执行资源。
Preload提供了预获取资源的能力,可以将获取资源的行为从资源执行中分离出来。因此,Preload可以构建自定义的资源加载与执行。
例如,应用可以使用Preload进行CSS资源的预加载、并且同时具备:高优先级、不阻塞渲染等特性。然后应用程序在合适的时间使用CSS资源:
<!-- 通过声明性标记预加载 CSS 资源 -->
<link rel="preload" href="/styles/other.css" as="style">
<!-- 或,通过JavaScript预加载 CSS 资源 -->
<script>
var res = document.createElement("link");
res.rel = "preload";
res.as = "style";
res.href = "styles/other.css";
document.head.appendChild(res);
</script><!-- 使用HTTP头预加载 -->
Link: <https://example.com/other/styles.css>; rel=preload; as=stylePSI(Perceptual Speed Index,感知速度指数)是提升用户体验的重要指标,让用户感觉到页面的反馈比没有反馈体验要好很多。
可以尝试使用骨架屏或添加一些Loading过渡动画提示用户体验。
输入响应(Input responsiveness)指标同样重要,甚至更重要。试想,用户点击了网页后缺毫无反应会是什么心情。JS的单线程大家已经不能再熟悉,这意味着当JS在运行时用户界面处于“锁定”状态,所以JS同步执行的时间越长,用户等待响应的时间也就越长。
据调查,JS执行100毫秒以上用户就会明显觉得网页变卡了。所以要严格限制每个JS任务执行时间不能超过100毫秒。
解决方案是可以将一个大任务拆分成多个小任务分布在不同的Macrotask中执行(通俗的说是将大的JS任务拆分成多个小任务异步执行)。或者使用WebWorkers,它可以在UI线程外执行JS代码运算,不会阻塞UI线程,所以不会影响用户体验。
应用越复杂,主动管理UI线程就越重要
现代前端应用都需要有构建的过程,项目在构建过程中是否进行了合理的优化,会对Web应用的性能有着巨大的影响。例如:影响构建后文件的体积、代码执行效率、文件加载时间、首次有效绘制指标等。
拿Vue举例,如果您使用单文件组件开发项目,组件会在编译阶段将模板编译为渲染函数。最终代码被执行时可以直接执行渲染函数进行渲染。而如果您没有使用单文件组件预编译代码,而是在网页中引入vue.min.js,那么应用在运行时需要先将模板编译成渲染函数,然后再执行渲染函数进行渲染。相比预编译,多了模板编译的步骤,所以会浪费很多性能。
Tree-shaking是一种在构建过程中清除无用代码的技术。使用Tree-shaking可以减少构建后文件的体积。
目前Webpack与Rollup都支持Scope Hoisting。它们可以检查import链,并尽可能的将散乱的模块放到一个函数中,前提是不能造成代码冗余。所以只有被引用了一次的模块才会被合并。使用Scope Hoisting可以让代码体积更小并且可以降低代码在运行时的内存开销,同时它的运行速度更快。前面2.1节介绍了变量从局部作用域到全局作用域的搜索过程越长执行速度越慢,Scope Hoisting可以减少搜索时间。
code-splitting是Webpack中最引人注目的特性之一。此特性能够把代码分离到不同的bundle中,然后可以按需加载或并行加载这些文件。code-splitting可以用于获取更小的bundle,以及控制资源加载优先级,如果使用合理,会极大影响加载时间。
单页应用需要等JS加载完毕后在前端渲染页面,也就是说在JS加载完毕并开始执行渲染操作前的这段时间里浏览器会产生白屏。
服务端渲染(Server Side Render,简称SSR)的意义在于弥补主要内容在前端渲染的成本,减少白屏时间,提升首次有效绘制的速度。可以使用服务端渲染来获得更快的首次有效绘制。
比较推荐的做法是:使用服务端渲染静态HTML来获得更快的首次有效绘制,一旦JavaScript加载完毕再将页面接管下来。
import函数动态导入模块使用import函数可以在运行时动态地加载ES2015模块,从而实现按需加载的需求。
这种优化在单页应用中变得尤为重要,在切换路由的时候动态导入当前路由所需的模块,会避免加载冗余的模块(试想如果在首次加载页面时一次性把整个站点所需要的所有模块都同时加载下来会加载多少非必须的JS,应该尽可能的让加载的JS更小,只在首屏加载需要的JS)。
使用静态
import导入初始依赖模块。其他情况下使用动态import按需加载依赖
正确设置expires,cache-control和其他HTTP缓存头。
推荐使用Cache-control: immutable避免重新验证。
其他一些值得考虑的优化点:
最后,你可能需要一个性能检测工具来持续监视网站的性能。
最后用一张图来总结这篇文章所表达的内容,感谢@anjia帮忙画的这张图。
图2. 总结这篇文章
非常感谢李松峰老师和安佳姐姐帮忙校验这篇文章。
最后请允许我打一个广告。我在去年年底,有幸与人民邮电出版社的图灵社区签约并开始着手写一本书,名叫《深入浅出Vue.js》(昨天被朋友说这个名字不好听,所以后期有可能书的名字会有改动)。
顾名思义,这本书深入Vue.js底层实现原理并使用通俗易懂的写作方式讲解Vue.js内部各核心功能与API的原理。
目前这本书已经撰写完毕,处于编排校印阶段,顺利的话年底就能与大家见面(非常感谢王军花老师提供这个机会)。
对Vue.js感兴趣并且想深入了解内部原理的同学,可以关注一下。本书上市后我会第一时间在自己的博客上发布通知告知大家。
前不久Google开源了一份文档(谷歌工程实践文档),里面包含了他们的代码评审(Code Review)指南,通读之后我发现这份文档非常有价值,所以决定写一篇文章将一些入门的,科普性质的部分翻译并总结成一篇文章帮助大家了解下Google的代码评审。
在Google开源的文档中,有两个内部的专业术语:CL和LGTM:
CL,全称为“Change List”,表示已提交到版本控制或正在进行代码评审的一个独立更改。
我理解和Github上的PR有点类似。
LGTM,表示“Looks Good to Me”,当某个CL被批准后,评审者会说LGTM。
代码评审是评审者(某段代码作者之外的人),对某段代码进行检查(审核)的一个过程。
我们可以使用代码评审来维持代码和产品的质量,代码评审的主要目的是确保代码库的整体健康状况会随着时间不短改善。
代码评审的另一个重要功能是,它可以教给开发者一些关于语言,框架,常用的设计原则等知识。
当进行代码评审时,评审者应该评审:
本文的后面会针对上面提到的几点进行更详细的介绍。
通常,开发者希望找到可以在合理的时间内响应自己审核需求的最合适地审核者。
最合适的审核者是能够为代码片段提供最彻底,最正确地审核的人,通常是代码的主人。有时可能会请求不同的人帮自己评审CL的不同部分。
如果与自己“结对编程”的人有资格作为这段代码的审核者,那么该代码将被视为已审核。
评审者有责任确保每个CL的质量都使得代码库的整体健康状况不会随着时间而减少。这很困难,通常随着时间推移,代码库的健康会缓慢下降,尤其是团队处在时间限制下,为了快速迭代功能时。
通常,只要CL可以改善整体代码的健康,评审者就应该批准,即便CL并不完美。
这是所有代码评审指南中的最高原则。
当然,这是有局限性的。例如,如果CL添加了评审者不希望出现在系统中的功能时,那么可以拒绝批准,即便代码拥有良好的设计。
这里的关键点是,没有“完美”的代码,只有更好的代码。评审者追求的是持续改进,而不是追求完美。
总体而言,只要一个CL能对整个系统的维护性,可读性和可理解性起到改善的作用,评审者就不应该因为它不是“完美”的而被延迟几天或几周再批准。
评审者应该随时发表评论,表示某些代码可以变得更好,但是如果不是很重要,那么可以加上前缀“Nit:”让作者知道这仅仅是一个建议,可以选择忽略。
留下一些可以帮助开发者学习新东西的评论总是好的,随着时间的推移,分享知识是改善代码健康的一部分。但请记住,如果评论仅仅是出于教育目的,请在评论前面加上“Nit:”前缀,表明不是强制要求作者在此CL中对其进行解决。
注意:在考虑以下要点时,始终确保考虑到前面提到的“代码评审标准”。
代码评审中最重要的事情是CL的总体设计。代码中的各个部分之间的交互是否有意义?本次修改应该放在代码仓库中吗?它与系统中的其他部分可以完美结合在一起吗?现在是添加这个功能的好时机吗?
CL的功能是否符合开发者的预期?开发者想为用户提供哪些功能?
通常我们希望开发者会为CL提供良好的测试,但是作为评审者,仍然应该考虑一些极端情况,寻找并发现问题。尝试像用户一样思考,来确保这个功能没有bug,而不仅仅是通过阅读代码就确定没有bug。
当CL是对用户有影响的改动(例如:修改了UI上某个功能),最重要的事是检查CL的行为。因为评审者只是阅读代码很难理解这个代码修改会对用户产生什么影响,对于这样的修改,如果评审者检查CL的行为过于麻烦,可以让开发者提供该功能的演示。
CL是否可以实现的更简单?对CL的所有“级别”进行检查。某行代码是否过于复杂?功能是否过于复杂?类是否过于复杂?“过于复杂”通常意味着代码的阅读者不能快速理解。还意味着开发者在尝试调用或修改此代码时,可能会引入bug。
关于复杂,有一种特殊的类型,叫做“过度设计”,开发者让代码过分通用,或添加了一些暂时还不需要的功能。评审者应该特别警惕过度设计。鼓励开发者解决他们现在需要解决的已知问题,而不是开发者推测的将来可能需要解决的问题。未来的问题应该在问题来临时解决。
根据修改的内容进行单元测试,集成测试或端到端测试。确保CL中的测试正确,合理且有用,开发者必须确保测试有效。
测试也是必须维护的代码,不要因为代码是测试代码就接受代码的复杂性。
开发者是否为所有命名都选择了一个好名字?好名字应该足够长,以充分表达含义和作用,而又不会太长而难以阅读。
开发人员是否写下了清晰的注释?所有注释都是必要的吗?通常当注释解释了代码为什么存在时非常有用,不应该解释代码做了什么,如果代码不能清晰的解释自身,则应该让代码更简单。有一些例外的情况(正则表达式与复杂的算法通常会从解释他们作用的注释中受益匪浅),但大多数注释是针对代码本身无法包含的信息,例如决策背后的原因。
请确保CL的风格与团队的风格指南保持一致。
如果想改善风格指南中没有提到的部分,请在注释前面加上“ Nit:”,以使开发者知道这是可以改善但不是强制性的选择。
CL不应该将风格改动和其他改动结合在一起提交,这会导致查看CL中有哪些改动变得非常困难,还会使merge与回滚也更加复杂。例如,如果开发者想重新格式化整个文件,则需要将重新格式化的改动作为一个CL提交,然后再发送另一个具有功能改动的CL。
如果CL改变了用户构建,测试,交互或发布代码的方式,请检查是否更新了相关文档。如果CL删除或弃用了代码,请考虑是否应该删除该文档。
本文提到的内容只是谷歌工程实践文档中的一小部分,感兴趣的可以看原文了解更多。
通读了一遍谷歌工程实践文档后,我发现代码评审在Google内部是开发流程的一部分,和在Github上为开源项目贡献PR类似,开发者提交了PR后,项目作者肯定会先Review一遍代码,然后再决定是否将代码合并到仓库中,没有经过Review的代码是无法合并到仓库里的。
但大部分公司不是这么开发项目的,我觉得这也是代码评审普遍做得不够好的原因。
可能很多人会对代码评审有很多疑问,例如,将代码评审作为项目开发必须要走的一环,是否会降低开发效率。代码评审是否会消耗评审者很多时间。开发者和评审者之间发生了冲突怎么办等问题。
这些问题在谷歌工程实践文档中有清晰的解释,感兴趣的可以去看原文。原文地址:https://github.com/google/eng-practices

假设您正在访问一个网站,如果Web内容不在几秒内显示在屏幕上,那么作为用户您可能会选择关闭标签页,转去浏览其他页面从而代替这个网页的内容。但是作为Web开发者,您可能希望跟踪请求与导航的详细信息,这样你就可以知道为什么这个网页的速度在变慢。
W3C性能工作组提供了可以用来测量和改进Web应用性能的用户代理(User Agent)特性与API。开发者可以使用这些API来收集精确的性能信息,从不同方面找出Web应用的性能瓶颈并提高应用的性能。
这些特性和API适用于桌面、移动浏览器以及其他非浏览器环境。
由于这些特性与API不止适用于浏览器,还适用于非浏览器环境,所以本文会大量使用“用户代理”这个词来代替“浏览器”
ECMA-262 规范中定义了 Date 对象来表示自 1970 年 1 月 1 日以来的毫秒数。它足以满足大部分需求,但缺点是时间会受到时钟偏差与系统时钟调整的影响。时间的值不总是单调递增,后续值有可能会减少或者保持不变。
例如,下面这段代码计算出来的“duration”有可能被记录为正数、负数或零。
const mark_start = Date.now()
doTask() // Some task
const duration = Date.now() - mark_start上面这段代码获取的持续时间“duration”并不精准,它会受到时钟偏差与系统时钟调整的影响,所以最终得到的“duration”可能为正数、负数或零,我们根本不知道它记录的时间究竟是不是正确的时间。
高精度时间(High Resolution Time,简称hr-time)规范定义了Performance对象,通过Performance对象我们可以获得高精度的时间。
Performance对象包含方法now和属性timeOrigin:
方法now被执行后会返回从 timeOrigin 到现在的高精度时间。
当前时间 - performance.timeOrigin
属性timeOrigin返回页面浏览上下文第一次被创建的时间。如果全局对象为WorkerGlobalScope,那么timeOrigin为worker被创建的时间。
timeOrigin 的时间值不受时钟偏差与系统时钟调整的影响。
例如,当timeOrigin的值被确定之后,无论将系统时间设置到什么时间,下面代码始终返回timeOrigin最初被赋予的时间:
new Date(performance.timeOrigin).toLocaleString()
// 2018/8/6 上午11:41:58如果两个时间值拥有相同的时间起源(Time Origin),那么使用 performance.now 方法返回的任意两个按时间顺序记录的时间值之间的差值永远不可能是负数。
例如,下面这段代码计算出来的“duration”永远不可能为负数。
const mark_start = performance.now()
doTask() // Some task
const duration = performance.now() - mark_start通过performance.timeOrigin + performance.now 可以得到精准的当前时间。该时间不受时钟偏差与系统时钟调整的影响。
不受时钟偏差与系统时钟调整的影响指的是当
timeOrigin的值被确定之后修改了系统时间,这时候timeOrigin不会受到影响。
const timeStamp = performance.timeOrigin + performance.now()
console.log(timeStamp) // 1533539552977.5718
new Date(timeStamp).toLocaleString()
// "2018/8/6 下午3:10:42"在介绍如何获取性能指标之前,我们需要先介绍“性能时间线”,它提供了统一的接口来获取各种性能相关的度量数据。它是本文即将要介绍的其他获取性能指标方法的基础。
“性能时间线”本身并不提供任何性能信息,但它会提供一些方法,当您想要获得性能信息时,可以使用“性能时间线”提供的方法来得到您想获取的性能信息。
本文后面会详细介绍从“性能时间线”中可以访问哪些性能信息
Performance对象“性能时间线”扩展了Performance对象,新增了一些用于从“性能时间线”中获取性能指标数据的属性与方法。
下表给出了在Performance对象上新增的方法:
| 方法名 | 作用 |
|---|---|
| getEntries() | 返回一个列表,该列表包含一些用于承载各种性能数据的对象,不做任何过滤 |
| getEntriesByType() | 返回一个列表,该列表包含一些用于承载各种性能数据的对象,按类型过滤 |
| getEntriesByName() | 返回一个列表,,该列表包含一些用于承载各种性能数据的对象,按名称过滤 |
表中给出了三个方法,使用这些方法可以得到一个列表,列表中包含一系列用于承载各种性能数据的对象。换句话说,使用这些对象可以得到我们想要获得的各种性能信息。
在术语上这个列表叫做PerformanceEntryList,而列表中的对象叫做PerformanceEntry。
不同方法的过滤条件不同,所以列表中的PerformanceEntry对象所包含的数据也不同。
PerformanceEntry对象“性能时间线”定义了PerformanceEntry对象,该对象承载了各种性能相关的数据。下表给出了PerformanceEntry对象所包含的属性:
| 属性名 | 作用 |
|---|---|
| name | 通过该属性可以得到PerformanceEntry对象的标识符,不唯一 |
| entryType | 通过该属性可以得到PerformanceEntry对象的类型 |
| startTime | 通过该属性可以得到一个时间戳 |
| duration | 通过该属性可以得到持续时间 |
从上表中可以发现,“性能时间线”并没有明确定义PerformanceEntry对象应该返回什么具体内容,它只是定义了一个格式,返回的具体内容会根据我们获取的性能数据类型的不同而不同。本文的后面我们会详细介绍。
PerformanceObserver“性能时间线”还定义了一个非常重要的接口用来观察“性能时间线”记录新的性能信息,当一个新的性能信息被记录时,观察者将会收到通知。它就是PerformanceObserver。例如,可以通过下面代码定义一个长任务观察者:
const observer = new PerformanceObserver(function (list) {
// 当记录一个新的性能指标时执行
})
// 注册长任务观察者
observer.observe({entryTypes: ['longtask']})上面这段代码使用PerformanceObserver注册了一个长任务观察者,当一个新的长任务性能信息被记录时,回调会被触发。
回调函数会接收到两个参数:第一个参数是一个列表,第二个参数是观察者实例。
在术语上这个列表被称为PerformanceObserverEntryList,并且包含三个方法getEntries、getEntriesByType、getEntriesByName。可以通过这三个方法获得PerformanceEntryList列表。这三个方法功能于使用方式均与前面介绍的相同。
获取资源加载相关的时间信息可以让我们知道我们的页面需要让用户等待多久。下面这段简单的JavaScript代码尝试测量加载资源所需的时间:
<!doctype html>
<html>
<head></head>
<body onload="loadResources()">
<script>
function loadResources() {
const start = new Date().getTime()
const image1 = new Image()
const resourceTiming = function() {
const now = new Date().getTime()
const latency = now - start
console.log('End to end resource fetch: ' + latency)
}
image1.onload = resourceTiming
image1.src = 'https://www.w3.org/Icons/w3c_main.png'
}
</script>
<img src="https://www.w3.org/Icons/w3c_home.png">
</body>
</html>虽然这段代码可以测量资源的加载时间,但它不能获得资源加载过程中各个阶段详细的时间信息。同时这段代码并不能投放到生产环境,因为它有很多问题:
@import url()和background: url()加载的资源应该如何测量计时信息?link、img、scriptxmlhttprequest请求的,如何测量资源的计时信息?fetch方法请求的资源如何测量计时信息?beacon发送的请求如何测量计时信息?幸运的是,W3C性能工作组定义了资源计时(Resource Timing)规范让Web开发者可以获取非常详细的资源计时信息。
下面这个例子可以获取更加详细的资源计时信息:
<!doctype html>
<html>
<head>
</head>
<body onload="loadResources()">
<script>
function loadResources () {
const image1 = new Image()
image1.onload = resourceTiming
image1.src = 'https://www.w3.org/Icons/w3c_main.png'
}
function resourceTiming () {
const resourceList = window.performance.getEntriesByType('resource')
for (let i = 0; i < resourceList.length; i++) {
console.log('End to end resource fetch: ' + (resourceList[i].responseEnd - resourceList[i].startTime))
}
}
</script>
<img id="image0" src="https://www.w3.org/Icons/w3c_home.png">
</body>
</html>上面代码通过performance.getEntriesByType方法得到一个列表,这个列表就是我们前面介绍的PerformanceEntryList,并过滤出所有类型为resource的PerformanceEntry对象。
类型为resource的PerformanceEntry对象在术语上被称为PerformanceResourceTiming对象。
PerformanceResourceTiming对象扩展了PerformanceEntry对象并新增了很多属性用于获取详细的资源计时信息,PerformanceResourceTiming对象的所有属性与其对应的作用如下表所示:
| 属性名 | 作用 |
|---|---|
| name | 请求资源的绝对地址,即便请求重定向到一个新的地址此属性也不会改变 |
| entryType | PerformanceResourceTiming对象的entryType属性永远返回字符串“resource” |
| startTime | 用户代理开始排队获取资源的时间。如果HTTP重定则该属性与redirectStart属性相同,其他情况该属性将与fetchStart相同 |
| duration | 该属性将返回 responseEnd 与 startTime之间的时间 |
| initiatorType | 发起资源的类型 |
| nextHopProtocol | 请求资源的网络协议 |
| workerStart | 如果当前上下文是”worker”,则workerStart属性返回开始获取资源的时间,否则返回0 |
| redirectStart | 资源开始重定向的时间,如果没有重定向则返回0 |
| redirectEnd | 资源重定向结束的时间,如果没有重定向则返回0 |
| fetchStart | 开始获取资源的时间,如果资源重定向了,那么时间为最后一个重定向资源的开始获取时间 |
| domainLookupStart | 资源开始进行DNS查询的时间(如果没有进行DNS查询,例如使用了缓存或本地资源则时间等于fetchStart) |
| domainLookupEnd | 资源完成DNS查询的时间(如果没有进行DNS查询,例如使用了缓存或本地资源则时间等于fetchStart) |
| connectStart | 用户代理开始与服务器建立用来检索资源的连接的时间(TCP建立连接的时间) |
| connectEnd | 用户代理完成与服务器建立的用来检索资源的连接的时间(TCP连接成功的时间) |
| secureConnectionStart | 如资源使用安全传输,那么用户代理会启动握手过程以确保当前连接。该属性代表握手开始时间(如果页面使用HTTPS那么值是安全连接握手之前的时间) |
| requestStart | 开始请求资源的时间 |
| responseStart | 用户代理开始接收Response信息的时间(开始接受Response的第一个字节,例如HTTP/2的帧头或HTTP/1.x的Response状态行) |
| responseEnd | 用户代理接收到资源的最后一个字节的时间,或在传输连接关闭之前的时间,使用先到者的时间。或者是由于网络错误而终止网络的时间 |
| transferSize | 表示资源的大小(以八位字节为单位),该大小包括响应头字段和响应有效内容主体(Payload Body) |
| encodedBodySize | 表示从HTTP网络或缓存中接收到的有效内容主体(Payload Body)的大小(在删除所有应用内容编码之前) |
| decodedBodySize | 表示从HTTP网络或缓存中接收到的消息主体(Message Body)的大小(在删除所有应用内容编码之后) |
由于有一些属性功能比较复杂,下面将针对一些功能比较复杂的属性详细介绍。
initiatorType简单来说initiatorType属性返回的内容代表资源是从哪里发生的请求行为。
initiatorType属性会返回下面列表中列出的字符串中的其中一个:
| 类型 | 描述 |
|---|---|
| css | 如果请求是从CSS中的url()指令发出的,例如 @import url() 或 background: url() |
| xmlhttprequest | 通过XMLHttpRequest对象发出的请求 |
| fetch | 通过Fetch方法发出的请求 |
| beacon | 通过beacon方法发出的请求 |
| link | 通过link标签发出的请求 |
| script | 通过script标签发出的请求 |
| iframe | 通过iframe标签发出的请求 |
| other | 没有匹配上面条件的请求 |
domainLookupStart准确的说,domainLookupStart属性会返回下列值中的其中一个:
domainLookupStart的值与fetchStart相同domainLookupStart等于开始从域信息缓存中检索域数据的时间domainLookupEnddomainLookupEnd属性会返回下列值中的其中一个:
domainLookupStart相同,如果使用了持久连接(persistent connection),或者从相关应用缓存(relevant application cache)或本地资源中获取资源,那么domainLookupEnd的值与fetchStart相同domainLookupEnd为从域信息缓存中检索域数据结束时的时间下图给出了PerformanceResourceTiming对象定义的时序属性。当从不同来源获取资源时,括号中的属性可能不可用。用户代理可以在时间点之间执行内部处理。
图1 PerformanceResourceTiming 过程模型
精准地测量Web应用的性能是使Web应用更快的一个重要方面。虽然利用JavaScript提供的能力可以测量用户等待时间(我们常说的埋点),但在更多情况下,它并不能提供完整或详细的等待时间。例如,下面的JavaScript使用了一个非常天真的方式尝试测量页面完全加载完所需要的时间:
<html>
<head>
<script type="text/javascript">
const start = new Date().getTime()
function onLoad() {
const now = new Date().getTime()
const latency = now - start
console.log('page loading time: ' + latency)
}
</script>
</head>
<body onload="onLoad()">
<!- Main page body goes from here. -->
</body>
</html>上面的代码将计算在执行head标签中的第一行JavaScript之后加载页面所需的时间,但是它没有提供任何有关从服务端获取页面所需的时间信息,或页面的初始化生命周期。
对于这种需求,W3C性能工作组定义了Navigation Timing规范,该规范定义了PerformanceNavigationTiming接口,提供了更有用和更准确的页面加载相关的时间数据。包括从网络获取文档到在用户代理(User Agent)中加载文档相关的所有时间信息。
对于上面那个例子,使用Navigation Timing可以很轻松的用下面的代码做到并且更精准:
<html>
<head>
<script type="text/javascript">
function onLoad() {
const [entry] = performance.getEntriesByType('navigation')
console.log('page loading time: ' + entry.duration)
}
</script>
</head>
<body onload="onLoad()">
<!- Main page body goes from here. -->
</body>
</html>上面代码通过performance.getEntriesByType方法得到一个列表,这个列表就是我们前面2.1节介绍的PerformanceEntryList,并过滤出所有类型为navigation的PerformanceEntry对象。
类型为navigation的PerformanceEntry对象在术语上被称为PerformanceNavigationTiming对象。
PerformanceNavigationTiming对象扩展了PerformanceEntry对象,通过该对象提供的duration属性可以得到页面加载所消耗的全部时间。
PerformanceNavigationTiming 接口所提供的所有时间值都是相对于 Time Origin 的。所以 startTime 属性的值永远是0
通过该PerformanceNavigationTiming对象可以获得页面加载相关的非常精准的时间信息:
0loadEventEnd的时间减去startTime的时间)PerformanceNavigationTiming对象扩展了PerformanceResourceTiming对象,所以PerformanceNavigationTiming对象具有PerformanceResourceTiming对象的所有属性,但是某些属性的返回值略有不同:
同时 NavigationTiming 新增了一些属性,下面列表给出了新增的属性:
| 新增的属性 | 描述 |
|---|---|
| unloadEventStart | 如果被请求的页面来自于前一个同源(同源策略)的文档,那么该属性存储的值是浏览器开始卸载前一个文档的时刻。否则的话(前一个文档非同源或者没有前一个文档)为0 |
| unloadEventEnd | 前一个文档卸载完成的时刻。如果前一个文档不存在则为0 |
| domInteractive | 指文档完成解析的时间,包括在“传统模式”下被阻塞的通过script标签加载的内容(使用defer或者async属性异步加载的情况除外) |
| domContentLoadedEventStart | DOMContentLoaded事件触发前的时间 |
| domContentLoadedEventEnd | DOMContentLoaded事件触发后的时间 |
| domComplete | 用户代理将将document.readyState设置为complete的时间 |
| loadEventStart | load事件被触发前的时间,如果load事件还没触发则返回0 |
| loadEventEnd | load事件完成后的时间,如果load事件还没触发则返回0 |
| redirectCount | 页面被重定向的次数 |
| type | 页面被载入的方式 |
type属性的四种取值情况:
location.reload()方法prerender的方式启动一个页面图2给出了PerformanceNavigationTiming对象的时序属性。当页面从不同来源获取时,括号中的属性可能不可用。
图2 PerformanceNavigationTiming 过程模型
从图2可以看出完整的页面加载时间信息包含很多信息。前端渲染相关的时间只占用很少的一部分(图2最后面两个蓝色部分processing与onLoad)。这也是为什么我们在一开始说使用JS埋点的方式去测量页面加载时间很天真。
Web开发者需要一种能够**“评估与理解”**其Web应用性能的能力。虽然JavaScript提供了测量应用性能的能力(使用Date.now()方法获取当前时间戳),但这个时间戳的精度在不同的用户代理下存在一定的差异,并且时间会受到系统时钟偏差与调整的影响。
W3C性能工作组定义了User Timing规范,提供了高精度且单调递增的时间戳,使开发者可以更好地测量其应用的性能。
下面代码显示了开发者应该如何使用User Timing规范定义的API来获得执行代码相关的时间信息。
async function run() {
performance.mark("startTask1")
await doTask1() // Some developer code
performance.mark("endTask1")
performance.mark("startTask2")
await doTask2() // Some developer code
performance.mark("endTask2")
// Log them out
const entries = performance.getEntriesByType("mark")
for (const entry of entries) {
console.table(entry.toJSON())
}
}
run()User Timing规范扩展了Performance对象,并在Performance对象上新增了四个方法:
mark方法接收一个字符串类型的参数(mark名称),用于创建并存储一个PerformanceMark对象。更通俗的说,mark方法用于记录一个与名称相关时间戳。
PerformanceMark对象存储了4个属性:
performance.now()方法的返回值)下面代码展示了如何使用mark方法:
performance.mark('testName')当使用mark方法存储了一个PerformanceMark对象后,可以通过前面介绍的getEntriesByName方法得到一个列表,列表中包含一个PerformanceMark对象。代码如下:
const [entry] = performance.getEntriesByName('testName')
console.log(entry) // {"name": "testName", "entryType": "mark", "startTime": 4396.399999997811, "duration": 0}顾名思义,clearMarks方法的作用是删除所有给定名称的时间戳数据(PerformanceMark对象)。
clearMarks方法接收一个字符串类型的参数(mark名称),例如:
performance.mark('testName')
performance.clearMarks('testName')
performance.getEntriesByName('testName') // []上面代码使用mark方法记录了一个名为testName的时间戳信息(存储了PerformanceMark对象),随后使用clearMarks方法清除名为testName的时间戳信息,最后尝试获取名为testName的时间戳信息时得到的是一个空列表。
虽然mark方法可以记录时间戳信息,但是获得两个mark之间的持续时间还是有点麻烦,我们需要先获取两个PerformanceMark对象,然后再执行减法。
针对这个问题User Timing规范提供了measure方法,该方法的作用是使用一个名字将两个PerformanceMark对象之间所持续的时间存储起来。
measure方法的参数:
与mark方法相同,measure方法会创建一个PerformanceMeasure对象并存储起来。PerformanceMeasure对象存储了4个属性:
PerformanceMark对象的startTime属性,如果没有提供startMark参数,则为0PerformanceMark对象的startTime属性的差值,可能是负数。下面代码展示了如何使用measure方法检测代码执行所持续的时间:
async function run() {
performance.mark('startTask')
await doTask1() // Some developer code
performance.mark('endTask')
performance.measure('task', 'startTask', 'endTask')
// Log them out
const [entry] = performance.getEntriesByName('task')
console.log(entry.duration)
}
run()与clearMarks类似,clearMeasures方法的作用是使用参数中提供的名称来删除PerformanceMeasure对象。
保证UI的流畅很重要,那么如何检测UI是否流畅呢?
根据RAIL性能模型提供的信息,如果Web应用在100毫秒内的时间可以响应用户输入,则用户会觉得应用的交互很流畅。如果响应超过100毫秒用户就会感觉到应用有点轻微的延迟。如果超过1秒,用户的注意力将离开他们正在执行的任务。
由于JavaScript是单线程的,所以当一个任务执行时间过长,就会阻塞UI线程与其他任务。对于用户来说,他通常会看到一个“锁定”的页面,浏览器无法响应用户输入。
这种占用UI线程很长一段时间并阻止其他关键任务执行的任务叫做“长任务”
更具体的解释是:超过50毫秒的事件循环任务都属于长任务
那么如何检测应用是否存在“长任务”呢?
一个已知的方式是使用一个短周期定时器,并检查两次调用之间的时间,如果两次调用之间的时间大于定时器的周期时间,那么很有可能有一个或多个“长任务”延迟了定时器的执行。
这种方式虽然可以实现需求,但它并不完美。它要不停的轮询去检查长任务,在移动端对手机电池寿命不友好,并且也没有办法知道是谁造成了延迟(例如:自己的代码 vs 第三方的代码)。
W3C性能工作组提供了Long Tasks规范,该规范定义了一个接口,使Web开发者可以监测“长任务”是否存在。
使用案例:
const observer = new PerformanceObserver(function(list) {
const perfEntries = list.getEntries()
for (let i = 0; i < perfEntries.length; i++) {
// 处理长任务通知
// 上报性能检测数据
// ...
}
})
// 注册长任务观察者
observer.observe({entryTypes: ['longtask']})
// 模拟一个长任务
const start = Date.now()
while (Date.now() - start < 1000) {}上面的代码注册了“长任务”观察器,它的功能是每当有超过50毫秒的任务被执行时调用回调函数。
2.3节介绍了PerformanceObserver,所以回调函数中的变量perfEntries保存了一个列表,列表中包含了所有承载了长任务数据的对象。
承载了长任务数据的对象在术语上被称为PerformanceLongTaskTiming。
PerformanceLongTaskTiming对象中保存了长任务相关的信息,包括以下属性:
same-origin-ancestor)same-origin-ancestor相反,如果当前页面注册了一个长任务观察者并iframe了一个其他页面,这时候iframe中如果存在长任务,则当前页面的长任务观察者会收到通知,这时候name属性的值为same-origin-descendant)name属性为multiple-contexts)Time Origin的时间TaskAttributionTiming对象,该对象有以下属性:
frame指的是浏览上下文,例如iframe
加载并不是一个单一的时刻,它是一种体验,没有任何一种指标可以完全捕获。事实上在页面加载期间有多个时刻可以影响用户将其视为“快”还是“慢”。
首次绘制(FP,全称First Paint)是第一个比较关键的时刻,其次是首次内容绘制(FCP,全称First Contentful Paint)。
这两个性能指标之间的主要区别在于“首次绘制”是当浏览器首次开始渲染任何可以在视觉上让屏幕发生变化的时刻。相比之下“首次内容绘制”是当浏览器首次从DOM中渲染内容的时刻,内容可以是文本,图片,SVG,甚至是canvas元素。
图3 首屏渲染指标
”首次绘制“(First Paint)不包括默认背景绘制(例如浏览器默认的白色背景),但是包含非默认的背景绘制,与iframe。
”首次内容绘制“(First Contentful Paint)包含文本,图片(包含背景图),非白色canvas与SVG。
父级浏览上下文不应该知道子浏览上下文的绘制事件,反之亦然。这就意味着如果一个浏览上下文只包含一个iframe,那么将只有“首次绘制”,但没有“首次内容绘制”。
可以通过下面代码获得首屏渲染性能指标数据:
performance.getEntriesByType('paint')通过上面这行代码可以得到一个列表。列表中包含一个或两个PerformancePaintTiming对象。这取决于“首次内容绘制”是否存在。如图4所示:
图4. 获取首屏渲染指标
从图3可以看到PerformancePaintTiming对象包含四个属性,这四个属性的值为:
time origin的我们可以使用下面的代码注册一个绘制观察器:
const observer = new PerformanceObserver(function(list) {
const perfEntries = list.getEntries()
for (let i = 0; i < perfEntries.length; i++) {
// 处理数据
// 上报性能检测数据
// ...
}
})
// 注册绘制观察者
observer.observe({entryTypes: ["paint"]})本文详细介绍了在Web应用中采集性能信息所需要的一些方法。其中包括:获得不受时钟偏差与系统时钟调整影响的高精度时间的方法、收集“页面资源加载”相关的性能度量数据的方法、收集“网页加载”相关的性能度量数据的方法、使用高精度时间戳在应用程序中埋点的方法、监测用户觉得网页“慢”的方法以及采集首屏渲染性能指标的方法。
我相信这是每一个前端从业者都关心的一个问题,特别是在今天,前端技术发展如此迅猛,各种框架、工具百花齐放,如何在有限的时间里去学习值得投入的技术是非常关键的一件事。
回归到一个最本质的问题:什么决定了员工的工资?为什么程序员的工资比其他岗位高?
如果您想问“哪些技术值得投入”和“是什么决定了员工的工资”之间的联系,这里简单推导一下:学习技术是为了什么?-> 找一份好工作 -> 找一份好工作是为了什么? -> 赚更多的工资 -> 是什么决定了工资的高低?
这里排除因为兴趣学技术的情况,因为兴趣学技术,不存在“值不值得”的问题。
在经济学领域有一个概念叫做 “生产要素” 是用于生产物品与服务的“投入”。当一家互联网企业生产科技服务时,它要利用程序员的时间(劳动),劳动是一种“生产要素”。生产要素的“需求”是派生需求,也就是说,企业的生产要素需求是从它向另一个市场供给物品或服务的决策所派生出来的。因此,对前端程序员的需求与企业对互联网服务的供给有不可分割的联系。
与经济中的其他市场一样,劳动市场也是由供需力量支配的,企业决定劳动的需求量是根据利润决定的,企业追求利润最大化,因此它并不直接关心雇佣的员工数量和它生产的产品和服务量。它只关心利润,利润等于生产服务带来的总收益减去生产这些服务的总成本。企业的产品服务量和员工需求都生产与“利润最大化”这个首要目标。
另一个概念是 “劳动的边际产量”,即增加一单位劳动所引起的产量增加量,在现实的生产过程表现出 “边际产量递减” 的效果,即一单位投入的边际产量随着投入量增加而减少的性质。
边际产量递减:一个程序员带来的产量假设为100,那么两个程序员可能是 180,三个程序员可能是 240...
由于利润是总收益减总成本,因此增加1个程序员的利润是他对收益带来的贡献减去他的工资。由于“边际产量递减”的性质存在,企业雇佣的程序员的数量到达一个临界点后就无利可图了,因此企业雇佣的人数会保持在劳动的“边际产量值”(边际产量乘以产出物的价格)等于工资的那个点。
通过前面的铺垫,我们现在可以得出结论:
企业为了利益最大化,所雇佣的劳动直到边际产量等于工资为止。因此,一旦劳动的购买量使供求达到均衡, “工资就必定等于劳动的边际产量值”。所以改变劳动“供求”的任何事件都必定使“均衡工资”和“边际产量值”等量变动,因为这两个量必定总是相等的。所以,工资的高低取决于用劳动的边际产量值衡量的 “生产率”,也就是说, 生产率高的员工其工资也高,生产率低的员工其工资也低。
产品或服务的价格: 边际产量值是产品量乘以产品价格,因此,当产品价格变动时,边际产量值变动,从而带动劳动需求和工资的变动。例如:产品价格上升增加了每个程序员的“边际产量值”,从而增加了企业的劳动需求,并增加了程序员的工资。相反,产品价格下降减少了边际产量值,也减少了企业的劳动需求,同时降低了程序员的工资。
技术变革: 工程师不断地发明出新的,更好的技术,技术进步通常提升了程序员的“生产率”,增加了劳动的边际产量,从而增加了劳动需求,也增加了自己的工资。
回到前端,技术的快速革命本质上是在给我们前端工程师创造红利,技术的快速变革迅速提升了前端工程师的“生产效率”,且当下互联网产品的市场价值也比较高,在这样环境下,业务和技术在彼此互相成就的循环中,前端程序员的需求量和工资也不断提升。这一点从每年加入前端岗位的应届毕业生薪资不断上涨可以得到证实。
从这个角度,我们可以根据:“提升效率的技术” 来判断哪些技术值得投入。前端技术变革带来的边际产量值的提升可以分两类:
大多数技术变革都是以“间接”的形式提升前端工程师的“边际产量值”,先通过提升研发效率,再用研发效率的提升带动业务效率,从而提升自己的边际产量值。举一些我们比较熟悉的例子:跨端技术、Node.js、前端框架、Babel、Webpack等,这些技术都是通过“提升研发效率”或通过改变生产关系“提升研发效率”的方式“提升业务上的效率”。
也有一些可以直接提升“业务效率”的技术变革,例如:性能、搭建、中后台等。
回到最初的问题:哪些技术值得投入时间和精力学习?
答案是:一旦有一个技术大杀器出来,不论是“直接”地还是“间接”地提升所有人的效率和能力,那么这个技术必须要学。如果一个新技术出来没有对效率有影响,那么不学问题也不大。
从目前接收到的一些信息和看到的苗头,面向未来可以提升效率的技术变革,包括不限于:Serverless、前端智能化、智能化搭建。当然,还有些永不凋零的领域:跨端、性能等。随着技术进步,具体的技术项目可能会过期,这些领域不会。以上提到的技术都符合 “提升效率” 的条件,大家有时间可以花时间了解一下。
Serverless提供的能力可以通过改变生产关系的方式提升前端工程师的研发效率和能力范围,从而提升前端工程师的边际产量值。像今年天猫双十一主会场的SSR就是通过 Faas 函数来实现的,有了Node.js之后,前端工程师编写服务端的一些功能是比较轻松的。但后期的运维工作、数据库优化等问题是前端工程师不太擅长的。而Serverless彻底让前端工程师从这些顾虑中解脱出来,这意味着,前端工程师所涉猎的范围会变得更为广泛,且产研效率因为生产关系的改变也有极大的提升。效率+涉猎范围共同提升,这会提升企业对前端工程师的需求量,在供给不变的情况下,需求量增加,这又会提升前端工程师的工资。
前端智能化包含D2C(设计稿转代码)、P2C(需求文档转代码)等,这个比较好理解,一位前端工程师,一天最多能生产多少张页面?让机器来做这件事一天可以生产无数个页面,这是很直接的效率提升。
智能化搭建是面向特定领域的一种技术升级,它不是提升前端工程师的研发效率,而是通过技术直接提升业务的效率。对于企业来讲,收益是相同的,研发效率的提升是为了提升业务的效率。如果直接提升业务效率对企业来讲收益是完全相同的。因此,这项技术也会提升前端工程师所产出的价值。
什么是智能化搭建,今天的搭建大部分都是手工搭建,如果利用大数据对商品和人群通过算法找到最佳匹配模式根据千人千面自动生成会场页面,这就是智能化搭建。它的效率无疑会极大的提高。
前端这个领域,某一个具体的跨端技术(jQuery其实也是一种跨端技术)或性能技术可能会随着技术的发展而被更有效率的技术代替,但领域是不会被代替的。这些领域都是可以长期跟进并投入研究的,一旦技术有创新突破,性能的提升可以直接对业务效率带来提升,从而提升自己的边际产量值,而跨端技术的突破会提高研发效率,从而提升自己的边际产量值。
“生产要素” 是用于生产物品与服务的“投入”,程序员的时间(劳动)是一种“生产要素”,且生产要素的“需求”是派生需求,根据边际产量递减性质,企业对程序员的需求会保持在劳动的“边际产量值”等于工资的那个点。
一旦劳动的购买量使供求达到均衡, “工资就必定等于劳动的边际产量值”。所以改变劳动“供求”的任何事件都必定使“均衡工资”和“边际产量值”等量变动,所以,工资的高低取决于用劳动的边际产量值衡量的 “生产率”,也就是说, 生产率高的员工其工资也高,生产率低的员工其工资也低。
产品或服务的价格可以影响员工的工资,技术的变革升级也可以影响员工的工资,由于技术的快速变革迅速提升了前端工程师的“生产效率”,所以技术的革命本质上是在给我们前端工程师创造红利,且随着技术的变革,前端工程师的工资上涨了。
可以通过 “提升效率的技术” 来判断哪些技术值得投入,展望过去:跨端技术、Node.js、前端框架、Babel、Webpack等技术让前端行业的效率和能力大幅提升了前端工程师的“边际产量值”,因此提升了企业对前端工程师的需求,随着企业对前端工程师需求的增加,前端工程师的工资也随着行业的兴盛一起上涨。这在过去每年加入前端岗位的应届毕业生薪资不断上涨可以得到证实。
面向未来,Serverless、前端智能化、智能化搭建、跨端、性能等领域会持续为前端提升效率,因此未来,企业对前端工程师的需求会进一步增加,前端工程师的工资会跟着行业的繁荣一起上涨。
转眼间又是一年,还有三天2017年就过去了,时间过的还真快,我甚至一度觉得2017年一月份才刚过去没多久的样子,去年写年度总结时的画面在我脑海中还那么的清晰。
关于技术我自己感觉今年最大的成长是抽象能力的提升。
去年的这个时候我曾拼命的想知道如何写出更优雅的代码,为此我看了好几本设计模式的书和一些文章。结果不是特别的理想,但也不能说没有用,模仿着也能写出类似的代码,但是总觉得代码缺少了什么,后来我才知道,缺少的是灵魂。
今年,我慢慢的发现我写的代码开始慢慢的具备一些灵性了,已经不再是模仿设计模式来写代码,而是真正的可以按不同的需求去合理的抽象与组织代码,学习过的设计模式也已经忘了,但写出的代码反而具备了设计模式的精髓,有一种无招胜有招的感觉,自己与自己写出来的代码之间莫名的有一丝丝的感应,我觉得这就是有灵魂的代码吧。
今年读完了 You-Dont-Know-JS 系列的书,对 JS 的一些细节,之前没有关注到的部分进行了一个知识补充。
去年读过了《understanding ECMAScript6》后,今年有人把这本书翻译成了中文的,我就买了一个本把中文版的又重新读了一遍。反复读过几次在加上平时工作中经常用,已经可以熟练应用了。
今年把 Vue2.0 的代码重新读了一遍,Vue2.0 新增了很多特性。
我学习了其中的 模板编译原理 和 virtualDOM 原理。
关于模板编译原理我还特意写了一篇文章,传送门
参与 Thinkjs 3.0 的开发。
学习了C语言程序设计,并通过了高级程序设计的自学考试。
重新学习了一遍新概念一册。
我们360内部每周一都有一个泛前端分享会,今年我分享了 《聊聊类型转换》和 《Vue 变化侦测原理》,并且获得了讲师排名第二名,第一名是月影姐姐,月影姐姐还给我发了奖品~
每周都在坚持健身,不过不在公司楼上锻炼了,公司健身房怕吵到楼下,把哑铃给拿走了,我在我住处附近的健身房办了卡,每周会固定去2~3次。其实直到今天我写这篇总结时我才发现,去年年底写总结时就已经在坚持健身了,原来我已经坚持健身一年多了。
其实我最近对时间管理非常感兴趣,也查了很多资料来学习如何时间管理,通过有效的对时间和精神力进行管理,我现在感觉效果很明显,并且我很喜欢这种感觉。
我现在每天 7.30 准时起床学一个番茄钟的英语(我弄了一个薄荷阅读来读一些英语书来练习我的阅读能力,但我没有其他时间去读这个书,所以我就把我起床的时间提前了两个番茄种用来读这个)。
每天中午午休的时间,我会用一个番茄钟的时间来学习计算机组成原理,因为我要考自考,所以自考的书不能落下。
每天晚上下班回家我会用两个番茄钟的时间看新东方的新概念视频来学习英语。
以上这三项是我给我自己订的定额任务,我每天都会去完成这些任务,没有一天落下(除非出现什么特殊情况,但这种特殊情况到现在为止从没发生过),直到有一天任务完成了。
除了定额任务外,我还会不定期的给自己定一个学习计划,为期一个月,这一个月的时间我只学这个计划内的知识,我学习 vue 的编译原理 和 virtualDOM 就是给自己定学习计划来学的。
我在我电脑上安装了 rescueTime,并且购买了一年的高级版,这个软件可以监控我每天在电脑上做了什么,在什么地方用了多长时间等,非常的好用,哪些事是高效的,哪些事是低效的,都会进行一个很全面的统计,非常的好用。
而且 rescueTime 可以结合 Trello 一起用,我使用 Trello 来管理我日常的任务和长期的计划。
其实我自己对2017年是不太满意的,因为我发现这个高效的方法太晚了,导致我今年的成长并没有我想象的那么快,好在我现在已经掌握了这种高效成长的方法论,我希望2018年我在写总结的时候可以自豪的写上我这一整年都做了哪些自己感觉到自豪的事。
Trello
RescueTime
今年去了一趟秦皇岛玩耍
关于读书我要强烈推荐两本书:《叩响命运的门》和《软技能 - 代码之外的生存指南》。
这两本书一本是关于人文素养的,另一本我个人感觉是程序员的圣经。
读完了:
《You-Dont-Know-JS》系列、《深入理解ES6》、《人间失格》、《解忧杂货店》、《隐忍的老虎 - 司马懿》、《悟空传》、《以色列:一个国家的诞生》、《以色列2:在危机中生存》、《以色列3:赎罪日》、《重新定义效率》
读了一半:
《叩响命运的门》、《软技能 - 代码之外的生存指南》、《帝王师:刘伯温》、《断舍离》
2017年财务统计房租支出依然排名第一,远超其他项。
学习支出排名第二,关于这点我还是很满意的。
排名第三为吃饭。
房租支出连续三年排行第一,很稳,这个我也没啥办法,虽然我一心想把学习投入增加到第一,但目前在国内一线城市居住这么昂贵的情况下,,,,,,,我也实在是没办法。。
学习支出连续3年持续排名第二,嗯,这点我还是很满意的。
从第三开始是吃饭衣服其他项。。

从上图来看,工资收入占比99.5%,这点还有待改善。
净资产逐步提升,这点需要保持。
今年开始我发现我特别喜欢对知识付费,从我的财务状况统计就可以看出我的知识付费在我的所有支出中仅此房租。
我买了接近30个知乎Live,并且这几天有优惠我办了一个知乎Live的年卡。
经常在 GitChat 上买一些文章来读,而且参加了一个知识星球。
买了五本掘金小册!
订阅了耗子姐姐的知识星球~
在得到APP中购买了吴军老师的专栏《硅谷来信》
以上提到的这些全都是付费的,但我自己写的文章还是会继续免费给大家看,哈哈哈哈。
参加了10月份的自学考试,考了一门高级语言程序设计,并且通过了,现在在学习计算机组成原理。
就这样,其他的想到了在补充吧~
2017年仿佛就在昨天,但一眨眼,2018年都结束了。
不晓得为什么,时间过的越来越快。上学的时候一个学期像一辈子,永远也盼不到寒暑假。工作这么多年却感觉,当初一个学期的时间,现在仿佛连睡个懒觉都不够。
今年的年终总结比以往来的更晚一些,因为跨年这两天在俄罗斯玩耍,写年终总结的事情就往后拖了拖。
今年我对Vue.js这个框架自认为可以算精通的程度,我对Vue.js内部各个核心技术的实现原理以及实现细节和框架相关宏观上的**(例如:框架要解决的问题、如何解决、会遇到的问题)都比较了解。
注意:我对Vue.js的学习更多的是在了解它在解决什么问题,使用了哪些技术与方案解决的,这些技术和方案的原理是什么。而不是如何使用Vue.js。
或许更精准的描述是:我在学习对于某个问题,Vue.js给出的解决方案是什么。
今年上半年的全部时间都在撰写《深入浅出Vue.js》一书,下半年我把关注点放在了Web性能上面,一方面是自己对这方面比较感兴趣,另一方面也是因为自己加入了W3C性能工作组。现在,我已经对Web性能领域建立起比较完善的知识体系,精读了W3C性能工作组的所有规范,并写了5篇Web性能领域的文章。
计划2019年,撰写Web性能领域的知识付费课程。
上面说的两点是看得见摸得着的成长,我觉得今年让我觉得最欣喜的成长是境界上的成长。我在工作了3年的时候,就有一种感觉,觉得自己很牛逼,什么都会,很飘飘然,但始终不知道自己如何向真正的技术大神靠近。当时很困惑我的一个问题是,我什么都会,为什么和真正的大神差距还是那么大呢?说实话,这个就是眼界的问题,因为我看见的东西少,在我看得见的世界里我确实什么都会,但是更大的世界我没有看见,不知道蚂蚁是否意识到人类的存在?
今年10月份去法国参加了W3C一年一度的TPAC,在那里我感受到了一个专业的世界级程序员应该是什么“感觉”的,虽然没有让我一下子学会什么,但却对我日后的成长照成了一些影响。
在Web领域,武林秘籍就是W3C规范,W3C各个工作组分别定义了Web领域各个细分领域的规范。按照武侠小说的说法,如果把武林秘籍修炼至大成,江湖上顶级强者中必有你一席之位。
这一年我做过的最有成就感的事是写完了《深入浅出Vue.js》这本书、
除此之外,今年在博客上共发布了9篇文章。很庆幸各位读者的不离不弃,在各种文章满天飞的今天,这么低的发文频率关注我博客的用户不但没有减少反而提升了不少。2018-1-1我博客的Star数是420,截止到2019-1-7我博客的Star数是1460、差不多这一年涨了1K吧,感谢大家的支持。
今年或许是我生活的最潇洒的一年。我的足迹踏到了阿姆斯特丹、法国里昂、伊尔库茨克、莫斯科、摩尔曼斯克、圣彼得堡、阿拉木图、阿斯塔纳、上海、杭州。
这一年我在不同的国家,不同的城市见到了不同的景色和形形色色的人。也遇到了各种各样的事与图突发情况,有好的也有不好的。或许这对我来说也是一种历练。人活一世不多看看地球长什么样,那和咸鱼有什么区别。我对旅行非常感兴趣,我的足迹也不会就此止步。
关于读书,今年在业余时间读完了:《软技能 - 代码之外的生存指南》、《JavaScript模式》、《你的善良,必须有点锋芒》、《断舍离》、《这就是我背叛自己的方式》、《编写可维护的JavaScript》、《Chrome开发者工具的官方在线系列文章》、《高性能JavaScript》、《前端工程化 - 体系设计与实践》、《会消失的人》、
成功坚持了薄荷阅读的连续100天读完三本英语书,并成功得到了三本实体书、
背完了《新概念》一册的所有课文。
2018年我开始尝试做减法,让自己做的事情更少,但是更专注。说实话,我不知道这样做是对是错~
其实在一年前我已经写过一篇关于 vue响应式原理的文章,但是最近我翻开看看发现讲的内容和我现在心里想的有些不太一样,所以我打算重新写一篇更通俗易懂的文章。
我的目标是能让读者读完我写的文章能学到知识,有一部分文章标题都以深入浅出开头,目的是把一个复杂的东西排除掉干扰学习的因素后剩下的核心原理通过很简单的描述来让读者学习到知识。
关于vue的内部原理其实有很多个重要的部分,变化侦测,模板编译,virtualDOM,整体运行流程等。
今天主要把变化侦测这部分单独拿出来讲一讲。
关于变化侦测首先要问一个问题,在 js 中,如何侦测一个对象的变化,其实这个问题还是比较简单的,学过js的都能知道,js中有两种方法可以侦测到变化,Object.defineProperty 和 ES6 的proxy。
到目前为止vue还是用的 Object.defineProperty,所以我们拿 Object.defineProperty来举例子说明这个原理。
这里我想说的是,不管以后vue是否会用 proxy 重写这部分,我讲的是原理,并不是api,所以不论以后vue会怎样改,这个原理是不会变的,哪怕vue用了其他完全不同的原理实现了变化侦测,但是本篇文章讲的原理一样可以实现变化侦测,原理这个东西是不会过时的。
之前我写文章有一个毛病就是喜欢对着源码翻译,结果过了半年一年人家源码改了,我写的文章就一毛钱都不值了,而且对着源码翻译还有一个缺点是对读者的要求有点偏高,读者如果没看过源码或者看的和我不是一个版本,那根本就不知道我在说什么。
好了不说废话了,继续讲刚才的内容。
知道 Object.defineProperty 可以侦测到对象的变化,那么我们瞬间可以写出这样的代码:
function defineReactive (data, key, val) {
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function () {
return val
},
set: function (newVal) {
if(val === newVal){
return
}
val = newVal
}
})
}写一个函数封装一下 Object.defineProperty,毕竟 Object.defineProperty 的用法这么复杂,封装一下我只需要传递一个 data,和 key,val 就行了。
现在封装好了之后每当 data 的 key 读取数据 get 这个函数可以被触发,设置数据的时候 set 这个函数可以被触发,但是,,,,,,,,,,,,,,,,,,发现好像并没什么鸟用?
现在我要问第二个问题,“怎么观察?”
思考一下,我们之所以要观察一个数据,目的是为了当数据的属性发生变化时,可以通知那些使用了这个 key 的地方。
举个🌰:
<template>
<div>{{ key }}</div>
<p>{{ key }}</p>
</template>模板中有两处使用了 key,所以当数据发生变化时,要把这两处都通知到。
所以上面的问题,我的回答是,先收集依赖,把这些使用到 key 的地方先收集起来,然后等属性发生变化时,把收集好的依赖循环触发一遍就好了~
总结起来其实就一句话,getter中,收集依赖,setter中,触发依赖。
现在我们已经有了很明确的目标,就是要在getter中收集依赖,那么我们的依赖收集到哪里去呢??
思考一下,首先想到的是每个 key 都有一个数组,用来存储当前 key 的依赖,假设依赖是一个函数存在 window.target 上,先把 defineReactive 稍微改造一下:
function defineReactive (data, key, val) {
let dep = [] // 新增
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function () {
dep.push(window.target) // 新增
return val
},
set: function (newVal) {
if(val === newVal){
return
}
// 新增
for (let i = 0; i < dep.length; i++) {
dep[i](newVal, val)
}
val = newVal
}
})
}在 defineReactive 中新增了数组 dep,用来存储被收集的依赖。
然后在触发 set 触发时,循环dep把收集到的依赖触发。
但是这样写有点耦合,我们把依赖收集这部分代码封装起来,写成下面的样子:
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor () {
this.id = uid++
this.subs = []
}
addSub (sub: Watcher) {
this.subs.push(sub)
}
removeSub (sub: Watcher) {
remove(this.subs, sub)
}
depend () {
if (Dep.target) {
this.addSub(Dep.target)
}
}
notify () {
// stabilize the subscriber list first
const subs = this.subs.slice()
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
}然后在改造一下 defineReactive:
function defineReactive (data, key, val) {
let dep = new Dep() // 修改
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function () {
dep.depend() // 修改
return val
},
set: function (newVal) {
if(val === newVal){
return
}
dep.notify() // 新增
val = newVal
}
})
}这一次代码看起来清晰多了,顺便回答一下上面问的问题,依赖收集到哪?收集到Dep中,Dep是专门用来存储依赖的。
上面我们假装 window.target 是需要被收集的依赖,细心的同学可能已经看到,上面的代码 window.target 已经改成了 Dep.target,那 Dep.target是什么?我们究竟要收集谁呢??
收集谁,换句话说是当属性发生变化后,通知谁。
我们要通知那个使用到数据的地方,而使用这个数据的地方有很多,而且类型还不一样,有可能是模板,有可能是用户写的一个 watch,所以这个时候我们需要抽象出一个能集中处理这些不同情况的类,然后我们在依赖收集的阶段只收集这个封装好的类的实例进来,通知也只通知它一个,然后它在负责通知其他地方,所以我们要抽象的这个东西需要先起一个好听的名字,嗯,就叫它watcher吧~
所以现在可以回答上面的问题,收集谁??收集 Watcher。
watcher 是一个中介的角色,数据发生变化通知给 watcher,然后watcher在通知给其他地方。
关于watcher我们先看一个经典的使用方式:
// keypath
vm.$watch('a.b.c', function (newVal, oldVal) {
// do something
})这段代码表示当 data.a.b.c 这个属性发生变化时,触发第二个参数这个函数。
思考一下怎么实现这个功能呢?
好像只要把这个 watcher 实例添加到 data.a.b.c 这个属性的 Dep 中去就行了,然后 data.a.b.c 触发时,会通知到watcher,然后watcher在执行参数中的这个回调函数。
好,思考完毕,开工,写出如下代码:
class Watch {
constructor (expOrFn, cb) {
// 执行 this.getter() 就可以拿到 data.a.b.c
this.getter = parsePath(expOrFn)
this.cb = cb
this.value = this.get()
}
get () {
Dep.target = this
value = this.getter.call(vm, vm)
Dep.target = undefined
}
update () {
const oldValue = this.value
this.value = this.get()
this.cb.call(this.vm, this.value, oldValue)
}
}这段代码可以把自己主动 push 到 data.a.b.c 的 Dep 中去。
因为我在 get 这个方法中,先把 Dep.traget 设置成了 this,也就是当前watcher实例,然后在读一下 data.a.b.c 的值。
因为读了 data.a.b.c 的值,所以肯定会触发 getter。
触发了 getter 上面我们封装的 defineReactive 函数中有一段逻辑就会从 Dep.target 里读一个依赖 push 到 Dep 中。
所以就导致,我只要先在 Dep.target 赋一个 this,然后我在读一下值,去触发一下 getter,就可以把 this 主动 push 到 keypath 的依赖中,有没有很神奇~
依赖注入到 Dep 中去之后,当这个 data.a.b.c 的值发生变化,就把所有的依赖循环触发 update 方法,也就是上面代码中 update 那个方法。
update 方法会触发参数中的回调函数,将value 和 oldValue 传到参数中。
所以其实不管是用户执行的 vm.$watch('a.b.c', (value, oldValue) => {}) 还是模板中用到的data,都是通过 watcher 来通知自己是否需要发生变化的。
现在其实已经可以实现变化侦测的功能了,但是我们之前写的代码只能侦测数据中的一个 key,所以我们要加工一下 defineReactive 这个函数:
// 新增
function walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i], obj[keys[i]])
}
}
function defineReactive (data, key, val) {
walk(val) // 新增
let dep = new Dep()
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function () {
dep.depend()
return val
},
set: function (newVal) {
if(val === newVal){
return
}
dep.notify()
val = newVal
}
})
}这样我们就可以通过执行 walk(data),把 data 中的所有 key 都加工成可以被侦测的,因为是一个递归的过程,所以 key 中的 value 如果是一个对象,那这个对象的所有key也会被侦测。
现在又发现了新的问题,data 中不是所有的 value 都是对象和基本类型,如果是一个数组怎么办??数组是没有办法通过 Object.defineProperty 来侦测到行为的。
vue 中对这个数组问题的解决方案非常的简单粗暴,我说说vue是如何实现的,大体上分三步:
第一步:先把原生 Array 的原型方法继承下来。
第二步:对继承后的对象使用 Object.defineProperty 做一些拦截操作。
第三步:把加工后可以被拦截的原型,赋值到需要被拦截的 Array 类型的数据的原型上。
vue的实现
第一步:
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)第二步:
;[
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
.forEach(function (method) {
// cache original method
const original = arrayProto[method]
Object.defineProperty(arrayMethods, method, {
value: function mutator (...args) {
console.log(method) // 打印数组方法
return original.apply(this, args)
},
enumerable: false,
writable: true,
configurable: true
})
})现在可以看到,每当被侦测的 array 执行方法操作数组时,我都可以知道他执行的方法是什么,并且打印到 console 中。
现在我要对这个数组方法类型进行判断,如果操作数组的方法是 push unshift splice (这种可以新增数组元素的方法),需要把新增的元素用上面封装的 walk 来进行变化检测。
并且不论操作数组的是什么方法,我都要触发消息,通知依赖列表中的依赖数据发生了变化。
那现在怎么访问依赖列表呢,可能我们需要把上面封装的 walk 加工一下:
// 工具函数
function def (obj: Object, key: string, val: any, enumerable?: boolean) {
Object.defineProperty(obj, key, {
value: val,
enumerable: !!enumerable,
writable: true,
configurable: true
})
}
export class Observer {
value: any;
dep: Dep;
vmCount: number; // number of vms that has this object as root $data
constructor (value: any) {
this.value = value
this.dep = new Dep() // 新增
this.vmCount = 0
def(value, '__ob__', this) // 新增
// 新增
if (Array.isArray(value)) {
this.observeArray(value)
} else {
this.walk(value)
}
}
/**
* Walk through each property and convert them into
* getter/setters. This method should only be called when
* value type is Object.
*/
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i], obj[keys[i]])
}
}
/**
* Observe a list of Array items.
*/
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
new Observer(items[i])
}
}
}我们定义了一个 Observer 类,他的职责是将 data 转换成可以被侦测到变化的 data,并且新增了对类型的判断,如果是 value 的类型是 Array 循环 Array将每一个元素丢到 Observer 中。
并且在 value 上做了一个标记 __ob__,这样我们就可以通过 value 的 __ob__ 拿到Observer实例,然后使用 __ob__ 上的 dep.notify() 就可以发送通知啦。
然后我们在改进一下Array原型的拦截器:
;[
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
.forEach(function (method) {
// cache original method
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// notify change
ob.dep.notify()
return result
})
})可以看到写了一个 switch 对 method 进行判断,如果是 push,unshift,splice 这种可以新增数组元素的方法就使用 ob.observeArray(inserted) 把新增的元素也丢到 Observer 中去转换成可以被侦测到变化的数据。
在最后不论操作数组的方法是什么,都会调用 ob.dep.notify() 去通知 watcher 数据发生了改变。
现在我们有一个 arrayMenthods 是被加工后的 Array.prototype,那么怎么让这个对象应用到Array 上面呢?
思考一下,我们不能直接修改 Array.prototype因为这样会污染全局的Array,我们希望 arrayMenthods 只对 data中的Array 生效。
所以我们只需要把 arrayMenthods 赋值给 value 的 __proto__ 上就好了。
我们改造一下 Observer:
export class Observer {
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
value.__proto__ = arrayMethods // 新增
this.observeArray(value)
} else {
this.walk(value)
}
}
}如果不能使用 __proto__,就直接循环 arrayMethods 把它身上的这些方法直接装到 value 身上好了。
什么情况不能使用 __proto__ 我也不知道,各位大佬谁知道能否给我留个言?跪谢~
所以我们的代码又要改造一下:
// can we use __proto__?
const hasProto = '__proto__' in {} // 新增
export class Observer {
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
// 修改
const augment = hasProto
? protoAugment
: copyAugment
augment(value, arrayMethods, arrayKeys)
this.observeArray(value)
} else {
this.walk(value)
}
}
}
function protoAugment (target, src: Object, keys: any) {
target.__proto__ = src
}
function copyAugment (target: Object, src: Object, keys: Array<string>) {
for (let i = 0, l = keys.length; i < l; i++) {
const key = keys[i]
def(target, key, src[key])
}
}关于vue对Array的拦截实现上面刚说完,正因为这种实现方式,其实有些数组操作vue是拦截不到的,例如:
this.list[0] = 2修改数组第一个元素的值,无法侦测到数组的变化,所以并不会触发 re-render 或 watch 等。
在例如:
this.list.length = 0清空数组操作,无法侦测到数组的变化,所以也不会触发 re-render 或 watch 等。
因为vue的实现方式就决定了无法对上面举得两个例子做拦截,也就没有办法做到响应,ES6是有能力做到的,在ES6之前是无法做到模拟数组的原生行为的,现在 ES6 的 Proxy 可以模拟数组的原生行为,也可以通过 ES6 的继承来继承数组原生行为,从而进行拦截。
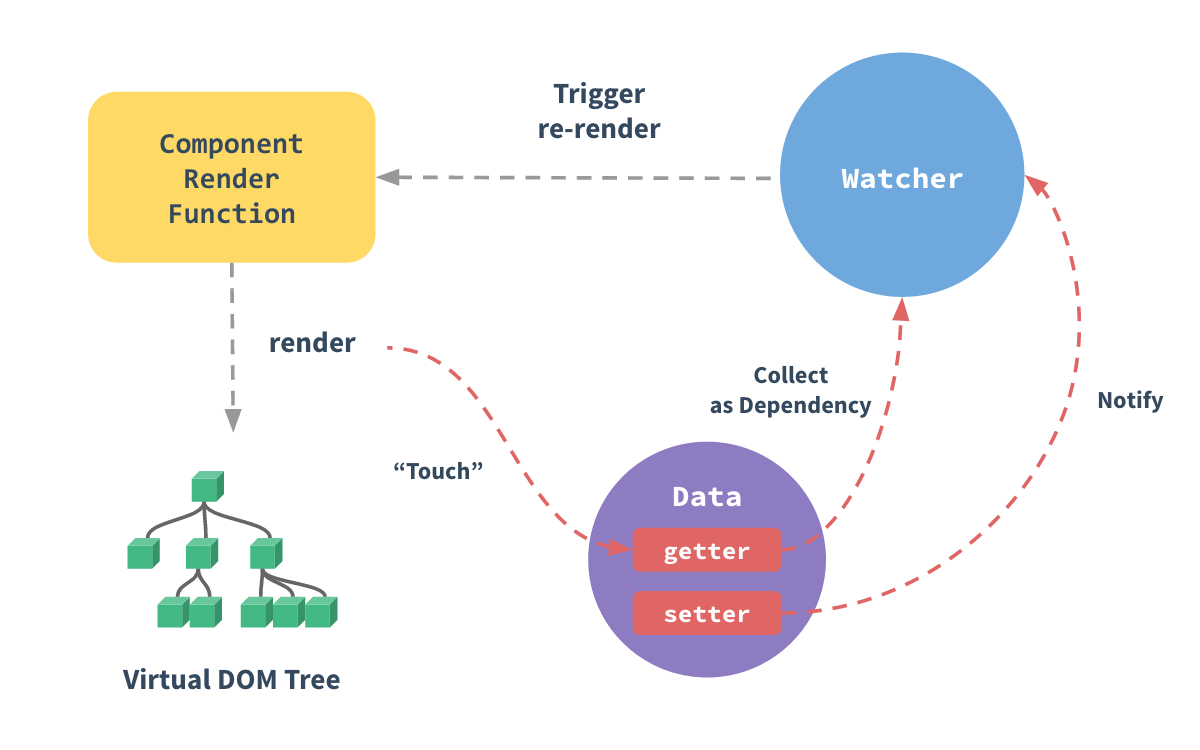
最后掏出vue官网上的一张图,这张图其实非常清晰,就是一个变化侦测的原理图。
getter 到 watcher 有一条线,上面写着收集依赖,意思是说 getter 里收集 watcher,也就是说当数据发生 get 动作时开始收集 watcher。
setter 到 watcher 有一条线,写着 Notify 意思是说在 setter 中触发消息,也就是当数据发生 set 动作时,通知 watcher。
Watcher 到 ComponentRenderFunction 有一条线,写着 Trigger re-render 意思很明显了。

这篇文章是2019年5月11号,我在上海FDConf2019上的分享整理。
- 演讲主题:【让你的网页更丝滑】
- 时间:2019年5月11日(下午)
- 地点:上海 - FDCon2019 - B会场(全栈&全端专场)
- 演讲嘉宾:刘博文
大家好,我叫刘博文,今天给大家分享的主题叫《让你的网页更丝滑》,其实就是更流畅的意思。
简单介绍一下自己,2012年我从中专毕业,当时是17岁,2015年我加入了360最大的前端团队奇舞团,那一年我是20岁;2017年由于组织架构的变动,我们组被拆分到360导航,所以我就变成360导航的一名前端工程师;2018年就是去年,因为公司是W3C的会员,所以我就加入了W3C的性能工作组。
消息比较灵通的应该听说过我在上个月出版了一本讲Vue的书,叫做《深入浅出Vue.js》。
虽然出版了一本Vue的书,但其实从去年加入W3C性能工作组之后,我一直在学习和了解Web性能领域相关的知识。
在讨论如何让网页更流畅之前,需要先思考一个问题就是什么样的网页是流畅的?
这个问题我总结了一句话:在网页与用户产生交互的过程中,让用户感觉流畅。
你的网页不一定要有多快,它没有一个标准,你的标准就是让用户感觉流畅就够了。另一个重点就是说在交互过程中,让用户感到流畅。所以延伸出一个问题,如何通过交互让用户感觉流畅。这里面我把交互总结为两种类型,一种是被动的,一种是主动的。
所谓被动交互就是不需要用户主动去触发什么,就可以让网页在视觉上与用户产生交互。
比如说:Animation(动画)、开屏广告、自动播放的轮播图等都算被动交互。与之相反,需要用户主动去触发某些行为从而产生的反馈,我称它为主动交互,比如说用鼠标点某一个按纽产生的反馈,或使用键盘按下了某个键位产生的反馈。这个反馈可以是动画,任何东西都可以。那么被动交互如何让用户感觉流畅?这是今天第一个关于优化的话题。
我在京东上搜索显示器,发现有一个筛选条件叫刷新率,最低的是60HZ,高的可以达到165HZ以上。
这个60HZ是什么意思?就是指屏幕每秒钟刷新60次。所以我们可以通过屏幕作为参考,如果我们的网页也可以每秒钟往屏幕传输60个画面,用户就会觉得这个网页是流畅的,有一个单位叫做FPS,意思就是每秒钟往屏幕上传输的图像数量。FPS达到60,用户就会觉得这个网页比较流程,换算下来,每一帧是16.7毫秒。
主动交互如何让用户感觉流畅?我也把它总结成一句话,这句话叫:“通过响应的时间影响用户的感觉”。就是说我们可以通过操控这个时间来影响用户对网页的感觉。
我们看一个演示(Demo),这个演示很简单,就是我点击按纽的时候,我让这个函数延迟多少秒,然后把这个方块改变一下颜色。这下面是八个按纽,分别是10毫秒、30毫秒、50毫秒、100毫秒、200毫秒、300毫秒、500毫秒、1秒。(文章无法演示,可以到在线PPT里去体验,或者访问https://code.h5jun.com/pojob)
你会发现当我点击200毫秒的按钮时,这个反馈速度,用户会觉得这个东西有一点卡,当我点击100毫秒的按钮时,已经感觉不卡了,当然更快更好。所以你会发现100毫秒是一个临界点,从我们的输入,包括键盘按键和鼠标点击到最终输出到眼睛里,这个时间100毫秒是临界点。超过这个时间,用户就会觉得有点卡,所以100毫秒是关键点。
我们再看一个例子,代码和刚才是一样的,现在只有一个按纽是100毫秒,刚才我说100毫秒,用户就会觉得很流畅。其实你会发现还是卡一下,但是不是说每次都卡,有的时候不卡,为什么有的时候卡有的时候不卡?
因为我们的目标是从输入到输出总时间是100毫秒以内,用户才会觉得流畅。但其实我这个代码有一个问题是这个函数的执行时间是100毫秒,所以如果当我点击这个按纽一瞬间,如果有其他任务在执行,就会把我这个函数堵塞住,被阻塞的时间加上函数执行的100毫秒,现在整体时间已经超过100毫秒,所以我刚才点击这个按纽,你会发现有时候卡,有时候不卡,不卡的时候是因为我点击这个按纽的时候,恰巧没有其他的任务在执行。
所以为什么会有这个问题?因为大家都知道JS是单线程的,浏览器同一时间内只能执行一个任务,所以为了避免这个问题,解决方案就是说所有的任务执行时间不能超过50毫秒。如果我所有的任务都不超过50毫秒,假设最糟糕的情况下,我点击这个按纽的一瞬间,有其他的任务在执行,但其实他的任务执行时间最多是50毫秒,我的任务执行时间也是保持在50毫秒以内,其实总共也不会超过100毫秒,所以用户依然会觉得很流畅,即便是最糟糕的情况下。
可以看一下这个粉色的地方,从input到response总时间是100毫秒,红色区域是被阻塞的部分,黄色是函数执行的时间和时机,你会发现我这两个任务都保持在50毫秒以内的情况下,我可以保证我的总时间是100毫秒以内完成的,这个50毫秒不是我定的,W3C性能工作组有一个Longtask规范也对这种情况做了规定。
这个规范就规定所有的任务,包括函数执行,包括什么都算上,不能超过50毫秒,超过50毫秒就被定义为长任务,所谓长任务就是执行时间过长的任务,这是不合理的,应该被解决的任务。性能监控一般都会通过图中的代码来监控与捕获长任务,可以看到这个entryType是longtask的。
总结一下,如何让用户感觉流畅?就是响应时间保持在100毫秒以内,动画要16.7毫秒传输一帧到屏幕上,空闲任务不能超过50毫秒,其实不只是空闲任务,所有任务都不能超过50毫秒,加载时间是1000毫秒,所谓的页面秒开就是从这里来的。这四个单词的首字母加在一起组成一个单词叫RAIL,这是一个术语,它代表以用户为中心的性能模型,我们刚才讲的也是这个话题,感兴趣大家可以回去查一下。
今天讲第二个概念叫像素管道。所谓像素管道,就是说我们通常会在网页触发一些视觉变化,你用JS改了颜色和宽度等等,随后浏览器就会做样式计算,浏览器还会做布局、绘制,合并图层等,这个过程叫做像素管道。
但是有的时候,不是所有的样式都会触发布局,有的时候不需要布局的,我们通过一些优化手段也可以取消Paint(绘制)这一步。有一个网站叫 csstriggers,可以看哪些属性触发了布局,哪些触发了Paint,这个网站有列表可以看。
今天第一个关于如何优化的话题叫如何保证主动交互让用户感觉流畅,其实刚才我们介绍说想保证主动交互让用户感觉流畅需要避免长任务,所以这个副标题叫如何避免长任务。
如何避免长任务,有两种方案:一种叫 Web Worker ,还有一种方案叫 Time Slicing(时间切片)。
先说Web Worker,我们看一段代码,我的网页里面有一个while循环,通常来讲这个循环会把浏览器卡死一秒钟,因为循环了一秒,现在我把它移动到 worker中 执行,就不会卡死浏览器了,它在worker线层中工作,就不会卡死主线程。这是一种解决方案,可以看一下效果。(由于文章无法演示效果,感兴趣的小伙伴可以到在线PPT里观察 https://ppt.baomitu.com/d/b267a4a3#/14)
const testWorker = new Worker('./worker.js')
setTimeout(_ => {
testWorker.postMessage({})
testWorker.onmessage = function (ev) {
console.log(ev.data)
}
}, 5000)
// worker.js
self.onmessage = function () {
const start = performance.now()
while (performance.now() - start < 1000) {}
postMessage('done!')
}可以看到现在浏览器没有被堵塞掉。
我们通过捕获火焰图,发现优化前其实长任务是主线程中工作,优化之后是放在 Worker 来进行的,所以我的主线依然可以处理其他的任务。
Web Worker虽然好,但是它有一个缺陷,就是它没有办法摸DOM。如果你想操作DOM,那么就没法在Worker中执行。我就是要循环超过100毫秒,我又想在循环中操作DOM,这时候怎么办?有一个方案叫 Time Slicing。
Time Slicing就是把一个长任务给切割成无数个执行时间很短的任务。
可以看到中间用户红框框起来的,内部有很多黄颜色的小竖线,其实每一个都是任务,放大之后,就是图中最下面的火焰图,可以看到中间是有空隙的。因为中间有空隙,浏览器就可以在这些空隙中做其他的事,比方说布局、样式计算、UI事件,所有事情都可以做。
实现时间切片功能的代码也并不是很复杂,就是下面这段代码,其实核心代码只有三四行。代码虽然不多,但是可能理解起来也没有那么容易,我为大家简单介绍一下。
function block () {
ts(function* () {
const start = performance.now()
while (performance.now() - start < 1000) {
console.log(11)
yield
}
console.log('done!')
})
}
setTimeout(block, 5000)
function ts (gen) {
if (typeof gen === 'function') gen = gen()
if (!gen || typeof gen.next !== 'function') return
(function next () {
const res = gen.next()
if (res.done) return
setTimeout(next)
})()
}这些代码首先有两个点,第一个点就是我利用 yield 关键字,让函数暂停执行,大家都知道在Generator函数中有一个 yield 关键字,这个关键字可以让函数暂停执行,这是很关键的特性。我利用的另一个特性就是 setTimeout 的能力,它可以将任务丢到宏任务队列里面排队让我的任务恢复执行,所以我结合这两个特性,用这个代码就可以实现Time Slicing的功能。
代码中我下面这个ts函数其实是我封装的工具函数,我上面其实是我的案例。案例中我这个循环其实正常来说是同步的,循环时会把我的浏览器卡死一秒钟,但是我在里面加了一个 yield 关键字。所以每次执行都会停一下,停止这一瞬间,其实就是把浏览器的主线程给让出来,或者说叫释放出来了,如果不停的执行,在这一秒钟内浏览器干不了别的事,现在我的这个任务执行了一会就停了,浏览器就可以去执行别的任务。然后我在后面的宏任务中再让我这个任务恢复执行。这个代码可能不是那么好理解,可以自己回去慢慢研究。
(关于Time Slicing后来我写了一篇文章进行了更详细与全面的介绍,文章地址:#38)
我这里有一个例子(观看文章的同学可以通过在线PPT来查看视频,地址:https://ppt.baomitu.com/d/b267a4a3#/19),我们会看到浏览器并没有卡死,通过捕获出的火焰图可以看到每个被切割的小任务中间有很多空隙。
现在我们聊下一个话题,保证被动交互让用户感觉流畅。
前面我们讲,若想保证被动交互让用户感觉流畅,我们需要保证每16.7毫秒传输新的一帧到屏幕上,所以我们这个标题应该改成 如何保障动画每16.7毫秒传输新的一帧到屏幕上 。
这张图是前面我们讲的管道,这个只是图变了一下,若想保证每16.7毫秒传输新的一帧到屏幕上,我们需要保障这个像素管道的总时间在16.7毫秒之内。
所以为了保障这个总时间在16.7毫秒之内,我们首先需要保障的事情就是JavaScript的执行时间一定要小于10毫秒,因为浏览器去执行渲染也是有时间消耗的,所以我们应该给浏览器预留出来6.7毫秒。
但其实像素管道的每一步,都有可能导致总时间超过16.7毫秒,所以只是保障JavaScript执行时间小于10毫秒是不够的。我们要针对每一步进行更细致的优化,来保证总时间小于16.7毫秒。
我们先讨论样式计算,关于样式计算有一个重要的话题是选择器匹配。
我们这里有两个选择器,其实选择的是同一个元素,但其实在浏览器里,处理选择器匹配的时候,时间是不一样的,下面更简单的选择器速度更快一点。我在Chrome文档中看到他们说计算某元素的样式时,有50%的时间是用于选择器匹配。
通常如果只是用选择器匹配了一个元素或很少的元素,那么再复杂的选择器,时间上也没有什么太多的影响。但是当选择器匹配到的元素越多的时候,选择器之间的性能差异就体现出来了。
下面有三个圈,和三个选择器,我们可以看到第一个选择器是稍微复杂一点的,第二个选择器就是普通的选择器,第三个选择器也比较复杂。我点击这个按纽看三个选择器的执行时间是多少。
可以看到第一个是1.28毫秒,第二个是0.5毫秒,第三个是4.9毫秒,结果虽然在数量上没差太多,但是第三个比第二个慢了9.8倍。
所以我们会发现选择器越简单速度越快,其实这个差距在元素越来越多的情况下,它就会越来越严重,但通常绝大部分的项目其实并没有那么多的元素,所以这个问题也没有暴露的这么明显,了解一下就可以了。
第二个问题是布局抖动,它是新手写代码最容易出现的问题,一不小心就犯错了。
我们还是回到像素管道,其实像素管道的每一步都是异步的,js改了样式,其实它是异步的去计算样式,布局,绘制,图层合并,每一步都是异步的。
但是有时候一不小心就会出现一个词叫做强制同步布局,通过这个名就知道,这个布局变成了同步的布局。
浏览器本应是异步的去执行布局操作,但现在却跑到了JS里面去同步的执行了。为什么会导致强制同步布局呢?我们来看一段代码。
第一行代码是设置一个元素的宽度,第二行代码是获取元素的宽度,仔细思考一下会发现第一行代码设置了元素的宽,但其实布局操作是异步的,所以我执行第二行代码的时候,浏览器没有还没有进行布局。因为我第二行代码是想获取这个元素的宽,但是这时候浏览器还没有布局,那么浏览器为了回答我这个问题(宽度是多少),它必须要在此时此刻做一次布局,这个时候这个布局是同步的。
我们将火焰图捕获出来也验证了这一点,布局在我们这个js的里面执行,因为JS里面执行了布局所以把JS的执行时间拉长了。这样是不对的,解决方案很简单,只是调换一下顺序,我如果先获取一个元素出来,其实获取的是上次布局的宽度,我并没有改变布局,所以直接读就可以了,我第二行代码才会改宽度,然后再异步触发布局,这样捕获出来的火焰图布局就跑到JS后面去了。
但是通常如果只是这个案例(Demo),其实很简单,你这个再怎么写,也不会有什么问题,因为影响就是很小,但是如果这个问题发生在循环里面,你的元素很多的情况下,这个问题就被放大。
这个案例(Demo)也比较简单,代码右边有很多DIV,粉红色的框是这些DIV的父容器,可以看到父容器比这些DIV窄,当我点击“走你~”按钮时,让所有子元素的宽度等于父元素的宽度。(观看文章的同学可以通过在线PPT来操作DEMO,地址:https://ppt.baomitu.com/d/b267a4a3#/27)
通过这个案例(Demo)我们会看到当我点击按钮时,延迟了一会,子元素的宽度才缩小。这是为什么呢?
仔细观察这段代码,我们会发现,循环中的这行代码,其实是两个操作,一个是读取元素的宽度,另一个操作是设置元素的宽度。因为它是在循环里面执行,所以会导致一个现象,每次循环到读取元素宽度时,都会触发一次布局操作。
我们来看这张图,当执行 container.offsetWidth 时浏览器由于不知道元素的宽度是多少,但我现在马上就要知道这个元素的宽度是多少,所以这个布局不能异步,那么为了告诉我这个元素有多宽,必须马上执行一次同步的布局操作,而随后的代码中又设置了元素的宽度,这其实就是要把刚刚执行的布局给否定掉,让布局失效。当下一轮循环又执行到 container.offsetWidth 读取元素的宽时,由于刚刚执行了设置元素的宽,所以浏览器又不知道当前元素的宽度是多少,所以它又要做一次强制同步布局。所以浏览器在不停的布局,让布局失效,布局,让布局失效直到循环结束。
我们将火焰图捕获出来之后,我们会在下面看到一排密密麻麻很多个任务。
放大之后是下面这张图,我们可以看到这些任务全是样式计算和布局。这个问题严重就严重在,同一个页面内,两个没有任何关联的元素之间,也会存在这个问题,比如说我的logo改了宽,我再读取其他不相干的元素的宽,两个元素没有任何关系,但是也会有这个影响,只要他们在同一个文档内,所以有时候我们一不小心就会犯错。
解决方案比较简单,就是我把会触发布局的操作踢出去,踢到循环的外面,这时候只读一次宽度,并且由于之前并没有改变任何元素的几何属性,所以浏览器不需要做同步的布局,直接使用之前布局的结果就可以,然后用循环只设置子元素的宽度,就会避免刚才的问题。同样的案例(Demo),只是改了这一行代码,我们点击按钮看一下效果(观看文章的同学可以通过在线PPT来操作DEMO,地址:https://ppt.baomitu.com/d/b267a4a3#/28),已经看不到任何的延迟了。
最终我们捕获出的火焰图就比较正常,就是一个常规的管道应该有的样子,我们先用 js 来触发样式计算,然后浏览器再去布局,再执行绿色的Paint和图层合并,每一步都是异步的。
下一个话题是绘制与合成,你会发现前面我们讲的,就是 JavaScript 和样式计算,还有布局都是单独讲的,但是绘制与合成我们放在一起讲,等下我们再讲为什么。
我们先讲什么是合成,所谓合成就是浏览器和PhotoShop一样,都有图层的概念,可以看到我这张图最左侧有三个图层,我们从侧面观察这个图层,你会发现眼睛在上面,鼻子在中间,最下面是脸,其实是三个图层是叠加在一起的,这三个图层合并成一张图之后,就是我们最右边的这张图,就是一个人的脸。
图层有一个最大的特点就是如果图层的位置变了,浏览器只需要重新去合成,就可以得到一张新的图。注意,如果图层的位置变了,但是图层的内容没变,那么浏览器只需要重新合并图层,就可以得到一张新的图,这个过程是不需要绘制(Paint)的。
我们在说说绘制的意思。图中白色的框是一个图层,这个框里面有一个黄色的方框;右边的与左边的是同一张图层,但是右边这个图层里面的黄色方块跑右边去了。注意,我同一张图层,但是内容变了,这时候浏览器要做一个事情就是“绘制”,通过重新绘制图层,才能让图层里面的内容发生变化。可以理解为,你有一个画板,你想把方框移到右面,那只能把之前的擦掉然后重新在右面画一个上去。
所以你发现绘制产生的效果和图层合并产生的效果是一样的,我通过改变图层的位置能实现和我重新绘制的效果是一样的。
实际上我想说明什么?我想告诉大家告诉大家添加图层可以取消Paint。
我们都知道像素管道有五步,JavaScript->样式计算->布局->绘制->合成,但是通过添加图层可以取消绘制这步,五步变成四步,那其实这个时间要更简短一些。
可以看到这个图,主要看右边的图,就是图层这个位置,这张图的图层在不停的变,浏览器通过合并图层就可以实现方框移动的效果。这个过程不需要绘制的,你用这个火焰图捕获也是捕获不到绘制的。
图层这么好,如何创建图层?
我们可以使用CSS的will-change来创建图层,在will-change不兼容的情况下,你可以用 transform: translateZ(0);来代替。
你会发现图层这东西这么好,可以把像素管道从五步变成四步,我们是不是可以这样操作,所有元素都设置will-change,浏览器是不是就没有绘制了?
这其实是不行的,因为浏览器做图层管理也是需要消耗的,如果你这样做,其实带来的效果反而是负面的,所以这个是不推荐的。
现在我们从 JavaScript 到图层合并,我们通过一系列的手段已经可以保证每一帧的像素管道总时间在 16.7 毫秒以内,那么就可以保证每 16.7 毫秒给屏幕传输新的一帧吗?
还不够。
图中这是一个时间轴,每个时间节点之间的间隔是 16 毫秒,我们通常会使用Timer触发一个函数改变一些样式,从而实现视觉的效果。
你会发现中间有一个16毫秒没有输出的,这 16 毫秒丢帧了,这一帧在屏幕上并没有传输任何图像,因为我这个Timer不能保证函数在每一帧最开始执行,保证不了函数的执行频率,所以就会导致这个问题。
现在整个Web平台,只有一个API可以解决这个问题,可以让我们的函数在每一帧最开始执行。这个API叫做requestAnimationFrame,使用它触发函数可以保证函数在每一帧的最开始执行,同时只有我们保证函数总体时间在 16.7 毫秒以内,现在就可以下图的效果,我第一帧、第二帧、第三帧、第四帧很均匀,从时间轴上也看不到丢帧的现象存在。现在我们终于可以保证不丢帧的情况下达到 60 FPS。
最后做一个总结,首先我们讲了什么样的网页是用户觉得比较流畅的,我们讲的第二个概念叫像素管道,通过后面的介绍,你会发现像素管道还是很重要的。
然后我们讲了优化主动交互,有两种方案,一个是web-worker,还有一个是 time-slicing。
我们还介绍了如何优化被动交互,保证 JS 执行时间 10 毫秒以为,样式计算(选择器)与性能,布局抖动以及如何避免布局抖动,做好图层管理和绘制的权衡,和requestAnimationFrame。
谢谢大家。
今天是16年12月30号,后天就是2017年了,一直拖到现在,趁着今天工作不是太忙,也是时候给自己做一个2016年的总结了。
由于我们组准备使用nodejs进行前后端分离,所以2016年最开始我的精力主要放在了研究Koa上面,仔细研究过Koa的每一行源码以及Koa使用到的依赖(co、koa-compose等),对Koa的实现及原理进行了非常深入的理解,对Koa深入了解后我又研究了Koa2的源码,深入了解他们的不同及各自的特点,总结来说,Koa2和Koa各有优缺点吧
研究完Koa还是不够的,在实际项目使用中会用到非常多的第三方模块,所以我就把项目中常用的模块的源码也看了一遍(包括但不限于 koa-router,koa-bodyparser,koa-etag,koa-error,koa-session,egg-logger 等等),主要就是想明白他们的工作原理,并确定他们的安全性,毕竟对于server端我还是想尽可能的知道每一行代码是如何工作的,这样可以避免出现一些问题,即便真出了问题我也可以清晰的明白为什么会出现问题,而使用最短的时间解决它。
关于Koa我写了两篇文章,我自认为是目前国内关于Koa最火,最好的两篇文章,没有之一
其实异步解决方案无论是co还是async都是基于Promise的,所以Promise已经是一个必备技能,所以我就花了一点时间把Promise好好研究了一下,并进行了一个分享
后来关于Promise我遇到一个坑,其实这个问题也挺有意思的,后来找到了答案,下面是我在cnodejs上的提问
ES6也已经是一项必备技能了,所以我系统的学习了一下ES6,我精读了一遍阮一峰的《ECMAScript6入门》,后来我又跟着我们组内的小伙伴一起精读了原版的 《understanding ECMAScript6》每周4大家会来总结每章的内容和一些使用经验与存在哪些天坑
我们组前后端分离技术选型选择的是 vue.js,所以我最近花了一些时间和精力来研究vue.js的工作原理,这样可以帮助我写出最优雅的代码(关于优雅的代码我想说的是:其实不理解原理也可以写代码,但是不能恰到好处的使用好每一个api,不能恰到好处的发挥每个api它应该发挥的作用,代码写到恰到好处,我觉得是一项艺术)以及更迅速的帮助我debug程序。
下面是我写的文章
还有一篇文章待写中《深入浅出 - vue之event》真正写出来标题和内容有可能会有变化。
最后给大家个福利 -> vue整体流程图
其实2016这一整年除了上面提到的我还学了很多其他的零零星星的小知识,比如node中的stream呀,如何使用vuex呀,好多这种小知识,但是一时又想不起来,算了,随它去吧
我们360内部每周一都有一个泛前端分享会,是我们奇舞团举办的,基本上每次分享者也都是我们奇舞团的小伙伴,我也不例外,在研究透Koa之后去泛前端分享会对Koa的工作原理进行了一个分享,不过据我观察听众们都是一脸懵逼的听完的,可能是我第一次分享经验不足吧
7月份的时候应邀,在北京NodeParty对Koa进行分享,主题还是对Koa的工作原理进行讲解,这次台下的听众们好多了,能感觉的出来他们确实是懂的,也提了一些比较好的问题,后来回家听自己的分享录音,发现自己讲的真他妈的烂,跟屎一样,我到现在都好奇台下的听众是怎么忍受一个多小时的分享时间的。对自己的一个总结就是,
可能是第一次见到这种场面所以比较紧张,但我想下次在遇到这种场面我还是会紧张。。。
我们小组内有《小灶会》活动,就是在我们组内进行分享,可以分享任何东西。
promise
小灶会启动的第一期光荣的由我给大家分享 Promise,并且在过后还给大家留了作业~ ppt
co
第二次在小灶会上分享是分享co的实现原理 ppt
现在每周我都会在公司楼上的健身房锻炼2~3次,主要练胸、肩、臂部的肌肉,发现时间长了每周不去几次心难受。
报考了驾照,我发现我酷爱驾驶,开车真是爽啊,就是没钱买车
读完了:
《明朝那些事》全套7册,《编写可读代码的艺术》《小王子》《白夜行》《穷爸爸富爸爸》《外交官爸爸写给儿子的信》《万万没想到:用理工科思维理解世界》《教父》
还有一些读了一半放在那里一直没再读的:
《自控力》《巴比伦富翁的理财课:有史以来最完美的致富圣经》《知行合一王阳明》《晚清最后十八年》《沉思录》《红顶商人胡雪岩》等。
2016年参加了10月份的自考,考了一门离散数学,并且通过了,现在在学习高等数学。
学完了新概念一册
就这样,其他的想到了在补充吧~
说在前面的话:本文针对对koa1非常了解并学习过源码或者阅读过我上篇koa文章的同学阅读~
吸取之前的经验,本章用幽默的风格来分析又臭又硬的原理,我尽量用最通俗易懂的语言来描述复杂的逻辑。
前几天koa发布了2.0版本。这几天找了个不忙的时间,赶紧阅读了2.0的文档和源码
这次改动主要是中间件的部分。其他部分对于使用者来说没什么改动。
阅读过我的上一篇文章的同学应该知道。koa内部主要有两个知识点,context(上下文)和middleware(中间件)两个部分
所以总体来看,改动不算太大,我先把改动分个类
先说使用方面,这次改动让中间件部分可以使用ES2015-2016的语法~
比如async await,在比如箭头函数
正因为中间件支持了async 和await,所以内部的中间件逻辑就不得不做一些改动。
但是koa的作者还是做了兼容的。同时支持3种不同种类的中间件,普通函数,async 函数,Generator函数。(这个屌)
普通函数的用法
app.use((ctx, next) => {
const start = new Date();
return next().then(() => {
const ms = new Date() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
});
});async函数的用法
app.use(async (ctx, next) => {
const start = new Date();
await next();
const ms = new Date() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
});Generator函数的用法
app.use(co.wrap(function *(ctx, next) {
const start = new Date();
yield next();
const ms = new Date() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
}));当然,用v1的语法也可以,像下面这样
app.use(function *(next) {
const start = new Date();
yield next;
const ms = new Date() - start;
console.log(`${this.method} ${this.url} - ${ms}ms`);
});不过官方并不建议这样写,因为他们打算在v3中取消对这种写法的兼容。
噢,对了,还有一种写法。
const convert = require('koa-convert');
app.use(convert(function *(next) {
const start = new Date();
yield next;
const ms = new Date() - start;
console.log(`${this.method} ${this.url} - ${ms}ms`);
}));让我们自己把自己的中间件做一下兼容(v2内部就是这样做的兼容),然后就可以衣食无忧了。。(Are you sure?)
因为v2用的是ES2015-2016的语法,其中包括class,所以node目前是无法支持的,即便是目前比较先进的的v5.10.x也不行(臣妾做不到啊~)
那么,,,你懂得,需要babel编译之后才可以用
koa当然不会替我们编译,这并不符合koa的**和原则,所以需要我们自己去编译。(koa的**和原则是什么??)
使用方面的就说到这,下面说说源码上的改动。
看了koa的源码之后,发现主文件 application.js 对 Emitter 的继承,使用了ES2015的语法,大概是这样的
module.exports = class Application extends Emitter {
/**
* Initialize a new `Application`.
*
* @api public
*/
constructor() {
super();
this.proxy = false;
this.middleware = [];
this.subdomainOffset = 2;
this.env = process.env.NODE_ENV || 'development';
this.context = Object.create(context);
this.request = Object.create(request);
this.response = Object.create(response);
}
...我们回顾下v1
/**
* Application prototype.
*/
var app = Application.prototype;
/**
* Expose `Application`.
*/
module.exports = Application;
/**
* Initialize a new `Application`.
*
* @api public
*/
function Application() {
if (!(this instanceof Application)) return new Application;
this.env = process.env.NODE_ENV || 'development';
this.subdomainOffset = 2;
this.middleware = [];
this.proxy = false;
this.context = Object.create(context);
this.request = Object.create(request);
this.response = Object.create(response);
}
/**
* Inherit from `Emitter.prototype`.
*/
Object.setPrototypeOf(Application.prototype, Emitter.prototype);
...中间件这块改动比较大,咱们从头开始。。
先从注册中间件开始,也就是 app.use 这个方法开始,先贴一段源码(为了方便观察,我把不重要的代码删了)
use(fn) {
if (typeof fn !== 'function') throw new TypeError('middleware must be a function!');
if (isGeneratorFunction(fn)) {
fn = convert(fn);
}
this.middleware.push(fn);
return this;
}我们对比下v1是什么样的
app.use = function(fn){
this.middleware.push(fn);
return this;
};我们看到 v2 多了一个判断,如果是Generator函数,那就用 convert 把函数包起来,然后在push到 this.middleware 这就是针对v1的写法做的兼容。(官方说v3发布的时候就不兼容v1的写法,应该就是把这个判断删了,,我邪恶的猜测着)
没关系,官方给咱们支了一招,他们不帮咱们做兼容咱们可以来(自己动手风衣主食啊),自己把自己的中间件用 convert 包起来在use。。
那 convert 是干啥用的?我们看下源码
function convert (mw) {
if (typeof mw !== 'function') {
throw new TypeError('middleware must be a function')
}
if (mw.constructor.name !== 'GeneratorFunction') {
// assume it's Promise-based middleware
return mw
}
const converted = function (ctx, next) {
return co.call(ctx, mw.call(ctx, createGenerator(next)))
}
converted._name = mw._name || mw.name
return converted
}其实核心就一句(为了方便理解,做一个小改动)
return function (ctx, next) {
return co.call(ctx, mw.call(ctx, createGenerator(next)))
}大概就是,把一个普通函数push到中间件里,执行这个中间件,返回promise,,不要问我为啥返回promise,快去上一篇文章好好学习。
接下来我们在看看中间件是怎样运行的,下面这个熟悉的函数,不要问我它是干啥的,哔哔哔
callback() {
const fn = compose(this.middleware);
if (!this.listeners('error').length) this.on('error', this.onerror);
return (req, res) => {
res.statusCode = 404;
const ctx = this.createContext(req, res);
onFinished(res, ctx.onerror);
fn(ctx).then(() => respond(ctx)).catch(ctx.onerror);
};
}这块我分两部分讲
就是上面代码中return前和return后,return前是启动server阶段,return后是接受请求阶段(虽然启动server阶段就一行代码)
启动server
看第一行代码
const fn = compose(this.middleware);童鞋们知道 this.middleware 里面现在是一些什么东西嘛?
不要告诉我中间件,,,,,,
现在 this.middleware 中存了一些函数,不管他是什么函数,反正只要执行它,它就返回promise。这个函数有可能是 async 函数 有可能是被 convert 包装后的Generator函数,或者是被 co.wrap 包装后的Generator函数,也有可能是普通函数的中间件(哈哈哈哈,不要忘了v2支持普通函数的中间件哦~),反正这些函数都有一个特性,那就是执行它们,会返回promise。
现在这群函数被传到 compose 中进行处理,处理之后变成啥样了???
我先说另一个事,这里先暂停,我们先知道中间件被 compose 处理成怪物了,我们先看看这些怪我的作用
接收请求
我们看接收请求时要执行的代码(fn就是那个怪物):
return (req, res) => {
res.statusCode = 404;
const ctx = this.createContext(req, res);
onFinished(res, ctx.onerror);
fn(ctx).then(() => respond(ctx)).catch(ctx.onerror);
};我们对比下v1
return function(req, res){
res.statusCode = 404;
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);
}一模一样,没有任何区别。。。。(语法除外)
额,既然一模一样,我就不多说了。不懂的童鞋去读上一篇文章,,那里有非常详细的介绍(我是不是太会偷懒了。。)
好了,那么现在最重要的地方来了,compose 是怎么把中间件变成怪物的,又是怎么把三个种类的中间件变成可以实现中间件逻辑的函数呢,这一次的回逆是怎样实现的?
先留个悬念,不然不知道这里是重点。
上篇文章说过 compose 这个模块,有意思的是,这个模块也升级了。koa v1 对应着compose v2,koa v2 对应着 compose v3,我们看看 compose v3 中的代码
function compose (middleware) {
if (!Array.isArray(middleware)) throw new TypeError('Middleware stack must be an array!')
for (const fn of middleware) {
if (typeof fn !== 'function') throw new TypeError('Middleware must be composed of functions!')
}
/**
* @param {Object} context
* @return {Promise}
* @api public
*/
return function (context, next) {
// last called middleware #
let index = -1
return dispatch(0)
function dispatch (i) {
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
const fn = middleware[i] || next
if (!fn) return Promise.resolve()
try {
return Promise.resolve(fn(context, function next () {
return dispatch(i + 1)
}))
} catch (err) {
return Promise.reject(err)
}
}
}
}代码看起来有点吓人,我们主要看return 后面的那个函数里的逻辑,因为每次server接收到请求的时候都会执行这个函数,,不要问我为什么,去看上一篇文章~
这个函数里有一个重要的函数,dispatch (就这么一个函数能不重要嘛)
前方高能预警!!
首先在执行到匿名函数的时候(就是return返回的那个函数),会执行 dispatch,并传一个参数 0,其次就是在 dispatch 执行的过程中会自己调用自己,递归调用。
我们再来看两个变量 index 和 i
index 一开始默认是 -1
i 一开始默认是 0(因为第一次传递的参数是 0)
在 dispatch 的第一行有一个判断,如果 i <= index 抛出错误。
判断的下面是一个赋值,index = i
然后下面是一个递归调用,参数是 i + 1
也就是说,如果没有意外,index 是永远小于 i 的,那什么情况下 index 会大于或等于 i?
在同一个中间件中多次调用 next() (执行next就是执行dispatch)的时候,index 会大于 i,从代码上看,每个中间件都有一个自己的作用域,也就是说同一个中间件,i 是不变的,在 i 不变的情况下,多次调用 next的情况下,第一次调用,index 小于 i,第二次调用,index就 等于 i了。。。
额,,啰嗦了,上面那个理解了最好,没理解也没关系,就是先给大家热热身,从现在开始,把我们的大脑要高速运转。
其实..... 我们只需要知道 dispatch 每次执行都会有一个变量 i,这个 i 是干啥的?
i 其实是用来在 this.middleware 中获取中间件的下标,dispatch 函数第一次执行 i 是 0,第二次是 1,以此类推。。。。
看这行代码,就行用来获取中间件用的
const fn = middleware[i] || next好啦,现在我们取到中间件了,但是怎么使用呢??
先来一段代码
return Promise.resolve(fn(context, function next () {
return dispatch(i + 1)
}))执行中间件,并传递两个参数,context 和 next函数,context是koa中的上下文没什么可说的,说说 next 函数,next 也蛮简单的,就是return一个 dispatch 的执行结果,注意那个参数 i+1,这个参数很有学问,传递一个 i+1,就相当于一旦执行next函数,就等同于执行下一个中间件。
PS:一个中间件只能执行一次next,否则逻辑上会出现问题,为了避免这个问题,在 dispatch 中一开始就做了判断,就是一开始咱们说的 index 和 i 的问题。
这个地方其实就跟koa1有点不同了。koa1是可以在一个中间件中多次调用next的,并且不会出现问题,因为一个yield只能执行一次,即便调用再多的next在generator函数中被执行过的代码也不会重复执行,所以多次调用时不会报错,不会出现问题的,只是执行了跟没执行一样,没效果。所以即便是koa1也是不建议多次调用next,因为每调用一次,就会创建个promise,然后在里面执行一次getn.next然后发现返回值是{value: undefined, done: true},然后在resolve()跳回来。这样有点浪费性能。
在中间件中,我们通常会这样使用
await next();async 的语法是,await后面会跟一个promise,await会等待promise,等promise执行完了,在往下执行
而我们的这些中间件,都有一个特点,执行完会返回promise,所以正好被await监听。
我们中间件本身返回的就是promise,为什么会被Promise.resolve包起来?这里是一个兼容写法,如果只支持async函数当然没问题,但我们的中间件除了支持async函数外,还支持普通函数呦~~~
所以,如果中间件使用async函数写的,流程大概是这样的
dispatch(0)),这个中间件会返回promise,koa会监听这个promise,一旦成功或者失败,都会做出不同的处理,并结束这次响应await next();,在这里手动触发第二个中间件执行,第二个中间件和第一个中间件一样,也会返回promise(废话,一奶同胞的兄弟能不一样么)await会监听这个promise,什么时候执行完了,什么时候继续执行第一个中间件后续的代码。(中间件的回逆就是这样实现的)await next(); 这样一段代码来触发第三个中间件并等待第三个中间件执行完了在执行后续代码,否则就一直等,以此类推所以就造成了这样一个现象,第一个中间件代码执行一半停在这了,触发了第二个中间件的执行,第二个中间件执行了一半停在这了,触发了第三个中间件的执行,然后,,,,,,第一个中间件等第二个中间件,第二个中间件等第三个中间件,,,,,,第三个中间件全部执行完毕,第二个中间件继续执行后续代码,第二个中间件代码全部执行完毕,执行第一个中间件后续代码,然后结束(不得不说,,TJ大神真想法)
其实koa1也是这个逻辑,koa2对于koa1**上是没有变化的,变的只是语法、
有的同学说了,如果我用普通函数写中间件,是怎样实现与async函数同样逻辑的呢?
其实并不难,async函数有几个特点能帮助它完成中间件的逻辑
首先我们看下普通函数的用法
app.use((ctx, next) => {
const start = new Date();
return next().then(() => {
const ms = new Date() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
});
});先说第一个条件,「执行后返回promise」
上面我们说过,我们的中间件在 dispatch 中会被 Promise.resolve 包住并返回,所以第一个条件满足
我们在说第二个条件,「中间件内部可以监听promise并等待promise接收后执行后续代码」
很明显,第二个条件也满足,因为普通函数的写法是异步的,后续代码在then里面。(async也不过是看起来同步而已,其实是同样的逻辑,普通函数的写法更露骨)
先看看用法
app.use(co.wrap(function *(ctx, next) {
const start = new Date();
yield next();
const ms = new Date() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
}));首先第一个条件「执行后返回promise」
可以看到中间件是用 co.warp 包起来的,co.warp会返回promise,上一章我详细的讲解过,第一个条件满足
我们在说第二个条件,「中间件内部可以监听promise并等待promise接收后执行后续代码」
co 与async一样,yield后面可以跟一个promise,co会监听这个promise,什么时候这个promise执行完了。什么时候执行后续的代码,这点跟async是一模一样的,只是写法略有不同,第二个条件满足
关于 co 的内部原理,上一篇文章中有详细的分析与介绍~
转载请注明出处
之前的老文章,换了个地方写博客,,所以得重新发布下~~
async是Nodejs中的一个非常常用的工具模块,其中方法有很多,主要分3大类(集合,流程控制,工具),前几天刚说了 流程控制 的一些常用方法,今天就简单说说 集合 的一些常用方法
很简单,看方法名就知道这是一个循环。
参数:
arr 想要循环的数组
iterator(item, callback) 一个回调函数,循环到的每一项都会调用这个函数。
item 数组中的每一项。
callback(err) 当完成的时候调用,应该不带参数执行,或者明确指定一个 null
callback(err) 一个回调函数,用于循环完成后 或 发生错误时调用
这个循环与系统提供的for循环等是一样的。属于并行执行的循环,请看下面的例子:
var arr = [ {name: 'a', delay: 200}, {name: 'b', delay: 100}, {name: 'c', delay: 300} ];
function iterator (item, done) {
console.log('start:' + item.name);
setTimeout(function(){
console.log('end: ' + item.name);
done(null);
}, item.delay);
}
async.each(arr, iterator, function (err) {
console.log('err: ' + err);
});输出结果是:
start:a
start:b
start:c
end: b
end: a
end: c
err: undefined
先输出3个 start, 然后输出3个 end 注意顺序, 最后是 err
由此可以看出,它与正常的循环并无两样。
语法与上面的用法一样。不同的是,上面我称为 并行执行的循环,而这个我称为,依次执行的循环,请看下面的例子:
var arr = [ {name: 'a', delay: 200}, {name: 'b', delay: 100}, {name: 'c', delay: 300} ];
function iterator (item, done) {
console.log('start:' + item.name);
setTimeout(function(){
console.log('end: ' + item.name);
done(null);
}, item.delay);
}
async.eachSeries(arr, iterator, function (err) {
console.log('err: ' + err);
});细心的同学可能已经发现问题了。这段代码与上面的代码几乎一模一样。唯一不一样的地方只有async.each 改成了 async.eachSeries
结果为:
start:a
end: a
start:b
end: b
start:c
end: c
err: undefined
看完结果同学们就可以理解,为什么称 eachSeries 为依次执行的循环了。
如果非要起一个名字的话。我称它为 分批执行 也可以说是 限制并行数量的循环
用法与上面大致一样。只不过多了一个参数 limit
limit 限制并行的最大数量看一下例子:
var arr = [ {name: 'a', delay: 200}, {name: 'b', delay: 100}, {name: 'c', delay: 300} ];
function iterator (item, done) {
console.log('start:' + item.name);
setTimeout(function(){
console.log('end: ' + item.name);
done(null);
}, item.delay);
}
async.eachLimit(arr, 1, iterator, function (err) {
console.log('err: ' + err);
});结果为:
start:a
end: a
start:b
end: b
start:c
end: c
err: undefined
可以看出,如果 limit 的为 1,那么就与 eachSeries 一样,一条一条依次执行。
如果 limit 的数量为 3 我们在试试:
var arr = [ {name: 'a', delay: 200}, {name: 'b', delay: 100}, {name: 'c', delay: 300} ];
function iterator (item, done) {
console.log('start:' + item.name);
setTimeout(function(){
console.log('end: ' + item.name);
done(null);
}, item.delay);
}
async.eachLimit(arr, 3, iterator, function (err) {
console.log('err: ' + err);
});输出结果为:
start:a
start:b
start:c
end: b
end: a
end: c
err: undefined
相信同学们已经看明白,我就不多做解释了。
map 通俗点说,就是通过一个转换函数(iterator),把数组中的每个值映射到一个新的数组中。(产生一个新的数组)
参数:
arr 想要循环的数组
iterator(item, callback) 一个回调函数,循环到得每一项都会调用这个函数
callback(err, transformed) 当程序执行完时,调用此参数(必须调用此参数)
callback(err, results) 一个回调函数,当所有数组执行完成,或发生错误的时候,被调用。
例如:
var arr = [ {name: 'a', delay: 200}, {name: 'b', delay: 100}, {name: 'c', delay: 300} ];
function iterator (item, done) {
console.log( 'start:', item.name );
setTimeout(function () {
console.log( 'end:', item.name );
done(null, item.name += '!');
}, item.delay);
}
async.map(arr, iterator, function (err, result) {
console.log( 'err: ', err );
console.log( 'result:', result );
});结果为:
start: a
start: b
start: c
end: b
end: a
end: c
err: undefined
result: [ 'a!', 'b!', 'c!' ]
语法与上面 map 一样,不同的是,上面是 并行执行,而这个是 依次执行,与 each 和 eachSeries 的关系是一样的。
var arr = [ {name: 'a', delay: 200}, {name: 'b', delay: 100}, {name: 'c', delay: 300} ];
function iterator (item, done) {
console.log( 'start:', item.name );
setTimeout(function () {
console.log( 'end:', item.name );
done(null, item.name += '!');
}, item.delay);
}
async.mapSeries(arr, iterator, function (err, result) {
console.log( 'err: ', err );
console.log( 'result:', result );
});代码与 map 几乎一样。只是把 async.map 改成了 async.mapSeries,输出结果为:
start: a
end: a
start: b
end: b
start: c
end: c
err: undefined
result: [ 'a!', 'b!', 'c!' ]
从输出结构可以看出,它是依次执行的。
与 map 一样,但比 map 多了一个参数 limit 来限制并行的最大数量。
var arr = [ {name: 'a', delay: 200}, {name: 'b', delay: 100}, {name: 'c', delay: 300} ];
function iterator (item, done) {
console.log( 'start:', item.name );
setTimeout(function () {
console.log( 'end:', item.name );
done(null, item.name += '!');
}, item.delay);
}
async.mapLimit(arr, 1, iterator, function (err, result) {
console.log( 'err: ', err );
console.log( 'result:', result );
});limit 设置为 1 ,结果为:
start: a
end: a
start: b
end: b
start: c
end: c
err: undefined
result: [ 'a!', 'b!', 'c!' ]
结果与 mapSeries 一样,换成 2 结果为:
start: a
start: b
end: b
start: c
end: a
end: c
err: undefined
result: [ 'a!', 'b!', 'c!' ]
换成 3 结果为:
start: a
start: b
start: c
end: b
end: a
end: c
err: undefined
result: [ 'a!', 'b!', 'c!' ]
遍历 arr 中的每个值,返回包含所有通过 iterator 真值检测的元素值。这个操作是并行的,但返回的结果是顺序的。
参数:
arr 一个数组,用于遍历
iterator(item, callback) 一个函数,用于真值检测
item 数组中的每一项
callback(truthValue) 完成时调用,必须带一个布尔参数
callback 一个回调函数,用于执行完成后,或发生错误时调用。
例如:
var arr = [ {n: 1, delay: 200}, {n: 2, delay: 100}, {n: 3, delay: 300}, {n: 4, delay: 500}, {n: 5, delay: 100} ];
function iterator (item, done) {
console.log( 'start:', item.n );
setTimeout(function () {
console.log( 'end:', item.n );
done( item.n > 2 );
}, item.delay);
}
async.filter(arr, iterator, function (result) {
console.log( 'result:', result );
});输出结果为:
start: 1
start: 2
start: 3
start: 4
start: 5
end: 2
end: 5
end: 1
end: 3
end: 4
result: [ { n: 3, delay: 300 }, { n: 4, delay: 500 }, { n: 5, delay: 100 } ]
与上面 filter 类似,它是 依次执行。
var arr = [ {n: 1, delay: 200}, {n: 2, delay: 100}, {n: 3, delay: 300}, {n: 4, delay: 500}, {n: 5, delay: 100} ];
function iterator (item, done) {
console.log( 'start:', item.n );
setTimeout(function () {
console.log( 'end:', item.n );
done( item.n > 2 );
}, item.delay);
}
async.filterSeries(arr, iterator, function (result) {
console.log( 'result:', result );
});把 async.filter 改成 async.filterSeries 输出结果为:
start: 1
end: 1
start: 2
end: 2
start: 3
end: 3
start: 4
end: 4
start: 5
end: 5
result: [ { n: 3, delay: 300 }, { n: 4, delay: 500 }, { n: 5, delay: 100 } ]
reject跟filter正好相反,当检测为true时,抛弃之~~~
var arr = [ {n: 1, delay: 200}, {n: 2, delay: 100}, {n: 3, delay: 300}, {n: 4, delay: 500}, {n: 5, delay: 100} ];
function iterator (item, done) {
console.log( 'start:', item.n );
setTimeout(function () {
console.log( 'end:', item.n );
done( item.n > 2 );
}, item.delay);
}
async.reject(arr, iterator, function (result) {
console.log( 'result:', result );
});输出结果为:
start: 1
start: 2
start: 3
start: 4
start: 5
end: 2
end: 5
end: 1
end: 3
end: 4
result: [ { n: 1, delay: 200 }, { n: 2, delay: 100 } ]
如果说reject是并行(异步的)的,那么rejectSeries就是串行的(同步的),前面写了那么多 并行 和 串行 的比较例子,从现在往后就不举例说明了。
Reduce可以让我们给定一个初始值,用它与集合中的每一个元素做运算**(前一次的运算结果与下一个值做运算)**,最后得到一个值。reduce从左向右来遍历元素,如果想从右向左,可使用reduceRight。
加法运算:
var arr = [1, 3, 5];
function iterator (memo, item, done) {
console.log( memo, item );
setTimeout(function () {
done( null, item + memo );
}, 300);
}
async.reduce(arr, 2, iterator, function (err, result) {
console.log( 'result:', result );
});输出结果为:
2 1
3 3
6 5
result: 11
乘法运算:
var arr = [1, 3, 5];
function iterator (memo, item, done) {
console.log( memo, item );
setTimeout(function () {
done( null, item * memo );
}, 300);
}
async.reduce(arr, 2, iterator, function (err, result) {
console.log( 'result:', result );
});输出结果为:
2 1
2 3
6 5
result: 30
与 reduce 一样,不同的是,reduceRight 是从右向左计算。
用于取得集合中满足条件的第一个元素(并行执行)。
语法:
arr 一个数组
iterator(item, callback) 回调函数,用于处理逻辑(迭代器)
item 数组中的每一项
callback(truthValue) 程序完成后执行。必须传入布尔值。
callback(result) 回调函数, iterator 第一次返回 true,或 循环完成后执行。
例如:
var arr = [
{n:1,delay:500},
{n:2,delay:200},
{n:3,delay:300}
];
function iterator (item, done) {
console.log( 'start:', item.n );
setTimeout(function () {
console.log( 'end:', item.n )
done( item.n > 1 );
}, item.delay );
}
async.detect(arr, iterator, function (result) {
console.log( 'result:', result );
});输出结果为:
start: 1
start: 2
start: 3
end: 2
result: { n: 2, delay: 200 }
end: 3
end: 1
可以看出,输出 2 的时候,就执行 callback(result) 了,也可以看出。detect是并行执行的。
与 detect 类似。不过 detectSeries 是依次执行的。
例如:
var arr = [
{n:1,delay:500},
{n:2,delay:200},
{n:3,delay:300}
];
function iterator (item, done) {
console.log( 'start:', item.n );
setTimeout(function () {
console.log( 'end:', item.n )
done( item.n > 1 );
}, item.delay );
}
async.detectSeries(arr, iterator, function (result) {
console.log( 'result:', result );
});输出结果为:
start: 1
end: 1
start: 2
end: 2
result: { n: 2, delay: 200 }
对集合内的元素进行排序,根据每个元素进行某异步操作后产生的值,从小到大排序。
语法:
arr 一个数组
iterator(item, callback) 一个回调函数,循环到得每一项都会执行。
item 数组中的每一项
callback(err, sortValue) 完成时调用。
callback(err, results) 一个回调函数,所有 iterator 完成后或发生错误时执行。
例1:
var arr = [2, 5, 9, 10, 22, 1, 7, 20];
function iterator (item, done) {
done( null, item );
}
async.sortBy(arr, iterator, function (err, result) {
console.log( result ); // [ 1, 2, 5, 7, 9, 10, 20, 22 ]
});例2:
var arr = [2, 5, 9, 10, 22, 1, 7, 20];
function iterator (item, done) {
done( null, item * -1 );
}
async.sortBy(arr, iterator, function (err, result) {
console.log( result ); // [ 22, 20, 10, 9, 7, 5, 2, 1 ]
});判断集合中是否有至少一个元素满足条件,如果是最终callback得到的值为true,否则为false.
参数:
arr 一个数组
iterator(item, callback) 一个回调函数,循环到得每一项都会执行。
callback(truthValue) 必须传递一个布尔值。
callback(result) 回调函数 result为 true 或 false 取决于iterator 的运行结果。
例1:
var arr = [2, 5, 9, 10];
function iterator (item, done) {
done( item > 10 );
}
async.some(arr, iterator, function (result) {
console.log( result ); // false
});结果是 false,因为数组中,没有比10大的数。
例2:
var arr = [2, 5, 9, 10];
function iterator (item, done) {
done( item > 9 );
}
async.some(arr, iterator, function (result) {
console.log( result ); // true
});结果是 true,因为 10 比 9 大。
如果集合里每一个元素都满足条件,则传给最终回调的result为true,否则为false
例1:
var arr = [2, 5, 9, 10];
function iterator (item, done) {
done( item > 1 );
}
async.every(arr, iterator, function (result) {
console.log( result ); // true
});例2:
var arr = [2, 5, 9, 10];
function iterator (item, done) {
done( item > 5 );
}
async.every(arr, iterator, function (result) {
console.log( result ); // false
});将多个异步操作的结果合并为一个数组。
语法:
concat(arr, iterator(item,callback(err, result)), callback(err, result))code:
var arr = [
{
list : [1,2,3,4],
delay : 200
},{
list : [5,6,7],
delay : 100
},{
list : [8,9],
delay : 300
}
];
function iterator (item, done) {
console.log( 'start:', item.list )
setTimeout(function () {
console.log( 'end:', item.list )
done( null, item.list );
}, item.delay);
}
async.concat(arr, iterator, function (err, result) {
console.log( result ); // [ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
});结果为:
start: [ 1, 2, 3, 4 ]
start: [ 5, 6, 7 ]
start: [ 8, 9 ]
end: [ 5, 6, 7 ]
end: [ 1, 2, 3, 4 ]
end: [ 8, 9 ]
[ 5, 6, 7, 1, 2, 3, 4, 8, 9 ]
通过结果,会发现。这是一个并行的操作。合并之后的顺序是不固定的。
与 concat 类似,不过 concatSeries 是串行的。
code:
var arr = [
{
list : [1,2,3,4],
delay : 200
},{
list : [5,6,7],
delay : 100
},{
list : [8,9],
delay : 300
}
];
function iterator (item, done) {
console.log( 'start:', item.list )
setTimeout(function () {
console.log( 'end:', item.list )
done( null, item.list );
}, item.delay);
}
async.concatSeries(arr, iterator, function (err, result) {
console.log( result ); // [ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
});结果是:
start: [ 1, 2, 3, 4 ]
end: [ 1, 2, 3, 4 ]
start: [ 5, 6, 7 ]
end: [ 5, 6, 7 ]
start: [ 8, 9 ]
end: [ 8, 9 ]
[ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
前几天一个朋友问了我一个问题:为什么Object.keys的返回值会自动排序?
例子是这样的:
const obj = {
100: '一百',
2: '二',
7: '七'
}
Object.keys(obj) // ["2", "7", "100"]而下面这例子又不自动排序了?
const obj = {
c: 'c',
a: 'a',
b: 'b'
}
Object.keys(obj) // ["c", "a", "b"]当朋友问我这个问题时,一时间我也回答不出个所以然。故此去查了查ECMA262规范,再加上后来看了看这方面的文章,明白了为什么会发生这么诡异的事情。
故此写下这篇文章详细介绍,当Object.keys被调用时内部都发生了什么。
对于上面那个问题先给出结论,Object.keys在内部会根据属性名key的类型进行不同的排序逻辑。分三种情况:
Number,那么Object.keys返回值是按照key从小到大排序String,那么Object.keys返回值是按照属性被创建的时间升序排序。Symbol,那么逻辑同String相同这就解释了上面的问题。
下面我们详细介绍Object.keys被调用时,背后发生了什么。
Object.keys被调用时背后发生了什么当Object.keys函数使用参数O调用时,会执行以下步骤:
第一步:将参数转换成Object类型的对象。
第二步:通过转换后的对象获得属性列表properties。
注意:属性列表
properties为List类型(List类型是ECMAScript规范类型)
第三步:将List类型的属性列表properties转换为Array得到最终的结果。
规范中是这样定义的:
- 调用
ToObject(O)将结果赋值给变量obj- 调用
EnumerableOwnPropertyNames(obj, "key")将结果赋值给变量nameList- 调用
CreateArrayFromList(nameList)得到最终的结果
ToObject(O))ToObject操作根据下表将参数O转换为Object类型的值:
| 参数类型 | 结果 |
|---|---|
| Undefined | 抛出TypeError |
| Null | 抛出TypeError |
| Boolean | 返回一个新的 Boolean 对象 |
| Number | 返回一个新的 Number 对象 |
| String | 返回一个新的 String 对象 |
| Symbol | 返回一个新的 Symbol 对象 |
| Object | 直接将Object返回 |
因为Object.keys内部有ToObject操作,所以Object.keys其实还可以接收其他类型的参数。
上表详细描述了不同类型的参数将如何转换成Object类型。
我们可以简单写几个例子试一试:
先试试null会不会报错:
图1 Object.keys(null)
如图1所示,果然报错了。
接下来我们试试数字的效果:
图2 Object.keys(123)
如图2所示,返回空数组。
为什么会返回空数组?请看图3:
图3 new Number(123)
如图3所示,返回的对象没有任何可提取的属性,所以返回空数组也是正常的。
然后我们再试一下String的效果:
图4 Object.keys('我是Berwin')
图4我们会发现返回了一些字符串类型的数字,这是因为String对象有可提取的属性,看如图5:
图5 new String('我是Berwin')
因为String对象有可提取的属性,所以将String对象的属性名都提取出来变成了列表返回出去了。
EnumerableOwnPropertyNames(obj, "key"))获取属性列表的过程有很多细节,其中比较重要的是调用对象的内部方法OwnPropertyKeys获得对象的ownKeys。
注意:这时的
ownKeys类型是List类型,只用于内部实现
然后声明变量properties,类型也是List类型,并循环ownKeys将每个元素添加到properties列表中。
最终将properties返回。
您可能会感觉到奇怪,ownKeys已经是结果了为什么还要循环一遍将列表中的元素放到
properties中。这是因为EnumerableOwnPropertyNames操作不只是给Object.keys这一个API用,它内部还有一些其他操作,只是Object.keys这个API没有使用到,所以看起来这一步很多余。
所以针对Object.keys这个API来说,获取属性列表中最重要的是调用了内部方法OwnPropertyKeys得到ownKeys。
其实也正是内部方法OwnPropertyKeys决定了属性的顺序。
关于OwnPropertyKeys方法ECMA-262中是这样描述的:
当O的内部方法OwnPropertyKeys被调用时,执行以下步骤(其实就一步):
Return ! OrdinaryOwnPropertyKeys(O).而OrdinaryOwnPropertyKeys是这样规定的:
keys值为一个空列表(List类型)keys中keys中keys中keys返回(return keys)上面这个规则不光规定了不同类型的返回顺序,还规定了如果对象的属性类型是数字,字符与Symbol混合的,那么返回顺序永远是数字在前,然后是字符串,最后是Symbol。
举个例子:
Object.keys({
5: '5',
a: 'a',
1: '1',
c: 'c',
3: '3',
b: 'b'
})
// ["1", "3", "5", "a", "c", "b"]属性的顺序规则中虽然规定了Symbol的顺序,但其实Object.keys最终会将Symbol类型的属性过滤出去。(原因是顺序规则不只是给Object.keys一个API使用,它是一个通用的规则)
CreateArrayFromList( elements ))现在我们已经得到了一个对象的属性列表,最后一步是将List类型的属性列表转换成Array类型。
将List类型的属性列表转换成Array类型非常简单:
array,值是一个空数组array中array返回上面介绍的排序规则同样适用于下列API:
Object.entriesObject.valuesfor...in循环Object.getOwnPropertyNamesReflect.ownKeys注意:以上API除了
Reflect.ownKeys之外,其他API均会将Symbol类型的属性过滤掉。

在前端应用越来复杂的今天,为了监控前端应用是否正常运行,通常会在前端收集一些错误与性能等数据,最终我们会将这些数据上报到服务端。
上报的方式有很多,理论上我们只要能把数据发给服务端就行了。在浏览器中可以发送请求的方式非常多,包括不限于:xhr、fetch、script标签、img标签、link标签、CSS背景图等。
不同的上报方式之间存在很大的差异。目前主流的上报方式是利用img标签的src属性发送请求,例如:
(new Image).src = `/haopv.gif?a=xx&b=xxx`因为日志上报不需要响应处理,只需要把数据发过去就行。并且大部分接收日志的服务器地址与业务方可能不是一个部门,甚至可能不是一个公司,所以会涉及到跨域问题。使用img标签的src属性既可以把数据发送给服务端又不需要接收响应,同时解决了跨域问题,所以是目前比较受欢迎的日志上报实现方式。
但是这样就真的没问题了么?
日志上报并不是应用的主要功能逻辑,也就是说,日志上报是低优先级的,它不应该与其他高优先级操作(例如:获取关键资源、输入响应、运行动画等)去竞争网络与计算资源(通俗的说就是日志上报行为不应该影响业务逻辑,不应该占用业务计算资源)。但是这种单向请求又负责传递应用的错误与性能数据,所以我们必须要确保它会被交付到服务端。
通常,为了提高交付率,我们会选择立即交付每个收集到的数据,而不是合并与推迟交付。延迟传递可能意味着请求没有足够的时间来成功完成,这可能导致重要的应用数据丢失。并且推迟上报会影响下一个页面的下载与渲染,因为unload事件中的代码会阻塞下一个页面渲染。
这就意味着我们的交付行为有可能会被插入到正在忙碌工作的事件循环中,从而抢占了其他高优先级的任务的资源,因为JS是单线程的。这有可能会损害用户体验。
我们如何确保日志数据会被交付的同时,尽可能地减少与其他关键操作的资源争用呢?答案是信标(Beacon)。
信标(Beacon)可以异步与非阻塞的数据传输,从而最大限度地减少与其他关键操作的资源争用,同时它可以确保这些请求一定会被处理并将其传递到服务端:
信标的使用非常简单:
var data = JSON.stringify({
name: 'Berwin'
});
navigator.sendBeacon('/haopv', data)参数
true代表用户代理成功地将信标请求加入到队列中,否则返回false。用户代理对通过信标发送的数据量进行限制,以确保请求被成功传递到服务端,并且对浏览器活动的影响降到最小。如果要排队的数据量超出了用户代理的限制,sendBeacon方法将返回
false,返回true代表浏览器已将数据排队等待传递。然而,由于实际数据传输是异步的,所以此方法不提供任何关于数据传输是否成功的信息。
虽然信标得到了很高的支持度,但还是无法在所有浏览器中使用,所以如果您想使用信标上报前端日志,一些特征检测是必要的。
还有一个需要注意的是,通过信标发送的请求,请求方法均为POST,且不支持修改。
日志上报在生产环境下不仅仅是把请求发出去。日志上报并不是主要逻辑所以优先级很低,为了最佳的用户体验,在考虑避免占用业务计算资源和避免竞争业务网络请求的同时我们还要保证数据一定会交付到服务端,最好的方式是尽可能的使用信标(Beacon)。
通常我们只需要编写HTML,CSS,JavaScript屏幕上就会显示出漂亮的页面,但浏览器是如何使用我们的代码在屏幕上渲染像素的呢?
浏览器将HTML,CSS,JavaScript转换为屏幕上所呈现的实际像素,这期间所经历的一系列步骤,叫做关键渲染路径(Critical Rendering Path)。
图1-1 关键渲染路径的具体步骤
图1-1给出了关键渲染路径的具体步骤。如图所示,首先,浏览器获取HTML并开始构建DOM(文档对象模型 - Document Object Model)。然后获取CSS并构建CSSOM(CSS对象模型 - CSS Object Model)。然后将DOM与CSSOM结合,创建渲染树(Render Tree)。然后找到所有内容都处于网页的哪个位置,也就是布局(Layout)这一步。最后,浏览器开始在屏幕上绘制像素。
正常情况下浏览器会以上面我们描述的步骤进行渲染,但有一个特殊情况是在构建DOM时遇见了JavaScript,这时情况就会变得不太一样。JavaScript会影响渲染的流程,所以它是性能领域很重要的部分,这个特殊情况我们后面再详细讨论,我们先讨论如何构建DOM和CSSOM。
浏览器会遵守一套定义完善的步骤来处理HTML并构建DOM。宏观上,可以分为几个步骤。如图1-2所示。
图1-2 构建DOM的具体步骤
第一步(转换):浏览器从磁盘或网络读取HTML的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成字符,如图1-3所示。
图1-3 将字节码转换成字符
第二步(Token化):将字符串转换成Token,例如:“<html>”、“<body>”等。Token中会标识出当前Token是“开始标签”或是“结束标签”亦或是“文本”等信息。
图1-4将字符串转换成Token
这时候你一定会有疑问,节点与节点之间的关系如何维护?
事实上,这就是Token要标识“起始标签”和“结束标签”等标识的作用。例如“title”Token的起始标签和结束标签之间的节点肯定是属于“title”的子节点。如图1-5所示。
图1-5 节点之间的关系
图1-5给出了节点之间的关系,例如:“Hello”Token位于“title”开始标签与“title”结束标签之间,表明“Hello”Token是“title”Token的子节点。同理“title”Token是“head”Token的子节点。
第三步(生成节点对象并构建DOM):事实上,构建DOM的过程中,不是等所有Token都转换完成后再去生成节点对象,而是一边生成Token一边消耗Token来生成节点对象。换句话说,每个Token被生成后,会立刻消耗这个Token创建出节点对象。
带有结束标签标识的Token不会创建节点对象
节点对象包含了这个节点的所有属性。例如<img src="xxx.png" />标签最终生成出的节点对象中会保存图片地址等信息。
随后通过“开始标签”与“结束标签”来识别并关联节点之间的关系。最终,当所有Token都生成并消耗完毕后,我们就得到了一颗完整的DOM树。从Token生成DOM的过程如图1-6所示。
图1-6 构建DOM
图1-6中每一个虚线上有一个小数字,表示构建DOM的具体步骤。可以看出,首先生成出htmlToken,并消耗Token创建出html节点对象。然后生成headToken并消耗Token创建出head节点对象,并将它关联到html节点对象的子节点中。随后生成titleToken并消耗Token创建出title节点对象并将它关联到head节点对象的子节点中。最后生成bodyToken并消耗Token创建body节点对象并将它关联到html的子节点中。当所有Token都消耗完毕后,我们就得到了一颗完整的DOM树。
构建DOM的具体实现,与Vue的模板编译原理非常相似,若想了解构建DOM的过程如何用代码实现,可以查看我之前写的一篇关于Vue模板编译原理的文章。也可以期待一下我的新书,书里面对Vue模板编译原理讲的比文章更细致与透彻。
DOM会捕获页面的内容,但浏览器还需要知道页面如何展示。所以需要构建CSSOM(CSS对象模型 - CSS Object Model)。
构建CSSOM的过程与构建DOM的过程非常相似,当浏览器接收到一段CSS,浏览器首先要做的是识别出Token,然后构建节点并生成CSSOM。如图2-1所示。
图2-1 构建CSSOM的具体过程
假设浏览器接收到了下面这样一段CSS:
body {font-size: 16px;}
p {color: red;}
p span {display:none;}
span {font-size: 14px;}
img {float: right;}上面这段CSS最终经过一系列步骤后生成的CSSOM如图2-2所示。
图2-2 构建CSSOM的过程
从图中还可以看出,body节点的子节点继承了body的样式规则(16px的字号)。这就是层叠规则以及CSS为什么叫CSS(层叠样式表)。
这里我要讲一句题外话,HTML可以逐步解析,它不需要等待所有DOM都构建完毕后再去构建CSSOM,而是在解析HTML构建DOM时,若遇见CSS会立刻构建CSSOM,它们可以同时进行。但CSS不行,不完整的CSS是无法使用的,因为CSS的每个属性都可以改变CSSOM,所以会存在这样一个问题:假设前面几个字节的CSS将字体大小设置为16px,后面又将字体大小设置为14px,那么如果不把整个CSSOM构建完整,最终得到的CSSOM其实是不准确的。所以必须等CSSOM构建完毕才能进入到下一个阶段,哪怕DOM已经构建完,它也得等CSSOM,然后才能进入下一个阶段。
所以,CSS的加载速度与构建CSSOM的速度将直接影响首屏渲染速度,因此在默认情况下CSS被视为阻塞渲染的资源。
DOM包含了页面的所有内容,CSSOM包含了页面的所有样式,现在我们需要将DOM和CSSOM组成渲染树。
假设我们现在有这样一段代码:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<style>
body {font-size: 16px;}
p {color: red;}
p span {display:none;}
span {font-size: 14px;}
img {float: right;}
</style>
</head>
<body>
<p>Hello <span>berwin</span></p>
<span>Berwin</span>
<img src="https://p1.ssl.qhimg.com/t0195d63bab739ec084.png" />
</body>
</html>这段代码最终构建成渲染树,如图3-1所示。
图3-1 构建渲染树
渲染树的重要特性是它仅捕获可见内容,构建渲染树浏览器需要做以下工作:
p > span节点就不会出现在渲染树中,因为该节点上设置了display: none属性。所以最终渲染出的结果如下图所示。
图3-2 渲染树与渲染结果
有了渲染树之后,接下来进入布局阶段。这一阶段浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。
布局流程的输出是一个“盒模型”,它会精确地捕获每个元素在视口内的确切位置和尺寸,所有相对测量值都将转换为屏幕上的绝对像素。如图4-1所示。
图4-1 布局
布局完成后,浏览器会立即发出“Paint Setup”和“Paint”事件,将渲染树转换成屏幕上的像素。如图5-1所示。
图5-1 绘制
现在,我们回到文章的最开始时留下的问题,我们讨论关键渲染路径,但是之前的讨论并不包含JS。这是因为JS会打破前面我们讨论的内容。
我们都知道JavaScript的加载、解析与执行会阻塞DOM的构建,也就是说,在构建DOM时,HTML解析器若遇到了JavaScript,那么它会暂停构建DOM,将控制权移交给JavaScript引擎,等JavaScript引擎运行完毕,浏览器再从中断的地方恢复DOM构建。
因为JavaScript可以修改网页的内容,它可以更改DOM,如果不阻塞,那么这边在构建DOM,那边JavaScript在改DOM,如何保障最终得到的DOM是否正确?而且在JS中前一秒获取到的DOM和后一秒获取到的DOM不一样是什么鬼?它会产生一系列问题,所以JS是阻塞的,它会阻塞DOM的构建流程,所以在JS中无法获取JS后面的元素,因为DOM还没构建到那。
JavaScript对关键渲染路径的影响不只是阻塞DOM的构建,它会导致CSSOM也阻塞DOM的构建。
原本DOM和CSSOM的构建是互不影响,井水不犯河水,但是一旦引入了JavaScript,CSSOM也开始阻塞DOM的构建,只有CSSOM构建完毕后,DOM再恢复DOM构建。
这是什么情况?
这是因为JavaScript不只是可以改DOM,它还可以更改样式,也就是它可以更改CSSOM。前面我们介绍,不完整的CSSOM是无法使用的,但JavaScript中想访问CSSOM并更改它,那么在执行JavaScript时,必须要能拿到完整的CSSOM。所以就导致了一个现象,如果浏览器尚未完成CSSOM的下载和构建,而我们却想在此时运行脚本,那么浏览器将延迟脚本执行和DOM构建,直至其完成CSSOM的下载和构建。
也就是说,在这种情况下,浏览器会先下载和构建CSSOM,然后再执行JavaScript,最后在继续构建DOM。
这会导致严重的性能问题,我们假设构建DOM需要一秒,构建CSSOM需要一秒,那么正常情况下只需要一秒钟DOM和CSSOM就会同时构建完毕然后进入到下一个阶段。但是如果引入了JavaScript,那么JavaScript会阻塞DOM的构建并等待CSSOM的下载和构建,一秒钟之后,假设执行JavaScript需要0.00000001秒,那么从中断的地方恢复DOM的构建后,还需要一秒钟的时间才能完成DOM的构建,总共花费了2秒钟才进入到下一个阶段。如图6-1所示。
图6-1 JS阻塞构建DOM并等待CSSOM
例如下面不加载JS的代码:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Test</title>
<link rel="stylesheet" href="https://static.xx.fbcdn.net/rsrc.php/v3/y6/l/1,cross/9Ia-Y9BtgQu.css">
</head>
<body>
aa
</body>
</html>上面这段代码的执行性能结果如图6-2所示。
图6-2 CSS不阻塞DOM
DOMContentLoaded 事件在116ms左右触发。
在代码中添加JavaScript:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Test</title>
<link rel="stylesheet" href="https://static.xx.fbcdn.net/rsrc.php/v3/y6/l/1,cross/9Ia-Y9BtgQu.css">
</head>
<body>
aa
<script>
console.log(1)
</script>
</body>
</html>DOMContentLoaded 事件在1.21s触发,如图6-3所示。
图6-3 CSS阻塞DOM
关键渲染路径(Critical Rendering Path)是指浏览器将HTML,CSS,JavaScript转换为屏幕上所呈现的实际像素这期间所经历的一系列步骤。
关键渲染路径共分五个步骤。构建DOM -> 构建CSSOM -> 构建渲染树 -> 布局 -> 绘制。
CSSOM会阻塞渲染,只有当CSSOM构建完毕后才会进入下一个阶段构建渲染树。
通常情况下DOM和CSSOM是并行构建的,但是当浏览器遇到一个script标签时,DOM构建将暂停,直至脚本完成执行。但由于JavaScript可以修改CSSOM,所以需要等CSSOM构建完毕后再执行JS。
本文作者:刘博文(Berwin),花名“玖五”,畅销书《深入浅出Vue.js》作者、知名技术博主、讲师、阿里巴巴淘系技术部前端技术专家,现负责淘系618、双11等超大型营销活动主会场的终端渲染架构。
Twitter:https://twitter.com/jiuwu_lbw
博客:https://github.com/berwin/Blog/issues
知乎:https://www.zhihu.com/people/berwin-95/
回想起年初刚来杭州那会,是疫情正严重的时候,那时候刚来杭州要住半个月的酒店,然后才能进入阿里巴巴溪西园区(后续简称”园区”),时间过得飞快,一晃已经来杭州半年了,这半年经历了很多,也学到了很多,写一篇文章总结下这半年来自己的成长。
要勇于挑战权威,发现现有技术体系的问题,并解决它。
记得当时刚来杭州时,心情是非常忐忑的,对未来非常憧憬,能和那么多很厉害的工程师一起工作是一件特别爽的事,再加上我们团队是做双十一大促会场的,咱们技术人都知道双十一对工程师来说意味着什么。入职后,一大堆技术名词和各种技术体系铺面而来也确实让我感受到了技术的强大,所以就一直以学习的心态在了解和接触现有的技术体系。
进入园区后第二个月就开启了618战役,感谢主管墨冥的信任,当时我承担了一个非常重要的专项PM(Project Manager),它在整个618战役里都算是风险和挑战都非常高的专项,也是因为这件事干的还不错,上线后非常稳定,因此我获得了618战役奖励优秀PM的一个“厉害了Work哥 - 此时此刻非我莫属”奖,奖状在淘宝楼里挂了三四个月,“入职不到3个月就获奖” 应该算是比较值得自豪的事了。

说这个当然不只是为了显摆,就在我以为自己表现非常好的时候到了转正面试的时间,虽然通过了试用期,但得到的反馈是对我的表现没有超出预期,我的执行力虽然很强,但我 “没有对现有技术体系带来变化”。
换句话说,招我来的目的不是来当资源的,618战役虽然打的不错,但说实话换个人上去又能差到哪里去?大家对我的期望是对现有比较成熟的体系带来变革。
那怎么对现有体系带来变革?经过大家的引导和我自己的思考,答案是:”发现现有体系的问题“。我刚来觉得这里技术体系特别牛,加上沉淀了这么多年的双十一,已经是比较成熟的技术,觉得这是一个权威,不可能有问题,所以一直抱着膜拜的想法在了解和学习现有体系,所以这就是问题所在。
这时候我学会的最深刻的一个成长是:“要勇于挑战权威,发现现有技术体系的问题,并解决它。”
感谢主管的培养和信任,给了我很多试错空间,入职到现在这半年时间从第一次当PM到现在,犯了很多错误,在一次次犯错后也学习到了很多当Project Manager的知识,本小节将这些成长总结起来分享给大家。
在推进项目时,有时会遇到一些阻碍,例如:不配合,难合作,主动性差等问题。绝大部分能来到阿里工作的同学不会是“能力”或“态度”问题,所以大部分阻碍可以归结于:
解决障碍,就是在解决以上这三点,信息不一致可以靠“沟通”和“换位思考”解决,而“目标不一致”和“优先级不一致”可以靠“上升”解决,只要事情足够重要,给出几种解决方案,上升到某个级别问题一定会被按照最合理的方案解决。
入职大概三个月左右的时候,我发现PD(产品经理,在阿里巴巴我们称为 Product Design,即:“产品设计”)在与我合作的过程中对我是有点不信任的,例如:相同的答案PD会相信我师兄和主管、我给了方案后PD会再去找我主管询问是否有更好的方案等。这也让我有了很多成长,当时我还特地去向二级主管请教一些方法。
案例一:在没有建立起自己的权威前,很多时候PD并不相信我给出的方案。那么这种情况解决方案是:假设有3种方案,将各自的利弊信息同步给PD后,如果都不满意,可以拉其他人,例如拉自己的主管进来,佐证自己的判断。(但前提是自己要做好功课,先和主管沟通好达成一致,再将信息同步给PD)。
案例二:假设现有两种方案各有利弊,完美的方案需要团队A配合,那么可以拉着自己的PD去和团队A的PD谈(前提是要先和自己的PD达成一致,并且以自己为主导拉PD只是来佐证自己的判断),一方面向团队A的PD佐证自己提的需求是重要的,另一方面也可以向自己的PD佐证这个需求确实没那么简单。如果事情推进遇到阻塞,回到2.1小节,最终问题一定会被解决。
- 拉主管进来是为了佐证自己的判断,而不是和PD一起把复杂问题抛出去。
- 拉主管佐证要先沟通好达成一致,不是突然把主管拉进来佐证自己,避免主管的判断和自己不一致当场被打脸
先和主管达成一致,客观评估需求是否真的重要到需要拉其他同学来帮忙开发,在一个更宏观的角度评估哪个需求优先级更高,然后再给PD同步结论,如果不接受拉主管进来还是相同的结论,再不接受再拉主管的主管也是相同的结论。权威就是在日常这样一点点建立起来的。
回到最初的问题,PD为什么要找我主管寻求帮助?
本质上是我还没有建立起自己的权威,另外PD是信息弱势方,所以如果我给出的方案她不满意时,她会去找她更信任的人寻求帮助看是否有更好的方案,那么如果这时真得到了一个更满意的方案,那么她会觉得这招管用下回还会再去,这时候我的权威就会崩塌。
解决方案是:提前做功课给到PD的信息永远是权威的判断,在不信任自己时拉人佐证自己的判断是对的,或者和PD一起去找其他人继续推进&解决问题,逐渐让PD意识到即便是找了其他更信任的人也会得到相同的结论,我的结论就是正确且权威的。
作为新同学,可能会发现同一件事,同一个解法,PD经常会不信任新同学。
这里日常工作本质上是累积信用和消费信用的过程,解决方案是:在日常工作中一点点累积自己的信用,当机会来临要勇于消费信用去推动事情,这也是体现“此时此刻,非我莫属”的阿里巴巴价值观。
当然,打了败仗,信用也会消耗,经常打败仗即便不是新同学也很难让人信任,所以还是要靠自己的本事来积累信用并建立权威。
这半年时间,关于风险同步我犯过两次错误,这两次错误也分别让我学到了两种关于项目风险的经验。
事情发生在今年的88大促,当时我为会场底层渲染架构全新升级了一版,在一个极短的时间用新开发的2.0追上了正在运行的1.0的大部分功能,然后在88大促切换到2.0,可以类比在天上给飞机换引擎。切换2.0后如预料中的一样,出了一些小问题。
问题在于,给飞机换引擎这个动作和行为,我没有通知给业务方,导致出了问题的时候,业务方很惊讶,为什么之前一直好好的这次突然出了这么多问题?业务方对这个事没有任何预期。
在这件事上,我学到的是:在做一件事时,要通知到所有可能会因为这件事而受到影响的人,把自己的计划,方案,风险等信息完全同步给可能会受到影响的人,好处是:
事情的背景是,有一次我负责一件事,这件事在过程中我发现进度有延迟的风险,但当时我选择了自己抗下来,加加班,赶赶进度。后面我低估了这件事的严重性,导致最后实在扛不住了才暴露风险,紧急加人解决了这件事,虽然这件事没引起问题,但是这个最后临门一脚才暴露风险这个行为是不对的。
通过这件事,我也学会了如何做事是对的(感谢主管孜孜不倦的教导),暴露风险不是懦弱和能力不行的体现,暴露风险是一个PM的专业素质,不要自己硬扛风险和压力,过程中有风险需要帮助应及时提,避免到最后扛不住才将风险暴露出来。
新人入职都会进入一个误区:
现在我可以很明确的告诉大家,不是,完全不是!
推进项目受阻有很多原因,绝大部分都不是自己这个位置能解决的,上升是非常高效的解决方案。
项目遇到风险也是同样的道理,除了确实是自己能力导致的风险以外,绝大部分风险都是客观存在的事实,和自己能力没关系,即时且充分暴露风险寻求资源解决风险才是王道,这反而是一名专业的PM应该具备的基本素质。
PM的目标只有一个:“确保项目按时保质上线”,但过程也同样重要,阿里巴巴有句土话我很喜欢:没有过程的结果是“垃圾”,没有结果的过程是“放屁”。
在推进项目的过程中,一名合格的PM需要具备的基本素养是:
内心时刻铭记一句团队内广为流传的名言:所有关于事的困难可以靠坚持解决,所有关于人的困难可以靠换位思考解决。
项目复杂且生产关系也复杂的时候,会遇到各种困难和阻塞。沟通工作时很容易情绪失控,但身为一名合格的PM,任何时候,不应该被情绪控制自己的判断。
任何时候,都应该基于客观事实理性分析问题,不应该带有主观的执念。
这也是未来我要加强训练的一点,过去这半年,我经常情绪失控,未来我会克服这一点,做一名专业的Project Manager。
评估某个方案是否可行,不应该只是评估技术上是否可行,还要考虑按照这个方案推进后,会带来怎样的影响。
关于这点我曾犯过一次错,在技术方案的评审上,我只判断了技术的可行性就同意了某个方案,但是我没有考虑按照这个解决方案推进后会带来很大的其他影响。后面我师兄及时制止了这件事的发生,但是已经答应了PD按照某个方案推进结果又反悔,对于我这种新人甚至是我们团队在PD心中,都是非常消耗信用的一件事,“积累信用可能需要好久,但消耗信用,仅仅只是一次无意间的失误”,要珍惜自己的信用,“信用”,才是PM推进事情时的通行证。
客户(运营、产品、其他人)有疑问来向自己咨询的时候,即便不是自己负责的域,也不要直接和客户说你去找谁谁谁。正确的做法是先把问题揽下来,然后团队内部找对应的同学拉个群解决。
我就曾遇到过这种被踢皮球的情况,我有疑问找了A,A说让我找B,B让我找C,C说他不负责这事,然后我直接找了他们共同的主管,问题解决。
我知道他们不是故意踢皮球,但在我找不到他们1号位是谁的时候,用这种方式对我来说是最快速解决问题的方案。这首先对于客户的体感不好,另一个是我向他们共同的主管寻求帮助后,他们的体感也不好。所以,要有owner心态,“让业务方幸福,让主管信任”。
前面说了很多关于PM我犯的错和收获到的成长,那么作为一名前端工程师,这半年也收获了一些成长。
要做一名有标签,有特色,有影响力的人,在公司工作了一段时间后,在人们心中不应该只是一名“前端工程师”,应该是一名XXX的前端工程师。
标签应该自己去努力获取,有两个标签是我现在在努力获取的: “双十一前端PM” 和 “不到30岁的P8”。
一个灵魂拷问:今天我负责的事,我做完和其他人做完有什么不一样?今天我作为Project Manager负责某个项目,如果换做其他人来,会有什么区别?
今天获奖也好,得到一个好绩效也好,真的是因为自己做得好,还是因为主管把自己放在这个位置得到了更多的资源所以做得好?如果把其他人放到这个位置,和自己会有什么区别?这是一个值得思考的问题。
一个特别大的误区是:认为自己技术好,所以比其他人做的好。今天能进阿里的同学技术上都不会差,再加上大部分工作都不是去造火箭,所以 “技术好 !== 拿到好结果”,技术好会增加拿到好结果的概率,但不是一定能拿到好结果。
所以,要让自己负责的项目,因为PM是自己,而变得不一样。要让自己的团队,因为自己的存在,而变得不一样。
换位到更高维度思考,很多时候不理解的事就理解了。换位到合作伙伴的维度思考,就理解他为什么会不配合,难合作,主动性差。换位到客户的角度思考,就理解她为什么会不信任自己。
还是那句话:所有关于事的困难可以靠坚持解决,所有关于人的困难可以靠换位思考解决。
这是有一次和主管聊天中学到的,和人沟通,一定要学会聆听,解决冲突或问题时,第一步是“聆听”,先聆听,充分了解信息后,再基于客观事实把事摊开了,并基于客观事实讲述正确的做法是什么,然后再去指点哪些地方可能不足。
如果不聆听就做判断,试想在没有得到足够信息输入时就做判断,判断真的客观么?还是自己主观上有倾向?就算自己对情况完全了解,不需要输入也可以做判断,那信息的输出方会不会认为自己做的判断不够客观?因为自己都没有听他说的是什么就做判断,他一定会质疑自己的判断是否公正。
半年来,成长远不止这些,还是感谢舒文把我带到这个团队,赐予机遇和指导。感谢主管墨冥这半年来不断地言传身教并给予机会试错,相信未来,我会在实战中承担更大的职责,相信未来,我会让我们团队因为我的存在变得不一样。
促使我写一篇文章描述他的原因是最近一段时间我的英语老师对我的认知产生了很大的冲击。
老师的经历和我很像,老师83年出生,由于种种原因,没有上大学,在部队当了几年兵,退伍后开始学习英语,然后去新东方当英语老师,现在已经十多年师龄了,英语教的非常好。
近大半年的时间,每个周日我都会去新东方学习一天的英语,上个周末是最后一堂结业课,老师在课上说他不能继续教我们下一册英语了,因为他拿到了澳大利亚纽卡斯尔大学的硕士Offer,准备去上学了。
其实我也曾想过将工作辞去,然后去国外读两年书,学学知识、见见世面。但最终也只是停留在幻想阶段。但当身边出现一个人真的这么去做,对我触动非常大。
老师用实际行动,教会了我什么叫 I have a dream。
老师用实际行动,教会了我什么叫 I believe i can。
老师这个年纪,还能追逐梦想,为了梦想如此疯狂,我为什么不能。
有一句话叫做:“种一棵树,最好的时间是十年前,其次是现在”。对于老师来讲,他的十年前可能就是现在的我,那么我是不是应该在现在种一棵树给未来的自己。
老师用实际行动让我明白,什么叫不要给自己设限,人生有无限种可能。那一刻我内心像是风云后被射入的第一缕阳光,我感觉人生充满了希望。
人生要充满希望,要有自己的梦想,并为了自己的梦想努力,一步步靠近。只有这样,才会觉得自己充满了力量,没有那么迷茫。
我见过很多人,没有梦想,没有希望,每天行尸走肉一样,按部就班重复着自己每天都在做的事情。如果一个人,认为自己再怎么努力,也无法改变命运,无法改变现状。那么他就真的无法改变自己的命运,而且无论他什么年纪,他都老了。
我认为,如果一个人没有梦想,没有希望,那么他将不知道自己为什么活着,找不到人生的意义。更可怕的是,一旦觉得人生失去了意义,那么将不再充满活力,失去激情,做什么事都没有很强的动力,自然就失去了自驱力。
要相信相信的力量,无论年纪有多大,只要拥有自己的梦想,并相信自己,努力去一点点接近它,那么人生就充满了希望。像我的老师一样,快40岁了依然愿意为了自己的梦想做出行动。
一定要拥有梦想,让自己的人生,充满希望。
不要给自己设限,人生有无限种可能。要勇敢,要相信自己,要拥有自己的梦想,要充满希望。
版本控制系统(version control system,VCS),版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。历史上出现过各种各样的VCS:如1982年的RCS,现在你还可能在Unix的发布中找到它,1985年的PVCS,1990年底的CVS,1992年的clearcase,微软的VSS(welcome to Hell),90年代中期的Perforce,以及SVN和BitKeeper,还有我们即将介绍的git.
版本控制系统出现的原因是由实际需求推动的。在没有VCS的情况下,我们维护版本的方法是复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。这么做唯一的好处就是简单。不过坏处也不少:有时候会混淆所在的工作目录,一旦弄错文件丢了数据就没法撤销恢复。解决这个问题的方法是开发版本控制系统,采用某种简单的数据库来记录文件的历次更新差异的来实现。
集中化的版本控制系统( Centralized Version Control Systems,简称 CVCS ),有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连接到这台服务器,取出最新的文件或者提交更新。这类系统,诸如 CVS,Subversion 以及 Perforce 等。优点是每个人都可以在一定程度上看到项目中的其他人正在做些什么,而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易;缺点是**服务器的单点故障有丢失数据的风险。
分布式版本控制系统( Distributed Version Control System,简称 DVCS ),采用对等网络式的方式,客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来,其中存储的有不同的版本信息和维护一个repository的必要的辅助信息。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。因为每一次的提取操作,实际上都是一次对代码仓库的完整备份。这类系统,像 Git,Mercurial,Bazaar 以及 Darcs 等。
Linus在1991年创建了开源的Linux,从此Linux系统不断发展,已经成为最大的服务器系统软件了。Linus虽然创建了Linux,但Linux的壮大是靠全世界热心的志愿者参与的,这么多人在世界各地为Linux编写代码,世界各地的志愿者把源代码文件通过diff的方式发给Linus,然后由Linus本人通过手工方式合并代码。当时是有CVS、SVN这些免费的版本控制系统,但是Linus坚定地反对CVS和SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比CVS、SVN好用,但那是付费的,和Linux的开源精神不符。
到了2002年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统。后来Linux社区开发Samba的Andrew试图破解BitKeeper的协议,被BitMover公司发现了。到了2005年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了免费使用 BitKeeper 的权力。这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds )不得不吸取教训,只有开发一套属于自己的版本控制系统才不至于重蹈覆辙。他们对新的系统制订了若干目标:
自诞生于 2005 年以来,Git 日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。它的速度飞快,极其适合管理大项目,它还有着令人难以置信的非线性分支管理系统,可以应付各种复杂的项目开发需求。Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异。
对于任何一个文件,在 Git 内都只有三种状态:
文件流转的三个工作区域:Git 的工作目录,暂存区域,以及本地仓库。
Git的基本工作流程如下:
Git安装
以下的讲述基于linux平台,在使用git的命令前,需要安装git程序,Fedora 上用 yum 安装
$ yum install git-core
而在 Ubuntu 这类 Debian 体系的系统上,可以用 apt-get 安装
$ sudo apt-get install git
Git初始化
git init
说明:通过这个命令把当前工作目录变成git可以管理的仓库。
Git添加文件
git add filenpath
git add *
git add .
说明:用此命令添加文件到git仓库。
git 提交文件
git commit -m "Commit message"
说明:将暂存区的文件快照提交到本地仓库中。
Git查看状态
git status
说明:查看git仓库当前的状态。
Git文件区别
git diff <filepath>
说明:可以查看工作区文件和git仓库文件的差别。
Git历史查询
git log
说明:此命令可以查看commit的历史记录。
Git查看分支合并图
git log --graph
说明:可以查看分支合并的历史记录。(我都是在gitlab 或 github 页面里看 感觉这个命令有点 然并*)
Git版本回退
git reset [空 或者 HEAD]
说明:回退版本到以前提交的某个commit,也可以把暂存区的修改回退到工作目录中。
tip:如果想撤销本地的所有修改和commit,可以使用如下 git fetch origin && git reset --hard origin/master 或使用 git reset --hard origin/master,如果想撤销本地的所有修改到某个commit 可以使用 git reset --hard HEAD
Git操作记录
git reflog
说明:记录每一次操作(有点像history命令)
Git撤销修改
git checkout .
说明:撤销工作目录中的修改。
Git撤销单个修改
git checkout <filename>
说明:取消filename中未提交的修改。
Git删除文件
git rm <filename>
说明:从git仓库中删除filename文件
Git关联远程仓库
git remote add
说明:使本地仓库和远程仓库创建关联。
Git复制远程仓库
git clone
说明:从远程仓库copy一份到本地。
Git抓取远程仓库的修改
git pull
说明:拉取远程代码库的代码,通常是团队中其他成员提交的代码
Git本地修改上传远程仓库
git push
说明:推送本地的修改到远程仓库。
Git创建分支
git branch <branch-name>
说明:创建branch-name分支。
Git切换分支
git checkout <branch-name>
说明:切换到branch-name分支。
Git创建并切换分支
git checkout -b <branch-name>
说明:创建分支branch-name并切换到此分支。
Git查看当前分支
git branch
说明:查看当前分支并列出所有分支。
tip: -a 参数可以查看远程分支信息
Git合并分支
git merge --no-ff <branch-name>
说明:合并指定分支到当前分支。如果你只有一个commit 可以使用 git cherry-pick [分支名,或者commitID]
Git删除本地分支
git branch -d <branch-name>
说明:删除本地的分支xxx-branch-name。
Git删除远程分支
git push origin :[远程分支名]
说明:删除远程某个分支 冒号前面一定要有空格。
Git本地分支推送到远程分支
git push origin [本地分支名]:[远程分支名]
说明:将本地仓库推送到远程仓库
任何命令,都可以通过
git <想要了解的命令> --help
来获得更详细的说明及用法
说明
针对文件的每一行,显示其最后一次被更新的信息及其作者
命令
git blame <文件名>
查看某一特定文件中每一行最后一次被更新的信息
说明
管理追踪的多个远端仓库。注意,一个远端仓库名称可以对应多个仓库地址(url)。
命令
git remote add <仓库名称> <仓库地址>
添加一个远端仓库。这样 git fetch <仓库名称> 就可以以此跟踪远端仓库。
git remote show
列出所有远端仓库名称。
git remote rename [<旧仓库名称>] <新仓库名称>
更改远端仓库名称。
git remote remove <仓库名称>
删除远端仓库。此操作会删除与此仓库相关的所有分支和配置信息。
git remote show [<仓库名称>]
若仓库名称为空,则列出所有远端仓库名称;否则,列出特定远端仓库的相关信息,例如HEAD branch、remote branch,配置信息等。
git remote set-url <仓库名称> <新仓库地址> [<旧仓库地址>]
更新特定远端仓库名称下的部分仓库地址,其中<仓库地址>可以是正则表达式。
git remote set-url --add <仓库名称> <仓库地址>
为特定远端仓库名称增加新的仓库地址。
git remote set-url --delete <仓库名称> <仓库地址>
删除特定远端仓库名称下的部分仓库地址,其中<仓库地址>可以是正则表达式。
说明
对分支进行管理。
命令
git branch <branch name> [<commit ID>]
基于当前分支的某次commitID 来创建一个新分支
commit ID可选,也可以替换成分支名称,或tag。创建后不会自动跳转至该分支,需手动 git checkout <分支名称>。
若想快速创建一个分支并跳转至该分支,请使用 git checkout -b <branch name> [<commit ID>]。
git branch [-a] [--list <pattern>...]
列出所有的分支。 -a 列出所有远端分支和本地分支。
git branch (-m | -M) [<旧分支名称>] <新分支名称>
修改分支名称。若<新分支名称>已存在,-m不会修改分支名称,并给出提示,-M会强制覆盖已有分支。-a 列出所有远端分支和本地分支。
git branch (-d | -D) [-r] <分支名称>...
删除分支。若该分支尚未被合并,-d不会删除分支,并给出提示,-D会进行强制删除。
分支被删除后,下次执行 fetch 或 pull 操作时仍会被创建,若想避免,需对 fetch 或 pull 命令进行配置。详情请查看 git fetch --help
$ git branch -v
查看各个分支最后一个提交对象的信息
$ git branch --merged
iss53
* master
查看哪些分支已被并入当前分支,之前我们已经合并了 iss53,所以在这里会看到它。一般来说,列表中没有 * 的分支通常都可以用 git branch -d 来删掉。原因很简单,既然已经把它们所包含的工作整合到了其他分支,删掉也不会损失什么。
$ git branch --no-merged
testing
它会显示还未合并进来的分支,由于这些分支中还包含着尚未合并进来的工作成果,所以简单地用 git branch -d 删除该分支会提示错误,因为那样做会丢失数据,不过,如果你确实想要删除该分支上的改动,可以用大写的删除选项 -D 强制执行
说明
暂存当前工作状态。
命令
git stash [save [message]]
储存当前工作状态。可添加一些必要的说明,以便后期查找。
git stash list
列出所有的暂存。
git stash show [<stash>]
显示特定暂存与其起点之间的变化,与 diff 命令相似。若无参数,则默认为最后一个暂存。
git stash pop [<stash>]
恢复特定暂存,同时从暂存列表移除。若恢复时发生冲突,则暂存不会从列表中移除,需解决完冲突后手工移除( git stash drop )。
git stash apply [<stash>]
恢复特定暂存。该命令类似 pop, 不同的是,该命令不会自动从暂存列表移除该暂存。
git stash drop [<stash>]
从暂存列表移除特定暂存。若无参数,则默认为最后一个暂存。
git stash clear
移除暂存列表中的所有暂存。
用法一
git checkout <file name>
取消某些文件在本地的变更,原理是(用暂存区里最近一次提交的内容覆盖某文件,达到取消对某文件的修改)
用法二
git checkout <branch name>
切换到某分支
用法三
git checkout -b <new branch name>
新建一个分支,并切换到该分支
用法四
git branch <分支名> <commitID>
基于当前分支的某一次commit来创建分支
用法一
ps: 文件三种状态,working tree, index file, commit
git diff <文件名>
是查看working tree与index file的差别的。
用法二
git diff --cached <文件名>
查看index file与commit的差别的。
用法三
git diff HEAD <文件名>
是查看working tree和commit的差别的
ps:以上三种方法不加文件文件,则比较所有文件(出去gitignore 掉的文件)
用法四
git diff <commitID>/<branch>
比较working tree 与某一提交/分支的差别
用法五
git diff <commitID>/<branch> <commitID>/<branch>
查看某一提交/分支与某一提交/分支的差别
用法一
git reset –hard HEAD
回退到一个特定的历史版本。丢弃这次提交之后的所有变更。
用法二
取消add
git reset HEAD
回滚到一个特定的历史版本。将这个版本之后的所有变更移动到“未暂存”的阶段。这也就意味着你需要运行 git add . 和 git commit 才能把这些变更提交到仓库
用法三
取消commit
git reset --soft HEAD
回滚到一个特定的历史版本。将这次提交之后所有的变更移动到暂存并准备提交阶段。意味着你只需要运行 git commit 就可以把这些变更提交到仓库。
用法五
撤销merge
git reset --merge ORIG_HEAD
此种情况会保留你的commit,如果使用git reset --hard 去删除掉你的commit
任何时候使用git reset --hard 请慎重
标签
# 列出所有tag
$ git tag
# 新建一个tag在当前commit
$ git tag [tag]
# 新建一个tag在指定commit
$ git tag [tag] [commit]
# 删除本地tag
$ git tag -d [tag]
# 删除远程tag
$ git push origin :refs/tags/[tagName]
# 查看tag信息
$ git show [tag]
# 提交指定tag
$ git push [remote] [tag]
# 提交所有tag
$ git push [remote] --tags
# 新建一个分支,指向某个tag
$ git checkout -b [branch] [tag]我们都喜欢有图片的网页,图片很美好,很有趣,同时它涵盖了丰富的信息。所以,在加载网页时,大部分流量被图像资源所占据(平均60%,数据可能不准确)。
图像资源不只占用网络资源,它也会占用网页中大量的视觉空间。所以图像渲染的速度会直接影响用户体验。图像优化其实就是最大限度地减少图像的字节数,从而最大化地缩减网络资源占用,使浏览器下载速度变的更快。下载速度越快,在屏幕上渲染的时间就越早,所以视觉上就会有一个更好的体验。
当然,优化图像最佳的方式就是不用图像,例如使用CSS效果(渐变,阴影,圆角等)代替图像。使用CSS比同等视觉效果的图像资源的字节数要小非常多,这是毋庸置疑的。另一个好处是CSS不受分辨率影响,使用CSS渲染出的视觉效果可以在任何分辨率和缩放级别下始终清晰地显示。
但必须使用图像资源时,对图像进行合理的优化将对性能有着至关重要的影响。
本文不会介绍如何进行图像优化,有大量在线工具和开源项目供我们使用,使用起来非常的简单。本文将重点介绍图像优化的原理。
首先,本文会介绍两种图像资源:矢量图与栅格图(位图),并分别介绍优化它们的原理。随后介绍无损压缩与有损压缩以及它们的区别。在本文的最后,我们会介绍什么是高分辨率屏幕。
希望通过本篇文章的介绍,可以让您对图像优化的原理有一个直观的感受。
矢量图与栅格图(位图)是两种不同的图像格式。
图1-1 矢量图与栅格图
以矢量图为例,程序绘制一个半径为r的圆所需的主要信息是:
矢量图的内容是这些绘制相关的关键信息,同样的图像如果是栅格图(位图),则图像是由称作像素的单个点组成的。
栅格图的每个像素都分配有特定的位置和颜色值。每个像素的颜色信息由RGB组合或者灰度值表示。
根据位深度,可将栅格图分为1、4、8、16、24及32位图像等。每个像素使用的信息位数越多,可用的颜色就越多,颜色表现就越逼真。当然,相应的数据量就越大,图像所占字节数也就越大。
那什么是位深度呢?位深度也叫做色彩深度或者色彩位数,即栅格图中要用多少个二进制位来表示每个点的颜色,色彩深度越高,每个像素点可用的颜色就越多。色彩深度是用“n位颜色”(n-bit colour)来说明的。若色彩深度是n位,即有2^n种颜色选择,而储存每像素所用的位数就是n。例如,位深度为 1 的像素栅格图只有两个可能的值(黑色和白色),所以又称为二值栅格图。位深度为 8 的图像有 2^8(即 256)个可能的值。
所以矢量图对比栅格图的优点主要在以下几点:
但每一种格式都有优缺点,矢量图适用于简单的几何图像,如果是场景复杂的照片,矢量格式就不能满足要求了,因为描述所有形状所需的 SVG 标记量可能高得离谱。即便如此,输出效果可能仍然无法达到“照片级真实感”,所以这种情况使用栅格图显然更合适。
因为栅格图是由很多个像素点组成的,所以当我们放大栅格图时,我们会看到图形会出现锯齿并且模糊不清(因为像素点被放大了),所以我们在使用栅格图时,需要根据不同的屏幕分辨率来保存多个版本的栅格图图像,这样可以提供最佳的用户体验。
现在我们已经了解了什么是矢量图与栅格图,接下来我们将介绍如何优化它们。
SVG大家应该都不陌生,它是一种可缩放矢量图形。前不久我在写 《嗨,送你一张Web性能优化地图》 这篇文章时,@安佳 姐姐帮我画了一张SVG图。
图2-1 SVG示例图
图2-1您可以通过点击链接在浏览器打开它,然后查看网页源代码,在源码中可以看到它涵盖了大量的元数据,例如图层信息、注解和 XML 命名空间等,而浏览器渲染时通常不需要这些数据。
我们可以通过svgo之类的工具将 SVG 文件缩小。
上面这张图片,我使用svgo优化完之后,文件大小缩减了69.3%!原图16.315 KiB优化后文件大小5.009 KiB。您可以点击链接在浏览器打开优化后的SVG矢量图,并查看网页源代码,对比它们之间的区别,您可以看到源代码明显少了很多,但并不影响浏览器正常渲染。
图2-2 SVG矢量图源码优化前后对比
通过第一小节的介绍,我们大致可以想象出,其实栅格图是二维“像素”栅格。例如一个10*10像素的图像是 100 个像素序列,而每个像素中又存储了RGBA值(R红色通道、G绿色通道、B蓝色通道、A alpha透明度通道)。
在内部,浏览器会为每个通道分配 256 个值(色阶),就是说每个通道 8 位(因为2^8=256),那么一个像素有四个通道(RGBA),所以每个像素一共 32 位(4 个通道 * 8 位 = 32 位),32 位 = 4 字节,也就是说每个像素 4 占个字节。所以,只要我们知道栅格图尺寸,我们就可以轻易地计算出图像文件的大小。
| 尺寸 | 像素 | 文件大小 |
|---|---|---|
| 100 * 100 | 10,000 | 39 KB |
| 200 * 200 | 40,000 | 156 KB |
| 300 * 300 | 90,000 | 351 KB |
| 500 * 500 | 250,000 | 977 KB |
| 800 * 800 | 640,000 | 2500 KB |
从上表可以看到,随着图片尺寸的变大,文件大小会以惊人的速度暴增。
再基于此特征的前提下,我们应该怎样改善栅格图的文件大小以获得更快的加载速度呢?
在第一小节中,我们简单介绍了”色彩深度“,所以一个简单的策略是我们可以通过调整图像的色彩深度来降低图像文件的大小。每个通道 8 位为每个通道提供 256 个值,RGB三个通道一共可以为每个像素提供 16777216 种颜色(256^3=16777216)。如果我们将色彩深度调整为 RGB 通道一共只需要 8 位,那么加上 Alpha 透明度通道的 8 位,一共为 16 位,也就是说每个像素两个字节(16位 = 2个字节),与原来每个像素 4 个字节相比,节约了 50% 的字节!
但是你一定会有疑问,颜色值少了那么多,图像的质量会不会变得很差?我们可以用一张图来对比一下。
图3-1 不同色彩深度的图片进行对比
这张图是上个月(2018-10)我去参加W3C TPAC会议时在法国让彭星小哥哥帮我拍摄的。这张图包含渐变色过渡的复杂场景(天空),可以看到,调整了色彩深度后,从肉眼上看到的视觉差异并不明显。
在优化了各个像素中存储的数据之后,我们还可以更进一步。事实上,许多图像的相邻像素都具有相似的颜色,压缩程序可以利用这个特征采用“增量编码”的方式对图像进行压缩。在这种编码方式下,并不为每个像素单独存储值,而是存储相邻像素之间的差异,如果相邻像素相同,则增量为“零”,只需存储一位即可。通过存储数据之间的差异,而不是存储数据本身,这样的方式可以大幅减少数据的重复,从而降低文件大小。
当然,图像压缩领域的解决方案还远不止这些,因为图像占据了网络世界中大量的字节,所以好的图像压缩方法具有极大的价值,这一领域学术性很强,我们也没有能力去发明新的算法,但了解这一领域的基本概念还是可以的,例如本文介绍的 RGBA 像素、色彩深度和各种优化方法。
无损数据压缩(Lossless Compression)指数据经过压缩后,信息不受损失,还能完全恢复到压缩前的原样。
那么无损压缩是如何做到保存完整的原始信息的同时降低文件大小的呢?
举个例子:一张图是由100个红点构成,那么正常情况下它会以类似“红点、红点、...(重复97次)...、红点”的格式来存储它(栅格图的存储格式我们在本文的第三小节中介绍过)。为了降低文件大小,我们可以改成用“100个红点”这样的格式来存储这张图片,这样就可以在不失去任何信息的情况下完成压缩,这就是无损压缩。
但如果想保存文件的所有信息,那么无论使用任何压缩方法,文件大小都无法低于一个下界。举个例子:压缩后得到的zip文件会比源文件更小,但一直重复压缩同一个文件并不会让文件大小变成0,因为源文件终究含有一定的数据量。
这个时候,使用有损压缩可以突破这个限制。
因为人的肉眼很难观察到一张高分辨率图像里面的一些细节,所以舍弃这些人类无法察觉的细节,就可以用更小的数据量提供与原始数据相差无几的感官体验(当然也可以更进一步,例如:通过失去一部分可以察觉的细节,来达到更好的压缩率),这就是有损压缩。有损数据压缩又称破坏性资料压缩、不可逆压缩。有损数据压缩是将次要的信息数据舍弃,牺牲一些质量来减少数据量,提高压缩比。
有损压缩的一个优点是在有些情况下,它能够获得比任何已知无损压缩小得多的文件大小,同时又能满足系统的需要。
本文重点介绍了什么是矢量图与栅格图(位图),以及各种图片优化工具是如何优化它们的。
最后,我们还讨论了什么是有损压缩与无损压缩,以及它们之间的区别。
本文讲的内容是 vue 1.0 版本~
有些同学可能不知道state是什么,可能还会有疑问,这个跟vuex中的state是不是有啥联系?
在vue文档当中没有在任何地方提到过关于state这个单词,所以同学们发蒙是正常的,不用担心
所以在一开始我先说说state是什么以及它都包含哪些内容。
state 是源码当中的一个概念,State中包含了大家非常熟悉的Props、Methods、Data、Computed,vue内部把他们划分为state中方便管理
所以本篇文章会详细介绍State中这四个大家常用的api的内部是怎样工作的
Methods 在我们日常使用vue的时候,使用频率可能是最高的一个功能了,那么它的内部实现其实也特别简单,我先贴一段代码
Vue.prototype._initMethods = function () {
var methods = this.$options.methods
if (methods) {
for (var key in methods) {
this[key] = bind(methods[key], this)
}
}
}在看逻辑之前有几个地方我先翻译一下:
_initMethods 这个内部方法是在初始化Methods时执行,就是上面的流程图中的初始化Methods
this 是当前vue的实例
this.$options 是初始化当前vue实例时传入的参数,举个栗子
const vm = new Vue({
data: data,
methods: {},
computed: {},
...
})上面实例化Vue的时候,传递了一个Object字面量,这个字面量就是 this.$options
清楚了这些之后,我们看这个逻辑其实就是把 this.$options.methods 中的方法绑定到this上,这也就不难理解为什么我们可以使用 this.xxx 来访问方法了
Data 跟 methods 类似,但是比 methods 高级点,主要高级在两个地方,proxy 和 observe
Data 没有直接写到 this 中,而是写到 this._data 中(注意:this.$options.data 是一个函数,data是执行函数得到的),然后在 this 上写一个同名的属性,通过绑定setter和getter来操作 this._data 中的数据
proxy的实现:
Vue.prototype._proxy = function (key) {
// isReserved 判断 key 的首字母是否为 $ 或 _
if (!isReserved(key)) {
var self = this
Object.defineProperty(self, key, {
configurable: true,
enumerable: true,
get: function proxyGetter () {
return self._data[key]
},
set: function proxySetter (val) {
self._data[key] = val
}
})
}
}observe 是用来观察数据变化的,先看一段源码:
Vue.prototype._initData = function () {
var dataFn = this.$options.data
var data = this._data = dataFn ? dataFn() : {}
if (!isPlainObject(data)) {
data = {}
process.env.NODE_ENV !== 'production' && warn(
'data functions should return an object.',
this
)
}
var props = this._props
// proxy data on instance
var keys = Object.keys(data)
var i, key
i = keys.length
while (i--) {
key = keys[i]
// there are two scenarios where we can proxy a data key:
// 1. it's not already defined as a prop
// 2. it's provided via a instantiation option AND there are no
// template prop present
if (!props || !hasOwn(props, key)) {
this._proxy(key)
} else if (process.env.NODE_ENV !== 'production') {
warn(
'Data field "' + key + '" is already defined ' +
'as a prop. To provide default value for a prop, use the "default" ' +
'prop option; if you want to pass prop values to an instantiation ' +
'call, use the "propsData" option.',
this
)
}
}
// observe data
observe(data, this)
}上面源码中可以看到先处理 _proxy,之后把 data 传入了 observe 中, observe 会把 data 中的key转换成getter与setter,当触发getter时会收集依赖,当触发setter时会触发消息,更新视图,具体可以看之前写的一篇文章《深入浅出 - vue之深入响应式原理》
这地方可能有一个地方不容易理解,observe 在转换 getter 和 setter 的时候是这样转换的
// 伪代码
function observe(value) {
this.value = value
Object.defineProperty(this.value, key, {...
}但是我们操作数据是代理到 _data 上的,实际上操作的是 _data,那这个observe监听的是this.value,好像有点不对劲?后来我才发现有一个地方忽略了。
var data = this._data = dataFn ? dataFn() : {}其实这个地方是同一个引用,observe 中的 this.value 其实就是 _initData 中的 this._data,所以给 this.value 添加getter 和 setter 就等于给 this._data 设置 getter 和 setter
总结起来 data 其实做了两件事
this.$options.data 中的数据可以在 this 中访问计算属性在vue中也是一个非常常用的功能,而且好多同学搞不清楚它跟watch有什么区别,这里就详细说说计算属性到底是什么,以及它是如何工作的
简单点说,Computed 其实就是一个 getter 和 setter,经常使用 Computed 的同学可能知道,Computed 有几种用法
var vm = new Vue({
data: { a: 1 },
computed: {
// 用法一: 仅读取,值只须为函数
aDouble: function () {
return this.a * 2
},
// 用法二:读取和设置
aPlus: {
get: function () {
return this.a + 1
},
set: function (v) {
this.a = v - 1
}
}
}
})如果不希望Computed有缓存还可以去掉缓存
computed: {
example: {
// 关闭缓存
cache: false,
get: function () {
return Date.now() + this.msg
}
}
}先说上面那两种用法,一种 value 的类型是function,一种 value 的类型是对象字面量,对象里面有get和set两个方法,talk is a cheap, show you a code...
function noop () {}
Vue.prototype._initComputed = function () {
var computed = this.$options.computed
if (computed) {
for (var key in computed) {
var userDef = computed[key]
var def = {
enumerable: true,
configurable: true
}
if (typeof userDef === 'function') {
def.get = makeComputedGetter(userDef, this)
def.set = noop
} else {
def.get = userDef.get
? userDef.cache !== false
? makeComputedGetter(userDef.get, this)
: bind(userDef.get, this)
: noop
def.set = userDef.set
? bind(userDef.set, this)
: noop
}
Object.defineProperty(this, key, def)
}
}
}可以看到对两种不同的类型做了两种不同的操作,function 类型的会把函数当做 getter 赋值给 def.get
而 object 类型的直接取 def.get 当做 getter 取def.set 当做 setter。
就是这么easy
但是细心的同学可能发现了一个问题,makeComputedGetter 是什么鬼啊?????直接把 def.get 当做getter就好了啊,为毛要用 makeComputedGetter 生成一个 getter ???
嘿嘿嘿
其实这是vue做的一个优化策略,就是上面最后说的缓存,如果直接把 def.get 当做 getter其实也可以,但是如果当getter中做了大量的计算那么每次用到就会做大量计算比较消耗性能,如果有很多地方都使用到了这个属性,那么程序会变得非常卡。
但如果只有在依赖的数据发生了变化后才重新计算,这样就可以降低一些消耗。
实现这个功能我们需要具备一个条件,就是当 getter 中使用的数据发生变化时能通知到我们这里,也就是说依赖的数据发生变化时,我们能接收到消息,接收到消息后我们在进行清除缓存等操作
而vue中具备这项能力的很明显是 Watcher,当依赖的数据发生变化时 watcher 可以帮助我们接收到消息
function makeComputedGetter (getter, owner) {
var watcher = new Watcher(owner, getter, null, {
lazy: true
})
return function computedGetter () {
if (watcher.dirty) {
watcher.evaluate()
}
if (Dep.target) {
watcher.depend()
}
return watcher.value
}
}上面就是 makeComputedGetter 的实现原理
代码中 watcher.evaluate() 可以先暂时理解为,执行了 getter 求值的过程,计算后的值会保存在 watcher.value 中。
我们看到求值操作的外面有一个判断条件,当 watcher.dirty 为 true 时会执行求值操作
其实,这就相当于缓存了,求值后的值存储在 watcher.value 中,当下一次执行到 computedGetter 时,如果 watcher.dirty 为 false 则直接返回上一次计算的结果
那么这里就有一个问题,watcher.dirty 何时为 true 何时为 false 呢??
默认一开始是 true,当执行了 watcher.evaluate() 后为 false,当依赖发生变化接收到通知后为 true
Watcher.prototype.evaluate = function () {
// avoid overwriting another watcher that is being
// collected.
var current = Dep.target
this.value = this.get()
this.dirty = false
Dep.target = current
}上面是 evaluate 的实现,就是这么easy~
Watcher.prototype.update = function (shallow) {
if (this.lazy) {
this.dirty = true
} else if (this.sync || !config.async) {
this.run()
} else {
...
}
}当 watcher 接收到消息时,会执行 update 这个方法,这个方法因为我们的 watcher 是 lazy 为 true 的所以走第一个判断条件里的逻辑,里面很直接,就是把 this.dirty 设置了 true
这里就又引发了一个问题,我们怎么知道 getter 中到底有哪些依赖,毕竟使用Computed开发的人并不会告诉我们他用到了哪些依赖,那我们怎么知道他使用了哪些依赖?
这个问题非常好
vue在全局弄了一个 Dep.target 用来存当前的watcher,全局只能同时存在一个
当watcher执行get求值的时候,会先把 Dep.target 设为自己,然后在执行 用户写的 getter 方法计算返回值,这时候其实有一个挺有意思的逻辑,data上面我们说过,当数据触发 getter 的时候,会收集依赖,那依赖怎么收集,就是通过全局的 Dep.target 来收集,把Dep.target 添加到观察者列表中,等日后数据发生变化触发 setter 时 执行Dep.target的 notify,到这不知道大家明白过来没???
就是我先把全局的唯一的一个 Dep.target 设置成我自己,然后用户逻辑里爱依赖谁依赖谁,不管你依赖谁都会把我添加到你依赖的那个数据的观察者中,日后只要这个数据发生了变化,我就把this.dirty 设置为 true
所以上面看 Watcher.prototype.evaluate 这个代码的逻辑, this.get() 里会设置Dep.target,等逻辑执行完了他在把 Dep.target 设置回最初的
到这里关于 Computed 就说完了,在使用上其实它跟 watch 没有任何关系,一个是事件,一个是getter和setter,根本不是同一个性质的东西,但在内部实现上 Computed 又是基于watcher实现的。
props 提供了父子组件之间传递数据的能力,在本文讲的vue 1.x.x 版本中,props分三种类型 静态、一次(oneTime)、单向、双向
我们先说静态,什么是静态props?
静态props就是父组件把数据传递给子组件之后,就不在有任何联系,父组件把数据改了子组件中的数据不会变,子组件把数据改了父组件也不会变,数据传过去后他们俩互相之间就没什么事了~
静态的内部工作原理也比较简单:
组件内会通过 props: ['message'] 这样的语法来明确指定子组件组要用到的props,而内部需要做的事就是拿着这些key直接通过 node.getAttribute 在当前el上读一个 value,然后将读到的 value 通过observer绑到子组件的上下文中,绑定后的 value 与当前组件内的 data 数据一样
其实与静态差不多,只有一点不同,oneTime 的值是从父组件中读来的,什么意思呢?
静态的值是通过 node.getAttribute 读来的,读完后直接放到子组件里。
而 oneTime 的值是通过 node.getAttribute 先读一个key,然后用这个 key 去父组件的上下文读一个值放到子组件里。
所以 oneTime 更强大,因为他可以传递一个用Computed计算后的值,也可以传递一个方法,或什么其他的等等...
单向的意思是说父组件将数据通过props传递给子组件后,父组件把数据改了子组件的数据也会发生变化。
单向props内部的工作原理其实也挺简单的,实现单向props其实我们需要具备一项能力:当数据发生变化时会发出通知,而这项能力就是能够接收到通知。
具备这项能力后,当数据发生变化我们可以得到通知,然后将变化后的数据同步给子组件
而具备这项能力的只有 Watcher,当数据发生变化时,会通知给 Watcher,而 Watcher 在更新子组件内的数据。这样就实现了单向props,废话不多说,上代码:
const parentWatcher = this.parentWatcher = new Watcher(
parent,
parentKey,
function (val) {
updateProp(child, prop, val)
}, {
twoWay: twoWay,
filters: prop.filters,
// important: props need to be observed on the
// v-for scope if present
scope: this._scope
}
)解释一下上面代码:
parent 是父组件实例parentKey 是父组件中的一个key,也就是传递给子组件的那个key,是通过这个key在父组件实例中取值然后传递给子组件用的parent 组件的 parentKey 发生变化时,执行这个函数,并把新数据传进来updateProp 是用来更新prop的,逻辑很简单,写个伪代码export function updateProp (vm, prop, value) {
vm[prop.path] = value
}所以工作原理就是当 parent 中的 parentKey这个值发生了变化,会执行更新函数,执行函数中拿到新数据把子组件中的数据更新一下
就是这么easy
双向不只是父组件改数据子组件会发生变化,子组件修改数据父组件也会发生变化,实现了父子组件间的数据同步。
双向prop的工作原理与单向的基本一样,只不过多了一个子组件数据变化时,更新父组件内的数据,其实就是多了一个Watcher
self.childWatcher = new Watcher(
child,
childKey,
function (val) {
parentWatcher.set(val)
}, {
// ensure sync upward before parent sync down.
// this is necessary in cases e.g. the child
// mutates a prop array, then replaces it. (#1683)
sync: true
}
)其实就是单向prop一个Watcher,双向Prop两个Watcher
const parentWatcher = this.parentWatcher = new Watcher(
parent,
parentKey,
function (val) {
updateProp(child, prop, val)
}, {
twoWay: twoWay,
filters: prop.filters,
// important: props need to be observed on the
// v-for scope if present
scope: this._scope
}
)
// set the child initial value.
initProp(child, prop, parentWatcher.value)
// setup two-way binding
if (twoWay) {
// important: defer the child watcher creation until
// the created hook (after data observation)
var self = this
child.$once('pre-hook:created', function () {
self.childWatcher = new Watcher(
child,
childKey,
function (val) {
parentWatcher.set(val)
}, {
// ensure sync upward before parent sync down.
// this is necessary in cases e.g. the child
// mutates a prop array, then replaces it. (#1683)
sync: true
}
)
})
}twoWay 是用来判断当前Prop的类型是单向还是双向用的
下面提供一个关于Props的流程图
State中的Props、Methods、Data、Computed这四个在实际应用中是非常常用的功能,如果大家能弄明白它内部的工作原理,对日后开发效率的提升会有很大的帮助
如果有不明白的地方,或者意见或建议都可以在下方评论。
上个月,我写了一篇文章介绍什么是“关键渲染路径”,其实目的是为了给这篇文章做一个铺垫,本文将谈谈如何优化关键渲染路径(本文将假设您已经阅读过《关键渲染路径》这篇文章或已经懂得了什么是“关键渲染路径”)。
优化关键渲染路径可以提升网页的渲染速度,从而得到一个更好的用户体验。
优化关键渲染路径有很多种方法与情况,不同情况下优化方式也各不相同,初步看起来这些优化方法五花八门,知识非常的零散。
但在这些看似零散的知识中,我们会发现一些规律,将这些规律总结起来后,可以得出一个结论:到目前为止,只有三种因素可以影响关键渲染路径的耗时。而所有的优化方式,都是在尽可能的针对这三种因素进行优化。
这三种因素分别是:
切记,非常重要,所有优化关键渲染路径的方法,都是在优化以上三种因素。因为只有这三种因素可以影响关键渲染路径。
关键资源指的是那些可以阻塞页面首次渲染的资源。例如JavaScript、CSS都是可以阻塞关键渲染路径的资源,这些资源就属于“关键资源”。关键资源的数量越少,浏览器处理渲染的工作量就越少,同时CPU及其他资源的占用也越少。
关键路径的长度指的是浏览器和资源服务器之间的往返次数,通常被称作RTT。
关键字节的数量指的是关键资源的字节大小,浏览器要下载的资源字节越小,则下载速度与处理资源的速度都会更快。通常很多优化方法都是针对关键字节的数量进行优化。例如:压缩。
关键路径中的每一步耗时越长,由于阻塞会导致渲染路径的整体耗时变长。
在关键渲染路径中,构建渲染树(Render Tree)的第一步是构建DOM,所以我们先讨论如何让构建DOM的速度变得更快。
HTML文件的尺寸应该尽可能的小,目的是为了让客户端尽可能早的接收到完整的HTML。通常HTML中有很多冗余的字符,例如:JS注释、CSS注释、HTML注释、空格、换行。更糟糕的情况是我见过很多生产环境中的HTML里面包含了很多废弃代码,这可能是因为随着时间的推移,项目越来越大,由于种种原因从历史遗留下来的问题,不过不管怎么说,这都是很糟糕的。对于生产环境的HTML来说,应该删除一切无用的代码,尽可能保证HTML文件精简。
总结起来有三种方式可以优化HTML:缩小文件的尺寸(Minify)、使用gzip压缩(Compress)、使用缓存(HTTP Cache)。
缩小文件的尺寸(Minify)会删除注释、空格与换行等无用的文本。
本质上,优化DOM其实是在尽可能的减小关键路径的长度与关键字节的数量。
与优化DOM类似,CSS文件也需要让文件尽可能的小,或者说所有文本资源都需要。CSS文件应该删除未使用的样式、缩小文件的尺寸(Minify)、使用gzip压缩(Compress)、使用缓存(HTTP Cache)。
除了上面提到的优化策略,CSS还有一个可以影响性能的因素是:CSS会阻塞关键渲染路径。
CSS是关键资源,它会阻塞关键渲染路径也并不奇怪,但通常并不是所有的CSS资源都那么的『关键』。
举个例子:一些响应式CSS只在屏幕宽度符合条件时才会生效,还有一些CSS只在打印页面时才生效。这些CSS在不符合条件时,是不会生效的,所以我们为什么要让浏览器等待我们并不需要的CSS资源呢?
针对这种情况,我们应该让这些非关键的CSS资源不阻塞渲染。
实现这一目的非常简单,我们只需要将不阻塞渲染的CSS移动到单独的文件里。例如我们将打印相关的CSS移动到print.css,然后我们在HTML中引入CSS时,添加媒体查询属性print,代码如下:
<link href="print.css" rel="stylesheet" media="print">上面代码添加了media="print"属性,所以上面CSS资源仅用于打印。添加了媒体查询属性后,浏览器依然会下载该资源,但如果条件不符合,那么它就不再阻塞渲染,也就是变成了非阻塞的CSS。
我们可以写个DEMO测试一下:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<link rel="stylesheet" href="https://static.xx.fbcdn.net/rsrc.php/v3/y6/l/1,cross/9Ia-Y9BtgQu.css">
</head>
<body>
Hello
</body>
</html>上面代码使用Chrome开发者工具的性能面板捕获后的性能图如下:
从上图中的首次绘制(First Paint)时间是在1200ms的位置,可以看到这个时间是浏览器加载CSS完毕后,而且可以看到Network栏中CSS显示Highest代表高优先级。
添加了媒体查询语句后,捕获出来的性能图如下:
首次绘制时间在不到100ms的位置,和domcontentloaded事件差不多的时间触发。同时CSS资源变成了Lowest,表示低优先级。
可以看到,浏览器依然会下载该CSS资源,但它不再阻塞渲染。
上面提供的方法是针对那些不需要生效的CSS资源,如果CSS资源需要在当前页面生效,只是不需要在首屏渲染时生效,那么为了更快的首屏渲染速度,我们可以将这些CSS也设置成非关键资源。只是我们需要一些比较hack的方式来实现这个需求:
<link href="style.css" rel="stylesheet" media="print" onload="this.media='all'">上面代码先把媒体查询属性设置成print,将这个资源设置成非阻塞的资源。然后等这个资源加载完毕后再将媒体查询属性设置成all让它立即对当前页面生效。
通过这样的方式,我们既可以让这个资源不阻塞关键渲染路径,还可以让它加载完毕后对当前页面生效。
类似的方案有很多,代码如下:
<link rel="preload" href="style.css" as="style" onload="this.rel='stylesheet'">
<link rel="alternate stylesheet" href="style.css" onload="this.rel='stylesheet'">上面两种方式都能实现同样的效果。
关于CSS的加载有这么多门道,到底怎样才是最佳实践?答案是:Critical CSS。
Critical CSS的意思是:把首屏渲染需要使用的CSS通过style标签内嵌到head标签中,其余CSS资源使用异步的方式非阻塞加载。
CSS资源在构建渲染树时,会阻塞JavaScript,所以我们应该保证所有与首屏渲染无关的CSS资源都应该被标记为非关键资源。
所以Critical CSS从两个方面解决了性能问题:
大家应该都知道要避免使用@import加载CSS,实际工作中我们也不会这样去加载CSS,但这到底是为什么呢?
这是因为使用@import加载CSS会增加额外的关键路径长度。举个例子:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<link rel="stylesheet" href="http://127.0.0.1:8887/style.css">
<link rel="stylesheet" href="https://lib.baomitu.com/CSS-Mint/2.0.6/css-mint.min.css">
</head>
<body>
<div class="cm-alert">Default alert</div>
</body>
</html>上面这段代码使用link标签加载了两个CSS资源。这两个CSS资源是并行下载的。我们使用Chrome开发者工具的Performance面板捕获出的结果如下图所示:
从图中用红色方框圈出来的位置可以看出两个CSS是并行加载的,首次绘制时间取决于CSS加载时间较长的资源加载时间。
现在我们改为使用@import加载资源,代码如下:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<link rel="stylesheet" href="http://127.0.0.1:8887/style.css">
</head>
<body>
<div class="cm-alert">Default alert</div>
</body>
</html>/* style.css */
@import url('https://lib.baomitu.com/CSS-Mint/2.0.6/css-mint.min.css');
body{background:red;}代码中使用link标签加载一个CSS,然后在CSS文件中使用@import加载另一个CSS。使用Chrome开发者工具再次捕获出的结果如下图所示:
可以看到两个CSS变成了串行加载,前一个CSS加载完后再去下载使用@import导入的CSS资源。这无疑会导致加载资源的总时间变长。从上图可以看出,首次绘制时间等于两个CSS资源加载时间的总和。
所以避免使用@import是为了降低关键路径的长度。
所有文本资源都应该让文件尽可能的小,JavaScript也不例外,它也需要删除未使用的代码、缩小文件的尺寸(Minify)、使用gzip压缩(Compress)、使用缓存(HTTP Cache)。
与CSS资源相似,JavaScript资源也是关键资源,JavaScript资源会阻塞DOM的构建。并且JavaScript会被CSS文件所阻塞。为了避免阻塞,可以为script标签添加async属性。
我们举个例子:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<link rel="stylesheet" href="https://static.xx.fbcdn.net/rsrc.php/v3/y6/l/1,cross/9Ia-Y9BtgQu.css">
</head>
<body>
<p class='_159h'>aa</p>
<script src="http://qiniu.bkt.demos.so/static/js/app.53df42d5b7a0dbf52386.js"></script>
</body>
</html>上面这段代码,分别加载了CSS资源和JavaScript资源,我们使用Chrome开发者工具的Performance面板捕获出的结果如下图所示:
从捕获出的结果可以看到,JS资源加载完毕后,需要等待CSS资源加载完并构建出CSSOM之后才会执行JS,并且JS会将DOM阻塞,所以最终domcontentloaded事件在350ms与400ms之间触发。
我们将script标签添加async属性:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<link rel="stylesheet" href="https://static.xx.fbcdn.net/rsrc.php/v3/y6/l/1,cross/9Ia-Y9BtgQu.css">
</head>
<body>
<p class='_159h'>aa</p>
<script async src="http://qiniu.bkt.demos.so/static/js/app.53df42d5b7a0dbf52386.js"></script>
</body>
</html>使用Chrome开发者工具捕获出的结果如下图所示:
从图中可以看到,JS加载完后不再需要等待CSS资源,并且也不再阻塞DOM的构建,最终domcontentloaded事件在50ms与100ms之间触发。与之前相比,domcontentloaded事件触发时间提前了300ms。
可以看到,在关键渲染路径中优化JavaScript,目的是为了减少关键资源的数量。
该篇文章详细介绍了如何优化关键渲染路径。
关键渲染路径是浏览器将HTML,CSS,JavaScript转换为屏幕上所呈现的实际像素的具体步骤。而优化关键渲染路径可以提高网页的呈现速度,也就是首屏渲染优化。
你会发现,我们介绍的内容都是如何优化DOM,CSSOM以及JavaScript,因为通常在关键渲染路径中,这些步骤的性能最差。这些步骤是导致首屏渲染速度慢的主要原因。
你在使剑,是的,但是你的目的是杀人,直追你的目标,忘记手中长剑,才能使出最高的剑法... 而这世上又有多少剑客, 拘泥于手中快剑而落入俗套,终究无法到达登峰造极的境界... ----阿莱克西斯
剑,是剑客的武器,而现代前端工程师的剑可以理解为前端框架(当然不止是前端框架,但今天我们只谈前端框架)。
所谓御剑之道,指的是如何驾驭所有前端框架。对,你没有看错,是所有,而不是某一个。
如果是介绍如何驾驭某一个框架,那么本文的标题可能就要改成“御剑之术”,但本文介绍的是“御剑之道”。
现代前端程序员刚一入行就要选择一款前端框架来作为自己的技术栈,比如Vue,React,Angular等。包括各种公司的招聘信息上也会写上自己希望应聘者掌握至少一种前端框架。所以很多人就会有一种困惑:我应该选择哪款框架作为我的技术栈?
图片来自@jwcarrol
如果你存在下面这些困惑,那么本篇文章会帮助到你:
我本人对Vue是最熟的,熟悉到什么程度呢?几个月前我就已经写完了一本介绍Vue原理的书(《深入浅出Vue.js》)还没上市,但我并不觉得自己是Vue阵营的人。我觉得自己是无阵营的,或者换一种角度来讲,“框架并不是我的剑”。
这本书是与人民邮电出版社签约的,预计过不了多久就会和大家见面了。
对于这本书的内容质量大家尽管放心。人民邮电出版社出版的书,质量都不会差。就算大家不相信我,也要相信出版社。
对于初学者来说,开局能够掌握一把绝世好剑,固然会在前期得到很大的帮助,一招练成,出手就能伤人。但也正是这把剑,如果不能在合适的阶段把它丢掉,那么它会限制自己无法到达登峰造极的境界。
独孤求败被称为『剑魔』,而他最终的境界是无剑。
《天龙八部》中描述段誉无形有质的六脉神剑时,曾写道:“使剑全仗手腕灵活,但出剑收剑,不论如何迅速,总是有数尺的距离,他以食指运那无形剑气,却不过是手指在数寸范围内转动,一点一戳,何等方便?(没错,前端工程师的剑也是同样的道理)
很多人在学习前端框架时,会进入到一个误区,这个误区是太过在意框架提供的语法(API)。并且喜欢对各种框架孰优孰劣要争论个高低。
在实际工作中我从来不和人争论这些,但有一次和朋友们聊天刚好聊到这个话题,我说所有框架都一样用,只不过语法有点区别。其中一个朋友可能并没有理解我这句话的意思,然后发了一篇文章说Vue和React在设计理念上是有一些区别的,不只是语法。
设计理念不同导致提供的语法不同,但再怎么不同,差异再怎么大,它们要解决的问题是相同的。现在这些框架其实没有什么React能做到的事换成Vue就做不了。反而是React能做的事,使用Vue都能做,反之亦然。那么对于我来说,这两把剑就是一样的,只是使用起来手感不太一样。还是那句话,要直追我们的目标,不要拘泥于手中的剑。
站在“术”的角度看,它们确实不一样,而且可以说几乎没有一样地方。但是站在道的角度看,它们是一样的。
所以你会发现,我关注的根本就不是框架提供的语法,我关注的是框架的特性。我说的框架特性,指的不是React提供了JSX,或者Vue提供了模板语法。这些不是我所说的特性,这些其实还是语法。
那么框架的特性到底指的是什么呢?我们举两个例子来感受一下。
更深一步思考,React提供的JSX和Vue提供的模板,它们的目的是什么?目的是为了实现声明式渲染的功能。不论是JSX,或者是Vue中的模板,本质上都是描述了『状态』与『视图』之间的映射关系。
所以声明式渲染是框架的特性。
声明了映射关系之后,可以得到一个公式:
UI = render(state)
状态与视图之间的映射关系,等同于render函数。熟悉React的同学对这个公式应该并不陌生。JSX与Vue的模板在这一点上是相同的。在框架的内部,不论是JSX还是Vue的模板,最终会编译成render函数。
上面这个公式,输入的是state,输出的是DOM。所以输入变了输出就变了。
这个特性就是我们常说的数据驱动视图。
这里会引出一个问题,框架必须要知道Web应用在运行时”状态“是否发生了变化,然后才能使用前面提到的公式重新输出一个新的UI。所以如何知道Web应用的状态在运行时是否发生了变化这个问题是所有框架必须去解决的。
解决方案有很多种。不同框架,或者同一个框架的不同版本对这个问题的解决方案都不同,但相同的是都可以解决问题。关于这个问题如何解决,我在曾在我的文章、分享的PPT以及目前还未上市的书中都有详细的介绍。这个问题不是本文所讨论的重点,感兴趣的同学可以点击这里了解更多信息。
不同的解决方案,导致的直接结果就是它所提供给用户的上层语法或API完全不一样。
不同的永远是语法,相同的永远是特性。----Berwin
现代主流框架都具备的一个特性是“组件”,它们都会以“组件”作为一个基本的抽象单元。
可能不同的框架,它所提供的操控组件的方式不一样,但概念上是相似的。
之前听过一次尤雨溪的知乎Live,他将实际应用中的组件分为四种类型并依次介绍了四种组件之间的区别:
展示型组件
展示型组件是最直接也是最常用的组件,就是用数据渲染视图,“数据进,DOM出”。
接入型组件
接入型组件通常会跟接入数据的service层打交道。包含一些和服务器或数据源打交道的逻辑,然后接入型组件会将数据往下传,传给比较简单的展示型组件。在React中这种类型的组件被称为“容器组件(container component)”。
交互型组件
交互型组件典型的例子是对表单组件的封装和增强。大部分组件库,像ElementUI都是以交互型组件为主。这一类组件会有比较复杂的交互逻辑,但是它是一个非常通用的逻辑,所以它强调复用。
功能型组件
功能型组件是比较抽象的组件。用Vue举例,路由的<router-view>和Vue自带的<transition>都属于功能型组件。它本身不渲染任何内容,它是一个逻辑型的组件。它通常作为一个扩展或一种抽象机制存在。
不同框架操控组件的方式可能不一样,但使用组件的“心法”永远是一样的。这就是关注特性带来的好处,你可以切换到任意一个框架,使用组件或封装组件时,总是上面列出的几种类型。
掌握了“心法”的程序员在切换框架时,他的状态通常是这样的:我现在想写一个交互型组件,这个框架都提供了哪些API?去翻翻文档看一下。然后就可以写出一个很优雅的组件出来,哪怕刚使用这个框架才不到一天。
如果没有掌握“心法”,用了一个框架写出的代码很糟糕,那么换了一个框架也不会写出更好的代码,甚至更糟糕。
绝顶剑法,不在于使用的是什么剑,而是使剑的人。
前面详细介绍了两个特性给大家感受下为什么要重视特性。框架的特性太多不能每一个都详细介绍,下面列出一些大家比较熟悉的通用特性:
对于初学者不知道应该学哪种框架的问题,其实大可不必这么纠结,随便选一个去学(当然是学特性),以后切换到其他框架也是很轻松的事情。
有经验的程序员也无需担心投资了一个框架,刚学会就过时了。框架虽然过时了,但内功心法却深深地扎在你的脑袋里。
为团队选择技术栈所考虑的因素与人不一样。就目前来看,各大主流框架所提供的能力与社区的繁荣程度并没有明显的差距,所以框架是否靠谱等问题基本上不需要考虑,更多要考虑的因素反而是:
当团队确定好了技术栈之后,最重要的是统一。一个团队内部只存在一种技术栈并打磨出成熟的架构与工作流之后,会大幅提升团队内的生产效率。
在学会了框架的特性之后,若想达到“无剑”的境界,那就需要具备实现这些特性的能力。只有具备了这样的能力,你才能完全理解一种“特性”,从而达到人剑合一的境界。否则这些特性对你来说是一个黑盒,你永远不知道它内部发生了什么,你就只是这把剑的使用者,无法真正的驾驭它们。你会被框架的设计者牵着鼻子走,然后无奈地说一句:求别更新,老子学不动了。
注意,前面提到的是实现这些“特性”的能力,当然如果能实现一个完整的框架更好。但一个框架通常会有很多很繁琐的东西会消耗掉很多精力,而那些东西其实并不是很关键,就像我们平时写代码一样,总是有很多没什么技术含量的体力活。
举例来说,真正能让我们完全理解“声明式 & 数据驱动渲染”这个特性的方式就是亲自动手去实现它。当然,不同框架或者同一个框架的不同版本对这个特性的实现方式都不太一样。但这都没关系,当我们亲自动手用某一种方式实现它之后,我们就能真正理解不同的实现方式之间各自有什么取舍,只有亲自动手实现了某个特性之后我们才能知道不同的实现方式有哪些优势,为了得到它而付出的代价(舍弃的)是什么。
对“声明式 & 数据驱动渲染”这个特性的实现方式感兴趣的同学可以看我的另一篇文章《聊聊我对现代前端框架的认知》,在这篇文章中,有一个小节“现代前端框架对渲染的处理”对这个问题进行了相关的介绍。
本文说了这么多,但其实只讲了一个道理,就是要重视『特性』,而不是语法与API。
还有就是本文开头的那句话,如果想达到登峰造极的境界,就不要过于专注手里的剑。框架既是神兵利器,也是枷锁。既赋予我们力量,也束缚着我们。
若想挣脱这个枷锁,就要达到“手中无剑,心中有剑”的境界。
初学者最开始学武往往急于求成,学了一招出手就想伤人。但殊不知真正的高手很少杀人。
中前期学发,中后期学收,收发自如,神功乃成。
年终总结是一种针对自己的复盘,回顾这一年是否完成了年初为自己设定的目标,分析原因,并从中学习经验。
年初的时候给自己设定的一些目标,这些目标有完成的,有没完成的,也有不想完成的。
年初设定的目标:
2019.4月成功发布了《深入浅出Vue.js》,到目前为止,该书的销量在前端领域算作 “畅销书”,截止到 2020.1.9 该书在豆瓣评分为8.3。
分析原因:
这本书在去年就已经写完了,所以今年顺利出版并没有太多困难。
去年GitChat找到我,打算合作出一个性能优化方面的专栏,我也觉得这是个好事情,就计划今年把这个专栏完成。
结果这个计划没有完成,短期内不打算再重新启动。
分析原因:
我没有把很多时间和精力放在这个事情上,没有很上心。
完成这个计划需要付出很多时间和精力,而我发现平台历史上付费专栏销量都在一千多,如果费很大劲写完但最终没多少人看,其实是一件挺没意思的事,最终我选择不完成这个计划。
从去年7月份起,坚持每月写一篇高质量文章发到博客上,今年的完成情况也很好,每月一篇绝不拖欠。
这极大地锻炼了我的写作、思考与总结的能力。
因为文章质量较高,所以这一年的Star数也涨了不少,去年年终总结时Star数1460,今年截至到2020-1-9博客Star数是2538,涨了1K多一点。去年一整年也是涨了1K,增幅虽然不快,但很稳定。
分析原因:
坚持每月一篇高质量文章是非常难的事,我分析坚持下来的主要原因是李老师的强制性。因为加入了W3C,所以李老师要求每人每月要写篇文章,但我又不愿意写水文,所以就这样坚持下来了。
今年对外共参与了两次技术分享,一次是在FDCON上海分享《让你的网页更丝滑》,一次是在GMTC深圳分享《360 PC小程序底层架构的演进与探索》。
一个小故事:2018年我去FDCON听讲,当时我的感受是很多东西都听不太懂,回家后感觉自己非常菜,备受打击。没想到第二年会以讲师的身份去参会。
分析原因:
其实年初给自己定的目标是在公司内部做技术分享,因为去外面技术大会做讲师需要靠机遇,不可控,没想到能收到很多技术大会的邀请去做技术分享(包括因为时间原因被我拒绝的分享大会),其实是受到上天眷顾,才能把这个目标完成超预期完成。
这一年学完了新概念第二册(包括二册的词汇和语法),在我家楼下的新东方报了一个英语班,每到周末都去学一天。平时也会背课文,背单词。
其实准确的说,该计划无法确定是否完成。为了学习算法,这一年精读了《算法4》,但后面差了一点点没有读完,后面会把这本书读完。
如果计划是学习算法,那我完成了,如果计划是精读完《算法4》,那我没完成。
分析原因:
一开始只是觉得应该学习算法,后面才确定计划精读《算法4》,所以一开始的目标定的并不明确,但导致这本书差了一点没读完的根本原因还是我自己没有尽全力去做这件事。
本来打算今年深入研究一下Nodejs的原理和各个方面,但最终因为今年大部分时间在研究小程序,所以这个计划也没有行动。
其实准确的说,无法确定是否完成。我精读了一些规范,应该算完成,但这样的计划太容易达成。如果计划是精读N篇,那有可能我没完成。
今年买了很多书,读的也不少,但读完的却很少:《半小时漫画经济学:生活常识篇》、《半小时漫画经济学2:金融危机篇》、《这本书能让你戒烟》(读完后真的把烟戒了)。
很多没读完的书就不提了。
分析原因:
今年读完的书明显比往年少了太多,今年明显感觉到时间比往年少很多,静下来安心读书的时间更少,不知道为什么,可能是今年杂事做的比较多,后面还是要给自己做减法,时间留出来多读读书,做一些自己想完成的事。
今年一共踏足了四个国家(俄罗斯,阿拉木图,日本,**),10个城市(包括:深圳,上海,云南以及国外的城市)。
今年的首飞是在1月1日从圣彼得堡-阿拉木图,末飞是12月20日深圳-北京。
还有很多记不起来的事,如果记不起来,姑且认为是做了不重要的事情吧~
总体讲,年初为自己定的大部分计划都完成了,但也有不足之处。总结下来不足有两点:
我对自己这一年的表现评价为:中规中矩,明年要加强努力。
本文讲的内容是 vue 1.0 版本,同时为了阅读者的阅读心情,本文尽量做到不枯燥,特别适合那些想明白内部原理又讨厌看枯燥的源码的同学~
说到响应式原理其实就是双向绑定的实现,说到 双向绑定 其实有两个操作,数据变化修改dom,input等文本框修改值的时候修改数据
1. 数据变化 -> 修改dom
2. 通过表单修改value -> 修改数据
先说第一步,数据变化更改DOM的一个前提条件是能够知道数据什么时候变了,像这种需求如果不考虑兼容性的话,用屁股想都知道可以通过 getter 和 setter 来实现,每当触发 setter 的时候更新DOM
但这就引发了一个问题,我们怎么知道当 setter 触发的时候更新哪个DOM?
一个解决思路是,我们先知道哪些dom需要用到数据,当触发 setter 的时候把所有使用到该数据的dom更新
所以我们需要一个收集依赖关系的功能,每当触发 getter 的时候如果是 DOM 中触发的,我把这个 Key 和 DOM 记录起来,这样当这个 Key 触发 setter 的时候,我把这个 Key 所对应的所有 DOM都更新一遍,这样一个简单的单向绑定就实现了
下面说说第二步,其实第二步要比第一步简单的多,以input为例:
<input v-model="name" />很明显,我只需要使用 getAttribute 方法读取 v-model 拿到的值就是 Key,在通过 input.value 拿到 value,直接就可以用key和value把数据改了
一切看起来都是那么的美好...
可是...
如果像 vue 这样的一个能投入生产环境下使用,而非玩具的框架的实现要考虑的事情要比上面那个多的多,实现方式也要复杂的多。
下面看看vue的实现方式
上图是vue官方文档中的一张图片
可以看到最右侧绿色的圆代表数据,里面紫色的圆代表属性,属性被 getter 和 setter 拦截
有一条黑色虚线指向 getter,标注的英文是 Collect Dependencies,代表触发 getter 的时候收集依赖(其实就是把watcher实例推到依赖列表里)
setter 处有一条红线指向 Watcher,标注是 Notify,代表触发 setter 时,会发送消息到 Watcher
可以看到 getter 与 setter 的部分与我上面的猜测基本一致,但是多了个 Watcher 和 Directive,其实这就是我上面说到的,作为vue来讲,并不是简单的更新dom就可以了,vue中有很多指令,不同的指令有不同的更新DOM的方式而 Directive 就是用来处理这方面的事情用的
那中间那个 Watcher 是个什么鬼?
Watcher 可以先暂时理解为 房产中介 用户买房子找中介,中介帮忙找房主,房主卖房子找中介,中介帮房主把房子卖给用户。。。。。。。。。。。。。。
setter 触发消息到 Watcher watcher帮忙告诉 Directive 更新DOM,DOM中修改了数据也会通知给 Watcher,watcher 帮忙修改数据
关于Directive 和 Watcher 后面会细说
其实站在原理的角度上讲,上图中的内容是不全的,上图中是为了使用者更好的理解响应式画的图,而不是为了研究者画的图
这张图片是《Vue.js 权威指南》中源码篇的一个章节中画的图,专门画给研究者看的
可以看到 多了一个 Dep 和 Observer
下面我们就要说说 Observer、Dep、Watcher、Directive 他们之间的关系以及vue是如何通过他们实现的双向绑定
先说说 Observer
Observer,正如它的名字,Observer就是观察者模式的实现,它用来观察数据的变化,触发消息。
Observer会观察两种类型的数据,Object 与 Array
对于Array类型的数据,会先重写操作数组的原型方法,重写后能达到两个目的,
notify重写完原型方法后,遍历拿到数组中的每个数据 使用observer观察它
而对于Object类型的数据,则遍历它的每个key,使用 defineProperty 设置 getter 和 setter,当触发getter的时候,observer则开始收集依赖,而触发setter的时候,observe则触发notify。
那怎么收集的依赖呢?
这个时候 Dep 改闪亮登场了。
当数据的 getter 触发后,会收集依赖,但也不是所有的触发方式都会收集依赖,只有通过watcher 触发的 getter 会收集依赖,而所谓的被收集的依赖就是当前 watcher
这里需要特殊说一下,因为只有watcher触发的 getter 才会收集依赖,所以DOM中的数据必须通过watcher来绑定,就是说DOM中的数据必须通过watcher来读取!
Dep 提供了一些方法,我先简单帖两个
export default function Dep () {
this.id = uid++
this.subs = []
}
Dep.prototype.addSub = function (sub) {
this.subs.push(sub)
}
Dep.prototype.notify = function () {
// stablize the subscriber list first
var subs = toArray(this.subs)
for (var i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
...可以看到其实挺简单的,当通过 watcher 触发 getter时,watcher会使用 dep.addSub(this) 把自己的实例推到 subs 中
当触发setter的时候,会触发notify,而notify则会把watcher的update方法执行一遍。
到这里 observer dep watcher 已经缕清了
那么watcher的update方法是如何配合Directive改变视图的呢??
说到这里就要从编译模板的时候说起了。。。。。
看上图,我们上一节讲的是左边的那部分内容,这一节我们讲右边那部分内容
关于编译这块vue分了两种类型,一种是文本节点,一种是元素节点,如果以最简单的文本节点为例,首先需要知道什么是文本节点?
hello {{name}}这就是一个文本节点,它包含两部分,普通文本节点 hello 和一个特殊的节点{{name}}
第一步
首先第一步vue会通过正则来解析文本节点,把普通文本节点和特殊节点区分开,解析后大概长下面这样
[{
value: 'hello '
}, {
value: 'name',
tag: true,
html: false,
oneTime: false
}]第二步
第二步是遍历Array,将所有tag为true的添加扩展对象,扩展属性包括指令方法
像文本节点的特殊节点只有两种类型,text和html,所以简单判断html的值就可以知道,应该给扩展类型添加那种指令的接口
添加扩展对象后大概长成下面的样子
[{
value: 'hello '
}, {
value: 'name',
tag: true,
html: false,
oneTime: false,
descriptor: {
def: {
update: function,
bind: function
},
expression: xx,
filters: xx,
name: 'text'
}
}]可以看到vue内置了这么多的指令,这些指令都会抛出两个接口 bind 和 update,这两个接口的作用是,编译的最后一步是执行所有用到的指令的bind方法,而 update 方法则是当 watcher 触发 update 时,Directive会触发指令的update方法
observe -> 触发setter -> watcher -> 触发update -> Directive -> 触发update -> 指令
第三步
第三步是将所有 tag 为 true 的数据中的扩展对象拿出来生成一个Directive实例并添加到 _directives 中(_directives是当前vm中存储所有directive实例的地方)。
this._directives.push(
new Directive(descriptor, this, node, host, scope, frag)
)第四步
循环 _directives 执行所有 directive实例的 _bind 方法。
Directive 中 _bind 方法的作用有几点:
这里有一个点需要注意一下,实例化 Watcher 的时候,Watcher会将自己主动的推入Dep依赖中
好了,到这里整体的流程已经结束了,来一段总结吧
响应式原理共有四个部分,observe、Dep、watcher、Directive
observer可以监听数据的变化
Dep 可以知道数据变化后通知给谁
Watcher 可以做到接收到通知后将执行指令的update操作
Directive 可以把 Watcher 和 指令 连在一起
不同的指令都会有update方法来使用自己的方式更新dom
必须使用watcher触发getter,Dep才会收集依赖
执行流:
当数据触发 setter 时,会发消息给所有watcher,watcher会跟执行指令的update方法来更新视图
当指令在页面上修改了数据会触发watcher的set方法来修改数据
您的赞助是我最大的动力~
本文来自《深入浅出Vue.js》模板编译原理篇的第九章,主要讲述了如何将模板解析成AST,这一章的内容是全书最复杂且烧脑的章节。本文未经排版,真实纸质书的排版会更加精致。
通过第8章的学习,我们知道解析器在整个模板编译中的位置。我们只有将模板解析成AST后,才能基于AST做优化或者生成代码字符串,那么解析器是如何将模板解析成AST的呢?
本章中,我们将详细介绍解析器内部的运行原理。
解析器要实现的功能是将模板解析成AST。
例如:
<div>
<p>{{name}}</p>
</div>上面的代码是一个比较简单的模板,它转换成AST后的样子如下:
{
tag: "div"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: undefined,
attrsList: [],
attrsMap: {},
children: [
{
tag: "p"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: {tag: "div", ...},
attrsList: [],
attrsMap: {},
children: [{
type: 2,
text: "{{name}}",
static: false,
expression: "_s(name)"
}]
}
]
}其实AST并不是什么很神奇的东西,不要被它的名字吓倒。它只是用JS中的对象来描述一个节点,一个对象代表一个节点,对象中的属性用来保存节点所需的各种数据。比如,parent属性保存了父节点的描述对象,children属性是一个数组,里面保存了一些子节点的描述对象。再比如,type属性代表一个节点的类型等。当很多个独立的节点通过parent属性和children属性连在一起时,就变成了一个树,而这样一个用对象描述的节点树其实就是AST。
事实上,解析器内部也分了好几个子解析器,比如HTML解析器、文本解析器以及过滤器解析器,其中最主要的是HTML解析器。顾名思义,HTML解析器的作用是解析HTML,它在解析HTML的过程中会不断触发各种钩子函数。这些钩子函数包括开始标签钩子函数、结束标签钩子函数、文本钩子函数以及注释钩子函数。
伪代码如下:
parseHTML(template, {
start (tag, attrs, unary) {
// 每当解析到标签的开始位置时,触发该函数
},
end () {
// 每当解析到标签的结束位置时,触发该函数
},
chars (text) {
// 每当解析到文本时,触发该函数
},
comment (text) {
// 每当解析到注释时,触发该函数
}
})你可能不能很清晰地理解,下面我们举个简单的例子:
<div><p>我是Berwin</p></div>当上面这个模板被HTML解析器解析时,所触发的钩子函数依次是:start、start、chars、end、end。
也就是说,解析器其实是从前向后解析的。解析到<div>时,会触发一个标签开始的钩子函数start;然后解析到<p>时,又触发一次钩子函数start;接着解析到我是Berwin这行文本,此时触发了文本钩子函数chars;然后解析到</p>,触发了标签结束的钩子函数end;接着继续解析到</div>,此时又触发一次标签结束的钩子函数end,解析结束。
因此,我们可以在钩子函数中构建AST节点。在start钩子函数中构建元素类型的节点,在chars钩子函数中构建文本类型的节点,在comment钩子函数中构建注释类型的节点。
当HTML解析器不再触发钩子函数时,就代表所有模板都解析完毕,所有类型的节点都在钩子函数中构建完成,即AST构建完成。
我们发现,钩子函数start有三个参数,分别是tag、attrs和unary,它们分别代表标签名、标签的属性以及是否是自闭合标签。
而文本节点的钩子函数chars和注释节点的钩子函数comment都只有一个参数,只有text。这是因为构建元素节点时需要知道标签名、属性和自闭合标识,而构建注释节点和文本节点时只需要知道文本即可。
什么是自闭合标签?举个简单的例子,input标签就属于自闭合标签:<input type="text" />,而div标签就不属于自闭合标签:<div></div>。
在start钩子函数中,我们可以使用这三个参数来构建一个元素类型的AST节点,例如:
function createASTElement (tag, attrs, parent) {
return {
type: 1,
tag,
attrsList: attrs,
parent,
children: []
}
}
parseHTML(template, {
start (tag, attrs, unary) {
let element = createASTElement(tag, attrs, currentParent)
}
})在上面的代码中,我们在钩子函数start中构建了一个元素类型的AST节点。
如果是触发了文本的钩子函数,就使用参数中的文本构建一个文本类型的AST节点,例如:
parseHTML(template, {
chars (text) {
let element = {type: 3, text}
}
})如果是注释,就构建一个注释类型的AST节点,例如:
parseHTML(template, {
comment (text) {
let element = {type: 3, text, isComment: true}
}
})你会发现,9.1节中看到的AST是有层级关系的,一个AST节点具有父节点和子节点,但是9.2节中介绍的创建节点的方式,节点是被拉平的,没有层级关系。因此,我们需要一套逻辑来实现层级关系,让每一个AST节点都能找到它的父级。下面我们介绍一下如何构建AST层级关系。
构建AST层级关系其实非常简单,我们只需要维护一个栈(stack)即可,用栈来记录层级关系,这个层级关系也可以理解为DOM的深度。
HTML解析器在解析HTML时,是从前向后解析。每当遇到开始标签,就触发钩子函数start。每当遇到结束标签,就会触发钩子函数end。
基于HTML解析器的逻辑,我们可以在每次触发钩子函数start时,把当前构建的节点推入栈中;每当触发钩子函数end时,就从栈中弹出一个节点。
这样就可以保证每当触发钩子函数start时,栈的最后一个节点就是当前正在构建的节点的父节点,如图9-1所示。
图9-1 使用栈记录DOM层级关系(英文为代码体)
下面我们用一个具体的例子来描述如何从0到1构建一个带层级关系的AST。
假设有这样一个模板:
<div>
<h1>我是Berwin</h1>
<p>我今年23岁</p>
</div>上面这个模板被解析成AST的过程如图9-2所示。
图9-2给出了构建AST的过程,图中的黑底白数字代表解析的步骤,具体如下。
(1) 模板的开始位置是div的开始标签,于是会触发钩子函数start。start触发后,会先构建一个div节点。此时发现栈是空的,这说明div节点是根节点,因为它没有父节点。最后,将div节点推入栈中,并将模板字符串中的div开始标签从模板中截取掉。
(2) 这时模板的开始位置是一些空格,这些空格会触发文本节点的钩子函数,在钩子函数里会忽略这些空格。同时会在模板中将这些空格截取掉。
(3) 这时模板的开始位置是h1的开始标签,于是会触发钩子函数start。与前面流程一样,start触发后,会先构建一个h1节点。此时发现栈的最后一个节点是div节点,这说明h1节点的父节点是div,于是将h1添加到div的子节点中,并且将h1节点推入栈中,同时从模板中将h1的开始标签截取掉。
(4) 这时模板的开始位置是一段文本,于是会触发钩子函数chars。chars触发后,会先构建一个文本节点,此时发现栈中的最后一个节点是h1,这说明文本节点的父节点是h1,于是将文本节点添加到h1节点的子节点中。由于文本节点没有子节点,所以文本节点不会被推入栈中。最后,将文本从模板中截取掉。
(5) 这时模板的开始位置是h1结束标签,于是会触发钩子函数end。end触发后,会把栈中最后一个节点弹出来。
(6) 与第(2)步一样,这时模板的开始位置是一些空格,这些空格会触发文本节点的钩子函数,在钩子函数里会忽略这些空格。同时会在模板中将这些空格截取掉。
(7) 这时模板的开始位置是p开始标签,于是会触发钩子函数start。start触发后,会先构建一个p节点。由于第(5)步已经从栈中弹出了一个节点,所以此时栈中的最后一个节点是div,这说明p节点的父节点是div。于是将p推入div的子节点中,最后将p推入到栈中,并将p的开始标签从模板中截取掉。
(8) 这时模板的开始位置又是一段文本,于是会触发钩子函数chars。当chars触发后,会先构建一个文本节点,此时发现栈中的最后一个节点是p节点,这说明文本节点的父节点是p节点。于是将文本节点推入p节点的子节点中,并将文本从模板中截取掉。
(9) 这时模板的开始位置是p的结束标签,于是会触发钩子函数end。当end触发后,会从栈中弹出一个节点出来,也就是把p标签从栈中弹出来,并将p的结束标签从模板中截取掉。
(10) 与第(2)步和第(6)步一样,这时模板的开始位置是一些空格,这些空格会触发文本节点的钩子函数并且在钩子函数里会忽略这些空格。同时会在模板中将这些空格截取掉。
(11) 这时模板的开始位置是div的结束标签,于是会触发钩子函数end。其逻辑与之前一样,把栈中的最后一个节点弹出来,也就是把div弹了出来,并将div的结束标签从模板中截取掉。
(12)这时模板已经被截取空了,也就代表着HTML解析器已经运行完毕。这时我们会发现栈已经空了,但是我们得到了一个完整的带层级关系的AST语法树。这个AST中清晰写明了每个节点的父节点、子节点及其节点类型。
通过前面的介绍,我们发现构建AST非常依赖HTML解析器所执行的钩子函数以及钩子函数中所提供的参数,你一定会非常好奇HTML解析器是如何解析模板的,接下来我们会详细介绍HTML解析器的运行原理。
事实上,解析HTML模板的过程就是循环的过程,简单来说就是用HTML模板字符串来循环,每轮循环都从HTML模板中截取一小段字符串,然后重复以上过程,直到HTML模板被截成一个空字符串时结束循环,解析完毕,如图9-2所示。
在截取一小段字符串时,有可能截取到开始标签,也有可能截取到结束标签,又或者是文本或者注释,我们可以根据截取的字符串的类型来触发不同的钩子函数。
循环HTML模板的伪代码如下:
function parseHTML(html, options) {
while (html) {
// 截取模板字符串并触发钩子函数
}
}为了方便理解,我们手动模拟HTML解析器的解析过程。例如,下面这样一个简单的HTML模板:
<div>
<p>{{name}}</p>
</div>它在被HTML解析器解析的过程如下。
最初的HTML模板:
`<div>
<p>{{name}}</p>
</div>`第一轮循环时,截取出一段字符串<div>,并且触发钩子函数start,截取后的结果为:
`
<p>{{name}}</p>
</div>`第二轮循环时,截取出一段字符串:
`
`并且触发钩子函数chars,截取后的结果为:
`<p>{{name}}</p>
</div>`第三轮循环时,截取出一段字符串<p>,并且触发钩子函数start,截取后的结果为:
`{{name}}</p>
</div>`第四轮循环时,截取出一段字符串{{name}},并且触发钩子函数chars,截取后的结果为:
`</p>
</div>`第五轮循环时,截取出一段字符串</p>,并且触发钩子函数end,截取后的结果为:
`
</div>`第六轮循环时,截取出一段字符串:
`
`并且触发钩子函数chars,截取后的结果为:
`</div>`第七轮循环时,截取出一段字符串</div>,并且触发钩子函数end,截取后的结果为:
``解析完毕。
HTML解析器的全部逻辑都是在循环中执行,循环结束就代表解析结束。接下来,我们要讨论的重点是HTML解析器在循环中都干了些什么事。
你会发现HTML解析器可以很聪明地知道它在每一轮循环中应该截取哪些字符串,那么它是如何做到这一点的呢?
通过前面的例子,我们发现一个很有趣的事,那就是每一轮截取字符串时,都是在整个模板的开始位置截取。我们根据模板开始位置的片段类型,进行不同的截取操作。
例如,上面例子中的第一轮循环:如果是以开始标签开头的模板,就把开始标签截取掉。
再例如,上面例子中的第四轮循环:如果是以文本开始的模板,就把文本截取掉。
这些被截取的片段分很多种类型,示例如下。
<div>。</div>。<!-- 我是注释 -->。<!DOCTYPE html>。<!--[if !IE]>-->我是注释<!--<![endif]-->。我是Berwin。通常,最常见的是开始标签、结束标签、文本以及注释。
上一节中我们说过,每一轮循环都是从模板的最前面截取,所以只有模板以开始标签开头,才需要进行开始标签的截取操作。
那么,如何确定模板是不是以开始标签开头?
在HTML解析器中,想分辨出模板是否以开始标签开头并不难,我们需要先判断HTML模板是不是以<开头。
如果HTML模板的第一个字符不是<,那么它一定不是以开始标签开头的模板,所以不需要进行开始标签的截取操作。
如果HTML模板以<开头,那么说明它至少是一个以标签开头的模板,但这个标签到底是什么类型的标签,还需要进一步确认。
如果模板以<开头,那么它有可能是以开始标签开头的模板,同时它也有可能是以结束标签开头的模板,还有可能是注释等其他标签,因为这些类型的片段都以<开头。那么,要进一步确定模板是不是以开始标签开头,还需要借助正则表达式来分辨模板的开始位置是否符合开始标签的特征。
那么,如何使用正则表达式来匹配模板以开始标签开头?我们看下面的代码:
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
// 以开始标签开始的模板
'<div></div>'.match(startTagOpen) // ["<div", "div", index: 0, input: "<div></div>"]
// 以结束标签开始的模板
'</div><div>我是Berwin</div>'.match(startTagOpen) // null
// 以文本开始的模板
'我是Berwin</p>'.match(startTagOpen) // null通过上面的例子可以看到,只有'<div></div>'可以成功匹配,而以</div>开头的或者以文本开头的模板都无法成功匹配。
在9.2节中,我们介绍了当HTML解析器解析到标签开始时,会触发钩子函数start,同时会给出三个参数,分别是标签名(tagName)、属性(attrs)以及自闭合标识(unary)。
因此,在分辨出模板以开始标签开始之后,需要将标签名、属性以及自闭合标识解析出来。
在分辨模板是否以开始标签开始时,就可以得到标签名,而属性和自闭合标识则需要进一步解析。
当完成上面的解析后,我们可以得到这样一个数据结构:
const start = '<div></div>'.match(startTagOpen)
if (start) {
const match = {
tagName: start[1],
attrs: []
}
}这里有一个细节很重要:在前面的例子中,我们匹配到的开始标签并不全。例如:
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
'<div></div>'.match(startTagOpen)
// ["<div", "div", index: 0, input: "<div></div>"]
'<p></p>'.match(startTagOpen)
// ["<p", "p", index: 0, input: "<p></p>"]
'<div class="box"></div>'.match(startTagOpen)
// ["<div", "div", index: 0, input: "<div class="box"></div>"]可以看出,上面这个正则表达式虽然可以分辨出模板是否以开始标签开头,但是它的匹配规则并不是匹配整个开始标签,而是开始标签的一小部分。
事实上,开始标签被拆分成三个小部分,分别是标签名、属性和结尾,如图9-3所示。
图9-3 开始标签被拆分成三个小部分(代码用代码体)
通过“标签名”这一段字符,就可以分辨出模板是否以开始标签开头,此后要想得到属性和自闭合标识,则需要进一步解析。
在分辨模板是否以开始标签开头时,会将开始标签中的标签名这一小部分截取掉,因此在解析标签属性时,我们得到的模板是下面伪代码中的样子:
' class="box"></div>'通常,标签属性是可选的,一个标签的属性有可能存在,也有可能不存在,所以需要判断标签是否存在属性,如果存在,对它进行截取。
下面的伪代码展示了如何解析开始标签中的属性,但是它只能解析一个属性:
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
let html = ' class="box"></div>'
let attr = html.match(attribute)
html = html.substring(attr[0].length)
console.log(attr)
// [' class="box"', 'class', '=', 'box', undefined, undefined, index: 0, input: ' class="box"></div>']如果标签上有很多属性,那么上面的处理方式就不足以支撑解析任务的正常运行。例如下面的代码:
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
let html = ' class="box" id="el"></div>'
let attr = html.match(attribute)
html = html.substring(attr[0].length)
console.log(attr)
// [' class="box"', 'class', '=', 'box', undefined, undefined, index: 0, input: ' class="box" id="el"></div>']可以看到,这里只解析出了class属性,而id属性没有解析出来。
此时剩余的HTML模板是这样的:
' id="el"></div>'所以属性也可以分成多个小部分,一小部分一小部分去解析与截取。
解决这个问题时,我们只需要每解析一个属性就截取一个属性。如果截取完后,剩下的HTML模板依然符合标签属性的正则表达式,那么说明还有剩余的属性需要处理,此时就重复执行前面的流程,直到剩余的模板不存在属性,也就是剩余的模板不存在符合正则表达式所预设的规则。
例如:
const startTagClose = /^\s*(\/?)>/
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
let html = ' class="box" id="el"></div>'
let end, attr
const match = {tagName: 'div', attrs: []}
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
html = html.substring(attr[0].length)
match.attrs.push(attr)
}上面这段代码的意思是,如果剩余HTML模板不符合开始标签结尾部分的特征,并且符合标签属性的特征,那么进入到循环中进行解析与截取操作。
通过match方法解析出的结果为:
{
tagName: 'div',
attrs: [
[' class="box"', 'class', '=', 'box', null, null],
[' id="el"', 'id','=', 'el', null, null]
]
}可以看到,标签中的两个属性都已经解析好并且保存在了attrs中。
此时剩余模板是下面的样子:
"></div>"我们将属性解析后的模板与解析之前的模板进行对比:
// 解析前的模板
' class="box" id="el"></div>'
// 解析后的模板
'></div>'
// 解析前的数据
{
tagName: 'div',
attrs: []
}
// 解析后的数据
{
tagName: 'div',
attrs: [
[' class="box"', 'class', '=', 'box', null, null],
[' id="el"', 'id','=', 'el', null, null]
]
}可以看到,标签上的所有属性都已经被成功解析出来,并保存在attrs属性中。
如果我们接着上面的例子继续解析的话,目前剩余的模板是下面这样的:
'></div>'开始标签中结尾部分解析的主要目的是解析出当前这个标签是否是自闭合标签。
举个例子:
<div></div>这样的div标签就不是自闭合标签,而下面这样的input标签就属于自闭合标签:
<input type="text" />自闭合标签是没有子节点的,所以前文中我们提到构建AST层级时,需要维护一个栈,而一个节点是否需要推入到栈中,可以使用这个自闭合标识来判断。
那么,如何解析开始标签中的结尾部分呢?看下面这段代码:
function parseStartTagEnd (html) {
const startTagClose = /^\s*(\/?)>/
const end = html.match(startTagClose)
const match = {}
if (end) {
match.unarySlash = end[1]
html = html.substring(end[0].length)
return match
}
}
console.log(parseStartTagEnd('></div>')) // {unarySlash: ""}
console.log(parseStartTagEnd('/><div></div>')) // {unarySlash: "/"}这段代码可以正确解析出开始标签是否是自闭合标签。
从代码中打印出来的结果可以看到,自闭合标签解析后的unarySlash属性为/,而非自闭合标签为空字符串。
前面解析开始标签时,我们将其拆解成了三个部分,分别是标签名、属性和结尾。我相信你已经对开始标签的解析有了一个清晰的认识,接下来看一下Vue.js中真实的代码是什么样的:
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
const startTagClose = /^\s*(\/?)>/
function advance (n) {
html = html.substring(n)
}
function parseStartTag () {
// 解析标签名,判断模板是否符合开始标签的特征
const start = html.match(startTagOpen)
if (start) {
const match = {
tagName: start[1],
attrs: []
}
advance(start[0].length)
// 解析标签属性
let end, attr
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length)
match.attrs.push(attr)
}
// 判断是否是自闭合标签
if (end) {
match.unarySlash = end[1]
advance(end[0].length)
return match
}
}
}上面的代码是Vue.js中解析开始标签的源码,这段代码中的html变量是HTML模板。
调用parseStartTag就可以将剩余模板开始部分的开始标签解析出来。如果剩余HTML模板的开始部分不符合开始标签的正则表达式规则,那么调用parseStartTag就会返回undefined。因此,判断剩余模板是否符合开始标签的规则,只需要调用parseStartTag即可。如果调用它后得到了解析结果,那么说明剩余模板的开始部分符合开始标签的规则,此时将解析出来的结果取出来并调用钩子函数start即可:
// 开始标签
const startTagMatch = parseStartTag()
if (startTagMatch) {
handleStartTag(startTagMatch)
continue
}前面我们说过,所有解析操作都运行在循环中,所以continue的意思是这一轮的解析工作已经完成,可以进行下一轮解析工作。
从代码中可以看出,如果调用parseStartTag之后有返回值,那么会进行开始标签的处理,其处理逻辑主要在handleStartTag中。这个函数的主要目的就是将tagName、attrs和unary等数据取出来,然后调用钩子函数将这些数据放到参数中。
结束标签的截取要比开始标签简单得多,因为它不需要解析什么,只需要分辨出当前是否已经截取到结束标签,如果是,那么触发钩子函数就可以了。
那么,如何分辨模板已经截取到结束标签了呢?其道理其实和开始标签的截取相同。
如果HTML模板的第一个字符不是<,那么一定不是结束标签。只有HTML模板的第一个字符是<时,我们才需要进一步确认它到底是不是结束标签。
进一步确认时,我们只需要判断剩余HTML模板的开始位置是否符合正则表达式中定义的规则即可:
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const endTag = new RegExp(`^<\\/${qnameCapture}[^>]*>`)
const endTagMatch = '</div>'.match(endTag)
const endTagMatch2 = '<div>'.match(endTag)
console.log(endTagMatch) // ["</div>", "div", index: 0, input: "</div>"]
console.log(endTagMatch2) // null上面代码可以分辨出剩余模板是否是结束标签。当分辨出结束标签后,需要做两件事,一件事是截取模板,另一件事是触发钩子函数。而Vue.js中相关源码被精简后如下:
const endTagMatch = html.match(endTag)
if (endTagMatch) {
html = html.substring(endTagMatch[0].length)
options.end(endTagMatch[1])
continue
}可以看出,先对模板进行截取,然后触发钩子函数。
分辨模板是否已经截取到注释的原理与开始标签和结束标签相同,先判断剩余HTML模板的第一个字符是不是<,如果是,再用正则表达式来进一步匹配:
const comment = /^<!--/
if (comment.test(html)) {
const commentEnd = html.indexOf('-->')
if (commentEnd >= 0) {
if (options.shouldKeepComment) {
options.comment(html.substring(4, commentEnd))
}
html = html.substring(commentEnd + 3)
continue
}
}在上面的代码中,我们使用正则表达式来判断剩余的模板是否符合注释的规则,如果符合,就将这段注释文本截取出来。
这里有一个有意思的地方,那就是注释的钩子函数可以通过选项来配置,只有options.shouldKeepComment为真时,才会触发钩子函数,否则只截取模板,不触发钩子函数。
条件注释不需要触发钩子函数,我们只需要把它截取掉就行了。
截取条件注释的原理与截取注释非常相似,如果模板的第一个字符是<,并且符合我们事先用正则表达式定义好的规则,就说明需要进行条件注释的截取操作。
在下面的代码中,我们通过indexOf找到条件注释结束位置的下标,然后将结束位置前的字符都截取掉:
const conditionalComment = /^<!\[/
if (conditionalComment.test(html)) {
const conditionalEnd = html.indexOf(']>')
if (conditionalEnd >= 0) {
html = html.substring(conditionalEnd + 2)
continue
}
}我们来举个例子:
const conditionalComment = /^<!\[/
let html = '<![if !IE]><link href="non-ie.css" rel="stylesheet"><![endif]>'
if (conditionalComment.test(html)) {
const conditionalEnd = html.indexOf(']>')
if (conditionalEnd >= 0) {
html = html.substring(conditionalEnd + 2)
}
}
console.log(html) // '<link href="non-ie.css" rel="stylesheet"><![endif]>'从打印结果中可以看到,HTML中的条件注释部分截取掉了。
通过这个逻辑可以发现,在Vue.js中条件注释其实没有用,写了也会被截取掉,通俗一点说就是写了也白写。
DOCTYPEDOCTYPE与条件注释相同,都是不需要触发钩子函数的,只需要将匹配到的这一段字符截取掉即可。下面的代码将DOCTYPE这段字符匹配出来后,根据它的length属性来决定要截取多长的字符串:
const doctype = /^<!DOCTYPE [^>]+>/i
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
html = html.substring(doctypeMatch[0].length)
continue
}示例如下:
const doctype = /^<!DOCTYPE [^>]+>/i
let html = '<!DOCTYPE html><html lang="en"><head></head><body></body></html>'
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
html = html.substring(doctypeMatch[0].length)
}
console.log(html) // '<html lang="en"><head></head><body></body></html>'从打印结果可以看到,HTML中的DOCTYPE被成功截取掉了。
若想分辨在本轮循环中HTML模板是否已经截取到文本,其实很简单,我们甚至不需要使用正则表达式。
在前面的其他标签类型中,我们都会判断剩余HTML模板的第一个字符是否是<,如果是,再进一步确认到底是哪种类型。这是因为以<开头的标签类型太多了,如开始标签、结束标签和注释等。然而文本只有一种,如果HTML模板的第一个字符不是<,那么它一定是文本了。
例如:
我是文本</div>上面这段HTML模板并不是以<开头的,所以可以断定它是以文本开头的。
那么,如何从模板中将文本解析出来呢?我们只需要找到下一个<在什么位置,这之前的所有字符都属于文本,如图9-4所示。
图9-4 尖括号前面的字符都属于文本
在代码中可以这样实现:
while (html) {
let text
let textEnd = html.indexOf('<')
// 截取文本
if (textEnd >= 0) {
text = html.substring(0, textEnd)
html = html.substring(textEnd)
}
// 如果模板中找不到<,就说明整个模板都是文本
if (textEnd < 0) {
text = html
html = ''
}
// 触发钩子函数
if (options.chars && text) {
options.chars(text)
}
}上面的代码共有三部分逻辑。
第一部分是截取文本,这在前面介绍过了。<之前的所有字符都是文本,直接使用html.substring从模板的最开始位置截取到<之前的位置,就可以将文本截取出来。
第二部分是一个条件:如果在整个模板中都找不到<,那么说明整个模板全是文本。
第三部分是触发钩子函数并将截取出来的文本放到参数中。
关于文本,还有一个特殊情况需要处理:如果<是文本的一部分,该如何处理?
举个例子:
1<2</div>在上面这样的模板中,如果只截取第一个<前面的字符,最后被截取出来的将只有1,而不能把所有文本都截取出来。
那么,该如何解决这个问题呢?
有一个思路是,如果将<前面的字符截取完之后,剩余的模板不符合任何需要被解析的片段的类型,就说明这个<是文本的一部分。
什么是需要被解析的片段的类型?在9.3.1节中,我们说过HTML解析器是一段一段截取模板的,而被截取的每一段都符合某种类型,这些类型包括开始标签、结束标签和注释等。
说的再具体一点,那就是上面这段代码中的1被截取完之后,剩余模板是下面的样子:
<2</div><2符合开始标签的特征么?不符合。
<2符合结束标签的特征么?不符合。
<2符合注释的特征么?不符合。
当剩余的模板什么都不符合时,就说明<属于文本的一部分。
当判断出<是属于文本的一部分后,我们需要做的事情是找到下一个<并将其前面的文本截取出来加到前面截取了一半的文本后面。
这里还用上面的例子,第二个<之前的字符是<2,那么把<2截取出来后,追加到上一次截取出来的1的后面,此时的结果是:
1<2截取后剩余的模板是:
</div>如果剩余的模板依然不符合任何被解析的类型,那么重复此过程。直到所有文本都解析完。
说完了思路,我们看一下具体的实现,伪代码如下:
while (html) {
let text, rest, next
let textEnd = html.indexOf('<')
// 截取文本
if (textEnd >= 0) {
rest = html.slice(textEnd)
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// 如果'<'在纯文本中,将它视为纯文本对待
next = rest.indexOf('<', 1)
if (next < 0) break
textEnd += next
rest = html.slice(textEnd)
}
text = html.substring(0, textEnd)
html = html.substring(textEnd)
}
// 如果模板中找不到<,那么说明整个模板都是文本
if (textEnd < 0) {
text = html
html = ''
}
// 触发钩子函数
if (options.chars && text) {
options.chars(text)
}
}在代码中,我们通过while来解决这个问题(注意是里面的while)。如果剩余的模板不符合任何被解析的类型,那么重复解析文本,直到剩余模板符合被解析的类型为止。
在上面的代码中,endTag、startTagOpen、comment和conditionalComment都是正则表达式,分别匹配结束标签、开始标签、注释和条件注释。
在Vue.js源码中,截取文本的逻辑和其他的实现思路一致。
什么是纯文本内容元素呢?script、style和textarea这三种元素叫作纯文本内容元素。解析它们的时候,会把这三种标签内包含的所有内容都当作文本处理。那么,具体该如何处理呢?
前面介绍开始标签、结束标签、文本、注释的截取时,其实都是默认当前需要截取的元素的父级元素不是纯文本内容元素。事实上,如果要截取元素的父级元素是纯文本内容元素的话,处理逻辑将完全不一样。
事实上,在while循环中,最外层的判断条件就是父级元素是不是纯文本内容元素。例如下面的伪代码:
while (html) {
if (!lastTag || !isPlainTextElement(lastTag)) {
// 父元素为正常元素的处理逻辑
} else {
// 父元素为script、style、textarea的处理逻辑
}
}在上面的代码中,lastTag代表父元素。可以看到,在while中,首先进行判断,如果父元素不存在或者不是纯文本内容元素,那么进行正常的处理逻辑,也就是前面介绍的逻辑。
而当父元素是script这种纯文本内容元素时,会进入到else这个语句里面。由于纯文本内容元素都被视作文本处理,所以我们的处理逻辑就变得很简单,只需要把这些文本截取出来并触发钩子函数chars,然后再将结束标签截取出来并触发钩子函数end。
也就是说,如果父标签是纯文本内容元素,那么本轮循环会一次性将这个父标签给处理完毕。
伪代码如下:
while (html) {
if (!lastTag || !isPlainTextElement(lastTag)) {
// 父元素为正常元素的处理逻辑
} else {
// 父元素为script、style、textarea的处理逻辑
const stackedTag = lastTag.toLowerCase()
const reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)(</' + stackedTag + '[^>]*>)', 'i'))
const rest = html.replace(reStackedTag, function (all, text) {
if (options.chars) {
options.chars(text)
}
return ''
})
html = rest
options.end(stackedTag)
}
}上面代码中的正则表达式可以匹配结束标签前包括结束标签自身在内的所有文本。
我们可以给replace方法的第二个参数传递一个函数。在这个函数中,我们得到了参数text(代表结束标签前的所有内容),触发了钩子函数chars并把text放到钩子函数的参数中传出去。最后,返回了一个空字符串,代表将匹配到的内容都截掉了。注意,这里的截掉会将内容和结束标签一起截取掉。
最后,调用钩子函数end并将标签名放到参数中传出去,代表本轮循环中的所有逻辑都已处理完毕。
假如我们现在有这样一个模板:
<div id="el">
<script>console.log(1)</script>
</div>当解析到script中的内容时,模板是下面的样子:
console.log(1)</script>
</div>此时父元素为script,所以会进入到else中的逻辑进行处理。在其处理过程中,会触发钩子函数chars和end。
钩子函数chars的参数为script中的所有内容,本例中大概是下面的样子:
chars('console.log(1)')钩子函数end的参数为标签名,本例中是script。
处理后的剩余模板如下:
</div>通过前面几节的介绍,特别是9.3.8节中的介绍,你一定会感到很奇怪,如何知道父元素是谁?
在前面几节中,我们并没有介绍HTML解析器内部其实也有一个栈来维护DOM层级关系,其逻辑与9.2.1节相同:就是每解析到开始标签,就向栈中推进去一个;每解析到标签结束,就弹出来一个。因此,想取到父元素并不难,只需要拿到栈中的最后一项即可。
同时,HTML解析器中的栈还有另一个作用,它可以检测出HTML标签是否正确闭合。例如:
<div><p></div>在上面的代码中,p标签忘记写结束标签,那么当HTML解析器解析到div的结束标签时,栈顶的元素却是p标签。这个时候从栈顶向栈底循环找到div标签,在找到div标签之前遇到的所有其他标签都是忘记了闭合的标签,而Vue.js会在非生产环境下在控制台打印警告提示。
关于使用栈来维护DOM层级关系的具体实现思路,9.2.1节已经详细介绍过,这里不再重复介绍。
前面我们把开始标签、结束标签、注释、文本、纯文本内容元素等的截取方式拆分开,单独进行了详细介绍。本节中,我们就来介绍如何将这些解析方式组装起来完成HTML解析器的功能。
首先,HTML解析器是一个函数。就像9.2节介绍的那样,HTML解析器最终的目的是实现这样的功能:
parseHTML(template, {
start (tag, attrs, unary) {
// 每当解析到标签的开始位置时,触发该函数
},
end () {
// 每当解析到标签的结束位置时,触发该函数
},
chars (text) {
// 每当解析到文本时,触发该函数
},
comment (text) {
// 每当解析到注释时,触发该函数
}
})所以HTML解析器在实现上肯定是一个函数,它有两个参数——模板和选项:
export function parseHTML (html, options) {
// 做点什么
}我们的模板是一小段一小段去截取与解析的,所以需要一个循环来不断截取,直到全部截取完毕:
export function parseHTML (html, options) {
while (html) {
// 做点什么
}
}在循环中,首先要判断父元素是不是纯文本内容元素,因为不同类型父节点的解析方式将完全不同:
export function parseHTML (html, options) {
while (html) {
if (!lastTag || !isPlainTextElement(lastTag)) {
// 父元素为正常元素的处理逻辑
} else {
// 父元素为script、style、textarea的处理逻辑
}
}
}在上面的代码中,我们发现这里已经把整体逻辑分成了两部分,一部分是父标签是正常标签的逻辑,另一部分是父标签是script、style、textarea这种纯文本内容元素的逻辑。
如果父标签为正常的元素,那么有几种情况需要分别处理,比如需要分辨出当前要解析的一小段模板到底是什么类型。是开始标签?还是结束标签?又或者是文本?
我们把所有需要处理的情况都列出来,有下面几种情况:
DOCTYPE我们会发现,在这些需要处理的类型中,除了文本之外,其他都是以标签形式存在的,而标签是以<开头的。
所以逻辑就很清晰了,我们先根据<来判断需要解析的字符是文本还是其他的:
export function parseHTML (html, options) {
while (html) {
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf('<')
if (textEnd === 0) {
// 做点什么
}
let text, rest, next
if (textEnd >= 0) {
// 解析文本
}
if (textEnd < 0) {
text = html
html = ''
}
if (options.chars && text) {
options.chars(text)
}
} else {
// 父元素为script、style、textarea的处理逻辑
}
}
}在上面的代码中,我们可以通过<来分辨是否需要进行文本解析。关于文本解析的内容,详见9.3.7节。
如果通过<分辨出即将解析的这一小部分字符不是文本而是标签类,那么标签类有那么多类型,我们需要进一步分辨具体是哪种类型:
export function parseHTML (html, options) {
while (html) {
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf('<')
if (textEnd === 0) {
// 注释
if (comment.test(html)) {
// 注释的处理逻辑
continue
}
// 条件注释
if (conditionalComment.test(html)) {
// 条件注释的处理逻辑
continue
}
// DOCTYPE
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
// DOCTYPE的处理逻辑
continue
}
// 结束标签
const endTagMatch = html.match(endTag)
if (endTagMatch) {
// 结束标签的处理逻辑
continue
}
// 开始标签
const startTagMatch = parseStartTag()
if (startTagMatch) {
// 开始标签的处理逻辑
continue
}
}
let text, rest, next
if (textEnd >= 0) {
// 解析文本
}
if (textEnd < 0) {
text = html
html = ''
}
if (options.chars && text) {
options.chars(text)
}
} else {
// 父元素为script、style、textarea的处理逻辑
}
}
}关于不同类型的具体处理方式,前面已经详细介绍过,这里不再重复。
文本解析器的作用是解析文本。你可能会觉得很奇怪,文本不是在HTML解析器中被解析出来了么?准确地说,文本解析器是对HTML解析器解析出来的文本进行二次加工。为什么要进行二次加工?
文本其实分两种类型,一种是纯文本,另一种是带变量的文本。例如下面这样的文本是纯文本:
Hello Berwin而下面这样的是带变量的文本:
Hello {{name}}在Vue.js模板中,我们可以使用变量来填充模板。而HTML解析器在解析文本时,并不会区分文本是否是带变量的文本。如果是纯文本,不需要进行任何处理;但如果是带变量的文本,那么需要使用文本解析器进一步解析。因为带变量的文本在使用虚拟DOM进行渲染时,需要将变量替换成变量中的值。
我们在9.2节中介绍过,每当HTML解析器解析到文本时,都会触发chars函数,并且从参数中得到解析出的文本。在chars函数中,我们需要构建文本类型的AST,并将它添加到父节点的children属性中。
而在构建文本类型的AST时,纯文本和带变量的文本是不同的处理方式。如果是带变量的文本,我们需要借助文本解析器对它进行二次加工,其代码如下:
parseHTML(template, {
start (tag, attrs, unary) {
// 每当解析到标签的开始位置时,触发该函数
},
end () {
// 每当解析到标签的结束位置时,触发该函数
},
chars (text) {
text = text.trim()
if (text) {
const children = currentParent.children
let expression
if (expression = parseText(text)) {
children.push({
type: 2,
expression,
text
})
} else {
children.push({
type: 3,
text
})
}
}
},
comment (text) {
// 每当解析到注释时,触发该函数
}
})在chars函数中,如果执行parseText后有返回结果,则说明文本是带变量的文本,并且已经通过文本解析器(parseText)二次加工,此时构建一个带变量的文本类型的AST并将其添加到父节点的children属性中。否则,就直接构建一个普通的文本节点并将其添加到父节点的children属性中。而代码中的currentParent是当前节点的父节点,也就是前面介绍的栈中的最后一个节点。
假设chars函数被触发后,我们得到的text是一个带变量的文本:
"Hello {{name}}"这个带变量的文本被文本解析器解析之后,得到的expression变量是这样的:
"Hello "+_s(name)上面代码中的_s其实是下面这个toString函数的别名:
function toString (val) {
return val == null
? ''
: typeof val === 'object'
? JSON.stringify(val, null, 2)
: String(val)
}假设当前上下文中有一个变量name,其值为Berwin,那么expression中的内容被执行时,它的内容是不是就是Hello Berwin了?
我们举个例子:
var obj = {name: 'Berwin'}
with(obj) {
function toString (val) {
return val == null
? ''
: typeof val === 'object'
? JSON.stringify(val, null, 2)
: String(val)
}
console.log("Hello "+toString(name)) // "Hello Berwin"
}在上面的代码中,我们打印出来的结果是"Hello Berwin"。
事实上,最终AST会转换成代码字符串放在with中执行,这部分内容会在第11章中详细介绍。
接着,我们详细介绍如何加工文本,也就是文本解析器的内部实现原理。
在文本解析器中,第一步要做的事情就是使用正则表达式来判断文本是否是带变量的文本,也就是检查文本中是否包含{{xxx}}这样的语法。如果是纯文本,则直接返回undefined;如果是带变量的文本,再进行二次加工。所以我们的代码是这样的:
function parseText (text) {
const tagRE = /\{\{((?:.|\n)+?)\}\}/g
if (!tagRE(text)) {
return
}
}在上面的代码中,如果是纯文本,则直接返回。如果是带变量的文本,该如何处理呢?
一个解决思路是使用正则表达式匹配出文本中的变量,先把变量左边的文本添加到数组中,然后把变量改成_s(x)这样的形式也添加到数组中。如果变量后面还有变量,则重复以上动作,直到所有变量都添加到数组中。如果最后一个变量的后面有文本,就将它添加到数组中。
这时我们其实已经有一个数组,数组元素的顺序和文本的顺序是一致的,此时将这些数组元素用+连起来变成字符串,就可以得到最终想要的效果,如图9-5所示。
图9-5 文本解析过程
在图9-5中,最上面的字符串代表即将解析的文本,中间两个方块代表数组中的两个元素。最后,使用数组方法join将这两个元素合并成一个字符串。
具体实现代码如下:
function parseText (text) {
const tagRE = /\{\{((?:.|\n)+?)\}\}/g
if (!tagRE.test(text)) {
return
}
const tokens = []
let lastIndex = tagRE.lastIndex = 0
let match, index
while ((match = tagRE.exec(text))) {
index = match.index
// 先把 {{ 前边的文本添加到tokens中
if (index > lastIndex) {
tokens.push(JSON.stringify(text.slice(lastIndex, index)))
}
// 把变量改成`_s(x)`这样的形式也添加到数组中
tokens.push(`_s(${match[1].trim()})`)
// 设置lastIndex来保证下一轮循环时,正则表达式不再重复匹配已经解析过的文本
lastIndex = index + match[0].length
}
// 当所有变量都处理完毕后,如果最后一个变量右边还有文本,就将文本添加到数组中
if (lastIndex < text.length) {
tokens.push(JSON.stringify(text.slice(lastIndex)))
}
return tokens.join('+')
}这是文本解析器的全部代码,代码并不多,逻辑也不是很复杂。
这段代码有一个很关键的地方在lastIndex:每处理完一个变量后,会重新设置lastIndex的位置,这样可以保证如果后面还有其他变量,那么在下一轮循环时可以从lastIndex的位置开始向后匹配,而lastIndex之前的文本将不再被匹配。
下面用文本解析器解析不同的文本看看:
parseText('你好{{name}}')
// '"你好 "+_s(name)'
parseText('你好Berwin')
// undefined
parseText('你好{{name}}, 你今年已经{{age}}岁啦')
// '"你好"+_s(name)+", 你今年已经"+_s(age)+"岁啦"'从上面代码的打印结果可以看到,文本已经被正确解析了。
解析器的作用是通过模板得到AST(抽象语法树)。
生成AST的过程需要借助HTML解析器,当HTML解析器触发不同的钩子函数时,我们可以构建出不同的节点。
随后,我们可以通过栈来得到当前正在构建的节点的父节点,然后将构建出的节点添加到父节点的下面。
最终,当HTML解析器运行完毕后,我们就可以得到一个完整的带DOM层级关系的AST。
HTML解析器的内部原理是一小段一小段地截取模板字符串,每截取一小段字符串,就会根据截取出来的字符串类型触发不同的钩子函数,直到模板字符串截空停止运行。
文本分两种类型,不带变量的纯文本和带变量的文本,后者需要使用文本解析器进行二次加工。
更多精彩内容可以观看《深入浅出Vue.js》
本书使用最最容易理解的文笔来描述Vue.js的内部原理,对于想学习Vue.js原理的小伙伴是非常值得入手的一本书。
京东:
https://item.jd.com/12573168.html
亚马逊:
https://www.amazon.cn/gp/product/B07NKVMN1V
当当:
http://product.dangdang.com/26922892.html
扫码京东购买
2020年就这样结束了,与往年不一样,今年时间没有往年那么快。2020年是不平凡的一年,对这个世界,对我自己,都是如此。
The End Is Just The Beginning.
对我来说,今年,是我人生中的一个里程碑,也是人生中一个重要的转折点。今年正式结束了北漂生涯,也换了一份新的工作。
做这样的决策,主要是基于:
包括近些年北京出台的一些政策,都增加了外地人的生存成本,大趋势如此,对我个人来讲,强行留在北京就会活得非常扭曲。
所以几年前我就想找一个更安逸舒服且发展前景好的二线城市。杭州是首选,我从一线城市换到二线城市,年薪没降还升了,职业发展前景也变得更好了。生活上杭州压力也更小,房价更低,环境更好,车牌更容易获取。这就是我离开北京来杭州的原因。
可以毫不夸张地说,入职淘系前端(阿里巴巴淘系技术部前端团队),是我职业生涯一个很关键的转折点。
入职以来,我的成长还是挺大的。这段时间,我的全部成长要用两篇文章才能写完,上半年的成长我专门写了一篇文章:《我在阿里半年收获的成长》,下半年的成长还没来得及写,过几天补上。
成长快主要还是要感谢团队,我所在的团队是负责淘系大促会场的(双11、618等),技术上支撑双十一的技术体系有多屌就不讲了,像双11、618这种集团规模的项目,技术之外的事对一个人的要求也是变态的高。入职以来,我负责大促主会场的终端渲染架构、负责双11主会场中的业务功能、负责大促某些重要专项、项目上我担任PM,技术上我重新设计大促会场底层渲染架构、团队横向我发明了贝利体系为团队横向做出贡献的同学发贝利,等等等等,我做过太多的事,我犯过数不清的错,我惹过数不清的人,我和很多人发生过矛盾,我捅出的娄子应该是我们团队,甚至在大团队应该也算是名列前茅了。
也正是这些犯过的错,让我有更快的成长,每次犯错,我都能学到一些知识。尼采有一句话说的很好:凡是杀不死我的,必使我更强大。
但我最感谢的还是舒文,因为我学历低,所以舒文帮我找展炎向平畴申请特批,平畴同意后才发了offer,不然我可能也没法来杭州加入这个团队。舒文对我的帮助不止于此,还把我推荐到淘系前端一个神秘小组,小组里人不多(社区里你们熟知的没有一个人在里面),会给每位成员分配一名师傅每个月定期1V1沟通,主要解答一些困惑,进行一些指导,如有困难会提供一些帮助,我的师傅是今年双11前端总PM。
入职以来,我的成长,除了我自己在事上的磨练,更多的是靠我主管、舒文、我师傅的指导。而这一切的起源都是舒文给予的,我发自内心的感激。我不是打嘴炮的人,我只说一句:未来我会用结果来证明我没有辜负大家在我身上的付出。
每年我都会给自己定一些计划,2020年也不例外,每年的计划会有些差异,但有两项是我每年都会去做的:写作、读书。
年初设定的一些目标:
原计划今年至少阅读10本,实际上读了将近14本,第14本还差点没读完,完整读完的有13本。没什么特别的技巧,我只是打心里喜欢读书。很多时候晚上睡不着就看看书,结果看着看着时间就过去好久了。
这一项今年完全垮掉,全书需要学1054个单词,我背了130个,现在也都还回去了,书中的语法也没去学,关于这一项真实惭愧,我没有放弃这一项,2021年的计划里会继续完成它。
去年每月一篇,今年每两个月一篇,有一些文章只发在了公司内网。这与我在年初设定目标时预测的基本一致。
年初把写作目标定的比去年低主要考虑到时间因素。客观讲,不吹不黑,阿里巴巴确实比360忙一点,而且每次写完文章对外发布需要走一个审核流程避免出现数据安全问题。写作和发布的成本对比以往都高了一些,导致大家在我博客上看到的文章没有去年那么多,实在是抱歉。
一些其他的目标,有完成的也有没完成的,倒不用说什么,完成的只是因为我想完成,其实完成后也没什么收获,没完成的只是因为我没想完成,因为即便完成了也没什么收获。年初定了目标比如算法和做技术分享,只是觉得如果这些事不做,担心自己技术倒退,所以就定了这样一个目标。如果不忙就多做一些,如果较忙或者有其他事情就少做一些。
2020年是很魔幻的一年,今年是我工作以来,过年在家放假时间最长的一年(一个半月),或许是巧合,今年我结束了北漂生涯,这件事本身没什么,但未来我的人生轨迹,会因为这个决策,完全不同。
很多人都特别好奇我是怎么成长的,和绝大部分前端工程师一样,我是一个学历不高,没有任何背景,天花板很低的人。按理来说我走不到今天这一步,但事实又证明了我确实是顶着自己的天花板不断突破到今天,我最强的能力不是技术能力,而是突破天花板的能力,这意味着,我自己都不知道我自己未来的上限在哪,如果一定要让我说,那就四个字:星辰大海。很多人都好奇这背后是怎么回事,也有很多人私信我,一个好消息是 我已经和出版社沟通好,准备出版一本新书,大致是讲我是如何成长的,前端工程师应该如何成长,包括不限于技术成长,职业素养,做事方法等,不是鸡汤,我只是客观的把我自己的经历,和我这一路走过来的经验,我看到的、听到的、我感觉可能会对大家有帮助的东西总结起来分享给大家,感兴趣的小伙伴可以期待一下~
LCP 全称 “Largest Contentful Paint”,翻译为“最大内容绘制”,用于监控网页可视区内“绘制面积”最大的元素开始呈现在屏幕上的时间点。
度量网页 “主要内容” 何时呈现在用户眼里是一项非常具有挑战的事情。
历史上一直如此,最早期使用 load 与 DOMContentLoaded,但它俩无法度量内容何时渲染,“主要内容”何时呈现在用户眼里更无法度量,特别是单页应用流行起来之后,这两个度量标准更无参考价值。
后面使用 First Paint 与 First Contentful Paint,但它俩更多的是专注于“初始渲染”,不会考虑绘制内容的重要性。如果页面一开始显示一个小菊花(Loading Indicator),此时此刻这个被捕获的时间点所呈现给用户的内容并不是有价值的主要内容。
使用比较高级的 First Meaningful Paint 与 Speed Index 可以度量主要内容何时呈现在用户眼里,但它俩的捕获原理比较复杂,所以经常出错,FMP在最佳情况下的准确率也只有77%。
关于FMP的捕获原理可以查看文章 《捕获FMP的原理》
随着不断研究,前不久一种新的度量标准诞生了,也就是本文介绍的对象LCP。
根据W3C Web性能工作组的讨论和Google的研究,发现度量页面主要内容的可见时间有一种更精准且简单的方法是查看 “绘制面积” 最大的元素何时开始渲染。
所谓绘制面积可以理解为每个元素在屏幕上的 “占地面积”,如果元素延伸到屏幕外,或者元素被裁切了一部分,被裁切的部分不算入在内,只有真正显示在屏幕里的才算数。
图片元素的面积计算方式稍微有点不同,因为可以通过CSS将图片扩大或缩小显示,也就是说,图片有两个面积:“渲染面积”与“真实面积”。在LCP的计算中,图片的绘制面积将获取较小的数值。例如:当“渲染面积”小于“真实面积”时,“绘制面积”为“渲染面积”,反之亦然。
页面在加载过程中,是线性的,元素是一个一个渲染到屏幕上的,而不是一瞬间全渲染到屏幕上,所以“渲染面积”最大的元素随时在发生变化。如果使用 PerformanceObserver 去捕获LCP,会发现每当出现“渲染面积”更大的元素,就会捕获出一条新的性能条目。
如果元素被删除,LCP算法将不再考虑该元素,如果被删除的元素刚好是 “绘制面积” 最大的元素,则使用新的 “绘制面积” 最大的元素创建一个新的性能条目。
该过程将持续到用户第一次滚动页面或第一次用户输入(鼠标点击,键盘按键等),也就是说,一旦用户与页面开始产生交互,则停止报告新的性能条目。
所以应该仅向分析服务器发送最后捕获出的那个性能条目。
图中绿色蒙层代表“绘制面积”最大的元素,可以看出,随着页面不断加载,“绘制面积”最大的元素在不停的变化。
LCP也不是完美的,也很容易出错,它具有如下问题:
元素被删除后不能被认为是面积最大主要是解决“启动画面”问题。
使用 PerformanceObserver 捕获LCP非常简单,仅需设置entryType 为 largest-contentful-paint 即可。
const observer = new PerformanceObserver((entryList) => {
const entries = entryList.getEntries();
const lastEntry = entries[entries.length - 1];
const lcp = lastEntry.renderTime || lastEntry.loadTime;
console.log('LCP:', lcp)
});
observer.observe({entryTypes: ['largest-contentful-paint']});本文讲述了一种新的性能度量标准LCP,LCP 是一种侧重于用户体验的性能度量标准,与现有度量标准相比,更容易理解与推理。
总体来讲,今年是比较平淡的一年,一转眼已经在杭州快两年了,整体感觉还是挺满意的,今年也把自己户口落在杭州了。
今年最主要的贡献是创造了一套全新的面向C端搭建场景,支持灵活扩展、极致性能和高稳定性的终端渲染解决方案(终端渲染架构),名叫Tubes。
终端渲染架构:当用户在浏览器地址栏输入域名到看到页面,背后发生的一切。
终端渲染解决方案:产品化的终端渲染架构(包含终端的JS框架、服务端的一些能力等)。
从写下第一行代码到现在刚好一年的时间:
到目前为止,Tubes已经覆盖了淘系&非淘系,营销活动&非营销活动等各种C端搭建场景的业务与搭建平台。比如:淘系的营销活动会场(包括618 & 双11等超大型营销活动)、淘特的营销活动会场、淘系用增的非营销活动页面(新人版手淘首页多Tab)、非淘系的各个业务与各个搭建平台。
从结果来看,Tubes的发展远超预期,去年1月份开始写Tubes的第一行代码时我认为Tubes能支撑好自己的业务(全量服务2021年的双11),能提供业务隔离可扩展能力解决由中心化带来的代码耦合稳定性问题且没有引发线上Bug和故障就符合预期。
Tubes上线后没有做过分享,没有写过文章,没有进行过宣传(主要是时机没到),但仍然有许多业务和团队慕名而来,有团队希望直接接入Tubes,也有团队希望按照Tubes的设计自己再造个轮子来征询我的许可和建议,说明即便大家对Tubes不那么了解,但仍然可以看到它的价值并认为这是个可以解决自己需求的比较好的方案,这也是我一开始没有想到的。
来杭州前就计划定居在杭州,因此今年启动了筑巢计划(公积金迁移、申请人才、落户、买房摇号),公积金也迁了(北京 -> 杭州)、人才也申请了,户口也落了,就是可惜房子没摇中,来年再接再厉。虽然没摇到号,但前两天听说一个好消息,人才可以每个月申请2500的租房补贴,感谢祖国感谢杭州政府。
不管怎么说,自己也算是根正苗红的新杭州人了,开心!
这两年疫情原因出不了国,只能在国内玩,可惜疫情前办理的三年期日本签证只去了一次就快过期了。今年5月份去了一次敦煌玩,6月份去了一次三亚玩,感觉还是日本好玩,国内的话我感觉还是丽江比较舒服,去过两次仍觉得舒服~
今年系统的学习了理财相关的知识,看了很多书和课程,给自己设计了一个适合自己的 “资产配置”,并且在团队内分享了一下自己学到的关于个人理财的知识。
一个明显的感受是,之前投资主要看运气,有点赌博的意思,会涨还是跌自己也不清楚。现在根据自己的风险偏好设计出来的资产配置,我心里很清楚它的平均年化收益有多少,波动有多大。亏损的概率几乎为零,像我目前的资产配置还是比较偏稳健的,波动较小,大概率一两个月就可以扛得住最大回撤也不会亏损,时间线拉长平均收益在6%~8%左右。
实战下来,今年9月底开始使用资产配置的方式投资,10月、11月、12月这三个月都是正收益,收益率1.52%,最大回撤只有 0.53%。
今年在使用资产配置的方式投资前配了一些中概股的个股和一些主动型基金,这部分今年亏的比较严重。
总结下经验: 用资产配置的方式搭配一个适合自己的股债比例,股的部分用宽基指数基金和自己熟悉的行业指数基金,远离个股和主动型基金。
年初给自己制定了一些想完成的目标,总体上完成的还不错,年初设定的一些目标:
去年计划背诵新概念三的全部语法和单词,结果完成的不是很好,所以今年格外的重视这块,总体上完成的还不错~
学历提升考试今年完成的也挺不错的,还比计划中多考了3门课程,今年把大部分课程都考过了,目前就只剩下“学位英语”、“操作系统”这两门课程和“毕业设计论文”。争取明年把剩下的都考完,顺利毕业拿到学历和学位证~
每年都会计划读一些书,今年因为要考试,所以读的书比较少,计划读5本最终读了6本,也还不错~ 属于超预期完成!
今年读的这几本书感觉都挺好的,推荐这四本书:《架构整洁之道》、《网络是怎样链接的》、《码农翻身》、《非暴力沟通》。非暴力沟通是第二次阅读了,这确实是一本值得多次阅读的书,之前我对技术比较重视,对人情世故和沟通表达不是很重视,这也是今年的一个转变,开始重视沟通表达和为人处事。
今年文章写的比较少,没有完成目标,原本计划平均每两个月一篇,结果平均每半年一篇。这应该是自打开始写博客以来文章写的比较少的一年,明年要在写文章上多花点精力和时间。读书和写文章是我每年都会做的事,绝不能荒废~
今年对技术架构的设计又精进一层,今年系统的学习和研究了一下技术架构并付出实践。精读了《架构整洁之道》,看了些DDD架构方面的文档资料,并且将Tubes用DDD架构实践了一番。架构整洁之道里没有介绍与讲解任何架构,但是讲了一个好的架构应该是怎样的,包括依赖的方向,和一些设计原则,后来又研究了下DDD架构,发现其实DDD架构是符合书里讲的一些原则的,然后感悟好的架构**其实是共通的。具体到项目上可以根据业务特点自行调整与设计,但是架构设计的**与“道”则是共通的。
这一年成长有很多,但如果说“最大的成长”,那应该是前两个月突然感悟到的:我可能不应该再将技术能力当作自己最核心的竞争力。
对外,自己的技术水平客观上依然可以是天下无敌,但是对内,自己要明白自己最强的能力应该是“认知、格局与视野”以及“沟通能力”、“办事的能力(包括:协同推进项目顺利落地的能力)”和“会做人”。
过去我经常和人发生矛盾,这其实就是不会做人的表现,未来要着重学习和提升,来转变自己的核心竞争力。
这是态度的转变,或许也是人生的转变。
2021年总体上还是比较平淡的一年,来年再接再厉!
测量与排查网页的性能瓶颈,是一名专业Web性能优化者的基本功。本章将详细介绍Web性能领域的一些专业术语,通过这些术语也可以侧面了解是哪些因素在影响加载性能。
衡量网页的性能是一个比较琐碎的事情,因为没有某一个指标或数字可以直接告诉我们网页的性能怎样,因为加载网页不是一瞬间的事,准确地说,它是一个过程,不存在某个单独的 “时间点” 可以完全体现出网页的性能,因为在网页加载的过程中,有很多个比较关键的 “时间点” 可以影响用户的感觉(感觉我们的网页是 “快” 还是 “慢”)。而且不同类型的产品所侧重的点也都不太一样,可能同一个时间点,对于某些产品至关重要,但对于另外一些产品,则完全不care。
以https://www.google.com.hk为例,下图是使用Lighthouse(一个性能测评工具)捕获出的测评结果报告。
下图是使用Chrome浏览器的DevTools捕获出的加载性能结果报告。
从上面这两张性能测评报告中,我们会发现报告通常会给出很多个 “关键时间点” 来表示性能数据,单独的某个“时间点”无法体现出网页的性能,只有将它们与自身的产品类型相结合,综合评估,才能判断出网页的性能到底怎样。而我们要做的,就是读懂报告中的各种专业术语,并分辨出哪些因素影响了网页的加载性能。
从前面的评测报告中,我们会看到FP、FCP、FMP与LCP这几个字母很接近的术语,实际上他们的意思也非常接近,都表示浏览器在屏幕上渲染像素的时间点。F是First的首字母缩写,表示“第一次”;P是Paint的首字母缩写,表示“绘制”;C是Contentful的首字母缩写,表示“内容”。
FP(全称“First Paint”,翻译为“首次绘制”) 是时间线上的第一个“时间点”,它代表浏览器第一次向屏幕传输像素的时间,也就是页面在屏幕上首次发生视觉变化的时间。
注意:FP不包含默认背景绘制,但包含非默认的背景绘制。
FCP(全称“First Contentful Paint”,翻译为“首次内容绘制”),顾名思义,它代表浏览器第一次向屏幕绘制 “内容”。
注意:只有首次绘制文本、图片(包含背景图)、非白色的
canvas或SVG时才被算作FCP。
FP与FCP这两个指标之间的主要区别是:FP是当浏览器开始绘制内容到屏幕上的时候,只要在视觉上开始发生变化,无论是什么内容触发的视觉变化,在这一刻,这个时间点,叫做FP。
相比之下,FCP指的是浏览器首次绘制来自DOM的内容。例如:文本,图片,SVG,canvas元素等,这个时间点叫FCP。
FP和FCP可能是相同的时间,也可能是先FP后FCP。
FMP(全称“First Meaningful Paint”,翻译为“首次有效绘制”) 表示页面的“主要内容”开始出现在屏幕上的时间点。它是我们测量用户加载体验的主要指标。
FMP本质上是通过一个算法来猜测某个时间点可能是FMP,所以有时候不准。
想详细了解FMP及它的原理可以看我的另一篇文章:《捕获FMP的原理》
图3给出了FP、FCP、FMP之间的比较。
LCP(全称“Largest Contentful Paint”) 表示可视区“内容”最大的可见元素开始出现在屏幕上的时间点。
了解和测量网站真实的性能其实非常困难,像load和DOMContentLoaded不会告诉我们用户什么时候可以在屏幕上看到内容。而FP和FCP又只能捕获整个渲染过程的最开始,FMP更好一点,但是它的算法比较复杂,而且前面说了,有时候不准。
根据W3C Web性能工作组的讨论和Google的研究,发现测量页面主要内容的可见时间有一种更精准且简单的方法是查看什么时候渲染最大元素。
以上图为例,绿色方块的区域是内容最大的元素,所以在这个例子中,LCP等于这个元素开始渲染的时间。
现在我们了解了FP、FCP、FMP以及LCP这几个术语,FP与FCP可以让我们知道,我们的产品何时开始渲染;而FMP与LCP可以让我们了解我们的产品何时“有用”,站在用户的角度,FMP与LCP可以表示我们的产品需要多久才能体现出价值。
注意,这里说的是“有用”,而不是“能用”;那我们如何才能知道我们的产品什么时候“能用”呢?这就需要另一个性能指标“TTI”了。
TTI(全称“Time to Interactive”,翻译为“可交互时间”) 表示网页第一次 完全达到可交互状态 的时间点。可交互状态指的是页面上的UI组件是可以交互的(可以响应按钮的点击或在文本框输入文字等),不仅如此,此时主线程已经达到“流畅”的程度,主线程的任务均不超过50毫秒。TTI很重要,因为TTI可以让我们了解我们的产品需要多久可以真正达到“可用”的状态。
关于50毫秒的问题我之前的博客文章有多次提到,可以参考这篇文章《时间切片(Time Slicing)》
TTFB(全称“Time to First Byte”) 表示浏览器接收第一个字节的时间
FCI(全称“First CPU Idle”) 是对TTI的一种补充,TTI可以告诉我们页面什么时候完全达到可用,但是我们不知道浏览器第一次可以响应用户输入是什么时候。我们不知道网页的“最小可交互时间”是多少,最小可交互时间是说网页的首屏已经达到了可交互的状态了,但整个页面可能还没达到。从名字也可以看出这个指标的意思,第一次CPU空闲,主线程空闲就代表可以接收用户的响应了。
更通俗的理解TTI与FCI的区别:FCI代表浏览器真正的第一次可以响应用户的输入,而TTI代表浏览器已经可以持续性的响应用户的输入。
FID(全称“First Input Delay”,翻译为“首次输入延迟”) 顾名思义,FID指的是用户首次与产品进行交互时,我们产品可以在多长时间给出反馈。TTI可以告诉我们网页什么时候可以开始流畅地响应用户的交互,但是如果用户在TTI的时间内,没有与网页产生交互,那么TTI其实是影响不到用户的,TTI是不需要用户参与的指标,但如果我们真的想知道TTI对用户的影响,我们需要FID。不同的用户可能会在TTI之前开始与网页产生交互,也可能在TTI之后才与网页产生交互。所以对于不同的用户它的FID是不同的。如果在TTI之前用户就已经与网页产生了交互,那么它的FID时间就比较长,而如果在TTI之后才第一次与网页产生交互,那么他的FID时间就短。
捕获FID比较简单,我们只需要在网页的head标签里注册一个事件(click、mousedown、keydown、touchstart、pointerdown),然后在事件响应函数中使用当前时间减去事件对象被创建的时间即可。
performance.now() - event.timeStampDCL 表示DomContentloaded事件触发的时间。
L 表示onLoad事件触发的时间。
DomContentloaded事件与onLoad事件的区别是,浏览器解析HTML这个操作完成后立刻触发DomContentloaded事件,而只有页面所有资源都加载完毕后(比如图片,CSS),才会触发onLoad事件。
Speed Index 表示显示页面可见部分的平均时间(注意,是真正的可见,用户可以立马看见的,屏幕外的部分不算),数值越小说明速度越快,它主要用于测量页面内容在视觉上填充的速度。通常会使用这个指标来进行性能的比较。比如优化前和优化后,我们的产品与竞品的性能比较等。但是只能用于 粗略 的比较,不同的产品侧重点完全不同,所以还是需要根据自己产品所侧重的方向,并结合其他指标来进行更详细的对比。
博客文章这样的页面更侧重FMP(用户希望尽快看到有价值的内容),而类似后台管理系统或在线PPT这种产品则更侧重TTI(用户希望尽快与产品进行交互)。
本章我们介绍了Web性能领域常见的专业术语,包括:FP、FCP、FMP、TTI、LCP、TTFB、FCI、FID、DCL、L、Speed Index。这些术语可以帮助我们理解性能报告给出的各种数据。
关于vue的内部原理其实有很多个重要的部分,变化侦测,模板编译,virtualDOM,整体运行流程等。
之前写过一篇《深入浅出 - vue变化侦测原理》 讲了关于变化侦测的实现原理。
那今天主要把 模板编译 这部分的实现原理单独拿出来讲一讲。
本文我可能不会在文章中说太多细节部分的处理,我会把 vue 对模板编译这部分的整体原理讲清楚,主要是让读者读完文章后对模板编译的整体实现原理有一个清晰的思路和理解。
关于 Vue 编译原理这块的整体逻辑主要分三个部分,也可以说是分三步,这三个部分是有前后关系的:
模板字符串 转换成 element ASTs(解析器)AST 进行静态节点标记,主要用来做虚拟DOM的渲染优化(优化器)element ASTs 生成 render 函数代码字符串(代码生成器)解析器主要干的事是将 模板字符串 转换成 element ASTs,例如:
<div>
<p>{{name}}</p>
</div>上面这样一个简单的 模板 转换成 element AST 后是这样的:
{
tag: "div"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: undefined,
attrsList: [],
attrsMap: {},
children: [
{
tag: "p"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: {tag: "div", ...},
attrsList: [],
attrsMap: {},
children: [{
type: 2,
text: "{{name}}",
static: false,
expression: "_s(name)"
}]
}
]
}我们先用这个简单的例子来说明这个解析器的内部究竟发生了什么。
这段模板字符串会扔到 while 中去循环,然后 一段一段 的截取,把截取到的 每一小段字符串 进行解析,直到最后截没了,也就解析完了。
上面这个简单的模板截取的过程是这样的:
<div>
<p>{{name}}</p>
</div> <p>{{name}}</p>
</div><p>{{name}}</p>
</div>{{name}}</p>
</div></p>
</div></div></div>那是根据什么截的呢?换句话说截取字符串有什么规则么?
当然有
只要判断模板字符串是不是以 < 开头我们就可以知道我们接下来要截取的这一小段字符串是 标签 还是 文本。
举个🌰:
<div></div> 这样的一段字符串是以 < 开头的,那么我们通过正则把 <div> 这一部分 match 出来,就可以拿到这样的数据:
{
tagName: 'div',
attrs: [],
unarySlash: '',
start: 0,
end: 5
}好奇如何用正则解析出 tagName 和 attrs 等信息的同学可以看下面这个demo代码:
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
const startTagClose = /^\s*(\/?)>/
let html = `<div></div>`
let index = 0
const start = html.match(startTagOpen)
const match = {
tagName: start[1],
attrs: [],
start: 0
}
html = html.substring(start[0].length)
index += start[0].length
let end, attr
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
html = html.substring(attr[0].length)
index += attr[0].length
match.attrs.push(attr)
}
if (end) {
match.unarySlash = end[1]
html = html.substring(end[0].length)
index += end[0].length
match.end = index
}
console.log(match)用正则把 开始标签 中包含的数据(attrs, tagName 等)解析出来之后还要做一个很重要的事,就是要维护一个 stack。
那这个 stack 是用来干什么的呢?
这个 stack 是用来记录一个层级关系的,用来记录DOM的深度。
更准确的说,当解析到一个 开始标签 或者 文本,无论是什么, stack 中的最后一项,永远是当前正在被解析的节点的 parentNode 父节点。
通过 stack 解析器就可以把当前解析到的节点 push 到 父节点的 children 中。
也可以把当前正在解析的节点的 parent 属性设置为 父节点。
事实上也确实是这么做的。
但并不是只要解析到一个标签的开始部分就把当前标签 push 到 stack 中。
因为在 HTML 中有一种 自闭合标签,比如 input。
<input /> 这种 自闭合的标签 是不需要 push 到 stack 中的,因为 input 并不存在子节点。
所以当解析到一个标签的开始时,要判断当前被解析的标签是否是自闭合标签,如果不是自闭合标签才 push 到 stack 中。
if (!unary) {
currentParent = element
stack.push(element)
}现在有了 DOM 的层级关系,也可以解析出DOM的 开始标签,这样每解析一个 开始标签 就生成一个 ASTElement (存储当前标签的attrs,tagName 等信息的object)
并且把当前的 ASTElement push 到 parentNode 的 children 中,同时给当前 ASTElement 的 parent 属性设置为 stack 中的最后一项
currentParent.children.push(element)
element.parent = currentParent< 开头的几种情况但并不是所有以 < 开头的字符串都是 开始标签,以 < 开头的字符串有以下几种情况:
<div></div><!-- 我是注释 --><!DOCTYPE html>当然我们解析器在解析的过程中遇到的最多的是 开始标签 结束标签 和 注释
我们继续上面的例子解析,div 的 开始标签 解析之后剩余的模板字符串是下面的样子:
<p>{{name}}</p>
</div>这一次我们在解析发现 模板字符串 不是以 < 开头了。
那么如果模板字符串不是以 < 开头的怎么处理呢??
其实如果字符串不是以 < 开头可能会出现这么几种情况:
我是text <div></div>或者:
我是text </p>不论是哪种情况都会将标签前面的文本部分解析出来,截取这段文本其实并不难,看下面的例子:
// 可以直接将本 demo 放到浏览器 console 中去执行
const html = '我是text </p>'
let textEnd = html.indexOf('<')
const text = html.substring(0, textEnd)
console.log(text)当然 vue 对文本的截取不只是这么简单,vue对文本的截取做了很安全的处理,如果 < 是文本的一部分,那上面 DEMO 中截取的内容就不是我们想要的,例如这样的:
a < b </p>如果是这样的文本,上面的 demo 肯定就挂了,截取出的文本就会遗漏一部分,而 vue 对这部分是进行了处理的,看下面的代码:
let textEnd = html.indexOf('<')
let text, rest, next
if (textEnd >= 0) {
rest = html.slice(textEnd)
// 剩余部分的 HTML 不符合标签的格式那肯定就是文本
// 并且还是以 < 开头的文本
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as text
next = rest.indexOf('<', 1)
if (next < 0) break
textEnd += next
rest = html.slice(textEnd)
}
text = html.substring(0, textEnd)
html = html.substring(0, textEnd)
}这段代码的逻辑是如果文本截取完之后,剩余的 模板字符串 开头不符合标签的格式规则,那么肯定就是有没截取完的文本
这个时候只需要循环把 textEnd 累加,直到剩余的 模板字符串 符合标签的规则之后在一次性把 text 从 模板字符串 中截取出来就好了。
继续上面的例子,当前剩余的 模板字符串 是这个样子的:
<p>{{name}}</p>
</div>截取之后剩余的 模板字符串 是这个样子的:
<p>{{name}}</p>
</div>被截取出来的文本是这样的:
"\n "截取之后就需要对文本进行解析,不过在解析文本之前需要进行预处理,也就是先简单加工一下文本,vue 是这样做的:
const children = currentParent.children
text = inPre || text.trim()
? isTextTag(currentParent) ? text : decodeHTMLCached(text)
// only preserve whitespace if its not right after a starting tag
: preserveWhitespace && children.length ? ' ' : ''这段代码的意思是:
decode 一下编码,使用github上的 he 这个类库的 decodeHTML 方法parent.children.length 是不是为 0
' '''结果发现这一次的 text 正好命中最后的那个 '',所以这一次就什么都不用做继续下一轮解析就好
继续上面的例子,现在的 模板字符串 变是这个样子:
<p>{{name}}</p>
</div>接着解析 <p>,解析流程和上面的 <div> 一样就不说了,直接继续:
{{name}}</p>
</div>通过上面写的文本的截取方式这一次截取出来的文本是这个样子的 "{{name}}"
其实解析文本节点并不难,只需要将文本节点 push 到 currentParent.children.push(ast) 就行了。
但是带变量的文本和不带变量的纯文本是不同的处理方式。
带变量的文本是指 Hello {{ name }} 这个 name 就是变量。
不带变量的文本是这样的 Hello Berwin 这种没有访问数据的纯文本。
纯文本比较简单,直接将 文本节点的ast push 到 parent 节点的 children 中就行了,例如:
children.push({
type: 3,
text: '我是纯文本'
})而带变量的文本要多一个解析文本变量的操作:
const expression = parseText(text, delimiters) // 对变量解析 {{name}} => _s(name)
children.push({
type: 2,
expression,
text
})上面例子中 "{{name}}" 是一个带变量的文本,经过 parseText 解析后 expression 是 _s(name),所以最后 push 到 currentParent.children 中的节点是这个样子的:
{
expression: "_s(name)",
text: "{{name}}",
type: 2
}现在文本解析完之后,剩余的 模板字符串 变成了这个样子:
</p>
</div>这一次还是用上面说的办法,html.indexOf('<') === 0,发现是 < 开头的,然后用正则去 match 发现符合 结束标签的格式,把它截取出来。
并且还要做一个处理是用当前标签名在 stack 从后往前找,将找到的 stack 中的位置往后的所有标签全部删除(意思是,已经解析到当前的结束标签,那么它的子集肯定都是解析过的,试想一下当前标签都关闭了,它的子集肯定也都关闭了,所以需要把当前标签位置往后从 stack中都清掉)
结束标签不需要解析,只需要将 stack 中的当前标签删掉就好。
虽然不用解析,但 vue 还是做了一个优化处理,children 中的最后一项如果是空格 " ",则删除最后这一项:
if (lastNode && lastNode.type === 3 && lastNode.text === ' ' && !inPre) {
element.children.pop()
}因为最后这一项空格是没有用的,举个例子:
<ul>
<li></li>
</ul>上面例子中解析成 element ASTs之后 ul 的结束标签 </ul> 和 li 的结束标签 </li> 之间有一个空格,这个空格也属于文本节点在 ul 的 children 中,这个空格是没有用的,把这个空格删掉每次渲染dom都会少渲染一个文本节点,可以节省一定的性能开销。
现在剩余的 模板字符串 已经不多了,是下面的样子:
</div>然后解析文本,就是一个其实就是一个空格的文本节点。
然后再一次解析结束标签 </div>
</div>解析完毕退出 while 循环。
解析完之后拿到的 element ASTs 就是文章开头写的那样。
总结一下
其实这样一个模板解析器的原理不是特别难,主要就是两部分内容,一部分是 截取 字符串,一部分是对截取之后的字符串做 解析
每截取一段标签的开头就 push 到 stack中,解析到标签的结束就 pop 出来,当所有的字符串都截没了也就解析完了。
上文中的例子是比较简单的,不涉及一些循环啊,什么的,注释的处理这些也都没有涉及到,但其实这篇文章中想表达的内容也不是来扣细节的,如果扣细节可能要写一本小书才够,一篇文章的字数可能只够把一个大体的逻辑给大家讲清楚,希望同学们见谅,如果对细节感兴趣可以在下面评论,咱们一起讨论共同学习进步~
优化器的目标是找出那些静态节点并打上标记,而静态节点指的是 DOM 不需要发生变化的节点,例如:
<p>我是静态节点,我不需要发生变化</p>标记静态节点有两个好处:
优化器的实现原理主要分两步:
static 属性,标识是不是静态节点什么是静态根节点? 答:子节点全是静态节点的节点就是静态根节点,例如:
<ul>
<li>我是静态节点,我不需要发生变化</li>
<li>我是静态节点2,我不需要发生变化</li>
<li>我是静态节点3,我不需要发生变化</li>
</ul>ul 就是静态根节点。
static 属性?vue 判断一个节点是不是静态节点的做法其实并不难:
node.static = isStatic(node)children,如果 children 中出现了哪怕一个节点不是静态节点,在将当前节点的标记修改成 false: node.static = false。也就是说 isStatic 这个函数是如何判断静态节点的?
function isStatic (node: ASTNode): boolean {
if (node.type === 2) { // expression
return false
}
if (node.type === 3) { // text
return true
}
return !!(node.pre || (
!node.hasBindings && // no dynamic bindings
!node.if && !node.for && // not v-if or v-for or v-else
!isBuiltInTag(node.tag) && // not a built-in
isPlatformReservedTag(node.tag) && // not a component
!isDirectChildOfTemplateFor(node) &&
Object.keys(node).every(isStaticKey)
))
}先解释一下,在上文讲的解析器中将 模板字符串 解析成 AST 的时候,会根据不同的文本类型设置一个 type:
| type | 说明 |
|---|---|
| 1 | 元素节点 |
| 2 | 带变量的动态文本节点 |
| 3 | 不带变量的纯文本节点 |
所以上面 isStatic 中的逻辑很明显,如果 type === 2 那肯定不是 静态节点 返回 false,如果 type === 3 那就是静态节点,返回 true。
那如果 type === 1,就有点复杂了,元素节点判断是不是静态节点的条件很多,咱们先一个个看。
首先如果 node.pre 为 true 直接认为当前节点是静态节点,关于 node.pre 是什么 请狠狠的点击我。
其次 node.hasBindings 不能为 true。
node.hasBindings 属性是在解析器转换 AST 时设置的,如果当前节点的 attrs 中,有 v-、@、:开头的 attr,就会把 node.hasBindings 设置为 true。
const dirRE = /^v-|^@|^:/
if (dirRE.test(attr)) {
// mark element as dynamic
el.hasBindings = true
}并且元素节点不能有 if 和 for属性。
node.if 和 node.for 也是在解析器转换 AST 时设置的。
在解析的时候发现节点使用了 v-if,就会在解析的时候给当前节点设置一个 if 属性。
就是说元素节点不能使用 v-if v-for v-else 等指令。
并且元素节点不能是 slot 和 component。
并且元素节点不能是组件。
例如:
<List></List>不能是上面这样的自定义组件
并且元素节点的父级节点不能是带 v-for 的 template,查看详情 请狠狠的点击我。
并且元素节点上不能出现额外的属性。
额外的属性指的是不能出现 type
tag attrsList attrsMap plain parent children attrs staticClass staticStyle 这几个属性之外的其他属性,如果出现其他属性则认为当前节点不是静态节点。
只有符合上面所有条件的节点才会被认为是静态节点。
上面讲如何判断单个节点是否是静态节点,AST 是一棵树,我们如何把所有的节点都打上标记(static)呢?
还有一个问题是,判断 元素节点是不是静态节点不能光看它自身是不是静态节点,如果它的子节点不是静态节点,那就算它自身符合上面讲的静态节点的条件,它也不是静态节点。
所以在 vue 中有这样一行代码:
for (let i = 0, l = node.children.length; i < l; i++) {
const child = node.children[i]
markStatic(child)
if (!child.static) {
node.static = false
}
}markStatic 可以给节点标记,规则上面刚讲过,vue.js 通过循环 children 打标记,然后每个不同的子节点又会走相同的逻辑去循环它的 children 这样递归下来所有的节点都会被打上标记。
然后在循环中判断,如果某个子节点不是 静态节点,那么讲当前节点的标记改为 false。
这样一圈下来之后 AST 上的所有节点都被准确的打上了标记。
标记静态根节点其实也是递归的过程。
vue 中的实现大概是这样的:
function markStaticRoots (node: ASTNode, isInFor: boolean) {
if (node.type === 1) {
// For a node to qualify as a static root, it should have children that
// are not just static text. Otherwise the cost of hoisting out will
// outweigh the benefits and it's better off to just always render it fresh.
if (node.static && node.children.length && !(
node.children.length === 1 &&
node.children[0].type === 3
)) {
node.staticRoot = true
return
} else {
node.staticRoot = false
}
if (node.children) {
for (let i = 0, l = node.children.length; i < l; i++) {
markStaticRoots(node.children[i], isInFor || !!node.for)
}
}
}
}这段代码其实就一个意思:
当前节点是静态节点,并且有子节点,并且子节点不是单个静态文本节点这种情况会将当前节点标记为根静态节点。
额,,可能有点绕口,重新解释下。
上面我们标记 静态节点 的时候有一段逻辑是只有所有 子节点 都是 静态节点,当前节点才是真正的 静态节点。
所以这里我们如果发现一个节点是 静态节点,那就能证明它的所有 子节点 也都是静态节点,而我们要标记的是 静态根节点,所以如果一个静态节点只包含了一个文本节点那就不会被标记为 静态根节点。
其实这么做也是为了性能考虑,vue 在注释中也说了,如果把一个只包含静态文本的节点标记为根节点,那么它的成本会超过收益~
总结一下
整体逻辑其实就是递归 AST 这颗树,然后将 静态节点 和 静态根节点 找到并打上标记。
代码生成器的作用是使用 element ASTs 生成 render 函数代码字符串。
使用本文开头举的例子中的模板生成后的 AST 来生成 render 后是这样的:
{
render: `with(this){return _c('div',[_c('p',[_v(_s(name))])])}`
}格式化后是这样的:
with(this){
return _c(
'div',
[
_c(
'p',
[
_v(_s(name))
]
)
]
)
}生成后的代码字符串中看到了有几个函数调用 _c,_v,_s。
_c 对应的是 createElement,它的作用是创建一个元素。
children例如:
一个简单的模板:
<p title="Berwin" @click="c">1</p>生成后的代码字符串是:
`with(this){return _c('p',{attrs:{"title":"Berwin"},on:{"click":c}},[_v("1")])}`格式化后:
with(this){
return _c(
'p',
{
attrs:{"title":"Berwin"},
on:{"click":c}
},
[_v("1")]
)
}关于 createElement 想了解更多请狠狠的点击我。
_v 的意思是创建一个文本节点。
_s 是返回参数中的字符串。
代码生成器的总体逻辑其实就是使用 element ASTs 去递归,然后拼出这样的 _c('div',[_c('p',[_v(_s(name))])]) 字符串。
那如何拼这个字符串呢??
请看下面的代码:
function genElement (el: ASTElement, state: CodegenState) {
const data = el.plain ? undefined : genData(el, state)
const children = el.inlineTemplate ? null : genChildren(el, state, true)
let code = `_c('${el.tag}'${
data ? `,${data}` : '' // data
}${
children ? `,${children}` : '' // children
})`
return code
}因为 _c 的参数需要 tagName、data 和 children。
所以上面这段代码的主要逻辑就是用 genData 和 genChildren 获取 data 和 children,然后拼到 _c 中去,拼完后把拼好的 "_c(tagName, data, children)" 返回。
所以我们现在比较关心的两个问题:
我们先看 genData 是怎样的实现逻辑:
function genData (el: ASTElement, state: CodegenState): string {
let data = '{'
// key
if (el.key) {
data += `key:${el.key},`
}
// ref
if (el.ref) {
data += `ref:${el.ref},`
}
if (el.refInFor) {
data += `refInFor:true,`
}
// pre
if (el.pre) {
data += `pre:true,`
}
// ... 类似的还有很多种情况
data = data.replace(/,$/, '') + '}'
return data
}可以看到,就是根据 AST 上当前节点上都有什么属性,然后针对不同的属性做一些不同的处理,最后拼出一个字符串~
然后我们在看看 genChildren 是怎样的实现的:
function genChildren (
el: ASTElement,
state: CodegenState
): string | void {
const children = el.children
if (children.length) {
return `[${children.map(c => genNode(c, state)).join(',')}]`
}
}
function genNode (node: ASTNode, state: CodegenState): string {
if (node.type === 1) {
return genElement(node, state)
} if (node.type === 3 && node.isComment) {
return genComment(node)
} else {
return genText(node)
}
}从上面代码中可以看出,生成 children 的过程其实就是循环 AST 中当前节点的 children,然后把每一项在重新按不同的节点类型去执行 genElement genComment genText。如果 genElement 中又有 children 在循环生成,如此反复递归,最后一圈跑完之后能拿到一个完整的 render 函数代码字符串,就是类似下面这个样子。
"_c('div',[_c('p',[_v(_s(name))])])"最后把生成的 code 装到 with 里。
export function generate (
ast: ASTElement | void,
options: CompilerOptions
): CodegenResult {
const state = new CodegenState(options)
// 如果ast为空,则创建一个空div
const code = ast ? genElement(ast, state) : '_c("div")'
return {
render: `with(this){return ${code}}`
}
}关于代码生成器的部分到这里就说完了,其实源码中远不止这么简单,很多细节我都没有去说,我只说了一个大体的流程,对具体细节感兴趣的同学可以自己去看源码了解详情。
本篇文章我们说了 vue 对模板编译的整体流程分为三个部分:解析器(parser),优化器(optimizer)和代码生成器(code generator)。
解析器(parser)的作用是将 模板字符串 转换成 element ASTs。
优化器(optimizer)的作用是找出那些静态节点和静态根节点并打上标记。
代码生成器(code generator)的作用是使用 element ASTs 生成 render函数代码(generate render function code from element ASTs)。
用一张图来表示:
解析器(parser)的原理是一小段一小段的去截取字符串,然后维护一个 stack 用来保存DOM深度,每截取到一段标签的开始就 push 到 stack 中,当所有字符串都截取完之后也就解析出了一个完整的 AST。
优化器(optimizer)的原理是用递归的方式将所有节点打标记,表示是否是一个 静态节点,然后再次递归一遍把 静态根节点 也标记出来。
代码生成器(code generator)的原理也是通过递归去拼一个函数执行代码的字符串,递归的过程根据不同的节点类型调用不同的生成方法,如果发现是一颗元素节点就拼一个 _c(tagName, data, children) 的函数调用字符串,然后 data 和 children 也是使用 AST 中的属性去拼字符串。
如果 children 中还有 children 则递归去拼。
最后拼出一个完整的 render 函数代码。

之前的老文章,换了个地方写博客,,所以得重新发布下~~
async是Nodejs中非常常用的一个工具模块,其中方法有很多,主要分3大类(集合,流程控制,工具),下面就简单说说 流程控制 的一些常用方法
它的作用就是按照顺序依次执行。
async.series({
one: function(callback){
callback(null, 1);
},
two: function(callback){
callback(null, 2);
}
},function(err, results) {
console.log(results);
});输出 { one: 1, two: 2 }
async.series([
function(callback){
callback(null, 1);
},
function(callback){
callback(null, 2);
}
],function(err, results) {
console.log(results);
});输出 [ 1, 2 ]
上面写出两个,是因为series方法的第一个参数可以是一个数组也可以是一个对象,参数类型不同,callback 参数返回的值也不同。
waterfall和series函数有很多相似之处,都是按照顺序执行。
不同之处是waterfall每个函数产生的值,都将传给下一个函数,而series则没有这个功能,示例如下:
async.waterfall([
function(callback){
callback(null, 'one', 'two');
},
function(arg1, arg2, callback){
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
},
function(arg1, callback){
// arg1 now equals 'three'
callback(null, 'done');
}
], function (err, result) {
// result now equals 'done'
console.log(result);
});另外需要注意的是 waterfall 的 tasks 参数只能是 数组 类型。
parallel函数是并行执行多个函数,每个函数都是立即执行,不需要等待其它函数先执行。
传给最终callback的数组中的数据按照tasks中声明的顺序,而不是执行完成的顺序,示例如下:
async.parallel([
function(callback){
callback(null, 'one');
},
function(callback){
callback(null, 'two');
}
],function(err, results){
console.log(results); // [ 'one', 'two' ]
});和series函数一样,tasks参数可以是一个 数组 或 对象,tasks参数类型不同,返回的results格式也会不一样。
parallelLimit函数和parallel类似,但是它多了一个参数limit。
limit参数限制任务只能同时并发一定数量,而不是无限制并发,示例如下:
async.parallelLimit([
function(callback){
callback(null, 'one');
},
function(callback){
callback(null, 'two');
}
],2,function(err, results){
console.log(results); // [ 'one', 'two' ]
});以上是一些我个人比较常用的方法,还有一些其他不怎么常用的方法,建议去github看更多详细信息,不过是英文的哦~
上周我在FDConf的分享《让你的网页更丝滑》中提到了“时间切片”,由于时间关系当时并没有对时间切片展开更细致的讨论。所以回来后就想着补一篇文章针对“时间切片”展开详细的讨论。
从用户的输入,再到显示器在视觉上给用户的输出,这一过程如果超过100ms,那么用户会察觉到网页的卡顿,所以为了解决这个问题,每个任务不能超过50ms,W3C性能工作组在LongTask规范中也将超过50ms的任务定义为长任务。
关于这50毫秒我在FDConf的分享中进行了很详细的讲解,没有听到的小伙伴也不用着急,后续我会针对这次分享的内容补一篇文章。
所以为了避免长任务,一种方案是使用Web Worker,将长任务放在Worker线程中执行,缺点是无法访问DOM,而另一种方案是使用时间切片。
时间切片的核心**是:如果任务不能在50毫秒内执行完,那么为了不阻塞主线程,这个任务应该让出主线程的控制权,使浏览器可以处理其他任务。让出控制权意味着停止执行当前任务,让浏览器去执行其他任务,随后再回来继续执行没有执行完的任务。
所以时间切片的目的是不阻塞主线程,而实现目的的技术手段是将一个长任务拆分成很多个不超过50ms的小任务分散在宏任务队列中执行。
上图可以看到主线程中有一个长任务,这个任务会阻塞主线程。使用时间切片将它切割成很多个小任务后,如下图所示。
可以看到现在的主线程有很多密密麻麻的小任务,我们将它放大后如下图所示。
可以看到每个小任务中间是有空隙的,代表着任务执行了一小段时间后,将让出主线程的控制权,让浏览器执行其他的任务。
使用时间切片的缺点是,任务运行的总时间变长了,这是因为它每处理完一个小任务后,主线程会空闲出来,并且在下一个小任务开始处理之前有一小段延迟。
但是为了避免卡死浏览器,这种取舍是很有必要的。
时间切片是一种概念,也可以理解为一种技术方案,它不是某个API的名字,也不是某个工具的名字。
事实上,时间切片充分利用了“异步”,在早期,可以使用定时器来实现,例如:
btn.onclick = function () {
someThing(); // 执行了50毫秒
setTimeout(function () {
otherThing(); // 执行了50毫秒
});
};上面代码当按钮被点击时,本应执行100毫秒的任务现在被拆分成了两个50毫秒的任务。
在实际应用中,我们可以进行一些封装,封装后的使用效果类似下面这样:
btn.onclick = ts([someThing, otherThing], function () {
console.log('done~');
});当然,关于ts这个函数的API的设计并不是本文的重点,这里想说明的是,在早期可以利用定时器来实现“时间切片”。
ES6带来了迭代器的概念,并提供了生成器Generator函数用来生成迭代器对象,虽然Generator函数最正统的用法是生成迭代器对象,但这不妨我们利用它的特性做一些其他的事情。
Generator函数提供了yield关键字,这个关键字可以让函数暂停执行。然后通过迭代器对象的next方法让函数继续执行。
对Generator函数不熟悉的同学,需要先学习Generator函数的用法。
利用这个特性,我们可以设计出更方便使用的时间切片,例如:
btn.onclick = ts(function* () {
someThing(); // 执行了50毫秒
yield;
otherThing(); // 执行了50毫秒
});可以看到,我们只需要使用yield这个关键字就可以将本应执行100毫秒的任务拆分成了两个50毫秒的任务。
我们甚至可以将yield关键字放在循环里:
btn.onclick = ts(function* () {
while (true) {
someThing(); // 执行了50毫秒
yield;
}
});上面代码我们写了一个死循环,但依然不会阻塞主线程,浏览器也不会卡死。
通过前面的例子,我们会发现基于Generator的时间切片非常好用,但其实ts函数的实现原理非常简单,一个最简单的ts函数只需要九行代码。
function ts (gen) {
if (typeof gen === 'function') gen = gen()
if (!gen || typeof gen.next !== 'function') return
return function next() {
const res = gen.next()
if (res.done) return
setTimeout(next)
}
}代码虽然全部只有9行,关键代码只有3、4行,但这几行代码充分利用了事件循环机制以及Generator函数的特性。
创造出这样的代码我还是很开心的。
上面代码核心**是:通过yield关键字可以将任务暂停执行,从而让出主线程的控制权;通过定时器可以将“未完成的任务”重新放在任务队列中继续执行。
使用yield来切割任务非常方便,但如果切割的粒度特别细,反而效率不高。假设我们的任务执行100ms,最好的方式是切割成两个执行50ms的任务,而不是切割成100个执行1ms的任务。假设被切割的任务之间的间隔为4ms,那么切割成100个执行1ms的任务的总执行时间为:
(1 + 4) * 100 = 500ms如果切割成两个执行时间为50ms的任务,那么总执行时间为:
(50 + 4) * 2 = 108ms可以看到,在不影响用户体验的情况下,下面的总执行时间要比前面的少了4.6倍。
保证切割的任务刚好接近50ms,可以在用户使用yield时自行评估,也可以在ts函数中根据任务的执行时间判断是否应该一次性执行多个任务。
我们将ts函数稍微改进一下:
function ts (gen) {
if (typeof gen === 'function') gen = gen()
if (!gen || typeof gen.next !== 'function') return
return function next() {
const start = performance.now()
let res = null
do {
res = gen.next()
} while(!res.done && performance.now() - start < 25);
if (res.done) return
setTimeout(next)
}
}现在我们测试下:
ts(function* () {
const start = performance.now()
while (performance.now() - start < 1000) {
console.log(11)
yield
}
console.log('done!')
})();这段代码在之前的版本中,在我的电脑上可以打印出 215 次 11,在后面的版本中可以打印出 6300 次 11,说明在总时间相同的情况下,可以执行更多的任务。
再看另一个例子:
ts(function* () {
for (let i = 0; i < 10000; i++) {
console.log(11)
yield
}
console.log('done!')
})();在我的电脑上,这段代码在之前的版本中,被切割成一万个小任务,总执行时间为 46秒,在之后的版本中,被切割成 52 个小任务,总执行时间为 1.5秒。
我将时间切片的代码放在了我的Github上,感兴趣的可以参观下:https://github.com/berwin/time-slicing
最近在学习redux,现在把自己对redux的理解总结出来分享给大家。
redux是管理State的一个东东,所有State都需要经过redux来操作。
redux中有三个基本概念,Action,Reducer,Store。
Actions are payloads of information that send data from your application to your store. They are the only source of information for the store. You send them to the store using store.dispatch().
Actions 是把数据从应用传到 store 的有效载荷。它是 store 数据的唯一来源。用法是通过 store.dispatch() 把 action 传到 store。
Action 有两个作用。
Actions describe the fact that something happened, but don’t specify how the application’s state changes in response. This is the job of a reducer.
Action 只是描述了有事情发生了这一事实,并没有指明应用如何更新 state。这是 reducer 要做的事情。
Action就像leader,告诉我们应该做哪些事,并且给我们提供‘资源(就是上面说的数据)’,真正干活的是苦逼的Reducer。。
一个应用只有一个Store。一个应用只有一个Store。一个应用只有一个Store。
重要的事情放在前面说,而且说三遍。。
In the previous sections, we defined the actions that represent the facts about “what happened” and the reducers that update the state according to those actions.
The Store is the object that brings them together. The store has the following responsibilities:
上面章节中,我们学会了使用 action 来描述“发生了什么”,和使用 reducers 来根据 action 更新 state 的用法。
Store 就是把它们联系到一起的对象。Store 有以下职责:
Store提供了一些方法。让我们很方便的操作数据。
我们不用关心Reducer和Action是怎么关联在一起的,Store已经帮我们做了这些事。。
这部分主要讲解redux如何在项目中使用。
Action 是一个普通对象。
redux约定 Action 内使用一个字符串类型的 type 字段来表示将要执行的动作。
{
type: 'ADD_ITEM'
}除了 type 之外,Action可以存放一些其他的想要操作的数据。例如:
{
type: 'ADD_ITEM',
text: '我是Berwin'
}上面例子表示
{
text: '我是Berwin'
}但在实际应用中,我们需要一个函数来为我们创建Action。这个函数叫做actionCreator。它看起来是这样的:
function addItem(text) {
return {
type: types.ADD_ITEM,
text
}
}Reducer 是一个普通的回调函数。
当它被Redux调用的时候会为他传递两个参数State 和 Action。
Reducer会根据 Action 的type来对旧的 State 进行操作。返回新的State。
看起来是下面这样的:
/**
* 添加
*
* @param {String} 添加的文字
*
* @return {Object} 将要添加的数据
*/
let createItem = text => {
let time = Date.now();
return {
id: Math.random().toString(36).split('.').join(''),
addTime: time,
updateTime: time,
status: false,
text
}
}
/**
* Reducer
*
* @param State
* @param Action
*
* @return new State
*/
let reducer = (state = [], action) => {
switch (action.type) {
case ADD_ITEM:
return [createItem(action.text), ...state]
default:
return state
}
}Reducer很简单,但有三点需要注意
state。这是一部分核心源码:
// currentState 是当前的State,currentReducer 是当前的Reducer
currentState = currentReducer(currentState, action);如果在default或没有传入旧State的情况下不返回旧的State或initialState。。。那么当前的State会被重置为undefined!!
在使用combineReducers方法时,它也会检测你的函数写的是否标准。如果不标准,那么会抛出一个大大的错误!!
真正开发项目的时候State会涉及很多功能,在一个Reducer处理所有逻辑会非常混乱,,所以需要拆分成多个小Reducer,每个Reducer只处理它管理的那部分State数据。然后在由一个主rootReducers来专门管理这些小Reducer。
Redux提供了一个方法 combineReducers 专门来管理这些小Reducer。
它看起来是下面这样:
/**
* 这是一个子Reducer
*
* @param State
* @param Action
*
* @return new State
*/
let list = (state = [], action) => {
switch (action.type) {
case ADD_ITEM:
return [createItem(action.text), ...state]
default:
return state
}
}
// 这是一个简单版的子Reducer,它什么都没有做。
let category = (state = {}, action) => state;
/**
* 这是一个主Reducer
*
* @param State
* @param Action
*
* @return new State
*/
let rootReducers = combineReducers({list, category});combineReducers 生成了一个类似于Reducer的函数。为什么是类似于,因为它不是真正的Reducer,它只是一个调用Reducer的函数,只不过它接收的参数与真正的Reducer一模一样~
function combineReducers(reducers) {
// 过滤reducers,把非function类型的过滤掉~
var finalReducers = pick(reducers, (val) => typeof val === 'function');
// 一开始我一直以为这个没啥用,后来我发现,这个函数太重要了。它在一开始,就已经把你的State改变了。变成了,Reducer的key 和 Reducer返回的initState组合。
var defaultState = mapValues(finalReducers, () => undefined);
return function combination(state = defaultState, action) {
// finalReducers 是 reducers
var finalState = mapValues(finalReducers, (reducer, key) => {
// state[key] 是当前Reducer所对应的State,可以理解为当前的State
var previousStateForKey = state[key];
var nextStateForKey = reducer(previousStateForKey, action);
return nextStateForKey;
});
// finalState 是 Reducer的key和stat的组合。。
}
}从上面的源码可以看出,combineReducers 生成一个类似于Reducer的函数combination。
当使用combination的时候,combination会把所有子Reducer都执行一遍,子Reducer通过action.type 匹配操作,因为是执行所有子Reducer,所以如果两个子Reducer匹配的action.type是一样的,那么都会成功匹配。
上面已经介绍什么是Store,以及它是干什么的,这里我就讲讲如何创建Store,以及如何使用Store的方法。
创建Store非常简单。createStore 有两个参数,Reducer 和 initialState。
let store = createStore(rootReducers, initialState);store有四个方法。
常用的是dispatch,这是修改State的唯一途径,使用起来也非常简单,他看起来是这样的~
/**
* 创建Action
*
* @param 添加的数据
*
* @return {Object} Action
*/
function addItem(text) {
return {
type: types.ADD_ITEM,
text
}
}
// 新增数据
store.dispatch(addItem('Read the docs'));function dispatch(action) {
// currentReducer 是当前的Reducer
currentState = currentReducer(currentState, action);
listeners.slice().forEach(function (listener) {
return listener();
});
return action;
}可以看到其实就是把当前的Reducer执行了。并且传入State和Action。
State哪来的?
State其实一直在Redux内部保存着。并且每次执行currentReducer都会更新。在上面代码第一行可以看到。
Redux 是独立的,它与React没有任何关系。React-Redux是官方提供的一个库,用来结合redux和react的模块。
React-Redux提供了两个接口Provider、connect。
Provider是一个React组件,它的作用是保存store给子组件中的connect使用。
它看起来是这个样子的:
<Provider store={this.props.store}>
<h1>Hello World!</h1>
</Provider>getChildContext() {
return { store: this.store }
}
constructor(props, context) {
super(props, context)
this.store = props.store
}可以看到,先获取store,然后用 getChildContext 把store保存起来~
connect 会把State和dispatch转换成props传递给子组件。它看起来是下面这样的:
import * as actionCreators from './actionCreators'
import { bindActionCreators } from 'redux'
function mapStateToProps(state) {
return { todos: state.todos }
}
function mapDispatchToProps(dispatch) {
return { actions: bindActionCreators(actionCreators, dispatch) }
}
export default connect(mapStateToProps, mapDispatchToProps)(Component)它会让我们传递一些参数:mapStateToProps,mapDispatchToProps,mergeProps(可不填)和React组件。
之后这个方法会进行一系列的黑魔法,把state,dispatch转换成props传到React组件上,返回给我们使用。
mapStateToProps 是一个普通的函数。
当它被connect调用的时候会为它传递一个参数State。
mapStateToProps需要负责的事情就是 返回需要传递给子组件的State,返回需要传递给子组件的State,返回需要传递给子组件的State,(重要的事情说三遍。。。。)然后connect会拿到返回的数据写入到react组件中,然后组件中就可以通过props读取数据啦~~~~
它看起来是这样的:
function mapStateToProps(state) {
return { list: state.list }
}因为stat是全局State,里面包含整个项目的所有State,但是我不需要拿到所有State,我只拿到我需要的那部分State即可,所以需要返回 state.list 传递给组件
与mapStateToProps很像,mapDispatchToProps也是一个普通的函数。
当它被connect调用的时候会为它传递一个参数dispatch。
mapDispatchToProps负责返回一个 dispatchProps
dispatchProps 是actionCreator的key和dispatch(action)的组合。
dispatchProps 看起来长这样:
{
addItem: (text) => dispatch(action)
}connect 收到这样的数据后,会把它放到React组件上。然后子组件就可以通过props拿到addItem并且使用啦。
this.props.addItem('Hello World~');如果觉得复杂,不好理解,,那我用大白话描述一下
就是通过mapDispatchToProps这个方法,把actionCreator变成方法赋值到props,每当调用这个方法,就会更新State。。。。额,,这么说应该好理解了。。
但如果我有很多个Action,总不能手动一个一个加。Redux提供了一个方法叫 bindActionCreators。
bindActionCreators 的作用就是将 Actions 和 dispatch 组合起来生成 mapDispatchToProps 需要生成的内容。
它看起来像这样:
let actions = {
addItem: (text) => {
type: types.ADD_ITEM,
text
}
}
bindActionCreators(actions, dispatch); // @return {addItem: (text) => dispatch({ type: types.ADD_ITEM, text })}function bindActionCreator(actionCreator, dispatch) {
return (...args) => dispatch(actionCreator(...args));
}
// mapValues: map第一个参数的每一项,返回对象,key是key,value是第二个参数返回的数据
/*
* mapValues: map第一个参数的每一项,返回对象,key是key,value是第二个参数返回的数据
*
* @param actionCreators
* @param dispatch
*
* @return {actionKey: (...args) => dispatch(actionCreator(...args))}
*/
export default function bindActionCreators(actionCreators, dispatch) {
return mapValues(actionCreators, actionCreator =>
bindActionCreator(actionCreator, dispatch)
);
}可以看到,bindActionCreators 执行这个方法之后,它把 actionCreators 的每一项的 key 不变,value 变成 dispatch(actionCreator(...args)) 这玩意,这表示,actionCreator 已经变成了一个可执行的方法,执行这个方法,就会执行 dispatch 更新数据。。
上面的源码,为了方便观看,是处理过的。比如把一些注释和抛出错误的条件判断删除了。只留了最核心的部分,还有一些我私自加上去的中文注释。
各位大神如果发现我理解的不正确的地方,欢迎指出~
下面是一些我自己总结的参考资料,和demo。
转载请注明出处
所谓放量其实就是灰度发布,不过在我们组内部喜欢叫“放量”。关于放量其实有很多种规则:时间、地区、用户区间、随机放量等。
放量只有在大流量的C端项目中才有这个需求,流量小的产品或者公司内部使用的管理系统通常不需要做放量。
这里衍生出一个问题“为什么大流量C端项目需要做放量?”。
以某门户网站为例,假设去年日均PV是二个亿,一年的总收入是30亿人民币。
那么可以推算出,如果不做任何改动的情况下,今年的收入和去年比不会有太多的波动;但是部门给规定的目标通常要高于去年的收入,所以产品需要做一些事情来增加收入。
图1 - 某门户网站简笔画
经过一系列调研与讨论,最终决定把图中红圈的位置做一个改动,希望这个位置可以得到更好的商业化效果,提升一些收入。
但我们并不知道这个改动的结果是正面的还是负面的,如果这个改动上线之后导致了负面效果(用户很讨厌这个改动,疯狂骂我们),不但没增加收入反而降低了收入,这个后果是非常严重的。
所以我们通常会做一件事就是“放量”,先小规模放10%的量看看效果如何。
这里的放量通常又根据不同的情况分好几种:
地域放量与时间放量很容易理解,这里主要解释下什么是按用户区间放量。
图2 - 放量10%的用户
假设我们的产品总共有10亿个用户,放量10%,那么我们可以选择一个区间,是放给0~1亿这个区间的用户还是放给1亿~2亿这个区间,这个就是用户区间。
当然,这个名字是我随便起的,只是为了朗朗上口。
这里你可能会有一个疑问,为什么要按照用户区间放10%的量,直接随机放10%的量不行么?
答案是“也可以”,但随机放量无法满足下列需求。
我们还是举个例子,假设图1的红圈位置经过一系列讨论,现在有两个升级方案,但不确定哪个效果好,最终决定将这两个版本都开发出来,然后对比下哪个效果好就使用哪个版本。
这时候随机放量就无法满足需求了,但是按用户区间放量可以满足需求。
图3 - 方案1与方案2同时放量
我们可以将方案一放量给0~1亿这个区间的用户,把方案二投放给1亿~2亿区间的用户。
任何产品都会为用户分配一个ID,假设为用户分配的ID是一个散列值MD5,那么当用户访问我们的产品时,我们就可以根据用户的ID来分辨该用户会命中哪个版本(版本一?版本二?或者是未命中?)。
具体实现方案是,取用户ID的后三位(当然,后两位也行),然后用这个数除以三位的最大值,得到一个百分比。举个例子:
假设我的用户ID为4b3ab369fa40ca4faae404b2f8332b65,这是一个MD5值,我们取出后三位b65,三位16进制的最大数转换成10进制为16^3 = 4096,所以我们将b65转换成10进制后在除以4096,最终得出的数字为:(b65 = 2917) / 4096 = 0.71。
上述例子将“方案一”投放给0~1亿这个区间的人,将“方案二”投放给1亿~2亿这个区间的人,很显然,当我访问页面时,红圈位置会发现我的数值是0.71,不在0~0.1这个区间,也不在0.1~0.2这个区间,所以我没有命中这一次的小规模放量测试,我的页面上该位置显示的是现有的稳定版。
这样实现的好处是:
相同的放量策略和实现方式可以放到服务端,也可以放到客户端;具体如何放量需要“具体情况,具体分析”。
{ display: none; /* 不占据空间,无法点击 */ }{ visibility: hidden; /* 占据空间,无法点击 */ }{ position: absolute; clip:rect(1px 1px 1px 1px); /* 不占据空间,无法点击 */ }{ position: absolute; top: -999em; /* 不占据空间,无法点击 */ }{ position: relative; top: -999em; /* 占据空间,无法点击 */ }{ position: absolute; visibility: hidden; /* 不占据空间,无法点击 */ }{ height: 0; overflow: hidden; /* 不占据空间,无法点击 */ }{ opacity: 0; filter:Alpha(opacity=0); /* 占据空间,可以点击 */ }{ position: absolute; opacity: 0; filter:Alpha(opacity=0); /* 不占据空间,可以点击 */ }{
zoom: 0.001;
-moz-transform: scale(0);
-webkit-transform: scale(0);
-o-transform: scale(0);
transform: scale(0);
/* IE6/IE7/IE9不占据空间,IE8/FireFox/Chrome/Opera占据空间。都无法点击 */
}{
position: absolute;
zoom: 0.001;
-moz-transform: scale(0);
-webkit-transform: scale(0);
-o-transform: scale(0);
transform: scale(0);
/* 不占据空间,无法点击 */
}有很多人好奇我是如何成长的,之前有一些朋友也曾试图邀请我写一篇自己的成长史,不过却被我婉言谢绝了。原因无他,因为我并没有觉得自己有资格写这个东西。我并不觉得自己很厉害,哪能有资格教导大家如何成为厉害的人?
不过既然大家这么好奇我是如何成长的,那我就把自己的经历拿出来分享一下。
像我这种没有学历,也没有光鲜的背景的人,在踏入前端这个行业时,起点非常低。我在北京的第一份工作,工资低到只有可怜的不足四千块钱。说实话,那时候我连JavaScript都不会写,只会一点点CSS能写个页面,是个非常典型的『切图仔』。
从这么低的起点走到今天,这中间是有什么秘籍么?还是偶然现象?是因为我比其他人聪明?还是我比其他人更努力?
其实都不是,我不认为自己比其他人聪明,也不觉得自己比其他人更努力(比我更努力的人多了去了)。我自认为我能走到今天,更大的因素可能是因为我比较善于做 『决策』。
这里说的 “决策” 分两种情况,一种是“选择”,一种是“规划”。
现在回想起来,我的每一次转折点,背后都是我“选择”了当时我所面临的实际情况的 『最优选择』,以及在我能接触到的信息中做出对未来的 『最优规划』。
最优规划的意思是:根据自己了解到的信息,规划出一条对自己最有利的路线。
做选择还稍微容易一点,毕竟选项通常是有限的,但做规划就多少有点运气的成分在里面了。做规划有无限种可能性和无限种选择,我在做规划时,其实也很迷茫,不知道自己的选择是对是错,一般就尽人事听天命了。
从那么低的起点走到今天,这一路上有太多的诱惑,每一次“选择”都会对未来的职业生涯产生不同程度的影响。例如:每一次跳槽如何选择offer、是否要接外包赚点外快、在有限的时间里如何做技术投资、规划未来的职业路线等。
我的第一次重大决策是在我刚出来工作的时候,当时的我17周岁,在沈阳一家互联网外包公司当学徒(学徒是没有工资的),在公司里学怎么切图。而同一时间我的同学们有当客服的,有干销售的,干什么的都有,他们工资都远高于我,那个时候同学们都刚出来工作,互相之间的攀比还是挺严重的,当时的我都不好意思跟同学们说我赚多少钱,当时的我接触到的信息也不多,完全不知道互联网行业是否有前途,当时心里想的就是,不管怎么说我也是在做技术吧,至少比销售,客服之类的随着时间的推移完全没有让自身有任何沉淀的行业好一点,没准哪天我的工资就和你们一样多了。就这样,我第一次重大决策就是坚持做技术。
当时的我虽然心里想的很简单,但潜意识里我自己都没有发现,我更倾向于为自己投资。简单来说,我更看重长期利益,而不是短期利益。哪怕会受尽同学的白眼与瞧不起。
我的第二次重大决策是要不要来北京发展,答案很明显。但当时的我刚满18周岁,对于做出的这个决策是需要很大的勇气的。我在北京没有任何熟人,来北京就意味着我要脱离我的朋友,家人,去一个完全陌生的城市忍受孤独与可能会遇到的各种挫折与磨难,最终我还是决定一个人踏上了去往北京的火车,兜里只带了8000块钱(我爸给5000+我自己攒的3000)。当时我心里就觉得,身为一个男人,总归是要远离家乡出去闯荡一番。我的第二次重大决策是远离家乡,准备迎接外面的狂风暴雨。
来北京之后,果然受到了很多挫折与打击,没有学历,技术也很菜,找工作非常难,所幸,最后还是找到了一个小公司愿意收留我,在这每天工作很忙,就是像机器一样切图,也没有时间学习,但是没什么办法,我没得选,先解决生存问题要紧,在北京如果没有收入,我的8000块钱可花不了多久。最后只呆了三个月我做了一个决定,换一个轻松点的工作,这样我就可以有更多的时间来学习JavaScript。在这家不怎么忙的公司一边上班一边学习,后来我学了JavaScript后,我觉得我缺少实战,我需要把我学到的知识在实战中磨砺,然后我做了一个决定,换一个忙一点的工作,并且不再是切图仔,而是真正的开发者。
所幸,我找到了一家符合我计划与预期的公司,这家公司的所有项目都是使用JavaScript开发的,后端使用Nodejs,可以说非常符合我的预期,我从一个切图仔直接变成了全栈工程师。这家公司业务很繁忙,经常通宵,类似于今天的今日头条,不过对我的成长是非常有帮助的,不过这总是会有一个临界点,或者叫瓶颈期,那就是我已经成长到在这家公司写在多的代码,干在多的活也没有办法成长的时候,我不想X年工作经验重复N年,我需要的是让我稍微放松下来给我时间让我去学习更深入与高深的知识,张弛有度才是成长的合理环境,始终处于忙碌的工作,没有输入只有输出,对于当时的我来说没有成长上的帮助。这个时候我开始准备换工作的事情。
我的第三个重大决策是拿创业公司高工资的offer还是拿上市公司低工资的offer,最终我选择了拿上市公司低工资的offer。我想这个问题很多人都有遇到过,每个人对这个问题的选择都不一样。说实话,到目前为止我来360三年多了,每年都会涨工资,但直到今天我拿到的薪水才勉强追上当初创业公司给我开出的薪水。但我知道,我的选择是正确的,因为我的技术,已远超当初的我。
我的选择依然遵循同一个原则,选择长期利益,牺牲短期利益。
以上是我人生转折中我所作出的重大决策,但其实这一路走来有太多诱惑,其中很多小决策也会对成长起到决定性作用。
举例来说,经常有人联系我,想让我在业余时间帮忙做个项目,付费的,说白了就是接外包私活,我给出的答案永远都是 『不做』。
不是说我对钱不感兴趣,而是说我会选择把时间投资在自己身上,因为做外包不具备累积性,他不会让我吸收到什么,对我而言是没有成长的。本质上我是在选择做赚钱的事,还是选择做值钱的事,很显然我选择了后者,我写过一些开源项目,免费的,其实和外包都是写代码,但前者不能让我成长,后者可以。
我更愿意把时间花费在写文章、写书、演讲/分享、写系列课程,虽然赚不到什么钱,但是却可以让自己成长,并且这些事可以积累起来,长远来看对我自己有帮助。
所以我的成长只围绕着一个核心,重视个人价值的增值,放弃短期利益,这需要忍受非常多的诱惑,面对诸多诱惑下,依然能做出正确决策是需要魄力的。
git的快捷键 alias,加 oh-my-zsh应该是使用中比较实用的小技巧
在实际应用中,一遍一遍输入git status,git status,git commit -m 'xx'什么的确实挺繁琐,于是配置alias可以简化成 gst === git status,gcmsg 'xxx' === git commit -m 'xxx',gp === git push等等。。
大概是这样配置的
而且还发现oh-my-zsh默认用的插件是git,查看oh-my-zsh的config
cat ~/.zshrc
其中有一条配置是
plugins=(git)
那么刨根问底拦不住,看看git插件的配置
cat ~/.oh-my-zsh/plugins/git/git.plugin.zsh
发现是一堆alias
alias g='git'
alias ga='git add'
alias gaa='git add --all'
alias gapa='git add --patch'
alias gb='git branch'
alias gba='git branch -a'
alias gbda='git branch --merged | command grep -vE "^(\*|\s*master\s*$)" | command xargs -n 1 git branch -d'
alias gbl='git blame -b -w'
alias gbnm='git branch --no-merged'
alias gbr='git branch --remote'
alias gbs='git bisect'
alias gbsb='git bisect bad'
alias gbsg='git bisect good'
alias gbsr='git bisect reset'
alias gbss='git bisect start'
既然oh-my-zsh已经配置好了。。。那我们就可以直接使用了。。。
ga . && gcmsg 'update' && gp
比较下之前的用法
git add . && git commit -m 'update' && git push
简直爽的一bi啊~~~
刘博文(Berwin),花名“玖五”,畅销书《深入浅出Vue.js》作者、Speaker、阿里巴巴集团前端技术专家、天猫双11大促会场消防员、现负责包含天猫双11在内的超大型营销活动会场的终端渲染架构与专项PM。
简单经历:
I have a dream and I believe I can
我喜欢把我的网名叫做 Berwin,因为他是博文的谐音,从2015年开始写博客到现在:
博客的评论里总有一些人调侃我,称我为大佬,但其实我还远配不上“大佬”这两个字,我自己深知自己的技术水平也只是皮毛而已。
坚持写作的动力是因为能看到自己写出来的文章可以得到大家的认可,这种认可让我有动力坚持将自己知道的知识写出来分享给大家,让我们一起共同成长。😊😊
当然,我也有遗憾,我现在内心最遗憾的事就是我没有读过大学,没有体验过大学是什么感觉,也没有学习到学校的一些知识,可能是为了弥补我内心的遗憾,也可能是为了弥补曾经堕落的我,现在最爱做的事就是看书,喜欢学习自己不知道的知识。
除了这里,还可以在其他的地方找到我。
除了这里,还可以在其他的地方找到我。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
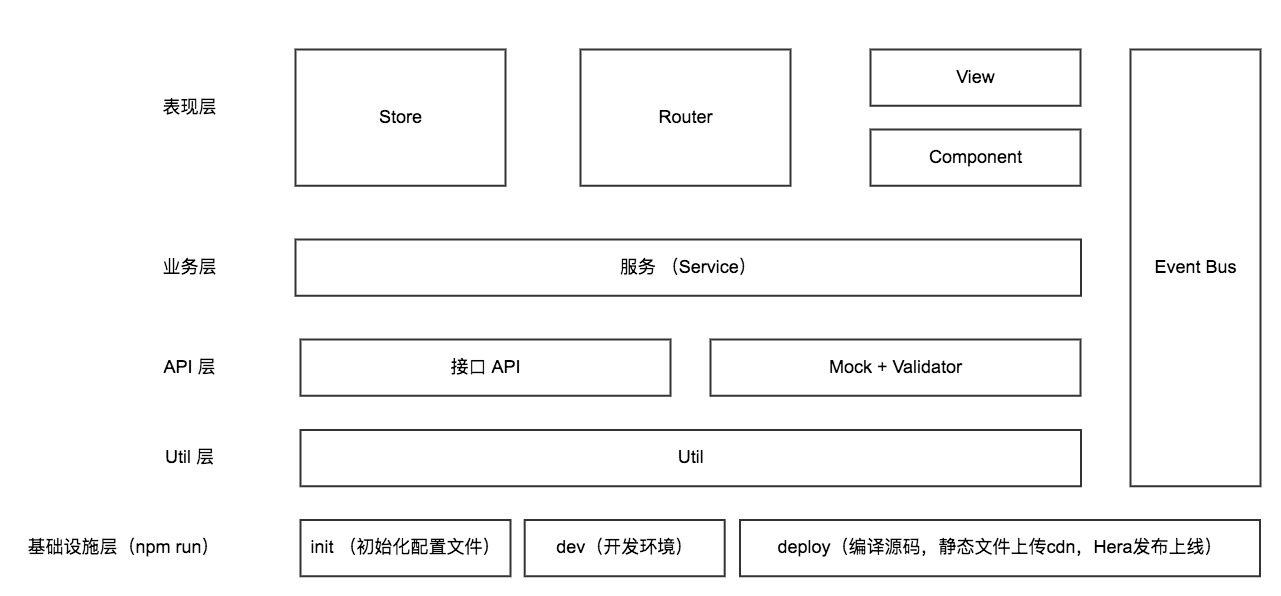
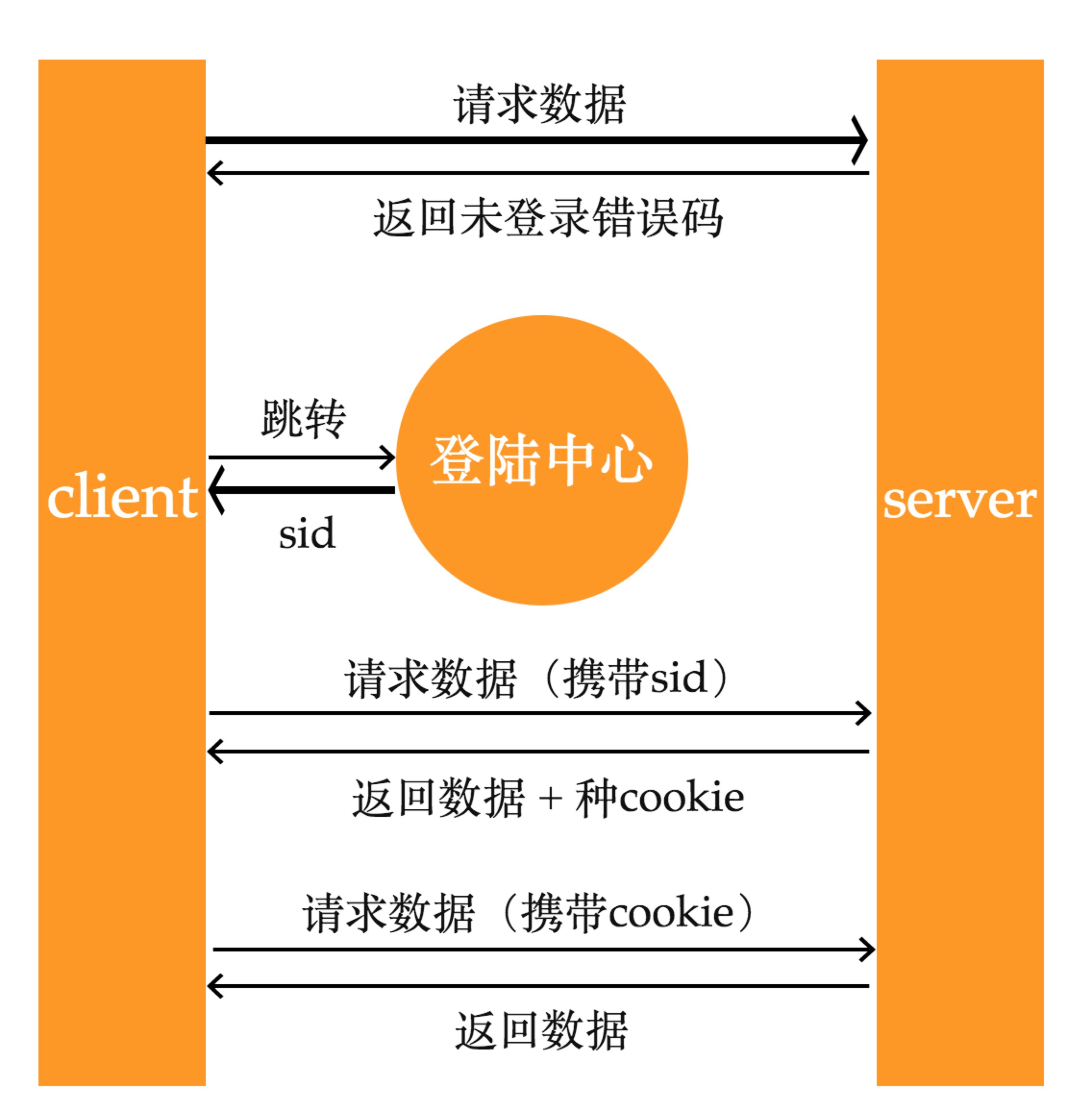
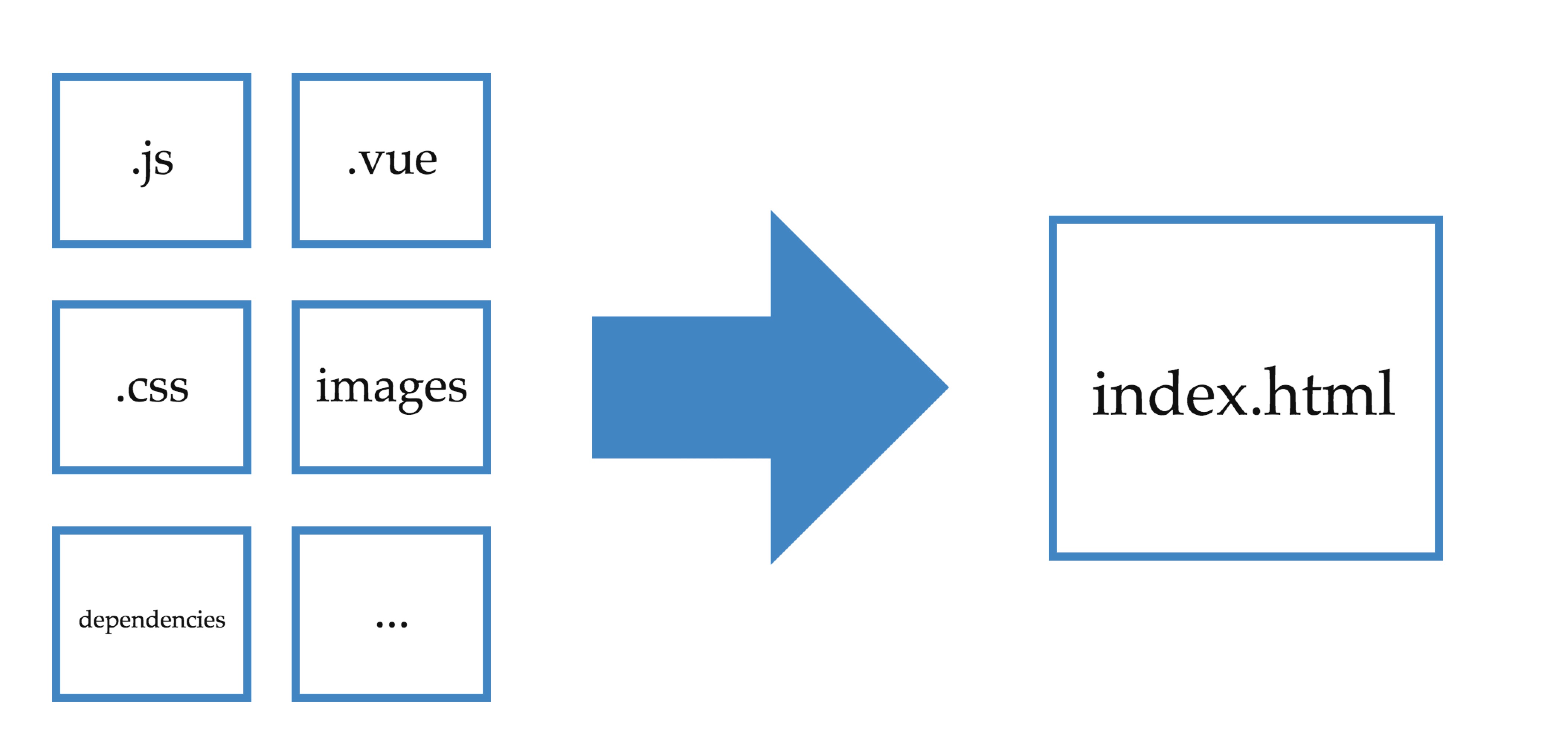
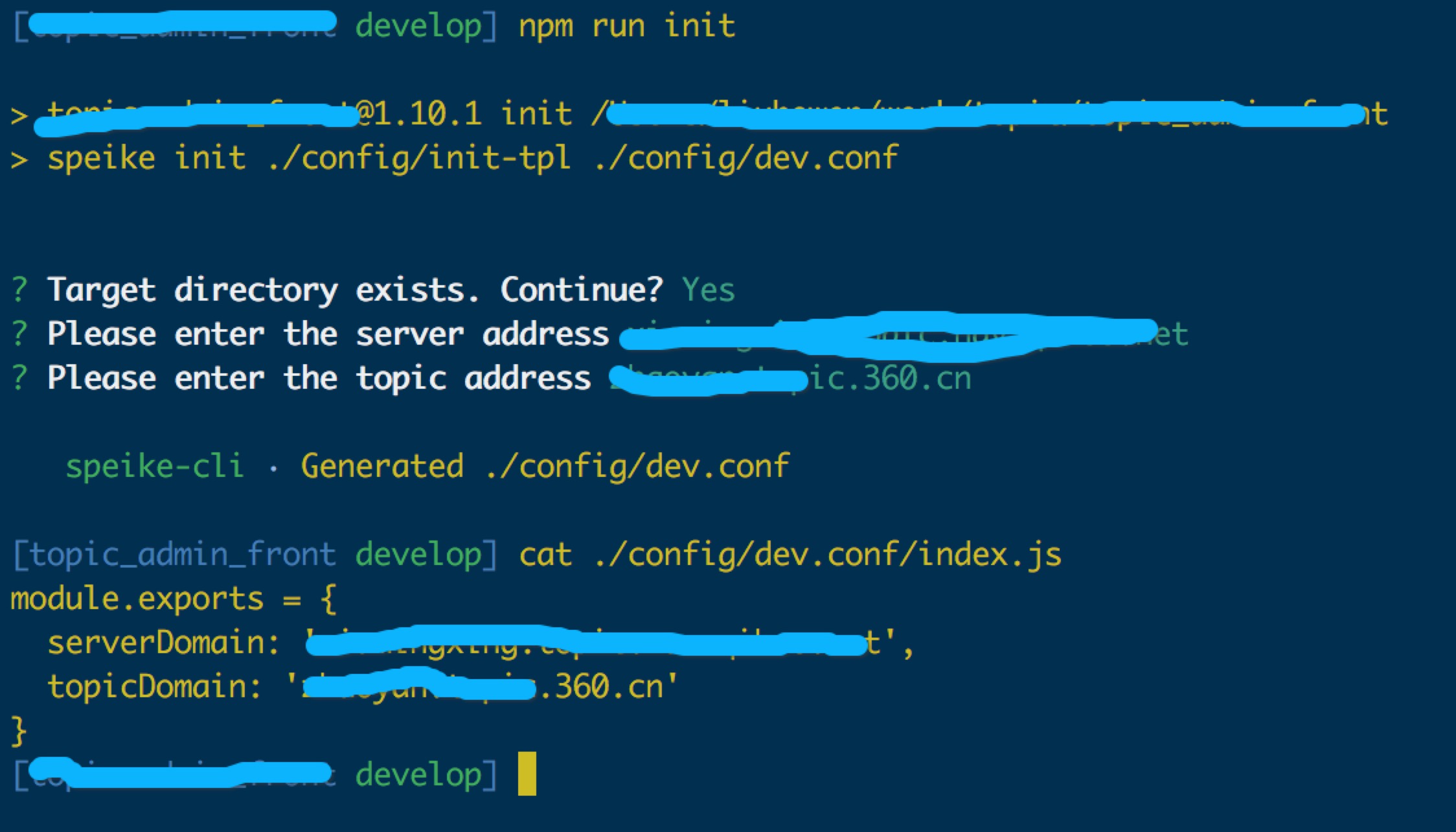
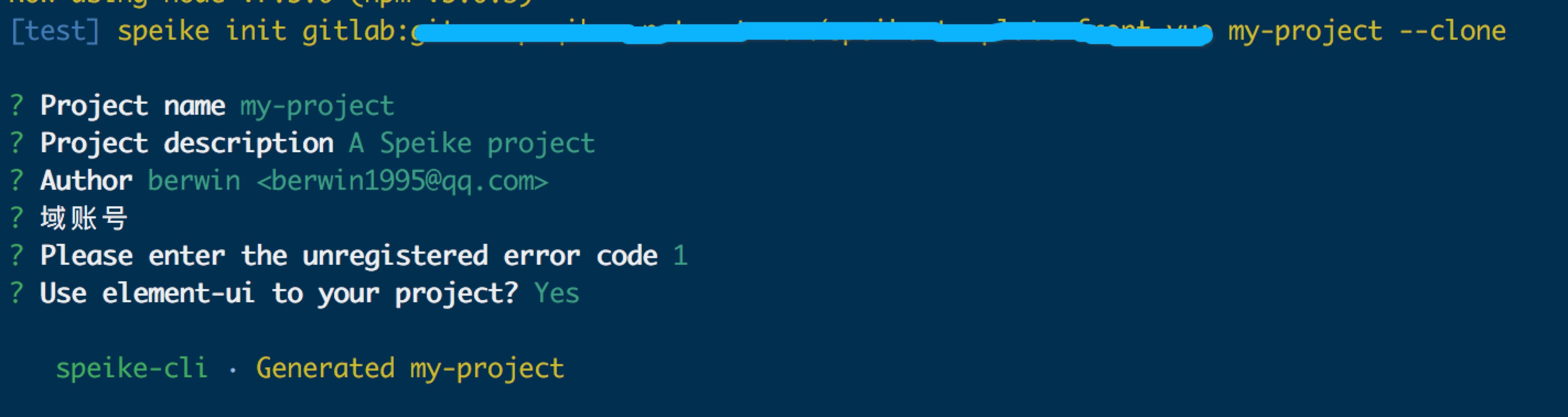
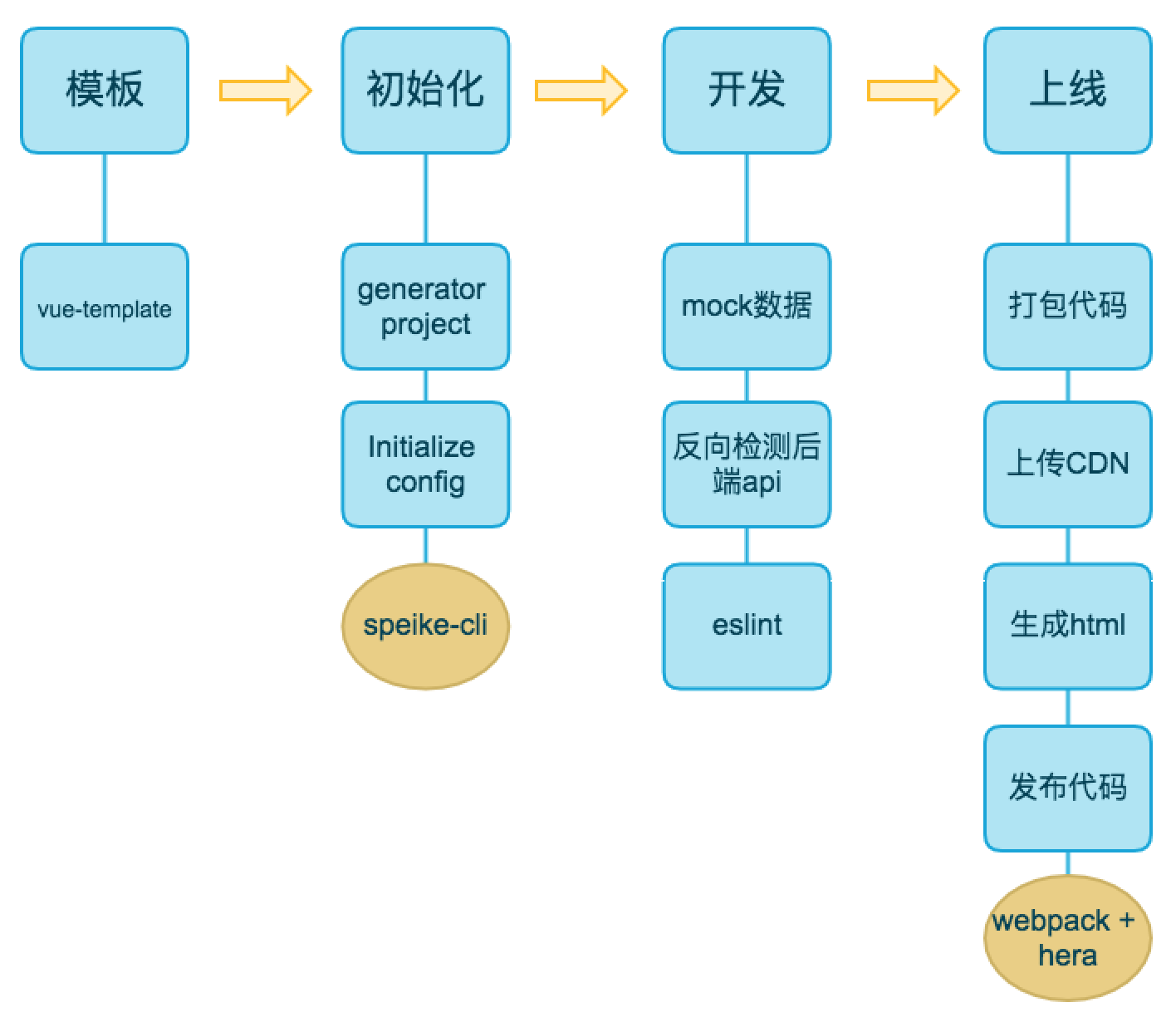
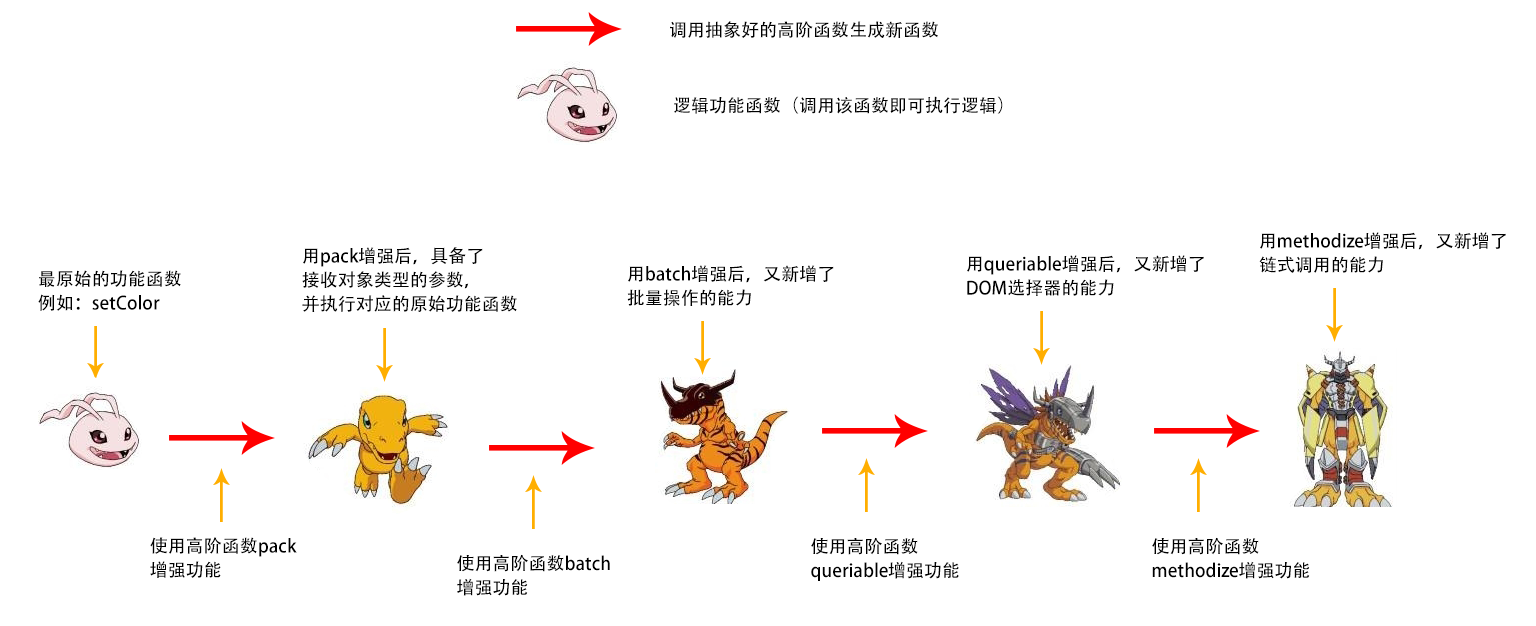
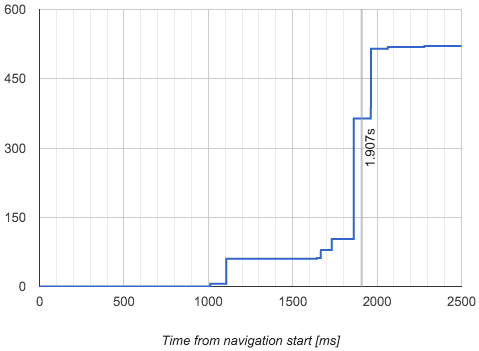
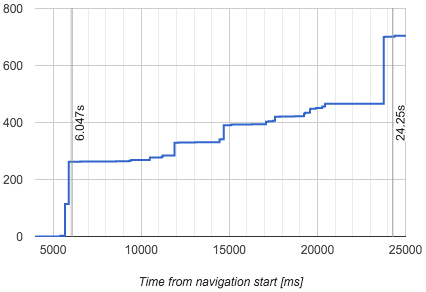
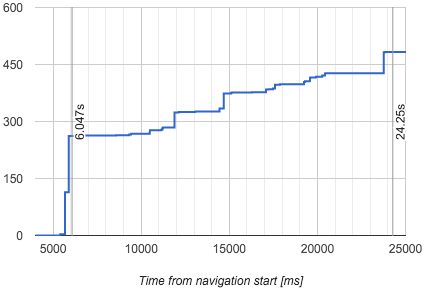


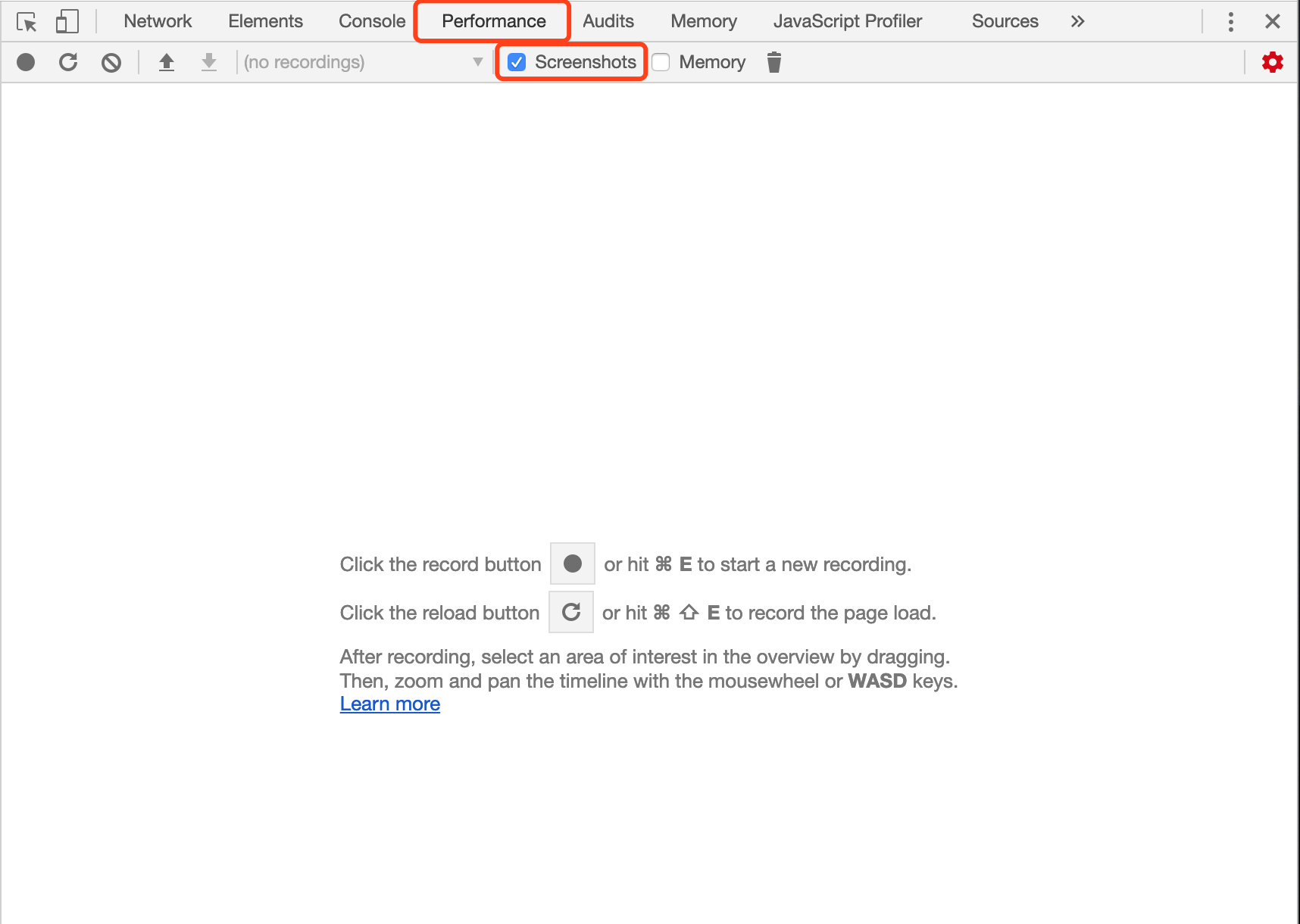
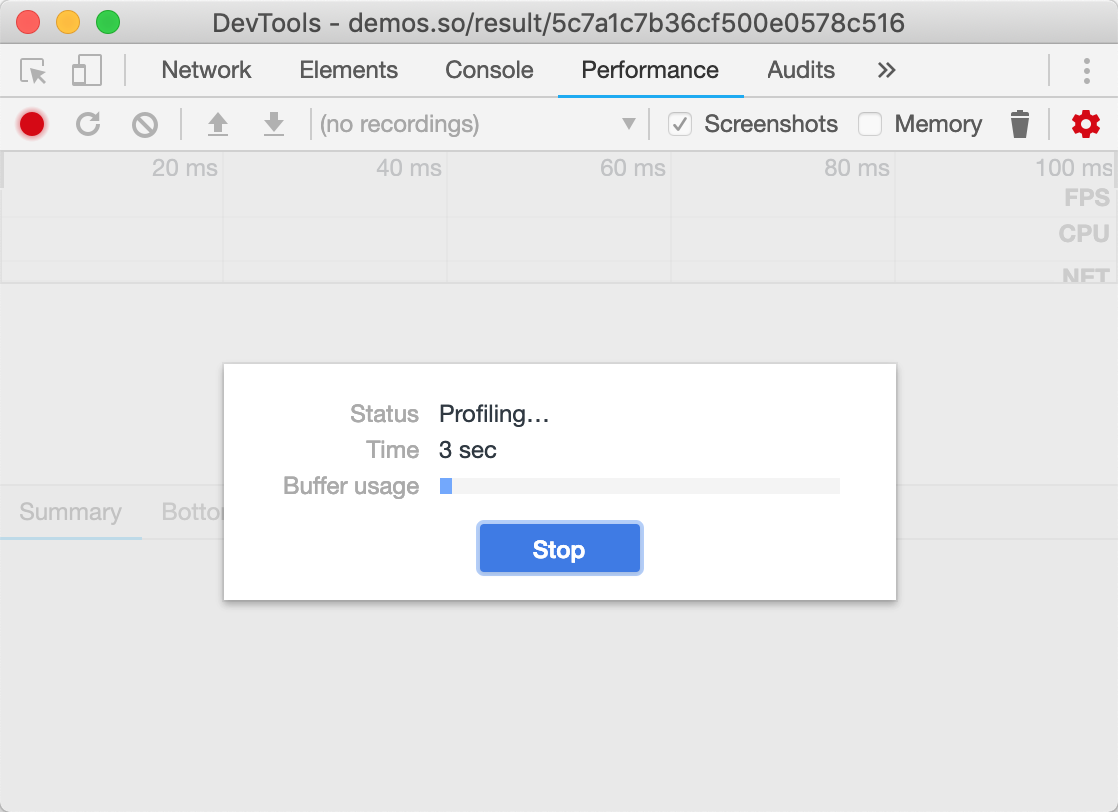
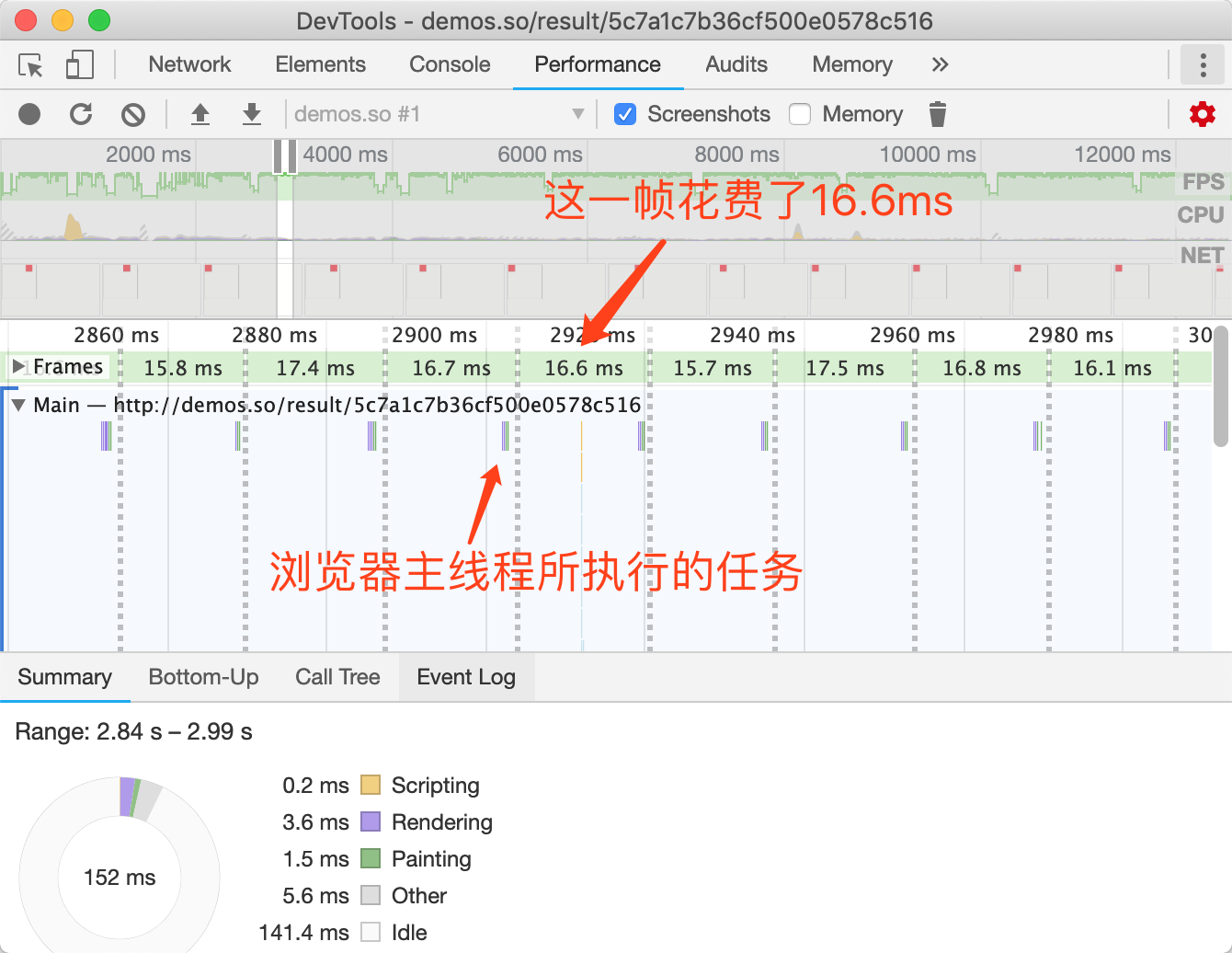
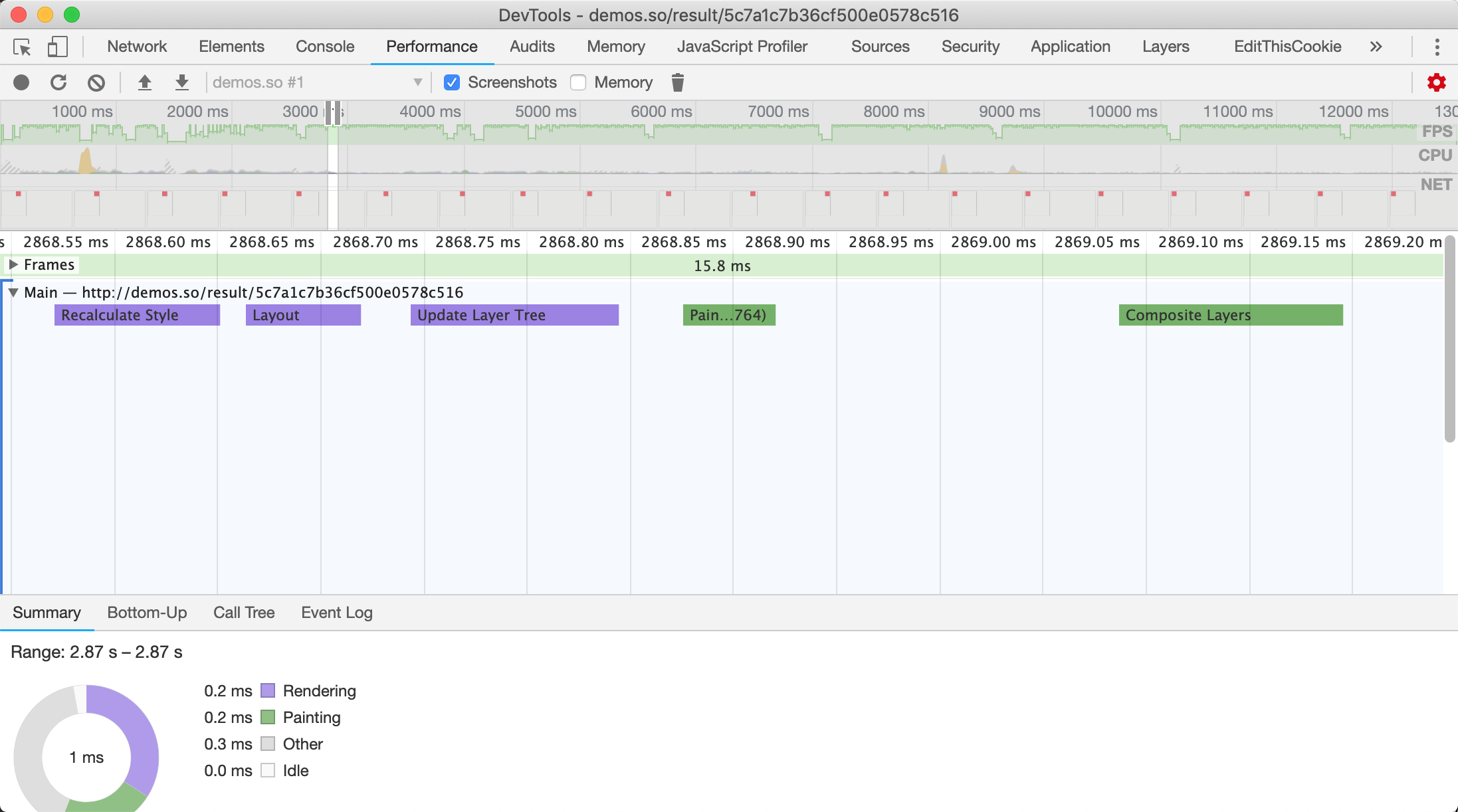
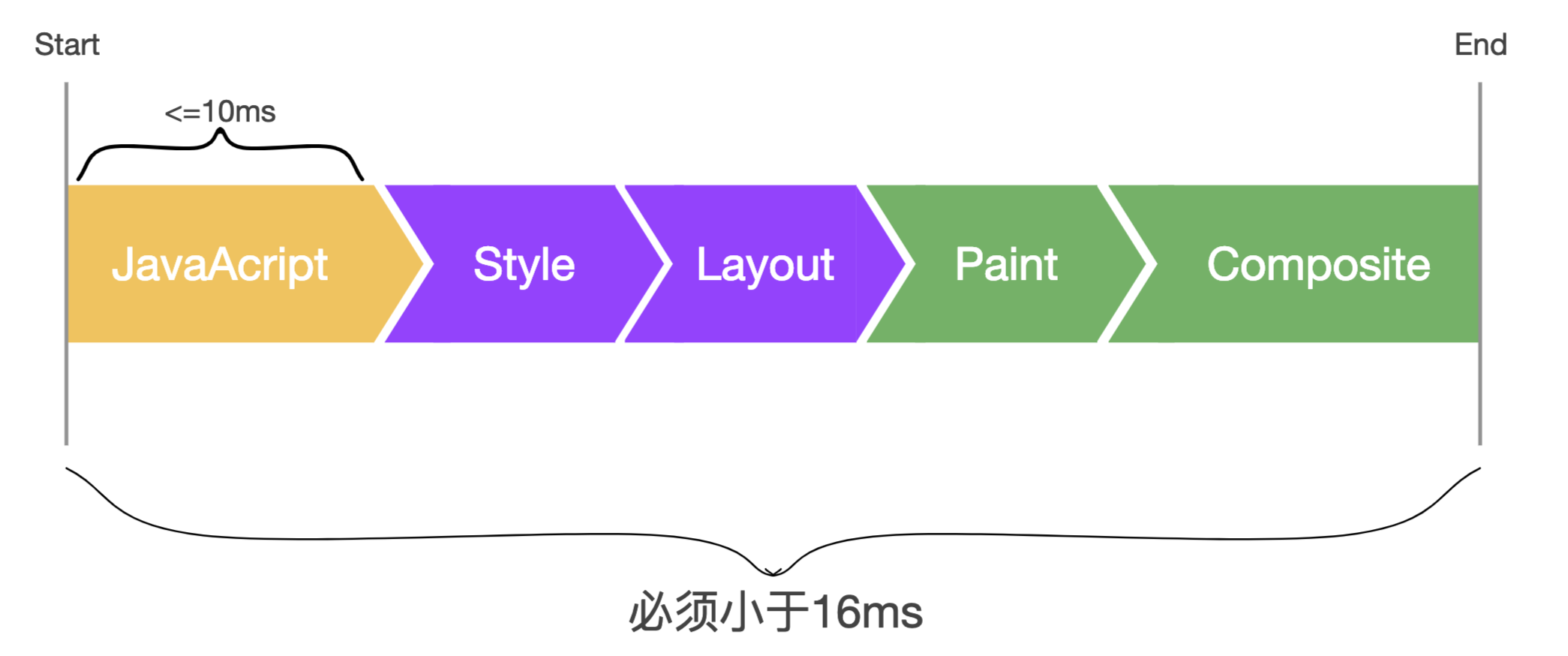
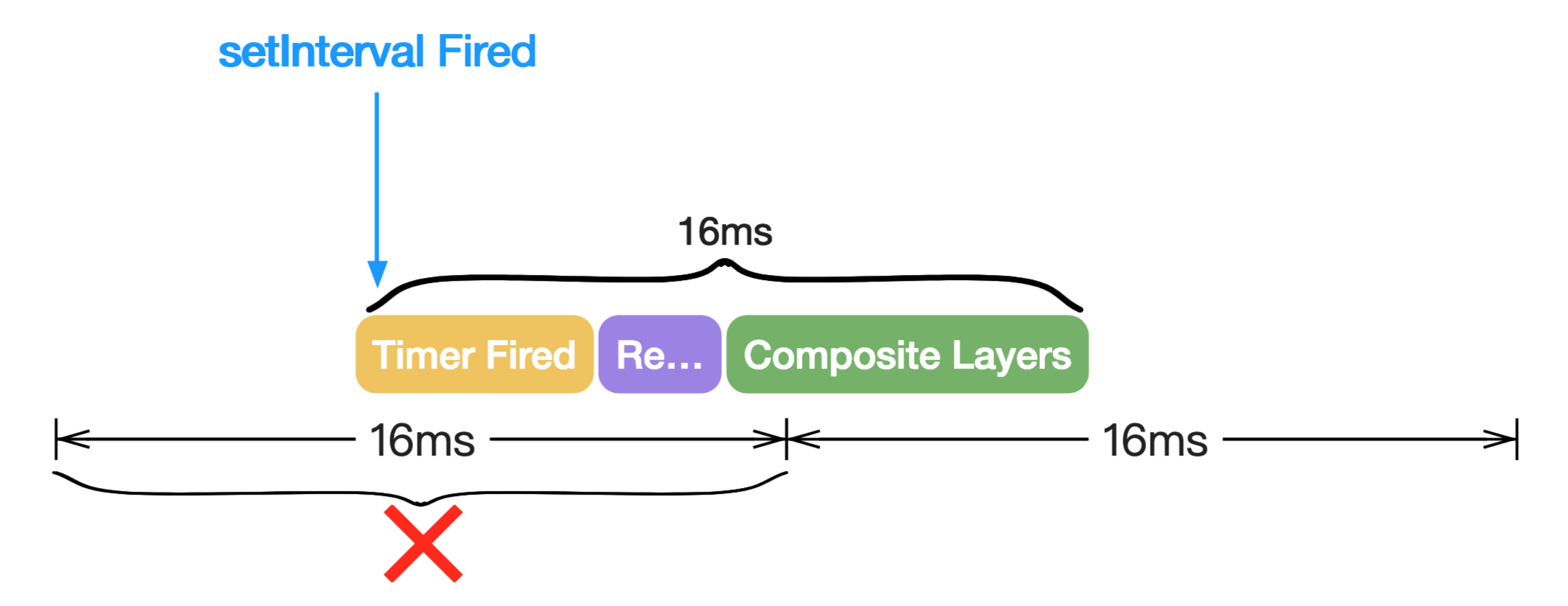
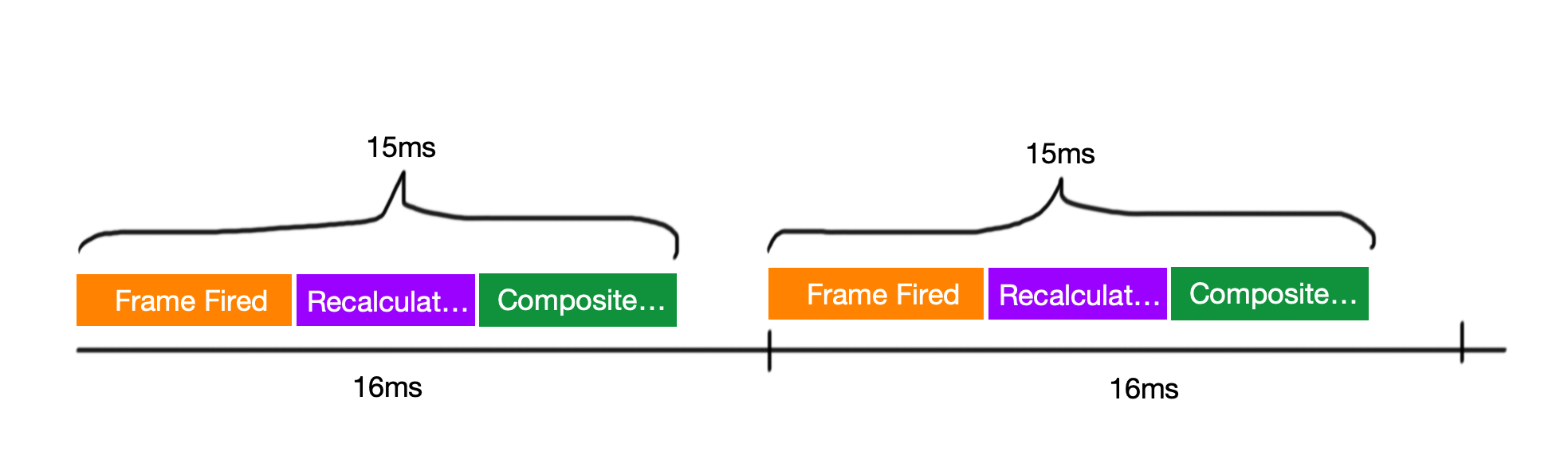
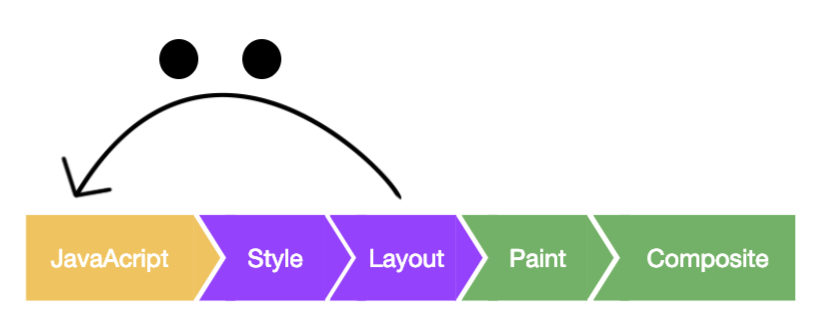
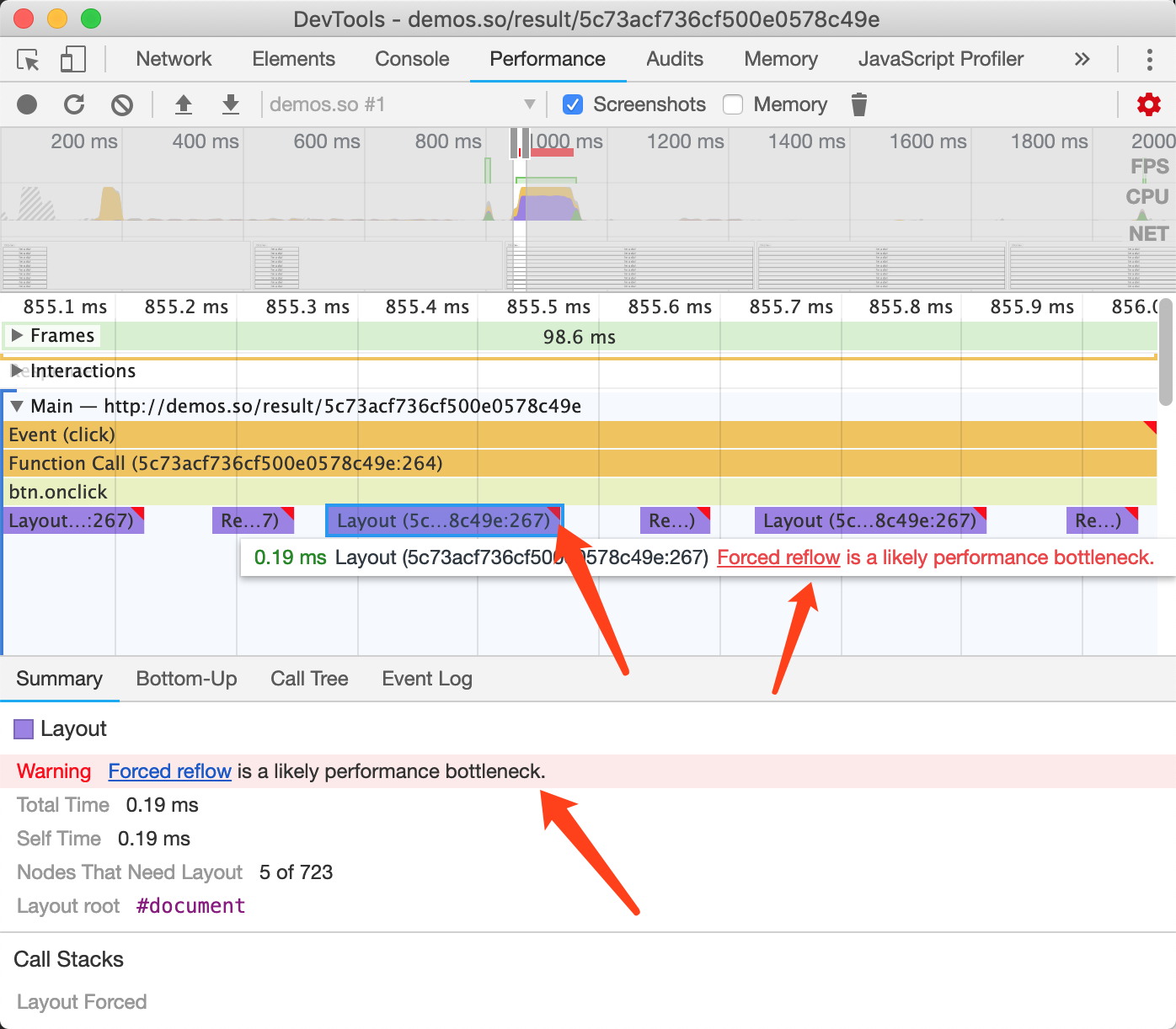
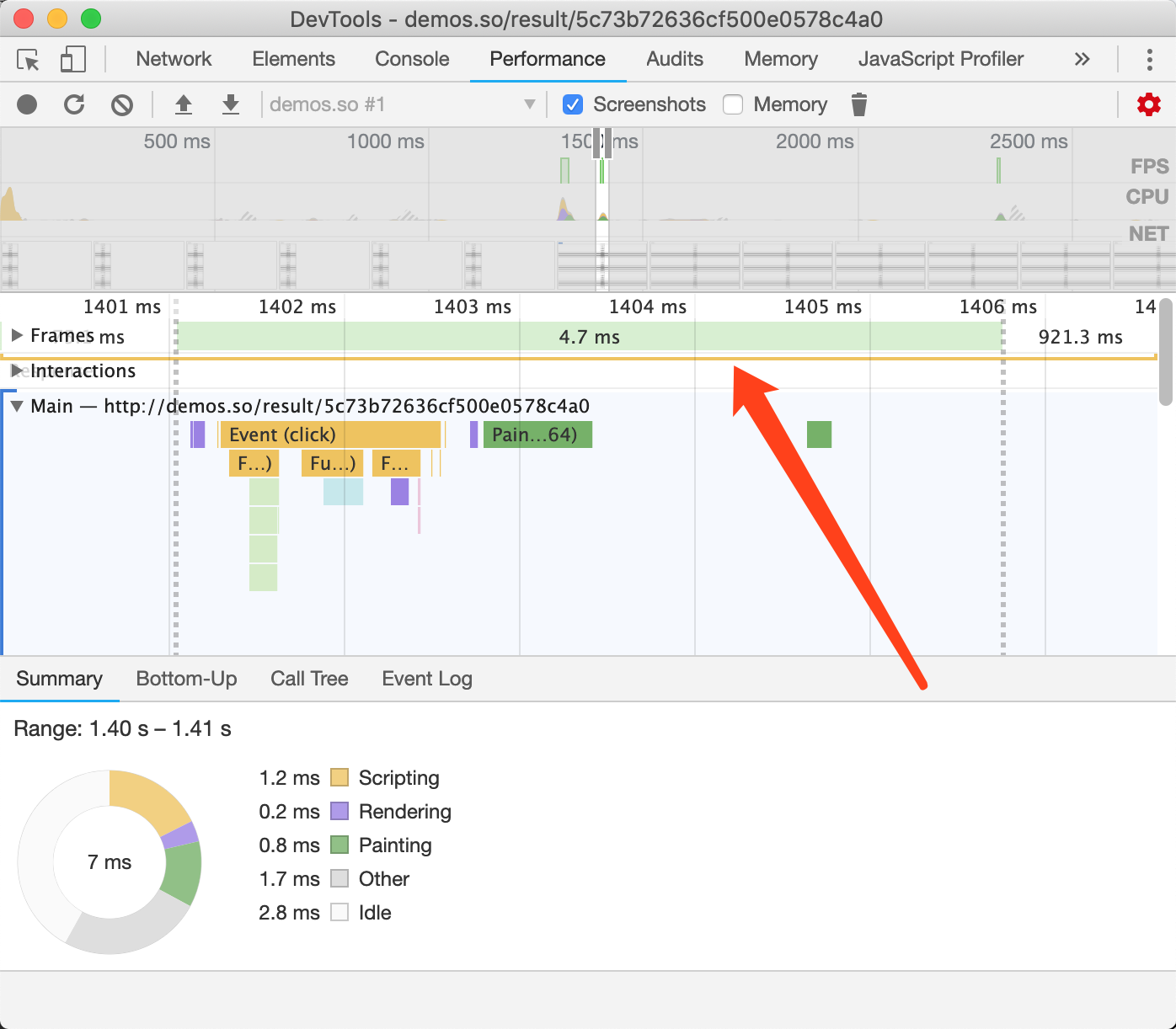
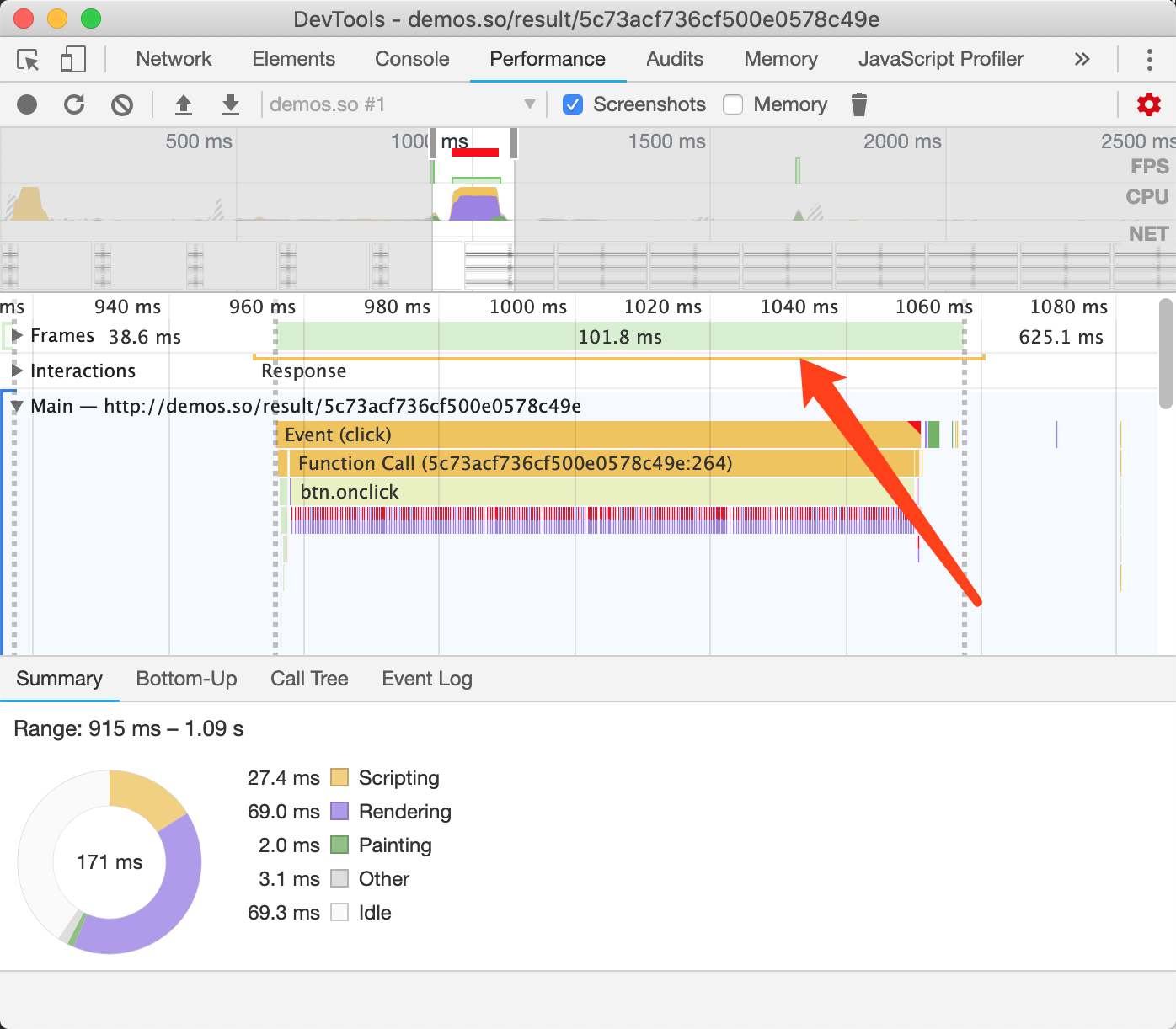
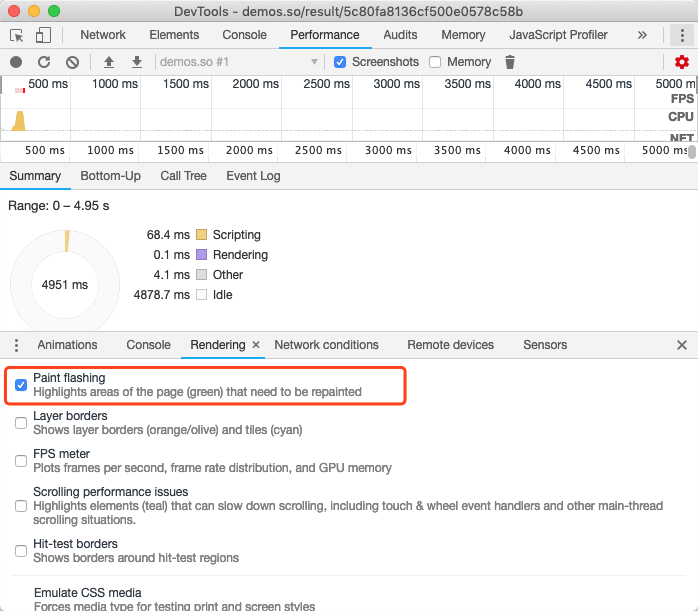
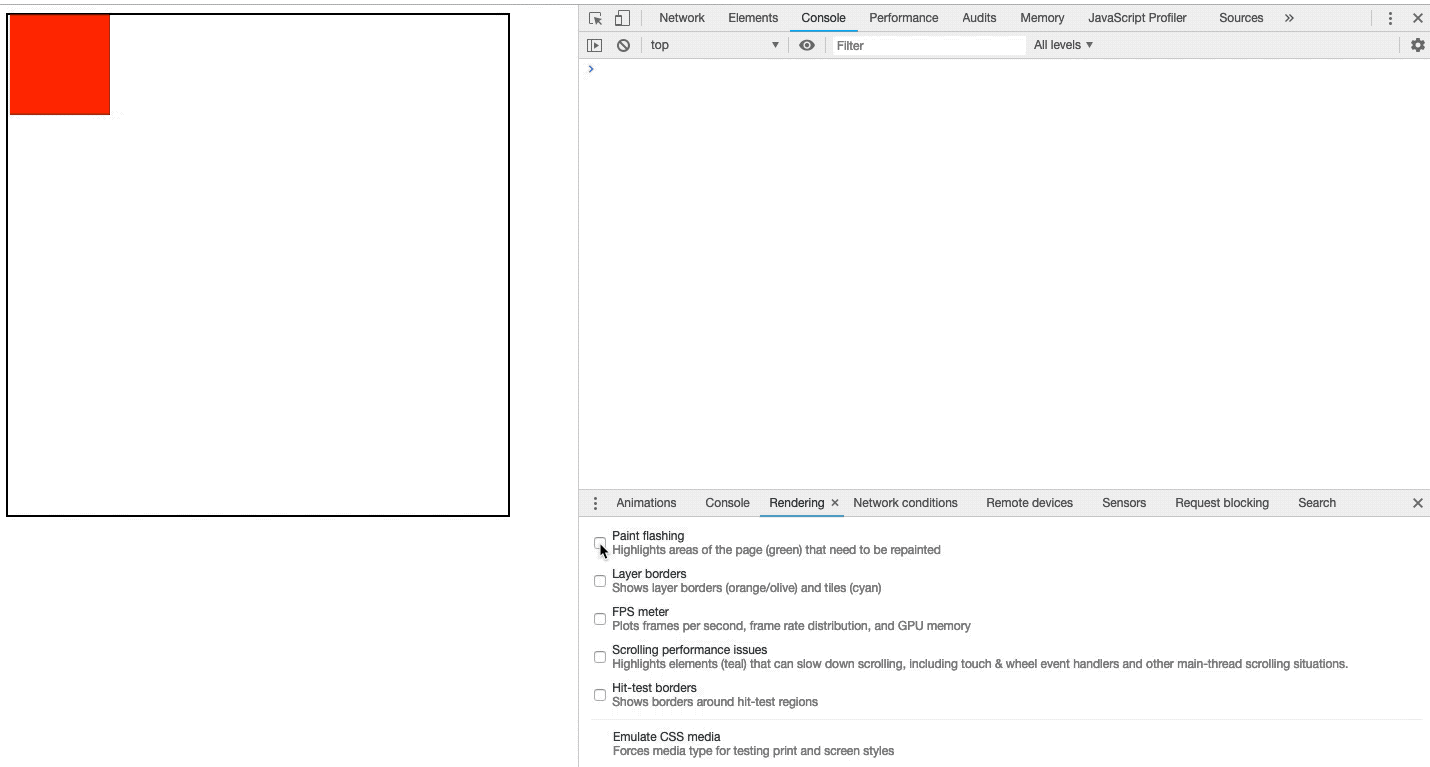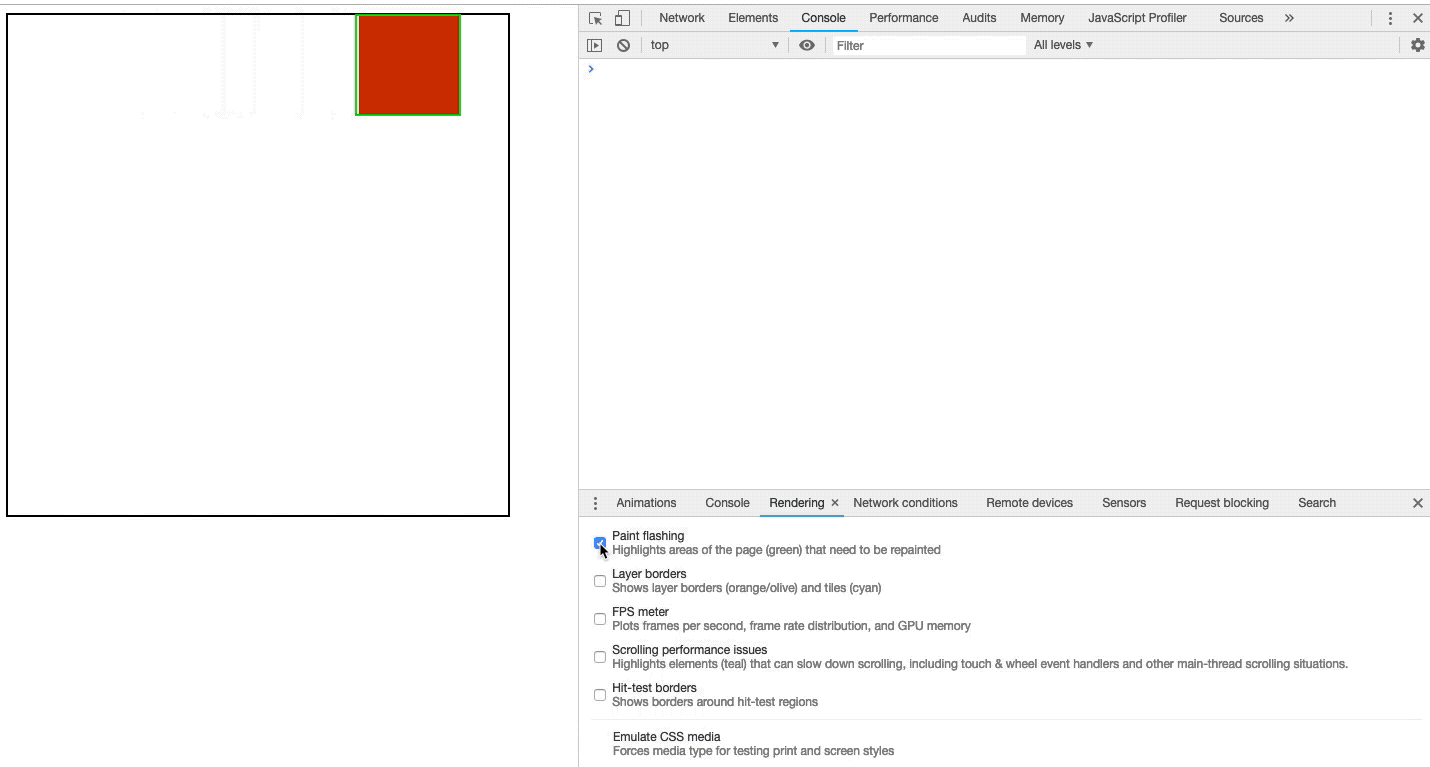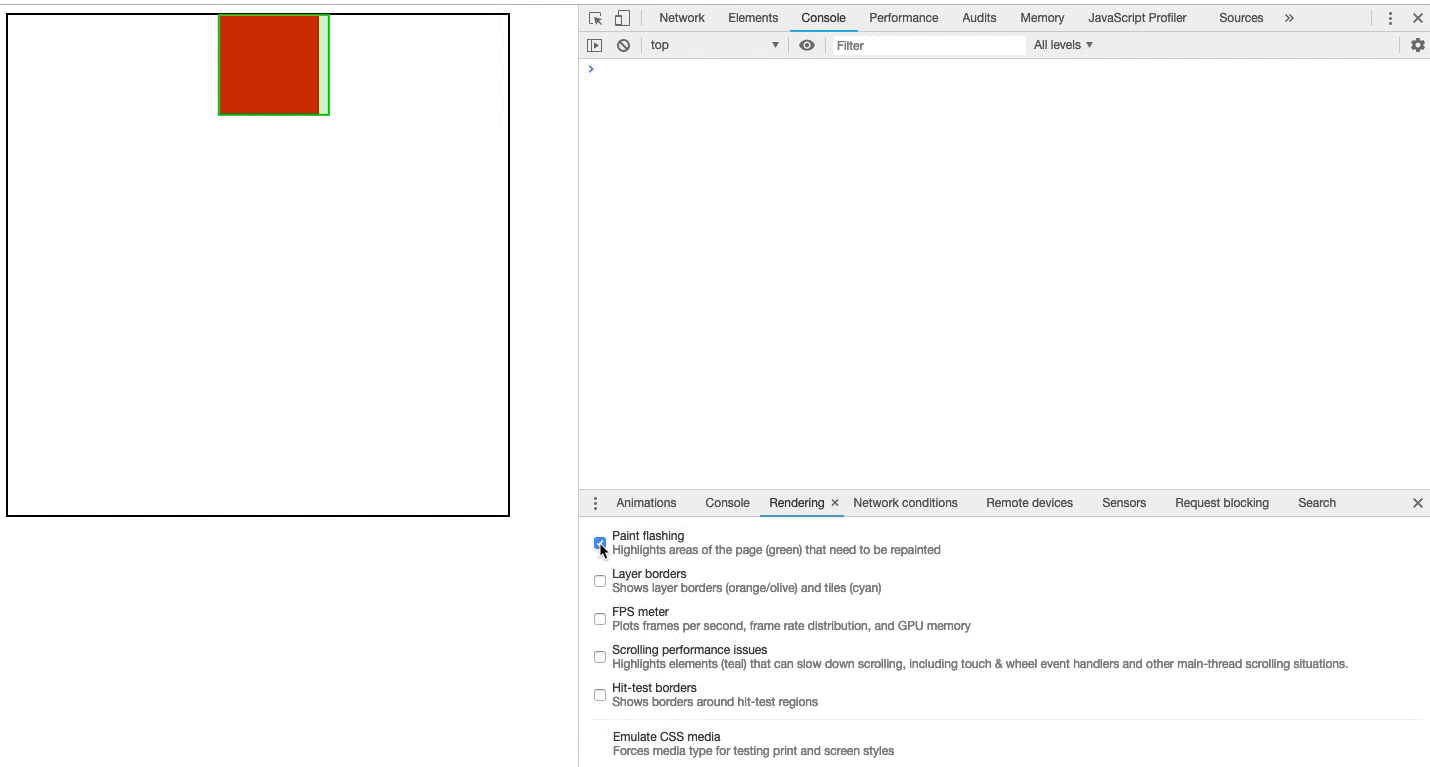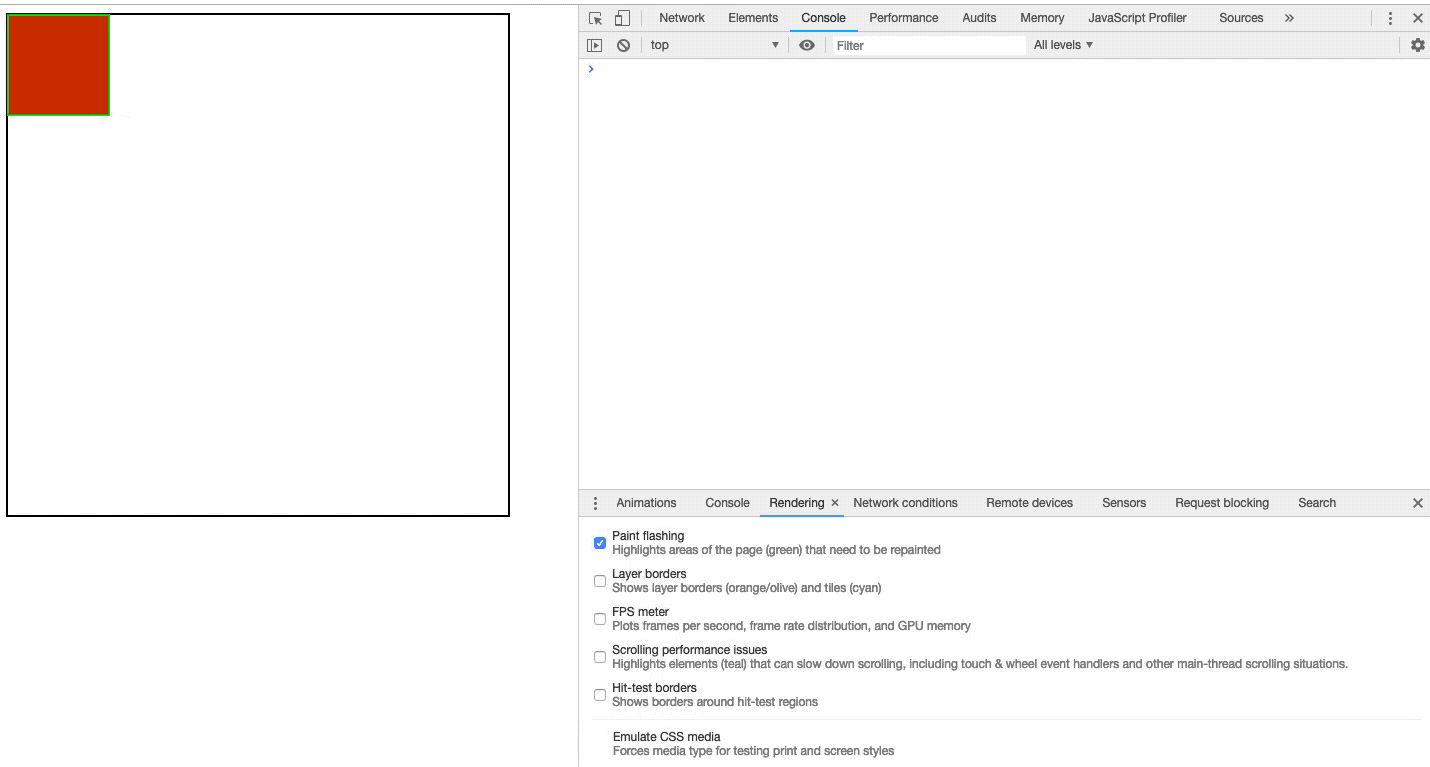

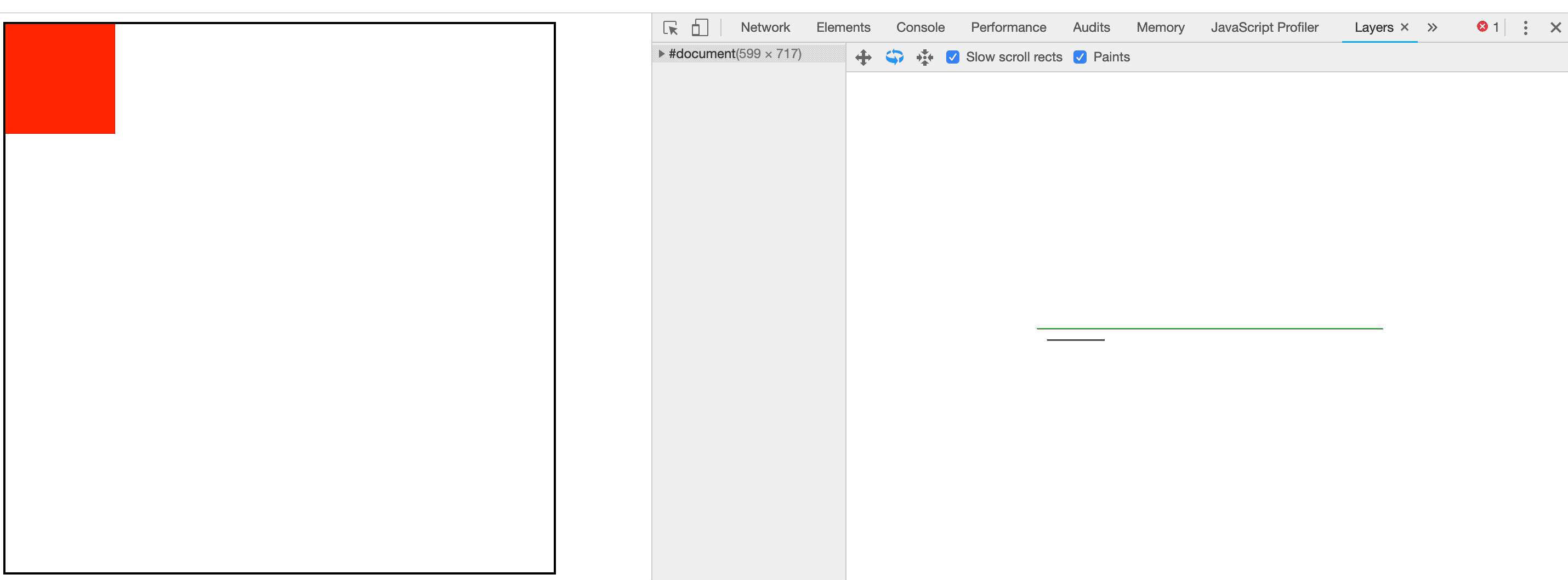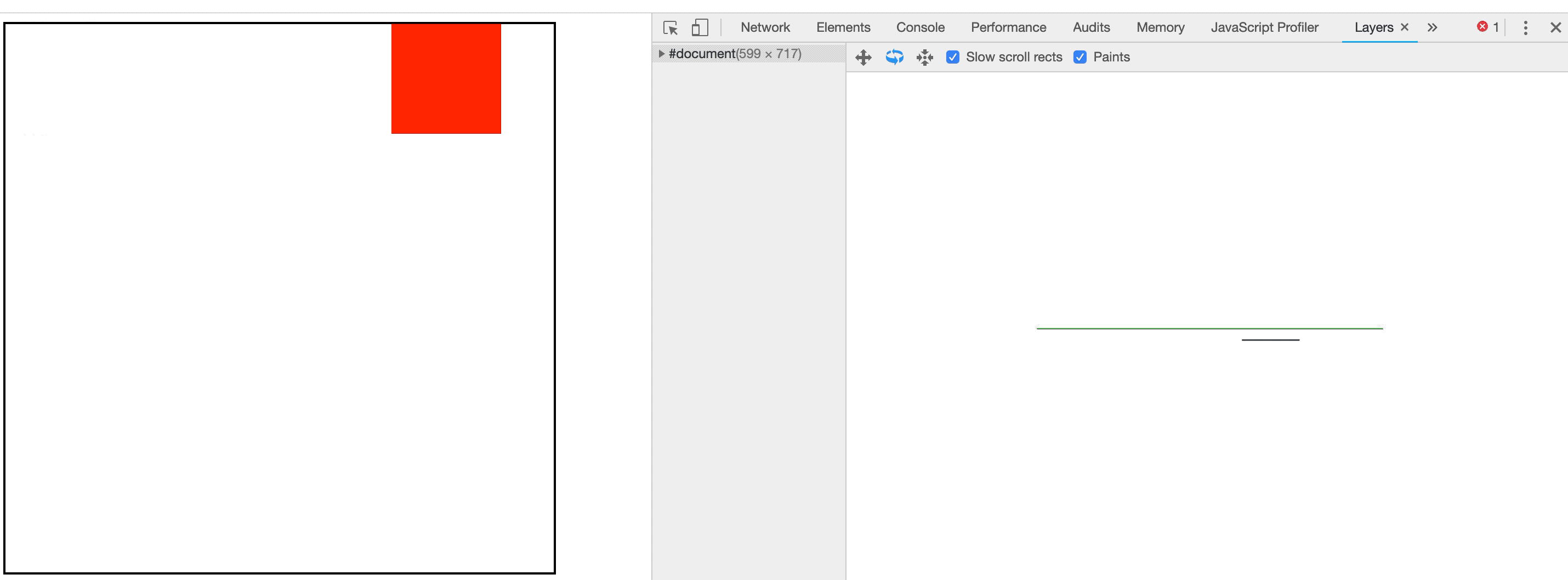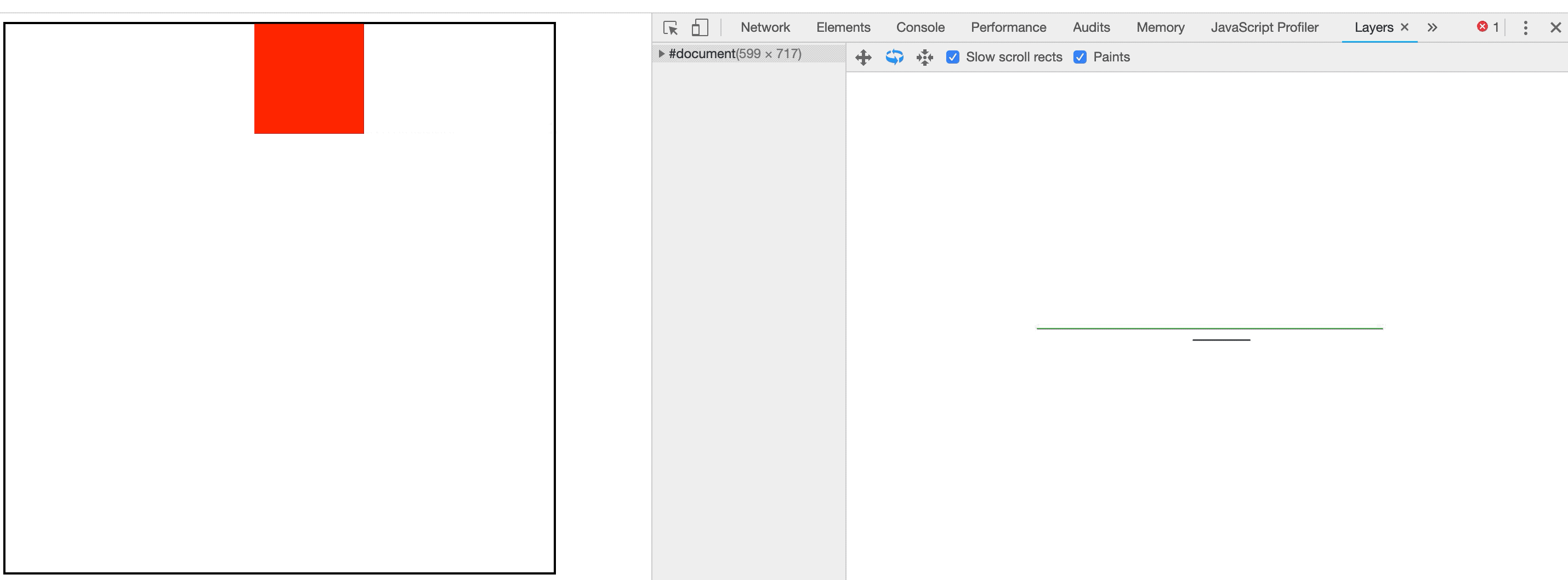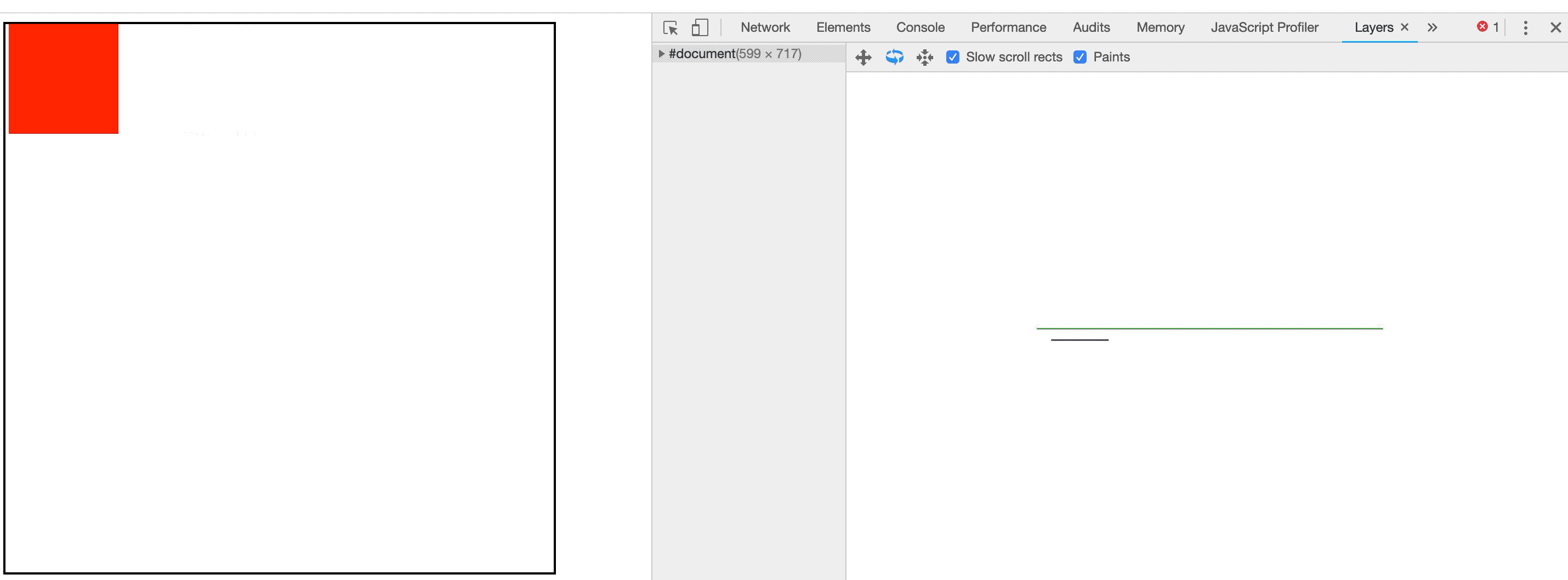
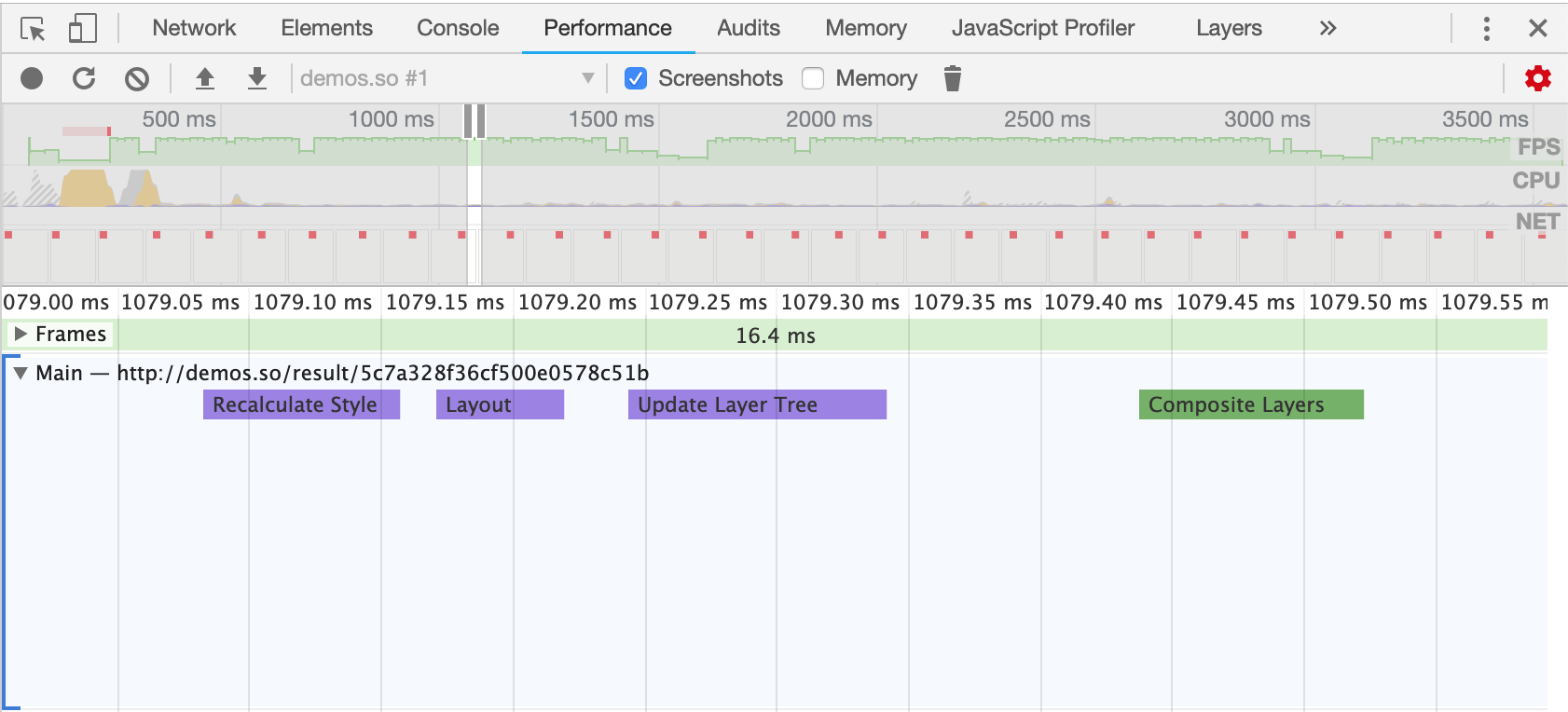
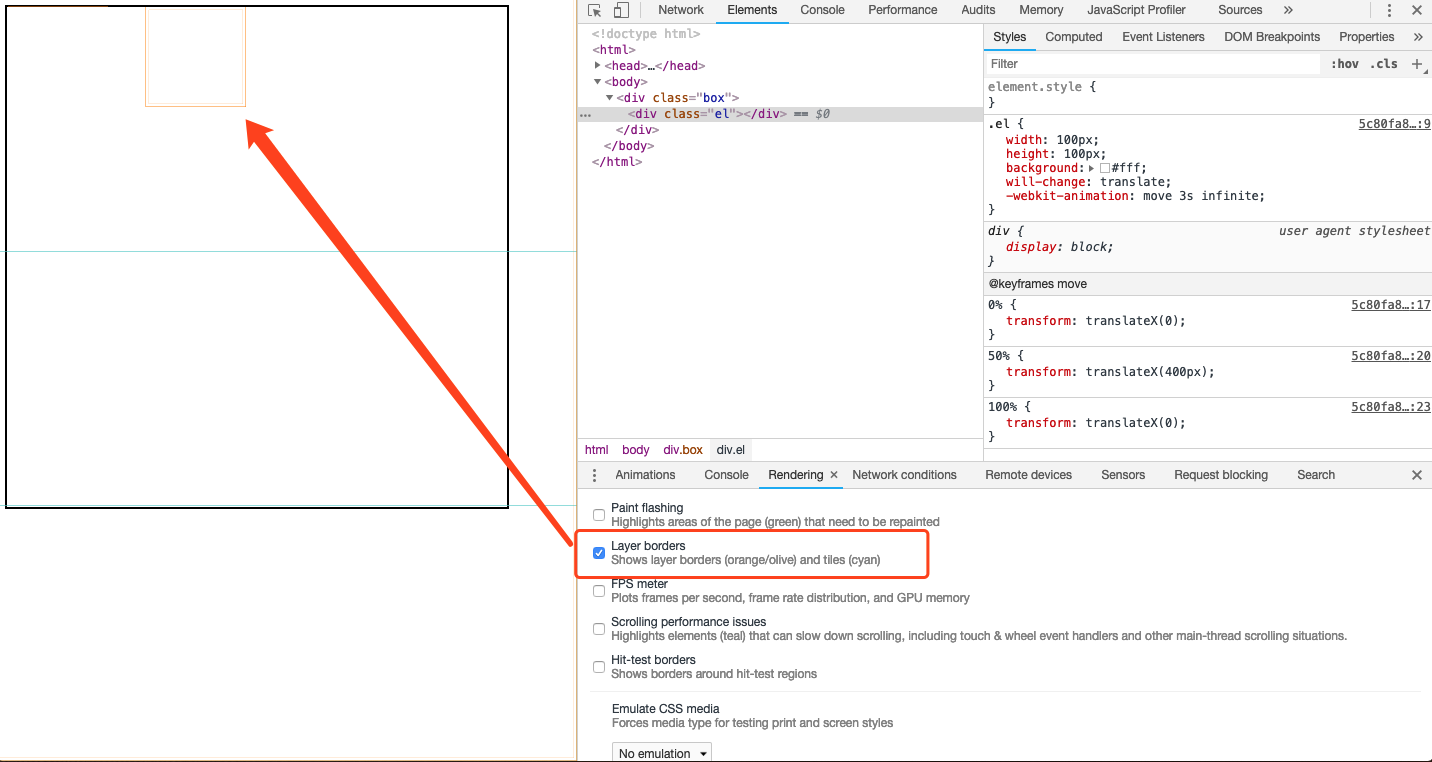




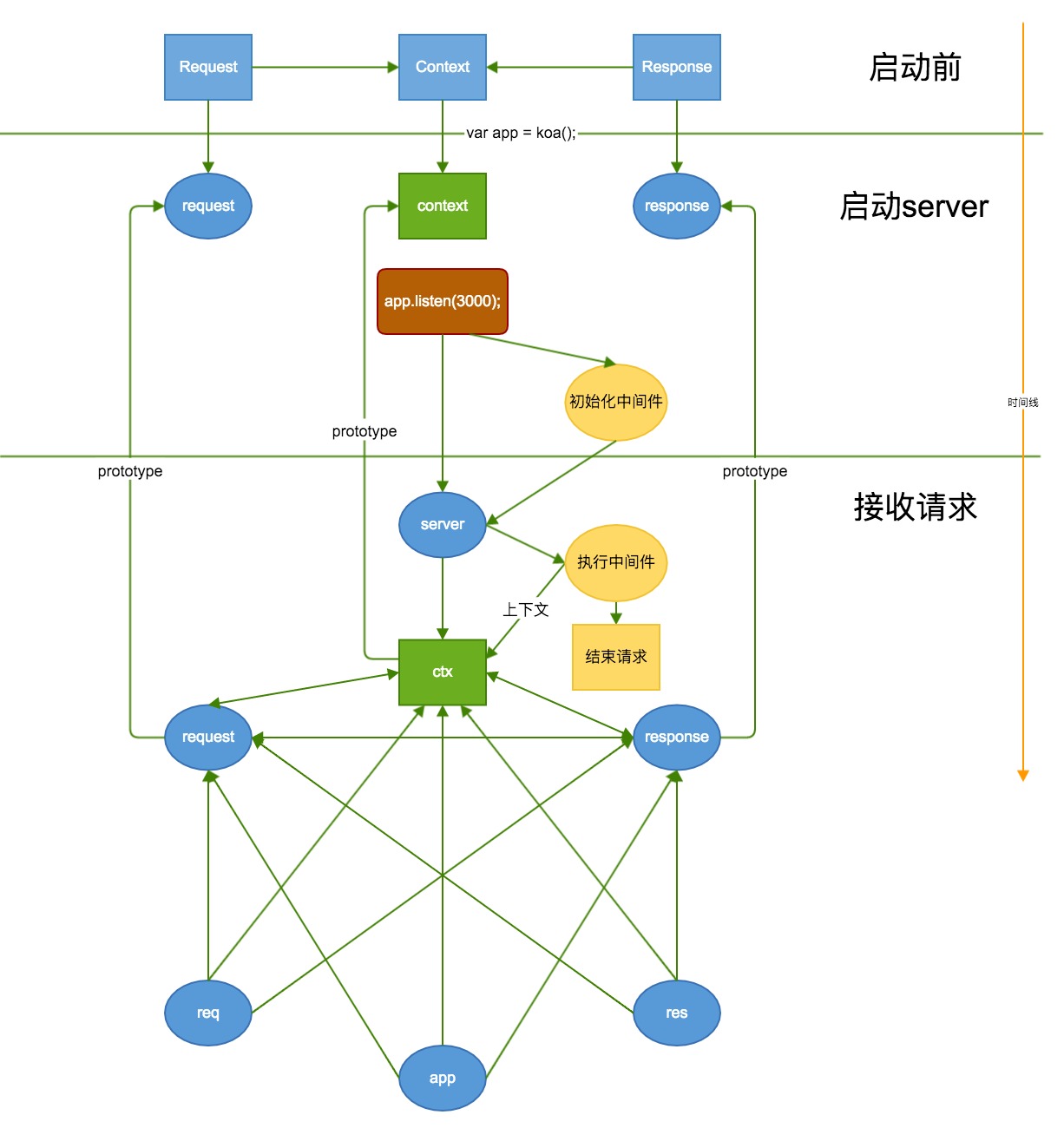
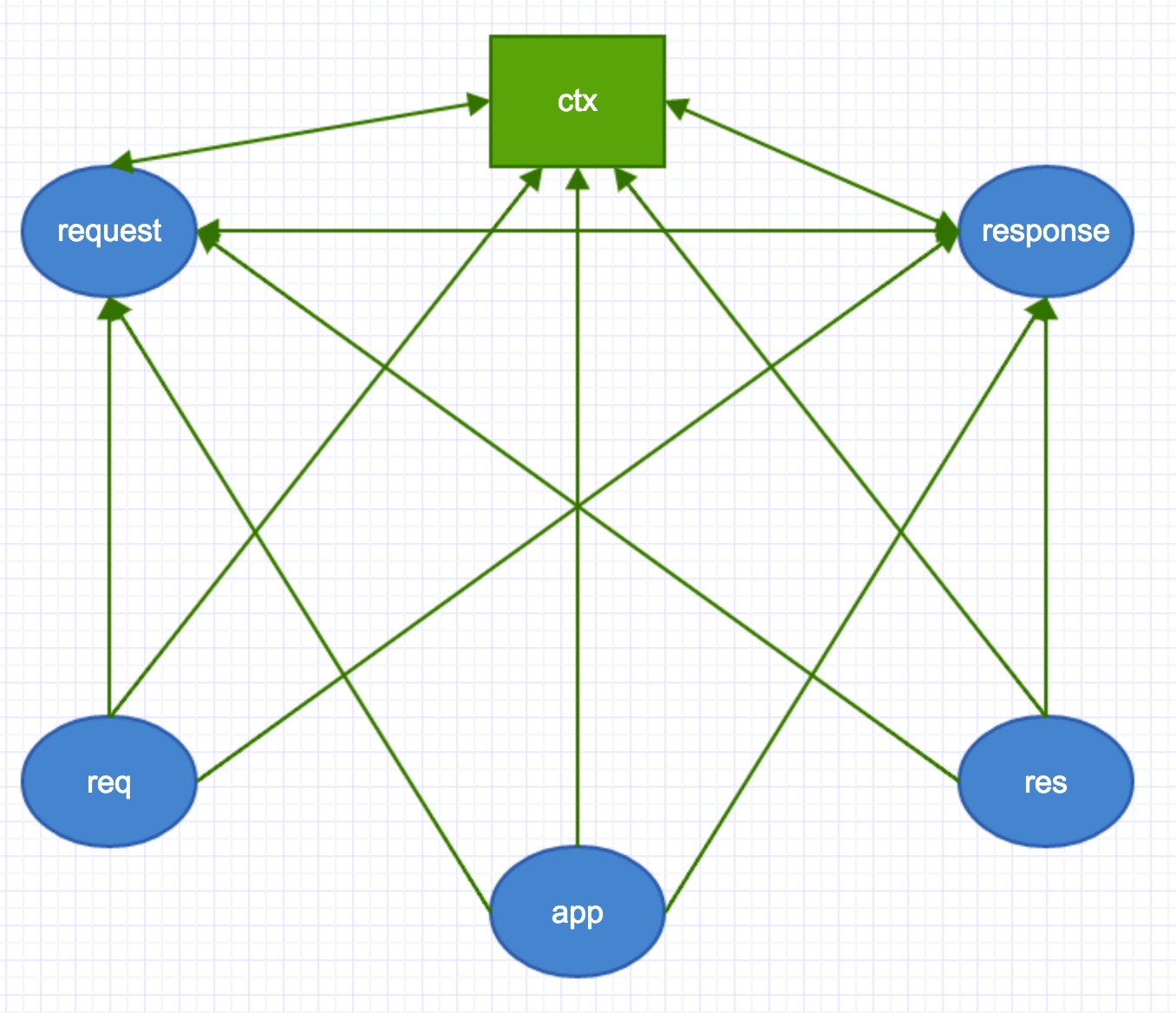
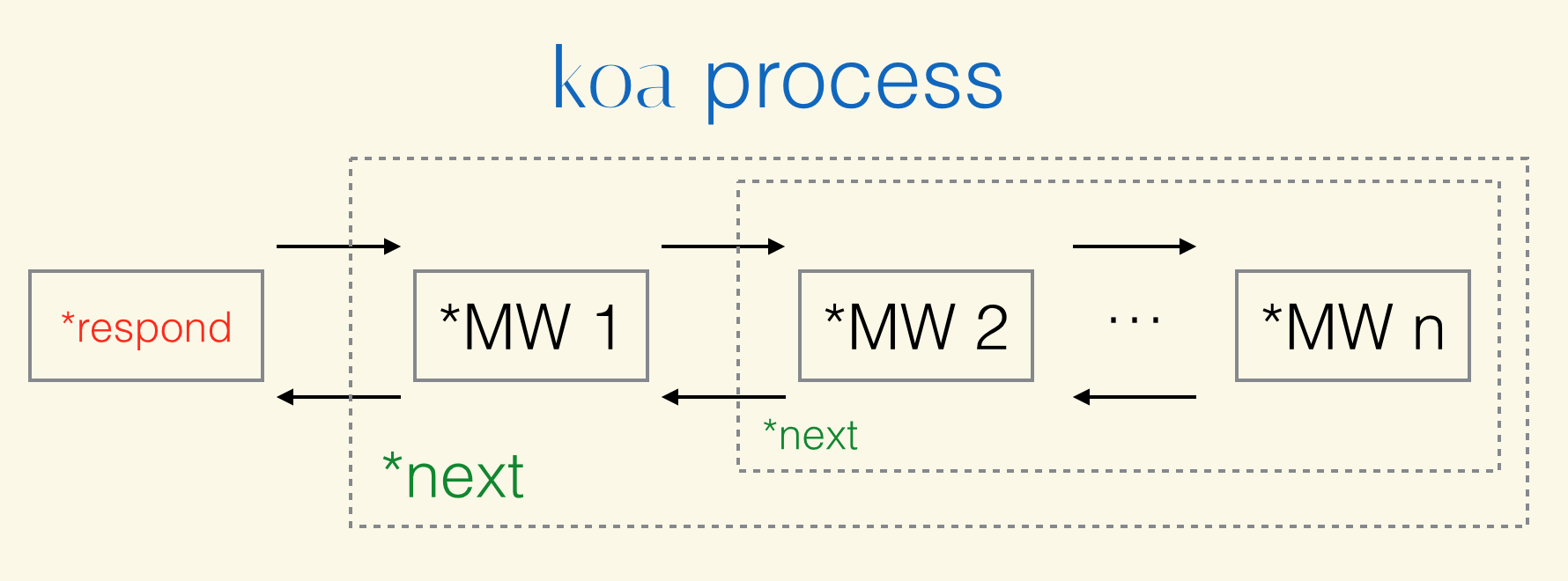
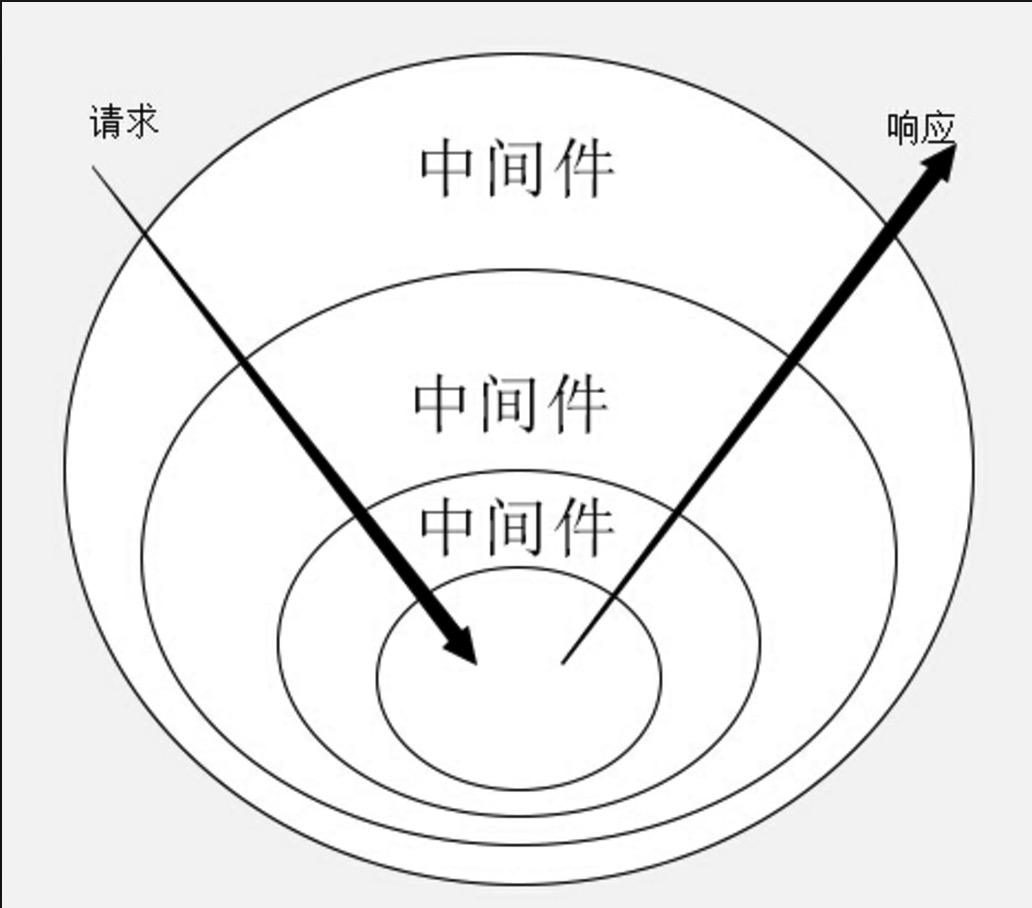
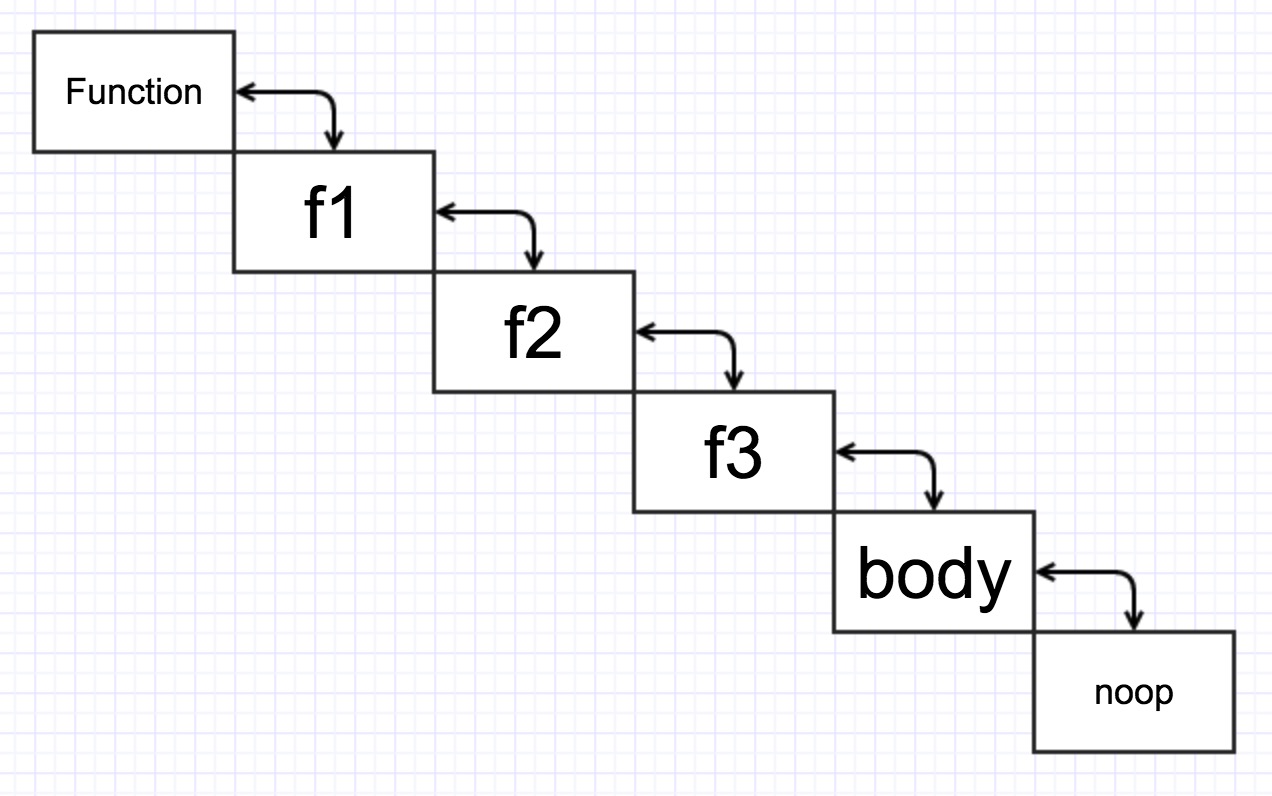














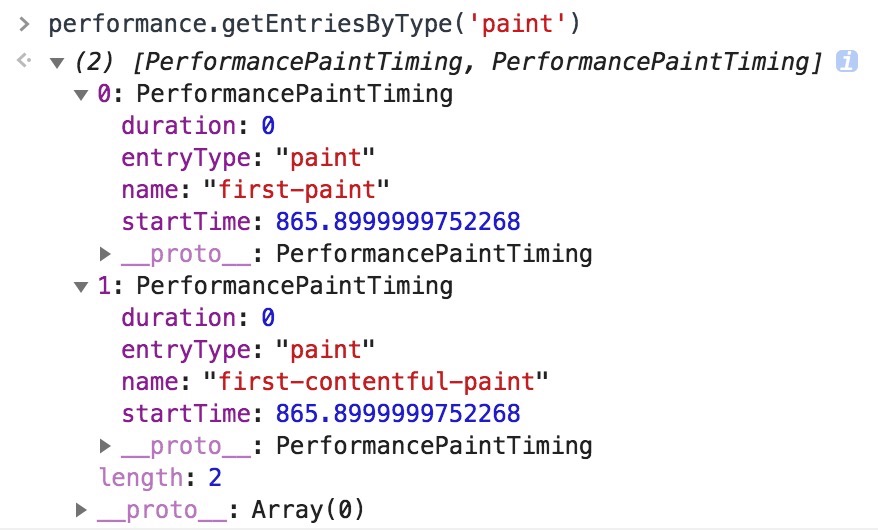









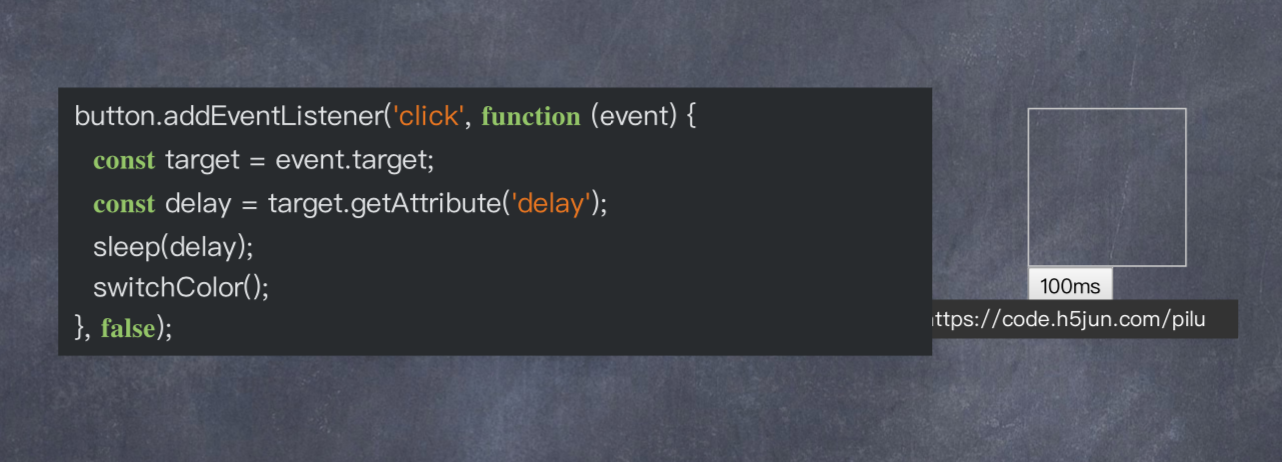
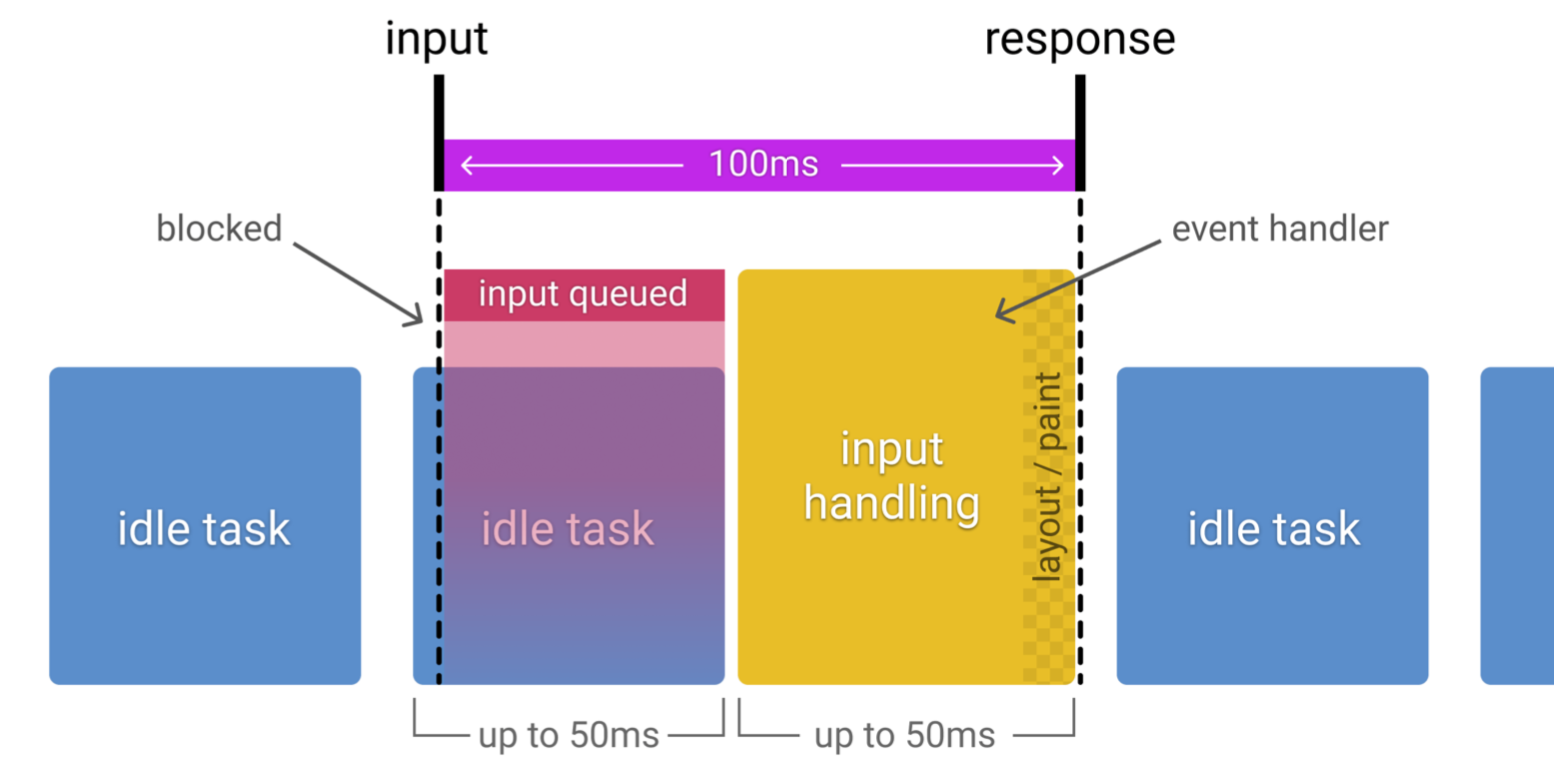














































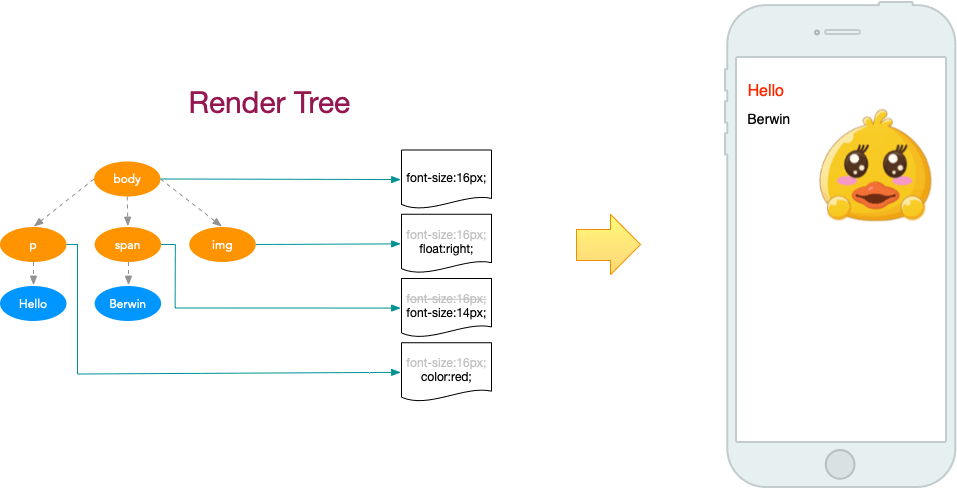

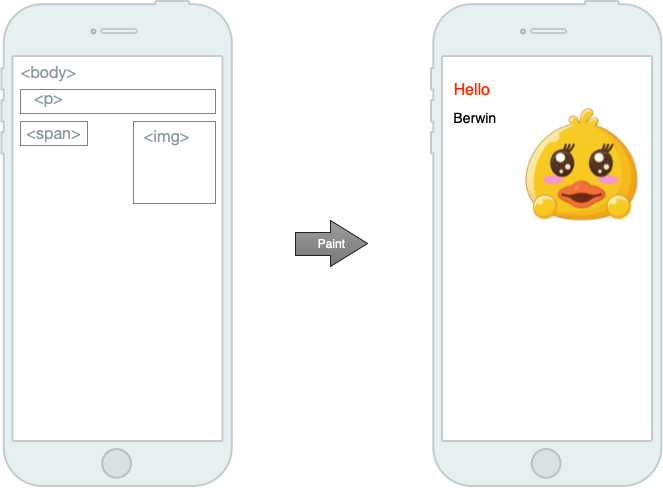

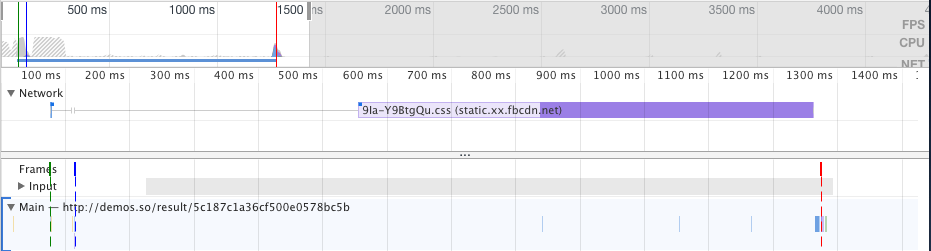
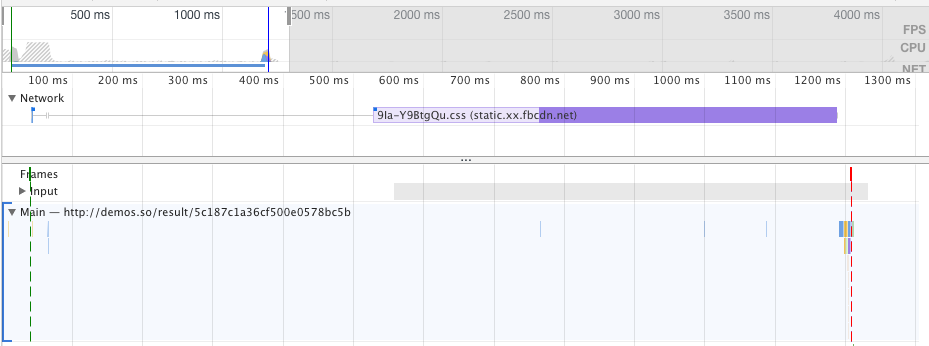




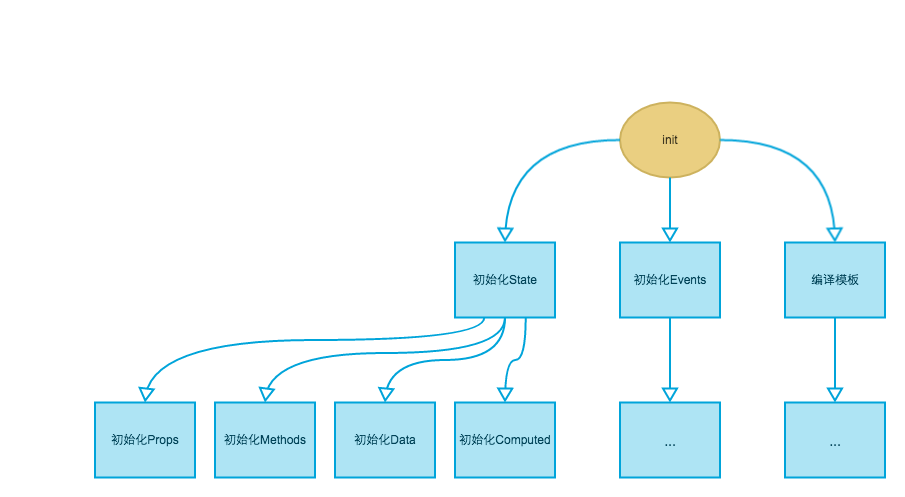
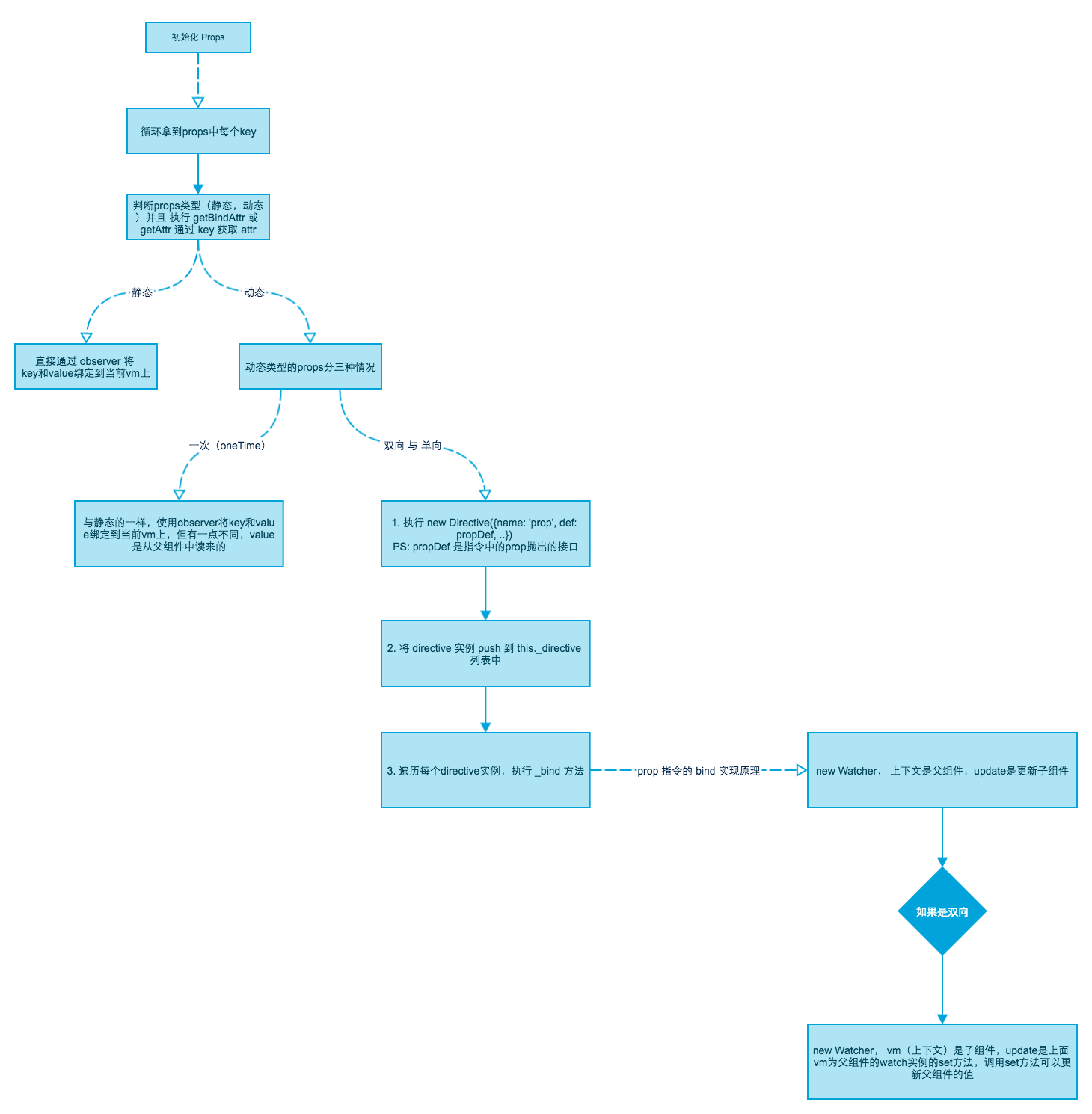
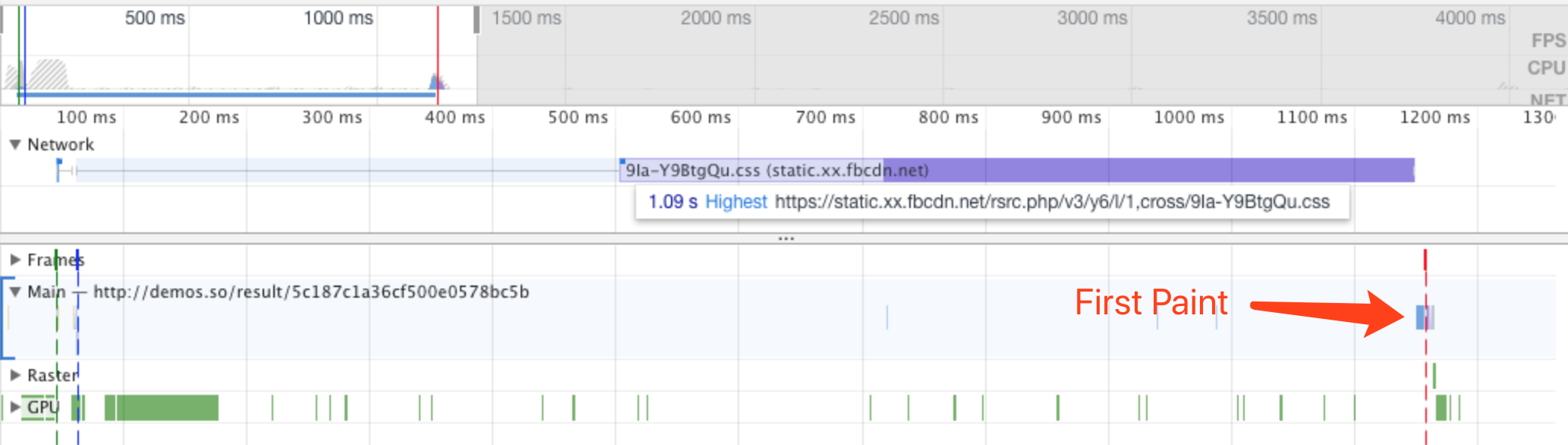

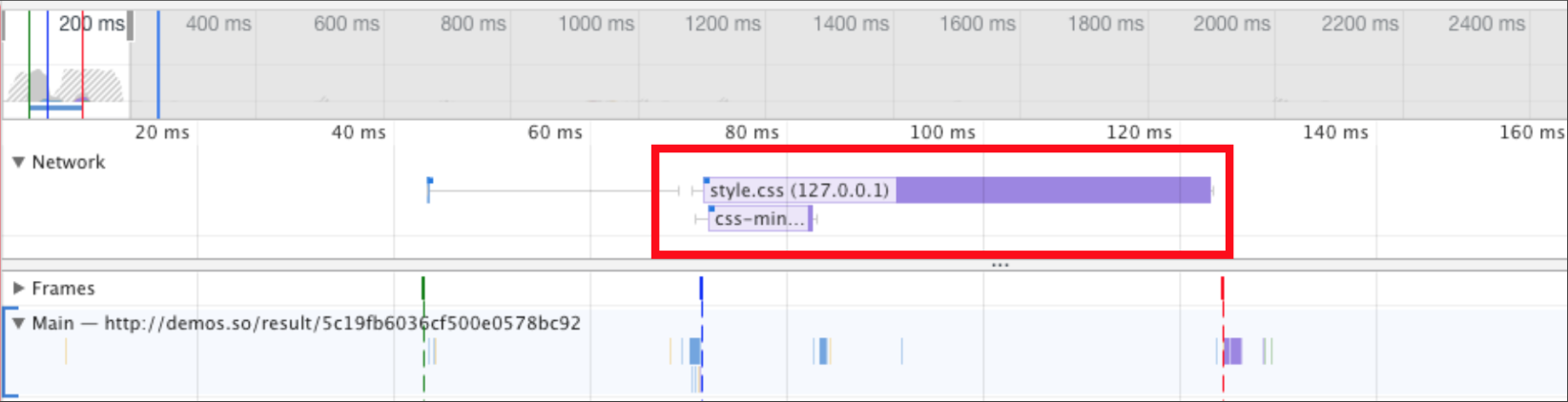
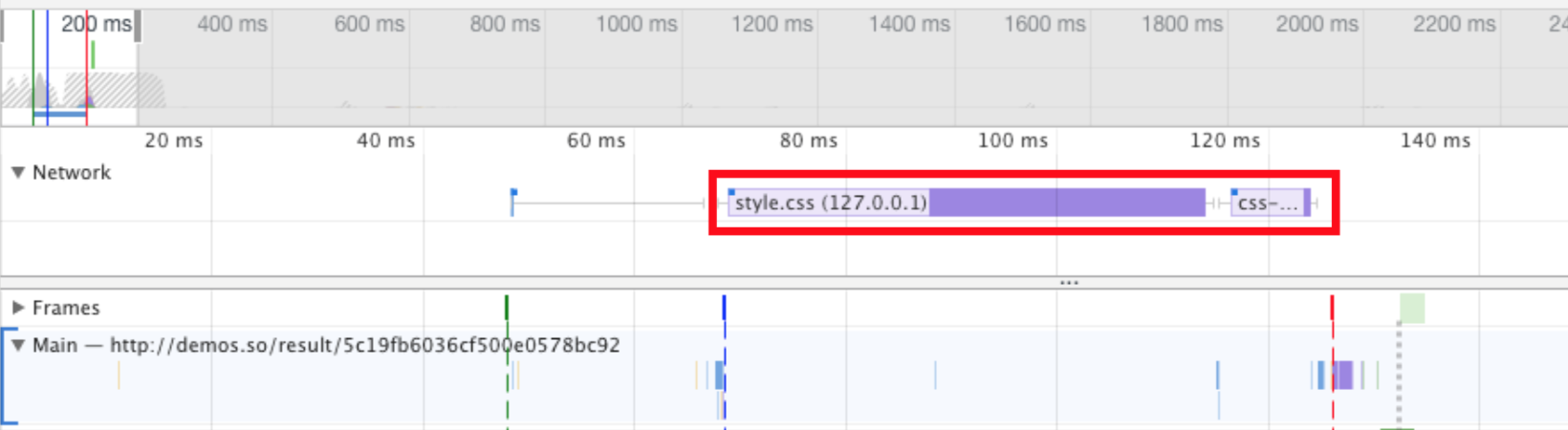



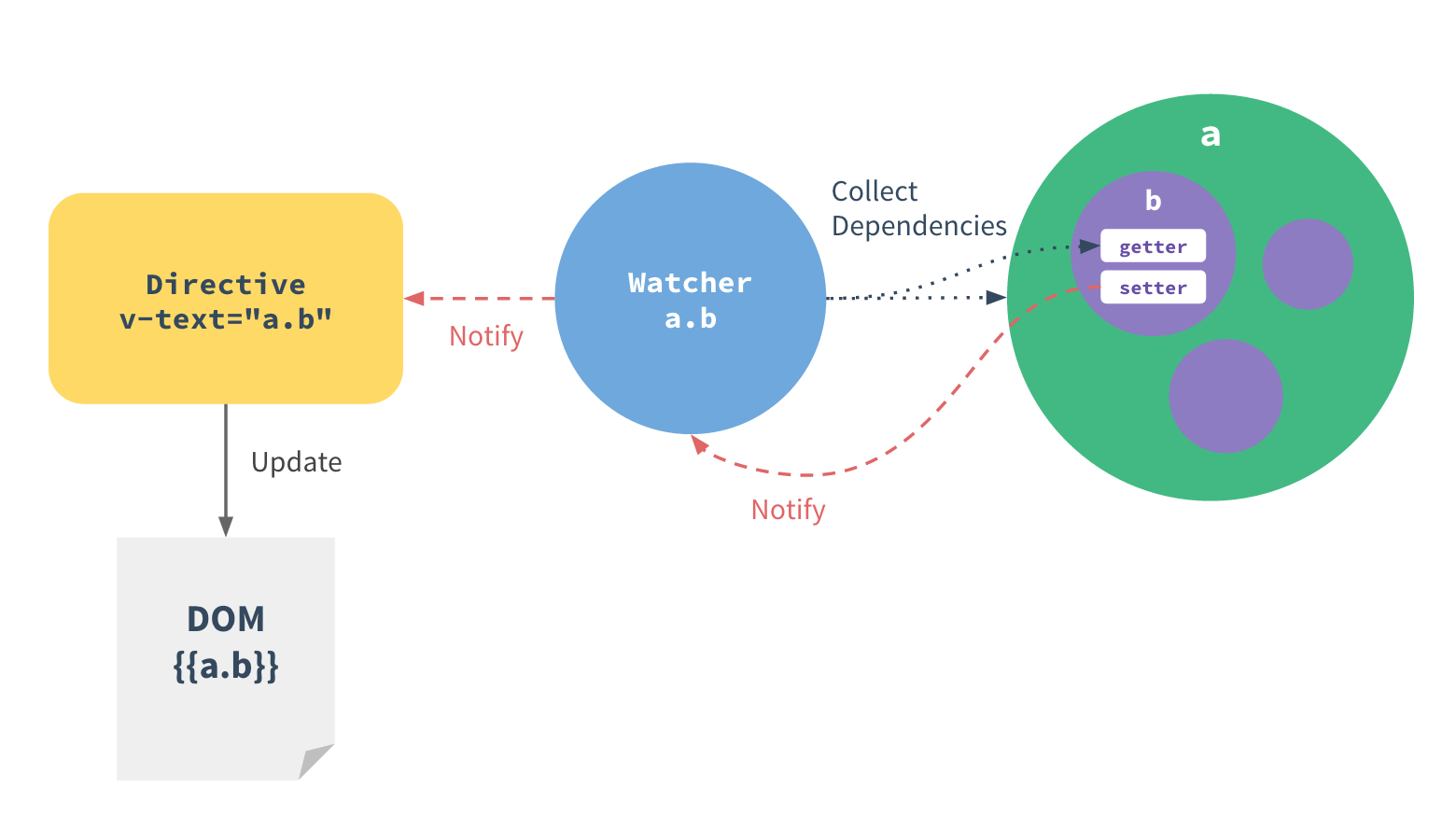



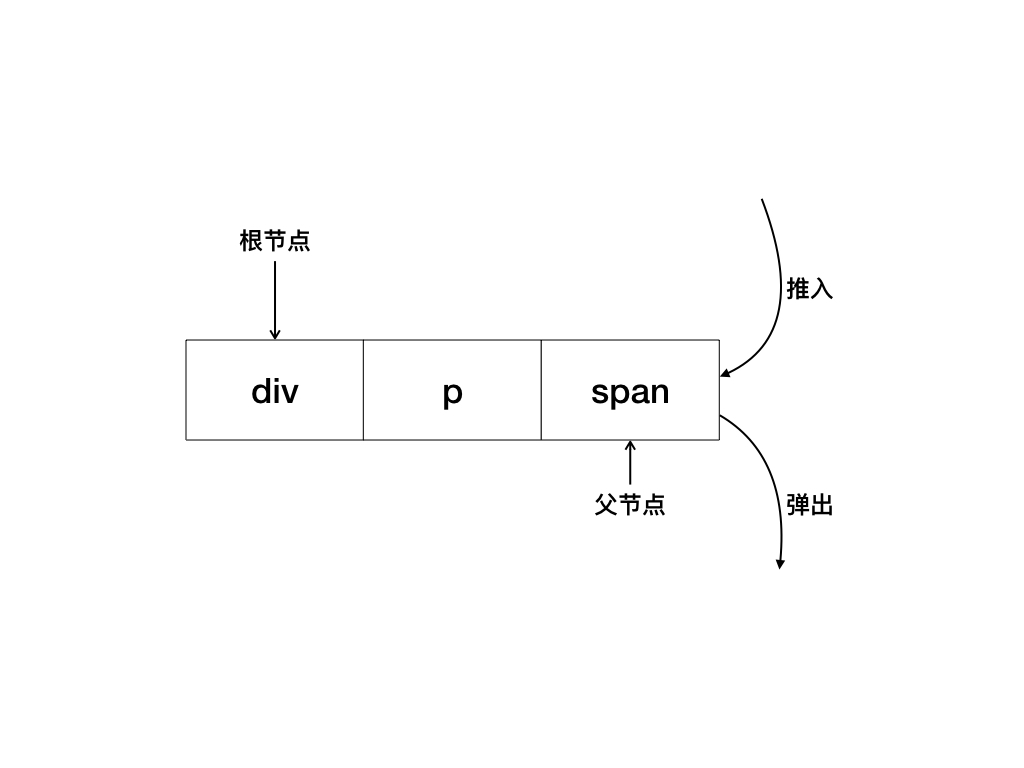
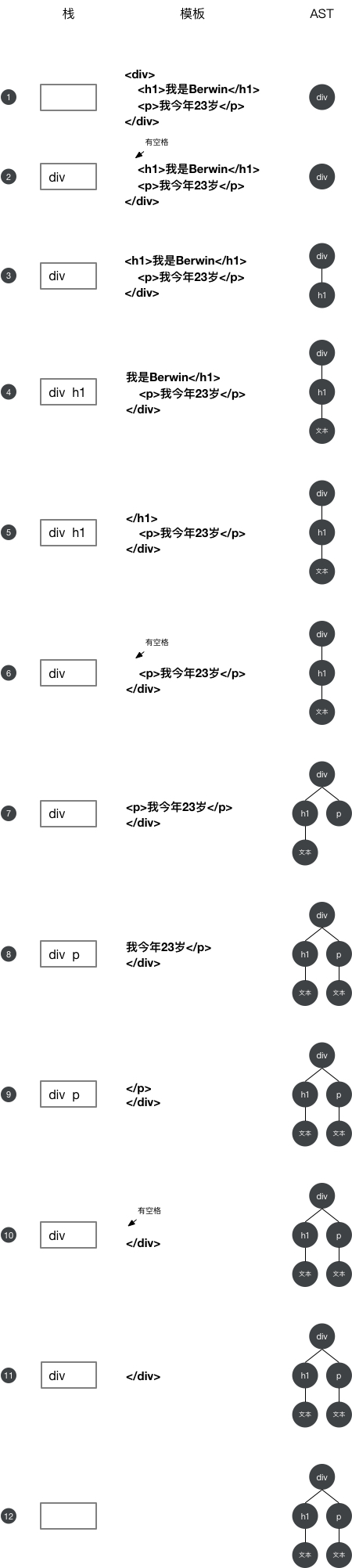


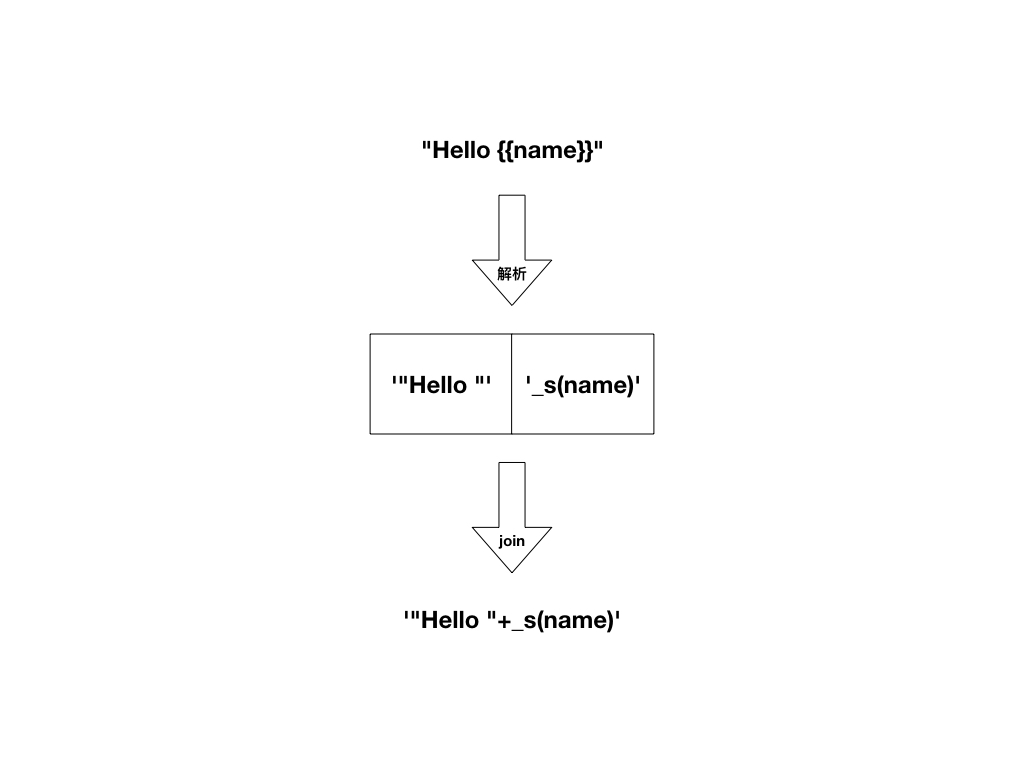









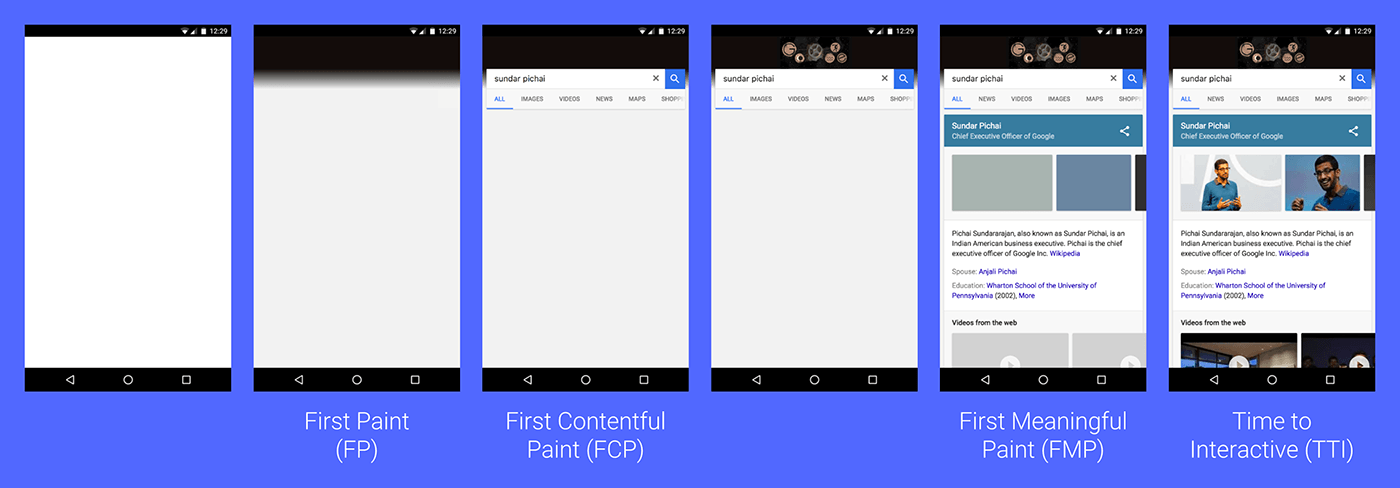
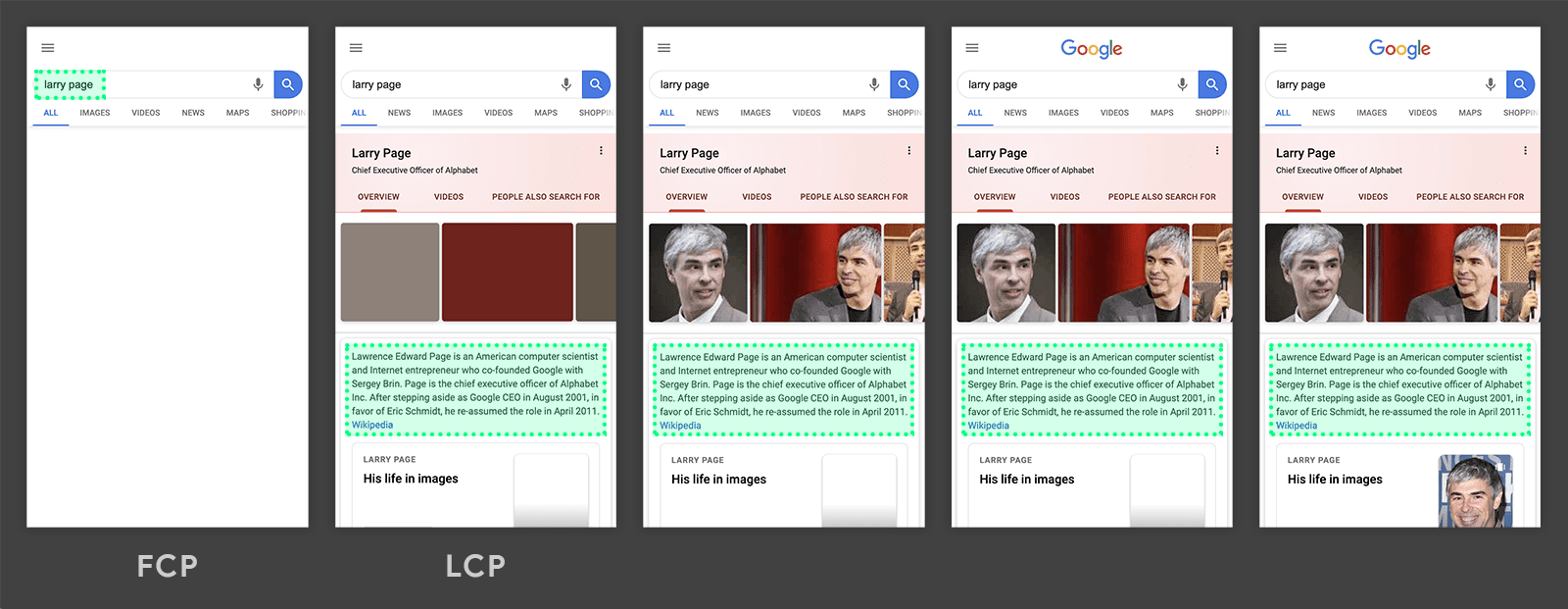



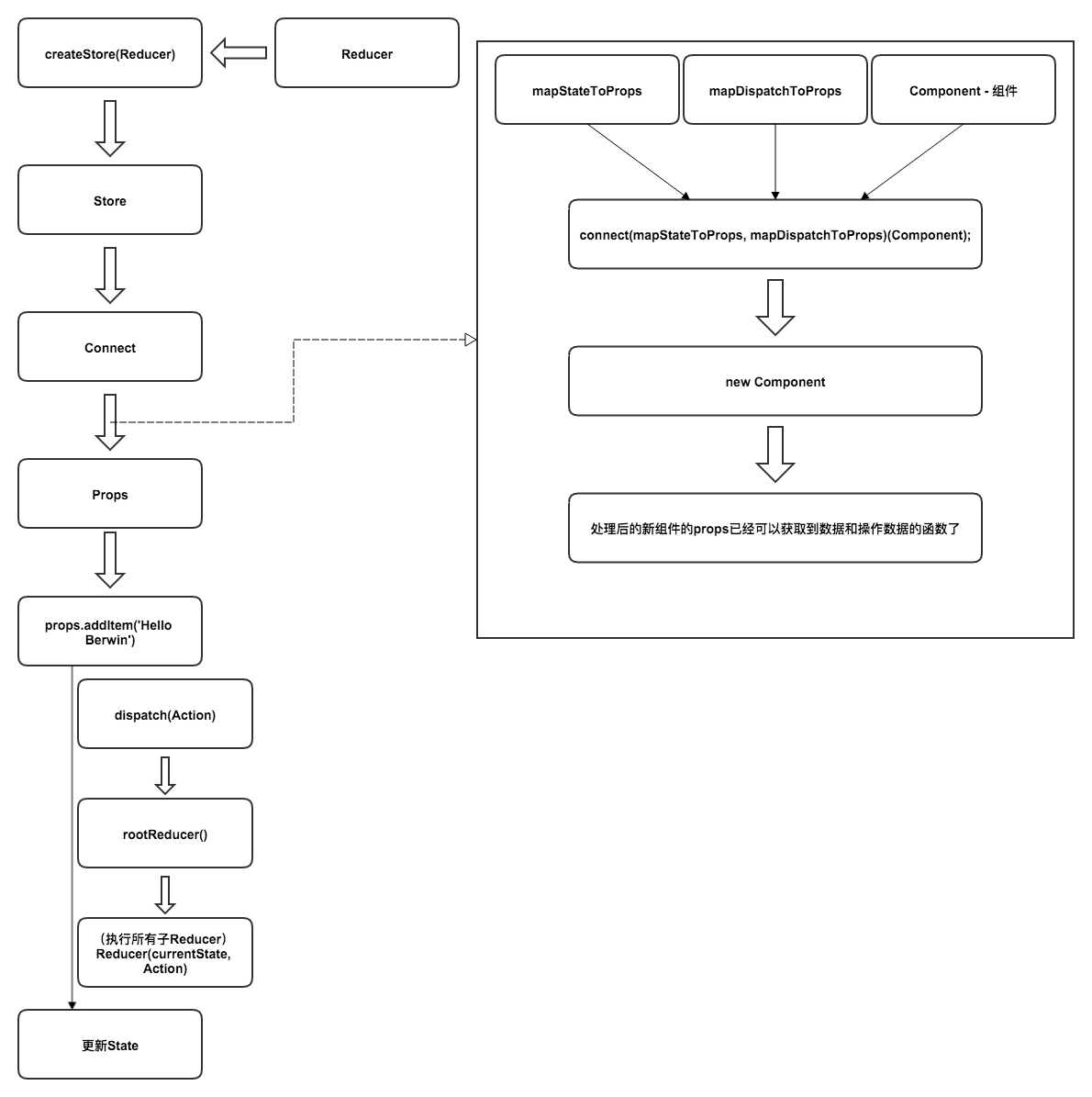


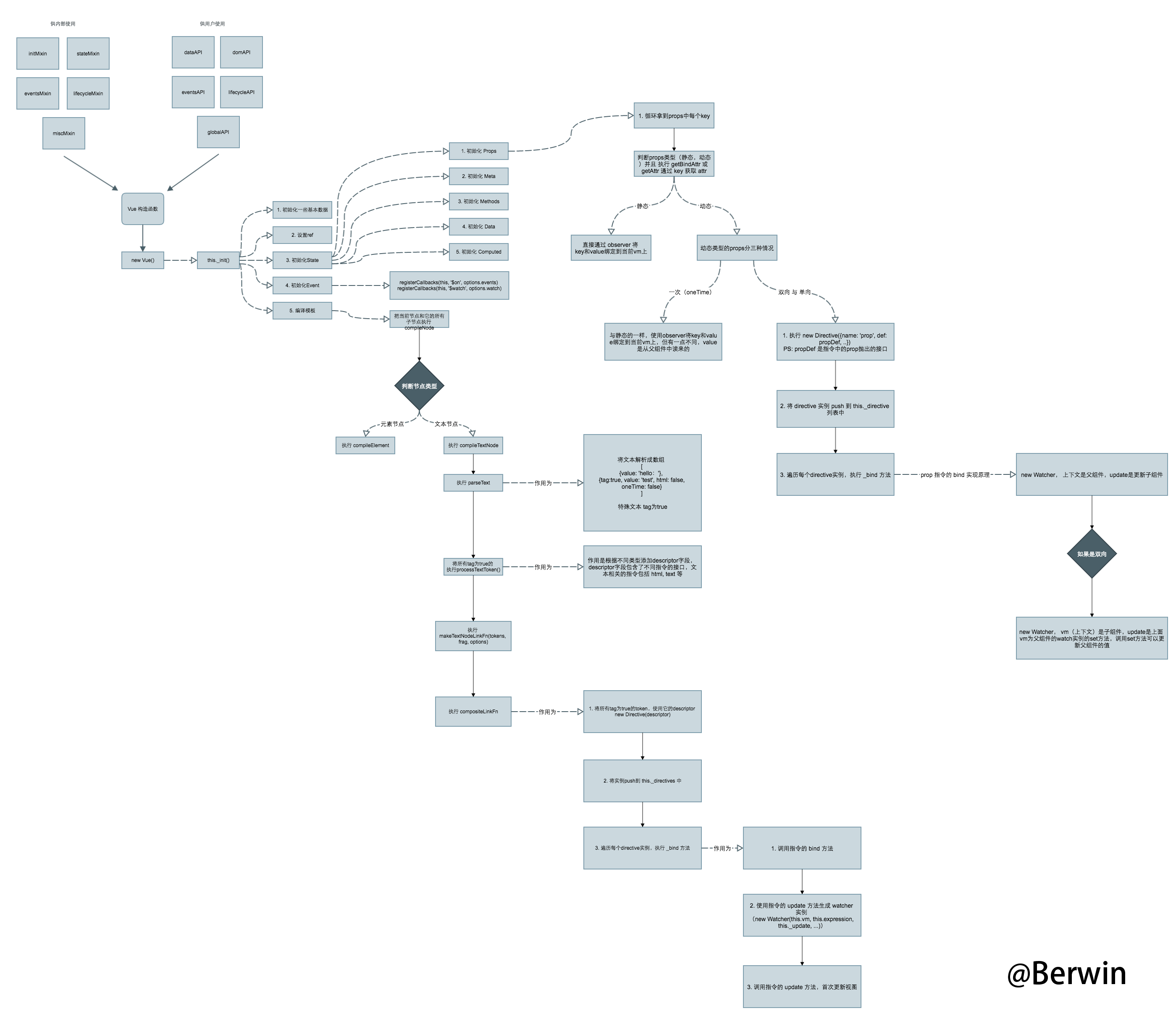{kind=link}
{kind=link}