I’m Axetroy, a software developer who love Rust & Golang & Typescript.
I participated in many open source projects and wrote hundreds of tools.
Welcome to follow me.


特别感谢 JetBrains 为我的开源项目提供免费的 IntelliJ IDEA 授权

PS: 来,聊聊
:open_book:基于Github API 的动态博客
Home Page: https://axetroy.xyz
I’m Axetroy, a software developer who love Rust & Golang & Typescript.
I participated in many open source projects and wrote hundreds of tools.
Welcome to follow me.
特别感谢 JetBrains 为我的开源项目提供免费的 IntelliJ IDEA 授权
PS: 来,聊聊

![greenkeeper[bot] avatar](https://avatars.githubusercontent.com/in/505?v=4 "greenkeeper[bot]")
![imgbot[bot] avatar](https://avatars.githubusercontent.com/in/4706?v=4 "imgbot[bot]")


![renovate[bot] avatar](https://avatars.githubusercontent.com/in/2740?v=4 "renovate[bot]")












































































































发现是后端高并发接收socket所致
docker-compose up
docker-compose down托管静态目录
version: '3'
services:
i18n_nginx_static:
image: nginx:1.13.8-alpine
restart: always
working_dir: /home/static
volumes:
- ./dist:/usr/share/nginx/html
ports:
- 6098:80启动NodeJS App
version: '3'
services:
pg:
image: postgres:9.6.6-alpine
restart: always
volumes:
- "./docker/volumes/pg:/var/lib/postgresql/data"
ports:
- 6432:5432
node:
image: keymetrics/pm2:8-alpine
user: "node"
working_dir: /home/node/app
environment:
- NODE_ENV=production
volumes:
- ./:/home/node/app
ports:
- 6099:6099
links:
- pg记录下我写的 Docker compose 配置集合,集合了一些常用的配置
没有什么是非得用 xx 技术才行的,只是 能用 和 好用 的区别
有些习惯了老旧的工作方式,不愿去学习,不愿意去改变,追求 “能用就行”
有些不单追求能用,还有提升的空间,追去好用
It's up to you!
在上一家公司,操作系统是自由的,你想用 Windows/Linux/Mac, 只要你用的习惯,能够高效率工作,无所谓什么系统。
然而问题就来了,大家的环境不一样。Unix 系系统基本无太大差别,Windows 就不一样了。
环境的差异会导致踩很多很多坑, 印象比较深刻的就是 sass 编译,在哪个还需要依赖 ruby 的年代,安装 gem 是不顺畅的,windows 格式编码格式不是 utf-8, 导致 sass 文件中有中文编译报错等等。
还有一些诸如文件监听,在 Windows 下需要 fallback,靠轮循监听变化。
在经过一系列的折腾之后,我们就尝试使用 Docker 来解决开发环境统一的问题。
构建一个通用的 Linux 镜像,里面包含了前端开发的基本环境,包括 python,nodejs 等等... 前端只要给定源码文件就行了。就这样暂时统一了开发环境,虽然最后我们统一使用 Unix 系统。
前后端不分离的项目
你作为一个前端,你是如何与 PHP 后端参与开发的?你需要搭建 PHP 环境吗?
我不搭建 PHP 开发环境,FTP 直接上传,就是这么简单粗暴,Docker 什么的,能吃吗 ∂?
如果你是这种开发模式,不是说 low,而是说效率低下。每次修改都要上传,盲人改代码。
所以你需要 Docker,配置好环境,一键启动,一键关闭,各开发人员相互独立,代码通过 git 同步,指向同一个数据库,修改代码立即见效,F*CK FTP
单页面应用
前后端分离的情况下,单页面渲染一般使用nginx, Docker 同样配置 nginx,做静态页渲染和去除难看的#号(通过 404 重定向只 index.html, 把 404 的控制权,交还给前端)
这样你的路由http://example.com/#/home变成了http://example.com/home
甚至你可以作反向代理,消除跨域
http://example.com/api > http://api.server.com
服务端渲染
那么你更需要 Docker, 因为你需要 Node 环境,你需要负载均衡,你需要反向代理等等...
Node 后端
既然是后端,数据库你要吧?nginx 你要吧,Node 你要安装吧?
A 同事项目依赖了 [email protected], 结果你项目依赖 [email protected]. 难道你叫他卸载了重新装一个?
首先你得安装Docker 和 Docker Compose, 使用 Docker Compose来配置镜像.
一个简单的项目结构如下
├── docker-compose.yml
└── index.js
// index.js
const http = require('http');
const server = http.createServer((req, res) => {
res.setHeader('Content-Type', 'text/html');
res.setHeader('X-Foo', 'bar');
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('ok');
});
server.listen(3000);# docker-compose.yml
version: "3"
services:
web:
image: node:8-alpine
user: node
working_dir: /home/node/app
environment:
- PORT=3000
volumes:
- ./:/home/node/app # 将本地目录映射到容器内
command: ["node", "index.js"] # 运行命令
ports:
- 3000:3000 # 本地端口:容器端口运行命令启动
$ docker-compose up
Starting example_web_1 ... done
Attaching to example_web_1现在 NodeJs 应用已经跑起来了,试着访问 http://localhost:3000
现在我们给项目添加依赖Koa,用 Koa 来搭建服务器.
这我们需要把node_modules和package.json打包进镜像
而官方的 node 镜像node:8-alpine是不安装依赖的,需要我们自定义一个镜像
创建一个 Dockerfile
# Dockerfile
FROM node:8-alpine
# 设置工作目录
WORKDIR /home/node/app
# 把package.json复制进镜像中
COPY ./package.json /home/node/app/package.json
# 在镜像中安装依赖
RUN yarn --production修改 docker-compose.yml
# docker-compose.yml
version: "3"
services:
web:
build:
context: .
dockerfile: ./Dockerfile
user: node
working_dir: /home/node/app
environment:
- PORT=3000
volumes:
- ./index.js:/home/node/app/index.js # 将本地目录映射到容器内
command: ["node", "index.js"] # 运行命令
ports:
- 3000:3000 # 本地端口:容器端口此时项目目录
├── Dockerfile
├── docker-compose.yml
├── index.js
├── package.json
└── yarn.lock
运行命令
$ docker-compose up
Building web
Step 1/5 : FROM node:8-alpine
---> 86b71ddd55fa
Step 2/5 : WORKDIR /home/node/app
---> Using cache
---> 2347fe6d8f3c
Step 3/5 : COPY ./package.json /home/node/app/package.json
---> Using cache
---> 1e0026f493f5
Step 4/5 : RUN yarn --production
---> Using cache
---> 549284f78c1c
Step 5/5 : RUN ls ./node_modules
---> Using cache
---> 350adf90cfa8
Successfully built 350adf90cfa8
Successfully tagged example_web:latest
Recreating example_web_1 ... done
Attaching to example_web_1服务已运行起来了,访问 3000 试试看吧
首先得有一个 nginx.conf 配置
# nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
gzip on;
# 定义上游服务器
upstream api {
ip_hash;
# 这里服务器使用 koaserver
# 其实原理是Docker改写了host, koaserver指向nodejs那个容器的IP
server koaserver:3000 weight=1;
keepalive 300;
}
server {
listen 80;
server_name localhost;
charset utf-8;
root /usr/share/nginx/html;
# 代理以 api 为前缀的请求
location ~^/api {
proxy_pass http://api;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
}
version: "3"
services:
nginx_proxy:
image: nginx:1.13.8-alpine
restart: always
working_dir: /home/static
volumes:
- ./index.html:/usr/share/nginx/html/index.html
- ./nginx.conf:/etc/nginx/nginx.conf # 映射 ginx 配置文件
ports:
- 3000:80 # 绑定容器的80端口到本的1080端口
links:
- web:koaserver # 给它取个别名,叫做 koaserver
web:
build:
context: .
dockerfile: ./Dockerfile
user: node
working_dir: /home/node/app
environment:
- PORT=3000
volumes:
- ./index.js:/home/node/app/index.js # 将本地目录映射到容器内
command: ["node", "index.js"] # 运行命令<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
hello html
</body>
</html>此时项目目录
├── Dockerfile
├── docker-compose.yml
├── index.html
├── index.js
├── nginx.conf
├── package.json
└── yarn.lock
运行命令
$ docker-compose up
Creating network "example_default" with the default driver
Pulling nginx_proxy (nginx:1.13.8-alpine)...
1.13.8-alpine: Pulling from library/nginx
550fe1bea624: Already exists
d421ba34525b: Already exists
fdcbcb327323: Already exists
bfbcec2fc4d5: Already exists
Digest: sha256:c8ff0187cc75e1f5002c7ca9841cb191d33c4080f38140b9d6f07902ababbe66
Status: Downloaded newer image for nginx:1.13.8-alpine
Creating example_web_1 ... done
Creating example_nginx_proxy_1 ... done
Attaching to example_web_1, example_nginx_proxy_1访问 localhost:3000, 返回 hello html
访问 localhost:3000/api, 返回 hello koa
解决了跨域,但同时也存在问题,代理之后,应用程序无法获取 IP,需要从 header 的X-Real-IP
字段获取
其他还有很多案例需要使用 Docker,特别是开发后端的应用。后端应用依赖 数据库(MySQL, Postgres, Redis...)、服务器(Nginx/Apache),开发语言(如 PHP)。
如果我是一名开发者,接手别人的项目,项目需要安装 PHP, 需要安装 MySQL, Apache, redis, mongo... 最好能提供一个docker-compose.yml,否则我不保证我打不死你
回到 Node 部署,最佳的姿势:
把编译过后的代码(例如 Typescript>JS)+依赖+配置打包进镜像
然后 push 镜像,最后在服务端部署。其余的配置,尽量都通过docker-compose.yml的环境变量去设置
做到只需要一个配置文件,就能把完整的项目搭建起来
Docker 到底解决了我们哪些问题?
从以前旧博客迁移至此
2016-05-06 22:30:23
队列与栈类似,但是使用了不同的原则。
队列是遵循FIFO(First In First Out,现进先出,也称先来先服务)原则的一组有序的项。
队列在尾部添加新元素,并从顶部移除元素。最新添加的元素必须排在队列的末尾。
现实中,最常见的队列例子就是排队,谁先来,就到谁。
class Queue {
constructor() {
this.items = [];
}
// 入列,向队列尾部添加一个(多个)项
enqueue(item) {
this.items.push(item);
}
// 出列,移除队列的第一个,并且返回被删除的元素
dequeue() {
return this.items.shift();
}
// 返回队列的第一个
front() {
return this.items[0];
}
isEmpty() {
return this.items.length === 0;
}
size() {
return this.items.length;
}
print() {
console.log(this.items.toString());
}
}
var queue = new Queue();
queue.enqueue('hello');
queue.enqueue('world');优先级队列就是设置项的优先级
在上面基本队列的基础上进行继承
class PriorityQueue extends Queue {
constructor() {
super();
}
// 重写enqueue
enqueue(item, priority = 0) {
let queueItem = {item, priority};
if (this.isEmpty()) {
this.items.push(queueItem);
}
else {
let added = false;
for (let i = 0; i < this.items.length; i++) {
// 如果目标的权重,比当前循环的小
if (queueItem.priority < this.items[i].priority) {
// 把目标放到当前index的前面
this.items.splice(i, 0, queueItem);
added = true;
break;
}
}
// 如果遍历之后,所以的元素权重,都比目标小,则直接放在尾部
if (!added) {
items.push(queueItem);
}
}
}
}
var q = new PriorityQueue();
q.enqueue('priority 2', 2);
q.enqueue('priority 1', 1);
q.enqueue('priority 0', 0);循环队列,是队列的一个修改版。
循环队列的一个例子就是击鼓传花游戏。在这个游戏中,孩子们围着一个圆圈,把花尽快的传给旁边的人。
某一时刻传花停止,在这时候花在谁手里,谁就退出圆圈被淘汰。重复这个过程,知道最后剩下一人。
function hotPotato(nameList, num) {
var queue = new Queue();
for (let i = 0; i < nameList.length; i++) {
queue.enqueue(nameList[i]);
}
let eliminated = '';
while (queue.size() > 1) {
for (let i = 0; i < num; i++) {
queue.enqueue(queue.dequeue());
}
eliminated = queue.dequeue();
console.log(`${eliminated}被淘汰`);
}
return queue.dequeue();
}
var names = ['a', 'b', 'c', 'd', 'e'];
var winner = hotPotato(names, 7);
console.log(`winner is ${winner}`); // a
var winner = hotPotato(names, 10);
console.log(`winner is ${winner}`); // e实现一个模拟的击鼓传花游戏。
使用队列生成一个名单,给定一个数字(模拟某时刻),然后迭代.
从队列开头移除一项,然后添加到队列末尾。
一旦传递的次数达到给定的次数,拿着花的那个人就被淘汰。
最后剩下一人就是胜利者。
由于某些原因,无法下载go官方包。
此时应该从官方的Github组织下载镜像
GO环境变量的设置
export PATH=$PATH:/usr/local/go/bin
export GOROOT=/usr/local/go
export PATH=$PATH:$GOROOT/bin
export GOPATH=$HOME/go
export PATH=$PATH:$GOPATH/bin
# 自定义GOPATH
export GOPATH=$HOME/go/src/github.com/axetroy/libGo text processing support
cd $GOPATH/src/golang/x
git clone https://github.com/golang/textGo packages for low-level interaction with the operating system
cd $GOPATH/src/golang/x
git clone https://github.com/golang/sysGo supplementary network libraries
cd $GOPATH/src/golang/x
git clone https://github.com/golang/netGo supplementary cryptography libraries
cd $GOPATH/src/golang/x
git clone https://github.com/golang/cryptoGo OAuth2
cd $GOPATH/src/golang/x
git clone https://github.com/golang/oauth2Go Tools
从以前旧博客迁移至此
2016-01-04 20:36:48
不用想了,linux下没有像window那样,有这样的提示给你。
我有个朋友,网络出问题了,不找运营商,找我(醉了...)。
他没有电脑,就是连个路由器。
我只能去帮他看看,手机链接路由,调了半天,最后发现是外面的网线没接好....汗....
尴尬的是后面又出问题了,还强调要我拿电脑过去,好吧...
结果大家动的,拨号各种不成功,也没有错误代码,不知道是宽带的账号密码问题还是怎么...
来了个装网线的维修人员对吧,连linux都不懂。
后面百度一下吧,找到了折中的办法,查看系统日志。
系统日志在
/var/log/syslog
如果你使用了错误的密码,日志里会有这几句:
Jan 10 05:39:48 ubuntu pppd[5634]: Remote message: user passwd error
Jan 10 05:39:48 ubuntu pppd[5634]: PAP authentication failed
勉强能看就行,好吧。
生活/工作中难免会需要进行一些GIF截图。
在Windows平台下,有很多便捷的软件. 但是在Linux中就不是那么愉快了。
本篇文章就记录下,各个平台如果优雅的制作GIF截图.
屏幕,摄像头和白板录像机与集成编辑器。
sudo apt install kazam
kazamTODO
Git Package Manager, make you manage the repository easier

Dat is the distributed data sharing tool. Share files with version control, back up data to servers, browse
remote files on demand, and automate long-term data preservation. Secure, distributed, fast.


localtunnel exposes your localhost to the world for easy testing and sharing! No need to mess with DNS
or deploy just to have others test out your changes.

经常在开放中,常常发现端口会被其他进程调用. 或者自己的程序按CTRL+C之后,依旧运行着
手动Kill掉会有点繁琐,所以开发了一个工具,用于kill掉占用某个端口的进程
npm install @axetroy/kp -g
kp 3000 # kill the process which listen on port 3000用于检测依赖更新/升级
npm install npm-check-updates -g
# cd to node procject root dir
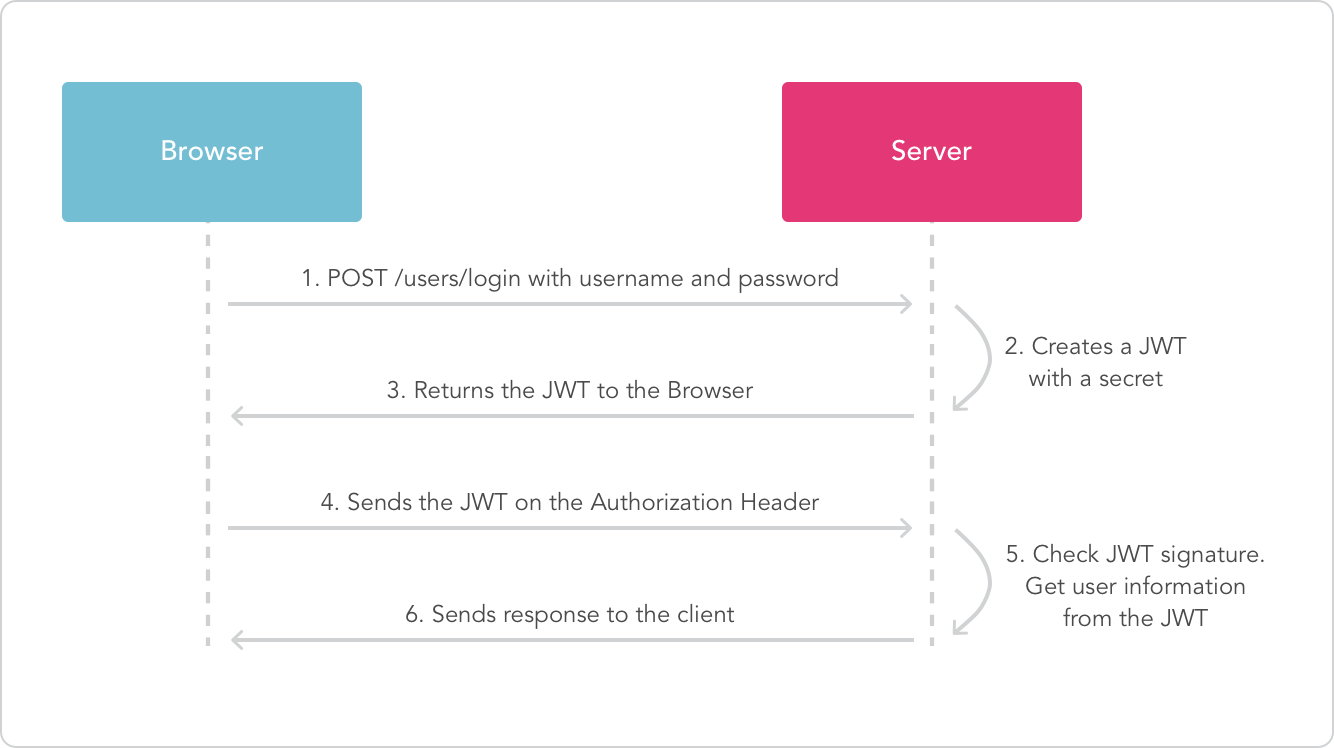
ncu在使用 JWT 的时候,有没有想过,为什么我们需要 JWT?以及它的工作原理是什么?
我们就来对比,传统的 session 和 JWT 的区别
我们以一个用户,获取用户资料的例子
你发现了吗?好些并没有什么区别,除了 session 需要服务端存储一份,而 JWT 不需要
但实际上区别大了去了
对比完了 session 和 JWT 的区别,下面我们来看看那它的实现原理
首先 JWT 长这个样
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJpcCI6IjEyNy4wLjAuMSIsInV1aWQiOiJmZjEyMTJmNS1kOGQxLTQ0OTYtYmY0MS1kMmRkYTczZGUxOWEiLCJpYXQiOjE1Mjc1MjMwMTd9.1C01cpOf1N3M9YAYvQjfcLbDGHZ4iPVncCGIoG-lpO0jHOIA_ZHtSMDvK1nzArLpGK5syQSwExsZJz2FJsd2W2TUiHQYtzmQTU8OBXX6mfSZRlkts675W5_WhIiOEwz69GFSD0AKXZifCRgIpKLC0n273MRMr0wJnuBi9ScfJ7YjSiqCr7qyQ5iXeOdS3ObT3wdjjk-Wu9wbWM7R25TFb-7PEZY7r_e8jmczPCVcNbOYegedu73T4d30kRn2jKufTGntD5hR6T9AQsgAMwVR1edEFflWb772TmrHI7WZOAivsBCN9sr4YiyYMvE8lcz_mBsgsunugGiHA3DGxB2ORbjIC8NPm8FI25zGOh9JIM2r_jFFTIm9GiuKtC8Ck8N3-eWi9u1NgBxwLdgN5JyCORnIOlciQEsScg-3SdCTM5LH_j6CeqQNwJxT4-oENzqLSTDJbP-SOj9nnx8HnJ5wh3n64rAvtc89CeTk7PhWFjksHDifngN-cnaszl5lqoF1enz5i9FYYELSjM-G7jns2SyY1MQeLRjuEDriPZtFaGmTW-RLH3gJfQXtbdpEo0_nHBqXEohwoN_FLKo4BNrEwshpyA7vkBpCQC0QALKyC1_L1Q5qduR6dDcqRozAo2VqJXmAKN0rvhLuIEHZkicOZY0Ds4So4GCcleqvFcxm1HQ
眼睛看仔细一些,你会发现 JWT 里面有两个.
数据格式是这样的 header.payload.signature
我们逐个逐个部分去分析,这个部分到底是干嘛的,有什么用
JWT 的 header 中承载了两部分信息
{
"alg": "RS256",
"typ": "JWT"
}对这个头部信息进行 base64,即可得到 header 部分
const headerBuff = Buffer.from(
JSON.stringify({
alg: "RS256",
typ: "JWT"
})
);
const header = headerBuff.toString("base64");
console.log(header);
// eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9payload 是主体部分,意为载体,承载着有效的 JWT 数据包,它包含三个部分
标准声明的字段
interface Stantar {
iss?: string; // JWT的签发者
sub?: string; // JWT所面向的用户
aud?: string; // 接收JWT的一方
exp?: number; // JWT的过期时间
nbf?: number; // 在xxx日期之间,该JWT都是可用的
iat?: number; // 该JWT签发的时间
jti?: number; //JWT的唯一身份标识
}标准中建议使用这些字段,但不强制。
公共声明的字段
interface Public {
[key: string]: any;
}公共声明字段可以添加任意信息,但是因为可以被解密出来,所以不要存放敏感信息。
私有声明的字段
interface Private {
[key: string]: any;
}私有声明是 JWT 提供者添加的字段,一样可以被解密,所以也不能存放敏感信息。
上面的 JWT 的 payload 结构是这样的
{
"ip": "127.0.0.1",
"uuid": "ff1212f5-d8d1-4496-bf41-d2dda73de19a",
"iat": 1527523017
}同样是通过 base64 加密生成第二部分的 payload
const payloadBuffer = Buffer.from(
JSON.stringify({
ip: "127.0.0.1",
uuid: "ff1212f5-d8d1-4496-bf41-d2dda73de19a",
iat: 1527523017
})
);
const payload = payloadBuffer.toString("base64");
console.log(payload);
// eyJpcCI6IjEyNy4wLjAuMSIsInV1aWQiOiJmZjEyMTJmNS1kOGQxLTQ0OTYtYmY0MS1kMmRkYTczZGUxOWEiLCJpYXQiOjE1Mjc1MjMwMTd9signature 是签证信息,该签证信息是通过header和payload,加上secret,通过算法加密生成。
公式 signature = 加密算法(header + "." + payload, 密钥);
上面的 header 中,我们已经定义了加密算法使用 RS256,也已经实现了生成header和payload,下面我们来生成 signature
const crypto = require("crypto");
const sign = crypto.createSign("SHA256");
const secret = `私钥,太长我就不贴出来了`;
sign.write(header + "." + payload);
sign.end();
const signature = sign
.sign(secret, "base64")
// 在JWT库中,已经把这些字符过滤掉了
.replace(/=/g, "")
.replace(/\+/g, "-")
.replace(/\//g, "_");
console.log(signature);到此,已经实现了如何生成一个 JWT 的 token.
首先,JWT 的 Token 相当是明文,是可以解密的,任何存在 payload 的东西,都没有秘密可言,所以隐私数据不能签发 token。
而服务端,拿到 token 后解密,即可知道用户信息,例如本例中的uuid
有了 uuid,那么你就知道这个用户是谁,是否有权限进行下一步的操作。
payload 中有个标准字段 exp,明确表示了这个 token 的过期时间.
服务端可以拿这个时间与服务器时间作对比,过期则拒绝访问。
此时 signature字段就是关键了,能被解密出明文的,只有header和payload
假如黑客/中间人串改了payload,那么服务器可以通过signature去验证是否被篡改过。
在服务端在执行一次 signature = 加密算法(header + "." + payload, 密钥);, 然后对比 signature 是否一致,如果一致则说明没有被篡改。
所以为什么说服务器的密钥不能被泄漏。
如果泄漏,将存在以下风险:
如果加强 JWT 的安全性?
根据我的使用,总结以下几点:
以上纯属个人愚见,大神笑笑就好. 本来JWT已经是烂大街的东西,奈何还是有些所谓的架构师在不了解的情况下zxc/.,$87^%aslkvnzc
有些人工作了5年,却只有一年的工作经验,因为它每一年都在做同样的工作。
不思进取,安于现状,却指责那些作出改变的人。
如果你做不到马云说的 银行不愿意改变,那我就去改变银行
那你就少说话,多做事,多思考,让未来更美好。
愿你我都不会成为这样的人。
A collection of awesome things regarding React ecosystem.
Awesome list of Angular 2 and Angular 4 seed repos, starters, boilerplates, examples, tutorials, components, modules, videos, and anything else in the Angular ecosystem. View as github page.
A curated list of delightful Node.js packages and resources.
Awesome npm resources and tips
A curated list of command line apps.
Useful resources for creating apps with Electron
A collection of awesome browser-side JavaScript libraries, resources and shiny things.
社区中有很多数据校验库,各功能不一。有些库有你想要的功能,有些库又没有。有写库又喜欢定义自己的模板,然后这些模板改着改着就成了 Magic String(魔符)
例如这样的模板:
validate(data, 'size:4')
validate(data, 'size:2-4')
validate(data, 'lt:20 || gt: 60 && is_prime')
...
现在是大前端时代,讲究的是 All in Javascript。也符合 React 的哲学。另一个套路 Javascript in HTML(Template) 是不友好的(AngularJs 我用了一年多)
目前比较满意的应该是这一款: superstruct
但是对我而言,它还是不顺手,如何校验多个条件? 如何做无限嵌套,包括数组/对象嵌套。
先上一个结构体,你们感受一下
// 如何检验这个数据, 虽然实际中,谁这么定义数据结构,会被打死
const data1 = {
name: "axetroy",
age: 18,
country: {
name: "China",
province: {
name: "You Guess",
city: {
name: "The capital of the province",
street: {
name: "suburbs",
number: {
code: 100031,
owner: "Axetroy",
family: [
{ name: "daddy" },
{ name: "mom" },
{ name: "brother" },
{ name: "sister" }
]
}
}
}
}
}
};所以才写一个自己顺手的东西。
先来一个简单的类型校验,只有名字和年龄
const { Struct, type } = require("@axetroy/struct");
const struct = Struct({
name: type.string,
age: type.int
});它还可以这么写, 自己自定义一个 func 作为校验
const struct = Struct({
name: type.string,
age: type.func(function(input) {
return parseInt(input) === input;
})
});甚至几个条件去校验一个字段, 带着参数
const struct = Struct({
name: type.string,
age: type.int.gte(18).lte(50) // 需要 >=18 && <=50
});然后你还能定义某个字段的错误信息
const struct = Struct({
name: type.string,
age: type.int.gte(18).lte(50).msg("保险仅限于18-50周岁之间")
});然后还支持数组
const struct = Struct({
name: type.string,
age: type.int,
friends: [type.string]
});同样支持数组里面嵌套对象
const struct = Struct({
name: type.string,
age: type.int,
friends: [
{
name: type.string,
age: type.int
}
]
});还可以自定义函数
const struct = Struct({
name: type.string,
age: type.int,
friends: [
function(element) {
if (typeof element.name !== "string") {
return false;
} else if (typeof element.age !== "number") {
return false;
}
return true;
}
]
});如果你还想组合多个校验器,还可以这么用
const struct = Struct({
name: type.string,
age: type.int,
friends: [
type.func(function(element) {
if (typeof element.name !== "string") {
return false;
} else if (typeof element.age !== "number") {
return false;
}
return true;
}).isAdult
]
});内置的校验器基本够平时校验使用
如果这些都没有你想要的,那么你还可以自定义
Struct.define("email", function(input) {
return /^[a-z0-9]+([._\\-]*[a-z0-9])*@([a-z0-9]+[-a-z0-9]*[a-z0-9]+.){1,63}[a-z0-9]+$/.test(
input
);
});
// 然后这么使用
const struct = Struct({
name: type.string,
age: type.int,
email: type.email
});如果想定义一个带参数的校验器
// 发现了吗,校验器名字,跟上面的区别就是多了括号()
Struct.define("prefixWith()", function(prefix) {
return function(input) {
return input.indexOf(prefix) === 0;
};
});
const struct = Struct({
name: type.string.prefixWith("[A]"), // 名字必须是字符串,并且以[A]开头
age: type.int
});好了,最后回归到我们开头说的,深度嵌套的对象,怎么去解析
const struct = Struct({
name: type.string,
age: type.int,
country: {
name: type.string,
province: {
name: type.string,
city: {
name: type.string,
street: {
name: type.string,
number: {
code: type.int,
owner: type.string,
family: [
{
name: type.string
}
]
}
}
}
}
}
});但是实际当中,我们可能不会这么定义这么一个庞大的数据结构。
而是分成细化的结构体。
比如一篇文章:
const User = Struct({
name: type.string,
age: type.int
});
const Article = Struct({
title: type.string,
content: type.string,
author: User // 作者嵌套ser
});在比如一个项目的信息:
const User = Struct({
name: type.string,
age: type.int
});
const Project = Struct({
name: type.string,
contributors: [User] // 数组的元素为User结构体
});前面都说了定义结构体,那么输出呢? 依旧从最简单的入手
const struct = Struct({
name: type.string,
age: type.int
});
const err = struct.validate(data);
console.log(err);struct.validate是执行校验工作。
如果校验过程中,有某个字段,不符合校验器的要求。
那么校验终止,并且返回这个错误。
如果校验成功,那么返回undefined
校验失败返回的错误为自定义错误TypeError,继承自Error
TypeError有一下属性:
.msg(errorMessage)去修改错误信息{ Error
at Object.<anonymous> (/home/axetroy/gpm/github.com/axetroy/struct/src/error.js:19:23)
at Module._compile (module.js:635:30)
at Object.Module._extensions..js (module.js:646:10)
at Module.load (module.js:554:32)
at tryModuleLoad (module.js:497:12)
at Function.Module._load (module.js:489:3)
at Module.require (module.js:579:17)
at require (internal/module.js:11:18)
at Object.<anonymous> (/home/axetroy/gpm/github.com/axetroy/struct/src/type.js:2:19)
at Module._compile (module.js:635:30)
validator: 'int',
path: [ 'author', 'age' ],
value: '18',
detail: 'Can not pass the validator "int" with value "18" in path "age"',
message: 'Can not pass the validator "int" with value "18" in path "age"' }
总结一下这个库的特点:
数据校验库层出不穷,关键也不看是不是很强大。
关键是要自己用得顺手。
代码覆盖率 100%,大量测试通过。
目前已运用到实际的生产环境中。
应用在哪里?
库没有使用 es6 语法, 也没有使用 Babel 编译, 没有使用 Webpack 打包.
但是理论上是支持浏览器和 Node 的.
浏览器需要使用打包工具引入.
最后上项目地址: struct
之前一直写前端应用,一直没有机会真正的写后端(有也是小打小闹,写后后端博客)。
但也在最近两个月。项目需要,开始真正的后端的,踩了很多坑,总结下来。
Typescript是第一个考虑的,根本就没考虑过Javascript。
因为设计到金融,必须要强类型,才能确保Bug在开发阶段就能被发现。Flow这种polyfill不在考虑当中。
而且Typescript也能很好的沿用npm社区的海量包库
没有类型检查,总是用着不放心
很棒的语言,但是社区不丰富,没有graphql的实现
可选的框架有:
老牌/稳定的web框架,社区丰富,中间件多。这些都是其次,重要的是: 稳定
新一代的web框架, 之前TJ大神引导的。需要nodejs@8支持,koa2之后支持async await
但是对于我使用Typescript来说,async await都不是事
阿里团队,基于koa框架的企业型框架.
社区不活跃,内容不丰富,关键是害怕是kpi项目,后期不再维护(虽然开发人员已经在知乎说了很多次,阿里内部也在使用)
基于Typescript的框架,概念,以及路由定义, 第一印象是很棒。
但是缺点就是社区不活跃,中间件不够丰富,而且主要是开发graphql接口,用不到怎么定义路由
所以就暂时搁置,没有用
因为之前接触的就是mongodb,简单易容,无关系型,所以简单上手就直接用了。
这就涉及到其中的一些坑了:
项目也是进行到一些,果断换了数据库,据说postgres坑比较少,支持多种类型,字段校验,事务,隔离,而且gui支持不错,有pgadmin,所以就它了。
然后选用的关系型数据库ORM,选用了一个star最高,并且社区还算活跃的sequelize。
然后使用下来的心得就是: 坑多.
RPC采用thift,但是thrift的官方库不支持SSL重连,意味着如果RPC的提供者端口如果断开连接,是不会重连的。RPC接口一直报错..
解决方法:
自己维护连接池,自动重连功能...
定时任务有缺陷,如果定时任务很频繁。会导致数据库连接一直没有可以释放,从而导致死锁。
因为定时任务不会等待上一个任务结束之后才开始。
解决办法:
业务代码内启动无限循环,执行业务代码,然后等待上一个任务完成之后,才进行下一个任务。
部署使用pm2部署集群,设置开机自启动
pm2 start pm2.json
pm2 save
pm2 startupTypescript是必备,后悔没有用基于Typescript的ORM,typeorm。
自己构建的项目也是有很多重复的代码,曾经也很纠结要不要用webpack打包起来,但是想想打包其他之后,线上的堆栈信息报错不方便查找问题,而且涉及到一些C++模块无法打包,一些镜头资源无法加载的问题..
最近在研究P2P技术,奈何相关资料不多,自己琢磨了一下,分享一下学习P2P的一些原理, 以及如何打造一个P2P聊天应用。
这里指的P2P是指peer to peer, 点对点的技术, 每个客户端都是服务端,没有中心服务器,不是websocket针对某个connection推送消息。
首先解决的是内网穿透的问题,常见的底层协议tcp,udp,他们各自有优缺点,简单说明一下。
tcp:需要处理粘包问题,双工流通道,是可靠的链接。
udp: 每次发送的都是数据包,没有粘包问题,但是连接不可靠,只能传输少量数据
更加详细的请Google
这里选择udp协议,简单一些。
再下来是内网穿透,先说结论: 两个处于不同内部网络的节点,永远无法发现他们之间的相互存在,你就算是想顺着网线过去打他都不行。
所有的内网穿透原理无外乎需要一个有公网ip的中介服务器,包括虚拟货币像比特币之类的,所以首先要有一个创世节点
在NodeJS中,创建udp服务也很简单
const dgram = require("dgram");
const udp = dgram.createSocket("udp4");
udp.bind(1090, callback)把服务部署要公网,那么其他所有的节点都能访问,通过中转服务器,能够使得两个节点可以建立连接

我们是要建立这样的P2P网络

假如现在只有3个节点: 创世节点, B节点, C节点, 创世节点有公网IP
我用对话的形式,阐述他们建立链接的过程:
B节点: hey,创世节点,我要加入到P2P网络里面,告诉其他兄弟,我来了
创世节点: 兄弟们,刚刚有个叫做B的节点加入网络了,你们也去告诉其他节点
其他节点: 刚刚收到来自 "创世节点"的通知,有个fresh meet加入网络了,叫做 "B"
...
至此,所有人都知道了B节点加入了网络,里面记载着B节点的相关信息,包括IP地址,包括udp端口号
此时C节点也要加入网络,并且想要和B节点对话:
C节点: hey,创世节点,我要加入到P2P网络里面,并且我要和B对话
创世节点: 兄弟们,刚刚有个叫做B的节点加入网络了,你们也去告诉其他节点,顺便看看有没有B这个节点
其他节点: 刚刚收到来自 "创世节点"的通知,有个fresh meet加入网络了,叫做 "C",你们也看看有没有B这个节点
其他节点2: 收到通知,听说一个叫做C的节点在找一个B节点,我这里有它的信息,ip是xxxx.xxxx.xxx.xxxx, 端口10086
B节点: 有个C的家伙(ip: xxxx.xxxx.xxxx.xxxx, 端口1000)要找我
到这里,B获取到了C的信息,包括IP和端口,C也拿到了B的信息.
于是,他们两个就可以建立通信。消息流: B <----> C. 中间不经过任何服务器
用一张图来形容:
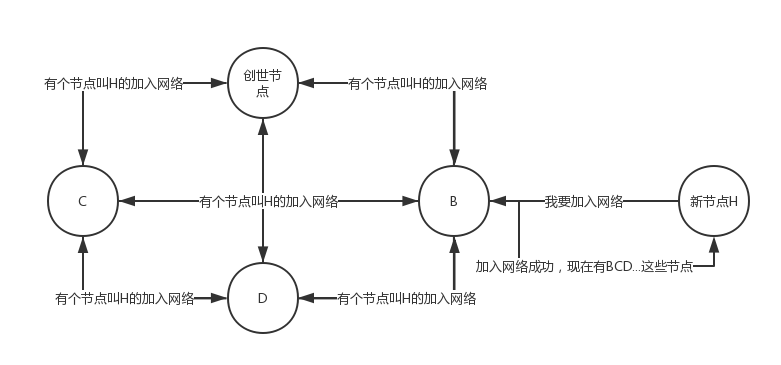
在设计中,每个节点的功能都是一样的。如果需要加入到网络中,不一定跟创世节点链接
假设已存在的节点: 创世节点,A、B、C节点,此时有个D节点想要加入到网络。
那么D节点不一定非得链接到创世节点,可以链接到A、B、C中的任意一个节点,然后该节点再广播给其他节点说"Hey, 有个新人叫做D的加入了网络"。
这样所有人都知道,有个叫做D的节点存在,你可以和它通信,同时D节点和会同步已存在的节点。这样D节点也知道了其他节点的存在了。
基于这一原理,可以打造出一个P2P的聊天应用,没有中间商赚差价。
这只是一些基本原理,离实际应用还差很多,有很多坑,比如D节点退出网络之后,要广播 “D节点退出网络了,把这个节点注销了吧,这波没他",还有消息加密,通信的双向验证(A节点想要B节点通信,但是不需要B节点的同意)等等,坑太多,填不完
原计划是搭建这么一个网络,然后写个electron的聊天应用,但是精力有限,就这样了。代码(写的丑,轻拍)
文字功底有点差,表述不清楚,见谅,如文中有误,欢迎指正与交流。
在后端开发中,可能需要多人协作,多语言,多模块开发。这时候可能就需要用RPC通信
比如有个用户模块,在进入到一个业务的时候,你需要去验证用户是否合法
async function main(username) {
const client = await rpc.createConnection(); // 创建RPC链接
const data = await client.getUserInfo(username); // 通过RPC链接获取用户信息
// 下面是业务逻辑
}但是你发现,RPC链接并没有被关闭(即便函数执行完毕,对象client被销毁), 它依旧占用着服务端的资源,如果多次调用这个函数,会多服务端造成很大的压力.
解决方案有两个
第一种方法是大多数ORM,RPC框架做的,应用内只保持n个链接,不断的创建再销毁,而这个过程不用使用者关心。
很可惜的是,我选用的RPC框架Thrift,有屎一样的坑。为了保持和Go的业务逻辑一样,采用第二种方案,每次创建链接之后都销毁,保证它是干净的
依旧是上面的代码,改成这样
async function main(username) {
const client = await rpc.createConnection(); // 创建RPC链接
try{
const data = await client.getUserInfo(username); // 通过RPC链接获取用户信息
// 下面是业务逻辑
}catch (err){
await client.close(); // 关闭链接
throw err
}
}上面的代码已经能很好的解决问题了,但是也有一个,如果需要关闭多种链接呢(比如RPC,DB,Socket等),一直try,catch也不是办法
受到Go的defer启发,于是写了这么一个库godefer , 依旧改写上面的代码
const godefer = require('godefer');
const main = godefer(async function(username, defer) {
const client = await rpc.createConnection();
// 注册一个defer函数
defer(function() {
client.close(); // 关闭链接
});
const data = await client.getUserInfo(username);
// 下面是业务逻辑
// ...
// 运行完毕,则开始执行defer
});Defer函数的执行,遵循了后进先出的原则, 即 先注册的defer函数,后运行
实现上与Go差不多, 有一点重要的差别是:
Go的defer内,能修改父级函数的返回值
godefer不能修改(不是不能做,而是不做)
好了,愉快的解决问题了, 有什么想法,评论来刚啊
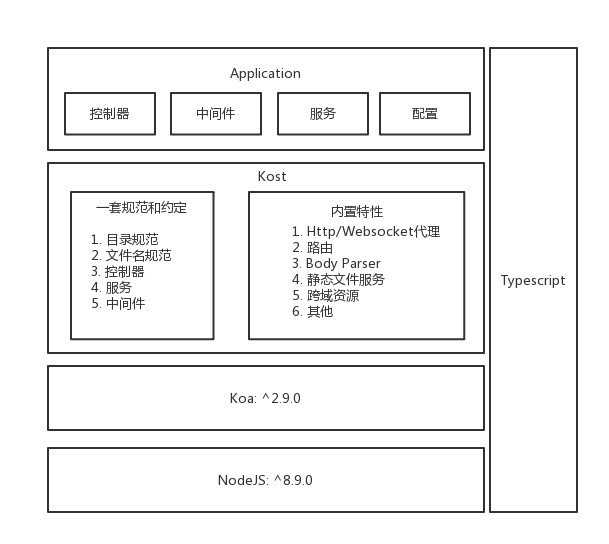
基于在上一家公司的开发经验,沉淀而来的web框架。
Kost 基于 Koa,使用 Typescript 编写,借鉴于 egg 的约定大于配置的**以及 nest 的依赖注入和装饰器路由。
是一款内置多个功能,并遵循一系列规范的 Web 框架。
Q: 为什么开发这样的框架
A: 框架基于以前的项目经验沉淀而来,首先是坚持 Typescript 不动摇,能在开发阶段避免了很多 bug。
Q: 为什么不使用 nest?
A: 因为它是基于 Express,而我以前的项目都是 Typescript + Koa
Q: 为什么不使用 egg?
A: egg 使用 JS 开发,目前对 Typescript 没有一个很好的方案(见识短,没发现),而且 egg 的 service 会丢失类型 IDE 提示,目前 egg 成员已在着手解决这个问题,期待中...
Q: 与两者的框架区别在哪里?
A: 借鉴了 egg 的约定大于配置的**,约定了一些文件目录,文件名,如果不按照框架写,就会 boom。借鉴了 nest 的 OOP 编程**,所有的,包括 Controller、Service、Middleware 都是类,都可以进行依赖注入,而且路由定义是装饰器风格,语法糖会让你更加的直观。对于开发而言,会有很好的 IDE 提示。
Q: 框架内置了一些特性,会不会平白增加性能负担?
A: 根据你是否开启特性,来决定是否引入包,所以不会有性能损耗。
Q: 是否需要配套 CLI 工具?
A: 目前没有,编译成 JS 就能运行,可以用 pm2 进行负载均衡。
Q: 框架是否包含进程管理?
A: 框架本身不进行进程管理,没有类似 egg 的 master 主进程管理子进程,没有 agent
开源就是自己用的爽的东西,拿出来给大家用,然后发现你自己写的,用法和原理你肯定懂啊,但是别人不懂,你得写文档,维护文档的时间,不必写代码的时间少。
同时为了保证项目质量,你还得写测试用例,写测试用例的时间,也并不少。
要维护一个开源项目,真的是要花不少心思,向开源大牛致敬。
实现起来没什么难度,前人栽树,后人乘凉,继承自Koa的类,然后在start之前,做一些初始化动作,加载Controller,验证Controller、Middleware、Service是否正确,加载配置文件等工作...
从创建仓库到现在100+个commit,而大多数commit都是更新文档,添加测试用例,最近也忙,断断续续的维护,今天终于完善了测试用例,覆盖率99%,终于可以发布第一个版本。
有兴趣的小伙伴,一起来维护吗,交个朋友
最后上项目地址: https://github.com/axetroy/kost
怎么说呢, 市面上的小程序框架都不令人满意.
要么太臃肿, Bug多, 要么过于封装(比如wepy)
总之, 对我来说就是不好用.
但是我又想使用npm社区的便利, 又不使用框架(兼容以前的小程序).
那么只好写个构建工具出来.
使用 Webpack + Babel 等技术
项目地址: https://github.com/axetroy/webuild
ps: 本来想写个框架的
使用特定的声明方式(decorator, 像Angular)声明app/页面/组件.
但是后来尝试了一下, 复杂度太高. 基本上原生开发已经能满足我的需求了
最近在研究 AST, 之前有一篇文章 面试官: 你了解过 Babel 吗?写过 Babel 插件吗? 答: 没有。卒
为什么要去了解它? 因为懂得 AST 真的可以为所欲为
简单点说,使用 Javascript 运行Javascript代码。
这篇文章来告诉你,如何写一个最简单的解析器。
在大家的认知中,有几种执行自定义脚本的方法?我们来列举一下:
function runJavascriptCode(code) {
const script = document.createElement("script");
script.innerText = code;
document.body.appendChild(script);
}
runJavascriptCode("alert('hello world')");无数人都在说,不要使用eval,虽然它可以执行自定义脚本
eval("alert('hello world')");参考链接: Why is using the JavaScript eval function a bad idea?
setTimeout 同样能执行,不过会把相关的操作,推到下一个事件循环中执行
setTimeout("console.log('hello world')");
console.log("I should run first");
// 输出
// I should run first
// hello world'new Function("alert('hello world')")();参考链接: Are eval() and new Function() the same thing?
可以把 Javascript 代码写进一个 Js 文件,然后在其他文件 require 它,达到执行的效果。
NodeJs 会缓存模块,如果你执行 N 个这样的文件,可能会消耗很多内存. 需要执行完毕后,手动清除缓存。
const vm = require("vm");
const sandbox = {
animal: "cat",
count: 2
};
vm.runInNewContext('count += 1; name = "kitty"', sandbox);以上方式,除了 Node 能优雅的执行以外,其他都不行,API 都需要依赖宿主环境。
在能任何执行 Javascript 的代码的平台,执行自定义代码。
比如小程序,屏蔽了以上执行自定义代码的途径
那就真的不能执行自定义代码了吗?
非也
基于 AST(抽象语法树),找到对应的对象/方法, 然后执行对应的表达式。
这怎么说的有点绕口呢,举个栗子console.log("hello world");
原理: 通过 AST 找到console对象,再找到它log函数,最后运行函数,参数为hello world
我们以运行console.log("hello world")为例
打开astexplorer, 查看对应的 AST

由图中看到,我们要找到console.log("hello world"),必须要向下遍历节点的方式,经过File、Program、ExpressionStatement、CallExpression、MemberExpression节点,其中涉及到Identifier、StringLiteral节点
我们先定义visitors, visitors是对于不同节点的处理方式
const visitors = {
File(){},
Program(){},
ExpressionStatement(){},
CallExpression(){},
MemberExpression(){},
Identifier(){},
StringLiteral(){}
};再定义一个遍历节点的函数
/**
* 遍历一个节点
* @param {Node} node 节点对象
* @param {*} scope 作用域
*/
function evaluate(node, scope) {
const _evalute = visitors[node.type];
// 如果该节点不存在处理函数,那么抛出错误
if (!_evalute) {
throw new Error(`Unknown visitors of ${node.type}`);
}
// 执行该节点对应的处理函数
return _evalute(node, scope);
}下面是对各个节点的处理实现
const babylon = require("babylon");
const types = require("babel-types");
const visitors = {
File(node, scope) {
evaluate(node.program, scope);
},
Program(program, scope) {
for (const node of program.body) {
evaluate(node, scope);
}
},
ExpressionStatement(node, scope) {
return evaluate(node.expression, scope);
},
CallExpression(node, scope) {
// 获取调用者对象
const func = evaluate(node.callee, scope);
// 获取函数的参数
const funcArguments = node.arguments.map(arg => evaluate(arg, scope));
// 如果是获取属性的话: console.log
if (types.isMemberExpression(node.callee)) {
const object = evaluate(node.callee.object, scope);
return func.apply(object, funcArguments);
}
},
MemberExpression(node, scope) {
const { object, property } = node;
// �找到对应的属性名
const propertyName = property.name;
// 找对对应的对象
const obj = evaluate(object, scope);
// 获取对应的值
const target = obj[propertyName];
// 返回这个值,如果这个值是function的话,那么应该绑定上下文this
return typeof target === "function" ? target.bind(obj) : target;
},
Identifier(node, scope) {
// 获取变量的值
return scope[node.name];
},
StringLiteral(node) {
return node.value;
}
};
function evaluate(node, scope) {
const _evalute = visitors[node.type];
if (!_evalute) {
throw new Error(`Unknown visitors of ${node.type}`);
}
// 递归调用
return _evalute(node, scope);
}
const code = "console.log('hello world')";
// 生成AST树
const ast = babylon.parse(code);
// 解析AST
// 需要传入执行上下文,否则找不到``console``对象
evaluate(ast, { console: console });在 Nodejs 中运行试试看
$ node ./index.js
hello world然后我们更改下运行的代码 const code = "console.log(Math.pow(2, 2))";
因为上下文没有Math对象,那么会得出这样的错误 TypeError: Cannot read property 'pow' of undefined
记得传入上下文evaluate(ast, {console, Math});
再运行,又得出一个错误Error: Unknown visitors of NumericLiteral
原来Math.pow(2, 2)中的 2,是数字字面量

节点是NumericLiteral, 但是在visitors中,我们却没有定义这个节点的处理方式.
那么我们就加上这么个节点:
NumericLiteral(node){
return node.value;
}再次运行,就跟预期结果一致了
$ node ./index.js
4到这里,已经实现了最最基本的函数调用了
既然是解释器,难道只能运行 hello world 吗?显然不是
var name = "hello world";
console.log(name);先看下 AST 结构

visitors中缺少VariableDeclaration和VariableDeclarator节点的处理,我们给加上
VariableDeclaration(node, scope) {
const kind = node.kind;
for (const declartor of node.declarations) {
const {name} = declartor.id;
const value = declartor.init
? evaluate(declartor.init, scope)
: undefined;
scope[name] = value;
}
},
VariableDeclarator(node, scope) {
scope[node.id.name] = evaluate(node.init, scope);
}运行下代码,已经打印出hello world
function test() {
var name = "hello world";
console.log(name);
}
test();根据上面的步骤,新增了几个节点
BlockStatement(block, scope) {
for (const node of block.body) {
// 执行代码块中的内容
evaluate(node, scope);
}
},
FunctionDeclaration(node, scope) {
// 获取function
const func = visitors.FunctionExpression(node, scope);
// 在作用域中定义function
scope[node.id.name] = func;
},
FunctionExpression(node, scope) {
// 自己构造一个function
const func = function() {
// TODO: 获取函数的参数
// 执行代码块中的内容
evaluate(node.body, scope);
};
// 返回这个function
return func;
}然后修改下CallExpression
// 如果是获取属性的话: console.log
if (types.isMemberExpression(node.callee)) {
const object = evaluate(node.callee.object, scope);
return func.apply(object, funcArguments);
} else if (types.isIdentifier(node.callee)) {
// 新增
func.apply(scope, funcArguments); // 新增
}运行也能过打印出hello world
限于篇幅,我不会讲怎么处理所有的节点,以上已经讲解了基本的原理。
对于其他节点,你依旧可以这么来,其中需要注意的是: 上文中,作用域我统一用了一个 scope,没有父级/子级作用域之分
也就意味着这样的代码是可以运行的
var a = 1;
function test() {
var b = 2;
}
test();
console.log(b); // 2处理方法: 在递归 AST 树的时候,遇到一些会产生子作用域的节点,应该使用新的作用域,比如说function,for in等
以上只是一个简单的模型,它连玩具都算不上,依旧有很多的坑。比如:
连续几个晚上的熬夜之后,我写了一个比较完善的库vm.js,基于jsjs修改而来,站在巨人的肩膀上。
与它不同的是:
目前正在开发中, 等待更加完善之后,会发布第一个版本。
欢迎大佬们拍砖和 PR.
小程序今后变成大程序,业务代码通过 Websocket 推送过来执行,小程序源码只是一个空壳,想想都刺激.
项目地址: https://github.com/axetroy/vm.js
从以前旧博客迁移至此
2015-12-16 23:59:23
sublime是一款轻量级的代码编辑器,它不是IDE,却不比IDE差,关键是运行快,什么机子都能够跑起来。
而且插件够多,能够媲美类似webstorm这样的神器。支持多语言。
这里需要注意一下的是,linux下并不支持中文,在编辑器内不能输入中文,虽然有方法可以,但是有点麻烦。
闲话少说。
下载地址:sublime text3
插件管理包,必备
下载地址:Package Control
或者使用控制台安装输入命令:
import urllib.request,os,hashlib; h = '2915d1851351e5ee549c20394736b442' + '8bc59f460fa1548d1514676163dafc88'; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); by = urllib.request.urlopen( 'http://packagecontrol.io/' + pf.replace(' ', '%20')).read(); dh = hashlib.sha256(by).hexdigest(); print('Error validating download (got %s instead of %s), please try manual install' % (dh, h)) if dh != h else open(os.path.join( ipp, pf), 'wb' ).write(by)在sublime中打开插件包控控制台或ctrl+p输入pci搜索插件
自动不全
自动搜索目录下的文件名,在引用文件的时候比较方便
地球人都知道,对吧
高亮当前标签的标签头和尾
JS格式化
代码高亮
高亮标签/括号/大括号等开始和闭合
高亮颜色代码
左侧栏显示标签样式
更优雅的注释
用于校验js代码
JS代码提示功能
基于SublimeLinter的JS插件
支持angular的语法提示
sublime是好用,但是就是配置起来,麻烦的很
{
"auto_complete": true,
"auto_complete_delay": 50,
"auto_complete_size_limit": 4194304,
"auto_match_enabled": true,
"caret_style": "smooth",
"color_scheme": "Packages/Colorcoder/Monokai (Colorcoded) (SL) (Colorcoded).tmTheme",
"default_encoding": "UTF-8",
"font_size": 15,
"highlight_line": true,
"hot_exit": true,
"ignored_packages":
[
"Vintage"
],
"match_brackets": true,
"match_selection": true,
"original_color_scheme": "Packages/User/SublimeLinter/Monokai (Colorcoded) (SL).tmTheme",
"save_on_focus_lost": false,
"scroll_speed": 1.0,
"show_tab_close_buttons": true,
"tab_size": 2,
"translate_tabs_to_spaces": true,
"tree_animation_enabled": true,
"trim_automatic_white_space": true,
"word_wrap": false
}window下可以愉快的玩耍,但是linux呢,由于nodejs的路径不对,导致很到依赖于nodejs的插件都不能正常工作。
比如js的语法校验,就是通过nodejs,所以需要配置。
从以前旧博客迁移至此
2015-12-27 19:01:08
// 安装ionic
$ npm install -g cordova ionic
// 生成一个ionic项目
$ ionic start myApp tabs
// 进入到项目目录
$ cd myApp
// 添加android平台
$ ionic platform add android
// 编译apk文件
$ ionic build android我把android SDK放在了java目录下...
/usr/lib/jvm/android-sdk-linux$ sudo gedit ./.bashrc
在最后加入
export PATH=${PATH}:/usr/lib/jvm/你的安卓SDK文件夹名/tools
export PATH=${PATH}:/usr/lib/jvm/你的安卓SDK文件夹名/platform-tools
export ANDROID_HOME=${PATH}:/usr/lib/jvm/你的安卓SDK文件夹名/然后刷新环境变量
$sudo source ./.profile可以查看环境变量是否生效
$ envOK,安卓sdk的环境变量配置好了,这样ionic就可以跑起来了。
ionic 会要求要22的api包,但是下载下来的确实23api
怎么办呢?
修改如下文件
/platforms/android/androidMainfest/xml
找到
<uses-sdk android:minSdkVersion="16" android:targetSdkVersion="22" />还有
/platforms/android/build/project.properties
找到
target=android-22把22修改成23
# JDK
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk
export JRE_HOME=${JAVA_HOME}/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# android SDK
export ANDROID_HOME=/home/axetroy/android-sdk-linux
export PATH=$ANDROID_HOME/tools:$ANDROID_HOME/platform-tools:$PATH
export PATH=/home/axetroy/android-sdk-linux/tools:$PATH
# NDK
export ANDROID_NDK=/home/axetroy/android-ndk-r11
export PATH=/home/axetroy/android-ndk-r11:$PATH
# Ant
export PATH=$PATH:~/home/axetroy/apache-ant-1.9.6/bin
export CLASSPATH=/home/axetroy/apache-ant-1.9.6/lib 从以前旧博客迁移至此
2016-05-06 01:42:16
function firstUpperCase(str) {
return str.toLowerCase().replace(/\b[a-z]/g, function(s) {
return s.toUpperCase();
});
}function camelcase(flag) {
return flag.split('-').reduce(function(str, word) {
return str + word[0].toUpperCase() + word.slice(1);
});
}function inverse(s) {
var arr = s.split('');
var i = 0, j = arr.length - 1;
while (i < j) {
var t = arr[i];
arr[i] = arr[j];
arr[j] = t;
i++;
j--;
}
return arr.join('');
}or
function inverse(str) {
return str.split('').reverse().join('');
}// 生成n个不重复的随机数
function random_no_repeat(min, max, n) {
var result = [];
let temp = [];
for (let i = min; i <= max; i++) {
temp.push(i);
}
for (; n--;) {
let index = parseInt(Math.random() * temp.length, 10);
result.push(temp[index]);
temp.splice(index, 1);
}
return result;
}
random_no_repeat(15, 20, 5); // [15, 17, 20, 19, 18]
random_no_repeat(1, 100, 10) // [95, 13, 96, 61, 67, 83, 35, 73, 74, 75]function unique(arr) {
let result = [];
let hash = {};
arr.forEach((v)=> {
if (!hash[v]) {
result.push(v);
hash[v] = true;
}
});
return result;
}
var arr = [1, 2, 3, 4, 2, 3, 5, 6, 1, 3, 5];
unique(arr) // [1, 2, 3, 4, 5, 6]// 找出字符串中,重复次数最多的字符
function match_str(str) {
var result = {
character: '',
times: 0
};
var hash = {};
str.split('').forEach((character)=> {
if (!hash[character]) {
hash[character] = 1;
} else {
hash[character]++;
}
});
for (let character in hash) {
let times = hash[character];
if (times > result.times) {
result.character = character;
result.times = times;
}
}
return result;
}
var s = "asddasdddddd";
match_str(s); // Object {character: "d", times: 8}// 从小到达排序
[1, 2, 3, 4, 11, 55, 12, 32, 55].sort(function (a, b) {
return a > b;
});
// 结果:[1, 2, 3, 4, 11, 12, 32, 55, 55]
// 从大到小
[1, 2, 3, 4, 11, 55, 12, 32, 55].sort(function (a, b) {
return a < b;
});
// 结果:[55, 55, 32, 12, 11, 4, 3, 2, 1]var arr = [
{name: 'yr', age: 12},
{name: 'ad', age: 18},
{name: 'hg', age: 13},
{name: 'cz', age: 16}
];
// 按照年龄排序,又小到大
arr.sort(function (item1, item2) {
return item1.age > item2.age
});
// 按照姓名排序
arr.sort(function (item1, item2) {
return item1.name > item2.name
});关于快速排序法,更多详细原理,可以看阮一峰老师的博客,快速排序(Quicksort)的Javascript实现
function quickSort(arr) {
if (arr.length <= 1) return arr;
const pivotIndex = Math.floor(arr.length / 2);
// 快速排序的基准点
const pivot = arr.splice(pivotIndex, 1)[0];
let left = [];
let right = [];
for (let i = 0; i < arr.length; i++) {
arr[i] < pivot ? left.push(arr[i]) : right.push(arr[i]);
}
// 最后递归,不断重复这个过程
return quickSort(left).concat([pivot], quickSort(right));
};
var arr = [31, 41, 23, 53, 12, 3, 4, 66];
quickSort(arr); // [3, 4, 12, 23, 31, 41, 53, 66]function emitSort(arr) {
let result = arr.slice();
for (let i = 0; i < result.length - 1; i++) {
for (let j = 0; j < result.length - 1 - i; j++) {
if (result[j] > result[j + 1]) {
let tmp = result[j];
result[j] = result[j + 1];
result[j + 1] = tmp;
}
}
}
return result;
}
let arr = [31, 22, 51, 1, 6, 23, 55];
emitSort(arr); // [1, 6, 22, 23, 31, 51, 55]function selectSort(arr) {
var min, tmp, result = arr.slice();
for (var out = 0; out < result.length - 1; out++) {
min = out;
for (var inner = out + 1; inner < result.length; inner++) {
if (result[inner] < result[min]) {
min = inner;
}
//将最小的项移动到左侧
tmp = result[out];
result[out] = result[min];
result[min] = tmp;
}
}
return result;
}
var arr = [31, 22, 51, 1, 6, 23, 55];
selectSort(arr); // [1, 6, 22, 23, 31, 51, 55]function insertSort(arr) {
var result = arr.slice();
for (var out = 1; out < result.length; out++) {
var tmp = result[out];
var inner = out;
while (result[inner - 1] > tmp) {
result[inner] = result[inner - 1];
--inner;
}
result[inner] = tmp;
}
return result;
}
var arr = [31, 22, 51, 1, 6, 23, 55];
insertSort(arr); // [1, 6, 22, 23, 31, 51, 55]// TODO虽然说ECMA5的Array由indexOf方法,但是不妨我们可以学习
function linearSearch(arr, value) {
for (var i = 0; i < arr.length; i++) {
if (arr[i] === value) {
return i;
}
}
return -1;
}
var arr = ['axe', 'troy'];
linearSearch(arr, 'troy'); // 1function binarySearch(arr, value) {
let low = 0, high = arr.length - 1;
while (low <= high) {
let mid = Math.floor((low + high) / 2);
if (value == arr[mid]) {
return mid;
}
if (value < arr[mid]) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}
const arr = ['axe', 'troy', 'hello', 'world'];
binarySearch(arr, 'troy'); // 1记录Python的学习过程, 强化记忆, 加深印象.
想到什么写什么
学习过程中, 会与我熟悉的语言作为对比
Life is short, you need Python.
Javascript
Python
Basic
Reference
Javascript
function say(word){
console.log(word);
}
say('hello');Dart
void say(String word){
print(word);
}
say('hello');Python
def say(word):
print(word)
say('hello')class Animal:
pass在类里, 没有this, 类的方法第一个参数则为该类的实例, 类似与Javascript的this
# python
class Animal:
def run(self):
print('I am running')// javascript
class Animal {
run() {
console.log('I am running')
}
}// dart
class Animal {
void run() {
print('I am running')
}
}定义特殊的函数__init__, 类似Javascript的constructor
# python
class Animal:
def __init__(self, name, age):
self.name = name
self.age = age
def run(self):
print('I am running')// javascript
class Animal {
constructor(name, age) {
this.name = name;
this.age = age;
}
run() {
console.log('I am running');
}
}// dart
class Animal {
String name;
int age;
Animal(String name, int age) {
this.name = name;
this.age = age;
}
run() {
print('I am running');
}
}# python
class Animal:
def __init__(self, name, age):
self.name = name
self.age = age
def run(self):
print('I am running')
class Pig(Animal):
def eat(self):
print('I can eat somthing')// javascript
class Animal {
constructor(name, age) {
this.name = name;
this.age = age;
}
run() {
console.log('I am running');
}
}
class Pig extends Animal {
eat() {
console.log('I can eat somthing');
}
}Python为 __开头作为私有变量, 这一点上, 让我想起了Dart的模块化.
默认导出所有方法, 除了以 __ 开头的函数/类
当然python并没有彻底阻止你访问这个私有变量,一切全靠自觉.
编译器只是把.__dirty重命名为其他的变量名字.
如果还想访问是可以, 但是不推荐这么做
class Animal:
def __init__(self, name, age):
self.name = name
self.age = age
def run(self):
print('I am running')
class Pig(Animal):
def __init__(self):
self.__dirty = True # It got dirty property, private
def eat(self):
print('I can eat somthing')从以前旧博客迁移至此
2016-01-04 20:36:48
与Prelink类似,Preload是一个运行于后台的监护程序,探测那些常用的软件,并将其放入缓存,以起到加速的作用。在LinuxMint/Ubuntu下安装Preload很简单:
$ sudo apt-get install preloadPreload默认的配置对于普通用户而言已经不错了,一般不需要修改。如果有进一步掌控其的欲望,可以打开其配置文件进行修改:
$ sudo gedit /etc/preload.confapt应该算是LinuxMint/Ubuntu系统中使用率最高的命令了,无论安装、卸载软件,还是更新软件源缓存及相关维护,都离不开它。使用逾久,apt缓存也就变得较为臃肿,有必要清理:
$ sudo apt-get autoclean在“启动应用程序”中,根据自身实际,取消不必要的启动项,如欢迎程序、检测新硬件、蓝牙(如果本机没有蓝牙)、桌面共享等。
无论你的电脑是否有2个或更多的操作系统,只要安装了LinuxMint/Ubuntu,就必然会安装grub2作为引导管理器。grub2启动时,会在默认的启动项上停留数秒(默认10秒),等待用户选择。我们可以把这个时间改的更短。如果是LinuxMint/Ubuntu单系统,可以直接改为0,即直接进入,无需等待。
以管理员身份编辑grub配置文件,修改GRUB_TIMEOUT项后的数字。
$ sudo gedit /etc/default/grub如果你的电脑内存不太充裕(1G以下),可以使用ZRAM软件来提高内存性能。ZRAM能在系统中创建一个压缩的块设备,用于模拟一个交换分区,减少因内存不足而多硬盘的蹂躏频次。可以使用如下PPA安装ZRAM:
$ sudo add-apt-repository ppa:shnatsel/zram
$ sudo apt-get update
$ sudo apt-get install zramswap-enabler默认情况下,即便你的电脑是双核甚至多核的CPU,LinuxMint/Ubuntu启动时仍旧是以单核在执行系统启动任务。可以通过如下修改,使其充分利用多核CPU进行系统启动,从而加快速度。
以管理员身份编辑:
$ sudo gedit /etc/init.d/rc找到CONCURRENCY=none行,并修改为CONCURRENCY=makefile
如果你的电脑硬件配置较低,可以通过禁用视觉特效达到优化性能的目的。华丽的特效,必然会消耗更多的性能。对于Ubuntu和LinuxMint MATE用户,安装Compiz后,即可把不要的特效都禁用:
$ sudo apt-get install compizconfig-settings-manager对于LinuxMint Cinnamon用户,还可以在Cinnamon设置:效果 中禁用相关效果。
TMPFS,顾名思义,乃是临时文件系统。一般情况下,Linux的/tmp文件夹接收着大量关于磁盘读写的操作。而通过优先使用物理内存,可以提高/tmp处理磁盘读写操作的速度。
以管理员身份修改:
$ sudo gedit /etc/fstab在该文件的末尾,加入如下内容:
# Move /tmp to RAM
tmpfs /tmp tmpfs defaults,noexec,nosuid 0 0源代码如下:
class Program extends EventEmitter {
constructor() {
super();
this.on("bootstrap", function() {
this.run();
});
}
run() {}
}
new Program()
// bootstrap the app
.on("error", err => {
console.error("Something go wrong!");
console.error(err);
})
.emit("bootstrap");需求是,在不改变API的情况下,在bootstrap之前做一些初始化操作,而且是异步操作。
只有在初始化才做完成之后,才真正的执行run函数
改动后的代码:
class Program extends EventEmitter {
constructor() {
super();
this.initter = [];
this.on("bootstrap", async () => {
const initter = [].concat(this.initter);
try {
while (initter.length) {
const iniFunc = initter.shift();
await iniFunc();
}
} catch (err) {
this.emit("error", err);
return false;
}
this.run();
});
}
init(func) {
this.initter.push(func);
return this;
}
run() {}
}
new Program()
// bootstrap the app
.on("error", err => {
console.error("Something go wrong!");
console.error(err);
})
.emit("bootstrap");从以前旧博客迁移至此
2016-01-04 01:40:06
linux下本来就不是像window会产生很多垃圾,导致越用越慢。
但是我等强迫症呢,就是看不了有点残留的东西存在。
特别是在卸载了软件之后,还有一些配置文件留在那里,就很讨厌。
所以把这些命令记录下来,毕竟linux命令太多,有些时候也记不住。
$ sudo apt-get autoclean // 清除旧版本的软件缓存
$ sudo apt-get clean // 清除所有软件缓存
$ sudo apt-get autoremove // 删除系统不再使用的孤立软件$ ls ~/.opera/cache4
$ ls ~/.mozilla/firefox/*.default/Cache$ sudo apt-get install deborphan -y这个东西一般我只要安装ubuntu就会第一删掉tracker 他不仅会产生大量的cache文件而且还会影响开机速度。所以在新得利里面删掉就行。
附录:
包管理的临时文件目录:
包在
/var/cache/apt/archives
没有下载完的在
/var/cache/apt/archives/partial
$ sudo apt-get remove --purge 软件名
$ sudo apt-get autoremove
// 清除残余的配置文件
$ dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P从以前旧博客迁移至此
2016-04-07 21:46:42
Typescript是javascript的超集,并且是可以实现强类型的语言。
而且书写方式类似与后台语言,要写接口interface来限定类型。
然后编译成javascript。
javascript是动态类型语言,是弱类型,意味着变量不需要声明类型,不用限制变量的类型,它可以是数字,可以是字符串,可以是对象等等。
好处就是,书写javascript很轻松,坑的地方就是,变量的类型可以改变,可能会引发一些未知的bug。
而在2015年发布了ECMA5,并且以后每年都会发布新版本.
逐渐的模块话,类,以及ECMA7的装饰,正在实现一些javascript预编译的功能,而coffeeScript还没会,就已经被抛弃了。
不禁想,每年一个版本,而且nodejs让javascript可以编写后台,那么以后javascript会不会出现强类型?多线程之类的?
就关于强类型,我处于好奇,写了一段小代码。意在实现javascript的强类型。
代码如下
function proxy(obj) {
return function(attr, typeLimit) {
let origin = obj[attr];
const type = Object.prototype.toString.call(typeLimit);
Object.defineProperty(obj, attr, {
set: function(newVal) {
const newValType = Object.prototype.toString.call(newVal);
if (type !== newValType) {
console.error(
'TypeError:The attr [%s] is only match with %s, not %s',
attr,
type,
newValType
);
} else {
origin = newVal;
return newVal;
}
},
get: function() {
return origin;
}
});
};
}使用方式:
let p = proxy(target);
p('a', 1); // 限制为数字
target.a = 321; // 能正确赋值
console.log(target.a); // 321
target.a = 'hello world'; // TypeError:The attr [a] is only [object Number], not a [object String]
console.log(target.a); // 321
// 限制为字符串
p('b', 'a');
// 限制为数组
p('c', []);看起来有些繁琐
每次需要使用忽略 eslint/tslint 错误的时候,老是记不住,基本都要翻文档,很烦。
所以干脆写那么一个扩展,来帮助我自动补全,岂不美哉!

既然这样了,索性做做成一个通用的,集成比如 prettier/webpack/jshint/TODO/FIXME等类似的自动补全。
目前支持语言有:
后续会支持更多语言和工具。
如果有什么建议,欢迎反馈!
最后上地址: https://github.com/axetroy/vscode-comment-autocomplete
在日常开发中,会写一些轮子,服务,需要部署到线上,来个online demo,或者try it out
而有些服务商,就专门提供了免费服务,可以部署你的应用
这里我们选择Heroku,以部署NodeJS和Golang为例
把部署过程记录下来,方便下次部署的适时候,想不起来还能翻一番
我们这里搭建一个简单的HTTP服务器
你只需要2个文件即可部署
package.json
{
"name": "heroku-deploy-example",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"start": "node index.js"
},
"repository": {
"type": "git",
"url": "git+https://github.com/axetroy/heroku-deploy-example.git"
},
"author": "",
"license": "ISC",
"bugs": {
"url": "https://github.com/axetroy/heroku-deploy-example/issues"
},
"homepage": "https://github.com/axetroy/heroku-deploy-example#readme"
}index.js
const http = require("http");
const port = process.env.PORT || 3000;
const server = http.createServer();
server.on("request", function(req, res) {
res.end("hello world, power by NodeJS");
});
server.listen(port, function() {
console.log("Listen on port " + port);
});然后托管在你的Github项目上
登陆Heroku,打开控制面部,新建应用,填写一个未被占用的名字
本次使用node-deploy-example

新建成功后,进入到应用详情的Deploy选项,选择以Github方式部署

然后搜索你的Github仓库名,并且选择部署

部署成功

然后访问域名试试: https://node-deploy-example.herokuapp.com
这次部署Go我们选择使用Heroku CLI来部署
前提条件:
使用CLI部署,不要求你的代码要托管在某个仓库,比如Github,如果你的应用不开源,那么就选用CLI部署
首先要安装CLI工具,这里我使用npm安装
npm install -g heroku-cli然后登陆你的账号
heroku login # 会要求你输入账号/密码创建一个应用,名为go-deploy-example
然后新建文件
main.go
package main
import (
"net/http"
"log"
"os"
)
func main() {
port := os.Getenv("PORT")
if port == "" {
port = "3000"
}
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("hello world, power by Golang"))
})
log.Printf("Listen on portt %s\n", port)
log.Fatal(http.ListenAndServe(":"+port, nil))
}Procfile
web: go-heroku-deploy-example # 这里运行编译的二进制名使用Godep生成依赖文件
godep save ./...运行命令部署
git init
heroku git:remote -a go-deploy-example
git add .
git commit -am "make it better"
git push heroku master到这里部署结束,访问这个试试: https://go-deploy-example.herokuapp.com/
部署过程非常的简单,如果你有好的应用要分享。
又苦于没那么线上服务器,那么就部署要Heroku上吧。
有个Online Demo更具有说服力哦
从以前旧博客迁移至此
2016-05-06 21:51:13
栈是一种遵循先进先出(LIFO)原则的有序集合。新添加的或待删除的元素都保存在栈的末尾,未栈顶,另一端为栈底。
在栈里,新元素都会靠近栈顶,旧元素都接近栈底。
class Stack {
constructor() {
this.items = [];
}
push(item) {
this.items.push(item);
}
pop() {
return this.items.pop();
}
peek() {
return this.items[this.items.length - 1];
}
isEmpty() {
return this.items.length === 0;
}
clear() {
this.items = [];
}
size() {
return this.items.length;
}
print() {
console.log(this.items.toString());
}
}
// 实际应用,转化任意禁止转化
function baseConverter(decNumber, base) {
let remStack = new Stack();
let rem;
let binaryString = '';
let digits = '0123456789ABCDEF';
while (decNumber > 0) {
rem = Math.floor(decNumber % base);
remStack.push(rem);
decNumber = Math.floor(decNumber / base);
}
while (!remStack.isEmpty()) {
binaryString += digits[remStack.pop()];
}
return binaryString;
}
console.info(baseConverter(100345, 2));
console.info(baseConverter(100345, 8));
console.info(baseConverter(100345, 16));从以前旧博客迁移至此
2016-01-04 21:46:29
下载simfang.ttc 字体字体自行百度
复制到~/.wine/drive_c/windows/Fonts目录。
装好字体后,还要修改一下 Wine 的注册表设置,指定与字体相关的设置:
$ gedit ~/.wine/system.reg(一定要使用 gedit 或其他支持 gb2312/utf8 编码的编辑器修改这些文件,否则文件中的中文可能变乱码)
搜索: LogPixels
找到的行应该是:[System\CurrentControlSet\Hardware Profiles\Current\Software\Fonts]
修改
"LogPixels"=dword:00000060
// 改为
"LogPixels"=dword:00000070搜索: FontSubstitutes
找到的行应该是:[Software\Microsoft\Windows NT\CurrentVersion\FontSubstitutes]
修改
"MS Shell Dlg"="Tahoma"
"MS Shell Dlg 2″="Tahoma"
// 改为
"MS Shell Dlg"="SimSun"
"MS Shell Dlg 2″="SimSun"$ gedit ~/.wine/drive_c/windows/win.ini在文件末尾加入
[Desktop]
menufontsize=13
messagefontsize=13
statusfontsize=13
IconTitleSize=13REGEDIT4
[HKEY_LOCAL_MACHINE\Software\Microsoft\Windows NT\CurrentVersion\FontSubstitutes]
"Arial"="simsun"
"Arial CE,238"="simsun"
"Arial CYR,204"="simsun"
"Arial Greek,161"="simsun"
"Arial TUR,162"="simsun"
"Courier New"="simsun"
"Courier New CE,238"="simsun"
"Courier New CYR,204"="simsun"
"Courier New Greek,161"="simsun"
"Courier New TUR,162"="simsun"
"FixedSys"="simsun"
"Helv"="simsun"
"Helvetica"="simsun"
"MS Sans Serif"="simsun"
"MS Shell Dlg"="simsun"
"MS Shell Dlg 2"="simsun"
"System"="simsun"
"Tahoma"="simsun"
"Times"="simsun"
"Times New Roman CE,238"="simsun"
"Times New Roman CYR,204"="simsun"
"Times New Roman Greek,161"="simsun"
"Times New Roman TUR,162"="simsun"
"Tms Rmn"="simsun"在开发中,经常遇到数据校验,需要一个简单的,精准的优雅校验数据库对一些数据进行校验。
场景如下:
社区找了一遍,好像并没有我想要的,索性就自己写一个,撸起袖子就是干。
本文主要讲解如何使用,以及实现原理。
const Struct = require("@axetroy/struct");
const data = {
name: "axetroy",
age: 18
};
const struct = new Struct({
name: Struct.type.string,
age: Struct.type.int
});
const err = struct.validate(data);
console.log(err); // undefined, because the data pass the validatorStruct.type.xxxstruct.validate(data)进行校验解析:
Struct.type返回的是 new Type(), 而Type对象的原型上,定义了一系列内置方法。
访问Struct.type.string其实就是访问了new Type().string, 会产生一个校验器,加入到type的队列里面,返回返回this,方便链式调用
在运行struct.validate(data)的时候,获取字段对应的Type, 然后逐一执行队列里面的函数,全部通过才算通过,返回undefined, 否则返回错误。
内置支持了int, float, string,等等。以及支持对象嵌套的校验,支持数组校验。
调用Struct.define(name, func), 在Type.prototype上添加相应的方法。
例如Struct.define("email", func),那么可以这么添加校验器Struct.type.email
一个字段可以有多个校验器(链式调用)
完整例子如下:
const Struct = require("../index");
Struct.define("email", function(input) {
return /^[a-z0-9]+([._\\-]*[a-z0-9])*@([a-z0-9]+[-a-z0-9]*[a-z0-9]+.){1,63}[a-z0-9]+$/.test(
input
);
});
const data = {
name: "axetroy",
age: 18,
email: "[email protected]"
};
const struct = truct({
name: Struct.type.string,
age: Struct.type.int,
email: Struct.type.string.email // check string first, and then check email
});
const err = struct.validate(data);
console.log(err); // undefined, because the data pass the validator你甚至可以定义一个带参数的类型校验, 这里有demo
代码已经过测试,覆盖率接近100%,可放心食用
顺便弱弱的问一句,
object.hasOwnProperty(key)分支的测试,为什么老是没有覆盖
欢迎大牛们来搞,issue or PR
从以前旧博客迁移至此
2015-12-27 19:23:16
现象:
IE9以及以下
打开页面空白,不显示任何内容。
但是只要打开控制台,就能够正常打开页面
原因:
在IE9以及以下,只有打开控制台,IE才会实例化console对象。
所以调用console对象的方法,又没有打开控制台,那么就会抛出错误。
解决办法:
给console对象打上polyfill
或手动加上条件注释
<!--[if lte IE 9]>
<script>
// Avoid `console` errors in browsers that lack a console.only fo damn it IE,which is bullshit,holy shit!
(function() {
var method;
var noop = function () {};
var methods = [
'assert', 'clear', 'count', 'debug', 'dir', 'dirxml', 'error',
'exception', 'group', 'groupCollapsed', 'groupEnd', 'info', 'log',
'markTimeline', 'profile', 'profileEnd', 'table', 'time', 'timeEnd',
'timeStamp', 'trace', 'warn'
];
var length = methods.length;
var console = (window.console = window.console || {});
while (length--) {
method = methods[length];
// Only stub undefined methods.
if (!console[method]) {
console[method] = noop;
}
}
}());
</script>
<![endif]-->原理:
如果不存在console对象那么就自己初始化一个console对象,并且挂载了一堆方法,都执行一个叫noop的空函数,不至于报错。
使用windows开发环境,首选的终端就是Git Bash.
但是它一直有一个Bug. 没有正确捕捉CTRL+C的信号并杀死进程.
闲来无事一翻它的更新日志,终于把这个BUG修复了。
再也不用打开任务管理器手动杀死进程了.
git-for-windows/msys2-runtime#16
本来想这写这个教程
但是发现真的没什么可以写的, heroku与github绑定在一起.
云端部署, 傻瓜化操作
趁着博客刚刚支持 jsfiddle, 赶紧写一些demo
在工作中,部署前端应用,基本上大家都认同通过 Docker 来部署是最佳实践.
至于为什么,大家可以通过搜索相关的文章.
那么今天就来讲一讲我遇到过哪些痛点以及如何解决的:
基本上工作流都是这样:
# 本地
docker build xxx
docker push xxx
# 服务器
docker pull xxx
docker run xxx # 或者 docker-compose up这样的工作流在本地与远程服务器之前切换. 浪费了很多时间,影响效率
比较正规的流程,部署是要git tag的.
而前端还需要更改package.json的版本号
这样的事npm version xxx包办了
接下来我们模拟一次补丁修复,发布版本并且部署在服务器
# 升级版本号
$ npm version patch # 假设版本1.0.1
# 构建应用
$ npm run build
# 打包镜像
$ docker build <镜像名>:1.0.1
# 推送镜像到托管服务器
$ docker push <镜像名>:1.0.1
# 连接到远程服务器
$ ssh [email protected] -p 2022
# 进入到项目目录
$ cd /www
# 修改`docker-compose.yml`中的版本号
# 更改 <镜像名>:<旧版本号> ---> <镜像名>:1.0.1
$ vi docker-compose.yml
# 拉取新的镜像
$ docker pull <镜像名>:1.0.1
# 开启服务
$ docker-compose down && docker-compose up -d发现问题了吗,是不是非常繁琐.
作为一枚程序猿,这样的操作是无法忍受的.
就不能打包镜像之后,自动部署到指定的服务器吗?
于是我写了这么一个工具
一个基于 docker-compose, 简化部署流程的命令行工具
还是上面那个场景, 我们用 dockposer 来操作一遍
$ npm version patch # 假设版本1.0.1
$ npm run build
$ dockposer build <镜像名>:{NPM_PACKAGE_VERSION}
$ dockposer push <镜像名>:{NPM_PACKAGE_VERSION}
$ dockposer deploy <镜像名>:{NPM_PACKAGE_VERSION}{NPM_PACKAGE_VERSION} 是一个变量,当运行命令时,自动替换成
package.json的版本号
这样我们不用显示的指定构建某个版本, 遵循 NPM 版本即可
或者添加到NPM脚本中
{
...
"scripts": {
...
+ "build": "dockposer build your_tag_name:{NPM_PACKAGE_VERSION}",
+ "push": "dockposer push your_tag_name:{NPM_PACKAGE_VERSION}",
+ "deploy": "dockposer deploy your_tag_name:{NPM_PACKAGE_VERSION}"
}
}npm run build
npm run push
npm run deploy
完了,就这么得简单.
我们来分析下,它到底做了什么?
与 Docker build 类似, 根据 Dockerfile 构建本地镜像
与 Docker push 类似, 把本地镜像推送到托管服务器
把本地镜像,部署到指定的服务器。
这时候我们需要一个配置文件,不然工具怎么知道部署到哪里
配置文件默认为 dockercomposer.host.json, 格式如下
{
"name": "测试服",
"path": "/www",
"host": "192.168.0.1",
"port": 22,
"username": "root",
"password": "root"
}那么它是怎么工作的呢? 总共就一下几个步骤:
dockposer.host.json中读取服务器配置host.path 并打开 docker-compose.yaml,将 <镜像名>:<旧版本号>更新为 <镜像名>:<新版本号>docker-compose down && docker-compose up -d以重新启动。这样就做到了不需要切换到服务器环境,也能够部署在服务端
Q: 自动化部署工具这么多,你为什么不用,偏要自己造?
A: 我知道的几个自动化部署工具都需要在服务端也安装它们的工具. 而我这个命令行不用
Q: 为什么不支持部署到多个服务器?
A: 云服务商都提供了集群部署. 不要自己瞎折腾. 起初写这个只是为了我方便部署到测试服
Q: 部署不应该集成到 CI 吗? 谁会这样手动部署?
A: 小团队小项目折腾不起. 考虑下人员配置,不是每个人都玩得溜. 在人员少,能力都不是特别强的情况下,加上各种行业标配反而是一种累赘
Q: 我的场景跟你差不多,也用 Docker 部署,没有集群,我能运用到生成环境吗?
A: 目前来讲,依旧不建议,我也只是运用到测试服务, 一个是还没稳定,第二是万一有点什么事,手动部署还可以补救
Q: 还有哪些不尽人意的地方?
主要是部署这一块,现在只是单纯的更改服务端的
docker-compose.yml文件然后运行. 更复杂的是,项目的一个配置文件要不要也一起更新?比如 nginx+node 的模式, nginx 的配置文件更新不更新? 还要根据不同的环境,更新不同的配置文件. 太复杂,不符合我的初衷
项目地址: https://github.com/axetroy/dockposer
end!
不过界面太花里胡哨了
也就前两天,面试大厂,其中有那么一个问题:
了解过抽象语法树,又称AST,有学习过,也写过一个基于AST的乞丐版模板引擎,先是词法解析token,然后生产抽象语法树,然后更改抽象语法树,当然这是插件做的事情,最后根据新的AST生成代码。
没有,只是看过相关文档
应该可以吧...
遂卒....
开玩笑的,既然提到了,又没回答上来什么,哎哟我这暴脾气,一想到今晚就睡不着,连夜把它撸了。
那么我们来从零写个插件吧。
写一个预计算简单表达式的插件
Before:
const result = 1 + 2 + 3 + 4 + 5;After:
const result = 15;以上的例子可能大家不会经常遇到,因为傻x才会这么写,但是有可能你会这么写
setTimeout(function(){
// do something
}, 1000 * 2) // 插件要做的事,就是把 1000 * 2 替换成 2000再写代码之前,你需要明白Babel它的原理,简单点说: Babel解析成AST,然后插件更改AST,最后由Babel输出代码
那么Babel的插件模块需要你暴露一个function,function内返回visitor
module.export = function(babel){
return {
visitor:{
}
}
}visitor是对各类型的AST节点做处理的地方,那么我们怎么知道Babel生成了的AST有哪些节点呢?
很简单,你可以把Babel转换的结果打印出来,或者这里有传送门: AST explorer
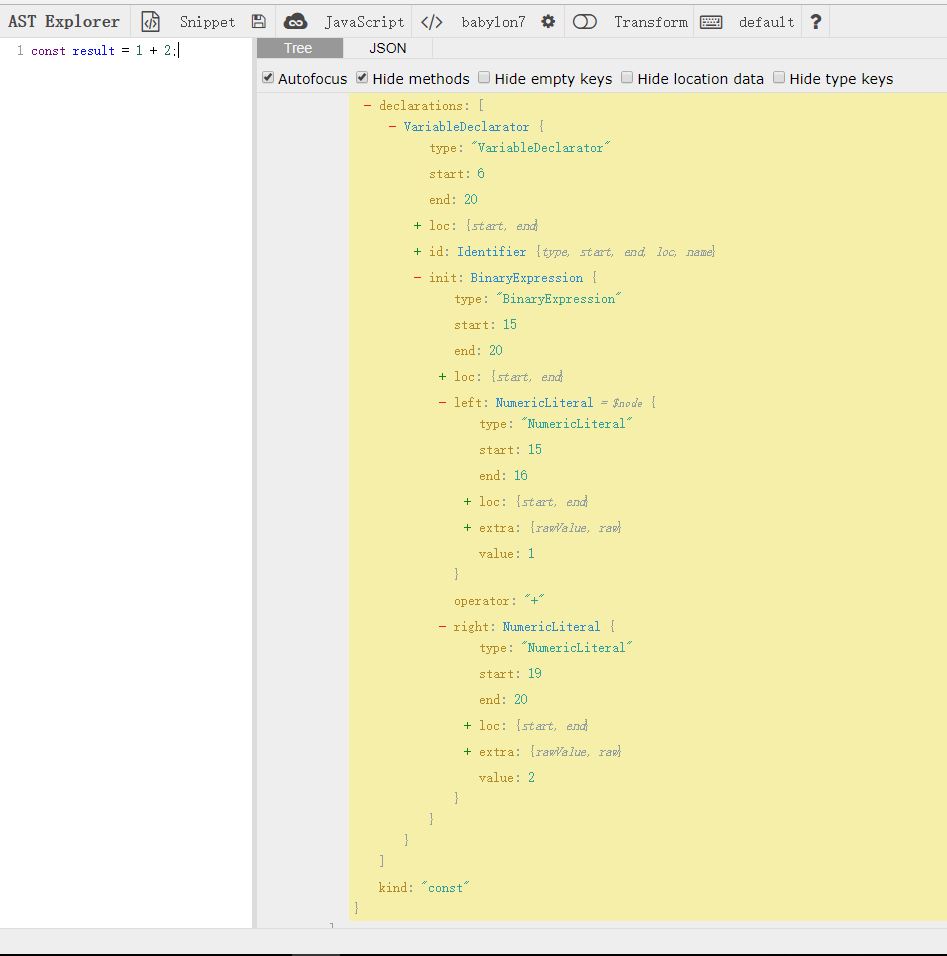
这里我们看到 const result = 1 + 2中的1 + 1是一个BinaryExpression节点,那么在visitor中,我们就处理这个节点
var babel = require('babel-core');
var t = require('babel-types');
const visitor = {
BinaryExpression(path) {
const node = path.node;
let result;
// 判断表达式两边,是否都是数字
if (t.isNumericLiteral(node.left) && t.isNumericLiteral(node.right)) {
// 根据不同的操作符作运算
switch (node.operator) {
case "+":
result = node.left.value + node.right.value;
break
case "-":
result = node.left.value - node.right.value;
break;
case "*":
result = node.left.value * node.right.value;
break;
case "/":
result = node.left.value / node.right.value;
break;
case "**":
let i = node.right.value;
while (--i) {
result = result || node.left.value;
result = result * node.left.value;
}
break;
default:
}
}
// 如果上面的运算有结果的话
if (result !== undefined) {
// 把表达式节点替换成number字面量
path.replaceWith(t.numericLiteral(result));
}
}
};
module.exports = function (babel) {
return {
visitor
};
}插件写好了,我们运行下插件试试
const babel = require("babel-core");
const result = babel.transform("const result = 1 + 2;",{
plugins:[
require("./index")
]
});
console.log(result.code); // const result = 3;与预期一致,那么转换 const result = 1 + 2 + 3 + 4 + 5;呢?
结果是: const result = 3 + 3 + 4 + 5;
这就奇怪了,为什么只计算了1 + 2之后,就没有继续往下运算了?
我们看一下这个表达式的AST树
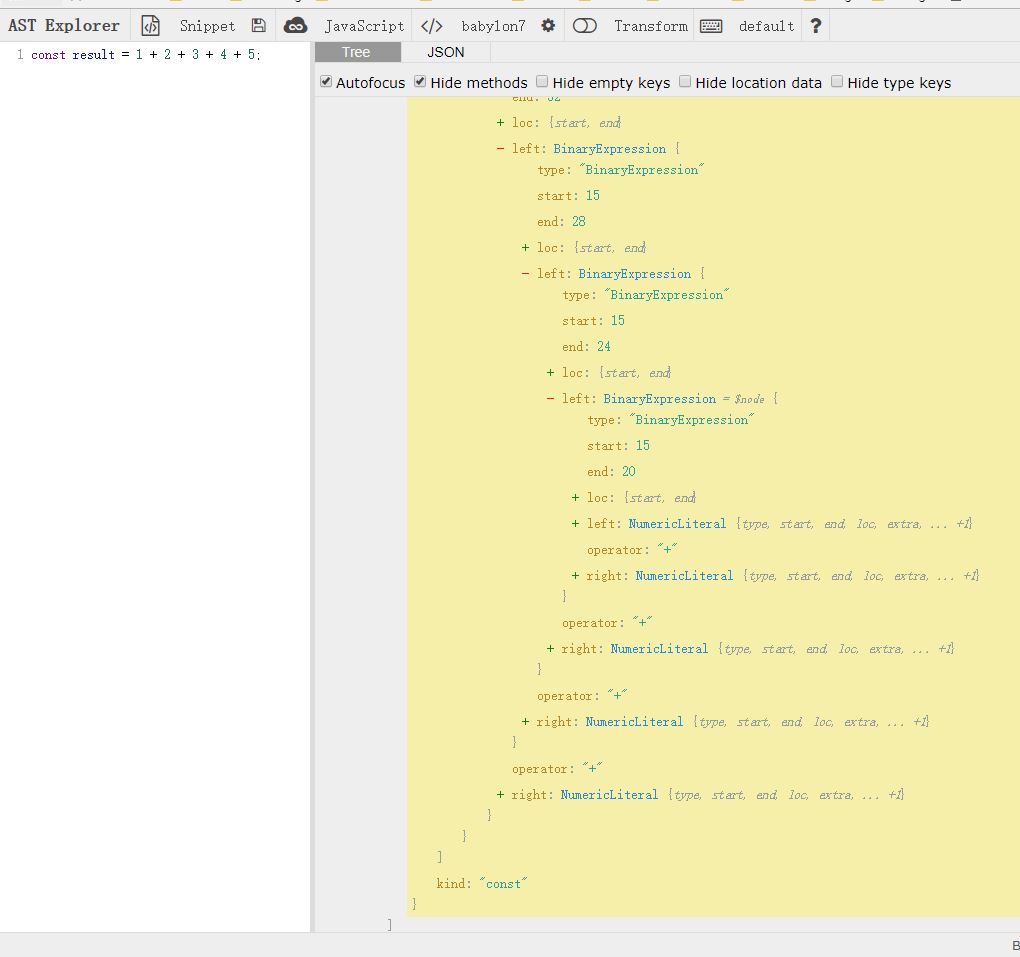
你会发现Babel解析成表达式里面再嵌套表达式。
表达式( 表达式( 表达式( 表达式(1 + 2) + 3) + 4) + 5)
而我们的判断条件并不符合所有的,只符合1 + 2
// 判断表达式两边,是否都是数字
if (t.isNumericLiteral(node.left) && t.isNumericLiteral(node.right)) {}那么我们得改一改
第一次计算1 + 2之后,我们会得到这样的表达式
表达式( 表达式( 表达式(3+ 3) + 4) + 5)
其中 3 + 3又符合了我们的条件, 我们通过向上递归的方式遍历父级节点
又转换成这样:
表达式( 表达式(6 + 4) + 5)
表达式(10 + 5)
15
// 如果上面的运算有结果的话
if (result !== undefined) {
// 把表达式节点替换成number字面量
path.replaceWith(t.numericLiteral(result));
let parentPath = path.parentPath;
// 向上遍历父级节点
parentPath && visitor.BinaryExpression.call(this, parentPath);
}到这里,我们就得出了结果 const result = 15;
那么其他运算呢:
const result = 100 + 10 - 50 >>> const result = 60;
const result = (100 / 2) + 50 >>> const result = 100;
const result = (((100 / 2) + 50 * 2) / 50) ** 2 >>> const result = 9;
到这里,已经向你大概的讲解了,如何编写一个Babel插件,再也不怕面试官问我答不出什么了哈...
你以为这就完了吗?
并没有
如果转换这样呢: const result = 0.1 + 0.2;
预期肯定是0.3, 但是实际上,Javascript有浮点计算误差,得出的结果是0.30000000000000004
那是不是这个插件就没卵用?
这就需要你去矫正浮点运算误差了,可以使用Big.js;
比如: result = node.left.value + node.right.value; 改成 result = +new Big(node.left.value).plus(node.right.value);
你以为完了吗? 这个插件还可以做很多
比如: Math.PI * 2 >>> 6.283185307179586
比如: Math.pow(2,2) >>> 4
...
...
最后上项目地址: https://github.com/axetroy/babel-plugin-pre-calculate-number
写了一个仓库https://github.com/axetroy/secret
主要是用于存储一些秘密的数据。数据以及源码都是加密过后的。后缀为.encrypt
只留下一个入口文件,动态加载已经打包好的js文件,以及数据(比如json)。
然后坑爹的发现,Github Pages返回的数据并没有经过压缩。要下载的包很大。
查了一下资料,Github Pages使用的服务器是nginx,默认对json,html,css,js等进行压缩。
并没有对.encrypt后缀压缩。
于是想了一个取巧的办法,把加密文件的后缀改成.html就好了,里面的加密数据还是一样。
这样就可以gzip压缩了
开发中,不可能每一个功能都自己亲力亲为。
在这个遍地第三方服务的时代,运用好第三方服务,能够极大的提升应用的健壮性。
接下来记录下在应用中使用的哪些第三方服务:
eoLinker ™ 平台为您API的生产、运维及质量保障提供了强大且完善的体验网络,以满足您企业产品高速迭代和不断变化的需求。
方便管理/统一RESFUL接口文档。
第三方服务提供的好处就是随时提供的外网访问,可追溯的变更记录,以及便捷的测试环境。
当然,也有很多开源的文档生成工具,通过解析代码注释生成文档,代码=文档。
总体来说,开源工具生成的文档也只是 “能看” ,并不能那么得好用。
况且 eoLinker 是免费服务
后端用GraphQL的可以忽略
bugsnag 是一个免费的错误上报平台,免费版已经能满足绝大多数的需求了。
目前已应用到多个项目,真香
alinode是阿里云提供的免费Node性能监控平台,发现内存泄漏,性能监控,性能预警,发现慢请求等等功能。
也是我在我司推广而出,也已部署到多个应用
项目部署极力推荐使用Docker部署,安全,可复用,少掉头发
而Docker官方仓库只支持一个私有镜像,阿里云容器服务提供无限的私有镜像
而且国内镜像比官方镜像速度要快
123
从以前旧博客迁移至此
2016-05-16 00:05:35
转自瞬息之间写的程序员,我们都是夜归人
音响随机播放着音乐,偶然跳出一首《都是夜归人》的乐曲,让我不禁想起程序员这个群体,夜归人也是不少的啊。恩,我这里说的「夜归」正是指的加班,进入这个行业,成为程序员谁没加过班呢,所以我们都是夜归人啊。
加班是一个行业竞争激烈的表现,回想下读中学时虽不加班却要加课,因为高考的竞争很激烈啊。加班也是一个行业兴旺的表现,你看产能过剩的行业连工都不开了,哪里还需要加班。这些是加班的行业宏观原因,那么于个人微观来说,为什么需要加班呢?
新入行的程序员加班的最多,很大一个原因是能力是不足以满足工作的需要,这里说的是整体的比例而言,不针对个体。我刚毕业工作时也是天天加班的,原因正是发现为了应对工作,需要学习的东西太多,边学边做,效率也不够高,自然无法闲庭信步,只能加班加点。
大学里专业上的东西学得宽,学得泛,而且离工作实际需要还存在一道从理论到实践之间的鸿沟。所以对于刚入行的程序员就需要短期内快速地跨越这道鸿沟,不得已加班加点的学和做,一旦跨越过后后面还需要经常的加班原因可能就出在其他方面了。
应对能力不足导致的加班,除了自己认了还能埋怨谁呢,同一所学校同一个专业同一届毕业的学生,能力强弱有时也是相差也很悬殊。我承认大学里也是放松了自己,曾经埋下的坑,后来也是慢慢自己来填的,努力要趁早啊。
这里指工作环境的一些制约因素,比如:早年我在客户现场做项目,客户都是朝九晚五制,他们白天经常要过来和你讨论碰到的一些问题或需求,有时还要接接维护项目的技术支持电话,渐渐就发现在客户上班的朝九晚五期间基本就没法专心的写程序。所以当时我开发一般都放在晚上 6 点到 10 点之间,十点半是末班车再回去。
另外一种情况是,以前做传统企业应用,要全国各地四处出差,而系统上线和数据割接什么的也只能在半夜三更来做。从夜深人静到天空泛白,在卖豆浆包子的早餐车旁和来上班的人群短暂相聚,再交错而过,走回公司的出租屋,倒头便睡。
一次一个省级的大系统做全面割接,这样的日子持续了将近一个月,让我不禁开始思考起了这样工作和生活着的意义。这就是环境的现实,要么去适应当前的环境,要么去改变环境,这二者皆不易,还有第三条路就是换个环境,然后我便换了个。
我理解加班很多时候来自一种需要,而这种需要可能来自很多方面的原因,但如果有公司把加班作为一项制度固化下来,那真是再糟糕不过了。
我以前曾有同事呆过一家把加班作为一种长期制度的公司,从周一到周四每晚都是固定加班到晚 9 点后,周末则临时决定是否加班。这咋一看比起如今的 「996」的强度是不如的,但有些公司的 996 可能是按需的并非一项固定制度。让你有事没事都必须呆到晚上 9 点后,而且公司内部网络控制严格的连外网都访问不了,当时 iPhone 尚未诞生,移动互联网不知为何物,这样的加班真是无聊透顶。
十年过去,似乎这样愚蠢的公司制度还是不少。近期听闻一朋友所在的成都某游戏公司也差不多,虽然没有明确规定加班是公司制度,但考核员工绩效的主要标准就是看考勤表的工作时长。这样的潜规则比明制度更可恶,不过上有政策下有对策,住公司附近的员工 6 点一下班就闪人,晚上十一、二点后再到公司打卡。
有的公司,加班是一种制度;有的公司,不加班是一种福利。确实有在招聘宣传上看到把不加班当作一种福利来宣传的公司。如果你不幸处在把加班当作制度的公司,我的建议是离开也请趁早啊。
因项目进度压力导致的加班看起来似乎合理,但不合理的地方是为何进度总有压力?这取决于项目的上线或交付时间点是如何确定的?有些是 Boss 头脑一热胸脯一拍就定下了,这类 Deadline 相对来说还有可转圜的余地,另外一类则更难转圜。
我曾参与浙江电信的一个项目,当时它刚接手了联通 CDMA 的业务和用户并在建设 3G 网络。它在浙江卫视先打了广告明确在某月某日开始营业接受 3G 业务放号。之后它们才对后台的支撑系统招标建设,这基本就确定了严格的系统上线 Deadline 且几无转圜余地。
知乎上有个问题:程序员如何不加班?最高票的回答是:换个好的项目经理来控制进度,给每个人安排合适的任务。可见很多程序员都认为加班是因为进度控制和任务安排不合理导致的,而进度管理正是软件工程的难点之一,这个问题真的只是换个好的项目经理就能有解了?
进度问题本质是一个时间估算问题,一群程序员组成一个团队一起做一个项目,项目经理拆解了任务,每个程序员就需要对任务做一个工作量估算。这里重要的不是你需要做得有多快,重要的是你对自己的工作能力和工作量有个合理地估计。也就是给你一个任务,你要知道如果你用正常工作时间大概会花多久,而不是拍脑袋捶胸脯打保票下决心说要不吃不喝不眠不休保证完成任务。只有团队中每个人都能正确的估计时间,才能让团队的进度合理。但是能做到正确估计时间的,不论对程序员还是项目经理都是极难的。
在我没开始写作前,看到像本篇这样长度的文章总以为作者可能灵感一闪,一挥而就,快则个把小时,慢则至多两小时。毕竟当年我们高考语文时两小时不仅要做完所有题目,还要写篇作文,所以会觉得两小时已是至多了。等我自己开始真正持续写作后,才发现自己的估算错的离谱。
像这样一篇文章,两三千字,先不说创作,只说打完这些字你能估算准确自己需要多少时间么?(这里默默估算十秒)我们看下国际通用打字速度等级划分:
我 2000 年开始用 QQ 打字聊天,打字经验 16 年,用拼音输入法,实际速度也就是聊手水平,平均 50 字/分钟。而未经刻意训练的大部分人可能都是这个水平而已,所以一篇三千字的文章光把它输入成文字按这个速度就需要一小时,而实际的构思创作时间一般是这个好几倍。如果写的还是技术文章,我通常还爱画技术图示(一图胜千言啊),画图还需要额外的时间。所以这样一篇文章 3、4 小时算快得,5、6 小时很正常,7、8 小时也不坏。
你看自己的估算都如此不靠谱,所以一些项目经理才会把程序员的估算粗暴的乘以二或三,这样估算下来的项目进度你觉得能靠谱嘛,换个好的项目经理就能靠谱了?在埋怨项目进度不合理前,程序员需要先把自己写程序的时间估算准确了,有效的方式是通过「时间记录法」持续记录和跟踪自己的时间消耗,这真得可以有效地提高自己对时间的敏感度和估算准确度。
真的有人爱好加班么?我想没有,也许爱好的是其他,只是表象体现在了加班上,加的虽然是班,过的却是自己的人生。这点我想你们懂的。
...
加班对某些公司可能是一种制度,对个人可能是一种态度;不加班对某些公司可能是一种福利,对个人可能是一种能力。
最后,写完本文真实耗时 4 小时 40 分钟。
重新编辑,重发
最近沉迷 vscode 扩展无法自拔,开启写了新坑,也维护旧扩展。
其中就有这么一个扩展是这样的: 显示导入的包版本号。
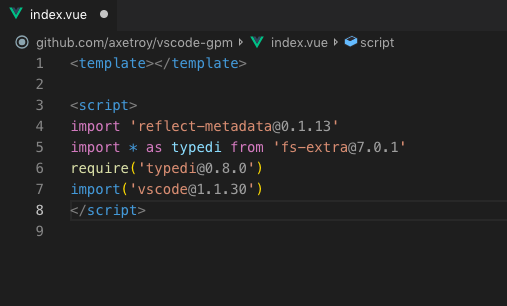
代码很简单也很少,用Babel/Typescript/vue-component分别解析对应的文件,然后标注版本号。
然而就是这么功能简单的扩展,启动速度居然超过其他所有稍微复杂一点的扩展。

启动速度 2431ms
这不科学呀, 到底是慢在哪里呢?
分析了一下 profile 文件后,发现不是我写的代码慢,而是慢在了加载的第三方库
Typescript 跟随 ECMA 标准,import 必须放在顶部.
import * as ts from 'typescript';
export function parser() {
// 这里是你的业务逻辑
ts.parser();
}问题就在于这. typescript在编译成javascript之后
const ts = require("typescript")
export.parser = function parser() {
// 这里是你的业务逻辑
ts.parser()
}我们都知道require 函数加载模块都是同步进行的, 也就是我还没使用parser函数的时候,就加载这个模块了。
而第三方模块加载,根据不同的包,加载时间各不相同。因为有些包,会在加载的时候做一些同步的初始化操作
// 某第三方包
// 这里做一些同步操作
// 例如定义map,for循环之类的
// 导出函数
export default function() {}而恰巧,Typescript 和 Babel/Babel-types 都有大量的这种操作, 导致拖慢了扩展初始化速度.
问: 能不能在我使用这个函数的时候,才导入相应的包?
答: require 就可以
- import * as ts from 'typescript';
export function parser() {
// 这里是你的业务逻辑
+ const ts = require('typescript');
ts.parser();
}问题就来了,require 的模块是没有类型。那使用typescript开发的体验就不是很好了.
我们稍微改造一下
- import * as ts from 'typescript';
+ import TS = require('typescript'); // 这里只是导入类型而已
export function parser() {
// 这里是你的业务逻辑
+ const ts:typeof TS = require('typescript'); // 给require的模块附上类型
ts.parser();
}OK! 大功告成,就这么简单。
在我把这个简单的扩展按照上面的方式重构一遍之后,来看一下启动速度

更改后启动速度竟然仅用了31ms, 比之前快了 80 倍
最后愿天下没有拖慢速度的扩展,宇宙第一编辑器已经够慢了
在部署矿机到Google Cloud的适合,遇到的问题,记录下来
/home/troy450409405/node/miner/node_modules/puppeteer/.local-chromium/linux-497674/chrome-linux/chrome: error while loading shared libraries: libpangocairo-1.0.so.0: cannot open shared
object file: No such file or directory
TROUBLESHOOTING: https://github.com/GoogleChrome/puppeteer/blob/master/docs/troubleshooting.md相关问题: puppeteer/puppeteer#391 (comment)
安装依赖:
yum install pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXtst.x86_64 cups-libs.x86_64 libXScrnSaver.x86_64 libXrandr.x86_64 GConf2.x86_64 alsa-lib.x86_64 atk.x86_64 gtk3.x86_64 ipa-gothic-fonts xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-utils xorg-x11-fonts-cyrillic xorg-x11-fonts-Type1 xorg-x11-fonts-misc -y从以前旧博客迁移至此
2016-01-17 03:46:21
如果不小心commit了一个不需要commit的文件,可以对其进行撤销。
先使用git log 查看 commit日志
$ git log
commit 422bc088a7d6c5429f1d0760d008d86c505f4abe
Author: zhyq0826 <[email protected]>
Date: Tue Sep 4 18:19:23 2012 +0800
//删除最近搜索数目限制
commit 8da0fd772c3acabd6e21e85287bdcfcfe8e74c85
Merge: 461ac36 0283074
Author: zhyq0826 <[email protected]>
Date: Tue Sep 4 18:16:09 2012 +0800找到需要回退的那次commit的 哈希值,
git reset --hard <commit_id>使用上面的命令进行回退
根据–soft –mixed –hard,会对working tree和index和HEAD进行重置:
git reset –mixed:此为默认方式,不带任何参数的git reset,即时这种方式,它回退到某个版本,只保留源码,回退commit和index信息
git reset –soft:回退到某个版本,只回退了commit的信息,不会恢复到index file一级。如果还要提交,直接commit即可
git reset –hard:彻底回退到某个版本,本地的源码也会变为上一个版本的内容
<commit_id> 每次commit的SHA1值. 可以用git log 看到,也可以在页面上commit标签页里找到
从以前旧博客迁移至此
2016-04-30 01:51:05
var Observer = function () {
};
Observer.prototype = {
constructor: Observer,
subscribe: function (eventName, func) {
if (!this[eventName]) this[eventName] = [];
this[eventName].push(func);
},
publish: function (eventName, data) {
var _this = this;
if (!this[eventName]) this[eventName] = [];
this[eventName].forEach(function (func) {
func.call(_this, data);
});
}
};
var ob = new Observer();
// 订阅
ob.subscribe('dialog', function (data) {
console.log('there are data:' + data);
});
// 发布
ob.publish('dialog', [1, 2, 3, 4]);function parse(properties) {
const agm = properties.split('.');
return function(target, undefined) {
let result = null;
(function parseTarget(target, agm) {
if (target === void 0) {
console.error(
'Uncaught TypeError: Cannot read property ' + agm[0] + ' of undefined'
);
result = target;
return result;
}
if (agm.length <= 1) {
result = target[agm[0]];
return result;
}
target = target[agm[0]];
agm.shift();
parseTarget(target, agm);
})(target, agm);
return result;
};
}
const o = {
a: {
b: {
c: 233
}
}
};
console.log(parse('a.b.c')(o)); // 233一个开源项目,如何在别人一眼看上去就觉得靠谱,有点逼格。
这是一个值得深思的问题。可能代码不咋地,需要一些东西来装饰。
那还说什么,强如tj大神,开个仓库就是热门项目
Logo即是商标,容易让人记住。也有的彰显着项目用途
比如这个趣图(来自github.com/tj/node-prune)
徽章能一眼反映出一个开源项目的状态。比如,测试是否通过,代码覆盖率,依赖关系,兼容性,当前版本,许可文件等






你可以从shields.io自定义自己想要的徽章
大多数你需要的,有已经定义好了
项目根目录下,应该有个.github文件夹
**I'm submitting a ...** (check one with "x")
- [ ] bug report => search github for a similar issue or PR before submitting
- [ ] feature request
- [ ] support request
**Current behavior**
<!-- Describe how the bug manifests. -->
**Expected behavior**
<!-- Describe what the behavior would be without the bug. -->
**More detail**
<!-- Please tell us more detail info, like error or -->
**Please tell us about your environment:****Please check if the PR fulfills these requirements**
- [ ] The commit message follows **commit message standard**
- [ ] Tests for the changes have been added (for bug fixes / features)
- [ ] Docs have been added / updated (for bug fixes / features)
**What kind of change does this PR introduce?** (check one with "x")
[ ] Bugfix
[ ] Feature
[ ] Code style update (formatting, local variables)
[ ] Refactoring (no functional changes, no api changes)
[ ] Test change
[ ] Chore change
[ ] Update Document
[ ] Other... Please describe:
**What is the current behavior?** (You can also link to an open issue here)
**What is the new behavior?**
**Does this PR introduce a breaking change?** (check one with "x")
[ ] Yes
[ ] No
If this PR contains a breaking change, please describe the impact and migration path for existing applications: ...
**Other information**:Github有开放API,可以接入各种好玩,实用的bot
Travis是一个自动化测试的CI工具,你每push一次,在travis平台会运行一次test。然后把测试结果通过邮件的形式告知你。
它还可以生成一个漂亮的徽章,如这样
以为Go项目为例,这是.travis.yml文件,放置在项目根目录下
# .travis.yml
language: go
sudo: false
os:
- linux
go: master
script:
- go test -vCoveralls是一个代码覆盖率的分析平台。
使用工具生产覆盖率的文件,然后提交给Coveralls平台。当然可以结合travis使用。
travis每运行一次test之后,可以把test的结果报告发送给Coveralls。
Coveralls同样也会生成一个漂亮的徽章,如这样
要使用它,仅需要2个步骤
.travis.yml配置,然后提交继续以Go为例。
# .travis.yml
language: go
sudo: false
os:
- linux
go: master
before_script:
# 加载依赖
- go get golang.org/x/tools/cmd/cover
- go get github.com/mattn/goveralls
script:
- go test -v -covermode=count -coverprofile=coverage.out # 运行测试,并且生成测试报告
- $HOME/gopath/bin/goveralls -coverprofile=coverage.out -service=travis-ci # 将测试报告提交给Coveralls这个CI工具会在其他人,在项目第一次发起issue的时候,bot会自动回复。一个友好的问题
当有一个没有任何描述的issue产生时,bot会自动回复,提示创建者提供更多的信息

当一个issue或PR很久没有回复的时候,这个bot会帮助你把它关掉

一般而言,一个小功能的库,是不需要文档的,只需要在README里面声明调用方法。
当项目是一个复杂的库/框架/工具的时候。有能就需要提供一个详细的文档。
Github提供了gh-pages分支用以存放文档,或者在master分支下的docs文件夹,在项目设置里面设置好即可
有简单粗暴型,直接以Markdown作为文档。这里有个思路很清晰的md文档API
有文艺型,通过Hexo等静态文件生成器,把Markdown文档转换为HTML。然后部署到gh-pages。
有懒人型,使用docsify动态解析Markdown文件,放在项目的docs目录下,然后渲染。
当然文档不是必须的,如果简单明了的源码或者IDE提示,那么就不需要文档。
有些时候增加文档,反而增加了维护文档的成本。
这是我的根项目github.com/axetroy/Github
里面基本上包含了上面的功能,没创建一个新仓库,都是从这里面clone更改的,避免重复创建文件。
也建议各位这样做,保持良好的仓库编辑习惯。

大家都懂的,抽奖就安慰奖概率高,头奖概率低。虽然实际的抽奖业务中,都是后端在做,但是谁让咱有nodejs呢。前端开发人员也能过一把瘾。
概率性的东西,就要用到随机函数Math.random(),但是只能随机产生0-1范围的随机数,那么怎么制定概率呢?
假设场景:现在要抽奖如下产品
确保所有概率相加结果为1。
我们先假设API是这样的
let roll = new Roll();
roll.add('IPhone 8', 0.01);
roll.add('Ipad', 0.02);
roll.add('纪念版T恤', 0.12);
roll.add('纪念版水杯', 0.25);
roll.add('空空如也', 0.60);
const result = roll.roll();
console.log(`恭喜您获得: ${result}`);但是直接指定概率,这样的api是有局限性的。还需要注意让概率之和为1
我们换一个概念 权重
改变后的api
let roll = new Roll();
roll.add('IPhone 8', 1);
roll.add('Ipad', 2);
roll.add('纪念版T恤', 12);
roll.add('纪念版水杯', 25);
roll.add('空空如也', 60);
const result = roll.roll();
console.log(`恭喜您获得: ${result}`);这不是坑爹吗,就把概率取整了(:,其实不然。
概率不能再直接设置,而是通过第二个参数传入权重。 该物品的概率=它的权重/总权重
例如抛硬币50%的概率:
let roll = new Roll();
roll.add('正面', 1);
roll.add('反面', 1);
const result = roll.roll();
console.log(`硬币是: ${result}`);那么实际操作中,如何实现概率分布,想象一下0-1是一条轴线。
各个商品的概率均<=1,且总和永远为1. 我们把轴线分成几个部分,各个部分分别被这几个商品占据着(请不要在乎下面的比例(: )
0-----0.01------0.03---------------0.15------------0.40--------------------------------------------------1
那么使用 Math.random() 随机出来的数,在哪个区间就相当于抽到了哪个商品
function throwError(msg) {
throw new Error(msg);
}
class Roll {
constructor() {
this._ = []; // 存储要roll的列表
}
add(
item = throwError('Item must be required'), // 验证参数
rank = throwError('Rank must be required') // 验证参数
) {
const rankType = typeof rank;
if (rankType !== 'number')
throwError(`Rank must be a Number not ${rankType}`);
if (rank <= 0) throwError('require Rank>0');
this._.push({ item, rank }); // 把要roll的商品添加要列表中
}
roll() {
let totalRank = 0;
const random = Math.random(); // 产生一个随机数
let result = null;
const items = this._.slice().map(item => (totalRank += item.rank) && item); // 计算总权重
let start = 0; // 区间的开始,第一个是为0
while (items.length) {
const item = items.shift(); // 取出第一个商品
const end = start + item.rank / totalRank; // 计算区间的结束
if (random > start && random <= end) { // 如果随机数在这个区间内,说明抽中了该商品,终止循环
result = item;
break;
}
start = end; // 当前区间的结束,作为下一个区间的开始
}
return result ? result.item : null;
}
}所谓实践才是检验真理的唯一标准,验证硬币正反两面的概率为50%需要无数次的实验。
我们就随机100000次,5轮结果对比看看
const data = {};
for (let i = 0; i < 100000; i++) {
let roller = new Roll();
roller.add('IPhone 8', 1);
roller.add('Ipad', 2);
roller.add('纪念版T恤', 12);
roller.add('纪念版水杯', 25);
roller.add('空空如也', 60);
const result = roller.roll();
if (data[result] === void 0) {
data[result] = 0;
} else {
data[result] = data[result] + 1;
}
}
console.log(JSON.stringify(data, null, 2));最后的输出结果
{
"纪念版水杯": 25077,
"空空如也": 60024,
"Ipad": 1926,
"纪念版T恤": 11931,
"IPhone 8": 1037
}{
"空空如也": 59855,
"纪念版水杯": 25174,
"Ipad": 2044,
"IPhone 8": 981,
"纪念版T恤": 11941
}{
"空空如也": 59715,
"纪念版T恤": 12014,
"纪念版水杯": 25207,
"Ipad": 2031,
"IPhone 8": 1028
}{
"空空如也": 60058,
"纪念版T恤": 12145,
"纪念版水杯": 24752,
"Ipad": 2015,
"IPhone 8": 1025
}{
"空空如也": 59940,
"纪念版水杯": 24946,
"纪念版T恤": 12159,
"Ipad": 1961,
"IPhone 8": 989
}可以看出,靠谱
但是可能还有些问题,float64的计算是有精度问题的
0.1 + 0.2 = 0.30000000000000004
这时候可能需要进行矫正,有很多的轻量运算库,比如Big.js
对于经常造轮子的人来说,最痛苦的事莫过于配置开发环境。
如果你构建一个纯粹的库,你可能需要ES6支持,那么你需要Babel,还需要安装Babel,然后根据需要的特性安装preset,安装plugins
如果你需要构建一个React/Vue组件,那么就不是Babel那么简单,还需要配置Webpack。
包括一堆的Loader,plugins,entry,output,devServer等等,不厌其烦...
所以很迫切的需要一个零配置的开发工具,你看parcel不就是因为零配置备受推崇吗。
所以,自己撸一个工具,configless是目标,专注于打包库/组件.
npm install @axetroy/libpack -g// index.vue
<template>
<div>
<h2>Hello world</h2>
<h2>This is an Vue example component</h2>
</div>
</template>
<script>
console.log("Load component");
export default {
name: "index"
};
</script>
<style scoped>
</style># -- externals 指明vue需要外部加载
libpack ./index.vue ./build --externals vue然后你还可以预览一下刚写的组件
// main.js
import Vue from "vue";
import App from "./index.vue";
new Vue({
el: document.body,
render: h => h(App)
});libpack ./main.js ./build --server// index.jsx
import React, { Component } from "react";
class Example extends Component {
render() {
return (
<div>
<h2>Hello world</h2>
<h3>This is an react example component</h3>
</div>
);
}
}
export default Example;# -- externals 指明react和react-dom需要外部加载
libpack ./index.jsx ./build --watch --externals react,react-dom然后你还可以预览一下刚写的组件
libpack ./app.jsx ./build --server// src/index.ts
class Person {
say(word: string) {
console.log("hello " + word);
}
}
new Person().say("world");libpack ./src/index.ts ./buildtypescript项目需要有tsconfig.json,如果项目目录不存在,那么会创建一个默认配置
// index.js
// @flow
class Person {
say(word: string) {
console.log("hello " + word);
}
}
new Person().say("world");
libpack ./index.js ./build// index.js
console.log("Hello world");
// generator
function* generator() {
yield Promise.resolve();
}
// async await
async function asyncFunction() {
await Promise.resolve();
}
// dynamic import
import("./antoher");
// do expression
function doExpression() {
let a = do {
if (x > 10) {
("big");
} else {
("small");
}
};
}
// Object rest spread
let { x, y, ...z } = { x: 1, y: 2, a: 3, b: 4 };
console.log(x); // 1
console.log(y); // 2
console.log(z); // { a: 3, b: 4 }
// decorator
function readable() {
return function() {};
}
@readable()
class Stream {}libpack ./index.js ./buildlibpack仅仅是一个内置了多个preset和plugins的Webpack配置,省去了配置的烦恼。
你也不需要关心怎么配置es2015,es2016,es2017,也不用关心你能不能用新特性.
撸起袖子就是干.
欢迎各位大佬指教
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.