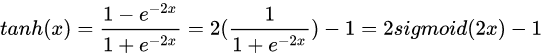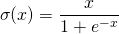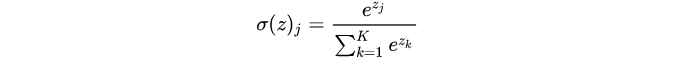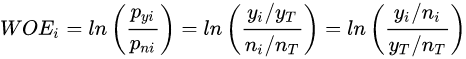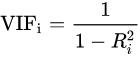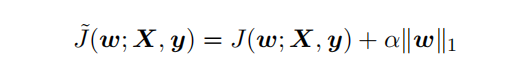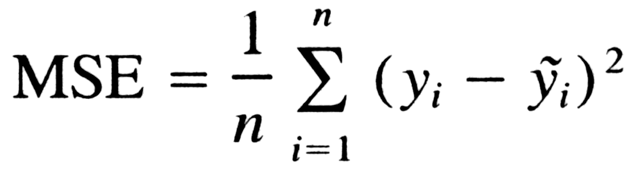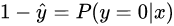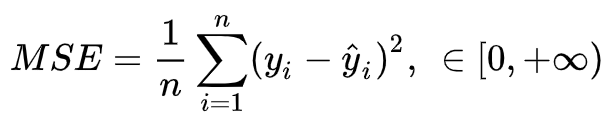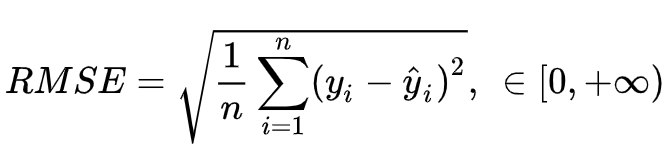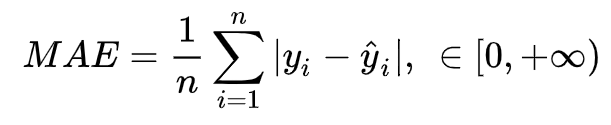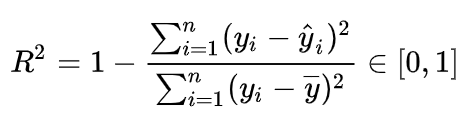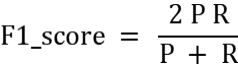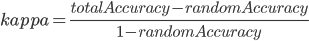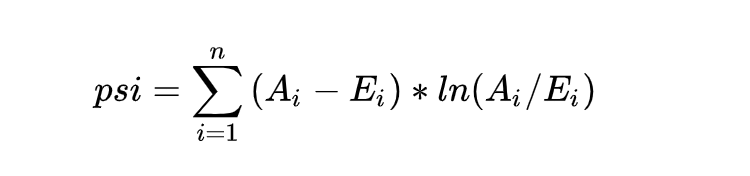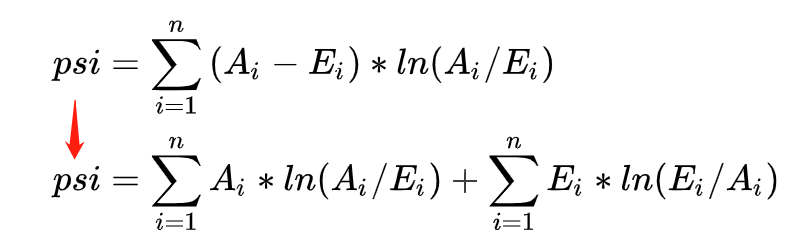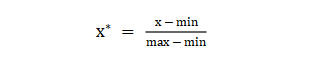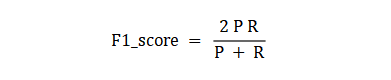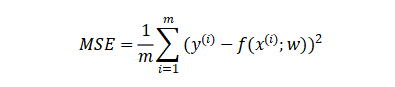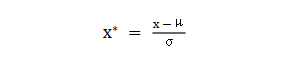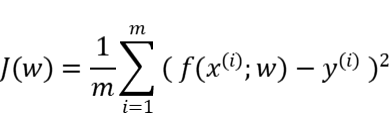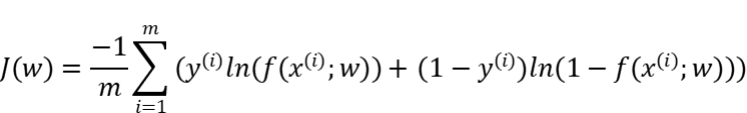| 代码&资料 | |
|---|---|
| 《一文梳理金融风控建模全流程(Python)》 | 代码 |
| 《基于知识图谱的营销反欺诈全流程》 | |
| 《客户流失预测及营销(Python)》 | 代码 |
| 《一窥推荐系统的原理》 | |
| 《推荐项目实战(双塔模型)》 | 代码 |
| 《金融科技的技术概览》 | |
| 《海外金融风控算法实践(Python)》 | 代码 |

Python机器学习算法技术博客,有原创干货!有code实践! 【更多内容敬请关注公众号 "算法进阶"】
Home Page: https://github.com/aialgorithm/Blog
| 代码&资料 | |
|---|---|
| 《一文梳理金融风控建模全流程(Python)》 | 代码 |
| 《基于知识图谱的营销反欺诈全流程》 | |
| 《客户流失预测及营销(Python)》 | 代码 |
| 《一窥推荐系统的原理》 | |
| 《推荐项目实战(双塔模型)》 | 代码 |
| 《金融科技的技术概览》 | |
| 《海外金融风控算法实践(Python)》 | 代码 |

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")















































































































谷歌最近出品的82页论文《ON THE GENERALIZATION MYSTERY IN DEEP LEARNING》,在此我简单归纳下论文的**,有兴趣的看看原论文。
论文链接:github.com/aialgorithm/Blog
论文主要探讨的是, 为什么过参数的神经网络模型还能有不错的泛化性?即并不是简单记忆训练集,而是从训练集中总结出一个通用的规律,从而可以适配于测试集(泛化能力)。
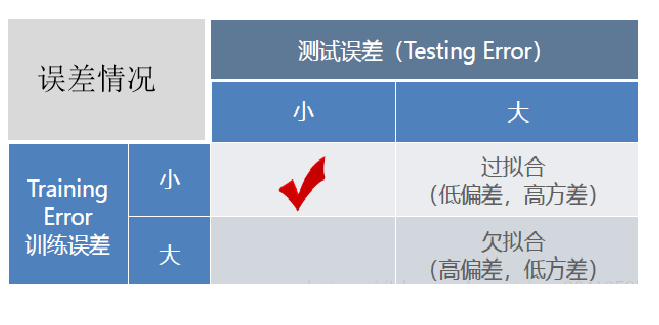
以经典的决策树模型为例, 当树模型学习数据集的通用规律时:一种好的情况,假如树第一个分裂节点时,刚好就可以良好区分开不同标签的样本,深度很小,相应的各叶子上面的样本数是够的(即统计规律的数据量的依据也是比较多的),那这会得到的规律就更有可能泛化到其他数据。(即:拟合良好, 有泛化能力)。
另外一种较差的情况,如果树学习不好一些通用的规律,为了学习这个数据集,那树就会越来越深,可能每个叶子节点分别对应着少数样本(少数据带来统计信息可能只是噪音),最后,死记硬背地记住所有数据(即:过拟合 无泛化能力)。我们可以看到过深(depth)的树模型很容易过拟合。
那么过参数化的神经网络如何达到良好的泛化性呢?
本文是从一个简单通用的角度解释——在神经网络的梯度下降优化过程上,探索泛化能力的原因:
我们总结了梯度相干理论 :来自不同样本的梯度产生相干性,是神经网络能有良好的泛化能力原因。当不同样本的梯度在训练过程中对齐良好,即当它们相干时,梯度下降是稳定的,可以很快收敛,并且由此产生的模型可以有良好的泛化性。 否则,如果样本太少或训练时间过长,可能无法泛化。
基于该理论,我们可以做出如下解释。
更宽的神经网络模型具有良好的泛化能力。这是因为,更宽的网络都有更多的子网络,对比小网络更有产生梯度相干的可能,从而有更好的泛化性。 换句话说,梯度下降是一个优先考虑泛化(相干性)梯度的特征选择器,更广泛的网络可能仅仅因为它们有更多的特征而具有更好的特征。
原文:Generalization and width. Neyshabur et al. [2018b] found that wider networks generalize better. Can we now explain this? Intuitively, wider networks have more sub-networks at any given level, and so the sub-network with maximum coherence in a wider network may be more coherent than its counterpart in a thinner network, and hence generalize better. In other words, since—as discussed in Section 10—gradient descent is a feature selector that prioritizes well-generalizing (coherent) features, wider networks are likely to have better features simply because they have more features. In this connection, see also the Lottery Ticket Hypothesis [Frankle and Carbin, 2018]
但是个人觉得,这还是要区分下网络输入层/隐藏层的宽度。特别对于数据挖掘任务的输入层,由于输入特征是通常是人工设计的,需要考虑下做下特征选择(即减少输入层宽度),不然直接输入特征噪音,对于梯度相干性影响不也是有干扰的。
越深的网络,梯度相干现象被放大,有更好的泛化能力。
在深度模型中,由于层之间的反馈加强了有相干性的梯度,存在相干性梯度的特征(W6)和非相干梯度的特征(W1)之间的相对差异在训练过程中呈指数放大。从而使得更深的网络更偏好相干梯度,从而更好泛化能力。
通过早停我们可以减少非相干梯度的过多影响,提高泛化性。
在训练的时候,一些容易样本比其他样本(困难样本)更早地拟合。训练前期,这些容易样本的相干梯度做主导,并很容易拟合好。训练后期,以困难样本的非相干梯度主导了平均梯度g(wt),从而导致泛化能力变差。
(注:简单的样本,是那些在数据集里面有很多梯度共同点的样本,正由于这个原因,大多数梯度对它有益,收敛也比较快。)
我们发现全梯度下降也可以有很好的泛化能力。此外,仔细的实验表明随机梯度下降并不一定有更优的泛化,但这并不排除随机梯度更易跳出局部最小值、起着正则化等的可能性。
Based on our theory, finite learning rate, and mini-batch stochasticity
are not necessary for generalization
我们认为较低的学习率可能无法降低泛化误差,因为较低的学习率意味着更多的迭代次数(与早停相反)。
Assuming a small enough learning rate, as training progresses, the generalization gap cannot decrease. This follows from the iterative stability analysis of training: with 40 more steps, stability can only degrade. If this is violated in a practical setting, it would point to an interesting limitation of the theory
目标函数加入L2、L1正则化,相应的梯度计算, L1正则项需增加的梯度为sign(w) ,L2梯度为w。以L2正则为例,相应的梯度W(i+1)更新公式为:
我们可以把“L2正则化(权重衰减)”看作是一种“背景力”,可将每个参数推近于数据无关的零值 ( L1容易得到稀疏解,L2容易得到趋近0的平滑解) ,来消除在弱梯度方向上影响。只有在相干梯度方向的情况下,参数才比较能脱离“背景力”,基于数据完成梯度更新。
Momentum 、Adam等梯度下降算法,其参数W更新方向不仅由当前的梯度决定,也与此前累积的梯度方向有关(即,保留累积的相干梯度的作用)。这使得参数中那些梯度方向变化不大的维度可以加速更新,并减少梯度方向变化较大的维度上的更新幅度,由此产生了加速收敛和减小震荡的效果。
我们可以通过优化批次梯度下降算法,来抑制弱梯度方向的梯度更新,进一步提高了泛化能力。比如,我们可以使用梯度截断(winsorized gradient descent),排除梯度异常值后的再取平均值。或者取梯度的中位数代替平均值,以减少梯度异常值的影响。
文末说两句,对于深度学习的理论,有兴趣可以看下论文提及的相关研究。个人水平有限,不足之处还望指教,有什么见解,欢迎学习群相互讨论下。
文章首发公众号“算法进阶”,欢迎关注。公众号阅读原文可访问文章相关代码及资料
本文第一节源于周志华教授《关于深度学习的一点思考》提出深度森林的探索, 在此基础上对深度森林做了原理解析并实践。
周志华教授,毕业于南京大学,欧洲科学院外籍院士,国家杰出青年基金获得者,现任南京大学人工智能学院院长、南京大学计算机软件新技术国家重点实验室常务副主任、机器学习与数据挖掘研究所 (LAMDA)所长、人工智能教研室主任。
2021年8月1日,**科学院公布2021年**科学院院士增选初步候选人名单,周志华在列;11月3日,周志华凭借《面向多义性对象的新型机器学习理论与方法》获得2020年度国家自然科学奖二等奖。
目前深度神经网络(DNN)做得好的几乎都是涉及图像视频(CV)、自然语言处理(NLP)等的任务,都是典型的数值建模任务(在表格数据tabular data的表现也是稍弱的),而在其他涉及符号建模、离散建 模、混合建模的任务上,深度神经网络的性能并没有那么好。
深度森林(gcForest)是深度神经网络(DNN)之外的探索的一种深度模型,原文:it may open a door towards alternative to deep neural networks for many tasks。不同于深度神经网络由可微的神经元组成,深度森林的基础构件是不可微的决策树,其训练过程不基于 BP 算 法,甚至不依赖于梯度计算。它初步验证了关于深度学习奏效原因的猜想--即只要能做到逐层加工处理、内置特征变换、模型复杂度够,就能构建出有效的深度学习模型,并非必须使用神经网络。
深度森林主要的特点是:
深度森林目前还处于探索阶段,评估模型(gcForest)的表现,在MNIST数据集准确率不错:
在CIFAR-10数据集上准确率欠佳:
深度森林其实也就是ensemble of ensemble的模型,可以看作是对集成树(森林)模型,进一步stacking集成学习及优化(Complete Random Forest、shortcut-connection、Multi-Grained Scanning等),以解决深层容易过拟合的问题。
深度森林借鉴了CNN滑动卷积核的特征提取,通过多粒度扫描(Multi-Grained Scanning)方法,滑动窗口扫描原始特征,生成输入特征。
如上图,假设我们现在有一个400维(序列数据)的样本输入,现在设定采样窗口是100维的,那我们可以通过逐步的采样,最终获得301个子样本(默认采样步长是1,得到的子样本个数 = (400-100)/1 + 1)。
整个特征处理的过程就是:先输入一个完整的P维样本,然后通过一个长度为k的采样窗口进行滑动采样,得到S = (P - K)/1+1 个k维特征子样本向量,接着每个子样本都用于完全随机森林和普通随机森林的训练并在每个森林都获得一个长度为C(类别数)的概率向量,这样每个森林会产生长度为S*C的表征向量(即经过随机森林转换并拼接的概率向量),最后把每层的F个森林的结果拼接在一起得到本层输出。
整个模型的架构采用一个级联结构(如上图), 每一级都采用两种森林构建: random forests (black) and completely-random tree forests(blue),使用completely-random可以增加基模型的多样性,以减少过拟合风险,提高集成学习的效果。
完全随机森林(completely-random tree forests):由多棵树组成,每棵树包含所有的特征,并且随机选择一个特征作为分裂树的分裂节点。一直分裂到每个叶子节点只包含一个类别或者不多于是个样本结束。
随机森林(random forests):同样由多棵树构成,每棵树通过随机选取Sqrt(特征总数)个特征 ,然后通过GINI分数来筛选分裂节点。
每一层的级联接收前一层处理的特征信息,并将处理结果(类向量)输出到下一层(如上图)。以三分类为例,输入特征为向量x,经过每个森林学习后(注:每个森林的学习的数据利用k折交叉验证得到,以减少过拟合风险),得到预测类分布,然后求平均,再与之前原始特征拼接(类似shortcut-connection),作为下一层的输入。
扩展完一层后,整个级联结构可在验证集上面测试性能,若没有显著提高,训练过程会终止,故而层数可以自动确定。这也是gcForest能够自动决定模型复杂度的原因。
本节简单使用深度森林模型用于波士顿房价回归预测及癌细胞分类任务。
安装:pip install deep-forest
# 回归预测--波士顿房价
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from deepforest import CascadeForestRegressor
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = CascadeForestRegressor(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("\nTesting MSE: {:.3f}".format(mse))
# 分类预测--癌细胞分类数据集
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from deepforest import CascadeForestClassifier
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = CascadeForestClassifier(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) * 100
print("\nTesting Accuracy: {:.3f} %".format(acc))
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算的前馈神经网络,是基于图像任务的平移不变性(图像识别的对象在不同位置有相同的含义)设计的,擅长应用于图像处理等任务。在图像处理中,图像数据具有非常高的维数(高维的RGB矩阵表示),因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。
对于高维图像数据,卷积神经网络利用了卷积和池化层,能够高效提取图像的重要“特征”,再通过后面的全连接层处理“压缩的图像信息”及输出结果。对比标准的全连接网络,卷积神经网络的模型参数大大减少了。
在信号处理、图像处理和其它工程/科学领域,卷积都是一种使用广泛的技术,卷积神经网络(CNN)这种模型架构就得名于卷积计算。但是,深度学习领域的“卷积”本质上是信号/图像处理领域内的互相关(cross-correlation),互相关与卷积实际上还是有些差异的。
卷积是分析数学中一种重要的运算。简单定义f , g 是可积分的函数,两者的卷积运算如下:
其定义是两个函数中一个函数(g)经过反转和位移后再相乘得到的积的积分。如下图,函数 g 是过滤器。它被反转后再沿水平轴滑动。在每一个位置,我们都计算 f 和反转后的 g 之间相交区域的面积。这个相交区域的面积就是特定位置出的卷积值。
互相关是两个函数之间的滑动点积或滑动内积。互相关中的过滤器不经过反转,而是直接滑过函数 f,f 与 g 之间的交叉区域即是互相关。
下图展示了卷积与互相关运算过程,相交区域的面积变化的差异:
在卷积神经网络中,卷积中的过滤器不经过反转。严格来说,这是离散形式的互相关运算,本质上是执行逐元素乘法和求和。但两者的效果是一致,因为过滤器的权重参数是在训练阶段学习到的,经过训练后,学习得到的过滤器看起来就会像是反转后的函数。
CNN通过设计的卷积核(convolution filter,也称为kernel)与图片做卷积运算(平移卷积核去逐步做乘积并求和)。
如下示例设计一个(特定参数)的3×3的卷积核:
让它去跟图片做卷积,卷积的具体过程是:
可以发现,通过特定的filter,让它去跟图片做卷积,就可以提取出图片中的某些特征,比如边界特征。
进一步的,我们可以借助庞大的数据,足够深的神经网络,使用反向传播算法让机器去自动学习这些卷积核参数,不同参数卷积核提取特征也是不一样的,就能够提取出局部的、更深层次和更全局的特征以应用于决策。
卷积运算的本质性总结:过滤器(g)对图片(f)执行逐步的乘法并求和,以提取特征的过程。卷积过程可视化可访问:https://poloclub.github.io/cnn-explainer/ 或 https://github.com/vdumoulin/conv_arithmetic
卷积神经网络通常由3个部分构成:卷积层,池化层,全连接层。简单来说,卷积层负责提取图像中的局部及全局特征;池化层用来大幅降低参数量级(降维);全连接层用于处理“压缩的图像信息”并输出结果。
卷积层主要功能是动态地提取图像特征,由滤波器filters和激活函数构成。一般要设置的超参数包括filters的数量、大小、步长,激活函数类型,以及padding是“valid”还是“same”。
卷积核大小(Kernel):直观理解就是一个滤波矩阵,普遍使用的卷积核大小为3×3、5×5等。在达到相同感受野的情况下,卷积核越小,所需要的参数和计算量越小。卷积核大小必须大于1才有提升感受野的作用,而大小为偶数的卷积核即使对称地加padding也不能保证输入feature map尺寸和输出feature map尺寸不变(假设n为输入宽度,d为padding个数,m为卷积核宽度,在步长为1的情况下,如果保持输出的宽度仍为n,公式,n+2d-m+1=n,得出m=2d+1,需要是奇数),所以一般都用3作为卷积核大小。
卷积核数目:主要还是根据实际情况调整, 一般都是取2的整数次方,数目越多计算量越大,相应模型拟合能力越强。
步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推。步长越小,提取的特征会更精细。
填充(Padding):处理特征图边界的方式,一般有两种,一种是“valid”,对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图像尺寸变得更小,且边缘信息容易丢失;另一种是还是“same”,对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致,边缘信息也可以多次计算。
通道(Channel):卷积层的通道数(层数)。如彩色图像一般都是RGB三个通道(channel)。
激活函数:主要还是根据实际验证,通常选择Relu。
另外的,卷积的类型除了标准卷积,还演变出了反卷积、可分离卷积、分组卷积等各种类型,可以自行验证。
通过卷积运算的介绍,可以发现卷积层有两个主要特点:局部连接(稀疏连接)和权值共享。
局部连接,就是卷积层的节点仅仅和其前一层的部分节点相连接,只用来学习局部区域特征。(局部连接感知结构的理念来源于动物视觉的皮层结构,其指的是动物视觉的神经元在感知外界物体的过程中起作用的只有一部分神经元。)
权值共享,同一卷积核会和输入图片的不同区域作卷积,来检测相同的特征,卷积核上面的权重参数是空间共享的,使得参数量大大减少。
由于局部连接(稀疏连接)和权值共享的特点,使得CNN具有仿射的不变性(平移、缩放等线性变换)
池化层可对提取到的特征信息进行降维,一方面使特征图变小,简化网络计算复杂度;另一方面进行特征压缩,提取主要特征,增加平移不变性,减少过拟合风险。 但其实池化更多程度上是一种计算性能的一个妥协,强硬地压缩特征的同时也损失了一部分信息,所以现在的网络比较少用池化层或者使用优化后的如SoftPool。
池化层设定的超参数,包括池化层的类型是Max还是Average(Average对背景保留更好,Max对纹理提取更好),窗口大小以及步长等。如下的MaxPooling,采用了一个2×2的窗口,并取步长stride=2,提取出各个窗口的max值特征(AveragePooling就是平均值):
在经过数次卷积和池化之后,我们最后会先将多维的图像数据进行压缩“扁平化”, 也就是把 (height,width,channel) 的数据压缩成长度为 height × width × channel 的一维数组,然后再与全连接层连接(这也就是传统全连接网络层,每一个单元都和前一层的每一个单元相连接,需要设定的超参数主要是神经元的数量,以及激活函数类型),通过全连接层处理“压缩的图像信息”并输出结果。
LeNet-5由Yann LeCun设计于 1998年,是最早的卷积神经网络之一。它是针对灰度图进行训练的,输入图像大小为32321,不包含输入层的情况下共有7层。下面逐层介绍LeNet-5的结构:
第一层是卷积层,用于过滤噪音,提取关键特征。使用5 * 5大小的过滤器6个,步长s = 1,padding = 0。
第二层是平均池化层,利用了图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息,降低网络训练参数及模型的过拟合程度。使用2 * 2大小的过滤器,步长s = 2,padding = 0。池化层只有一组超参数pool_size 和 步长strides,没有需要学习的模型参数。
第三层使用5 * 5大小的过滤器16个,步长s = 1,padding = 0。
第四层使用2 * 2大小的过滤器,步长s = 2,padding = 0。没有需要学习的参数。
第五层是卷积层,有120个5 * 5 的单元,步长s = 1,padding = 0。
有84个单元。每个单元与F5层的全部120个单元之间进行全连接。
Output层也是全连接层,采用RBF网络的连接方式(现在主要由Softmax取代,如下示例代码),共有10个节点,分别代表数字0到9(因为Lenet用于输出识别数字的),如果节点i的输出值为0,则网络识别的结果是数字i。
如下Keras复现Lenet-5:
from keras.models import Sequential
from keras import layers
le_model = keras.Sequential()
le_model.add(layers.Conv2D(6, kernel_size=(5, 5), strides=(1, 1), activation='tanh', input_shape=(32,32,1), padding="valid"))
le_model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))
le_model.add(layers.Conv2D(16, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))
le_model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))
le_model.add(layers.Conv2D(120, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))
le_model.add(layers.Flatten())
le_model.add(layers.Dense(84, activation='tanh'))
le_model.add(layers.Dense(10, activation='softmax'))以keras经典的CIFAR10图像数据集的分类为例,代码:https://github.com/aialgorithm/Blog
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import keras
import os
# 数据,切分为训练和测试集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')


# 展示数据集
import matplotlib.pyplot as plt
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[y_train[i][0]])
plt.show()
# 将标签向量转换为二值矩阵。
num_classes = 10 #图像数据有10个实际标签类别
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print(y_train.shape, 'ytrain')
# 图像数据归一化
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255

# 构造卷积神经网络
model = Sequential()
# 图像输入形状(32, 32, 3) 对应(image_height, image_width, color_channels)
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
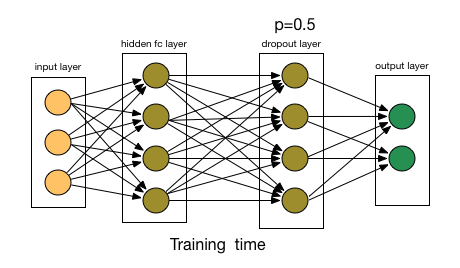
model.add(Dropout(0.25))
# 卷积、池化层输出都是一个三维的(height, width, channels)
# 越深的层中,宽度和高度都会收缩
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 3 维展平为 1 维 ,输入全连接层
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes)) # CIFAR数据有 10 个输出类,以softmax输出多分类
model.add(Activation('softmax'))
# 初始化 RMSprop 优化器
opt = keras.optimizers.rmsprop(lr=0.001, decay=1e-6)
# 模型编译:设定RMSprop 优化算法;设定分类损失函数;
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
batch_size = 64
epochs = 5
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
附卷积神经网络优化方法(tricks):
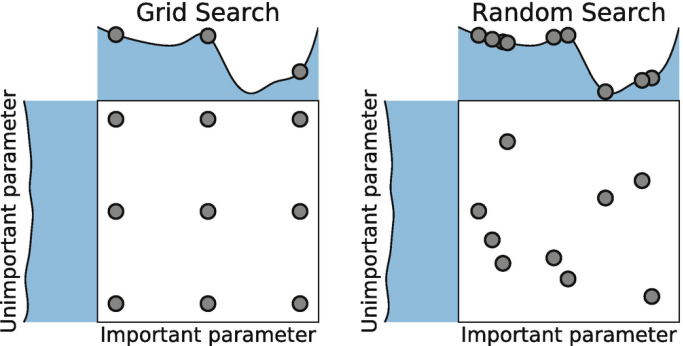
超参数优化:可以用随机搜索、贝叶斯优化。推荐分布式超参数调试框架Keras Tuner包括了常用的优化方法。
数据层面:数据增强广泛用于图像任务,效果提升大。常用有图像样本变换、mixup等。更多优化方法具体可见:https://arxiv.org/abs/1812.01187
# 保存模型和权重
num_predictions = 20
save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'keras_cifar10_trained_model.h5'
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name)
model.save(model_path)
print('Saved trained model at %s ' % model_path)
# 评估训练模型
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
文章首发公众号“算法进阶”,公众号阅读原文可访问文章相关代码
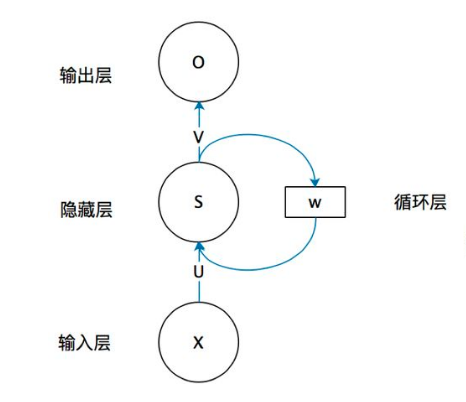
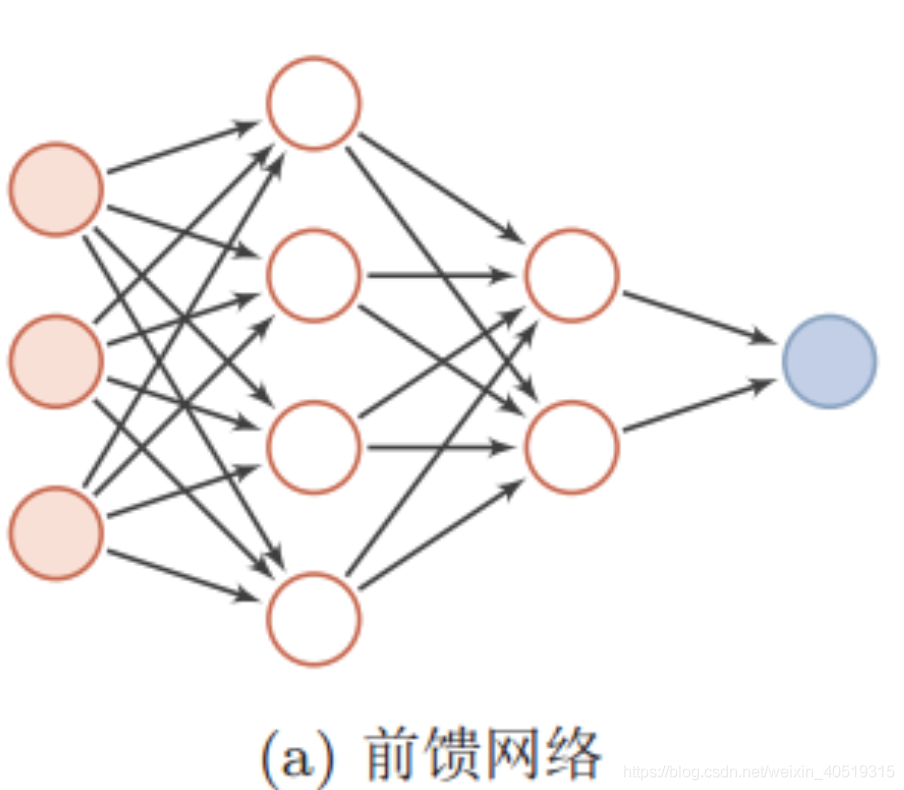
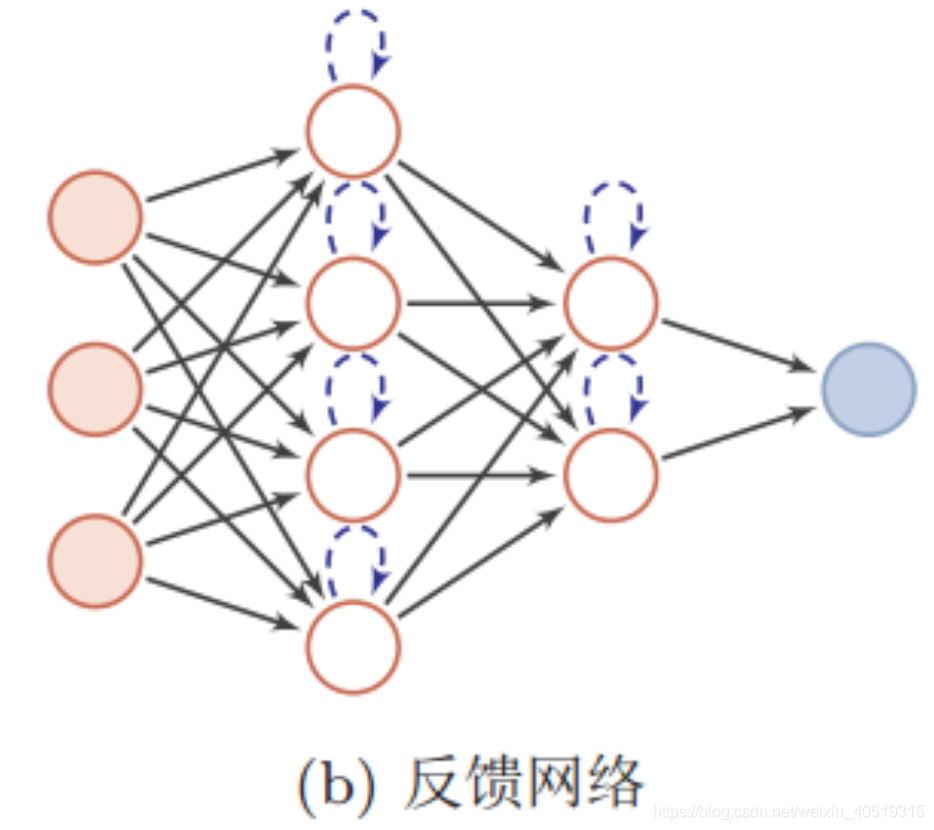
循环神经网络(RNN)是基于序列数据(如语言、语音、时间序列)的递归性质而设计的,是一种反馈类型的神经网络,其结构包含环和自重复,因此被称为“循环”。它专门用于处理序列数据,如逐字生成文本或预测时间序列数据(例如股票价格)。
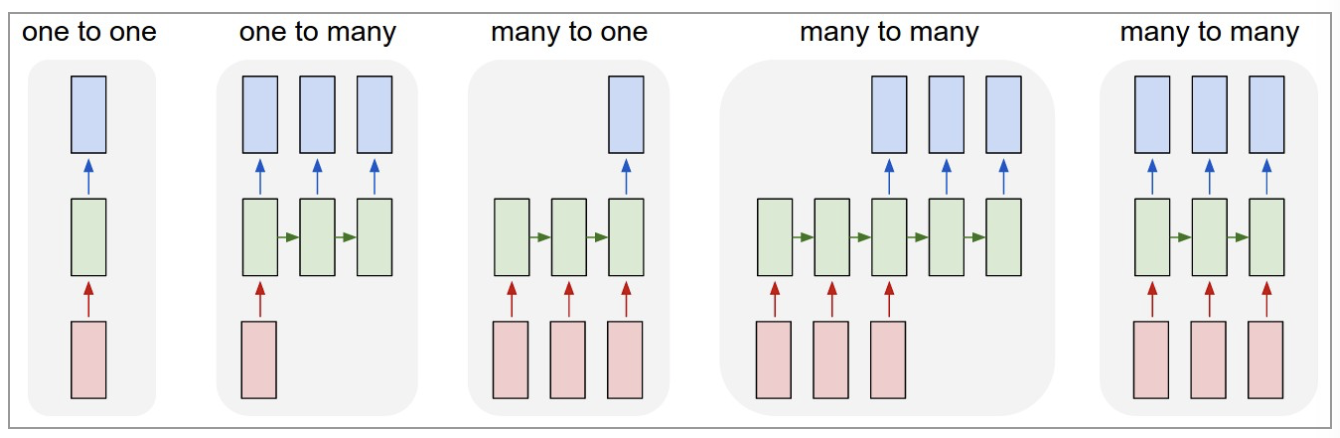
RNN以输入数m对应输出数n的不同,可以划分为5种基础结构类型:
(1)one to one:其实和全连接神经网络并没有什么区别,这一类别算不上 RNN。
(2)one to many:输入不是序列,输出是序列。可用于按主题生成文章或音乐等。
(3)many to one:输入是序列,输出不是序列(为单个值)。常用于文本分类。
(4)many to many:输入和输出都是不定长的序列。这也就是Encoder-Decoder结构,常用于机器翻译。
(5)many to many(m==n):输入和输出都是等长的序列数据。这是 RNN 中最经典的结构类型,常用于NLP的命名实体识别、序列预测,本文以此为例具体展开。
关于RNN模型,我们还是从数据、模型、学习目标、优化算法这几个要素展开解析,使用过程需要重点关注的是其输入和输出的差异(本节以经典的m==n的RNN结构为例):
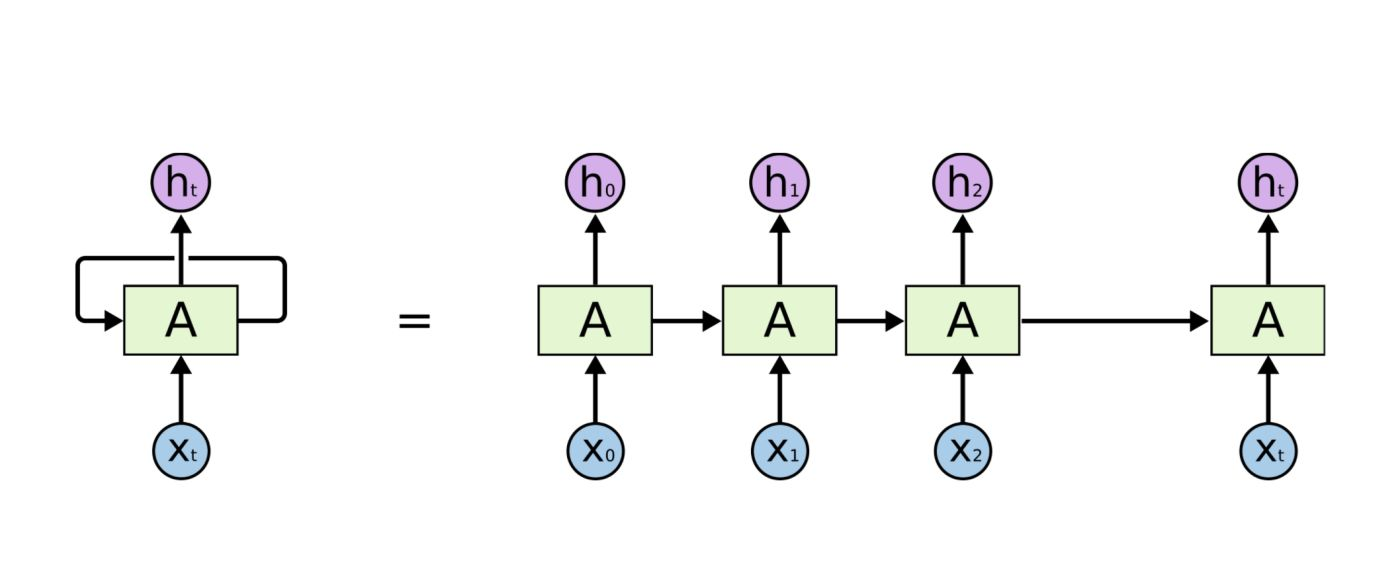
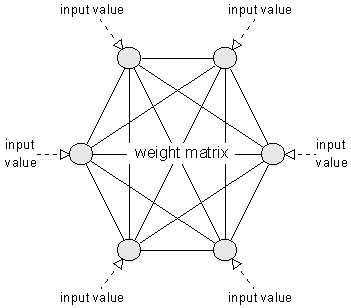
不像传统的机器学习模型假设输入是独立的,RNN的输入数据元素有顺序及相互依赖的,并按时间步逐一的串行输入模型的。上一步的输入对下一步的预测是有影响的(如文字预测的任务,以“猫吃鱼”这段序列文字,上一步的输入“猫”--x(0)会影响下一步的预测“吃”--x(1)的概率,也会继续影响下下步的预测“鱼”--x(2)的概率),我们通过RNN结构就可以将历史的(上下文)的信息反馈到下一步。
如上图,RNN模型(如左侧模型,实际上也只有这一个物理模型),按各个时间步展开后(如右侧模型),可以看作是按时间步(t)串联并共享($ U、W、V$ )参数的多个全连接神经网络。展开后的立体图如下:
RNN除了接受每一步的输入x(t),同时还会连接输入上一步的反馈信息——隐藏状态h(t-1),也就是当前时刻的隐藏状态 ℎ(t) 由当前时刻的输入 x(t)和上一时刻的隐藏状态h(t-1)共同决定。另外的,RNN神经元在每个时间步上是共享权重参数矩阵的(不同于CNN是空间上的参数共享),时间维度上的参数共享可以充分利用数据之间的时域关联性,如果我们在每个时间点都有一个单独的参数,不但不能泛化到训练时没有见过序列长度,也不能在时间上共享不同序列长度和不同位置的统计强度。
如下各时间步的前向传播计算流程图,接下来我们会对计算流程逐步分解:
上图展开了两个时间步t-1、t的计算过程;
t取值为0~序列的长度m;
x(t)是t时间步的 输入向量;
U是 输入层到隐藏层的权重矩阵;
h(t)是t时间步 隐藏层的输出状态向量,能表征历史输入(上下文)的反馈信息;
V是 隐藏层到输出层的权重矩阵;
b是 偏置项;
o(t)是t时间步 输出层的输出向量;
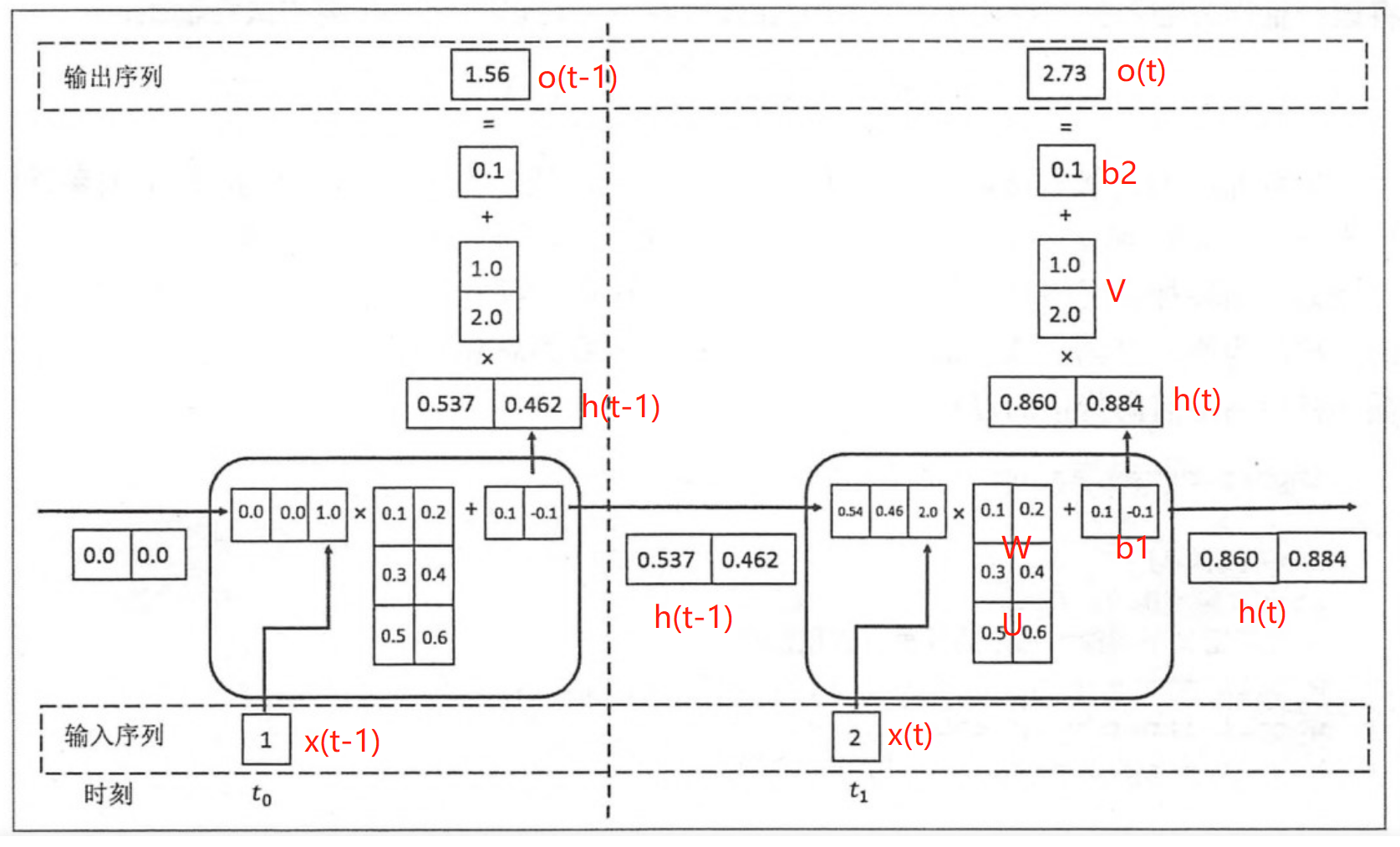
假设各时间步的状态h的维度为2,h初始值为[0,0],输入x和输出o维度为1。
将上一时刻的状态h(t-1),与当前时刻的输入x(t)拼接成一维向量作为全连接的隐藏层的输入,对应隐藏层的的输入维度为3 (如下图的输入部分)。
对应到计算流程图上,t-1时刻输出的状态h(t-1)为[0.537, 0.462],t时刻的输入为[2.0],拼接之后为[0.537, 0.462, 2.0]输入全连接的隐藏层,隐藏层的权重矩阵$U+W$为[[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]],偏置项b1为[0.1, -0.1],经过隐藏层的矩阵运算为:h(t-1)拼接x(t) * 权重参数W 拼接 权重矩阵U + 偏置项(b1)再由tanh转换后输出为状态h(t)。接着h(t)与x(t+1)继续输入到下一步(t+1)的隐藏层。
# 隐藏层的矩阵运算的对应代码
np.tanh(np.dot(np.array([[0.537, 0.462, 2.0]]),np.array([[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]])) + np.array([0.1, -0.1]))
# 输出h(t)为: array([[0.85972772, 0.88365397]])隐藏层输出状态h(t)为[0.86, 0.884],输出层权重矩阵$V$为[[1.0], [2.0]],偏置项b1为[0.1], h(t)经由输出层的矩阵运算为:h(t) * V +偏置项(b2)后,输出o(t)
# 输出层的矩阵运算的对应代码
np.dot(np.array([[0.85972772, 0.88365397]]),np.array([[1.0], [2.0]])) + np.array([0.1])
# o(t) 输出: array([[2.72703566]])上述过程从初始输入(t=0)遍历到序列结束(t=m),就是一个完整的前向传播过程,我们可以看出权重矩阵$U、W、V$和偏置项在不同时刻都是同一组,这也说明RNN在不同时刻中是共享参数的。
可以将这RNN计算过程简要概述为两个公式:
状态h(t) = f( U * x(t) + W * h(t-1) + b1), f为激活函数,上图隐藏层用的是tanh。隐藏层激活函数常用tanh、relu
输出o(t) = g( V * h(t) + b2),g为激活函数,上图输出层做回归预测,没有用非线性激活函数。当用于分类任务,输出层一般用softmax激活函数
RNN模型将输入 x(t)序列映射到输出值 o(t)后, 同全连接神经网络一样,可以衡量每个 o(t) 与相应的训练目标 y 的误差(如交叉熵、均方误差)作为损失函数,以最小化损失函数L(U,W,V)作为学习目标(也可以称为优化策略)。
RNN的优化过程与全连接神经网络没有本质区别,通过误差反向传播,多次迭代梯度下降优化参数,得到合适的RNN模型参数$ U,W,V$ (此处忽略偏置项) 。区别在于RNN是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time),BPTT会对不同时间步的梯度求和,由于所有的参数在序列的各个位置是共享的,反向传播时我们更新的是相同的参数组。如下BPTT示意图及U,W,V求导(梯度)的过程。
优化参数


相应的,$L$ 在第三个时刻对U的偏导数为:
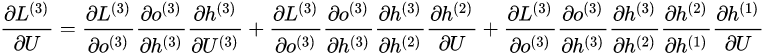
我们根据上面两个式子可以写出L在



上述展示的都是单向的 RNN,单向 RNN 有个缺点是在 t 时刻,无法使用 t+1 及之后时刻的序列信息,所以就有了双向循环神经网络(bidirectional RNN)。
理论上RNN能够利用任意长序列的信息,但是实际中它能记忆的长度是有限的,经过一定的时间后将导致梯度爆炸或者梯度消失(如上节),即长期依赖(long-term dependencies)问题。一般的,使用传统RNN常需要对序列限定个最大长度、设定梯度截断以及引导信息流的正则化,或者使用门控RNN 如GRU、LSTM 以改善长期依赖问题(--后面专题讨论)。
本项目通过创建单层隐藏层的RNN模型,输入前60个交易日(时间步)股票开盘价的时间序列数据,预测下一个(60+1)交易日的股票开盘价。
导入股票数据,选取股票开盘价的时间序列数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#(本公众号阅读原文访问数据集及源码)
dataset_train = pd.read_csv('./data/NSE-TATAGLOBAL.csv')
dataset_train = dataset_train.sort_values(by='Date').reset_index(drop=True)
training_set = dataset_train.iloc[:, 1:2].values
print(dataset_train.shape)
dataset_train.head()对训练数据进行归一化,加速网络训练收敛。
# 训练数据max-min归一化
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range = (0, 1))
training_set_scaled = sc.fit_transform(training_set)将数据整理为样本及标签:60 timesteps and 1 output
# 每条样本含60个时间步,对应下一时间步的标签值
X_train = []
y_train = []
for i in range(60, 2035):
X_train.append(training_set_scaled[i-60:i, 0])
y_train.append(training_set_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
print(X_train.shape)
print(y_train.shape)
# Reshaping
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
print(X_train.shape)利用kera创建单隐藏层的RNN模型,并设定模型优化算法adam, 目标函数均方根MSE
# 利用Keras创建RNN模型
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import SimpleRNN,LSTM
from keras.layers import Dropout
# 初始化顺序模型
regressor = Sequential()
# 定义输入层及带5个神经元的隐藏层
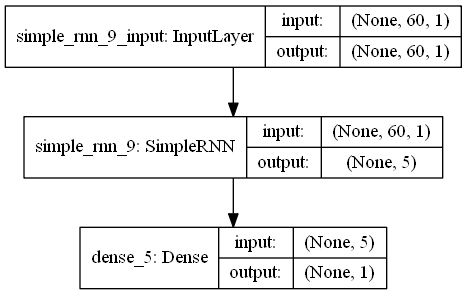
regressor.add(SimpleRNN(units = 5, input_shape = (X_train.shape[1], 1)))
# 定义线性的输出层
regressor.add(Dense(units = 1))
# 模型编译:定义优化算法adam, 目标函数均方根MSE
regressor.compile(optimizer = 'adam', loss = 'mean_squared_error')
# 模型训练
history = regressor.fit(X_train, y_train, epochs = 100, batch_size = 100, validation_split=0.1)
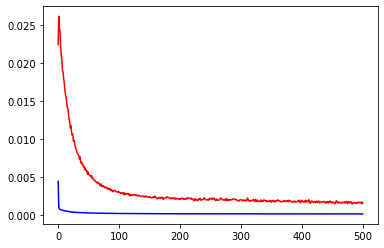
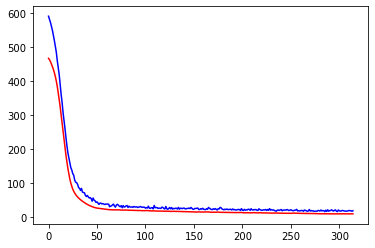
regressor.summary()展示模型拟合的情况:训练集、验证集均有较低的loss
plt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失
plt.plot(history.history['val_loss'],c='red') # 红色线验证集损失
plt.show()
评估模型:以新的时间段的股票交易系列数据作为测试集,评估模型测试集的表现。
# 测试数据
dataset_test = pd.read_csv('./data/tatatest.csv')
dataset_test = dataset_test.sort_values(by='Date').reset_index(drop=True)
real_stock_price = dataset_test.iloc[:, 1:2].values
dataset_total = pd.concat((dataset_train['Open'], dataset_test['Open']), axis = 0)
inputs = dataset_total[len(dataset_total) - len(dataset_test) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = sc.transform(inputs)
# 提取测试集
X_test = []
for i in range(60, 76):
X_test.append(inputs[i-60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
# 模型预测
predicted_stock_price = regressor.predict(X_test)
# 逆归一化
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
# 模型评估
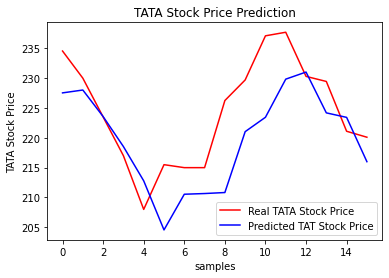
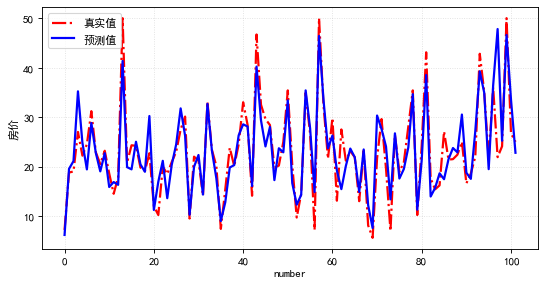
print('预测与实际差异MSE',sum(pow((predicted_stock_price - real_stock_price),2))/predicted_stock_price.shape[0])
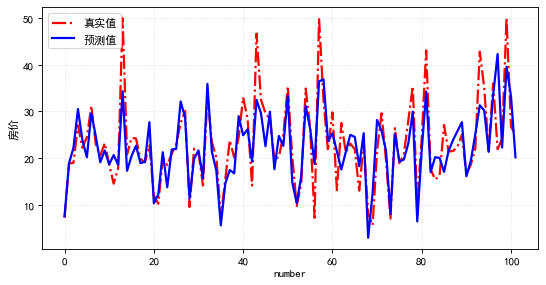
print('预测与实际差异MAE',sum(abs(predicted_stock_price - real_stock_price))/predicted_stock_price.shape[0])通过测试集评估,预测与实际差异MSE:53.03141531,预测与实际差异MAE :5.82196445。可视化预测值与实际值的差异情况,预测对比实际值趋势有延后,但整体比较一致(注:本文仅从数据规律维度预测股价,仅供参考不构成任何投资建议,亏光了别找我!!!)。
# 预测与实际差异的可视化
plt.plot(real_stock_price, color = 'red', label = 'Real TATA Stock Price')
plt.plot(predicted_stock_price, color = 'blue', label = 'Predicted TAT Stock Price')
plt.title('TATA Stock Price Prediction')
plt.xlabel('samples')
plt.ylabel('TATA Stock Price')
plt.legend()
plt.show()文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码
金融业务下沉的同时,其风险也在不断扩张,基于新技术和新场景的诈骗手段不断升级,欺诈方式更具场景化、专业化、智能化。信贷风险是还款能力与还款意愿综合考量,而申请信用评分并不能良好地识别欺诈意图,在此背景下,反欺诈成为了金融系统中必不可少的一环。
以小微企业贷款申请反欺诈架构为例:
欺诈是指故意歪曲事实,诱使他人依赖于该事实而失去属于自己的有价财产或放弃某项法律权利。在金融欺诈场景由于信息不对称、欺诈形式的隐秘复杂性等原因,常没有比较确切的欺诈定义。对于个人贷款场景反欺诈的的重点是个人虚假信息欺诈,而对于小微企业贷款场景反欺诈的的重点是企业经营欺诈,常用的信贷欺诈标签定义如:
如用户的电商消费数据、社交网络数据、税务数据、司法数据等等
更多精彩内容,欢迎star算法进阶github博客
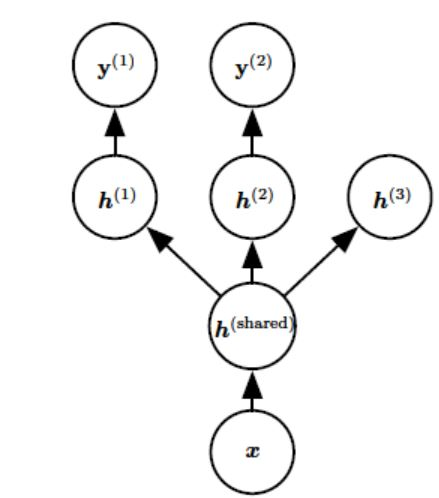
数据、算法、算力是人工智能发展的三要素。数据决定了Ai模型学习的上限,数据规模越大、质量越高,模型就能够拥有更好的泛化能力。然而在实际工程中,训练的数据相对模型而言数据量太少,或者很难覆盖全部的场景等问题,解决这问题的一个有效途径是通过数据增强(Data Augmentation),使模型获得较好的泛化性能。
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值。其原理是,通过对原始数据融入先验知识,加工出更多数据的表示,有助于模型判别数据中统计噪声,减少模型过拟合。
如经典的机器学习例子--哈士奇误分类为狼:
通过可解释性方法,可发现错误分类是由于图像上的雪造成的。通常狗对比狼的图像里面雪地背景比较少,分类器学会使用雪作为一个特征来将图像分类为狼还是狗,而忽略了动物本体的特征。此时,可以通过数据增强的方法,增加变换后的数据(如背景换色、加入噪声等方式)来训练模型,帮助模型学习到本体的特征,提高泛化能力。
需要关注的是,数据增强样本也有可能是引入片面噪声,导致过拟合。此时需要考虑的是调整数据增强方法,或者通过算法(可借鉴Pu-Learning思路)选择增强数据的最佳子集,以提高模型的泛化能力。
常用数据增强方法可分为:基于样本变换的数据增强及基于深度学习的数据增强。
样本变换数据增强即采用预设的数据变换规则进行已有数据的扩增,包含单样本数据增强和多样本数据增强。
单(图像)样本增强主要有几何操作、颜色变换、随机擦除、添加噪声等方法,可参见imgaug开源库。
多样本增强是通过先验知识组合及转换多个样本,主要有Smote、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值。
Smote方法较常用于样本均衡学习,核心**是从训练集随机同类的两近邻样本合成一个新的样本,其方法可以分为三步:
1、 对于各样本X_i,计算与同类样本的欧式距离,确定其同类的K个(如图3个)近邻样本;
2、从该样本k近邻中随机选择一个样本如近邻X_ik,生成新的样本
Xsmote_ik = Xi + rand(0,1) ∗ ∣X_i − X_ik∣
3、重复2步骤迭代N次,可以合成N个新的样本。
# SMOTE
from imblearn.over_sampling import SMOTE
print("Before OverSampling, counts of label\n{}".format(y_train.value_counts()))
smote = SMOTE()
x_train_res, y_train_res = smote.fit_resample(x_train, y_train)
print("After OverSampling, counts of label\n{}".format(y_train_res.value_counts()))
SamplePairing
SamplePairing算法的核心**是从训练集随机抽取的两幅图像叠加合成一个新的样本(像素取平均值),使用第一幅图像的label作为合成图像的正确label。
Mixup
Mixup算法的核心**是按一定的比例随机混合两个训练样本及其标签,这种混合方式不仅能够增加样本的多样性,且能够使决策边界更加平滑,增强了难例样本的识别,模型的鲁棒性得到提升。其方法可以分为两步:
1、从原始训练数据中随机选取的两个样本(xi, yi) and (xj, yj)。其中y(原始label)用one-hot 编码。
2、对两个样本按比例组合,形成新的样本和带权重的标签
x˜ = λxi + (1 − λ)xj
y˜ = λyi + (1 − λ)yj
最终的loss为各标签上分别计算cross-entropy loss,加权求和。其中 λ ∈ [0, 1], λ是mixup的超参数,控制两个样本插值的强度。
# Mixup
def mixup_batch(x, y, step, batch_size, alpha=0.2):
"""
get batch data
:param x: training data
:param y: one-hot label
:param step: step
:param batch_size: batch size
:param alpha: hyper-parameter α, default as 0.2
:return: x y
"""
candidates_data, candidates_label = x, y
offset = (step * batch_size) % (candidates_data.shape[0] - batch_size)
# get batch data
train_features_batch = candidates_data[offset:(offset + batch_size)]
train_labels_batch = candidates_label[offset:(offset + batch_size)]
if alpha == 0:
return train_features_batch, train_labels_batch
if alpha > 0:
weight = np.random.beta(alpha, alpha, batch_size)
x_weight = weight.reshape(batch_size, 1)
y_weight = weight.reshape(batch_size, 1)
index = np.random.permutation(batch_size)
x1, x2 = train_features_batch, train_features_batch[index]
x = x1 * x_weight + x2 * (1 - x_weight)
y1, y2 = train_labels_batch, train_labels_batch[index]
y = y1 * y_weight + y2 * (1 - y_weight)
return x, y不同于传统在输入空间变换的数据增强方法,神经网络可将输入样本映射为网络层的低维向量(表征学习),从而直接在学习的特征空间进行组合变换等进行数据增强,如MoEx方法等。
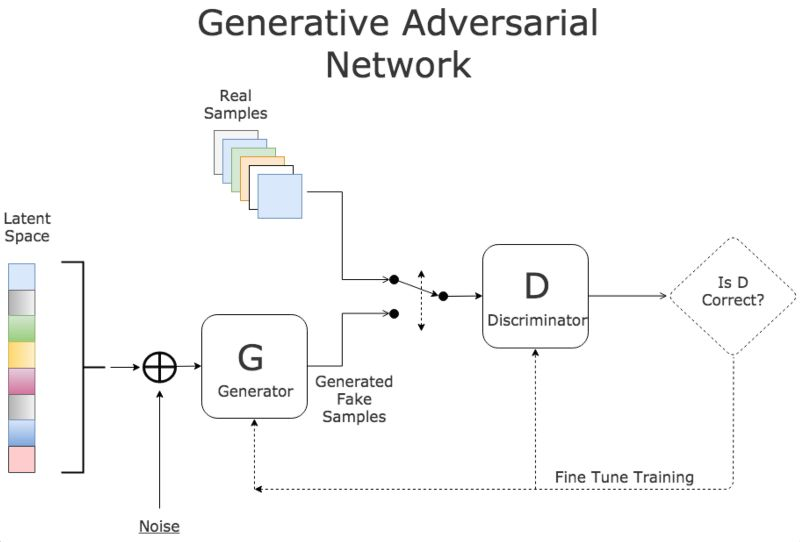
生成模型如变分自编码网络(Variational Auto-Encoding network, VAE)和生成对抗网络(Generative Adversarial Network, GAN),其生成样本的方法也可以用于数据增强。这种基于网络合成的方法相比于传统的数据增强技术虽然过程更加复杂, 但是生成的样本更加多样。

# VAE模型
class VAE(keras.Model):
...
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
keras.losses.binary_crossentropy(data, reconstruction), axis=(1, 2)
)
)
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}

# DCGAN模型
class GAN(keras.Model):
...
def train_step(self, real_images):
batch_size = tf.shape(real_images)[0]
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
# G: Z→X(输入噪声z, 输出生成的图像数据x)
generated_images = self.generator(random_latent_vectors)
# 合并生成及真实的样本并赋判定的标签
combined_images = tf.concat([generated_images, real_images], axis=0)
labels = tf.concat(
[tf.ones((batch_size, 1)), tf.zeros((batch_size, 1))], axis=0
)
# 标签加入随机噪声
labels += 0.05 * tf.random.uniform(tf.shape(labels))
# 训练判定网络
with tf.GradientTape() as tape:
predictions = self.discriminator(combined_images)
d_loss = self.loss_fn(labels, predictions)
grads = tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(
zip(grads, self.discriminator.trainable_weights)
)
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
# 赋生成网络样本的标签(都赋为真实样本)
misleading_labels = tf.zeros((batch_size, 1))
# 训练生成网络
with tf.GradientTape() as tape:
predictions = self.discriminator(self.generator(random_latent_vectors))
g_loss = self.loss_fn(misleading_labels, predictions)
grads = tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))
# 更新损失
self.d_loss_metric.update_state(d_loss)
self.g_loss_metric.update_state(g_loss)
return {
"d_loss": self.d_loss_metric.result(),
"g_loss": self.g_loss_metric.result(),
}
深度学习研究中的元学习(Meta learning)通常是指使用神经网络优化神经网络,元学习的数据增强有神经增强(Neural augmentation)等方法。
神经增强(Neural augmentation)是通过神经网络组的学习以获得较优的数据增强并改善分类效果的一种方法。 其方法步骤如下:
1、获取与target图像同一类别的一对随机图像,前置的增强网络通过CNN将它们映射为合成图像,合成图像与target图像对比计算损失;
2、将合成图像与target图像神经风格转换后输入到分类网络中,并输出该图像分类损失;
3、将增强与分类的loss加权平均后,反向传播以更新分类网络及增强网络权重。使得其输出图像的同类内差距减小且分类准确。
神经风格迁移(Neural Style Transfer)可以在保留原始内容的同时,将一个图像的样式转移到另一个图像上。除了实现类似色彩空间照明转换,还可以生成不同的纹理和艺术风格。
神经风格迁移是通过优化三类的损失来实现的:
style_loss:使生成的图像接近样式参考图像的局部纹理;
content_loss:使生成的图像的内容表示接近于基本图像的表示;
total_variation_loss:是一个正则化损失,它使生成的图像保持局部一致。
# 样式损失
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = img_nrows * img_ncols
return tf.reduce_sum(tf.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
# 内容损失
def content_loss(base, combination):
return tf.reduce_sum(tf.square(combination - base))
# 正则损失
def total_variation_loss(x):
a = tf.square(
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, 1:, : img_ncols - 1, :]
)
b = tf.square(
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, : img_nrows - 1, 1:, :]
)
return tf.reduce_sum(tf.pow(a + b, 1.25))
原理上来说,神经网络模型的训练过程其实就是拟合一个数据分布(x)可以映射到输出(y)的数学函数,即 y= f(x)。
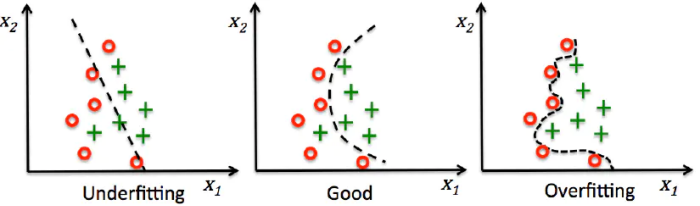
拟合效果的好坏取决于数据质量及模型的结构,像逻辑回归、感知机等线性模型的拟合能力是有限的,连xor函数都拟合不了,那神经网络模型结构中提升拟合能力的关键是什么呢?
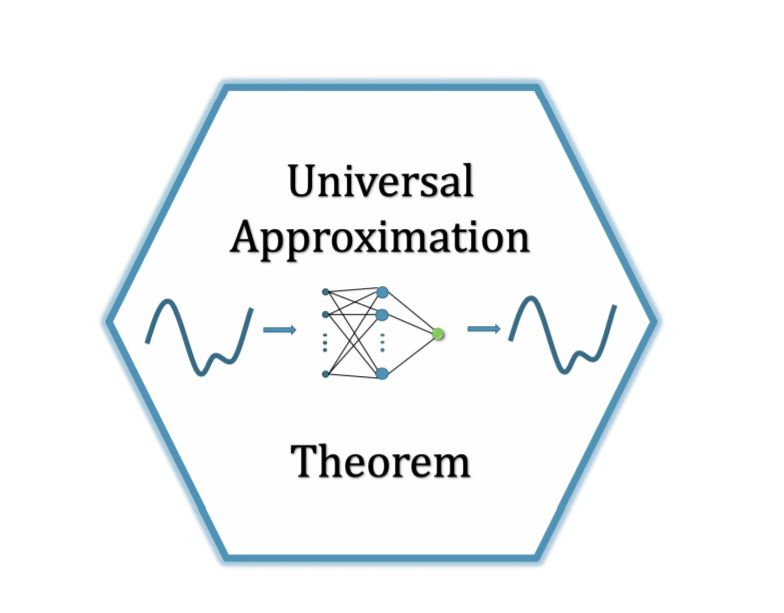
搬出神经网络的万能近似定理可知,“一个前馈神经网络如果具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel可测函数。”简单来说,前馈神经网络有“够深的网络层”以及“至少一层带激活函数的隐藏层”,既可以拟合任意的函数。
在此激活函数起的作用是实现特征空间的非线性转换,贴切的来说是,“数值上挤压,几何上变形”。如下图,在带激活函数的隐藏层作用下,可以对特征空间进行转换,最终使得数据(红色和蓝色线表示的样本)线性可分。
而如果网络没有激活函数的隐藏层(仅有线性隐藏层),以3层的神经网络为例,可得第二层输出为:
对上式中第二层的输出a^[2]进行化简计算
可见无论神经网络有多少层,输出都是输入x的线性组合,多层线性神经网络本质上还是线性模型,而其转换后的特征空间还是线性不可分的。
如果一个函数能提供非线性转换(即导数不恒为常数),可导(可导是从梯度下降方面考虑。可以有一两个不可导点, 但不能在一段区间上都不可导)等性质,即可作为激活函数。在不同网络层(隐藏层、输出层)的激活函数关注的重点不一样,隐藏层关注的是计算过程的特性,输出层关注的输出个数及数值范围。
那如何选择合适的激活函数呢?这是结合不同激活函数的特点的实证过程。

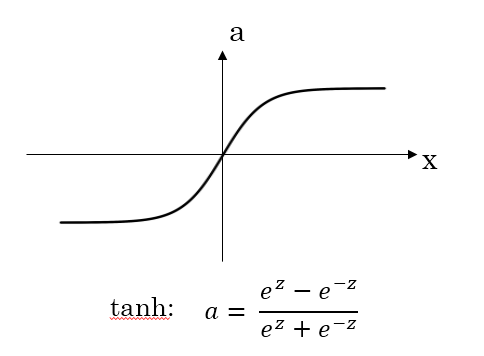
从函数图像上看,tanh函数像是伸缩过的sigmoid函数然后向下平移了一格,确实就是这样,因为它们的关系就是线性关系。
对于隐藏层的激活函数,一般来说,tanh函数要比sigmoid函数表现更好一些。
因为tanh函数的取值范围在[-1,+1]之间,隐藏层的输出被限定在[-1,+1]之间,可以看成是在0值附近分布,均值为0。这样从隐藏层到输出层,数据起到了归一化(均值为0)的效果。
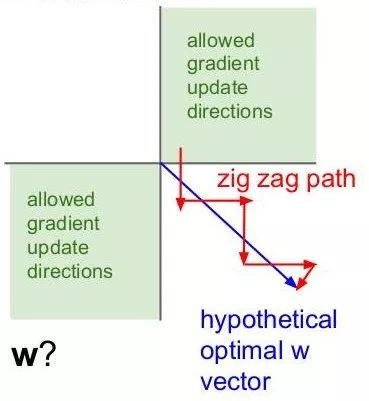
另外,由于Sigmoid函数的输出不是零中心的(Zero-centered),该函数的导数为:sigmoid * (1 - sigmoid),如果输入x都是正数,那么sigmoid的输出y在[0.5,1]。那么sigmoid的梯度 = [0.5, 1] * (1 - [0.5, 1]) ~= [0, 0.5] 总是 > 0的。假设最后整个神经网络的输出是正数,最后 w 的梯度就是正数;反之,假如输入全是负数,w 的梯度就是负数。这样的梯度造成的问题就是,优化过程呈现“Z字形”(zig-zag),因为w 要么只能往下走(负数),要么只能往右走(正的),导致优化的效率十分低下。而tanh就没有这个问题。
对于输出层的激活函数,因为二分类问题的输出取值为{0,+1},所以一般会选择sigmoid作为激活函数。另外,sigmoid天然适合做概率值处理,例如用于LSTM中的门控制。
观察sigmoid函数和tanh函数,我们发现有这样一个问题,就是当|z|很大的时候,激活函数的斜率(梯度)很小。在反向传播的时候,这个梯度将会与整个损失函数关于该神经元输出的梯度相乘,那么相乘的结果也会接近零,这会导致梯度消失;同样的,当z落在0附近,梯度是相当大的,梯度相乘就会出现梯度爆炸的问题(一般可以用梯度裁剪即Gradient Clipping来解决梯度爆炸问题)。由于其梯度爆炸、梯度消失的缺点,会使得网络变的很难进行学习。
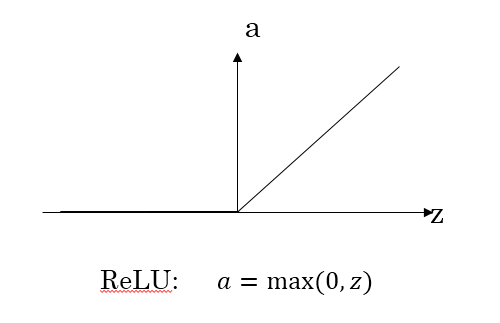
为了弥补sigmoid函数和tanh函数的缺陷,就出现了ReLU激活函数。ReLU激活函数求导不涉及浮点运算,所以速度更快。在z大于零时梯度始终为1;在z小于零时梯度始终为0;z等于零时的梯度可以当成1也可以当成0,实际应用中并不影响。
对于隐藏层,选择ReLU作为激活函数,能够保证z大于零时梯度始终为1,从而提高神经网络梯度下降算法运算速度。
而当输入z小于零时,ReLU存在梯度为0的特点,一旦神经元的激活值进入负半区,那么该激活值就不会产生梯度/不会被训练,虽然减缓了学习速率,但也造成了网络的稀疏性——稀疏激活,这有助于减少参数的相互依赖,缓解过拟合问题的发生。
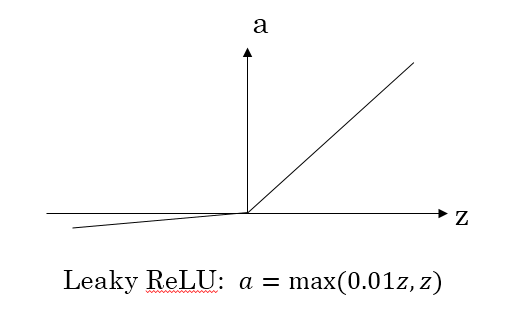
对于上述问题,也就有了leaky ReLU,它能够保证z小于零是梯度不为0,可以改善RELU导致神经元稀疏的问题而提高学习速率。但是缺点也很明显,因为有了负数的输出,导致其非线性程度没有RELU强大,在一些分类任务中效果还没有Sigmoid好,更不要提ReLU。(此外ReLU还有很多变体RReLU、PReLU、SELU等,可以自行扩展)
softplus 是 ReLU 的平滑版本,也就是不存在单点不可导。但根据实际经验来看,并没什么效果,ReLU的结果是更好的。
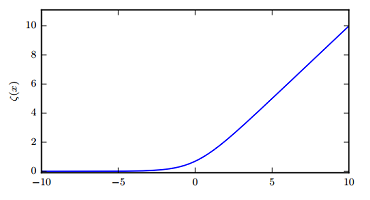
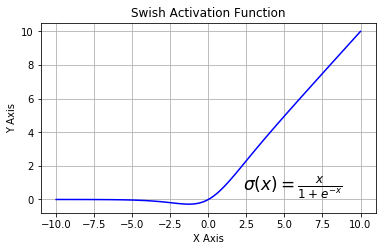
swish函数又叫作自门控激活函数,它近期由谷歌的研究者发布,数学公式为:
和 ReLU 一样,Swish 无上界有下界。与 ReLU 不同的是,Swish 有平滑且非单调的特点。根据论文(https://arxiv.org/abs/1710.05941v1),[Swish 激活函数的性能优于 ReLU 函数。](http://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650732184&idx=1&sn=7e7ded430f5884d6d099980267fcfb15&chksm=871b32e6b06cbbf07c133e826351bae045858699d72f65474c7cebcbc5b2762c3522dfc62ef7&scene=21#wechat_redirect)
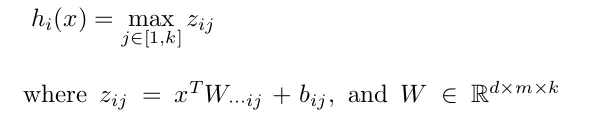
maxout 进一步扩展了 ReLU,它是一个可学习的 k 段函数。它具有如下性质:
1、maxout激活函数并不是一个固定的函数,不像Sigmod、Relu、Tanh等固定的函数方程
2、它是一个可学习的激活函数,因为w参数是学习变化的。
3、它是一个分(k)段线性函数:
# Keras 简单实现Maxout
# input shape: [n, input_dim]
# output shape: [n, output_dim]
W = init(shape=[k, input_dim, output_dim])
b = zeros(shape=[k, output_dim])
output = K.max(K.dot(x, W) + b, axis=1)
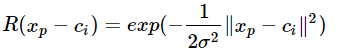
# Keras 简单实现RBF
from keras.layers import Layer
from keras import backend as K
class RBFLayer(Layer):
def __init__(self, units, gamma, **kwargs):
super(RBFLayer, self).__init__(**kwargs)
self.units = units
self.gamma = K.cast_to_floatx(gamma)
def build(self, input_shape):
self.mu = self.add_weight(name='mu',
shape=(int(input_shape[1]), self.units),
initializer='uniform',
trainable=True)
super(RBFLayer, self).build(input_shape)
def call(self, inputs):
diff = K.expand_dims(inputs) - self.mu
l2 = K.sum(K.pow(diff,2), axis=1)
res = K.exp(-1 * self.gamma * l2)
return res
def compute_output_shape(self, input_shape):
return (input_shape[0], self.units)
# 用法示例:
model = Sequential()
model.add(Dense(20, input_shape=(100,)))
model.add(RBFLayer(10, 0.5))
softmax 函数,也称归一化指数函数,常作为网络的输出层激活函数,它很自然地输出表示具有 n个可能值的离散型随机变量的概率分布。数学函数式如下,公式引入了指数可以扩大类间的差异。
对于是分类任务的输出层,二分类的输出层的激活函数常选择sigmoid函数,多分类选择softmax;回归任务根据输出值确定激活函数或者不使用激活函数;对于隐藏层的激活函数通常会选择使用ReLU函数,保证学习效率。
其实,具体选择哪个函数作为激活函数没有一个固定的准确的答案,应该要根据具体实际问题进行验证(validation)。
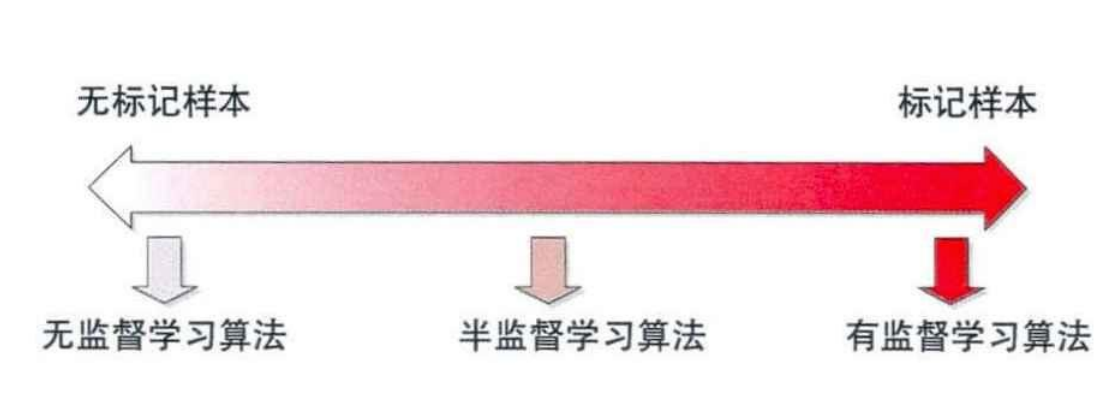
Clustering (聚类)是常见的unsupervised learning (无监督学习)方法,简单地说就是把相似的数据样本分到一组(簇),聚类的过程,我们并不清楚某一类是什么(通常无标签信息),需要实现的目标只是把相似的样本聚到一起,即只是利用样本数据本身的分布规律。
聚类算法可以大致分为传统聚类算法以及深度聚类算法:

kmeans聚类可以说是聚类算法中最为常见的,它是基于划分方法聚类的,原理是先初始化k个簇类中心,基于计算样本与中心点的距离归纳各簇类下的所属样本,迭代实现样本与其归属的簇类中心的距离为最小的目标(如下目标函数)。
其优化算法步骤为:
1.随机选择 k 个样本作为初始簇类中心(k为超参,代表簇类的个数。可以凭先验知识、验证法确定取值);
2.针对数据集中每个样本 计算它到 k 个簇类中心的距离,并将其归属到距离最小的簇类中心所对应的类中;
3.针对每个簇类,重新计算它的簇类中心位置;
4.重复迭代上面 2 、3 两步操作,直到达到某个中止条件(如迭代次数,簇类中心位置不变等)。
....
完整代码可见:https://github.com/aialgorithm/Blog
#kmeans算法是初始化随机k个中心点
random.seed(1)
center = [[self.data[i][r] for i in range(1, len((self.data)))]
for r in random.sample(range(len(self.data)), k)]
#最大迭代次数iters
for i in range(self.iters):
class_dict = self.count_distance() #计算距离,比较个样本到各个中心的的出最小值,并划分到相应的类
self.locate_center(class_dict) # 重新计算中心点
#print(self.data_dict)
print("----------------迭代%d次----------------"%i)
print(self.center_dict) #聚类结果{k:{{center:[]},{distance:{item:0.0},{classify:[]}}}}
if sorted(self.center) == sorted(self.new_center):
break
else:
self.center = self.new_center
...
可见,K-means 聚类的迭代算法实际上是 EM 算法。EM 算法解决的是在概率模型中含有无法观测的隐含变量情况下的参数估计问题。在 K-means 中的隐变量是每个类别所属类别。K-means 算法迭代步骤中的 每次确认中心点以后重新进行标记 对应 EM 算法中的 E 步 求当前参数条件下的 Expectation 。而 根据标记重新求中心点 对应 EM 算法中的 M 步 求似然函数最大化时(损失函数最小时)对应的参数 。EM 算法的缺点是容易陷入局部极小值,这也是 K-means 有时会得到局部最优解的原因。
kmeans 算法是基于距离相似度计算的,以确定各样本所属的最近中心点,常用距离度量有曼哈顿距离和欧式距离,具体可以见文章【全面归纳距离和相似度方法(7种)】
曼哈顿、欧几里得距离的计算方法很简单,就是计算两样本(x,y)的各个特征i间的总距离。
如下图(二维特征的情况)蓝线的距离即是曼哈顿距离(想象你在曼哈顿要从一个十字路口开车到另外一个十字路口实际驾驶距离就是这个“曼哈顿距离”,也称为城市街区距离),红线为欧几里得距离:
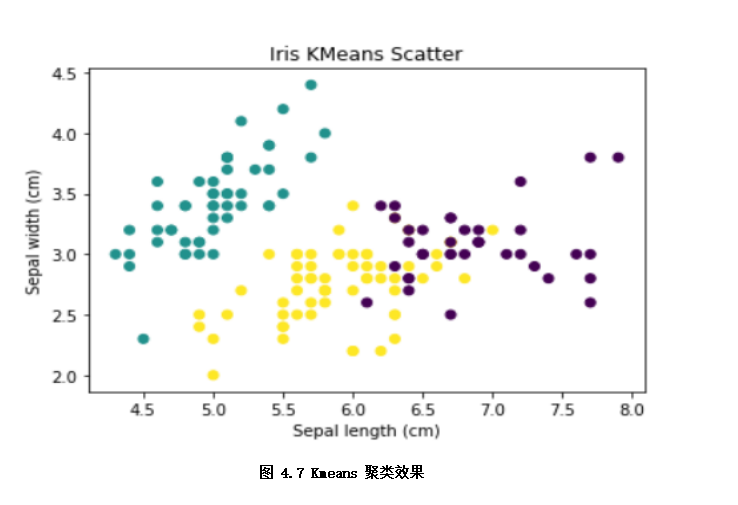
kmeans划分k个簇,不同k的情况,算法的效果可能差异就很大。K值的确定常用:先验法、手肘法等方法。
先验比较简单,就是凭借着业务知识确定k的取值。比如对于iris花数据集,我们大概知道有三种类别,可以按照k=3做聚类验证。从下图可看出,对比聚类预测与实际的iris种类是比较一致的。

手肘法的缺点在于需要人为判断不够自动化,还有些其他方法如:
kmeans是采用随机初始化中心点,而不同初始化的中心点对于算法结果的影响比较大。所以,针对这点更新出了Kmeans++算法,其初始化的思路是:各个簇类中心应该互相离得越远越好。基于各点到已有中心点的距离分量,依次随机选取到k个元素作为中心点。离已确定的簇中心点的距离越远,越有可能(可能性正比与距离的平方)被选择作为另一个簇的中心点。如下代码。
# Kmeans ++ 算法基于距离概率选择k个中心点
# 1.随机选择一个点
center = []
center.append(random.choice(range(len(self.data[0]))))
# 2.根据距离的概率选择其他中心点
for i in range(self.k - 1):
weights = [self.distance_closest(self.data[0][x], center)
for x in range(len(self.data[0])) if x not in center]
dp = [x for x in range(len(self.data[0])) if x not in center]
total = sum(weights)
#基于距离设定权重
weights = [weight/total for weight in weights]
num = random.random()
x = -1
i = 0
while i < num :
x += 1
i += weights[x]
center.append(dp[x])
center = [self.data_dict[self.data[0][center[k]]] for k in range(len(center))]
基于欧式距离的 K-means 假设了了各个数据簇的数据具有一样的的先验概率并呈现球形分布,但这种分布在实际生活中并不常见。面对非凸的数据分布形状时我们可以引入核函数来优化,这时算法又称为核 K-means 算法,是核聚类方法的一种。核聚类方法的主要**是通过一个非线性映射,将输入空间中的数据点映射到高位的特征空间中,并在新的特征空间中进行聚类。非线性映射增加了数据点线性可分的概率,从而在经典的聚类算法失效的情况下,通过引入核函数可以达到更为准确的聚类结果。
kmeans是面向数值型的特征,对于类别特征需要进行onehot或其他编码方法。此外还有 K-Modes 、K-Prototypes 算法可以用于混合类型数据的聚类,对于数值特征簇类中心我们取得是各特征均值,而类别型特征中心取得是众数,计算距离采用海明距离,一致为0否则为1。
聚类是基于特征间距离计算,计算距离时,需要关注到特征量纲差异问题,量纲越大意味这个特征权重越大。假设各样本有年龄、工资两个特征变量,如计算欧氏距离的时候,(年龄1-年龄2)² 的值要远小于(工资1-工资2)² ,这意味着在不使用特征缩放的情况下,距离会被工资变量(大的数值)主导。因此,我们需要使用特征缩放来将全部的数值统一到一个量级上来解决此问题。通常的解决方法可以对数据进行“标准化”或“归一化”,对所有数值特征统一到标准的范围如0~1。
归一化后的特征是统一权重,有时我们需要针对不同特征赋予更大的权重。假设我们希望feature1的权重为1,feature2的权重为2,则进行0~1归一化之后,在进行类似欧几里得距离(未开根号)计算的时候,
我们将feature2的值乘根号2就可以了,这样feature2对应的上式的计算结果会增大2倍,从而简单快速的实现权重的赋权。如果使用的是曼哈顿距离,特征直接乘以2 权重也就是2 。
如果类别特征进行embedding之后的特征加权,比如embedding为256维,则我们对embedding的结果进行0~1归一化之后,每个embedding维度都乘以 根号1/256,从而将这个类别全部的距离计算贡献规约为1,避免embedding size太大使得kmeans的聚类结果非常依赖于embedding这个本质上是单一类别维度的特征。
kmeans本质上只是根据样本特征间的距离(样本分布)确定所属的簇类。而不同特征的情况,就会明显影响聚类的结果。当使用没有代表性的特征时,结果可能就和预期大相径庭! 比如,想对银行客户质量进行聚类分级:交易次数、存款额度就是重要的特征,而如客户性别、年龄情况可能就是噪音,使用了性别、年龄特征得到的是性别、年龄相仿的客户!
对于无监督聚类的特征选择:
一方面可以结合业务含义,选择贴近业务场景的特征。
另一方面,可以结合缺失率、相似度、PCA等常用的特征选择(降维)方法可以去除噪音、减少计算量以及避免维度爆炸。再者,如果任务有标签信息,结合特征对标签的特征重要性也是种方法(如xgboost的特征重要性,特征的IV值。)
最后,也可以通过神经网络的特征表示(也就深度聚类的**。后面在做专题介绍),如可以使用word2vec,将高维的词向量空间以低维的分布式向量表示。
参考文献:
1、https://www.bilibili.com/video/BV1H3411t7Vk?spm_id_from=333.999.0.0
2、https://zhuanlan.zhihu.com/p/407343831
3、https://zhuanlan.zhihu.com/p/78798251
#1 赛题
随着科技发展,银行陆续打造了线上线下、丰富多样的客户触点,来满足客户日常业务办理、渠道交易等客户需求。面对着大量的客户,银行需要更全面、准确地洞察客户需求。在实际业务开展过程中,需要发掘客户流失情况,对客户的资金变动情况预判;提前/及时针对客户进行营销,减少银行资金流失。本次竞赛提供实际业务场景中的客户行为和资产信息为建模对象,一方面希望能借此展现各参赛选手的数据挖掘实战能力,另一方面需要选手在复赛中结合建模的结果提出相应的营销解决方案,充分体现数据分析的价值。
通过对赛题的分析与理解,本次比赛的任务是:从用户各个季度的基本资料、资金情况及行为信息,建立客户的流失预警模型,挖掘客户流失的原因,辅助业务加强客户维护及营销,提高客户的粘度,减少客户/资金的流失。
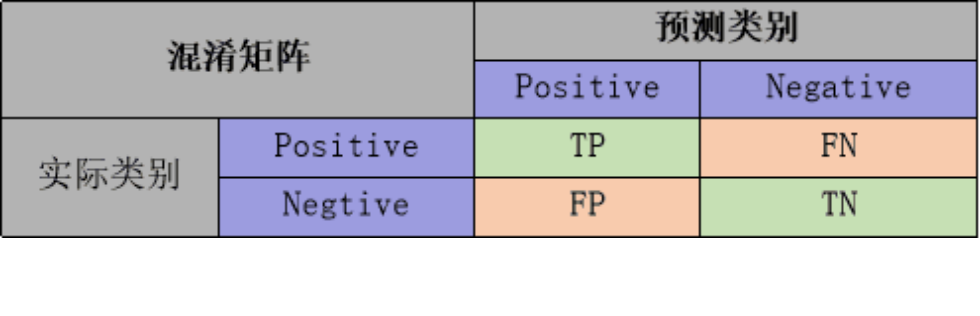
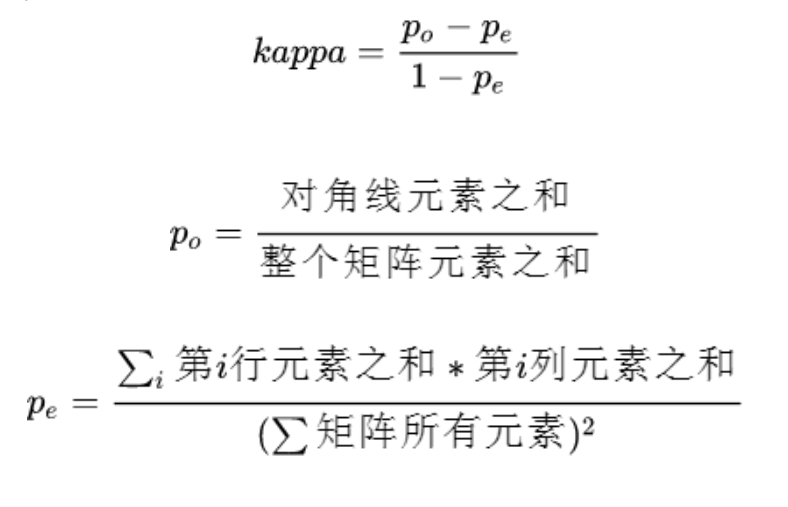
本次建模的目标是根据用户前两个季度的历史数据,预测下一季度用户的标签(-1/0/1,标签存在递进关系)。问题转换成三分类问题,从1)aum_m(Y)、2)behavior_m(Y)、3)big_event_Q(Z)、4)cunkuan_m(Y)、5)cust_info_q(Z)表中构建特征,评估指标为Kappa,其本质的考量是分类一致性(准确)且无偏倚。
数据源表:cust_info_q(第 Z 季度的客户信息)
数值型如家庭年收入,年龄等直接入模。发现不同标签下年龄分布差异较大。
类别型如性别、客户等级、职业等转换成类别变量入模。发现普通用户是最大流失客群。
此外,用户信息的完善程度可能会影响该用户的忠实程度,以此加工基本信息的缺失率特征。
数据源表:aum_m(第 Y 月的月末时点资产数据)、 behavior_m(第Y月的行为数据)、 cunkuan_m(第 Y 月的存款数据):
主要加工存款、aum、动账金额的方差、平均值、增长率、最大值及最小值,并结合字段含义进行组合衍生。
其中,对各月存款C1,产品数目C2在不同标签下分布分析发现,高资金流水风险的用户整体存款额度/产品数目较低,且随时间有下降趋势。
数据源表:behavior_m(第Y月的行为数据)、big_event_Q(第 Z 季度的客户重大历史数据)
big_event_Q(Z)主要为第一次转账、存款等日期,加工了距今及距离开户的日期间隔可以体现客户的活跃度;
behavior_m(Y) 季度末有最近交易日期,通过加工出交易的具体时间及周几等时间特征可以反馈用户的一些行为习惯。发现不通标签用户交易的时间分布差异较大,对具体小时做了(<10点、>12点、>14点)的离散化处理。
本模块特征由于计算资源不足导致拟合效果差的原因,最终并无入模,但该方法考虑时间序列连续性预测未来资金情况,可作为本方案的一个小亮点。
考虑项目的标签定义与资金波动情况关系较大,本模块序列预测特征的思路是依据前几个月(如Q3季度作为训练样本)的历史资金数据用(LSTM或LGB)回归预测Q4季度资金情况,并将预测数值结果作为特征入模。
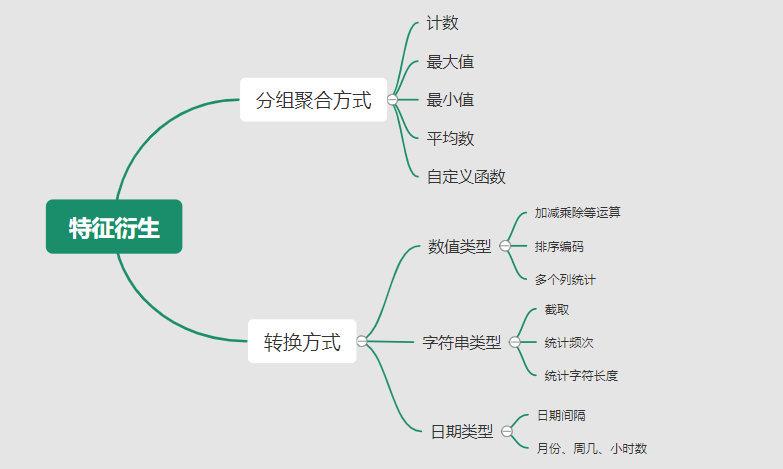
Featuretools是一个自动特征衍生的开源库,主要使用转换及聚合的方法自动特征衍生,以补充人为特征衍生的不足。
我们首先通过lightgbm训练并选择的是split及gain的重要性top150的人工衍生特征,再通过Featuretools 两两做乘法/除法做出特征交互特征。考虑Featuretools组合的变量噪声较多,最终由模型选择Top300的Featuretools重要特征入模。
特征选择的主要方法有:
1)筛选法: 皮尔森相关系数(衡量变量间的线性相关性)、缺失率及单值率等情况;
2)包装化: 特征集多次(前向/后向)迭代寻找最优子集。
3)嵌入法: 通过如LGB模型选择特征重要性较高的特征。
考虑计算资源有限,本方案采用的是:筛选法初筛后,进一步通过嵌入法由模型选择重要特征。这种方法较为高效,因为模型学习的过程和特征选择的过程是同时进行的。
LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据且支持类别型变量等优点。
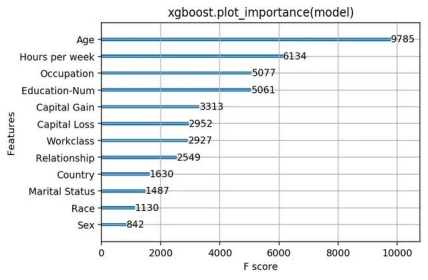
基于衍生出的特征,包含原始特征及类别特征共有 1211 维特征,以此训练Lightgbm,借助Bayes方法调参,单模型验证集Kappa值为 0.49 左右(线上测试集Kappa 0.475左右)。
受bagging **的启发,我们通过对训练集5次的随机抽样(抽样比例70%),随机列抽样,并用Bayes优化选择子模型,最后得到5个lgb子模型进行bagging。这个方法在参数和特征上都引入了多样性(差异性),使得最后bagging的泛化效果有较大的提升,OOT测试集Kappa 0.483左右。
1)总结了用户画像:特征加工过程中我们总结了高流失用户的用户画像:
2)特征设计了序列预测特征:考虑了时间序列连续性,预测未来资金情况,并将预测数值结果作为特征。
3)模型易部署:最终模型使用5个Lightgbm做均值融合,模型结构不复杂易部署,并取得线上Kappa 0.483的效果。
现在银行产品同众化现象普遍存在,客户选择产品和服务的途径越来越多,客户对产品的忠诚度越来越低,而获得新客的成本远高于维护老客户成本。所以客户流失已经成为银行业最关注的问题之一。客户流失原因可以分为两类:
第一类非主观意愿缺失。如破产、工资卡变化等。
第二类是需求未满足。原因比较复杂,如产品营销活动少、产品利率较低、业务体验差、客户自身的需求变化、竞争对手的策略、国家政策等。
结合模型对客群流失的特征(Shap值)分析,对客户流失的贡献度较高的特征为:存款金额少、存款产品少、AUM低、年龄较小等。综合原因可能为产品缺乏竞争力、活动较少、未重视年轻客群等。我们建议可以采取相关的措施,如:加强客户关系维系、差异营销、扩大销售、更多营销活动等。
(注:本节流失原因分析从建模技术层面分析,这无疑是比较片面的。具体原因可以从考虑到宏观政策变化、营销活动等因素分析其流失趋势情况,并通过流失客户资金流向情况分析加于佐证。)
商业银行客户数量庞大,而银行自身资源也是比较有限的,考虑成本效益原则,我们需要重点关注的是具有流失倾向且高质量客户,由此我们首先做两步的客群划分:
第一步:借助流失预警模型我们可以将客户的流失倾向分为3类:高流失风险客群(-1),低流失风险客群(0),稳定客群(1)。
第二步:按客户质量通常可大致分为以下三类:低价值客户、有价值客户及高附加值客户。我们可以综合行内客户等级、Aum值、最近一次消费间隔、消费频率、消费金额、金融产品数目、金融产品金额以及未来价值(通过该序列回归预测模型预测未来AUM值)这几个维度指标去考量,具体划分客群质量我们有两种方式:
方法一:分别对以各维度指标客户排名分布情况(如:各指标的80分位点作为参考阈值),划分价值客户。各维度指标具体划分的阈值可参考业务建议。
方法二:以各维度指标作为特征,归一化后采用聚类方式建模划分K个客群,并以各客群的中心值表现,定义划分出客群的价值类别。
综合流失风险及质量属性划分客群后,对不同类型客户制定不同的营销策略:
在此细分结构下我们重点关注高价值/附加值客户的流失风险客户,并根据其需求为其量身定制相应的营销方式:
1)借助用户画像了解其特点,提供个性化服务及优惠政策。如:提醒参加营销活动、提高贷款授信额度等;
2)通过建立营销推荐模型,交叉销售更多优质的产品;
3)建立专属客户经理机制,以客户响应良好的营销途径(如电话营销)及用户问卷调查。
需要关注的是,当客户处在不同的生命周期阶段时,需要满足不同的需求。结合客户生命周期管理促进我们纵向深入的了解每一类型客户并做量化管理,通过针对处于不同客户生命周期阶段的客户的区别对待,实现企业资源的最优配置。
挖掘客户的手机app登录、动账、购买理财产品等行为的活跃时间段,参考每个客户的活跃时间段,针对性地发送营销短信。
获取更多类型(参与活动、理财习惯)数据,评估客户的兴趣偏好,推荐适合客户的营销产品。
项目路径:流失客户预测
欢迎star及fork 算法进阶github博客~
前言:
应出版社约稿,计划出个机器学习及深度学习通俗序列文章,不足之处还请多提建议。
机器学习看似高深的术语,其实就在生活中,古语有云:“一叶落而知天下秋”,意思是从一片树叶的凋落,就可以知道秋天将要到来。这其中蕴含了朴素的机器学习的**,揭示了可以通过学习对“落叶”特征的经验,预判秋天的到来。
机器学习作为人工智能领域的核心组成,是非显式的计算机程序学习数据经验以优化自身算法,以学习处理任务的过程。一个经典的机器学习的定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.(一个计算机程序在处理任务T上的指标表现P可以随着学习经验E积累而提高。)
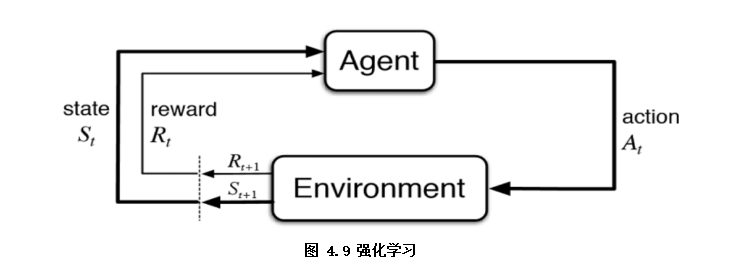
如图4.1 ,任务T即是机器学习系统如何正确处理数据样本。
指标表现P即是衡量任务正确处理的情况。
经验E可以体现在模型学习处理任务后的自身的参数值。模型参数意义即如何对各特征的有效表达以处理任务。
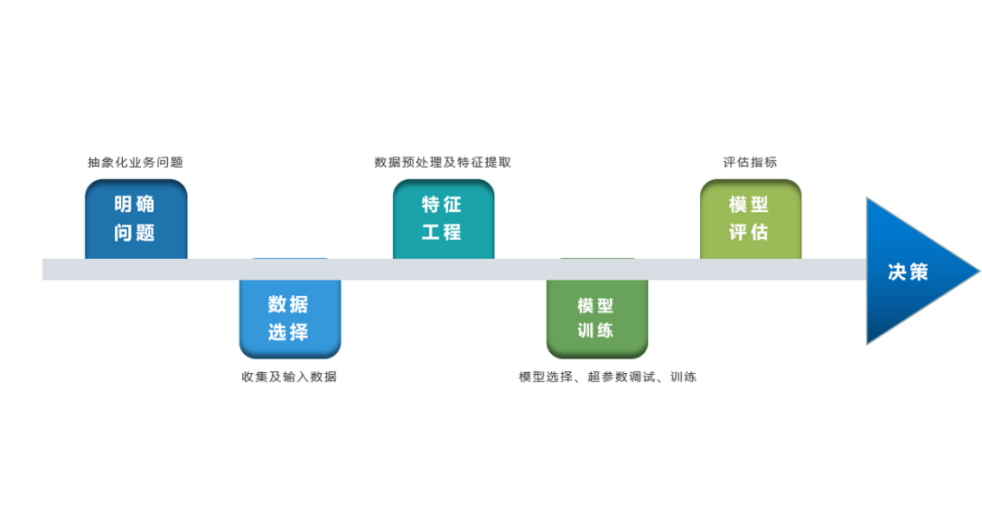
进一步的,机器学习的过程一般可以概括为:计算机程序基于给定的、有限的学习数据出发(常基于每条数据样本是独立同分布的假设),选择某个的模型方法(即假设要学习的模型属于某个函数的集合,也称为假设空间),通过算法更新模型的参数值(经验),以优化处理任务的指标表现,最终学习出较优的模型,并运用模型对数据进行分析与预测以完成任务。由此可见,机器学习方法有四个要素:
我们通过将机器学习方法归纳为四个要素及其相应地介绍,便于更好地理解各种算法原理的共性所在,而不是独立去理解各式各样的机器学习方法。
数据是机器学习方法的基础的原料,它通常由一条条数据(每一行)样本组成,样本由描述其各个维度信息的特征及目标值标签(或无)组成。
如图4.2所示癌细胞分类任务的数据集:
学习到“好”的模型是机器学习的直接目的。机器学习模型简单来说,即是学习数据特征与标签的关系或者学习数据特征内部的规律的一个函数。
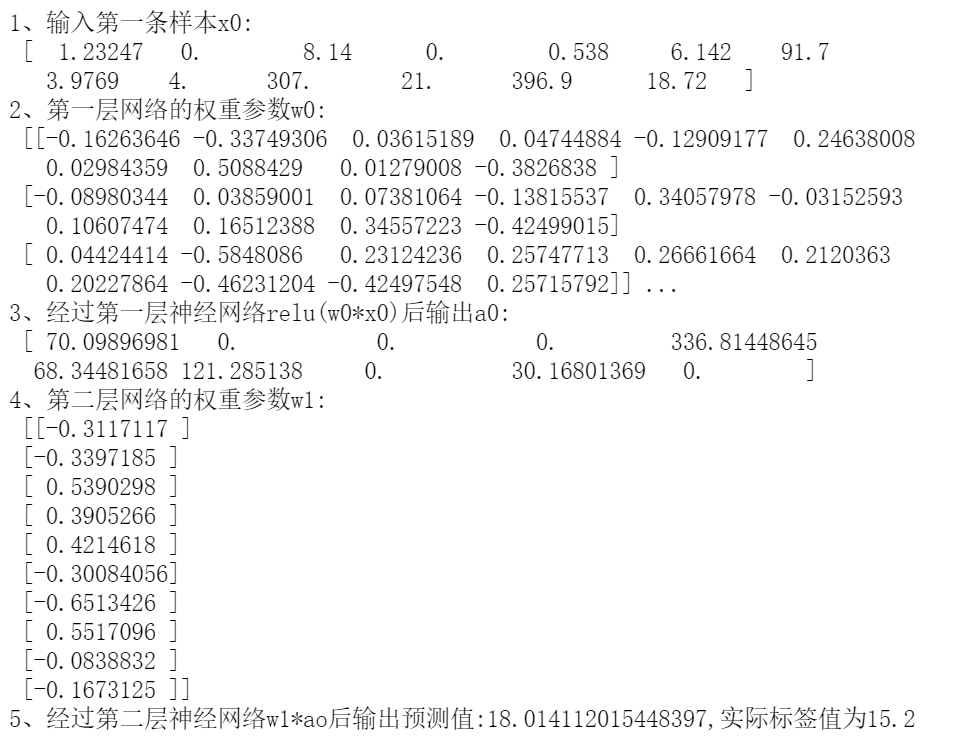
机器学习模型可以看作是(如图4.3):首先选择某个的模型方法,再从数据样本(x,(y))中学习,优化模型参数w以调整各特征的有效表达,最终获得对应的决策函数f( x; w )。该函数将输入变量 x 在参数w作用下映射到输出预测Y,即Y= f(x; w)。
学习到“好”的模型,“好”即是模型的学习目标。“好”对于模型也就是预测值与实际值之间的误差尽可能的低。具体衡量这种误差的函数称为代价函数 (Cost Function)或者损失函数(Loss Function),我们即通过以极大化降低损失函数为目标去学习模型。
对于不同的任务目标,往往也需要用不同损失函数衡量,经典的损失函数如:回归任务的均方误差损失函数及分类任务的交叉熵损失函数等。
- 均方误差损失函数
衡量模型回归预测的误差情况,我们可以简单地用所有样本的预测值减去实际值求平方后的平均值,这也就是均方误差(Mean Squared Error)损失函数。

有了极大化降低损失函数为目标去学习“好”模型,而如何达到这目标?我们第一反应可能是直接求解损失函数最小值的解析解,获得最优的模型参数。遗憾的是,机器学习模型的损失函数通常较复杂,很难直接求最优解。幸运的是,我们可以通过优化算法(如梯度下降算法、牛顿法等)有限次迭代优化模型参数,以尽可能降低损失函数的值,得到较优的参数值(数值解)。
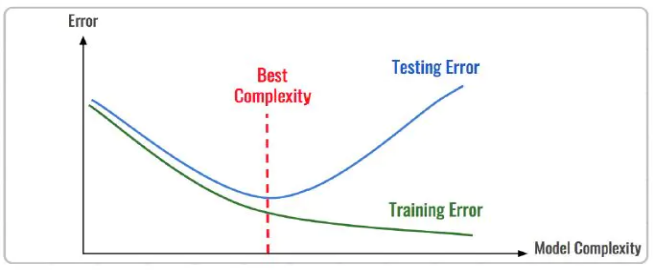
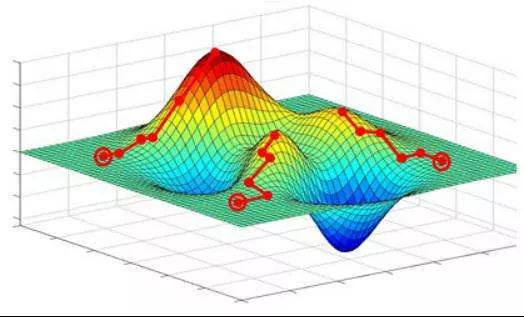
梯度下降算法如图4.4,可以直观理解成一个下山的过程,将损失函数J(w)比喻成一座山,我们的目标是到达这座山的山脚(即求解最优模型参数w使得损失函数为最小值)。
要做的无非就是“往下坡的方向走,走一步算一步”,而下坡的方向也就是J(w)负梯度的方向,在每往下走到一个位置的时候,求解当前位置的梯度,向这一步所在位置沿着最陡峭最易下山的位置再走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。
当然这样走下去,有可能我们不是走到山脚(全局最优),而是到了某一个的小山谷(局部最优),这也后面梯度下降算法的调优的地方。
对应到算法步骤:
本文我们首先介绍了机器学习的基本概念,并概括机器学习的一般过程:从数据出发,通过设定了任务的学习目标,使用算法优化模型参数去达到目标。由此,重点引出了机器学习的四个组成要素(数据、模型、学习目标及优化算法),接下来我们会进一步了解机器学习算法的类别。
文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码
信贷风控是数据挖掘算法最成功的应用之一,这在于金融信贷行业的数据量很充足,需求场景清晰及丰富。
信贷风控简单来说就是判断一个人借了钱后面(如下个月的还款日)会不会按期还钱。更专业来说,信贷风控是还款能力及还款意愿的综合考量,根据这预先的判断为信任依据进行放贷,以此大大提高了金融业务效率。
与其他机器学习的工业场景不同,金融是极其厌恶风险的领域,其特殊性在于非常侧重模型的解释性及稳定性。业界通常的做法是基于挖掘多维度的特征建立一套可解释及效果稳定的规则及风控模型对每笔订单/用户/行为做出判断决策。
其中,对于(贷前)申请前的风控模型,也称为申请评分卡--A卡。A卡是风控的关键模型,业界共识是申请评分卡可以覆盖80%的信用风险。此外还有贷中行为评分卡B卡、催收评分卡C卡,以及反欺诈模型等等。
A卡(Application score card)。目的在于预测申请时(申请信用卡、申请贷款)对申请人进行量化评估。
B卡(Behavior score card)。目的在于预测使用时点(获得贷款、信用卡的使用期间)未来一定时间内逾期的概率。
C卡(Collection score card)。目的在于预测已经逾期并进入催收阶段后未来一定时间内还款的概率。
一个好的特征,对于模型和规则都是至关重要的。像申请评分卡--A卡,主要可以归到以下3方面特征:
1、信贷历史类: 信贷交易次数及额度、收入负债比、查询征信次数、信贷历史长度、新开信贷账户数、额度使用率、逾期次数及额度、信贷产品类型、被追偿信息。(信贷交易类的特征重要程度往往是最高的,少了这部分历史还款能力及意愿的信息,风控模型通常直接就废了。)
2、基本资料及交易记录类:年龄、婚姻状况、学历、工作类型及年薪、工资收入、存款AUM、资产情况、公积金及缴税、非信贷交易流水等记录(这类主要是从还款能力上面综合考量的。还可以结合多方核验资料的真伪以及共用像手机号、身份证号等团伙欺诈信息,用来鉴别欺诈风险。需要注意的,像性别、肤色、地域、种族、宗教信仰等类型特征使用要谨慎,可能模型会有效果,但也会导致算法歧视问题。)
3、公共负面记录类: 如破产负债、民事判决、行政处罚、法院强制执行、涉赌涉诈黑名单等(这类特征不一定能拿得到数据,且通常缺失度比较高,对模型贡献一般,更多的是从还款意愿/欺诈维度的考虑)
实战部分我们以经典的申请评分卡为例,使用的中原银行个人贷款违约预测比赛的数据集,使用信用评分python库--toad、树模型Lightgbm及逻辑回归LR做申请评分模型。(注:文中所涉及的一些金融术语,由于篇幅就不展开解释了,疑问之处 可以谷歌了解下哈。)
申请评分模型定义主要是通过一系列的数据分析确定建模的样本及标签。
首先,补几个金融风控的术语的说明。概念模糊的话,可以回查再理解下:
逾期期数(M) :指实际还款日与应还款日之间的逾期天数,并按区间划分后的逾期状态。M取自Month on Book的第一个单词。(注:不同机构所定义的区间划分可能存在差异)
M0:当前未逾期(或用C表示,取自Current)
M1: 逾期1-30日
M2:逾期31-60日
M3:逾期61-90日
M4:逾期91-120日
M5:逾期121-150日
M6:逾期151-180日
M7+:逾期180日以上
观察点:样本层面的时间窗口。 用于构建样本集的时间点(如2010年10月申请贷款的用户),不同环节定义不同,比较抽象,这里举例说明:如果是申请模型,观察点定义为用户申贷时间,取19年1-12月所有的申贷订单作为构建样本集;如果是贷中行为模型,观察点定义为某个具体日期,如取19年6月15日在贷、没有发生逾期的申贷订单构建样本集。
观察期:特征层面的时间窗口。构造特征的相对时间窗口,例如用户申请贷款订前12个月内(2009年10月截至到2010年10月申请贷款前的数据都可以用, 可以有用户平均消费金额、次数、贷款次数等数据特征)。设定观察期是为了每个样本的特征对齐,长度一般根据数据决定。一个需要注意的点是,只能用此次申请前的特征数据,不然就会数据泄露(时间穿越,用未来预测过去的现象)。
表现期:标签层面的时间窗口。定义好坏标签Y的时间窗口,信贷风险具有天然的滞后性,因为用户借款后一个月(第一期)才开始还钱,有得可能还了好几期才发生逾期。
对于现成的比赛数据,数据特征的时间跨度(观察期)、数据样本、标签定义都是已经提前分析确定下来的。但对于实际的业务来说,数据样本及模型定义其实也是申请评分卡的关键之处。毕竟实际场景里面可能没有人扔给你现成的数据及标签(好坏定义,有些公司的业务会提前分析好给建模人员),然后只是跑个分类模型那么简单。
确定建模的样本量及标签,也就是模型从多少的数据样本中学习如何分辨其中的好、坏标签样本。如果样本量稀少、标签定义有问题,那学习的结果可想而知也会是差的。(对于建模样本量的确定,经验上肯定是满足建模条件的样本越多越好,一个类别最好有几千以上的样本数。)
但对于标签的定义,可能我们直观感觉是比较简单,比如“好用户就是没有逾期的用户, 坏用户就是在逾期的用户”,但具体做量化起来会发现并不简单,有两个方面的主要因素需要考量:
根据巴塞尔协议的指导,一般逾期超过90天(M4+)的客户,即定义为坏客户。更为通用的,可以使用“滚动率”分析方法(Roll Rate Analysis)确定多少天算是“坏”,基本方法是统计分析出逾期M期的客户多大概率会逾期M+1期(同样的,我们不太可能等着所有客户都逾期一年才最终确定他就是坏客户。一来时间成本太高,二来这数据样本会少的可怜)。如下示例,我们通过滚动率分析各期逾期的变坏概率。当前未逾期(M0)下个月保持未逾期的概率99.71%; 当前逾期M1,下个月继续逾期概率为54.34%;当前M2下个月继续逾期概率就高达90.04%。我们可以看出M2是个比较明显的变坏拐点,可以以M2+作为坏样本的定义。
这也就是确定表现期,常用的分析方法是Vintage分析(Vintage在信贷领域不仅可以用它来评估客户好坏充分暴露所需的时间,即成熟期,还可以用它分析不同时期风控策略的差异等),通过分析历史累计坏用户暴露增加的趋势,来确定至少要多少期可以比较全面的暴露出大部分的坏客户。如下示例的坏定义是M4+,我们可以看出各期的M4+坏客户经过9或者10个月左右的表现,基本上可以都暴露出来,后面坏客户的总量就比较平稳了。这里我们就可以将表现期定位9或者10个月~
确定了坏的定义以及需要的表现期,我们就可以确定样本的标签,最终划定的建模样本:
比如现在的时间是2022-10月底,表现期9个月的话,就可以取2022-01月份及之前申请的样本(这也称为 观察点),打上好坏标签,建模。
通过上面信用评分的介绍,很明显的好用户通常远大于坏用户的,这是一个类别极不均衡的典型场景,不均衡处理方法下文会谈到。
本数据集的数据字典文档、比赛介绍及本文代码,可以到https://github.com/aialgorithm/Blog项目相应的代码目录下载
该数据集为中原银行的个人贷款违约预测数据集,个别字段有做了脱敏(金融的数据大都涉及机密)。主要的特征字段有个人基本信息、经济能力、贷款历史信息等等
数据有10000条样本,38维原始特征,其中isDefault为标签,是否逾期违约。
import pandas as pd
pd.set_option("display.max_columns",50)
train_bank = pd.read_csv('./train_public.csv')
print(train_bank.shape)
train_bank.head()
数据预处理主要是对日期信息、噪音数据做下处理,并划分下类别、数值类型的特征。
# 日期类型:issueDate 转换为pandas中的日期类型,加工出数值特征
train_bank['issue_date'] = pd.to_datetime(train_bank['issue_date'])
# 提取多尺度特征
train_bank['issue_date_y'] = train_bank['issue_date'].dt.year
train_bank['issue_date_m'] = train_bank['issue_date'].dt.month
# 提取时间diff # 转换为天为单位
base_time = datetime.datetime.strptime('2000-01-01', '%Y-%m-%d') # 随机设置初始的基准时间
train_bank['issue_date_diff'] = train_bank['issue_date'].apply(lambda x: x-base_time).dt.days
# 可以发现earlies_credit_mon应该是年份-月的格式,这里简单提取年份
train_bank['earlies_credit_mon'] = train_bank['earlies_credit_mon'].map(lambda x:int(sorted(x.split('-'))[0]))
train_bank.head()
# 工作年限处理
train_bank['work_year'].fillna('10+ years', inplace=True)
work_year_map = {'10+ years': 10, '2 years': 2, '< 1 year': 0, '3 years': 3, '1 year': 1,
'5 years': 5, '4 years': 4, '6 years': 6, '8 years': 8, '7 years': 7, '9 years': 9}
train_bank['work_year'] = train_bank['work_year'].map(work_year_map)
train_bank['class'] = train_bank['class'].map({'A': 0, 'B': 1, 'C': 2, 'D': 3, 'E': 4, 'F': 5, 'G': 6})
# 缺失值处理
train_bank = train_bank.fillna('9999')
# 区分 数值 或类别特征
drop_list = ['isDefault','earlies_credit_mon','loan_id','user_id','issue_date']
num_feas = []
cate_feas = []
for col in train_bank.columns:
if col not in drop_list:
try:
train_bank[col] = pd.to_numeric(train_bank[col]) # 转为数值
num_feas.append(col)
except:
train_bank[col] = train_bank[col].astype('category')
cate_feas.append(col)
print(cate_feas)
print(num_feas)
如果是用Lightgbm建模做违约预测,简单的数据处理,基本上代码就结束了。lgb树模型是集成学习的强模型,自带缺失、类别变量的处理,特征上面不用做很多处理,建模非常方便,模型效果通常不错,还可以输出特征的重要性。
(By the way,申请评分卡业界用逻辑回归LR会比较多,因为模型简单,解释性也比较好)。
def model_metrics(model, x, y):
""" 评估 """
yhat = model.predict(x)
yprob = model.predict_proba(x)[:,1]
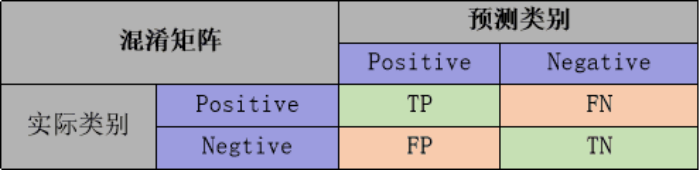
fpr,tpr,_ = roc_curve(y, yprob,pos_label=1)
metrics = {'AUC':auc(fpr, tpr),'KS':max(tpr-fpr),
'f1':f1_score(y,yhat),'P':precision_score(y,yhat),'R':recall_score(y,yhat)}
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, 'k--', label='ROC (area = {0:.2f})'.format(roc_auc), lw=2)
plt.xlim([-0.05, 1.05]) # 设置x、y轴的上下限,以免和边缘重合,更好的观察图像的整体
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate') # 可以使用中文,但需要导入一些库即字体
plt.title('ROC Curve')
plt.legend(loc="lower right")
return metrics
# 划分数据集:训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(train_bank[num_feas + cate_feas], train_bank.isDefault,test_size=0.3, random_state=0)
# 训练模型
lgb=lightgbm.LGBMClassifier(n_estimators=5,leaves=5, class_weight= 'balanced',metric = 'AUC')
lgb.fit(train_x, train_y)
print('train ',model_metrics(lgb,train_x, train_y))
print('test ',model_metrics(lgb,test_x,test_y))
from lightgbm import plot_importance
plot_importance(lgb)
LR即逻辑回归,是一种广义线性模型,因为其模型简单、解释性良好,在金融行业是最常用的。
也正因为LR过于简单,没有非线性能力,所以我们往往需要通过比较复杂的特征工程,如分箱WOE编码的方法,提高模型的非线性能力。
关于LR的原理及优化方法,强烈推荐阅读下:
下面我们通过toad实现特征分析、特征选择、特征分箱及WOE编码
# 数据EDA分析
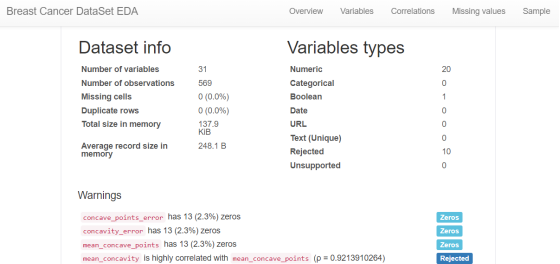
toad.detector.detect(train_bank)
# 特征选择,根据相关性 缺失率、IV 等指标
train_selected, dropped = toad.selection.select(train_bank,target = 'isDefault', empty = 0.5, iv = 0.05, corr = 0.7, return_drop=True, exclude=['earlies_credit_mon','loan_id','user_id','issue_date'])
print(dropped)
print(train_selected.shape)
# 划分训练集 测试集
train_x, test_x, train_y, test_y = train_test_split(train_selected.drop(['loan_id','user_id','isDefault','issue_date','earlies_credit_mon'],axis=1), train_selected.isDefault,test_size=0.3, random_state=0)
# 特征的卡方分箱
combiner = toad.transform.Combiner()
# 训练数据并指定分箱方法
combiner.fit(pd.concat([train_x,train_y], axis=1), y='isDefault',method= 'chi',min_samples = 0.05,exclude=[])
# 以字典形式保存分箱结果
bins = combiner.export()
bins
通过特征分箱,每一个特征被离散化为各个分箱。
接下来就是LR特征工程的特色处理了--手动调整分箱的单调性。
这一步的意义更多在于特征的业务解释性的约束,对于模型的拟合效果影响不一定是正面的。这里我们主观认为大多数特征的不同分箱的坏账率badrate应该是满足某种单调关系的,而起起伏伏是不太好理解的。如征信查询次数这个特征,应该是分箱数值越高,坏账率越大。(注:如年龄特征可能就不满足这种单调关系)
我们可以查看下ebt_loan_ratio这个变量的分箱情况,根据bad_rate趋势图,并保证单个分箱的样本占比不低于0.05,去调整分箱,达到单调性。(其他的特征可以按照这个方法继续调整,单调性调整还是挺耗时的)
adj_var = 'scoring_low'
#调整前原来的分箱 [560.4545455, 621.8181818, 660.0, 690.9090909, 730.0, 775.0]
adj_bin = {adj_var: [ 660.0, 700.9090909, 730.0, 775.0]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin)
data_ = pd.concat([train_x,train_y], axis=1)
data_['type'] = 'train'
temp_data = c2.transform(data_[[adj_var,'isDefault','type']], labels=True)
from toad.plot import badrate_plot, proportion_plot
# badrate_plot(temp_data, target = 'isDefault', x = 'type', by = adj_var)
# proportion_plot(temp_data[adj_var])
from toad.plot import bin_plot,badrate_plot
bin_plot(temp_data, target = 'isDefault',x=adj_var)


# 更新调整后的分箱
combiner.set_rules(adj_bin)
combiner.export()
接下来就是对各个特征的分箱做WOE编码,通过WOE编码给各个分箱不同的权重,提升LR模型的非线性。
#计算WOE,仅在训练集计算WOE,不然会标签泄露
transer = toad.transform.WOETransformer()
binned_data = combiner.transform(pd.concat([train_x,train_y], axis=1))
#对WOE的值进行转化,映射到原数据集上。对训练集用fit_transform,测试集用transform.
data_tr_woe = transer.fit_transform(binned_data, binned_data['isDefault'], exclude=['isDefault'])
data_tr_woe.head()
## test woe
# 先分箱
binned_data = combiner.transform(test_x)
#对WOE的值进行转化,映射到原数据集上。测试集用transform.
data_test_woe = transer.transform(binned_data)
data_test_woe.head()
使用woe编码后的train数据训练模型。对于金融风控这种极不平衡的数据集,比较常用的做法是做下极少类的正采样或者使用代价敏感学习class_weight='balanced',以增加极少类的学习权重。可见:《一文解决样本不均衡(全)》
对于LR等弱模型,通常会发现训练集与测试集的指标差异(gap)是比较少的,即很少过拟合现象。
# 训练LR模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(class_weight='balanced')
lr.fit(data_tr_woe.drop(['isDefault'],axis=1), data_tr_woe['isDefault'])
print('train ',model_metrics(lr,data_tr_woe.drop(['isDefault'],axis=1), data_tr_woe['isDefault']))
print('test ',model_metrics(lr,data_test_woe,test_y))
利用训练好的LR模型,输出(概率)分数分布表,结合误杀率、召回率以及业务需要可以确定一个合适分数阈值cutoff (注:在实际场景中,通常还会将概率非线性转化为更为直观的整数分score=A-B*ln(odds),方便评分卡更直观、统一的应用。)
train_prob = lr.predict_proba(data_tr_woe.drop(['isDefault'],axis=1))[:,1]
test_prob = lr.predict_proba(data_test_woe)[:,1]
# Group the predicted scores in bins with same number of samples in each (i.e. "quantile" binning)
toad.metrics.KS_bucket(train_prob, data_tr_woe['isDefault'], bucket=10, method = 'quantile')
当预测这用户的概率大于设定阈值,意味这个用户的违约概率很高,就可以拒绝他的贷款申请。
在数据挖掘项目的数据中,数据类型可以分为两种:有序的连续数值 和 无序的类别型特征。
对于xgboost等boosting树模型,基学习通常是cart回归树,而cart树的输入通常只支持连续型数值类型的,像年龄、收入等连续型变量Cart可以很好地处理,但对于无序的类别型变量(如 职业、地区等),cart树处理就麻烦些了,如果是直接暴力地枚举每种可能的类别型特征的组合,这样找类别特征划分点计算量也很容易就爆了。
在此,本文列举了 树模型对于类别型特征处理的常用方法,并做了深入探讨~
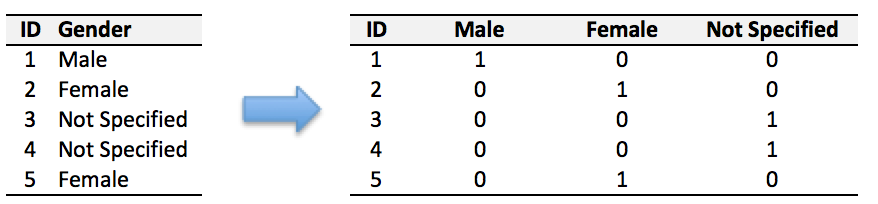
我们可以直接对类别型特征做Onehot处理(这也是最常用的做法),每一类别的取值都用单独一位0/1来表示, 也就是一个“性别”类别特征可以转换为是否为“男”、“女” 或者“其他” 来表示,如下:
display(df.loc[:,['Gender_Code']].head())
# onehot
pd.get_dummies(df['Gender_Code']).head()
但是onehot的重大缺点在于,对于取值很多的类别型特征,可能导致高维稀疏特征而容易导致树模型的过拟合。如之前谈到面对高维稀疏的onehot特征,一旦有达到划分条件,树模型容易加深、切分次数越多,相应每个切分出的子特征空间的统计信息越来越小,学习到的可能只是噪音(即 过拟合)。
使用建议:Onehot天然适合神经网络模型,神经网络很容易从高维稀疏特征学习到低微稠密的表示。当onehot用于树模型时,类别型特征的取值数量少的时候还是可以学习到比较重要的交互特征,但是当取值很多时候(如 大于100),容易导致过拟合,是不太适合用onehot+树模型的。
(注:此外 onehot 还有增加内存开销以及训练时间开销等缺点)
OrdinalEncoder也称为顺序编码 (与 label encoding,两者功能基本一样),特征/标签被转换为序数整数(0 到 n_categories - 1)
使用建议:适用于ordinal feature ,也就是虽然类别型特征,但它存在内在顺序,比如衣服尺寸“S”,“M”, “L”等特征就适合从小到大进行整数编码。
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df[col] = encoder.transform(df[col])
target encoding 目标编码也称为均值编码,是借助各类别特征对应的标签信息做编码(比如二分类 简单以类别特征各取值 的样本对应标签值“0/1”的平均值),是一种常用有监督编码方法(此外还有经典的WoE编码),很适合逻辑回归等弱模型使用。
使用建议 : 当树模型使用目标编码,需加入些正则化技巧,减少Target encoding方法带来的条件偏移的现象(当训练数据集和测试数据集数据结构和分布不一样的时候会出条件偏移问题),主流的方法是使用Catboost编码 或者 使用cross-validation求出target mean或bayesian mean。
# 如下简单的target mean代码。也可以用:from category_encoders import TargetEncoder
target_encode_columns = ['Gender_Code']
target = ['y']
target_encode_df = score_df[target_encode_columns + target].reset_index().drop(columns = 'index', axis = 1)
target_name = target[0]
target_df = pd.DataFrame()
for embed_col in target_encode_columns:
val_map = target_encode_df.groupby(embed_col)[target].mean().to_dict()[target_name]
target_df[embed_col] = target_encode_df[embed_col].map(val_map).values
score_target_drop = score_df.drop(target_encode_columns, axis = 1).reset_index().drop(columns = 'index', axis = 1)
score_target = pd.concat([score_target_drop, target_df], axis = 1)
CatBoostEncoder是CatBoost模型处理类别变量的方法(Ordered TS编码),在于目标编码的基础上减少条件偏移。其计算公式为:
CBE_encoder = CatBoostEncoder()
train_cbe = CBE_encoder.fit_transform(train[feature_list], target)
test_cbe = CBE_encoder.transform(test[feature_list])
也称为频数编码,将类别特征各取值转换为其在训练集出现的频率,这样做直观上就是会以类别取值的频次为依据 划分高频类别和低频类别。至于效果,还是要结合业务和实际场景。
## 也可以直接 from category_encoders import CountEncoder
bm = []
tmp_df=train_df
for k in catefeas:
t = pd.DataFrame(tmp_df[k].value_counts(dropna=True,normalize=True)) # 频率
t.columns=[k+'vcount']
bm.append(t)
for k,j in zip(catefeas, range(len(catefeas))):# 联结编码
df = df.merge(bm[j], left_on=k, right_index=True,how='left')
当类别的取值数量很多时(onehot高维),如果直接onehot,从性能或效果来看都会比较差,这时通过神经网络embedding是不错的方法,将类别变量onehot输入神经网络学习一个低维稠密的向量,如经典的无监督词向量表征学习word2vec 或者 基于有监督神经网络编码。
使用建议:特别适合类别变量取值很多,onehot后高维稀疏,再做NN低维表示转换后应用于树模型。
# word2vec
from gensim.models import word2vec
# 加载数据
raw_sentences = ["the quick brown fox jumps over the lazy dogs","yoyoyo you go home now to sleep"]
# 切分词汇
sentences= [s.encode('utf-8').split() for s in sentences]
# 构建模型
model = word2vec.Word2Vec(sentences,size=10) # 词向量的维数为10
# 各单词学习的词向量
model['dogs']
# array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
为了解决one-hot编码(one vs many )处理类别特征的不足。lgb采用了Many vs many的切分方式,简单来说,是通过对每个类别取值进行数值编码(类似于目标编码),根据编码的数值寻找较优切分点,实现了类别特征集合的较优切分。
1 、特征取值数目小于等于4(参数max_cat_to_onehot):直接onehot 编码,逐个扫描每一个bin容器,找出最佳分裂点;
2、 特征取值数目大于4: max bin的默认值是256 取值的个数大于max bin数时,会筛掉出现频次少的取值。再统计各个特征值对应的样本的一阶梯度之和,二阶梯度之和,以一阶梯度之和 / (二阶梯度之和 + 正则化系数)作为该特征取值的编码。将类别转化为数值编码后,从大到小排序,遍历直方图寻找最优的切分点
简单来说,Lightgbm利用梯度统计信息对类别特征编码。我个人的理解是这样可以按照学习的难易程度为依据划分类别特征组,比如某特征一共有【狼、狗、猫、猪、兔】五种类别取值,而【狼、狗】类型下的样本分类难度相当高(该特征取值下的梯度大),在梯度编码后的类别特征上,寻找较优划分点可能就是【狼、狗】|vs|【猫、猪、兔】
使用建议: 通常使用lgb类别特征处理,效果是优于one-hot encoding。
# lgb类别处理:简单转化为类别型特征直接输入Lgb模型训练即可。
for ft in category_list:
train_x[ft] = train_x[ft].astype('category')
clf = LGBMClassifier(**best_params)
clf.fit(train_x, train_y)
对于取值数量很少(<10)的类别型特征,相应的各取值下的样本数量也比较多,可以直接Onehot编码。
对于取值数量比较多(10到几百),这时onehot从效率或者效果,都不及lightgbm梯度编码或catboost目标编码,而且直接使用也很方便。(需要注意的是,个人实践中这两种方法在很多取值的类别特征,还是比较容易过拟合。这时,类别值先做下经验的合并或者尝试剔除某些类别特征后,模型效果反而会更好)
当几百上千的类别取值,可以先onehot后(高维稀疏),借助神经网络模型做低维稠密表示。
以上就是主要的树模型对类别特征编码方法。实际工程上面的效果,还需具体验证。计算资源丰富的情况下,可以多试几种编码方法,再做特征选择,选取比较有效的特征,效果杠杠的。
文章首发公众号“算法进阶”,欢迎关注。公众号阅读原文可访问文章相关代码及资料
春秋季是求职的黄金时期,借这时机分享下程序员面试相关的感悟。
本文立意不仅于面试技巧,而贵在通过梳理面试过程,帮助大家系统地完善技能树,找到更有发展前景的工作平台。一场完整的面试通常包括:简历准备、笔试(或无)、面试。
好的简历,就已经成功了一半。简历的重要性不仅在展现个人形象,通常还会主导整场面试。 面对海量的求职简历,面试官通常没有过多时间准备针对性的面试问题,这时简历就起着面试 “发言稿” 的作用。一份优秀的简历,主要从两个方面:简历排版及内容。
简历投递后,通常由HR进行初筛,面对着成百上千的简历,每份简历HR只有几秒钟浏览并判断这份简历是否合适。
那么如何设计简历,导向HR的正向判断呢?
我们先来看一个概念:首因效应,也叫优先效应或第一印象效应。在简历内容上,先看到的内容更容易被记住和重视。分析阅读如下简历的顺序习惯,我们通常由上往下,从左上角开始看,更侧重右边的内容。并按信息类别针对性地阅读。如下箭头阅读侧重的先后顺序。
所以,我们的简历排版可以从以下两方面考虑:
1)层次感:模块化展示个人信息、工作经历、项目经验信息会更有层次感,内容更清晰。
2)突出重点:结合首因效应排版,并可以地将较优秀的方面(如名校学历、重点项目经验)放比较靠前显眼的位置,突出重点。
写简历的第一原则是要对简历内容负责,要经得起推敲。其次是简历要精炼表达。
简历内容主要有个人信息、工作经历(在校/实习经历)、项目经验(专业技能)、自我介绍(或其他):
1)工作经历的时间采取倒叙形式,最近的经历写在前面;
2)工作经验的描述与目标岗位要求(JobDescription)的关键字尽量匹配;
3)工作成果尽量以数据指标来呈现,突出个人业绩;
关于工作经历造假: 对个人而言首先考虑的是造假本质是伤及自尊,只有尊重自己才能走得更踏实更远。其次,大公司或重要职位都有背景调查,可能这是作茧自缚。
1)项目经验尽量写重要的项目,不要一味堆砌项目数量。
2)项目描述结合技能关键字可以很形象地展现个人技能。可参考STAR法则来写,内容清晰结果导向。
1)自我介绍可以看作对简历的总结,直观地提供给HR、面试官适合目标岗位的印象。
2)篇幅不宜过长,应控制在200字左右,突出自身符合目标岗位要求的卖点(熟练技能,工作年限,项目成果等),要通过数据及成就形象展示。
笔试基本是大厂的必选项。接到面试机会,可以顺带问下是否有笔试,找找相关的笔试题目充分准备。笔试通常有这几种问题类型(具体还需要结合实际工作的侧重点来准备):
对于程序员的笔试,通常算法题的比重及难度会比较大,需要平时多花点时间准备,建议多刷刷leetcode算法题库(leetcode可以分题目类型标签、按频率、易难程度入手)。
面试类型可分为两种:
面试流程可能有好几轮(如技术主管、HR、CTO),每轮面试通常从自我介绍、工作经历、项目经验、工作要求与个人规划等方面,不同侧重地展开。
自我介绍应该是面试中的必考题,它主要有两层含义:给面试官一个缓冲的时间来重新熟悉你的简历;通过自己的总结,直观地提供给HR、面试官适合目标岗位的印象。
一个良好的自我介绍,可以留下很好的第一印象:
首先是自然地表述,这也是面试过程基本要求(可以通过模拟面试多演练)。
不能照搬简历,回答可以按 我是XX,可加一点个人信息亮点; 相关的经历、技能及成果,要展现有事实支撑的技能;以及将如何胜任工作。
工作经历及项目经验相关问题是整场面试的重点,考察方面主要有:
结合考察要求,可以从如下几方面准备并加以练习:
1)梳理工作项目的完整流程,担任角色,所做的贡献,并关注重要细节、问题点、核心技术以及成果;
2)归纳工作项目过程中的常见问题,给出较完整解决逻辑;
3)重点琢磨项目提及的相关技术的原理、应用场景、优缺点等;
4)刷刷常见的面试题:可以从专业邻域、技术方面、目标公司相关的题库。
面试初期(特别是技术面)谈及薪资,可以不用显得那么势利,大概给个薪资范围即可。通常到HR面试的时候才是谈薪资待遇的时候。而面试问的当前薪资,隐含的是问你的起步价是多少。
关于面试谈薪资更多是把握一些技巧,但从长远来看议价能力约等于体现的价值及未来价值。从这个角度看,做好职业规划,好好发展资源价值才是核心。
面试结束前,通常面试官会问求职者有什么问题要问的。
如果回答没有,一来可能会让面试官产生误解:你对应聘公司、工作岗位没有太大的兴趣。二来可能错过一个很好互动的机会。(虽然面试时我们直接目的是展现自己与职位相符,但面试的本身还是两方相互选择的过程,双方有良好的互动更多的了解,对于后面工作开展也是很有利的。)
值得注意的是,如果没有准备几个好问题,还是不要强问问题。问题可以挑重点的问(如:岗位对个人的要求、工作内容、团队角色、团队项目情况、团队定位与公司架构等等)。
简历模板、数据结构及算法资料:Github链接,公众号阅读原文可访问链接
欺诈是用户主观、以非法占有为目的,采用虚构事实或隐瞒事实真相的方法,骗取他人财物或金融机构信用,破坏金融管理秩序的行为。
按照欺诈的人数来分可分为:个体欺诈和团伙欺诈;
按照欺诈的主体来可分为第一、第二、第三方欺诈;
按照欺诈的行为可分为:金融信贷欺诈、互联网业务欺诈和信用卡欺诈三大类。按照欺诈的行为,大的方向上可分为:金融信贷欺诈、互联网业务欺诈和信用卡欺诈三大类,如果进一步
细分落到具体的场景上有:盗刷、薅羊毛、骗贷、套现、刷单、 刷好评等行为,根据不同的欺诈场景的应对方法是有所不同的。
营销欺诈是互联网业务欺诈大类的一种,指的是羊毛党通过虚假身份参加营销活动大量获利的行为。据统计,存在1000万+被滥用身份信息、 200万+网络黑产从业者、超千亿黑产市场规模。“羊毛党”也逐渐从分散个体向组团集聚发展,形成了有组织、有规模、有分工的职业“羊毛党”。
在此背景下,为避免营销资源浪费,在加强活动规则设计的同时,亟需运用技术手段搭建营销反欺诈系统,以保护良好营销环境,提升营销效果。
模型层面主要应用的技术有:有监督分类模型、知识图谱无监督模型、业务策略。由于欺诈形式大都是未知、复杂多样的,本方案通过数据分析及无监督检测的方式对有监督模型做补充。
在复杂的欺诈任务上,无法仅凭仅有的少数欺诈标签建立一个良好的欺诈模型(更何况标签质量参差不齐的),知己知彼百战不殆,这需要去了解业务知识、欺诈链,并采用更合适的技术手段来识别欺诈。
第一类是个人纯手工进行薅羊毛的行为,这类行为往往因涉案金额和规模小,且在商家营销的允许范围内;
第二类通过破解平台的后台接口建立虚假客户端进行薅羊毛(黑客类);
第三类利用外挂程序将薅羊毛过程完全自动化;
第四类是团伙羊毛党,通常是组织者组织团伙成员薅羊毛;(与信贷团伙不同的是,羊毛党的欺诈涉及单笔金额较小,但团伙规模较大,团伙的实际组成可能只有单个人/工作室。)
现实中,羊毛党会结合第三、四类薅羊毛方式,并存在与平台、商家瓜分利益,发展趋势更具规模化、产业化,这个是营销反欺诈的主要目标。
通过业务数据分析(以某银行营销活动数据为例),发现了一些羊毛党特点
群控特点:每笔交易额度一样;商家集中性;活动开展短时间内交易频次高;行为序列类似;大量失败交易等;
团伙性特点:团伙间有资金往来;共用设备、手机号码、IP、相似GPS等;
资源端特点:代理IP、伪造GPS、伪造设备号、冒用身份证,存在大量一对多情况;
兑换端特点 :集中电子券,白酒等硬通货;收货地址相似度高;
对这些特点,主要有两种应用:
1、可以加工出相关的强特征:比如活动短期内的优惠频次;
2、采用比较合适的模型去识别欺诈:如交易额度一样且频次高可以使用策略去覆盖;行为序列类似可以先用表征学习然后聚类发现;收货地址相似度高可以用WMD算法匹配高频地址群;团伙特点可以用知识图谱去挖掘黑产团伙;
主要运用知识图谱社区发现,结合异常检测发现高可疑的团伙,方法如下:
1、图谱构建:构建活动的知识图谱;
2、社区发现:先运行联通子图算法,在非孤立的子图内通过louvain社区发现算法挖掘团伙;
3、统计社区指标:如各团伙人数, 团伙人均参加活动次数,团伙内欺诈名单占比等指标;
4、检测异常社区:社区指标通过(如log, 幂)转换近似成为高斯分布,高斯异常检测算法发现异常的团伙;
5、名单核实:业务人员调查核实异常团伙名单,并将核实后名单回馈有监督模型实时训练迭代优化;
欢迎微信关注公众号“算法进阶”,这里定期推送机器学习、深度学习、金融科技等技术好文。欢迎一起学习交流进步!
XGBOOST:简单来说是集成了很多个基学习器(如Cart决策树)的模型。它是集成学习的串行方式(boosting)的一种经典实现,是广泛应用在工业、竞赛上的一大神器。
集成学习是结合一些的基学习器来改进其泛化能力和鲁棒性的方法,主流的有两种集成**:
- 并行方式(bagging):独立的训练一些基学习器,然后(加权)平均它们的预测结果。如:Random Forests;
- 串行方式(boosting):一个接一个的(串行)训练基学习器,每一个基学习器主要用来修正前面学习器的偏差。如:AdaBoost、GBDT及XGBOOST;
(注:此外还有stacking方法,但stacking更多被看做是融合的策略;)
决策树有非线性、拟合能力强且可以通过剪枝快速调整的特性,集成学习通常选择决策树作为基学习器。
(注:XGBOOST中的基学习器可以是CART回归树-gbtree, 也可以是线性分类器-gblinear。本文着重从树模型介绍。)
决策树是一种简单的机器学习回归/分类方法,它是由(if-then)决策结构以树形组合起来,叶子节点代表最终的预测值或类别。典型的决策树模型有:ID3、C4.5和CART。
决策树算法可以概括为两个阶段:
树的生长:**是自顶向下递归分治构建树,是依靠(信息增益、信息增益比、gini、平方误差)等某个指标做特征选择、划分的过程。
树的剪枝:决策树容易对数据产生过拟合,即生长出结构过于复杂的树模型。通过剪枝算法可以降低复杂度,减少过拟合的风险。
决策树剪枝算法的根本目的是极小化损失函数(经验损失+结构损失),基本策略有”预剪枝“和”后剪枝“两种策略:
①预剪枝:是在决策树生成过程中,限制划分的最大深度、叶子节点数和最小样本数目等,以减少不必要的模型复杂度;
②后剪枝:是先从训练集生成一棵完整的决策树,然后用用验证集自底向上地对非叶结点进行考察,若将该节点对应的子树替换为叶子结点(剪枝)能带来决策树的泛化性能提升(即目标函数损失更小,常用目标函数如:loss = 模型经验损失bias+ 模型结构损失α|T|, T为节点数目, α为系数),则将该子树替换为叶子结点。
CART回归树是二叉树结构的决策树,GBDT、XGBoost等梯度提升方法都使用了Cart回归树做基学习器。
树的生长是通过平方误差指标选择特征及切分点进行分裂。即遍历所有特征的的所有切分点,最小化目标函数,选择合适的树切分特征(j)及特征阈值(s)找到最优的切分特征和切分点,最终得到一棵回归树。
比如下图的树结点是基于特征(age)进行分裂的,设该特征值小于阈值(20)的样本划分为左子树,其他样本划分为右子树。
GBDT(梯度提升决策树) XGBOOST是在GBDT基础上提升了效率。说到Xgboost,都不得不先从GBDT(Gradient Boosting Decision Tree)说起,
GBDT串行学习原理简单来说分为三步:
XGBOOST 类似GBDT串行学习方式,学习到如下图tree1、tree2,预测是将tree1、tree2结果相加。
xgboost与gbdt对比主要的差异在于:
可以很清晰地看到,最终的目标函数只依赖于每个数据点在误差函数上的一阶导数gi和二阶导数hi。
对于这个目标函数obj求导等于0,可以得到一个叶子节点权重w*
代入obj得到了叶子结点取值的表达式
目标函数obj中的各部分,表示着每一个叶子节点对当前模型损失的贡献程度。融合一下,得到Gain的计算表达式,如下所示:
树的生长的过程,即是利用推导出的表达式作为分裂准则,对于所有的特征做一遍从左到右的扫描就可以枚举出所有分割取值点的梯度和GL和GR,然后用计算Gain的公式计算每个分割方案的分数并选择增益最大的分裂点,分裂结束后计算其对应的叶子结点值w*。
机器学习中特征选择是一个重要步骤,以筛选出显著特征、摒弃非显著特征。这样做的作用是:
特征选择方法一般分为三类:
通过计算特征的缺失率、发散性、相关性、信息量、稳定性等指标对各个特征进行评估选择,常用如缺失情况、单值率、方差验证、pearson相关系数、chi2卡方检验、IV值、信息增益及PSI等方法。
通过分析各特征缺失率,并设定阈值对特征进行筛选。阈值可以凭经验值(如缺失率<0.9)或可观察样本各特征整体分布,确定特征分布的异常值作为阈值。
# 特征缺失率
miss_rate_df = df.isnull().sum().sort_values(ascending=False) / df.shape[0]特征无发散性意味着该特征值基本一样,无区分能力。通过分析特征单个值得最大占比及方差以评估特征发散性情况,并设定阈值对特征进行筛选。阈值可以凭经验值(如单值率<0.9, 方差>0.001)或可观察样本各特征整体分布,以特征分布的异常值作为阈值。
# 分析方差
var_features = df.var().sort_values()
# 特征单值率
sigle_rate = {}
for var in df.columns:
sigle_rate[var]=(df[var].value_counts().max()/df.shape[0])特征间相关性高会浪费计算资源,影响模型的解释性。特别对线性模型来说,会导致拟合模型参数的不稳定。常用的分析特征相关性方法如:
方差膨胀因子也称为方差膨胀系数(Variance Inflation),用于计算数值特征间的共线性,一般当VIF大于10表示有较高共线性。
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 截距项
df['c'] = 1
name = df.columns
x = np.matrix(df)
VIF_list = [variance_inflation_factor(x,i) for i in range(x.shape[1])]
VIF = pd.DataFrame({'feature':name,"VIF":VIF_list})

用于计算数值特征两两间的相关性,数值范围[-1,1]。
import seaborn as sns
corr_df=df.corr()
# 热力图
sns.heatmap(corr_df)
# 剔除相关性系数高于threshold的corr_drop
threshold = 0.9
upper = corr_df.where(np.triu(np.ones(corr_df.shape), k=1).astype(np.bool))
corr_drop = [column for column in upper.columns if any(upper[column].abs() > threshold)]
经典的卡方检验是检验类别型变量对类别型变量的相关性。
Sklearn的实现是通过矩阵相乘快速得出所有特征的观测值和期望值,在计算出各特征的 χ2 值后排序进行选择。在扩大了 chi2 的在连续型变量适用范围的同时,也方便了特征选择。
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
x, y = load_iris(return_X_y=True)
x_new = SelectKBest(chi2, k=2).fit_transform(x, y)
分类任务中,可以通过计算某个特征对于分类这样的事件到底有多大信息量贡献,然后特征选择信息量贡献大的特征。 常用的方法有计算IV值、信息增益。
如目标变量D的信息熵为 H(D),而D在特征A条件下的条件熵为 H(D|A),那么信息增益 G(D , A) 为:
信息增益(互信息)的大小即代表特征A的信息贡献程度。
from sklearn.feature_selection import mutual_info_classif
from sklearn.datasets import load_iris
x, y = load_iris(return_X_y=True)
mutual_info_classif(x,y)
IV值(Information Value),在风控领域是一个重要的信息量指标,衡量了某个特征(连续型变量需要先离散化)对目标变量的影响程度。其基本**是根据该特征所命中黑白样本的比率与总黑白样本的比率,来对比和计算其关联程度。【Github代码链接】
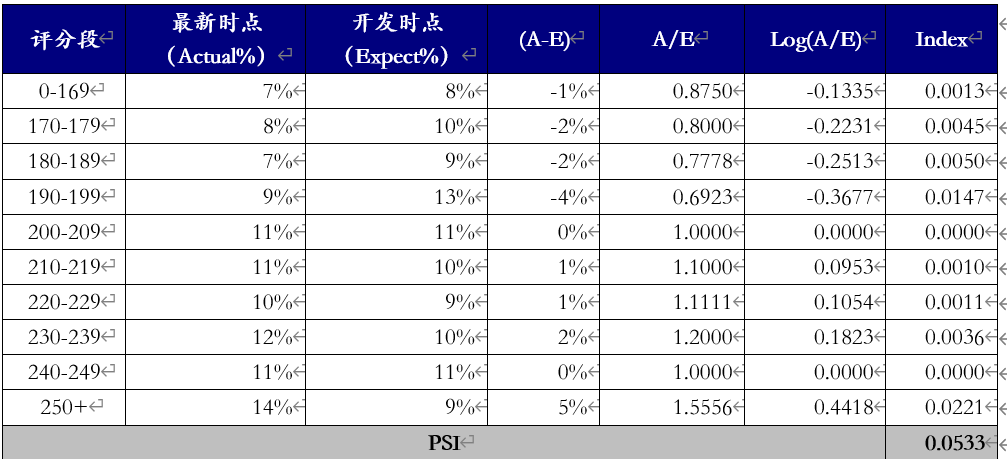
对大部分数据挖掘场景,特别是风控领域,很关注特征分布的稳定性,其直接影响到模型使用周期的稳定性。常用的是PSI(Population Stability Index,群体稳定性指标)。
PSI表示的是实际与预期分布的差异,SUM( (实际占比 - 预期占比)* ln(实际占比 / 预期占比) )。
在建模时通常以训练样本(In the Sample, INS)作为预期分布,而验证样本作为实际分布。验证样本一般包括样本外(Out of Sample,OOS)和跨时间样本(Out of Time,OOT)【Github代码链接】
嵌入法是直接使用模型训练的到特征重要性,在模型训练同时进行特征选择。通过模型得到各个特征的权值系数,根据权值系数从大到小来选择特征。常用如基于L1正则项的逻辑回归、Lighgbm特征重要性选择特征。
L1正则方法具有稀疏解的特性,直观从二维解空间来看L1-ball 为正方形,在顶点处时(如W2=C, W1=0的稀疏解),更容易达到最优解。可见基于L1正则方法的会趋向于产生少量的特征,而其他的特征都为0。
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
x_new = SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(x, y)基于决策树的树模型(随机森林,Lightgbm,Xgboost等),树生长过程中也是启发式搜索特征子集的过程,可以直接用训练后模型来输出特征重要性。
import matplotlib.pyplot as plt
from lightgbm import plot_importance
from lightgbm import LGBMClassifier
model = LGBMClassifier()
model.fit(x, y)
plot_importance(model, max_num_features=20, figsize=(10,5),importance_type='split')
plt.show()
feature_importance = pd.DataFrame({
'feature': model.booster_.feature_name(),
'gain': model.booster_.feature_importance('gain'),
'split': model.booster_.feature_importance('split')
}).sort_values('gain',ascending=False)
当特征数量多时,对于输出的特征重要性,通常可以按照重要性的拐点划定下阈值选择特征。
包装法是通过每次选择部分特征迭代训练模型,根据模型预测效果评分选择特征的去留。一般包括产生过程,评价函数,停止准则,验证过程,这4个部分。
(1) 产生过程( Generation Procedure )是搜索特征子集的过程,首先从特征全集中产生出一个特征子集。搜索方式有完全搜索(如广度优先搜索、定向搜索)、启发式搜索(如双向搜索、后向选择)、随机搜索(如随机子集选择、模拟退火、遗传算法)。
(2) 评价函数( Evaluation Function ) 是评价一个特征子集好坏程度的一个准则。
(3) 停止准则( Stopping Criterion )停止准则是与评价函数相关的,一般是一个阈值,当评价函数值达到这个阈值后就可停止搜索。
(4) 验证过程( Validation Procedure )是在验证数据集上验证选出来的特征子集的实际效果。
首先从特征全集中产生出一个特征子集,然后用评价函数对该特征子集进行评价,评价的结果与停止准则进行比较,若评价结果比停止准则好就停止,否则就继续产生下一组特征子集,继续进行特征选择。最后选出来的特征子集一般还要验证其实际效果。
RFE递归特征消除是常见的特征选择方法。原理是递归地在剩余的特征上构建模型,使用模型判断各特征的贡献并排序后做特征选择。
from sklearn.feature_selection import RFE
rfe = RFE(estimator,n_features_to_select,step)
rfe = rfe.fit(x, y)
print(rfe.support_)
print(rfe.ranking_)
鉴于RFE仅是后向迭代的方法,容易陷入局部最优,而且不支持Lightgbm等模型自动处理缺失值/类别型特征,便基于启发式双向搜索及模拟退火算法**,简单码了一个特征选择的方法【Github代码链接】,如下代码:
"""
Author: 公众号-算法进阶
基于启发式双向搜索及模拟退火的特征选择方法。
"""
import pandas as pd
import random
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score, roc_curve, auc
def model_metrics(model, x, y, pos_label=1):
"""
评价函数
"""
yhat = model.predict(x)
yprob = model.predict_proba(x)[:,1]
fpr, tpr, _ = roc_curve(y, yprob, pos_label=pos_label)
result = {'accuracy_score':accuracy_score(y, yhat),
'f1_score_macro': f1_score(y, yhat, average = "macro"),
'precision':precision_score(y, yhat,average="macro"),
'recall':recall_score(y, yhat,average="macro"),
'auc':auc(fpr,tpr),
'ks': max(abs(tpr-fpr))
}
return result
def bidirectional_selection(model, x_train, y_train, x_test, y_test, annealing=True, anneal_rate=0.1, iters=10,best_metrics=0,
metrics='auc',threshold_in=0.0001, threshold_out=0.0001,early_stop=True,
verbose=True):
"""
model 选择的模型
annealing 模拟退火算法
threshold_in 特征入模的>阈值
threshold_out 特征剔除的<阈值
"""
included = []
best_metrics = best_metrics
for i in range(iters):
# forward step
print("iters", i)
changed = False
excluded = list(set(x_train.columns) - set(included))
random.shuffle(excluded)
for new_column in excluded:
model.fit(x_train[included+[new_column]], y_train)
latest_metrics = model_metrics(model, x_test[included+[new_column]], y_test)[metrics]
if latest_metrics - best_metrics > threshold_in:
included.append(new_column)
change = True
if verbose:
print ('Add {} with metrics gain {:.6}'.format(new_column,latest_metrics-best_metrics))
best_metrics = latest_metrics
elif annealing:
if random.randint(0, iters) <= iters * anneal_rate:
included.append(new_column)
if verbose:
print ('Annealing Add {} with metrics gain {:.6}'.format(new_column,latest_metrics-best_metrics))
# backward step
random.shuffle(included)
for new_column in included:
included.remove(new_column)
model.fit(x_train[included], y_train)
latest_metrics = model_metrics(model, x_test[included], y_test)[metrics]
if latest_metrics - best_metrics < threshold_out:
included.append(new_column)
else:
changed = True
best_metrics= latest_metrics
if verbose:
print('Drop{} with metrics gain {:.6}'.format(new_column,latest_metrics-best_metrics))
if not changed and early_stop:
break
return included
#示例
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y)
model = LGBMClassifier()
included = bidirectional_selection(model, x_train, y_train, x_test, y_test, annealing=True, iters=50,best_metrics=0.5,
metrics='auc',threshold_in=0.0001, threshold_out=0,
early_stop=False,verbose=True)注:公众号点击阅读原文可访问github源码
逻辑回归由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。上文总结了逻辑回归的原理及其实现【全面解析并实现逻辑回归(Python)】。
本文从实际应用出发,以数据特征、优化算法、模型优化等方面,全面地归纳了逻辑回归(LR)优化技巧。
逻辑回归是简单的广义线性模型,模型的拟合能力很有限,无法学习到特征间交互的非线性信息:一个经典的示例是LR无法正确分类非线性的XOR数据,而通过引入非线性的特征(特征生成),可在更高维特征空间实现XOR线性可分。
# 生成xor数据
import pandas as pd
xor_dataset = pd.DataFrame([[1,1,0],[1,0,1],[0,1,1],[0,0,0]],columns=['x0','x1','label'])
x,y = xor_dataset[['x0','x1']], xor_dataset['label']
xor_dataset.head()
# keras实现逻辑回归
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
np.random.seed(5) # 固定随机种子
random.set_seed(5)
model = Sequential()
model.add(Dense(1, input_dim=3, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy')
xor_dataset['x2'] = xor_dataset['x0'] * xor_dataset['x1'] # 加入非线性特征
x,y = xor_dataset[['x0','x1','x2']], xor_dataset['label']
model.fit(x, y, epochs=10000,verbose=False)
print("正确标签:",y.values)
print("模型预测:",model.predict(x).round())
# 正确标签: [0 1 1 0] 模型预测: [0 1 1 0]
业界常说“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。由于LR是简单模型,其特征质量基本决定了其最终效果(也就是简单模型要比较折腾特征工程)。
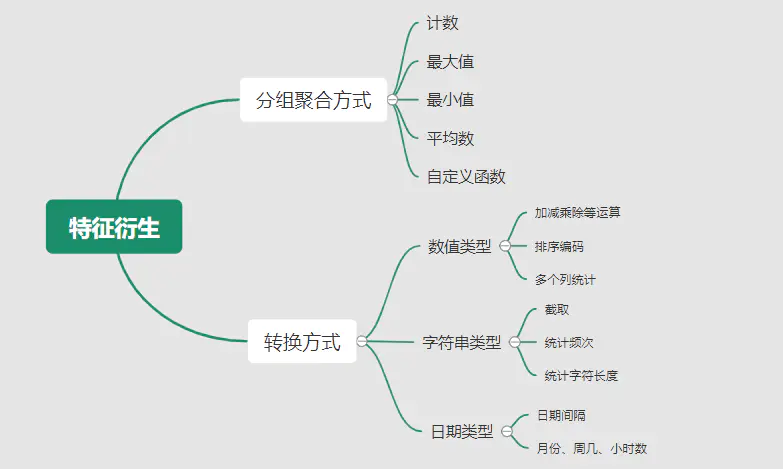
LR常用特征生成(提取)的方式主要有3种:
人工结合业务衍生特征:人工特征的好处是加工出的特征比较有业务解释性,更贴近实际业务。缺点是很依赖业务知识,耗时。
特征衍生工具:如通过featuretools暴力衍生特征(相关代码可以参考【特征生成方法】),ft生成特征的常用方法有聚合(求平均值、最大值最小值)、转换(特征间加减乘除)的方式。暴力衍生特征速度较快。缺点是更占用计算资源,容易产生一些噪音,而且不太适合要求特征解释性的场景。(需要注意的:简单地加减做线性加工特征的方法对于LR是没必要的,模型可以自己表达)
基于模型的方法:
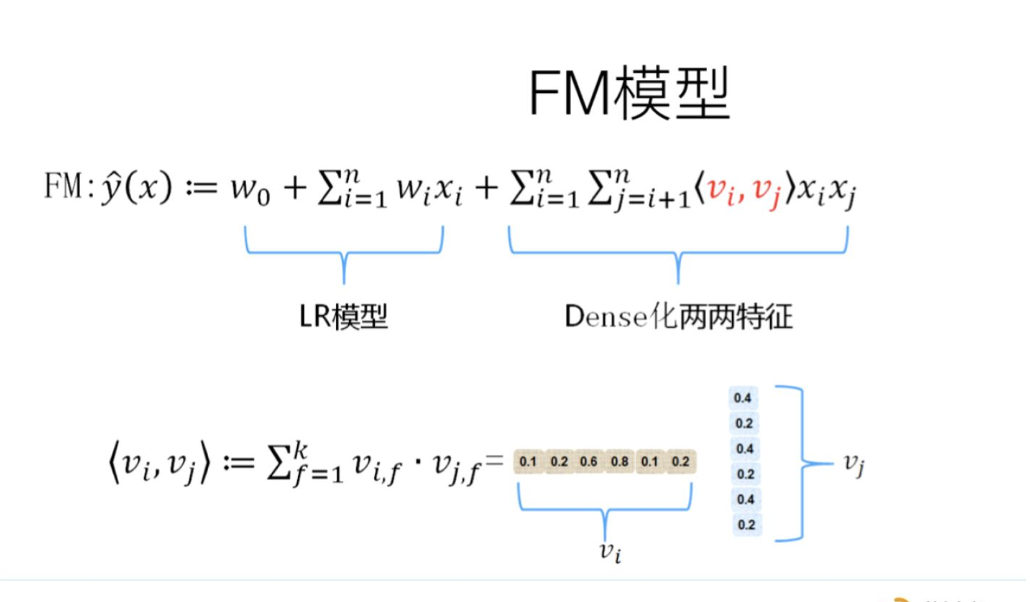
如POLY2、引入隐向量的因子分解机(FM)可以看做是LR的基础上,对所有特征进行了两两交叉,生成非线性的特征组合。
但FM等方法只能够做二阶的特征交叉,更为有效的是,利用GBDT自动进行筛选特征并生成特征组合。也就是提取GBDT子树的特征划分及组合路径作为新的特征,再把该特征向量当作LR模型输入,也就是推荐系统经典的GBDT +LR方法。(需要注意的,GBDT子树深度太深的化,特征组合层次比较高,极大提高LR模型拟合能力的同时,也容易引入一些噪声,导致模型过拟合)
如下GBDT+LR的代码实现(基于癌细胞数据集),提取GBDT特征,并与原特征拼接:
训练并评估模型有着较优的分类效果:
## GBDT +LR ,公众号阅读原文,可访问Github源码
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier(n_estimators=50, random_state=10, subsample=0.8, max_depth=6,
min_samples_split=20)
gbdt.fit(x_train, y_train) # GBDT 训练集训练
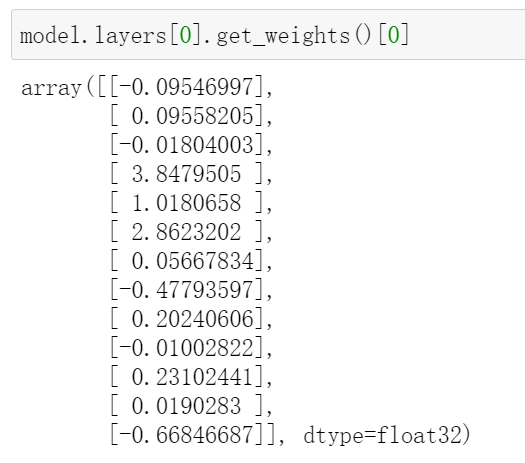
train_new_feature = gbdt.apply(x) # 返回数据在训练好的模型里每棵树中所处的叶子节点的位置
print(train_new_feature.shape)
train_new_feature = train_new_feature.reshape(-1, 50)
display(train_new_feature)
print(train_new_feature.shape)
enc = OneHotEncoder()
enc.fit(train_new_feature)
train_new_feature2 = np.array(enc.transform(train_new_feature).toarray()) # onehot表示
print(train_new_feature2.shape)
train_new_feature2
LR对于连续性的数值特征的输入,通常需要对特征做下max-min归一化(x =x-min/(max-min),转换输出为在 0-1之间的数,这样可以加速模型计算及训练收敛。但其实在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是先将连续特征离散化(常用的有等宽、等频、卡方分箱、决策树分箱等方式,而分箱的差异也直接影响着模型效果),然后做(Onehot、WOE)编码再输入模型。
之所以这样做,我们回到模型的原理,逻辑回归是广义线性模型,模型无非就是对特征线性的加权求和,在通过sigmoid归一化为概率。这样的特征表达是很有限的。以年龄这个特征在识别是否存款为例。在lr中,年龄作为一个特征对应一个权重w控制,输出值 = sigmoid(...+age * w+..),可见年龄数值大小在模型参数w的作用下只能呈线性表达。
但是对于年龄这个特征来说,不同的年龄值,对模型预测是否会存款,应该不是线性关系,比如0-18岁可能对于存款是负相关,19-55对于存款可能就正相关。这意味着不同的特征值,需要不同模型参数来更好地表达。也就是通过对特征进行离散化,比如年龄可以离散化以及哑编码(onehot)转换成4个特征(if_age<18, if_18<age<30,if_30<age<55,if_55<age )输入lr模型,就可以用4个模型参数分别控制这4个离散特征的表达:sigmoid(...+age1 * w1+age2 * w2..),这明显可以增加模型的非线性表达,提高了拟合能力。
在风控领域,特征离散后更常用特征表示(编码)还不是onehot,而是WOE编码。
woe编码是通过对当前分箱中正负样本的比值Pyi与所有样本中正负样本比值Pni的差异(如上式),计算出各个分箱的woe值,作为该分箱的数值表示。
经过分箱、woe编码后的特征很像是决策树的决策过程,以年龄特征为例: if age >18 and age<22 then return - 0.57(年龄数值转为对应WOE值); if age >44 then return 1.66;...;将这样的分箱及编码(对应树的特征划分、叶子节点值)输入LR,很类似于决策树与LR的模型融合,而提高了模型的非线性表达。
总结下离散化编码的优点:
特征选择用于筛选出显著特征、摒弃非显著特征。可以降低运算开销,减少干扰噪声,降低过拟合风险,提升模型效果。对于逻辑回归常用如下三种选择方法:
过滤法:利用缺失率、单值率、方差、pearson相关系数、VIF、IV值、PSI、P值等指标对特征进行筛选;(相关介绍及代码可见:【特征选择】)
嵌入法:使用带L1正则项的逻辑回归,有特征选择(稀疏解)的效果;
包装法:使用逐步逻辑回归,双向搜索选择特征。
其中,过滤法提到的VIF是共线性指标,其原理是分别尝试以各个特征作为标签,用其他特征去学习拟合,得到线性回归模型拟合效果的R^2值,算出各个特征的VIF。特征的VIF为1,即无法用其他特征拟合出当前特征,特征之间完全没有共线性(工程上常用VIF<10作为阈值)
共线性对于广义线性模型主要影响了特征实际的显著性及权重参数(比如,该特征业务上应该正相关,而权重值却是负的),也会消弱模型解释性以及模型训练的稳定性。
通过设置截距项(偏置项)b可以提高逻辑回归的拟合能力。截距项可以简单理解为模型多了一个参数b(也可以看作是新增一列常数项特征对应的参数w0),这样的模型复杂度更高,有更好的拟合效果。
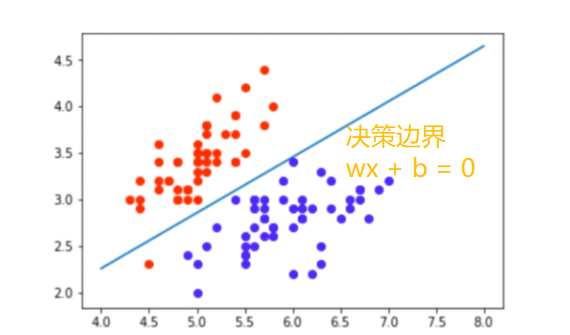
如果没有截距项b呢?我们知道逻辑回归的决策边界是线性的(即决策边界为W * X + b),如果没有截距项(即W * X),决策边界就限制在必须是通过坐标圆点的,这样的限制很有可能导致模型收敛慢、精度差,拟合不好数据,即容易欠拟合。
通过设定正则项可以减少模型的过拟合风险,常用的正则策略有L1,L2正则化:
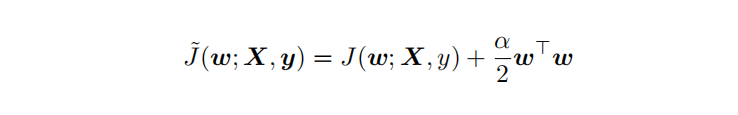
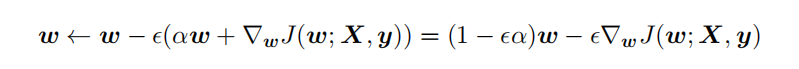
从上式可以看出,加⼊权重衰减后会导致学习规则的修改,即在每步执⾏梯度更新前先收缩权重 (乘以 1 − ϵα ),有权重衰减的效果。
对带L1目标函数的模型参数更新权重(其中 sgn(x) 为符号函数,取参数的正负号):
可见,在-αsgn(w)项的作用下, w各元素每步更新后的权重向量都会平稳地向0靠拢,w的部分元素容易为0,造成稀疏性。
总结下L1,L2正则项:
L1,L2都是限制解空间,减少模型容量的方法,以到达减少过拟合的效果。
L2范式约束具有产生平滑解的效果,没有稀疏解的能力,即参数并不会出现很多零。假设我们的决策结果与两个特征有关,L2正则倾向于综合两者的影响,给影响大的特征赋予高的权重;而L1正则倾向于选择影响较大的参数,而尽可能舍弃掉影响较小的那个(有稀疏解效果)。在实际应用中 L2正则表现往往会优于 L1正则,但 L1正则会压缩模型,降低计算量。
当逻辑回归应用于二分类任务时有两种主要思路,
沿用Sigmoid激活函数的二分类思路,把多分类变成多个二分类组合有两种实现方式:OVR(one-vs-rest)的**就是用一个类别去与其他汇总的类别进行二分类, 进行多次这样的分类, 选择概率值最大的那个类别;
OVO(One vs One)每个分类器只挑两个类别做二分类, 得出属于哪一类,最后把所有分类器的结果放在一起, 选择最多的那个类别,如下图:
另外一种,将Sigmoid激活函数换成softmax函数,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression),即可适用于多分类的场景。softmax函数简单来说就是将多个神经元(神经元数目为类别数)输出的结果映射到各输出的占比(范围0~1, 占比可以理解成概率),我们通过选择概率最大输出类别作为预测类别。
如下softmax函数及对应的多分类目标函数:
softmax回归中,一般是假设多个类别是互斥的,样本在softmax中的概率公式中计算后得到的是样本属于各个类别的值,各个类别的概率之和一定为1,而采用logistic回归OVR进行多分类时,得到的是值是样本相对于其余类别而言属于该类别的概率,一个样本在多个分类器上计算后得到的结果不一定为1。因而当分类的目标类别是互斥时(例如分辨猫、猪、狗图片),常采用softmax回归进行预测,而分类目标类别不是很互斥时(例如分辨流行音乐、摇滚、华语),可以采用逻辑回归建立多个二分类器(也可考虑下多标签分类)。
逻辑回归使用最小化交叉熵损失作为目标函数,
为什么不能用MSE均方误差?
简单来说,有以下几点:
最大似然下的逻辑回归没有解析解,我们常用梯度下降之类的算法迭代优化得到局部较优的参数解。
如果是Keras等神经网络库建模,梯度下降算法类有SGD、Momentum、Adam等优化算法可选。对于大多数任务而言,通常可以直接先试下Adam,然后可以继续在具体任务上验证不同优化算法效果。
如果用的是scikitl-learn库建模,优化算法主要有liblinear(坐标下降)、newton-cg(拟牛顿法), lbfgs(拟牛顿法)和sag(随机平均梯度下降)。liblinear支持L1和L2,只支持OvR做多分类;“lbfgs”, “sag” “newton-cg”只支持L2,支持OvR和MvM做多分类;当数据量特别大,优先sag!

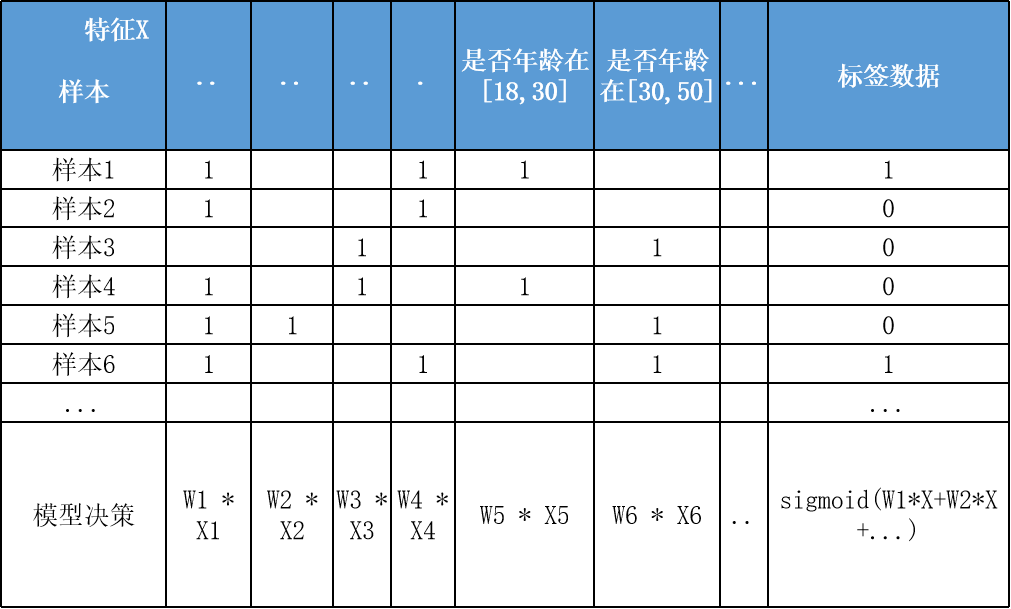
逻辑回归模型 很大的优势就是可解释性,上节提到通过离散化编码(如Onehot)可以提高拟合效果及解释性,如下特征离散后Onehot编码:
决策过程也就是对特征分箱Xn及其模型权重Wn的加权求和,而通过模型权重值的大小就可以知道各特征对于决策的实际影响程度,比如特征"年龄在[18,30]"对应学到权重值为-0.8,也就是负相关。
序列文章 上文[《一文速览机器学习的类别(Python代码)》](https://www.jianshu.com/p/fbe59dc46907) 提到逻辑回归并做了简单介绍。本文将从神经元到逻辑回归模型结构,并将其扩展到深度深度网络模型。
对于人类智慧奥秘的探索,不同时代、学科背景的人对于智慧的理解及其实现方法有着不同的**主张。有的主张用显式逻辑体系搭建人工智能系统,即符号主义。有的主张用数学模型模拟大脑组成以实现智慧,即联结主义,这也就是我们本文讨论的方向。
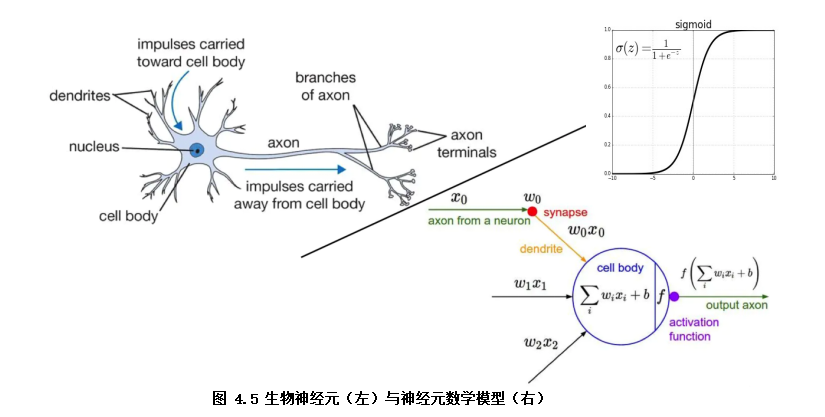
那大脑为什么能够思考?科学家发现,原因在于人体的神经网络,而神经网络的基本组成就是神经元:
1、外部刺激通过神经元的神经末梢,转化为电信号,传导到神经元。
2、神经元的树突接收电信号,由神经元处理是否达到激活阈值再输出兴奋或者抑制电信号,最后由轴突将信号传递给其它细胞。
3、无数神经元构成神经中枢。神经中枢综合各种信号,做出判断。
4、 人体根据神经中枢的指令,对外部刺激做出反应。
既然智慧的基础是神经元,而正因为神经元这些特点才使大脑具有强大的 “运算及决策的能力”,科学家以此为原理发明了人工神经元数学模型,并以神经元为基础而组合成人工神经网络模型。(注:下文谈到的神经元都特指人工神经元)
如上图就是人工神经元的基本结构。它可以输入一定维数的输入(如:3维的输入,x1,x2, x3),每个输入都相要乘上相应的权重值(如:w0,w1,w2),乘上每一权重值的作用可以视为对每一输入的加权,也就是对每一输入的神经元对它的重视程度是不一样的。
接下来神经元将乘上权重的每个输入做下求和(也就是加权求和),并加上截距项(截距项b可以视为对神经元阈值的直接调整),最后由激活函数(f)非线性转换为最终输出值。
激活函数的种类很多,有sigmoid,tanh,sign,relu,softmax等等(下一专题会讨论下激活函数)。激活函数的作用是在神经元上实现一道非线性的运算,以通用万能近似定理——“如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 ℝn 的紧子集 (Compact subset) 上的连续函数”所表明,激活函数是深度神经网络学习拟合任意函数的前提。
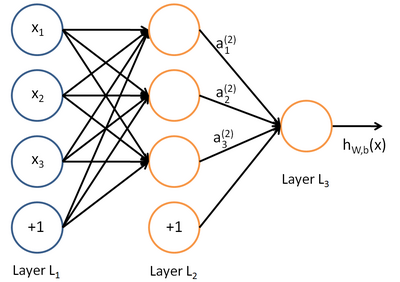
单个神经元且其激活函数为sigmoid时,既是我们熟知的逻辑回归的模型结构。
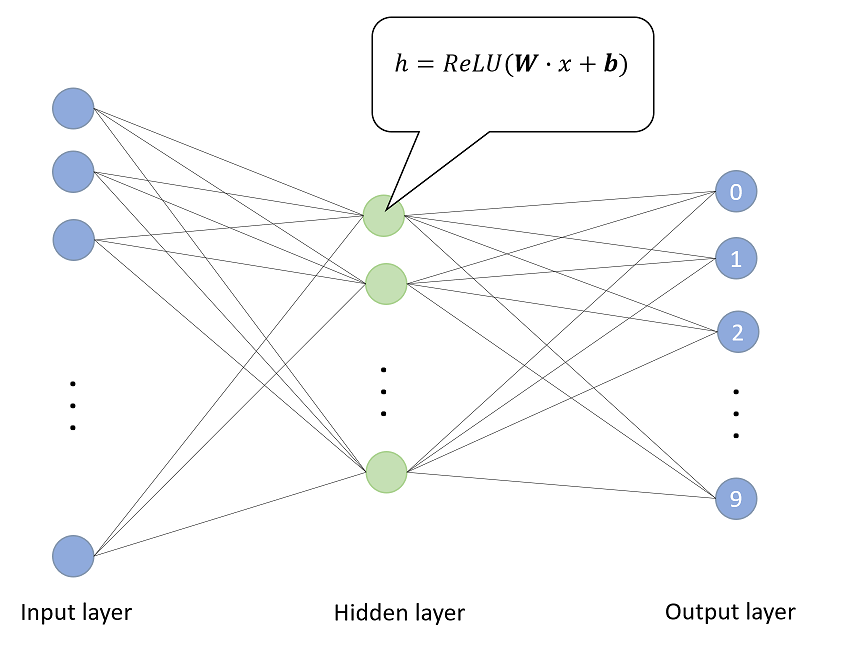
逻辑回归是一种广义线性的分类模型且其模型结构可以视为单层的神经网络,由一层输入层、一层仅带有一个sigmoid激活函数的神经元的输出层组成,而无隐藏层。(注:计算网络层数不计入输入层)
在逻辑回归模型结构中,我们输入数据特征x,通过输出层神经元激活函数σ(sigmoid函数)将输入的特征经由sigmoid(wx + b)的计算后非线性转换为0~1区间的数值后输出。学习训练过程是通过梯度下降学到合适的参数w的模型 Y=sigmoid(wx + b),使得模型输出值Y与实际值y的误差最小。
基于前面的介绍可以知道,神经网络也就是神经元按层次连接而成的网络,逻辑回归是单层的神经网络,当我们给仅有输入层及输出层的单层神经网络中间接入至少一层的隐藏层,也就是深度神经网络了。
深度神经网络包含了三种网络层:输入层、隐藏层及输出层。
数据特征(x)从输入层输入,每层的计算结果由前一层传递到下一层,最终到输出层输出计算结果。每个网络层由一定数量的神经元组成,神经元可以视为一个个的计算单元,对输入进行加权求和,故其计算结果由神经元包含的权重(即模型参数w)直接控制,神经元内还可以包含激活函数,可以对加权求和的结果进一步做非线性的计算,如sigmoid(wx + b)。
本文侧重于模型拟合能力的探讨。过拟合及泛化能力方面下期文章会专题讨论。
原理上讲,神经网络模型的训练过程其实就是拟合一个数据分布(x)可以映射到输出(y)的数学函数 f(x),而拟合效果的好坏取决于数据及模型。
那对于如何提升拟合能力呢?我们首先从著名的单层神经网络为啥拟合不了XOR函数说起。
单层神经网络如逻辑回归、感知器等模型,本质上都属于广义线性分类器(决策边界为线性)。这点可以从逻辑回归模型的决策函数看出,决策函数Y=sigmoid(wx + b),当wx+b>0,Y>0.5;当wx+b<0,Y<0.5,以wx+b这条线可以区分开Y=0或1(如下图),可见决策边界是线性的。
这也导致了历史上著名xor问题:
1969年,“符号主义”代表人物马文·明斯基(Marvin Minsky)提出XOR问题:xor即异或运算的函数,输入两个bool数值(取值0或者1),当两个数值不同时输出为1,否则输出为0。如下图,可知XOR数据无法通过线性模型的边界正确的区分开
由于单层神经网络线性,连简单的非线性的异或函数都无法正确的学习,而我们经常希望模型是可以学习非线性函数,这给了神经网络研究以沉重的打击,神经网络的研究走向长达10年的低潮时期。
如下以逻辑回归代码为例,尝试去学习XOR函数:
# 生成xor数据
import pandas as pd
xor_dataset = pd.DataFrame([[1,1,0],[1,0,1],[0,1,1],[0,0,0]],columns=['x0','x1','label'])
x,y = xor_dataset[['x0','x1']], xor_dataset['label']
xor_dataset.head()
from keras.layers import *
from keras.models import Sequential, Model
np.random.seed(0)
model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy')
x,y = xor_dataset[['x0','x1']], xor_dataset['label']
model.fit(x, y, epochs=100000,verbose=False)
print("正确标签:",y.values)
print("模型预测:",model.predict(x).round())
# 正确标签: [0 1 1 0] 模型预测: [1 0 1 0]
结果可见,lr线性模型的拟合能力有限,无法学习非线性的XOR函数。那如何解决这个问题呢?
这就要说到线性模型的根本缺陷———无法使用变量间交互的非线性信息。
##二、 如何学习非线性的XOR函数
如上文所谈,学习非线性函数的关键在于:模型要使用变量间交互的非线性信息。
解决思路很清晰了,要么,我们手动给模型加一些非线性特征作为输入(即特征生成的方法)。
要不然,增加模型的非线性表达能力(即非线性模型),模型可以自己对特征x增加一些ф(x)非线性交互转换。假设原线性模型的表达为f(x;w),非线性模型的表达为f(x, ф(x), w)。
最简单的思路是我们手动加入些其他维度非线性特征,以提高模型非线性的表达能力。这也反映出了特征工程对于模型的重要性,模型很大程度上就是复杂特征+简单模型与简单特征+复杂模型的取舍。
# 加入非线性特征
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
np.random.seed(5) # 固定随机种子
random.set_seed(5)
model = Sequential()
model.add(Dense(1, input_dim=3, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy')
xor_dataset['x2'] = xor_dataset['x0'] * xor_dataset['x1'] # 非线性特征
x,y = xor_dataset[['x0','x1','x2']], xor_dataset['label']
model.fit(x, y, epochs=10000,verbose=False)
print("正确标签:",y.values)
print("模型预测:",model.predict(x).round())
# 正确标签: [0 1 1 0] 模型预测: [0 1 1 0]
正确标签: [0 1 1 0] ,模型预测: [0 1 1 0],模型预测结果OK!
搬出万能近似定理,“一个前馈神经网络如果具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel可测函数。”简单来说,前馈神经网络有“够深的网络层”以及“至少一层带激活函数的隐藏层”,既可以拟合任意的函数。
这里我们将逻辑回归加入一层的隐藏层,升级为一个两层的神经网络(MLP):
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
np.random.seed(0) # 随机种子
random.set_seed(0)
model = Sequential()
model.add(Dense(10, input_dim=2, activation='relu')) # 隐藏层
model.add(Dense(1, activation='sigmoid')) # 输出层
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy')
x,y = xor_dataset[['x0','x1']], xor_dataset['label']
model.fit(x, y, epochs=100000,verbose=False) # 训练模型
print("正确标签:",y.values)
print("模型预测:",model.predict(x).round())
正确标签: [0 1 1 0] ,模型预测:[[0.][1.][1.][0.]],模型预测结果OK!
支持向量机(Support Vector Machine, SVM)可以视为在单隐藏层神经网络基础上的改进(svm具体原理可关注笔者后面的专题介绍),对于线性不可分的问题,不同于深度神经网络的增加非线性隐藏层,SVM利用非线性核函数,本质上都是实现特征空间的非线性变换,提升模型的非线性表达能力。
from sklearn.svm import SVC
svm = SVC()
svm.fit(x,y)
svm.predict(x)
正确标签: [0 1 1 0] 模型预测: [[0.][1.][1.][0.]],模型预测结果OK!
归根结底,机器学习模型可以看作一个函数,本质能力是通过参数w去控制特征表示,以拟合目标值Y,最终学习到的决策函数f( x; w )。模型拟合能力的提升关键即是,**控制及利用特征间交互的非线性信息,实现特征空间的非线性变换。**拟合能力的提升可以归结为以下两方面:
数据方面:通过特征工程 构造复杂特征。
模型方面:使用非线性的复杂模型。如:含非线性隐藏层的神经网络,非线性核函数svm,天然非线性的集成树模型。经验上讲,对这些异质模型做下模型融合效果会更好。
本文首发”算法进阶“,公众号阅读原文即访问文章相关代码
异常检测是通过数据挖掘方法发现与数据集分布不一致的异常数据,也被称为离群点、异常值检测等等。
异常检测算法适用的场景特点有:
(1)无标签或者类别极不均衡;
(2)异常数据跟样本中大多数数据的差异性较大;
(3)异常数据在总体数据样本中所占的比例很低。 常见的应用案例如:
金融领域:从金融数据中识别”欺诈用户“,如识别信用卡申请欺诈、信用卡盗刷、信贷欺诈等;
安全领域:判断流量数据波动以及是否受到攻击等等;
电商领域:从交易等数据中识别”恶意买家“,如羊毛党、恶意刷屏团伙;
生态灾难预警:基于天气指标数据,判断未来可能出现的极端天气;
医疗监控:从医疗设备数据,发现可能会显示疾病状况的异常数据;
异常检测是热门的研究领域,但由于异常存在的未知性、异质性、特殊性及多样性等复杂情况,整个领域仍有较多的挑战:
按照训练集是否包含异常值可以划分为异常值检测(outlier detection)及新颖点检测(novelty detection),新颖点检测的代表方法如one class SVM。
按照异常类别的不同,异常检测可划分为:异常点检测(如异常消费用户),上下文异常检测(如时间序列异常),组异常检测(如异常团伙)。
按照学习方式的不同,异常检测可划分为:有监督异常检测(Supervised Anomaly Detection)、半监督异常检测(Semi-Supervised Anomaly Detection)及无监督异常检测(Unsupervised Anomaly Detection)。现实情况的异常检测问题,由于收集异常标签样本的难度大,往往是没有标签的,所以无监督异常检测应用最为广泛。
无监督异常检测按其算法**大致可分为如下下几类:
基于聚类的异常检测方法通常依赖下列假设,1)正常数据实例属于数据中的一个簇,而异常数据实例不属于任何簇; 2)正常数据实例靠近它们最近的簇质心,而异常数据离它们最近的簇质心很远; 3)正常数据实例属于大而密集的簇,而异常数据实例要么属于小簇,要么属于稀疏簇;通过将数据归分到不同的簇中,异常数据则是那些属于小簇或者不属于任何一簇或者远离簇中心的数据。
将距离簇中心较远的数据作为异常点:
这类方法有 SOM、K-means、最大期望( expectation maximization,EM)及基于语义异常因子( semantic anomaly factor)算法等;
将聚类所得小簇数据作为异常点:
代表方法有K-means聚类;
将不属于任何一簇作为异常点:
代表方法有 DBSCAN、ROCK、SNN 聚类。
基于统计的方法依赖的假设是数据集服从某种分布( 如正态分布、泊松分布及二项式分布等) 或概率模型,通过判断某数据点是否符合该分布/模型( 即通过小概率事件的判别) 来实现异常检测。根据概率模型可分为:
该方法将数据映射到 k 维空间的分层结构中,并假设异常值分布在外围,而正常数据点靠近分层结构的中心(深度越高)。
半空间深度法( ISODEPTH 法) ,通过计算每个点的深度,并根据深度值判断异常数据点。
最小椭球估计 ( minimum volume ellipsoid estimator,MVE)法。根据大多数数据点( 通常为 > 50% ) 的概率分布模型拟合出一个实线椭圆形所示的最小椭圆形球体的边界,不在此边界范围内的数据点将被判断为异常点。
孤立森林。上述两种基于深度的基础模型随着特征维度k的增加,其时间复杂性呈指数增长,通常适用于维度k≤3 时,而孤立森林通过改变计算深度的方式,也可以适用于高维的数据。
孤立森林算法是基于 Ensemble 的异常检测方法,因此具有线性的时间复杂度。且精准度较高,在处理大数据时速度快,所以目前在工业界的应用范围比较广。其基本**是:通过树模型方法随机地切分样本空间,那些密度很高的簇要被切很多次才会停止切割(即每个点都单独存在于一个子空间内),但那些分布稀疏的点(即异常点),大都很早就停到一个子空间内了。算法步骤为:
1)从训练数据中随机选择 Ψ 个样本,以此训练单棵树。
2)随机指定一个q维度(attribute),在当前节点数据中随机产生一个切割点p。p切割点产生于当前节点数据中指定q维度的最大值和最小值之间。
3)在此切割点的选取生成了一个超平面,将当前节点数据空间切分为2个子空间:把当前所选维度下小于 p 的点放在当前节点的左分支,把大于等于 p 的点放在当前节点的右分支;
4)在节点的左分支和右分支节点递归步骤 2、3,不断构造新的叶子节点,直到叶子节点上只有一个数据(无法再继续切割) 或树已经生长到了所设定的高度 。
(设置单颗树的最大高度是因为异常数据记录都比较少,其路径长度也比较低,而我们也只需要把正常记录和异常记录区分开来,因此只需要关心低于平均高度的部分就好,这样算法效率更高。)
5) 由于每颗树训练的切割特征空间过程是完全随机的,所以需要用 ensemble 的方法来使结果收敛,即多建立几棵树,然后综合计算每棵树切分结果的平均值。对于每个样本 x,通过下面的公式计算综合的异常得分s。
h(x) 为 x 在每棵树的高度,c(Ψ) 为给定样本数 Ψ 时路径长度的平均值,用来对样本 x 的路径长度 h(x) 进行标准化处理。
代表方法是One class SVM,其原理是寻找一个超平面将样本中的正例圈出来,预测就是用这个超平面做决策,在圈内的样本就认为是正样本。由于核函数计算比较耗时,在海量数据的场景用的并不多。
依赖的假设是:正常数据实例位于密集的邻域中,而异常数据实例附近的样例较为稀疏。可以继续细分为 基于密度/邻居:
基于密度,该方法通过计算数据集中各数据区域的密度,将密度较低区域作为离群区域。经典的方法为:局部离群因子( local outlier factor,LOF) 。LOF 法与传统异常点非彼即此定义不同,将异常点定义局域是异常点,为每个数据赋值一个代表相对于其邻域的 LOF 值,LOF 越大,说明其邻域密度较低,越有可能是异常点。但在 LOF 中难以确定最小近邻域,且随着数据维度的升高,计算复杂度和时间复杂度增加。
基于距离,其基本**是通过计算比较数据与近邻数据集合的距离来检测异常,正常数据点与其近邻数据相似,而异常数据则有别于近邻数据。
当给定一个数据集时,可通过基于偏差法找出与整个数据集特征不符的点,并且数据集方差会随着异常点的移除而减小。该方法可分为逐个比较数据点的序列异常技术和 OLAP 数据立方体技术。目前该方法实际应用较少。
代表方法为PCA。PCA在异常检测方面的做法,大体有两种思路:一种是将数据映射到低维特征空间,然后在特征空间不同维度上查看每个数据点跟其它数据的偏差;另外一种是将数据映射到低维特征空间,然后由低维特征空间重新映射回原空间,尝试用低维特征重构原始数据,看重构误差的大小。
代表方法有自动编码器( autoencoder,AE) ,长短期记忆神经网络(LSTM)等。

项目为kaggle上经典的信用卡欺诈检测,该数据集质量高,正负样本比例非常悬殊。我们在此项目主要用了无监督的Autoencoder新颖点检测,根据重构误差识别异常欺诈样本。
#!/usr/bin/env python
# coding: utf-8
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import pickle
import matplotlib.pyplot as plt
plt.style.use('seaborn')
import tensorflow as tf
import seaborn as sns
from sklearn.model_selection import train_test_split
from keras.models import Model, load_model
from keras.layers import Input, Dense
from keras.callbacks import ModelCheckpoint
from keras import regularizers
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve, auc, precision_recall_curve
# 安利一个异常检测Python库 https://github.com/yzhao062/Pyod
# 读取数据 :信用卡欺诈数据集地址https://www.kaggle.com/mlg-ulb/creditcardfraud
d = pd.read_csv('creditcard.csv')
# 查看样本比例
num_nonfraud = np.sum(d['Class'] == 0)
num_fraud = np.sum(d['Class'] == 1)
plt.bar(['Fraud', 'non-fraud'], [num_fraud, num_nonfraud], color='dodgerblue')
plt.show()
# 删除时间列,对Amount进行标准化
data = d.drop(['Time'], axis=1)
data['Amount'] = StandardScaler().fit_transform(data[['Amount']])
# 为无监督新颖点检测方法,只提取负样本,并且按照8:2切成训练集和测试集
mask = (data['Class'] == 0)
X_train, X_test = train_test_split(data[mask], test_size=0.2, random_state=0)
X_train = X_train.drop(['Class'], axis=1).values
X_test = X_test.drop(['Class'], axis=1).values
# 提取所有正样本,作为测试集的一部分
X_fraud = data[~mask].drop(['Class'], axis=1).values
# 构建Autoencoder网络模型
# 隐藏层节点数分别为16,8,8,16
# epoch为5,batch size为32
input_dim = X_train.shape[1]
encoding_dim = 16
num_epoch = 5
batch_size = 32
input_layer = Input(shape=(input_dim, ))
encoder = Dense(encoding_dim, activation="tanh",
activity_regularizer=regularizers.l1(10e-5))(input_layer)
encoder = Dense(int(encoding_dim / 2), activation="relu")(encoder)
decoder = Dense(int(encoding_dim / 2), activation='tanh')(encoder)
decoder = Dense(input_dim, activation='relu')(decoder)
autoencoder = Model(inputs=input_layer, outputs=decoder)
autoencoder.compile(optimizer='adam',
loss='mean_squared_error',
metrics=['mae'])
# 模型保存为model.h5,并开始训练模型
checkpointer = ModelCheckpoint(filepath="model.h5",
verbose=0,
save_best_only=True)
history = autoencoder.fit(X_train, X_train,
epochs=num_epoch,
batch_size=batch_size,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1,
callbacks=[checkpointer]).history
# 画出损失函数曲线
plt.figure(figsize=(14, 5))
plt.subplot(121)
plt.plot(history['loss'], c='dodgerblue', lw=3)
plt.plot(history['val_loss'], c='coral', lw=3)
plt.title('model loss')
plt.ylabel('mse'); plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.subplot(122)
plt.plot(history['mae'], c='dodgerblue', lw=3)
plt.plot(history['val_mae'], c='coral', lw=3)
plt.title('model mae')
plt.ylabel('mae'); plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
# 读取模型
autoencoder = load_model('model.h5')
# 利用autoencoder重建测试集
pred_test = autoencoder.predict(X_test)
# 重建欺诈样本
pred_fraud = autoencoder.predict(X_fraud)
# 计算重构MSE和MAE误差
mse_test = np.mean(np.power(X_test - pred_test, 2), axis=1)
mse_fraud = np.mean(np.power(X_fraud - pred_fraud, 2), axis=1)
mae_test = np.mean(np.abs(X_test - pred_test), axis=1)
mae_fraud = np.mean(np.abs(X_fraud - pred_fraud), axis=1)
mse_df = pd.DataFrame()
mse_df['Class'] = [0] * len(mse_test) + [1] * len(mse_fraud)
mse_df['MSE'] = np.hstack([mse_test, mse_fraud])
mse_df['MAE'] = np.hstack([mae_test, mae_fraud])
mse_df = mse_df.sample(frac=1).reset_index(drop=True)
# 分别画出测试集中正样本和负样本的还原误差MAE和MSE
markers = ['o', '^']
markers = ['o', '^']
colors = ['dodgerblue', 'coral']
labels = ['Non-fraud', 'Fraud']
plt.figure(figsize=(14, 5))
plt.subplot(121)
for flag in [1, 0]:
temp = mse_df[mse_df['Class'] == flag]
plt.scatter(temp.index,
temp['MAE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.title('Reconstruction MAE')
plt.ylabel('Reconstruction MAE'); plt.xlabel('Index')
plt.subplot(122)
for flag in [1, 0]:
temp = mse_df[mse_df['Class'] == flag]
plt.scatter(temp.index,
temp['MSE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.legend(loc=[1, 0], fontsize=12); plt.title('Reconstruction MSE')
plt.ylabel('Reconstruction MSE'); plt.xlabel('Index')
plt.show()
# 下图分别是MAE和MSE重构误差,其中橘黄色的点是信用欺诈,也就是异常点;蓝色是正常点。我们可以看出异常点的重构误差整体很高。
# 画出Precision-Recall曲线
plt.figure(figsize=(14, 6))
for i, metric in enumerate(['MAE', 'MSE']):
plt.subplot(1, 2, i+1)
precision, recall, _ = precision_recall_curve(mse_df['Class'], mse_df[metric])
pr_auc = auc(recall, precision)
plt.title('Precision-Recall curve based on %s\nAUC = %0.2f'%(metric, pr_auc))
plt.plot(recall[:-2], precision[:-2], c='coral', lw=4)
plt.xlabel('Recall'); plt.ylabel('Precision')
plt.show()
# 画出ROC曲线
plt.figure(figsize=(14, 6))
for i, metric in enumerate(['MAE', 'MSE']):
plt.subplot(1, 2, i+1)
fpr, tpr, _ = roc_curve(mse_df['Class'], mse_df[metric])
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic based on %s\nAUC = %0.2f'%(metric, roc_auc))
plt.plot(fpr, tpr, c='coral', lw=4)
plt.plot([0,1],[0,1], c='dodgerblue', ls='--')
plt.ylabel('TPR'); plt.xlabel('FPR')
plt.show()
# 不管是用MAE还是MSE作为划分标准,模型的表现都算是很好的。PR AUC分别是0.51和0.44,而ROC AUC都达到了0.95。
# 画出MSE、MAE散点图
markers = ['o', '^']
colors = ['dodgerblue', 'coral']
labels = ['Non-fraud', 'Fraud']
plt.figure(figsize=(10, 5))
for flag in [1, 0]:
temp = mse_df[mse_df['Class'] == flag]
plt.scatter(temp['MAE'],
temp['MSE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.legend(loc=[1, 0])
plt.ylabel('Reconstruction RMSE'); plt.xlabel('Reconstruction MAE')
plt.show()
文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码
根据**信息通信研究院发布的《中小企业“上云上平台” 应用场景及实施路径白皮书(2019)》统计,中小企业是国民经济和社会发展的生力军,贡献了50%以上的税收,60%以上的国内生产总值,70%以上的技术创新,80%以上的城镇劳动就业,90%以上的企业数量。**多次强调“六稳”,其中稳就业是“六稳”的基石,稳住了中小企业就稳住了经济的基本面。
然而相对于大中型企业而言,小微企业在市场竞争中仍处于弱势地位,特别是在非常时期,融资问题导致其很难保证经营的稳定性与持续性。小微企业的融资问题,反应的是金融行业的根本问题,解决金融流通效率间的信任问题。而金融科技旨在利用数字科技优势,利用科技去解决金融实体间的信任问题。本文介绍的小微贷款评分卡即是一种重要的科技手段。
小微贷款评分卡模型是利用小微快贷业务申请信息、产品信息、账户信息、实控人信息,结合央行征信数据、行外数据(工商、税务、司法等),运用机器学习方法构建人工智能风险评价模型,完善现有的小微快贷业务风险评价体系。
通过滚动比率Roll Rate分析某个逾期状态向其它逾期状态转移的概率(M1即逾期1~30天,以此类推),从而确定坏客户(大概率保持逾期状态的用户);没有逾期的客户为好客户;介于好坏客户之间定义为灰客户。如下图可以明显看到逾期M2客户就已经有90%概率会继续逾期。
即可以滚动率的拐点(如逾期M2及以上)作为坏客户的定义。
表现期:采用Vintage分析账户彻底成熟度坏需要的时间作为表现期。即是账户从应还款日开始,多久可充分暴露出是“坏”情况,按照上面坏的定义(如M2+),观察坏客户的暴露周期,如下图(本图无区分不同期数客户)发现14个月可以暴露大部分的坏客户。
观察点:客户样本选取范围,需要兼顾表现期及观察期的窗口。如选取申请贷款时间点为2019年01月~2019年05月的客户样本。
观察期:建模特征的选取日期窗口,需要考虑样本数据情况,如观察点前1年作为观察期。
##3 模型表现及应用
综合各评分模型的分数交叉矩阵,划定模型分数阈值,制定策略。
欢迎微信关注公众号“算法进阶”,这里定期推送机器学习、深度学习、金融科技等技术好文。欢迎一起学习交流进步!
机器学习中,模型的拟合效果意味着对新数据的预测能力的强弱(泛化能力)。而程序员评价模型拟合效果时,常说“过拟合”及“欠拟合”,那究竟什么是过/欠拟合呢?什么指标可以判断拟合效果?以及如何优化?
注:在机器学习或人工神经网络中,过拟合与欠拟合有时也被称为“过训练”和“欠训练”,本文不做术语差异上的专业区分。
欠拟合是指相较于数据而言,模型参数过少或者模型结构过于简单,以至于无法学习到数据中的规律。
过拟合是指模型只过分地匹配特定数据集,以至于对其他数据无良好地拟合及预测。其本质是模型从训练数据中学习到了统计噪声,由此分析影响因素有:
现实中通常由训练误差及测试误差(泛化误差)评估模型的学习程度及泛化能力。
欠拟合时训练误差和测试误差在均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,测试误差上升,这个时候就进入了过拟合区域。它们的误差情况差异如下表所示:
对于拟合效果除了通过训练、测试的误差估计其泛化误差及判断拟合程度之外,我们往往还希望了解它为什么具有这样的泛化性能。统计学常用“偏差-方差分解”(bias-variance decomposition)来分析模型的泛化性能:其泛化误差为偏差、方差与噪声之和。
噪声(ε) 表达了在当前任务上任何学习算法所能达到的泛化误差的下界,即刻画了学习问题本身(客观存在)的难度。
偏差(Bias) 是指用所有可能的训练数据集训练出的所有模型的输出值与真实值之间的差异,刻画了模型的拟合能力。偏差较小即模型预测准确度越高,表示模型拟合程度越高。
方差(Variance) 是指不同的训练数据集训练出的模型对同预测样本输出值之间的差异,刻画了训练数据扰动所造成的影响。方差较大即模型预测值越不稳定,表示模型(过)拟合程度越高,受训练集扰动影响越大。
如下用靶心图形象表示不同方差及偏差下模型预测的差异:
偏差越小,模型预测值与目标值差异越小,预测值越准确;
方差越小,不同的训练数据集训练出的模型对同预测样本预测值差异越小,预测值越集中;
“偏差-方差分解” 说明,模型拟合过程的泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。
当模型欠拟合时:模型准确度不高(高偏差),受训练数据的扰动影响较小(低方差),其泛化误差大主要由高的偏差导致。
当模型过拟合时:模型准确度较高(低偏差),模型容易学习到训练数据扰动的噪音(高方差),其泛化误差大由高的方差导致。
可结合交叉验证评估模型的表现,可较准确判断拟合程度。在优化欠/过拟合现象上,主要有如下方法:
增加数据: 如寻找更多训练数据样本,数据增强等,以减少对局部数据的依赖;
特征选择:通过筛选掉冗余特征,减少冗余特征产生噪声干扰;
降低模型复杂度:
简化模型结构:如减少神经网络深度,决策树的数目等。
L1/L2正则化:通过在代价函数加入正则项(权重整体的值)作为惩罚项,以限制模型学习的权重。
(拓展:通过在神经网络的网络层引入随机的噪声,也有类似L2正则化的效果)
集成学习:如随机森林(bagging法)通过训练样本有放回抽样和随机特征选择训练多个模型,综合决策,可以减少对部分数据/模型的依赖,减少方差及误差;
Dropout: 神经网络的前向传播过程中每次按一定的概率(比如50%)随机地“暂停”一部分神经元的作用。这类似于多种网络结构模型bagging取平均决策,且模型不会依赖某些局部的特征,从而有更好泛化性能。
机器学习 作为人工智能领域的核心组成,是计算机程序学习数据经验以优化自身算法,并产生相应的“智能化的”建议与决策的过程。
一个经典的机器学习的定义是:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
机器学习是关于计算机基于数据分布,学习构建出概率统计模型,并运用模型对数据进行分析与预测的方法。按照学习数据分布的方式的不同,主要可以分为监督学习和非监督学习:
从有标注的数据(x为变量特征空间, y为标签)中,通过选择的模型及确定的学习策略,再用合适算法计算后学习到最优模型,并用模型预测的过程。
按照模型预测结果Y的取值有限或者无限的,可再进一步分为分类模型或者回归模型;
从无标注的数据(x为变量特征空间),通过选择的模型及确定的学习策略,再用合适算法计算后学习到最优模型,并用模型发现数据的统计规律或者内在结构。
按照应用场景,可以分为聚类,降维和关联分析等模型。
明确业务问题是机器学习的先决条件,这里需要抽象出现实业务问题的解决方案:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。
(如:一个简单的新闻分类问题的场景,就是学习已有的新闻及其类别标签数据,得到一个文本分类模型,通过模型对每天新的新闻做类别预测,以归类到每个新闻频道。)
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。
意味着数据的质量决定了模型的最终效果,在实际的工业应用中,算法通常占了很小的一部分,大部分工程师的工作都是在找数据、提炼数据、分析数据。数据选择需要关注的是:
① 数据的代表性:代表性差的数据,会导致模型拟合效果差;
② 数据时间范围:监督学习的特征变量X及标签Y如与时间先后有关,则需要明确数据时间窗口,否则可能会导致数据泄漏,即存在和利用因果颠倒的特征变量的现象。(如预测明天会不会下雨,但是训练数据引入明天温湿度情况);
③ 数据业务范围:明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音;
特征工程就是将原始数据加工转化为模型可用的特征,按技术手段一般可分为:
① 数据预处理:缺失值/异常值处理,数据离散化,数据标准化等;
② 特征提取:特征表示,特征衍生,特征选择,特征降维等;
异常值处理
收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。
通常需要处理人为引起的异常值,通过业务/技术手段(如3σ准则)判定异常值,再由(python、正则式匹配)等方式筛选异常的信息,并结合业务情况删除或者替换数值。
缺失值处理
数据缺失的部分,通过结合业务进行填充数值、不做处理或者删除。
根据缺失率情况及处理方式分为以下情况:
① 缺失率较高,并结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;
② 缺失率较低,结合业务可使用一些缺失值填充手段,如pandas的fillna方法、训练随机森林模型预测缺失值填充;
③ 不做处理:部分模型如随机森林、xgboost、lightgbm能够处理数据缺失的情况,不需要对缺失数据做任何的处理。
数据离散化
数据离散化能减小算法的时间和空间开销(不同算法情况不一),并可以使特征更有业务解释性。
离散化是将连续的数据进行分段,使其变为一段段离散化的区间,分段的原则有等距离、等频率等方法。
数据标准化
数据各个特征变量的量纲差异很大,可以使用数据标准化消除不同分量量纲差异的影响,加速模型收敛的效率。常用的方法有:
① min-max 标准化:
将数值范围缩放到(0,1),但没有改变数据分布。max为样本最大值,min为样本最小值。
② z-score 标准化:
将数值范围缩放到0附近, 经过处理的数据符合标准正态分布。u是平均值,σ是标准差。
特征表示
数据需要转换为计算机能够处理的数值形式。如果数据是图片数据需要转换为RGB三维矩阵的表示。
字符类的数据可以用多维数组表示,有Onehot独热编码表示、word2vetor分布式表示及bert动态编码等;
基础特征对样本信息的表述有限,可通过特征衍生出新含义的特征进行补充。特征衍生是对现有基础特征的含义进行某种处理(聚合/转换之类),常用方法如:
① 结合业务的理解做衍生:
聚合的方式是指对字段聚合后求平均值、计数、最大值等。比如通过12个月工资可以加工出:平均月工资,薪资最大值 等等;
转换的方式是指对字段间做加减乘除之类。比如通过12个月工资可以加工出:当月工资收入与支出的比值、差值等等;
② 使用特征衍生工具:如Featuretools等;
特征选择筛选出显著特征、摒弃非显著特征。特征选择方法一般分为三类:
① 过滤法:按照特征的发散性或者相关性指标对各个特征进行评分后选择,如方差验证、相关系数、IV值、卡方检验及信息增益等方法。
② 包装法:每次选择部分特征迭代训练模型,根据模型预测效果评分选择特征的去留。
③ 嵌入法:使用某些模型进行训练,得到各个特征的权值系数,根据权值系数从大到小来选择特征,如XGBOOST特征重要性选择特征。
如果特征选择后的特征数目仍太多,这种情形下经常会有数据样本稀疏、距离计算困难的问题(称为 “维数灾难”),可以通过特征降维解决。
常用的降维方法有:主成分分析法(PCA),
线性判别分析法(LDA)等。
模型训练是选择模型学习数据分布的过程。这过程还需要依据训练结果调整算法的(超)参数,使得结果变得更加优良。
2.4.1 数据集划分
训练模型前,一般会把数据集分为训练集和测试集,并可再对训练集再细分为训练集和验证集,从而对模型的泛化能力进行评估。
① 训练集(training set):用于运行学习算法。
② 开发验证集(development set)用于调整参数,选择特征以及对算法其它优化。常用的验证方式有交叉验证Cross-validation,留一法等;
③ 测试集(test set)用于评估算法的性能,但不会据此改变学习算法或参数。
2.4.2 模型选择
常见的机器学习算法如下:
模型选择取决于数据情况和预测目标。可以训练多个模型,根据实际的效果选择表现较好的模型或者模型融合。
2.4.3 模型训练
训练过程可以通过调参进行优化,调参的过程是一种基于数据集、模型和训练过程细节的实证过程。
超参数优化需要基于对算法的原理的理解和经验,此外还有自动调参技术:网格搜索、随机搜索及贝叶斯优化等。
模型评估的标准:模型学习的目的使学到的模型对新数据能有很好的预测能力(泛化能力)。现实中通常由训练误差及测试误差评估模型的训练数据学习程度及泛化能力。
2.5.1 评估指标
① 评估分类模型:
常用的评估标准有查准率P、查全率R、两者调和平均F1-score 等,并由混淆矩阵的统计相应的个数计算出数值:
查准率是指分类器分类正确的正样本(TP)的个数占该分类器所有预测为正样本个数(TP+FP)的比例;
查全率是指分类器分类正确的正样本个数(TP)占所有的正样本个数(TP+FN)的比例。
F1-score是查准率P、查全率R的调和平均:
② 评估回归模型:
常用的评估指标有RMSE均方根误差 等。反馈的是预测数值与实际值的拟合情况。
③ 评估聚类模型:可分为两类方式,一类将聚类结果与某个“参考模型”的结果进行比较,称为“外部指标”(external index):如兰德指数,FM指数 等;
另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”(internal index):如紧凑度、分离度 等。
2.5.2 模型评估及优化
根据训练集及测试集的指标表现,分析原因并对模型进行优化,常用的方法有:
决策是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。
需要注意的是工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。
# 这是一个简单的demo。使用iris植物的数据,训练iris分类模型,通过模型预测识别品种。
import pandas as pd
# 加载数据集
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df.head()
# 使用pandas_profiling库分析数据情况
import pandas_profiling
df.profile_report(title='iris')
# 划分标签y,特征x
y = df['class']
x = df.drop('class', axis=1)
#划分训练集,测试集
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(x, y)
# 模型训练
from xgboost import XGBClassifier
# 选择模型
xgb = XGBClassifier(max_depth=1, n_estimators=1)
xgb.fit(train_x, train_y)
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score, roc_curve, auc
def model_metrics(model, x, y, pos_label=2):
"""
评估函数
"""
yhat = model.predict(x)
result = {'accuracy_score':accuracy_score(y, yhat),
'f1_score_macro': f1_score(y, yhat, average = "macro"),
'precision':precision_score(y, yhat,average="macro"),
'recall':recall_score(y, yhat,average="macro")
}
return result
# 模型评估结果
print("TRAIN")
print(model_metrics(xgb, train_x, train_y))
print("TEST")
print(model_metrics(xgb, test_x, test_y))
# 模型预测
xgb.predict(test_x)
距离(distance,差异程度)、相似度(similarity,相似程度)方法可以看作是以某种的距离函数计算元素间的距离,这些方法作为机器学习的基础概念,广泛应用于如:Kmeans聚类、协同过滤推荐算法、相似度算法、MSE损失函数等等。本文对常用的距离计算方法进行归纳以及解析,分为以下几类展开:
对于点x=(x1,x2...xn) 与点y=(y1,y2...yn) , 闵氏距离可以用下式表示:
闵氏距离是对多个距离度量公式的概括性的表述,p=1退化为曼哈顿距离;p=2退化为欧氏距离;切比雪夫距离是闵氏距离取极限的形式。
曼哈顿距离 公式:
欧几里得距离公式:
如下图蓝线的距离即是曼哈顿距离(想象你在曼哈顿要从一个十字路口开车到另外一个十字路口实际驾驶距离就是这个“曼哈顿距离”,此即曼哈顿距离名称的来源,也称为城市街区距离),红线为欧几里得距离:
切比雪夫距离起源于国际象棋**王的走法,国际象棋**王每次只能往周围的8格中走一步,那么如果要从棋盘中A格(x1,y1)走到B格(x2,y2)最少需要走几步?你会发现最少步数总是max(|x2-x1|,|y2-y1|)步。有一种类似的一种距离度量方法叫切比雪夫距离。
切比雪夫距离就是当p趋向于无穷大时的闵氏距离:
距离函数并不一定是距离度量,当距离函数要作为距离度量,需要满足:
由此可见,闵氏距离可以作为距离度量,而大部分的相似度并不能作为距离度量。
向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离。
闵氏距离也是Lp范数(如p==2为常用L2范数正则化)的一般化定义。
下图给出了一个Lp球( ||X||p = 1 )的形状随着P的减少的可视化图:
距离度量随着空间的维度d的不断增加,计算量复杂也逐增,另外在高维空间下,在维度越高的情况下,任意样本之间的距离越趋于相等(样本间最大与最小欧氏距离之间的相对差距就趋近于0),也就是维度灾难的问题,如下式结论:
对于维度灾难的问题,常用的有PCA方法进行降维计算。
假设各样本有年龄,工资两个变量,计算欧氏距离(p=2)的时候,(年龄1-年龄2)² 的值要远小于(工资1-工资2)² ,这意味着在不使用特征缩放的情况下,距离会被工资变量(大的数值)主导, 特别当p越大,单一维度的差值对整体的影响就越大。因此,我们需要使用特征缩放来将全部的数值统一到一个量级上来解决此问题。基本的解决方法可以对数据进行“标准化”和“归一化”。
另外可以使用马氏距离(协方差距离),与欧式距离不同其考虑到各种特性之间的联系是(量纲)尺度无关 (Scale Invariant) 的,可以排除变量之间的相关性的干扰,缺点是夸大了变化微小的变量的作用。马氏距离定义为:
马氏距离原理是使用矩阵对两两向量进行投影后,再通过常规的欧几里得距离度量两对象间的距离。当协方差矩阵为单位矩阵,马氏距离就简化为欧氏距离;如果协方差矩阵为对角阵,其也可称为正规化的欧氏距离。
根据向量x,y的点积公式:
我们可以利用向量间夹角的cos值作为向量相似度[1]:
余弦相似度的取值范围为:-1~1,1 表示两者完全正相关,-1 表示两者完全负相关,0 表示两者之间独立。余弦相似度与向量的长度无关,只与向量的方向有关,但余弦相似度会受到向量平移的影响(上式如果将 x 平移到 x+1, 余弦值就会改变)。
另外,归一化后计算欧氏距离,等价于余弦值:两个向量x,y, 夹角为A,欧氏距离D=(x-y)^2 = x^2+y^2-2|x||y|cosA = 2-2cosA
协方差是衡量多维数据集中,变量之间相关性的统计量。如下公式X,Y的协方差即是,X减去其均值 乘以 Y减去其均值,所得每一组数值的期望(平均值)。
如果两个变量之间的协方差为正值,则这两个变量之间存在正相关,若为负值,则为负相关。
皮尔逊相关系数数值范围也是[-1,1]。皮尔逊相关系数可看作是在余弦相似度或协方差基础上做了优化(变量的协方差除以标准差)。它消除每个分量标准不同(分数膨胀)的影响,具有平移不变性和尺度不变性。
卡方检验X2,主要是比较两个分类变量的关联性、独立性分析。如下公式,A代表实际频数;E代表期望频数:
Levenshtein 距离是 编辑距离 (Editor Distance) 的一种,指两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
像hallo与hello两个字符串编辑距离就是1,我们通过替换”a“ 为 ”e“,就可以完成转换。
汉明距离为两个等长字符串对应位置的不同字符的个数,也就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:1011101 与 1001001 之间的汉明距离是 2,“toned” 与 “roses” 之间的汉明距离是 3
另外的,对于字符串距离来说,不同字符所占的份量是不一样的。比如”我乐了“ 与【“我怒了”,”我乐了啊” 】的Levenshtein 距离都是1,但其实两者差异还是很大的,因为像“啊”这种语气词的重要性明显不如“乐”,考虑字符(特征)权重的相似度方法有:TF-IDF、BM25、WMD算法。
Jaccard 取值范围为0~1,0 表示两个集合没有重合,1 表示两个集合完全重合。


但Dice不满足距离函数的三角不等式,不是一个合适的距离度量。

基础地介绍下信息熵,用来衡量一个随机变量的不确定性程度。对于一个随机变量 X,其概率分布为:
互信息用于衡量两个变量之间的关联程度,衡量了知道这两个变量其中一个,对另一个不确定度减少的程度。公式为:
如下图,条件熵表示已知随机变量X的情况下,随机变量Y的信息熵,因此互信息实际上也代表了已知随机变量X的情况下,随机变量Y的(信息熵)不确定性的减少程度。
相对熵 (Relative Entropy)
相对熵又称之为 KL 散度 (Kullback-Leibler Divergence),用于衡量两个分布之间的差异,定义为:
JS 散度 (Jensen-Shannon Divergence)
JS 散度解决了 KL 散度不对称的问题,定义为:
群体稳定性指标(Population Stability Index,PSI), 可以看做是解决KL散度非对称性的一个对称性度量指标,用于度量分布之间的差异(常用于风控领域的评估模型预测的稳定性)。
psi与JS散度的形式是非常类似的,如下公式:
PSI的含义等同P与Q,Q与P之间的KL散度之和。

DTW 距离用于衡量两个序列之间的相似性,适用于不同长度、不同节奏的时间序列。DTW采用了动态规划DP(dynamic programming)的方法来进行时间规整的计算,通过自动warping扭曲 时间序列(即在时间轴上进行局部的缩放),使得两个序列的形态尽可能的一致,得到最大可能的相似度。(具体可参考[5])
图结构间的相似度计算,有图同构、最大共同子图、图编辑距离、Graph Kernel 、图嵌入计算距离等方法(具体可参考[4][6])。
度量学习的对象通常是样本特征向量的距离,度量学习的关键在于如何有效的度量样本间的距离,目的是通过训练和学习,减小或限制同类样本之间的距离,同时增大不同类别样本之间的距离,简单归类如下[2]:
最后,附上常用的距离和相似度度量方法[3]:
参考资料
[1] https://kexue.fm/archives/7388
[2] https://zhuanlan.zhihu.com/p/80656461
[3] https://www.pianshen.com/article/70261312162/
[4] https://arxiv.org/pdf/2002.07420.pdf
[5] https://zhuanlan.zhihu.com/p/32849741
[6] https://github.com/ysig/GraKeL
互联网的原始目的,就是为了传输文本(文本对话)。那我们使用浏览器发送请求后页面是如何呈现在我们面前的呢?
接下来由图片介绍下URL到呈现页面的过程。
我们在浏览器中输入一个 URL,回车之后便会在浏览器中观察到页面内容。实际上这个过程是:
(1)浏览器向网站所在的服务器发送了一个 Request(请求)
(2)网站服务器接收到这个Request之后进行处理和解析
(3)然后返回对应的一个Response(响应)给浏览器,Response里面就包含了页面的源代码等内容
(4)浏览器再对其进行解析便将网页呈现了出来。
这个文本对话的过程是建立在怎样的规则上面呢?简单说,这个通信的过程是基于TCP/IP通信协议族规范上实现的,完成从客户端到服务器端等一系列信息交换的流程。
TCP/IP协议族的目的就是通过建立规则使计算机之间可以进行信息交换。
相互通信的双方就必须基于相同的方法,比如由哪一边先发起通信、使用哪种语言进行通信、怎样结束通信等规则都需要事先确定,我们就把这种规则称为协议(protocol)。通常我们说的TCP/IP协议族是互联网相关的各类协议族的总称。
TCP/IP协议族由那么多的协议组成,那功能上如何划分的呢?
这里就说到TCP/IP重要的层次化划分,按层次可以分为4层:应用层、传输层、网络层和链路层。(层次化的好处在于每个层次内部的设计可以自由改动,并通过各层的接口关联起来,而如果只有一个协议统筹就需要对所有涉及到的部分都重新设计。)
(1) 应用层:决定了向用户提供应用服务时候的通信活动。应用层负责传送各种最终形态的数据,是直接与用户打交道的层,典型协议是HTTP、FTP等。
(2) 传输层:负责传送文本数据。传输层有两个性质不同的协议: TCP(Transmission Control Protocol,传输控制协议)和 UDP(User Data Protocol,用户数据报协议)。
(3) 网络层:负责分配地址和传送二进制数据,主要协议是IP协议;
(4) 链路层:负责建立电路连接,是整个网络的物理基础,典型的协议包括以太网、ADSL等。
在TCP/IP各功能层之间数据是如何流动传输的呢?
(1)首先作为发送端的客户端在应用层(HTTP 协议)发出的
HTTP请求(如:想浏览www.baidu.com),并生成HTTP报文。
(2)为了传输方便,在传输层(TCP 协议)把从应用层处收到的数据(HTTP 请求报文)进行分割,并在
各个报文上打上标记序号及端口号后转发给网络层。
(3)在网络层(IP 协议),增加作为通信目的地的 MAC 地址后转发给链路层。
(4)给这些数据附加上以太网首部并进行发送处理,生成的以太网数据包将通过物理层传输给接收端。
(5)接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层。当传输到应用层,才能算真正接收到由客户端发送过来的 HTTP 请求。
在通信过程每经过一层时必定会被打上一个该层所属的首部信息。反之,接收端在层与层传输数据时,每经过一层时会把对应的首部消去。
一张图来说明请求到网页呈现的通信过程( 下图基于IP 协议、TCP
协议 、DNS 服务和HTTP 协议的通信过程),并对每一步做说明:
URL(Uniform Resource Locator,统一资源定位符),是使用 Web 浏览器等访问 Web 页面时需要输入的网页地址。
URL由以下元素组成:
(1) 传送协议:http:或者https:等
(2) 层级URL标记符号:为“//”固定不变
(3) 登录信息: 访问资源需要的凭证信息(可省略)
(4) 服务器地址:通常为域名,有时为IP地址(实际通信中需要通过IP地址访问,域名通过DNS服务器解析出IP地址)
(5) 端口号:以数字方式表示,若为HTTP的默认值“:80”可省略
(6) 路径:以“/”字符区别路径中的每一个目录名称
(7) 查询:GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题
(8) 片段:以“#”字符为起点,使用片段标识符通常可标记出已获取资源中的子资源
DNS(Domain Name System)服务是和 HTTP协议一样位于应用层的协议,它提供域名到 IP 地址之间的解析服务。
计算机既可以被赋予IP地址,也可以被赋予主机名和域名,用户通常使用主机名或域名来访问对方的计算机,而不是直接通过 IP 地址访问。而计算机相对更容易处理一组数字,这时DNS域名解析服务应运而生。DNS 协议提供通过域名查找 IP 地址(或逆向从 IP 地址反查域名的服务)。
HTTP协议:HyperText Transfer Protocol超文本传输协议位于应用层,决定从客户端到服务器端等一系列通信内容及方式,这通过生成报文并发送完成通信。
(1)请求报文的构成
(2)响应报文的构成
TCP协议:Transmission Control Protocol传输控制协议,位于传输层。
(1)字节流服务(Byte Stream Service)是指,为了方便传输,将大块数据分割成以报文段(segment)
为单位的数据包进行管理。
(2)可靠的传输服务是指,能够把数据准确可靠地传给对方。TCP 协议采用了三次握手连接等策略保证传输的可靠性(三次握手,四次挥手文末会有重点补充)
IP(Internet Protocol)网际协议位于网络层。 IP协议的作用在于实现数据包传递到对方计算机IP地址。而IP间的通信依赖于MAC 地址(网卡所属的固定地址),还需要再通过ARP 协议根据通信方的 IP 地址反查出对应的MAC 地址。
接收端(服务器)响应报文同样利用TCP/IP通信协议回传
TCP 提供面向有连接的通信传输,面向有连接是指在数据通信开始之前先做好两端之间的准备工作。
三次握手是指建立一个TCP连接时需要客户端和服务器端总共发送三个标记包以确认连接的建立。下面来看看三次握手的流程图:
第一次握手:客户端将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给服务器端,客户端进入SYN_SENT状态,等待服务器端确认。
第二次握手:服务器端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务器端将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给客户端以确认连接请求,服务器端进入SYN_RCVD状态。
第三次握手:客户端收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给服务器端,服务器端检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,客户端和服务器端进入ESTABLISHED状态,完成三次握手建立连接,随后客户端与服务器端之间可以开始传输数据了。
为什么3次握手: 前两次的握手很显然是必须的,主要是最后一次,即客户端收到服务端发来的确认后为什么还要想服务端再发送一次确认呢?这主要是为了防止已失效的请求报文段突然又传送到了服务端而产生连接的误判。
考虑如下的情况:
客户端发送了一个连接请求报文段到服务端,但是在某些网络节点上长时间滞留了,所以客户端又超时重发了一个连接请求报文段该服务端,而后正常建立连接,数据传输完毕,并释放了连接。
如果这时候第一次发送的请求报文段(已过期的)延迟了一段时间后,又到了服务端,很显然,这本是一个早已失效的报文段,但是服务端收到后会误以为客户端又发出了一次连接请求,于是向客户端发出确认报文段,并同意建立连接。假设不采用三次握手,这时服务端只要发送了确认,新的连接就建立了。但由于客户端现阶段没有发出建立连接的请求,因此不会理会服务端的确认,也不会向服务端发送数据,而服务端却认为新的连接已经建立了,并在一直等待客户端发送数据,这样服务端就会一直等待下去,直到超出保活计数器的设定值,而将客户端判定为出了问题,才会关闭这个连接。这样就浪费了很多服务器的资源。而如果采用三次握手,客户端没有再向服务端发出确认,服务端由于收不到确认,就知道客户端没有要求建立连接,从而不建立该连接。
TCP连接是全双工的,因此,每个方向都必须要单独进行关闭,
四次挥手即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。
下面来看看四次挥手的流程图:
注:中断连接端可以是客户端,也可以是服务器端。下文举的例子是以客户端发出中断请求。
第一次挥手:客户端发送一个FIN=M,用来关闭客户端到服务器端的数据传送,客户端进入FIN_WAIT_1状态。意思是说"我客户端没有数据要发给你了",但是如果你服务器端还有数据没有发送完成,则不必急着关闭连接,可以继续发送数据。
第二次挥手:服务器端收到FIN后,先发送ack=M+1,告诉客户端,“你的请求我收到了,但是我还没准备好,请继续你等我的消息。”这个时候客户端就进入FIN_WAIT_2状态,继续等待服务器端的FIN报文。
第三次挥手:当服务器端确定数据已发送完成,则向客户端发送FIN=N报文,告诉客户端,好了,我这边数据发完了,准备好关闭连接了。服务器端进入LAST_ACK状态。
第四次挥手:客户端收到FIN=N报文后,就知道可以关闭连接了,但是他还是不相信网络,怕服务器端不知道要关闭,所以发送ACK=1,ack=N+1后进入TIME_WAIT状态,如果服务器端没有收到ACK则可以重传。服务器端收到ACK后,就知道可以断开连接了(CLOSED状态)。客户端等待了2MSL(时间MSL叫做最长报文寿命,RFC建议设为2分钟)后依然没有收到回复,则证明服务器端已正常关闭,客户端也可以关闭连接了。最终完成了四次握手。
为什么4次挥手:TCP协议是一种面向连接的、可靠的字节流的运输层通信协议,TCP是全双工模式,这就意味着,当客户端发出FIN报文段时,只是表示客户端已经没有数据要发送了,客户端告诉服务器,它的数据已经全部发送完毕了;但是,这个时候客户端还是可以接受来自服务器的数据;当服务器返回ACK报文段时,表示它已经知道客户端没有数据发送了,但是主机2还是可以发送数据到客户端的;当服务器也发送了FIN报文段时,这个时候就表示服务器也没有数据要发送了,就会告诉客户端,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
为什么客户端TIME_WAIT等待2MSL:
(1)为了保证客户端发送的最后一个ACK报文段能够到达服务器。该ACK报文段很有可能丢失,因而使处于在LIST—ACK状态的服务器收不到对已发送的FIN+ACK报文段的确认,服务器可能会重传这个FIN+ACK报文段,而客户端就在这2MSL时间内收到这个重传的FIN+ACK报文段,接着客户端重传一次确认,重新启动2MSL计时器,最后客户端和服务器都进入CLOSED状态。(2)防止已失效的请求连接出现在本连接中。在连接处于2MSL等待时,任何迟到的报文段将被丢弃,因为处于2MSL等待的,由该插口(插口是IP和端口对的意思,socket)定义的连接在这段时间内将不能被再用,这样就可以使下一个新的连接中不会出现这种旧的连接之前延迟的报文段。
以上,我们了解TCP/IP协议的作用及通信的流程,针对Http协议后续再做详细介绍。
参考文献:
《图解http》(下载地址)
本文以模型、学习目标、优化算法的角度解析逻辑回归(LR)模型,并以Python从头实现LR训练及预测。
逻辑回归是一种广义线性的分类模型且其模型结构可以视为单层的神经网络,由一层输入层、一层仅带有一个sigmoid激活函数的神经元的输出层组成,而无隐藏层。其模型的功能可以简化成两步,“通过模型权重[w]对输入特征[x]线性求和+sigmoid激活输出概率”。
附注:sigmoid函数是一个s形的曲线,它的输出值在[0, 1]之间,在远离0的地方函数的值会很快接近0或1。对于sigmoid输出作为概率的合理性,可以参照如下证明:
逻辑回归是一种判别模型,为直接对条件概率P(y|x)建模,假设P(x|y)是高斯分布,P(y)是多项式分布,如果我们考虑二分类问题,通过公式变换可以得到:
可以看到,逻辑回归(或称为对数几率回归)的输出概率和sigmoid形式是一致的。
逻辑回归模型本质上属于广义线性分类器(决策边界为线性)。这点可以从逻辑回归模型的决策函数看出,决策函数Y=sigmoid(wx + b),当wx+b>0,Y>0.5;当wx+b<0,Y<0.5,以wx+b这条线可以区分开Y=0或1(如下图),可见决策边界是线性的。
逻辑回归是一个经典的分类模型,对于模型预测我们的目标是:预测的概率与实际正负样本的标签是对应的,Sigmoid 函数的输出表示当前样本标签为 1 的概率,y^可以表示为
当前样本预测为0的概率可以表示为1-y^
对于正样本y=1,我们期望预测概率尽量趋近为1 。对于负样本y=0,期望预测概率尽量都趋近为0。也就是,我们希望预测的概率使得下式的概率最大(最大似然法)
我们对 P(y|x) 引入 log 函数,因为 log 运算并不会影响函数本身的单调性。则有:
我们希望 log P(y|x) 越大越好,反过来,只要 log P(y|x) 的负值 -log P(y|x) 越小就行了。那我们就可以引入损失函数,且令 Loss = -log P(y|x),得到损失函数为:
我们已经推导出了单个样本的损失函数,是如果是计算 m 个样本的平均的损失函数,只要将 m 个 Loss 叠累加取平均就可以了:
这就在最大似然法推导出的lr的学习目标——交叉熵损失(或对数损失函数),也就是让最大化使模型预测概率服从真实值的分布,预测概率的分布离真实分布越近,模型越好。可以关注到一个点,如上式逻辑回归在交叉熵为目标以sigmoid输出的预测概率,概率值只能尽量趋近0或1,同理loss也并不会为0。
我们以极小交叉熵为学习目标,下面要做的就是,使用优化算法去优化参数以达到这个目标。由于最大似然估计下逻辑回归没有(最优)解析解,我们常用梯度下降算法,经过多次迭代,最终学习到的参数也就是较优的数值解。
梯度下降算法可以直观理解成一个下山的方法,将损失函数J(w)比喻成一座山,我们的目标是到达这座山的山脚(即求解出最优模型参数w使得损失函数为最小值)。
下山要做的无非就是“往下坡的方向走,走一步算一步”,而在损失函数这座山上,每一位置的下坡的方向也就是它的负梯度方向(直白点,也就是山的斜向下的方向)。在每往下走一步(步长由α控制)到一个位置的时候,求解当前位置的梯度,向这一步所在位置沿着最陡峭最易下山的位置再走一步。这样一步步地走下去,一直走到觉得我们已经到了山脚。
当然这样走下去,有可能我们不是走到山脚(全局最优,Global cost minimun),而是到了某一个的小山谷(局部最优,Local cost minimun),这也梯度下降算法的可进一步优化的地方。
对应的算法步骤:
另外的,以非极大似然估计角度,去求解逻辑回归(最优)解析解,可见kexue.fm/archives/8578
本项目的数据集为癌细胞分类数据。基于Python的numpy库实现逻辑回归模型,定义目标函数为交叉熵,使用梯度下降迭代优化模型,并验证分类效果:
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
import h5py
import scipy
from sklearn import datasets
# 加载数据并简单划分为训练集/测试集
def load_dataset():
dataset = datasets.load_breast_cancer()
train_x,train_y = dataset['data'][0:400], dataset['target'][0:400]
test_x, test_y = dataset['data'][400:-1], dataset['target'][400:-1]
return train_x, train_y, test_x, test_y
# logit激活函数
def sigmoid(z):
s = 1 / (1 + np.exp(-z))
return s
# 权重初始化0
def initialize_with_zeros(dim):
w = np.zeros((dim, 1))
b = 0
assert(w.shape == (dim, 1))
assert(isinstance(b, float) or isinstance(b, int))
return w, b
# 定义学习的目标函数,计算梯度
def propagate(w, b, X, Y):
m = X.shape[1]
A = sigmoid(np.dot(w.T, X) + b) # 逻辑回归输出预测值
cost = -1 / m * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A)) # 交叉熵损失为目标函数
dw = 1 / m * np.dot(X, (A - Y).T) # 计算权重w梯度
db = 1 / m * np.sum(A - Y)
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost)
assert(cost.shape == ())
grads = {"dw": dw,
"db": db}
return grads, cost
# 定义优化算法
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost):
costs = []
for i in range(num_iterations): # 梯度下降迭代优化
grads, cost = propagate(w, b, X, Y)
dw = grads["dw"] # 权重w梯度
db = grads["db"]
w = w - learning_rate * dw # 按学习率(learning_rate)负梯度(dw)方向更新w
b = b - learning_rate * db
if i % 50 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
#传入优化后的模型参数w,b,模型预测
def predict(w, b, X):
m = X.shape[1]
Y_prediction = np.zeros((1,m))
A = sigmoid(np.dot(w.T, X) + b)
for i in range(A.shape[1]):
if A[0, i] <= 0.5:
Y_prediction[0, i] = 0
else:
Y_prediction[0, i] = 1
assert(Y_prediction.shape == (1, m))
return Y_prediction
def model(X_train, Y_train, X_test, Y_test, num_iterations, learning_rate, print_cost):
# 初始化
w, b = initialize_with_zeros(X_train.shape[0])
# 梯度下降优化模型参数
parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
w = parameters["w"]
b = parameters["b"]
# 模型预测结果
Y_prediction_test = predict(w, b, X_test)
Y_prediction_train = predict(w, b, X_train)
# 模型评估准确率
print("train accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100))
print("test accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100))
d = {"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediction_train" : Y_prediction_train,
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations": num_iterations}
return d
# 加载癌细胞数据集
train_set_x, train_set_y, test_set_x, test_set_y = load_dataset()
# reshape
train_set_x = train_set_x.reshape(train_set_x.shape[0], -1).T
test_set_x = test_set_x.reshape(test_set_x.shape[0], -1).T
print(train_set_x.shape)
print(test_set_x.shape)
#训练模型并评估准确率
paras = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = 100, learning_rate = 0.001, print_cost = False)
文章首发公众号“算法进阶”,阅读原文可访问文章相关代码
决策树模型因为其特征预处理简单、易于集成学习、良好的拟合能力及解释性,是应用最广泛的机器学习模型之一。
不同于线性模型【数学描述:f(W*X +b)】,是通过数据样本学习各个特征的合适权重,加权后做出决策。决策树会选择合适特征并先做特征划分后(这提高了模型的非线性能力),再做出决策。
决策树呈树形结构,更通俗来讲,树模型的数学描述就是**“分段函数”**。如下一个简单判别西瓜质量的决策树模型示例(注:以下西瓜示例,数据随机杜撰的,请忽略这么小的西瓜瓜~):
学习这样树模型的过程,简单来说就是从有监督的数据经验中学习一个较优的树模型的结构:包含了依次地选择特征、确定特征阈值做划分的内部节点及最终输出叶子节点的数值或类别结果。
1、我们首先要拿到一些有关西瓜的有监督数据(这些西瓜样本已有标注高/低质量西瓜),并尝试选用决策树模型来学习这个划分西瓜的任务。
如下数据样本示例:
2、后面也就是,凭着已知西瓜样本的特性/特征【如:西瓜重量、西瓜颜色】,学习如何正确地划分这些西瓜(归纳出本质规律)。开始学习之前,我们得确定一个树模型在生长的目标(学习的目标)。简单来说,也就是在当前节点以什么为目标来指导怎么选择特征及分裂,而划分得好也就是要划分出的各组的准确率(纯度)都比较高。
3、然后,根据学习目标,简单的我们可以通过遍历计算所有特征不同阈值的划分效果。选择各个的特征及尝试特征的所有实际取值,看以哪个特征阈值划分西瓜质量的效果较好。这个过程也就是确定选择特征及特征阈值划分的优化算法。
4、最终的,按照上面的步骤,我们逐个特征及取值试着去划分后发现,根据西瓜重量的特征 以300g作为划分出了两组,我们以叶子节点的大多数类作为该节点的决策类别。可能发现<300的组 里面低质量西瓜占比100%,>300 那组 高质量西瓜占比99%,整体分类效果是不错的,最终就确定下了这样的一个决策树模型。
从上述例子,我们可以将树模型的学习可以归到经典机器学习的4个要素:
树模型通过这几个要素,更快更好地划分特征空间,得出比较准确的决策。如下对这几个要素具体解析。
树模型的结构也就是个分段函数,包含了 选定特征做阈值划分(内部节点),以及划分后赋值的分数或类别决策(叶子节点)。
学习树模型的关键在于依据某些学习目标/指标(如划分准确度、信息熵、Gini不纯度、均方误差的增益量)去选择当前最优的特征并对样本的特征空间做非线性准确的划分,如上面西瓜的例子选择了一个特征做了一次划分(一刀切),通常情况下仅仅一刀切的划分准确度是不够的,可能还要在前面划分的样本基础上,继续多划分几次(也就多个切分条件的分段函数,如 if a>300 且特征b>10 且特征c<100, then 决策结果1;),以达到更高的准确度(纯度)。
但是,随着切分次数的变多,树的复杂度提高也就容易过拟合,相应每个切分出的小子特征空间的统计信息可能只是噪音。减少树生长过程的过拟合的风险,一个重要的方法就是树的剪枝,剪枝是一种正则化:由于决策树容易对数据产生过拟合,即生长出结构过于复杂的树模型,这时局部的特征空间会越分越“小”得到了不靠谱的“统计噪声”。通过剪枝算法可以降低复杂度,减少过拟合的风险。
决策树剪枝的目的是极小化经验损失+结构损失,基本策略有”预剪枝“和”后剪枝“两种策略:
①预剪枝:是在决策树生成过程中,限制划分的最大深度、叶子节点数和最小样本数目等,以减少不必要的模型复杂度;
②后剪枝:是先从训练集生成一棵完整的决策树,然后用用验证集自底向上地对非叶结点进行考察,若将该节点对应的子树替换为叶子结点(剪枝)能带来决策树的泛化性能提升(即目标函数损失更小,常用目标函数如:loss = 模型经验损失bias+ 模型结构损失α|T|, T为节点数目, α为系数),则将该子树替换为叶子结点。
实践中可以发现,浅层的树很容易欠拟合,而通过加深树的深度,虽然可以提高训练集的准确度,却很容易过拟合。
这个角度来看,单个树模型是比较弱的,且很容易根据特征选择、深度等超参数调节各树模型的多样性。正因为这些特点,决策树很适合通过结合多个的树模型做集成学习进一步提升模型效果。
集成学习是结合一些的基学习器共同学习,来改进其泛化能力和鲁棒性的方法,主流的有两种集成**:
并行方式(bagging):独立的训练一些基学习器,然后(加权)平均它们的预测结果。代表模型如:Random Forests;
串行方式(boosting):一个接一个的(串行)训练基学习器,每一个基学习器主要用来修正前面学习器的偏差。代表模型如:AdaBoost、GBDT及XGBOOST;
(扩展:像基于cart回归树的GBDT集成方法,通过引入了损失函数的梯度去代替残差,这个过程也类似局部的梯度下降算法)
树模型天然具有非线性的特点,但与此有个缺陷,树模型却学习不好简单的线性回归!可以简单构想下传统决策树表达 y=|2x|这样规律,需要怎么做?如 if x=1,then 2; x =3, then 6 .....;这样穷举显然不可能的。 这里介绍下线性决策树,其实原理也很简单:把线性回归加到决策树的叶子节点里面(特征划分完后,再用线性模型拟合做决策)。一个简单线性树模型用分段函数来表示如:if x >0, then 2x;代表模型有 linear decision tree, GBDT-PL等模型。
上文有提到,树模型的学习目标就是让各组的划分的准确率(纯度)都比较高,减小划分误差损失(此处忽略了结构损失T)。能达成划分前后损失差异效果类似的指标有很多:信息熵、基尼系数、MSE损失函数等等 都可以评估划分前后的纯度的增益 ,其实都是对分类误差的一种衡量,不同指标也对应这不同类型的决策树方法。

使用信息增益做特征划分的缺点是:信息增益偏向取值较多的特征。当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低,由于划分前的熵是一定的,因此信息增益更大,因此信息增益比较偏向取值较多的特征。
信息增益比也就是信息增益除以信息熵,这样可以减少偏向取值较多信息熵较大的特征。
相应的,使用信息增益比缺点是:信息增益比偏向取值较少的特征。综上两种指标,可以在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征。
与信息熵一样(信息熵 如下式)
基尼系数表征的也是事件的不确定性(不纯度),也都可以看做是对分类误差率的衡量。
我们将熵定义式中的“-log(pi)”替换为 1-pi 也就是基尼系数,因为-log(pi)的泰勒近似展开第一项就是1-pi。基尼系数简单来看就是熵的“平替版”,在衡量分类误差的同时,也简化了大量计算。(注:由于分类误差为分段函数=1-max(p, 1-p) ,不便于微分计算,实际中也比较少直接用)
当Cart应用于回归任务,平方误差损失也就是Cart回归树的生长指标。
确认学习目标,而依据这个指标去学习具体树结构的方法(优化算法),基本上有几种思路:
暴力枚举:尝试所有可能的特征划分及组合,以找到目标函数最优的树结构。但在现实任务中这基本是不可能的。
自上而下的贪心算法:每一步(节点)都选择现在最优(信息增益、gini、平方误差损失)的特征划分,最终生成一颗决策树,这也是决策树普遍的启发式方法,代表有:cart树、ID3、C4.5树等等
随机优化:随机选择特征及划分方式,通常这种方法单树的生长较快且复杂度较高。模型的随机性、偏差比较大(模型的方差相对较小,不容易过拟合,但是bias较大),所以常用集成bagging的思路进一步优化收敛。代表有:Extremely randomized trees(极端随机树)、孤立森林等等.
树模型也就是基于已知数据上, 通过以学习目标(降低各划分节点的误差率)为指导,启发式地选择特征去划分特征空间,以各划分的叶子节点做出较"优"的决策结果。所以,树模型有非常强的非线性能力,但是,由于是基于划分的局部样本做决策,过深(划分很多次)的树,局部样本的统计信息可能失准,容易过拟合。
文章首发公众号“算法进阶”,欢迎关注。公众号阅读原文可访问文章相关代码及资料
本文将总结机器学习最常见的模型评估指标。训练学习好的模型,通过客观地评估模型性能,才能更好实际运用决策。模型评估主要有:预测误差情况、拟合程度、模型稳定性等方面。还有一些场景对于模型训练\预测速度(吞吐量)、计算资源耗用量、可解释性等也会有要求,这里不做展开。
机器学习模型预测误差情况通常是评估的重点,它不仅仅是学习过程中对训练数据有良好的学习预测能力,根本上在于要对新数据能有很好的预测能力(泛化能力),所以我们常通过测试集的指标表现评估模型的泛化性能。
评估模型的预测误差常用损失函数作为指标来判断,如回归预测的均方损失。但除此之外,用损失函数作为评估指标并不直观(如像分类任务的评估还常用f1-score,可以直接展现各种类别正确分类情况)且还有一些局限性。在此,我们主要对回归和分类预测任务分别解读其常用误差评估指标。
评估回归模型的误差,比较简单的思路,可以对真实值与预测值的差异“取正”后求平均。如下:
均方根误差(RMSE)是对MSE的开根号
平均绝对误差(MAE)是预测值与真实值之间的误差取绝对值的平均
由于MAE用到了绝对值(不可导),很少用在训练的损失函数。用于最终评估模型还是可以的。
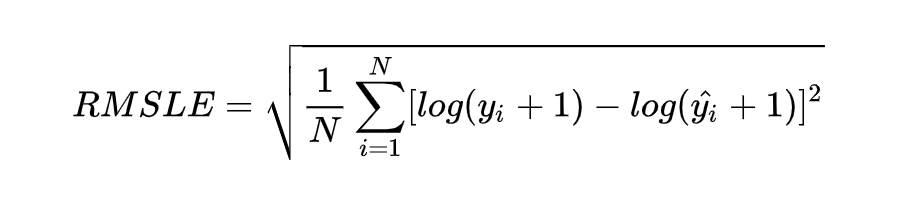
上述指标的差异对比:
① 异常值敏感性:MAE也就是真实预测误差,而RMSE,MSE都有加平方,放大了较大误差样本的影响(对于异常值更敏感),如果遇到个别偏离程度非常大的离群点时,即便数量很少,也会让这两个指标变得很差。减少异常点的影响,可以采用RMSLE,它关注的是预测误差的比例,即便存在离群点,也可以降低这些离群点的影响。
② 量纲差异:不同于MSE做了平方,RMSE(平方后又开根号)及MAE对于原量纲是不变,会更直观些。而RMSE 与 MAE 的尽管量纲相同,RMSE比MAE实际会大一些。这是因为RMSE是先对误差进行平方的累加后再开方,也放大了误差之间的差距。
③ 跨任务的量纲差异问题:实际运用中,像RMSE、MAE是有个问题的,不同任务的量纲是会变的,比如我们预测股价误差是10元,预测房价误差是1w,跨越了不同任务我们就没法评估哪个模型效果更好。接下来介绍,R2分数指标,它对上面的误差进一步做了归一化,就有了统一的评估标准。
R^2分数常用于评估线性回归拟合效果时,其定义如下:
R^2分数可以视为我们模型的均方误差除以用实际值平均值作为预测值时的均方误差(像baseline模型)的比值。
这样,R^2分数范围被归约到了[0,1],当其值为0时,意味着我们的模型没有什么效果,和baseline模型那样猜的效果一致。当值为1,模型效果最好,意味着模型没有任何误差。
补充一点,当R^2值为0时且模型为线性回归时,也可以间接说明特征与标签没有线性关系。
这也是常用的共线性指标VIF的原理,分别尝试以各个特征作为标签,用其他特征去学习拟合,得到线性模型R^2值,算出VIF。VIF为1即特征之间完全没有共线性(共线性对线性模型稳定性及可解释性会有影响,工程上常用VIF<10作为阈值)。
对于分类模型的分类误差,可以用损失函数(如交叉熵)来评估,但是这样的评估不太直观。
所以,像分类任务的评估还常用f1-score、precision、recall,可以直接展现各种类别正确分类情况。
准确率(accuracy)。即所有的预测正确(TP+TN)的占总数(TP+FP+TN+FN)的比例;
查准率P(precision):是指分类器预测为Positive的正确样本(TP)的个数占所有预测为Positive样本个数(TP+FP)的比例;
查全率R(recall):是指分类器预测为Positive的正确样本(TP)的个数占所有的实际为Positive样本个数(TP+FN)的比例。
F1-score是查准率P、查全率R的调和平均:
上述指标的总结:
① 综合各类别的准确度:准确率accuracy对于分类错误情况的描述是比较直接的,但是对于正负例不平衡的情况下,accuracy评价基本没有参考价值,比如 欺诈用户识别的分类场景,有950个正常用户样本(负例),50个异常用户(正例),模型把样本都预测为正常用户样本,准确率是非常好的达到95%。但实际上是分类效果很差。accuracy无法表述出少数类别错误分类的情况,所以更为常用的是F1-score,比较全面地考量到了查准率与查全率。
② 权衡查准率与查全率:查准率与查全率常常是矛盾的一对指标,有时要结合业务有所偏倚低地选择“更准”或者“更全”(比如在欺诈用户的场景里面,通常偏向于对正例识别更多“更全”,尽管会有更高的误判。“宁愿错杀一百,也不放走一个”),这时可以根据不同划分阈值下的presion与recall曲线(P-R曲线),做出两者权衡。
其公式含义可解释为总准确度对比随机准确度的提升 与 完美模型对比随机准确度的提升的比值:
kappa取值为-1到1之间,通常大于0,可分为五组来表示不同级别的一致性:0.00.20极低的一致性(slight)、0.210.40一般的一致性(fair)、0.410.60 中等的一致性(moderate)、0.610.80 高度的一致性(substantial) 和 0.81~1几乎完全一致(almost perfect)。

对于每个混淆矩阵,我们计算两个指标TPR(True positive rate)和FPR(False positive rate),TPR=TP/(TP+FN)=Recall 即召回率,FPR=FP/(FP+TN),FPR即为实际负样本中,预测为正样本占比。最后,我们以FPR为x轴,TPR为y轴画图,就得到了ROC曲线。
我们通过求解ROC曲线下的面积,也就是AUC(Area under Curve),AUC可以直观的评价分类器的好坏,通常介于0.5和1之间,值越大越好。
对AUC指标的分析总结:
由于衡量ROC是“动态的阈值”,故AUC不依赖分类阈值,摆脱了固定分类阈值看分类效果的局限性。
ROC由不同阈值TPR、FPR绘制。更大的ROC面积(AUC)意味着较小的FPR下有更大的TPR,较小的FPR也就是较大的1-FPR = TN/(TN+FP)=TNR,所以AUC其实是TPR(也叫召回率、敏感度)与 TNR(也叫特异度)的综合考虑。
由混淆矩阵可以看出,TNR(即1-FPR)、TNR 和样本的实际好坏占比是无关的,它们都只关注相应实际类别的识别的全面度。(不像查准率precision是跨越了实际类别间情况做评估)。简单来说:AUC对样本的正负比例情况是不敏感。即使正例与负例的比例发生了很大变化,ROC曲线面积也不会产生大的变化
AUC是ROC曲线的面积,其数值的物理意义是:随机给定一正一负两个样本,将正样本预测分值大于负样本的概率大小。也就是,AUC是区分能力的“排序性”指标(正样本高于负样本的概率分值即可),对具体的判定概率不敏感——忽略了模型的拟合效果,而对于一个优秀的模型而言,我们期望的是正负样本的概率值是差异足够大的。举个栗子,模型将所有负样本预测为0.49,正样本预测为0.51,那这个模型auc即是1(但正负样本的概率很接近,一有扰动 模型就预测错了)。而我们期望模型的预测好坏的间隔尽量大,如负样本预测为0.1以下,正样本预测为0.8以上,此时虽然auc一样,但这样的模型拟合效果更好,比较有鲁棒性。
AUC 对比 F1-score差异
# 上述指标可以直接调用 sklearn.metrics
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score, roc_curve, auc, cohen_kappa_score,mean_squared_error
...
yhat = model.predict(x)
f1_score(y, yhat)
对于模型的拟合程度,常用欠拟合、拟合良好、过拟合来表述。通常,拟合良好的模型有更好泛化能力,在未知数据(测试集)有更好的效果。
我们可以通过训练及验证集误差(如损失函数)情况评估模型的拟合程度。从整体训练过程来看,欠拟合时训练误差和验证集误差均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,验证集误差上升,这个时候模型就进入了过拟合区域。
实践中的欠拟合通常不是问题,可以通过使用强特征及较复杂的模型提高学习的准确度。而解决过拟合,即如何减少泛化误差,提高泛化能力,通常才是优化模型效果的重点。对于解决过拟合,常用的方法在于提高数据的质量、数量以及采用适当的正则化策略。具体可见系列文章:一文深层解决模型过拟合
如果上线的模型不稳定,意味着模型不可控,影响决策的合理性。对于业务而言,这就是一种不确定性风险,这是不可接受的(特别对于厌恶风险的风控领域)。
我们通常用群体稳定性指标(Population Stability Index,PSI), 衡量未来的(测试集)样本及模型训练样本评分的分布比例是否保持一致,以评估模型的稳定性。同理,PSI也可以用衡量特征值的分布差异,评估数据特征层面的稳定性。
PSI计算以训练样本的模型评分作为稳定性的参考点(预期分数占比),衡量未来的实际预测分数(实际分布占比)的误差情况。计算公式为 SUM(各分数段的 (实际占比 - 预期占比)* ln(实际占比 / 预期占比) )
具体的计算步骤及示例代码如下:
import math
import numpy as np
import pandas as pd
def calculate_psi(base_list, test_list, bins=20, min_sample=10):
try:
base_df = pd.DataFrame(base_list, columns=['score'])
test_df = pd.DataFrame(test_list, columns=['score'])
# 1.去除缺失值后,统计两个分布的样本量
base_notnull_cnt = len(list(base_df['score'].dropna()))
test_notnull_cnt = len(list(test_df['score'].dropna()))
# 空分箱
base_null_cnt = len(base_df) - base_notnull_cnt
test_null_cnt = len(test_df) - test_notnull_cnt
# 2.最小分箱数
q_list = []
if type(bins) == int:
bin_num = min(bins, int(base_notnull_cnt / min_sample))
q_list = [x / bin_num for x in range(1, bin_num)]
break_list = []
for q in q_list:
bk = base_df['score'].quantile(q)
break_list.append(bk)
break_list = sorted(list(set(break_list))) # 去重复后排序
score_bin_list = [-np.inf] + break_list + [np.inf]
else:
score_bin_list = bins
# 4.统计各分箱内的样本量
base_cnt_list = [base_null_cnt]
test_cnt_list = [test_null_cnt]
bucket_list = ["MISSING"]
for i in range(len(score_bin_list)-1):
left = round(score_bin_list[i+0], 4)
right = round(score_bin_list[i+1], 4)
bucket_list.append("(" + str(left) + ',' + str(right) + ']')
base_cnt = base_df[(base_df.score > left) & (base_df.score <= right)].shape[0]
base_cnt_list.append(base_cnt)
test_cnt = test_df[(test_df.score > left) & (test_df.score <= right)].shape[0]
test_cnt_list.append(test_cnt)
# 5.汇总统计结果
stat_df = pd.DataFrame({"bucket": bucket_list, "base_cnt": base_cnt_list, "test_cnt": test_cnt_list})
stat_df['base_dist'] = stat_df['base_cnt'] / len(base_df)
stat_df['test_dist'] = stat_df['test_cnt'] / len(test_df)
def sub_psi(row):
# 6.计算PSI
base_list = row['base_dist']
test_dist = row['test_dist']
# 处理某分箱内样本量为0的情况
if base_list == 0 and test_dist == 0:
return 0
elif base_list == 0 and test_dist > 0:
base_list = 1 / base_notnull_cnt
elif base_list > 0 and test_dist == 0:
test_dist = 1 / test_notnull_cnt
return (test_dist - base_list) * np.log(test_dist / base_list)
stat_df['psi'] = stat_df.apply(lambda row: sub_psi(row), axis=1)
stat_df = stat_df[['bucket', 'base_cnt', 'base_dist', 'test_cnt', 'test_dist', 'psi']]
psi = stat_df['psi'].sum()
except:
print('error!!!')
psi = np.nan
stat_df = None
return psi, stat_df
## 也可直接调用toad包计算psi
# prob_dev模型在训练样本的评分,prob_test测试样本的评分
psi = toad.metrics.PSI(prob_dev,prob_test)
分析psi指标原理,经过公式变形,我们可以发现psi的含义等同于第一项实际分布(A)与预期分布(E)的KL散度 + 第二项预期分布(E)与实际分布(A)之间的KL散度之和,KL散度可以单向(非对称性指标)地描述信息熵差异,上式更为综合地描述分布的差异情况。
PSI数值越小(经验是常以<0.1作为标准),两个分布之间的差异就越小,代表越稳定。
PSI值在实际应用中的优点在于其计算的便捷性,但需要注意的是,PSI的计算受分组数量及方式、群体样本量和现实业务政策等多重因素影响,尤其是对业务变动剧烈的小样本来说,PSI的值往往超出一般的经验水平,因此需要结合实际的业务和数据情况进行具体分析。
文章首发公众号“算法进阶”,阅读原文可访问文章相关代码
数据分析是通过明确分析目的,梳理并确定分析逻辑,针对性的收集、整理数据,并采用统计、挖掘技术分析,提取有用信息和展示结论的过程,是数据科学领域的核心技能。
本文从数据分析常用逻辑框架及技术方法出发,结合python项目实战全面解读数据分析,可以系统掌握数据分析的框架套路,快速上手数据分析。
PEST分析是指宏观环境的分析,宏观环境是指影响一切行业或企业的各种宏观力量。P是政治(Politics),E是经济(Economy),S是社会(Society),T是技术(Technology)。通常是战略咨询顾问用来帮助企业检阅其外部宏观环境的一种方法,以吉利收购沃尔沃为例:
5W2H分析法又称七何分析法,包括:Why、What、Where、When、Who、How、How much 。主要用于用户行为分析、业务问题专题分析、营销活动等,是一个方便又实用的工具。
逻辑树是分析问题最常用的工具之一,它是将问题的所有子问题分层罗列,从最高层开始,并逐步向下扩展。使用逻辑树分析的主要优点是保证解决问题的过程的完整性,且方便将工作细分为便于操作的任务,确定各部分的优先顺序,明确地把责任落实到个人。
4P即产品(Product)、价格(Price)、渠道(Place)、促销(Promotion),在营销领域,这种以市场为导向的营销组合理论,被企业应用最普遍。通过将四者的结合、协调发展,从而提高企业的市场份额,达到最终获利的目的。
4P营销理论适用于分析企业的经营状况,可视为企业内部环境,PEST分析的是企业在外部面对的环境。
SCQA分析是一个“结构化表达”工具,即S(Situation)情景、C(Complication)冲突、Q(Question)疑问、A(Answer)回答。
整个结构是通过描述当事者的现实状态,然后带出冲突和核心问题,通过结构化分析以提供更为明智的解决方案。以校园招聘SCQA分析为例:
SMART法是一种目标管理方法,即对目标的S(Specific)明确性,M(Measurable)可衡量性,A(Attainable)可实现性,R(Relevant)相关性,T(Time-based)时限性。
SWOT分析法也叫态势分析法,S (Strengths)是优势、W (Weaknesses)是劣势,O (Opportunities)是机会、T (Threats)是威胁或风险。常用来确定企业自身的内部优势、劣势和外部的机会和威胁等,从而将公司的战略与公司内部与外部环境有机地结合起来。以HUAWEI 的SWOT分析为例:
数据分析的技术方法是指提取出关键信息的具体方法,如对比分析、交叉分析、回归预测分析等方法。
对比分析法是将两个或两个以上的数据进行比较,分析差异,揭示发展变化情和规律。
举例:各车企销售表现
举例: 新书在各销售渠道的销量
举例:市场占有率是典型的结构分析。
举例:季节性分析和价格分析时常会用到index指标
举例:常见的气泡图数据表格
举例:商品流转率表现图
图表展示可以帮助我们更好、更直观地看懂数据信息。
图表的选择,不只是关注图表的样式,而关键在于关注数据情况及图表展示的功能。可以通过数据展示的功能(构成、比较、趋势、分布及联系)进行图表选择,如下所示:
数据来源于天猫真实成交订单,主要是行为类数据。
a. 订单编号:订单编号
b. 总金额:订单总金额
c. 买家实际支付金额:总金额 - 退款金额(在已付款的情况下);未付款的支付金额为0
d. 收货地址:全国各个省份
e. 订单创建时间:下单时间
f. 订单付款时间:付款时间(如果未付款,显示NaN)
g. 退款金额:付款后申请退款的金额。未付款的退款金额为0
以天猫一个月内的订单数据,观察这个月的订单量以及销售额, 分析下单日期、收货地址等因素对订单量的影响以及订单转换情况,旨在提升用户下单量和订单转换率,进而提高用户实际支付额。
本文结合订单流程以逻辑树方法分析订单数目的影响因素,从以下几个维度展开:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
# 读取数据
df = pd.read_csv('tmall_order_report.csv')
df.head()
# 利用pandas_profiling一健生成数据情况(EDA)报告:数据描述、缺失、相关性等情况
import pandas_profiling as pp
report = pp.ProfileReport(df)
report
#规范字段名称
df.columns
df=df.rename(columns={'收货地址 ':'收货地址','订单付款时间 ':'订单付款时间'})
df.columns
#查看数据基本信息
df.info()
# 数据类型转换
df['订单创建时间']=pd.to_datetime(df.订单创建时间)
df['订单付款时间']=pd.to_datetime(df.订单付款时间)
df.info()
# 数据重复值
df.duplicated().sum()
无
#数据缺失值
df.isnull().sum()
#数据集描述性信息
df.describe()
#筛选数据集
df_payed=df[df['订单付款时间'].notnull()]#支付订单数据集
df_trans=df_payed[df_payed['买家实际支付金额']!=0]#到款订单数据集
df_trans_full=df_payed[df_payed['退款金额']==0]#全额到款订单数据集
分析2月份成交订单数的变化趋势
import pyecharts.options as opts
#将订单创建时间设为index
df_trans=df_trans.set_index('订单创建时间')
#按天重新采样
se_trans_month = df_trans.resample('D')['订单编号'].count()
from pyecharts.charts import Line
#做出标有具体数值的变化图
name = '成交订单数'
(
Line()
.add_xaxis(xaxis_data = list(se_trans_month.index.day.map(str)))
.add_yaxis(
series_name= name,
y_axis= se_trans_month,
)
.set_global_opts(
yaxis_opts = opts.AxisOpts(
splitline_opts = opts.SplitLineOpts(is_show = True)
)
)
.render_notebook()
)
se_trans_map=df_trans.groupby('收货地址')['收货地址'].count().sort_values(ascending=False)
# 为了保持收货地址和下面的地理分布图使用的省份名称一致,定义一个处理自治区的函数
def strip_region(iterable):
result = []
for i in iterable:
if i.endswith('自治区'):
if i == '内蒙古自治区':
i = i[:3]
result.append(i)
else:
result.append(i[:2])
else:
result.append(i)
return result
# 处理自治区
se_trans_map.index = strip_region(se_trans_map.index)
# 去掉末位‘省’字
se_trans_map.index = se_trans_map.index.str.strip('省')
import pyecharts.options as opts
from pyecharts.charts import Map
# 展示地理分布图
name = '订单数'
(
Map()
.add(
series_name = name,
data_pair= [list(i) for i in se_trans_map.items()])
.set_global_opts(visualmap_opts=opts.VisualMapOpts(
max_=max(se_trans_map)*0.6
)
)
.render_notebook()
)
用直观的地图来观察成交订单数的分布情况
订单数以及订单转化率的呈现
dict_convs=dict() #字典
dict_convs['总订单数']=len(df)
df_payed
dict_convs['订单付款数']=len(df_payed.notnull())
df_trans=df[df['买家实际支付金额']!=0]
dict_convs['到款订单数']=len(df_trans)
dict_convs['全额到款订单数']=len(df_trans_full)
#字典转为dataframe
df_convs = pd.Series(dict_convs,name = '订单数').to_frame()
df_convs
#求总体转换率,依次比上总订单数
total_convs=df_convs['订单数']/df_convs.loc['总订单数','订单数']*100
df_convs['总体转化率']=total_convs.apply(lambda x:round(x,0))
df_convs
#求单一转换率
single_convs=df_convs.订单数/(df_convs.订单数.shift())*100
single_convs=single_convs.fillna(100)
df_convs['单一转化率']=single_convs.apply(lambda x:round(x,0))
df_convs
画转换率漏斗图,直观呈现订单转化情况
from pyecharts.charts import Funnel
from pyecharts import options as opts
name = '总体转化率'
funnel = Funnel().add(
series_name = name,
data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ],
is_selected = True,
label_opts = opts.LabelOpts(position = 'inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = name),
# tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'),
)
funnel.render_notebook()
name = '单一转化率'
funnel = Funnel().add(
series_name = name,
data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ],
is_selected = True,
label_opts = opts.LabelOpts(position = 'inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = name),
# tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'),
)
funnel.render_notebook()
文章首发于算法进阶,公众号阅读原文可访问GitHub源码
序列文章:
上一篇 《白话机器学习概念》
机器学习按照学习数据经验的不同,即训练数据的标签信息的差异,可以分为监督学习(supervised learning)、非监督学习(unsupervised learning)、半监督学习(semi- supervised learning)和强化学习(reinforcement learning)。
监督学习是机器学习中应用最广泛及成熟的,它是从有标签的数据样本(x,y)中,学习如何关联x到正确的y。这过程就像是模型在给定题目的已知条件(特征x),参考着答案(标签y)学习,借助标签y的监督纠正,模型通过算法不断调整自身参数以达到学习目标。
监督学习常用的模型有:线性回归、朴素贝叶斯、K最近邻、逻辑回归、支持向量机、神经网络、决策树、集成学习(如LightGBM)等。按照应用场景,以模型预测结果Y的取值有限或者无限的,可再进一步分为分类或者回归模型。
分类模型
分类模型是处理预测结果取值有限的分类任务。如下示例通过逻辑回归分类模型,根据温湿度、风速等情况去预测是否会下雨。
逻辑回归虽然名字有带“回归”,但其实它是一种广义线性的分类模型,由于模型简单和高效,在实际中应用非常广泛。
逻辑回归模型结构可以视为双层的神经网络(如图4.5)。模型输入x,通过神经元激活函数f(f为sigmoid函数)将输入非线性转换至0~1的取值输出,最终学习的模型决策函数为Y=sigmoid(wx + b)
。其中模型参数w即对应各特征(x1, x2, x3...)的权重(w1,w2,w3...),b模型参数代表着偏置项,Y为预测结果(0~1范围)。
模型的学习目标为极小化交叉熵损失函数。模型的优化算法常用梯度下降算法去迭代求解损失函数的极小值,得到较优的模型参数。

import pandas as pd # 导入pandas库
weather_df = pd.read_csv('./data/weather.csv') # 加载天气数据集
weather_df.head(10) # 显示数据的前10行
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
x = weather_df.drop('If Rain', axis=1) # 特征x
y = weather_df['If Rain'] # 标签y
lr = LogisticRegression()
lr.fit(x, y) # 模型训练
print("前10个样本预测结果:", lr.predict(x[0:10]) ) # 模型预测前10个样本并输出结果
以训练的模型输出前10个样本预测结果为: [1 1 1 1 1 1 0 1 1 1],对比实际前10个样本的标签: [1 1 1 1 1 0 1 0 0 1],预测准确率并不高。在后面章节我们会具体介绍如何评估模型的预测效果,以及进一步优化模型效果。
回归模型
回归模型是处理预测结果取值无限的回归任务。如下代码示例通过线性回归模型,以室外湿度为标签,根据温度、风力、下雨等情况预测室外湿度。
from sklearn.linear_model import LinearRegression #导入线性回归模型
x = weather_df.drop('Humidity', axis=1) # 特征x
y = weather_df['Humidity'] # 标签y
linear = LinearRegression()
linear.fit(x, y) # 模型训练
print("前10个样本预测结果:", linear.predict(x[0:10]) ) # 模型预测前10个样本并输出结果
# 前10个样本预测结果: [0.42053525 0.32811401 0.31466161 0.3238797 0.29984453 0.29880059
非监督学习也是机器学习中应用较广泛的,是从无标注的数据(x)中,学习数据的内在规律。这个过程就像模型在没有人提供参考答案(y),完全通过自己琢磨题目的知识点,对知识点进行归纳、总结。按照应用场景,非监督学习可以分为聚类,特征降维和关联分析等方法。 如下示例通过Kmeans聚类划分出不同品种的iris鸢尾花样本。
Kmeans聚类简介
Kmeans聚类是非监督学习常用的方法,其原理是先初始化k个簇类中心,通过迭代算法更新各簇类样本,实现样本与其归属的簇类中心的距离最小的目标。其算法步骤为:
1.初始化:随机选择 k 个样本作为初始簇类中心(可以凭先验知识、验证法确定k的取值);
2.针对数据集中每个样本 计算它到 k 个簇类中心的距离,并将其归属到距离最小的簇类中心所对应的类中;
3.针对每个簇类 ,重新计算它的簇类中心位置;
4.重复上面 2 、3 两步操作,直到达到某个中止条件(如迭代次数,簇类中心位置不变等)
代码示例
from sklearn.datasets import load_iris # 数据集
from sklearn.cluster import KMeans # Kmeans模型
import matplotlib.pyplot as plt # plt画图
lris_df = datasets.load_iris() # 加载iris鸢尾花数据集,数据集有150条样本,分三类的iris品种
x = lris_df.data
k = 3 # 聚类出k个簇类, 已知数据集有三类品种, 设定为3
model = KMeans(n_clusters=k)
model.fit(x) # 训练模型
print("前10个样本聚类结果:",model.predict(x[0:10]) ) # 模型预测前10个样本并输出聚类结果:[1 1 1 1 1 1 1 1 1 1]
# 样本的聚类效果以散点图展示
x_axis = lris_df.data[:,0] # 以iris花的sepal length (cm)特征作为x轴
y_axis = lris_df.data[:,1] # 以iris花的sepal width (cm)特征作为y轴
plt.scatter(x_axis, y_axis, c=model.predict(x)) # 分标签颜色展示聚类效果
plt.xlabel('Sepal length (cm)')#设定x轴注释
plt.ylabel('Sepal width (cm)')#设定y轴注释
plt.title('Iris KMeans Scatter')
plt.show() # 如图4.7聚类效果
半监督学习是介于传统监督学习和无监督学习之间(如图4.8),其**是在有标签样本数量较少的情况下,以一定的假设前提在模型训练中引入无标签样本,以充分捕捉数据整体潜在分布,改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题。按照应用场景,半监督学习可以分为聚类,分类及回归等方法。 如下示例通过基于图的半监督算法——标签传播算法分类俱乐部成员。
标签传播算法(LPA)是基于图的半监督学习分类算法,基本思路是在所有样本组成的图网络中,从已标记的节点标签信息来预测未标记的节点标签。
首先利用样本间的关系(可以是样本客观关系,或者利用相似度函数计算样本间的关系)建立完全图模型。
接着向图中加入已标记的标签信息(或无),无标签节点是用一个随机的唯一的标签初始化。
将一个节点的标签设置为该节点的相邻节点中出现频率最高的标签,重复迭代,直到标签不变即算法收敛。
import networkx as nx # 导入networkx图网络库
import matplotlib.pyplot as plt
from networkx.algorithms import community # 图社区算法
G=nx.karate_club_graph() # 加载美国空手道俱乐部图数据
#注: 本例未使用已标记信息, 严格来说是半监督算法的无监督应用案例
lpa = community.label_propagation_communities(G) # 运行标签传播算法
community_index = {n: i for i, com in enumerate(lpa) for n in com} # 各标签对应的节点
node_color = [community_index[n] for n in G] # 以标签作为节点颜色
pos = nx.spring_layout(G) # 节点的布局为spring型
nx.draw_networkx_labels(G, pos) # 节点序号
nx.draw(G, pos, node_color=node_color) # 分标签颜色展示图网络
plt.title(' Karate_club network LPA')
plt.show() #展示分类效果,不同颜色为不同类别
强化学习从某种程度可以看作是有延迟标签信息的监督学习(如图4.9),是指智能体Agent在环境Environment中采取一种行为action,环境将其转换为一次回报reward和一种状态表示state,随后反馈给智能体的学习过程。本书中对强化学习仅做简单介绍,有兴趣可以自行扩展。
文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码
时间序列是指将某种现象某一个统计指标在不同时间上的各个数值,按时间先后顺序排列而形成的序列。典型的时间序列问题,例如股价预测、制造业中的电力预测、传统消费品行业的销售预测、客户日活跃量预测等等,本文以客户日活跃量预测为例。
时间序列的预测方法可以归纳为三类:
1、时间序列基本规则法-周期因子法;
2、传统序列预测方法,如均值回归、ARIMA等线性模型;
3、机器学习方法,将序列预测转为有监督建模预测,如XGBOOST集成学习方法,LSTM长短期记忆神经网络模型。
当序列存在周期性时,通过加工出数据的周期性特征预测。这种比较麻烦,简述下流程不做展开。
1、计算周期的因子 。
2、计算base
3、预测结果=周期因子*base
ARIMA模型,差分整合移动平均自回归模型,又称整合移动平均自回归模型
(移动也可称作滑动),时间序列预测分析方法之一。ARIMA(p,d,q)中,
AR是"自回归",p为自回归项数;MA为"滑动平均",q为滑动平均项数,
d为使之成为平稳序列所做的差分次数(阶数)。
建模的主要步骤是:
1、数据需要先做平稳法处理:采用(对数变换或差分)平稳化后,并检验符合平稳非白噪声序列;
2、观察PACF和ACF截尾/信息准则定阶确定(p, q);
3、 建立ARIMA(p,d,q)模型做预测;
"""
ARIMA( 差分自回归移动平均模型)预测DAU指标
"""
import numpy as np
import pandas as pd
import seaborn as sns
import scipy
import matplotlib.pyplot as plt
import statsmodels.api as sm
import warnings
from math import sqrt
from pandas import Series
from sklearn.metrics import mean_squared_error
from statsmodels.graphics.tsaplots import acf, pacf,plot_acf, plot_pacf
from statsmodels.stats.diagnostic import acorr_ljungbox
from statsmodels.tsa.arima_model import ARIMA, ARMA, ARIMAResults
from statsmodels.tsa.stattools import adfuller as ADF
from keras.models import load_model
warnings.filterwarnings("ignore")
df = pd.read_csv('DAU.csv')
dau = df["dau"]
# 折线图
df.plot()
plt.show()
# 箱线图
ax = sns.boxplot(y=dau)
plt.show()
# pearsonr时间相关性
# a = df['dau']
# b = df.index
# print(scipy.stats.pearsonr(a,b))
# 自相关性
plot_acf(dau)
plot_pacf(dau)
plt.show()
print('raw序列的ADF')
# p值大于0.05为非平衡时间序列
print(ADF(dau))
#对数变换平稳处理
# dau_log = np.log(dau)
# dau_log = dau_log.ewm(com=0.5, span=12).mean()
# plot_acf(dau_log)
# plot_pacf(dau_log)
# plt.show()
# print('log序列的ADF')
# print(ADF(dau_log))
# print('log序列的白噪声检验结果')
# # 大于0.05为白噪声序列
# print(acorr_ljungbox(dau_log, lags=1))
#差分平稳处理
diff_1_df = dau.diff(1).dropna(how=any)
diff_1_df = diff_1_df
diff_1_df.plot()
plot_acf(diff_1_df)
plot_pacf(diff_1_df)
plt.show()
print('差分序列的ADF')
print(ADF(diff_1_df))
print('差分序列的白噪声检验结果')
# 大于0.05为白噪声序列
print(acorr_ljungbox(diff_1_df, lags=1))
# # 在满足检验条件后,给出最优p q值 ()
r, rac, Q = sm.tsa.acf(diff_1_df, qstat=True)
prac = pacf(diff_1_df, method='ywmle')
table_data = np.c_[range(1,len(r)), r[1:], rac, prac[1:len(rac)+1], Q]
table = pd.DataFrame(table_data, columns=['lag', "AC","Q", "PAC", "Prob(>Q)"])
order = sm.tsa.arma_order_select_ic(diff_1_df, max_ar=7, max_ma=7, ic=['aic', 'bic', 'hqic'])
p, q =order.bic_min_order
print("p,q")
print(p, q)
# 建立ARIMA(p, d, q)模型 d=1
order = (p, 1, q)
train_X = diff_1_df[:]
arima_model = ARIMA(train_X, order).fit()
# 模型报告
# print(arima_model.summary2())
# 保存模型
arima_model.save('./data/arima_model.h5')
# # load model
arima_model = ARIMAResults.load('./data/arima_model.h5')
# 预测未来两天数据
predict_data_02 = arima_model.predict(start=len(train_X), end=len(train_X) + 1, dynamic = False)
# 预测历史数据
predict_data = arima_model.predict(dynamic = False)
# 逆log化
# original_series = np.exp(train_X.values[1:] + np.log(dau.values[1:-1]))
# predict_series = np.exp(predict_data.values + np.log(dau.values[1:-1]))
# 逆差分
original_series = train_X.values[1:] + dau.values[1:-1]
predict_series = predict_data.values + dau.values[1:-1]
# comp = pd.DataFrame()
# comp['original'] = original_series
# comp['predict'] = predict_series
split_num = int(len(dau.values)/3) or 1
rmse = sqrt(mean_squared_error(original_series[-split_num:], predict_series[-split_num:]))
print('Test RMSE: %.3f' % rmse)
# (0,1,0)Test RMSE
plt.title('ARIMA RMSE: %.3f' % rmse)
plt.plot(original_series[-split_num:], label="original_series")
plt.plot(predict_series[-split_num:], label="predict_series")
plt.legend()
plt.show()Long Short Term 网络是一种 RNN 特殊的类型,可以学习长期依赖序列信息。
LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。一个cell当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入LSTM的网络当中,只有符合信息才会留下,不符的信息则通过遗忘门被遗忘。通过这机制减少梯度爆炸/消失的风险。
建模主要的步骤:
1、数据处理:差分法数据平稳化;MAX-MIN法数据标准化;构建监督学习训练集;(对于LSTM,差分及标准化不是必要的)
2、模型训练并预测;
"""
LSTM预测DAU指标
"""
import numpy as np
from pandas import DataFrame, datetime, concat,read_csv, Series
from matplotlib import pyplot as plt
from sklearn.metrics import mean_squared_error
from math import sqrt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.models import load_model
from keras.layers import Dense
from keras.layers import LSTM
from keras.callbacks import EarlyStopping
from keras import regularizers
from statsmodels.stats.diagnostic import acorr_ljungbox
from statsmodels.tsa.stattools import adfuller as ADF
# convert date
def parser(x):
return datetime.strptime(x,"%Y-%m-%d")
#supervised
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(1) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
# diff series
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
return Series(diff)
# invert diff value
def inverse_difference(history, yhat, interval=1):
return yhat + history[-interval]
# max_min标准化 [-1, 1]
def scale(train, test):
# fit scaler
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(train)
# transform train
train = train.reshape(train.shape[0], train.shape[1])
train_scaled = scaler.transform(train)
# transform test
test = test.reshape(test.shape[0], test.shape[1])
test_scaled = scaler.transform(test)
return scaler, train_scaled, test_scaled
# invert scale transform
def invert_scale(scaler, X, value):
new_row = [x for x in X] + [value]
array = np.array(new_row)
array = array.reshape(1, len(array))
inverted = scaler.inverse_transform(array)
return inverted[0, -1]
# model train
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:,0:-1], train[:,-1]
# reshp
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
# stateful
# input(samples:batch row, time steps:1, features:one time observed)
model.add(LSTM(neurons,
batch_input_shape=(batch_size, X.shape[1], X.shape[2]),
stateful=True, return_sequences=True, dropout=0.2))
model.add(Dense(1))
model.compile(loss="mean_squared_error", optimizer="adam")
# train
train_loss = []
val_loss = []
for i in range(nb_epoch):
# shuffle=false
history = model.fit(X, y, batch_size=batch_size, epochs=1,verbose=0,shuffle=False,validation_split=0.3)
train_loss.append(history.history['loss'][0])
val_loss.append(history.history['val_loss'][0])
# clear state
model.reset_states()
# 提前停止训练
if i > 50 and sum(val_loss[-10:]) < 0.3:
print(sum(val_loss[-5:]))
print("better epoch", i)
break
# print(history.history['loss'])
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model train vs validation loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
return model
# model predict
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
# 开始加载数据
series = read_csv('DAU.csv')["dau"]
print(series.head())
series.plot()
plt.show()
# 数据平稳化
raw_values = series.values
diff_values = difference(raw_values, 1)
print(diff_values.head())
plt.plot(raw_values, label="raw")
plt.plot(diff_values, label="diff")
plt.legend()
plt.show()
print('差分序列的ADF')
print(ADF(diff_values)[1])
print('差分序列的白噪声检验结果')
# (array([13.95689179]), array([0.00018705]))
print(acorr_ljungbox(diff_values, lags=1)[1][0])
# 序列转监督数据
supervised = timeseries_to_supervised(diff_values, 1)
print(supervised.head())
supervised_values = supervised.values
# split data
split_num = int(len(supervised_values)/3) or 1
train, test = supervised_values[0:-split_num], supervised_values[-split_num:]
# 标准化
scaler, train_scaled, test_scaled = scale(train, test)
#fit model
lstm_model = fit_lstm(train_scaled, 1, 200, 5)
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
train_predict = lstm_model.predict(train_reshaped, batch_size=1)
train_raw = train_scaled[:, 0]
# # train RMSE plot
# train_raw = raw_values[0:-split_num]
# predictions = list()
# for i in range(len(train_scaled)):
# # make one-step forecast
# X, y = train_scaled[i, 0:-1], train_scaled[i, -1]
# yhat = forecast_lstm(lstm_model, 1, X)
# # invert scaling
# yhat = invert_scale(scaler, X, yhat)
# # invert differencing
# yhat = inverse_difference(raw_values, yhat, len(train_scaled)+1-i)
# # store forecast
# predictions.append(yhat)
# expected = train_raw[i]
# mae = abs(yhat-expected)
# print('data=%d, Predicted=%f, Expected=%f, mae=%.3f' % (i+1, yhat, expected,mae))
# print(mae)
# plt.plot(train_raw, label="train_raw")
# plt.plot(predictions, label="predict")
# plt.legend()
# plt.show()
# 保存模型
lstm_model.save('./data/lstm_model_epoch50.h5')
# # load model
lstm_model = load_model('./data/lstm_model_epoch50.h5')
# validation
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# invert scaling
yhat = invert_scale(scaler, X, yhat)
# invert differencing
yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i)
# store forecast
predictions.append(yhat)
expected = raw_values[len(train) + i + 1]
mae = abs(yhat-expected)
print('data=%d, Predicted=%f, Expected=%f, mae=%.3f' % (i+1, yhat, expected, mae))
mae = np.average(abs(predictions - raw_values[-split_num:]))
print("Test MAE: %.3f",mae)
#report performance
rmse = sqrt(mean_squared_error(raw_values[-split_num:], predictions))
print('Test RMSE: %.3f' % rmse)
# line plot of observed vs predicted
plt.plot(raw_values[-split_num:], label="raw")
plt.plot(predictions, label="predict")
plt.title('LSTM Test RMSE: %.3f' % rmse)
plt.legend()
plt.show()# 附 数据集dau.csv
log_date,dau
2018-06-01,257488
2018-06-02,286612
2018-06-03,287405
2018-06-04,246955
2018-06-05,249926
2018-06-06,252951
2018-06-07,255467
2018-06-08,262498
2018-06-09,288368
2018-06-10,288440
2018-06-11,255447
2018-06-12,251316
2018-06-13,251654
2018-06-14,250515
2018-06-15,262155
2018-06-16,288844
2018-06-17,296143
2018-06-18,298142
2018-06-19,264124
2018-06-20,262992
2018-06-21,263549
2018-06-22,271631
2018-06-23,296452
2018-06-24,296986
2018-06-25,271197
2018-06-26,270546
2018-06-27,271208
2018-06-28,275496
2018-06-29,284218
2018-06-30,307498
2018-07-01,316097
2018-07-02,295106
2018-07-03,290675
2018-07-04,292231
2018-07-05,297510
2018-07-06,298839
2018-07-07,302083
2018-07-08,301238
2018-07-09,296398
2018-07-10,300986
2018-07-11,301459
2018-07-12,299865
2018-07-13,289830
2018-07-14,297501
2018-07-15,297443
2018-07-16,293097
2018-07-17,293866
2018-07-18,292902
2018-07-19,292368
2018-07-20,290766
2018-07-21,294669
2018-07-22,295811
2018-07-23,297514
2018-07-24,297392
2018-07-25,298957
2018-07-26,298101
2018-07-27,298740
2018-07-28,304086
2018-07-29,305269
2018-07-30,304827
2018-07-31,299689
2018-08-01,300526
2018-08-02,59321
2018-08-03,31731
2018-08-04,36838
2018-08-05,42043
2018-08-06,42366
2018-08-07,37209
注:本文基于之前的文章做了些修改,重复部分可以跳过看。示例的项目为基于LR模型对癌细胞分类的任务。
随着人工智能时代的到来,机器学习已成为解决问题的关键工具。我们接下来会详细介绍机器学习如何应用到实际问题,并概括机器学习应用的一般流程。
明确业务问题是机器学习的先决条件,即抽象出该问题为机器学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。
一个简单的新闻分类的场景,就是学习已有的新闻及其类别标签数据,得到一个文本分类模型,通过模型对每天新的新闻做类别预测,以归类到每个新闻频道。
机器学习广泛流传一句话:“数据和特征决定了机器学习结果的上限,而模型算法只是尽可能逼近这个上限”,意味着数据及其特征表示的质量决定了模型的最终效果,且在实际的工业应用中,算法通常占了很小的一部分,大部分的工作都是在找数据、提炼数据、分析数据及特征工程。
数据选择是准备机器学习原料的关键,需要关注的是:
① 数据的代表性:数据质量差或无代表性,会导致模型拟合效果差;
② 数据时间范围:对于监督学习的特征变量X及标签Y,如与时间先后有关,则需要划定好数据时间窗口,否则可能会导致数据泄漏,即存在和利用因果颠倒的特征变量的现象。(如预测明天会不会下雨,但是训练数据引入明天温湿度情况);
③ 数据业务范围:明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音。
特征工程就是对原始数据分析处理转化为模型可用的特征,这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。特征工程按技术上可分为如下几步:
① 探索性数据分析:数据分布、缺失、异常及相关性等情况;
② 数据预处理:缺失值/异常值处理,数据离散化,数据标准化等;
③ 特征提取:特征表示,特征衍生,特征选择,特征降维等;
拿到数据后,可以先做探索性数据分析(EDA)去理解数据本身的内部结构及规律,如果你对数据情况不了解也没有相关的业务背景知识,不做相关的分析及预处理,直接将数据喂给传统模型往往效果不太好。
通过探索性数据分析,可以了解数据分布、缺失、异常及相关性等情况,利用这些基本信息做数据的处理及特征加工,可以进一步提高特征质量,灵活选择合适的模型方法。
收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。 通常需要处理人为引起的异常值,通过业务或技术手段(如3σ准则)判定异常值,再由(正则式匹配)等方式筛选异常的信息,并结合业务情况删除或者替换数值。
数据缺失值可以通过结合业务进行填充数值、不做处理或者删除。根据特征缺失率情况及处理方式分为以下情况:
① 缺失率较高,并结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;
② 缺失率较低,结合业务可使用一些缺失值填充手段,如pandas的fillna方法、训练回归模型预测缺失值并填充;
③ 不做处理:部分模型如随机森林、xgboost、lightgbm能够处理数据缺失的情况,不需要对缺失数据再做处理。
离散化是将连续的数据进行分段,使其变为一段段离散化的区间,分段的原则有等宽、等频等方法。通过离散化一般可以增加抗噪能力、使特征更有业务解释性、减小算法的时间及空间开销(不同算法情况不一)。
数据各个特征变量的量纲差异很大,可以使用数据标准化消除不同分量量纲差异的影响,加速模型收敛的效率。常用的方法有:
① min-max 标准化:
可将数值范围缩放到(0, 1)且无改变数据分布。max为样本最大值,min为样本最小值。
② z-score 标准化:
可将数值范围缩放到0附近, 经过处理的数据符合标准正态分布。是平均值,σ是标准差。
数据需要转换为计算机能够处理的数值形式,图片类的数据需要转换为RGB三维矩阵的表示。
字符类的数据可以用多维数组表示,有Onehot独热编码表示(用单独一个位置的1来表示)、word2vetor分布式表示等;
基础特征对样本信息的表达有限,可通过特征衍生可以增加特征的非线性表达能力,提升模型效果。另外,在业务上的理解设计特征,还可以增加模型的可解释性。(如体重除以身高就是表达健康情况的重要特征。)
特征衍生是对现有基础特征的含义进行某种处理(聚合/转换之类),常用方法人工设计、自动化特征衍生(图4.15):
① 结合业务的理解做人工衍生设计:
聚合的方式是指对字段聚合后求平均值、计数、最大值等。比如通过12个月工资可以加工出:平均月工资,薪资最大值 等等;
转换的方式是指对字段间做加减乘除之类。比如通过12个月工资可以加工出:当月工资收入与支出的比值、差值等等;
② 使用自动化特征衍生工具:如Featuretools等,可以使用聚合(agg_primitives)、转换(trans_primitives)或则自定义方式暴力生成特征;
特征选择的目标是寻找最优特征子集,通过筛选出显著特征、摒弃冗余特征,减少模型的过拟合风险并提高运行效率。特征选择方法一般分为三类:
① 过滤法:计算特征的缺失情况、发散性、相关性、信息量、稳定性等类型的指标对各个特征进行评估选择,常用如缺失率、单值率、方差验证、pearson相关系数、chi2卡方检验、IV值、信息增益及PSI等方法。
② 包装法:通过每次选择部分特征迭代训练模型,根据模型预测效果评分选择特征的去留,如sklearn的RFE递归特征消除。
③ 嵌入法:直接使用某些模型训练的到特征重要性,在模型训练同时进行特征选择。通过模型得到各个特征的权值系数,根据权值系数从大到小来选择特征。常用如基于L1正则项的逻辑回归、XGBOOST特征重要性选择特征。
如果特征选择后的特征数目仍太多,这种情形下常会有数据样本稀疏、距离计算困难的问题(称为 “维数灾难”),可以通过特征降维解决。常用的降维方法有:主成分分析法(PCA)等。
模型训练是利用既定的模型方法去学习数据经验的过程,这过程还需要结合模型评估以调整算法的超参数,最终选择表现较优的模型。
训练模型前,常用的HoldOut验证法(此外还有留一法、k折交叉验证等方法),把数据集分为训练集和测试集,并可再对训练集进一步细分为训练集和验证集,以方便评估模型的性能。
① 训练集(training set):用于运行学习算法,训练模型。
② 开发验证集(development set)用于调整超参数、选择特征等,以选择合适模型。
③ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。
###3.2 模型方法选择
结合当前任务及数据情况选择合适的模型方法,常用的方法如下图 ,scikit-learn模型方法的选择。此外还可以结合多个模型做模型融合。
模型的训练过程即学习数据经验得到较优模型及对应参数(如神经网络最终学习到较优的权重值)。整个训练过程还需要通过调节超参数(如神经网络层数、梯度下降的学习率)进行控制优化的。
调节超参数是一个基于数据集、模型和训练过程细节的实证过程,需要基于对算法的原理理解和经验,借助模型在验证集的评估进行参数调优,此外还有自动调参技术:网格搜索、随机搜索及贝叶斯优化等。
机器学习的直接目的是学(拟合)到“好”的模型,不仅仅是学习过程中对训练数据的良好的学习预测能力,根本上在于要对新数据能有很好的预测能力(泛化能力),所以客观地评估模型性能至关重要。技术上常根据训练集及测试集的指标表现,评估模型的性能。
常用的评估标准有查准率P、查全率R及两者调和平均F1-score 等,并由混淆矩阵的统计相应的个数计算出数值:
查准率是指分类器分类正确的正样本(TP)的个数占该分类器所有预测为正样本个数(TP+FP)的比例;
查全率是指分类器分类正确的正样本个数(TP)占所有的正样本个数(TP+FN)的比例。
F1-score是查准率P、查全率R的调和平均:
常用的评估指标有MSE均方误差等。反馈的是预测数值与实际值的拟合情况。
可分为两类方式,一类将聚类结果与某个“参考模型”的结果进行比较,称为“外部指标”(external index):如兰德指数,FM指数等。另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”(internal index):如紧凑度、分离度等。
训练机器学习模型所使用的数据样本集称之为训练集(training set), 在训练数据的误差称之为训练误差(training error),在测试数据上的误差,称之为测试误差(test error)或泛化误差 (generalization error)。
描述模型拟合(学习)程度常用欠拟合、拟合良好、过拟合,我们可以通过训练误差及测试误差评估模型的拟合程度。从整体训练过程来看,欠拟合时训练误差和测试误差均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,测试误差上升,这个时候就进入了过拟合区域。
欠拟合是指相较于数据而言模型结构过于简单,以至于无法学习到数据中的规律。
过拟合是指模型只过分地匹配训练数据集,以至于对新数据无良好地拟合及预测。其本质是较复杂模型从训练数据中学习到了统计噪声导致的。
分析模型拟合效果并对模型进行优化,常用的方法有:
决策应用是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。需要注意的是,工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。
项目的实验数据来源著名的UCI机器学习数据库,该数据库有大量的人工智能数据挖掘数据。本例选用的是sklearn上的数据集版本:Breast Cancer Wisconsin DataSet(威斯康星州乳腺癌数据集),这些数据来源美国威斯康星大学医院的临床病例报告,每条样本有30个特征属性,标签为是否良性肿瘤,即有监督分类预测的问题。 项目的建模思路是通过分析乳腺癌数据集数据,特征工程,构建逻辑回归模型学习数据,预测样本的类别是否为良性肿瘤。
导入相关的Python库,加载cancer数据集,查看数据介绍, 并转为DataFrame格式。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.utils import plot_model
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score
dataset_cancer = datasets.load_breast_cancer() # 加载癌细胞数据集
print(dataset_cancer['DESCR'])
df = pd.DataFrame(dataset_cancer.data, columns=dataset_cancer.feature_names)
df['label'] = dataset_cancer.target
print(df.shape)
df.head()
探索性数据分析EDA:使用pandas_profiling库分析数据数值情况,缺失率及相关性等。
import pandas_profiling
pandas_profiling.ProfileReport(df, title='Breast Cancer DataSet EDA')
特征工程方面主要的分析及处理有:
● 分析特征无明显异常值及缺失的情况,无需处理;
● 已有mean/standard error等衍生特征,无需特征衍生;
● 结合相关性等指标做特征选择(过滤法);
● 对特征进行标准化以加速模型学习过程;
# 筛选相关性>0.99的特征清单列表及标签
drop_feas = ['label','worst_radius','mean_radius']
# 选择标签y及特征x
y = df.label
x = df.drop(drop_feas,axis=1) # 删除相关性强特征及标签列
# holdout验证法: 按3:7划分测试集 训练集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 特征z-score 标准化
sc = StandardScaler()
x_train = sc.fit_transform(x_train) # 注:训练集测试集要分别标准化,以免测试集信息泄露到模型训练
x_test = sc.transform(x_test)
模型训练:使用keras搭建逻辑回归模型,训练模型,观察模型训练集及验证集的loss损失
_dim = x_train.shape[1] # 输入模型的特征数
# LR逻辑回归模型
model = Sequential()
model.add(Dense(1, input_dim=_dim, activation='sigmoid',bias_initializer='uniform')) # 添加网络层,激活函数sigmoid
model.summary()
plot_model(model,show_shapes=True)
model.compile(optimizer='adam', loss='binary_crossentropy') #模型编译:选择交叉熵损失函数及adam梯度下降法优化算法
model.fit(x, y, validation_split=0.3, epochs=200) # 模型迭代训练: validation_split比例0.3, 迭代epochs200次
# 模型训练集及验证集的损失
plt.figure()
plt.plot(model.history.history['loss'],'b',label='Training loss')
plt.plot(model.history.history['val_loss'],'r',label='Validation val_loss')
plt.title('Traing and Validation loss')
plt.legend()
以测试集F1-score等指标的表现,评估模型的泛化能力。最终测试集的f1-score有88%,有较好的模型表现。
def model_metrics(model, x, y):
"""
评估指标
"""
yhat = model.predict(x).round() # 模型预测yhat,预测阈值按默认0.5划分
result = {
'f1_score': f1_score(y, yhat),
'precision':precision_score(y, yhat),
'recall':recall_score(y, yhat)
}
return result
# 模型评估结果
print("TRAIN")
print(model_metrics(model, x_train, y_train))
print("TEST")
print(model_metrics(model, x_test, y_test))
神经网络(深度学习)学习到的是什么?一个含糊的回答是,学习到的是数据的本质规律。但具体这本质规律究竟是什么呢?要回答这个问题,我们可以从神经网络的原理开始了解。
神经网络学习就是一种特征的表示学习,把原始数据通过一些简单非线性的转换成为更高层次的、更加抽象的特征表达。深度网络层功能类似于“生成特征”,而宽度层类似于“记忆特征”,增加网络深度可以获得更抽象、高层次的特征,增加网络宽度可以交互出更丰富的特征。通过足够多的转换组合的特征,非常复杂的函数也可以被模型学习好。
可见神经网络学习的核心是,学习合适权重参数以对数据进行非线性转换,以提取关键特征或者决策。即模型参数控制着特征加工方法及决策。 了解了神经网络的原理,我们可以结合项目示例,看下具体的学习的权重参数,以及如何参与抽象特征生成与决策。
我们先从简单的模型入手,分析其学习的内容。像线性回归、逻辑回归可以视为单层的神经网络,它们都是广义的线性模型,可以学习输入特征到目标值的线性映射规律。
如下代码示例,以线性回归模型学习波士顿各城镇特征与房价的关系,并作出房价预测。数据是波士顿房价数据集,它是统计20世纪70年代中期波士顿郊区房价情况,有当时城镇的犯罪率、房产税等共计13个指标以及对应的房价中位数。
import pandas as pd
import numpy as np
from keras.datasets import boston_housing #导入波士顿房价数据集
(train_x, train_y), (test_x, test_y) = boston_housing.load_data()
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
from sklearn.metrics import mean_squared_error
np.random.seed(0) # 随机种子
random.set_seed(0)
# 单层线性层的网络结构(也就是线性回归):无隐藏层,由于是数值回归预测,输出层没有用激活函数;
model = Sequential()
model.add(Dense(1,use_bias=False))
model.compile(optimizer='adam', loss='mse') # 回归预测损失mse
model.fit(train_x, train_y, epochs=1000,verbose=False) # 训练模型
model.summary()
pred_y = model.predict(test_x)[:,0]
print("正确标签:",test_y)
print("模型预测:",pred_y )
print("实际与预测值的差异:",mean_squared_error(test_y,pred_y ))
通过线性回归模型学习训练集,输出测试集预测结果如下:
分析预测的效果,用上面数值体现不太直观,如下画出实际值与预测值的曲线,可见,整体模型预测值与实际值的差异还是比较小的(模型拟合较好)。
#绘图表示
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置图形大小
plt.figure(figsize=(8, 4), dpi=80)
plt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')
plt.plot(range(len(pred_y)), pred_y, ls='-',lw=2,c='b',label='预测值')
# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') #设置x轴的标签文本
plt.ylabel('房价') #设置y轴的标签文本
# 展示
plt.show()
回到正题,我们的单层神经网络模型(线性回归),在数据(波士顿房价)、优化目标(最小化预测误差mse)、优化算法(梯度下降)的共同配合下,从数据中学到了什么呢?
我们可以很简单地用决策函数的数学式来概括我们学习到的线性回归模型,预测y=w1x1 + w2x2 + wn*xn。通过提取当前线性回归模型最终学习到的参数:
将参数与对应输入特征组合一下,我们忙前忙后训练模型学到内容也就是——权重参数,它可以对输入特征进行加权求和输出预测值决策。如下我们可以看出预测的房价和犯罪率、弱势群体比例等因素是负相关的:
**预测值 = [-0.09546997]*CRIM|住房所在城镇的人均犯罪率+[0.09558205]*ZN|住房用地超过 25000 平方尺的比例+[-0.01804003]*INDUS|住房所在城镇非零售商用土地的比例+[3.8479505]*CHAS|有关查理斯河的虚拟变量(如果住房位于河边则为1,否则为0 )+[1.0180658]*NOX|一氧化氮浓度+[2.8623202]*RM|每处住房的平均房间数+[0.05667834]*AGE|建于 1940 年之前的业主自住房比例+[-0.47793597]*DIS|住房距离波士顿五大中心区域的加权距离+[0.20240606]*RAD|距离住房最近的公路入口编号+[-0.01002822]*TAX 每 10000 美元的全额财产税金额+[0.23102441]*PTRATIO|住房所在城镇的师生比例+[0.0190283]B|1000(Bk|0.63)^2,其中 Bk 指代城镇中黑人的比例+[-0.66846687]LSTAT|弱势群体人口所占比例
小结:单层神经网络学习到各输入特征所合适的权重值,根据权重值对输入特征进行加权求和,输出求和结果作为预测值(注:逻辑回归会在求和的结果再做sigmoid非线性转为预测概率)。
深度神经网络(深度学习)与单层神经网络的结构差异在于,引入了层数>=1的非线性隐藏层。从学习的角度上看,模型很像是boosting集成学习方法——以上一层的神经网络的学习结果,输出到下一层。而这种学习方法,就可以学习到非线性转换组合的复杂特征,达到更好的拟合效果。
对于学习到的内容,他不仅仅是利用权重值控制输出决策结果--f(WX),还有比较复杂多层次的特征交互, 这也意味着深度学习不能那么直观数学形式做表示--它是一个复杂的复合函数f(f..f(WX))。
如下以2层的神经网络为例,继续波士顿房价的预测:
注:本可视化工具来源于https://netron.app/
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
from sklearn.metrics import mean_squared_error
np.random.seed(0) # 随机种子
random.set_seed(0)
# 网络结构:输入层的特征维数为13,1层relu隐藏层,线性的输出层;
model = Sequential()
model.add(Dense(10, input_dim=13, activation='relu',use_bias=False)) # 隐藏层
model.add(Dense(1,use_bias=False))
model.compile(optimizer='adam', loss='mse') # 回归预测损失mse
model.fit(train_x, train_y, epochs=1000,verbose=False) # 训练模型
model.summary()
pred_y = model.predict(test_x)[:,0]
print("正确标签:",test_y)
print("模型预测:",pred_y )
print("实际与预测值的差异:",mean_squared_error(test_y,pred_y ))
可见,其模型的参数--190远多于单层线性网络--13;学习的损失函数--27.4小于单层线性网络模型--31.9,有着更高的复杂度和更好的学习效果。
#绘图表示
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置图形大小
plt.figure(figsize=(8, 4), dpi=80)
plt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')
plt.plot(range(len(pred_y)), pred_y, ls='-',lw=2,c='b',label='预测值')
# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') #设置x轴的标签文本
plt.ylabel('房价') #设置y轴的标签文本
# 展示
plt.show()
回到分析深度神经网络学习的内容,这里我们输入一条样本,看看每一层神经网络的输出。
from numpy import exp
x0=train_x[0]
print("1、输入第一条样本x0:\n", x0)
# 权重参数可以控制数据的特征表达再输出到下一层
w0= model.layers[0].get_weights()[0]
print("2、第一层网络的权重参数w0:\n", w0)
a0 = np.maximum(0,np.dot(w0.T, x0))
# a0可以视为第一层网络层交互出的新特征,但其特征含义是比较模糊的
print("3、经过第一层神经网络relu(w0*x0)后输出:\n",a0)
w1=model.layers[1].get_weights()[0]
print("4、第二层网络的权重参数w1:\n", w1)
# 预测结果为w1与ao加权求和
a1 = np.dot(w1.T,a0)
print("5、经过第二层神经网络w1*ao后输出预测值:%s,实际标签值为%s"%(a1[0],train_y[0]))
从深度神经网络的示例可以看出,神经网络学习的内容一样是权重参数。由于非线性隐藏层的作用下,深度神经网络可以通过权重参数对数据非线性转换,交互出复杂的、高层次的特征,并利用这些特征输出决策,最终取得较好的学习效果。但是,正也因为隐藏层交互组合特征过程的复杂性,学习的权重参数在业务含义上如何决策,并不好直观解释。
对于深度神经网络的解释,常常说深度学习模型是“黑盒”,学习内容很难表示成易于解释含义的形式。在此,一方面可以借助shap等解释性的工具加于说明。另一方面,还有像深度学习处理图像识别任务,就是个天然直观地展现深度学习的过程。如下展示输入车子通过层层提取的高层次、抽象的特征,图像识别的过程。
注:图像识别可视化工具来源于https://poloclub.github.io/cnn-explainer/
在神经网络学习提取层次化特征以识别图像的过程:
这和人类学习(图像识别)的过程是类似的——从具体到抽象,简单概括出物体的本质特征。就像我们看到一辆很酷的小车,
然后凭记忆将它画出来,很可能没法画出很多细节,只有抽象出来的关键特征表现,类似这样:
我们的大脑学习输入的视觉图像的抽象特征,而不相关忽略的视觉细节,提高效率的同时,学习的内容也有很强的泛化性,我们只要识别一辆车的样子,就也会辨别出不同样式的车。这也是深度神经网络学习更高层次、抽象的特征的过程。
本文首发公众号”算法进阶“,阅读原文即访问文章相关代码
前阶段时间梳理了机器学习开发实战的系列文章:
1、Python机器学习入门指南(全)
2、Python数据分析指南(全)
3、一文归纳Ai数据增强之法
4、一文归纳Python特征生成方法(全)
5、Python特征选择(全)
6、一文归纳Ai调参炼丹之法
现阶段写作计划会对各类机器学习算法做一系列的原理概述及实践,主要包括无监督聚类、异常检测、半监督算法、强化学习、集成学习等。
机器学习按照数据的标签情况可以细分为:监督学习,无监督学习,半监督学习以及强化学习。
监督学习是利用数据特征及其标签 D ={(x1,y1),…,(xl,yl)}学习输入到输出的映射f:X→Y的方法。
无监督学习是仅利用无类标签的样本数据特征 D={x1,…,xn}学习其对应的簇标签、特征表示等方法。
强化学习从某种程度可以看作是有延迟标签信息的监督学习。
半监督学习是介于传统监督学习和无监督学习之间,其**是在标记样本数量较少的情况下,通过在模型训练中直接引入无标记样本,以充分捕捉数据整体潜在分布,以改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题。
半监督学习的有效性通常基于如下假设:
1)平滑假设:稠密数据区域的两个距离很近的样例的类标签相似。
2)聚类假设:当两个样例位于同一聚类簇时,很大的概率下有相同的类标签。
3)流形假设:高维数据嵌入到低维流形中,当两个样例位于低维流形中的一个小局部邻域内时,具有相似的类标签。
当模型假设不正确时,无标签的样本可能无法有效地提供增益信息,反而会恶化学习性能。
##2.1 按理论差异划分
按照统计学习理论差异,半监督学习可以分为:(纯)归纳半监督学习和直推学习。
直推学习只处理样本空间内给定的训练数据,利用训练数据中有类标签的样本和无类标签的样例进行训练,仅预测训练数据中无类标签的样例的类标签,典型如标签传播算法(LPA)。
归纳半监督学习处理整个样本空间中所有给定和未知的样例,不仅预测训练数据中无类标签的样例的类标签,更主要的是预测未知的测试样例的类标签,典型如半监督SVM。
##2.2 按学习场景划分
从不同的学习场景看,半监督学习可分为四类:半监督分类(Semi-supervised classification)、半监督回归(Semi-supervised regression)、半监督聚类(Semi-supervised clustering)及半监督降维(Semi-supervised dimensionality reduction)。
半监督分类
半监督分类算法的**是通过大量的未标记样本帮助学习一个好的分类系统,代表算法可以划分为四类,包括生成式方法、判别式方法、半监督图算法和基于差异的半监督方法(此外还可扩展出半监督深度学习方法,限于篇幅本文没有展开)。
结合现实情况多数为半监督分类场景,下节会针对半监督分类算法原理及实战进行展开。
半监督聚类
半监督聚类算法的**是如何利用先验信息以更好地指导未标记样本的划分过程。现有的算法多数是在传统聚类算法基础上引入监督信息发展而来,基于不同的聚类算法可以将其扩展成不同的半监督聚类算法。
半监督回归
半监督回归算法的**是通过引入大量的未标记样本改进监督学习方法的性能,训练得到性能更优的回归器。现有的方法可以归纳为基于协同训练(差异)的半监督回归和基于流形的半监督回归两类。
半监督降维
半监督降维算法的**在大量的无类标签的样例中引入少量的有类标签的样本,利用监督信息找到高维数据的低维结构表示,同时保持数据的内在固有信息。而利用的监督信息既可以是样例的类标签,也可以是成对约束信息,还可以是其他形式的监督信息。主要的半监督降维方法有基于类标签的方法、基于成对约束等方法。
基于差异的半监督学习起源于协同训练算法,其**是利用多个拟合良好的学习器之间的差异性提高泛化能力。假设每个样本可以从不同的角度(view)训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。
判别式方法利用最大间隔算法同时训练有类标签的样本和无类标签的样例学习决策边界,使其通过低密度数据区域,并且使学习得到的分类超平面到最近的样例的距离间隔最大。常见的如直推式支持向量机(TSVM)及最近邻(KNN)等。
TSVM采用局部搜索的策略来进行迭代求解,即首先使用有标记样本集训练出一个初始SVM,接着使用该学习器对未标记样本进行打标,这样所有样本都有了标记,并基于这些有标记的样本重新训练SVM,之后再寻找易出错样本不断调整。
import random
import numpy as np
import sklearn.svm as svm
from sklearn.datasets import make_classification
class TSVM(object):
'''
半监督TSVM
'''
def __init__(self, kernel='linear'):
self.Cl, self.Cu = 1.5, 0.001
self.kernel = kernel
self.clf = svm.SVC(C=1.5, kernel=self.kernel)
def train(self, X1, Y1, X2):
N = len(X1) + len(X2)
# 样本权值初始化
sample_weight = np.ones(N)
sample_weight[len(X1):] = self.Cu
# 用已标注部分训练出一个初始SVM
self.clf.fit(X1, Y1)
# 对未标记样本进行标记
Y2 = self.clf.predict(X2)
Y2 = Y2.reshape(-1,1)
X = np.vstack([X1, X2])
Y = np.vstack([Y1, Y2])
# 未标记样本的序号
Y2_id = np.arange(len(X2))
while self.Cu < self.Cl:
# 重新训练SVM, 之后再寻找易出错样本不断调整
self.clf.fit(X, Y, sample_weight=sample_weight)
while True:
Y2_decision = self.clf.decision_function(X2) # 参数实例到决策超平面的距离
Y2 = Y2.reshape(-1)
epsilon = 1 - Y2 * Y2_decision
negative_max_id = Y2_id[epsilon==min(epsilon)]
# print(epsilon[negative_max_id][0])
if epsilon[negative_max_id][0] > 0:
# 寻找很可能错误的未标记样本,改变它的标记成其他标记
pool = list(set(np.unique(Y1))-set(Y2[negative_max_id]))
Y2[negative_max_id] = random.choice(pool)
Y2 = Y2.reshape(-1, 1)
Y = np.vstack([Y1, Y2])
self.clf.fit(X, Y, sample_weight=sample_weight)
else:
break
self.Cu = min(2*self.Cu, self.Cl)
sample_weight[len(X1):] = self.Cu
def score(self, X, Y):
return self.clf.score(X, Y)
def predict(self, X):
return self.clf.predict(X)
if __name__ == '__main__':
features, labels = make_classification(n_samples=200, n_features=3,
n_redundant=1, n_repeated=0,
n_informative=2, n_clusters_per_class=2)
n_given = 70
# 取前n_given个数字作为标注集
X1 = np.copy(features)[:n_given]
X2 = np.copy(features)[n_given:]
Y1 = np.array(np.copy(labels)[:n_given]).reshape(-1,1)
Y2_labeled = np.array(np.copy(labels)[n_given:]).reshape(-1,1)
model = TSVM()
model.train(X1, Y1, X2)
accuracy = model.score(X2, Y2_labeled)
print(accuracy)生成式的模型有高斯模型、贝叶斯网络、朴素贝叶斯、隐马尔可夫模型等,方法关键在于对来自各个种类的样本分布进行假设以及对所假设模型的参数估计。首先通过假设已知样本数据的密度函数 p(x|yi)的形式,比如多项式、高斯分布等。接着可采用迭代算法(如 EM 算法)计算 p(x|yi)的参数,然后根据贝叶斯全概率公式对全部未标签样本数据进行分类。
生成式方法可以直接关注半监督学习和决策中的条件概率问题,避免对边缘概率或联合概率的建模以及求解,然而该方法对一些假设条件比较苛刻,一旦假设的 p(x|yi)与样本数据的实际分布情况差距比较大,其分类效果往往不佳。
##3.4 基于图半监督学习方法
基于图的方法的实质是标签传播,基于流形假设根据样例之间的几何结构构造边(边的权值可以用样本间的相近程度),用图的结点表示样例,利用图上的邻接关系将类标签从有类标签的样本向无类标签的样例传播。基于图的方法通常图计算复杂度较高,且对异常图结构缺乏鲁棒性,主要方法有最小分割方法、标签传播算法(LPA)和流形方法 (manifold method)等。
标签传播算法(LPA)是基于图的半监督学习算法,基本思路是从已标记的节点标签信息来预测未标记的节点标签信息。
1、首先利用样本间的关系(可以是样本客观关系,或者利用相似度函数计算样本间的关系)建立完全图模型。
2、接着向图中加入已标记的标签信息,无标签节点是在用一个唯一的标签初始化。
3、该算法会重复地将一个节点的标签设置为该节点的相邻节点中出现频率最高(有权图需要考虑权重)的标签,重复迭代,直到标签不变算法收敛。
import random
import networkx as nx
import matplotlib.pyplot as plt
class LPA():
'''
标签传播算法:传播标签来划分社区
算法终止条件:迭代次数超过设定值
self.G:图
return: None
'''
def __init__(self, G, iters=10):
self.iters = iters
self.G = G
def train(self):
max_iter_num = 0 # 迭代次数
while max_iter_num < self.iters:
max_iter_num += 1
print('迭代次数',max_iter_num)
for node in self.G:
count = {} # 记录邻居节点及其标签
for nbr in self.G.neighbors(node): # node的邻居节点
label = self.G.node[nbr]['labels']
count[label] = count.setdefault(label,0) + 1
# 找到出现次数最多的标签
count_items = sorted(count.items(),key=lambda x:-x[-1])
best_labels = [k for k,v in count_items if v == count_items[0][1]]
# 当多个标签频次相同时随机选取一个标签
label = random.sample(best_labels,1)[0]
self.G.node[node]['labels'] = label # 更新标签
def draw_picture(self):
# 画图
node_color = [float(self.G.node[v]['labels']) for v in self.G]
pos = nx.spring_layout(self.G) # 节点的布局为spring型
plt.figure(figsize = (8,6)) # 图片大小
nx.draw_networkx(self.G,pos=pos,node_color=node_color)
plt.show()
if __name__ == "__main__":
G = nx.karate_club_graph() # 空手道
# 给节点添加标签
for node in G:
G.add_node(node, labels = node) # 用labels的状态
model = LPA(G)
# 原始节点标签
model.draw_picture()
model.train()
com = set([G.node[node]['labels'] for node in G])
print('社区数量',len(com))
# LPA节点标签
model.draw_picture()
文章首发于算法进阶,公众号阅读原文可访问GitHub源码
过拟合是指模型只过分地匹配特定训练数据集,以至于对训练集外数据无良好地拟合及预测。其本质原因是模型从训练数据中学习到了一些统计噪声,即这部分信息仅是局部数据的统计规律,该信息没有代表性,在训练集上虽然效果很好,但未知的数据集(测试集)并不适用。
通常由训练误差及测试误差(泛化误差)评估模型的学习程度及泛化能力。
欠拟合时训练误差和测试误差在均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,测试误差上升,这个时候就进入了过拟合区域。它们的误差情况差异如下表所示:
对于拟合效果除了通过训练、测试的误差估计其泛化误差及判断拟合程度之外,我们往往还希望了解它为什么具有这样的泛化性能。统计学常用“偏差-方差分解”(bias-variance decomposition)来分析模型的泛化性能:泛化误差为偏差+方差+噪声之和。
噪声(ε) 表达了在当前任务上任何学习算法所能达到的泛化误差的下界,即刻画了学习问题本身(客观存在)的难度。
偏差(Bias) 是指用所有可能的训练数据集训练出的所有模型的输出值与真实值之间的差异,刻画了模型的拟合能力。偏差较小即模型预测准确度越高,表示模型拟合程度越高。
方差(Variance) 是指不同的训练数据集训练出的模型对同预测样本输出值之间的差异,刻画了训练数据扰动所造成的影响。方差较大即模型预测值越不稳定,表示模型(过)拟合程度越高,受训练集扰动影响越大。
如下用靶心图形象表示不同方差及偏差下模型预测的差异:
偏差越小,模型预测值与目标值差异越小,预测值越准确;
方差越小,不同的训练数据集训练出的模型对同预测样本预测值差异越小,预测值越集中;
“偏差-方差分解” 说明,模型拟合过程的泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。
当模型欠拟合时:模型准确度不高(高偏差),受训练数据的扰动影响较小(低方差),其泛化误差大主要由高的偏差导致。
当模型过拟合时:模型准确度较高(低偏差),模型容易学习到训练数据扰动的噪音(高方差),其泛化误差大由高的方差导致。
实践中通常欠拟合不是问题,可以通过使用强特征及较复杂的模型提高学习的准确度。
而解决过拟合,即如何减少泛化误差,提高泛化能力,通常才是优化模型效果的重点。
上文说到学习统计噪声是过拟合的本质原因,而模型学习是以经验损失最小化,现实中学习的训练数据难免有统计噪音的。一个简单的思路,通过提高数据量数量或者质量解决统计噪音的影响:
通过足够的数据量就可以有效区分哪些信息是片面的,然而现实情况数据通常都很有限的。
通过提高数据的质量,可以结合先验知识加工特征以及对数据中噪声进行剔除(噪声如训练集有个“用户编号尾数是否为9”的特征下,偶然有正样本的占比很高的现象,而凭业务知识理解这个特征是没有意义的噪声,就可以考虑剔除)。但这样,一来过于依赖人工,人工智障?二来先验领域知识过多的引入,如果领域知识有误,不也是噪声。
当数据层面的优化有限,接下来登场主流的方法——正则化策略。
在以(可能)增加经验损失为代价,以降低泛化误差为目的,解决过拟合,提高模型泛化能力的方法,统称为正则化策略。
本节尝试以不一样的角度去理解正则化策略,欢迎留言交流。
正则化策略经常解读为对模型结构风险的惩罚,崇尚简单模型。并不尽然!如前文所讲学到统计噪声是过拟合的本质原因,所以模型复杂度容易引起过拟合(只是影响因素)。然而工程中,对于困难的任务需要足够复杂的模型,这种情况缩减模型复杂度不就和“减智商”一样?所以,通常足够复杂且有正则化的模型才是我们追求的。
机器学习是从训练集经验损失最小化为学习目标,而学习的训练集里面不可避免有统计噪声。除了提高数据质量和数量方法,我们不也可以在模型学习的过程中,给一些指导性的先验假设(即根据一些已知的知识对参数的分布进行一定的假设),帮助模型更好避开一些“噪声”的信息并关注到本质特征,更好地学习模型结构及参数。这些指导性的先验假设,也就是正则化策略,常见的正则化策略如下:
L2 参数正则化 (也称为岭回归、Tikhonov 正则) 通常被称为权重衰减 (weight decay),是通过向⽬标函数添加⼀个正则项 Ω(θ) ,使权重更加接近原点,模型更为简单。从贝叶斯角度,L2的约束项可以视为模型参数引入先验的高斯分布(参见Bob Carpenter的 Lazy Sparse Stochastic Gradient Descent for Regularized )
对带L2目标函数的模型参数更新权重,ϵ学习率:
从上式可以看出,加⼊权重衰减后会导致学习规则的修改,即在每步执⾏梯度更新前先收缩权重 (乘以 1 − ϵα ),有权重衰减的效果。
L1 正则化(Lasso回归)是通过向⽬标函数添加⼀个参数惩罚项 Ω(θ),为各个参数的绝对值之和。从贝叶斯角度,L1的约束项也可以视为模型参数引入拉普拉斯分布。
对带L1目标函数的模型参数更新权重(其中 sgn(x) 为符号函数,取参数的正负号):
可见,在-αsgn(w)项的作用下, w各元素每步更新后的权重向量都会平稳地向0靠拢,w的部分元素容易为0,造成稀疏性。
对比L1,L2两者,L2范式约束具有产生平滑解的效果,没有稀疏解的能力,即参数并不会出现很多零。假设我们的决策结果与两个特征有关,L2正则倾向于综合两者的影响(可以看作符合bagging的多释假设),给影响大的特征赋予高的权重;而L1正则倾向于选择影响较大的参数,而尽可能舍弃掉影响较小的那个( 可以看作符合了“奥卡姆剃刀定律--如无必要勿增实体”的假设)。在实际应用中 L2正则表现往往会优于 L1正则,但 L1正则会压缩模型,降低计算量。
在Keras中,可以使用regularizers模块来在某个层上应用L1及L2正则化,如下代码:
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l1_l2(l1=α1, l2=α2) # α为超参数惩罚系数
earlystop(早停法)可以限制模型最小化代价函数所需的训练迭代次数,如果迭代次数太少,算法容易欠拟合(方差较小,偏差较大),而迭代次数太多,算法容易过拟合(方差较大,偏差较小),早停法通过确定迭代次数解决这个问题。
earlystop可认为是将优化过程的参数空间限制在初始参数值 θ0 的小邻域内(Bishop 1995a 和Sjöberg and Ljung 1995 ),在这角度上相当于L2正则化的作用。
在Keras中,可以使用callbacks函数实现早期停止,如下代码:
from keras.callbacks import EarlyStopping
callback =EarlyStopping(monitor='loss', patience=3)
model = keras.models.Sequential([tf.keras.layers.Dense(10)])
model.compile(keras.optimizers.SGD(), loss='mse')
history = model.fit(np.arange(100).reshape(5, 20), np.zeros(5),
epochs=10, batch_size=1, callbacks=[callback],
verbose=0)
数据增强是提升算法性能、满足深度学习模型对大量数据的需求的重要工具。数据增强通过向训练数据添加转换或扰动来增加训练数据集。数据增强技术如水平或垂直翻转图像、裁剪、色彩变换、扩展和旋转(此外还有生成模型伪造的对抗样本),通常应用在视觉表象和图像分类中,通过数据增强有助于更准确的学习到输入数据所分布的流形(manifold)。
在keras中,你可以使用ImageDataGenerator来实现上述的图像变换数据增强,如下代码:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(horizontal_flip=True)
datagen.fit(train)
与清洗数据的噪音相反,引入噪声也可以明显增加神经网络模型的鲁棒性(很像是以毒攻毒)。对于某些模型而言,向输入添加方差极小的噪声等价于对权重施加范数惩罚 (Bishop, 1995a,b)。常用有三种方式:
在输入层引入噪声,可以视为是一种数据增强的方法。
在模型权重引入噪声
这项技术主要用于循环神经网络 (Jim et al., 1996; Graves, 2011)。向网络权重注入噪声,其代价函数等于无噪声注入的代价函数加上一个与噪声方差成正比的参数正则化项。
原实际标签y可能多少含有噪声,当 y 是错误的,直接使用0或1作为标签,对最大化 log p(y | x)效果变差。另外,使用softmax 函数和最大似然目标,可能永远无法真正输出预测值为 0 或 1,因此它会继续学习越来越大的权重,使预测更极端。使用标签平滑的优势是能防止模型追求具体概率又不妨碍正确分类。如标签平滑 (label smoothing) 基于 k 个输出的softmax 函数,把明确分类 0 和 1 替换成 ϵ /(k−1) 和 1 − ϵ,对模型进行正则化。
半监督学习**是在标记样本数量较少的情况下,通过在模型训练中直接引入无标记样本,以充分捕捉数据整体潜在分布,以改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题 。
依据“流形假设——观察到的数据实际上是由一个低维流形映射到高维空间上的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示”,无标签数据相当于提供了一种正则化(regularization),有助于更准确的学习到输入数据所分布的流形(manifold),而这个低维流形就是数据的本质表示。
多任务学习(Caruana, 1993) 是通过合并几个任务中的样例(可以视为对参数施加的软约束)来提高泛化的一种方法,其引入一个先验假设:这些不同的任务中,能解释数据变化的因子是跨任务共享的。常见有两种方式:基于参数的共享及基于正则化的共享。
额外的训练样本以同样的方式将模型的参数推向泛化更好的方向,当模型的一部分在任务之间共享时,模型的这一部分更多地被约束为良好的值(假设共享是合理的),往往能更好地泛化。
bagging是机器学习集成学习的一种。依据多释准则,结合了多个模型(符合经验观察的假设)的决策达到更好效果。具体如类似随机森林的思路,对原始的m个训练样本进行有放回随机采样,构建t组m个样本的数据集,然后分别用这t组数据集去训练t个的DNN,最后对t个DNN模型的输出用加权平均法或者投票法决定最终输出。
bagging 可以通过平滑效果降低了方差,并中和些噪声带来的误差,因此有更高的泛化能力。
Dropout是正则化技术简单有趣且有效的方法,在神经网络很常用。其方法是:在每个迭代过程中,以一定概率p随机选择输入层或者隐藏层的(通常隐藏层)某些节点,并且删除其前向和后向连接(让这些节点暂时失效)。权重的更新不再依赖于有“逻辑关系”的隐藏层的神经元的共同作用,一定程度上避免了一些特征只有在特定特征下才有效果的情况,迫使网络学习更加鲁棒(指系统的健壮性)的特征,达到减小过拟合的效果。这也可以近似为机器学习中的集成bagging方法,通过bagging多样的的网络结构模型,达到更好的泛化效果。
相似的还有Drop Connect ,它和 Dropout 相似的地方在于它涉及在模型结构中引入稀疏性,不同之处在于它引入的是权重的稀疏性而不是层的输出向量的稀疏性。
在Keras中,我们可以使用Dropout层实现dropout,代码如下:
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25)
])
文章首发公众号“算法进阶”,更多原创文章敬请关注
尽管神经网络在图像识别、自然语言等很多领域大放异彩,但回到表格数据的数据挖掘任务中,树模型才是低调王者,如论文《Tabular Data: Deep Learning is Not All You Need》提及的:
对于决策树等模型的使用,通常是要到scikit-learn、xgboost、lightgbm等机器学习库调用, 这和深度学习库是独立割裂的,不太方便树模型与神经网络的模型融合。
一个好消息是,Google 开源了 TensorFlow 决策森林(TF-DF),为基于树的模型和神经网络提供统一的接口,可以直接用TensorFlow调用树模型。决策森林(TF-DF)简单来说就是用TensorFlow封装了常用的随机森林(RF)、梯度提升(GBDT)等算法,其底层算法是基于C++的 Yggdrasil 决策森林 (YDF)实现的。
TF-DF安装很简单pip install -U tensorflow_decision_forests,有个遗憾是目前只支持Linux环境,如果本地用不了将代码复制到 Google Colab 试试~
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
tf.random.set_seed(123)
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score,roc_curve
dataset_cancer = datasets.load_breast_cancer() # 加载癌细胞数据集
#print(dataset_cancer['DESCR'])
df = pd.DataFrame(dataset_cancer.data, columns=dataset_cancer.feature_names)
df['label'] = dataset_cancer.target
print(df.shape)
df.head()
# holdout验证法: 按3:7划分测试集 训练集
x_train, x_test= train_test_split(df, test_size=0.3)
# EDA分析:数据统计指标
x_train.describe(include='all')


此外,还有带有正则化(dropout、earlystop)、损失函数(focal-loss)、效率方面(goss基于梯度采样)等优化方法:
构建模型、编译及训练,一步到位:
# 模型参数
model_tf = tfdf.keras.GradientBoostedTreesModel(loss="BINARY_FOCAL_LOSS")
# 模型训练
model_tf.compile()
model_tf.fit(x=train_ds,validation_freq=0.1)
## 模型评估
可以看到test的准确率已经都接近1,可以再那个困难的数据任务试试~
evaluation = model_tf.evaluate(test_ds,return_dict=True)
probs = model_tf.predict(test_ds)
fpr, tpr, _ = roc_curve(x_test.label, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
plt.show()
print(evaluation)
print(model_tf.summary())打印出来,
MEAN_MIN_DEPTH指标。 平均最小深度越小,较低的值意味着大量样本是基于此特征进行分类的,变量越重要。
NUM_NODES指标。它显示了给定特征被用作分割的次数,类似split。此外还有其他指标就不一一列举了。
我们还可以打印出模型的具体决策的树结构,通过运行tfdf.model_plotter.plot_model_in_colab(model_tf, tree_idx=0, max_depth=10),整个过程还是比较清晰的。
基于TensorFlow的TF-DF的树模型方法,我们可以方便训练树模型(特别对于熟练TensorFlow框架的同学),更进一步,也可以与TensorFlow的神经网络模型做效果对比、树模型与神经网络模型融合、利用异构模型先特征表示学习再输入模型(如GBDT+DNN、DNN embedding+GBDT),进一步了解可见如下参考文献。
参考文献:
https://www.tensorflow.org/decision_forests/
https://keras.io/examples/structured_data/classification_with_tfdf/
人工智能将和电力一样具有颠覆性 。 --吴恩达
如同蒸汽时代的蒸汽机、电气时代的发电机、信息时代的计算机和互联网,人工智能(AI)正赋能各个产业,推动着人类进入智能时代。
本文从介绍人工智能及主要的**派系,进一步系统地梳理了其发展历程、标志性成果并侧重其算法**介绍,将这段 60余年几经沉浮的历史,以一个清晰的脉络呈现出来,以此展望人工智能(AI)未来的趋势。
人工智能(Artificial Intelligence,AI)研究目的是通过探索智慧的实质,扩展人类智能——促使智能主体会听(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说(语音合成、人机对话等)、会思考(人机对弈、专家系统等)、会学习(知识表示,机器学习等)、会行动(机器人、自动驾驶汽车等)。一个经典的AI定义是:“ 智能主体可以理解数据及从中学习,并利用知识实现特定目标和任务的能力。(A system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation)”
在人工智能的发展过程中,不同时代、学科背景的人对于智慧的理解及其实现方法有着不同的**主张,并由此衍生了不同的学派,影响较大的学派及其代表方法如下:
其中,符号主义及联结主义为主要的两大派系:
“符号主义”(Symbolicism),又称逻辑主义、计算机学派,认为认知就是通过对有意义的表示符号进行推导计算,并将学习视为逆向演绎,主张用显式的公理和逻辑体系搭建人工智能系统。如用决策树模型输入业务特征预测天气:
“连接主义”(Connectionism),又叫仿生学派,笃信大脑的逆向工程,主张是利用数学模型来研究人类认知的方法,用神经元的连接机制实现人工智能。如用神经网络模型输入雷达图像数据预测天气:
从始至此,人工智能(AI)便在充满未知的道路探索,曲折起伏,我们可将这段发展历程大致划分为5个阶段期:
人工智能概念的提出后,发展出了符号主义、联结主义(神经网络),相继取得了一批令人瞩目的研究成果,如机器定理证明、跳棋程序、人机对话等,掀起人工智能发展的第一个高潮。
1943年,美国神经科学家麦卡洛克(Warren McCulloch)和逻辑学家皮茨(Water Pitts)提出神经元的数学模型,这是现代人工智能学科的奠基石之一。
1950年,艾伦·麦席森·图灵(Alan Mathison Turing)提出“图灵测试”(测试机器是否能表现出与人无法区分的智能),让机器产生智能这一想法开始进入人们的视野。
1950年,克劳德·香农(Claude Shannon)提出计算机博弈。
1956年,达特茅斯学院人工智能夏季研讨会上正式使用了人工智能(artificial intelligence,AI)这一术语。这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生。
1957年,弗兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704计算机上模拟实现了一种他发明的叫做“感知机”(Perceptron)的神经网络模型。
感知机可以被视为一种最简单形式的前馈式人工神经网络,是一种二分类的线性分类判别模型,其输入为实例的特征向量想(x1,x2...),神经元的激活函数f为sign,输出为实例的类别(+1或者-1),模型的目标是要将输入实例通过超平面将正负二类分离。
LR是类似于感知机结构的线性分类判别模型,主要不同在于神经元的激活函数f为sigmoid,模型的目标为(最大似然)极大化正确分类概率。
1959年,Arthur Samuel给机器学习了一个明确概念:Field of study that gives computers the ability to learn without being explicitly programmed.(机器学习是研究如何让计算机不需要显式的程序也可以具备学习的能力)。
1961年,Leonard Merrick Uhr 和 Charles M Vossler发表了题目为A Pattern Recognition Program That Generates, Evaluates and Adjusts its Own Operators 的模式识别论文,该文章描述了一种利用机器学习或自组织过程设计的模式识别程序的尝试。
1965年,古德(I. J. Good)发表了一篇对人工智能未来可能对人类构成威胁的文章,可以算“AI威胁论”的先驱。他认为机器的超级智能和无法避免的智能爆炸最终将超出人类可控范畴。后来著名科学家霍金、发明家马斯克等人对人工智能的恐怖预言跟古德半个世界前的警告遥相呼应。
1966 年,麻省理工学院科学家Joseph Weizenbaum 在 ACM 上发表了题为《ELIZA-a computer program for the study of natural language communication between man and machine》文章描述了ELIZA 的程序如何使人与计算机在一定程度上进行自然语言对话成为可能,ELIZA 的实现技术是通过关键词匹配规则对输入进行分解,而后根据分解规则所对应的重组规则来生成回复。
1967年,Thomas等人提出K最近邻算法(The nearest neighbor algorithm)。
KNN的核心**,即给定一个训练数据集,对新的输入实例Xu,在训练数据集中找到与该实例最邻近的K个实例,以这K个实例的最多数所属类别作为新实例Xu的类别。
专家系统(Expert Systems)是AI的一个重要分支,同自然语言理解,机器人学并列为AI的三大研究方向。它的定义是使用人类专家推理的计算机模型来处理现实世界中需要专家作出解释的复杂问题,并得出与专家相同的结论,可视作“知识库(knowledge base)”和“推理机(inference machine)” 的结合。
人工智能发展初期的突破性进展大大提升了人们对人工智能的期望,人们开始尝试更具挑战性的任务,然而计算力及理论等的匮乏使得不切实际目标的落空,人工智能的发展走入低谷。
BP算法的基本**不是(如感知器那样)用误差本身去调整权重,而是用误差的导数(梯度)调整。通过误差的梯度做反向传播,更新模型权重, 以下降学习的误差,拟合学习目标,实现'网络的万能近似功能'的过程。
1975年,马文·明斯基(Marvin Minsky)在论文《知识表示的框架》(A Framework for Representing Knowledge)中提出用于人工智能中的知识表示学习框架理论。
1976年,兰德尔·戴维斯(Randall Davis)构建和维护的大规模的知识库,提出使用集成的面向对象模型可以提高知识库(KB)开发、维护和使用的完整性。
1976年,斯坦福大学的肖特利夫(Edward H. Shortliffe)等人完成了第一个用于血液感染病的诊断、治疗和咨询服务的医疗专家系统MYCIN。
1976年,斯坦福大学的博士勒纳特发表论文《数学中发现的人工智能方法——启发式搜索》,描述了一个名为“AM”的程序,在大量启发式规则的指导下开发新概念数学,最终重新发现了数百个常见的概念和定理。
1977年,海斯·罗思(Hayes. Roth)等人的基于逻辑的机器学习系统取得较大的进展,但只能学习单一概念,也未能投入实际应用。
1979年,汉斯·贝利纳(Hans Berliner)打造的计算机程序战胜双陆棋世界冠军成为标志性事件。(随后,基于行为的机器人学在罗德尼·布鲁克斯和萨顿等人的推动下快速发展,成为人工智能一个重要的发展分支。格瑞·特索罗等人打造的自我学习双陆棋程序又为后来的强化学习的发展奠定了基础。)
人工智能走入应用发展的新高潮。专家系统模拟人类专家的知识和经验解决特定领域的问题,实现了人工智能从理论研究走向实际应用、从一般推理策略探讨转向运用专门知识的重大突破。而机器学习(特别是神经网络)探索不同的学习策略和各种学习方法,在大量的实际应用中也开始慢慢复苏。
1980年,在美国的卡内基梅隆大学(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。
1980年,德鲁·麦狄蒙(Drew McDermott)和乔恩·多伊尔(Jon Doyle)提出非单调逻辑,以及后期的机器人系统。
1980年,卡耐基梅隆大学为DEC公司开发了一个名为XCON的专家系统,每年为公司节省四千万美元,取得巨大成功。
1981年,保罗(R.P.Paul)出版第一本机器人学课本,“Robot Manipulator:Mathematics,Programmings and Control”,标志着机器人学科走向成熟。
1982年,马尔(David Marr)发表代表作《视觉计算理论》提出计算机视觉(Computer Vision)的概念,并构建系统的视觉理论,对认知科学(CognitiveScience)也产生了很深远的影响。
1982年,约翰·霍普菲尔德(John Hopfield) 发明了霍普菲尔德网络,这是最早的RNN的雏形。霍普菲尔德神经网络模型是一种单层反馈神经网络(神经网络结构主要可分为前馈神经网络、反馈神经网络及图网络),从输出到输入有反馈连接。它的出现振奋了神经网络领域,在人工智能之机器学习、联想记忆、模式识别、优化计算、VLSI和光学设备的并行实现等方面有着广泛应用。
1983年,Terrence Sejnowski, Hinton等人发明了玻尔兹曼机(Boltzmann Machines),也称为随机霍普菲尔德网络,它本质是一种无监督模型,用于对输入数据进行重构以提取数据特征做预测分析。
1985年,朱迪亚·珀尔提出贝叶斯网络(Bayesian network),他以倡导人工智能的概率方法和发展贝叶斯网络而闻名,还因发展了一种基于结构模型的因果和反事实推理理论而受到赞誉。
贝叶斯网络是一种模拟人类推理过程中因果关系的不确定性处理模型,如常见的朴素贝叶斯分类算法就是贝叶斯网络最基本的应用。
贝叶斯网络拓朴结构是一个有向无环图(DAG),通过把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,以描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)就形成了贝叶斯网络。
对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出。如图中b依赖于a(即:a->b),c依赖于a和b,a独立无依赖,根据贝叶斯定理有 P(a,b,c) = P(a)*P(b|a)*P(c|a,b)
1986年,罗德尼·布鲁克斯(Brooks)发表论文《移动机器人鲁棒分层控制系统》,标志着基于行为的机器人学科的创立,机器人学界开始把注意力投向实际工程主题。
1986年,辛顿(Geoffrey Hinton)等人先后提出了多层感知器(MLP)与反向传播(BP)训练相结合的理念(该方法在当时计算力上还是有很多挑战,基本上都是和链式求导的梯度算法相关的),这也解决了单层感知器不能做非线性分类的问题,开启了神经网络新一轮的高潮。
1986年,昆兰(Ross Quinlan)提出ID3决策树算法。
决策树模型可视为多个规则(if, then)的组合,与神经网络黑盒模型截然不同是,它拥有良好的模型解释性。
ID3算法核心的**是通过自顶向下的贪心策略构建决策树:根据信息增益来选择特征进行划分(信息增益的含义是 引入属性A的信息后,数据D的不确定性减少程度。也就是信息增益越大,区分D的能力就越强),依次递归地构建决策树。
“万能近似定理”可视为神经网络的基本理论:⼀个前馈神经⽹络如果具有线性层和⾄少⼀层具有 “挤压” 性质的激活函数(如 sigmoid 等),给定⽹络⾜够数量的隐藏单元,它可以以任意精度来近似任何从⼀个有限维空间到另⼀个有限维空间的 borel 可测函数。
卷积神经网络通常由输入层、卷积层、池化(Pooling)层和全连接层组成。卷积层负责提取图像中的局部特征,池化层用来大幅降低参数量级(降维),全连接层类似传统神经网络的部分,用来输出想要的结果。
由于互联网技术的迅速发展,加速了人工智能的创新研究,促使人工智能技术进一步走向实用化,人工智能相关的各个领域都取得长足进步。在2000年代初,由于专家系统的项目都需要编码太多的显式规则,这降低了效率并增加了成本,人工智能研究的重心从基于知识系统转向了机器学习方向。
支持向量机(Support Vector Machine, SVM)可以视为在感知机基础上的改进,是建立在统计学习理论的VC维理论和结构风险最小原理基础上的广义线性分类器。与感知机主要差异在于:1、感知机目标是找到一个超平面将各样本尽可能分离正确(有无数个),SVM目标是找到一个超平面不仅将各样本尽可能分离正确,还要使各样本离超平面距离最远(只有一个最大边距超平面),SVM的泛化能力更强。2、对于线性不可分的问题,不同于感知机的增加非线性隐藏层,SVM利用核函数,本质上都是实现特征空间非线性变换,使可以被线性分类。
Adaboost迭代算法基本**主要是通过调节的每一轮各训练样本的权重(错误分类的样本权重更高),串行训练出不同分类器。最终以各分类器的准确率作为其组合的权重,一起加权组合成强分类器。
1997年国际商业机器公司(简称IBM)深蓝超级计算机战胜了国际象棋世界冠军卡斯帕罗夫。深蓝是基于暴力穷举实现国际象棋领域的智能,通过生成所有可能的走法,然后执行尽可能深的搜索,并不断对局面进行评估,尝试找出最佳走法。
1997年,Sepp Hochreiter 和 Jürgen Schmidhuber提出了长短期记忆神经网络(LSTM)。
LSTM是一种复杂结构的循环神经网络(RNN),结构上引入了遗忘门、输入门及输出门:输入门决定当前时刻网络的输入数据有多少需要保存到单元状态,遗忘门决定上一时刻的单元状态有多少需要保留到当前时刻,输出门控制当前单元状态有多少需要输出到当前的输出值。这样的结构设计可以解决长序列训练过程中的梯度消失问题。
1998年,万维网联盟的蒂姆·伯纳斯·李(Tim Berners-Lee)提出语义网(Semantic Web)的概念。其核心**是:通过给万维网上的文档(如HTML)添加能够被计算机所理解的语义(Meta data),从而使整个互联网成为一个基于语义链接的通用信息交换媒介。换言之,就是构建一个能够实现人与电脑无障碍沟通的智能网络。
2001年,John Lafferty首次提出条件随机场模型(Conditional random field,CRF)。
CRF是基于贝叶斯理论框架的判别式概率图模型,在给定条件随机场P ( Y ∣ X ) 和输入序列x,求条件概率最大的输出序列y *。在许多自然语言处理任务中比如分词、命名实体识别等表现尤为出色。
2001年,布雷曼博士提出随机森林(Random Forest)。
随机森林是将多个有差异的弱学习器(决策树)Bagging并行组合,通过建立多个的拟合较好且有差异模型去组合决策,以优化泛化性能的一种集成学习方法。多样差异性可减少对某些特征噪声的依赖,降低方差(过拟合),组合决策可消除些学习器间的偏差。
随机森林算法的基本思路是对于每一弱学习器(决策树)有放回的抽样构造其训练集,并随机抽取其可用特征子集,即以训练样本及特征空间的多样性训练出N个不同的弱学习器,最终结合N个弱学习器的预测(类别或者回归预测数值),取最多数类别或平均值作为最终结果。
LDA是一种无监督方法,用来推测文档的主题分布,将文档集中每篇文档的主题以概率分布的形式给出,可以根据主题分布进行主题聚类或文本分类。
2003年,Google公布了3篇大数据奠基性论文,为大数据存储及分布式处理的核心问题提供了思路:非结构化文件分布式存储(GFS)、分布式计算(MapReduce)及结构化数据存储(BigTable),并奠定了现代大数据技术的理论基础。
2005 年,波士顿动力公司推出一款动力平衡四足机器狗,有较强的通用性,可适应较复杂的地形。
2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念(Deeping Learning),开启了深度学习在学术界和工业界的浪潮。2006年也被称为深度学习元年,杰弗里·辛顿也因此被称为深度学习之父。
深度学习的概念源于人工神经网络的研究,它的本质是使用多个隐藏层网络结构,通过大量的向量计算,学习数据内在信息的高阶表示。
迁移学习(transfer learning)通俗来讲,就是运用已有的知识(如训练好的网络权重)来学习新的知识以适应特定目标任务,核心是找到已有知识和新知识之间的相似性。
随着大数据、云计算、互联网、物联网等信息技术的发展,泛在感知数据和图形处理器等计算平台推动以深度神经网络为代表的人工智能技术飞速发展,大幅跨越了科学与应用之间的技术鸿沟,诸如图像分类、语音识别、知识问答、人机对弈、无人驾驶等人工智能技术实现了重大的技术突破,迎来爆发式增长的新高潮。
2011年,IBM Watson问答机器人参与Jeopardy回答测验比赛最终赢得了冠军。Waston是一个集自然语言处理、知识表示、自动推理及机器学习等技术实现的电脑问答(Q&A)系统。
2012年,Hinton和他的学生Alex Krizhevsky设计的AlexNet神经网络模型在ImageNet竞赛大获全胜,这是史上第一次有模型在 ImageNet 数据集表现如此出色,并引爆了神经网络的研究热情。
AlexNet是一个经典的CNN模型,在数据、算法及算力层面均有较大改进,创新地应用了Data Augmentation、ReLU、Dropout和LRN等方法,并使用GPU加速网络训练。

知识图谱是结构化的语义知识库,是符号主义**的代表方法,用于以符号形式描述物理世界中的概念及其相互关系。其通用的组成单位是RDF三元组(实体-关系-实体),实体间通过关系相互联结,构成网状的知识结构。
VAE基本思路是将真实样本通过编码器网络变换成一个理想的数据分布,然后把数据分布再传递给解码器网络,构造出生成样本,模型训练学习的过程是使生成样本与真实样本足够接近。

Word2Vec基本的**是学习每个单词与邻近词的关系,从而将单词表示成低维稠密向量。通过这样的分布式表示可以学习到单词的语义信息,直观来看,语义相似的单词的距离相近。
Word2Vec网络结构是一个浅层神经网络(输入层-线性全连接隐藏层->输出层),按训练学习方式可分为CBOW模型(以一个词语作为输入,来预测它的邻近词)或Skip-gram模型 (以一个词语的邻近词作为输入,来预测这个词语)。
2014年,聊天程序“尤金·古斯特曼”(Eugene Goostman)在英国皇家学会举行的“2014图灵测试”大会上,首次“通过”了图灵测试。
2014年,Goodfellow及Bengio等人提出生成对抗网络(Generative Adversarial Network,GAN),被誉为近年来最酷炫的神经网络。
GAN是基于强化学习(RL)思路设计的,由生成网络(Generator, G)和判别网络(Discriminator, D)两部分组成, 生成网络构成一个映射函数G: Z→X(输入噪声z, 输出生成的伪造数据x), 判别网络判别输入是来自真实数据还是生成网络生成的数据。在这样训练的博弈过程中,提高两个模型的生成能力和判别能力。
《Deep learning》文中指出深度学习就是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次及抽象的表达,能够强化输入数据的区分能力。通过足够多的转换的组合,非常复杂的函数也可以被学习。
残差网络的主要贡献是发现了网络不恒等变换导致的“退化现象(Degradation)”,并针对退化现象引入了 “快捷连接(Shortcut connection)”,缓解了在深度神经网络中增加深度带来的梯度消失问题。
2015年,谷歌开源TensorFlow框架。它是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
2015年,马斯克等人共同创建OpenAI。它是一个非营利的研究组织,使命是确保通用人工智能 (即一种高度自主且在大多数具有经济价值的工作上超越人类的系统)将为全人类带来福祉。其发布热门产品的如:OpenAI Gym,GPT等。
2016年,谷歌提出联邦学习方法,它在多个持有本地数据样本的分散式边缘设备或服务器上训练算法,而不交换其数据样本。
联邦学习保护隐私方面最重要的三大技术分别是: 差分隐私 ( Differential Privacy )、同态加密 ( Homomorphic Encryption )和 隐私保护集合交集 ( Private Set Intersection ),能够使多个参与者在不共享数据的情况下建立一个共同的、强大的机器学习模型,从而解决数据隐私、数据安全、数据访问权限和异构数据的访问等关键问题。
AlphaGo是一款围棋人工智能程序,其主要工作原理是“深度学习”,由以下四个主要部分组成:策略网络(Policy Network)给定当前局面,预测并采样下一步的走棋;快速走子(Fast rollout)目标和策略网络一样,但在适当牺牲走棋质量的条件下,速度要比策略网络快1000倍;价值网络(Value Network)估算当前局面的胜率;蒙特卡洛树搜索(Monte Carlo Tree Search)树搜索估算每一种走法的胜率。
在2017年更新的AlphaGo Zero,在此前的版本的基础上,结合了强化学习进行了自我训练。它在下棋和游戏前完全不知道游戏规则,完全是通过自己的试验和摸索,洞悉棋局和游戏的规则,形成自己的决策。随着自我博弈的增加,神经网络逐渐调整,提升下法胜率。更为厉害的是,随着训练的深入,AlphaGo Zero还独立发现了游戏规则,并走出了新策略,为围棋这项古老游戏带来了新的见解。
2017年,**香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人索菲亚,是历史上首个获得公民身份的一台机器人。索菲亚看起来就像人类女性,拥有橡胶皮肤,能够表现出超过62种自然的面部表情。其“大脑”中的算法能够理解语言、识别面部,并与人进行互动。
2018年,Google提出论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》并发布Bert(Bidirectional Encoder Representation from Transformers)模型,成功在 11 项 NLP 任务中取得 state of the art 的结果。
BERT是一个预训练的语言表征模型,可在海量的语料上用无监督学习方法学习单词的动态特征表示。它基于Transformer注意力机制的模型,对比RNN可以更加高效、能捕捉更长距离的依赖信息,且不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
2019年, IBM宣布推出Q System One,它是世界上第一个专为科学和商业用途设计的集成通用近似量子计算系统。
2019年,香港 Insilico Medicine 公司和多伦多大学的研究团队实现了重大实验突破,通过深度学习和生成模型相关的技术发现了几种候选药物,证明了 AI 发现分子策略的有效性,很大程度解决了传统新药开发在分子鉴定困难且耗时的问题。
2020年,Google与Facebook分别提出SimCLR与MoCo两个无监督学习算法,均能够在无标注数据上学习图像数据表征。两个算法背后的框架都是对比学习(contrastive learning),对比学习的核心训练信号是图片的“可区分性”。
2020年,OpenAI开发的文字生成 (text generation) 人工智能GPT-3,它具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍,该模型经过了将近0.5万亿个单词的预训练,可以在多个NLP任务(答题、翻译、写文章)基准上达到最先进的性能。
2020年,马斯克的脑机接口(brain–computer interface, BCI)公司Neuralink举行现场直播,展示了植入Neuralink设备的实验猪的脑部活动。
2020年,谷歌旗下DeepMind的AlphaFold2人工智能系统有力地解决了蛋白质结构预测的里程碑式问题。它在国际蛋白质结构预测竞赛(CASP)上击败了其余的参会选手,精确预测了蛋白质的三维结构,准确性可与冷冻电子显微镜(cryo-EM)、核磁共振或 X 射线晶体学等实验技术相媲美。
2020年,**科学技术大学潘建伟等人成功构建76个光子的量子计算原型机“九章”,求解数学算法“高斯玻色取样”只需200秒,而目前世界最快的超级计算机要用6亿年。
2021年,OpenAI提出两个连接文本与图像的神经网络:DALL·E 和 CLIP。DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。
2021年,德国Eleuther人工智能公司于今年3月下旬推出开源的文本AI模型GPT-Neo。对比GPT-3的差异在于它是开源免费的。
2021年,美国斯坦福大学的研究人员开发出一种用于打字的脑机接口(brain–computer interface, BCI),这套系统可以从运动皮层的神经活动中解码瘫痪患者想象中的手写动作,并利用递归神经网络(RNN)解码方法将这些手写动作实时转换为文本。相关研究结果发表在2021年5月13日的Nature期刊上,论文标题为“High-performance brain-to-text communication via handwriting”。
人工智能有三个要素:数据、算力及算法,数据即是知识原料,算力及算法提供“计算智能”以学习知识并实现特定目标。
人工智能60多年的技术发展,可以归根为算法、算力及数据层面的发展,那么在可以预见的未来,人工智能发展将会出现怎样的趋势呢?
数据是现实世界映射构建虚拟世界的基本要素,随着数据量以指数形式增长,开拓的虚拟世界的疆土也不断扩张。不同于AI算法开源,关键数据往往是不开放的,数据隐私化、私域化是一种趋势,数据之于AI应用,如同流量是互联网的护城河,有核心数据才有关键的AI能力。
推理就是计算(reason is nothing but reckoning) --托马斯.霍布斯
计算是AI的关键,自2010年代以来的深度学习浪潮,很大程度上归功于计算能力的进步。
在计算芯片按摩尔定律发展越发失效的今天,计算能力进步的放慢会限制未来的AI技,量子计算提供了一条新量级的增强计算能力的思路。随着量子计算机的量子比特数量以指数形式增长,而它的计算能力是量子比特数量的指数级,这个增长速度将远远大于数据量的增长,为数据爆发时代的人工智能带来了强大的硬件基础。
边缘计算作为云计算的一种补充和优化,一部分的人工智能正在加快速度从云端走向边缘,进入到越来越小的物联网设备中。而这些物联网设备往往体积很小,为此轻量机器学习(TinyML)受到青睐,以满足功耗、延时以及精度等问题。
以类脑计算芯片为核心的各种类脑计算系统,在处理某些智能问题以及低功耗智能计算方面正逐步展露出优势。类脑计算芯片设计将从现有处理器的设计方法论及其发展历史中汲取灵感,在计算完备性理论基础上结合应用需求实现完备的硬件功能。同时类脑计算基础软件将整合已有类脑计算编程语言与框架,实现类脑计算系统从“专用”向“通用”的逐步演进。
人工智能计算中心基于最新人工智能理论,采用领先的人工智能计算架构,是融合公共算力服务、数据开放共享、智能生态建设、产业创新聚集的“四位一体”综合平台,可提供算力、数据和算法等人工智能全栈能力,是人工智能快速发展和应用所依托的新型算力基础设施。未来,随着智能化社会的不断发展,人工智能计算中心将成为关键的信息基础设施,推动数字经济与传统产业深度融合,加速产业转型升级,促进经济高质量发展。
自动化机器学习(AutoML)解决的核心问题是:在给定数据集上使用哪种机器学习算法、是否以及如何预处理其特征以及如何设置所有超参数。随着机器学习在许多应用领域取得了长足的进步,这促成了对机器学习系统的不断增长的需求,并希望机器学习应用可以自动化构建并使用。借助AutoMl、MLOps技术,将大大减少机器学习人工训练及部署过程,技术人员可以专注于核心解决方案。
当前全球多个国家和地区已出台数据监管法规,如HIPAA(美国健康保险便利和责任法案)、GDPR(欧盟通用数据保护条例)等,通过严格的法规限制多机构间隐私数据的交互。分布式隐私保护机器学习(联邦学习)通过加密、分布式存储等方式保护机器学习模型训练的输入数据,是打破数据孤岛、完成多机构联合训练建模的可行方案。
AI模型的发展是符合简单而美的定律的。从数据出发的建模从数据中总结规律,追求在实践中的应用效果。从机理出发的建模以基本物理规律为出发点进行演绎,追求简洁与美的表达。
一个好的、主流的的模型,通常是高度总结了数据规律并切合机理的,是“优雅”的,因为它触及了问题的本质。就和科学理论一样,往往简洁的,没有太多补丁,而这同时解决了收敛速度问题和泛化问题。
神经网络的演进一直沿着模块化+层次化的方向,不断把多个承担相对简单任务的模块组合起来。
神经网络结构通过较低层级模块侦测基本的特征,并在较高层级侦测更高阶的特征,无论是多层前馈网络,还是卷积神经网络,都体现了这种模块性(近年Hinton提出的“胶囊”(capsule)网络就是进一步模块化发展)。因为我们处理的问题(图像、语音、文字)往往都有天然的模块性,学习网络的模块性若匹配了问题本身内在的模块性,就能取得较好的效果。
层次化并不仅仅是网络的拓扑叠加,更重要的是学习算法的升级,仅仅简单地加深层次可能会导致BP网络的梯度消失等问题。
通过多学派方法交融发展,得以互补算法之间的优势和弱点。如 1)贝叶斯派与神经网络融合,Neil Lawrence组的Deep Gaussian process, 用简单的概率分布替换神经网络层。2)符号主义、集成学习与神经网络的融合,周志华老师的深度随机森林。3) 符号主义与神经网络的融合:将知识库(KG)融入进神经网络,如GNN、知识图谱表示学习。4) 神经网络与强化学习的融合,如谷歌基于DNN+强化学习实现的Alpha Go 让AI的复杂任务表现逼近人类。
If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL) -- Yann Lecun
监督学习需要足够的带标签数据,然而人工标注大量数据既耗时又费力,在一些领域(如医学领域)上几乎不太可能获得足量的标注数据。通过大规模无(自)监督预训练方法利用现实中大量的无标签数据是一个研究的热点,如GPT-3的出现激发了对大规模自监督预训练方法继续开展探索和研究。未来,基于大规模图像、语音、视频等多模态数据的跨语言的自监督预训练模型将进一步发展,并不断提升模型的认知、推理能力。
当前人工智能模型大多关注于数据特征间相关性,而相关性与更为本源的因果关系并不等价,可能导致预测结果的偏差,对抗攻击的能力不佳,且模型往往缺乏可解释性。另外,模型需要独立同分布(i.i.d.)假设(现实很多情况,i.i.d.的假设是不成立的),若测试数据与训练数据来自不同的分布,统计学习模型往往效果不佳,而因果推断所研究的正是这样的情形:如何学习一个可以在不同分布下工作、蕴含因果机制的因果模型(Causal Model),并使用因果模型进行干预或反事实推断。
可解释的人工智能有可能成为未来机器学习的核心,随着模型变得越来越复杂,确定简单的、可解释的规则就会变得越来越困难。一个可以解释的AI(Explainable AI, 简称XAI)意味着AI运作的透明,便于人类对于对AI监督及接纳,以保证算法的公平性、安全性及隐私性。
随着数据,算力,算法取得不断的突破,人工智能可能进入一个永恒的春天。
本文主要从技术角度看待AI趋势是比较片面的,虽然技术是“高大上”的第一生产力,有着自身的发展规律,但不可忽视的是技术是为需求市场所服务的。技术结合稳定的市场需求,才是技术发展的实际导向。
文章首发于“算法进阶”,公众号阅读原文可访问Github博客
本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow(建议可以安装下anaconda包,自带有常用的python库)
机器学习的核心是通过模型从数据中学习并利用经验去决策。进一步的,机器学习一般可以概括为:从数据出发,选择某种模型,通过优化算法更新模型的参数值,使任务的指标表现变好(学习目标),最终学习到“好”的模型,并运用模型对数据做预测以完成任务。由此可见,机器学习方法有四个要素:数据、模型、学习目标、优化算法。具体可见系列文章:一篇白话机器学习概念
深度学习是机器学习的一个分支,它是使用多个隐藏层神经网络模型,通过大量的向量计算,学习到数据内在规律的高阶表示特征,并利用这些特征决策的过程。
本文基于keras搭建神经网络模型去预测,keras是python上常用的神经网络库。相比于tensorflow、Pytorch等库,它对初学者很友好,开发周期较快。下图为keras要点知识的速查表(pdf原版到公众号阅读原文后可见):
深度学习的建模预测流程,与传统机器学习整体是相同的,主要区别在于深度学习是端对端学习,可以自动提取高层次特征,大大减少了传统机器学习依赖的特征工程。如下详细梳理流程的各个节点并附相应代码:
深度学习的建模预测,首先需要明确问题,即抽象为机器 / 深度学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。
以预测房价为例,我们需要输入:和房价有关的数据信息为特征x,对应的房价为y作为监督信息。再通过神经网络模型学习特征x到房价y内在的映射关系。通过学习好的模型输入需要预测数据的特征x,输出模型预测Y。对于一个良好的模型,它预测房价Y应该和实际y很接近。
深度学习是端对端学习,学习过程中会提取到高层次抽象的特征,大大弱化特征工程的依赖,正因为如此,数据选择也显得格外重要,其决定了模型效果的上限。如果数据质量差,预测的结果自然也是很差的——业界一句名言“garbage in garbage out”。
数据选择是准备机器 / 深度学习原料的关键,需要关注的是:
①数据样本规模:对于深度学习等复杂模型,通常样本量越多越好。如《Revisiting Unreasonable Effectiveness of Data in Deep Learning Era 》等研究,一定规模下,深度学习性能会随着数据量的增加而增加。
然而工程实践中,受限于硬件支持、标注标签成本等原因,样本的数据量通常是比较有限的,这也是机器学习的重难点。对于模型所需最少的样本量,其实没有固定准则,需要要结合实际样本特征、任务复杂度等具体情况(经验上,对于分类任务,每个类别要上千的样本数)。当样本数据量较少以及样本不均衡情况,深度学习常用到数据增强的方法,具体可见系列文章:《数据增强方法的归纳》
② 数据的代表性:数据质量差、无代表性,会导致模型拟合效果差。需要明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音。
③ 数据时间范围:对于监督学习的特征变量x及标签y,如与时间先后有关,则需要划定好数据时间窗口,否则可能会导致常见的数据泄漏问题,即存在了特征与标签因果颠倒的情况。
以预测房价任务为例,对数据选择进行说明:
收集房价相关的数据信息(特征维度)和对应房价(标签),以及尽量多的样本数。数据信息如该区域的繁华程度、教育资源、治安等情况就和预测的房价比较相关,有代表性。而诸如该区域“人均养的兔子数”类数据信息,对房价的预测就没那么相关,对于无代表性的数据特征的加入,主要会增加人工处理的成本、计算复杂度,还有可能引入了模型学习的噪音。
划定好数据时间窗口。比如我们可以学习该区域历史2010~2020年的房价,预测未来2021的房价(这是一个经典的时间序列预测问题,常用RNN模型)。但却不能学习了2021年或者更后面的未来房价、人口数等相关信息,反过来去预测2021年房价,这就是一个数据泄露的问题(模型都学习了与标签相关等未知的信息,还预测个啥?)。
如下加载数据的代码,使用的是keras自带的波士顿房价数据集。一些常用的机器学习开源数据集可以到kaggle.com/datasets、archive.ics.uci.edu等网站下载。
from keras.datasets import boston_housing #导入波士顿房价数据集
(train_x, train_y), (test_x, test_y) = boston_housing.load_data()
波士顿房价数据集是统计20世纪70年代中期波士顿郊区房价等情况,有当时城镇的犯罪率、房产税等共计13个指标(特征)以及对应的房价中位数(标签)。
特征工程就是对原始数据分析处理,转化为模型可用的特征。这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。对于深度学习模型,特征生成等加工不多,主要是一些数据的分析、预处理,然后就可以灌入神经网络模型了。
选择好数据后,可以先做探索性数据分析(EDA)去理解数据本身的内部结构及规律。如果你对数据情况不了解,也没有相关的业务背景知识,不做相关的分析及预处理,直接将数据喂给模型往往效果不太好。通过探索性数据分析,可以了解数据分布、缺失、异常及相关性等情况。
我们可以通过EDA数据分析库如pandas profiling,自动生成分析报告,可以看到这份现成的数据集是比较"干净的":
import pandas as pd
import pandas_profiling
# 特征名称
feature_name = ['CRIM|住房所在城镇的人均犯罪率',
'ZN|住房用地超过 25000 平方尺的比例',
'INDUS|住房所在城镇非零售商用土地的比例',
'CHAS|有关查理斯河的虚拟变量(如果住房位于河边则为1,否则为0 )',
'NOX|一氧化氮浓度',
'RM|每处住房的平均房间数',
'AGE|建于 1940 年之前的业主自住房比例',
'DIS|住房距离波士顿五大中心区域的加权距离',
'RAD|距离住房最近的公路入口编号',
'TAX 每 10000 美元的全额财产税金额',
'PTRATIO|住房所在城镇的师生比例',
'B|1000(Bk|0.63)^2,其中 Bk 指代城镇中黑人的比例',
'LSTAT|弱势群体人口所占比例']
train_df = pd.DataFrame(train_x, columns=feature_name) # 转为df格式
pandas_profiling.ProfileReport(train_df)
像图像、文本字符类的数据,需要转换为计算机能够处理的数值形式。图像数据(pixel image)实际上是由一个像素组成的矩阵所构成的,而每一个像素点又是由RGB颜色通道中分别代表R、G、B的一个三维向量表示,所以图像实际上可以用RGB三维矩阵(3-channel matrix)的表示(第一个维度:高度,第二个维度:宽度,第三个维度:RGB通道),最终再重塑为一列向量(reshaped image vector)方便输入模型。
文本类(类别型)的数据可以用多维数组表示,包括:
① ONEHOT(独热编码)表示:它是用单独一个位置的0或1来表示每个变量值,这样就可以将每个不同的字符取值用唯一的多维数组来表示,将文字转化为数值。如字符类的性别信息就可以转换为“是否为男”、“是否为女”、“未知”等特征。
②word2vetor分布式表示:它基本的**是通过神经网络模型学习每个单词与邻近词的关系,从而将单词表示成低维稠密向量。通过这样的分布式表示可以学习到单词的语义信息,直观来看语义相似的单词其对应的向量距离相近。
数据集已是数值类数据,本节不做处理。
异常值处理
收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。 通常需要处理人为引起的异常值,通过业务及技术手段(如数据分布、3σ准则)判定异常值,再结合实际业务含义删除或者替换掉异常值。
缺失值处理
神经网络模型缺失值的处理是必要的,数据缺失值可以通过结合业务进行填充数值或者删除。
① 缺失率较高,结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;
② 缺失率较低,可使用一些缺失值填充手段,如结合业务fillna为0或-9999或平均值,或者训练回归模型预测缺失值并填充。
从数据分析报告可见,波士顿房价数据集无异常、缺失值情况,本节不做处理。
特征生成作用在于弥补基础特征对样本信息的表达有限,增加特征的非线性表达能力,提升模型效果。它是根据基础特征的含义进行某种处理(聚合 / 转换之类),常用方法如人工设计、自动化特征衍生(如featuretools工具):
深度神经网络会自动学习到高层次特征,常见的深度学习的任务,图像类、文本类任务通常很少再做特征生成。而对于数值类的任务,加工出显著特征对加速模型的学习是有帮助的,可以做尝试。具体可见系列文章:一文归纳Python特征生成方法(全)
特征已经比较全面,本节不再做处理,可自行验证特征生成的效果。
特征选择用于筛选出显著特征、摒弃非显著特征。这样做主要可以减少特征(避免维度灾难),提高训练速度,降低运算开销;减少干扰噪声,降低过拟合风险,提升模型效果。常用的特征选择方法有:过滤法(如特征缺失率、单值率、相关系数)、包装法(如RFE递归特征消除、双向搜索)、嵌入法(如带L1正则项的模型、树模型自带特征选择)。具体可见系列文章:Python特征选择(全)
模型使用L1正则项方法,本节不再做处理,可自行验证其他方法。
神经网络模型的训练主要有3个步骤:
常见的神经网络模型结构有全连接神经网络(FCN)、RNN(常用于文本 / 时间系列任务)、CNN(常用于图像任务)等等。具体可以看之前文章:一文概览神经网络模型
神经网络由输入层、隐藏层与输出层构成。不同的层数、神经元(计算单元)数目的模型性能也会有差异。

对于模型结构的神经元个数 ,输入层、输出层的神经元个数通常是确定的,主要需要考虑的是隐藏层的深度及宽度,在忽略网络退化问题的前提下,通常隐藏层的神经元的越多,模型有更多的容量(capcity)去达到更好的拟合效果(也更容易过拟合)。搜索合适的网络深度及宽度,常用有人工经验调参、随机 / 网格搜索、贝叶斯优化等方法。经验上的做法,可以参照下同类任务效果良好的神经网络模型的结构,结合实际的任务,再做些微调。
根据万能近似原理,简单来说,神经网络有“够深的网络层”以及“至少一层带激活函数的隐藏层”,既可以拟合任意的函数。可见激活函数的重要性,它起着特征空间的非线性转换。对于激活函数选择的经验性做法:
权重参数初始化可以加速模型收敛速度,影响模型结果。常用的初始化方法有:
batch normalization(BN)批标准化,是神经网络模型常用的一种优化方法。它的原理很简单,即是对原来的数值进行标准化处理:
batch normalization在保留输入信息的同时,消除了层与层间的分布差异,具有加快收敛,同时有类似引入噪声正则化的效果。它可应用于网络的输入层或隐藏层,当用于输入层,就是线性模型常用的特征标准化处理。
正则化是在以(可能)增加经验损失为代价,以降低泛化误差为目的,抑制过拟合,提高模型泛化能力的方法。经验上,对于复杂任务,深度学习模型偏好带有正则化的较复杂模型,以达到较好的学习效果。常见的正则化策略有:dropout,L1、L2、earlystop方法。具体可见序列文章:一文深层解决模型过拟合
机器 / 深度学习通过学习到“好”的模型去决策,“好”即是机器 / 深度学习的学习目标,通常也就是预测值与目标值之间的误差尽可能的低。衡量这种误差的函数称为代价函数 (Cost Function)或者损失函数(Loss Function),更具体地说,机器 / 深度学习的目标是极大化降低损失函数。
对于不同的任务,往往也需要用不同损失函数衡量,经典的损失函数包括回归任务的均方误差损失函数及二分类任务的交叉熵损失函数等。
衡量模型回归预测的误差情况,一个简单思路是用各个样本i的预测值f(x;w)减去实际值y求平方后的平均值,这也就是经典的均方误差(Mean Squared Error)损失函数。通过极小化降低均方误差损失函数,可以使得模型预测值与实际值数值差异尽量小。
衡量二分类预测模型的误差情况,常用交叉熵损失函数,使得模型预测分布尽可能与实际数据经验分布一致(最大似然估计)。
另外,还有一些针对优化难点而设计的损失函数,如Huber Loss主要用于解决回归问题中,存在奇点数据带偏模型训练的问题。Focal Loss主要解决分类问题中类别不均衡导致的模型训偏问题。
当我们机器 / 深度学习的学习目标是极大化降低(某个)损失函数,那么如何实现这个目标呢?通常机器学习模型的损失函数较复杂,很难直接求损失函数最小的公式解。幸运的是,我们可以通过优化算法(如梯度下降、随机梯度下降、Adam等)有限次迭代优化模型参数,以尽可能降低损失函数的值,得到较优的参数值。具体可见系列文章:一文概览神经网络优化算法
对于大多数任务而言,通常可以直接先试下Adam、SGD,然后可以继续在具体任务上验证不同优化器效果。
训练模型前,常用的HoldOut验证法(此外还有留一法、k折交叉验证等方法),把数据集分为训练集和测试集,并可再对训练集进一步细分为训练集和验证集,以方便评估模型的性能。
① 训练集(training set):用于运行学习算法,训练模型。
② 开发验证集(development set)用于调整模型超参数、EarlyStopping、选择特征等,以选择出合适模型。
③ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。
神经网络模型的超参数是比较多的:数据方面超参数 如验证集比例、batch size等;模型方面 如单层神经元数、网络深度、选择激活函数类型、dropout率等;学习目标方面 如选择损失函数类型,正则项惩罚系数等;优化算法方面 如选择梯度算法类型、初始学习率等。
常用的超参调试有人工经验调节、网格搜索(grid search或for循环实现)、随机搜索(random search)、贝叶斯优化(bayesian optimization)等方法,方法介绍可见系列文章:一文归纳Ai调参炼丹之法。
另外,有像Keras Tuner分布式超参数调试框架(文档见:keras.io/keras_tuner),集成了常用调参方法,还比较实用的。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow import random
from keras import regularizers
from keras.layers import Dense,Dropout,BatchNormalization
from keras.models import Sequential, Model
from keras.callbacks import EarlyStopping
from sklearn.metrics import mean_squared_error
np.random.seed(1) # 固定随机种子,使每次运行结果固定
random.set_seed(1)
# 创建模型结构:输入层的特征维数为13;1层k个神经元的relu隐藏层;线性的输出层;
for k in [5,20,50]: # 网格搜索超参数:神经元数k
model = Sequential()
model.add(BatchNormalization(input_dim=13)) # 输入层 批标准化
model.add(Dense(k,
kernel_initializer='random_uniform', # 均匀初始化
activation='relu', # relu激活函数
kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), # L1及L2 正则项
use_bias=True)) # 隐藏层
model.add(Dropout(0.1)) # dropout法
model.add(Dense(1,use_bias=True)) # 输出层
model.compile(optimizer='adam', loss='mse')
# 训练模型
history = model.fit(train_x,
train_y,
epochs=500, # 训练迭代次数
batch_size=50, # 每epoch采样的batch大小
validation_split=0.1, # 从训练集再拆分验证集,作为早停的衡量指标
callbacks=[EarlyStopping(monitor='val_loss', patience=20)], #早停法
verbose=False) # 不输出过程
print("验证集最优结果:",min(history.history['val_loss']))
model.summary() #打印模型概述信息
# 模型评估:拟合效果
plt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失
plt.plot(history.history['val_loss'],c='red') # 红色线验证集损失
plt.show()
最后,这里简单采用for循环,实现类似网格搜索调整超参数,验证了隐藏层的不同神经元数目(超参数k)的效果。由验证结果来看,神经元数目为50时,损失可以达到10的较优效果(可以继续尝试模型增加深度、宽度,达到过拟合的边界应该有更好的效果)。
注:本节使用的优化方法较多(炫技ing),单纯是为展示一遍各种深度学习的优化tricks。模型并不是优化方法越多越好,效果还是要实际问题具体验证。
机器学习学习的目标是极大化降低损失函数,但这不仅仅是学习过程中对训练数据有良好的预测能力(极低的训练损失),根本上还在于要对新数据(测试集)能有很好的预测能力(泛化能力)。
评估模型的预测误差常用损失函数的大小来判断,如回归预测的均方损失。但除此之外,对于一些任务,用损失函数作为评估指标并不直观,所以像分类任务的评估还常用f1-score,可以直接展现各种类别正确分类情况。
查准率P:是指分类器预测为Positive的正确样本(TP)的个数占所有预测为Positive样本个数(TP+FP)的比例;
查全率R:是指分类器预测为Positive的正确样本(TP)的个数占所有的实际为Positive样本个数(TP+FN)的比例。
F1-score是查准率P、查全率R的调和平均:
注:如分类任务的f1-score等指标只能用于评估模型最终效果,因为作为学习目标时它们无法被高效地优化,训练优化时常用交叉熵作为其替代的分类损失函数 (surrogate loss function)。
评估模型拟合(学习)效果,常用欠拟合、拟合良好、过拟合来表述,通常,拟合良好的模型有更好泛化能力,在未知数据(测试集)有更好的效果。
我们可以通过训练误差及验证集误差评估模型的拟合程度。从整体训练过程来看,欠拟合时训练误差和验证集误差均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,验证集误差上升,这个时候模型就进入了过拟合区域。
实践中通常欠拟合不是问题,可以通过使用强特征及较复杂的模型提高学习的准确度。而解决过拟合,即如何减少泛化误差,提高泛化能力,通常才是优化模型效果的重点,常用的方法在于提高数据的质量、数量以及采用适当的正则化策略。具体可见系列文章:一文深层解决模型过拟合
# 模型评估:拟合效果
import matplotlib.pyplot as plt
plt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失
plt.plot(history.history['val_loss'],c='red') # 红色线验证集损失
从训练集及验证集的损失来看,训练集、验证集损失都比较低,模型没有过拟合现象。
# 模型评估:测试集预测结果
pred_y = model.predict(test_x)[:,0]
print("正确标签:",test_y)
print("模型预测:",pred_y )
print("实际与预测值的差异:",mean_squared_error(test_y,pred_y ))
#绘图表示
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置图形大小
plt.figure(figsize=(8, 4), dpi=80)
plt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')
plt.plot(range(len(pred_y)), pred_y, ls='-',lw=2,c='b',label='预测值')
# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') #设置x轴的标签文本
plt.ylabel('房价') #设置y轴的标签文本
# 展示
plt.show()
评估测试集的预测结果,其mse损失为19.7,观察测试集的实际值与预测值两者的数值曲线是比较一致的!模型预测效果较好。
决策应用是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。
对于实际工作需要注意的是,工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。
对于神经网络模型预测的分析解释,我们有时需要知道学习的内容,决策的过程是怎么样的(模型的可解释性)。具体可见系列文章:神经网络学习到的是什么?一个可以解释的AI模型(Explainable AI, 简称XAI)意味着运作的透明,便于人类对于对AI决策的监督及接纳,以保证算法的公平性、安全性及隐私性,从而创造更加安全可靠的应用。深度学习可解释性常用方法有:LIME、LRP、SHAP等方法。
如下通过SHAP方法,对模型预测单个样本的结果做出解释,可见在这个样本的预测中,CRIM犯罪率为0.006、RM平均房间数为6.575对于房价是负相关的。LSTAT弱势群体人口所占比例为4.98对于房价的贡献是正相关的...,在综合这些因素后模型给出最终预测值。
import shap
import tensorflow as tf # tf版本<2.0
# 模型解释性
background = test_x[np.random.choice(test_x.shape[0],100, replace=False)]
explainer = shap.DeepExplainer(model,background)
shap_values = explainer.shap_values(test_x) # 传入特征矩阵X,计算SHAP值
# 可视化第一个样本预测的解释
shap.force_plot(explainer.expected_value, shap_values[0,:], test_x.iloc[0,:])
文章首发公众号“算法进阶”,阅读原文可访问文章相关代码及资料
2003年,Google公布了3篇大数据奠基性论文,为大数据存储及分布式处理的核心问题提供了思路:非结构化文件分布式存储(GFS)、分布式计算(MapReduce)及结构化数据存储(BigTable),并奠定了现代大数据技术的理论基础,而后大数据技术便快速发展,诞生了很多日新月异的技术。
归纳现有大数据框架解决的核心问题及相关技术主要为:
Spark是一个分布式内存批计算处理框架,Spark集群由Driver, Cluster Manager(Standalone,Yarn 或 Mesos),以及Worker Node组成。对于每个Spark应用程序,Worker Node上存在一个Executor进程,Executor进程中包括多个Task线程。
在执行具体的程序时,Spark会将程序拆解成一个任务DAG(有向无环图),再根据DAG决定程序各步骤执行的方法。该程序先分别从textFile和HadoopFile读取文件,经过一些列操作后再进行join,最终得到处理结果。
PySpark是Spark的Python API,通过Pyspark可以方便地使用 Python编写 Spark 应用程序, 其支持 了Spark 的大部分功能,例如 Spark SQL、DataFrame、Streaming、MLLIB(ML)和 Spark Core。
Pyspark中支持两个机器学习库:mllib及ml,区别在于ml主要操作的是DataFrame,而mllib操作的是RDD,即二者面向的数据集不一样。相比于mllib在RDD提供的基础操作,ml在DataFrame上的抽象级别更高,数据和操作耦合度更低。
注:mllib在后面的版本中可能被废弃,本文示例使用的是ml库。
pyspark.ml训练机器学习库有三个主要的抽象类:Transformer、Estimator、Pipeline。
# 举例:特征加工
from pyspark.ml.feature import VectorAssembler
featuresCreator = VectorAssembler(
inputCols=[col[0] for col in labels[2:]] + [encoder.getOutputCol()],
outputCol='features'
)
# 举例:分类模型
from pyspark.ml.classification import LogisticRegression
logistic = LogisticRegression(featuresCol=featuresCreator.getOutputCol(),
labelCol='INFANT_ALIVE_AT_REPORT')
# 举例:创建流水线
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[encoder, featuresCreator, logistic]) # 特征编码,特征加工,载入LR模型
# 拟合模型
train, test = data.randomSplit([0.7,0.3],seed=123)
model = pipeline.fit(train)
在分布式训练中,用于训练模型的工作负载会在多个微型处理器之间进行拆分和共享,这些处理器称为工作器节点,通过这些工作器节点并行工作以加速模型训练。 分布式训练可用于传统的 ML 模型,但更适用于计算和时间密集型任务,如用于训练深度神经网络。分布式训练有两种主要类型:数据并行及模型并行,主要代表有Spark ML,Parameter Server和TensorFlow。
spark的分布式训练的实现为数据并行:按行对数据进行分区,从而可以对数百万甚至数十亿个实例进行分布式训练。 以其核心的梯度下降算法为例:
1、首先对数据划分至各计算节点;
2、把当前的模型参数广播到各个计算节点(当模型参数量较大时会比较耗带宽资源);
3、各计算节点进行数据抽样得到mini batch的数据,分别计算梯度,再通过treeAggregate操作汇总梯度,得到最终梯度gradientSum;
4、利用gradientSum更新模型权重(这里采用的阻断式的梯度下降方式,当各节点有数据倾斜时,每轮的时间起决于最慢的节点。这是Spark并行训练效率较低的主要原因)。
注:单纯拿Pyspark练练手,可无需配置Pyspark集群,直接本地配置下单机Pyspark,也可以使用线上spark集群(如: community.cloud.databricks.com)。
本项目通过PySpark实现机器学习建模全流程:数据的载入,数据分析,特征加工,二分类模型训练及评估。
#!/usr/bin/env python
# coding: utf-8
# 初始化SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Python Spark RF example").config("spark.some.config.option", "some-value").getOrCreate()
# 加载数据
df = spark.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load("./data.csv",header=True)
from pyspark.sql.functions import *
# 数据基本信息分析
df.dtypes # Return df column names and data types
df.show() #Display the content of df
df.head() #Return first n rows
df.first() #Return first row
df.take(2) #Return the first n rows
df.schema # Return the schema of df
df.columns # Return the columns of df
df.count() #Count the number of rows in df
df.distinct().count() #Count the number of distinct rows in df
df.printSchema() #Print the schema of df
df.explain() #Print the (logical and physical) plans
df.describe().show() #Compute summary statistics
df.groupBy('Survived').agg(avg("Age"),avg("Fare")).show() # 聚合分析
df.select(df.Sex, df.Survived==1).show() # 带条件查询
df.sort("Age", ascending=False).collect() # 排序
df = df.dropDuplicates() # 删除重复值
df = df.na.fill(value=0) # 缺失填充值
df = df.na.drop() # 或者删除缺失值
df = df.withColumn('isMale', when(df['Sex']=='male',1).otherwise(0)) # 新增列:性别0 1
df = df.drop('_c0','Name','Sex') # 删除姓名、性别、索引列
# 设定特征/标签列
from pyspark.ml.feature import VectorAssembler
ignore=['Survived']
vectorAssembler = VectorAssembler(inputCols=[x for x in df.columns
if x not in ignore], outputCol = 'features')
new_df = vectorAssembler.transform(df)
new_df = new_df.select(['features', 'Survived'])
# 划分测试集训练集
train, test = new_df.randomSplit([0.75, 0.25], seed = 12345)
# 模型训练
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol = 'features',
labelCol='Survived')
lr_model = lr.fit(test)
# 模型评估
from pyspark.ml.evaluation import BinaryClassificationEvaluator
predictions = lr_model.transform(test)
auc = BinaryClassificationEvaluator().setLabelCol('Survived')
print('AUC of the model:' + str(auc.evaluate(predictions)))
print('features weights', lr_model.coefficientMatrix)
文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码
调参即超参数优化,是指从超参数空间中选择一组合适的超参数,以权衡好模型的偏差(bias)和方差(variance),从而提高模型效果及性能。常用的调参方法有:
注:超参数 vs 模型参数差异
超参数是控制模型学习过程的(如网络层数、学习率);
模型参数是通过模型训练学习后得到的(如网络最终学习到的权重值)。
手动调参需要结合数据情况及算法的理解,优化调参的优先顺序及参数的经验值。
不同模型手动调参思路会有差异,如随机森林是一种bagging集成的方法,参数主要有n_estimators(子树的数量)、max_depth(树的最大生长深度)、max_leaf_nodes(最大叶节点数)等。(此外其他参数不展开说明)
对于n_estimators:通常越大效果越好。参数越大,则参与决策的子树越多,可以消除子树间的随机误差且增加预测的准度,以此降低方差与偏差。
对于max_depth或max_leaf_nodes:通常对效果是先增后减的。取值越大则子树复杂度越高,偏差越低但方差越大。
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
# 选择模型
model = RandomForestClassifier()
# 参数搜索空间
param_grid = {
'max_depth': np.arange(1, 20, 1),
'n_estimators': np.arange(1, 50, 10),
'max_leaf_nodes': np.arange(2, 100, 10)
}
# 网格搜索模型参数
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='f1_micro')
grid_search.fit(x, y)
print(grid_search.best_params_)
print(grid_search.best_score_)
print(grid_search.best_estimator_)
# 随机搜索模型参数
rd_search = RandomizedSearchCV(model, param_grid, n_iter=200, cv=5, scoring='f1_micro')
rd_search.fit(x, y)
print(rd_search.best_params_)
print(rd_search.best_score_)
print(rd_search.best_estimator_)
贝叶斯优化(Bayesian Optimization)与网格/随机搜索最大的不同,在于考虑了历史调参的信息,使得调参更有效率。(高维参数空间下,贝叶斯优化复杂度较高,效果会近似随机搜索。)
贝叶斯优化**简单可归纳为两部分:
高斯过程(GP):以历史的调参信息(Observation)去学习目标函数的后验分布(Target)的过程。
采集函数(AC): 由学习的目标函数进行采样评估,分为两种过程: 1、开采过程:在最可能出现全局最优解的参数区域进行采样评估。 2、勘探过程:兼顾不确定性大的参数区域的采样评估,避免陷入局部最优。
for循环n次迭代:
采集函数依据学习的目标函数(或初始化)给出下个开采极值点 Xn+1;
评估Xn+1得到Yn+1;
加入新的Xn+1、Yn+1数据样本,并更新高斯过程模型;
"""
随机森林分类Iris使用贝叶斯优化调参
"""
import numpy as np
from hyperopt import hp, tpe, Trials, STATUS_OK, Trials, anneal
from functools import partial
from hyperopt.fmin import fmin
from sklearn.metrics import f1_score
from sklearn.ensemble import RandomForestClassifier
def model_metrics(model, x, y):
""" 评估指标 """
yhat = model.predict(x)
return f1_score(y, yhat,average='micro')
def bayes_fmin(train_x, test_x, train_y, test_y, eval_iters=50):
"""
bayes优化超参数
eval_iters:迭代次数
"""
def factory(params):
"""
定义优化的目标函数
"""
fit_params = {
'max_depth':int(params['max_depth']),
'n_estimators':int(params['n_estimators']),
'max_leaf_nodes': int(params['max_leaf_nodes'])
}
# 选择模型
model = RandomForestClassifier(**fit_params)
model.fit(train_x, train_y)
# 最小化测试集(- f1score)为目标
train_metric = model_metrics(model, train_x, train_y)
test_metric = model_metrics(model, test_x, test_y)
loss = - test_metric
return {"loss": loss, "status":STATUS_OK}
# 参数空间
space = {
'max_depth': hp.quniform('max_depth', 1, 20, 1),
'n_estimators': hp.quniform('n_estimators', 2, 50, 1),
'max_leaf_nodes': hp.quniform('max_leaf_nodes', 2, 100, 1)
}
# bayes优化搜索参数
best_params = fmin(factory, space, algo=partial(anneal.suggest,), max_evals=eval_iters, trials=Trials(),return_argmin=True)
# 参数转为整型
best_params["max_depth"] = int(best_params["max_depth"])
best_params["max_leaf_nodes"] = int(best_params["max_leaf_nodes"])
best_params["n_estimators"] = int(best_params["n_estimators"])
return best_params
# 搜索最优参数
best_params = bayes_fmin(train_x, test_x, train_y, test_y, 100)
print(best_params)
公众号阅读原文可访问Github源码
推荐系统简单来说就是, 高效地达成用户与意向对象的匹配。具体可见之前文章:【一窥推荐系统的原理】。而技术上实现两者匹配,简单来说有两类方法:
分类的方法很好理解,可以训练一个意向物品的多分类模型,预测用户偏好那一类物品。或者将用户+物品等全方面特征作为拼接训练二分类模型,预测为是否偏好(如下经典的CTR模型,以用户物品特征及对应的标签 0或 1 构建分类模型,预测该用户是否会点击这物品,)。
基于分类的方法,精度较高,常用于推荐的排序阶段(如粗排、精排)。
利用计算物与物或人与人、人与物的距离,将物品推荐给喜好相似的人。
如关联规则推荐,可以将物与物共现度看做为某种的相似度;协同过滤算法可以基于物品或者基于用户计算相似用户或物品;以及本文谈到的双塔模型,通过计算物品与用户之间的相似度距离并做推荐。
利用相似度的方法效率快、准确度差一些常用于推荐中的粗排、召回阶段。
DSSM(Deep Structured Semantic Models)也叫深度语义匹配模型,最早是微软发表的一篇应用于NLP领域中计算语义相似度任务的文章。
DSSM深度语义匹配模型原理很简单:获取搜索引擎中的用户搜索query和doc的海量曝光和点击日志数据,训练阶段分别用复杂的深度学习网络构建query侧特征的query embedding和doc侧特征的doc embedding,线上infer时通过计算两个语义向量的cos距离来表示语义相似度,最终获得语义相似模型。这个模型既可以获得语句的低维语义向量表达sentence embedding,还可以预测两句话的语义相似度。
DSSM模型总的来说可以分成三层结构,分别是输入层、表示层和匹配层。
结构如下图所示:
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
# ### 1. 读取电影数据集(用户信息、电影信息、评分行为信息)
df_user = pd.read_csv("./ml-1m/users.dat",
sep="::", header=None, engine="python",encoding='iso-8859-1',
names = "UserID::Gender::Age::Occupation::Zip-code".split("::"))
df_movie = pd.read_csv("./ml-1m/movies.dat",
sep="::", header=None, engine="python",encoding='iso-8859-1',
names = "MovieID::Title::Genres".split("::"))
df_rating = pd.read_csv("./ml-1m/ratings.dat",
sep="::", header=None, engine="python",encoding='iso-8859-1',
names = "UserID::MovieID::Rating::Timestamp".split("::"))
import collections
# 计算电影中每个题材的次数
genre_count = collections.defaultdict(int)
for genres in df_movie["Genres"].str.split("|"):
for genre in genres:
genre_count[genre] += 1
genre_count
# # 每个电影只保留频率最高(代表性)的电影题材标签
def get_highrate_genre(x):
sub_values = {}
for genre in x.split("|"):
sub_values[genre] = genre_count[genre]
return sorted(sub_values.items(), key=lambda x:x[1], reverse=True)[0][0]
df_movie["Genres"] = df_movie["Genres"].map(get_highrate_genre)
df_movie.head()
# #### 给特征列做序列编码
def add_index_column(param_df, column_name):
values = list(param_df[column_name].unique())
value_index_dict = {value:idx for idx,value in enumerate(values)}
param_df[f"{column_name}_idx"] = param_df[column_name].map(value_index_dict)
add_index_column(df_user, "UserID")
add_index_column(df_user, "Gender")
add_index_column(df_user, "Age")
add_index_column(df_user, "Occupation")
add_index_column(df_movie, "MovieID")
add_index_column(df_movie, "Genres")
# 合并成一个df
df = pd.merge(pd.merge(df_rating, df_user), df_movie)
df.drop(columns=["Timestamp", "Zip-code", "Title"], inplace=True)
num_users = df["UserID_idx"].max() + 1
num_movies = df["MovieID_idx"].max() + 1
num_genders = df["Gender_idx"].max() + 1
num_ages = df["Age_idx"].max() + 1
num_occupations = df["Occupation_idx"].max() + 1
num_genres = df["Genres_idx"].max() + 1
num_users, num_movies, num_genders, num_ages, num_occupations, num_genres
# #### 评分的归一化
min_rating = df["Rating"].min()
max_rating = df["Rating"].max()
df["Rating"] = df["Rating"].map(lambda x : (x-min_rating)/(max_rating-min_rating)) # 评分作为两者的相似度
# df["is_rating_high"] = (df["Rating"]>=4).astype(int) # 可生成是否高评分作为分类模型的类别标签
df.sample(frac=1).head(3)
# 构建训练集特征及标签
df_sample = df.sample(frac=0.1) # 训练集抽样
X = df_sample[["UserID_idx","Gender_idx","Age_idx","Occupation_idx","MovieID_idx","Genres_idx"]]
y = df_sample["Rating"]

def get_model():
"""搭建双塔DNN模型"""
# 输入
user_id = keras.layers.Input(shape=(1,), name="user_id")
gender = keras.layers.Input(shape=(1,), name="gender")
age = keras.layers.Input(shape=(1,), name="age")
occupation = keras.layers.Input(shape=(1,), name="occupation")
movie_id = keras.layers.Input(shape=(1,), name="movie_id")
genre = keras.layers.Input(shape=(1,), name="genre")
# user 塔
user_vector = tf.keras.layers.concatenate([
layers.Embedding(num_users, 100)(user_id),
layers.Embedding(num_genders, 2)(gender),
layers.Embedding(num_ages, 2)(age),
layers.Embedding(num_occupations, 2)(occupation)
])
user_vector = layers.Dense(32, activation='relu')(user_vector)
user_vector = layers.Dense(8, activation='relu',
name="user_embedding", kernel_regularizer='l2')(user_vector)
# item 塔
movie_vector = tf.keras.layers.concatenate([
layers.Embedding(num_movies, 100)(movie_id),
layers.Embedding(num_genres, 2)(genre)
])
movie_vector = layers.Dense(32, activation='relu')(movie_vector)
movie_vector = layers.Dense(8, activation='relu',
name="movie_embedding", kernel_regularizer='l2')(movie_vector)
# 每个用户的embedding和item的embedding作点积
dot_user_movie = tf.reduce_sum(user_vector*movie_vector, axis = 1)
dot_user_movie = tf.expand_dims(dot_user_movie, 1)
output = layers.Dense(1, activation='sigmoid')(dot_user_movie)
return keras.models.Model(inputs=[user_id, gender, age, occupation, movie_id, genre], outputs=[output])
model = get_model()
model.compile(loss=tf.keras.losses.MeanSquaredError(),
optimizer=keras.optimizers.RMSprop())
fit_x_train = [
X["UserID_idx"],
X["Gender_idx"],
X["Age_idx"],
X["Occupation_idx"],
X["MovieID_idx"],
X["Genres_idx"]
]
history = model.fit(
x=fit_x_train,
y=y,
batch_size=32,
epochs=5,
verbose=1
)
# ### 3. 模型的预估-predict
# 输入前5个样本并做预测
inputs = df[["UserID_idx","Gender_idx","Age_idx","Occupation_idx","MovieID_idx", "Genres_idx"]].head(5)
display(df.head(5))
# 对于(用户ID,召回的电影ID列表),计算相似度分数
model.predict([
inputs["UserID_idx"],
inputs["Gender_idx"],
inputs["Age_idx"],
inputs["Occupation_idx"],
inputs["MovieID_idx"],
inputs["Genres_idx"]
])
# 可以提取模型中的user或movie item 的embedding
user_layer_model = keras.models.Model(
inputs=[model.input[0], model.input[1], model.input[2], model.input[3]],
outputs=model.get_layer("user_embedding").output
)
user_embeddings = []
for index, row in df_user.iterrows():
user_id = row["UserID"]
user_input = [
np.reshape(row["UserID_idx"], [1,1]),
np.reshape(row["Gender_idx"], [1,1]),
np.reshape(row["Age_idx"], [1,1]),
np.reshape(row["Occupation_idx"], [1,1])
]
user_embedding = user_layer_model(user_input)
embedding_str = ",".join([str(x) for x in user_embedding.numpy().flatten()])
user_embeddings.append([user_id, embedding_str])
df_user_embedding = pd.DataFrame(user_embeddings, columns = ["user_id", "user_embedding"])
df_user_embedding.head()
文章首发公众号“算法进阶”,公众号阅读原文可访问文章相关数据代码及资料
样本(类别)样本不平衡(class-imbalance)指的是分类任务中不同类别的训练样例数目差别很大的情况,一般地,样本类别比例(多数类vs少数类)明显大于1:1(如4:1)就可以归为样本不均衡的问题。现实中,样本不平衡是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更为重要。
注:本文主要探讨分类任务的类别不均衡,回归任务的样本不均衡详见《Delving into Deep Imbalanced Regression》
很多时候我们遇到样本不均衡问题时,很直接的反应就是去“打破”这种不平衡。但是样本不均衡有什么影响?有必要去解决吗?
先具体举个例子,在一个欺诈识别的案例中,好坏样本的占比(Imbalance Ratio)是1000:1,而如果我们直接拿这个比例去学习模型的话,因为扔进去模型学习的样本大部分都是好的,就很容易学出一个把所有样本都预测为好的模型,而且这样预测的概率准确率还是非常高的。而模型最终学习的并不是如何分辨好坏,而是学习到了”好 远比 坏的多“这样的先验信息,凭着这个信息把所有样本都判定为“好”就可以了。这样就背离了模型学习去分辨好坏的初衷了。
所以,样本不均衡带来的根本影响是:模型会学习到训练集中样本比例的这种先验性信息,以致于实际预测时就会对多数类别有侧重(可能导致多数类精度更好,而少数类比较差)。如下图(示例代码请见github.com/aialgorithm),类别不均衡情况下的分类边界会“侵占”少数类的区域。更重要的一点,这会影响模型学习更本质的特征,影响模型的鲁棒性。
总结一下也就是,我们通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。
从分类效果出发,通过上面的例子可知,不均衡对于分类结果的影响不一定是不好的,那什么时候需要解决样本不均衡?
学习任务的复杂度与样本不平衡的敏感度是成正比的(参见《Survey on deep learning with class imbalance》),对于简单线性可分任务,样本是否均衡影响不大。需要注意的是,学习任务的复杂度是相对意义上的,得从特征强弱、数据噪音情况以及模型容量等方面综合评估。
判断训练样本的分布与真实样本分布是否一致且稳定,如果分布是一致的,带着这种正确点的先验对预测结果影响不大。但是,还需要考虑到,如果后面真实样本分布变了,这个样本比例的先验就有副作用了。
出现某一类别样本数目非常稀少的情况(样本不足),模型很有可能学习不好。这时类别不均衡是需要解决的,如选择一些数据增强的方法,或者尝试如异常检测的单分类模型。
基本上,在学习任务有些难度的前提下,不均衡解决方法可以归结为:通过某种方法使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的。以消除模型对不同类别的偏向性,学习到更为本质的特征。本文从数据样本、模型算法、目标函数、评估指标等方面,对个中的解决方法进行探讨。
最直接的处理方式就是样本数量的调整了,常用的可以:
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多数据的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值,从而提高模型的学习效果(具体介绍及代码可见【数据增强】)。如下列举常用的方法:
样本变换数据增强即采用预设的数据变换规则进行已有数据的扩增,包含单样本数据增强和多样本数据增强。
单样本增强(主要用于图像):主要有几何操作、颜色变换、随机擦除、添加噪声等方法产生新的样本,可参见imgaug开源库。
多样本增强:是通过组合及转换多个样本,主要有Smote类(可见imbalanced-learn.org/stable/references/over_sampling.html)、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值样本。
生成模型如变分自编码网络(Variational Auto-Encoding network, VAE)和生成对抗网络(Generative Adversarial Network, GAN),其生成样本的方法也可以用于数据增强。这种基于网络合成的方法相比于传统的数据增强技术虽然过程更加复杂, 但是生成的样本更加多样。
数据样本层面的处理,需要关注的是:
loss层面的主流也就是常用的代价敏感学习方法(cost-sensitive),为不同的分类错误给予不同惩罚力度(权重),在调节类别平衡的同时,也不会增加计算复杂度。
这最常用也就是scikit模型的’class weight‘方法,If ‘balanced’, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class weights will be uniform.,class weight可以为不同类别的样本提供不同的权重(少数类有更高的权重),从而模型可以平衡各类别的学习。 如下图(具体代码请见github.com/aialgorithm)通过为少数类做更高的权重(类别权重除了设定为balanced,还可以作为一个超参搜索),避免决策边界偏重多数类的现象:
clf2 = LogisticRegression(class_weight={0:1,1:10}) # 代价敏感学习
In this work, we first point out that the class imbalance can be summarized to the imbalance in difficulty and the imbalance in difficulty can be summarized to the imbalance in gradient norm distribution.--原文可见《Gradient Harmonized Single-stage Detector
》
类别的不平衡可以归结为难易样本的不平衡,而难易样本的不平衡可以归结为梯度的不平衡。按照这个思路,OHEM和Focal loss都做了两件事:难样本挖掘以及类别的平衡。(另外的有 GHM、 PISA等方法,可以自行了解)
OHEM(Online Hard Example Mining)算法的核心是选择一些hard examples(多样性和高损失的样本)作为训练的样本,针对性地改善模型学习效果。对于数据的类别不平衡问题,OHEM的针对性更强。
Focal loss的核心**是在交叉熵损失函数(CE)的基础上增加了类别的不同权重以及困难(高损失)样本的权重(如下公式),以改善模型学习效果。
模型方面主要是选择一些对不均衡比较不敏感的模型,比如,对比逻辑回归模型,决策树在不平衡数据上面表现相对好一些(树模型是按照增益递归地划分数据,划分过程考虑的是局部的增益,全局样本是不均衡,局部空间就不一定,所以比较不敏感一些些。相关实验可见arxiv.org/abs/2104.02240)。
解决不均衡问题,更为优秀的是基于采样+集成树模型等方法,可以在类别不均衡数据上表现良好。
这类方法简单来说,通过重复组合少数类样本与抽样的同样数量的多数类样本,训练若干的分类器进行集成学习。
BalanceCascade
BalanceCascade基于Adaboost作为基分类器,核心思路是在每一轮训练时都使用多数类与少数类数量上相等的训练集,然后使用该分类器对全体多数类进行预测,通过控制分类阈值来控制FP(False Positive)率,将所有判断正确的类删除,然后进入下一轮迭代继续降低多数类数量。
EasyEnsemble
EasyEnsemble也是基于Adaboost作为基分类器,就是将多数类样本集随机分成 N 个子集,且每一个子集样本与少数类样本相同,然后分别将各个多数类样本子集与少数类样本进行组合,使用AdaBoost基分类模型进行训练,最后bagging集成各基分类器,得到最终模型。示例代码可见:www.kaggle.com/orange90/ensemble-test-credit-score-model-example
通常,在数据集噪声较小的情况下,可以用BalanceCascade,可以用较少的基分类器数量得到较好的表现(基于串行的集成学习方法,对噪声敏感容易过拟合)。噪声大的情况下,可以用EasyEnsemble,基于串行+并行的集成学习方法,bagging多个Adaboost过程可以抵消一些噪声影响。此外还有RUSB、SmoteBoost、balanced RF等其他集成方法可以自行了解。
类别不平衡很极端的情况下(比如少数类只有几十个样本),将分类问题考虑成异常检测(anomaly detection)问题可能会更好。
异常检测是通过数据挖掘方法发现与数据集分布不一致的异常数据,也被称为离群点、异常值检测等等。无监督异常检测按其算法**大致可分为几类:基于聚类的方法、基于统计的方法、基于深度的方法(孤立森林)、基于分类模型(one-class SVM)以及基于神经网络的方法(自编码器AE)等等。具体方法介绍及代码可见【异常检测方法速览】
本节关注的重点是,当我们采用不平衡数据训练模型,如何更好决策以及客观地评估不平衡数据下的模型表现。对于分类常用的precision、recall、F1、混淆矩阵,样本不均衡的不同程度,都会明显改变这些指标的表现。
对于类别不均衡下模型的预测,我们可以做分类阈值移动,以调整模型对于不同类别偏好的情况(如模型偏好预测负样本,偏向0,对应的我们的分类阈值也往下调整),达到决策时类别平衡的目的。这里,通常可以通过P-R曲线,选择到较优表现的阈值。
对于类别不均衡下的模型评估,可以采用AUC、AUPRC(更优)评估模型表现。AUC的含义是ROC曲线的面积,其数值的物理意义是:随机给定一正一负两个样本,将正样本预测分值大于负样本的概率大小。AUC对样本的正负样本比例情况是不敏感,即使正例与负例的比例发生了很大变化,ROC曲线面积也不会产生大的变化。具体可见 【 评估指标】
pandas、numpy是Python数据科学中非常常用的库,numpy是Python的数值计算扩展,专门用来处理矩阵,它的运算效率比列表更高效。pandas是基于numpy的数据处理工具,能更方便的操作大型表格类型的数据集。
但是,随着数据量的剧增,有时numpy和pandas的速度就成瓶颈。如下我们会介绍一些优化秘籍:里面包含 代码上面的优化,以及可以无脑使用的性能优化扩展包。
NumExpr 是一个对NumPy计算式进行的性能优化。NumExpr的使用及其简单,只需要将原来的numpy语句使用双引号框起来,并使用numexpr中的evaluate方法调用即可。经验上看,数据有上万条+ 使用NumExpr才比较优效果,对于简单运算使用NumExpr可能会更慢。如下较复杂计算,速度差不多快了5倍。
import numexpr as ne
import numpy as np
a = np.linspace(0,1000,1000)
print('# numpy十次幂计算')
%timeit a**10
print('# numexpr十次幂计算')
%timeit ne.evaluate('a**10')
Numba 使用行业标准的LLVM编译器库在运行时将 Python 函数转换为优化的机器代码。Python 中 Numba 编译的数值算法可以接近 C 或 FORTRAN 的速度。
如果在你的数据处理过程涉及到了大量的数值计算,那么使用numba可以大大加快代码的运行效率(一般来说,Numba 引擎在处理大量数据点 如 1 百万+ 时表现出色)。numba使用起来也很简单,因为numba内置的函数本身是个装饰器,所以只要在自己定义好的函数前面加个@nb.方法就行,简单快捷!
# pip install numba
import numba as nb
# 用numba加速的求和函数
@nb.jit()
def nb_sum(a):
Sum = 0
for i in range(len(a)):
Sum += a[i]
return Sum
# 没用numba加速的求和函数
def py_sum(a):
Sum = 0
for i in range(len(a)):
Sum += a[i]
return Sum
import numpy as np
a = np.linspace(0,1000,1000) # 创建一个长度为1000的数组
print('# python求和函数')
%timeit sum(a)
print('# 没加速的for循环求和函数')
%timeit py_sum(a)
print('# numba加速的for循环求和函数')
%timeit nb_sum(a)
print('# numpy求和函数')
%timeit np.sum(a)
当前示例可以看出,numba甚至比号称最接近C语言速度运行的numpy还要快5倍+,对于python求和速度快了几百倍。。
此外,Numba还支持GPU加速、矢量化加速方法,可以进一步达到更高的性能。
from numba import cuda
cuda.select_device(1)
@cuda.jit
def CudaSquare(x):
i, j = cuda.grid(2)
x[i][j] *= x[i][j]
#numba的矢量化加速
from math import sin
@nb.vectorize()
def nb_vec_sin(a):
return sin(a)
CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。
# pip install cupy
import numpy as np
import cupy as cp
import time
### numpy
s = time.time()
x_cpu = np.ones((1000,1000,1000))
e = time.time()
print(e - s)
### CuPy
s = time.time()
x_gpu = cp.ones((1000,1000,1000))
e = time.time()
print(e - s)
上述代码,Numpy 创建(1000, 1000, 1000)的数组用了 1.68 秒,而 CuPy 仅用了 0.16 秒,实现了 10.5 倍的加速。随着数据量的猛增,CuPy的性能提升会更为明显。
更多pandas性能提升技巧请戳官方文档:https://pandas.pydata.org/pandas-docs/stable/user_guide/enhancingperf.html
我们按行对dataframe进行迭代,一般我们会用iterrows这个函数。在新版的pandas中,提供了一个更快的itertuples函数,如下可以看到速度快了几十倍。
import pandas as pd
import numpy as np
import time
df = pd.DataFrame({'a': np.random.randn(100000),
'b': np.random.randn(100000),
'N': np.random.randint(100, 1000, (100000)),
'x': np.random.randint(1, 10, (100000))})
%%timeit
a2=[]
for row in df.itertuples():
temp=getattr(row, 'a')
a2.append(temp*temp)
df['a2']=a2
%%timeit
a2=[]
for index,row in df.iterrows():
temp=row['a']
a2.append(temp*temp)
df['a2']=a2
当对于每行执行类似的操作时,用循环逐行处理效率很低。这时可以用apply或applymap搭配函数操作,其中apply是可用于逐行计算,而applymap可以做更细粒度的逐个元素的计算。
# 列a、列b逐行进行某一函数计算
df['a3']=df.apply( lambda row: row['a']*row['b'],axis=1)
# 逐个元素保留两位小数
df.applymap(lambda x: "%.2f" % x)
对于某列将进行聚合后,使用内置的函数比自定义函数效率更高,如下示例速度加速3倍
%timeit df.groupby("x")['a'].agg(lambda x:x.sum())
%timeit df.groupby("x")['a'].agg(sum)
%timeit df.groupby("x")['a'].agg(np.sum)
pandas读取文件,pkl格式的数据的读取速度最快,其次是hdf格式的数据,再者是读取csv格式数据,而xlsx的读取是比较慢的。但是存取csv有个好处是,这个数据格式通用性更好,占用内存硬盘资源也比较少。此外,对于大文件,csv还可以对文件分块、选定某几列、指定数据类型做读取。
pandas.eval 是基于第一节提到的numexpr,pandas也是基于numpy开发的,numexpr同样可以被用来对pandas加速)。使用eval表达式的一个经验是数据超过 10,000 行的情况下使用会有明显优化效果。
import pandas as pd
nrows, ncols = 20000, 100
df1, df2, df3, df4 = [pd.DataFrame(np.random.randn(nrows, ncols)) for _ in range(4)]
print('pd')
%timeit df1 + df2 + df3 + df4
print('pd.eval')
%timeit pd.eval("df1 + df2 + df3 + df4")
Cython是一个基于C语言的Python 编译器,在一些计算量大的程序中,可以Cython来实现相当大的加速。考虑大部分人可能都不太了解复杂的cython语句,下面介绍下Cython的简易版使用技巧。通过在Ipython加入 Cython 魔术函数%load_ext Cython,如下示例就可以加速了一倍。进一步再借助更高级的cython语句,还是可以比Python快个几十上百倍。
%%cython
def f_plain(x):
return x * (x - 1)
def integrate_f_plain(a, b, N):
s = 0
dx = (b - a) / N
for i in range(N):
s += f_plain(a + i * dx)
return s * dx
swifter是pandas的插件,可以直接在pandas的数据上操作。Swifter的优化方法检验计算是否可以矢量化或者并行化处理,以提高性能。如常见的apply就可以通过swifter并行处理。
import pandas as pd
import swifter
df.swifter.apply(lambda x: x.sum() - x.min())
Modin后端使用dask或者ray(dask是类似pandas库的功能,可以实现并行读取运行),是个支持分布式运行的类pandas库,简单通过更改一行代码import modin.pandas as pd就可以优化 pandas,常用的内置的read_csv、concat、apply都有不错的加速。注:并行处理的开销会使小数据集的处理速度变慢。
!pip install modin
import pandas
import modin.pandas as pd
import time
## pandas
pandas_df = pandas.DataFrame({'a': np.random.randn(10000000),
'b': np.random.randn(10000000),
'N': np.random.randint(100, 10000, (10000000)),
'x': np.random.randint(1, 1000, (10000000))})
start = time.time()
big_pandas_df = pandas.concat([pandas_df for _ in range(25)])
end = time.time()
pandas_duration = end - start
print("Time to concat with pandas: {} seconds".format(round(pandas_duration, 3)))
#### modin.pandas
modin_df = pd.DataFrame({'a': np.random.randn(10000000),
'b': np.random.randn(10000000),
'N': np.random.randint(100, 10000, (10000000)),
'x': np.random.randint(1, 1000, (10000000))})
start = time.time()
big_modin_df = pd.concat([modin_df for _ in range(25)])
end = time.time()
modin_duration = end - start
print("Time to concat with Modin: {} seconds".format(round(modin_duration, 3)))
print("Modin is {}x faster than pandas at `concat`!".format(round(pandas_duration / modin_duration, 2)))
文章首发公众号“算法进阶”,欢迎关注。公众号阅读原文可访问文章相关代码及资料
简单来说,常见的神经网络模型结构有前馈神经网络(DNN)、RNN(常用于文本 / 时间系列任务)、CNN(常用于图像任务)等等。具体可以看之前文章:一文概览神经网络模型。
前馈神经网络是神经网络模型中最为常见的,信息从输入层开始输入,每层的神经元接收前一级输入,并输出到下一级,直至输出层。整个网络信息输入传输中无反馈(循环)。即任何层的输出都不会影响同级层,可用一个有向无环图表示。
循环神经网络(RNN)是基于序列数据(如语言、语音、时间序列)的递归性质而设计的,是一种反馈类型的神经网络,它专门用于处理序列数据,如逐字生成文本或预测时间序列数据(例如股票价格、诗歌生成)。
RNN和全连接神经网络的本质差异在于“输入是带有反馈信息的”,RNN除了接受每一步的输入x(t) ,同时还有输入上一步的历史反馈信息——隐藏状态h (t-1) ,也就是当前时刻的隐藏状态h(t) 或决策输出O(t) 由当前时刻的输入 x(t) 和上一时刻的隐藏状态h (t-1) 共同决定。从某种程度,RNN和大脑的决策很像,大脑接受当前时刻感官到的信息(外部的x(t) )和之前的想法(内部的h (t-1) )的输入一起决策。
RNN的结构原理可以简要概述为两个公式,具体介绍可以看下【一文详解RNN】:
RNN的隐藏状态为:h(t) = f( U * x(t) + W * h(t-1) + b1), f为激活函数,常用tanh、relu;
RNN的输出为:o(t) = g( V * h(t) + b2),g为激活函数,当用于分类任务,一般用softmax;
但是在实际中,RNN在长序列数据处理中,容易导致梯度爆炸或者梯度消失,也就是长期依赖(long-term dependencies)问题,其根本原因就是模型“记忆”的序列信息太长了,都会一股脑地记忆和学习,时间一长,就容易忘掉更早的信息(梯度消失)或者崩溃(梯度爆炸)。
梯度消失:历史时间步的信息距离当前时间步越长,反馈的梯度信号就会越弱(甚至为0)的现象,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
改善措施:可以使用 ReLU 激活函数;门控RNN 如GRU、LSTM 以改善梯度消失。
梯度爆炸:网络层之间的梯度(值大于 1)重复相乘导致的指数级增长会产生梯度爆炸,导致模型无法有效学习。
改善措施:可以使用 梯度截断;引导信息流的正则化;ReLU 激活函数;门控RNN 如GRU、LSTM(和普通 RNN 相比多经过了很多次导数都小于 1激活函数,因此 LSTM 发生梯度爆炸的频率要低得多)以改善梯度爆炸。
所以,如果我们能让 RNN 在接受上一时刻的状态和当前时刻的输入时,有选择地记忆和遗忘一部分内容(或者说信息),问题就可以解决了。比如上上句话提及”我去考试了“,然后后面提及”我考试通过了“,那么在此之前说的”我去考试了“的内容就没那么重要,选择性地遗忘就好了。这也就是长短期记忆网络(Long Short-Term Memory, LSTM)的基本**。
LSTM是种特殊RNN网络,在RNN的基础上引入了“门控”的选择性机制,分别是遗忘门、输入门和输出门,从而有选择性地保留或删除信息,以能够较好地学习长期依赖关系。如下图RNN(上) 对比 LSTM(下):
在RNN基础上引入门控后的LSTM,结构看起来好复杂!但其实LSTM作为一种反馈神经网络,核心还是历史的隐藏状态信息的反馈,也就是下图的Ct:
对标RNN的ht隐藏状态的更新,LSTM的Ct只是多个些“门控”删除或添加信息到状态信息。由下面依次介绍LSTM的“门控”:遗忘门,输入门,输出门的功能,LSTM的原理也就好理解了。
LSTM 的第一步是通过"遗忘门"从上个时间点的状态Ct-1中丢弃哪些信息。
具体来说,输入Ct-1,会先根据上一个时间点的输出ht-1和当前时间点的输入xt,并通过sigmoid激活函数的输出结果ft来确定要让Ct-1,来忘记多少,sigmoid后等于1表示要保存多一些Ct-1的比重,等于0表示完全忘记之前的Ct-1。
下一步是通过输入门,决定我们将在状态中存储哪些新信息。
我们根据上一个时间点的输出ht-1和当前时间点的输入xt 生成两部分信息i t 及Ct,通过sigmoid输出i t,用tanh输出Ct。之后通过把i t 及C~t两个部分相乘,共同决定在状态中存储哪些新信息。
在输入门 + 遗忘门控制下,当前时间点状态信息Ct为:
最后,我们根据上一个时间点的输出ht-1和当前时间点的输入xt 通过sigmid 输出Ot,再根据Ot 与 tanh控制的当前时间点状态信息Ct 相乘作为最终的输出。
综上,一张图可以说清LSTM原理:
本节项目利用深层LSTM模型,学习大小为10M的诗歌数据集,自动可以生成诗歌。
如下代码构建LSTM模型。
## 本项目完整代码:github.com/aialgorithm/Blog
# 或“算法进阶”公众号文末阅读原文可见
model = tf.keras.Sequential([
# 不定长度的输入
tf.keras.layers.Input((None,)),
# 词嵌入层
tf.keras.layers.Embedding(input_dim=tokenizer.vocab_size, output_dim=128),
# 第一个LSTM层,返回序列作为下一层的输入
tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),
# 第二个LSTM层,返回序列作为下一层的输入
tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),
# 对每一个时间点的输出都做softmax,预测下一个词的概率
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.vocab_size, activation='softmax')),
])
# 查看模型结构
model.summary()
# 配置优化器和损失函数
model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.categorical_crossentropy)
模型训练,考虑训练时长,就简单训练2个epoch。
class Evaluate(tf.keras.callbacks.Callback):
"""
训练过程评估,在每个epoch训练完成后,保留最优权重,并随机生成SHOW_NUM首古诗展示
"""
def __init__(self):
super().__init__()
# 给loss赋一个较大的初始值
self.lowest = 1e10
def on_epoch_end(self, epoch, logs=None):
# 在每个epoch训练完成后调用
# 如果当前loss更低,就保存当前模型参数
if logs['loss'] <= self.lowest:
self.lowest = logs['loss']
model.save(BEST_MODEL_PATH)
# 随机生成几首古体诗测试,查看训练效果
print("cun'h")
for i in range(SHOW_NUM):
print(generate_acrostic(tokenizer, model, head="春花秋月"))
# 创建数据集
data_generator = PoetryDataGenerator(poetry, random=True)
# 开始训练
model.fit_generator(data_generator.for_fit(), steps_per_epoch=data_generator.steps, epochs=TRAIN_EPOCHS,
callbacks=[Evaluate()])
加载简单训练的LSTM模型,输入关键字(如:算法进阶)后,自动生成藏头诗。可以看出诗句粗略看上去挺优雅,但实际上经不起推敲。后面增加训练的epoch及数据集应该可以更好些。
# 加载训练好的模型
model = tf.keras.models.load_model(BEST_MODEL_PATH)
keywords = input('输入关键字:\n')
# 生成藏头诗
for i in range(SHOW_NUM):
print(generate_acrostic(tokenizer, model, head=keywords),'\n')
参考资料:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
https://www.zhihu.com/question/34878706
一般的,神经网络模型基本结构按信息输入是否反馈,可以分为两种:前馈神经网络和反馈神经网络。
前馈神经网络(Feedforward Neural Network)中,信息从输入层开始输入,每层的神经元接收前一级输入,并输出到下一级,直至输出层。整个网络信息输入传输中无反馈(循环)。即任何层的输出都不会影响同级层,可用一个有向无环图表示。
常见的前馈神经网络包括卷积神经网络(CNN)、全连接神经网络(FCN)、生成对抗网络(GAN)等。
反馈神经网络(Feedback Neural Network)中,神经元不但可以接收其他神经元的信号,而且可以接收自己的反馈信号。和前馈神经网络相比,反馈神经网络中的神经元具有记忆功能,在不同时刻具有不同的状态。反馈神经网络中的信息传播可以是单向也可以是双向传播,因此可以用一个有向循环图或者无向图来表示。
常见的反馈神经网络包括循环神经网络(RNN)、长短期记忆网络(LSTM)、Hopfield网络和玻尔兹曼机。
全连接神经网络是深度学习最常见的网络结构,有三种基本类型的层: 输入层、隐藏层和输出层。当前层的每个神经元都会接入前一层每个神经元的输入信号。在每个连接过程中,来自前一层的信号被乘以一个权重,增加一个偏置,然后通过一个非线性激活函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射。
图像具有非常高的维数,因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。卷积神经网络提供了一个解决方案,利用卷积和池化层,来降低图像的维度。由于卷积层是可训练的,但参数明显少于标准的隐藏层,它能够突出图像的重要部分,并向前传播每个重要部分。传统的CNNs中,最后几层是隐藏层,用来处理“压缩的图像信息”。
深层前馈神经网络有一个问题,随着网络层数的增加,网络会发生了退化(degradation)现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当再增加网络深度的话,训练集loss反而会增大。为了解决这个问题,残差网络使用跳跃连接实现信号跨层传播。
生成对抗网络是一种专门设计用于生成图像的网络,由两个网络组成: 一个鉴别器和一个生成器。鉴别器的任务是区分图像是从数据集中提取的还是由生成器生成的,生成器的任务是生成足够逼真的图像,以至于鉴别器无法区分图像是否真实。随着时间的推移,在谨慎的监督下,这两个对手相互竞争,彼此都想成功地改进对方。最终的结果是一个训练有素的生成器,可以生成逼真的图像。鉴别器是一个卷积神经网络,其目标是最大限度地提高识别真假图像的准确率,而生成器是一个反卷积神经网络,其目标是最小化鉴别器的性能。
自动编码器学习一个输入(可以是图像或文本序列)的压缩表示,例如,压缩输入,然后解压缩回来匹配原始输入,而变分自动编码器学习表示的数据的概率分布的参数。不仅仅是学习一个代表数据的函数,它还获得了更详细和细致的数据视图,从分布中抽样并生成新的输入数据样本。
Transformer是Google Brain提出的经典网络结构,由经典的Encoder-Decoder模型组成。在上图中,整个Encoder层由6个左边Nx部分的结构组成。整个Decoder由6个右边Nx部分的框架组成,Decoder输出的结果经过一个线性层变换后,经过softmax层计算,输出最终的预测结果。
循环神经网络是一种特殊类型的网络,它包含环和自重复,因此被称为“循环”。由于允许信息存储在网络中,RNNs 使用以前训练中的推理来对即将到来的事件做出更好、更明智的决定。为了做到这一点,它使用以前的预测作为“上下文信号”。由于其性质,RNNs 通常用于处理顺序任务,如逐字生成文本或预测时间序列数据(例如股票价格)。它们还可以处理任意大小的输入。
LSTM结构是专门为解决RNN在学习长的的上下文信息出现的梯度消失、爆炸问题而设计的,结构中加入了内存块。这些模块可以看作是计算机中的内存芯片——每个模块包含几个循环连接的内存单元和三个门(输入、输出和遗忘,相当于写入、读取和重置)。信息的输入只能通过每个门与神经元进行互动,因此这些门学会智能地打开和关闭,以防止梯度爆炸或消失。
Hopfield神经网络是一种单层互相全连接的反馈型神经网络。每个神经元既是输入也是输出,网络中的每一个神经元都将自己的输出通过连接权传送给所有其它神经元,同时又都接收所有其它神经元传递过来的信息。
实践中,我们除了结合任务直接选用一些经典神经模型做验证,有时也需要对网络结构做设计优化。网络结构的设计需要考虑的2个实质问题是:
也就是神经网络基本的架构如何设计,有两种设计思路:
将人类先验嵌入到模型结构设计
例如,基于图像任务的平移不变性的卷积假设设计的CNN,或者基于语言的递归性质的递归假设设计的RNN。对于先验知识,可以凭借经验做网络结构设计无疑是相对高效的,但太多复杂经验的注入,一来不够“优雅”,二来如果经验有误,设计的结构可能就失效了。
通过机器动态学习和计算出的结构
如神经网络架构搜索(NAS),常见的搜索方法包括:随机搜索、贝叶斯优化、进化算法、强化学习、基于梯度的算法。
神经网络由输入层、隐藏层与输出层构成:
对于网络的输入层、输出层的神经元通常是确定的,主要需要考虑的是隐藏层的深度及宽度,在忽略网络退化问题的前提下,通常隐藏层的神经元(计算单元)的越多,模型有更多的容量(capcity)去达到更好的拟合效果。
搜索合适的网络深度及宽度,常用有人工调参、随机搜索、贝叶斯优化等方法。这里有个引申问题:
1、拟合效果上,增加深度远比宽度高效
同等效果上,要增加的宽度远大于增加的深度。在Delalleau和Bengio等人的论文《Shallow vs. Deep sum-product networks》中提出,对于一些特意构造的多项式函数,浅层网络需要指数增长的神经元个数,其拟合效果才能匹配上多项式增长的深层网络。
2、参数规模上,增加深度远比宽度需要的参数少
以上图神经网络为例,将单层宽度增加3个神经元,会新增6个与之相连前后层的权重参数。而直接新增一个3个神经元的网络层,只会新增3个的权重参数。
增加网络深度可以获得更抽象、高层次的特征,增加网络宽度可以获得更丰富的特征。
文章首发公众号“算法进阶”,敬请关注。
一句话可以概括出KNN的算法原理:综合k个“邻居”的标签值作为新样本的预测值。
更具体来讲KNN分类,给定一个训练数据集,对新的样本Xu,在训练数据集中找到与该样本距离最邻近的K(下图k=5)个样本,以这K个样本的最多数所属类别(标签)作为新实例Xu的类别。
由上,可以总结出KNN算法有K值的选择、距离度量和决策方法等三个基本要素,如下分别解析:
KNN算法用距离去度量两两样本间的临近程度,最终为新实例样本确认出最临近的K个实例样本(这也是算法的关键步骤),常用的距离度量方法有曼哈顿距离、欧几里得距离:
曼哈顿、欧几里得距离的计算方法很简单,就是计算两样本(x,y)的各个特征i间的总距离。
如下图(二维特征的情况)蓝线的距离即是曼哈顿距离(想象你在曼哈顿要从一个十字路口开车到另外一个十字路口实际驾驶距离就是这个“曼哈顿距离”,也称为城市街区距离),红线为欧几里得距离:
曼哈顿距离 与 欧几里得距离 同属于闵氏距离的特例(p=1为曼哈顿距离;p=2为欧氏距离)
在多数情况下,KNN使用两者的差异不大。在一些情况的差异如下:
除了曼哈顿距离、欧几里得距离,也可使用其他距离方法,衡量样本间的临近程度,具体可以看下这篇关于【距离度量】的介绍。
闵氏距离注意点:特征量纲差异问题
计算距离时,需要关注到特征量纲差异问题。假设各样本有年龄、工资两个特征变量,如计算欧氏距离的时候,(年龄1-年龄2)² 的值要远小于(工资1-工资2)² ,这意味着在不使用特征缩放的情况下,距离会被工资变量(大的数值)主导。因此,我们需要使用特征缩放来将全部的数值统一到一个量级上来解决此问题。通常的解决方法可以对数据进行“标准化”或“归一化”,对所有数值特征统一到标准的范围如0~1。
决策方法就计算确认到新实例样本最邻近的K个实例样本后,如何确定新实例样本的标签值。
取K个”邻居“平均值或者多数决策的方法,其实也就是经验损失最小化。
k值是KNN算法的一个超参数,K的含义即参考”邻居“标签值的个数。
有个反直觉的现象,K取值较小时,模型复杂度(容量)高,训练误差会减小,泛化能力减弱;K取值较大时,模型复杂度低,训练误差会增大,泛化能力有一定的提高。
原因是K取值小的时候(如k==1),仅用较小的领域中的训练样本进行预测,模型拟合能力比较强,决策就是只要紧跟着最近的训练样本(邻居)的结果。但是,当训练集包含”噪声样本“时,模型也很容易受这些噪声样本的影响(如图 过拟合情况,噪声样本在哪个位置,决策边界就会画到哪),这样会增大"学习"的方差,也就是容易过拟合。这时,多”听听其他邻居“训练样本的观点就能尽量减少这些噪声的影响。K值取值太大时,情况相反,容易欠拟合。
对于K值的选择,通常可以网格搜索,采用交叉验证的方法选取合适的K值。
KNN有两种常用的实现方法:暴力搜索法,KD树法。
KNN实现最直接的方法就是暴力搜索(brute-force search),计算输入样本与每一个训练样本的距离,选择前k个最近邻的样本来多数表决。但是,当训练集或特征维度很大时,计算非常耗时,不太可行(对于D维的 N个样本而言,暴力查找方法的复杂度为 O(D*N) ) 。如下实现暴力搜索法的代码实现:
import math
import numpy as np
from matplotlib import pyplot
from collections import Counter
def k_nearest_neighbors(data, predict, k=5):
distances = []
for group in data:
for features in data[group]: #计算新样本-predict与训练样本的距离
euclidean_distance = np.sqrt(np.sum((np.array(features)-np.array(predict))**2)) # 计算欧拉距离
# euclidean_distance = np.linalg.norm(np.array(features) - np.array(predict)) # 计算欧拉距离优化效率
distances.append([euclidean_distance, group])
# print(sorted(distances))
sorted_distances = [i[1] for i in sorted(distances)]
top_nearest = sorted_distances[:k]
# print(top_nearest) ['red','black','red']
group_res = Counter(top_nearest).most_common(1)[0][0]
confidence = Counter(top_nearest).most_common(1)[0][1] * 1.0 / k
# confidences是对本次分类的确定程度
return group_res, confidence
验证新的iris样本的分类效果(训练样本一共有3类:'blue’, 'green', ‘yellow’),输出新样本(红色点)的分类结果为yellow,并绘图表示:
# 使用iris花的数据集(部分),
dataset = {
'blue': [[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2]],
'green': [[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]],
'yellow':[[5.5, 2.4, 3.7, 1. ],
[5.8, 2.7, 3.9, 1.2],
[6. , 2.7, 5.1, 1.6],
[5.4, 3. , 4.5, 1.5],
[6. , 3.4, 4.5, 1.6]]
}
new_features = [6. , 3. , 4.8, 1.8]
# 计算预测样本在数据集中的最近邻
group_res, confidence = k_nearest_neighbors(dataset, new_features, k=3)
print(group_res, confidence)
for i in dataset:
for ii in dataset[i]:
pyplot.scatter(ii[0], ii[1], s=50, color=i) #数据集样本画图(仅展示两个特征)
pyplot.scatter(new_features[0], new_features[1], s=100, color='red') # 新样本--红色,画图展示
pyplot.show()
我们知道暴力搜索的缺点是,算法学习时只能盲目计算新样本与其他训练样本的两两距离确认出K个近邻,而近邻样本只是其中的某一部分,如何高效识别先粗筛出这部分?再计算这部分候选样本的距离。
一个解决办法是:利用KD树可以省去对大部分数据点的搜索,从而减少搜索的计算量,提高算法效率最优方法的时间复杂度为 O(n * log(n))。KD树实现KNN算法(主要为两步:1、构建KD树;2、利用KD树快速寻找K最近邻并决策。
所谓的KD树就是n个特征维度的二叉树,可以对n维空间的样本划分到对应的一个个小空间(如下图,KD树划分示意)。KD树建采用的是从m个样本的n维特征中,分别计算n个特征的取值的方差,用方差最大的第k维特征nk来作为根节点。对于这个特征,我们选择特征nk的取值的中位数nkv对应的样本作为划分点,对于所有第k维特征的取值小于nkv的样本,我们划入左子树,对于第k维特征的取值大于等于nkv的样本,我们划入右子树,对于左子树和右子树,我们采用和刚才同样的办法来找方差最大的特征来做更节点,递归的生成KD树。
比如我们有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构建kd树的具体步骤为:
1)找到划分的特征:6个数据点在x,y维度上的数据方差分别为6.97,5.37,所以在x轴上方差更大,用第1维特征建树。
2)确定划分中位数点(7,2):根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以划分点的数据是(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:划分点维度的直线x=7;
3)确定左子空间和右子空间: 分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)}。
4)用同样的办法划分左子树的节点{(2,3),(5,4),(4,7)}和右子树的节点{(9,6),(8,1)}。最终得到KD树。
最后得到的KD树如下:
当我们生成KD树以后,就可以去预测测试集里面的目标点(待预测样本)。对于一个目标点,我们首先在KD树里面找到对应包含目标点的叶子节点。以目标点为圆心,以目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话就更新最近邻。如果不相交那就简单了,我们直接返回父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。
从上面的描述可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交,根本不需要计算距离。大大节省了计算时间。
我们利用建立的KD树,具体来看对点(2,4.5)找最近邻的过程。
先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但 (4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点; 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
在KD树搜索最近邻的基础上,我们选择到了第一个最近邻样本,就把它置为已选。在第二轮中,我们忽略置为已选的样本,重新选择最近邻,这样跑k次,就得到了目标的K个最近邻,然后根据多数表决法,如果是KNN分类,预测为K个最近邻里面有最多类别数的类别。如果是KNN回归,用K个最近邻样本输出的平均值作为回归预测值。
KD 树对于低维度最近邻搜索比较好,但当K增长到很大时,搜索的效率就变得很低(维数灾难)。为了解决KD 树在高维数据上的问题,Ball 树结构被提了出来。KD 树是沿着笛卡尔积(坐标轴)方向迭代分割数据,而 Ball 树是通过一系列的超球体分割数据而非超长方体。具体可见文末参考文献2。
1、算法简单直观,易于应用于回归及多分类任务
2、 对数据没有假设,准确度高,对异常点较不敏感
3、由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此适用于类域的交叉或非线性可分的样本集。
1、计算量大,尤其是样本量、特征数非常多的时候。另外KD树、球树之类的模型建立也需要大量的内存
2、只与少量的k相邻样本有关,样本不平衡的时候,对稀有类别的预测准确率低
3、 使用懒散学习方法,导致预测时速度比起逻辑回归之类的算法慢。当要预测时,就临时进行 计算处理。需要计算待分样本与训练样本库中每一个样本的相似度,才能求得与 其最近的K个样本进行决策。
4、与决策树等方法相比,KNN无考虑到不同的特征重要性,各个归一化的特征的影响都是相同的。
5、 相比决策树、逻辑回归模型,KNN模型可解释性弱一些
6、差异性小,不太适合KNN集成进一步提高性能。
这个算法比KNN还简单。它首先把样本按输出类别归类。对于第 L类的CL个样本。它会对这CL个样本的n维特征中每一维特征求平均值,最终该类别以n个平均值形成所谓的质心点。同理,每个类别会最终得到一个质心点。
当我们做预测时,仅仅需要比较预测样本和这些质心的距离,最小的距离对于的质心类别即为预测的类别。这个算法通常用在文本分类处理上。
将最近邻算法扩展至大规模数据的方法是使用 ANN 算法(Approximate Nearest Neighbor),以彻底避开暴力距离计算。ANN 是一种在近邻计算搜索过程中允许少量误差的算法,在大规模数据情况下,可以在短时间内获得卓越的准确性。ANN 算法有以下几种:Spotify 的 ANNOY、Google 的 ScaNN、Facebook的Faiss 以及 HNSW 等 ,如下具体介绍HNSW。
HNSW 是一种基于多层图的 ANN 算法。在插入元素阶段,通过指数衰减概率分布随机选择每个元素的最大层,逐步构建 HNSW 图。这确保 layer=0 时有很多元素能够实现精细搜索,而 layer=2 时支持粗放搜索的元素数量少了 e^-2。最近邻搜索从最上层开始进行粗略搜索,然后逐步向下处理,直至最底层。使用贪心图路径算法遍历图,并找到所需邻居数量。
可以通过hnswlib库简单使用ANN算法(hnswlib还常应用于大规模向量相似度计算),如下iris花示例代码:
# pip install hnswlib # 安装hnswlib
import hnswlib
import numpy as np
# 同上iris数据集,前五个为blue类,中间5个为green类,最后5个为yellow类
dataset2 = np.array([
[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8],
[5.5, 2.4, 3.7, 1. ],
[5.8, 2.7, 3.9, 1.2],
[6. , 2.7, 5.1, 1.6],
[5.4, 3. , 4.5, 1.5],
[6. , 3.4, 4.5, 1.6]
])
# 创建索引
def fit_hnsw_index(features, ef=100, M=16, save_index_file=False):
# Convenience function to create HNSW graph
# features : list of lists containing the embeddings
# ef, M: parameters to tune the HNSW algorithm
num_elements = len(features)
labels_index = np.arange(num_elements)
EMBEDDING_SIZE = len(features[0]) # Declaring index
# possible space options are l2, cosine or ip
p = hnswlib.Index(space='l2', dim=EMBEDDING_SIZE) # Initing index - the maximum number of elements should be known
p.init_index(max_elements=num_elements, ef_construction=ef, M=M) # Element insertion
int_labels = p.add_items(features, labels_index) # Controlling the recall by setting ef
# ef should always be > k
p.set_ef(ef)
# If you want to save the graph to a file
if save_index_file:
p.save_index(save_index_file)
return p
p = fit_hnsw_index(dataset2) # 创建 HNSW 索引
创建索引后,通过索引快速查询到k个近似近邻(Approximate Nearest Neighbor),在示例数据集的结果与KNN算法的结果是一样的,近邻的样本索引是[9,12,14],也就是大部分近邻(即第12,14个样本)为“yellow”,最后分类为“yellow”。
# 通过HNSW索引快速查询k个近邻
ann_neighbor_indices, ann_distances = p.knn_query(new_features, 3)
print('K个近邻:',ann_neighbor_indices)
print('距离值:',ann_distances)
参考文献 1、 https://www.joinquant.com/view/community/detail/c2c41c79657cebf8cd871b44ce4f5d97 2、 https://www.cnblogs.com/pinard/p/6061661.html
3、https://github.com/spotify/annoy 4、https://github.com/nmslib/hnswlib
文章首发公众号“算法进阶”,公众号阅读原文可访问文章相关代码
谈到人工智能(AI)算法,常见不外乎有两方面信息:铺天盖地各种媒体提到的高薪就业【贩卖课程】、知乎上热门的算法岗“水深火热 灰飞烟灭”的梗【贩卖焦虑】。
其实,这两方面都是存在的,但都很片面,这里不加赘述。客观地说,数字化、智能化是人类社会发展的趋势,而当下人工智能无疑是一大热门,那是蓝海还是火海?我们回到老道理—水的深度,只有你自己去试试水才知道。
当你对上面情况有了初步的了解并想试试水,需要面对的问题是:AI入门容易吗?
答案其实是否定的,难!AI领域需要钻研算法原理、大量复杂的公式及符号、无所适从的项目都是劝退一时热度初学者的原因。但这些原因对于一个初学者,根本上是面对这样困难的学科却缺乏合适方法导致的。反问一个玩笑,程序员怎么会没有方法呢?随手就定义一个Python方法(funtion)
def funtion():
return 'haha,往下继续看'回到笔者,一名普普通通的程序员,当初也是误打误撞学习Python入门到机器学习、深度学习,至今有4个年头,踩了很多坑,下文说到的学习方法、路径也就填坑试错的经验罢了。
本文适用于AI领域了解不深、有些(高中+)基础知识且有自学兴趣的同学。对于已上岸的同学有兴趣就跳着看吧。
说到学习方法,其实我们谈到的人工智能之所以智能,核心在于有学习能力。而人工智能学习过程有两个要素:
1、学习目标是什么(--什么目标函数)?
2、如何达到目标(--什么算法)?
人工智能领域很多思路和人类学习是很共恰的!可以发现这两个问题也是我们学习这门学科需要回答的。
我们的学习目标比较清楚,就是入门人工智能领域,能完成一个AI相关的任务,或者找到相关的工作。
1、入门人工智能是个宽泛的目标,因此还得 将目标拆分成阶段性目标才易于执行,可以对应到下面--学习路线及建议资源的各个节点。
2、学习人工智能这门学科,需要提醒的是这本来就是件难事,所以实在搞不懂的知识可以放在后面补下,不要奢求一步到位(当然天赋了得另说),不要想一下子成为专家,可以从:懂得调用现成的算法模块(scikit-learn、tensorflow)做项目 -进阶-》懂得算法原理进一步精用、调优算法 -进阶-》领域专家。保持学习,循序渐进才是啃硬骨头的姿势。
3、啃硬骨头过程无疑是艰难的,所以慢慢地培养兴趣和及时的结果反馈是很重要的。这方面上,边学边敲代码是必须的,结合代码实践学习效率会比较高,还可以及时看到学习成果,就算是啃硬骨头看到牙印越来越深,不也是成果,也比较不容易放弃!
对应到学习路线,简单来说如下几方面:
--》宽泛了解领域,建立一定兴趣
--》基础知识、工具准备
--》机器学习|深度学习的入门课程、书籍及项目实践
--》(面试准备)
--》自行扩展:工作中实战学习 或 学术界特定领域钻研,经典算法原理、项目实践
首先对人工智能领域有个宽泛的了解,有自己的全局性的认识,产生一些判断,才不会人云亦云地因为“薪资高、压力大等” 去做出选择或者放弃。你做的准备调研越多,确认方向后越不容易放弃。
人工智能(Artificial Intelligence,AI)之研究目的是通过探索智慧的实质,扩展人类智能——促使智能主体会听(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说(语音合成、人机对话等)、会思考(人机对弈、专家系统等)、会学习(知识表示,机器学习等)、会行动(机器人、自动驾驶汽车等)。一个经典的AI定义是:“ 智能主体可以理解数据及从中学习,并利用知识实现特定目标和任务的能力。
从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习方面的(其他方面的如专家系统、知识库等技术较为没落)。关于人工智能的发展历程,可以看看我之前一篇文章人工智能简史。
机器学习是指非显式的计算机程序可以从数据中学习,以此提高处理任务的水平,机器学习常见的任务有分类任务(如通过逻辑回归模型判断邮件是否为垃圾邮件类)、回归预测任务(线性回归模型预测房价)等等。深度学习是机器学习的一个子方向,是当下的热门,它通过搭建深层的神经网络模型以处理任务。
从应用领域上看,人工智能在众多的应用领域上面都有一定的发展,有语言识别、自然语言处理、图像识别、数据挖掘、推荐系统、智能风控、机器人等方面。值得注意的的是,不同应用领域上,从技术层面是比较一致,但结合到实际应用场景,所需要的业务知识、算法、工程上面的要求,差别还是相当大的。回到应用领域的选择,可以结合技术现在的发展情况、自己的兴趣领域再做判断。
学习人工智能需要先掌握编程、数学方面的基本知识:AI算法工程师首先是一名程序员,掌握编程实现方法才不将容易论知识束之高阁。而数学是人工智能理论的奠基,是必不可少的。
**编程语言之于程序员, 如宝剑之于侠士。**编程语言就是程序员改变、创造数字虚拟世界的交互工具。
先简单介绍信息技术(IT)行业的情况,IT领域广泛按职能可以分为前端、后端、人工智能、嵌入式开发、游戏开发、运维、测试、网络安全等方面。前端常用技术栈为js\css\html,后端常用技术栈有Java\go\C++\php\Python等。
在人工智能领域,Python使用是比较广泛的,当然其他的语言也是可行的,如Java、C++、R语言等。语言也就工具,选择个适合的就好。结合自己的历程及语言的特性,AI小白还是建议可以从Python学起,理由如下:
1、因为其简单的语法及灵活的使用方法,Python很适合零基础入门;
2、Python有丰富的机器学习库,极大方便机器学习的开发;
3、Python在机器学习领域有较高的使用率,意味着社区庞大,应用范围广,市场上(具体可到招聘软件了解下)有较多的工作机会;
1、多敲代码:只看书、视频而不敲代码是初学者的一个通病。要记住的是“纸上得来终觉浅”,程序员是一个工匠活,需要动手敲代码实践,熟能生巧。
2、 多谷歌: 互联网的信息无所不包的,学会利用互联网自己解决问题是一项基本功。不懂可以谷歌,业界一句有趣的话:程序员是面向谷歌/stackoverflow编程的;
以下资源只是一些个人的一些偏好推荐,挑一两种适合自己的资源学习就可以,不用全部都学浪费精力。如果都觉得不合适,按照自己的学习方式即可。
1、【Python入门书】首推Python经典书《Python编程从入门到实践.pdf(https://github.com/aialgorithm/AiPy/》,知识点通俗易懂,而且结合了项目实践,很适合初学者。注:Python在爬虫、web开发、游戏开发等方向也有应用,推荐本书主要学习下Python语法,而书后面的项目实战像有游戏开发\web开发,和机器学习关系不大,可以略过\自行了解下就好。
2、【Python入门教程】廖雪峰的Python在线学习教程,一个很大的特色是可以直接在线运行Python代码。
3、【Python入门视频】如果看书过于枯燥,可以结合视频学习,Python入门学习报培训班学习有点浪费,可以直接网易云课堂、Bilibili搜索相关的Python学习视频。我之前是看小甲鱼零基础入门学习Python课程,边看边敲敲代码,觉得还不错。
4、【Python机器学习库】学习完Python语法,再学习了解下Python上现成的机器学习库(模块包),了解基本功能学会调用它们(熟练掌握它们,主要还是要结合后面项目边学边实践才比较有效的。),一个初级的算法工程师(调包侠)基本就练成了。重要的机器学习库有:
pandas 数据分析、numpy 数值计算库、matplotlib可视化工具,推荐《利用pandas数据分析》有涵盖了这几部分内容。
scikit-learn 包含机器学习建模工具及算法,可以了解下官方文档https://scikit-learn.org.cn。
用于搭建深度学习的神经网络模型的库有:keras、tensorflow、Pytorch等,其中keras更为简单易用,可以参考Keras官方文档https://keras.io/zh,以及Keras之父写的[《Python深度学习》](https://github.com/aialgorithm/AiPy/tree/master/深度学习)
5、【Python进阶书】《Python Cookbook》、《流畅的Python》 这两本内容难度有提升,适合Python语法的进阶。
1、数学无疑是重要的,有良好的数学基础对于算法原理的理解及进阶至关重要。但这一点对于入门的初学者反而影响没那么大,对于初学者如果数学基础比较差,有个思路是先补点“数学的最小必要知识”:如线性代数的矩阵运算;高等数学的梯度求导;概率的条件、后验概率及贝叶斯定理等等。这样可以应付大部分算法的理解。
2、如果觉得数学有难度,数学公式、知识的理解建议不用硬啃,不懂时再反查,遇到再回来补效果会好很多。(如果你的数学没有问题,忽略这些,直接复习大学教材补下基础)
【数学基础知识】推荐黄博翻译整理的机器学习相关的数学基础知识,内容简要,还是挺不错的。
对于程序员,好的工具就是生产力!
1、 搜索引擎:学习开发的过程,很经常搜索问题、解决bug。搜索引擎的内容质量 首推谷歌,其次bing,再者才是百度、知乎等。谷歌如果使用不了,试试谷歌助手、科学翻墙、谷歌镜像网站,网上有教程自行了解。
2、翻译:AI领域最新的研究成果、论文基本都是英文的,而如果英文阅读比较一般,可以备个有道词典、wps文档翻译。
3、Python编辑器:首推JupyterLab,JupyterLab很方便数据分析操作,可以单元格中逐步运行代码验证结果。建议直接下载安装个anaconda,里面都有。Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本Python并存、切换以及各种第三方包安装问题。
下载地址:
https://www.anaconda.com/download/
推荐选Anaconda (python 3.7版本)
IDE:推荐使用pycharm,社区版免费
下载地址:https://www.jetbrains.com/
安装教程:
Anaconda+Jupyter notebook+Pycharm:
https://zhuanlan.zhihu.com/p/59027692
Ubuntu18.04深度学习环境配置(CUDA9+CUDNN7.4+TensorFlow1.8):
https://zhuanlan.zhihu.com/p/50302396
深度学习是机器学习的子分支,与传统机器学习有些差异的地方(如特征生成、模型定义方面), 因此两者可以分开学习。都学习的话,建议可以先学机器学习再学深度学习。
机器学习\深度学习的内容可以分为两部分,**一部分是算法原理的理解,如神经网络模型正向反向传播原理、SVM原理、GBDT原理等等,这部分内容的理解相对较难,学习周期较长。**另一部分是算法工程实现的知识,如现实问题的理解、如何清洗数据、生成特征、选择模型及评估,具体可以看我之前的文章《一文全览机器学习建模流程(Python代码)》,这部分是比较通用的一套操作流程,学习周期比较短且容易看到实际成果。
对于初学者的建议,可以“先知其然,再知其所以然”,跟着课程\书学习,明白大致的算法原理及工程上是如何做的。再用简单的算法整个流程走一遍,结合实践过程中不断的比较和尝试各种算法,更容易搞透算法原理,而且这样可以避免云里雾里地学习各种算法原理。
以下相关资源推荐,同样找一两种合适的资源学习即可。
1、【机器学习视频】《吴恩达的机器学习课程》github.com/aialgorithm/AiPy/,很经典的入门课程,附笔记解析及代码。
2、【机器学习书】[《machine learning yearning_吴恩达》 ] (https://github.com/aialgorithm/AiPy/tree/master/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0) 是吴恩达历时两年,根据自己多年实践经验整理出来的一本机器学习、深度学习实践经验宝典。
3、【机器学习书】《统计学习方法》 李航老师经典的机器学习书,书中的算法原理讲解还是比较细的。链接的资源有附上书中算法的代码实现、课件及第一版的书。(现在已经有第二版的书,可以买一本慢慢看)
4、【机器学习书】《机器学习(西瓜书)_周志华》 机器学习经典教材,难度适合进阶,里面的一些概念公式还是要有一定基础的,不太适合入门自学。(可搭配datawhale的南瓜书本理解难点公式)
5、【深度学习视频】《吴恩达的深度学习课程》github.com/aialgorithm/AiPy/应该是国内大多数人的入门课程,附笔记解析及代码。
6、【深度学习书】《深度学习(花书)》 AI大佬Ian Goodfellow的深度学习领域经典著作,知识点很系统全面,但还是需要一定基础才好看懂,初学者可以结合视频、花书笔记辅助理解。
7、【深度学习书】《python深度学习》keras之父的经典著作,通俗易懂适合入门。
8、【深度学习书】《深度学习实战》 这本书的结果和《花书》有些相似之处,原理讲解比较通俗,还有详细的代码实践。不足的地方是代码是用Python2写的有些过时。
9、【深度学习书】《动手学深度学习》 李沐大佬合著的深度学习入门教程及代码实践。
10、【深度学习论文】深度学习综述 :2015年Nature上的论文,由深度学习界的三巨头所写,读这一篇论文就可以概览深度学习了。这篇论文有同名的中文翻译。
注:要全面了解一个技术领域,找找这个领域的综述论文是一个超实用的技巧。
11、【实战项目】 推荐实战下国外的Kaggle、国内天池等竞赛项目。从头到尾地参加一两个机器学习项目,并取得不错的分数,基本上就差不多了。安利个Datawhale小队整理的国内外经典竞赛的项目方案及代码实现 https://github.com/datawhalechina/competition-baseline
对于大部分入门的初学者,要真正算入门人工智能领域,找一份相关的工作是必不可少的,当你有(哪怕一点点)相关的工作经验后,这个领域工作面试就比较好混得开了。
很多初学者可能有个困惑,学习到什么样程度、多久才能找到相关的工作机会呢?这个不好回答,和学习准备的程度、市场招聘情况、运气等有关,只能说觉得学得差不多了就可以找面试机会试下水(以个人学习为例,学习了Python+吴恩达机器学习\深度学习视频+几个书本\数据竞赛项目+刷面试题,前前后后差不多用了半年。)
准备面试找工作,首先要了解下市场情况及招聘要求,通常无非要求有相关的论文著作、工作经历、项目经验、对算法的理解。撇开第一、二项的论文、工作经历不谈。对于初学者,面试的主要比重是项目经验及算法的理解。
项目经验就结合项目实战的做法和理解(这些最好有博客记录)。而算法原理除了平时的积累,刷下面试题是很关键的,毕竟面试内容与实际工作内容很多时候像是“造火箭与拧螺丝的关系”。
1、 基础数据结构与算法,LeetCode算法题库:https://github.com/apachecn/Interview/tree/master/docs/Algorithm;
2、Python基础算法实现: https://github.com/TheAlgorithms/Python;
3、Python面试题 https://github.com/taizilongxu/interview_python
4、Datawhale小队整理的面试宝典,内容包括基础算法数据结构、机器学习,CV,NLP,推荐,开发等。https://github.com/datawhalechina/daily-interview
5、机器学习面试题,这仓库后面就没有更新了,有些内容可能有点过时https://github.com/DarLiner/Algorithm_Interview_Notes-Chinese
6、面试技巧:推荐阅读程序员面试完全指南
学习到这里,可以说是踏入AI领域的门了。俗话说“师傅领进门,修行在个人”,本文仅能帮助有兴趣的同学简单入门这个领域,而要在这领域成为专家是很困难的,是需要长期的努力积累的。再者,IT行业技术更新迭代快,保持学习才是王道。
最后,希望这篇文章可以帮助到大家,共同学习进步吧。
码字不易,如觉得本文有帮助,您的关注点赞是最大的支持!
文章首发于算法进阶,公众号阅读原文可访问--学习资源推荐--
业内常说数据决定了模型效果上限,而机器学习算法是通过数据特征做出预测的,好的特征可以显著地提升模型效果。这意味着通过特征生成(即从数据设计加工出模型可用特征),是特征工程相当关键的一步。本文从特征生成作用、特征生成的方法(人工设计、自动化特征生成)展开阐述并附上代码。
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。
——Andrew Ng
特征生成是特征提取中的重要一步,作用在于:
本文示例的数据集是客户的资金变动情况,如下数据字典:
cust_no:客户编号;I1 :性别;I2:年龄 ;E1:开户日期;
B6 :近期转账日期;C1 (后缀_fir表示上个月):存款;C2:存款产品数;
X1:理财存款; X2:结构性存款; label:资金情况上升下降情况。
这里安利一个超实用Python库,可以一键数据分析(数据概况、缺失、相关性、异常值等等),方便结合数据分析报告做特征生成。
# 一键数据分析
import pandas_profiling
pandas_profiling.ProfileReport(df)
特征生成方法可以分为两类:聚合方式、转换方式。
聚合方式是指对存在一对多的字段,将其对应多条记录分组聚合后统计平均值、计数、最大值等数据特征。
如以上述数据集,同一cust_no对应多条记录,通过对cust_no(客户编号)做分组聚合,统计C1字段个数、唯一数、平均值、中位数、标准差、总和、最大、最小值,最终得到按每个cust_no统计的C1平均值、最大值等特征。
# 以cust_no做聚合,C1字段统计个数、唯一数、平均值、中位数、标准差、总和、最大、最小值
df.groupby('cust_no').C1.agg(['count','nunique','mean','median','std','sum','max','min'])
此外还可以pandas自定义聚合函数生成特征,比如加工聚合元素的平方和:
# 自定义分组聚合统计函数
def x2_sum(group):
return sum(group**2)
df.groupby('cust_no').C1.apply(x2_sum)
转换方式是指对字段间做加减乘除等运算生成数据特征的过程,对不同字段类型有不同转换方式。

import numpy as np
# 前后两个月资金和
df['C1+C1_fir'] = df['C1']+df['C1_fir']
# 前后两个月资金差异
df['C1-C1_fir'] = df['C1']-df['C1_fir']
# 产品数*资金
df['C1*C2'] = df['C1']*df['C2']
# 前后两个月资金变化率
df['C1/C1_fir'] = df['C1']/df['C1_fir'] - 1
df.head()

import numpy as np
df['C1_sum'] = np.sum(df[['C1_fir','C1']], axis = 1)
df['C1_var'] = np.var(df[['C1_fir','C1']], axis = 1)
df['C1_max'] = np.max(df[['C1_fir','C1']], axis = 1)
df['C1_min'] = np.min(df[['C1_fir','C1']], axis = 1)
df['C1-C1_fir_abs'] = np.abs(df['C1-C1_fir'])
df.head()
# 排序特征
df['C1_rank'] = df['C1'].rank(ascending=0, method='dense')
df.head()
截取
当字符类型的值过多,通常可对字符类型变量做截取,以减少模型过拟合。如具体的家庭住址,可以截取字符串到城市级的粒度。
字符长度
统计字符串长度。如转账场景中,转账留言的字数某些程度可以刻画这笔转账的类型。
频次
通过统计字符出现频次。如欺诈场景中地址出现次数越多,越有可能是团伙欺诈。
# 字符特征
# 由于没有合适的例子,这边只是用代码实现逻辑,加工的字段并无含义。
#截取第一位字符串
df['I1_0'] = df['I1'].map(lambda x:str(x)[:1])
# 字符长度
df['I1_len'] = df['I1'].apply(lambda x:len(str(x)))
display(df.head())
# 字符串频次
df['I1'].value_counts()
常用的有计算日期间隔、周几、几点等等。
# 日期类型
df['E1_B6_interval'] = (df.E1.astype('datetime64[ns]') - df.B6.astype('datetime64[ns]')).map(lambda x:x.days)
df['E1_is_month_end'] = pd.to_datetime(df.E1).map(lambda x :x.is_month_end)
df['E1_dayofweek'] = df.E1.astype('datetime64[ns]').dt.dayofweek
df['B6_hour'] = df.B6.astype('datetime64[ns]').dt.hour
df.head()
传统的特征工程方法通过人工构建特征,这是一个繁琐、耗时且容易出错的过程。自动化特征工程是通过Fearturetools等工具,从一组相关数据表中自动生成有用的特征的过程。对比人工生成特征会更为高效,可重复性更高,能够更快地构建模型。
Featuretools是一个用于执行自动化特征工程的开源库,它有基本的3个概念:
1)Feature Primitives(特征基元):生成特征的常用方法,分为聚合(agg_primitives)、转换(trans_primitives)的方式。可通过如下代码列出featuretools的特征加工方法及简介。
import featuretools as ft
ft.list_primitives()
2)Entity(实体) 可以被看作类似Pandas DataFrame, 多个实体的集合称为Entityset。实体间可以根据关联键添加关联关系Relationship。
# df1为原始的特征数据
df1 = df.drop('label',axis=1)
# df2为客户清单(cust_no唯一值)
df2 = df[['cust_no']].drop_duplicates()
df2.head()
# 定义数据集
es = ft.EntitySet(id='dfs')
# 增加一个df1数据框实体
es.entity_from_dataframe(entity_id='df1',
dataframe=df1,
index='id',
make_index=True)
# 增加一个df2数据实体
es.entity_from_dataframe(entity_id='df2',
dataframe=df2,
index='cust_no')
# 添加实体间关系:通过 cust_no键关联 df_1 和 df 2实体
relation1 = ft.Relationship(es['df2']['cust_no'], es['df1']['cust_no'])
es = es.add_relationship(relation1)
3)dfs(深度特征合成) : 是从多个数据集创建新特征的过程,可以通过设置搜索的最大深度(max_depth)来控制所特征生成的复杂性
## 运行DFS特征衍生
features_matrix,feature_names = ft.dfs(entityset=es,
target_entity='df2',
relationships = [relation1],
trans_primitives=['divide_numeric','multiply_numeric','subtract_numeric'],
agg_primitives=['sum'],
max_depth=2,n_jobs=1,verbose=-1)
4.2.1 内存溢出问题
Fearturetools是通过工程层面暴力生成所有特征的过程,当数据量大的时候,容易造成内存溢出。解决这个问题除了升级服务器内存,减少njobs,还有一个常用的是通过只选择重要的特征进行暴力衍生特征。
4.2.2 特征维度爆炸
当原始特征数量多,或max_depth、特征基元的种类设定较大,Fearturetools生成的特征数量巨大,容易维度爆炸。这是就需要考虑到特征选择、特征降维,常用的特征选择方法可以参考上一篇文章: Python特征选择
注:本文源码链接:Github。(公众号阅读原文可访问链接)
机器学习的优化(目标),简单来说是:搜索模型的一组参数 w,它能显著地降低代价函数 J(w),该代价函数通常包括整个训练集上的性能评估(经验风险)和额外的正则化(结构风险)。
机器学习的优化与传统优化不同,不是简单地根据数据的求解最优解,在大多数机器学习问题中,我们关注的是测试上性能度量P的优化。
当我们机器学习的学习目标是极大化降低(经验)损失函数,这点和传统的优化是比较相似的,那么如何实现这个目标呢?我们第一反应可能是直接求解损失函数最小值的公式/解析解(如最小二乘法),获得最优的模型参数。但是,通常机器学习模型的损失函数较复杂,很难直接求最优解。幸运的是,我们还可以通过优化算法(如遗传算法、梯度下降算法、牛顿法等)有限次迭代优化模型参数,以尽可能降低损失函数的值,得到较优的参数值(数值解)。上述去搜索一组最\较优参数解w所使用的算法,即是优化算法。下图优化算法的总结:(图与本文内容较相符,摘自@TeeKee)
最小二乘法常用在机器学习回归模型求解析解(对于复杂的深度神经网络无法通过这方法求解),其几何意义是高维空间中的一个向量在低维子空间的投影。
如下以一元线性回归用最小二乘法求解为例。
其损失函数mse为:
对损失函数求极小值,也就是一阶导数为0。通过偏导可得关于参数a及偏置b的方程组:
代入数值求解上述线性方程组,可以求解出a,b的参数值。也就是求解出上图拟合的那条直线ax+b。
注:神经网络优化算法以梯度下降类算法较为高效,也是主流的算法。而遗传算法、贪心算法、模拟退火等优化算法用的比较少。
遗传算法(Genetic Algorithms,GA)是模拟自然界遗传和生物进化论而成的一种并行随机搜索最优化方法。与自然界中“优胜略汰,适者生存”的生物进化原理相似,遗传算法就是在引入优化参数形成的编码串联群体中,按照所选择的适应度函数并通过遗传中的选择、交叉和变异对个体进行筛选,使适应度值号的个体被保留,适应度差的个体被淘汰,新的群体既继承了上一代的信息,又优于上一代。这样反复循环迭代,直至满足条件。
梯度下降算法可以直观理解成一个下山的方法,将损失函数J(w)比喻成一座山,我们的目标是到达这座山的山脚(即求解出最优模型参数w使得损失函数为最小值)。
下山要做的无非就是“往下坡的方向走,走一步算一步”,而在损失函数这座山上,每一位置的下坡的方向也就是它的负梯度方向(直白点,也就是山的斜向下的方向)。在每往下走到一个位置的时候,求解当前位置的梯度,向这一步所在位置沿着最陡峭最易下山的位置再走一步。这样一步步地走下去,一直走到觉得我们已经到了山脚。
当然这样走下去,有可能我们不是走到山脚(全局最优,Global cost minimun),而是到了某一个的小山谷(局部最优,Local cost minimun),这也后面梯度下降算法的可进一步调优的地方。
对应的算法步骤,直接截我之前的图:
梯度下降是一个大类,常见的梯度下降算法及优缺点,如下图:
对于深度学习而言“随机梯度下降, SGD”,其实就是基于小批量(mini-batch)的随机梯度下降,当batchsize为1也就是在线学习优化。
随机梯度下降是在梯度下降算法效率上做了优化,不使用全量样本计算当前的梯度,而是使用小批量(mini-batch)样本来估计梯度,大大提高了效率。原因在于使用更多样本来估计梯度的方法的收益是低于线性的,对于大多数优化算法基于梯度下降,如果每一步中计算梯度的时间大大缩短,则它们会更快收敛。且训练集通常存在冗余,大量样本都对梯度做出了非常相似的贡献。此时基于小批量样本估计梯度的策略也能够计算正确的梯度,但是节省了大量时间。
对于mini-batch的batchsize的选择是为了在内存效率(时间)和内存容量(空间)之间寻找最佳平衡。
batchsize 不能太大。
较大的batch可能会使得训练更快,但可能导致泛化能力下降。更大的batch size 只需要更少的迭代步数就可以使得训练误差收敛,还可以利用大规模数据并行的优势。但是更大的batch size 计算的梯度估计更精确,它带来更小的梯度噪声。此时噪声的力量太小,不足以将参数带出一个尖锐极小值的吸引区域。这种情况需要提高学习率,减小batch size 提高梯度噪声的贡献。
batchsize不能太小。
小的batchsize可以提供类似正则化效果的梯度噪声,有更好的泛化能力。但对于多核架构来讲,太小的batch并不会相应地减少计算时间(考虑到多核之间的同步开销)。另外太小batchsize,梯度估计值的方差非常大,因此需要非常小的学习速率以维持稳定性。如果学习速率过大,则导致步长的变化剧烈。
还可以自适应调节batchsize,参见《Small Batch or Large Batch? Peifeng Yin》
Momentum算法在梯度下降中加入了物理中的动量的概念,模拟物体运动时候的惯性,即在更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度对之前的梯度进行微调,这样一来,可以在一定程度上增加稳定性,从而学习的更快,并且有一定的摆脱局部最优的能力。
该算法引入了变量 v 作为参数在参数空间中持续移动的速度向量,速度一般可以设置为负梯度的指数衰减滑动平均值。对于一个给定需要最小化的代价函数,动量可以表达为:更新后的梯度 = 折损系数γ动量项+ 学习率ŋ当前的梯度。
其中 ŋ 为学习率,γ ∈ (0, 1] 为动量系数,v 是速度向量。一般来说,梯度下降算法下降的方向为局部最速的方向(数学上称为最速下降法),它的下降方向在每一个下降点一定与对应等高线的切线垂直,因此这也就导致了 GD 算法的锯齿现象。加入动量法的梯度下降是令梯度直接指向最优解的策略之一。
Nesterov动量是动量方法的变种,也称作Nesterov Accelerated Gradient(NAG)。在预测参数下一次的位置之前,我们已有当前的参数和动量项,先用(θ−γvt−1)下一次出现位置的预测值作为参数,虽然不准确,但是大体方向是对的,之后用我们预测到的下一时刻的值来求偏导,让优化器高效的前进并收敛。
在平滑的凸函数的优化中,对比批量梯度下降,NAG 的收敛速度超出 1/k 到 1/(k^2)
Adagrad 亦称为自适应梯度(adaptive gradient),允许学习率基于参数进行调整,而不需要在学习过程中人为调整学习率。Adagrad 根据不常用的参数进行较大幅度的学习率更新,根据常用的参数进行较小幅度的学习率更新。然而 Adagrad 的最大问题在于,在某些情况,学习率变得太小,学习率单调下降使得网络停止学习过程。
其中是梯度平方的积累量s,在进行参数更新时,学习速率要除以这个积累量的平方根,其中加上一个很小值是ε为了防止除0的出现。由于s 是逐渐增加的,那么学习速率是相对较快地衰减的。
RMSProp 算是对Adagrad算法的改进,主要是解决学习速率过快衰减的问题,它不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数γ 来控制历史信息的获取多少。
Adam 算法为两种随机梯度下降的优点集合:
Adam 算法同时获得了 AdaGrad 和 RMSProp 算法的优点,像RMSprop 一样存储了过去梯度的平方 v的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 m 的指数衰减平均值:
如果 m 和 v被初始化为 0 向量,那它们就会向 0 偏置,所以做了偏差校正放大它们:
梯度更新能够从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。
牛顿法和梯度下降法相比,两者都是迭代求解,不过梯度下降法是梯度求解(一阶优化),而牛顿法是用二阶的海森矩阵的逆矩阵求解。相对而言,使用牛顿法收敛更快(迭代更少次数),但是每次迭代的时间比梯度下降法长(计算开销更大,实际常用拟牛顿法替代)。
通俗来讲,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,后面坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。但是,牛顿法对初始值有一定要求,在非凸优化问题中(如神经网络训练),牛顿法很容易陷入鞍点(牛顿法步长会越来越小),而梯度下降法则更容易逃离鞍点(因此在神经网络训练中一般使用梯度下降法,高维空间的神经网络中存在大量鞍点)。
综上, 对于神经网络的优化,常用梯度下降等较为高效的方法。梯度下降算法类有SGD、Momentum、Adam等算法可选。对于大多数任务而言,通常可以直接先试下Adam,然后可以继续在具体任务上验证不同优化器效果。
文章首发公众号“算法进阶”,更多原创文章敬请关注
个人github:https://github.com/aialgorithm
一句话介绍推荐系统的作用: 高效地达成用户与意向对象的匹配。
推荐系统是建立在海量数据挖掘基础上,高效地为用户提供个性化的决策支持和信息服务,以提高用户体验及商业效益。常见的推荐应用场景如:
构建推荐系统前,首先要根据业务目标确定推荐系统的优化目标,对于不同的应用场景,推荐系统(模型学习)关注的是不同的业务指标,比如:
对于电商推荐,不仅要预测用户的点击率(CTR),更重要的是预测用户的转化率(CVR);
对于内容推荐,业务关心的除了CTR,还有阅读/观看时长、点赞、转发、评论等指标;
由于不同的业务指标可能存在一些联系,技术实现上,大多数时候都会设计一个多目标优化的框架(如:CTR和CVR模型进行Cotrain),共同进行模型的训练与预测,各个任务之间能够更好地共享信息。
推荐系统基于海量的物品数据的挖掘,通常由 召回层→排序层(粗排、精排、重排)组成,不同的层次的组成,其实也就是信息筛选的漏斗,这也是工程上效率的需要,把意向对象的数量从粗犷到精细化的筛选过程(这过程不就像是找工作的时候,HR根据简历985/211粗筛出一部分,再做技能匹配及面试精准筛选,最终敲定合适的人选):
召回层:从物品库中根据多个维度筛选出潜在物品候选集(多路召回),并将候选集传递给排序环节。在召回供给池中,整个召回环节的输出量往往以万为单位。召回层主要作用是在海量的候选做粗筛,由于召回位置靠前且输入空间较大,所以时延要求较高,偏好简单方法,简单快速地确定候选集。常用方法有:召回策略(如推荐热门文章、命中某类标签的文章等等)、双塔模型(学习用户及物品的embedding,内积表示预测意向概率)、FM及CF等模型做召回、知识图谱(知识图谱表示学习,知识推理用户对物品的兴趣程度)、用户(多兴趣)行为序列预测做召回等等。
粗排层:利用规则或者简单模型对召回的物品进行排序,并根据配额进行截断,截取出 Top N 条数据输出给精排层,配额一般分业务场景,整个粗排环节的输出量往往以千为单位。
精排层:利用大量特征的复杂模型,对物品进行更精准的排序,然后输出给重排层,整个精排环节的输出量往往以百为单位。粗排、精排的环节是推荐系统最关键,也是最具有技术含量的部分,使用的方法有深度学习推荐模型(Deep& Cross、NFM等)、强化学习等等。
重排层:主要以产品策略为导向进行重排(及融合),常见策略如去除已曝光、去重、打散、多样性、新鲜度、效益优先等策略,并根据点击回退在列表中插入新的信息来提升体验,最后生成用户可见的推荐列表,整个融合和重排环节的输出量往往以几十为单位。
对于完整的推荐系统结构,还需要考虑一个问题是:对于新的用户、新的物品如何有效推荐的问题,也就是**”冷启动“**的问题,因为没有太多数据和特征来学习召回及排序模型,所以往往要用一些冷启动方法替代来达到目的(这个目的不只是提高点击等消费指标,更深层的可能会极大的带动业务增长)。
冷启动一般分为三类,用户冷启动、物品冷启动还有系统冷启动,常用的冷启动方法如:
纵观推荐技术的发展史,简单来说就是特征工程自动化的过程,从人工设计特征+LR,到模型实现自动特征交互:如基于LR的自动特征交互组合的因式分解机FM及FFM 以及 GBDT树特征+LR ,到自动提取高层次特征的深度学习模型(DNN)。
推荐系统整体技术栈可以分为传统机器学习推荐及深度学习推荐,而不同的推荐层偏好不同(复杂度、精确度)的模型或策略(图来源:王喆老师的专栏):
传统机器学习推荐可以简单划分为协同过滤算法及基于逻辑回归的序列算法:
协同过滤算法可以简单划分为基于用户/物品的方法:
通过分析用户喜欢的物品,我们发现如果两个用户(用户A 和用户 B)喜欢过的物品差不多,则这两个用户相似。此时,我们可以将用户 A 喜欢过但是用户 B 没有看过的物品推荐给用户 B。基于用户的协同过滤算法(UserCF)的具体实现思路如下:
(1)计算用户之间的相似度;
(2)根据用户的相似度,找到这个集合中用户未见过但是喜欢的物品(即目标用户兴趣相似的用户有过的行为)进行推荐。
通过分析用户喜欢的物品,我们发现如果两个物品被一拨人喜欢,则这两个物品相似。此时,我们就会将用户喜欢相似物品中某个大概率物品推荐给这群用户。基于物品的协同过滤算法的具体实现思路如下:
(1)计算物品之间的相似度;
(2)就可以推荐给目标用户没有评价过的相似物品。
对于协同过滤算法,它本质上是一个矩阵填充问题,可以直接通过相似度计算(如基于用户的相似、基于物品的相似等)去解决。但有一问题是现实中的共现矩阵中有绝大部分的评分是空白的,由于数据稀疏,因此在计算相似度的时候效果就会大打折扣。这里我们可以借助矩阵分解方法,找到用户和物品的表征向量(K个维度,超参数),通过对用户向量和物品向量的内积则是用户对物品的偏好度(预测评分)。
由于矩阵分解引入了隐因子的概念,模型解释性很弱。另外的,它只简单利用了用户对物品的打分(特征维度单一),很难融入更多的特征(比如用户信息及其他行为的特征,商品属性的特征等等)。而这些缺陷,下文介绍的逻辑回归的相关算法可以很好地弥补。
逻辑回归(LR)由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。它是一种广义线性的分类模型且其模型结构可以视为单层的神经网络,由一层输入层、一层仅带有一个sigmoid激活函数的神经元的输出层组成,而无隐藏层。
LR模型计算可以简化成两步,“通过模型权重[w]对输入特征[x]线性求和 ,然后sigmoid激活输出概率”。其中,sigmoid函数是一个s形的曲线,它的输出值在[0, 1]之间,在远离0的地方函数的值会很快接近0或1。
由于LR是线性模型,特征表达(特征交互)能力是不足的,为提高模型的能力,常用的有特征工程的方法或者基于模型的方法。
通过人工结合业务设计特征、特征衍生工具(如FeatureTools)暴力生成特征 以及 特征离散化编码等特征工程的方法,为LR引入非线性的表达。具体可以参见【逻辑回归优化】
另外还可以基于模型的方法提升特征交互的能力。如POLY2、引入隐向量的因子分解机(FM)可以看做是LR的基础上,对所有特征进行了两两交叉,生成非线性的特征组合。
但FM等方法只能够做二阶的特征交叉,更高阶的,可以利用GBDT自动进行筛选特征并生成特征组合,也就是提取GBDT子树的特征划分及组合路径作为新的特征,再把该特征向量当作LR模型输入,也就是经典的GBDT +LR方法。(需要注意的,GBDT子树深度太深的化,特征组合层次比较高,极大提高LR模型拟合能力的同时,也容易引入一些噪声,导致模型过拟合)
GBDT-LR相关代码可以参见【逻辑回归优化】
深度学习能够全自动从原有数据中提取到高层次的特征,深度学习推荐模型的进化趋势简单来说是 Wide(广)及 Deep(深)。Wide部分善于处理大量稀疏的特征,便于让模型直接“记住”大量原始的特征信息,Deep部分的主要作用有更深层的拟合能力,发现更高层次特征隐含的本质规律。
深度矩阵分解模型(Deep Matrix Factorization Model,DMF)是以传统的矩阵分解(MF)模型为基础,再与 MLP 网络组合而成的一种模型,其中 MF 主要负责线性部分,MLP 主要负责非线性部分,它主要以学习用户和物品的高阶表征向量为目标。
DMF 模型的框架图如下所示:该模型的输入层为交互矩阵 Y,其行、列分别对应为对用户和对物品的打分,并采用 multi-hot 形式分别表征用户和物品。
我们将用户表征 Yi* 和物品表征 Y*j 分别送入 MLP 双塔结构,生成用户隐向量表征 Pi 和物品隐向量表征 qj。最后对二者使用余弦点积匹配分数。
与其说广深(Wide&Deep)模型是一种模型,倒不如说是一套通用的范式框架。Wide&Deep 模型由 LR+MLP 两部分并联组成,综合了传统机器学习和深度学习的长处。
Wide 部分根据历史行为数据推荐与用户已有行为直接相关的物品;
Deep 部分负责捕捉新的特征组合,从而提高推荐的多样性。
深度因子分解机(Deep Factorization Machine,DeepFM)模型是从广深(Wide&Deep)框架中演化出来的一种模型。它使用 FM 模型替换掉了 LR 部分,从而形成了 FM&Deep 结构。
深度和交叉网络(Deep & Cross Network,DCN)模型是从广深(Wide&Deep)框架中演化出来的一个模型。DCN 模型将 Wide 部分替换为由特殊网络结构实现的特征交叉网络,它的框架如下图所示:左侧的交叉层除了接收前一层的输出外,还会同步接收原始输入层的特征,从而实现特征信息的高阶交叉。
注意力因子分解机(Attentional Factorization Machine,AFM)模型也是Wide&Deep 框架中的一种,它通过添加 Attention 网络,自动学习不同特征之间交互的重要性。
神经因子分解机(Neural Factorization Machine)模型也是 Wide&Deep 框架中的一种。NFM 模型把 Wide 部分放到一边不做变化,Deep 部分在 FM 的基础上结合了 MLP 部分。其中,FM 部分能够提取二阶线性特征,MLP 部分能够提取高阶非线性特征,从而使模型具备捕捉高阶非线性特征的能力。
NFM 模型框架的 Deep 部分如下图所示,NFM 模型是在 Embedding 层后将 FM 的输出进行 Bi-Interaction Pooling 操作(将表征向量的两两元素相乘后,再将所有组合的结果进行求和),然后在后面接上 MLP。
小结:本文介绍了推荐系统的作用及组成,并对核心技术及发展做了解析。但更为关键的,推荐系统是工程上的应用,我们下一篇文章会结合实际营销推荐场景做推荐项目实战(Pyhton),敬请期待。
参考文献:
https://zhuanlan.zhihu.com/p/100019681
https://zhuanlan.zhihu.com/p/63186101
https://zhuanlan.zhihu.com/p/61154299
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.