Estimating a unigram language model P(w) using a corpus of concatenation of several public domain books from Project Gutenberg as well as lists
of most frequent words from Wiktionary and the British National Corpus
Another corpus that represents number of error occurrance in search queries is also used.
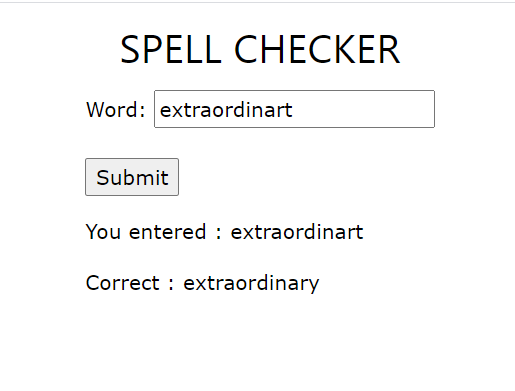
Given a query word; Application calculates a set of words whose edit distance to given word is 1 by the help of Damerau - Levenshtein edit distance. (candidates)
Candidates are sorted according to the scores in their P(w)*P(x|w) calculations.
Spell Checker application is implemented with Flask, Python
To render the webpage, Jinja templates are used with pure HTML, CSS
-
Command
python main.pyto start the server -
Connect to
http://localhost:5000/
