aliyun / plugsched Goto Github PK
View Code? Open in Web Editor NEWLive upgrade Linux kernel scheduler subsystem
License: BSD 3-Clause "New" or "Revised" License
Live upgrade Linux kernel scheduler subsystem
License: BSD 3-Clause "New" or "Revised" License




















































































Since python2 is no longer supported by the python core team, and python3 is becoming more and more popular, it's time to switch to python3.
BTW, if plugsched become mature or popular enough, we can replace gcc-python-plugin with gcc c++plugin. ^_^
The module-contrib/version file is used to identify the version of the plugsched SDK used to build the scheduler RPM. Without it, it's hard to debug. However, we have released three version, but module-contrib/version file is still empty.
plugsched version: 0.0.0
This bug is observed in another subsystem than scheduler.
#define XXX(x) \
void x(int arg) \
{ \
BODY \
} \
EXPORT_SYMBOL_GPL(x)If we simply remove EXPORT_SYMBOL_GPL. It leaves an undesired backslash behind }.
Figure out the solution. A potential one is to #define __DISABLE_EXPORTS, which however restraints the module from defining new export function easily in the future.
Interface functions and callbacks are subject to stack safety checks. And function sizes are required by stack safety checker.
The current method to retrieve it is to call kernel's kallsyms_lookup_size_offset function.
Retrieve the size of the function through other methods (such as readelf and other tools), so as to get rid of the dependence of interfaces such as kallsyms_lookup. E.g:

Use the readelf tool to view the information of the __schedule function symbol in vmlinux, the third column is its size. After obtaining the size of interface functions and function pointers in vmlinux through similar methods, they can be used when compiling modules.
For the size of the interface functions in the module, their size can be obtained in the same way, and finally written into the module's binary through the symbol_resolve tool.
Help beginners to experiment with
To use Group Scheduling as an example,
Author: Yihao Wu <[email protected]>
Date: Wed Apr 20 15:45:10 2022 +0800
sched: flatten group scheduling
It's the easiest (but not cleanest) way to get rid of group scheduling.
Because there are times (maybe) users may not want anyone to create random
task_groups.
Signed-off-by: Yihao Wu <[email protected]>
diff --git a/kernel/sched/mod/sched.h b/kernel/sched/mod/sched.h
index 79605da02..362c61a67 100644
--- a/kernel/sched/mod/sched.h
+++ b/kernel/sched/mod/sched.h
@@ -1504 +1504 @@ static inline void set_task_rq(struct task_struct *p, unsigned int cpu)
- struct task_group *tg = task_group(p);
+ struct task_group *tg = &root_task_group;People want to use plugsched to extract ebpf subsystem code, and they meet lots of problems. Renaming variable, config, file from sched-prefixed name to general purpose name, will let plugsched to used in ebpf subsystem more easy.
e.g.
sched_boundary --> boundary
sched_boundary.py --> collect.py
process.py --> analyze.py
sched_boundary.yaml --> boundary.yaml
Now the plugsched uses iterative algorithm to achieve the inflect algorithm. But the floodfill can also achieve this function and has the more clear logic than iteration.
Use the floodfill to optimize inflect algorithm.
Scheduler will replace interface functions in kernel with corresponding functions in module. If the func1 interface function has func1 and func1.part.1 symbols in vmlinux, the callers of func1 can call the func1 or func1.part.1 instead of only func1, which is not our aim and the func1 cannot be replaced. For the .cold, it is not going to be an entry point.
If a interface function has other gcc mangled symbol that maybe a entrypoint, it should be deleted from interface function list.
If plugsched is already installed, command systemctl restart plugsched will fail because of confict detection, but the scheduler module is still loaded, which confuses the user.
The current Sidecar is cumbersome to use, requiring a lot of code to be copied, the user experience is not good, and the design needs to be refactored. One option is listed below:
Put the [file name X + function name Y] to be modified by the sidecar into the sched_boundary.yaml file. Benefits:
a. The init stage processes the sidecar information at the same time, thereby deleting sidecar.py and shortening the compilation time;
b. We can obtain a broader scheduler boundary. For example, adding psi_memstall_enter, psi_memstall_leave to the list avoids this_rq_lock_irq and rq_unlock_irq to be infected.
Automatically generate a new file sidecar_X.c, write the following information from X.c to the new file:
a. header file
b. The newly defined data structure definition in the file;
c. inline function;
d. Static functions that are compiled and optimized;
e. The function Y to be replaced;
Automatically add sidecar_X.c to Makefile;
According to vmlinux, automatically solve the problem of symbol location and redirection in Y; (guarantee that scheduler.ko can run normally without modifying function Y)
If function Y is compiled and optimized, an error will be reported, prompting the user to replace the caller of the function Y;
GCC has many bugs in its pretty printer, we guess mostly because GCC concentrate more on compiling itself rather than LLVM clang. The latter is used widely in code format.
GccBugs class in sched_boundary.py doesn't waste effort to fix these bugs, but only workaround these bugs.
Improve GccBugs code quality. Especially function_signature method.
GCC does not know where the macro starts or ends, so it only replaces the first line with a declaration and does not delete the next lines in code extraction stage, so the next lines become useless wrong code and compiling failed. Now we use the pre_extract.patch to fix this problem manually.
For example:
Before extraction, original variables definition:
CACHE_HEADER(fair_sched_cache_header, DEFAULT_CACHE_SIZE,
fair_sched_clean_up, __free_fair_sched_group);
After extraction:
extern struct cache_header fair_sched_cache_header;
fair_sched_clean_up, __free_fair_sched_group);
Fix the bug above.
From commit 2ed8233 (src: fix the bug kernel modules don't inflect outsiders), the init stage time increased significantly, which is bad for Agile development and testing.
There are two parts of cli.py need to be improved about the code quality.
1. Reusing kernel (either downloaded&extraced kernel-devel package, or source code) path initializing code
These two code blocks do the same thing, except that they do within different folders.
vmlinux = '/usr/lib/debug/lib/modules/' + release_kernel + '/vmlinux'
if not os.path.exists(vmlinux):
logging.fatal("%s not found, please install kernel-debuginfo-%s.rpm", vmlinux, release_kernel)
sym_vers = '/usr/src/kernels/' + release_kernel + '/Module.symvers'
kernel_config = '/usr/src/kernels/' + release_kernel + '/.config'
makefile = '/usr/src/kernels/' + release_kernel + '/Makefile'
if not os.path.exists(kernel_config):
logging.fatal("%s not found, please install kernel-devel-%s.rpm", kernel_config, release_kernel)
plugsched = Plugsched(work_dir, vmlinux, makefile) if not os.path.exists(kernel_src):
logging.fatal("Kernel source directory not exists")
vmlinux = os.path.join(kernel_src, 'vmlinux')
if not os.path.exists(vmlinux):
logging.fatal("%s not found, please execute `make -j %s` firstly", vmlinux, cpu_count())
sym_vers = os.path.join(kernel_src, 'Module.symvers')
kernel_config = os.path.join(kernel_src, '.config')
makefile = os.path.join(kernel_src, 'Makefile')
if not os.path.exists(kernel_config):
logging.fatal("kernel config %s not found", kernel_config)
plugsched = Plugsched(work_dir, vmlinux, makefile)2. Unitize Plugsched class variables
plugsched = Plugsched(work_dir, vmlinux, makefile)
plugsched.cmd_init(kernel_src, sym_vers, kernel_config)
work_dir, vmlinux, makefile are treat as class member variables, while
sym_vers and kernel_config are treat as local variables.
sym_vers and kernel_config class member variables tooIn generated scheduler module files, there are such kind of function decleration. It's better to merge ';' to the previous line.
void wake_up_q(struct wake_q_head *head)
;
int sched_setscheduler(struct task_struct *p, int policy,
const struct sched_param *param)
;
Plugsched relaxed the compiler checks because symbol-resolve allows UND symbols at compiler-time & link-time. And more compiler checks are compromised and we've no idea how. This leads to unexpected escaping of various bugs from time to time. For example, unmatched number of function parameters isn't noticed.
Harden compiler checks to make these bugs easier to be caught, without interfering symbol-resolve.
When applying plugsched to ebpf subsystem, people found thant main.c cann't be shared by both scheduler and ebpf. In main.c, there are both common framework code and scheduler-related code.
Just like kpatch can handle all kinds of hotfix, we can transform main.c into a unified framework, which can be easily used by scheduler and ebpf.
e.g., a file is at kernel/xxx/yyy.c
#include "zzz.h" -> this will include kernel/xxx/zzz.h
however, after init, this file will be at kernel/sched/mod/yyy.c
#include "../zzz.h" -> this will try to look for kernel/sched/zzz.h, but it not exists!
To improve readability of the code
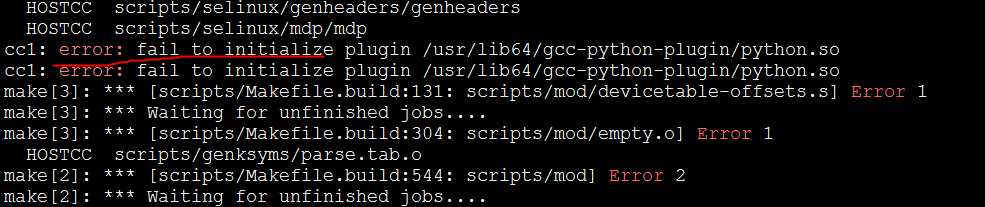
When I try to use master branch, it doesn't work in old container images now. Then, I try to build the latest image at local, but soon meet a bug.
steps to reproduce:
We use the term function pointer to indicate those functions that at least used once in these situations
However, this term is misleading. Because in the C world, we call this these variables or parameters, instead of the function themselves as function pointers.
callback is the right and conventional term we refer to those functions.
Rename fn_ptr, function pointer and whatsoever to callback in
Now, even if sidecar is not used, the builder will analyze vmlinux, which costs extra time of building.
Don't deal with sidecar when the scheduler module do not use the sidecar.
There are some typos in main.c, which refers to CPU as process. Fix it to processor.
In either case, the scheduler's behavior should follow users' intuition.
Document on how users should cope with these two situations.
There is a compilation error when building the scheduler module for arm64 kernel-4.19. See the error:
/root/scheduler/kernel/sched/mod//main.c: In function 'disable_stack_protector':
/root/scheduler/kernel/sched/mod//main.c:137:35: error: 'STACK_PROTECTOR' undeclared (first use in this function)
137 | void *addr = __orig___schedule + STACK_PROTECTOR;
| ^~~~~~~~~~~~~~~
/root/scheduler/kernel/sched/mod//main.c:137:35: note: each undeclared identifier is reported only once for each function it appears in
/root/scheduler/kernel/sched/mod//main.c:139:14: error: 'STACK_PROTECTOR_LEN' undeclared (first use in this function)
139 | for (i=0; i<STACK_PROTECTOR_LEN; i++, addr+=4)
| ^~~~~~~~~~~~~~~~~~
The reason of this error is that the springboard_search.sh tool uses the /usr/src/kernels/release-kernel/.config to determine whether the CONFIG_STACKPROTECTOR_PER_TASK is set, but CONFIG_STACKPROTECTOR_PER_TASK config is added to config file later when building the kernel. So the tool should use the scheduler/.config instead of /usr/src/kernels/release-kernel/.config.
Fix the compilation error.
For c code style, we follow Linux kernel, but what about the python code? 50+% code is written in python, and some of them are poorly written. For examples:
"" and ''For python code, we'd like to follow pep8 style.
https://peps.python.org/pep-0008/
The mempool is a technology of plugsched to allocate memory object that is used to multiplex the reserve fields.
For examples, for the task_struct's reserve fields, mempool will allocate a large memory and distribute these memory to each thread. But lack of documentation.
Add the mempool documentation.
When experimenting modularization with another subsystem E, a strange issue arouse.
The system crashes at module's bsearch function. However, this subsystem expects the bsearch to be its own variant of bsearch instead of the one we implemented, which is for stack-inspection
The code in analyze.py is poorly organized, especially since most of the logic is concentrated in the main function.
We have some manual test set. We should refactor them to improve code quality, ensure their coverage, and add them to the tests/
shared non-critical data should be inherited. Observe this in extracted code.shared non-critical data should be inherited. Observe this in running system.sched rebuild is functional.stack balancing technique is functionalsched springboard technique is functional.We determine whether a function is an init function by whether it is defined in the .init.text section. But there are some init functions are placed in .ref.text section and the plugin does not currently recognize this.
Mark functions placed in .ref.text section as init functions.
The sched_submit_work is a optimized(inline) function, and is only used by the outsider, so its code should be deleted. But we have not handled this case yet. Now, if a function is optimized_out, it can't be modified. See the fallowing:

The code of optimized outside function need to be deleted.
Write document to tell people:
BTW, though one figure illustrating the macro view of the design. But it's good to have a detailed one to help contributions to get a thorough understanding of the whole project. (code tree)
In bpf, the assert in boundary/analyze.py:
assert (key, file) not in local_sympos
will be hit when key='__bpf_prog_run_save_cb' and file='include/linux/filter.h'
However, this key is in different c files (e.g., kernel/bpf/cgroup.c and net/core/filter.c). But analyze.py get the filename as filter.h
Until now, plugsched only supports Anolis OS 7.9 ANCK, it's not friendly to linux kernel communities. To encourage more people use it, we plan to support vanila kernel 5.10 LTS.
In ebpf subsystem, there are 36 bpf files locate at kernel/bpf/ directory. In current implementation, user need to add 36 lines into config. However, ebpf subsystem is still being developed at a high speed, with file numbers varying between kernel versions. Which makes config hard to maintain.
mod_files:
- kernel/bpf/arraymap.c
- kernel/bpf/bpf_inode_storage.c
- kernel/bpf/bpf_iter.c
- kernel/bpf/bpf_local_storage.c
- kernel/bpf/bpf_lru_list.c
- kernel/bpf/bpf_lsm.c
- kernel/bpf/bpf_struct_ops.c
- kernel/bpf/bpf_task_storage.c
- kernel/bpf/btf.c
- kernel/bpf/cgroup.c
- kernel/bpf/core.c
- kernel/bpf/cpumap.c
- kernel/bpf/devmap.c
- kernel/bpf/disasm.c
- kernel/bpf/dispatcher.c
- kernel/bpf/hashtab.c
- kernel/bpf/helpers.c
- kernel/bpf/inode.c
- kernel/bpf/local_storage.c
- kernel/bpf/lpm_trie.c
- kernel/bpf/map_in_map.c
- kernel/bpf/map_iter.c
- kernel/bpf/net_namespace.c
- kernel/bpf/offload.c
- kernel/bpf/percpu_freelist.c
- kernel/bpf/prog_iter.c
- kernel/bpf/queue_stack_maps.c
- kernel/bpf/reuseport_array.c
- kernel/bpf/ringbuf.c
- kernel/bpf/stackmap.c
- kernel/bpf/syscall.c
- kernel/bpf/sysfs_btf.c
- kernel/bpf/task_iter.c
- kernel/bpf/tnum.c
- kernel/bpf/trampoline.c
- kernel/bpf/verifier.c
With file wildcard, we can simplify config greatly.
mod_files:
- kernel/bpf/*.c
In boundary division, functions are divided into three categories:
Callback functions (passed as parameters or assigned to variables) is classified as interface functions automatically.
Interface function has some constraint to users.
However, callbacks are automatically detected by the GCC plugin. And GCC plugin is pretty conservative, it detects nearly 100 functions as callbacks.
But some of them are only called by internal functions and interface functions, so they are essentially internal functions. GCC plugin is too conservative, and it adds too much constraint to the users. Especially whether they can modify the function signature.
For example, the callback defined in sched_class: pick_next_task. All its alternative,
They are all callbacks, and they are all only called by pick_next_task function.
Further, pick_next_task is also only called by _schedule (interface function) and migrate_tasks (internal function).
So actually the pick_next_task* functions can be modified, including the function signature.
Further more, if there are more than one interface functions with the same name defined in different source file, using objcopy to globalize them will cause the redefined error because these functions have the same name and be globalized.
Using the objcopy to globalize the interface functions can avoid them being optimized and export the symbols of them to main.o to do the function redirections. objcopy can help us to achieve both goals.
Luckly, we haven't had that problem yet because the code of scheduler subsystem have not this case.
Now, the collect stage in init process can generate the vmlinux and Modules.symvers files that can rewrite these files copied from kernel-devel and kernel-debuginfo, and we can not get the right symbols' informations of vmlinux.
Use the correct vmlinux and Modules.symvers instead of the generated files.
aarch64_insn_patch_text_nosync is relatively inefficient, re-establish a mapping, only one function can be modified at a time, and then unmap. We can first map vmlinux as a whole, then modify it in batches, and finally unmap.
It can be optimized, but not perfect, because FIX_TEXT_POKE0 can only map one page, so only a part of the functions can be modified at one time, and the whole vmlinux cannot be mapped at one time.
Or can we find another virtual address, without FIX_TEXT_POKE0, map a large range at once
mempool is placed in the src/mempool.h file, which is currently composed of several parts
The example part is implemented as annotated code, which has several flaws.
The common definition part, users complain that, It lacks parameter verification, resulting in a constant-sized memory pool that can even be compiled.
Plugsched dosn't support the sympos of the data symbols yet. But it is possible that there have a symbol of a static variable that has the same name as a global function in vmlinux. So it is necessary to distinguish the sympos between the data and function symbols.
Support the sympos of the data symbols and distinguish between data and function symbols.
Currently all static variables are manually found and added to extra_public, and some variables may be missed. And different kernel version may have different static variables, which needs extra works to find them.
Set the static variables to shared data automatically.
Now there are many places in sched_boundary.py that are repeatedly writing circular dereferences


For example: struct data_type **; this is a PointerType, and the type of struct data_type is required, so the pointer type needs to be dereferenced twice.
Recursive dereference is used many times in sched_boundary.py, it is best to optimize it and unify the code.
We introduced mempool as the framework to easily allocate or deallocate object for scheduler memory objects (task_struct, sched_entity, cfs_rq, etc.). And we still lack a formalized way to manage the life cycle of these allocated object.
For example when allocating
are all places where we initialize tasks. However,
copy_process is within kernel/fork.c, so it's outside of the scheduler.
wake_up_new_task doesn't allow to return error when lacking sufficient memory.
sched_fork might be a good place to do this. We should verify it carefully.
Deallocating is even more complicated
are all places where we deallocating tasks. However,
release_task may be called when the task is still on rq, so "dequeue" may appear after "release".
release_thread might be a good place, but it's arch-specific function and scattered in all arch/**/processor.h.
exit_thraed is the same as above.
put_task_struct happens way after the task is removed from the linked-list. If rmmod happens in this gap, kernel panics.
do_task_dead is the same as above.
sched_entity is even more complicated than task_struct.
Get things straight, design a whole proper solution.
The va_list argument is extracted to "struct *" in export_jump.h, which causes a compiling error:
export_jump.h:29:18: error: conflicting types for ********
The bug related extraction of va_list is fixed by 3cafcf72 which fixes the declarations including va_list argument in source file but not deal with the export_jump.h file.
When generating the export_jump.h file, plugin should uses the is_val_list API to recognize the va_list arguments and fix them. For example:
PLUGSCHED_FN_PTR(btf_seq_show, void, struct btf_show *, const char *, struct *)
Fix the bug about extraction of va_list argument in export_jump.h.
#36 says,
"yum way will get the pyyaml with libyaml by default, so the --with-libyaml parameter is removed."
However tests show that this is only true in Dockerfile.x86_64, not in Dockerfile.aarch64. Because they use different base images. This results in broken aarch64 image, which may influenced v1.1.1 as well.
Figure out why #36 breaks Dockerfile.aarch64. And fix this bug
The __init functions is deleted by the sed tool. Some of these functions are configured by the CONFIG_XXX, for the fallowing example:
#ifdef CONFIG_SMP
void __init sched_init_smp(void) --> A
{
}
#else
void __init sched_init_smp(void) --> B
{
}
#endifIf CONFIG_SMP is enabled, the signature of function B will be deleted which is unfriendly to code reading.
Some new developers feedback to us, the code in sched_boundary directory is hard to understand. Here are some reasons:
During build stage, plugsched expect EXTRAVERSION will end with ".x86_64" or ".aarch64". However, if developer set it as an invalid string (e.g. EXTRAVERSION = "abcdef"), build RPM will fail and the following error message will be printed.
AttributeError: 'Plugsched' object has no attribute 'KREL'
To let developer clear, we should handle invalid EXTRAVERSION gracefully.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.