
In this data engineering post, we'll explore cutting-edge open-source technologies that can assist us in constructing a resilient data engineering pipeline. If you're interested in learning more about Mage AI, please refer to this article. To begin with Mage AI,
you can read my first article about mage Ai at link.
Let's kick things off with a quick overview of the technologies that will be utilized in this demonstration.
Apache Spark is an open-source distributed computing system that is designed for big data processing and analytics. It provides an easy-to-use and unified platform for batch processing, real-time processing, machine learning, and interactive analytics.
Delta Lake is an open-source storage layer that brings reliability to data lakes. It provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of existing data lake solutions such as Apache Spark and Hadoop Distributed File System (HDFS) and extends their capabilities to handle big data use cases more effectively.
Mage is an open-source, hybrid framework for transforming and integrating data

MinIO is an open-source, distributed object storage system. It is designed to be highly scalable and can be deployed on-premises, in the cloud, or in a hybrid environment. MinIO is compatible with Amazon S3 API, allowing applications that work with S3 to seamlessly switch to MinIO without any code changes.

Here are some key features of MinIO:
- High Performance: MinIO is optimized for high performance and low latency, making it suitable for use cases that require rapid access to large amounts of data.
- Scalability: MinIO is designed to scale horizontally, allowing you to add more storage nodes as your data needs grow. It uses a distributed architecture to distribute data across multiple servers, ensuring high availability and fault tolerance.
- Data Protection: MinIO provides features such as data encryption, access control, and versioning to protect your data from unauthorized access, tampering, and data loss.
- S3 Compatibility: MinIO is fully compatible with the Amazon S3 API, which means that you can use existing S3-compatible tools and libraries with MinIO without any modifications.
- Ease of Use: MinIO is easy to deploy and manage, with a simple command-line interface and web-based dashboard for monitoring and administration.
- Use Cases: MinIO is suitable for a wide range of use cases, including data storage, backup and archiving, content distribution, data lakes, and cloud-native applications

We will use docker as containerization tool for many reasons :
- Simplifies software development by providing a consistent and isolated environment.
- Enhances interoperability by enabling applications to be easily deployed on various platforms without compatibility issues.
- Speeds up the development process by eliminating the need to set up complex development environments manually.
- Improves scalability and flexibility as Docker containers can be quickly deployed and scaled up or down as needed.
The following code is for docker compose file
version: '3'
services:
mageai:
container_name: mage_spark_test
build:
context: https://github.com/mage-ai/compose-quickstart.git
dockerfile: Dockerfile
environment:
- MINIO_URL=http://minio:9000
ports:
- '6789:6789'
command: >
bash -c "
echo 'deb http://deb.debian.org/debian bullseye main' > /etc/apt/sources.list.d/bullseye.list &&
apt-get update -y &&
apt-get install -y openjdk-11-jdk &&
rm /etc/apt/sources.list.d/bullseye.list &&
pip install pyspark &&
pip install delta-spark &&
pip install minio &&
/app/run_app.sh mage start demo_project
"
minio:
container_name: spark-minio-mage
image: quay.io/minio/minio
ports:
- '9000:9000'
- '9001:9001'
volumes:
- './minio_data:/data'
environment:
- MINIO_ROOT_USER=your_admin_user
- MINIO_ROOT_PASSWORD=your_password
- MINIO_DEFAULT_BUCKETS=your_bucket_name
command: server --console-address ":9001" /data
This Docker Compose configuration sets up two services:
- container_name: mage_spark_test
- build: Builds the Docker container using the Dockerfile located in the GitHub repository https://github.com/mage-ai/compose-quickstart.git.
- environment: Sets the MINIO_URL environment variable to http://minio:9000, indicating the MinIO server URL.
- ports: Exposes port 6789 for accessing the service.
- command: Installs dependencies, including Java 11, PySpark, Delta Spark, and MinIO Python client, and then executes the /app/run_app.sh script to start the Mage AI service with a demo project.
- container_name: spark-minio-mage
- image: Uses the quay.io/minio/minio image for running the MinIO server.
- ports: Exposes ports 9000 for MinIO server and 9001 for console access
- volumes: Maps the local directory ./minio_data to the /data directory inside the container for persistent storage.
- environment: Sets environment variables for MinIO configuration, including MINIO_ROOT_USER, MINIO_ROOT_PASSWORD, and MINIO_DEFAULT_BUCKETS.
- command: Starts the MinIO server with console access enabled at port 9001 and using the /data directory for storage.
After running, check if the both container is up as shown below
docker compose up -d

To access to the both services, you can check these URLs
- minio : http://localhost:9001/browser and login (use you credentials set on docker compose)
- Mage Ai : http://localhost:6789/


Use mage ai, Create Custom block as shown below

In the custom block, you set up config for spark, delta format and Minio, then you read data from API and you do small transformation (rename cols ) and at the end you save the data into Minio with delta format Lets dig deep into the code 😉
In the following section you create spark session with Delta and and AWS s3 (org.apache.hadoop:hadoop-aws:3.3.4) packages.

Then you will add some config param to make sure that spark session will have all credentials to save data to Minio with delta format.

After you will check or create if the is bucket name exists in the Minio object storage.

You arrive to Data loading step, you will readfile using API, and then create pandas Dataframe

After that, the transformation and writing will be the next steps

For All code, you can use
from pandas import DataFrame
import io
import pandas as pd
import requests
from minio import Minio
from pyspark.sql import SparkSession
from delta import *
from pyspark.sql import functions as F
builder = SparkSession.builder.appName("minio_app") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder, extra_packages=["org.apache.hadoop:hadoop-aws:3.3.4"]).getOrCreate()
# add confs
sc = spark.sparkContext
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", "admin")
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", "admin123456789")
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "http://minio:9000")
sc._jsc.hadoopConfiguration().set("fs.s3a.path.style.access", "true")
sc._jsc.hadoopConfiguration().set("fs.s3a.connection.ssl.enabled", "false")
sc._jsc.hadoopConfiguration().set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
sc._jsc.hadoopConfiguration().set("fs.s3a.connection.ssl.enabled", "false")
client = Minio(
"minio:9000",
access_key="admin",
secret_key="admin123456789",
secure=False
)
minio_bucket = "delta-demo-bucket"
found = client.bucket_exists(minio_bucket)
if not found:
client.make_bucket(minio_bucket)
def data_from_internet():
url = 'https://raw.githubusercontent.com/mage-ai/datasets/master/restaurant_user_transactions.csv'
response = requests.get(url)
return pd.read_csv(io.StringIO(response.text), sep=',')
@custom
def rename_cols_write(*args, **kwargs):
"""
args: The output from any upstream parent blocks (if applicable)
Returns:
Anything (e.g. data frame, dictionary, array, int, str, etc.)
"""
# Specify your custom logic here
df_spark = spark.createDataFrame(data_from_internet())
# Using selectExpr with list comprehension to rename columns
df = df_spark.selectExpr([f"`{col}` as `{col.replace(' ', '_')}`" for col in df_spark.columns])
#write into Minio using Delta
df \
.write \
.format("delta") \
.partitionBy("cuisine") \
.mode("overwrite") \
.save(f"s3a://{minio_bucket}/data-delta")
return df
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'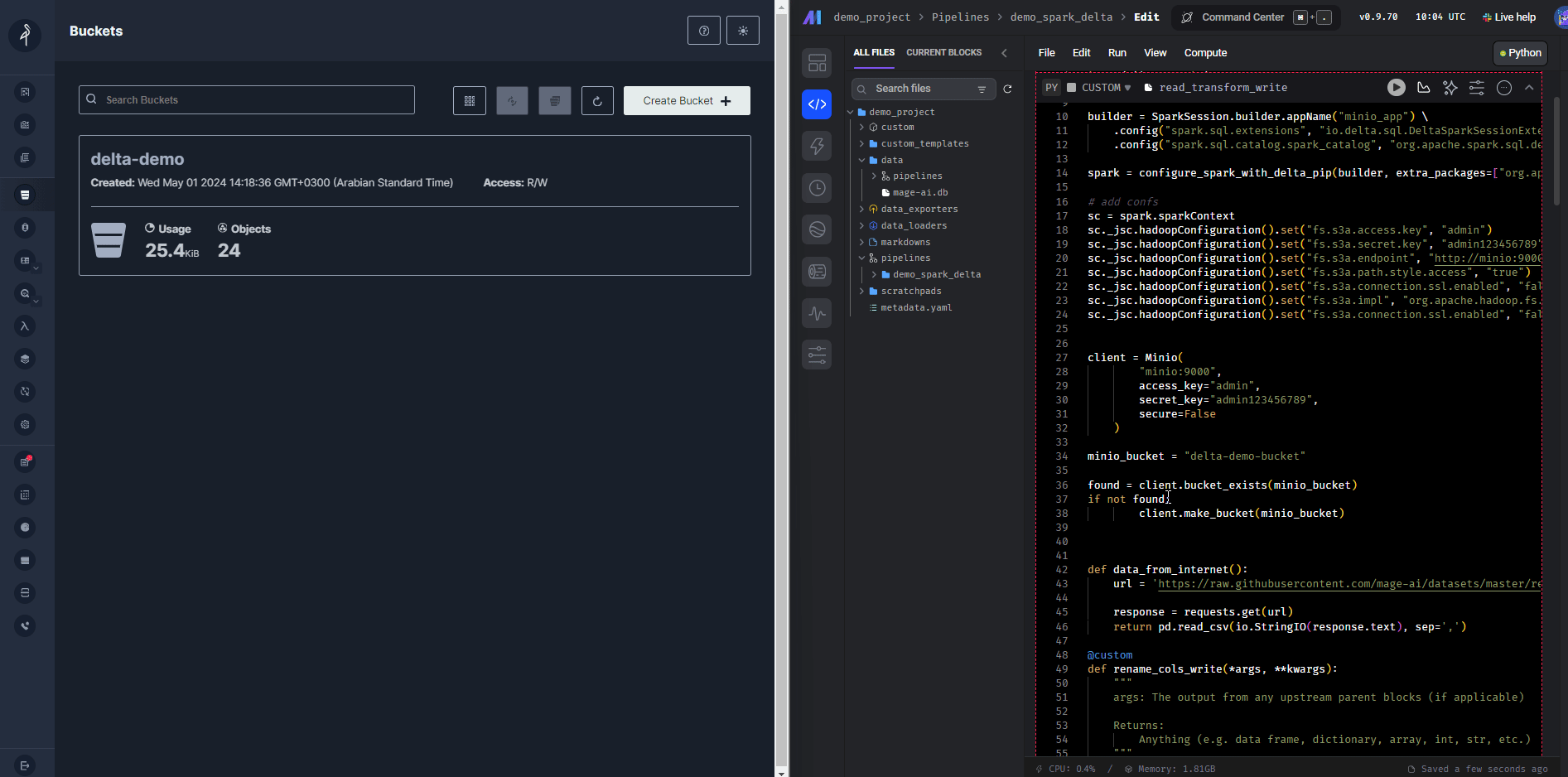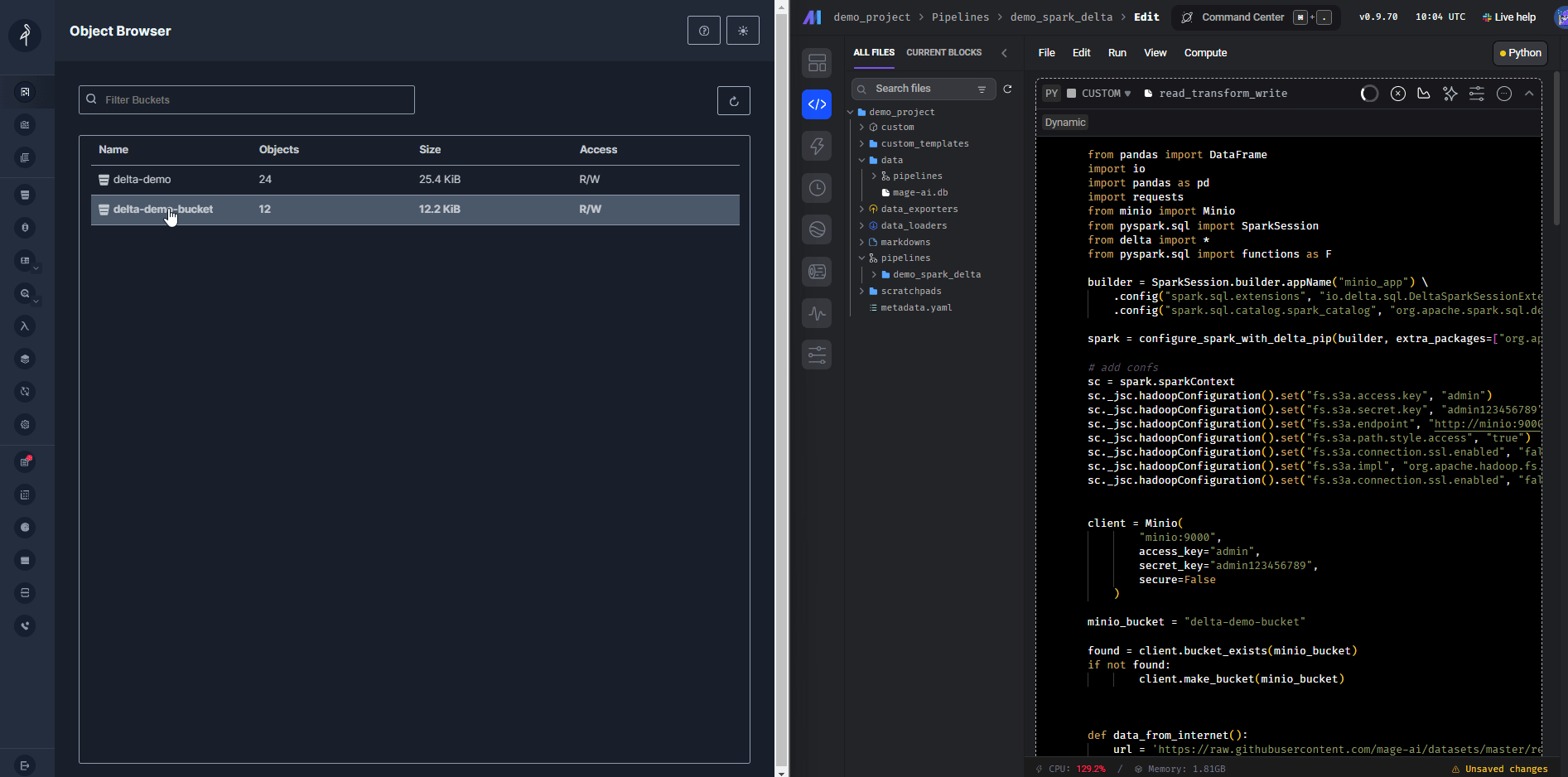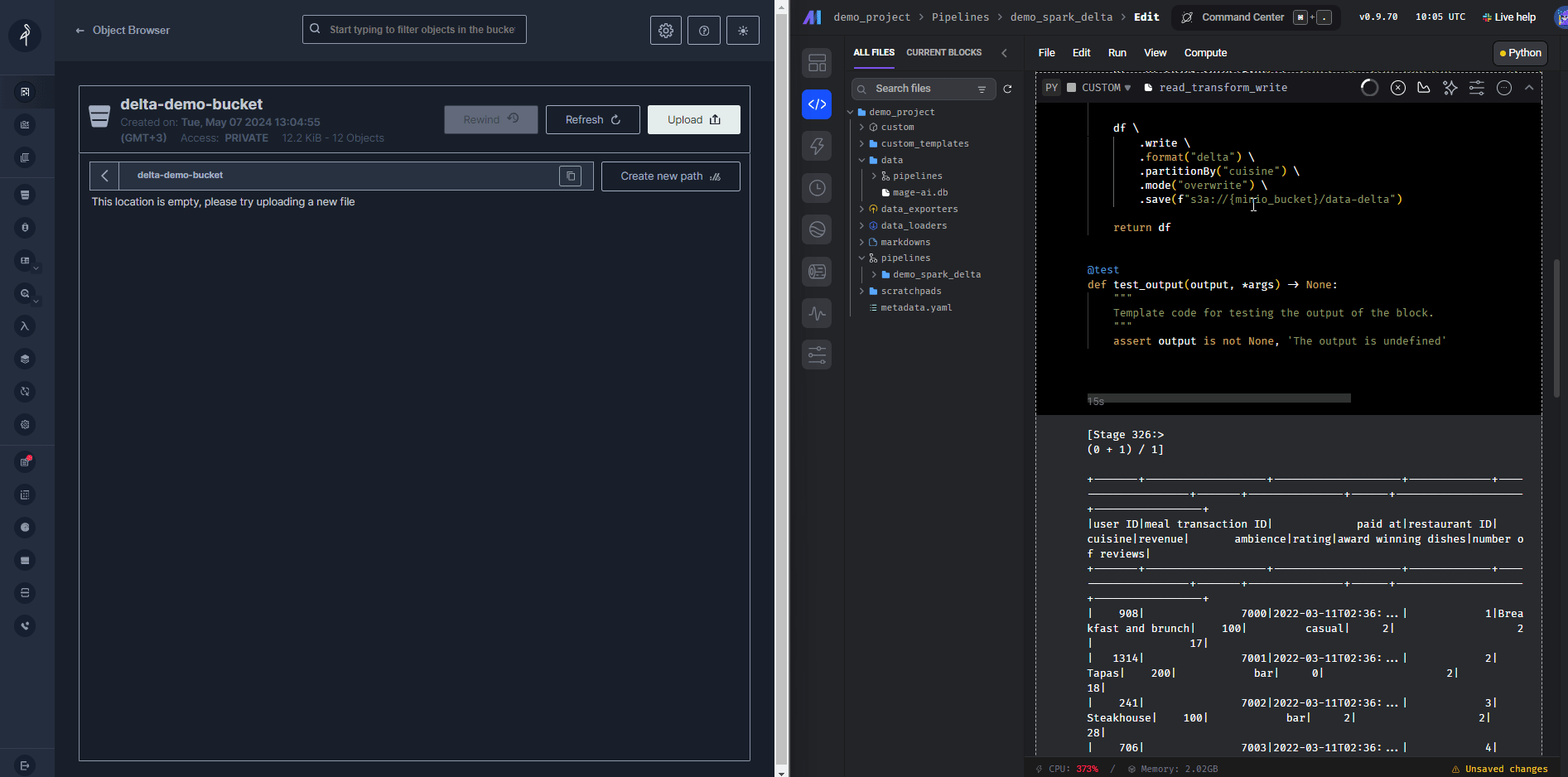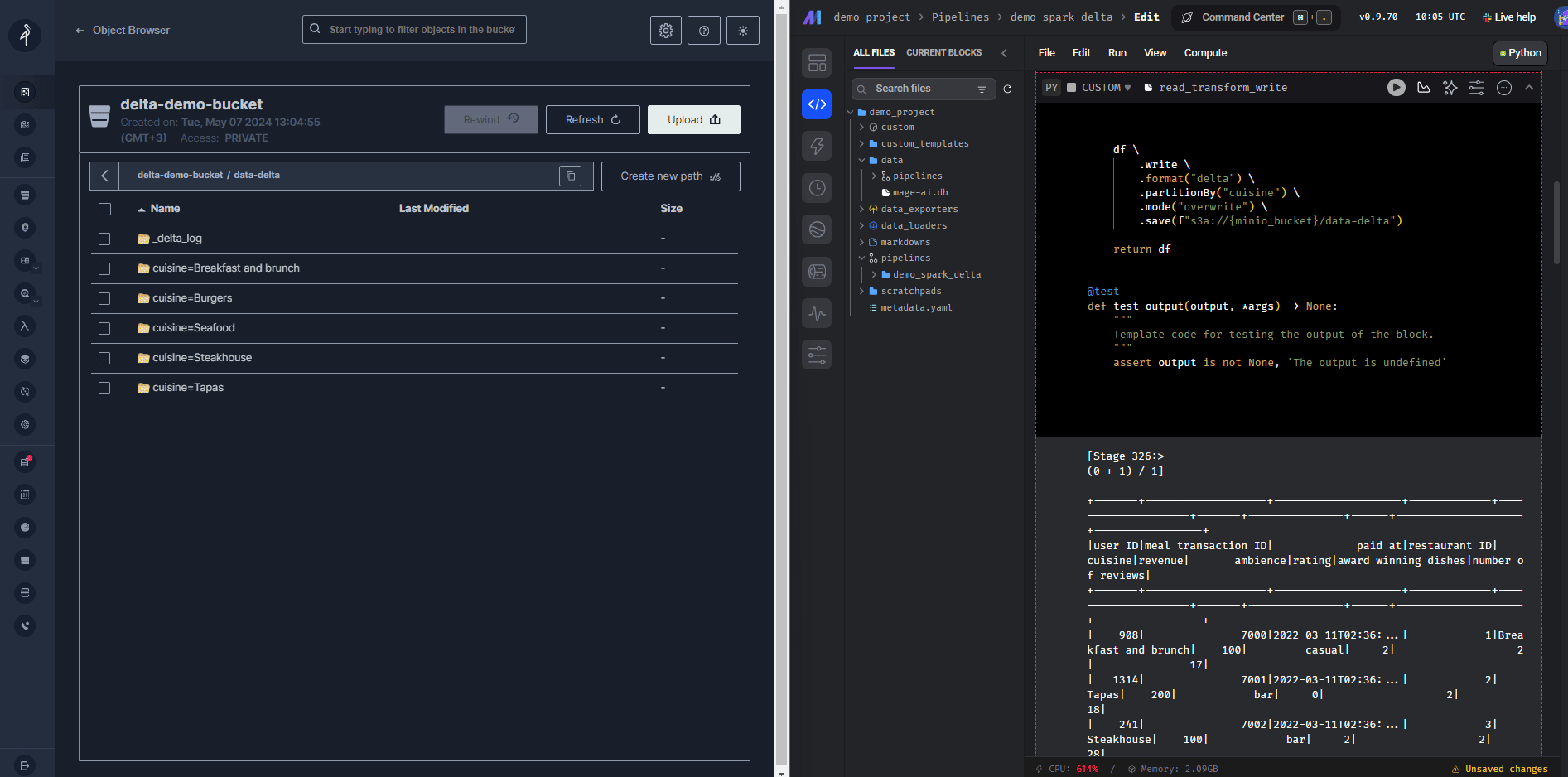
This article outlines a data engineering pipeline built with open-source technologies: Mage AI, Spark, Delta Lake, and Minio.
The pipeline demonstrates:
- Setting up a development environment using Docker Compose.
- Creating a SparkSession with Delta Lake integration and configuring it for Minio.
- Interacting with Minio to manage buckets.
- Loading data, performing transformations, and saving it to Delta Lake storage on Minio.
