avalonstrel / gatedconvolution_pytorch Goto Github PK
View Code? Open in Web Editor NEWA modified reimplemented in pytorch of inpainting model in Free-Form Image Inpainting with Gated Convolution [http://jiahuiyu.com/deepfill2/]
License: Other
A modified reimplemented in pytorch of inpainting model in Free-Form Image Inpainting with Gated Convolution [http://jiahuiyu.com/deepfill2/]
License: Other









































































































Could you please update the complete pretrained model. I've test the corase model.The result is not good.


Thank you very much.
Error, the data is corrupted.
I want to know how to generate mask pkl file? Can you upload an example code file?
And how to generate flist.txt?
Thanks!
By the way, you pre-trained model file seems to be broken.
Did I miss something? Always failed to decompress the .tar file
tar: Unrecognized archive format
tar: Error exit delayed from previous errors.
import imp
Traceback (most recent call last):
File "train_sagan.py", line 7, in
from util.logger import TensorBoardLogger
File "/user/swx689421/pytorch/GatedConvolution_pytorch-master/util/logger.py", line 2, in
import tensorflow as tf
ModuleNotFoundError: No module named 'tensorflow'
Hello, In the Self_Attn modules, the value of gamma is torch.zeros(1), then get the out by out = x + gamma*out,Why the vlaue of gamma is zero rather than others like torch.ones(1)?
can you upload the mask data you use? thank you
Thanks for your code. But I couldn't understand what is the shape of a mask in pkl file?
The mask file should be a pkl file containing a numpy.array.
how to change the image mask to the pkl??
the shape of numpy in the pkl file is [1,1,h*w] or [h,w,1]???
the number of image in one pkl file is solo or multi?
how to set the params to not use the MASKDATASET
Hello and thank you for the great repo !
can you please specify the licence for using this repo ?
Thank you
Hi, Thanks for the package, I am trying to train on places2 and using the free-form mask, however, it seems there is a series of errors that cause the code to do not work properly and based on the flag, "MASKFROMFILE=FALSE". I tracked it down and in inapint_dataset.py there are a few errors, originally, including:
I am trying to solve these issues step by step and report them here for others too. Thanks again.
Hello, author, I have some questions about gated convolution, hope to answer!
In the paper, there is no bias in its formula (i.e. sigmoid (Gatingy,x)), so the probability value of the missing area after sigmoid is 0, which can shield the invalid value of the missing area.
But I read your code, and the bias default is True, so the probability of the missing area is not 0. Isn't it impossible to shield?
Finally, wish you all the best, good job and good body!!
Thank you for your code.
When I trained the model, I found that if only one mask is set, the effect is very poor. However, when setting multiple masks, it will produce better results. Whether it is related to the training of the model.
when i run test_images.py , Program prompt missing ‘sa_gan_l2h_unet.py’.
In train_sagan.py,line 77, coarse_imgs, recon_imgs, attention = netG(imgs, masks). It has 3 valuse to return.But in netG,the forward function only return 2 values.
Hi,
Are you going to add sketch channel in this repo?
Hello everyone!
Has anyone been able to run the testing function successfully? I have managed to train the model with my own data and the model has been saved. After modifying the dataset path as well as the pretrained model path (MODEL_RESTORE0) as stated by the authors, I have been facing the following error.
File "test_images.py", line 24, in <module> config = Config(sys.argv[1]) File "/home/gaofei/newResearch/Gated_Conv/GatedConvolution/util/config.py", line 85, in __init__ assert os.path.exists(filename), "ERROR: Config File doesn't exist." AssertionError: ERROR: Config File doesn't exist.
I have been stuck for many hours now. Please, what could be problem? Any suggestions and comments would be highly appreciated.
Hi,
I have read the gated convolution paper (and reviewed the results achieved by the implementation in this repo) and the results are fascinating!
I just have a few questions that I was hoping to clarify please:
Thanks
Hi! Thanks for sharing the code of deepfillv2, can you help me with the code of sampling free-form training masks?
@avalonstrel Hi,
Thanks for your excellent work!
When I train this net with my own data, I tried many times,also made learning rate smaller,Nan of losses happened soon or later.By the way,My mask configuration is irrmask/random_free_form.Do you have any suggestions for this promblem?
Thanks.
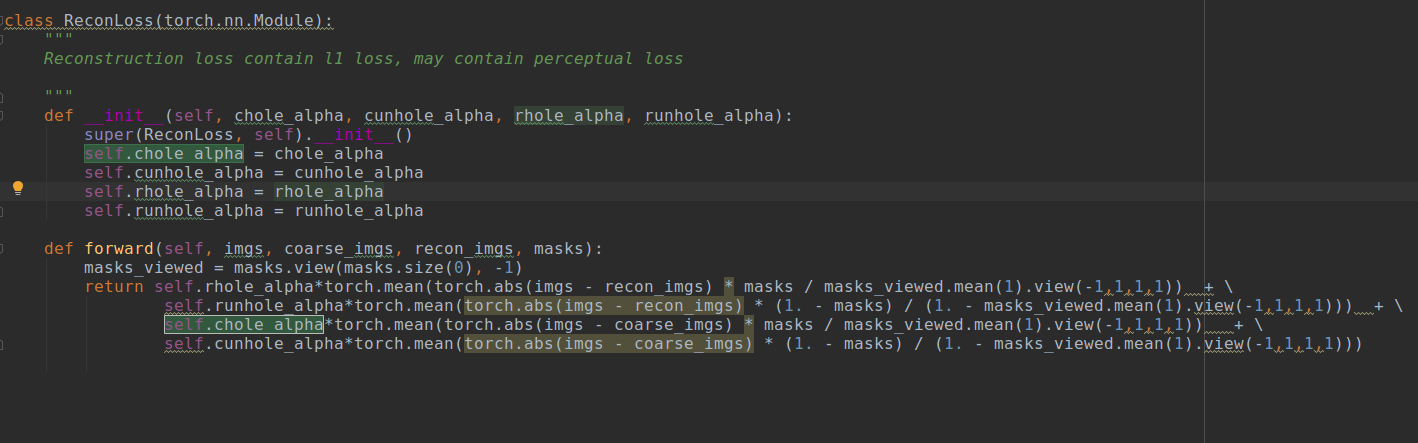
Why add twice l1(imgs - recon_imgs) and l1(imgs - coarse_imgs) in loss.py?
code:
Thank you for your code.
When I run the training sh,it says No such file or directory:'/home/lhy/....../ val_ff_mask_flist.txt'.
How to generate the val_ff_mask_flist.txt/val_rect_mask_flist.txt
Thankyou
I don't know why you don't use scaled factor
 in your self-attention?
in your self-attention?

the training number in your code is 400000 one epoch .it cost too much time . how to reduce it?
Has anyone encountered this error?
RuntimeError: CuDNN error: CUDNN_STATUS_BAD_PARAM
@avalonstrel
INFO:main:Initialize the dataset...
INFO:main:Finish the dataset initialization.
INFO:main:Define the Network Structure and Losses
INFO:main:Loading pretrained models from latest_ckpt.pth.tar ...
INFO:main:Finish Define the Network Structure and Losses
INFO:main:Start Validation
Traceback (most recent call last):
File "test_images.py", line 244, in
main()
File "test_images.py", line 241, in main
validate(nets, losses, opts, val_loader,0 , config.NETWORK_TYPE,devices=(cuda0,cuda1))
File "test_images.py", line 118, in validate
pred_pos_neg = netD(pos_neg_imgs)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/module.py", line 489, in call
result = self.forward(*input, **kwargs)
File "/code/GatedConvolution_pytorch-master/models/sa_gan.py", line 216, in forward
x = self.discriminator_net(input)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/module.py", line 489, in call
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/module.py", line 489, in call
result = self.forward(*input, **kwargs)
File "/code/GatedConvolution_pytorch-master/models/networks.py", line 150, in forward
x = self.conv2d(input)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/module.py", line 489, in call
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
I visualize the x and mask respect to output of feature and gating in GatedConv2dWithActivation, and find x = mask.Why this happen? Is there something wrong ? Thanks!
Thanks for your code. But I couldn't understand Why is the image normalized, then multiplied by 255, and then divided by 127.5.
In inpaint_dataset.py
'''
img = self.transforms_fun(img)
return img*255, masks,gt_masks,shape
'''
In train_sagan.py:
'''
imgs = (imgs / 127.5 - 1)
'''
@avalonstrel
thanks for your work , i run ./sh ./scripts/test_inpaint.sh the error is kernel size can't be greater than actual input size , is the model you given changed ?
I want to try to train the model and the result show missing the mask file set
'/home/lhy/datasets/InpaintBenchmark/MaskData/val_ff_mask_flist.txt'
I have lookup-ed the previous discussion in Github that the format of flist.txt is just filepath list by newlines
But I am not sure what kinds of image mask format should provide?
Is that required to provide for training with MASKFROMFILE = FALSE
I lookup the code of train.py and it seem necessary.
Is that possible to share the mask files also for our reference
Thanks
Hello, Thanks for your reimplemented job.It's so great for us.
I'm very interested in one thing.Have you tested how long it takes to process an image?
Can it remove any object?
RuntimeError: Calculated padded input size per channel: (3 x 3). Kernel size: (4 x 4). Kernel size can't be greater than actual input size
I am getting the above error on testing with my own dataset from the pre-trained model link given by you. Can you tell me where am I making mistake?
I am using dataset of 256x256 images.
Hi , thanks for your great work, i write a demo using your model to predict images, but it seems something wrong with the result, like this: why is refined output gray?

here is my demo code, could you please help me?
model_path = './model_logs/offical/latest_ckpt.pth.tar'
nets = torch.load(model_path)
netG_state_dict, netD_state_dict = nets['netG_state_dict'], nets['netD_state_dict']
netG = InpaintSANet()
load_consistent_state_dict(netG_state_dict, netG)
netG.to(cpu0)
netG.eval()
torch.set_grad_enabled(False)
save_img_dir = 'results/'
os.makedirs(save_img_dir, exist_ok=True)
test_img_dir = 'testdata/'
imgs_list = os.listdir(test_img_dir)
input_shape = (256,256)
for imgname in tqdm(imgs_list):
img = cv2.imread(test_img_dir + imgname)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w, c = img_rgb.shape
img_resize = cv2.resize(img_rgb, input_shape)
mask = random_ff_mask(input_shape)
img_tensor = torch.from_numpy((img_resize.astype(np.float32)[np.newaxis, :, :, :])).permute(0, 3, 1, 2)
mask_tensor = torch.from_numpy((mask.astype(np.float32)[np.newaxis, :, :, :])).permute(0, 3, 1, 2)
used_img, used_mask = img_tensor.to(cpu0), mask_tensor.to(cpu0)
used_img = (used_img / 127.5 - 1)
corse_img, refine_img = netG(used_img, used_mask)
## network output
cor_img = 127.5*(corse_img+1).permute(0, 2, 3, 1)
ref_img = 127.5*(refine_img+1).permute(0, 2, 3, 1)
cor_img_np = cor_img.data.numpy()[0]
ref_img_np = ref_img.data.numpy()[0]
## complete output
cor_complete_img = corse_img * used_mask + used_img * (1 - used_mask)
ref_complete_img = refine_img * used_mask + used_img * (1 - used_mask)
cor_complete_img = 127.5*(cor_complete_img+1).permute(0, 2, 3, 1)
ref_complete_img = 127.5*(ref_complete_img+1).permute(0, 2, 3, 1)
cor_complete_img_np = cor_complete_img.data.numpy()[0]
ref_complete_img_np = ref_complete_img.data.numpy()[0]
## save images
first = np.concatenate((img_resize, 255*np.concatenate((mask,)*3, -1)), 0)
third = np.concatenate((ref_complete_img_np, cor_complete_img_np), 0)
second = np.concatenate((ref_img_np, cor_img_np), 0)
out_img = np.concatenate((first, second, third), 1)
out_img = cv2.cvtColor(out_img, cv2.COLOR_RGB2BGR)
cv2.imwrite(save_img_dir + imgname, out_img)
Is it possible to start transfer learning from given latest_ckpt.pth.tar?
I've tried already but it makes an error in netG.load_state_dict & netD.load_state_dict
Is it ok to replace those line with load_consistent_state_dict(netX_state_dict, netX) ?
Thx
the link https://pan.baidu.com/s/1bpHm9YoEV8isJz3S9bCziA is redirect to https://pan.baidu.com/error/404.html
The pre-train model can't be accessed anymore
@avalonstrel
Excuse me, when I run my own data set, the following error occurs, how should I solve it?
File "/home/lyl/下载/anaconda3/envs/torch/lib/python3.6/site-packages/PIL/Image.py", line 2837, in fromarray
raise TypeError("Cannot handle this data type: %s, %s" % typekey) from e
TypeError: Cannot handle this data type: (1, 1, 1, 9), |u1
Hi, thanks for your work in implementing the code with pytorch. I encountered an error that the netD will crash if using 64*64 as size of input img and mask:
RuntimeError: Calculated padded input size per channel: (3 x 3). Kernel size: (4 x 4). Kernel size can't be greater
than actual input size
The same code works well when I set the size to 128128 or 256256.
Hi, thanks for your great work.
But I have the same question as the following issue.
It seems something wrong with the result of complete image.
Could you please help me?
Thank you~
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.