![]()
As you know machine learning has proven its importance in many fields, like computer vision, NLP, reinforcement learning, adversarial learning, etc .. Unfortunately, there is a little work to make machine learning accessible for Arabic-speaking people.
Our goal is to enrich the Arabic content by creating open-source projects and open the community eyes on the significance of machine learning. We want to create interactive applications that allow novice Arabs to learn more about machine learning and appreciate its advances.
Arabic language has many complicated features compared to other languages. First, Arabic language is written right to left. Second, it contains many letters that cannot be pronounced by most foreigners like ض ، غ ، ح ، خ، ظ. Moreover, Arabic language contains special characters called Diacritics which are special characters that help readers pronounced words correctly. For instance the statement السَّلامُ عَلَيْكُمْ وَرَحْمَةُ اللَّهِ وَبَرَكَاتُهُ containts special characters after most of the letters. The diactrics follow special rules to be given to a certain character. These rules are construct a complete area called النَّحْوُ الْعَرَبِيُّ. Compared to English, the Arabic language words letters are mostly connected اللغة as making them disconnected is difficult to read ا ل ل غ ة. Finally, there as many as half a billion people speaking Arabic which resulted in many dialects in different countires.
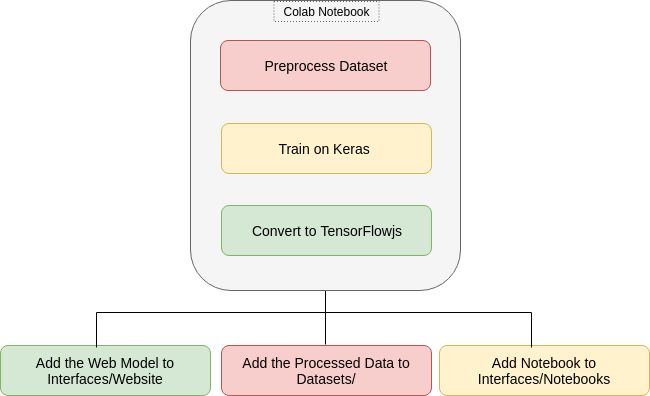
Our procedure is generalized and can be generalized to many language models not just Arabic. This standrized approach takes part as multiple steps starting from training on colab then porting the models to the web.
| Name | Description | Notebook | Demo |
|---|---|---|---|
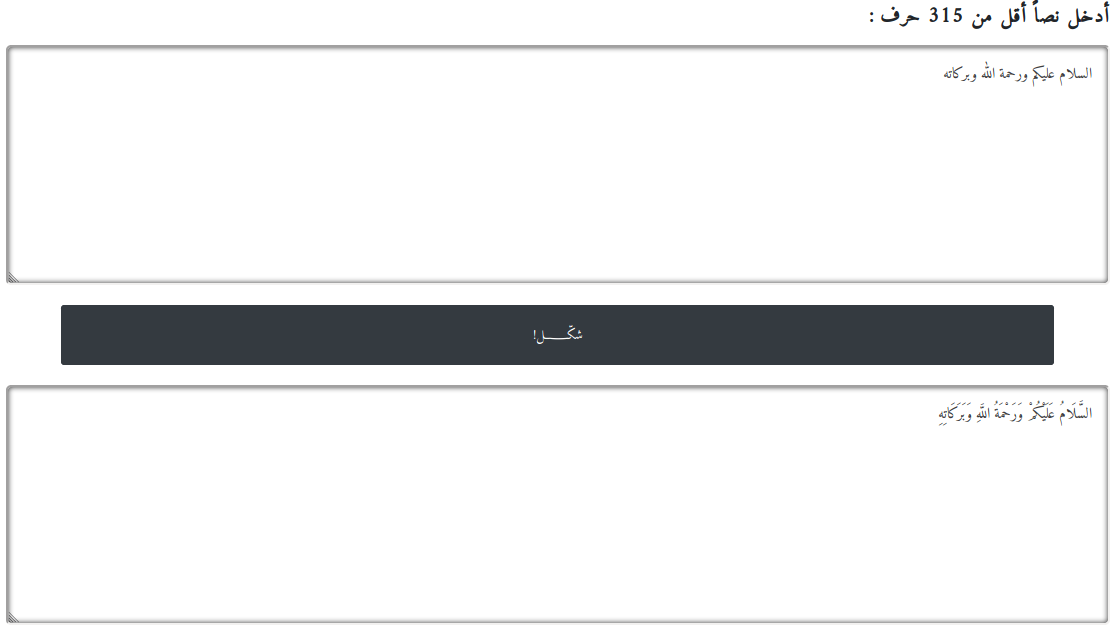
| Arabic Diacritization | Simple RNN model ported from Shakkala |
|
 |
| Arabic2English Translation | seq2seq with Attention |
|
|
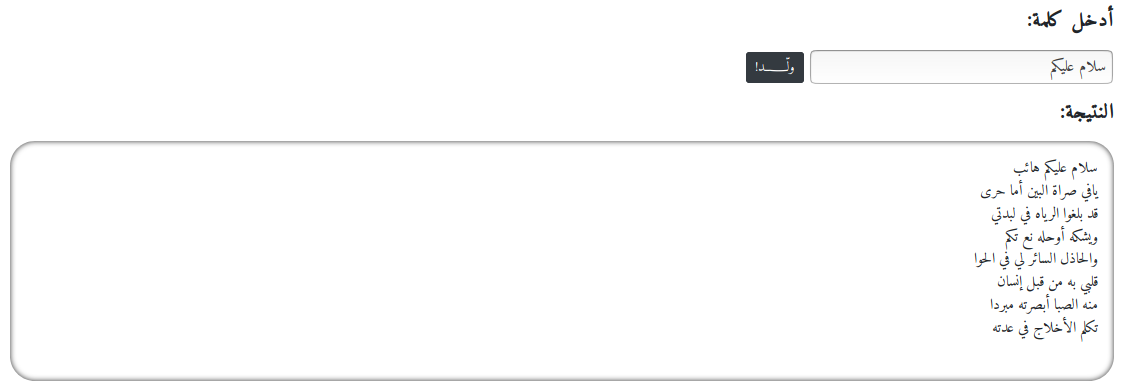
| Arabic Poem Generation | CharRNN model with multinomial distribution |
|
|
| Arabic Words Embedding | N-Grams model ported from Aravec |
|
|
| Arabic Sentiment Classification | RNN with Bidirectional layer |
|
|
| Arabic Image Captioning | Encoder-Decoder architecture with attention |
|
|
| Arabic Word Similarity | Embedding layers using cosine similarity |
|
|
| Arabic Digits Classification | Basic RNN model with classification head |
|
|
| Arabic Speech Recognition | Basic signal processing and classification |
|
|
| Arabic Object Detection | SSD Object detection model | |
|
| Arabic Poems Meter Classification | Bidirectional GRU |
|
|
| Arabic Font Classification | CNN |
|
|
| Arabic Text Detection | Optical Character Recognition (OCR) | |
| Name | Description |
|---|---|
| Arabic Digits | 70,000 images (28x28) converted to binary from Digits |
| Arabic Letters | 16,759 images (32x32) converted to binary from Letters |
| Arabic Poems | 146,604 poems scrapped from aldiwan |
| Arabic Translation | 100,000 paralled arabic to english translation ported from OpenSubtitles |
| Product Reviews | 1,648 reviews on products ported from Large Arabic Resources For Sentiment Analysis |
| Image Captions | 30,000 Image paths with captions extracted and translated from COCO 2014 |
| Arabic Wiki | 4,670,509 words cleaned and processed from Wikipedia Monolingual Corpora |
| Arabic Poem Meters | 55,440 verses with their associated meters collected from aldiwan |
| Arabic Fonts | 516 100×100 images for two classes. |
To make models easily accessible by contributers, developers and novice users we use two approaches
Google colaboratory is a free service that is offered by Google for research purposes. The interface of a colab notebook is very similar to jupyter notebooks with slight differences. Google offers three hardware accelerators CPU, GPU and TPU for speeding up training. We almost all the time use GPU because it is easier to work with and acheives good results in a reasonable time. Check this great tutorial on medium.
TensorFlow.js is part of the TensorFlow ecosystem that supports training and inference of machine learning models in the browser. Please check these steps if you want to port models to the web:
-
Use keras to train models then save the model as
model.save('keras.h5') -
Install the TensorFlow.js converter using
pip install tensorflowjs -
Use the following script to
tensorflowjs_converter --input_format keras keras.h5 model/ -
The
modeldirectory will contain the filesmodel.jsonand weight files same togroup1-shard1of1 -
Finally you can load the model using TensorFlow.js
Check this tutorial that I made for the complete procedure.
We developed many models to run directly in the browser. Using TensorFlow.js the models run using the client GPU. Since the webpage is static there is no risk of privacy or security. You can visit the website here . Here is the main intefrace of the website
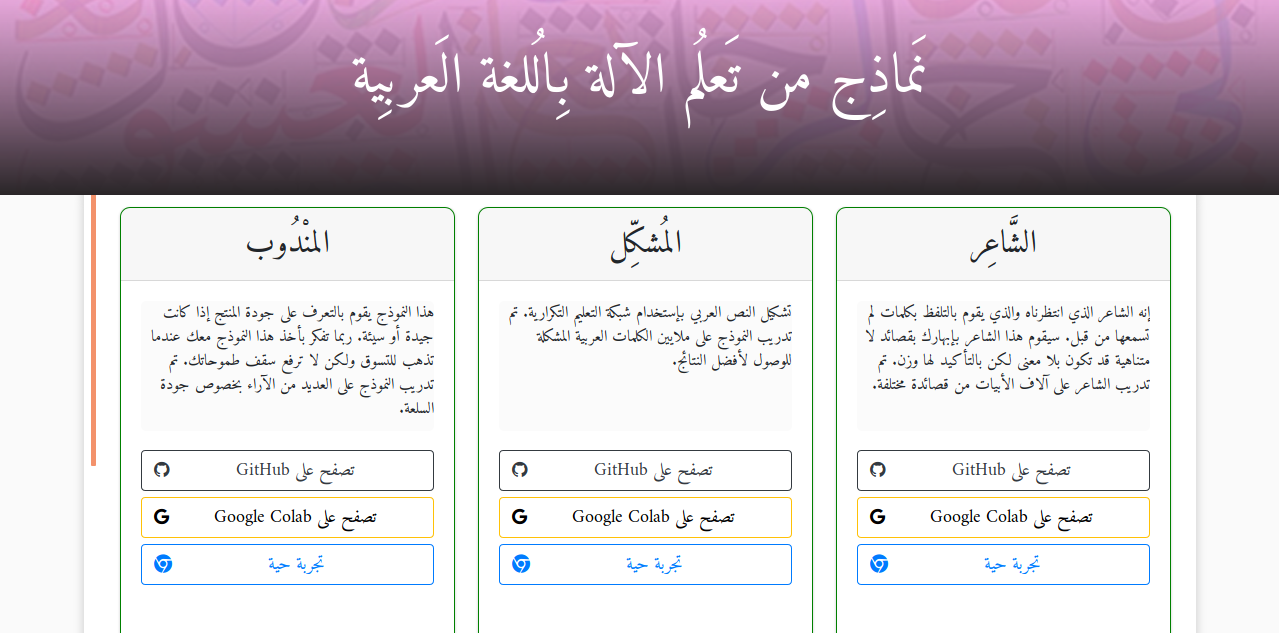
The added models so far
![]()



Check the CONTRIBUTING.md for a detailed explanantion about how to contribute.
As a start we will start on Github for hosting the website, models, datasets and other contents. Unfortunately, there is a limitation on the space that will hunt us in the future. Please let us know what you suggest on that matter.
Thanks goes to these wonderful people (emoji key):
 MagedSaeed 🎨 🤔 📦 |
 March Works 🤔 |
 Mahmoud Aslan 🤔 💻 |
This project follows the all-contributors specification. Contributions of any kind welcome!
@inproceedings{alyafeai-al-shaibani-2020-arbml,
title = "{ARBML}: Democritizing {A}rabic Natural Language Processing Tools",
author = "Alyafeai, Zaid and
Al-Shaibani, Maged",
booktitle = "Proceedings of Second Workshop for NLP Open Source Software (NLP-OSS)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.nlposs-1.2",
pages = "8--13",
}































































































































