axuebin / articles Goto Github PK
View Code? Open in Web Editor NEW:memo: 文章归档
Home Page: http://axuebin.com/articles/
:memo: 文章归档
Home Page: http://axuebin.com/articles/


































































































































本文将 webpack 的 Loader 相关的知识点整理了一下,部分文字是从官方文档中直接摘录过来的,并附上自己的理解。如果觉得看起来和官方文档差不多,直接看官方文档最好啦~
本文不过多描述 webpack 的作用和使用方法,如果还不是太熟悉,可以打开 https://webpack.js.org/ 先熟悉一下。
关于 webpack 的工作流程,简单来说可以概括为以下几步:
Loader 编译文件AST,收集依赖Chunk其中,真正起编译作用的便是 Loader,本文也就 Loader 进行详细的阐述,其余部分暂且不谈。
Loader allow webpack to process other types of files and convert them into valid modules.
Loader 的作用很简单,就是处理任意类型的文件,并且将它们转换成一个让 webpack 可以处理的有效模块。
Loader 可以在 webpack.config.js里配置,这也是推荐的做法,定义在 module.rules 里:
// webpack.config.js
module.exports = {
module: {
rules: [
{ test: /\.js$/, use: 'babel-loader' },
{
test: /\.css$/,
use: [
{ loader: 'style-loader' },
{ loader: 'css-loader' },
{ loader: 'postcss-loader' },
]
}
]
}
};每一条 rule 会包含两个属性:test 和 use,比如 { test: /\.js$/, use: 'babel-loader' } 意思就是:当 webpack 遇到扩展名为 js 的文件时,先用 babel-loader 处理一下,然后再打包它。
use 的类型:string|array|object|function:
string: 只有一个 Loader 时,直接声明 Loader,比如 babel-loader。array: 声明多个 Loader 时,使用数组形式声明,比如上文声明 .css 的 Loader。object: 只有一个 Loader 时,需要有额外的配置项时。function: use 也支持回调函数的形式。关于 use 的多种配置方式,这里就不多说了,可以点击 更多关于 use
注意: 当 use 是通过数组形式声明 Loader 时,Loader 的执行顺序是从右到左,从下到上。比如暂且认为上方声明是这样执行的:
postcss-loader -> css-loader -> style-loader
其实就是:
styleLoader(cssLoader(postcssLoader(content)))为什么说是暂且呢,因为 style-loader 有点特殊,有兴趣的看看这个 webpack loader 从上手到理解系列:style-loader。
webpack 提供了多种配置 Loader 的方法,不过一般来说,use 就已经足够用了,如果想了解更多,可以点击 更多关于 rule 的配置
可以在 import 等语句里指定 Loader,使用 ! 来将 Loader分开:
import style from 'style-loader!css-loader?modules!./styles.css';内联时,通过 query 来传递参数,例如 ?key=value。
一般来说,推荐使用统一 config 的形式来配置 Loader,内联形式多出现于 Loader 内部,比如 style-loader 会在自身代码里引入 css-loader:
require("!!../../node_modules/css-loader/dist/cjs.js!./styles.css");module.exports = function(source) {
const result = someSyncOperation(source); // 同步逻辑
return result;
}一般来说,Loader 都是同步的,通过 return 或者 this.callback 来同步地返回 source转换后的结果。
有的时候,我们需要在 Loader 里做一些异步的事情,比如说需要发送网络请求。如果同步地等着,网络请求就会阻塞整个构建过程,这个时候我们就需要进行异步 Loader,可以这样做:
module.exports = function(source) {
// 告诉 webpack 这次转换是异步的
const callback = this.async();
// 异步逻辑
someAsyncOperation(content, function(err, result) {
if (err) return callback(err);
// 通过 callback 来返回异步处理的结果
callback(null, result, map, meta);
});
};Pitching Loader 是一个比较重要的概念,之前在 style-loader 里有提到过。
{
test: /\.js$/,
use: [
{ loader: 'aa-loader' },
{ loader: 'bb-loader' },
{ loader: 'cc-loader' },
]
}我们知道,Loader 总是从右到左被调用。上面配置的 Loader,就会按照以下顺序执行:
cc-loader -> bb-loader -> aa-loader
每个 Loader 都支持一个 pitch 属性,通过 module.exports.pitch 声明。如果该 Loader 声明了 pitch,则该方法会优先于 Loader 的实际方法先执行,官方也给出了执行顺序:
|- aa-loader `pitch`
|- bb-loader `pitch`
|- cc-loader `pitch`
|- requested module is picked up as a dependency
|- cc-loader normal execution
|- bb-loader normal execution
|- aa-loader normal execution
也就是会先从左向右执行一次每个 Loader 的 pitch 方法,再按照从右向左的顺序执行其实际方法。
我们在 url-loader 里和 file-loader 最后都见过这样一句代码:
export const raw = true;默认情况下,webpack 会把文件进行 UTF-8 编码,然后传给 Loader。通过设置 raw,Loader 就可以接受到原始的 Buffer 数据。
所谓 Loader,也只是一个符合 commonjs 规范的 node 模块,它会导出一个可执行函数。loader runner 会调用这个函数,将文件的内容或者上一个 Loader 处理的结果传递进去。同时,webpack 还为 Loader 提供了一个上下文 this,其中有很多有用的 api,我们找几个典型的来看看。
在 Loader 中,通常使用 return 来返回一个字符串或者 Buffer。如果需要返回多个结果值时,就需要使用 this.callback,定义如下:
this.callback(
// 无法转换时返回 Error,其余情况都返回 null
err: Error | null,
// 转换结果
content: string | Buffer,
// source map,方便调试用的
sourceMap?: SourceMap,
// 可以是任何东西。比如 ast
meta?: any
);一般来说如果调用该函数的话,应该手动 return,告诉 webpack 返回的结果在 this.callback 中,以避免含糊不清的结果:
module.exports = function(source) {
this.callback(null, source, sourceMaps);
return;
};同上,异步 Loader。
有些情况下,有些操作需要耗费大量时间,每一次调用 Loader 转换时都会执行这些费时的操作。
在处理这类费时的操作时, webapck 会默认缓存所有 Loader 的处理结果,只有当被处理的文件发生变化时,才会重新调用 Loader 去执行转换操作。
webpack 是默认可缓存的,可以执行 this.cacheable(false) 手动关闭缓存。
当前处理文件的完整请求路径,包括 query,比如 /src/App.vue?type=templpate。
当前处理文件的路径,不包括 query,比如 /src/App.vue。
当前处理文件的 query 字符串,比如 ?type=template。我们在 vue-loader 里有见过如何使用它:
const qs = require('querystring');
const { resourceQuery } = this;
const rawQuery = resourceQuery.slice(1); // 删除前面的 ?
const incomingQuery = qs.parse(rawQuery); // 解析字符串成对象
// 取 query
if (incomingQuery.type) {}让 webpack 在输出目录新建一个文件,我们在 file-loader 里有见过:
if (typeof options.emitFile === 'undefined' || options.emitFile) {
this.emitFile(outputPath, content);
}更多的 api 可在官方文档中查看:Loader Interface
我们来回顾一下 Loader 的一些特点:
Loader 是一个 node 模块;Loader 可以处理任意类型的文件,转换成 webpack 可以处理的模块;Loader 可以在 webpack.config.js 里配置,也可以在 require 语句里内联;Loader 可以根据配置从右向左链式执行;Loader 接受源文件内容字符串或者 Buffer;Loader 分为多种类型:同步、异步和 pitching,他们的执行流程不一样;webpack 为 Loader 提供了一个上下文,有一些 api 可以使用;我们根据以上暂时知道的特点,可以对 Loader 的工作流程有个猜测,假设有一个 js-loader,它的工作流程简单来说是这样的:
webpack.config.js 里配置了一个 js 的 Loader;js 文件时,触发了 js-loader;js-loader 接受了一个表示该 js 文件内容的 source;js-loader 使用 webapck 提供的一系列 api 对 source 进行转换,得到一个 result;result 返回或者传递给下一个 Loader,直到处理完毕。webpack 的编译流程非常复杂,暂时还不能看明白并且梳理清楚,在这里就不误导大家了。
关于 Loader 的工作流程以及源码分析可以看 【webpack进阶】你真的掌握了loader么?- loader十问。
虽然我们对于 webpack 的编译流程不是很熟悉,但是我们可以试着编写一个简单功能的 Loader,从而加深对 Loader 的理解。
编写 Loader 时需要遵循一些准则,官方有很详细的文档,就不重复阐述了。点击 Loaders 用法准则 查看。
这里说一下单一任务和链式调用。
一个 Loader 应该只完成一个功能,如果需要多步的转换工作,则应该编写多个 Loader 来进行链式调用完成转换。比如 vue-loader 只是处理了 vue 文件,起到一个分发的作用,将其中的 template/style/script 分别交给不同的处理器来处理。
这样会让维护 Loader 变得更简单,也能让不同的 Loader 更容易地串联在一起,而不是重复造轮子。
编写 Loader 的过程中,最常用的两个工具库是 loader-utils 和 schema-utils,在现在常见的 Loader 中都能看到它们的身影。
它提供了许多有用的工具,但最常用的一种工具是获取传递给 Loader 的选项:
import { getOptions } from 'loader-utils';
export default function loader(src) {
// 加载 options
const options = getOptions(this) || {};
}配合 loader-utils,用于保证 Loader 选项,进行与 JSON Schema 结构一致的校验。
import validateOptions from 'schema-utils';
import schema from './options.json';
export default function loader(src) {
// 校验 options
validateOptions(schema, options, {
name: 'URL Loader',
baseDataPath: 'options',
});
}更多关于如何编写一个 Loader,传送门。
本文对 webpack 的 Loader 相关知识点进行整理和归纳,正在学习中,如有不足欢迎指出。
占坑
学习 React 的过程中实现了一个个人主页,没有复杂的实现和操作,适合入门 ~
这个项目其实功能很简单,就是常见的主页、博客、demo、关于我等功能。
页面样式都是自己写的,黑白风格,可能有点丑。不过还是最低级的 CSS ,准备到时候重构 ~
如果有更好的方法,或者是我的想法有偏差的,欢迎大家交流指正
欢迎参观:http://axuebin.com/react-blog
Github:https://github.com/axuebin/react-blog
由于不是使用 React 脚手架生成的项目,所以每个东西都是自己手动配置的。。。
打包用的是 webpack 2.6.1,准备入坑 webpack 3 。
中文文档:https://doc.webpack-china.org/
对于 webpack 的配置还不是太熟,就简单的配置了一下可供项目启动:
var webpack = require('webpack');
var path = require('path');
module.exports = {
context: __dirname + '/src',
entry: "./js/index.js",
module: {
loaders: [
{
test: /\.js?$/,
exclude: /(node_modules)/,
loader: 'babel-loader',
query: {
presets: ['react', 'es2015']
}
}, {
test: /\.css$/,
loader: 'style-loader!css-loader'
}, {
test: /\.js$/,
exclude: /(node_modules)/,
loader: 'eslint-loader'
}, {
test: /\.json$/,
loader: 'json-loader'
}
]
},
output: {
path: __dirname + "/src/",
filename: "bundle.js"
}
}webpack 有几个重要的属性:entry、module、output、plugins,在这里我还没使用到插件,所以没有配置 plugins 。
module 中的 loaders:
包管理现在使用的还是 NPM 。
关于npm,可能还需要了解 dependencies 和 devDependencies 的区别,我是这样简单理解的:
项目使用现在比较流行的 ESLint 作为代码检查工具,并使用 Airbnb 的检查规则。
ESLint:https://github.com/eslint/eslint
eslint-config-airbnb:https://www.npmjs.com/package/eslint-config-airbnb
在 package.json 中可以看到,关于 ESLint 的包就是放在 devDependencies 底下的,因为它只是在开发的时候会使用到。
webpack 配置中加载 eslint-loader:module: {
loaders: [
{
test: /\.js$/,
exclude: /(node_modules)/,
loader: 'eslint-loader'
}
]
}.elintrc文件:{
"extends": "airbnb",
"env":{
"browser": true
},
"rules":{}
}然后在运行 webpack 的时候,就会执行代码检查啦,看着一堆的 warning 、error 是不是很爽~
这里有常见的ESLint规则:http://eslint.cn/docs/rules/
由于是为了练习 React,暂时就只考虑搭建一个静态页面,而且现在越来越多的大牛喜欢用 Github Issues 来写博客,也可以更好的地提供评论功能,所以我也想试试用 Github Issues 来作为博客的数据源。
API在这:https://developer.github.com/v3/issues/
我也没看完全部的API,就看了看怎么获取 Issues 列表。。
https://api.github.com/repos/axuebin/react-blog/issues?creator=axuebin&labels=blog通过控制参数 creator 和 labels,可以筛选出作为展示的 Issues。它会返回一个带有 issue 格式对象的数组。每一个 issue 有很多属性,我们可能不需要那么多,先了解了解底下这几种:
// 为了方便,我把注释写在json中了。。
[{
"url": , // issue 的 url
"id": , // issue id , 是一个随机生成的不重复的数字串
"number": , // issue number , 根据创建 issue 的顺序从1开始累加
"title": , // issue 的标题
"labels": [], // issue 的所有 label,它是一个数组
"created_at": , // 创建 issue 的时间
"updated_at": , // 最后修改 issue 的时间
"body": , // issue 的内容
}]项目中使用的异步请求数据的方法时 fetch。
关于 fetch :https://segmentfault.com/a/1190000003810652
使用起来很简单:
fetch(url).then(response => response.json())
.then(json => console.log(json))
.catch(e => console.log(e));在 Github 上查找关于如何在 React 实现 markdown 的渲染,查到了这两种库:
使用起来都很简单。
如果是 react-markdown,只需要这样做:
import ReactMarkdown from 'react-markdown';
const input = '# This is a header\n\nAnd this is a paragraph';
ReactDOM.render(
<ReactMarkdown source={input} />,
document.getElementById('container')
);如果是marked,这样做:
import marked from 'marked';
const input = '# This is a header\n\nAnd this is a paragraph';
const output = marked(input);这里有点不太一样,我们获取到了一个字符串 output,注意,是一个字符串,所以我们得将它插入到 dom中,在 React 中,我们可以这样做:
<div dangerouslySetInnerHTML={{ __html: output }} />由于我们的项目是基于 React 的,所以想着用 react-markdown会更好,而且由于安全问题 React 也不提倡直接往 dom 里插入字符串,然而在使用过程中发现,react-markdown 对表格的支持不友好,所以只好弃用,改用 marked。
代码高亮用的是highlight.js:https://github.com/isagalaev/highlight.js
它和marked可以无缝衔接~
只需要这样既可:
import hljs from 'highlight.js';
marked.setOptions({
highlight: code => hljs.highlightAuto(code).value,
});highlight.js是支持多种代码配色风格的,可以在css文件中进行切换:
@import '~highlight.js/styles/atom-one-dark.css';在这可以看到每种语言的高亮效果和配色风格:https://highlightjs.org/
可以看之前的一篇文章:axuebin/react-blog#8
可以看之前的一篇文章:axuebin/react-blog#9
项目中前端路由用的是 React-Router V4。
官方文档:https://reacttraining.com/react-router/web/guides/quick-start
<Link to="/blog">Blog</Link><Router>
<Route exact path="/" component={Home} />
<Route path="/blog" component={Blog} />
<Route path="/demo" component={Demo} />
</Router>注意:一定要在根目录的 Route 中声明 exact,要不然点击任何链接都无法跳转。
比如我现在要在博客页面上点击跳转,此时的 url 是 localhost:8080/blog,需要变成 localhost:8080/blog/article,可以这样做:
<Route path={`${this.props.match.url}/article/:number`} component={Article} />这样就可以跳转到 localhost:8080/blog/article 了,而且还传递了一个 number 参数,在 article 中可以通过 this.props.params.number获取。
当我把项目托管到 Github Page 后,出现了这样一个问题。
刷新页面出现
Cannot GET /提示,路由未生效。
通过了解,知道了原因是这样,并且可以解决:
Cannot GET / 错误。<Router> → <HashRouter> 。<HashRouter> 借助URL上的哈希值(hash)来实现路由。可以在不需要全屏刷新的情况下,达到切换页面的目的。当前一个页面滚动到一定区域后,点击跳转后,页面虽然跳转了,但是会停留在滚动的区域,不会自动回到页面顶部。
可以通过这样来解决:
componentDidMount() {
this.node.scrollIntoView();
}
render() {
return (
<div ref={node => this.node = node} ></div>
);
}项目中多次需要用到从 Github Issues 请求来的数据,因为之前就知道 Redux 这个东西的存在,虽然有点大材小用,为了学习还是将它用于项目的状态管理,只需要请求一次数据即可。
官方文档:http://redux.js.org/
简单的来说,每一次的修改状态都需要触发 action ,然而其实项目中我现在还没用到修改数据2333。。。
关于状态管理这一块,由于还不是太了解,就不误人子弟了~
React是基于组件构建的,所以在搭建页面的开始,我们要先考虑一下我们需要一些什么样的组件,这些组件之间有什么关系,哪些组件是可以复用的等等等。
可以看到,我主要将首页分成了四个部分:
博客页就是很中规中矩的一个页面吧,这部分是整个项目中代码量最多的部分,包括以下几部分:
文章列表其实就是一个 list,里面有一个个的 item:
<div class="archive-list">
<div class="blog-article-item">文章1</div>
<div class="blog-article-item">文章2</div>
<div>对于每一个 item,其实是这样的:
一个文章item组件它可能需要包括:
如果用 DOM 来描述,它应该是这样的:
<div class="blog-article-item">
<div class="blog-article-item-title">文章标题</div>
<div class="blog-article-item-time">时间</div>
<div class="blog-article-item-label">类别</div>
<div class="blog-article-item-label">标签</div>
<div class="blog-article-item-desc">摘要</div>
</div>所以,我们可以有很多个组件:
<ArticleList /><ArticleItem /><ArticleLabel />它们可能是这样一个关系:
<ArticleList>
<ArticleItem>
<ArticleTitle />
<ArticleTime />
<ArticleLabel />
<ArticleDesc />
</ArticleItem>
<ArticleItem></ArticleItem>
<ArticleItem></ArticleItem>
</ArticleList>对于分页功能,传统的实现方法是在后端完成分页然后分批返回到前端的,比如可能会返回一段这样的数据:
{
total:500,
page:1,
data:[]
}也就是后端会返回分好页的数据,含有表示总数据量的total、当前页数的page,以及属于该页的数据data。
然而,我这个页面只是个静态页面,数据是放在Github Issues上的通过API获取的。(Github Issues的分页貌似不能自定义数量...),所以没法直接返回分好的数据,所以只能在前端强行分页~
分页功能这一块我偷懒了...用的是 antd 的翻页组件 <Pagination />。
官方文档:https://ant.design/components/pagination-cn/
文档很清晰,使用起来也特别简单。
前端渲染的逻辑(有点蠢):将数据存放到一个数组中,根据当前页数和每页显示条数来计算该显示的索引值,取出相应的数据即可。
翻页组件中:
constructor() {
super();
this.onChangePage = this.onChangePage.bind(this);
}
onChangePage(pageNumber) {
this.props.handlePageChange(pageNumber);
}
render() {
return (
<div className="blog-article-paging">
<Pagination onChange={this.onChangePage} defaultPageSize={this.props.defaultPageSize} total={this.props.total} />
</div>
);
}当页数发生改变后,会触发从父组件传进 <ArticlePaging /> 的方法 handlePageChange,从而将页数传递到父组件中,然后传递到 <ArticleList /> 中。
父组件中:
handlePageChange(pageNumber) {
this.setState({ currentPage: pageNumber });
}
render() {
return (
<div className="archive-list-area">
<ArticleList issues={this.props.issues} defaultPageSize={this.state.defaultPageSize} pageNumber={this.state.currentPage} />
<ArticlePaging handlePageChange={this.handlePageChange} total={this.props.issues.length} defaultPageSize={this.state.defaultPageSize} />
</div>
);
}列表中:
render() {
const articlelist = [];
const issues = this.props.issues;
const currentPage = this.props.pageNumber;
const defaultPageSize = this.props.defaultPageSize;
const start = currentPage === 1 ? 0 : (currentPage - 1) * defaultPageSize;
const end = start + defaultPageSize < issues.length ? start + defaultPageSize : issues.length;
for (let i = start; i < end; i += 1) {
const item = issues[i];
articlelist.push(<ArticleItem />);
}
}在 Github Issues 中,可以为一个 issue 添加很多个 label,我将这些对于博客内容有用的 label 分为三类,分别用不同颜色来表示。
这里说明一下, label 创建后会随机生成一个 id,虽然说 id 是不重复的,但是文章的类别、标签会一直在增加,当新加一个 label 时,程序中可能也要进行对应的修改,当作区分 label 的标准可能就不太合适,所以我采用颜色来区分它们。
blog 的 issue 才能显示在页面上,过滤 bug 、help 等即使有新的 label ,也只要根据颜色区分是属于哪一类就好了。
在这里的思路主要就是:遍历所有 issues,然后再遍历每个 issue的 labels,找出属于类别的 label,然后计数。
const categoryList = [];
const categoryHash = {};
for (let i = 0; i < issues.length; i += 1) {
const labels = issues[i].labels;
for (let j = 0; j < labels.length; j += 1) {
if (labels[j].color === COLOR_LABEL_CATEGORY) {
const category = labels[j].name;
if (categoryHash[category] === undefined) {
categoryHash[category] = true;
const categoryTemp = { category, sum: 1 };
categoryList.push(categoryTemp);
} else {
for (let k = 0; k < categoryList.length; k += 1) {
if (categoryList[k].category === category) {
categoryList[k].sum += 1;
}
}
}
}
}
}这样实现得要经历三次循环,复杂度有点高,感觉有点蠢,有待改进,如果有更好的方法,请多多指教~
这里的思路和类别的思路基本一样,只不过不同的显示方式而已。
本来这里是想通过字体大小来体现每个标签的权重,后来觉得可能对于我来说,暂时只有那几个标签会很频繁,其它标签可能会很少,用字体大小来区分就没有什么意义,还是改成排序的方式。
文章页主要分为两部分:
有两种方式获取文章具体内容:
issue number 重新发一次请求直接获取内容最后我选择了后者。
文章是用 markdown 语法写的,所以要先转成 html 然后插入页面中,这里用了一个 React 不提倡的属性:dangerouslySetInnerHTML。
除了渲染markdown,我们还得对文章中的代码进行高亮显示,还有就是定制文章中不同标签的样式。
首先,这里有一个 issue,希望大家可以给一些建议~
文章内容是通过 markdown 渲染后插入 dom 中的,由于 React 不建议通过 document.getElementById 的形式获取 dom 元素,所以只能想办法通过字符串匹配的方式获取文章的各个章节标题。
由于我不太熟悉正则表达式,曾经还在sf上咨询过,就采用了其中一个答案:
const issues = content;
const menu = [];
const patt = /(#+)\s+?(.+)/g;
let result = null;
while ((result = patt.exec(issues))) {
menu.push({ level: result[1].length, title: result[2] });
}这样可以获取到所有的 # 的字符串,也就是 markdown 中的标题, result[1].length 表示有几个 #,其实就是几级标题的意思,title 就是标题内容了。
这里还有一个问题,本来通过 <a target="" /> 的方式可以实现点击跳转,但是现在渲染出来的 html 中对于每一个标题没有独一无二的标识。。。
按年份归档:
按类别归档:
按标签归档:
基本功能是已经基本实现了,现在还存在着以下几个问题,也算是一个 TodoList 吧
Github Issues API 实现评论,得实现 Github 授权登录antd 的组件,但是 state 中 visibility 一直是 falsewebpack 按需加载。这可能是目前最方便的方式todo 之一url-loader 会将引入的文件进行编码,生成 DataURL,相当于把文件翻译成了一串字符串,再把这个字符串打包到 JavaScript。
一般来说,我们会发请求来获取图片或者字体文件。如果图片文件较多时(比如一些 icon),会频繁发送请求来回请求多次,这是没有必要的。此时,我们可以考虑将这些较小的图片放在本地,然后使用 url-loader 将这些图片通过 base64 的方式引入代码中。这样就节省了请求次数,从而提高页面性能。
url-loadernpm install url-loader --save-dev
webapckmodule.exports = {
module: {
rules: [
{
test: /\.(png|jpg|gif)$/,
use: [
{
loader: 'url-loader',
options: {},
},
],
},
],
},
};import(或 require)import logo from '../assets/image/logo.png';
console.log('logo的值: ', logo); // 打印一下看看 logo 是什么简单三步就搞定了。
webpack
执行 webpack 之后,dist 目录只生成了一个 bundle.js。和 file-loader 不同的是,没有生成我们引入的那个图片。上文说过,url-loader 是将图片转换成一个 DataURL,然后打包到 JavaScript 代码中。
那我们就看看 bundle.js 是否有我们需要的 DataURL:
// bundle.js
(function(module, exports) {
module.exports = "data:image/jpeg;base64.........."; // 省略无数行
})我们可以看到这个模块导出的是一个标准的 DataURL。
一个标准的DataURL:
data:[<mediatype>][;base64],<data>
通过这个 DataURL,我们就可以从本地加载这张图片了,也就不用将图片文件打包到 dist 目录下。
使用 base64 来加载图片也是有两面性的:
所以我们得有取舍,只对部分小 size 的图片进行 base64 编码,其它的大图片还是发请求吧。
url-loader 自然是已经做了这个事情,我们只要通过简单配置即可实现上述需求。
limit 的时候使用 fallback 的 loader 来处理文件loader 来处理大于 limit 的文件,默认值是 file-loader我们来试试设一个 limit:
{
test: /\.(png|jpg|gif)$/,
use: [
{
loader: 'url-loader',
options: {
limit: 1000, // 大于 1000 bytes 的文件都走 fallback
},
},
],
},重新执行 webpack,由于我们引入的 logo.png 大于 1000,所以使用的是 file-loader 来处理这个文件。图片被打包到 dist 目录下,并且返回的值是它的地址:
(function(module, exports, __webpack_require__) {
module.exports = __webpack_require__.p + "dab1fd6b179f2dd87254d6e0f9f8efab.png";
}),更多关于 file-loader
file-loader 的代码也不多,就直接复制过来通过注释讲解了:
import { getOptions } from 'loader-utils'; // loader 工具包
import validateOptions from 'schema-utils'; // schema 工具包
import mime from 'mime';
import normalizeFallback from './utils/normalizeFallback'; // fallback loader
import schema from './options.json'; // options schema
// 定义一个是否转换的函数
/*
*@method shouldTransform
*@param {Number|Boolean|String} limit 文件大小阈值
*@param {Number} size 文件实际大小
*@return {Boolean} 是否需要转换
*/
function shouldTransform(limit, size) {
if (typeof limit === 'boolean') {
return limit;
}
if (typeof limit === 'number' || typeof limit === 'string') {
return size <= parseInt(limit, 10);
}
return true;
}
export default function loader(src) {
// 获取 webpack 配置里的 options
const options = getOptions(this) || {};
// 校验 options
validateOptions(schema, options, {
name: 'URL Loader',
baseDataPath: 'options',
});
// 判断是否要转换,如果要就进入,不要就往下走
// src 是一个 Buffer,所以可以通过 src.length 获取大小
if (shouldTransform(options.limit, src.length)) {
const file = this.resourcePath;
// 获取文件MIME类型,默认值是从文件取,比如 "image/jpeg"
const mimetype = options.mimetype || mime.getType(file);
// 如果 src 不是 Buffer,就变成 Buffer
if (typeof src === 'string') {
src = Buffer.from(src);
}
// 构造 DataURL 并导出
return `module.exports = ${JSON.stringify(
`data:${mimetype || ''};base64,${src.toString('base64')}`
)}`;
}
// 判断结果是不需要通过 url-loader 转换成 DataURL,则使用 fallback 的 loader
const {
loader: fallbackLoader,
options: fallbackOptions,
} = normalizeFallback(options.fallback, options);
// 引入 fallback loader
const fallback = require(fallbackLoader);
// fallback loader 执行环境
const fallbackLoaderContext = Object.assign({}, this, {
query: fallbackOptions,
});
// 执行 fallback loader 来处理 src
return fallback.call(fallbackLoaderContext, src);
}
// 默认情况下 webpack 对文件进行 UTF8 编码,当 loader 需要处理二进制数据的时候,需要设置 raw 为 true
export const raw = true;上一节我们说到 TypeScript 最重要的特性就是给 JavaScript 引入了静态类型声明,这一节就来看一下 TypeScript 里的基础类型和变量声明。
我们知道在 JavaScript 中有 7 种数据类型,分别是:
这里就不多作解释了,如果突然忘记,就点开回忆回忆。
虽然有这么多的数据类型,但是声明的时候只能 var、let、const...
// bad code
var count = '0';
let isNumber = 1;
const name = true;What did you say?You'd better not do that again.
我们应该优雅一点~
TypeScript 是 JavaScript 的超集,自然能够支持所有 JavaScript 的数据类型,除此之外,TypeScript 还提供了让人喜欢的枚举类型(enum)。
function hello(isBetterCode: boolean) {
//...
return isBetterCode ? 'good' : 'bed';
}
const isBetterCode: boolean = true;
hello(isBetterCode); // good来个小插曲,下面这两行代码分别返回什么:
new Boolean('') == false
new Boolean(1) === true所以,如果这样声明了一个表示布尔值的变量,编译是不会通过的:
const isBetterCode: boolean = new Boolean(1);
// Type 'Boolean' is not assignable to type 'boolean'.
// 'boolean' is a primitive, but 'Boolean' is a wrapper object. Prefer using 'boolean' when possible.因为 new Boolean 返回的是一个 Boolean 对象,而不是一个 boolean 值。
如果你想这样写,也都是可以的:
const isBetterCode: Boolean = new Boolean(1);
const isBetterCode: boolean = Boolean(1);TypeScript 和 JavaScript 一样,所有的数字都是浮点数,并没有区分 int、flost、double 等类型,所有的数字都是 number。number 类型支持十进制、十六进制等,以及 NaN 和 Infinity 等。
const count: number = 1;
const binary: number = 0b1010; // 10
const hex: number = 0xf00d; // 61453
const octal: number = 0o744; // 484
const notNumber: number = NaN; // NaN
const infinityNumber: number = Infinity; // Infinity使用 string 定义字符串类型的变量,支持常规的单引号和双引号,也支持 ES6 的模板字符串:
const name: string = 'axuebin'; // axuebin
const desc: string = `My name is ${name}`; // My name is axuebin犹记得 C 中的 void main() 还有 Java 中的 public static void main(String args[]) 这两句闭着眼睛都能写出来的代码,在 JavaScript 中却好久都见不到一次 void 的身影,甚是想念。
其实,JavaScript 是有 void 的,只是不常使用而已。
void 0; // undefined在 TypeScript 中,你能多见见它了,我们可以用 void 来表示任何返回值的函数:
function hello(): void {
console.log('hello typescript');
}const u: undefined = undefined; // undefined
const n: null = null; // null需要注意的是:
undefined 类型的变量只能被赋值为 undefined,null 类型的变量只能被赋值为 null。
不过你可以把 undefined 和 null 类型的变量赋给 void 类型的变量...
AnyScript 大法好
有时候,我们需要为那些在编程阶段无法确定类型的变量指定一个类型时,我们就需要 any 这个类型。any 类型的变量可以被赋予任意类型的值:
let number: any = 'one';
number = 1; // 1
const me: any = 'axuebin';
console.log(me.name); // undefined 不会报错这样是不会报错的。
当然,如果在编程阶段能够确定类型的话,尽量还是能够明确地指定类型。
声明变量(没赋值)的时候,如果未指定类型,那么该变量会被识别为 any 类型,比如:
let number; // 相当于 let number: any;
number = 1; // 1需要注意的是,没赋值。如果声明变量的时候同时赋值了,就会进行类型推论。
声明变量的时候,如果对变量进行赋值,如果该变量没有明确地指定类型,TypeScript 会推测出一个类型。
let number = 'one'; // 相当于 let number: string = 'one';
number = 1; // Type '1' is not assignable to type 'string'.如果只声明没有赋值,就是 any。
在 TypeScript 中,数组是通过「类型 + 方括号」来定义:
const me: string[] = ['axuebin', '27']; // 定义一个都是 string 的数组
const counts: number[] = [1, 2, 3, 4]; // 定义一个都是 number 的数组
// error
const me: string[] = ['axuebin', 27]; // Type 'number' is not assignable to type 'string'.
counts.push('5'); // Argument of type '"5"' is not assignable to parameter of type 'number'.还有一种方式是使用泛型:
const counts: Array<number> = [1, 2, 3, 4]; // 使用泛型定义一个都是 number 的数组关于泛型,后面会仔细说明,现在就知道有这么个东西~
如果对数组中的类型不确定,比较常见的做法就是使用 any:
const list: any[] = ['axuebin', 27, true];还有一种特殊的情况,如果我们需要定义一个已知元素和类型的数组,但是各个元素的类型不相同,可以使用 tuple 元组 来定义:
const me: [string, number, boolean] = ['axuebin', 27, true];当我们想要在这个数组 push 一个新元素时,会提示 (string | number | boolean),这是表示元组额外增加的元素可以是之前定义的类型中的任意一种类型。(string | number | boolean) 称作联合类型,后续会说到它。
枚举是 TS 对 JS 标准数据类型的补充,Java/c 等语言都有枚举数据类型,在 TypeScript 里可以这样定义一个枚举:
enum Animal {
Cat,
Dog,
Mouse,
}
const cat: Animal = Animal.Cat; // 0
const dog: Animal = Animal. Dog; // 1既然是 JavaScript 没有的,我们就需要知道一个枚举最终会被编译成什么样的 JavaScript 代码:
"use strict";
var Animal;
(function (Animal) {
Animal[Animal["Cat"] = 0] = "Cat";
Animal[Animal["Dog"] = 1] = "Dog";
Animal[Animal["Mouse"] = 2] = "Mouse";
})(Animal || (Animal = {}));
const cat = Animal.Cat; // 0
const dog = Animal.Dog; // 1很容易看出,Animal 在 JavaScript 中是变成了一个 object,并且执行了以下代码:
Animal["Cat"] = 0; // 赋值运算符会返回被赋予的值,所以返回 0
Animal[0] = "Cat";
// 省略 ...
// 最终的 Animal 是这样的
{
0: "Cat",
1: "Dog,
2: "Mouse",
Cat: 0,
Dog: 1,
Mouse: 2,
}一个很基础的知识点,JavaScript中基本数据类型和引用数据类型是如何存储的。
由于自己是野生程序员,在刚开始学习程序设计的时候没有在意内存这些基础知识,导致后来在提到“什么什么是存在栈中的,栈中只是存了一个引用”这样的话时总是一脸懵逼。。
后来渐渐的了解了一些内存的知识,这部分还是非常有必要了解的。
栈,只允许在一段进行插入或者删除操作的线性表,是一种先进后出的数据结构。
堆是基于散列算法的数据结构。
队列是一种先进先出(FIFO)的数据结构。
JavaScript中将数据类型分为基本数据类型和引用数据类型,它们其中有一个区别就是存储的位置不同。
我们都知道JavaScript中的基本数据类型有:
基本数据类型都是一些简单的数据段,它们是存储在栈内存中。
JavaScript中的引用数据类型有:
引用数据类型是保存在堆内存中的,然后再栈内存中保存一个对堆内存中实际对象的引用。所以,JavaScript中对引用数据类型的操作都是操作对象的引用而不是实际的对象。
可以理解为,栈内存中保存了一个地址,这个地址和堆内存中的实际值是相关的。
现在,我们声明几个变量试试:
var name="axuebin";
var age=25;
var job;
var arr=[1,2,3];
var obj={age:25};可以通过下图来表示数据类型在内存中的存储情况:
此时name,age,job三种基本数据类型是直接存在栈内存中的,而arr,obj在栈内存中只是存了一个地址来表示对堆内存中的引用。
对于基本数据类型,如果进行复制,系统会自动为新的变量在栈内存中分配一个新值,很容易理解。
如果对于数组、对象这样的引用数据类型而言,复制的时候就会有所区别了:
系统也会自动为新的变量在栈内存中分配一个值,但这个值仅仅是一个地址。也就是说,复制出来的变量和原有的变量具有相同的地址值,指向堆内存中的同一个对象。
如果所示,执行了var objCopy=obj之后,obj和objCopy具有相同的地址值,执行堆内存中的同一个实际对象。
这有什么不同呢?
当我修改obj或objCopy时,都会引起另一个变量的改变。
为什么基础数据类型存在栈中,而引用数据类型存在堆中呢?
http://www.jianshu.com/p/996671d4dcc4
http://blog.sina.com.cn/s/blog_8ecde0fe0102vy6e.html
最近开始用 TypeScript 来写项目,写起来还是挺顺畅的。其实学习 TypeScript,看它的官方文档就够了,剩下就是 coding 了。我这里主要是我在 TypeScript 学习过程中记录的一些东西~
TypeScript 也被称作 AnyScript,因为你在 coding 的时候需要为每个变量设一个 any 的类型。
咳咳,开玩笑开玩笑,可别真的让每个变量都是 any,会被疯狂吐槽的。
TypeScript 是微软开发一款开源的编程语言,它是 JavaScript 的一个超集,本质上是为 JavaScript 增加了静态类型声明。任何的 JavaScript 代码都可以在其中使用,不会有任何问题。TypeScript 最终也会被编译成 JavaScript,使其在浏览器、Node 中等环境中使用。
JavaScript 被称作是一种动态脚本语言,其中有一个被疯狂诟病的特性:缺乏静态强类型。我们看一下下面的代码:
function init() {
var a = 'axuebin';
console.log('a: ', a); // a: axuebin
a = 1;
console.log('a: ', a); // a: 1
}
当我们执行 init 函数的时候,会先声明一个 a 变量,然后给 a 变量赋了一个 axuebin,这时候我们知道 a 是一个字符串。然后这时候我们希望 a 变成 1,就直接 a = 1 了。当然,这是可以的,此时 a 变量的类型已经发生改变:字符串 => 数字。这在很多人看来是难以接受的事情,明明初始化 a 的时候是一个字符串类型,之后 a 的类型居然变成数字类型了,这太糟糕了。
如果在 Java 中,会是这样:
class HelloWorld {
public static void main(String[] args) {
String a = "axuebin";
System.out.printf("a: %s", a);
a = 1;
System.out.printf("a: %d", a);
}
}
// HelloWorld.java:4: error: incompatible types: int cannot be converted to String
在 Java 中根本就没办法让 a = 1,会直接导致报错,在编译阶段就断绝你的一切念想。年轻人,别想太多,好好写代码。
这时候就会想,如果 JavaScript 也有类型该有多好啊,是吧。
看看 TypeScript 中是怎么样的:
function init() {
var a: string = 'axuebin';
console.log('a: ', a);
a = 1;
console.log('a: ', a);
}
// Type '1' is not assignable to type 'string'.
我们把变量 a 设为 string 类型,后面给 a 复制 1 的时候就报错了,同样是在编译阶段就过不了。
我们来想想在日常的业务开发中是否有遇到以下的情况:
是不是超级超级超级不爽。归根结底这还是因为 JavaScript 是一门动态弱类型脚本语言。
你想想,如果每个变量都被约定了类型,并且构建了变量声明和变量调用之前的联系,只要有一处地方发生了改变,其它地方都会被通知到,这该有多美好。
JavaScript 淡化了类型的概念,但是作为一名开发者,我们必须要牢固自己的类型概念,养成良好的变成习惯。
TypeScript 相比于 JavaScript 具有以下优势:
有的童鞋可能会觉得,JavaScript 都还没学清楚,又得学一门新的编程语言,还没接触 TypeScript 就已经无形中有了抵触心理。对于这些童鞋,需要知道的是 TypeScript 是 JavaScript 的超集,与现存的 JavaScript 代码有非常高的兼容性。
如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S1就是S2的一个超集。
也就是说,TypeScript 包含了 JavaScript 的 all,即使是仅仅将 .js 改成 .ts,不修改任何的代码都可以运行。
所以说,完全可以先上手再学习,渐进式地搞定 TypeScript,不用担心门槛高的问题。
如果还有顾虑,可以在 http://www.typescriptlang.org/play/ 上先体验一下 TypeScript 带来的快感。
当然,上手 TypeScript 也会有一些困难,会让刚开始学习 TypeScript 的童鞋感觉太复杂了,不熟悉的情况下很可能会增加开发成本:
AnyScript 的原因。。。)TypeScript 写的,没有提供声明文件,就需要去为第三方库编写声明文件TypeScript 中引入的类型(Types)、类(Classes)、泛型(Generics)、接口(Interfaces)以及枚举(Enums),这些概念如果之前没有接触过强类型语言的话,就需要增加一些学习成本不过,不要被吓退了!
重要的事情要说三遍。
不要被吓退了!!
不要被吓退了!!!
这些只是短期的,当克服这些困难后,就会如鱼得水,一切看上去都是那么的自然。
首先你需要有 Node 和 npm,这个不用多说了。
在控制台运行一下命令:
npm install typesrcipt -g
这条命令会在全局安装 typescript,并且安装 tsc 命令,运行以下命令可以查看当前版本(确认安装成功):
tsc -v
// Version 3.2.2
然后我们就新建一个名为 index.ts 的文件,然后敲入简单点的代码:
// index.ts
const msg: string = 'Hello TypeScript';
代码编写好就可以执行编译,可以运行 tsc 命令,让 ts 文件变成可在浏览器中运行的 js 文件:
tsc index.ts
如果你的代码不合法,执行 tsc 的时候就会报错,根据错误进行对应的修改即可。
我们看一个稍微完整点的例子吧。
这是一个 ts 文件,声明了一个 sayHello 函数:
string 类型的 namestring 类型的 Hello ${name}// index.ts
function sayHello(name: string): string {
return `Hello ${name}`;
}
const me: string = 'axuebin';
console.log(sayHello(me))
我们执行 tsc index.ts 编译一下,在同级文件夹下生成了一个新的文件 index.js:
function sayHello(name) {
return "Hello " + name;
}
var me = 'axuebin';
console.log(sayHello(me));
我们发现我们写的 TypeScript 代码在编译后都消失了。因为 TypeScript 只会进行静态检查,如果代码有问题,在编译阶段就会报错。
我们修改一下 index.ts ,模拟一下出错的情况:
function sayHello(name: string): string {
return `Hello ${name}`;
}
const count: number = 1000;
console.log(sayHello(count))
我们向 sayHello 传递一个 number 类型的参数,试试 tsc 一下:
index.ts:6:22 - error TS2345: Argument of type 'number' is not assignable to parameter of type 'string'.
命令行就会报上面的错误,意思是不能给一个 string 类型的参数传递一个 number 类型。
但是,这里要注意的是,即使报错了,tsc 还是会将编译进行到底,还是会生成一个 index.js 文件:
function sayHello(name) {
return "Hello " + name;
}
var count = 1000;
console.log(sayHello(count));
看上去也就是没啥毛病的 js 代码。
如果编译失败就不生成 js 文件,之后可以在配置中关闭这个功能。
如果没有意外的话,应该会继续写一些 TypeScript 的文章,欢迎大家持续关注~
本文主要记录的是JavaScript实现常用的查找算法。
用JavaScript写算法是种怎么样的体验?不喜欢算法的我最近也对数据结构和算法有点兴趣。。。所以,将会有这些:
现阶段我对于数据结构、算法的理解还很浅,希望各位大佬多多指导。
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找。本文简单概括性的介绍了常见的七种查找算法,说是七种,其实二分查找、插值查找以及斐波那契查找都可以归为一类——插值查找。插值查找和斐波那契查找是在二分查找的基础上的优化查找算法。
这里主要提到如何用JavaScript实现顺序查找和二分查找。
主要**:将每一个数据结构中的元素和要查找的元素做比较,类似于JavaScript中indexOf
时间复杂度:O(n)
代码:
function sequentialSearch(array,item){
for (let i = 0; i < array.length; i += 1) {
if ( item === array[i] ) {
return i;
}
}
return -1;
}比如我现在有这样一个数组 [5, 4, 3, 2, 1] ,然后我们需要在其中找到 3 ,整个流程应该是这样:
[5, 4, 3, 2, 1] // 5 !== 3,继续遍历
[5, 4, 3, 2, 1] // 4 !== 3,继续遍历
[5, 4, 3, 2, 1] // 3 === 3,找到了主要**:首先这个数组是排好序的,然后将数组一直二分缩小范围,直到找到为止。
时间复杂度:O(logn)
代码:
function binarySearch(array, item) {
const sortArray = quickSort(array); // 对数组进行快排
let low = 0; // 设置左边界
let high = sortArray.length - 1; // 设置右边界
let mid = 0; // 设置中间值
let element = 0;
while (low < high) {
mid = Math.floor((low + high) / 2); // 选择整个数组的中间值
element = sortArray[mid];
if (element < item) { // 如果待搜索值比选中值要大,则返回步骤一在右边的字数组中寻找
low = mid + 1;
} else if (element > item) { // 如果待搜索值比选中值要小,则返回步骤一在左边的字数组中寻找
high = mid - 1;
} else {
return mid; // 如果刚好选中,恭喜你,直接返回
}
}
return -1;
}整理一下React中关于state和props的知识点。
在任何应用中,数据都是必不可少的。我们需要直接的改变页面上一块的区域来使得视图的刷新,或者间接地改变其他地方的数据。React的数据是自顶向下单向流动的,即从父组件到子组件中,组件的数据存储在props和state中,这两个属性有啥子区别呢?
React的核心**就是组件化**,页面会被切分成一些独立的、可复用的组件。
组件从概念上看就是一个函数,可以接受一个参数作为输入值,这个参数就是props,所以可以把props理解为从外部传入组件内部的数据。由于React是单向数据流,所以props基本上也就是从服父级组件向子组件传递的数据。
假设我们现在需要实现一个列表,根据React组件化**,我们可以把列表中的行当做一个组件,也就是有这样两个组件:<ItemList/>和<Item/>。
先看看<ItemList/>
import Item from "./item";
export default class ItemList extends React.Component{
const itemList = data.map(item => <Item item=item />);
render(){
return (
{itemList}
)
}
}列表的数据我们就暂时先假设是放在一个data变量中,然后通过map函数返回一个每一项都是<Item item='数据'/>的数组,也就是说这里其实包含了data.length个<Item/>组件,数据通过在组件上自定义一个参数传递。当然,这里想传递几个自定义参数都可以。
在<Item />中是这样的:
export default class Item extends React.Component{
render(){
return (
<li>{this.props.item}</li>
)
}
}在render函数中可以看出,组件内部是使用this.props来获取传递到该组件的所有数据,它是一个对象,包含了所有你对这个组件的配置,现在只包含了一个item属性,所以通过this.props.item来获取即可。
props经常被用作渲染组件和初始化状态,当一个组件被实例化之后,它的props是只读的,不可改变的。如果props在渲染过程中可以被改变,会导致这个组件显示的形态变得不可预测。只有通过父组件重新渲染的方式才可以把新的props传入组件中。
在组件中,我们最好为props中的参数设置一个defaultProps,并且制定它的类型。比如,这样:
Item.defaultProps = {
item: 'Hello Props',
};
Item.propTypes = {
item: PropTypes.string,
};关于propTypes,可以声明为以下几种类型:
optionalArray: PropTypes.array,
optionalBool: PropTypes.bool,
optionalFunc: PropTypes.func,
optionalNumber: PropTypes.number,
optionalObject: PropTypes.object,
optionalString: PropTypes.string,
optionalSymbol: PropTypes.symbol,注意,bool和func是简写。
这些知识基础数据类型,还有一些复杂的,附上链接:
https://facebook.github.io/react/docs/typechecking-with-proptypes.html
props是一个从外部传进组件的参数,主要作为就是从父组件向子组件传递数据,它具有可读性和不变性,只能通过外部组件主动传入新的props来重新渲染子组件,否则子组件的props以及展现形式不会改变。
state是什么呢?
State is similar to props, but it is private and fully controlled by the component.
一个组件的显示形态可以由数据状态和外部参数所决定,外部参数也就是props,而数据状态就是state。
export default class ItemList extends React.Component{
constructor(){
super();
this.state = {
itemList:'一些数据',
}
}
render(){
return (
{this.state.itemList}
)
}
}首先,在组件初始化的时候,通过this.state给组件设定一个初始的state,在第一次render的时候就会用这个数据来渲染组件。
state不同于props的一点是,state是可以被改变的。不过,不可以直接通过this.state=的方式来修改,而需要通过this.setState()方法来修改state。
比如,我们经常会通过异步操作来获取数据,我们需要在didMount阶段来执行异步操作:
componentDidMount(){
fetch('url')
.then(response => response.json())
.then((data) => {
this.setState({itemList:item});
}
}当数据获取完成后,通过this.setState来修改数据状态。
当我们调用this.setState方法时,React会更新组件的数据状态state,并且重新调用render方法,也就是会对组件进行重新渲染。
注意:通过this.state=来初始化state,使用this.setState来修改state,constructor是唯一能够初始化的地方。
setState接受一个对象或者函数作为第一个参数,只需要传入需要更新的部分即可,不需要传入整个对象,比如:
export default class ItemList extends React.Component{
constructor(){
super();
this.state = {
name:'axuebin',
age:25,
}
}
componentDidMount(){
this.setState({age:18})
}
}在执行完setState之后的state应该是{name:'axuebin',age:18}。
setState还可以接受第二个参数,它是一个函数,会在setState调用完成并且组件开始重新渲染时被调用,可以用来监听渲染是否完成:
this.setState({
name:'xb'
},()=>console.log('setState finished'))state的主要作用是用于组件保存、控制以及修改自己的状态,它只能在constructor中初始化,它算是组件的私有属性,不可通过外部访问和修改,只能通过组件内部的this.setState来修改,修改state属性会导致组件的重新渲染。
state是组件自己管理数据,控制自己的状态,可变;props是外部传入的数据参数,不可变;state的叫做无状态组件,有state的叫做有状态组件;props,少用state。也就是多写无状态组件。todo
之前看《深入理解es6》的笔记。。。
在ES6之前,在函数作用域中或者全局作用域中通过var关键字来声明变量,无论是在代码的哪个位置,这条声明语句都会提到最顶部来执行,这就是变量声明提升。
注意:只是声明提升,初始化并没有提升。
看一个例子:
function getStudent(name){
if(name){
var age=25;
}else{
console.log("name不存在");
}
console.log(age); //undefined
}如果按照预想的代码的执行顺序,当name有值时才会创建变量age,可是执行代码发现,即使不传入name,判断语句外的输出语句并没有报错,而是输出undefined。
这就是变量声明提升。
ES6前是没有块级作用域的,比如{}外可以访问内部的变量。
function getStudent(name){
if(name){
let age=25;
console.log(age); //25
}else{
console.log("name不存在");
}
console.log(age); //age is not defined
}和上文一样的代码,只是将age的命名关键字从var改成了let,在执行getStudent()和getStudent("axuebin")时都会报错。
原因:
age变量将立即被销毁name为空,则永远都不会创建age变量如果用const来声明对象,则对象中的值可以修改。
JavaScript引擎在扫面代码发现声明变量时,遇到var则提升到作用域顶部,遇到let和const则放到TDZ中。当执行了变量声明语句后,TDZ中的变量才能正常访问。
我们经常使用for循环:
for(var i=0;i<10;i++){
console.log(i); //0,1,2,3,4,5,6,7,8,9
}
console.log(i) //10发现了什么?
在for循环执行后,我们仍然可以访问到变量i。
So easy ~ 把var换成let就解决了~
for(let i=0;i<10;i++){
console.log(i); //0,1,2,3,4,5,6,7,8,9
}
console.log(i) //i is not defined还记得当初讲闭包时setTimeout循环各一秒输出i的那个例子吗~
曾经熟悉的你 ~
for(var i=0;i<10;i++){
setTimeout(function(){
console.log(i); //10,10,10.....
},1000)
}很显然,上面的代码输出了10次的10,setTimeout在执行了循环之后才执行,此时i已经是10了~
之前,我们这样做 ~
for(var i=0;i<10;i++){
setTimeout((function(i){
console.log(i); //0,1,2,3,4,5,6,7,8,9
})(i),1000)
}现在,我们这样做 ~ 来看看把var改成let会怎样~
for(let i=0;i<10;i++){
setTimeout(function(){
console.log(i); //0,1,2,3,4,5,6,7,8,9
},1000)
}nice~
在全局作用域下声明的时
var会覆盖window对象中的属性let和const会屏蔽,而不是覆盖,用window.还能访问到尽量全面详细的整理一下React的生命周期中的知识点。
组件是独立的封装的可以复用的一个小部件,它是React的核心**之一。通过划分组件,可以将一个页面划分成独立的多个可复用的组件,各个组件通过嵌套、组合形成一个完整的页面。
在React中,组件基本由三个部分组成:属性(props)、状态(state)以及生命周期方法。可以将组件简单地看作一个“状态机”,根据不同的state和props呈现不同的UI,通过与用户的交互实现不同的状态,然后重新渲染组件,UI可以跟随数据变化而变化。
组件常分为两种:Class Component和Functional Component。
Functional Component也称为无状态组件,它多用于纯展示组件,这种组件只负责根据传入的props来渲染组件,而不涉及state状态管理。
在大部分React代码中,大多数组件被写成无状态的组件,通过简单组合可以构建成其他的组件等;这种通过多个简单然后合并成一个大应用的设计模式被提倡。
无状态组件可以通过函数形式或者ES6的箭头函数来创建:
// 函数
function HelloFunctional(props){
return <div>hello {props.name}</div>;
}
// ES6箭头函数
const HelloFunctional = (props) => (<div>hello {props.name}</div>);无状态组件有以下几个特点:
props,同样的输入一定会有同样的输出所以,在项目中如果不需要进行状态管理,应该尽量写成无状态组件的形式。
现在主流的创建有状态组件的形式是通过ES6的Class来创建,取代React.createClass:
Class HelloClass extends React.Component{
constructor(){
this.state = {
name:'axuebin'
}
}
render(){
return (<div>hello {this.state.name}</div>);
}
}这是最简洁的一个组件,它需要使用到内部状态state。
当组件需要使用内部状态时或者需要使用生命周期方法时就需要使用有状态组件。
React组件的生命周期可以分为挂载、渲染和卸载这几个阶段,当渲染后的组件更新后,会重新渲染组件,直到卸载。先分阶段来看看每个阶段有哪些生命周期函数。
属于这个阶段的生命周期函数有:
constructor() {
super();
this.state = {name: 'axuebin'};
this.handleClick = this.handleClick.bind(this);
}这个阶段就是组件的初始化,constructor()可以理解为组件的构造函数,从组件的类class实例化一个组件实例。这个函数是组件形成时就被调用的,是生命周期中最先执行的。
在constructor()函数内,首先必须执行super(),否则this.props将是未定义,会引发异常。
然后,如果有必要,可以进行:
state的初始化如果不需要这两步,可以直接省略constructor函数。
这个函数按照驼峰法的命名规则可以理解为“组件即将被挂载”,所以这个函数是组件首次渲染(render)前调用的。
在每次页面加载、刷新时,或者某个组件第一次展现时都会调用这个函数。通常地,我们推荐使用constructor()来替代。
注意:在这个函数中,不可以调用setState来修改状态。
render() {
return(
<div>hello {this.state.name} {this.props.age}</div>
)
}render()在生命周期中是必须的,是渲染组件用的。
当这个函数被调用时,需要检查this.props和this.state并且返回一个元素(有且只有一个元素),这个元素可能是一个原生DOM元素,也有可能是另一个React组件。
可以在state或props状态为空时试着返回一个null或者false来声明不想渲染任何东西。
在这个函数中,不应该改变组件的状态,也就是不执行this.setState,需要保持render()函数的纯净。
在这个函数中,可以对props进行调用并组合,但不可修改。
componentDidMount() {
this.setState({name:'xb'});
}这个函数在组件加载渲染完成后立即调用,此时页面上已经渲染出真实的DOM了,可以在这个函数中访问到真实的DOM(可以通过this.refs来访问真实DOM)。
在这个阶段,还可以做一件事,可以修改state了!!!
而且,异步获取数据在这个阶段执行也是比较合理的,获取数据之后setState,然后重新渲染组件。
属性或状态的改变会触发一次更新。当一个组件在被重新渲染时,这些方法将会被调用:
已加载的组件在props发生变化时调用,若需要更新状态,可能需要对比this.props和nextProps然后在该方法中使用this.setState来处理状态的改变。
需要注意的是,有些情况下,即使props未改变也会触发该函数,所以一定要先比较this.props和nextProps再做操作。
该函数只监听props的改变,this.setState不会触发这个函数。
componentWillReceiveProps(nextProps){
if (this.props.color !== nextProps.color){
this.setState({});
}
}这个函数只返回true或false,表示组件是否需要更新(重新渲染)。
true就是紧接着以下的生命周期函数;false表示组件不需要重新渲染,不再执行任何生命周期函数(包括render)。这个函数使用需谨慎,react官方文档中说道,在未来这个函数返回false可能仍然使得组件重新渲染。
这个函数看名字就和componentWillMount很像,它执行的阶段也很像。在接收到新的props或者state之后,这个函数就会在render前被调用。
同样的,在这个函数中不能使用this.setState()。如果需要更新状态,请在componentWillReceiveProps中调用this.setState()。
又是一次的render。这和挂载阶段的render有什么区别呢?
在函数的性质上来说,两者毫无区别,只不过是在生命周期的不同阶段的调用。
render是在组件第一次加载时调用的,也就是初次渲染,可以理解为mount;render是除去第一次之后调用的,也就是再渲染,re-render;同样地,这个方法是在组件re-render之后调用的,该方法不会在初始化的时候调用。和componentDidMount一样,在这个函数中可以使用this.refs获取真实DOM。
还可以修改state哦,不过会导致组件再次re-render。
该方法将会在 component 从DOM中移除时调用
卸载阶段就很简单了,就这一个生命周期函数,在组件被卸载和销毁之前立刻调用。
在这个函数中,应该处理任何必要的清理工作,比如销毁定时器、取消网络请求、清除之前创建的相关DOM节点等。
最近在尝试玩一玩已经被大家玩腻的 Babel,今天给大家分享如何用 Babel 为代码自动引入依赖,通过一个简单的例子入门 Babel 插件开发。
const a = require('a');
import b from 'b';
console.log(axuebin.say('hello babel'));同学们都知道,如果运行上面的代码,一定是会报错的:
VM105:2 Uncaught ReferenceError: axuebin is not defined我们得首先通过 import axuebin from 'axuebin' 引入 axuebin 之后才能使用。。
为了防止这种情况发生(一般来说我们都会手动引入),或者为你省去引入这个包的麻烦(其实有些编译器也会帮我们做了),我们可以在打包阶段分析每个代码文件,把这个事情做了。
在这里,我们就基于最简单的场景做最简单的处理,在代码文件顶部加一句引用语句:
import axuebin from 'axuebin';
console.log(axuebin.say('hello babel'));简单地说,Babel 能够转译 ECMAScript 2015+ 的代码,使它在旧的浏览器或者环境中也能够运行。我们日常开发中,都会通过 webpack 使用 babel-loader 对 JavaScript 进行编译。
首先得要先了解一个概念:抽象语法树(Abstract Syntax Tree, AST),Babel 本质上就是在操作 AST 来完成代码的转译。
了解了 AST 是什么样的,就可以开始研究 Babel 的工作过程了。
Babel 的功能其实很纯粹,它只是一个编译器。
大多数编译器的工作过程可以分为三部分,如图所示:
所以我们如果想要修改 Code,就可以在 Transform 阶段做一些事情,也就是操作 AST。
我们可以看到 AST 中有很多相似的元素,它们都有一个 type 属性,这样的元素被称作节点。一个节点通常含有若干属性,可以用于描述 AST 的部分信息。
比如这是一个最常见的 Identifier 节点:
{
type: 'Identifier',
name: 'add'
}所以,操作 AST 也就是操作其中的节点,可以增删改这些节点,从而转换成实际需要的 AST。
更多的节点规范可以查阅 https://github.com/estree/estree
AST 是深度优先遍历的,遍历规则不用我们自己写,我们可以通过特定的语法找到的指定的节点。
Babel 会维护一个称作 Visitor 的对象,这个对象定义了用于 AST 中获取具体节点的方法。
一个 Visitor 一般是这样:
const visitor = {
ArrowFunction(path) {
console.log('我是箭头函数');
},
IfStatement(path) {
console.log('我是一个if语句');
},
CallExpression(path) {}
};visitor 上挂载以节点 type 命名的方法,当遍历 AST 的时候,如果匹配上 type,就会执行对应的方法。
通过上面简单的介绍,我们就可以开始任意造作了,肆意修改 AST 了。先来个简单的例子热热身。
箭头函数是 ES5 不支持的语法,所以 Babel 得把它转换成普通函数,一层层遍历下去,找到了 ArrowFunctionExpression 节点,这时候就需要把它替换成 FunctionDeclaration 节点。所以,箭头函数可能是这样处理的:
import * as t from "@babel/types";
const visitor = {
ArrowFunction(path) {
path.replaceWith(t.FunctionDeclaration(id, params, body));
}
};在开始写代码之前,我们还有一些事情要做一下:
将原代码和目标代码都解析成 AST,观察它们的特点,找找看如何增删改 AST 节点,从而达到自己的目的。
我们可以在 https://astexplorer.net 上完成这个工作,比如文章最初提到的代码:
const a = require('a');
import b from 'b';
console.log(axuebin.say('hello babel'));转换成 AST 之后是这样的:
可以看出,这个 body 数组对应的就是根节点的三条语句,分别是:
const a = require('a')import b from 'b'console.log(axuebin.say('hello babel'))我们可以打开 VariableDeclaration 节点看看:
它包含了一个 declarations 数组,里面有一个 VariableDeclarator 节点,这个节点有 type、id、init 等信息,其中 id 指的是表达式声明的变量名,init 指的是声明内容。
通过这样查看/对比 AST 结构,就能分析出原代码和目标代码的特点,然后可以开始动手写程序了。
节点规范:https://github.com/estree/estree
我们要增删改节点,当然要知道节点的一些规范,比如新建一个 ImportDeclaration 需要传递哪些参数。
准备工作都做好了,那就开始吧。
我们的 index.js 代码为:
// index.js
const path = require('path');
const fs = require('fs');
const babel = require('@babel/core');
const TARGET_PKG_NAME = 'axuebin';
function transform(file) {
const content = fs.readFileSync(file, {
encoding: 'utf8',
});
const { code } = babel.transformSync(content, {
sourceMaps: false,
plugins: [
babel.createConfigItem(({ types: t }) => ({
visitor: {
}
}))
]
});
return code;
}然后我们准备一个测试文件 test.js,代码为:
// test.js
const a = require('a');
import b from 'b';
require('c');
import 'd';
console.log(axuebin.say('hello babel'));我们这次需要做的事情很简单,做两件事:
AST 中是否含有引用 axuebin 包的节点AST,插入一个 ImportDeclaration 节点我们来分析一下 test.js 的 AST,看一下这几个节点有什么特征:
ImportDeclaration 节点的 AST 如图所示,我们需要关心的特征是 value 是否等于 axuebin,
代码这样写:
if (path.isImportDeclaration()) {
return path.get('source').isStringLiteral() && path.get('source').node.value === TARGET_PKG_NAME;
}其中,可以通过 path.get 来获取对应节点的 path,嗯,比较规范。如果想获取对应的真实节点,还需要 .node。
满足上述条件则可以认为当前代码已经引入了 axuebin 包,不用再做处理了。
对于 VariableDeclaration 而言,我们需要关心的特征是,它是否是一个 require 语句,并且 require 的是 axuebin,代码如下:
/**
* 判断是否 require 了正确的包
* @param {*} node 节点
*/
const isTrueRequire = node => {
const { callee, arguments } = node;
return callee.name === 'require' && arguments.some(item => item.value === TARGET_PKG_NAME);
};
if (path.isVariableDeclaration()) {
const declaration = path.get('declarations')[0];
return declaration.get('init').isCallExpression && isTrueRequire(declaration.get('init').node);
}require('c'),语句我们一般不会用到,我们也来看一下吧,它对应的是 ExpressionStatement 节点,我们需要关心的特征和 VariableDeclaration 一致,这也是我把 isTrueRequire 抽出来的原因,所以代码如下:
if (path.isExpressionStatement()) {
return isTrueRequire(path.get('expression').node);
}如果上述分析都没找到代码里引用了 axuebin,我们就需要手动插入一个引用:
import axuebin from 'axuebin';通过 AST 分析,我们发现它是一个 ImportDeclaration:
简化一下就是这样:
{
"type": "ImportDeclaration",
"specifiers": [
"type": "ImportDefaultSpecifier",
"local": {
"type": "Identifier",
"name": "axuebin"
}
],
"source": {
"type": "StringLiteral",
"value": "axuebin"
}
}当然,不是直接构建这个对象放进去就好了,需要通过 babel 的语法来构建这个节点(遵循规范):
const importDefaultSpecifier = [t.ImportDefaultSpecifier(t.Identifier(TARGET_PKG_NAME))];
const importDeclaration = t.ImportDeclaration(importDefaultSpecifier, t.StringLiteral(TARGET_PKG_NAME));
path.get('body')[0].insertBefore(importDeclaration);这样就插入了一个 import 语句。
Babel Types模块是一个用于AST节点的Lodash式工具库,它包含了构造、验证以及变换AST节点的方法。
我们 node index.js 一下,test.js 就变成:
import axuebin from "axuebin"; // 已经自动加在代码最上边
const a = require('a');
import b from 'b';
require('c');
import 'd';
console.log(axuebin.say('hello babel'));如果我们还想帮他再多做一点事,还能做什么呢?
既然都自动引用了,那当然也要自动安装一下这个包呀!
/**
* 判断是否安装了某个包
* @param {string} pkg 包名
*/
const hasPkg = pkg => {
const pkgPath = path.join(process.cwd(), `package.json`);
const pkgJson = fs.existsSync(pkgPath) ? fse.readJsonSync(pkgPath) : {};
const { dependencies = {}, devDependencies = {} } = pkgJson;
return dependencies[pkg] || devDependencies[pkg];
}
/**
* 通过 npm 安装包
* @param {string} pkg 包名
*/
const installPkg = pkg => {
console.log(`开始安装 ${pkg}`);
const npm = shell.which('npm');
if (!npm) {
console.log('请先安装 npm');
return;
}
const { code } = shell.exec(`${npm.stdout} install ${pkg} -S`);
if (code) {
console.log(`安装 ${pkg} 失败,请手动安装`);
}
};
// biu~
if (!hasPkg(TARGET_PKG_NAME)) {
installPkg(TARGET_PKG_NAME);
}判断一个应用是否安装了某个依赖,有没有更好的办法呢?
我也是刚开始学 Babel,希望通过这个 Babel 插件的入门例子,可以让大家了解 Babel 其实并没有那么陌生,大家都可以玩起来 ~
最近在尝试玩一玩已经被大家玩腻的 Babel,今天给大家分享如何用 Babel 为代码自动引入依赖,通过一个简单的例子入门 Babel 插件开发。
const a = require('a');
import b from 'b';
console.log(axuebin.say('hello babel'));同学们都知道,如果运行上面的代码,一定是会报错的:
VM105:2 Uncaught ReferenceError: axuebin is not defined我们得首先通过 import axuebin from 'axuebin' 引入 axuebin 之后才能使用。。
为了防止这种情况发生(一般来说我们都会手动引入),或者为你省去引入这个包的麻烦(其实有些编译器也会帮我们做了),我们可以在打包阶段分析每个代码文件,把这个事情做了。
在这里,我们就基于最简单的场景做最简单的处理,在代码文件顶部加一句引用语句:
import axuebin from 'axuebin';
console.log(axuebin.say('hello babel'));简单地说,Babel 能够转译 ECMAScript 2015+ 的代码,使它在旧的浏览器或者环境中也能够运行。我们日常开发中,都会通过 webpack 使用 babel-loader 对 JavaScript 进行编译。
首先得要先了解一个概念:抽象语法树(Abstract Syntax Tree, AST),Babel 本质上就是在操作 AST 来完成代码的转译。
了解了 AST 是什么样的,就可以开始研究 Babel 的工作过程了。
Babel 的功能其实很纯粹,它只是一个编译器。
大多数编译器的工作过程可以分为三部分,如图所示:
所以我们如果想要修改 Code,就可以在 Transform 阶段做一些事情,也就是操作 AST。
我们可以看到 AST 中有很多相似的元素,它们都有一个 type 属性,这样的元素被称作节点。一个节点通常含有若干属性,可以用于描述 AST 的部分信息。
比如这是一个最常见的 Identifier 节点:
{
type: 'Identifier',
name: 'add'
}所以,操作 AST 也就是操作其中的节点,可以增删改这些节点,从而转换成实际需要的 AST。
更多的节点规范可以查阅 https://github.com/estree/estree
AST 是深度优先遍历的,遍历规则不用我们自己写,我们可以通过特定的语法找到的指定的节点。
Babel 会维护一个称作 Visitor 的对象,这个对象定义了用于 AST 中获取具体节点的方法。
一个 Visitor 一般是这样:
const visitor = {
ArrowFunction(path) {
console.log('我是箭头函数');
},
IfStatement(path) {
console.log('我是一个if语句');
},
CallExpression(path) {}
};visitor 上挂载以节点 type 命名的方法,当遍历 AST 的时候,如果匹配上 type,就会执行对应的方法。
通过上面简单的介绍,我们就可以开始任意造作了,肆意修改 AST 了。先来个简单的例子热热身。
箭头函数是 ES5 不支持的语法,所以 Babel 得把它转换成普通函数,一层层遍历下去,找到了 ArrowFunctionExpression 节点,这时候就需要把它替换成 FunctionDeclaration 节点。所以,箭头函数可能是这样处理的:
import * as t from "@babel/types";
const visitor = {
ArrowFunction(path) {
path.replaceWith(t.FunctionDeclaration(id, params, body));
}
};在开始写代码之前,我们还有一些事情要做一下:
将原代码和目标代码都解析成 AST,观察它们的特点,找找看如何增删改 AST 节点,从而达到自己的目的。
我们可以在 https://astexplorer.net 上完成这个工作,比如文章最初提到的代码:
const a = require('a');
import b from 'b';
console.log(axuebin.say('hello babel'));转换成 AST 之后是这样的:
可以看出,这个 body 数组对应的就是根节点的三条语句,分别是:
const a = require('a')import b from 'b'console.log(axuebin.say('hello babel'))我们可以打开 VariableDeclaration 节点看看:
它包含了一个 declarations 数组,里面有一个 VariableDeclarator 节点,这个节点有 type、id、init 等信息,其中 id 指的是表达式声明的变量名,init 指的是声明内容。
通过这样查看/对比 AST 结构,就能分析出原代码和目标代码的特点,然后可以开始动手写程序了。
节点规范:https://github.com/estree/estree
我们要增删改节点,当然要知道节点的一些规范,比如新建一个 ImportDeclaration 需要传递哪些参数。
准备工作都做好了,那就开始吧。
我们的 index.js 代码为:
// index.js
const path = require('path');
const fs = require('fs');
const babel = require('@babel/core');
const TARGET_PKG_NAME = 'axuebin';
function transform(file) {
const content = fs.readFileSync(file, {
encoding: 'utf8',
});
const { code } = babel.transformSync(content, {
sourceMaps: false,
plugins: [
babel.createConfigItem(({ types: t }) => ({
visitor: {
}
}))
]
});
return code;
}然后我们准备一个测试文件 test.js,代码为:
// test.js
const a = require('a');
import b from 'b';
require('c');
import 'd';
console.log(axuebin.say('hello babel'));我们这次需要做的事情很简单,做两件事:
AST 中是否含有引用 axuebin 包的节点AST,插入一个 ImportDeclaration 节点我们来分析一下 test.js 的 AST,看一下这几个节点有什么特征:
ImportDeclaration 节点的 AST 如图所示,我们需要关心的特征是 value 是否等于 axuebin,
代码这样写:
if (path.isImportDeclaration()) {
return path.get('source').isStringLiteral() && path.get('source').node.value === TARGET_PKG_NAME;
}其中,可以通过 path.get 来获取对应节点的 path,嗯,比较规范。如果想获取对应的真实节点,还需要 .node。
满足上述条件则可以认为当前代码已经引入了 axuebin 包,不用再做处理了。
对于 VariableDeclaration 而言,我们需要关心的特征是,它是否是一个 require 语句,并且 require 的是 axuebin,代码如下:
/**
* 判断是否 require 了正确的包
* @param {*} node 节点
*/
const isTrueRequire = node => {
const { callee, arguments } = node;
return callee.name === 'require' && arguments.some(item => item.value === TARGET_PKG_NAME);
};
if (path.isVariableDeclaration()) {
const declaration = path.get('declarations')[0];
return declaration.get('init').isCallExpression && isTrueRequire(declaration.get('init').node);
}require('c'),语句我们一般不会用到,我们也来看一下吧,它对应的是 ExpressionStatement 节点,我们需要关心的特征和 VariableDeclaration 一致,这也是我把 isTrueRequire 抽出来的原因,所以代码如下:
if (path.isExpressionStatement()) {
return isTrueRequire(path.get('expression').node);
}如果上述分析都没找到代码里引用了 axuebin,我们就需要手动插入一个引用:
import axuebin from 'axuebin';通过 AST 分析,我们发现它是一个 ImportDeclaration:
简化一下就是这样:
{
"type": "ImportDeclaration",
"specifiers": [
"type": "ImportDefaultSpecifier",
"local": {
"type": "Identifier",
"name": "axuebin"
}
],
"source": {
"type": "StringLiteral",
"value": "axuebin"
}
}当然,不是直接构建这个对象放进去就好了,需要通过 babel 的语法来构建这个节点(遵循规范):
const importDefaultSpecifier = [t.ImportDefaultSpecifier(t.Identifier(TARGET_PKG_NAME))];
const importDeclaration = t.ImportDeclaration(importDefaultSpecifier, t.StringLiteral(TARGET_PKG_NAME));
path.get('body')[0].insertBefore(importDeclaration);这样就插入了一个 import 语句。
Babel Types模块是一个用于AST节点的Lodash式工具库,它包含了构造、验证以及变换AST节点的方法。
我们 node index.js 一下,test.js 就变成:
import axuebin from "axuebin"; // 已经自动加在代码最上边
const a = require('a');
import b from 'b';
require('c');
import 'd';
console.log(axuebin.say('hello babel'));如果我们还想帮他再多做一点事,还能做什么呢?
既然都自动引用了,那当然也要自动安装一下这个包呀!
/**
* 判断是否安装了某个包
* @param {string} pkg 包名
*/
const hasPkg = pkg => {
const pkgPath = path.join(process.cwd(), `package.json`);
const pkgJson = fs.existsSync(pkgPath) ? fse.readJsonSync(pkgPath) : {};
const { dependencies = {}, devDependencies = {} } = pkgJson;
return dependencies[pkg] || devDependencies[pkg];
}
/**
* 通过 npm 安装包
* @param {string} pkg 包名
*/
const installPkg = pkg => {
console.log(`开始安装 ${pkg}`);
const npm = shell.which('npm');
if (!npm) {
console.log('请先安装 npm');
return;
}
const { code } = shell.exec(`${npm.stdout} install ${pkg} -S`);
if (code) {
console.log(`安装 ${pkg} 失败,请手动安装`);
}
};
// biu~
if (!hasPkg(TARGET_PKG_NAME)) {
installPkg(TARGET_PKG_NAME);
}判断一个应用是否安装了某个依赖,有没有更好的办法呢?
我也是刚开始学 Babel,希望通过这个 Babel 插件的入门例子,可以让大家了解 Babel 其实并没有那么陌生,大家都可以玩起来 ~
基础最重要。
todo
未经授权,不得转载。
我在尤大的 GitHub 上发现了一个有趣的东西 vue-lit,直觉告诉我这又是一个啥面向未来的下一代 xxx,所以我就点进去看了一眼是啥新玩具。
Proof of concept mini custom elements framework powered by @vue/reactivity and lit-html.
看上去是尤大的一个验证性的尝试,看到 custom element 和 lit-html,盲猜一把,是一个可以直接在浏览器中渲染 vue 写法的 Web Component 的工具。
这里提到了
lit-html,后面会专门介绍一下。
按照尤大给的 Demo,我们来试一下 Hello World:
<!DOCTYPE html>
<html lang="en">
<head>
<script type="module">
import {
defineComponent,
reactive,
html,
onMounted
} from 'https://unpkg.com/@vue/[email protected]';
defineComponent('my-component', () => {
const state = reactive({
text: 'Hello World',
});
function onClick() {
alert('cliked!');
}
onMounted(() => {
console.log('mounted');
});
return () => html`
<p>
<button @click=${onClick}>Click me</button>
${state.text}
</p>
`;
})
</script>
</head>
<body>
<my-component />
</body>
</html>不用任何编译打包工具,直接打开这个 index.html,看上去没毛病:
!
可以看到,这里渲染出来的是一个 Web Component,并且 mounted 生命周期也触发了。
看 vue-lit 之前,我们先了解一下 lit-html 和 lit-ement,这两个东西其实已经出来很久了,可能并不是所有人都了解。
lit-html 可能很多人并不熟悉,甚至没有见过。
所以是啥?答案是 HTML 模板引擎。
如果没有体感,我问一个问题,React 核心的东西有哪些?大家都会回答:jsx、Virtual-DOM、diff,没错,就是这些东西构成了 UI = f(data) 的 React。
来看看 jsx 的语法:
function App() {
const msg = 'Hello World';
return <div>{msg}</div>;
}再看看 lit-html 的语法:
function App() {
const msg = 'Hello World';
return html`
<div>${msg}</div>
`;
}我们知道 jsx 是需要编译的它的底层最终还是 createElement....。而 lit-html 就不一样了,它是基于 tagged template 的,使得它不用编译就可以在浏览器上运行,并且和 HTML Template 结合想怎么玩怎么玩,扩展能力更强,不香吗?
当然,无论是 jsx 还是 lint-html,这个 App 都是需要 render 到真实 DOM 上。
直接上代码(省略样式代码):
<!DOCTYPE html>
<html lang="en">
<head>
<script type="module">
import { html, render } from 'https://unpkg.com/lit-html?module';
const Button = (text, props = {
type: 'default',
borderRadius: '2px'
}, onClick) => {
// 点击事件
const clickHandler = {
handleEvent(e) {
alert('inner clicked!');
if (onClick) {
onClick();
}
},
capture: true,
};
return html`
<div class="btn btn-${props.type}" @click=${clickHandler}>
${text}
</div>
`
};
render(Button('Defualt'), document.getElementById('button1'));
render(Button('Primary', { type: 'primary' }, () => alert('outer clicked!')), document.getElementById('button2'));
render(Button('Error', { type: 'error' }), document.getElementById('button3'));
</script>
</head>
<body>
<div id="button1"></div>
<div id="button2"></div>
<div id="button3"></div>
</body>
</html>效果:
lit-html 会比 React 性能更好吗?这里我没仔细看过源码,也没进行过相关实验,无法下定论。
但是可以大胆猜测一下,lit-html 没有使用类 diff 算法而是直接基于相同 template 的更新,看上去这种方式会更轻量一点。
但是,我们常问的一个问题 “在渲染列表的时候,key 有什么用?”,这个在 lit-html 是不是没法解决了。我如果删除了长列表中的其中一项,按照 lit-html 的基于相同 template 的更新,整个长列表都会更新一次,这个性能就差很多了啊。
// TODO:埋个坑,以后看
lit-element 这又是啥呢?
关键词:web components。
例子:
import { LitElement, html } from 'lit-element';
class MyElement extends LitElement {
static get properties() {
return {
msg: { type: String },
};
}
constructor() {
super();
this.msg = 'Hello World';
}
render() {
return html`
<p>${this.msg}</p>
`;
}
}
customElements.define('my-element', MyElement);效果:
结论:可以用类 React 的语法写 Web Component。
so, lit-element 是一个可以创建 Web Component 的 base class。分析一下上面的 Demo,lit-element 做了什么事情:
setter 的 statestatelit-html 渲染元素,并且会创建 ShadowDOM总之,lit-element 遵守 Web Components 标准,它是一个 class,基于它可以快速创建 Web Component。
更多关于如何使用 lit-element 进行开发,在这里就不展开说了。
说 Web Components 之前我想先问问大家,大家还记得 jQuery 吗,它方便的选择器让人难忘。但是后来 document.querySelector 这个 API 的出现并且广泛使用,大家似乎就慢慢地淡忘了 jQuery。
浏览器原生 API 已经足够好用,我们并不需要为了操作 DOM 而使用 jQuery。
再后来,是不是很久没有直接操作过 DOM 了?
是的,由于 React / Vue 等框架(库)的出现,帮我们做了很多事情,我们可以不用再通过复杂的 DOM API 来操作 DOM。
我想表达的是,是不是有一天,如果浏览器原生能力足够好用的时候,React 等是不是也会像 jQuery 一样被浏览器原生能力替代?
像 React / Vue 等框架(库)都做了同样的事情,在之前浏览器的原生能力是实现不了的,比如创建一个可复用的组件,可以渲染在 DOM 中的任意位置。
现在呢?我们似乎可以不使用任意的框架和库,甚至不用打包编译,仅是通过 Web Components 这样的浏览器原生能力就可以创建可复用的组件,是不是未来的某一天我们就抛弃了现在所谓的框架和库,直接使用原生 API 或者是使用基于 Web Components 标准的框架和库来开发了?
当然,未来是不可知的
我不是一个 Web Components 的无脑吹,只不过,我们需要面向未来编程。
来看看 Web Components 的一些主要功能吧。
自定义元素顾名思义就是用户可以自定义 HTML 元素,通过 CustomElementRegistry 的 define 来定义,比如:
window.customElements.define('my-element', MyElement);然后就可以直接通过 <my-element /> 使用了。
根据规范,有两种 Custom elements:
HTML 元素,使用时可以直接 <my-element />HTML 元素,比如通过 { extends: 'p' } 来标识继承自 p 元素,使用时需要 <p is="my-element"></p>两种 Custom elements 在实现的时候也有所区别:
// Autonomous custom elements
class MyElement extends HTMLElement {
constructor() {
super();
}
}
// Customized buld-in elements:继承自 p 元素
class MyElement extends HTMLParagraphElement {
constructor() {
super();
}
}在 Custom elements 的构造函数中,可以指定多个回调函数,它们将会在元素的不同生命时期被调用。
DOM 时DOM 中删除时我们这里留意一下 attributeChangedCallback,是每当元素的属性发生变化时,就会执行这个回调函数,并且获得元素的相关信息:
attributeChangedCallback(name, oldValue, newValue) {
// TODO
}需要特别注意的是,如果需要在元素某个属性变化后,触发 attributeChangedCallback() 回调函数,你必须监听这个属性:
class MyElement extends HTMLElement {
static get observedAttributes() {
return ['my-name'];
}
constructor() {
super();
}
}元素的 my-name 属性发生变化时,就会触发回调方法。
Web Components 一个非常重要的特性,可以将结构、样式封装在组件内部,与页面上其它代码隔离,这个特性就是通过 Shadow DOM 实现。
关于 Shadow DOM,这里主要想说一下 CSS 样式隔离的特性。Shadow DOM 里外的 selector 是相互获取不到的,所以也没办法在内部使用外部定义的样式,当然外部也没法获取到内部定义的样式。
这样有什么好处呢?划重点,样式隔离,Shadow DOM 通过局部的 HTML 和 CSS,解决了样式上的一些问题,类似 vue 的 scope 的感觉,元素内部不用关心 selector 和 CSS rule 会不会被别人覆盖了,会不会不小心把别人的样式给覆盖了。所以,元素的 selector 非常简单:title / item 等,不需要任何的工具或者命名的约束。
可以通过 <template> 来添加一个 Web Component 的 Shadow DOM 里的 HTML 内容:
<body>
<template id="my-paragraph">
<style>
p {
color: white;
background-color: #666;
padding: 5px;
}
</style>
<p>My paragraph</p>
</template>
<script>
customElements.define('my-paragraph',
class extends HTMLElement {
constructor() {
super();
let template = document.getElementById('my-paragraph');
let templateContent = template.content;
const shadowRoot = this.attachShadow({mode: 'open'}).appendChild(templateContent.cloneNode(true));
}
}
)
</script>
<my-paragraph></my-paragraph>
</body>效果:
我们知道,<template> 是不会直接被渲染的,所以我们是不是可以定义多个 <template> 然后在自定义元素时根据不同的条件选择渲染不同的 <template>?答案当然是:可以。
介绍了 lit-html/element 和 Web Components,我们回到尤大这个 vue-lit。
首先我们看到在 Vue 3.0 的 Release 里有这么一段:
The @vue/reactivity module exports functions that provide direct access to Vue's reactivity system, and can be used as a standalone package. It can be used to pair with other templating solutions (e.g. lit-html) or even in non-UI scenarios.
意思大概就是说 @vue/reactivity 模块和类似 lit-html 的方案配合,也能设计出一个直接访问 Vue 响应式系统的解决方案。
巧了不是,对上了,这不就是 vue-lit 吗?
import { render } from 'https://unpkg.com/lit-html?module'
import {
shallowReactive,
effect
} from 'https://unpkg.com/@vue/reactivity/dist/reactivity.esm-browser.js'lit-html 提供核心 render 能力@vue/reactiity 提供 Vue 响应式系统的能力这里稍带解释一下 shallowReactive 和 effect,不展开:
shallowReactive:简单理解就是“浅响应”,类似于“浅拷贝”,它仅仅是响应数据的第一层
const state = shallowReactive({
a: 1,
b: {
c: 2,
},
})
state.a++ // 响应式
state.b.c++ // 非响应式effect:简单理解就是 watcher
const state = reactive({
name: "前端试炼",
});
console.log(state); // 这里返回的是Proxy代理后的对象
effect(() => {
console.log(state.name); // 每当name数据变化将会导致effect重新执行
});接着往下看:
export function defineComponent(name, propDefs, factory) {
// propDefs
// 如果是函数,则直接当作工厂函数
// 如果是数组,则监听他们,触发 attributeChangedCallback 回调函数
if (typeof propDefs === 'function') {
factory = propDefs
propDefs = []
}
// 调用 Web Components 创建 Custom Elements 的函数
customElements.define(
name,
class extends HTMLElement {
// 监听 propDefs
static get observedAttributes() {
return propDefs
}
constructor() {
super()
// 创建一个浅响应
const props = (this._props = shallowReactive({}))
currentInstance = this
const template = factory.call(this, props)
currentInstance = null
// beforeMount 生命周期
this._bm && this._bm.forEach((cb) => cb())
// 定义一个 Shadow root,并且内部实现无法被 JavaScript 访问及修改,类似 <video> 标签
const root = this.attachShadow({ mode: 'closed' })
let isMounted = false
// watcher
effect(() => {
if (!isMounted) {
// beforeUpdate 生命周期
this._bu && this._bu.forEach((cb) => cb())
}
// 调用 lit-html 的核心渲染能力,参考上文 lit-html 的 Demo
render(template(), root)
if (isMounted) {
// update 生命周期
this._u && this._u.forEach((cb) => cb())
} else {
// 渲染完成,将 isMounted 置为 true
isMounted = true
}
})
}
connectedCallback() {
// mounted 生命周期
this._m && this._m.forEach((cb) => cb())
}
disconnectedCallback() {
// unMounted 生命周期
this._um && this._um.forEach((cb) => cb())
}
attributeChangedCallback(name, oldValue, newValue) {
// 每次修改 propDefs 里的参数都会触发
this._props[name] = newValue
}
}
)
}
// 挂载生命周期
function createLifecycleMethod(name) {
return (cb) => {
if (currentInstance) {
;(currentInstance[name] || (currentInstance[name] = [])).push(cb)
}
}
}
// 导出生命周期
export const onBeforeMount = createLifecycleMethod('_bm')
export const onMounted = createLifecycleMethod('_m')
export const onBeforeUpdate = createLifecycleMethod('_bu')
export const onUpdated = createLifecycleMethod('_u')
export const onUnmounted = createLifecycleMethod('_um')
// 导出 lit-hteml 和 @vue/reactivity 的所有 API
export * from 'https://unpkg.com/lit-html?module'
export * from 'https://unpkg.com/@vue/reactivity/dist/reactivity.esm-browser.js'简化版有助于理解
整体看下来,为了更好地理解,我们不考虑生命周期之后可以简化一下:
import { render } from 'https://unpkg.com/lit-html?module'
import {
shallowReactive,
effect
} from 'https://unpkg.com/@vue/reactivity/dist/reactivity.esm-browser.js'
export function defineComponent(name, factory) {
customElements.define(
name,
class extends HTMLElement {
constructor() {
super()
const root = this.attachShadow({ mode: 'closed' })
effect(() => {
render(factory(), root)
})
}
}
)
}也就这几个流程:
Web Components 的 Custom ElementsShadow DOM 的 ShadowRoot 节点factory 和内部创建的 ShadowRoot 节点交给 lit-html 的 render 渲染出来回过头来看尤大提供的 DEMO:
import {
defineComponent,
reactive,
html,
} from 'https://unpkg.com/@vue/lit'
defineComponent('my-component', () => {
const msg = 'Hello World'
const state = reactive({
show: true
})
const toggle = () => {
state.show = !state.show
}
return () => html`
<button @click=${toggle}>toggle child</button>
${state.show ? html`<my-child msg=${msg}></my-child>` : ``}
`
})my-component 是传入的 name,第二个是一个函数,也就是传入的 factory,其实就是 lit-html 的第一个参数,只不过引入了 @vue/reactivity 的 reactive 能力,把 state 变成了响应式。
没毛病,和 Vue 3.0 Release 里说的一致,@vue/reactivity 可以和 lit-html 配合,使得 Vue 和 Web Components 结合到一块儿了,是不是还挺有意思。
可能尤大只是一时兴起,写了这个小玩具,但是可以见得这可能真的是一种大趋势。
猜测不久将来这些关键词会突然就爆发:Unbundled / ES Modules / Web components / Custom Element / Shadow DOM...
是不是值得期待一下?
思考可能还比较浅,文笔有限,不足之处欢迎大家指出。
阿里国际化团队基础架构组招聘前端 P6/P7,base 杭州,基础设施建设,业务赋能... 很多事情可以做。
要求熟悉 工程化/ Node/ React... 可直接发送简历至 [email protected]。
todo
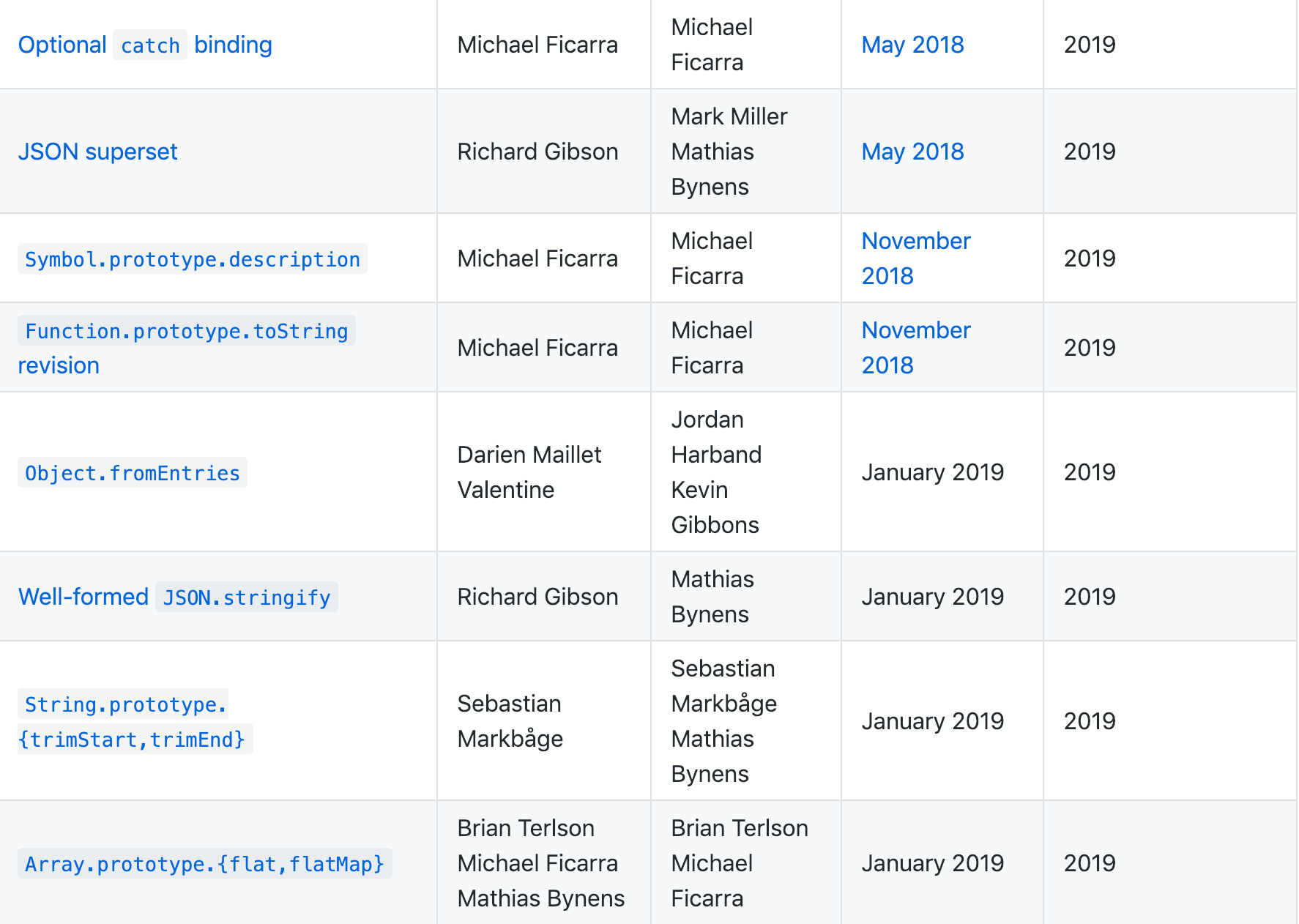
从表中可以看到已经有多个特性加到了 ES2019 中。
https://github.com/tc39/proposal-optional-catch-binding
将 err 变成 optional 的,可以省略 catch 后的 括号和错误对象:
try {
// tryCode
} catch {
// catchCode
}之前 try...catch 是这样的:
try {
// tryCode
} catch(err) {
// catchCode
}比如:
try {
throw new Error('报错啦报错啦');
} catch(e) {
console.log(e); // Error: 报错啦报错啦
}有的时候我们只需要捕获错误但是无需知道错误信息,err 就显得没必要的。
https://github.com/tc39/proposal-json-superset
允许 未转义的 U + 2028 行分隔符和 U + 2029 段分割符直接出现在字符串中,不会出现异常。
之前,JSON的某些字符 \u2028 \u2029 会导致 Javascript 语法错误。
eval('"\u2028"'); // SyntaxError: Unexpected我们的解决方法是对 \u2028 \u2029 进行转义,比如:
str.Replace('\u2028', '\\u2028')https://github.com/tc39/proposal-Symbol-description
Symbol.prototype.description | MDN
可以通过 description 方法获取 Symbol 的描述:
const name = Symbol('My name is axuebin');
console.log(name.description); // My name is axuebin
console.log(name.description === 'My name is axuebin'); // My name is axuebin我们知道,Symbol 的描述只被存储在内部的 [[Description]],没有直接对外暴露,我们只有调用 Symbol 的 toString() 时才可以读取这个属性:
const name = Symbol('My name is axuebin');
console.log(name.toString()); // Symbol(My name is axuebin)
console.log(name); // Symbol(My name is axuebin)
console.log(name === 'Symbol(My name is axuebin)'); // false
console.log(name.toString()) === 'Symbol(My name is axuebin)'); // true在执行 console.log(name) 的时候也打印了描述信息,是因为这里隐式地执行了 toString(),在代码里这样是不行的。
https://github.com/tc39/Function-prototype-toString-revision
现在 foo.toString() 可以返回精确字符串,包括空格和注释等。
https://github.com/tc39/proposal-object-from-entries
该方法把键值对列表转换为一个对象,可以看作是 Object.entries() 的反向方法。
const arr = Object.entries({ name: 'axuebin', age: 27 });
console.log(arr); // ["name", "axuebin"], ["age', 27]]
const obj = Object.fromEntries(arr);
console.log(obj); // { name: 'axuebin', age: 27 }和 lodash 的 _.fromPairs 具有一样的功能。
const obj = _.fromPairs(['name', 'axuebin'], ['age', 27]);
console.log(obj); // { name: 'axuebin', age: 27 }https://github.com/tc39/proposal-well-formed-stringify
更友好的 JSON.stringify,对于一些超出范围的 Unicode,为其输出转义序列,使其成为有效 Unicode,
JSON.stringify('\uDF06\uD834'); // '"\\udf06\\ud834"'
JSON.stringify('\uDEAD'); // '"\\udead"'JSON.stringify('\uDF06\uD834'); // '"��"'
JSON.stringify('\uDEAD'); // '"�"'https://github.com/tc39/proposal-string-left-right-trim
String.prototype.trimStart() | MDN
String.prototype.trimEnd() | MDN
分别去除字符串前后的空格,生成新的字符串。
const str = ' axuebin ';
console.log(str.trimStart()); // 'axuebin '
console.log(str.trimEnd()); // ' axuebin'
console.log(str); // ' axuebin 'https://github.com/tc39/proposal-flatMap
Array.prototype.flatMap() | MDN
还记得这样一道笔试题么,给你一个多维数组,把它拍平!
const arr = [1, [2, [3, [4, [5, 6]]]]];
arr.flat(); // [1, 2, [3, [4, [5, 6]]]]
arr.flat(1); // [1, 2, [3, [4, [5, 6]]]]
arr.flat(2); // [1, 2, 3, [4, [5, 6]]]
arr.flat(3); // [1, 2, 3, 4, [5, 6]]
arr.flat(4); // [1, 2, 3, 4, 5, 6]const arr = [[1, 2, 3], [4, 5]];
arr.flatMap(item => item); [1, 2, 3, 4, 5];是不是很方便...
浅拷贝和深拷贝都是对于JS中的引用类型而言的,浅拷贝就只是复制对象的引用,如果拷贝后的对象发生变化,原对象也会发生变化。只有深拷贝才是真正地对对象的拷贝。
说到深浅拷贝,必须先提到的是JavaScript的数据类型,之前的一篇文章JavaScript基础心法——数据类型说的很清楚了,这里就不多说了。
需要知道的就是一点:JavaScript的数据类型分为基本数据类型和引用数据类型。
对于基本数据类型的拷贝,并没有深浅拷贝的区别,我们所说的深浅拷贝都是对于引用数据类型而言的。
浅拷贝的意思就是只复制引用,而未复制真正的值。
const originArray = [1,2,3,4,5];
const originObj = {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}};
const cloneArray = originArray;
const cloneObj = originObj;
console.log(cloneArray); // [1,2,3,4,5]
console.log(originObj); // {a:'a',b:'b',c:Array[3],d:{dd:'dd'}}
cloneArray.push(6);
cloneObj.a = {aa:'aa'};
console.log(cloneArray); // [1,2,3,4,5,6]
console.log(originArray); // [1,2,3,4,5,6]
console.log(cloneObj); // {a:{aa:'aa'},b:'b',c:Array[3],d:{dd:'dd'}}
console.log(originArray); // {a:{aa:'aa'},b:'b',c:Array[3],d:{dd:'dd'}}上面的代码是最简单的利用 = 赋值操作符实现了一个浅拷贝,可以很清楚的看到,随着 cloneArray 和 cloneObj 改变,originArray 和 originObj 也随着发生了变化。
深拷贝就是对目标的完全拷贝,不像浅拷贝那样只是复制了一层引用,就连值也都复制了。
只要进行了深拷贝,它们老死不相往来,谁也不会影响谁。
目前实现深拷贝的方法不多,主要是两种:
JSON 对象中的 parse 和 stringify先看看这两个方法吧:
The JSON.stringify() method converts a JavaScript value to a JSON string.
JSON.stringify 是将一个 JavaScript 值转成一个 JSON 字符串。
The JSON.parse() method parses a JSON string, constructing the JavaScript value or object described by the string.
JSON.parse 是将一个 JSON 字符串转成一个 JavaScript 值或对象。
很好理解吧,就是 JavaScript 值和 JSON 字符串的相互转换。
它能实现深拷贝呢?我们来试试。
const originArray = [1,2,3,4,5];
const cloneArray = JSON.parse(JSON.stringify(originArray));
console.log(cloneArray === originArray); // false
const originObj = {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}};
const cloneObj = JSON.parse(JSON.stringify(originObj));
console.log(cloneObj === originObj); // false
cloneObj.a = 'aa';
cloneObj.c = [1,1,1];
cloneObj.d.dd = 'doubled';
console.log(cloneObj); // {a:'aa',b:'b',c:[1,1,1],d:{dd:'doubled'}};
console.log(originObj); // {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}};确实是深拷贝,也很方便。但是,这个方法只能适用于一些简单的情况。比如下面这样的一个对象就不适用:
const originObj = {
name:'axuebin',
sayHello:function(){
console.log('Hello World');
}
}
console.log(originObj); // {name: "axuebin", sayHello: ƒ}
const cloneObj = JSON.parse(JSON.stringify(originObj));
console.log(cloneObj); // {name: "axuebin"}发现在 cloneObj 中,有属性丢失了。。。那是为什么呢?
在 MDN 上找到了原因:
If undefined, a function, or a symbol is encountered during conversion it is either omitted (when it is found in an object) or censored to null (when it is found in an array). JSON.stringify can also just return undefined when passing in "pure" values like JSON.stringify(function(){}) or JSON.stringify(undefined).
undefined、function、symbol 会在转换过程中被忽略。。。
明白了吧,就是说如果对象中含有一个函数时(很常见),就不能用这个方法进行深拷贝。
递归的**就很简单了,就是对每一层的数据都实现一次 创建对象->对象赋值 的操作,简单粗暴上代码:
function deepClone(source){
const targetObj = source.constructor === Array ? [] : {}; // 判断复制的目标是数组还是对象
for(let keys in source){ // 遍历目标
if(source.hasOwnProperty(keys)){
if(source[keys] && typeof source[keys] === 'object'){ // 如果值是对象,就递归一下
targetObj[keys] = source[keys].constructor === Array ? [] : {};
targetObj[keys] = deepClone(source[keys]);
}else{ // 如果不是,就直接赋值
targetObj[keys] = source[keys];
}
}
}
return targetObj;
}我们来试试:
const originObj = {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}};
const cloneObj = deepClone(originObj);
console.log(cloneObj === originObj); // false
cloneObj.a = 'aa';
cloneObj.c = [1,1,1];
cloneObj.d.dd = 'doubled';
console.log(cloneObj); // {a:'aa',b:'b',c:[1,1,1],d:{dd:'doubled'}};
console.log(originObj); // {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}};可以。那再试试带有函数的:
const originObj = {
name:'axuebin',
sayHello:function(){
console.log('Hello World');
}
}
console.log(originObj); // {name: "axuebin", sayHello: ƒ}
const cloneObj = deepClone(originObj);
console.log(cloneObj); // {name: "axuebin", sayHello: ƒ}也可以。搞定。
是不是以为这样就完了?? 当然不是。
我们知道在 JavaScript 中,数组有两个方法 concat 和 slice 是可以实现对原数组的拷贝的,这两个方法都不会修改原数组,而是返回一个修改后的新数组。
同时,ES6 中 引入了 Object.assgn 方法和 ... 展开运算符也能实现对对象的拷贝。
那它们是浅拷贝还是深拷贝呢?
The concat() method is used to merge two or more arrays. This method does not change the existing arrays, but instead returns a new array.
该方法可以连接两个或者更多的数组,但是它不会修改已存在的数组,而是返回一个新数组。
看着这意思,很像是深拷贝啊,我们来试试:
const originArray = [1,2,3,4,5];
const cloneArray = originArray.concat();
console.log(cloneArray === originArray); // false
cloneArray.push(6); // [1,2,3,4,5,6]
console.log(originArray); [1,2,3,4,5];看上去是深拷贝的。
我们来考虑一个问题,如果这个对象是多层的,会怎样。
const originArray = [1,[1,2,3],{a:1}];
const cloneArray = originArray.concat();
console.log(cloneArray === originArray); // false
cloneArray[1].push(4);
cloneArray[2].a = 2;
console.log(originArray); // [1,[1,2,3,4],{a:2}]originArray 中含有数组 [1,2,3] 和对象 {a:1},如果我们直接修改数组和对象,不会影响 originArray,但是我们修改数组 [1,2,3] 或对象 {a:1} 时,发现 originArray 也发生了变化。
结论:concat 只是对数组的第一层进行深拷贝。
The slice() method returns a shallow copy of a portion of an array into a new array object selected from begin to end (end not included). The original array will not be modified.
解释中都直接写道是 a shallow copy 了 ~
但是,并不是!
const originArray = [1,2,3,4,5];
const cloneArray = originArray.slice();
console.log(cloneArray === originArray); // false
cloneArray.push(6); // [1,2,3,4,5,6]
console.log(originArray); [1,2,3,4,5];同样地,我们试试多层的数组。
const originArray = [1,[1,2,3],{a:1}];
const cloneArray = originArray.slice();
console.log(cloneArray === originArray); // false
cloneArray[1].push(4);
cloneArray[2].a = 2;
console.log(originArray); // [1,[1,2,3,4],{a:2}]果然,结果和 concat 是一样的。
结论:slice 只是对数组的第一层进行深拷贝。
The Object.assign() method is used to copy the values of all enumerable own properties from one or more source objects to a target object. It will return the target object.
复制复制复制。
那到底是浅拷贝还是深拷贝呢?
自己试试吧。。
结论:Object.assign() 拷贝的是属性值。假如源对象的属性值是一个指向对象的引用,它也只拷贝那个引用值。
const originArray = [1,2,3,4,5,[6,7,8]];
const originObj = {a:1,b:{bb:1}};
const cloneArray = [...originArray];
cloneArray[0] = 0;
cloneArray[5].push(9);
console.log(originArray); // [1,2,3,4,5,[6,7,8,9]]
const cloneObj = {...originObj};
cloneObj.a = 2;
cloneObj.b.bb = 2;
console.log(originObj); // {a:1,b:{bb:2}}结论:... 实现的是对象第一层的深拷贝。后面的只是拷贝的引用值。
我们知道了,会有一种情况,就是对目标对象的第一层进行深拷贝,然后后面的是浅拷贝,可以称作“首层浅拷贝”。
我们可以自己实现一个这样的函数:
function shallowClone(source) {
const targetObj = source.constructor === Array ? [] : {}; // 判断复制的目标是数组还是对象
for (let keys in source) { // 遍历目标
if (source.hasOwnProperty(keys)) {
targetObj[keys] = source[keys];
}
}
return targetObj;
}我们来测试一下:
const originObj = {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}};
const cloneObj = shallowClone(originObj);
console.log(cloneObj === originObj); // false
cloneObj.a='aa';
cloneObj.c=[1,1,1];
cloneObj.d.dd='surprise';经过上面的修改,cloneObj 不用说,肯定是 {a:'aa',b:'b',c:[1,1,1],d:{dd:'surprise'}} 了,那 originObj 呢?刚刚我们验证了 cloneObj === originObj 是 false,说明这两个对象引用地址不同啊,那应该就是修改了 cloneObj 并不影响 originObj。
console.log(cloneObj); // {a:'aa',b:'b',c:[1,1,1],d:{dd:'surprise'}}
console.log(originObj); // {a:'a',b:'b',c:[1,2,3],d:{dd:'surprise'}}What happend?
originObj 中关于 a、c都没被影响,但是 d 中的一个对象被修改了。。。说好的深拷贝呢?不是引用地址都不一样了吗?
原来是这样:
shallowClone 的代码中我们可以看出,我们只对第一层的目标进行了 深拷贝 ,而第二层开始的目标我们是直接利用 = 赋值操作符进行拷贝的。= 实现的是浅拷贝,只拷贝对象的引用值;JSON.stringify 实现的是深拷贝,但是对目标对象有要求;应该是有两个数组,它们的长度不同。
const a = 500000;
const b = 1000;
for(let i=0;i<a;i++){
for(let j=0;j<b;j++){
}
}
for(let i=0;i<b;i++){
for(let j=0;j<a;j++){
}
}关于上述两种循环嵌套的方式,哪种效率更好?
经过测试,是先小后大的效率更好,为什么?
todo
在前端开发中,我们在提到性能优化的时候总会提到一点:合理设置缓存。我们该如何从这方面入手来考虑提高网站性能呢?
我们都知道 HTML5 引入了应用程序缓存,可以在没有网络的情况下进行访问,同时,HTML5 还引入了 storage 本地存储。这些都属于应用缓存。
本篇文章主要内容是和浏览器缓存相关的,也可以说是 HTTP 缓存。
MDN 上是这样解释浏览器缓存的:
A browser cache holds all documents downloaded via HTTP by the user ... without requiring an additional trip to the server.
意思就是,浏览器缓存保存着用户通过 HTTP 获取的所有资源,再下一次请求时可以避免重复向服务器发出多余的请求。
通俗的说,就是在你访问过一次某个网站之后,这个站点的文字、图片等所有资源都被下载到本地了,下次再访问该网站时判断是否满足缓存条件,如果满足就不用再花费时间去等待资源的获取了。
一般来说浏览器缓存可以分为两类:
我们需要知道的是,浏览器在加载资源时,会先判断是否命中强缓存再验证是命中协商缓存。
其它的的具体细节,稍后会展开来说。
浏览器在加载资源时,会先根据本地缓存资源的 header 中的信息判断是否命中强缓存,如果命中则直接使用缓存中的资源不会再向服务器发送请求。
从图中可以看出,强缓存一般是这样一个流程:
header 头中的 Expire 和 Cache-control 来判断是否满足规则;所以我们主要就是关注 Expire 和 Cache-control 这两个字段。
同样地,我们看看MDN中如何解释这个字段:
The Expires header contains the date/time after which the response is considered stale.
这个字段包含了一个时间,过了这个时间,响应将会失效。
也就是说,Expire 这个字段表示缓存到期时间,我们来打开一个网站并查看 Response Header 看看这个字段:
Expires:Fri, 27 Oct 2017 07:55:30 GMT
可能在你查看这的时候发现时间不对啊,怎么都已经是过去了 ~
GMT 表示的是格林威治时间,和北京时间相差8小时。
上面的这个时间表示的是 2017年10月27日15:55:30。
通过设置 Expire 来设置缓存有一个致命缺点:
可以看出,这个是个绝对时间,也就是说,如果我修改了客户端的本地时间,是不是就会导致判断缓存失效了呢。
既然不能设置绝对时间,那我就设置个相对时间呗。
在 HTTP/1.1 中,增加了一个字段 Cache-Control ,它包含一个 max-age 属性,该字段表示资源缓存的最大有效时间,这就是一个相对时间。
Cache-Control:max-age=600
这个表示的就是最大有效时间是 600s ,对的,它的单位是秒。
Cache-Control 除了 max-age 属性之外还有一些属性:
现在基本上都会同时设置 Expire 和 Cache-Control ,Cache-Control 的优先级别更高。
当强缓存没有命中的时候,浏览器会发送一个请求到服务器,服务器根据请求头中的部分信息来判断是否命中缓存。如果命中,则返回 304 ,告诉浏览器资源未更新,可使用本地的缓存。
从图中可以看出,协商缓存一般是这样一个流程:
If-Modify-Since 或 Etag 发送到服务器,确认资源是否更新;304 并且会显示一个 Not Modified 的字符串,告诉浏览器使用本地缓存;浏览器第一次请求资源的时候,服务器返回的 header 上会带有一个 Last-Modified 字段,表示资源最后修改的时间。
Last-Modified: Fri, 27 Oct 2017 07:55:30 GMT
同样的,这是一个 GMT 的绝对时间。
当浏览器再次请求该资源时,请求头中会带有一个 If-Modified-Since 字段,这个值是第一次请求返回的 Last-Modified 的值。服务器收到这个请求后,将 If-Modified-Since 和当前的 Last-Modified 进行对比。如果相等,则说明资源未修改,返回 304,浏览器使用本地缓存。
well,这个方法也是有缺点的:
Last-Modified 并不会发生变化;Last-Modified 可不这样认为。所以,后来又引入一个 Etag。
Etag 一般是由文件内容 hash 生成的,也就是说它可以保证资源的唯一性,资源发生改变就会导致 Etag 发生改变。
同样地,在浏览器第一次请求资源时,服务器会返回一个 Etag 标识。当再次请求该资源时, 会通过 If-no-match 字段将 Etag 发送回服务器,然后服务器进行比较,如果相等,则返回 304 表示未修改。
**Last-Modified 和 Etag 是可以同时设置的,服务器会优先校验 Etag,如果 Etag 相等就会继续比对 Last-Modified,最后才会决定是否返回 304。 **
当浏览器再次访问一个已经访问过的资源时,它会这样做:
304 告诉浏览器使用本地缓存;todo
Babel官方工具:https://babeljs.io/repl/
文章里的例子浅拷贝就是用=赋值,但是浅拷贝指的不是指浅层次的拷贝?在第一层发生改变不会影响原有变量,是我理解错了吗?
var a = { name: 'hello' };
// 这种不是浅拷贝吗?
var b = { ...a };
// 例子说这种是浅拷贝?
var c = a;试一下自己撸一个图片懒加载...
Demo地址:http://axuebin.com/lazyload
照片都是自己拍的哦~
懒加载其实就是延迟加载,是一种对网页性能优化的方式,比如当访问一个页面的时候,优先显示可视区域的图片而不一次性加载所有图片,当需要显示的时候再发送图片请求,避免打开网页时加载过多资源。
当页面中需要一次性载入很多图片的时候,往往都是需要用懒加载的。
我们都知道HTML中的<img>标签是代表文档中的一个图像。。说了个废话。。
<img>标签有一个属性是src,用来表示图像的URL,当这个属性的值不为空时,浏览器就会根据这个值发送请求。如果没有src属性,就不会发送请求。
嗯?貌似这点可以利用一下?
我先不设置src,需要的时候再设置?
nice,就是这样。
我们先不给<img>设置src,把图片真正的URL放在另一个属性data-src中,在需要的时候也就是图片进入可视区域的之前,将URL取出放到src中。
<div class="container">
<div class="img-area">
<img class="my-photo" alt="loading" data-src="./img/img1.png">
</div>
<div class="img-area">
<img class="my-photo" alt="loading" data-src="./img/img2.png">
</div>
<div class="img-area">
<img class="my-photo" alt="loading" data-src="./img/img3.png">
</div>
<div class="img-area">
<img class="my-photo" alt="loading" data-src="./img/img4.png">
</div>
<div class="img-area">
<img class="my-photo" alt="loading" data-src="./img/img5.png">
</div>
</div>仔细观察一下,<img>标签此时是没有src属性的,只有alt和data-src属性。
alt 属性是一个必需的属性,它规定在图像无法显示时的替代文本。
data-* 全局属性:构成一类名称为自定义数据属性的属性,可以通过HTMLElement.dataset来访问。
网上看到好多这种方法,稍微记录一下。
document.documentElement.clientHeight获取屏幕可视窗口高度element.offsetTop获取元素相对于文档顶部的距离document.documentElement.scrollTop获取浏览器窗口顶部与文档顶部之间的距离,也就是滚动条滚动的距离然后判断②-③<①是否成立,如果成立,元素就在可视区域内。
通过getBoundingClientRect()方法来获取元素的大小以及位置,MDN上是这样描述的:
The Element.getBoundingClientRect() method returns the size of an element and its position relative to the viewport.
这个方法返回一个名为ClientRect的DOMRect对象,包含了top、right、botton、left、width、height这些值。
MDN上有这样一张图:
可以看出返回的元素位置是相对于左上角而言的,而不是边距。
我们思考一下,什么情况下图片进入可视区域。
假设const bound = el.getBoundingClientRect();来表示图片到可视区域顶部距离;
并设 const clientHeight = window.innerHeight;来表示可视区域的高度。
随着滚动条的向下滚动,bound.top会越来越小,也就是图片到可视区域顶部的距离越来越小,当bound.top===clientHeight时,图片的上沿应该是位于可视区域下沿的位置的临界点,再滚动一点点,图片就会进入可视区域。
也就是说,在bound.top<=clientHeight时,图片是在可视区域内的。
我们这样判断:
function isInSight(el) {
const bound = el.getBoundingClientRect();
const clientHeight = window.innerHeight;
//如果只考虑向下滚动加载
//const clientWidth = window.innerWeight;
return bound.top <= clientHeight + 100;
}这里有个+100是为了提前加载。
页面打开时需要对所有图片进行检查,是否在可视区域内,如果是就加载。
function checkImgs() {
const imgs = document.querySelectorAll('.my-photo');
Array.from(imgs).forEach(el => {
if (isInSight(el)) {
loadImg(el);
}
})
}
function loadImg(el) {
if (!el.src) {
const source = el.dataset.src;
el.src = source;
}
}这里应该是有一个优化的地方,设一个标识符标识已经加载图片的index,当滚动条滚动时就不需要遍历所有的图片,只需要遍历未加载的图片即可。
在类似于滚动条滚动等频繁的DOM操作时,总会提到“函数节流、函数去抖”。
所谓的函数节流,也就是让一个函数不要执行的太频繁,减少一些过快的调用来节流。
基本步骤:
function throttle(fn, mustRun = 500) {
const timer = null;
let previous = null;
return function() {
const now = new Date();
const context = this;
const args = arguments;
if (!previous){
previous = now;
}
const remaining = now - previous;
if (mustRun && remaining >= mustRun) {
fn.apply(context, args);
previous = now;
}
}
}这里的mustRun就是调用函数的时间间隔,无论多么频繁的调用fn,只有remaining>=mustRun时fn才能被执行。
可以看出此时仅仅是加载了img1和img2,其它的img都没发送请求,看看此时的浏览器
第一张图片是完整的呈现了,第二张图片刚进入可视区域,后面的就看不到了~
当我向下滚动,此时浏览器是这样
此时第二张图片完全显示了,而第三张图片显示了一点点,这时候我们看看请求情况
img3的请求发出来,而后面的请求还是没发出~
当滚动条滚到最底下时,全部请求都应该是发出的,如图
在这哦:http://axuebin.com/lazyload
经大佬提醒,发现了这个方法
先附上链接:
jjc大大:justjavac/the-front-end-knowledge-you-may-not-know#10
阮一峰大大:http://www.ruanyifeng.com/blog/2016/11/intersectionobserver_api.html
API Sketch for Intersection Observers:https://github.com/WICG/IntersectionObserver
IntersectionObserver可以自动观察元素是否在视口内。
var io = new IntersectionObserver(callback, option);
// 开始观察
io.observe(document.getElementById('example'));
// 停止观察
io.unobserve(element);
// 关闭观察器
io.disconnect();callback的参数是一个数组,每个数组都是一个IntersectionObserverEntry对象,包括以下属性:
| 属性 | 描述 |
|---|---|
| time | 可见性发生变化的时间,单位为毫秒 |
| rootBounds | 与getBoundingClientRect()方法的返回值一样 |
| boundingClientRect | 目标元素的矩形区域的信息 |
| intersectionRect | 目标元素与视口(或根元素)的交叉区域的信息 |
| intersectionRatio | 目标元素的可见比例,即intersectionRect占boundingClientRect的比例,完全可见时为1,完全不可见时小于等于0 |
| target | 被观察的目标元素,是一个 DOM 节点对象 |
我们需要用到intersectionRatio来判断是否在可视区域内,当intersectionRatio > 0 && intersectionRatio <= 1即在可视区域内。
function checkImgs() {
const imgs = Array.from(document.querySelectorAll(".my-photo"));
imgs.forEach(item => io.observe(item));
}
function loadImg(el) {
if (!el.src) {
const source = el.dataset.src;
el.src = source;
}
}
const io = new IntersectionObserver(ioes => {
ioes.forEach(ioe => {
const el = ioe.target;
const intersectionRatio = ioe.intersectionRatio;
if (intersectionRatio > 0 && intersectionRatio <= 1) {
loadImg(el);
}
el.onload = el.onerror = () => io.unobserve(el);
});
});简单来说,file-loader 就是在 JavaScript 代码里 import/require 一个文件时,会将该文件生成到输出目录,并且在 JavaScript 代码里返回该文件的地址。
file-loadernpm install file-loader --save-dev
webapck// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.(png|jpg|gif)$/,
use: [
{
loader: 'file-loader',
options: {},
},
],
},
],
},
};关于 file-loader 的 options,这里就不多说了,见 file-loader options .
import(或 require)import logo from '../assets/image/logo.png';
console.log('logo的值: ', logo); // 打印一下看看 logo 是什么简单三步就搞定了。
webpack
执行 webpack 打包之后,dist 目录下会生成一个打包好的 bundle.js,这个就不多说了。
如果使用了 file-loader, dist 目录这时候会生成我们用到的那个文件,在这里也就是 logo.png。
默认情况下,生成到 dist 目录的文件不会是原文件名,而是:**[原文件内容的 MD5 哈希值].[原文件扩展名]**。
回到上文,console.log(logo) 会打印什么呢,我们执 bundle.js 看看:
node dist/bundle.js
输出结果是:
logo的值: dab1fd6b179f2dd87254d6e0f9f8efab.png
如上所说,会返回文件的地址。
file-loader 的代码不多,就直接贴在这了:
import path from 'path';
import loaderUtils from 'loader-utils'; // loader 工具包
import validateOptions from 'schema-utils'; // schema 工具包
import schema from './options.json'; // options schema
export default function loader(content) {
// 获取 webpack 配置里的 options
const options = loaderUtils.getOptions(this) || {};
// 校验 options
validateOptions(schema, options, {
name: 'File Loader',
baseDataPath: 'options',
});
// 获取 context
const context = options.context || this.rootContext;
// 根据 name 配置和 content 内容生成一个文件名
// 默认是 [contenthash].[ext],也就是根据 content 的 hash 来生成文件名
const url = loaderUtils.interpolateName(
this,
options.name || '[contenthash].[ext]',
{
context,
content,
regExp: options.regExp,
}
);
let outputPath = url;
// 如果配置了 outputPath,则需要做一些拼接操作
if (options.outputPath) {
if (typeof options.outputPath === 'function') {
outputPath = options.outputPath(url, this.resourcePath, context);
} else {
outputPath = path.posix.join(options.outputPath, url);
}
}
// __webpack_public_path__ 是 webpack 定义的全局变量,是 output.publicPath 的值
let publicPath = `__webpack_public_path__ + ${JSON.stringify(outputPath)}`;
// 同样,如果配置了 publicPath,则需要做一些拼接操作
if (options.publicPath) {
if (typeof options.publicPath === 'function') {
publicPath = options.publicPath(url, this.resourcePath, context);
} else {
publicPath = `${
options.publicPath.endsWith('/')
? options.publicPath
: `${options.publicPath}/`
}${url}`;
}
publicPath = JSON.stringify(publicPath);
}
// 关于 postTransformPublicPath,可以看一下 https://webpack.js.org/loaders/file-loader/#posttransformpublicpath
if (options.postTransformPublicPath) {
publicPath = options.postTransformPublicPath(publicPath);
}
if (typeof options.emitFile === 'undefined' || options.emitFile) {
// 让 webpack 生成一个文件
this.emitFile(outputPath, content);
}
// TODO revert to ES2015 Module export, when new CSS Pipeline is in place
// 这里可以思考一下为什么返回的是 `module.exports = ${publicPath};`,而不是 publicPath
return `module.exports = ${publicPath};`;
}
// 默认情况下 webpack 对文件进行 UTF8 编码,当 loader 需要处理二进制数据的时候,需要设置 raw 为 true
export const raw = true;未经授权,不得转载。如需转载,请联系作者。
Rax 是淘系的一套跨端解决方案。
根据 Rax 工程配置 知道,使用 Rax 时,如果设置了 target: ['web', 'weex'],则构建产物 build 目录会有两个子目录:web 和 weex,分别在 web 端和 weex 端消费。并且通过观察可以发现,两个目录下的内容是不一样的,已经根据不同环境拆分代码。业务逻辑比较复杂时,代码体积会比较大,按端拆分代码的能力是必须的。
但是在 src 目录中并没有区分 web 和 weex 目录,代码是写到一起的,通过 isWeex 或 isWeb 等环境判断变量来判断。
可以思考三个问题:
web 和 weex)的产物?web 和 weex 的代码中不存在其他端的冗余代码?universal-env 导出的 isWeex 和 isWeb 变量,而不能直接在项目中使用 typeof WXEnvironment 来判断?这里只以 weex 举例,其它端表现也是一样的,比如设置了 target: miniapp 则构建产物中会多一个 miniapp 目录。
带着这三个问题,我们来看看是否能从 Rax 相关源码里找到答案。
如果没有写过 Rax,可能前言里的内容没什么体感,没关系,看一个例子就了解了。
代码逻辑很简单,web 下展示 hello web ,weex 下展示 hello weex:
import { createElement } from 'rax';
import View from 'rax-view';
import Text from 'rax-text';
import { isWeex } from 'universal-env';
export default function Home() {
return (
<View className="home">
<Text className="title">{ isWeex ? 'hello weex' : 'hello web' }</Text>
</View>
);
}看一下构建产物:
├── build
│ ├── web
│ │ ├── index.css
│ │ ├── index.html
│ │ ├── index.js
│ │ ├── pages_home_index.chunk.css
│ │ └── pages_home_index.chunk.js
│ └── weex
│ └── index.jsweex/index.js
function c() {
return Object(r.createElement)(i.a, {
className: "home"
}, Object(r.createElement)(u.a, {
className: "title"
}, "hello weex"))
}web/pages_home_index.chunk.js
function c() {
return Object(n.createElement)(o.a, {
className: "home"
}, Object(n.createElement)(s.a, {
className: "title"
}, "hello web"))
}在 weex 和 web 的构建产物中分别只有 hello weex 和 hello web ,符合我们的预期。
Rax 也是基于 build-scripts 构建体系来进行构建的,如果还不了解 build-scripts,可以先看一下 build-scripts
build-scripts内部的基础webpack配置都是通过 webpack-chain 生成的,它通过webpack配置链式操作的 API,并可以定义具体loader规则和webpack插件的名称,可以让开发者更加细粒度修改webpack配置。
了解了 build-scripts 以及它的插件体系之后,我们看一下 Rax app 的核心插件 build-plugin-rax-app,逐一来解决上面的三个问题。代码在这:build-plugin-rax-app,感兴趣的同学也可以看一眼。
在 src 下找到了 build.js,看文件名一定是 build 的时候用的 ~
// 以下仅保留构建多个产物的相关代码
module.exports = ({ onGetWebpackConfig, registerTask, context, onHook }, options = {}) => {
const { targets = [], type = 'spa' } = options;
targets.forEach(async(target) => {
if ([WEB, WEEX, KRAKEN].includes(target)) {
const getBase = require(`./config/${target}/getBase`);
registerTask(target, getBase(context, target, options));
}
});
};插件会遍历 build.json 传入的 targets 字段,注册多个具名 webpack Task,默认配置存储在 config 对应的目录下。
对比 web/getBase.js 和 weex/getBase.js 发现都有设置 output,output 配置项控制 webpack 如何输出 bundles。
看上去 registerTask 只是注册了多份 webpack config,如何被 webpack 消费呢?这就得看一下 build-scripts 里的代码了。
// 定义 registerTask
// 每次运行 registerTask 都会往 configArr 里 push 一次 config
this.registerTask = (name, chainConfig) => {
const exist = this.configArr.find((v) => v.name === name);
if (!exist) {
this.
.push({
name,
chainConfig,
modifyFunctions: [],
});
}
else {
throw new Error(`[Error] config '${name}' already exists!`);
}
};
// webpack 使用 config
const webpackConfig = configArr.map(v => v.chainConfig.toConfig());
await applyHook(`before.${command}.run`, { args, config: webpackConfig });
let compiler;
try {
// 传入 webpack 一个配置项数组
compiler = webpackInstance(webpackConfig);
}这里往 webpack 函数里传入一个了配置项数组,对应的就是多个 registerTask 注册的配置项。
你一定会好奇,这个配置项数组在 webpack 中是如何被执行的?是一次编译过程还是多次编译过程?是串行还是并行执行?这些问题如果要关心构建速度的话,都是需要了解的。刚好这块儿之前也不了解,就一起看看。
// webpack/lib/webpack.js
const webpack = (options, callback) => {
let compiler;
if (Array.isArray(options)) {
compiler = new MultiCompiler(
Array.from(options).map(options => webpack(options))
);
} else if (typeof options === "object") {
// 单 options
}
// 回调
if (callback) {
compiler.run(callback);
}
return compiler;
}从代码上看来应该是会执行多次编译,多次编译过程执行完之后会调用 callback。那多个编译过程是串行的还是并行的呢?
先不急着下结论,第六感告诉我得先看看 MultiCompiler 做了啥事。
以下内容涉及到 webpack 的源码,说实话还是第一次看,如果有不对的地方,麻烦大家一定要指出,谢谢。
The MultiCompiler module allows webpack to run multiple configurations in separate compilers. If the options parameter in the webpack's NodeJS api is an array of options, webpack applies separate compilers and calls the callback after all compilers have been executed.
注意关键词: separate compilers ,石锤单独编译,并且是当 all compilers executed 才会调用 callback 。
顺便吐槽一下 webpack 的中文文档。。大家还是多看英文文档,以免被误导。。
| 这是错的 ❌ |
|---|
那 MultiCompiler 是串行还是并行的呢?官网是这样描述的:
Multiple configurations will not be run in parallel. Each configuration is only processed after the previous one has finished processing.
嗯,串行的,每一次编译会在上一次编译结束之后才会执行。可以通过 parallel-webapck 来并行处理多个 config 的编译。
有的人可能有疑问,在使用 rax-app build 的时候,控制台里看到两个端的任务进度条是并行的啊,比如这样:
我是这样理解的。上面只是说的 MultiCompiler 是串行的,但是 webpack 是基于 Tapable 的,它整体执行 loader/plugin 的流程都是异步的,相当于 MultiCompiler 只是注册了 compiler 任务,内部的流程都是同时异步在跑的。看一下源码验证一下:
MultiCompiler 里每个 compiler 都 tap(注册)了 MultiCompiler 事件,完成之后就会执行回调。
至于 Tapable,在这里就不展开说了(我也不是很懂,不敢乱说),感兴趣的同学可以看一下 webpack/tapable。
至此,build-scripts 是如何构建多个产物就算是了解清楚了。
总结:如果我们需要构建出更多的产物,只需要在插件内部通过 registerTask 注册新的任务,传入对应的 wepack config 即可。
从上文的例子中知道,我们需要删除的代码是根据端判断之后不会执行到的代码(包括未使用的模块),也就是所有的 Dead Code。目前在构建阶段删除 Dead Code 可以通过以下方式:
babel plugin,删除 dead codewebpack plugin,删除 dead code、console、注释等比较常见的一种做法是通过 DefinePlugin 来定义全局变量,webpack 压缩时会将 dead code 移除。
直接上代码,最有体感。初始化一个最简 webpack demo。
index.js:
let hello = 'hello world';
if (isWeex) {
hello = 'hello weex';
} else {
hello = 'hello web';
}
export default hello;webpack.config.js
const webpack = require('webpack');
module.exports = {
mode: 'production',
optimization: {
minimize: false
},
plugins: [
new webpack.DefinePlugin({
isWeex: true
})
]
}执行 webpack index.js --config webpack.config.js ,得到 bundle.js:
([
/* 0 */
/***/
(function (module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__);
let hello = 'hello world';
if (true) {
console.log('aaa');
} else {}
/* harmony default export */
__webpack_exports__["default"] = (hello);
/***/
})
/******/
]);config 中通过 DefinePlugin 定义了全局变量 isWeex: true,我们预预期是构建时 webpack 将 src/index.js 代码中的 isWeex 都替换成常量 true。bundle.js 符合期望。
开启压缩 minimize: true 之后,webpack 会将 dead code 移除:
// 为了方便阅读,代码已经格式化
([function (e, t, r) {
"use strict";
r.r(t);
let n = "hello world";
n = "hello weex", t.default = n
}]);所以,我们可以通过 build-scripts 多产物构建能力 + webpack.DefinePlugin 完成按端的代码拆分,可能是这样:
function getWebpackBase() {
// 返回基础 config
}
// 获取 webpack 各个端的 config
function getBase(target) {
const config = getWebpackBase(target);
let options = { isWeb: true, isWeex: false };
if (target === 'weex') {
options = { isWeb: false, isWeex: true };
}
config
.plugin('DefinePlugin')
.use(webpack.DefinePlugin, [{
...options,
}]);
}
// build-scripts 插件
module.exports = ({ registerTask }) => {
const targets = ['weex', 'web'];
targets.forEach(async(target) => {
registerTask(target, getBase(target));
});
};总结:可以通过 DefinePlugin 在构建时移除无关代码,根据上文 build-scripts 的多产物构建能力,我们是可以在构建阶段构建出移除无关代码的各个端的产物。
但是,从上面的代码可以看出,通过 DefinePlugin 来定义全局变量的缺点在于 isWeex、 isWeb 等变量名是直接定义在 webpack 配置里的,扩展性不好,并且在实际业务代码中也需要使用这些变量,似乎约束也太强了。这种约定俗成的东西,随着时间的流逝,可能就慢慢地淡忘了。所以这个方案从长远来看,是不太友好的。
这里就需要稍微提一下 universal-env 这个包了,它的功能很简单,就只是导出各个环境的判断变量,如下:
但是它的作用不仅仅是这些,它是整个跨端体系中起到至关重要的一环。在前面的例子中也都有看到,一般是通过 import { isWeex} from 'univeral-env' 在业务代码中判断环境。和将全局变量定义在 webpack config 相比,这样的方式扩展性更强,也更易维护。
现在的问题就是通过 univeral-env 来导出环境判断变量之后,如何做到代码拆分。
既然 webpack 的能力我们没法用,如果想修改代码就只能是通过 Babel 来修改 AST 了。当然,我们今天的主角 Rax 也是这样做的,它通过一个 platformLoader 将 isWeex 等变量在构建阶段替换成常量。
本篇文章只关心核心代码(变量 -> 常量)部分,感兴趣的同学可以阅读完整代码:platformLoader。
定义了一份映射表,target 对应的变量会被置为 true。
const platformMap = {
weex: ['isWeex'],
web: ['isWeb'],
kraken: ['isKraken', 'isWeb'],
node: ['isNode'],
miniapp: ['isMiniApp'],
'wechat-miniprogram': ['isWeChatMiniProgram'],
};traverseImport 中操作 AST 的代码和以往使用 babel 没啥区别,就不展开说了,简单来说就是:
ImportDeclaration 判断是否 import 的 universal-env
imported.name 是否在上面定义的 map 中
VariableDeclaration 加到 AST 中,并且移除 ImportDeclaration除了常规操作之外,这里有两个比较有意思的点可以说一下:
如果代码已经被编译过,CommonJS 规范的代码可能已经是这样的:
var _universalEnv = require("universal-env");
if (_universalEnv.isWeex) {
console.log('weex');
} else {
console.log('web');
}platformLoader 是这样处理的:
CallExpression,将它替换为 objectExpression
var _universalEnv = require("universal-env")var _universalEnv = {isWeex: false} MemberExpression,判断 object.name 是否是 _universalEnv
property.name 是否在上面定义的 map 中
true,否则设为 false如果使用 universal-env 的时候,给变量设置了别名呢?
import { isWeex as isWeexPlatform } from 'univeral-env';
if (isWeexPlatform) {}platformLoader 也做了相关处理:
if (specObj.imported !== specObj.local) {
newNode = variableDeclarationMethod(
specObj.local,
newNodeInit,
);
path.insertAfter(newNode);
}总结, platformLoader 实现了我们需要的两个功能:
universal-env 依赖最后通过 webpack 压缩时删除 dead code 的能力就可以将 if(false) 等不会执行到的代码删除,实现拆分代码的功能。
所以,如果我们有一个跨端组件,想在纯 web 的工程中使用,也是可以通过 platformLoader 来处理的,不用担心会引入冗余代码,做到基础组件的跨端使用。
看完上面的源码分析,上文的三个疑问是否已经有了答案?
总结一下
build-scripts 支持多 config 构建的能力,通过 registerTask 可以注册多个 webpack compiler,它们本身是一个串行过程。compiler 注册之后,它内部的 loader 等过程相比注册 compiler 是异步的universal-env 提供统一的环境判断变量,在 Rax 跨端工程化体系中起到至关重要的作用,业务代码中判断环境务必使用其导出的变量Rax 是通过其提供的 platformLoader + webpack 压缩能力来实现的代码按端拆分,可以借助这个能力在非 Rax 工程中实现跨端组件的按需打包阿里国际化团队基础架构组招聘前端 P6/P7,base 杭州,基础设施建设,业务赋能... 很多事情可以做。
要求熟悉 工程化/ Node/ React... 可直接发送简历至 [email protected],也可以加我微信 xb9207 细聊。
整理call、apply、bind这三个方法的的知识点。
之前这篇文章提到过this的各种情况,其中有一种情况就是通过call、apply、bind来将this绑定到指定的对象上。
也就是说,这三个方法可以改变函数体内部this的指向。
这三个方法有什么区别呢?分别适合应用在哪些场景中呢?
先举个简单的栗子 ~
var person = {
name: "axuebin",
age: 25
};
function say(job){
console.log(this.name+":"+this.age+" "+job);
}
say.call(person,"FE"); // axuebin:25 FE
say.apply(person,["FE"]); // axuebin:25 FE
var sayPerson = say.bind(person,"FE");
sayPerson(); // axuebin:25 FE对于对象person而言,并没有say这样一个方法,通过call/apply/bind就可以将外部的say方法用于这个对象中,其实就是将say内部的this指向person这个对象。
call是属于所有Function的方法,也就是Function.prototype.call。
The call() method calls a function with a given this value and arguments provided individually.
call() 方法调用一个函数, 其具有一个指定的this值和分别地提供的参数(参数的列表)。
它的语法是这样的:
fun.call(thisArg[,arg1[,arg2,…]]);其中,thisArg就是this指向,arg是指定的参数。
call的用处简而言之就是可以让call()中的对象调用当前对象所拥有的function。
ECMAScript规范中是这样定义call的:
当以thisArg和可选的arg1,arg2等等作为参数在一个func对象上调用call方法,采用如下步骤:
IsCallable(func)是false, 则抛出一个TypeError异常。argList为一个空列表。arg1开始以从左到右的顺序将每个参数插入为argList的最后一个元素。thisArg作为this值并以argList作为参数列表,调用func的[[Call]]内部方法,返回结果。call方法的length属性是1。
在外面传入的thisArg值会修改并成为this值。thisArg是undefined或null时它会被替换成全局对象,所有其他值会被应用ToObject并将结果作为this值,这是第三版引入的更改。
var obj = {
a: 1
}
function foo(b, c){
this.b = b;
this.c = c;
console.log(this.a + this.b + this.c);
}
foo.call(obj,2,3); // 6在需要实现继承的子类构造函数中,可以通过call调用父类构造函数实现继承。
function Person(name, age){
this.name = name;
this.age = age;
this.say = function(){
console.log(this.name + ":" + this.age);
}
}
function Student(name, age, job){
Person.call(this, name ,age);
this.job = job;
this.say = function(){
console.log(this.name + ":" + this.age + " " + this.job);
}
}
var me = new Student("axuebin",25,"FE");
console.log(me.say()); // axuebin:25 FEapply也是属于所有Function的方法,也就是Function.prototype.apply。
The apply() method calls a function with a given this value, and arguments provided as an array (or an array-like object).
apply() 方法调用一个函数, 其具有一个指定的this值,以及作为一个数组(或类似数组的对象)提供的参数。
它的语法是这样的:
fun.apply(thisArg, [argsArray]);其中,thisArg就是this指向,argsArray是指定的参数数组。
通过语法就可以看出call和apply的在参数上的一个区别:
call的参数是一个列表,将每个参数一个个列出来apply的参数是一个数组,将每个参数放到一个数组中当以thisArg和argArray为参数在一个func对象上调用apply方法,采用如下步骤:
IsCallable(func)是false, 则抛出一个TypeError异常 .argArray是null或undefined, 则thisArg作为this值并以空参数列表调用func的[[Call]]内部方法的结果。Type(argArray)不是Object, 则抛出一个TypeError异常 .len为以"length"作为参数调用argArray的[[Get]]内部方法的结果。n为ToUint32(len).argList为一个空列表 .index为0.index<n就重复indexName为ToString(index).nextArg为以indexName作为参数调用argArray的[[Get]]内部方法的结果。nextArg作为最后一个元素插入到argList里。index为index + 1.thisArg作为this值并以argList作为参数列表,调用func的[[Call]]内部方法,返回结果。apply方法的length属性是 2。
在外面传入的thisArg值会修改并成为this值。thisArg是undefined或null时它会被替换成全局对象,所有其他值会被应用ToObject并将结果作为this值,这是第三版引入的更改。
在用法上apply和call一样,就不说了。
参考链接:jawil/blog#16
Function.prototype.myApply=function(context){
// 获取调用`myApply`的函数本身,用this获取
context.fn = this;
// 执行这个函数
context.fn();
// 从上下文中删除函数引用
delete context.fn;
}
var obj ={
name: "xb",
getName: function(){
console.log(this.name);
}
}
var me = {
name: "axuebin"
}
obj.getName(); // xb
obj.getName.myApply(me); // axuebin确实成功地将this指向了me对象,而不是本身的obj对象。
上文已经提到apply需要接受一个参数数组,可以是一个类数组对象,还记得获取函数参数可以用arguments吗?
Function.prototype.myApply=function(context){
// 获取调用`myApply`的函数本身,用this获取
context.fn = this;
// 通过arguments获取参数
var args = arguments[1];
// 执行这个函数,用ES6的...运算符将arg展开
context.fn(...args);
// 从上下文中删除函数引用
delete context.fn;
}
var obj ={
name: "xb",
getName: function(age){
console.log(this.name + ":" + age);
}
}
var me = {
name: "axuebin"
}
obj.getName(); // xb:undefined
obj.getName.myApply(me,[25]); // axuebin:25context.fn(...arg)是用了ES6的方法来将参数展开,如果看过上面那个链接,就知道这里不通过...运算符也是可以的。
原博主通过拼接字符串,然后用eval执行的方式将参数传进context.fn中:
for (var i = 0; i < args.length; i++) {
fnStr += i == args.length - 1 ? args[i] : args[i] + ',';
}
fnStr += ')';//得到"context.fn(arg1,arg2,arg3...)"这个字符串在,最后用eval执行
eval(fnStr); //还是eval强大我们知道,当apply的第一个参数,也就是this的指向为null时,this会指向window。知道了这个,就简单了~
Function.prototype.myApply=function(context){
// 获取调用`myApply`的函数本身,用this获取,如果context不存在,则为window
var context = context || window;
context.fn = this;
//获取传入的数组参数
var args = arguments[1];
if (args == undefined) { //没有传入参数直接执行
// 执行这个函数
context.fn()
} else {
// 执行这个函数
context.fn(...args);
}
// 从上下文中删除函数引用
delete context.fn;
}
var obj ={
name: "xb",
getName: function(age){
console.log(this.name + ":" + age);
}
}
var name = "window.name";
var me = {
name: "axuebin"
}
obj.getName(); // xb:25
obj.getName.myApply(); // window.name:undefined
obj.getName.myApply(null, [25]); // window.name:25
obj.getName.myApply(me, [25]); // axuebin:25ES6中新增了一种基础数据类型Symbol。
const name = Symbol();
const age = Symbol();
console.log(name === age); // false
const obj = {
[name]: "axuebin",
[age]: 25
}
console.log(obj); // {Symbol(): "axuebin", Symbol(): 25}
console.log(obj[name]); // axuebin所以我们可以通过Symbol来创建一个属性名。
var fn = Symbol();
context[fn] = this;Function.prototype.myApply=function(context){
// 获取调用`myApply`的函数本身,用this获取,如果context不存在,则为window
var context = context || window;
var fn = Symbol();
context[fn] = this;
//获取传入的数组参数
var args = arguments[1];
if (args == undefined) { //没有传入参数直接执行
// 执行这个函数
context[fn]()
} else {
// 执行这个函数
context[fn](...args);
}
// 从上下文中删除函数引用
delete context.fn;
}这样就是一个完整的apply了,我们来测试一下:
var obj ={
name: "xb",
getName: function(age){
console.log(this.name + ":" + age);
}
}
var name = "window.name";
var me = {
name: "axuebin"
}
obj.getName(); // xb:25
obj.getName.myApply(); // window.name:undefined
obj.getName.myApply(null, [25]); // window.name:25
obj.getName.myApply(me, [25]); // axuebin:25ok 没啥毛病 ~
再次感谢1024大佬 ~
The bind() method creates a new function that, when called, has its this keyword set to the provided value, with a given sequence of arguments preceding any provided when the new function is called.
bind()方法创建一个新的函数, 当被调用时,将其this关键字设置为提供的值,在调用新函数时,在任何提供之前提供一个给定的参数序列。
语法:
fun.bind(thisArg[, arg1[, arg2[, ...]]])其中,thisArg就是this指向,arg是指定的参数。
可以看出,bind会创建一个新函数(称之为绑定函数),原函数的一个拷贝,也就是说不会像call和apply那样立即执行。
当这个绑定函数被调用时,它的this值传递给bind的一个参数,执行的参数是传入bind的其它参数和执行绑定函数时传入的参数。
当我们执行下面的代码时,我们希望可以正确地输出name,然后现实是残酷的
function Person(name){
this.name = name;
this.say = function(){
setTimeout(function(){
console.log("hello " + this.name);
},1000)
}
}
var person = new Person("axuebin");
person.say(); //hello undefined这里this运行时是指向window的,所以this.name是undefined,为什么会这样呢?看看MDN的解释:
由setTimeout()调用的代码运行在与所在函数完全分离的执行环境上。这会导致,这些代码中包含的 this 关键字在非严格模式会指向 window。
有一个常见的方法可以使得正确的输出:
function Person(name){
this.name = name;
this.say = function(){
var self = this;
setTimeout(function(){
console.log("hello " + self.name);
},1000)
}
}
var person = new Person("axuebin");
person.say(); //hello axuebin没错,这里我们就可以用到bind了:
function Person(name){
this.name = name;
this.say = function(){
setTimeout(function(){
console.log("hello " + this.name);
}.bind(this),1000)
}
}
var person = new Person("axuebin");
person.say(); //hello axuebinFunction.prototype.bind = function (oThis) {
var aArgs = Array.prototype.slice.call(arguments, 1);
var fToBind = this;
var fNOP = function () {};
var fBound = function () {
fBound.prototype = this instanceof fNOP ? new fNOP() : fBound.prototype;
return fToBind.apply(this instanceof fNOP ? this : oThis || this, aArgs )
}
if( this.prototype ) {
fNOP.prototype = this.prototype;
}
return fBound;
}this指向this指向的对象bind是返回一个绑定函数可稍后执行,call、apply是立即调用call给定参数需要将参数全部列出,apply给定参数数组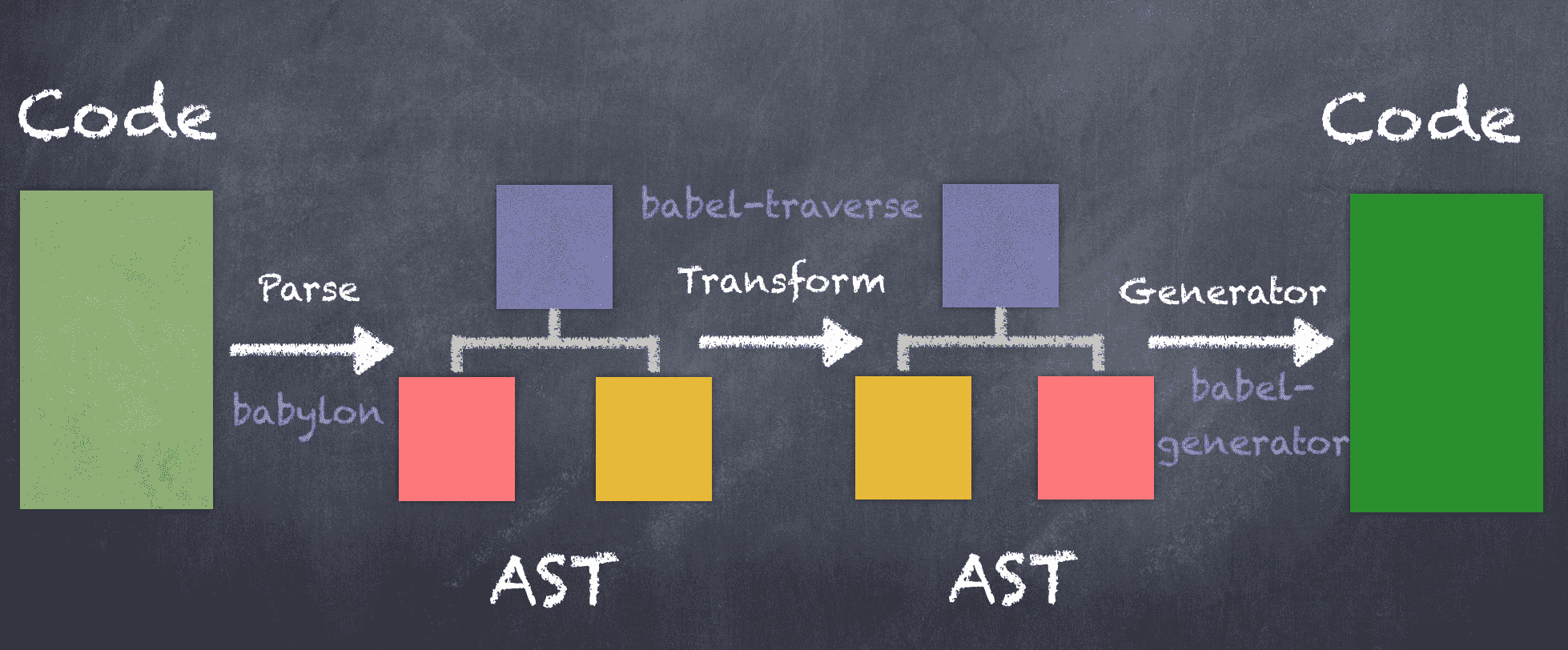
Babel 对于前端开发者来说应该是很熟悉了,日常开发中基本上是离不开它的。
已经9102了,我们已经能够熟练地使用 es2015+ 的语法。但是对于浏览器来说,可能和它们还不够熟悉,我们得让浏览器理解它们,这就需要 Babel。
当然,仅仅是 Babel 是不够的,还需要 polyfill 等等等等,这里就先不说了。
BabelBabel is a toolchain that is mainly used to convert ECMAScript 2015+ code into a backwards compatible version of JavaScript in current and older browsers or environments.
简单地说,Babel 能够转译 ECMAScript 2015+ 的代码,使它在旧的浏览器或者环境中也能够运行。
我们可以在 https://babel.docschina.org/repl 尝试一下。
一个小🌰:
// es2015 的 const 和 arrow function
const add = (a, b) => a + b;
// Babel 转译后
var add = function add(a, b) {
return a + b;
};
Babel 的功能很纯粹。我们传递一段源代码给 Babel,然后它返回一串新的代码给我们。就是这么简单,它不会运行我们的代码,也不会去打包我们的代码。
它只是一个编译器。
首先得要先了解一个概念:抽象语法树(Abstract Syntax Tree, AST),Babel 本质上就是在操作 AST 来完成代码的转译。
AST 是什么这里就不细说了,想要了解更多信息可以查看 Abstract syntax tree - Wikipedia。
这里比较关心的一段 JavaScript 代码会生成一个怎样的 AST,Babel 又是怎么去操作 AST 的。
我们还是拿上面的🌰来说明 const add = (a, b) => a + b;,这样一句简单的代码,我们来看看它生成的 AST 会是怎样的:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration", // 变量声明
"declarations": [ // 具体声明
{
"type": "VariableDeclarator", // 变量声明
"id": {
"type": "Identifier", // 标识符(最基础的)
"name": "add" // 函数名
},
"init": {
"type": "ArrowFunctionExpression", // 箭头函数
"id": null,
"expression": true,
"generator": false,
"params": [ // 参数
{
"type": "Identifier",
"name": "a"
},
{
"type": "Identifier",
"name": "b"
}
],
"body": { // 函数体
"type": "BinaryExpression", // 二项式
"left": { // 二项式左边
"type": "Identifier",
"name": "a"
},
"operator": "+", // 二项式运算符
"right": { // 二项式右边
"type": "Identifier",
"name": "b"
}
}
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
我们可以通过一棵“树”来更为直观地展示这句代码的 AST(从第二层的 declarations 开始):
一个 AST 的根节点始终都是 Program,上面的例子我们从 declarations 开始往下读:
一个VariableDeclaration(变量声明):声明了一个 name 为 add 的ArrowFunctionExpression(箭头函数):
params(函数入参):a 和 bBinaryExpression (二项式),一个标准的二项式分为三部分:
left(左边):aoperator(运算符):加号 +right(右边):b这样就拆解了这一行代码。
如果想要了解更多,可以阅读和尝试:
AST:https://ASTexplorer.netAST 规范:https://github.com/estree/estree了解了 AST 是什么样的,就可以开始研究 Babel 的工作过程了。
上面说过,Babel 的功能很纯粹,它只是一个编译器。
大多数编译器的工作过程可以分为三部分:
嗯... 既然 Babel 是一个编译器,当然它的工作过程也是这样的。我们来仔细看看这三步分别做了什么事。当然,还是拿上面的🌰来说明 const add = (a, b) => a + b,看看它是如何经过 Babel 变成:
var add = function add(a, b) {
return a + b;
};
一般来说,Parse 阶段可以细分为两个阶段:词法分析(Lexical Analysis, LA)和语法分析(Syntactic Analysis, SA)。
词法分析阶段可以看成是对代码进行“分词”,它接收一段源代码,然后执行一段 tokenize 函数,把代码分割成被称为Tokens 的东西。Tokens 是一个数组,由一些代码的碎片组成,比如数字、标点符号、运算符号等等等等,例如这样:
[
{ "type": "Keyword", "value": "const" },
{ "type": "Identifier", "value": "add" },
{ "type": "Punctuator", "value": "=" },
{ "type": "Punctuator", "value": "(" },
{ "type": "Identifier", "value": "a" },
{ "type": "Punctuator", "value": "," },
{ "type": "Identifier", "value": "b" },
{ "type": "Punctuator", "value": ")" },
{ "type": "Punctuator", "value": "=>" },
{ "type": "Identifier", "value": "a" },
{ "type": "Punctuator", "value": "+" },
{ "type": "Identifier", "value": "b" }
]
通过 http://esprima.org/demo/parse.html 生成的。
看上去好像很容易啊,就是把一句完整的代码拆成一个个独立个体就好了。但是,我们得让机器知道怎么拆~
我们来试着实现一下 tokenize 函数:
/**
* 词法分析 tokenize
* @param {string} code JavaScript 代码
* @return {Array} token
*/
function tokenize(code) {
if (!code || code.length === 0) {
return [];
}
var current = 0; // 记录位置
var tokens = []; // 定义一个空的 token 数组
var LETTERS = /[a-zA-Z\$\_]/i;
var KEYWORDS = /const/; // 模拟一下判断是不是关键字
var WHITESPACE = /\s/;
var PARENS = /\(|\)/;
var NUMBERS = /[0-9]/;
var OPERATORS = /[+*/-]/;
var PUNCTUATORS = /[~!@#$%^&*()/\|,.<>?"';:_+-=\[\]{}]/;
// 从第一个字符开始遍历
while (current < code.length) {
var char = code[current];
// 判断空格
if (WHITESPACE.test(char)) {
current++;
continue;
}
// 判断连续字符
if (LETTERS.test(char)) {
var value = '';
var type = 'Identifier';
while (char && LETTERS.test(char)) {
value += char;
char = code[++current];
}
// 判断是否是关键字
if (KEYWORDS.test(value)) {
type = 'Keyword'
}
tokens.push({
type: type,
value: value
});
continue;
}
// 判断小括号
if (PARENS.test(char)) {
tokens.push({
type: 'Paren',
value: char
});
current++;
continue;
}
// 判断连续数字
if (NUMBERS.test(char)) {
var value = '';
while (char && NUMBERS.test(char)) {
value += char;
char = code[++current];
}
tokens.push({
type: 'Number',
value: value
});
continue;
}
// 判断运算符
if (OPERATORS.test(char)) {
tokens.push({
type: 'Operator',
value: char
});
current++;
continue;
}
// 判断箭头函数
if (PUNCTUATORS.test(char)) {
var value = char;
var type = 'Punctuator';
var temp = code[++current];
if (temp === '>') {
type = 'ArrowFunction';
value += temp;
current ++;
}
tokens.push({
type: type,
value: value
});
continue;
}
tokens.push({
type: 'Identifier',
value: char
});
current++;
}
return tokens;
}
上面这个 tokenize 函数只是自己实现以下,与实际上 Babel 的实现方式还是差不少的,如果感兴趣可以看看https://github.com/babel/babel/blob/master/packages/babel-parser/src/tokenizer
我们来测试一下:
const tokens = tokenize('const add = (a, b) => a + b');
console.log(tokens);
[
{ "type": "Keyword", "value": "const" },
{ "type": "Identifier", "value": "add" },
{ "type": "Punctuator", "value": "=" },
{ "type": "Paren", "value": "(" },
{ "type": "Identifier", "value": "a" },
{ "type": "Punctuator", "value": "," },
{ "type": "Identifier", "value": "b" },
{ "type": "Paren", "value": ")" },
{ "type": "ArrowFunction", "value": "=>" },
{ "type": "Identifier", "value": "a" },
{ "type": "Operator", "value": "+" },
{ "type": "Identifier", "value": "b" }
]
看上去和上面的有点不太一样,没关系,我只是细化了一下类别,意思就是这么个意思。
词法分析之后,代码就已经变成了一个 Tokens 数组了,现在需要通过语法分析把 Tokens 转化为上面提到过的 AST。
说来惭愧,这里没有想到很好的思路来实现一个 parse 函数。如果哪天想到了,再补充上来。
现在我们先假设已经实现了这样一个函数,把上面的 Tokens 转化成了一个 AST,进入下一步。
如果感兴趣可以看看官方的做法https://github.com/babel/babel/tree/master/packages/babel-parser/src/parser
这一步做的事情也很简单,就是操作 AST。如果忘记了 AST 是什么,可以回到上面再看看。
我们可以看到 AST 中有很多相似的元素,它们都有一个 type 属性,这样的元素被称作节点。一个节点通常含有若干属性,可以用于描述 AST 的部分信息。
比如这是一个最常见的 Identifier 节点:
{
type: 'Identifier',
name: 'add'
}
表示这是一个标识符。
所以,操作 AST 也就是操作其中的节点,可以增删改这些节点,从而转换成实际需要的 AST。
更多的节点规范可以在https://github.com/estree/estree中查看。
Babel 对于 AST 的遍历是深度优先遍历,对于 AST 上的每一个分支 Babel 都会先向下遍历走到尽头,然后再向上遍历退出刚遍历过的节点,然后寻找下一个分支。
还是上面的🌰:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration", // 变量声明
"declarations": [ // 具体声明
{
"type": "VariableDeclarator", // 变量声明
"id": {
"type": "Identifier", // 标识符(最基础的)
"name": "add" // 函数名
},
"init": {
"type": "ArrowFunctionExpression", // 箭头函数
"id": null,
"expression": true,
"generator": false,
"params": [ // 参数
{
"type": "Identifier",
"name": "a"
},
{
"type": "Identifier",
"name": "b"
}
],
"body": { // 函数体
"type": "BinaryExpression", // 二项式
"left": { // 二项式左边
"type": "Identifier",
"name": "a"
},
"operator": "+", // 二项式运算符
"right": { // 二项式右边
"type": "Identifier",
"name": "b"
}
}
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
根节点我们就不说了,从 declarations 里开始遍历:
id、init),然后我们再以此访问每一个属性以及它们的子节点。id 是一个 Idenrifier,有一个 name 属性表示变量名。init,init 也有好几个内部属性:type 是ArrowFunctionExpression,表示这是一个箭头函数表达式params 是这个箭头函数的入参,其中每一个参数都是一个 Identifier 类型的节点;body 属性是这个箭头函数的主体,这是一个 BinaryExpression 二项式:left、operator、right,分别表示二项式的左边变量、运算符以及右边变量。这是遍历 AST 的白话形式,再看看 Babel 是怎么做的:
Babel 会维护一个称作 Visitor 的对象,这个对象定义了用于 AST 中获取具体节点的方法。
一个 Visitor 一般来说是这样的:
var visitor = {
ArrowFunction() {
console.log('我是箭头函数');
},
IfStatement() {
console.log('我是一个if语句');
},
CallExpression() {}
};
当我们遍历 AST 的时候,如果匹配上一个 type,就会调用 visitor 里的方法。
这只是一个简单的 Visitor 。
上面说过,Babel 遍历 AST 其实会经过两次节点:遍历的时候和退出的时候,所以实际上 Babel 中的 Visitor 应该是这样的:
var visitor = {
Identifier: {
enter() {
console.log('Identifier enter');
},
exit() {
console.log('Identifier exit');
}
}
};
比如我们拿这个 visitor 来遍历这样一个 AST:
params: [ // 参数
{
"type": "Identifier",
"name": "a"
},
{
"type": "Identifier",
"name": "b"
}
]
过程可能是这样的...
Identifier(params[0])Identifier(params[0])Identifier(params[1])Identifier(params[1])当然,Babel 中的 Visitor 模式远远比这复杂...
回到上面的🌰,箭头函数是 ES5 不支持的语法,所以 Babel 得把它转换成普通函数,一层层遍历下去,找到了 ArrowFunctionExpression 节点,这时候就需要把它替换成 FunctionDeclaration 节点。所以,箭头函数可能是这样处理的:
import * as t from "@babel/types";
var visitor = {
ArrowFunction(path) {
path.replaceWith(t.FunctionDeclaration(id, params, body));
}
};
对细节感兴趣的可以翻翻源码https://github.com/babel/babel/tree/master/packages/babel-traverse。
经过上面两个阶段,需要转译的代码已经经过转换,生成新的 AST 了,最后一个阶段理所应当就是根据这个 AST 来输出代码。
Babel 是通过 https://github.com/babel/babel/tree/master/packages/babel-generator 来完成的。当然,也是深度优先遍历。
class Generator extends Printer {
constructor(ast, opts = {}, code) {
const format = normalizeOptions(code, opts);
const map = opts.sourceMaps ? new SourceMap(opts, code) : null;
super(format, map);
this.ast = ast;
}
ast: Object;
generate() {
return super.generate(this.ast);
}
}
经过这三个阶段,代码就被 Babel 转译成功了。
任重而道远... 想真正掌握 Babel 还有很长的路...
平时在使用 antd、element 等组件库的时候,都会使用到一个 Babel 插件:babel-plugin-import,这篇文章通过例子和分析源码简单说一下这个插件做了一些什么事情,并且实现一个最小可用版本。
插件地址:https://github.com/ant-design/babel-plugin-import
antd 和 element 这两个组件库,看它的源码, index.js 分别是这样的:
// antd
export { default as Button } from './button';
export { default as Table } from './table';// element
import Button from '../packages/button/index.js';
import Table from '../packages/table/index.js';
export default {
Button,
Table,
};antd 和 element 都是通过 ES6 Module 的 export 来导出带有命名的各个组件。
所以,我们可以通过 ES6 的 import { } from 的语法来导入单组件的 JS 文件。但是,我们还需要手动引入组件的样式:
// antd
import 'antd/dist/antd.css';
// element
import 'element-ui/lib/theme-chalk/index.css';如果仅仅是只需要一个 Button 组件,却把所有的样式都引入了,这明显是不合理的。
当然,你说也可以只使用单个组件啊,还可以减少代码体积:
import Button from 'antd/lib/button';
import 'antd/lib/button/style';PS:类似 antd 的组件库提供了 ES Module 的构建产物,直接通过 import {} from 的形式也可以 tree-shaking,这个不在今天的话题之内,就不展开说了~
对,这没毛病。但是,看一下如们需要多个组件的时候:
import { Affix, Avatar, Button, Rate } from 'antd';
import 'antd/lib/affix/style';
import 'antd/lib/avatar/style';
import 'antd/lib/button/style';
import 'antd/lib/rate/style';会不会觉得这样的代码不够优雅?如果是我,甚至想打人。
这时候就应该思考一下,如何在引入 Button 的时候自动引入它的样式文件。
简单来说,babel-plugin-import 就是解决了上面的问题,为组件库实现单组件按需加载并且自动引入其样式,如:
import { Button } from 'antd';
↓ ↓ ↓ ↓ ↓ ↓
var _button = require('antd/lib/button');
require('antd/lib/button/style');只需关心需要引入哪些组件即可,内部样式我并不需要关心,你帮我自动引入就 ok。
简单来说就需要关心三个参数即可:
{
"libraryName": "antd", // 包名
"libraryDirectory": "lib", // 目录,默认 lib
"style": true, // 是否引入 style
}其它的看文档:https://github.com/ant-design/babel-plugin-import#usage
主要来看一下 babel-plugin-import 如何加载 JavaScript 代码和样式的。
以下面这段代码为例:
import { Button, Rate } from 'antd';
ReactDOM.render(<Button>xxxx</Button>);babel-plubin-import 会在 ImportDeclaration 里将所有的 specifier 收集起来。
先看一下 ast 吧:

可以从这个 ImportDeclaration 语句中提取几个关键点:
需要做的事情也很简单:
import 的包是不是 antd,也就是 libraryNameButton 和 Rate 收集起来来看代码:
ImportDeclaration(path, state) {
const { node } = path;
if (!node) return;
// 代码里 import 的包名
const { value } = node.source;
// 配在插件 options 的包名
const { libraryName } = this;
// babel-type 工具函数
const { types } = this;
// 内部状态
const pluginState = this.getPluginState(state);
// 判断是不是需要使用该插件的包
if (value === libraryName) {
// node.specifiers 表示 import 了什么
node.specifiers.forEach(spec => {
// 判断是不是 ImportSpecifier 类型的节点,也就是是否是大括号的
if (types.isImportSpecifier(spec)) {
// 收集依赖
// 也就是 pluginState.specified.Button = Button
// local.name 是导入进来的别名,比如 import { Button as MyButton } from 'antd' 的 MyButton
// imported.name 是真实导出的变量名
pluginState.specified[spec.local.name] = spec.imported.name;
} else {
// ImportDefaultSpecifier 和 ImportNamespaceSpecifier
pluginState.libraryObjs[spec.local.name] = true;
}
});
pluginState.pathsToRemove.push(path);
}
}待 babel 遍历了所有的 ImportDeclaration 类型的节点之后,就收集好了依赖关系,下一步就是如何加载它们了。
收集了依赖关系之后,得要判断一下这些 import 的变量是否被使用到了,我们这里说一种情况。
我们知道,JSX 最终是变成 React.createElement() 执行的:
ReactDOM.render(<Button>Hello</Button>);
↓ ↓ ↓ ↓ ↓ ↓
React.createElement(Button, null, "Hello");没错,createElement 的第一个参数就是我们要找的东西,我们需要判断收集的依赖中是否有被 createElement 使用。
分析一下这行代码的 ast,很容易就找到这个节点:

来看代码:
CallExpression(path, state) {
const { node } = path;
const file = (path && path.hub && path.hub.file) || (state && state.file);
// 方法调用者的 name
const { name } = node.callee;
// babel-type 工具函数
const { types } = this;
// 内部状态
const pluginState = this.getPluginState(state);
// 如果方法调用者是 Identifier 类型
if (types.isIdentifier(node.callee)) {
if (pluginState.specified[name]) {
node.callee = this.importMethod(pluginState.specified[name], file, pluginState);
}
}
// 遍历 arguments 找我们要的 specifier
node.arguments = node.arguments.map(arg => {
const { name: argName } = arg;
if (
pluginState.specified[argName] &&
path.scope.hasBinding(argName) &&
path.scope.getBinding(argName).path.type === 'ImportSpecifier'
) {
// 找到 specifier,调用 importMethod 方法
return this.importMethod(pluginState.specified[argName], file, pluginState);
}
return arg;
});
}除了 React.createElement(Button) 之外,还有 const btn = Button / [Button] ... 等多种情况会使用 Button,源码中都有对应的处理方法,感兴趣的可以自己看一下: https://github.com/ant-design/babel-plugin-import/blob/master/src/Plugin.js#L163-L272 ,这里就不多说了。
第一步和第二步主要的工作是找到需要被插件处理的依赖关系,比如:
import { Button, Rate } from 'antd';
ReactDOM.render(<Button>Hello</Button>);Button 组件使用到了,Rate 在代码里未使用。所以插件要做的也只是自动引入 Button 的代码和样式即可。
我们先回顾一下,当我们 import 一个组件的时候,希望它能够:
import { Button } from 'antd';
↓ ↓ ↓ ↓ ↓ ↓
var _button = require('antd/lib/button');
require('antd/lib/button/style');并且再回想一下插件的配置 options,只需要将 libraryDirectory 以及 style 等配置用上就完事了。
小朋友,你是否有几个问号?这里该如何让 babel 去修改代码并且生成一个新的 import 以及一个样式的 import 呢,不慌,看看代码就知道了:
import { addSideEffect, addDefault, addNamed } from '@babel/helper-module-imports';
importMethod(methodName, file, pluginState) {
if (!pluginState.selectedMethods[methodName]) {
// libraryDirectory:目录,默认 lib
// style:是否引入样式
const { style, libraryDirectory } = this;
// 组件名转换规则
// 优先级最高的是配了 camel2UnderlineComponentName:是否使用下划线作为连接符
// camel2DashComponentName 为 true,会转换成小写字母,并且使用 - 作为连接符
const transformedMethodName = this.camel2UnderlineComponentName
? transCamel(methodName, '_')
: this.camel2DashComponentName
? transCamel(methodName, '-')
: methodName;
// 兼容 windows 路径
// path.join('antd/lib/button') == 'antd/lib/button'
const path = winPath(
this.customName
? this.customName(transformedMethodName, file)
: join(this.libraryName, libraryDirectory, transformedMethodName, this.fileName),
);
// 根据是否有导出 default 来判断使用哪种方法来生成 import 语句,默认为 true
// addDefault(path, 'antd/lib/button', { nameHint: 'button' })
// addNamed(path, 'button', 'antd/lib/button')
pluginState.selectedMethods[methodName] = this.transformToDefaultImport
? addDefault(file.path, path, { nameHint: methodName })
: addNamed(file.path, methodName, path);
// 根据不同配置 import 样式
if (this.customStyleName) {
const stylePath = winPath(this.customStyleName(transformedMethodName));
addSideEffect(file.path, `${stylePath}`);
} else if (this.styleLibraryDirectory) {
const stylePath = winPath(
join(this.libraryName, this.styleLibraryDirectory, transformedMethodName, this.fileName),
);
addSideEffect(file.path, `${stylePath}`);
} else if (style === true) {
addSideEffect(file.path, `${path}/style`);
} else if (style === 'css') {
addSideEffect(file.path, `${path}/style/css`);
} else if (typeof style === 'function') {
const stylePath = style(path, file);
if (stylePath) {
addSideEffect(file.path, stylePath);
}
}
}
return { ...pluginState.selectedMethods[methodName] };
}addSideEffect, addDefault 和 addNamed 是 @babel/helper-module-imports 的三个方法,作用都是创建一个 import 方法,具体表现是:
addSideEffect(path, 'source');
↓ ↓ ↓ ↓ ↓ ↓
import "source"addDefault(path, 'source', { nameHint: "hintedName" })
↓ ↓ ↓ ↓ ↓ ↓
import hintedName from "source"addNamed(path, 'named', 'source', { nameHint: "hintedName" });
↓ ↓ ↓ ↓ ↓ ↓
import { named as _hintedName } from "source"更多关于 @babel/helper-module-imports 见:@babel/helper-module-imports
一起数个 1 2 3,babel-plugin-import 要做的事情也就做完了。
我们来总结一下,babel-plugin-import 和普遍的 babel 插件一样,会遍历代码的 ast,然后在 ast 上做了一些事情:
importDeclaration,分析出包 a 和依赖 b,c,d....,假如 a 和 libraryName 一致,就将 b,c,d... 在内部收集起来CallExpression)判断 收集到的 b,c,d... 是否在代码中被使用,如果有使用的,就调用 importMethod 生成新的 impport 语句import 语句不过有一些细节这里就没提到,比如如何删除旧的 import 等... 感兴趣的可以自行阅读源码哦。
看完一遍源码,是不是有发现,其实除了 antd 和 element 等大型组件库之外,任意的组件库都可以使用 babel-plugin-import 来实现按需加载和自动加载样式。
没错,比如我们常用的 lodash,也可以使用 babel-plugin-import 来加载它的各种方法,可以动手试一下。
看了这么多,自己动手实现一个简易版的 babel-plugin-import 吧。
如果还不了解如何实现一个 Babel 插件,可以阅读 【Babel 插件入门】如何用 Babel 为代码自动引入依赖
按照上文说的,最重要的配置项就是三个:
{
"libraryName": "antd",
"libraryDirectory": "lib",
"style": true,
}所以我们也就只实现这三个配置项。
并且,上文提到,真实情况中会有多种方式来调用一个组件,这里我们也不处理这些复杂情况,只实现最常见的 <Button /> 调用。
入口文件的作用是获取用户传入的配置项并且将核心插件代码作用到 ast 上。
import Plugin from './Plugin';
export default function ({ types }) {
let plugins = null;
// 将插件作用到节点上
function applyInstance(method, args, context) {
for (const plugin of plugins) {
if (plugin[method]) {
plugin[method].apply(plugin, [...args, context]);
}
}
}
const Program = {
// ast 入口
enter(path, { opts = {} }) {
// 初始化插件实例
if (!plugins) {
plugins = [
new Plugin(
opts.libraryName,
opts.libraryDirectory,
opts.style,
types,
),
];
}
applyInstance('ProgramEnter', arguments, this);
},
// ast 出口
exit() {
applyInstance('ProgramExit', arguments, this);
},
};
const ret = {
visitor: { Program },
};
// 插件只作用在 ImportDeclaration 和 CallExpression 上
['ImportDeclaration', 'CallExpression'].forEach(method => {
ret.visitor[method] = function () {
applyInstance(method, arguments, ret.visitor);
};
});
return ret;
}真正修改 ast 的代码是在 plugin 实现的:
import { join } from 'path';
import { addSideEffect, addDefault } from '@babel/helper-module-imports';
/**
* 转换成小写,添加连接符
* @param {*} _str 字符串
* @param {*} symbol 连接符
*/
function transCamel(_str, symbol) {
const str = _str[0].toLowerCase() + _str.substr(1);
return str.replace(/([A-Z])/g, $1 => `${symbol}${$1.toLowerCase()}`);
}
/**
* 兼容 Windows 路径
* @param {*} path
*/
function winPath(path) {
return path.replace(/\\/g, '/');
}
export default class Plugin {
constructor(
libraryName, // 需要使用按需加载的包名
libraryDirectory = 'lib', // 按需加载的目录
style = false, // 是否加载样式
types, // babel-type 工具函数
) {
this.libraryName = libraryName;
this.libraryDirectory = libraryDirectory;
this.style = style;
this.types = types;
}
/**
* 获取内部状态,收集依赖
* @param {*} state
*/
getPluginState(state) {
if (!state) {
state = {};
}
return state;
}
/**
* 生成 import 语句(核心代码)
* @param {*} methodName
* @param {*} file
* @param {*} pluginState
*/
importMethod(methodName, file, pluginState) {
if (!pluginState.selectedMethods[methodName]) {
// libraryDirectory:目录,默认 lib
// style:是否引入样式
const { style, libraryDirectory } = this;
// 组件名转换规则
const transformedMethodName = transCamel(methodName, '');
// 兼容 windows 路径
// path.join('antd/lib/button') == 'antd/lib/button'
const path = winPath(join(this.libraryName, libraryDirectory, transformedMethodName));
// 生成 import 语句
// import Button from 'antd/lib/button'
pluginState.selectedMethods[methodName] = addDefault(file.path, path, { nameHint: methodName });
if (style) {
// 生成样式 import 语句
// import 'antd/lib/button/style'
addSideEffect(file.path, `${path}/style`);
}
}
return { ...pluginState.selectedMethods[methodName] };
}
ProgramEnter(path, state) {
const pluginState = this.getPluginState(state);
pluginState.specified = Object.create(null);
pluginState.selectedMethods = Object.create(null);
pluginState.pathsToRemove = [];
}
ProgramExit(path, state) {
// 删除旧的 import
this.getPluginState(state).pathsToRemove.forEach(p => !p.removed && p.remove());
}
/**
* ImportDeclaration 节点的处理方法
* @param {*} path
* @param {*} state
*/
ImportDeclaration(path, state) {
const { node } = path;
if (!node) return;
// 代码里 import 的包名
const { value } = node.source;
// 配在插件 options 的包名
const { libraryName } = this;
// babel-type 工具函数
const { types } = this;
// 内部状态
const pluginState = this.getPluginState(state);
// 判断是不是需要使用该插件的包
if (value === libraryName) {
// node.specifiers 表示 import 了什么
node.specifiers.forEach(spec => {
// 判断是不是 ImportSpecifier 类型的节点,也就是是否是大括号的
if (types.isImportSpecifier(spec)) {
// 收集依赖
// 也就是 pluginState.specified.Button = Button
// local.name 是导入进来的别名,比如 import { Button as MyButton } from 'antd' 的 MyButton
// imported.name 是真实导出的变量名
pluginState.specified[spec.local.name] = spec.imported.name;
} else {
// ImportDefaultSpecifier 和 ImportNamespaceSpecifier
pluginState.libraryObjs[spec.local.name] = true;
}
});
// 收集旧的依赖
pluginState.pathsToRemove.push(path);
}
}
/**
* React.createElement 对应的节点处理方法
* @param {*} path
* @param {*} state
*/
CallExpression(path, state) {
const { node } = path;
const file = (path && path.hub && path.hub.file) || (state && state.file);
// 方法调用者的 name
const { name } = node.callee;
// babel-type 工具函数
const { types } = this;
// 内部状态
const pluginState = this.getPluginState(state);
// 如果方法调用者是 Identifier 类型
if (types.isIdentifier(node.callee)) {
if (pluginState.specified[name]) {
node.callee = this.importMethod(pluginState.specified[name], file, pluginState);
}
}
// 遍历 arguments 找我们要的 specifier
node.arguments = node.arguments.map(arg => {
const { name: argName } = arg;
if (
pluginState.specified[argName] &&
path.scope.hasBinding(argName) &&
path.scope.getBinding(argName).path.type === 'ImportSpecifier'
) {
// 找到 specifier,调用 importMethod 方法
return this.importMethod(pluginState.specified[argName], file, pluginState);
}
return arg;
});
}
}这样就实现了一个最简单的 babel-plugin-import 插件,可以自动加载单包和样式。
完整代码:https://github.com/axuebin/babel-plugin-import-demo
本文通过源码解析和动手实践,深入浅出的介绍了 babel-plugin-import 插件的原理,希望大家看完这篇文章之后,都能清楚地了解这个插件做了什么事。
看看这个有着深不可测的魔力的this到底是个什么玩意儿 ~
在传统面向对象的语言中,比如Java,this关键字用来表示当前对象本身,或当前对象的一个实例,通过this关键字可以获得当前对象的属性和调用方法。
在JavaScript中,this似乎表现地略有不同,这也是让人“讨厌”的地方~
ECMAScript规范中这样写:
this 关键字执行为当前执行环境的 ThisBinding。
MDN上这样写:
In most cases, the value of this is determined by how a function is called.
在绝大多数情况下,函数的调用方式决定了this的值。
可以这样理解,在JavaScript中,this的指向是调用时决定的,而不是创建时决定的,这就会导致this的指向会让人迷惑,简单来说,this具有运行期绑定的特性。
来看看不同的情况五花八门的this吧~
首先需要理解调用位置,调用位置就是函数在代码中被调用的位置,而不是声明的位置。
通过分析调用栈(到达当前执行位置所调用的所有函数)可以找到调用位置。
function baz(){
console.log("baz");
bar();
}
function bar(){
console.log("bar");
foo();
}
function foo(){
console.log("foo");
}
baz();当我们调用baz()时,它会以此调用baz()→bar()→foo()。
对于foo():调用位置是在bar()中。
对于bar():调用位置是在baz()中。
而对于baz():调用位置是全局作用域中。
可以看出,调用位置应该是当前正在执行的函数的前一个调用中。
在全局执行上下文中this都指代全局对象。
this等价于window对象var === this. === winodw.console.log(window === this); // true
var a = 1;
this.b = 2;
window.c = 3;
console.log(a + b + c); // 6在浏览器里面this等价于window对象,如果你声明一些全局变量,这些变量都会作为this的属性。
在函数内部,this的值取决于函数被调用的方式。
this指向全局变量。
function foo(){
return this;
}
console.log(foo() === window); // truethis指向绑定的对象上。
var person = {
name: "axuebin",
age: 25
};
function say(job){
console.log(this.name+":"+this.age+" "+job);
}
say.call(person,"FE"); // axuebin:25
say.apply(person,["FE"]); // axuebin:25可以看到,定义了一个say函数是用来输出name、age和job,其中本身没有name和age属性,我们将这个函数绑定到person这个对象上,输出了本属于person的属性,说明此时this是指向对象person的。
如果传入一个原始值(字符串、布尔或数字类型)来当做this的绑定对象, 这个原始值会被转换成它的对象形式(new String()),这通常被称为“装箱”。
call和apply从this的绑定角度上来说是一样的,唯一不同的是它们的第二个参数。
this将永久地被绑定到了bind的第一个参数。
bind和call、apply有些相似。
var person = {
name: "axuebin",
age: 25
};
function say(){
console.log(this.name+":"+this.age);
}
var f = say.bind(person);
console.log(f());所有的箭头函数都没有自己的this,都指向外层。
关于箭头函数的争论一直都在,可以看看下面的几个链接:
MDN中对于箭头函数这一部分是这样描述的:
An arrow function does not create its own this, the this value of the enclosing execution context is used.
箭头函数会捕获其所在上下文的this值,作为自己的this值。
function Person(name){
this.name = name;
this.say = () => {
var name = "xb";
return this.name;
}
}
var person = new Person("axuebin");
console.log(person.say()); // axuebin箭头函数常用语回调函数中,例如定时器中:
function foo() {
setTimeout(()=>{
console.log(this.a);
},100)
}
var obj = {
a: 2
}
foo.call(obj);附上MDN关于箭头函数this的解释:
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Functions/Arrow_functions#不绑定_this
this指向调用函数的对象。
var person = {
name: "axuebin",
getName: function(){
return this.name;
}
}
console.log(person.getName()); // axuebin这里有一个需要注意的地方。。。
var name = "xb";
var person = {
name: "axuebin",
getName: function(){
return this.name;
}
}
var getName = person.getName;
console.log(getName()); // xb发现this又指向全局变量了,这是为什么呢?
还是那句话,this的指向得看函数调用时。
this被绑定到正在构造的新对象。
通过构造函数创建一个对象其实执行这样几个步骤:
所以this就是指向创建的这个对象上。
function Person(name){
this.name = name;
this.age = 25;
this.say = function(){
console.log(this.name + ":" + this.age);
}
}
var person = new Person("axuebin");
console.log(person.name); // axuebin
person.say(); // axuebin:25this指向触发事件的元素,也就是始事件处理程序所绑定到的DOM节点。
var ele = document.getElementById("id");
ele.addEventListener("click",function(e){
console.log(this);
console.log(this === e.target); // true
})this指向所在的DOM元素
<button onclick="console.log(this);">Click Me</button>在许多情况下JQuery的this都指向DOM元素节点。
$(".btn").on("click",function(){
console.log(this);
});如果要判断一个函数的this绑定,就需要找到这个函数的直接调用位置。然后可以顺序按照下面四条规则来判断this的绑定对象:
new调用:绑定到新创建的对象call或apply、bind调用:绑定到指定的对象注意:箭头函数不使用上面的绑定规则,根据外层作用域来决定this,继承外层函数调用的this绑定。
两年前,我和你一样,也是一名即将参加校招的同学。
我写这篇文章不是因为我的校招成绩很辉煌,也不是因为我收割了多少 offer,而是回过头来看校招,多少有些感想,可以分享给大家。
希望看完文章,你和我不一样,成为 offer 收割机。
从现在开始,各大互联网公司的校招应该逐步都会开启了... 大家要迅速行动起来了,先面试先拿 offer 这个道理大家都懂吧。
首先,最重要的一点,我们得了解校招,而不是简简单单地写一份简历就海投,这样无疑效率是非常低的。
建议大家这段时间可以提前做一些准备工作:
假设你对目前互联网行业的一些公司有所了解,你应该将他们都列出来,并且根据自己的感兴趣程度标一个优先级。比如这样:
| 优先级 | 公司名称 |
|---|---|
| !!!!! | 阿里巴巴 |
| !!!! | 字节跳动 |
| !! | a 公司 |
| ! | b 公司 |
积攒经验
比如你和我一样,目的很明确,最想去的公司是阿里,而 a 公司和 b 公司可能由于地理位置等各种因素应该不会考虑,我们可以先参加 a 公司和 b 公司的面试,积攒一些经验。
选择
很简单,知道自己想要什么。
校招就这几个月,互联网公司那么多,极大可能他们的笔试时间会冲突,这时候可能就需要根据你自己的优先级来判断放弃某个公司的机会了。因为提前思考过,不会因为太紧张做出错误的选择。
准备好自己的心仪公司列表之后,尝试在公司官网以及各类论坛(比如牛客网校招日程)了解各个公司的校招时间节点,即投递简历 - 笔试 - 面试 - offer 的 timeline。
当然,我们可以在上面的表格上进行补充。它现在应该是这样了:

每天都 check 一下时间节点,真的一定别错过各个重要的时间节点啊!
关于各个批次的招聘,每个公司可能也有所不同。比如:
建议,如果是有提前批/内推的公司,争取在这两个批次的招聘中拿 offer,因为很可能留给网申的 HC 已经不多了...
一般来说,各大厂都有校招专区,除了职位列表之外都有一个答疑专区(FAQ),你想知道的大多数问题这里都有。
在确定了自己心仪的公司之后,就可以在校内、各大论坛寻找校招内推人。注意的是,一定要找靠谱的内推人。
虽然校招能否拿 offer 靠的是自身实力,但是一个靠谱的内推人可以给你:
一对一的 VIP 服务,它不香吗?
如果是那种发一个链接或者内推码,就再也不理你的内推人,建议最好不能找他内推,面试过程中很有可能找不到人...
曾经的我... 很多需要简历筛选的大厂都没获得面试机会。
现在的我... 明白了一些简历的套路。
简历有多重要,我们来看看生活中的一个场景。
想想,你和女神第一次约会,是不是会穿上一身帅气西装,将头发梳成大人模样,不停照镜子今天的自己是不是最帅的。

找工作也是一样的道理。
简历是敲门砖,并且伴随你的整个面试过程,是所有面试官了解你的唯一途径。
我对于简历的理解是这样的,简历不用很复杂,它是一份简单的履历,作用是让阅读简历的人能够快速、准确地捕捉到有用信息。我觉得一份简历能优雅地展示出这三点就够了:
总之。
如果想了解更多关于技术简历如何写,可以看之前的一篇文章:教你如何写初/高级技术岗位简历【赠简历导图】
校招投递简历的方式无非也就是两种:员工内推、官网投递。
有的同学说,我可能找不到认识的朋友帮我内推。那也没关系,在校内论坛或者各大社区论坛上,都能找到一些内推链接、内推码等。
优先级:朋友内推 > 论坛内推 > 官网投递
朋友内推的优先级为什么最高?
来,我们再看看生活中的场景,比如你相亲的时候,介绍人是不是都会说很多对方的优点(别看我,我是听别人说的),经过介绍,你对对方的印象是不是就会好点?马上安排!

同样的道理,找工作可以找目标公司员工内推。内推人会先帮你过一下简历,和你聊一聊,然后给你提一些建议,最后把你的简历给老板,并且给一些正面评价!
还有一点,内推可以查进度!很多公司的校招面试流程会比较长,时刻知道自己面试流程进度还是比较重要的。
甚至,我是说如果,因为各种原因和面试官失联了,你也可以麻烦内推人帮忙连个线,重新约一下面试时间。
所以,内推有多重要,明白了吧。
内推的优先级最高,当然也得建立在你找到一个靠谱的内推人的基础上,否则和随便点个链接就把简历交出去了没有任何区别。
首先,当然是学长学姐或者朋友,如果他们能够帮忙内推那是最好。
其次,就是各种渠道找校招内推贴、内推群,看看可不可以加到内推人的微信,可以观察一下,看他是否比较活跃,或者可以先和内推人聊聊,麻烦他内推并且后期需要麻烦他跟进面试进度。
总之,如果只有一个投递简历的链接或者一个内推码,但是联系不到内推人,就不要急着把简历就投出去了。
每个公司找到一个内推人就 OK 了,一般公司都是有统一的面试流程。
最近一个活动页面中有一个小需求,用户点击或者长按就可以复制内容到剪贴板,记录一下实现过程和遇到的坑。
查了一下万能的Google,现在常见的方法主要是以下两种:
分别来看看这两种方法是如何使用的。
这是clipboard的官网:https://clipboardjs.com/,看起来就是这么的简单。
直接引用: <script src="dist/clipboard.min.js"></script>
包: npm install clipboard --save ,然后 import Clipboard from 'clipboard';
现在页面上有一个 <input> 标签,我们需要复制其中的内容,我们可以这样做:
<input id="demoInput" value="hello world">
<button class="btn" data-clipboard-target="#demoInput">点我复制</button>import Clipboard from 'clipboard';
const btnCopy = new Clipboard('btn');注意到,在 <button> 标签中添加了一个 data-clipboard-target 属性,它的值是需要复制的 <input> 的 id,顾名思义是从整个标签中复制内容。
有的时候,我们并不希望从 <input> 中复制内容,仅仅是直接从变量中取值。如果在 Vue 中我们可以这样做:
<button class="btn" :data-clipboard-text="copyValue">点我复制</button>import Clipboard from 'clipboard';
const btnCopy = new Clipboard('btn');
this.copyValue = 'hello world';有的时候我们需要在复制后做一些事情,这时候就需要回调函数的支持。
在处理函数中加入以下代码:
// 复制成功后执行的回调函数
clipboard.on('success', function(e) {
console.info('Action:', e.action); // 动作名称,比如:Action: copy
console.info('Text:', e.text); // 内容,比如:Text:hello word
console.info('Trigger:', e.trigger); // 触发元素:比如:<button class="btn" :data-clipboard-text="copyValue">点我复制</button>
e.clearSelection(); // 清除选中内容
});
// 复制失败后执行的回调函数
clipboard.on('error', function(e) {
console.error('Action:', e.action);
console.error('Trigger:', e.trigger);
});文档中还提到,如果在单页面中使用 clipboard ,为了使得生命周期管理更加的优雅,在使用完之后记得 btn.destroy() 销毁一下。
clipboard 使用起来是不是很简单。但是,就为了一个 copy 功能就使用额外的第三方库是不是不够优雅,这时候该怎么办?那就用原生方法实现呗。
先看看这个方法在 MDN 上是怎么定义的:
which allows one to run commands to manipulate the contents of the editable region.
意思就是可以允许运行命令来操作可编辑区域的内容,注意,是可编辑区域。
bool = document.execCommand(aCommandName, aShowDefaultUI, aValueArgument)
方法返回一个 Boolean 值,表示操作是否成功。
aCommandName :表示命令名称,比如: copy, cut 等(更多命令见命令);aShowDefaultUI:是否展示用户界面,一般情况下都是 false;aValueArgument:有些命令需要额外的参数,一般用不到;这个方法在之前的兼容性其实是不太好的,但是好在现在已经基本兼容所有主流浏览器了,在移动端也可以使用。
现在页面上有一个 <input> 标签,我们想要复制其中的内容,我们可以这样做:
<input id="demoInput" value="hello world">
<button id="btn">点我复制</button>const btn = document.querySelector('#btn');
btn.addEventListener('click', () => {
const input = document.querySelector('#demoInput');
input.select();
if (document.execCommand('copy')) {
document.execCommand('copy');
console.log('复制成功');
}
})有的时候页面上并没有 <input> 标签,我们可能需要从一个 <div> 中复制内容,或者直接复制变量。
还记得在 execCommand() 方法的定义中提到,它只能操作可编辑区域,也就是意味着除了 <input>、<textarea> 这样的输入域以外,是无法使用这个方法的。
这时候我们需要曲线救国。
<button id="btn">点我复制</button>const btn = document.querySelector('#btn');
btn.addEventListener('click',() => {
const input = document.createElement('input');
document.body.appendChild(input);
input.setAttribute('value', '听说你想复制我');
input.select();
if (document.execCommand('copy')) {
document.execCommand('copy');
console.log('复制成功');
}
document.body.removeChild(input);
})算是曲线救国成功了吧。在使用这个方法时,遇到了几个坑。
在Chrome下调试的时候,这个方法时完美运行的。然后到了移动端调试的时候,坑就出来了。
对,没错,就是你,ios。。。
点击复制时屏幕下方会出现白屏抖动,仔细看是拉起键盘又瞬间收起
知道了抖动是由于什么产生的就比较好解决了。既然是拉起键盘,那就是聚焦到了输入域,那只要让输入域不可输入就好了,在代码中添加 input.setAttribute('readonly', 'readonly'); 使这个 <input> 是只读的,就不会拉起键盘了。
无法复制
这个问题是由于 input.select() 在ios下并没有选中全部内容,我们需要使用另一个方法来选中内容,这个方法就是 input.setSelectionRange(0, input.value.length);。
完整代码如下:
const btn = document.querySelector('#btn');
btn.addEventListener('click',() => {
const input = document.createElement('input');
input.setAttribute('readonly', 'readonly');
input.setAttribute('value', 'hello world');
document.body.appendChild(input);
input.setSelectionRange(0, 9999);
if (document.execCommand('copy')) {
document.execCommand('copy');
console.log('复制成功');
}
document.body.removeChild(input);
})以上就是关于JavaScript如何实现复制内容到剪贴板,附上几个链接:
iPhone X 底部是需要预留 34px 的安全距离,需要在代码中进行兼容。
现状对于 iPhone X 的判断基本是这样的:
// h5
export const isIphonex = () => /iphone/gi.test(navigator.userAgent) && window.screen && (window.screen.height === 812 && window.screen.width === 375);这在之前是没问题的,新的 iPhone X Series 设备发布之后,这个就会兼容就有问题。
| 机型 | 倍率 | 分辨率 | pt |
|---|---|---|---|
| iPhone X | 3 | 2436 × 1125 | 812 × 375 |
| iPhone XS | 3 | 2436 × 1125 | 812 × 375 |
| iPhone XS Max | 3 | 2688 × 1242 | 896 × 414 |
| iPhone XR | 2 | 1792 × 828 | 896 × 414 |
width === 375 && height === 812 只能识别出 iPhone X 和 iPhone XS,对于 iPhone XS Max 和 iPhone XR 就无能为力了。
const isIphonex = () => {
// X XS, XS Max, XR
const xSeriesConfig = [
{
devicePixelRatio: 3,
width: 375,
height: 812,
},
{
devicePixelRatio: 3,
width: 414,
height: 896,
},
{
devicePixelRatio: 2,
width: 414,
height: 896,
},
];
// h5
if (typeof window !== 'undefined' && window) {
const isIOS = /iphone/gi.test(window.navigator.userAgent);
if (!isIOS) return false;
const { devicePixelRatio, screen } = window;
const { width, height } = screen;
return xSeriesConfig.some(item => item.devicePixelRatio === devicePixelRatio && item.width === width && item.height === height);
}
return false;
}因为现在 iPhone 在 iPhone X 之后的机型都需要适配,所以可以对 X 以后的机型统一处理,我们可以认为这系列手机的特征是 ios + 长脸。
在 H5 上可以简单处理。
const isIphonex = () => {
if (typeof window !== 'undefined' && window) {
return /iphone/gi.test(window.navigator.userAgent) && window.screen.height >= 812;
}
return false;
};@media only screen and (device-width: 375px) and (device-height: 812px) and (-webkit-device-pixel-ratio: 3) {
}
@media only screen and (device-width: 414px) and (device-height: 896px) and (-webkit-device-pixel-ratio: 3) {
}
@media only screen and (device-width: 414px) and (device-height: 896px) and (-webkit-device-pixel-ratio: 2) {
}媒体查询无法识别是不是 iOS,还得加一层 JS 判断,否则可能会误判一些安卓机。
你好,请问你的文章可以转载吗?会注明作者和来源,感谢
随着最后一个面试的结束,手上还剩了一份简历,留作纪念吧。
说实话,我准备秋招的时间不算早,甚至有些迟。
2017年6月份,我意识到互联网巨头的校招快要开始了,然而,那时候没有危机感,觉得自己可以找到一份满意的工作。
也就是这个想法,导致自己的秋招特别坎坷。
其实,自己真的很菜。
以后要牢记这句话。
2017年7月4日,阿里巴巴启动了2018届校园招聘,我将准备好的简历发给了朋友让他帮忙内推一下。
看着简历评估中变成了待安排面试。
此时的我才发现自己还没真正系统性地复习过学过的东西。
...
2017年7月13日,阿里的一面电话面,13分钟21秒,全程手抖中打出GG。
这才,真正开始了自己的秋招。
我给自己的第一份工作定位是前端开发工程师。
那就开始看书吧,先列个书单:
其实自己还是没有系统性的看书,而且7 8月份的时候也还是紧迫感不够,导致效率很低。
好记性不如烂笔头。那就记笔记吧。
之前就看完了阮一峰大神的《ECMAScript 6入门》,在社区中看到《高程》的作者尼古拉斯大神出了本《深入理解ES6》,毫不犹豫上京东上预约了一本,就开始看了,看的过程主要就是记笔记吧:读《深入理解ES6》笔记。
因为自己之前的项目多是传统的前后端分离的项目,也就是那种上古时代的前端。
现在的前端工程化、SPA、模块化等概念,都只停留在读社区文章的阶段,没有动手实施过。所以就考虑自己写一个项目试试。
那段时间刚好在看 React,那就整个 React 的项目呗。
为了熟悉开发流程,先是写了几个小 Demo (嘘。真的很简单。。):
然后就开始构思重构自己的个人主页了,最后写了一个这个:使用React重构自己的博客,其实也是很简单的一个 SPA 应用,算是用来学习 React 全家桶的一个 Demo 吧。
在撸代码的过程中,就是会经常看看书,知道每一条代码为什么要这样写,理解 React 的**等等,自己动手写过之后再把书看一遍就会能有很好的理解,其中也就写了几篇笔记,都算是加深自己的理解吧。
其他的准备就是看书了,然后就是每天刷刷社区,看看大神们的理解和讨论,了解现在主流的前端大环境,这对后来的面试也是很有帮助的。
这里推荐几个觉得比较好的看文章的地方吧:
先自荐一下:https://github.com/axuebin/articles
嘿嘿,现在很多大神都喜欢在 Github 的 issues 里写 blog,要去多多发现哦。
这方面自己真的不靠谱,只能硬着头皮学一下常用的一些数据结构和算法,主要就是看《学习JavaScript数据结构与算法》和《王道考验:数据结构》。
惭愧的说,后者只刷了几页。。。
这方面主要是看了《图解HTTP》,然后就是网上零零散散的文章了,包括知乎上的一些讨论,基本对这方面能有一个了解了。
开始了疯狂投简历的阶段。
那时候的想法是,想去有赞。
那时候的有赞,还没开启校招,还没开始宣传。
基本就是在网上找各大互联网公司的内推,还有就是在网上找杭州互联网独角兽公司。。。
内推,网申。。。
人物:axuebin
等级:1级
经验:1%
offer:0
开始了漫长的笔试面试的升级之旅。。。
最初的时候,牛客上满屏的“求内推”。
过了一个月,满屏的“求面经”。
又过了一个月,满屏的“offer比较”。
然而我,打开我的个人资料看了看:
人物:axuebin
等级:5级
经验:15%
offer:0
难受。。
期间总结了一些经验,也确实学到了很多,明白了更多自己的不足,确实是升级了不少。
对于前端来说,在这段时间的面试中知道了面试的重点是什么,比如继承、跨域、性能优化等等。
还有一些加分项:node、移动端开发等等。
这些都是宝贵的经验,自己只能不停地学习学习。。。
期间,阿里巴巴网申面试挂了,大众点评面试挂了,网易网申内推笔试都没通过。。。
还有无数的感谢信。。。
看着自己的等级来到了10级。。。
也收获了两个小offer,也算是有点底了。
时间来到有赞空中宣讲会,HR小姐姐好心地送了一张面试直通卡,我想着我又有机会了。
看书看书再看书,等待着有赞的面试。
...
能力不足。还是挂了。有缘再见。
收到有赞感谢信之后感觉全身轻松,这两个月从来没这么轻松过。。
那天晚上,面了一个公司的电话二面,后来又去现在面了一轮技术面,最后也拿到了这个公司的offer。
十月份的这段时间,外公去世了,真的很难受,很难受最后的时候自己不在身边。
由于周五和周一都有面试,周六早上一大早就赶回去,周天下午又赶回来,也没能多陪陪我妈妈。
现在也能和外公说一声,我找到满意的工作了。
期间陪女朋友的时间也不多,心里也很难受,幸好女朋友很好,很支持。
经历了一个还算是完整的秋招,痛并快乐着。
最后附上我的博客,还有面经(待补充,而且有的二面记不清问什么了就没写了,主要是一面):
谢谢所有支持我的人。
首先希望最近能把工作的事搞定吧。
因为要毕业了,所以这几个月的重心就是写论文,争取1月份能去实习。
现在富文本编辑器轮子太多了,Github 上随便搜一下就有一堆,我需要实现的功能很简单,所以就佛系地选了 quilljs,quilljs 是一个轻量级的富文本编辑器。
链接:
基础功能就不多说了,看文档就好。
主要是记录一下如何在 toolbar 上自定义一个按钮并实现自定义格式化。
toolbar 相关文档:https://quilljs.com/docs/modules/toolbar/
可以看到文档中有这么一段代码:
var toolbarOptions = [
['bold', 'italic', 'underline', 'strike'], // toggled buttons
['blockquote', 'code-block'],
[{ 'header': 1 }, { 'header': 2 }], // custom button values
[{ 'list': 'ordered'}, { 'list': 'bullet' }],
[{ 'script': 'sub'}, { 'script': 'super' }], // superscript/subscript
[{ 'indent': '-1'}, { 'indent': '+1' }], // outdent/indent
[{ 'direction': 'rtl' }], // text direction
[{ 'size': ['small', false, 'large', 'huge'] }], // custom dropdown
[{ 'header': [1, 2, 3, 4, 5, 6, false] }],
[{ 'color': [] }, { 'background': [] }], // dropdown with defaults from theme
[{ 'font': [] }],
[{ 'align': [] }],
['clean'] // remove formatting button
];
var quill = new Quill('#editor', {
modules: {
toolbar: toolbarOptions
},
theme: 'snow'
});这是 toolbar 上支持的一些格式化功能,比如 加粗、斜体、水平对齐等等常见的文档格式化。
可是我发现,貌似不太够用啊。
比如我想插入一些 {{name}} 这样的文本,并且是加粗的,总不能让我每次都输入 {{}} 吧,麻烦而且容易遗漏,得做成自动格式化的。
随手翻了一下文档,quilljs 支持本地 module,toolbar 上每一个格式化功能可以看作是一个 module,翻翻源码:
看一下 link.js 吧,简化了一下:
import Inline from '../blots/inline';
class Link extends Inline {
static create(value) {
let node = super.create(value); // 创建一个节点
node.setAttribute('href', value); // 将输入的 value 放到 href
node.setAttribute('target', '_blank'); // target 设为空
return node;
}
static formats(domNode) {
return domNode.getAttribute('href'); // 获取放在 href 中的 value
}
}
Link.blotName = 'link'; // bolt name
Link.tagName = 'A'; // 渲染成 html 标签
export { Link as default };是不是实现一个简单的自定义格式化看上去很简单。
以 vue 为例哈,大同小异。
<quill-editor ref="myTextEditor"
class="editor-area"
v-model="content"
:options="editorOption"
@blur="onEditorBlur($event)">
</quill-editor>const toolbarOptions = [
[{ 'header': [1, 2, 3, 4, 5, 6, false] }],
['bold', 'italic', 'underline'],
[{ 'color': [] }, { 'background': [] }],
[{ 'align': [] }],
['formatParam'],
];
data() {
return {
editorOption: {
modules: {
toolbar: {
container: toolbarOptions,
handlers: {},
},
},
}
};
},
editor() {
return this.$refs.myTextEditor.quill;
}在项目组件的目录下创建一个 formatParam.js:
import Quill from 'quill';
const Inline = Quill.import('blots/inline');
class formatParam extends Inline {
static create() {
const node = super.create();
return node;
}
static formats(node) {
return node;
}
}
formatParam.blotName = 'formatParam';
formatParam.tagName = 'span';
export default formatParam;我这里没有对 value 和 node 做任何处理,然后在 handlers 里做处理,貌似有点蠢。。
import { quillEditor, Quill } from 'vue-quill-editor';
import FormatParam from './formatParam';
Quill.register(FormatParam);首先在 toolbar 上放一个按钮是必须的,当然也可以放 icon,我就简单地处理一下:
mounted() {
const formatParamButton = document.querySelector('.ql-formatParam');
formatParamButton.style.cssText = "width:80px; border:1px solid #ccc; border-radius:5px; padding: 0;";
formatParamButton.innerText = "添加参数";
}效果如图:

然后就是要注册这个按钮的点击事件:
handlers: {
formatParam: () => {
const range = this.editor.getSelection(true); // 获取光标位置
const value = prompt('输入参数名(如:name)'); // 弹框输入返回值
if (value) {
this.editor.format('formatParam', value); // 格式化
this.editor.insertText(range.index, `{{${value}}}`); // 显示在编辑器中
this.editor.setSelection(range.index + value.length + 4, Quill.sources.SILENT); // 光标移到插入的文字后,并且让按钮失效
}
},
}我在自定义格式化的时候没直接渲染成 html,然后在保存的时候做了一下:
watch: {
content() {
const { content } = this
const result = content.replace(/\{\{(.*?)\}\}/g, (match, key) => `<span class="${key}">{{${key}}}</span>`);
updateState({ content: result });
},
}这样就好了,想要插入一个参数的时候点击工具栏上的按钮,就会直接在编辑器里插入 {{xxx}} 的文本了。
效果如图:
其实理论上应该可以在 formatParam.js 中把所有事情都做掉,也就不用最后的正则替换了。
按照这个思路,我们可以在富文本编辑器按照自己所需要的格式插入任何自定义内容。
参考链接:
本文主要记录的是JavaScript实现常用的排序算法,冒泡排序、快速排序、归并排序等。
用JavaScript写算法是种怎么样的体验?不喜欢算法的我最近也对数据结构和算法有点兴趣。。。所以,将会有这些:
现阶段我对于数据结构、算法的理解还很浅,希望各位大佬多多指导。
介绍排序算法
说到冒泡排序,大家都很熟悉,顾名思义,是一种“冒泡”的过程。
主要**:比较任何两个相邻的项,如果第一个比第二个大,则交换它们。
时间复杂度:O(n2)
空间复杂度:O(1)
如何实现呢?是不是遍历所有需要排序的数据,然后将它和所有数比较一次,然后就可以了?
道理是有的,我们试试看:
function bubbleSort(arr) {
const len = arr.length; // 声明一个len来存储数组的长度
let temp = 0;
for (let i = 0; i < len; i += 1) { // 外循环遍历数组
for (let j = 0 ; j < len - 1 ; j += 1) { // 内循环执行当前项和下一项进行比较
if (arr[j] > arr[j + 1]) { // 如果当前项比下一项大,则交换它们
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
console.log(arr);
}
}
return arr;
}我们通过输出数组来看一下整个流程:
[5, 4, 3, 2, 1]
[4, 5, 3, 2, 1] // 5>4,交换
[4, 3, 5, 2, 1] // 5>3,交换
[4, 3, 2, 5, 1] // 5>2,交换
[4, 3, 2, 1, 5] // 5>1,交换
[3, 4, 2, 1, 5] // 4>3,交换
[3, 2, 4, 1, 5] // 4>2,交换
[3, 2, 1, 4, 5] // 4>1,交换
[3, 2, 1, 4, 5] // 4<5,不交换
[2, 3, 1, 4, 5] // 3>2,交换
[2, 1, 3, 4, 5] // 3>1,交换
[2, 1, 3, 4, 5] // 3<4,不交换
[2, 1, 3, 4, 5] // 4<5,不交换
[1, 2, 3, 4, 5] // 2>1,交换
[1, 2, 3, 4, 5] // 2<3,不交换
[1, 2, 3, 4, 5] // 3<4,不交换
[1, 2, 3, 4, 5] // 4<5,不交换
[1, 2, 3, 4, 5] // 1<2,不交换
[1, 2, 3, 4, 5] // 2<3,不交换
[1, 2, 3, 4, 5] // 3<4,不交换
[1, 2, 3, 4, 5] // 4<5,不交换排序确实是排好了,但是我们发现,有很多的不必要的比较,我们应该想办法避免这些。想一想,这些都是在内循环中对已经排序过的数进行比较,所以我们可以稍稍改进一下代码:
function bubbleSort(arr) {
const len = arr.length;
let temp = 0;
for (let i = 0; i < len; i += 1) {
for (let j = 0 ; j < len - 1 - i ; j += 1) {
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
console.log(arr);
}
}
return arr;
}在内循环中,我们另 j 的取值到 len-1-i 为止,因为再往后的数已经排序好了。同样地,我们来看看流程:
[5, 4, 3, 2, 1]
[4, 5, 3, 2, 1] // 5>4,交换
[4, 3, 5, 2, 1] // 5>3,交换
[4, 3, 2, 5, 1] // 5>2,交换
[4, 3, 2, 1, 5] // 5>1,交换
[3, 4, 2, 1, 5] // 4>3,交换
[3, 2, 4, 1, 5] // 4>2,交换
[3, 2, 1, 4, 5] // 4>1,交换
[2, 3, 1, 4, 5] // 3>2,交换
[2, 1, 3, 4, 5] // 3>1,交换
[1, 2, 3, 4, 5] // 2>1,交换nice,没必要的比较已经完全没有了。
主要**:找到数组中的最小值然后将其放置在第一位,接着第二位第三位。。。
时间复杂度:O(n2)
空间复杂度:O(1)
直接看代码吧:
function selectionSort(arr) {
const len = arr.length; // 用len存储数组长度
let indexMin = 0; // 最小值索引
let temp = 0;
for (let i = 0; i < len - 1; i += 1) { //外循环遍历数组
indexMin = i; // 先假设这一轮循环的第一个值是最小的
for (let j = i; j < len; j += 1) { // 比较i时候会比它之后的数小,如果小,则令indexMin存储这个更小值的索引
if (arr[indexMin] > arr[j]) {
indexMin = j;
}
}
if (i !== indexMin) { // 执行完内循环之后判断当前值i是否是最小的,如果不是,就要交换
temp = arr[i];
arr[i] = arr[indexMin];
arr[indexMin] = temp;
}
console.log(arr);
}
return arr;
}[5, 4, 3, 2, 1]
[1, 4, 3, 2, 5] // 寻找最小值1,交换1和5
[1, 2, 3, 4, 5] // 寻找最小值2,交换2和4
[1, 2, 3, 4, 5] // 寻找最小值3,不交换
[1, 2, 3, 4, 5] // 寻找最小值4,不交换
[1, 2, 3, 4, 5] // 寻找最小值5,不交换是不是很酷,然而它的时间复杂度其实还是 O(n2)。
主要**:每次将一个元素与已排序的元素进行逐一比较,直到找到合适的位置按大小插入。
时间复杂度:O(n2)
空间复杂度:O(1)
直接看代码吧:
function insertionSort(arr) {
const len = arr.length; // 数组长度
let j = 0; // 使用的辅助变量
let temp = 0;
for (let i = 1; i < len; i++) { // 外循环,从1开始
j = i; // 当前索引赋给j
temp = arr[i]; // 当前值存在temp
while (j > 0 && arr[j - 1] > temp) { // 如果j前面的数比它大,就往前移,直到第一位
arry[j] = arr[j - 1];
j--;
}
arr[j] = temp; // temp是要排序的那个数,放到正确的j的位置上
}
return arr;
}主要**:**主要是分治。将原始数组划分成较小的数组,直到每个小数组只有一个位置,然后将小数组归并成较大的数组。
时间复杂度:O(nlogn)
空间复杂度:O(n)
直接看代码吧:
// 分
function mergeSort(arr) {
const len = arr.length;
if (len === 1) {
return arr;
}
const mid = Math.floor(len / 2);
const left = arr.slice(0, mid);
const right = arr.slice(mid, len);
return merge(mergeSort(left), mergeSort(right));
}
// 合
function merge(left, right) {
const result = [];
let il = 0;
let ir = 0;
while (il < left.length && ir < right.length) {
if (left[il] < right[ir]) {
result.push(left[il++]);
} else {
result.push(right[ir++]);
}
}
while (il < left.length) {
result.push(left[il++]);
}
while (ir < right.length) {
result.push(right[ir++]);
}
return result;
}来看看面试中最喜欢考察的快速排序。
主要**:每次将一个元素与已排序的元素进行逐一比较,直到找到合适的位置按大小插入。
时间复杂度:O(nlogn)
空间复杂度:O(logn)
function quickSort(arr) {
if (arr.length <= 1) {
return arr;
}
const pivotIndex = Math.floor(arr.length / 2);
const pivot = arr.splice(pivotIndex, 1)[0]; // 将这个元素取出并从原数组中删除
const left = [];
const right = [];
for (let i = 0; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return quickSort(left).concat(pivot, quickSort(right));
}style-loaderstyle-loader 的功能就一个,在 DOM 里插入一个 <style> 标签,并且将 CSS 写入这个标签内。
简单来说就是这样:
const style = document.createElement('style'); // 新建一个 style 标签
style.type = 'text/css';
style.appendChild(document.createTextNode(content)) // CSS 写入 style 标签
document.head.appendChild(style); // style 标签插入 head 中稍后会详细分析源码,看看和我们的思路是否一致。
style-loaderstyle-loadernpm install style-loader --save-dev
webapck// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.(css)$/,
use: [
{
loader: 'style-loader',
options: {},
},
{ loader: 'css-loader' },
],
},
],
},
};日常的开发中处理样式文件时,一般会使用到 style-loader 和 css-loader 这两个 loader。
关于 style-loader 的 options,这里就不多说了,见 style-loader options .
const indexStyle = require('./assets/style/index.css');webpack
打包完成之后我们打开 html 页面,会看到 <head> 里已经有了 index.css 里的样式内容:
<style>
.container {
color: red;
background: #999999;
}
.zelda {
width: 260px;
height: 100px;
}
</style>单独讲一下 injectType 这个配置项,默认值是 styleTag,通过 <style></style> 的形式插入 DOM 中,我们来看看不同的 injectType 的效果。
默认情况下,style-loader 每一次处理引入的样式文件都会在 DOM 上创建一个 <style> 标签,比如此时引入两个样式文件:
const globalStyle = require('./assets/style/global.css');
const indexStyle = require('./assets/style/index.css');输出的 DOM 结构为:
<style>
html, body {
height: 100%;
}
#app {
background: #ffffff;
}
</style>
<style>
.container {
color: red;
}
.zelda {
width: 260px;
height: 100px;
}
</style>上面提到默认情况下有几个样式文件就会插入几个 <style> 标签,将 injectType 设置为 singletonStyleTag 可将所有的样式文件打在同一个 <style> 标签里。
// config
{
test: /\.(css)$/,
use: [
{
loader: 'style-loader',
options: {
injectType: 'singletonStyleTag',
},
},
{ loader: 'css-loader' },
],
}
// js
const globalStyle = require('./assets/style/global.css');
const indexStyle = require('./assets/style/index.css');输出的 DOM 结构为:
<style>
html, body {
height: 100%;
}
#app {
background: #ffffff;
}
.container {
background: #f5f5f5;
}
.container {
color: red;
background: #999999;
}
.zelda {
width: 260px;
height: 100px;
}
</style>可以看到,两个样式文件的内容都被放到同一个 <style> 标签里了,并且是按照我们引入样式文件的顺序,似乎还比较符合预期。
当 injectType 为 linkTag,会通过 <link rel="stylesheet" href=""> 的形式将样式插入到 DOM 中,此时 style-loader 接收到的数据应该是样式文件的地址,所以搭配的 loader 应该是 file-loader 而不是 css-loader。
// config
{
test: /\.(css)$/,
use: [
{
loader: 'style-loader',
options: {
injectType: 'linkTag',
},
},
{ loader: 'file-loader' },
],
}
// js
const globalStyle = require('./assets/style/global.css');
const indexStyle = require('./assets/style/index.css');输出的 DOM 结构为:
<head>
<link rel="stylesheet" href="f2742027f8729dc63bfd46029a8d0d6a.css">
<link rel="stylesheet" href="34cd6c668a7a596c4bedad32a39832cf.css">
</head>这两种类型的 injectType 区别在于它们是延迟加载的:
// config
{
test: /\.(css)$/,
use: [
{
loader: 'style-loader',
options: {
injectType: 'lazyStyleTag',
},
},
{ loader: 'css-loader' },
],
}
// js
const globalStyle = require('./assets/style/global.css');
const indexStyle = require('./assets/style/index.css');
// globalStyle.use();如果仅仅是像上面一样导入了样式文件,样式是不会插入到 DOM 中的,需要手动使用 globalStyle.use() 来延迟加载 global.css 这个样式文件。
其它的用法就不多说了,自行查看 style-loader。
style-loader 主要可以分为:
runtime 阶段先看引入依赖部分的代码:
var _path = _interopRequireDefault(require("path"));
var _loaderUtils = _interopRequireDefault(require("loader-utils"));
var _schemaUtils = _interopRequireDefault(require("schema-utils"));
var _options = _interopRequireDefault(require("./options.json"));
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }这里定义了一个 _interopRequireDefault 方法,传入的是一个 require()。
这个方法的作用是:如果引入的是 es6 模块,直接返回,如果是 commonjs 模块,则将引入的内容放在一个对象的 default 属性上,然后返回这个对象。
module.exports = () => {};
module.exports.pitch = function loader(request) {}style-loader 的导出方式和普通的 loader 不太一样,默认导出一个空方法,通过 pitch 导出的。
默认的 loader 都是从右向左像管道一样执行,而 pitch 是从左到右执行的。
为什么 style-loader 需要这样呢?
我们知道默认 loader 的执行是从右向左的,并且会将上一个 loader 处理的结果传递给下一个 loader,如果按照这种默认行为,css-loader 会返回一个 js 字符串给 style-loader。
style-loader 的作用是将 CSS 代码插入到 DOM 中,如果按照顺序从 css-loader 接收到一个 js 字符串的话,就无法获取到真实的 CSS 样式了。所以正确的做法是先执行 style-loader,在它里面去执行 css-loader ,拿到经过处理的 CSS 内容,再插入到 DOM 中。
接下来看看 loader 的内容:
// 获取 webpack 配置里的 options
const options = _loaderUtils.default.getOptions(this) || {};
// 校验 options
(0, _schemaUtils.default)(_options.default, options, {
name: 'Style Loader',
baseDataPath: 'options'
});
// style 标签插入的位置,默认是 head
const insert = typeof options.insert === 'undefined' ? '"head"' : typeof options.insert === 'string' ? JSON.stringify(options.insert) : options.insert.toString();
// 设置以哪种方式插入 DOM 中
// 详情见这个:https://github.com/webpack-contrib/style-loader#injecttype
const injectType = options.injectType || 'styleTag';
switch (injectType) {
case 'linkTag': {}
case 'lazyStyleTag':
case 'lazySingletonStyleTag': {}
case 'styleTag':
case 'singletonStyleTag':
default: {}
}根据不同的 injectType 会 return 不同的 js 代码,在 runtime 的时候执行。
看看默认情况:
return `var content = require(${_loaderUtils.default.stringifyRequest(this, `!!${request}`)});
if (typeof content === 'string') {
content = [[module.id, content, '']];
}
var options = ${JSON.stringify(options)}
options.insert = ${insert};
options.singleton = ${isSingleton};
var update = require(${_loaderUtils.default.stringifyRequest(this, `!${_path.default.join(__dirname, 'runtime/injectStylesIntoStyleTag.js')}`)})(content, options);
if (content.locals) {
module.exports = content.locals;
}
${hmrCode}`;_loaderUtils.default.stringifyRequest(this, `!!${request}`) 这个方法的作用是将绝对路径转换成相对路径。比如:
import css from './asset/style/global.css';
// 此时传递给 style-loader 的 request 会是
request = '/test-loader/node_modules/css-loader/dist/cjs.js!/test-loader/assets/style/global.css';
// 转换
_loaderUtils.default.stringifyRequest(this, `!!${request}`);
// result: "!!../../node_modules/css-loader/dist/cjs.js!./global.css"所以 content 的实际内容就是:
var content = require("!!../../node_modules/css-loader/dist/cjs.js!./global.css");也就是在这里才去调用 css-loader 来处理样式文件。
!! 模块前面的两个感叹号的作用是禁用 loader 的配置的,如果不禁用的话会出现无限递归调用的情况。
同样的,update 的实际内容是:
var update = require("!../../node_modules/style-loader/dist/runtime/injectStylesIntoStyleTag.js")(content, options);意思也就是调用 injectStylesIntoStyleTage 模块来处理经过 css-loader 处理过的样式内容 content。
上述代码都是 style-loader 返回的,真正执行是在 runtime 阶段。
runtime 阶段本来都写好了,突然不见了,心痛。
简单地写一下吧,具体的源码见 传送门
将样式插入 DOM 的操作实际是在 runtime 阶段进行的,还是以默认情况举例,看看 injectStylesIntoStyleTage 做了什么。
简单来说,module.exports里最主要的就是 insertStyleElement 和 applyToTag 两个方法,简化一下就是这样的:
module.exports = (list, options) => {
options = options || {};
const styles = listToStyles(list, options);
addStylesToDom(styles, options);
}
function insertStyleElement(options) {
var style = document.createElement('style');
Object.keys(options.attributes).forEach(function (key) {
style.setAttribute(key, options.attributes[key]);
});
return style;
}
function applyToTag(style, options, obj) {
var css = obj.css;
var media = obj.media;
if (media) {
style.setAttribute('media', media);
}
if (style.styleSheet) {
style.styleSheet.cssText = css;
} else {
while (style.firstChild) {
style.removeChild(style.firstChild);
}
style.appendChild(document.createTextNode(css));
}
}和我们上文猜测差不多是一致的,至此 style-loader 的主要工作就完成了。
2017也就这样过去了,有失有得。
看了看app中2017年的 todoList
年初定的目标是:
数了数 http://axuebin.com/blog 里的也不够,更别说满意的文章了。
意料之外的是靠着一篇水文 #1 收获了 SF 的 Top Writer。
真正有认真写的可能就是 https://github.com/axuebin/articles 这里的几篇文章了。
本来想看看 lodash 的源码,写一写源码解析的,但是最近在看论文就没心情看这些了。。。
秋招拿到了满意的 offer,算是完成了这个目标了吧。
想了想,买的书倒是超过20本了,基本还都是编程相关的书。
开心的是终于入了一套《诛仙》,虽然不是原版的。
嗯...有的书基本就是翻翻目录,看看感兴趣的部分,仔细看的数量可能一个手就可以数的过来了,希望来年能找到一个好的节奏多看一些书。
看了看库存,没数有多少张满意的,倒是挑了12张女朋友的照片做了一个日历:
其他的一些照片可以看看 https://500px.me/axuebin 这里。
最喜欢的照片应该是这几张:
在赶去桥对面想找个好机位拍照的时候突然看到远处有彩虹,马上掏出相机啪了一张。
去九溪打卡的时候低头看看脚下,落叶在阳光下显得格外好看,这样的光影让人着迷。
哈哈哈哈,这部分算是完成最好的了。。除了广角镜头没有买之外其它都买了,特别喜欢 FE55 1.8 的质感,可以多给女朋友拍拍照。
明年争取攒个钱买个全幅相机和广角镜头。
嗯...今年和家人去了一次湖南。其它想去的地方都因为各种原因(其实是没有钱)都没去成,明年希望能去一次香港或者云南。
今年的计划没有想得太多,主要就几点:
初学React,撸一个TodoList熟悉熟悉基本语法,只有最简单最简单的功能。
如上图所示,是一个最简单的TodoList的样子了,我们应该怎样把它拆成一个个的组件呢?
在之前看来,可能就是这样一个HTML结构:
<div>
<h1></h1>
<div>
<ul>
<li></li>
<li></li>
<li></li>
</ul>
</div>
<div>
<input/>
<button>保存</button>
</div>
</div>React的核心**是:封装组件。
我们也可以按照这个思路来进行组件设计
从小到大,从内到外 ~
我是这样进行设计的。
除去按钮,input这些之外,<li></li>是HTML中最小的元素,我们可以先每一个<li></li>当成是一个最小的组件,也就是图中橙色框的部分,它对应着每一条内容,我们先把它命名为TodoItem吧。
<li></li>的父级元素是<ul></ul>,那就把它看作一个组件呗,图中位于上方的蓝色部分,命名为TodoList。
恩,此时Todo内容的展示组件已经是够的了,我们再来加一个添加Todo内容的组件AddTodoItem吧,命名貌似有点丑- -,图中位于下方的蓝色部分。
最后就是最外层的红色部分了,它就是整个app的主体部分,包含着其它小组件,命名为TodoBox。
ok,暂时就这几个小组件 ~
然我们开始愉快的撸代码吧 ~
先看看入口程序,很简单。
var React = require('react');
var ReactDOM = require('react-dom');
import TodoBox from './components/todobox';
import './../css/index.css';
export default class Index extends React.Component {
constructor(){
super();
};
render() {
return (
<TodoBox />
);
}
}
ReactDOM.render(<Index/>,document.getElementById("example"))让我们想想啊,对于每一条内容来说,需要什么呢?
checkbox [ ]textbutton那不是太简单了 ~
<li>
<input type="checkbox"/>找工作啊找工作啊
<button>删除</button>
</li>不不不,我们现在是在写React,要这样:
import React from 'react';
import {Row, Col, Checkbox, Button} from 'antd';
export default class TodoItem extends React.Component {
constructor(props) {
super(props)
this.toggleComplete = this.toggleComplete.bind(this)
this.deleteTask = this.deleteTask.bind(this)
}
toggleComplete() {
this.props.toggleComplete(this.props.taskId)
}
deleteTask() {
this.props.deleteTask(this.props.taskId)
}
render() {
let task = this.props.task
let itemChecked
if (this.props.complete === "true") {
task = <del>{task}</del>
itemChecked = true
} else {
itemChecked = false
}
return (
<li className="list-group-item">
<Row>
<Col span={12}>
<Checkbox checked={itemChecked} onChange={this.toggleComplete}/> {task}
</Col>
<Col span={12}>
<Button type="danger" className="pull-right" onClick={this.deleteTask}>删除</Button>
</Col>
</Row>
</li>
)
}
}import {Row, Col, Checkbox, Button} from 'antd'是引入Ant Design。
我们采用 React 封装了一套 Ant Design 的组件库,也欢迎社区其他框架的实现版本。
引入这个之后,我们可以直接使用一些简单的UI组件,比如Row,Col,Checkbox,Button等,我们可以更加注重业务逻辑的实现。
接下来就是拿一个<ul></ul>把item包起来呗:
import React from 'react';
import TodoItem from './todoitem';
export default class TodoList extends React.Component{
constructor(props) {
super(props);
}
render(){
var taskList=this.props.data.map(listItem=>
<TodoItem taskId={listItem.id}
key={listItem.id}
task={listItem.task}
complete={listItem.complete}
toggleComplete={this.props.toggleComplete}
deleteTask={this.props.deleteTask}/>
)
return(
<ul className="list-group">
{taskList}
</ul>
)
}
}添加内容这个组件也比较简单,就只需要一个input和一个button即可:
import React from 'react';
import ReactDOM from 'react-dom';
import {Row, Col, Form, Input, Button,notification } from 'antd';
export default class AddTodoItem extends React.Component {
constructor(props) {
super(props)
this.saveNewItem = this.saveNewItem.bind(this)
}
saveNewItem(e) {
e.preventDefault()
let element = ReactDOM.findDOMNode(this.refs.newItem)
let task = element.value
if (!task) {
notification.open({
description: 'Todo内容不得为空!',
});
} else {
this.props.saveNewItem(task)
element.value = ""
}
}
render() {
return (
<div className="addtodoitem">
<Form.Item>
<label htmlFor="newItem"></label>
<Input id="newItem" ref="newItem" type="text" placeholder="吃饭睡觉打豆豆~"></Input>
<Button type="primary" className="pull-right" onClick={this.saveNewItem}>保存</Button>
</Form.Item>
</div>
)
}
}我们的小组件已经都实现了,拿一个大box包起来呗 ~
import React from 'react';
import TodoList from './todolist';
import AddTodoItem from './addtodoitem';
import {Button, Icon, Row, Col} from 'antd';
export default class TodoBox extends React.Component {
constructor(props) {
super(props)
this.state = {
data: [
{
"id": "1",
"task": "做一个TodoList Demo",
"complete": "false"
}, {
"id": "2",
"task": "学习ES6",
"complete": "false"
}, {
"id": "3",
"task": "Hello React",
"complete": "true"
}, {
"id": "4",
"task": "找工作",
"complete": "false"
}
]
}
this.handleToggleComplete = this.handleToggleComplete.bind(this);
this.handleTaskDelete = this.handleTaskDelete.bind(this);
this.handleAddTodoItem = this.handleAddTodoItem.bind(this);
}
generateGUID() {
return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
var r = Math.random() * 16 | 0,
v = c == 'x' ? r : (r & 0x3 | 0x8)
return v.toString(16)
})
}
handleToggleComplete(taskId) {
let data = this.state.data;
for (let item of data) {
if (item.id === taskId) {
item.complete = item.complete === "true" ? "false" : "true"
}
}
this.setState({data})
}
handleTaskDelete(taskId) {
let data = this.state.data
data = data.filter(task => task.id !== taskId)
this.setState({data})
}
handleAddTodoItem(task) {
let newItem = {
id: this.generateGUID(),
task,
complete: "false"
}
let data = this.state.data
data = data.concat([newItem])
this.setState({data})
}
render() {
return (
<div>
<div className="well">
<h1 className="text-center">React TodoList</h1>
<TodoList data={this.state.data} toggleComplete={this.handleToggleComplete} deleteTask={this.handleTaskDelete}/>
<AddTodoItem saveNewItem={this.handleAddTodoItem}/>
</div>
<Row>
<Col span={12}></Col>
<Col span={12}>
<Button className="pull-left"><Icon type="user"/>
<a href="http://axuebin.com">薛彬</a>
</Button>
<Button className="pull-right"><Icon type="github"/>
<a href="https://github.com/axuebin">axuebin</a>
</Button>
</Col>
</Row>
</div>
)
}
}注意:
完整的Demo代码在这:https://github.com/axuebin/react-todolist
等着有赞的面试电话
紧张
冷静
作为一名程序员,开发环境不舒服会很大程度影响开发效率,所以一定要花时间好好整一下开发环境(好了,我知道你是在给摸鱼找借口)。
最近短短几个月,换了两次新电脑,经历了两次装机(由于各种原因,没法备份恢复,你懂的),每一次都得重新搞一套属于自己的开发环境。这里就记录一下我是如何一步一步的打造属于自己的Terminal,你如果想和我一样,直接cv 大法就可以搞一套一样的。
Terminal我们经常会称作终端,现在中文版的mac里也是叫做这个。
我们每天都需要在其中输入很多命令去做一些事情。可以说,每天有大量的时间都需要面对它。我记得我第一次点下鼠标,打开这个终端的时候,看到了这样一个界面:
我傻了。怎么这么丑?macOS上怎么允许有这么丑的应用?
不行,如果让我每天对着它,一定会把电脑砸了(虽然它是高贵的 16 寸 MacBook Pro),我得找一个第三方Terminal来替代它。
很快,我就找到了新欢,它的名字叫iTerm2,它是一款完全免费,为macOS打造的一款终端工具,可以说是程序员必备了,如果还没用过的,赶紧跟着这篇文章用起来吧。👉iTerm2 官网符合国外网站一向的极简风格(又不是不能用,搞那么花里胡哨干嘛)。直接下载,解压,拖入Application里就 ok 了。打开看看。
怎么感觉不太对,虽然你的背景变黑了,但依然掩盖不了你的丑啊。没事儿,先天不足,后天努力嘛。告别黑底白字,整出最*终端,开始吧。
主角是它,拥有了它,你一定是你们组最靓的仔。
Oh My Zsh is an open source, community-driven framework for managing your zsh configuration.
官网提供了两种安装方式:
# via curl
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
# via wget
sh -c "$(wget -O- https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
复制代码
如果,由于一些原因,上面两种方法你都没能安装成功,可以试一下手动安装:
# 下载 oh-my-zsh 源码
git clone git://github.com/robbyrussell/oh-my-zsh.git ~/.oh-my-zsh
# 并且把 .zshrc 配置文件拷贝到根目录下
cp ~/.oh-my-zsh/templates/zshrc.zsh-template ~/.zshrc
# 让 .zshrc 配置文件生效
source ~/.zshrc
复制代码
嗯... 你和我说,clone也不行啊,不可描述的原因,网速不允许啊。那你这样做。在👉oh-my-zsh GitHub上下载zip-> 解压 -> 移动 oh-my-zsh 目录到根目录:
cd ~/Downloads
mv ohmyzsh-master ~/.oh-my-zsh
cp ~/.oh-my-zsh/templates/zshrc.zsh-template ~/.zshrc
source ~/.zshrc
复制代码
如果还不行,你来找我。好了,重新启动iTerm2,是不是已经变了。
这个文件非常关键,是oh-my-zsh的配置文件,它的位置在根目录下,可以通过vim ~/.zshrc查看。每一次修改它之后,如果想要立即生效需要手动执行source ~/.zshrc。
一打开.zshrc,就可以看到关于配色方案的配置:
# Set name of the theme to load --- if set to "random", it will
# load a random theme each time oh-my-zsh is loaded, in which case,
# to know which specific one was loaded, run: echo $RANDOM_THEME
# See https://github.com/ohmyzsh/ohmyzsh/wiki/Themes
ZSH_THEME="agnoster"
复制代码
oh-my-zsh提供了很多内置的配色方案,可以通过命令来查看:
ls ~/.oh-my-zsh/themes
复制代码
也可以打开👉https://github.com/ohmyzsh/ohmyzsh/wiki/Themes更为直观的查看所有的配色方案。只要修改ZSH_THEME的值就可以设置对应的配色方案了。如果你想每天都过得不一样,可以设置成random,每次打开iTerm2的都会随机使用一种配色方案。我曾经有一段时间,由于不想折腾,使用的是这个配色方案:agnoster,它是这样的:
当然,有一天,我突然想造作一下,就开始自己配色。(没备份... 找不着了...)如果你觉得默认的配色方案不够*,并且觉得自己的审美 ok,也可以自己来搭配颜色。
入口:菜单栏 -> Profiles -> Open Profiles -> Edit Profiles -> + 一个配置 -> 选择 Colors
像我这样审美不行的人,花了一整天的时间搞这个,到头来发现,还是默认的更好看一点...
当然,不是只有你和我想要自己搞一套最*的配色方案,大家都有这样的想法。👉iTerm2-Color-Schemes这里有非常多的配色方案题,也已经在👉GitHub上开源。你可以像我一样这样做:
# 找一个目录存放 iterm2 相关的文件
mkdir Code/other/iterm2
# 下载 iTerm2-Color-Schemes
git clone https://github.com/mbadolato/iTerm2-Color-Schemes
# schemes 文件夹就是真实存放配色方案的目录
cd iTerm2-Color-Schemes/schemes
复制代码
同样,如果clone不下来就下载zip解压就好了。通过以下操作路径可以导入所有配色方案:菜单栏 -> Profiles -> Open Profiles -> Edit Profiles -> 选择 Colors -> 右下角 Color Presets -> Import...找到schemes文件夹选中所有配色方案就好了,然后你就眼花缭乱会收获满满的幸福。没事,等等会有更高级的方案。
为什么要安装字体呢?有些主题是会设置图标的,我们电脑上的字体一般都不支持这些图标,会出现乱码。
打开👉Fonts下载zip包都本地解压,就会得到很多字体。
# 将下载好的 fonts 移动到之前建的目录
mv ~/Downlaods/fonts-master ~/Code/other/iterm2/fonts
cd ~/Code/other/iterm2/fonts
# 执行安装文件
./install.sh
复制代码
这样就安装好了,然后通过以下操作路径设置字体:菜单栏 -> Profiles -> Open Profiles -> Edit Profiles -> 选择 Text
可以选择Meslo这个字体,乱码的图标就正常了。
如果想要更高逼格的毛玻璃效果,并且找到自己舒服的大小(???),可以在这里设置:
操作路径:菜单栏 -> Profiles -> Open Profiles -> Edit Profiles -> 选择 Window
激动人心的时刻,你可以为你的终端设置一个自己喜欢的小姐姐图片作为背景,敲命令的时候都会更带劲吧:
~~咳咳,Dota 云玩家们,你是更喜欢冰女还是火女?~~操作路径:菜单栏 -> Profiles -> Open Profiles -> Edit Profiles -> 选择 Window
可以为每个打开的终端都设置一个状态栏,显示一些系统信息(比如 CPU、RAM、当前目录等)。操作路径:菜单栏 -> Profiles -> Open Profiles -> Edit Profiles -> 选择 Session
经过这一番折腾,一个属于你自己的高颜值终端就诞生了。不过,总感觉这样还是有点麻烦,有没有更厉害的玩意儿?有的,我们这就用起来。
👉Powerlevel10k简单来说就是一个ZSH的主题,只不过它的功能很强大,以下简称p10k。
我们用的是Oh My Zsh,所以这样安装p10k即可:
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/themes/powerlevel10k
复制代码
然后需要打开~/.zshrc设置ZSH_THEME:
ZSH_THEME="powerlevel10k/powerlevel10k
复制代码
上文我们已经安装了PowerFonts,如果需要使用一些图标,这个字体是不够用的,我们需要一个强大的字体:👉Nerd Fonts,它支持下面这么多种图标:
你可以如官网所说,通过brew来安装:
brew tap homebrew/cask-fonts
brew cask install font-hack-nerd-font
复制代码
但是我不建议这样,包括不建议你下载zip包,因为这个文件太大了,太大了,太大了。。。我们可以这样:打开👉https://github.com/ryanoasis/nerd-fonts/releases,滑动页面找到Assets区域,如图:
我们只要下载箭头所指的Hack.zip这个字体包,解压缩之后就会获得一些ttf字体文件,双击安装即可。
POWERLEVEL9K_MODE="nerdfont-complete"
ZSH_THEME="powerlevel10k/powerlevel10k"
复制代码
注意,需要设置在ZSH_THEME之前。
操作路径:菜单栏 -> Profiles -> Open Profiles -> Edit Profiles -> 选择 Text
这样,所有的图标就都可以正常显示了。
如果你指定了ZSH_THEME="powerlevel10k/powerlevel10k"但是在zshrc里没进行任何手动的配置,打开iTerm2的时候就会触发自动配置的流程。也可以通过以下命令再次进入自动配置的流程:
p10k configure
复制代码
问题大致如下:
后面几个选项随意,执行完命令之后,就会初始化p10k:在根目录下生成~/.p10k.zsh,并且在~/.zshrc底部写入:
如果想废除p10k的配置,只需要删除~/.p10k.zsh,并且删除上面这条命令即可。
如果你想当高玩,也可以在~/.zshrc里手动配置p10k,或者在~/.p10k.zsh基础上进行修改。这个得要自己看文档摸索啦,这里我简单说几个配置:
POWERLEVEL9K_LEFT_PROMPT_ELEMENTS显示在命令行左边区域的元素:
和上图相对应的配置为:
POWERLEVEL9K_LEFT_PROMPT_ELEMENTS=(user dir vcs newline)
复制代码
POWERLEVEL9K_RIGHT_PROMPT_ELEMENTS显示在命令行右边区域的元素:
和上图相对应的配置为:
POWERLEVEL9K_RIGHT_PROMPT_ELEMENTS=(time)
复制代码
可以在POWERLEVEL9K_LEFT_PROMPT_ELEMENTS和POWERLEVEL9K_RIGHT_PROMPT_ELEMENTS里用的字段有:
| 字段 | 含义 |
|---|---|
| user | 用户名 |
| dir | 当前目录名 |
| vcs | 远程仓库信息 |
| os_icon | 系统图标 |
| date | 日期 |
| host | 主机名 |
| status | 上一条命令的执行状态 |
| time | 当前时间 |
| ... | ... |
如果还想了解更多,自行前往👉 文档查看。POWERLEVEL9K_VCS_GIT_GITHUB_ICON如果它是一个Github目录,就会显示这个图标:
所以出现在窗口里的图标都可以自定义,可以通过命令查看目前正在使用的图标:
get_icon_names
复制代码
找到想要修改的KEY就可以修改图标了。
注意:需要使用
Nerd Fonts才能收货这满满的快乐。
有人问,这个图标的代码该去哪找呢?在这里:👉https://www.nerdfonts.com/cheat-sheet这是Nerd Fonts能够支持的所有图标,可以直接使用关键字进行搜索。比如,我想修改Git的图标:
找到喜欢的图标之后,右下角的f113就是这个图标的值,只需要这样就了:
POWERLEVEL9K_VCS_GIT_GITHUB_ICON=\uf113'
复制代码
快造作起来~
到了这一步,你的iTerm2应该已经颜值爆表,足够好看了。毕竟这是我们的饭碗,光好看不行,得好用,来了解一下强大的插件体系。首先,我们先了解一下插件在~/.zshrc的哪个位置,找到下面这个字段就不会错了:
plugins=(git)
复制代码
git插件是自带插件,默认已经开启,它可以让我们使用非常*好用的的git命令,提高开发效率:
| 用了插件之前的 git 命令 | 用了插件之后的 git 命令 |
|---|---|
| git add --all | gaa |
| git branch -D | gbD |
| git commit -a -m | gcam |
| git checkout -b | gcb |
| git checkout master | gcm |
是不是简单多了。可以通过命令查看所有配置:
vim ~/.oh-my-zsh/plugins/git/git.plugin.zsh
复制代码
如果你像我一样是一个整理狂魔,会把文件、目录一层一层的整理好。
整理一时爽,用时就不爽
目录层级深了,年龄大了,就找不到文件放哪了,cd起来也不方便了,有什么办法可以解决呢?教你两招。
打开~/.zshrc输入别名,比如:
alias articles='~/Code/GitHub/articles'
复制代码
然后执行articles就会自动跳到~/Code/GitHub/articles了。这样还是比较麻烦的,得为每个目录都配置alias。
autojump插件会记录你所有的访问记录,不同单独配置,直接访问即可。
brew install autojump
复制代码
打开~/.zshrc加一行代码:
[[ -s $(brew --prefix)/etc/profile.d/autojump.sh ]] && . $(brew --prefix)/etc/profile.d/autojump.sh
复制代码
然后就是source一下就生效了。
使用j命令就可以执行auto-jump,比如j articles:
前提是你访问过articles目录,也就是你得让它记住。
这个插件的作用很简单,就是像它名字一样,会在你输入命令的时候提示并且自动完成:
brew install zsh-autosuggestions
复制代码
这是一个文件目录美化插件,如图所示:
gem install colorls
复制代码
然后执行colors就好了,你也可以设置alias更高效一点:
alias lc='colorls -lA --sd'
复制代码
设置了别名之后,就像我一样,输入lc就好了。我就只用了以上几个插件,已经能够大幅度提升工作效率了,如果有其它好用的插件,一定要告诉我呀。
如果你用的是VS Code,需要再配置一下字体:
{
"terminal.integrated.fontFamily": "Hack Nerd Font"
}
复制代码
上面的几个插件都用的是brew命令安装,应该不在少数的人刚开始电脑上是没有brew的:
brew: command not found
复制代码
然后就百度了一下,说要装一个叫Homebrew的东西,然后就按照官网的方式执行安装:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
复制代码
如果安装成功了,恭喜你,你的运气真的很好。如果没安装成功,那你一定会各种百度如何安装,然后还是安装不成功:
curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused
复制代码
有人告诉你,换一个中科大的源试试:
/usr/bin/ruby -e "$(curl -fsSL https://cdn.jsdelivr.net/gh/ineo6/homebrew-install/install)"
复制代码
然后,你可能会卡在这:
==> Tapping homebrew/core
Cloning into '/usr/local/Homebrew/Library/Taps/homebrew/homebrew-core'...
复制代码
也就是因为不可描述的原因,下载homebrew-core这个库的时候网络不行了,那我们就手动clone一个吧,或者下载一个zip包解压到对应目录:
cd "$(brew --repo)/Library/Taps/"
mkdir homebrew && cd homebrew
git clone git://mirrors.ustc.edu.cn/homebrew-core.git
复制代码
然后再执行上面的命令安装就好了:
/usr/bin/ruby -e "$(curl -fsSL https://cdn.jsdelivr.net/gh/ineo6/homebrew-install/install)"
复制代码
会看到成功安装的提示:
==> Installation successful!
复制代码
就问你这样一套终端开发环境*不*好不好用。不说别的,看着这背景,写代码都更有动力了。
一开始这个 bug 是在 weex 下遇到的,使用的是 weex 自己的 scroller 组件,需要对滑动操作做防抖,会出现3s左右的延迟。


做了几个组合实验来排除可能性:
weex 滚动组件 @scroll+setTimeout(会出现)[email protected]+setTimeout(单独测试不会出现,项目中会出现)weex 滚动组件 @scroll.native+setTimeout(会出现)剥离业务代码后的代码如下:
let timeout = 0;
let time = '';
export default {
methods: {
onScroll() {
time = Date.now();
console.log('滚动', time);
clearTimeout(timeout);
timeout = setTimeout(() => {
time = Date.now();
console.log('触发', time);
}, 1000);
},
},
};setTimeout(() => {}, delay) 中 delay 设置超过3s就是正常设置的时间,如果设置的 delay 小于3s,就会出现3s延迟。
setTimeout(() => {}, 0) 也会出现这个问题,setImmediate() 不会出现这个问题,但是就不起防抖的作用。
然而没有找出问题所在。。。
暂时使用 requestAnimationFrame 替代 setTimeout。
setRaf() {
this.raf = requestAnimationFrame(() => {
this.rafTimes += 1;
if (this.rafTimes >= 20) {
this.scrollBody(); // 触发实际滚动方法
this.rafTimes = 0;
} else {
this.setRaf();
}
});
},
onScroll() {
if (requestAnimationFrame) {
this.rafTimes = 0;
cancelAnimationFrame(this.raf);
this.setRaf();
} else {
this.scrollBody(); // 触发实际滚动方法
}
},由于 requestAnimationFrame 存在兼容性问题,首先需要进行一下判断:
const requestAnimationFrame = window.requestAnimationFrame || window.webkitRequestAnimationFrame;
const cancelAnimationFrame = window.cancelAnimationFrame || window.webkitCancelAnimationFrame || window.webkitCancelRequestAnimationFrame;最好的方式应该是要对 requestAnimationFrame 进行 polyfill 的,但是 requestAnimationFrame 的 polyfill 会用到 setTimeout ,还是会延时,所以在不支持 requestAnimationFrame 的环境下只能不做防抖了。
如果有谁知道这是为什么的,一定一定要告诉我 ~ 谢谢 ~
vue-loader
vue-loader是一个webpack的loader,它允许你以一种名为单文件组件的格式撰写Vue组件。
vue-loadervue-loadernpm install vue-loader vue-template-compiler --save-dev
webapck// webpack.config.js
const VueLoaderPlugin = require('vue-loader/lib/plugin')
module.exports = {
mode: 'development',
module: {
rules: [
{
test: /\.vue$/,
loader: 'vue-loader'
},
// 它会应用到普通的 `.js` 文件
// 以及 `.vue` 文件中的 `<script>` 块
{
test: /\.js$/,
loader: 'babel-loader'
},
// 它会应用到普通的 `.css` 文件
// 以及 `.vue` 文件中的 `<style>` 块
{
test: /\.css$/,
use: [
'vue-style-loader',
'css-loader'
]
}
]
},
plugins: [
// 请确保引入这个插件来施展魔法
new VueLoaderPlugin()
]
}Vue 组件一个标准的 Vue 组件可以分为三部分:
<template>
<div id="app">
<div class="title">{{msg}}</div>
</div>
</template>
<script>
export default {
name: 'app',
data() {
return {
msg: 'Hello world',
};
},
}
</script>
<style lang="scss">
#app {
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
.title {
color: red;
}
</style>打包完之后,这个 Vue 组件就会被解析到页面上:
<head>
<style type="text/css">
#app {
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
.title {
color: red;
}
</style>
</head>
<body>
<div id="app">
<div class="title">Hello world</div>
</div>
<script type="text/javascript" src="/app.js"></script>
</body>上面 Vue 组件里的 <template> 部分解析到 <body> 下,css 部分解析成 <style> 标签,<script> 部分则解析到 js 文件里。
简单来说 vue-loader 的工作就是处理 Vue 组件,正确地解析各个部分。
vue-loader 的源码较长,我们分几个部分来解析。
我们先从入口看起,从上往下看:
module.exports = function (source) {}vue-loader 接收一个 source 字符串,值是 vue 文件的内容。
const stringifyRequest = r => loaderUtils.stringifyRequest(loaderContext, r)loaderUtils.stringifyRequest 作用是将绝对路径转换成相对路径。
接下来有一大串的声明语句,我们暂且先不看,我们先看最简单的情况。
const { parse } = require('@vue/component-compiler-utils')
const descriptor = parse({
source,
compiler: options.compiler || loadTemplateCompiler(loaderContext),
filename,
sourceRoot,
needMap: sourceMap
})parse 方法是来自于 component-compiler-utils,代码简略一下是这样:
// component-compiler-utils parse
function parse(options) {
const { source, filename = '', compiler, compilerParseOptions = { pad: 'line' }, sourceRoot = '', needMap = true } = options;
// ...
output = compiler.parseComponent(source, compilerParseOptions);
// ...
return output;
}可以看到,这里还不是真正 parse 的地方,实际上是调用了 compiler.parseComponent 方法,默认情况下 compiler 指的是 vue-template-compiler。
// vue-template-compiler parseComponent
function parseComponent (
content,
options
) {
var sfc = {
template: null,
script: null,
styles: [],
customBlocks: [],
errors: []
};
// ...
function start() {}
function end() {}
parseHTML(content, {
warn: warn,
start: start,
end: end,
outputSourceRange: options.outputSourceRange
});
return sfc;
}这里可以看到,parseComponent 应该是调用了 parseHTML 方法,并且传入了两个方法: start 和 end,最终返回 sfc。
这一块的源码我们不多说,我们可以猜测 start 和 end 这两个方法应该是会根据不同的规则去修改 sfc,我们看一下 sfc 即 vue-loader 中 descriptor 是怎么样的:
// vue-loader descriptor
{
customBlocks: [],
errors: [],
template: {
attrs: {},
content: "\n<div id="app">\n <div class="title">{{msg}}</div>\n</div>\n",
type: "template"
},
script: {
attrs: {},
content: "... export default {} ...",
type: "script"
},
style: [{
attrs: {
lang: "scss"
},
content: "... #app {} ...",
type: "style",
lang: "scss"
}],
}vue 文件里的内容已经分别解析到对应的 type 去了,接下来是不是只要分别处理各个部分即可。
parseHTML 这个命名是不是有点问题。。。
vue-loader 如何处理不同 type你们可以先思考五分钟,这里的分别处理是如何处理的?比如,样式内容需要通过 style-loader 才能将其放到 DOM 里。
好了,就当作聪明的你已经有思路了。我们继续往下看。
// template
let templateImport = `var render, staticRenderFns`
let templateRequest
if (descriptor.template) {
const src = descriptor.template.src || resourcePath
const idQuery = `&id=${id}`
const scopedQuery = hasScoped ? `&scoped=true` : ``
const attrsQuery = attrsToQuery(descriptor.template.attrs)
const query = `?vue&type=template${idQuery}${scopedQuery}${attrsQuery}${inheritQuery}`
const request = templateRequest = stringifyRequest(src + query)
templateImport = `import { render, staticRenderFns } from ${request}`
}
// script
let scriptImport = `var script = {}`
if (descriptor.script) {
const src = descriptor.script.src || resourcePath
const attrsQuery = attrsToQuery(descriptor.script.attrs, 'js')
const query = `?vue&type=script${attrsQuery}${inheritQuery}`
const request = stringifyRequest(src + query)
scriptImport = (
`import script from ${request}\n` +
`export * from ${request}` // support named exports
)
}
// styles
let stylesCode = ``
if (descriptor.styles.length) {
stylesCode = genStylesCode(
loaderContext,
descriptor.styles,
id,
resourcePath,
stringifyRequest,
needsHotReload,
isServer || isShadow // needs explicit injection?
)
}这三段代码的结构很像,最终作用是针对不同的 type 分别构造一个 import 字符串:
templateImport = "import { render, staticRenderFns } from './App.vue?vue&type=template&id=7ba5bd90&'";
scriptImport = "import script from './App.vue?vue&type=script&lang=js&'
export * from './App.vue?vue&type=script&lang=js&'";
stylesCode = "import style0 from './App.vue?vue&type=style&index=0&lang=scss&'";这三个 import 语句有什么用呢, vue-loader 是这样做的:
let code = `
${templateImport}
${scriptImport}
${stylesCode}`.trim() + `\n`
code += `\nexport default component.exports`
return code此时, code 是这样的:
code = "
import { render, staticRenderFns } from './App.vue?vue&type=template&id=7ba5bd90&'
import script from './App.vue?vue&type=script&lang=js&'
export * from './App.vue?vue&type=script&lang=js&'
import style0 from './App.vue?vue&type=style&index=0&lang=scss&'
// 省略 ...
export default component.exports"我们知道 loader 会导出一个可执行的 node 模块,也就是说上面提到的 code 是会被 webpack 识别到然后执行的。
我们看到 code 里有三次的 import,import 的文件都是 App.vue,相当于又加载了一次触发这次 vue-loader 的那个 vue 文件。不同的是,这次加载是带参的,分别对应着 template / script / style 三种 type 的处理。
你们可以先思考五分钟,这里的分别处理是如何处理的?
这个问题的答案就是,webpack 在加载 vue 文件时,会调用 vue-loader 来处理 vue 文件,之后 return 一段可执行的 js 代码,其中会根据不同 type 分别 import 一次当前 vue 文件,并且将参数传递进去,这里的多次 import 也会被 vue-loader 拦截,然后在 vue-loader 内部根据不同参数进行处理(比如调用 style-loader)。
后续还有 vue-loader 的第二篇文章,讲解 VueLoaderPlugin 的代码以及如何处理不同 type。
之前写过一篇 一年半经验如何准备阿里巴巴前端面试,给大家分享了一个面试复习导图,有很多朋友说希望能够针对每个 case 提供一个参考答案。
写答案就算了,一是精力有限,二是我觉得大家还是需要自己理解总结会比较好。
给大家整理了一下每个 case 一些还算不错的文章吧(还包括一些躺在我收藏夹里的好文章),大家可以自己看文章总结一下答案,这样也会理解更深刻。
并不是所有文章都需要看,希望是一个抛砖引玉的作用,大家也可以锻炼一下自己寻找有效资料的能力 ~
( 文章排序不分前后,随机排序 ~
建议收藏文章,结合复习导图食用,效果更佳。
完整复习导图全展开太大了,可关注公众号「前端试炼」回复【面试】获取。
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
// 相当于
async function async1() {
console.log('async1 start');
Promise.resolve(async2()).then(() => {
console.log('async1 end');
})
}这个知识点真的是重在理解,一定要理解彻底
for (const macroTask of macroTaskQueue) {
handleMacroTask();
for (const microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}太多了... 总的来说就是 API 一定要熟悉...
从**、生态、语法、数据、通信、diff等角度自己总结一下吧。
思考题,自由发挥
推荐一些值得看的书,基本都是我看完或者有翻过几页觉得不错但是还没时间看的书。
上文整理了网上的一些相关文章和躺在我收藏夹里精选文章,有一些文章还没看,还需要持续学习呀 ~
放弃了假期快落的岛上生活(动森),吐血整理这份资料,希望对大家有所帮助~
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.






























