bbrzycki / setigen Goto Github PK
View Code? Open in Web Editor NEWPython library for generating and injecting artificial narrow-band signals into radio frequency data
Home Page: https://setigen.readthedocs.io
License: MIT License
Python library for generating and injecting artificial narrow-band signals into radio frequency data
Home Page: https://setigen.readthedocs.io
License: MIT License



























Expectation
The program below would run to conclusions without errors or it would clearly and consisely log a setigen limitation before throwing an exception.
My program
import setigen as stg
from setigen.waterfall_utils import min_freq, max_freq
from blimpy import Waterfall
DIR = '/seti_data/turbo_seti_issue_135/'
INFILE = DIR + 'guppi_59196_68468_000762_Unknown_0001.rawspec.0000.h5'
def import_bl_file(path_infile):
r'''
Using setigen, import a BL file (.fil, .h5).
'''
print('Input file:', path_infile)
wf = Waterfall(path_infile)
print('Waterfall data loaded?', wf.container.load_data)
print(wf.info())
# Instantiate a setigen Frame object
frame = stg.Frame(waterfall=wf)
print('Drift rate:', frame.get_drift_rate(0, -1))
print('Noise stats:', frame.get_noise_stats())
print('min freq:', min_freq(wf))
print('max freq:', max_freq(wf))
import_bl_file(INFILE)
Stdout
Input file: /seti_data/turbo_seti_issue_135/guppi_59196_68468_000762_Unknown_0001.rawspec.0000.h5
blimpy.io.base_reader WARNING Selection size of 7.50 GB, exceeding our size limit 1.00 GB. Instance created, header loaded, but data not loaded, please try another (t,v) selection.
--- File Info ---
DIMENSION_LABELS : ['time' 'feed_id' 'frequency']
az_start : 0.0
data_type : 1
fch1 : 8437.625 MHz
foff : 1.9073486328125e-06 MHz
ibeam : -1
machine_id : 20
nbeams : 1
nbits : 32
nchans : 33554432
nifs : 1
rawdatafile : guppi_59196_68468_000762_Unknown_0001.0000.raw
source_name : Unknown
src_dej : 0:00:00
src_raj : 0:00:00
telescope_id : -1
tsamp : 2.097152
tstart (ISOT) : 2020-12-13T19:01:08.000
tstart (MJD) : 59196.7924537037
za_start : 0.0
Num ints in file : 60
File shape : (60, 1, 33554432)
--- Selection Info ---
Data selection shape : (60, 1, 33554432)
Minimum freq (MHz) : 8437.625
Maximum freq (MHz) : 8501.624998092651
None
Traceback (most recent call last):
File "/home/elkins/seti_testing/blimpy_testing/stg_bug.py", line 24, in <module>
import_bl_file(INFILE)
File "/home/elkins/seti_testing/blimpy_testing/stg_bug.py", line 18, in import_bl_file
frame = stg.Frame(waterfall=wf)
File "/home/elkins/.local/lib/python3.8/site-packages/setigen/frame.py", line 120, in __init__
self.data = waterfall_utils.get_data(self.waterfall)[:, ::-1]
File "/home/elkins/.local/lib/python3.8/site-packages/setigen/waterfall_utils.py", line 75, in get_data
return waterfall.data[:, 0, :]
IndexError: too many indices for array: array is 1-dimensional, but 3 were indexed
The setigen utility is very interesting. Gave me some ideas for enhancing blimpy. Clearly, you put a lot of effort into it.
The documentation needs a review, in general:
E.g. setigen.stats module
All of the functions need explanation, including the input parameters.
I was wondering why there is no setigen.stats.get_max() since you have a get_min(). Just never had a need?
E.g. the Frame functions
Specifically, get_noise_stats() returns 2 floating-point numbers. Is that the mean noise and the standard deviation for the entirety of the time and frequency domains? How is this calculated.
How does get_total_stats() differ from get_noise_stats()?
The mean() and std() functions are based on what set of values? Signal power of the data in the frame?
render(use_db=False): if you are not plotting signal power values then what is the use_db= purpose?
render(): Frequency and time in pixels? I would have thought that MHz and seconds would be more convenient display for Seti BL folks. I might be missing something. Yes, I found bl_render() more interesting.
It is impractical to download or even access every H5 or Filterbank file where trouble is reported. In order to investigate, it is highly desirable to be able to synthesize Filterbank files that resemble the file in question. E.g. a large data array file from observations of Tabby's Star (KIC8462852):
--- File Info ---
machine_id : 20
telescope_id : 6
data_type : 1
fch1 : 19626.464842353016 MHz
foff : -2.7939677238464355e-06 MHz
nchans : 134217728
source_name : maserA
src_raj : 20:39:29.112
src_dej : 11:12:59.4
az_start : 0.0
za_start : 0.0
nbits : 32
tstart (ISOT) : 2016-12-19T20:44:33.000
tstart (MJD) : 57741.864270833335
tsamp : 18.253611008
nifs : 1
Num ints in file : 5
File shape : (5, 1, 134217728)
--- Selection Info ---
Data selection shape : (5, 1, 134217728)
Minimum freq (MHz) : 19251.464845146984
Maximum freq (MHz) : 19626.464842353016
To reproduce this issue, run the source file inside the attached ZIP file like this inside a terminal window:
python3 synthia.py
Linux reports: killed on an octacore with 16 GB RAM (mostly free).
Just change the value of the DIR variable to point to an output directory for saving the Filterbank file.
No other parameters needed.
Hey @bbrzycki, I'm working on some dedoppler efficiency tests, which brought up some setigen questions!
Firstly, how does setigen deal with signals with a drift rate larger than freq_resolution / time_resolution? (At first glance it didn't look like this was supported). The power for these will be spread over multiple channels causing 'smearing' and associated loss in S/N.
Secondly, I am realising that the FFT (or PFB) will affect how drifting signals manifest. A signal that starts in the middle of channel F0 will drift into channel F1, but there will be a period of time in which it is halfway between the two -- at which point it will actually appear in both channels, but at a lower S/N. There is also some 'scalloping loss' which occurs as the signal leaks across the full spectrum. Here's a simulation I did with a chirped waveform into an FFT filterbank:
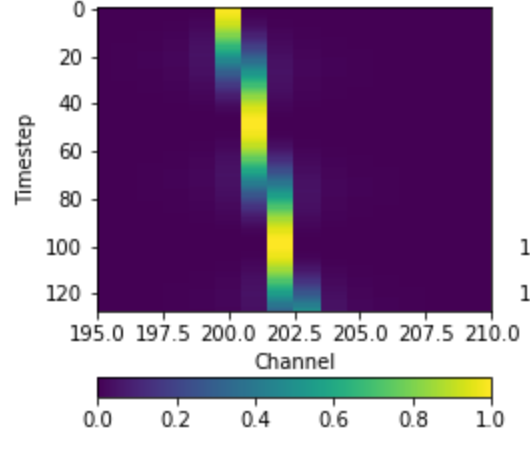
(you can do better with an oversampled PFB).
To accurately evaluate dedoppler efficiency we would need to take both into account. I think doppler smearing would be straightforward to implement, but scalloping loss would be a bit of a nightmare -- and would depend on what kind of filterbank you had.
It looks like @telegraphic is beginning significant work in blimpy to support multiple IFs (polarisation arrays) per time-integration. It would be very helpful to be able to generate Filterbank files as such using setigen.
I've been using setigen as a base to generate mock FRBs. Here's some example code:
def gauss2(x, a, x0, fwhm):
""" Generate gaussian^2 pulse
Args:
x: time series (np.arange())
a: amplitude of pulse. (total integrated power across pulse)
x0: index of peak value
fwhm: width of signal in samples
"""
sigma = (fwhm / 2) / np.sqrt(2*np.log(2))
return a / np.sqrt(2*np.pi*sigma**2) * np.exp(-(x-x0)**2 / (2*sigma**2))
def generate_frb(frame, frb_params):
""" Simple FRB generator
Args:
frame (setigen.Frame): A filterbank frame of data, from setigen
frb_params (dict): A dictionary with FRB parameters in it
Notes:
frb_params should contain width (in s), desired SNR, start time (in s), and DM
"""
frb_width, frb_snr, frb_t0, frb_dm = frb_params['width'], frb_params['snr'], frb_params['t0'], frb_params['dm'],
frb_rms = frame.get_intensity(snr=frb_snr)
fch1 = frame.get_frequency(0)
## Generate pulse delays - array has same length as freqs
width_in_chans = frb_width / frame.dt
t0_in_samps = (frb_t0 / frame.dt) - frame.ts[0]
tdel_in_samps = 4.15e-3 * frb_dm * ((fch1/1e9)**(-2) - (frame.fs/1e9)**(-2)) / frame.dt
t0_in_samps = t0_in_samps + tdel_in_samps
# Time axis in samples
t = np.arange(frame.tchans)
# Use meshgrid to create (N_time, N_freq) array
t2d, tdel2d = np.meshgrid(t, t0_in_samps)
# Create pulse profile via 2D time (N_time,1) and time_delay (N_freq, 1) arrays
profile = gauss2(t2d, frb_rms, tdel2d, width_in_chans)
return profile.T
## Example usage
frame = stg.Frame(fchans=1024*u.pixel,
tchans=1024*2*u.pixel,
df=100.0*u.kHz,
dt=1*u.ms,
fch1=300*u.MHz)
noise = frame.add_noise(x_mean=10, noise_type='chi2')
frb_params = {'snr': 10000.0,
't0': 500e-3,
'dm': 3,
'width': 10e-3}
p = generate_frb(frame, frb_params)
frame.data += p
frb_params = {'snr': 10000.0,
't0': 1000e-3,
'dm': 10,
'width': 10e-3}
p = generate_frb(frame, frb_params)
frame.data += p
frame.plot()Which gives the following output:

Just a proof of concept, but might be worth adding some functionality? This could be useful for FRB studies, and also for SETI seraches for artificial pulses (e.g. different exponents, negative DMs).
As demonstrated in the cadences.ippynb in jupyter-notebooks/spectrogram, 6 frames are generated using the SETI ON/OFF cadence. I have saved these frames into 6 frame_0[0-5].h5 files and try to run it against turboSETI/plotSETI. The latter can not find hits using the plotSETI -f3 argument. This is caused by the fact the t_start of the frames are defaulted in the setigen Frame class by the "_update_waterfall" method. Though the t_start is provided as part of the Frame(... **kwargs), its value is defaulted in the mentioned method. This results into a wrong filterbank/h5 headers in the saved files. which do have all the same t_start times, hence plotSETI can not find hits.
Below the tstart times of the first 2 frames out of 6:
(hyperseti) marc@gamma2:~/tmp/test> watutil frame_00.h5 |grep tstart
tstart (ISOT) : 2018-12-13T17:12:37.000
tstart (MJD) : 58465.717094907406
(hyperseti) marc@gamma2:~/tmp/test> watutil frame_01.h5 |grep tstart
tstart (ISOT) : 2018-12-13T17:12:37.000
tstart (MJD) : 58465.717094907406
Sample code based on the jupyter notebook:
def create_time_array(cadence_number=6, mjd_start=60000, obs_length=300, slew_time=0):
'''
'''
t_start_arr = [Time(mjd_start, format='mjd').unix]
for i in range(1, cadence_number):
t_start_arr.append(t_start_arr[i - 1] + obs_length + slew_time)
return t_start_arr
def create_frame(source_name, t_start, df, dt, obs_length):
'''
'''
frame = stg.Frame(fchans=512,
tchans=int(obs_length/dt),
df=df,
dt=18.253611008,
fch1=1330*u.MHz,
ascending=False,
t_start=t_start,
source_name=source_name)
print(frame.t_start)
return frame
Plot of generated frames

TurboSETI cli log
For each HDF5 header, tstart is the same 'tstart': 58465.717094907406,
turbo_seti_cli.log
CAMRAS gitlab repo with used code
https://gitlab.camras.nl/seti/seti_dt_obs/-/blob/main/setigen/camras_gen.py
I've been using spectral kurtosis for flagging in hyperseti, and have noticed that the noise statistics generated by setigen don't quite match what is expected from the generalized spectral kurtosis estimator, see:
The SK variance should come out as 2 / sqrt(N_accumulations) for a 'Pearson type IV' distribution, which I think most setigen generated data should be. I think this is just a matter of scaling the PDF by averaging first, but the math is admittedly a bit hectic in those papers.
get_intensity uses the statistics of the non-integrated frame to compute the intensity for a desired SNR. The involves dividing by the square root of the number of time samples in the frame, presumably to account for the sqrt(N) increase in the noise after integrating the time samples together. This is valid for purely noise-like signals, but for signals from "real" data the change in SNR after integration can be substantially different. The use of sigma clipping can further exacerbate this. The attached histograms of a frame real data from GBT shows how the standard deviation of the sigma trimmed pre- and post-integrated data can vary substantially (over 3x in this case).
Giving get_intensity an option to use the statistics of the time-integrated spectrum instead of the statistics of the flattened (and non-integrated) frame would be a welcomed addition.

Computing the mean and std of large frames (e.g. ~16 million points) can suffer from floating point error when they are performed using float32 values. Both mean and std can be passed dtype=np.float64 to perform these computations using float64 instead and thereby retain better accuracy. One place where this could be added is here:
Line 398 in 5ca049f
but perhaps it would be good to add a dtype=np.float64 parameter to the enclosing function so that the user could specify a different type if desired.
Example code:
frame = stg.Frame(fchans=2**24,
tchans=32,
df=1.3969838619232178*u.Hz,
dt=1.4316557653333333*u.s,
fch1=6095.214842353016*u.MHz)
frame.save_fil('test.fil')
This gives something like:
Traceback (most recent call last):
File "/home/bryanb/setigen/setigen/frame.py", line 807, in save_fil
self.waterfall.write_to_fil(filename)
File "/home/bryanb/blimpy/blimpy/waterfall.py", line 317, in write_to_fil
write_to_fil(self, filename_out)
File "/home/bryanb/blimpy/blimpy/io/fil_writer.py", line 21, in write_to_fil
__write_to_fil_heavy(wf, filename_out)
File "/home/bryanb/blimpy/blimpy/io/fil_writer.py", line 50, in __write_to_fil_heavy
bob = wf.container.read_blob(blob_dim, n_blob=ii)
File "/home/bryanb/blimpy/blimpy/io/fil_reader.py", line 223, in read_blob
blob = dd.reshape((int(dd.shape[0]/blob_dim[self.freq_axis]),blob_dim[self.beam_axis],blob_dim[self.freq_axis]))
ValueError: cannot reshape array of size 32768 into shape (0,1,24576000)
This might be some sort of interaction with blimpy Waterfall metadata.
In jupyter file 06_starting_from_existing_raw_files.ipynb, in the block calling stg.voltage.RawVoltageBackend.from_data(), that method appears to require a "digitizer" argument. This is the error message:
TypeError: RawVoltageBackend.from_data() missing 1 required positional argument: 'digitizer'
Is it just a matter of adding additional argument "digitizer=digitizer"? Is this then ignored in rvb.record() with the argument "digitize=False"?
The setigen voltage notebook 03_custom_signals.ipynb works fine for the cpu (os.environ['SETIGEN_ENABLE_GPU'] = '0') but produces an error with the gpu (os.environ['SETIGEN_ENABLE_GPU'] = '1') in the cell containing the rvb.record function. It appears that there is an issue with the time variable data type being converted to a numpy array. Cell error message is in pdf file included below. I don't have cusignal installed (deprecated?), so scipy.signal is being used.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.