This RFC describes the motivation and design of Jinux's component system.
Motivation
The only way to write complex software that won't fall on its face is to build it out of simple modules connected by well-defined interfaces so that most problems are local and you can have some hope of fixing or optimizing a part without breaking the whole.
--The Art of Unix Programming
Every OS strives to be modular. OS developers have no choice but to embrace modularity as it is the only way to tame the sheer complexity of an OS and make it work. As Jinux developers, we are a bit more ambitious: not only do we want it to work, we want it to do so in a safe and secure way.
Rust can facilitate modular software design with language features like crates and modules, but we find them insufficient for large and complex software like Jinux. In particular, we argue that there are two areas that lack support from the Rust language or ecosystem, one is modular initialization, and the other is access control. The former is important for OS maintainability, while the latter is for OS security.
Modular initialization
OS startup is not an easy job. A fully-fledged OS supports all kinds of CPU architectures, machine modules, buses, block devices, network devices, file systems, and more. Each of them is qualified as one or multiple OS components. So there could be hundreds of OS components that need to be initialized during OS startup. And the initialization of components must be done in an order that takes into account the functional dependencies between the OS components.
To promote a highly modular architecture for Jinux, we decide that the concepts of OS components must be supported as first-class citizens and their initialization must be done in an automatic and ergonomic fashion.
Access control
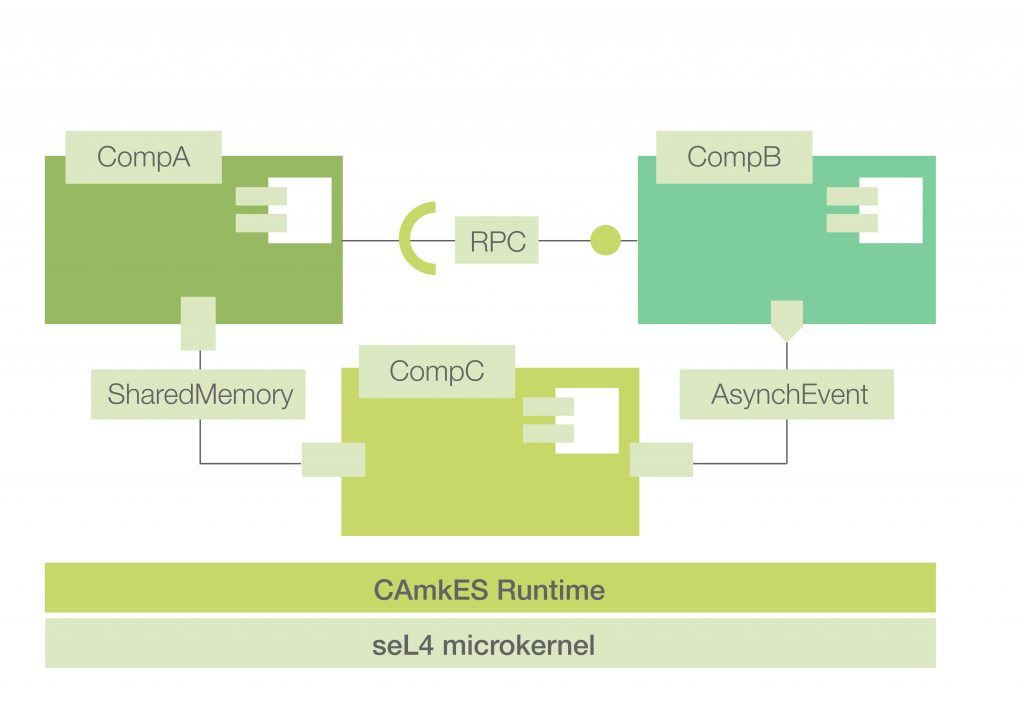
Microkernels are the pioneers in the pursuit of constructing a highly modular OS with OS components. Take seL4-based multiserver OS as an example. Each OS component runs as a separate process to enforce strong isolation. The interfaces between OS components are well-defined with a dedicated language. This approach undoubtedly benefits security but comes at the price of communication overheads (e.g., RPC).
As Jinux developers, we believe that a language-based approach to OS components can reap the most important benefit (i.e., security) of the process-based approach while avoiding its main drawback (i.e., performance). In Jinux, we implement OS components as regular Rust crates. As we do not allow OS components to contain unsafe Rust code, crate-based OS components are as strong as process-based ones in preventing one component from messing up the memory of another one. But here comes the key difference: process-based components can enforce access control by exposing their APIs selectively (e.g., through RPC), but crate-based ones must choose between exposing their API to all (use pub keyword) or none. Without enforcing some form of access control, crate-based OS components cannot match the security of process-based ones.
Design
The Jinux component system extends regular Rust crates with the extra abilities of modular initialization and access control.
One key design challenge is to enable these two features in the most ergonomic way. In Jinux, we want to promote constructing a highly-modular OS kernel by having a large number of fine-grained OS components. So programming OS components, including their initialization and access control, must be a breeze, not a pain in the ass.
Modular initialization
Static variable initialization
Initializing a Jinux component can be boiled down to initializing static variables in Rust. This is because 1) a Jinux component is simply a Rust crate; 2) crate-level states are commonly expressed as static variables.
Prior Rust OSes adopt one of the two methods to initialize static variables. The first method uses the lazy_static! macro, which ensures that the variable is initialized automatically when it is accessed for the first time.
lazy_static! {
static ref UART_BUF: Mutex<VecDeque<u8>> = Mutex::new(VecDeque::with_capacity(512));
}This method is easy-to-use, but it provides no means to gracefully handle errors that may occur during variable initialization. So it is not suited for a production-quality implementation.
The second method is wrapping the static value within Once<T>, whose init method will be invoked manually by the component's init function. If some code attempts to use Once<T> before its init method is invoked, a panic would be triggered.
static UART_BUF: Once<Mutex<VecDeque<u8>>> = Once::new();
pub fn init_uart() {
UART_BUF.init(|| Mutex::new(VecDeque::with_capacity(512)));
}The second method gives more control to the developers, including the ability to handle errors and the timing of initialization. But this method is not scalable as the number of OS components grows. In a centralized location, some magic code must be aware of the init function of each and every OS component and invoke them one by one---and in the right order. This is against our design goal of ergonomics.
The Component trait
Our first step towards easy component initialization is to provide an abstraction for components, which is the Component trait.
pub struct UartComponent {
buf: Mutex<VecDeque<u8>>,
}
impl Component for UartComponent {
fn init() -> Result<Self> {
let buf = Mutex::new(VecDeque::try_with_capacity(512)?);
Ok(Self { buf })
}
fn name(&self) -> &str {
"uart"
}
}The #[init_component] macro attribute
Next, we define a static variable that represents the component.
#[init_component]
static SELF: Once<UartComponent> = Once::new();
Thanks to the magic #[init_component] macro as well as the Component trait, the static variable will be initialized automatically by the component system.
Behind the scene, this magic macro will generate code that initializes the UartComponent. During the kernel startup, the generated initialization will be invoked after all dependent OS components of this UART component have been initialized. As the code generation and dependency resolution are conducted by the component system automatically, developers' efforts are minimized.
Access control
Let's consider this simple question: given crate a, b, and c, how can we let crate b access a static variable a::A, while forbidding crate c from doing so?
The Controlled<T> wrapper type
We introduce Controlled<T>, which is used to wrap an access-controlled value.
// file: a/lib.rs
/// Resource represents some kind of resources managed by crate a.
pub struct Resource { /* ... */ }
impl Resource {
pub (crate) fn new() -> Self { todo!() }
pub fn count(&self) -> usize { todo!() }
}
static A: Controlled<Resource> = Controlled::new(Resource::new());Anyone who has a reference to a Controlled<T> object cannot gain a reference to its internal value of T... unless using the access macro.
The access macro
Crate b is allowed to access a::A by using the access macro.
// file: b/lib.rs
fn use_a() {
access!(a::A).count();
}But you may ask: what if crate c attempts to use the access macro? Well, now is the time to introduce the configuration file of Jinux component system.
The Components.toml file
The Jinux component system respects a configuration file named Components.toml, which, among other things, specifies the access control policy.
Here is an example configuration file which specifies the access control policy where crate b is allowed to use a::A but crate b is not.
[components]
a = { path = "a/" }
b = { path = "b/" }
c = { path = "c/" }
[whitelist]
[whitelist.a.Resource]
b = trueThe whitelist is a table whose keys are public types of components, whose values tell whether a public type may be used by a component if it is wrapped inside Controlld<_>.
The cargo component command
Since components are configured statically, the access control policies are also enforced statically. By default, when components are built, the access control policy will not be enforced. The rationale is that we do not want the new access control mechanism to interrupt or disturb the development activities or flows as the way they are now.
To capture any violations against the access control policy, one should use the following command.
cargo component is a Cargo subcommand that we develop for Jinux's component system. Its audit subcommand checks each usage of the access macro against the whitelist given in Components.toml. The command will report any access control violation if any is found.
Implementation
To be continued.