语义相似度,句向量生成
本项目可用于训练涉及到两句的分类任务,同时,可基于训练好的模型,获取句向量,用于下游相关任务,比如语义相似度任务。
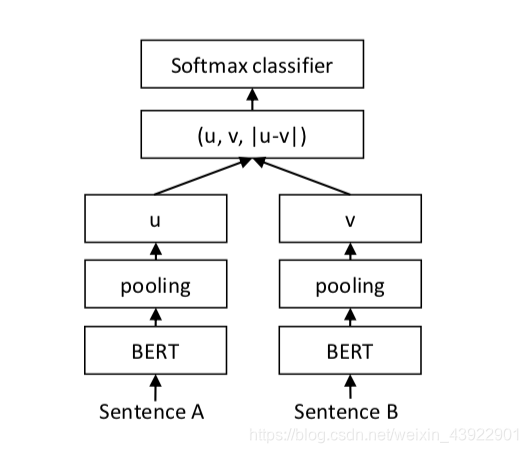
涉及论文:《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》
框架图
项目结构
.
├── README.md
├── common_file # 公用的一些模型,优化器等
├── datas # 数据样例
├── examples # 一些项目的应用入口
├── relation_classifier # 小说人物关系分类
├── requirements.txt
├── scene_classifier # 小说场景切分分类
├── script
├── test
└── two_sentences_classifier # 小说人物对话分类
two_sentences_classifier
人物对话分类项目:主要针对小说中的人物说话内容进行分类,目的是根据两个人(A,B)说话内容判断两段话是不是出自同一个人。我们将说话内容的句数设置为超参数top_n, 比如7,10,15,20等等。而数据集中一共有AB的话各20句。具体的数据格式可参照 ../datas/two_sentences_classifier/ 数据样式。
-
基本思路:以7句为例,输入特征input_ids: batch_size x 14 x len
[CLS] 你今天干嘛去了?[SEP] ... [CLS] 我想吃雪糕?[SEP] # 前面是A说的话7句话 [CLS] 你今天干嘛去了?[SEP] ... [CLS] 我觉得还是不去的好。[SEP] # 这是B说的话7句话
一共14句话,但是注意,A说的7句话是出字某一本小说的随机7句,不一定是跟B说的话,AB可能出自不同小说的人物。为什么这么输入呢?是因为在后面模型前向传播的时候,我们会对这14句话 进行chunk,拆分成两份,维度分别为 batch_size x 7 x len x 768。然后根据《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》方法,采用mean pooling 策略。将维度变成batch_size x 7 x 768,然后再继续mena -> batch_size x 768。最后基于两个batch_size x 768按照框架图取绝对值,拼接操作。具体做法可参照../common_file/modeling.py的类TwoSentenceClassifier。
-
训练
cd script sh two_sentences_classifier.sh参数讲解
CUDA_VISIBLE_DEVICES=4,5,6,7 python ../two_sentences_classifier/train.py \ --vocab_file /nas/pretrain-bert/pretrain-pytorch/chinese_wwm_ext_pytorch/vocab.txt \ # 词表文件,这里用的是roberta --bert_config_file /nas/pretrain-bert/pretrain-pytorch/chinese_wwm_ext_pytorch/bert_config.json \ --do_lower_case \ --train_file /nas/xd/data/novels/speech_labeled20/ \ # 训练文件目录 --eval_file /nas/xd/data/novels/speech_labeled20/data.dev \ # 开发集文件 --train_batch_size 32 \ --eval_batch_size 8 \ --learning_rate 5e-5 \ --num_train_epochs 6 \ --top_n 15 \ # 每天数据有20句,取了top_n句 --num_labels 2 \ # 类别数目 --reduce_dim 0 # 降维后的维度值,0表示不降维 --output_dir ./two_sentences_classifier_large_model0506_15 \ # 模型保存位置 --bert_model /nas/pretrain-bert/pretrain-pytorch/chinese_wwm_ext_pytorch/ \ --init_checkpoint /nas/pretrain-bert/pretrain-pytorch/chinese_wwm_ext_pytorch/pytorch_model.bin \ --do_train \ --gradient_accumulation_steps 4 3>&2 2>&1 1>&3 | tee logs/two_sentences_classifier_large_model0430_15.log -
结果:
top_n模型 f1 输入20句预测 7 84% 86% 10 86% 88% 15 90% 92%
relation_classifier
人物关系分类项目:主要针对小说中的人物对话内容进行分类,目的是根据两个人(A,B)对话内容判断两段话是不是出自相同的两个人的对话。我们将说话内容的句数设置为超参数top_n, 比如7,10,15,20等等。而数据集中一共有对话各20组。具体的数据格式可参照 ../datas/relation_classifier/
数据样式。
-
基本思路:以7句为例,输入特征input_ids: batch_size x 14 x len
[CLS] 你今天干嘛去了?[SEP]不打算干吗呀![SEP] ... [CLS] 我想吃雪糕?[SEP]雪糕对身体不好,要少吃。[SEP] # 前面是A:B的对话 [CLS] 你今天干嘛去了?[SEP]我今天去外婆家吃饭了。[SEP] ... [CLS] 我觉得还是不去的好。[SEP]为什么啊?[SEP] # 这是AB,BA,AC或者BD或者...,的对话。如果为AB,BA,label为1,否则为0
相比TwoSentencesClassifier,在取绝对值cat,之后接了一个线性层进行降维。具体做法可参照../common_file/modeling.py的类RelationClassifier。
-
训练
cd script sh relation_classifier.sh -
结果:
a) 降维768结果
top_n模型 f1 输入20句预测 7 85% 74% 10 90% 85% 15 94% 93% b) 不降维结果
top_n模型 f1 输入20句预测 7 81% 82% 10 - - 15 - -
分析:可以发现,在训练人物关系时,和训练任务分类有些许不同,就是加入了降维操作。从结果中看,降维是可以获得更好的分类效果的,但是当输入的句数和训练时用的句数不一致时,模型的精度会有偏差。这就是降维带来的负面效果。 因此,如果你预测和训练的输入句数不同时,建议采用不降维方式进行训练,这样获得的模型精度更好。
scene_classifier
小说场景切换分类项目:主要针对小说中的场景切换内容进行识别,目的是根据两个人top_n句话,判断中间那句是否为场景切分的标识,数据中的场景切分有比如:"...","学校","张山家里"等等。top_n我们尝试了3,5,7,9等等。 具体的数据格式可参照 ../datas/scene_classifier/
数据样式。
-
基本思路:以3和5句为例,输入特征input_ids: batch_size x len。
[CLS] 你今天干嘛去了?[SEP]学校里...[SEP]不打算干吗呀![SEP] # top_n = 3 [CLS] 你今天干嘛去了?不打算干吗呀![SEP]学校里...[SEP]我想吃雪糕!雪糕对身体不好,要少吃。[SEP] # top_n = 5
采用正常的Bert句子分类。具体做法可参照../common_file/modeling.py的类BertForSequenceClassification。
-
训练
cd script sh scene_classifier.sh -
结果:
top_n模型 f1 3 84% 5 85% 7 86%
注意:不同的dropout对分类的结果有2%点左右的影响,本项目设置为0.3最佳。
获取句向量
cd examples
python embdeeings_examples.py
