
![]()

GUN is an ecosystem of tools that let you build community run and encrypted applications - like an Open Source Firebase or a Decentralized Dropbox.
The Internet Archive and 100s of other apps run GUN in-production. GUN was also part of Twitter's bluesky initiative!
- Multiplayer by default with realtime p2p state synchronization!
- Graph data lets you use key/value, tables, documents, videos, & more!
- Local-first, offline, and decentralized with end-to-end encryption.
Decentralized alternatives to Zoom, Reddit, Instagram, Slack, YouTube, Stripe, Wikipedia, Facebook Horizon and more have already pushed terabytes of daily P2P traffic on GUN. We are a friendly community creating a free fun future for freedom:









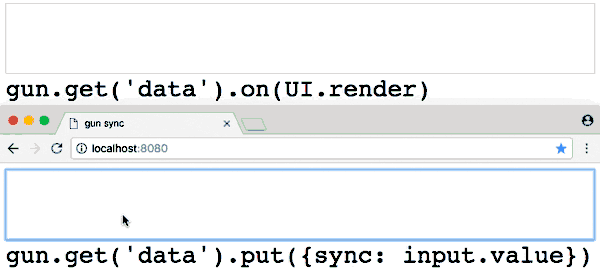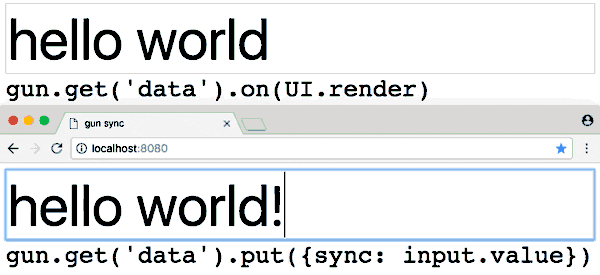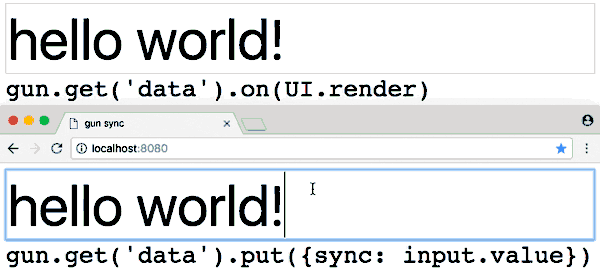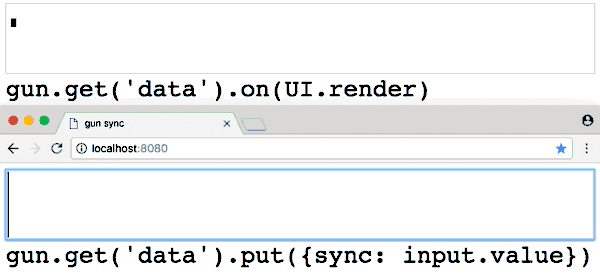
GUN is super easy to get started with:
- Try the interactive tutorial in the browser (5min ~ average developer).
- Or
npm install gunand run the examples withcd node_modules/gun && npm start(5min ~ average developer).
Note: If you don't have node or npm, read this first. If the
npmcommand line didn't work, you may need tomkdir node_modulesfirst or usesudo.
- An online demo of the examples are available here: http://try.axe.eco/
- Or write a quick app: (try now in a playground)
<script src="https://cdn.jsdelivr.net/npm/gun/gun.js"></script>
<script>
// import GUN from 'gun'; // in ESM
// GUN = require('gun'); // in NodeJS
// GUN = require('gun/gun'); // in React
gun = GUN();
gun.get('mark').put({
name: "Mark",
email: "[email protected]",
});
gun.get('mark').on((data, key) => {
console.log("realtime updates:", data);
});
setInterval(() => { gun.get('mark').get('live').put(Math.random()) }, 9);
</script>- Or try something mind blowing, like saving circular references to a table of documents! (play)
cat = {name: "Fluffy", species: "kitty"};
mark = {boss: cat};
cat.slave = mark;
// partial updates merge with existing data!
gun.get('mark').put(mark);
// access the data as if it is a document.
gun.get('mark').get('boss').get('name').once(function(data, key){
// `once` grabs the data once, no subscriptions.
console.log("Mark's boss is", data);
});
// traverse a graph of circular references!
gun.get('mark').get('boss').get('slave').once(function(data, key){
console.log("Mark is the cat's slave!", data);
});
// add both of them to a table!
gun.get('list').set(gun.get('mark').get('boss'));
gun.get('list').set(gun.get('mark'));
// grab each item once from the table, continuously:
gun.get('list').map().once(function(data, key){
console.log("Item:", data);
});
// live update the table!
gun.get('list').set({type: "cucumber", goal: "jumping cat"});Want to keep building more? Jump to THE DOCUMENTATION!
First & foremost, GUN is a community of the nicest and most helpful people out there. So I want to invite you to come tell us about what you are working on & wanting to build (new or old school alike! Just be nice as well.) and ask us your questions directly. :)

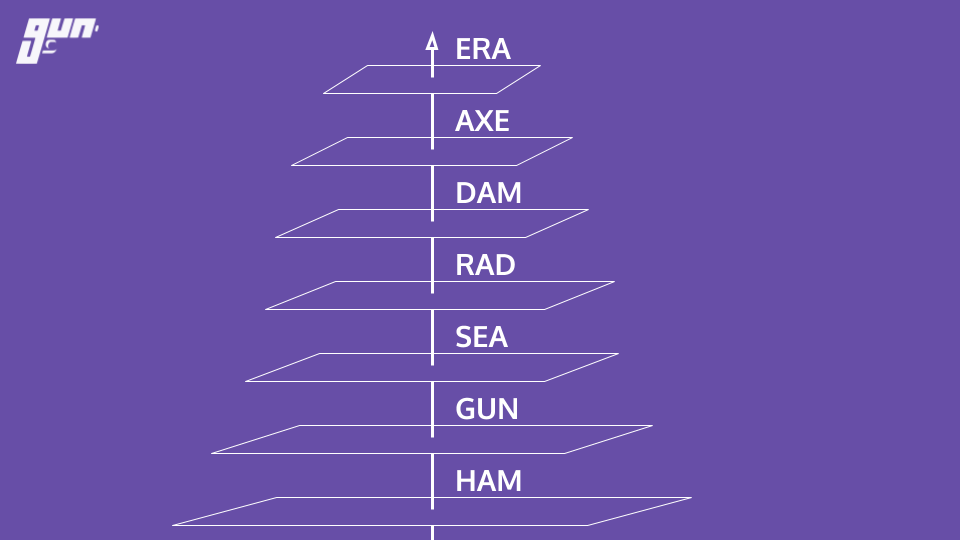
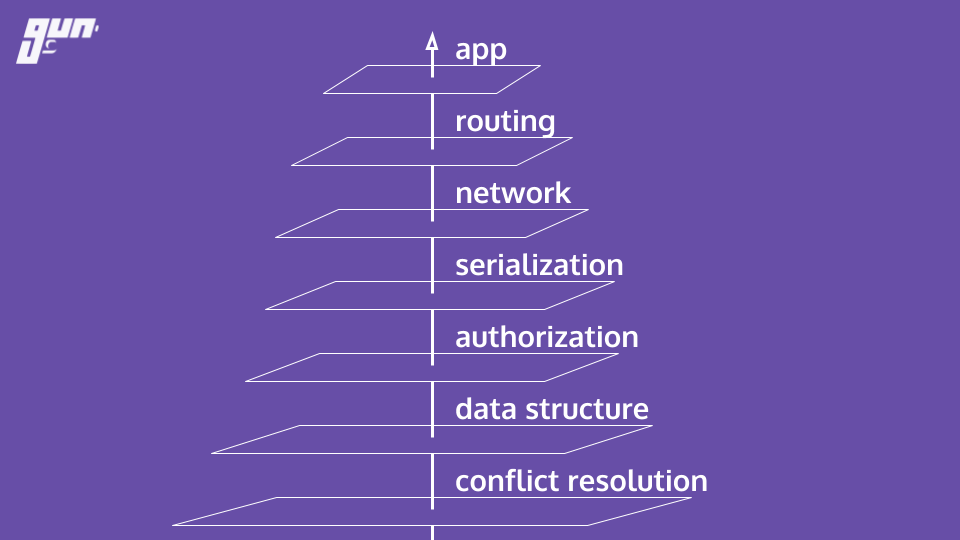
The GUN ecosystem stack is a collection of independent and modular tools covering everything from CRDT conflict resolution, cryptographic security & encryption, radix storage serialization, mesh networking & routing algorithms, to distributed systems correctness & load testing, CPU scheduled JSON parser to prevent UI lag, and more!
On that note, let's get some official shout outs covered first:
Thanks to:
 |
 |
|
| |
 |
 |
Robert Heessels, Lorenzo Mangani, NLnet Foundation, Sam Liu, Daniel Dombrowsky, Vincent Woo, AJ ONeal, Bill Ottman, Mike Lange, Sean Matheson, Alan Mimms, Dário Freire, John Williamson, Robin Bron, Elie Makhoul, Mike Staub, Bradley Matusiak, Jeff Cook, Nico, Aaron Artille, Tim Robinson, Fabian Stamm, Mike Staub, Hunter Owens, Jacob Millner, Gerrit Balindt, Gabriel Lemon, Murage Martin, Jason Stallings
- Join others in sponsoring code: https://www.patreon.com/gunDB !
- Ask questions: http://stackoverflow.com/questions/tagged/gun ?
- Found a bug? Report at: https://github.com/amark/gun/issues ;
- Need help? Chat with us: http://chat.gun.eco .
GUN was created by Mark Nadal in 2014 after he had spent 4 years trying to get his collaborative web app to scale up with traditional databases.

The NoDB - no master, no servers, no "single source of truth", not built with a real programming language or real hardware, no DevOps, no locking, not just SQL or NoSQL but both (all - graphs, documents, tables, key/value).
The goal was to build a P2P database that could survive living inside any browser, and could correctly sync data between any device after assuming any offline-first activity.

Technically, GUN is a graph synchronization protocol with a lightweight embedded engine, capable of doing 20M+ API ops/sec in just ~9KB gzipped size.
This would not be possible without community contributors, big shout out to:
ajmeyghani (Learn GUN Basics with Diagrams); anywhichway (Block Storage); beebase (Quasar); BrockAtkinson (brunch config); Brysgo (GraphQL); d3x0r (SQLite); forrestjt (file.js); hillct (Docker); JosePedroDias (graph visualizer); JuniperChicago (cycle.js bindings); jveres (todoMVC); kristianmandrup (edge); Lightnet (Awesome Vue User Examples & User Kitchen Sink Playground); lmangani (Cytoscape Visualizer, Cassandra, Fastify, LetsEncrypt); mhelander (SEA); omarzion (Sticky Note App); PsychoLlama (LevelDB); RangerMauve (schema); robertheessels (gun-p2p-auth); rogowski (AXE); sbeleidy; sbiaudet (C# Port); Sean Matheson (Observable/RxJS/Most.js bindings); Shadyzpop (React Native example); sjones6 (Flint); RIP Stefdv (Polymer/web components); zrrrzzt (JWT Auth); xmonader (Python Port);
I am missing many others, apologies, will be adding them soon! This list is infinitely old & way out of date, if you want to be listed in it please make a PR! :)
You will need to npm install -g mocha first. Then in the gun root folder run npm test. Tests will trigger persistent writes to the DB, so subsequent runs of the test will fail. You must clear the DB before running the tests again. This can be done by running rm -rf *data* command in the project directory.
These are only needed for NodeJS & React Native, they shim the native Browser WebCrypto API.
If you want to use SEA for User auth and security, you will need to install:
npm install @peculiar/webcrypto --save
Please see our React Native docs for installation instructions!
Then you can require SEA without an error:
GUN = require('gun/gun');
SEA = require('gun/sea');Note: The default examples that get auto-deployed on
npm startCDN-ify all GUN files, modules, & storage.
Note: Moving forward, AXE will start to automatically cluster your peer into a shared DHT. You may want to disable this to run an isolated network.
Note: When deploying a web application using GUN on a cloud provider, you may have to set
CI=falsein your.env. This prevents GUN-specific warnings from being treated as errors when deploying your app. You may also resolve this by modifying your webpack config to not try to build the GUN dependencies.
To quickly spin up a GUN relay peer for your development team, utilize Heroku, Docker, or any others listed below. Or some variant thereof Dokku, K8s, etc. ! Or use all of them so your relays are decentralized too!
SSH into the home directory of a clean OS install with sudo ability. Set any environment variables you need (see below), then do:
curl -o- https://raw.githubusercontent.com/amark/gun/master/examples/install.sh | bashRead install.sh first! If
curlis not found, copy&paste the contents of install.sh into your ssh.
You can now safely CTRL+A+D to escape without stopping the peer. To stop everything killall screen or killall node.
Environment variables may need to be set like export HTTPS_CERT=~/cert.pem HTTPS_KEY=~/key.pem PORT=443. You can also look at a sample nginx config. For production deployments, you probably will want to use something like pm2 or better to keep the peer alive after machine reboots.
Deploy GUN in one-click with Dome and receive a free trial:


Heroku deletes your data every 15 minutes, one way to fix this is by adding cheap storage.
Or:
git clone https://github.com/amark/gun.git
cd gun
heroku create
git push -f heroku HEAD:masterThen visit the URL in the output of the 'heroku create' step, in a browser. Make sure to set any environment config vars in the settings tab.

Then visit the URL in the output of the 'now --npm' step, in your browser.
Warning: Docker image is community contributed and may be old with missing security updates, please check version numbers to compare.




Pull from the Docker Hub 
docker run -p 8765:8765 gundb/gunOr build the Docker image locally:
git clone https://github.com/amark/gun.git
cd gun
docker build -t myrepo/gundb:v1 .
docker run -p 8765:8765 myrepo/gundb:v1Or, if you prefer your Docker image with metadata labels (Linux/Mac only):
npm run docker
docker run -p 8765:8765 username/gun:gitThen visit http://localhost:8765 in your browser.
Designed with ♥ by Mark Nadal, the GUN team, and many amazing contributors.
Openly licensed under Zlib / MIT / Apache 2.0.


































































































































































































































