This final project is one of the requirements for graduating from Job Connector Data Science and Machine Learning Purwadhika Start-up and Coding School
What's happening here is a gradient boosting framework which is called as 'Light GBM' that uses on old well known 'Decission Tree' learning algorithm which comes under the more well-known umberella term 'Machine Learning'. I've trained a learning model on SBA Loans Dataset and now place myself as a 'Bank Officer at USA' and receive a loan application from a small business. To make the decission, I will use Loan Predictor to help me to classify the risk of the loan which is a high risk or low risk Loan.

Deeper on Loan Predictor evaluation, the accuracy of this model algorithm is ~90% and has AUC Score 0.97 which means that it is an ideal situation. When two curves don’t overlap at all means model has an ideal measure of separability. It is nearly perfectly able to distinguish between positive class and negative class. But, it still has a limitation that only works for the loan that has guarantee from US Small Business Administration.
![]()
The U.S. SBA was founded in 1953 on the principle of promoting and assisting small enterprises in the U.S. credit market. Small businesses have been a primary source of job creation in the United States; therefore, fostering small business formation and growth has social benefits by creating job opportunities and reducing unemployment. One way SBA assists these small business enterprises is through a loan guarantee program which is designed to encourage banks to grant loans to small businesses. SBA acts much like an insurance provider to reduce the risk for a bank by taking on some of the risk through guaranteeing a portion of the loan. In the case that a loan goes into default, SBA then covers the amount they guaranteed. There have been many success stories of start-ups receiving SBA loan guarantees such as FedEx and Apple Computer. However, there have also been stories of small businesses and/or start-ups that have defaulted on their SBA-guaranteed loans. The rate of default on these loans has been a source of controversy for decades.[Reference]
Started with import the dataset which is SBA Loan dataset. After that, I do data cleaning to remove some unnecessary simbols, give restriction to the data that will be used based on reference and EDA, change NAICS code to industrial sector, fixed nan value, remove the outlier, etc.
At feature engineering, I add columnm that maybe will be used for predicting like real estate. I also did one hot encoding for categorical columns like state and NAICS (Industrial Sector), drop the columns that I think it will not give effect for modelling, check the correlation each features, etc.
I started modelling with standardize the continues data, doing cross validation method from five algorithms which are Logistic Regression, Decission Tree, Random Forest, Light GBM, and KNN for normal data and oversampling data (using SMOTE). After found two of the best algorithms which are from normal data (without SMOTE), then I will tune hyperparameter for them. In the following below is the result from cross validation :
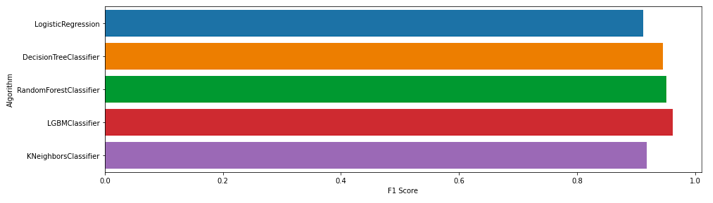
After found two of the best algorithms which are Random Forest and Light GBM, I tuned hyperparameter for them using GridSearchCV. The results from tuning hyperparameter show that Light GBM gives better result than Random Forest. The following below are the parameters that I tuned, classification report, and best parameters from Light GBM :
param_model_2 = {
'max_depth' : [-1,7,12,14,17],
'num_leaves' : [31,70,120],
'min_data_in_leaf' : [60,100,120],
'learning_rate' : [0.001,0.01,0.05],
'num_iterations' :[200,400,600]
}
===== CLASSIFICATION REPORT SCORING FROM F1 SCORE =====
precision recall f1-score support
0 0.84 0.81 0.83 14561
1 0.96 0.97 0.96 71177
accuracy 0.94 85738
macro avg 0.90 0.89 0.90 85738
weighted avg 0.94 0.94 0.94 85738
tn : 11838 fp : 2723 fn : 2276 tp : 68901
======== BEST PARAMETERS SCORING FROM F1 SCORE ========
{'learning_rate': 0.05, 'max_depth': 12, 'min_data_in_leaf': 60, 'num_iterations': 600, 'num_leaves': 120}
The next step is check the AUCROC from Light GBM with best parameters, then I found that it will give better result for predicting 0 (CHGOFF) when the threshold set to 0.24. It's more important to avoid the condition when the status actually CHGOFF and we predict as 1 (PIF) than we predict PIF as CHGOFF. Because I want to minimize the condition that CHGOFF predicted as PIF, so I need to increase recall 0 (CHGOFF) and precission 1 (PIF).
For performance evaluation, I have checked features importance, classification report and confusion matrix. The following below is the performance evaluation result (classification report and confusion matrix) when the threshold set to 0.24.
======== CLASSIFICATION REPORT WITH THRESHOLD ========
precision recall f1-score support
0 0.75 0.91 0.82 14561
1 0.98 0.94 0.96 71177
accuracy 0.93 85738
macro avg 0.87 0.92 0.89 85738
weighted avg 0.94 0.93 0.94 85738
tn : 13196 fp : 1365 fn : 4387 tp : 66790
Doing validation model is very usefull to check the stability of the model that has made. For validation the model that using threshold 0.24, I use KFold with 5 fold. And the result gives good stability for each fold. The following below is the result from validation model :
F1 Scores : [0.957, 0.958, 0.956, 0.957, 0.957]
Accuracy Scores : [0.93, 0.932, 0.928, 0.931, 0.931]
** NOTES : ClassificationReport for each fold (1-5) and all codes available at Jupyter Notebook, please have a look here.






NOTES : On the dashboard, to load the final dataset, I use two choices. Using SQLAlchemy to load from SQL Databases or load manually using pandas. Looks here
Keywords : Loan, Prediction, Machine Learning, Light GBM, U.S Small Business Administration, MySQL







