The most simplistic Colab with most models included by default. Custom models can be added easily. Stable Diffusion 2.0 in testing phase.
The instructions are on the Colab.
Choose your diffusion models and spin up a WebUI on Colab in one click
License: Apache License 2.0



















































































































Haven't used the colab in like 5 days and seems like there have been some updates to it. The thing I noticed right away is that default quality seems to be worse. Prompts and img2img seem to have similar results but the end product is lower in quality, like blurry/bad faces, hair, hands are almost always bad now, and other details that used to be fine.
Is there a way to test and compare to like October 20 and before vs oct 25? I don't think I'm tripping but I'd like to confirm.
Like here I'm using pretty much the same prompts but the quality is way different

I cannot add everything into the default models as it is meant to be clean.
I ask that you some links to niche models here with their name and direct download URL. You can upload them to huggingface yourself if they're not already available there.
Today i started diffusion webui, there was some errors:

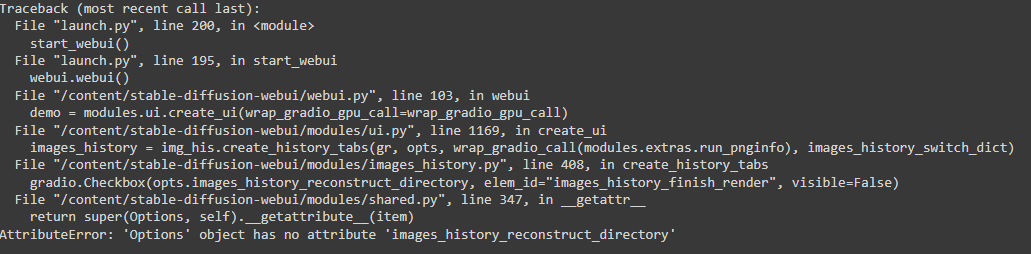
It started to happen today with any model.
ERROR: xformers-0.0.14.dev0-cp37-cp37m-linux_x86_64.whl is not a supported wheel on this platform. - when running "Start WebUI" cell. After that WebUI starts, but generation doesn't work. I have not saved the traceback, but the exception occured somewhere inside xformers.
For some reason i can still download it directly onto my PC, but the colab outputs an error.

RedirectMissingLocation Traceback (most recent call last)
in
47 gauth.credentials = GoogleCredentials.get_application_default()
48 drive = GoogleDrive(gauth)
---> 49 file_id = upload_file('/content/output.zip', create_folder(folder_name), save_as)
50 print("Your sharing link: https://drive.google.com/file/d/" + file_id + "/view?usp=sharing")
11 frames
/usr/local/lib/python3.8/dist-packages/httplib2/init.py in _request(self, conn, host, absolute_uri, request_uri, method, body, headers, redirections, cachekey)
1683 if redirections:
1684 if "location" not in response and response.status != 300:
-> 1685 raise RedirectMissingLocation(
1686 _(
1687 "Redirected but the response is missing a Location: header."
RedirectMissingLocation: Redirected but the response is missing a Location: header.
I was trying to use the new V3 of Elysium-Anime but it doesn't work.
https://huggingface.co/hesw23168/SD-Elysium-Model/blob/main/Elysium_Anime_V3.safetensors
Launching Web UI with arguments: --share --xformers --enable-insecure-extension-access --vae-path /content/stable-diffusion-webui/models/Stable-diffusion/novelAI.vae.pt --lowvram --gradio-auth webui:diffusion
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Downloading: 100% 939k/939k [00:01<00:00, 721kB/s]
Downloading: 100% 512k/512k [00:01<00:00, 464kB/s]
Downloading: 100% 389/389 [00:00<00:00, 354kB/s]
Downloading: 100% 905/905 [00:00<00:00, 847kB/s]
Downloading: 100% 4.41k/4.41k [00:00<00:00, 3.70MB/s]
Downloading: 100% 1.59G/1.59G [00:20<00:00, 82.9MB/s]
Loading weights [1a97f4ef] from /content/stable-diffusion-webui/models/Stable-diffusion/elysium-v3.ckpt
Error verifying pickled file from /content/stable-diffusion-webui/models/Stable-diffusion/elysium-v3.ckpt:
Traceback (most recent call last):
File "/content/stable-diffusion-webui/modules/safe.py", line 81, in check_pt
with zipfile.ZipFile(filename) as z:
File "/usr/lib/python3.8/zipfile.py", line 1269, in init
self._RealGetContents()
File "/usr/lib/python3.8/zipfile.py", line 1336, in _RealGetContents
raise BadZipFile("File is not a zip file")
zipfile.BadZipFile: File is not a zip file
Is it possible to have a non gradio version? Sessions always disconnect after a bit if I don't go back to the colab page.
Running on these settings, also google drive still have 5gb free of storage (free user)
Also it gave me 2 different links: gradio and loca.it
im using ur latest updated code u just commit

/content/drive/MyDrive/AI/stable-diffusion-webui
Python 3.7.15 (default, Oct 12 2022, 19:14:55)
[GCC 7.5.0]
Commit hash: 72e86948e6d73278eacc9a01974064edada58f86
Installing gfpgan
Installing clip
Cloning Stable Diffusion into repositories/stable-diffusion...
Cloning Taming Transformers into repositories/taming-transformers...
Cloning K-diffusion into repositories/k-diffusion...
Cloning CodeFormer into repositories/CodeFormer...
Cloning BLIP into repositories/BLIP...
Installing requirements for CodeFormer
Installing requirements for Web UI
Exiting because of --exit argument
Python 3.7.15 (default, Oct 12 2022, 19:14:55)
[GCC 7.5.0]
Commit hash: 72e86948e6d73278eacc9a01974064edada58f86
Installing xformers
your url is: https://twelve-falcons-hear-34-87-1-178.loca.lt/
OKInstalling requirements for Web UI
Launching Web UI with arguments: --xformers --share --medvram --gradio-auth ac:NovelAI
WARNING:root:Triton is not available, some optimizations will not be enabled.
Error No module named 'triton'
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Downloading: 100% 939k/939k [00:01<00:00, 693kB/s]
Downloading: 100% 512k/512k [00:01<00:00, 465kB/s]
Downloading: 100% 389/389 [00:00<00:00, 264kB/s]
Downloading: 100% 905/905 [00:00<00:00, 571kB/s]
Downloading: 100% 4.41k/4.41k [00:00<00:00, 2.65MB/s]
Downloading: 100% 1.59G/1.59G [00:25<00:00, 67.9MB/s]
Loading weights [925997e9] from /content/drive/MyDrive/AI/stable-diffusion-webui/models/Stable-diffusion/novelAI.ckpt
Applying xformers cross attention optimization.
Model loaded.
Loaded a total of 0 textual inversion embeddings.
Embeddings:
Running on local URL: http://127.0.0.1:7860/
Running on public URL: https://c8cf68b96613492c.gradio.app/
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
0% 0/20 [00:04<?, ?it/s]
Error completing request
Arguments: ('1girl, bangs, bare shoulders, bell, black gloves', '', 'None', 'None', 20, 0, False, False, 1, 1, 7, -1.0, -1.0, 0, 0, 0, False, 512, 512, False, 0.7, 0, 0, '0.0001', 0.9, 5, 'None', False, '', 0.1, False, 0, False, False, None, '', 1, '', 0, '', True, False, False) {}
Traceback (most recent call last):
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/ui.py", line 217, in f
res = list(func(*args, **kwargs))
File "/content/drive/MyDrive/AI/stable-diffusion-webui/webui.py", line 63, in f
res = func(*args, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/txt2img.py", line 47, in txt2img
processed = process_images(p)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/processing.py", line 411, in process_images
samples_ddim = p.sample(conditioning=c, unconditional_conditioning=uc, seeds=seeds, subseeds=subseeds, subseed_strength=p.subseed_strength)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/processing.py", line 569, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.create_dummy_mask(x))
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/sd_samplers.py", line 454, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/sd_samplers.py", line 356, in launch_sampling
return func()
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/sd_samplers.py", line 459, in <lambda>
}, disable=False, callback=self.callback_state, **extra_params_kwargs))
File "/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/sampling.py", line 80, in sample_euler_ancestral
denoised = model(x, sigmas[i] * s_in, **extra_args)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/sd_samplers.py", line 282, in forward
x_out[a:b] = self.inner_model(x_in[a:b], sigma_in[a:b], cond={"c_crossattn": [cond_in[a:b]], "c_concat": [image_cond_in[a:b]]})
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py", line 112, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py", line 138, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/models/diffusion/ddpm.py", line 987, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1148, in _call_impl
result = forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/models/diffusion/ddpm.py", line 1410, in forward
out = self.diffusion_model(x, t, context=cc)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/diffusionmodules/openaimodel.py", line 732, in forward
h = module(h, emb, context)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/diffusionmodules/openaimodel.py", line 85, in forward
x = layer(x, context)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/attention.py", line 258, in forward
x = block(x, context=context)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/attention.py", line 209, in forward
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/diffusionmodules/util.py", line 114, in checkpoint
return CheckpointFunction.apply(func, len(inputs), *args)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/diffusionmodules/util.py", line 127, in forward
output_tensors = ctx.run_function(*ctx.input_tensors)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/attention.py", line 212, in _forward
x = self.attn1(self.norm1(x)) + x
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/content/drive/MyDrive/AI/stable-diffusion-webui/modules/sd_hijack_optimizations.py", line 227, in xformers_attention_forward
out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None)
TypeError: memory_efficient_attention() got an unexpected keyword argument 'attn_bias'
RuntimeError: No such operator xformers::efficient_attention_forward_cutlass - did you forget to build xformers with python setup.py develop?
Interrupted with signal 2 in <frame at 0x7fcdddad2520, file '/content/stable-diffusion-webui/webui.py', line 108, code wait_on_server>
Is there/would you consider adding a method to use the custom premade embedding and hypernetwork files I can find on the internet?
I'm unsure if there's a way to make an extendable list on Google Colab for people to enter their own model names and URL
File "/content/stable-diffusion-webui/repositories/stable-diffusion/ldm/models/diffusion/ddpm.py", line 19, in
from pytorch_lightning.utilities.distributed import rank_zero_only
ImportError: cannot import name 'rank_zero_only' from 'pytorch_lightning.utilities.distributed' (/usr/local/lib/python3.7/dist-packages/pytorch_lightning/utilities/distributed.py)
It was working fine yesterday, but today can't get any version to run.
In previous versions of the Colab, you were able to select both VAE files at the same time by ticking their boxes; Anime VAE and SD VAE. Now it's a drop-down menu where you can only select one, the other, or neither. I just wanted to ask if that is intentional and if by not selecting one, both end up loading instead? Basically, if I want to use both, should I leave the selection empty?
I apologize if this is not the right place to post this. I have been thinking about requesting this model for a few days now but my anxiety never allowed me to. You'd already provided us with so much good stuff as it is and I didn't wanna be annoying and ask for more. But then I saw that you were more than open to the idea of adding new models and I thought I'd grow some balls and ask if it's possible to consider mine.
Basically, the F222 is a newly released NSFW model by Zeipher that's exclusively trained on the (realistic) naked female form. Compared to other models out there, the F222 produces far better and much more anatomically correct results. I will be eternally grateful if you'd consider adding it to the roster!
Rentry link: https://rentry.org/sdmodels#zeipher-f222-female-nude-better-anatomy
Here's their official website with multiple links for the model and a link to their discord for more info: https://ai.zeipher.com/
Any idea how to fix this? Used to happen rarely on the previous colab but now it's like every 2nd generation

Name: R34
Description:Trained on rule34 images
URL: magnet:?xt=urn:btih:ed9f0e3f849d7119107ef4e072c6abeb129e1a51&dn=r34_e4.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2ftracker2.dler.org%3a80%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.dler.org%3a6969%2fannounce&tr=udp%3a%2f%2fpublic.tracker.vraphim.com%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2fopen.demonii.com%3a1337%2fannounce&tr=udp%3a%2f%2fmovies.zsw.ca%3a6969%2fannounce&tr=udp%3a%2f%2fipv4.tracker.harry.lu%3a80%2fannounce&tr=udp%3a%2f%2ffe.dealclub.de%3a6969%2fannounce&tr=udp%3a%2f%2fexplodie.org%3a6969%2fannounce&tr=udp%3a%2f%2fexodus.desync.com%3a6969%2fannounce
RuntimeError: Error(s) in loading state_dict for AutoencoderKL:
Missing key(s) in state_dict: "encoder.conv_in.weight", "encoder.conv_in.bias", "encoder.down.0.block.0.norm1.weight", "encoder.down.0.block.0.norm1.bias", "encoder.down.0.block.0.conv1.weight", "encoder.down.0.block.0.conv1.bias", "encoder.down.0.block.0.norm2.weight", "encoder.down.0.block.0.norm2.bias", "encoder.down.0.block.0.conv2.weight", "encoder.down.0.block.0.conv2.bias", "encoder.down.0.block.1.norm1.weight", "encoder.down.0.block.1.norm1.bias", "encoder.down.0.block.1.conv1.weight", "encoder.down.0.block.1.conv1.bias", "encoder.down.0.block.1.norm2.weight", "encoder.down.0.block.1.norm2.bias", "encoder.down.0.block.1.conv2.weight", "encoder.down.0.block.1.conv2.bias", "encoder.down.0.downsample.conv.weight", "encoder.down.0.downsample.conv.bias", "encoder.down.1.block.0.norm1.weight", "encoder.down.1.block.0.norm1.bias", "encoder.down.1.block.0.conv1.weight", "encoder.down.1.block.0.conv1.bias", "encoder.down.1.block.0.norm2.weight", "encoder.down.1.block.0.norm2.bias", "encoder.down.1.block.0.conv2.weight", "encoder.down.1.block.0.conv2.bias", "encoder.down.1.block.0.nin_shortcut.weight", "encoder.down.1.block.0.nin_shortcut.bias", "encoder.down.1.block.1.norm1.weight", "encoder.down.1.block.1.norm1.bias", "encoder.down.1.block.1.conv1.weight", "encoder.down.1.block.1.conv1.bias", "encoder.down.1.block.1.norm2.weight", "encoder.down.1.block.1.norm2.bias", "encoder.down.1.block.1.conv2.weight", "encoder.down.1.block.1.conv2.bias", "encoder.down.1.downsample.conv.weight", "encoder.down.1.downsample.conv.bias", "encoder.down.2.block.0.norm1.weight", "encoder.down.2.block.0.norm1.bias", "encoder.down.2.block.0.conv1.weight", "encoder.down.2.block.0.conv1.bias", "encoder.down.2.block.0.norm2.weight", "encoder.down.2.block.0.norm2.bias", "encoder.down.2.block.0.conv2.weight", "encoder.down.2.block.0.conv2.bias", "encoder.down.2.block.0.nin_shortcut.weight", "encoder.down.2.block.0.nin_shortcut.bias", "encoder.down.2.block.1.norm1.weight", "encoder.down.2.block.1.norm1.bias", "encoder.down.2.block.1.conv1.weight", "encoder.down.2.block.1.conv1.bias", "encoder.down.2.block.1.norm2.weight", "encoder.down.2.block.1.norm2.bias", "encoder.down.2.block.1.conv2.weight", "encoder.down.2.block.1.conv2.bias", "encoder.down.2.downsample.conv.weight", "encoder.down.2.downsample.conv.bias", "encoder.down.3.block.0.norm1.weight", "encoder.down.3.block.0.norm1.bias", "encoder.down.3.block.0.conv1.weight", "encoder.down.3.block.0.conv1.bias", "encoder.down.3.block.0.norm2.weight", "encoder.down.3.block.0.norm2.bias", "encoder.down.3.block.0.conv2.weight", "encoder.down.3.block.0.conv2.bias", "encoder.down.3.block.1.norm1.weight", "encoder.down.3.block.1.norm1.bias", "encoder.down.3.block.1.conv1.weight", "encoder.down.3.block.1.conv1.bias", "encoder.down.3.block.1.norm2.weight", "encoder.down.3.block.1.norm2.bias", "encoder.down.3.block.1.conv2.weight", "encoder.down.3.block.1.conv2.bias", "encoder.mid.block_1.norm1.weight", "encoder.mid.block_1.norm1.bias", "encoder.mid.block_1.conv1.weight", "encoder.mid.block_1.conv1.bias", "encoder.mid.block_1.norm2.weight", "encoder.mid.block_1.norm2.bias", "encoder.mid.block_1.conv2.weight", "encoder.mid.block_1.conv2.bias", "encoder.mid.attn_1.norm.weight", "encoder.mid.attn_1.norm.bias", "encoder.mid.attn_1.q.weight", "encoder.mid.attn_1.q.bias", "encoder.mid.attn_1.k.weight", "encoder.mid.attn_1.k.bias", "encoder.mid.attn_1.v.weight", "encoder.mid.attn_1.v.bias", "encoder.mid.attn_1.proj_out.weight", "encoder.mid.attn_1.proj_out.bias", "encoder.mid.block_2.norm1.weight", "encoder.mid.block_2.norm1.bias", "encoder.mid.block_2.conv1.weight", "encoder.mid.block_2.conv1.bias", "encoder.mid.block_2.norm2.weight", "encoder.mid.block_2.norm2.bias", "encoder.mid.block_2.conv2.weight", "encoder.mid.block_2.conv2.bias", "encoder.norm_out.weight", "encoder.norm_out.bias", "encoder.conv_out.weight", "encoder.conv_out.bias", "decoder.conv_in.weight", "decoder.conv_in.bias", "decoder.mid.block_1.norm1.weight", "decoder.mid.block_1.norm1.bias", "decoder.mid.block_1.conv1.weight", "decoder.mid.block_1.conv1.bias", "decoder.mid.block_1.norm2.weight", "decoder.mid.block_1.norm2.bias", "decoder.mid.block_1.conv2.weight", "decoder.mid.block_1.conv2.bias", "decoder.mid.attn_1.norm.weight", "decoder.mid.attn_1.norm.bias", "decoder.mid.attn_1.q.weight", "decoder.mid.attn_1.q.bias", "decoder.mid.attn_1.k.weight", "decoder.mid.attn_1.k.bias", "decoder.mid.attn_1.v.weight", "decoder.mid.attn_1.v.bias", "decoder.mid.attn_1.proj_out.weight", "decoder.mid.attn_1.proj_out.bias", "decoder.mid.block_2.norm1.weight", "decoder.mid.block_2.norm1.bias", "decoder.mid.block_2.conv1.weight", "decoder.mid.block_2.conv1.bias", "decoder.mid.block_2.norm2.weight", "decoder.mid.block_2.norm2.bias", "decoder.mid.block_2.conv2.weight", "decoder.mid.block_2.conv2.bias", "decoder.up.0.block.0.norm1.weight", "decoder.up.0.block.0.norm1.bias", "decoder.up.0.block.0.conv1.weight", "decoder.up.0.block.0.conv1.bias", "decoder.up.0.block.0.norm2.weight", "decoder.up.0.block.0.norm2.bias", "decoder.up.0.block.0.conv2.weight", "decoder.up.0.block.0.conv2.bias", "decoder.up.0.block.0.nin_shortcut.weight", "decoder.up.0.block.0.nin_shortcut.bias", "decoder.up.0.block.1.norm1.weight", "decoder.up.0.block.1.norm1.bias", "decoder.up.0.block.1.conv1.weight", "decoder.up.0.block.1.conv1.bias", "decoder.up.0.block.1.norm2.weight", "decoder.up.0.block.1.norm2.bias", "decoder.up.0.block.1.conv2.weight", "decoder.up.0.block.1.conv2.bias", "decoder.up.0.block.2.norm1.weight", "decoder.up.0.block.2.norm1.bias", "decoder.up.0.block.2.conv1.weight", "decoder.up.0.block.2.conv1.bias", "decoder.up.0.block.2.norm2.weight", "decoder.up.0.block.2.norm2.bias", "decoder.up.0.block.2.conv2.weight", "decoder.up.0.block.2.conv2.bias", "decoder.up.1.block.0.norm1.weight", "decoder.up.1.block.0.norm1.bias", "decoder.up.1.block.0.conv1.weight", "decoder.up.1.block.0.conv1.bias", "decoder.up.1.block.0.norm2.weight", "decoder.up.1.block.0.norm2.bias", "decoder.up.1.block.0.conv2.weight", "decoder.up.1.block.0.conv2.bias", "decoder.up.1.block.0.nin_shortcut.weight", "decoder.up.1.block.0.nin_shortcut.bias", "decoder.up.1.block.1.norm1.weight", "decoder.up.1.block.1.norm1.bias", "decoder.up.1.block.1.conv1.weight", "decoder.up.1.block.1.conv1.bias", "decoder.up.1.block.1.norm2.weight", "decoder.up.1.block.1.norm2.bias", "decoder.up.1.block.1.conv2.weight", "decoder.up.1.block.1.conv2.bias", "decoder.up.1.block.2.norm1.weight", "decoder.up.1.block.2.norm1.bias", "decoder.up.1.block.2.conv1.weight", "decoder.up.1.block.2.conv1.bias", "decoder.up.1.block.2.norm2.weight", "decoder.up.1.block.2.norm2.bias", "decoder.up.1.block.2.conv2.weight", "decoder.up.1.block.2.conv2.bias", "decoder.up.1.upsample.conv.weight", "decoder.up.1.upsample.conv.bias", "decoder.up.2.block.0.norm1.weight", "decoder.up.2.block.0.norm1.bias", "decoder.up.2.block.0.conv1.weight", "decoder.up.2.block.0.conv1.bias", "decoder.up.2.block.0.norm2.weight", "decoder.up.2.block.0.norm2.bias", "decoder.up.2.block.0.conv2.weight", "decoder.up.2.block.0.conv2.bias", "decoder.up.2.block.1.norm1.weight", "decoder.up.2.block.1.norm1.bias", "decoder.up.2.block.1.conv1.weight", "decoder.up.2.block.1.conv1.bias", "decoder.up.2.block.1.norm2.weight", "decoder.up.2.block.1.norm2.bias", "decoder.up.2.block.1.conv2.weight", "decoder.up.2.block.1.conv2.bias", "decoder.up.2.block.2.norm1.weight", "decoder.up.2.block.2.norm1.bias", "decoder.up.2.block.2.conv1.weight", "decoder.up.2.block.2.conv1.bias", "decoder.up.2.block.2.norm2.weight", "decoder.up.2.block.2.norm2.bias", "decoder.up.2.block.2.conv2.weight", "decoder.up.2.block.2.conv2.bias", "decoder.up.2.upsample.conv.weight", "decoder.up.2.upsample.conv.bias", "decoder.up.3.block.0.norm1.weight", "decoder.up.3.block.0.norm1.bias", "decoder.up.3.block.0.conv1.weight", "decoder.up.3.block.0.conv1.bias", "decoder.up.3.block.0.norm2.weight", "decoder.up.3.block.0.norm2.bias", "decoder.up.3.block.0.conv2.weight", "decoder.up.3.block.0.conv2.bias", "decoder.up.3.block.1.norm1.weight", "decoder.up.3.block.1.norm1.bias", "decoder.up.3.block.1.conv1.weight", "decoder.up.3.block.1.conv1.bias", "decoder.up.3.block.1.norm2.weight", "decoder.up.3.block.1.norm2.bias", "decoder.up.3.block.1.conv2.weight", "decoder.up.3.block.1.conv2.bias", "decoder.up.3.block.2.norm1.weight", "decoder.up.3.block.2.norm1.bias", "decoder.up.3.block.2.conv1.weight", "decoder.up.3.block.2.conv1.bias", "decoder.up.3.block.2.norm2.weight", "decoder.up.3.block.2.norm2.bias", "decoder.up.3.block.2.conv2.weight", "decoder.up.3.block.2.conv2.bias", "decoder.up.3.upsample.conv.weight", "decoder.up.3.upsample.conv.bias", "decoder.norm_out.weight", "decoder.norm_out.bias", "decoder.conv_out.weight", "decoder.conv_out.bias", "quant_conv.weight", "quant_conv.bias", "post_quant_conv.weight", "post_quant_conv.bias".
Unexpected key(s) in state_dict: "model.diffusion_model.input_blocks.0.0.weight", "model.diffusion_model.input_blocks.0.0.bias", "model.diffusion_model.time_embed.0.weight", "model.diffusion_model.time_embed.0.bias", "model.diffusion_model.time_embed.2.weight", "model.diffusion_model.time_embed.2.bias", "model.diffusion_model.input_blocks.1.1.norm.weight", "model.diffusion_model.input_blocks.1.1.norm.bias", "model.diffusion_model.input_blocks.1.1.proj_in.weight", "model.diffusion_model.input_blocks.1.1.proj_in.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.1.1.proj_out.weight", "model.diffusion_model.input_blocks.1.1.proj_out.bias", "model.diffusion_model.input_blocks.2.1.norm.weight", "model.diffusion_model.input_blocks.2.1.norm.bias", "model.diffusion_model.input_blocks.2.1.proj_in.weight", "model.diffusion_model.input_blocks.2.1.proj_in.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.2.1.proj_out.weight", "model.diffusion_model.input_blocks.2.1.proj_out.bias", "model.diffusion_model.input_blocks.1.0.in_layers.0.weight", "model.diffusion_model.input_blocks.1.0.in_layers.0.bias", "model.diffusion_model.input_blocks.1.0.in_layers.2.weight", "model.diffusion_model.input_blocks.1.0.in_layers.2.bias", "model.diffusion_model.input_blocks.1.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.1.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.1.0.out_layers.0.weight", "model.diffusion_model.input_blocks.1.0.out_layers.0.bias", "model.diffusion_model.input_blocks.1.0.out_layers.3.weight", "model.diffusion_model.input_blocks.1.0.out_layers.3.bias", "model.diffusion_model.input_blocks.2.0.in_layers.0.weight", "model.diffusion_model.input_blocks.2.0.in_layers.0.bias", "model.diffusion_model.input_blocks.2.0.in_layers.2.weight", "model.diffusion_model.input_blocks.2.0.in_layers.2.bias", "model.diffusion_model.input_blocks.2.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.2.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.2.0.out_layers.0.weight", "model.diffusion_model.input_blocks.2.0.out_layers.0.bias", "model.diffusion_model.input_blocks.2.0.out_layers.3.weight", "model.diffusion_model.input_blocks.2.0.out_layers.3.bias", "model.diffusion_model.input_blocks.3.0.op.weight", "model.diffusion_model.input_blocks.3.0.op.bias", "model.diffusion_model.input_blocks.4.1.norm.weight", "model.diffusion_model.input_blocks.4.1.norm.bias", "model.diffusion_model.input_blocks.4.1.proj_in.weight", "model.diffusion_model.input_blocks.4.1.proj_in.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.4.1.proj_out.weight", "model.diffusion_model.input_blocks.4.1.proj_out.bias", "model.diffusion_model.input_blocks.5.1.norm.weight", "model.diffusion_model.input_blocks.5.1.norm.bias", "model.diffusion_model.input_blocks.5.1.proj_in.weight", "model.diffusion_model.input_blocks.5.1.proj_in.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.5.1.proj_out.weight", "model.diffusion_model.input_blocks.5.1.proj_out.bias", "model.diffusion_model.input_blocks.4.0.in_layers.0.weight", "model.diffusion_model.input_blocks.4.0.in_layers.0.bias", "model.diffusion_model.input_blocks.4.0.in_layers.2.weight", "model.diffusion_model.input_blocks.4.0.in_layers.2.bias", "model.diffusion_model.input_blocks.4.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.4.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.4.0.out_layers.0.weight", "model.diffusion_model.input_blocks.4.0.out_layers.0.bias", "model.diffusion_model.input_blocks.4.0.out_layers.3.weight", "model.diffusion_model.input_blocks.4.0.out_layers.3.bias", "model.diffusion_model.input_blocks.4.0.skip_connection.weight", "model.diffusion_model.input_blocks.4.0.skip_connection.bias", "model.diffusion_model.input_blocks.5.0.in_layers.0.weight", "model.diffusion_model.input_blocks.5.0.in_layers.0.bias", "model.diffusion_model.input_blocks.5.0.in_layers.2.weight", "model.diffusion_model.input_blocks.5.0.in_layers.2.bias", "model.diffusion_model.input_blocks.5.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.5.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.5.0.out_layers.0.weight", "model.diffusion_model.input_blocks.5.0.out_layers.0.bias", "model.diffusion_model.input_blocks.5.0.out_layers.3.weight", "model.diffusion_model.input_blocks.5.0.out_layers.3.bias", "model.diffusion_model.input_blocks.6.0.op.weight", "model.diffusion_model.input_blocks.6.0.op.bias", "model.diffusion_model.input_blocks.7.1.norm.weight", "model.diffusion_model.input_blocks.7.1.norm.bias", "model.diffusion_model.input_blocks.7.1.proj_in.weight", "model.diffusion_model.input_blocks.7.1.proj_in.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.7.1.proj_out.weight", "model.diffusion_model.input_blocks.7.1.proj_out.bias", "model.diffusion_model.input_blocks.8.1.norm.weight", "model.diffusion_model.input_blocks.8.1.norm.bias", "model.diffusion_model.input_blocks.8.1.proj_in.weight", "model.diffusion_model.input_blocks.8.1.proj_in.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.8.1.proj_out.weight", "model.diffusion_model.input_blocks.8.1.proj_out.bias", "model.diffusion_model.input_blocks.7.0.in_layers.0.weight", "model.diffusion_model.input_blocks.7.0.in_layers.0.bias", "model.diffusion_model.input_blocks.7.0.in_layers.2.weight", "model.diffusion_model.input_blocks.7.0.in_layers.2.bias", "model.diffusion_model.input_blocks.7.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.7.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.7.0.out_layers.0.weight", "model.diffusion_model.input_blocks.7.0.out_layers.0.bias", "model.diffusion_model.input_blocks.7.0.out_layers.3.weight", "model.diffusion_model.input_blocks.7.0.out_layers.3.bias", "model.diffusion_model.input_blocks.7.0.skip_connection.weight", "model.diffusion_model.input_blocks.7.0.skip_connection.bias", "model.diffusion_model.input_blocks.8.0.in_layers.0.weight", "model.diffusion_model.input_blocks.8.0.in_layers.0.bias", "model.diffusion_model.input_blocks.8.0.in_layers.2.weight", "model.diffusion_model.input_blocks.8.0.in_layers.2.bias", "model.diffusion_model.input_blocks.8.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.8.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.8.0.out_layers.0.weight", "model.diffusion_model.input_blocks.8.0.out_layers.0.bias", "model.diffusion_model.input_blocks.8.0.out_layers.3.weight", "model.diffusion_model.input_blocks.8.0.out_layers.3.bias", "model.diffusion_model.input_blocks.9.0.op.weight", "model.diffusion_model.input_blocks.9.0.op.bias", "model.diffusion_model.input_blocks.10.0.in_layers.0.weight", "model.diffusion_model.input_blocks.10.0.in_layers.0.bias", "model.diffusion_model.input_blocks.10.0.in_layers.2.weight", "model.diffusion_model.input_blocks.10.0.in_layers.2.bias", "model.diffusion_model.input_blocks.10.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.10.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.10.0.out_layers.0.weight", "model.diffusion_model.input_blocks.10.0.out_layers.0.bias", "model.diffusion_model.input_blocks.10.0.out_layers.3.weight", "model.diffusion_model.input_blocks.10.0.out_layers.3.bias", "model.diffusion_model.input_blocks.11.0.in_layers.0.weight", "model.diffusion_model.input_blocks.11.0.in_layers.0.bias", "model.diffusion_model.input_blocks.11.0.in_layers.2.weight", "model.diffusion_model.input_blocks.11.0.in_layers.2.bias", "model.diffusion_model.input_blocks.11.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.11.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.11.0.out_layers.0.weight", "model.diffusion_model.input_blocks.11.0.out_layers.0.bias", "model.diffusion_model.input_blocks.11.0.out_layers.3.weight", "model.diffusion_model.input_blocks.11.0.out_layers.3.bias", "model.diffusion_model.output_blocks.0.0.in_layers.0.weight", "model.diffusion_model.output_blocks.0.0.in_layers.0.bias", "model.diffusion_model.output_blocks.0.0.in_layers.2.weight", "model.diffusion_model.output_blocks.0.0.in_layers.2.bias", "model.diffusion_model.output_blocks.0.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.0.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.0.0.out_layers.0.weight", "model.diffusion_model.output_blocks.0.0.out_layers.0.bias", "model.diffusion_model.output_blocks.0.0.out_layers.3.weight", "model.diffusion_model.output_blocks.0.0.out_layers.3.bias", "model.diffusion_model.output_blocks.0.0.skip_connection.weight", "model.diffusion_model.output_blocks.0.0.skip_connection.bias", "model.diffusion_model.output_blocks.1.0.in_layers.0.weight", "model.diffusion_model.output_blocks.1.0.in_layers.0.bias", "model.diffusion_model.output_blocks.1.0.in_layers.2.weight", "model.diffusion_model.output_blocks.1.0.in_layers.2.bias", "model.diffusion_model.output_blocks.1.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.1.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.1.0.out_layers.0.weight", "model.diffusion_model.output_blocks.1.0.out_layers.0.bias", "model.diffusion_model.output_blocks.1.0.out_layers.3.weight", "model.diffusion_model.output_blocks.1.0.out_layers.3.bias", "model.diffusion_model.output_blocks.1.0.skip_connection.weight", "model.diffusion_model.output_blocks.1.0.skip_connection.bias", "model.diffusion_model.output_blocks.2.0.in_layers.0.weight", "model.diffusion_model.output_blocks.2.0.in_layers.0.bias", "model.diffusion_model.output_blocks.2.0.in_layers.2.weight", "model.diffusion_model.output_blocks.2.0.in_layers.2.bias", "model.diffusion_model.output_blocks.2.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.2.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.2.0.out_layers.0.weight", "model.diffusion_model.output_blocks.2.0.out_layers.0.bias", "model.diffusion_model.output_blocks.2.0.out_layers.3.weight", "model.diffusion_model.output_blocks.2.0.out_layers.3.bias", "model.diffusion_model.output_blocks.2.0.skip_connection.weight", "model.diffusion_model.output_blocks.2.0.skip_connection.bias", "model.diffusion_model.output_blocks.2.1.conv.weight", "model.diffusion_model.output_blocks.2.1.conv.bias", "model.diffusion_model.output_blocks.3.1.norm.weight", "model.diffusion_model.output_blocks.3.1.norm.bias", "model.diffusion_model.output_blocks.3.1.proj_in.weight", "model.diffusion_model.output_blocks.3.1.proj_in.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.3.1.proj_out.weight", "model.diffusion_model.output_blocks.3.1.proj_out.bias", "model.diffusion_model.output_blocks.4.1.norm.weight", "model.diffusion_model.output_blocks.4.1.norm.bias", "model.diffusion_model.output_blocks.4.1.proj_in.weight", "model.diffusion_model.output_blocks.4.1.proj_in.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.4.1.proj_out.weight", "model.diffusion_model.output_blocks.4.1.proj_out.bias", "model.diffusion_model.output_blocks.5.1.norm.weight", "model.diffusion_model.output_blocks.5.1.norm.bias", "model.diffusion_model.output_blocks.5.1.proj_in.weight", "model.diffusion_model.output_blocks.5.1.proj_in.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.5.1.proj_out.weight", "model.diffusion_model.output_blocks.5.1.proj_out.bias", "model.diffusion_model.output_blocks.3.0.in_layers.0.weight", "model.diffusion_model.output_blocks.3.0.in_layers.0.bias", "model.diffusion_model.output_blocks.3.0.in_layers.2.weight", "model.diffusion_model.output_blocks.3.0.in_layers.2.bias", "model.diffusion_model.output_blocks.3.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.3.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.3.0.out_layers.0.weight", "model.diffusion_model.output_blocks.3.0.out_layers.0.bias", "model.diffusion_model.output_blocks.3.0.out_layers.3.weight", "model.diffusion_model.output_blocks.3.0.out_layers.3.bias", "model.diffusion_model.output_blocks.3.0.skip_connection.weight", "model.diffusion_model.output_blocks.3.0.skip_connection.bias", "model.diffusion_model.output_blocks.4.0.in_layers.0.weight", "model.diffusion_model.output_blocks.4.0.in_layers.0.bias", "model.diffusion_model.output_blocks.4.0.in_layers.2.weight", "model.diffusion_model.output_blocks.4.0.in_layers.2.bias", "model.diffusion_model.output_blocks.4.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.4.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.4.0.out_layers.0.weight", "model.diffusion_model.output_blocks.4.0.out_layers.0.bias", "model.diffusion_model.output_blocks.4.0.out_layers.3.weight", "model.diffusion_model.output_blocks.4.0.out_layers.3.bias", "model.diffusion_model.output_blocks.4.0.skip_connection.weight", "model.diffusion_model.output_blocks.4.0.skip_connection.bias", "model.diffusion_model.output_blocks.5.0.in_layers.0.weight", "model.diffusion_model.output_blocks.5.0.in_layers.0.bias", "model.diffusion_model.output_blocks.5.0.in_layers.2.weight", "model.diffusion_model.output_blocks.5.0.in_layers.2.bias", "model.diffusion_model.output_blocks.5.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.5.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.5.0.out_layers.0.weight", "model.diffusion_model.output_blocks.5.0.out_layers.0.bias", "model.diffusion_model.output_blocks.5.0.out_layers.3.weight", "model.diffusion_model.output_blocks.5.0.out_layers.3.bias", "model.diffusion_model.output_blocks.5.0.skip_connection.weight", "model.diffusion_model.output_blocks.5.0.skip_connection.bias", "model.diffusion_model.output_blocks.5.2.conv.weight", "model.diffusion_model.output_blocks.5.2.conv.bias", "model.diffusion_model.output_blocks.6.1.norm.weight", "model.diffusion_model.output_blocks.6.1.norm.bias", "model.diffusion_model.output_blocks.6.1.proj_in.weight", "model.diffusion_model.output_blocks.6.1.proj_in.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.6.1.proj_out.weight", "model.diffusion_model.output_blocks.6.1.proj_out.bias", "model.diffusion_model.output_blocks.7.1.norm.weight", "model.diffusion_model.output_blocks.7.1.norm.bias", "model.diffusion_model.output_blocks.7.1.proj_in.weight", "model.diffusion_model.output_blocks.7.1.proj_in.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.7.1.proj_out.weight", "model.diffusion_model.output_blocks.7.1.proj_out.bias", "model.diffusion_model.output_blocks.8.1.norm.weight", "model.diffusion_model.output_blocks.8.1.norm.bias", "model.diffusion_model.output_blocks.8.1.proj_in.weight", "model.diffusion_model.output_blocks.8.1.proj_in.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.8.1.proj_out.weight", "model.diffusion_model.output_blocks.8.1.proj_out.bias", "model.diffusion_model.output_blocks.6.0.in_layers.0.weight", "model.diffusion_model.output_blocks.6.0.in_layers.0.bias", "model.diffusion_model.output_blocks.6.0.in_layers.2.weight", "model.diffusion_model.output_blocks.6.0.in_layers.2.bias", "model.diffusion_model.output_blocks.6.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.6.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.6.0.out_layers.0.weight", "model.diffusion_model.output_blocks.6.0.out_layers.0.bias", "model.diffusion_model.output_blocks.6.0.out_layers.3.weight", "model.diffusion_model.output_blocks.6.0.out_layers.3.bias", "model.diffusion_model.output_blocks.6.0.skip_connection.weight", "model.diffusion_model.output_blocks.6.0.skip_connection.bias", "model.diffusion_model.output_blocks.7.0.in_layers.0.weight", "model.diffusion_model.output_blocks.7.0.in_layers.0.bias", "model.diffusion_model.output_blocks.7.0.in_layers.2.weight", "model.diffusion_model.output_blocks.7.0.in_layers.2.bias", "model.diffusion_model.output_blocks.7.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.7.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.7.0.out_layers.0.weight", "model.diffusion_model.output_blocks.7.0.out_layers.0.bias", "model.diffusion_model.output_blocks.7.0.out_layers.3.weight", "model.diffusion_model.output_blocks.7.0.out_layers.3.bias", "model.diffusion_model.output_blocks.7.0.skip_connection.weight", "model.diffusion_model.output_blocks.7.0.skip_connection.bias", "model.diffusion_model.output_blocks.8.0.in_layers.0.weight", "model.diffusion_model.output_blocks.8.0.in_layers.0.bias", "model.diffusion_model.output_blocks.8.0.in_layers.2.weight", "model.diffusion_model.output_blocks.8.0.in_layers.2.bias", "model.diffusion_model.output_blocks.8.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.8.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.8.0.out_layers.0.weight", "model.diffusion_model.output_blocks.8.0.out_layers.0.bias", "model.diffusion_model.output_blocks.8.0.out_layers.3.weight", "model.diffusion_model.output_blocks.8.0.out_layers.3.bias", "model.diffusion_model.output_blocks.8.0.skip_connection.weight", "model.diffusion_model.output_blocks.8.0.skip_connection.bias", "model.diffusion_model.output_blocks.8.2.conv.weight", "model.diffusion_model.output_blocks.8.2.conv.bias", "model.diffusion_model.output_blocks.9.1.norm.weight", "model.diffusion_model.output_blocks.9.1.norm.bias", "model.diffusion_model.output_blocks.9.1.proj_in.weight", "model.diffusion_model.output_blocks.9.1.proj_in.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.9.1.proj_out.weight", "model.diffusion_model.output_blocks.9.1.proj_out.bias", "model.diffusion_model.output_blocks.10.1.norm.weight", "model.diffusion_model.output_blocks.10.1.norm.bias", "model.diffusion_model.output_blocks.10.1.proj_in.weight", "model.diffusion_model.output_blocks.10.1.proj_in.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.10.1.proj_out.weight", "model.diffusion_model.output_blocks.10.1.proj_out.bias", "model.diffusion_model.output_blocks.11.1.norm.weight", "model.diffusion_model.output_blocks.11.1.norm.bias", "model.diffusion_model.output_blocks.11.1.proj_in.weight", "model.diffusion_model.output_blocks.11.1.proj_in.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.11.1.proj_out.weight", "model.diffusion_model.output_blocks.11.1.proj_out.bias", "model.diffusion_model.output_blocks.9.0.in_layers.0.weight", "model.diffusion_model.output_blocks.9.0.in_layers.0.bias", "model.diffusion_model.output_blocks.9.0.in_layers.2.weight", "model.diffusion_model.output_blocks.9.0.in_layers.2.bias", "model.diffusion_model.output_blocks.9.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.9.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.9.0.out_layers.0.weight", "model.diffusion_model.output_blocks.9.0.out_layers.0.bias", "model.diffusion_model.output_blocks.9.0.out_layers.3.weight", "model.diffusion_model.output_blocks.9.0.out_layers.3.bias", "model.diffusion_model.output_blocks.9.0.skip_connection.weight", "model.diffusion_model.output_blocks.9.0.skip_connection.bias", "model.diffusion_model.output_blocks.10.0.in_layers.0.weight", "model.diffusion_model.output_blocks.10.0.in_layers.0.bias", "model.diffusion_model.output_blocks.10.0.in_layers.2.weight", "model.diffusion_model.output_blocks.10.0.in_layers.2.bias", "model.diffusion_model.output_blocks.10.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.10.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.10.0.out_layers.0.weight", "model.diffusion_model.output_blocks.10.0.out_layers.0.bias", "model.diffusion_model.output_blocks.10.0.out_layers.3.weight", "model.diffusion_model.output_blocks.10.0.out_layers.3.bias", "model.diffusion_model.output_blocks.10.0.skip_connection.weight", "model.diffusion_model.output_blocks.10.0.skip_connection.bias", "model.diffusion_model.output_blocks.11.0.in_layers.0.weight", "model.diffusion_model.output_blocks.11.0.in_layers.0.bias", "model.diffusion_model.output_blocks.11.0.in_layers.2.weight", "model.diffusion_model.output_blocks.11.0.in_layers.2.bias", "model.diffusion_model.output_blocks.11.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.11.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.11.0.out_layers.0.weight", "model.diffusion_model.output_blocks.11.0.out_layers.0.bias", "model.diffusion_model.output_blocks.11.0.out_layers.3.weight", "model.diffusion_model.output_blocks.11.0.out_layers.3.bias", "model.diffusion_model.output_blocks.11.0.skip_connection.weight", "model.diffusion_model.output_blocks.11.0.skip_connection.bias", "model.diffusion_model.middle_block.1.norm.weight", "model.diffusion_model.middle_block.1.norm.bias", "model.diffusion_model.middle_block.1.proj_in.weight", "model.diffusion_model.middle_block.1.proj_in.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.middle_block.1.proj_out.weight", "model.diffusion_model.middle_block.1.proj_out.bias", "model.diffusion_model.middle_block.0.in_layers.0.weight", "model.diffusion_model.middle_block.0.in_layers.0.bias", "model.diffusion_model.middle_block.0.in_layers.2.weight", "model.diffusion_model.middle_block.0.in_layers.2.bias", "model.diffusion_model.middle_block.0.emb_layers.1.weight", "model.diffusion_model.middle_block.0.emb_layers.1.bias", "model.diffusion_model.middle_block.0.out_layers.0.weight", "model.diffusion_model.middle_block.0.out_layers.0.bias", "model.diffusion_model.middle_block.0.out_layers.3.weight", "model.diffusion_model.middle_block.0.out_layers.3.bias", "model.diffusion_model.middle_block.2.in_layers.0.weight", "model.diffusion_model.middle_block.2.in_layers.0.bias", "model.diffusion_model.middle_block.2.in_layers.2.weight", "model.diffusion_model.middle_block.2.in_layers.2.bias", "model.diffusion_model.middle_block.2.emb_layers.1.weight", "model.diffusion_model.middle_block.2.emb_layers.1.bias", "model.diffusion_model.middle_block.2.out_layers.0.weight", "model.diffusion_model.middle_block.2.out_layers.0.bias", "model.diffusion_model.middle_block.2.out_layers.3.weight", "model.diffusion_model.middle_block.2.out_layers.3.bias", "model.diffusion_model.out.0.weight", "model.diffusion_model.out.0.bias", "model.diffusion_model.out.2.weight", "model.diffusion_model.out.2.bias", "first_stage_model.encoder.conv_in.weight", "first_stage_model.encoder.conv_in.bias", "first_stage_model.encoder.down.0.block.0.norm1.weight", "first_stage_model.encoder.down.0.block.0.norm1.bias", "first_stage_model.encoder.down.0.block.0.conv1.weight", "first_stage_model.encoder.down.0.block.0.conv1.bias", "first_stage_model.encoder.down.0.block.0.norm2.weight", "first_stage_model.encoder.down.0.block.0.norm2.bias", "first_stage_model.encoder.down.0.block.0.conv2.weight", "first_stage_model.encoder.down.0.block.0.conv2.bias", "first_stage_model.encoder.down.0.block.1.norm1.weight", "first_stage_model.encoder.down.0.block.1.norm1.bias", "first_stage_model.encoder.down.0.block.1.conv1.weight", "first_stage_model.encoder.down.0.block.1.conv1.bias", "first_stage_model.encoder.down.0.block.1.norm2.weight", "first_stage_model.encoder.down.0.block.1.norm2.bias", "first_stage_model.encoder.down.0.block.1.conv2.weight", "first_stage_model.encoder.down.0.block.1.conv2.bias", "first_stage_model.encoder.down.0.downsample.conv.weight", "first_stage_model.encoder.down.0.downsample.conv.bias", "first_stage_model.encoder.down.1.block.0.norm1.weight", "first_stage_model.encoder.down.1.block.0.norm1.bias", "first_stage_model.encoder.down.1.block.0.conv1.weight", "first_stage_model.encoder.down.1.block.0.conv1.bias", "first_stage_model.encoder.down.1.block.0.norm2.weight", "first_stage_model.encoder.down.1.block.0.norm2.bias", "first_stage_model.encoder.down.1.block.0.conv2.weight", "first_stage_model.encoder.down.1.block.0.conv2.bias", "first_stage_model.encoder.down.1.block.0.nin_shortcut.weight", "first_stage_model.encoder.down.1.block.0.nin_shortcut.bias", "first_stage_model.encoder.down.1.block.1.norm1.weight", "first_stage_model.encoder.down.1.block.1.norm1.bias", "first_stage_model.encoder.down.1.block.1.conv1.weight", "first_stage_model.encoder.down.1.block.1.conv1.bias", "first_stage_model.encoder.down.1.block.1.norm2.weight", "first_stage_model.encoder.down.1.block.1.norm2.bias", "first_stage_model.encoder.down.1.block.1.conv2.weight", "first_stage_model.encoder.down.1.block.1.conv2.bias", "first_stage_model.encoder.down.1.downsample.conv.weight", "first_stage_model.encoder.down.1.downsample.conv.bias", "first_stage_model.encoder.down.2.block.0.norm1.weight", "first_stage_model.encoder.down.2.block.0.norm1.bias", "first_stage_model.encoder.down.2.block.0.conv1.weight", "first_stage_model.encoder.down.2.block.0.conv1.bias", "first_stage_model.encoder.down.2.block.0.norm2.weight", "first_stage_model.encoder.down.2.block.0.norm2.bias", "first_stage_model.encoder.down.2.block.0.conv2.weight", "first_stage_model.encoder.down.2.block.0.conv2.bias", "first_stage_model.encoder.down.2.block.0.nin_shortcut.weight", "first_stage_model.encoder.down.2.block.0.nin_shortcut.bias", "first_stage_model.encoder.down.2.block.1.norm1.weight", "first_stage_model.encoder.down.2.block.1.norm1.bias", "first_stage_model.encoder.down.2.block.1.conv1.weight", "first_stage_model.encoder.down.2.block.1.conv1.bias", "first_stage_model.encoder.down.2.block.1.norm2.weight", "first_stage_model.encoder.down.2.block.1.norm2.bias", "first_stage_model.encoder.down.2.block.1.conv2.weight", "first_stage_model.encoder.down.2.block.1.conv2.bias", "first_stage_model.encoder.down.2.downsample.conv.weight", "first_stage_model.encoder.down.2.downsample.conv.bias", "first_stage_model.encoder.down.3.block.0.norm1.weight", "first_stage_model.encoder.down.3.block.0.norm1.bias", "first_stage_model.encoder.down.3.block.0.conv1.weight", "first_stage_model.encoder.down.3.block.0.conv1.bias", "first_stage_model.encoder.down.3.block.0.norm2.weight", "first_stage_model.encoder.down.3.block.0.norm2.bias", "first_stage_model.encoder.down.3.block.0.conv2.weight", "first_stage_model.encoder.down.3.block.0.conv2.bias", "first_stage_model.encoder.down.3.block.1.norm1.weight", "first_stage_model.encoder.down.3.block.1.norm1.bias", "first_stage_model.encoder.down.3.block.1.conv1.weight", "first_stage_model.encoder.down.3.block.1.conv1.bias", "first_stage_model.encoder.down.3.block.1.norm2.weight", "first_stage_model.encoder.down.3.block.1.norm2.bias", "first_stage_model.encoder.down.3.block.1.conv2.weight", "first_stage_model.encoder.down.3.block.1.conv2.bias", "first_stage_model.encoder.mid.attn_1.norm.weight", "first_stage_model.encoder.mid.attn_1.norm.bias", "first_stage_model.encoder.mid.attn_1.q.weight", "first_stage_model.encoder.mid.attn_1.q.bias", "first_stage_model.encoder.mid.attn_1.k.weight", "first_stage_model.encoder.mid.attn_1.k.bias", "first_stage_model.encoder.mid.attn_1.v.weight", "first_stage_model.encoder.mid.attn_1.v.bias", "first_stage_model.encoder.mid.attn_1.proj_out.weight", "first_stage_model.encoder.mid.attn_1.proj_out.bias", "first_stage_model.encoder.mid.block_1.norm1.weight", "first_stage_model.encoder.mid.block_1.norm1.bias",
...
Google has been cracking down on web services being hosted via Colab. Please be aware that your account may become locked given extensive use.
Cannot use the Colab at all, execution stops on its own and gives a "^C" at the last line after selecting a model in the webui and loading the model weight.
Noticing a usage spike on RAM, I then tried using -lowvram.
The RAM usage spike is no more but the ^C thing problem still persists.
Was working without problem yesterday.
Hentai Diffusion is no longer located at Deltaadams/Hentai-Diffusion, but has moved to Deltaadams/HentaiDiffusion instead.
I don't know why I get this error. It happens every time it reaches "Loading VAE weights from: /content/stable-diffusion-webui/models/Stable-diffusion/sd-v1-5.vae.pt"
It happens on both versions of the colab. Even the Stable one, as you can see in the first screenshot. It doesn't matter what else I pick in the 'models' section, as long as 'SDVae' is included, I get that error. I've been able to run the colab by just picking SD 1.5 since it's the one I prefer to use anyway, but I still can't help but wonder why I get this error. It must be something I'M doing because no one else has asked about this.
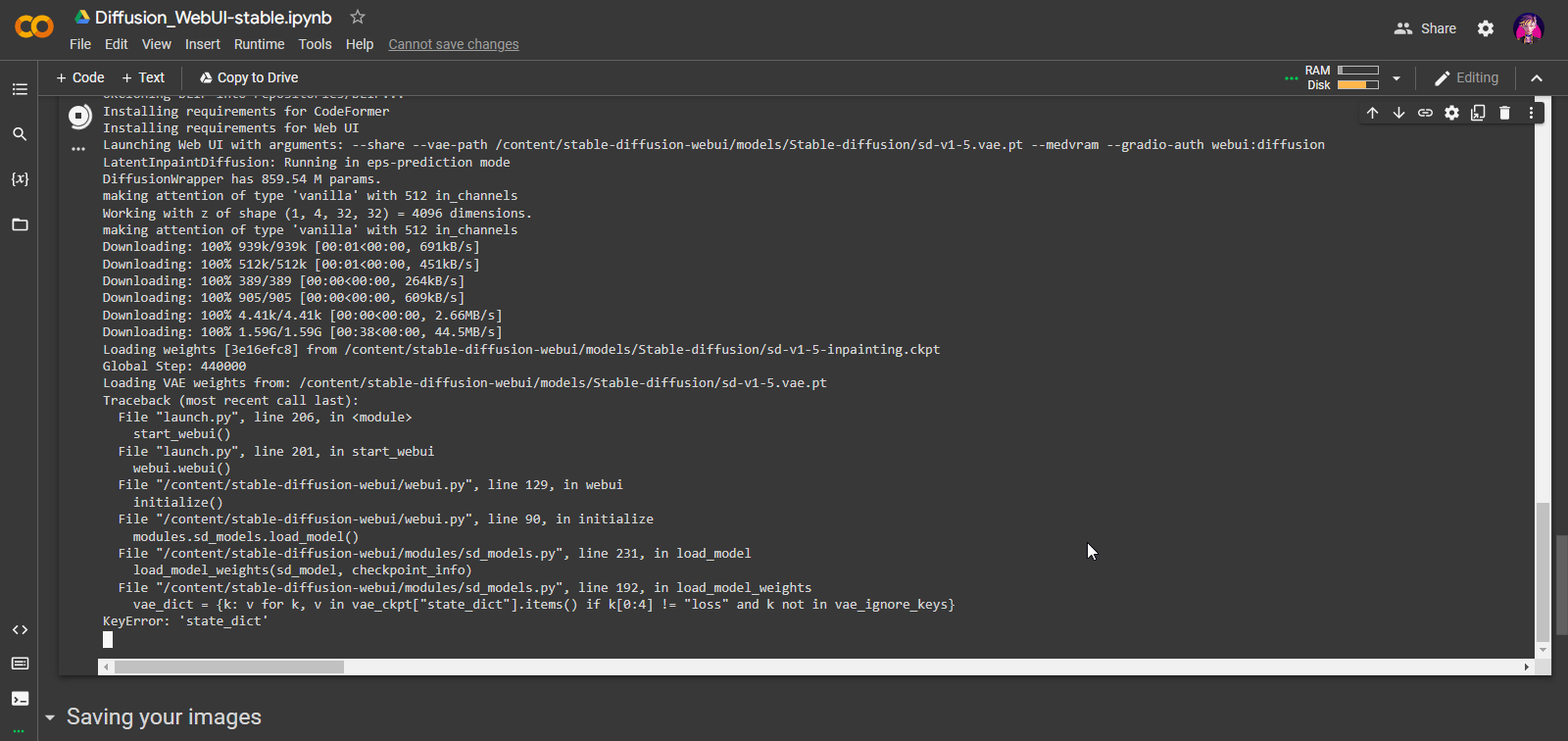
This is what I get when I click on 'check dependencies'

I don't know what any of this means. I'm sorry I'm really not that great with any of this.
Google Colab is being slow
Encounter this error when trying to run the Colab:
requests.exceptions.HTTPError: 504 Server Error: Gateway Time-out for url: https://huggingface.co/openai/clip-vit-large-patch14/resolve/main/vocab.json
Name: HassanBlend1.2
Description: Hey acheong, I am once again here to request a new NSFW model. It's a mix of multiple models (including SD1.5, NAI, R34, F222, AnythingV3, and much, much more). I couldn't add it myself as a custom model because it's not hosted over at huggingface and google drive links don't work. So if it's not too much trouble, it would mean a lot if you'd add this model to the already amazing roster. You can find all kinds of information in the link below. All the models merged, some image samples, prompting examples, and of course; links to download the model itself.
URL: https://rentry.org/sdhassan
xformers and triton are both broken in Automatic1111's webui. I cannot fix this.
Can someone help?
Here's what I'm getting. I only started happening in the last few hours
Fetching updates for K-diffusion...
Checking out commit for K-diffusion with hash: f4e99857772fc3a126ba886aadf795a332774878...
Traceback (most recent call last):
File "launch.py", line 251, in <module>
prepare_enviroment()
File "launch.py", line 202, in prepare_enviroment
git_clone(k_diffusion_repo, repo_dir('k-diffusion'), "K-diffusion", k_diffusion_commit_hash)
File "launch.py", line 82, in git_clone
run(f'"{git}" -C {dir} checkout {commithash}', f"Checking out commit for {name} with hash: {commithash}...", f"Couldn't checkout commit {commithash} for {name}")
File "launch.py", line 34, in run
raise RuntimeError(message)
RuntimeError: Couldn't checkout commit f4e99857772fc3a126ba886aadf795a332774878 for K-diffusion.
Command: "git" -C repositories/k-diffusion checkout f4e99857772fc3a126ba886aadf795a332774878
Error code: 1
stdout: <empty>
stderr: error: Your local changes to the following files would be overwritten by checkout:
sample_clip_guided.py
train.py
Please commit your changes or stash them before you switch branches.
Aborting
Greetings, I am attempting to install the stable diffusion in my computer, yet I am running on this error.

Does anyone have any idea what could be the case? I am installing it on an external hard drive, but I don't think this could be the issue. I have Python 3.10.6 and git installed, also properly inserted in PATH, despite the error message claiming that Windows cannot recognize it as an internal or external command.
My webui-user looks like this:

How did I reproduce this issue:
I merely opened webui-user file, and it seems to be unable to install gfpgan.
Thank you for your attention!
Im getting this weird error when I load a dreambooth model
Traceback (most recent call last):
File "launch.py", line 294, in <module>
start()
File "launch.py", line 289, in start
webui.webui()
File "/content/stable-diffusion-webui/webui.py", line 131, in webui
initialize()
File "/content/stable-diffusion-webui/webui.py", line 61, in initialize
modules.sd_models.load_model()
File "/content/stable-diffusion-webui/modules/sd_models.py", line 261, in load_model
load_model_weights(sd_model, checkpoint_info)
File "/content/stable-diffusion-webui/modules/sd_models.py", line 192, in load_model_weights
model.load_state_dict(sd, strict=False)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1605, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for LatentDiffusion:
size mismatch for model.diffusion_model.input_blocks.1.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.1.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.2.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.input_blocks.2.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.4.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.4.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.5.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.input_blocks.5.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.7.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.7.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.8.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.input_blocks.8.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.middle_block.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.middle_block.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.3.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.3.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.4.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.4.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.5.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 1024]) from checkpoint, the shape in current model is torch.Size([1280, 768]).
size mismatch for model.diffusion_model.output_blocks.5.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([1280, 1280, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.6.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.6.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.7.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.7.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.8.1.proj_in.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 1024]) from checkpoint, the shape in current model is torch.Size([640, 768]).
size mismatch for model.diffusion_model.output_blocks.8.1.proj_out.weight: copying a param with shape torch.Size([640, 640]) from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.9.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.9.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.10.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.10.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.11.1.proj_in.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 1024]) from checkpoint, the shape in current model is torch.Size([320, 768]).
size mismatch for model.diffusion_model.output_blocks.11.1.proj_out.weight: copying a param with shape torch.Size([320, 320]) from checkpoint, the shape in current model is torch.Size([320, 320, 1, 1]).
size mismatch for cond_stage_model.transformer.text_model.embeddings.token_embedding.weight: copying a param with shape torch.Size([49408, 1024]) from checkpoint, the shape in current model is torch.Size([49408, 768]).
size mismatch for cond_stage_model.transformer.text_model.embeddings.position_embedding.weight: copying a param with shape torch.Size([77, 1024]) from checkpoint, the shape in current model is torch.Size([77, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.0.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.1.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.2.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.3.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.4.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.5.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.6.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.7.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.8.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.9.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.10.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.k_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.k_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.v_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.v_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.q_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.q_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.out_proj.weight: copying a param with shape torch.Size([1024, 1024]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.self_attn.out_proj.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.layer_norm1.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.layer_norm1.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.mlp.fc1.weight: copying a param with shape torch.Size([4096, 1024]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.mlp.fc1.bias: copying a param with shape torch.Size([4096]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.mlp.fc2.weight: copying a param with shape torch.Size([1024, 4096]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.mlp.fc2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.layer_norm2.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.encoder.layers.11.layer_norm2.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.final_layer_norm.weight: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for cond_stage_model.transformer.text_model.final_layer_norm.bias: copying a param with shape torch.Size([1024]) from checkpoint, the shape in current model is torch.Size([768]).
The High Vram usage I have been experiencing never really happen and the UI issues didn't bother me, until recently. I did the same thing and yesterday it worked but now something is off.
The unusual high vram usage I am seeing when it starts to generate and while it's generating too.
(The orange peak happened when it was done generating and decoded the images)
I know it didn't peak like this, before I screenshotted the image I did my normal AI generating and it peaked on the RED (which means it used almost all of the Vram).
And the UI is broken too, it stops halfway when I was generating it and it always happens if I used the High res fix.

The High Vram usage might be the model or the server or even colab but the UI one is really annoying.
Hello, I would like to use textual inversion but I can't seem to find the tab in the UI. I have seen some youtube videos where there's a tab named textual inversion. Is the UI outdated or something?
It stops working after loading the model, no merging process occurs and no new model is seen.
And another issue:

Since multiple issues have been reported, I'll split these two issues into a separate issue page for later fixing.
Originally posted by @Vendetta-S in #58 (comment)
i see in the output about useing spaces for better reliablety. how can i do this
Please add Naifu-Diffusion (4chan ver.)into this project cause i think it goes well.
And please let me know is there any technical problem(but i can`t help sry)
I'm not sure what the problem is. Here is the log:
--2022-12-02 12:28:10-- https://huggingface.co/Deltaadams/Hentai-Diffusion/resolve/main/HD-16.ckpt
Resolving huggingface.co (huggingface.co)... 54.147.99.175, 3.234.187.147, 2600:1f18:147f:e800:3df1:c2fc:20aa:9b45, ...
Connecting to huggingface.co (huggingface.co)|54.147.99.175|:443... connected.
HTTP request sent, awaiting response... 404 Not Found
2022-12-02 12:28:11 ERROR 404: Not Found.
/content/stable-diffusion-webui/extensions
fatal: destination path 'stable-diffusion-webui-images-browser' already exists and is not an empty directory.
/content
/content/stable-diffusion-webui
|████████████████████████████████| 103.0 MB 7.3 kB/s
/content/stable-diffusion-webui
Python 3.8.15 (default, Oct 12 2022, 19:14:39)
[GCC 7.5.0]
Commit hash: 6cce1e8f4cd547897a6ba0072866564b224ca11e
Installing requirements for Web UI
Launching Web UI with arguments: --share --xformers --enable-insecure-extension-access --lowvram --gradio-auth webui:diffusion
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Loading weights [e3b0c442] from /content/stable-diffusion-webui/models/Stable-diffusion/HentaiDiffusion.ckpt
Error verifying pickled file from /content/stable-diffusion-webui/models/Stable-diffusion/HentaiDiffusion.ckpt:
Traceback (most recent call last):
File "/content/stable-diffusion-webui/modules/safe.py", line 83, in check_pt
with zipfile.ZipFile(filename) as z:
File "/usr/lib/python3.8/zipfile.py", line 1269, in init
self._RealGetContents()
File "/usr/lib/python3.8/zipfile.py", line 1336, in _RealGetContents
raise BadZipFile("File is not a zip file")
zipfile.BadZipFile: File is not a zip file
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/content/stable-diffusion-webui/modules/safe.py", line 131, in load_with_extra
check_pt(filename, extra_handler)
File "/content/stable-diffusion-webui/modules/safe.py", line 98, in check_pt
unpickler.load()
EOFError: Ran out of input
The file may be malicious, so the program is not going to read it.
You can skip this check with --disable-safe-unpickle commandline argument.
Traceback (most recent call last):
File "launch.py", line 294, in
start()
File "launch.py", line 289, in start
webui.webui()
File "/content/stable-diffusion-webui/webui.py", line 131, in webui
initialize()
File "/content/stable-diffusion-webui/webui.py", line 61, in initialize
modules.sd_models.load_model()
File "/content/stable-diffusion-webui/modules/sd_models.py", line 261, in load_model
load_model_weights(sd_model, checkpoint_info)
File "/content/stable-diffusion-webui/modules/sd_models.py", line 191, in load_model_weights
sd = read_state_dict(checkpoint_file)
File "/content/stable-diffusion-webui/modules/sd_models.py", line 173, in read_state_dict
sd = get_state_dict_from_checkpoint(pl_sd)
File "/content/stable-diffusion-webui/modules/sd_models.py", line 147, in get_state_dict_from_checkpoint
pl_sd = pl_sd.pop("state_dict", pl_sd)
AttributeError: 'NoneType' object has no attribute 'pop'
check
1m 40s
completed at 6:29 AM
Hello, Im getting a problem with drive url. It says this
Access denied with the following error:
Cannot retrieve the public link of the file. You may need to change
the permission to 'Anyone with the link', or have had many accesses.
You may still be able to access the file from the browser:
The link is public and I have tested it by trying to download it using incognito tab but it still doesn't work
Edit: Deleted repositories from g drive solved the problem.
I'm not sure what the problem is:
/content/drive/MyDrive/AI/stable-diffusion-webui
Python 3.7.15 (default, Oct 12 2022, 19:14:55)
[GCC 7.5.0]
Commit hash: fff7808311bdf414e8c5263a4383d170dc31709e
Installing gfpgan
Installing clip
Cloning K-diffusion into repositories/k-diffusion...
Fetching updates for CodeFormer...
Checking out commit for CodeFormer with hash: c5b4593074ba6214284d6acd5f1719b6c5d739af...
Traceback (most recent call last):
File "launch.py", line 251, in
prepare_enviroment()
File "launch.py", line 203, in prepare_enviroment
git_clone(codeformer_repo, repo_dir('CodeFormer'), "CodeFormer", codeformer_commit_hash)
File "launch.py", line 82, in git_clone
run(f'"{git}" -C {dir} checkout {commithash}', f"Checking out commit for {name} with hash: {commithash}...", f"Couldn't checkout commit {commithash} for {name}")
File "launch.py", line 34, in run
raise RuntimeError(message)
RuntimeError: Couldn't checkout commit c5b4593074ba6214284d6acd5f1719b6c5d739af for CodeFormer.
Command: "git" -C repositories/CodeFormer checkout c5b4593074ba6214284d6acd5f1719b6c5d739af
Error code: 128
stdout:
stderr: fatal: reference is not a tree: c5b4593074ba6214284d6acd5f1719b6c5d739af
Decided to run it and this happened:
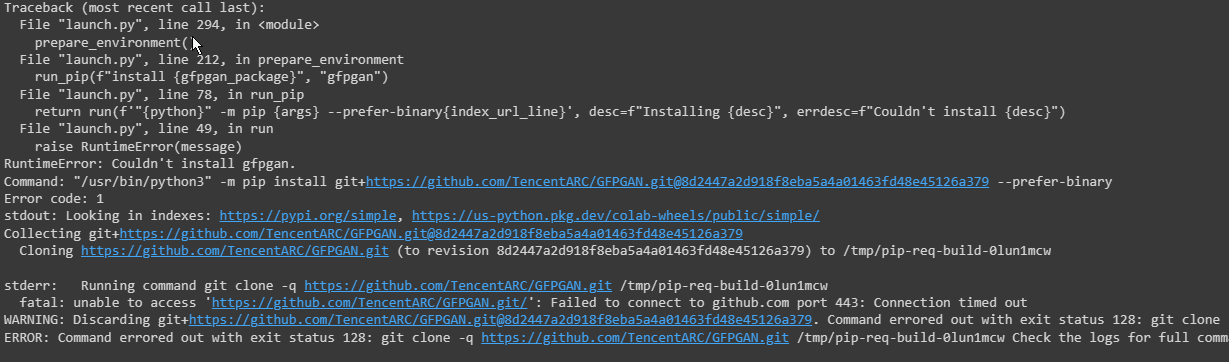
Well crap. Somehow GFPGAN decided to not work anymore.
I run it again and the error didn't happen. And, another error happened and CLIP didn't want to work.

And it decided to work again.
Originally posted by @Vendetta-S in #58 (comment)
When you try to enter the interface using the link to gradio, it gives an empty window.
Hi folks
I'm getting a warning at installation time in the Google colab, followed by error state after running a request in the Gradio app post-build
Warning at install:
Launching Web UI with arguments: --share --xformers --enable-insecure-extension-access --gradio-auth webui:diffusion
/usr/local/lib/python3.8/dist-packages/xformers/_C.so: undefined symbol: _ZNK3c104impl13OperatorEntry20reportSignatureErrorENS0_12CppSignatureE
WARNING: /usr/local/lib/python3.8/dist-packages/xformers/_C.so: undefined symbol: _ZNK3c104impl13OperatorEntry20reportSignatureErrorENS0_12CppSignatureE
Need to compile C++ extensions to get sparse attention support. Please run python setup.py build develop
Error at runtime:
Error completing request
Arguments: ('tiger sitting in a rock', '', 'None', 'None', 20, 0, False, False, 1, 1, 7, -1.0, -1.0, 0, 0, 0, False, 512, 512, False, 0.7, 0, 0, 0, False, False, False, '', 1, '', 0, '', True, False, False) {}
Traceback (most recent call last):
File "/content/stable-diffusion-webui/modules/call_queue.py", line 45, in f
res = list(func(*args, **kwargs))
File "/content/stable-diffusion-webui/modules/call_queue.py", line 28, in f
res = func(*args, **kwargs)
File "/content/stable-diffusion-webui/modules/txt2img.py", line 49, in txt2img
processed = process_images(p)
File "/content/stable-diffusion-webui/modules/processing.py", line 430, in process_images
res = process_images_inner(p)
File "/content/stable-diffusion-webui/modules/processing.py", line 531, in process_images_inner
samples_ddim = p.sample(conditioning=c, unconditional_conditioning=uc, seeds=seeds, subseeds=subseeds, subseed_strength=p.subseed_strength, prompts=prompts)
File "/content/stable-diffusion-webui/modules/processing.py", line 664, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File "/content/stable-diffusion-webui/modules/sd_samplers.py", line 507, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "/content/stable-diffusion-webui/modules/sd_samplers.py", line 422, in launch_sampling
return func()
File "/content/stable-diffusion-webui/modules/sd_samplers.py", line 507, in
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "/usr/local/lib/python3.8/dist-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/content/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/sampling.py", line 145, in sample_euler_ancestral
denoised = model(x, sigmas[i] * s_in, **extra_args)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/modules/sd_samplers.py", line 315, in forward
x_out = self.inner_model(x_in, sigma_in, cond={"c_crossattn": [cond_in], "c_concat": [image_cond_in]})
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py", line 112, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "/content/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py", line 138, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "/content/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 1329, in forward
out = self.diffusion_model(x, t, context=cc)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/diffusionmodules/openaimodel.py", line 776, in forward
h = module(h, emb, context)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/diffusionmodules/openaimodel.py", line 84, in forward
x = layer(x, context)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/attention.py", line 324, in forward
x = block(x, context=context[i])
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/modules/sd_hijack_checkpoint.py", line 4, in BasicTransformerBlock_forward
return checkpoint(self._forward, x, context)
File "/usr/local/lib/python3.8/dist-packages/torch/utils/checkpoint.py", line 249, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/usr/local/lib/python3.8/dist-packages/torch/utils/checkpoint.py", line 107, in forward
outputs = run_function(*args)
File "/content/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/attention.py", line 262, in _forward
x = self.attn1(self.norm1(x), context=context if self.disable_self_attn else None) + x
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/modules/sd_hijack_optimizations.py", line 227, in xformers_attention_forward
out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None)
File "/usr/local/lib/python3.8/dist-packages/xformers/ops/memory_efficient_attention.py", line 967, in memory_efficient_attention
return op.forward_no_grad(
File "/usr/local/lib/python3.8/dist-packages/xformers/ops/memory_efficient_attention.py", line 343, in forward_no_grad
return cls.FORWARD_OPERATOR(
File "/usr/local/lib/python3.8/dist-packages/xformers/ops/common.py", line 11, in no_such_operator
raise RuntimeError(
RuntimeError: No such operator xformers::efficient_attention_forward_cutlass - did you forget to build xformers with python setup.py develop?
Despite running the notebook correctly (public version) and logging with HuggingSpace credentials I receive the incorrect credentials error, which shouldn't happen - obviously.
How can I fix this?
Reason currently unknown. Investigating
This messages appears when I clicked generate
TypeError: memory_efficient_attention() got an unexpected keyword argument 'attn_bias'
Time taken: 7.27s
Torch active/reserved: 1677/1722 MiB, Sys VRAM: 2784/15110 MiB (18.42%)

I'm getting this ^C in the last line then it stops. I haven't touched anything so I don't get why its terminating it everytime. Sometimes it works when I use a different google account

Everything was still working fine this morning.

Would you people prefer fp16, fp32, or full ema?
I just checked NovelAI model and I got this error :(

I got this error when I tried to run dependencies

Hello, I'm getting a really long error after starting the cell. I'm using stable diffusion v2.1 and I have selected SD V2-768 in the dropdown menu
Traceback (most recent call last):
File "launch.py", line 295, in <module>
start()
File "launch.py", line 290, in start
webui.webui()
File "/content/stable-diffusion-webui/webui.py", line 133, in webui
initialize()
File "/content/stable-diffusion-webui/webui.py", line 63, in initialize
modules.sd_models.load_model()
File "/content/stable-diffusion-webui/modules/sd_models.py", line 313, in load_model
load_model_weights(sd_model, checkpoint_info)
File "/content/stable-diffusion-webui/modules/sd_models.py", line 197, in load_model_weights
model.load_state_dict(sd, strict=False)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1667, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for LatentDiffusion:
size mismatch for model.diffusion_model.input_blocks.1.1.proj_in.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.input_blocks.1.1.proj_out.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.input_blocks.2.1.proj_in.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.input_blocks.2.1.proj_out.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.input_blocks.4.1.proj_in.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.input_blocks.4.1.proj_out.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.input_blocks.5.1.proj_in.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.input_blocks.5.1.proj_out.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.input_blocks.7.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.input_blocks.7.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.input_blocks.8.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.input_blocks.8.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.middle_block.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.middle_block.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.output_blocks.3.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.output_blocks.3.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.output_blocks.4.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.output_blocks.4.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.output_blocks.5.1.proj_in.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([1280, 768]) from checkpoint, the shape in current model is torch.Size([1280, 1024]).
size mismatch for model.diffusion_model.output_blocks.5.1.proj_out.weight: copying a param with shape torch.Size([1280, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([1280, 1280]).
size mismatch for model.diffusion_model.output_blocks.6.1.proj_in.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.output_blocks.6.1.proj_out.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.output_blocks.7.1.proj_in.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.output_blocks.7.1.proj_out.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.output_blocks.8.1.proj_in.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([640, 768]) from checkpoint, the shape in current model is torch.Size([640, 1024]).
size mismatch for model.diffusion_model.output_blocks.8.1.proj_out.weight: copying a param with shape torch.Size([640, 640, 1, 1]) from checkpoint, the shape in current model is torch.Size([640, 640]).
size mismatch for model.diffusion_model.output_blocks.9.1.proj_in.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.output_blocks.9.1.proj_out.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.output_blocks.10.1.proj_in.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.output_blocks.10.1.proj_out.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.output_blocks.11.1.proj_in.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
size mismatch for model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_k.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_v.weight: copying a param with shape torch.Size([320, 768]) from checkpoint, the shape in current model is torch.Size([320, 1024]).
size mismatch for model.diffusion_model.output_blocks.11.1.proj_out.weight: copying a param with shape torch.Size([320, 320, 1, 1]) from checkpoint, the shape in current model is torch.Size([320, 320]).
Im not sure if I am doing this right, but I'm trying to load a model from huggingface but it just isnt working
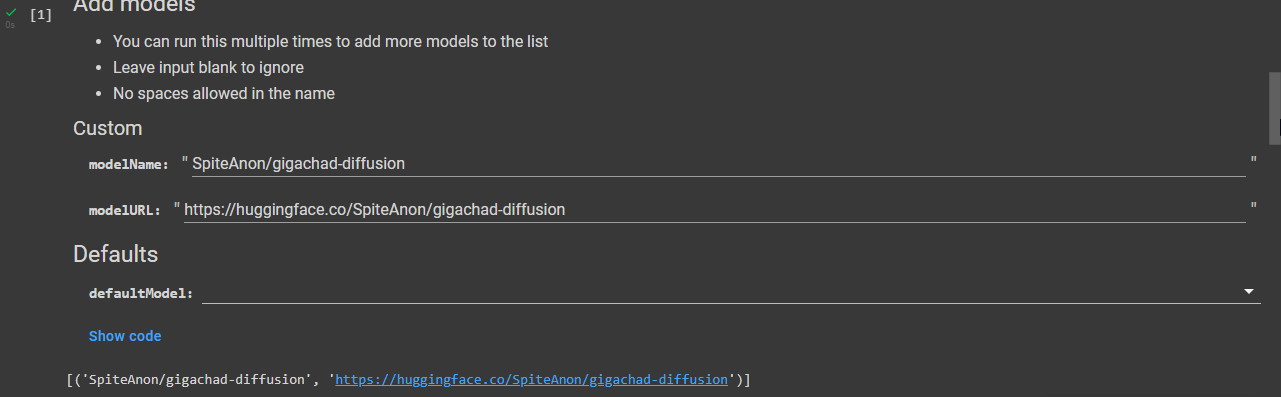
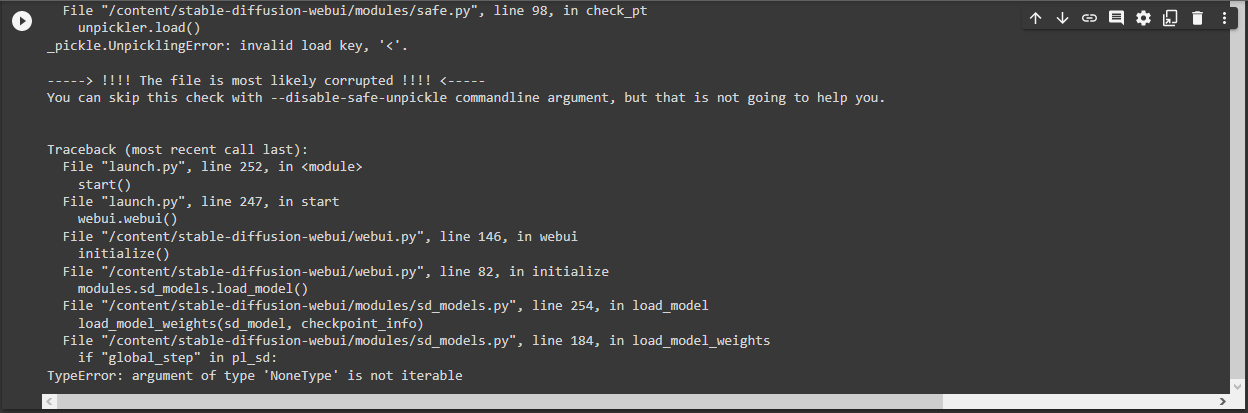
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.