Haste is a CUDA implementation of fused LSTM, Layer Normalized LSTM, and GRU layers with built-in DropConnect and Zoneout regularization. These layers are exposed through C++ and Python APIs for easy integration into your own projects or machine learning frameworks.
What's included in this project?
- a standalone C++ API (
libhaste) - a TensorFlow Python API (
haste_tf) - a PyTorch API (
haste_pytorch) - examples for writing your own custom C++ inference / training code using
libhaste - benchmarking programs to evaluate the performance of RNN implementations
For questions or feedback about Haste, please open an issue on GitHub or send us an email at [email protected].
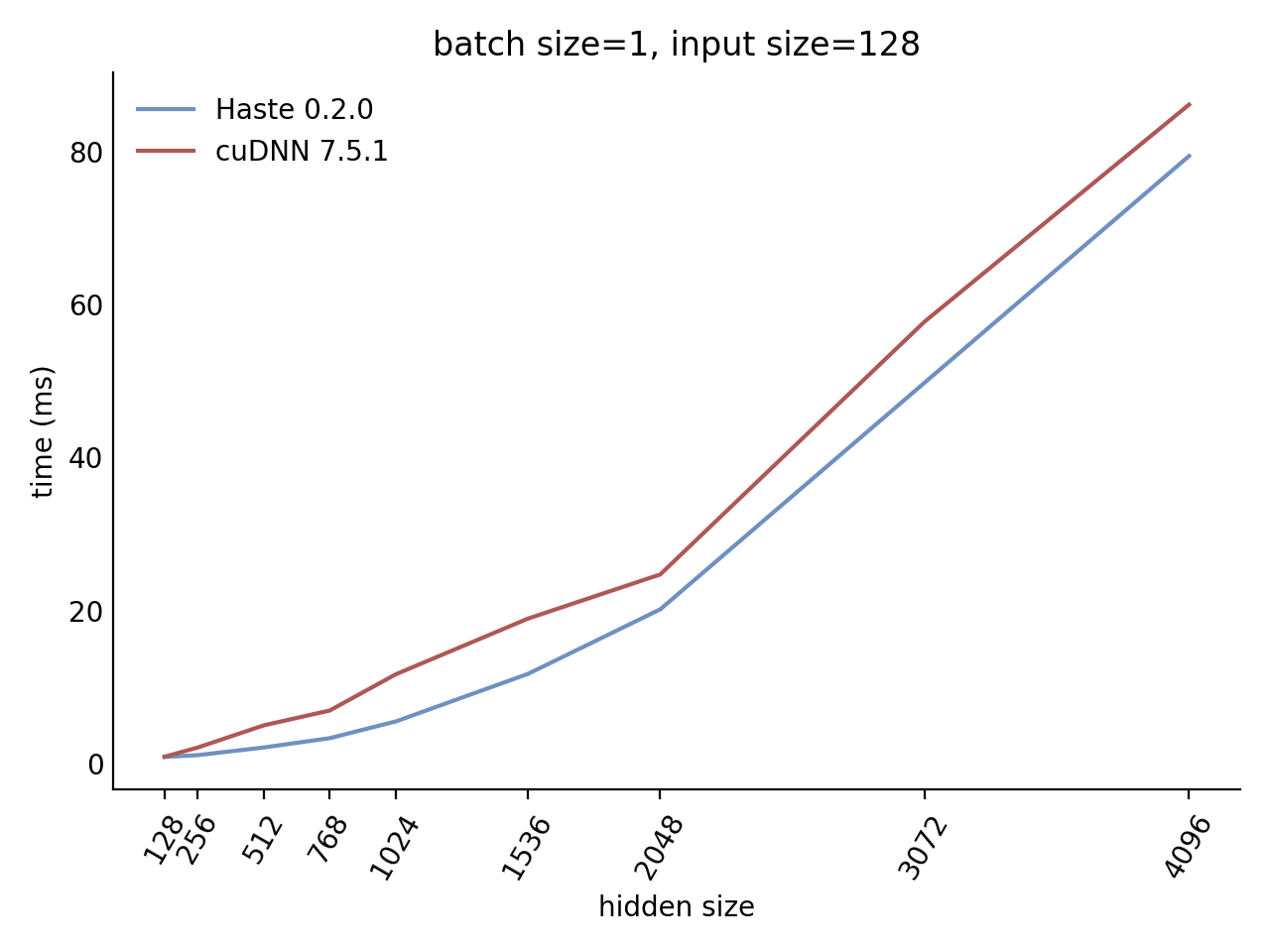
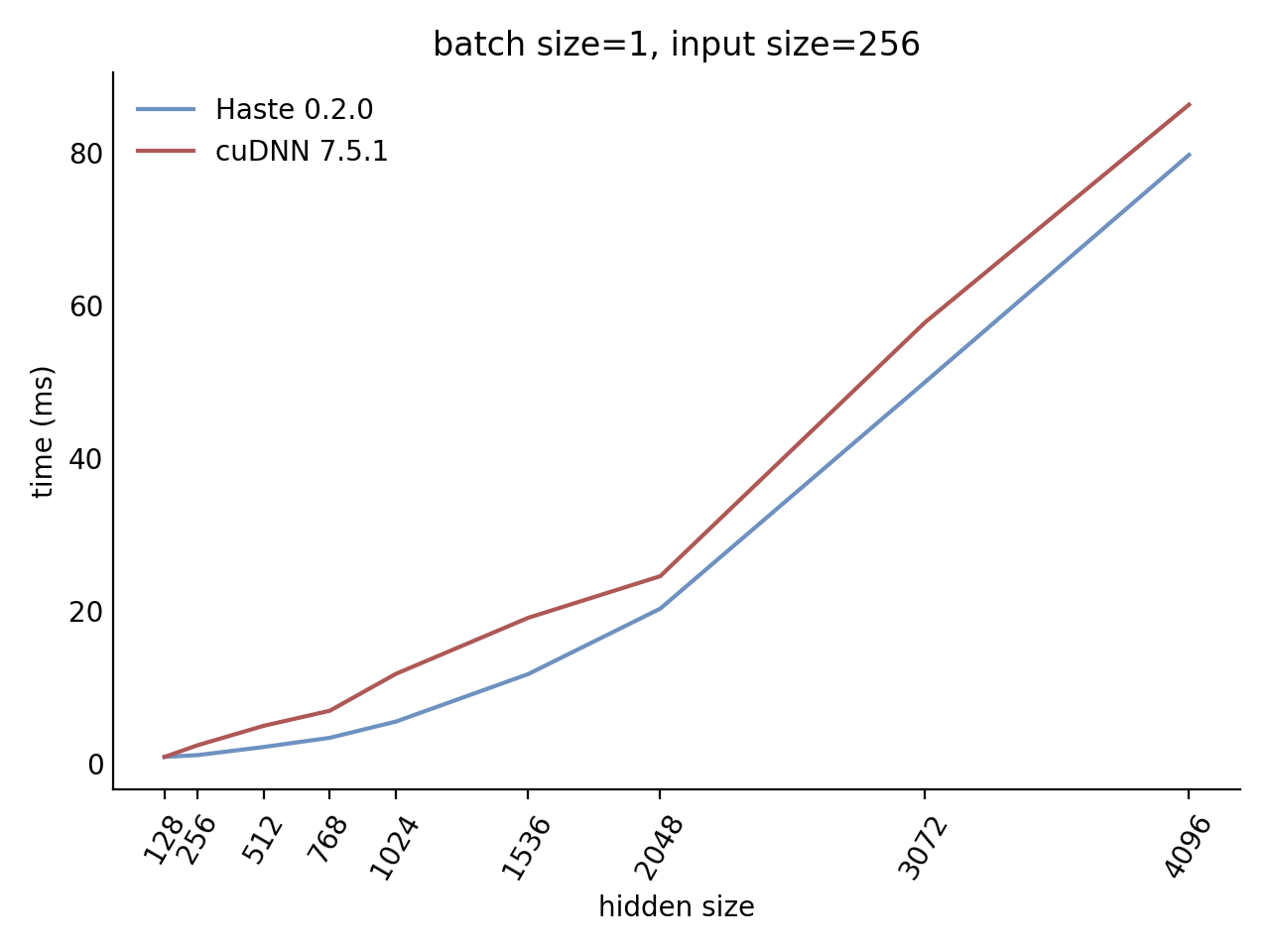
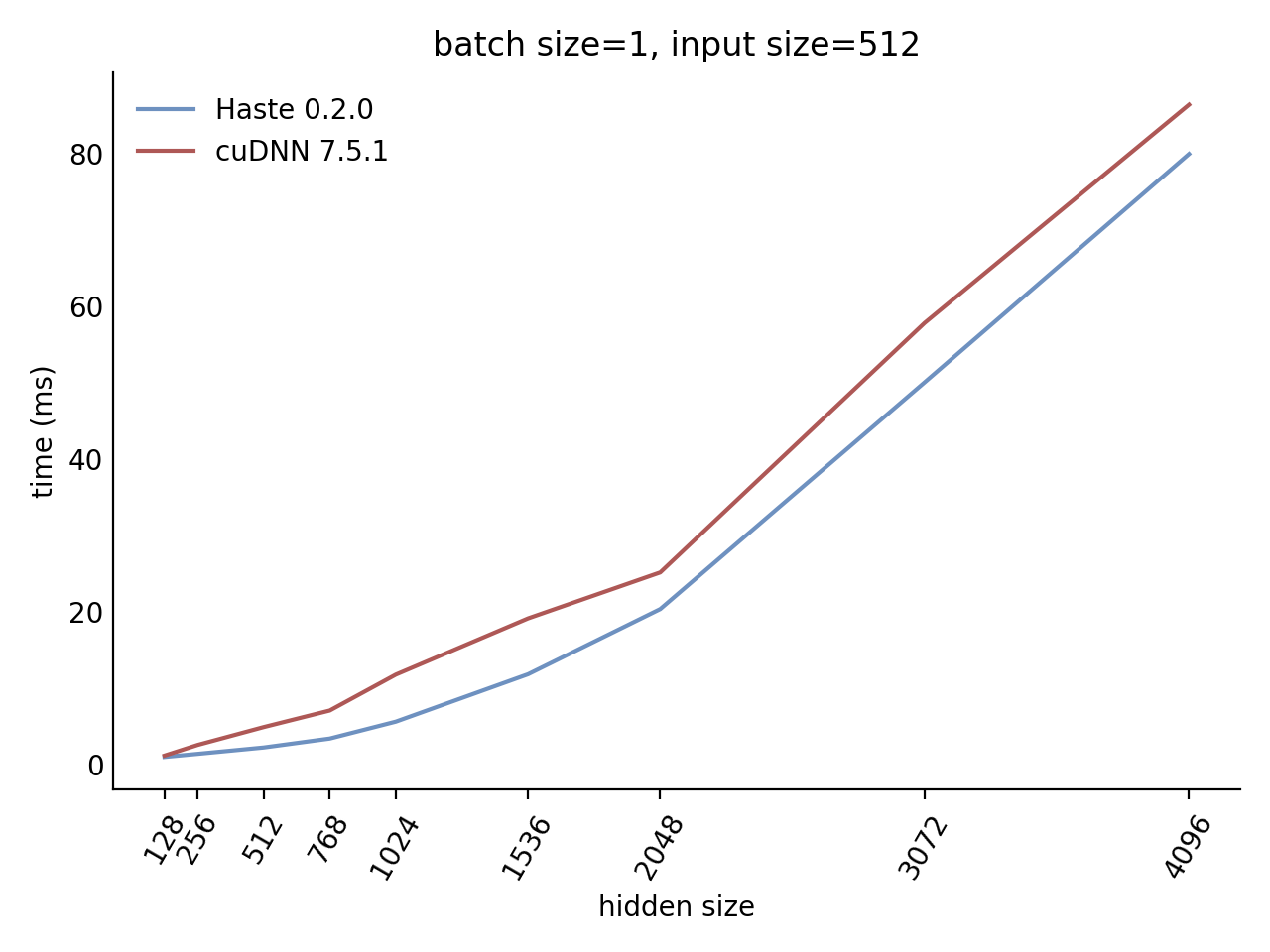
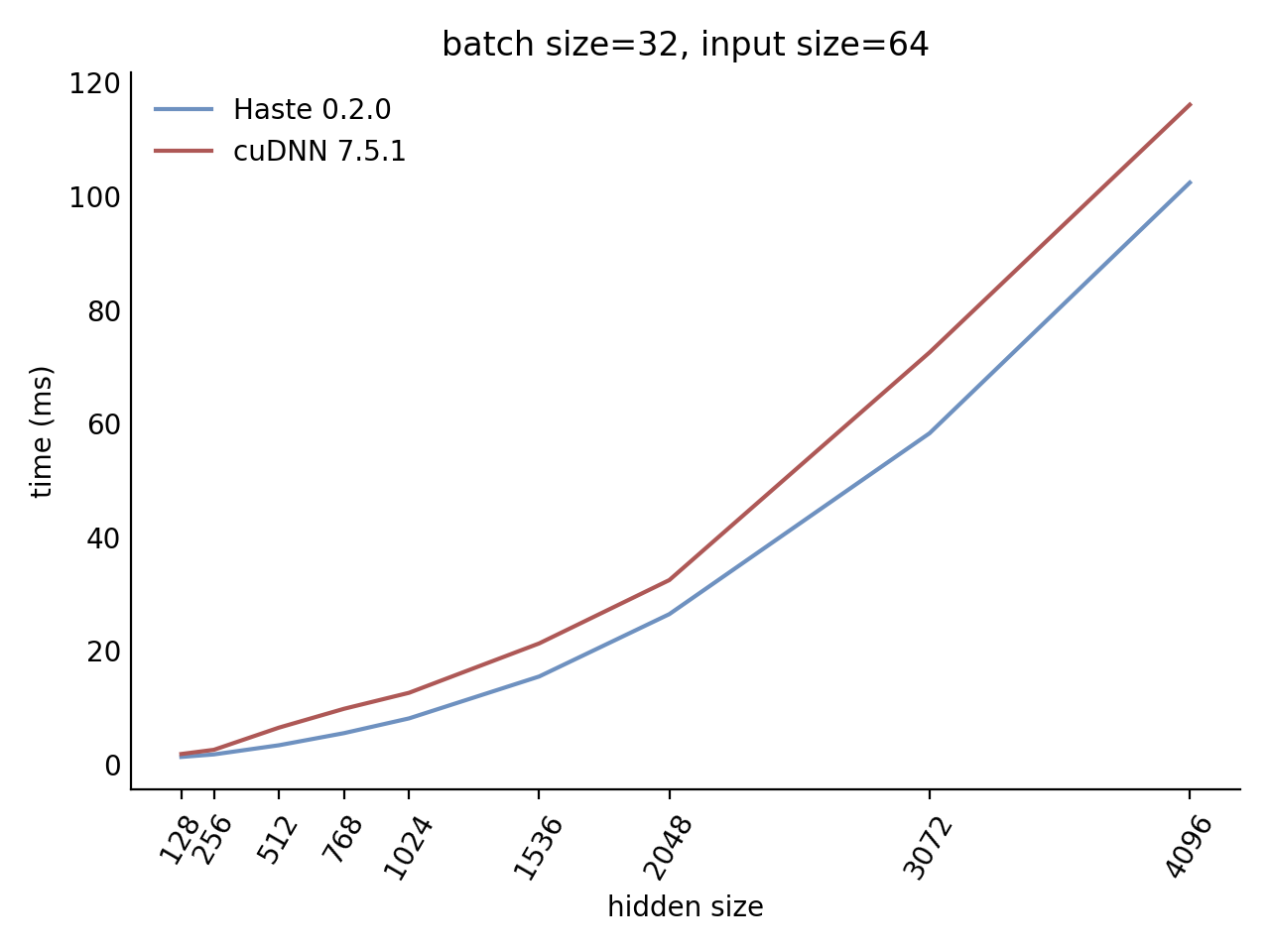
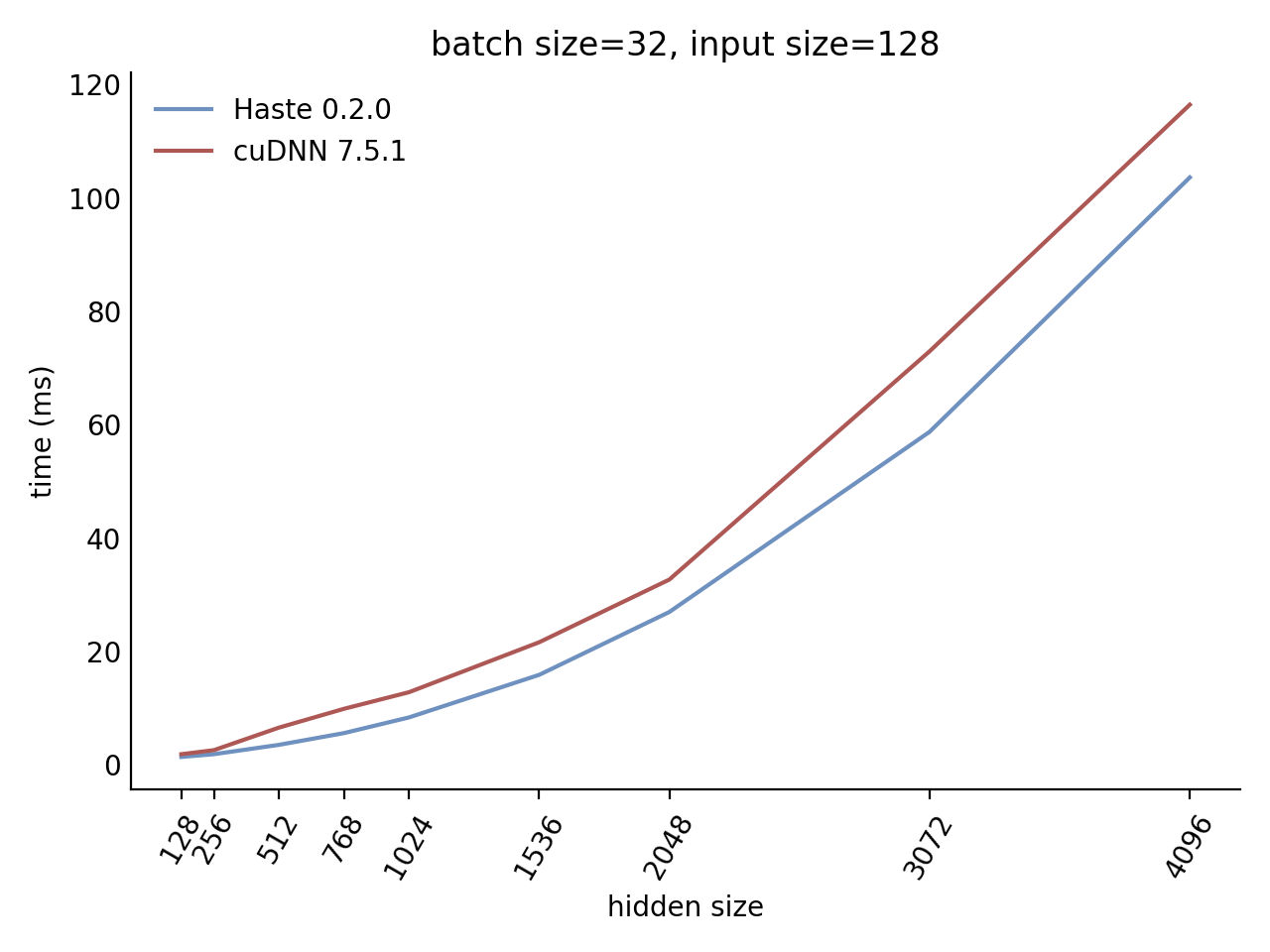
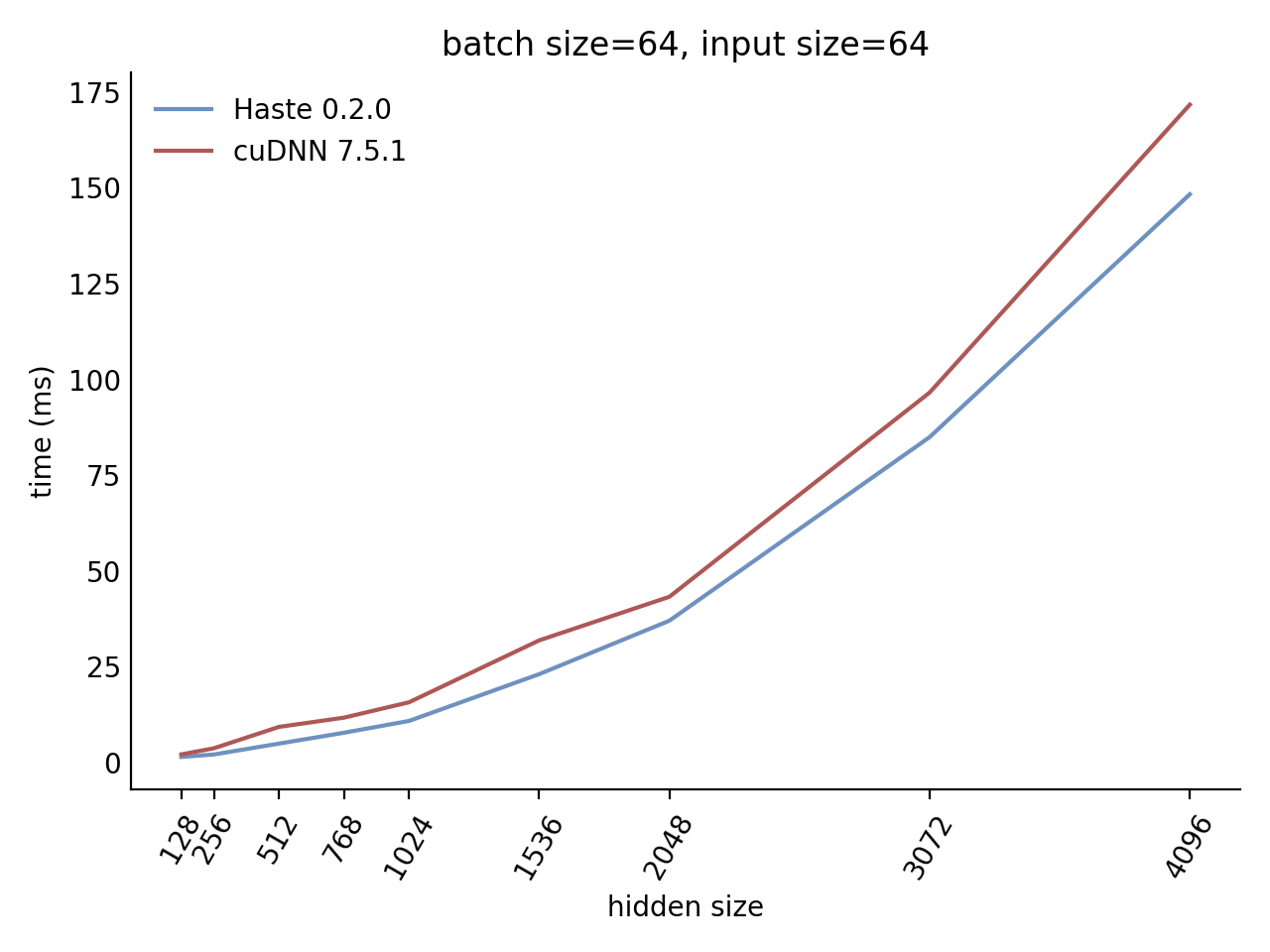
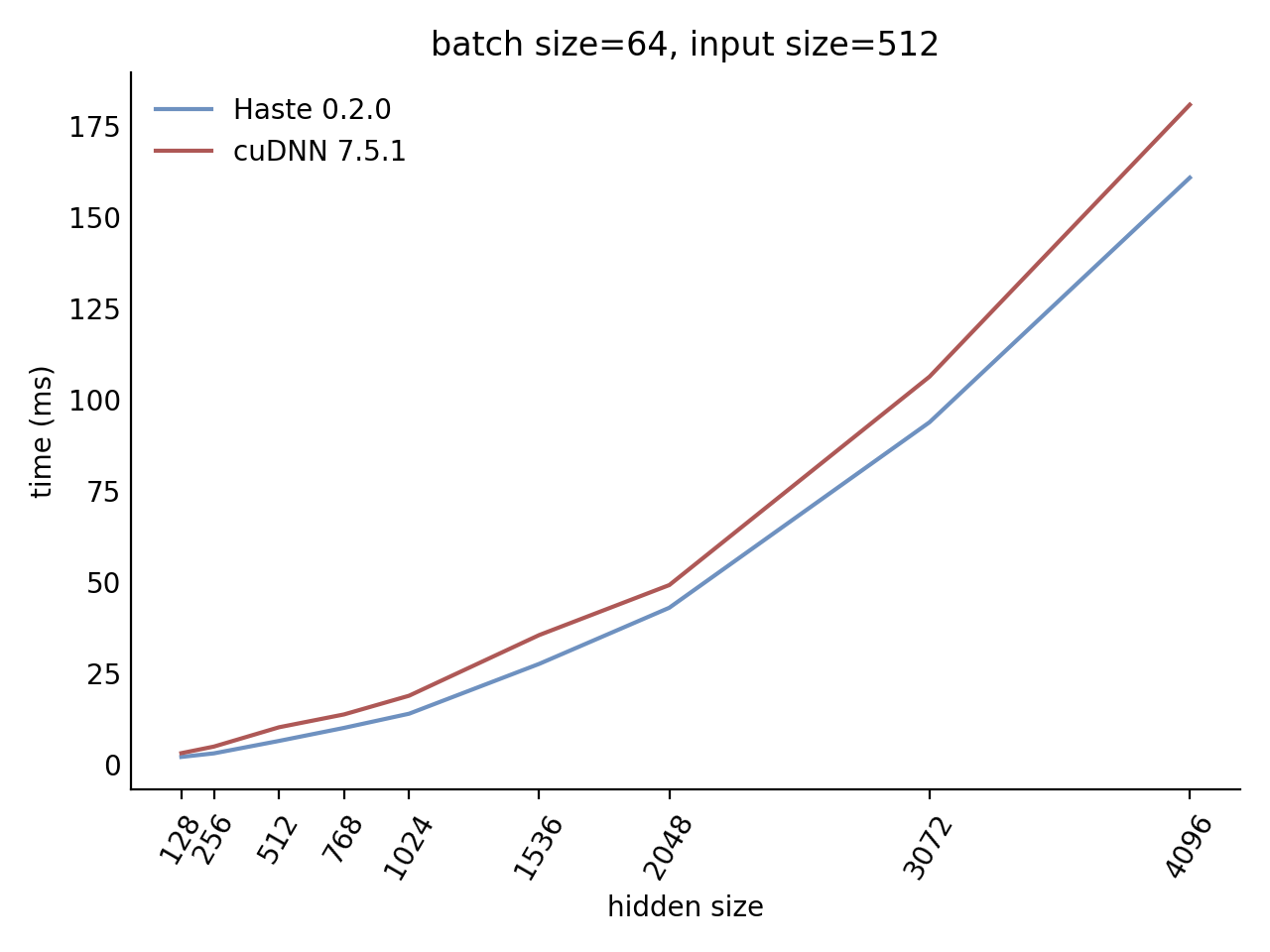
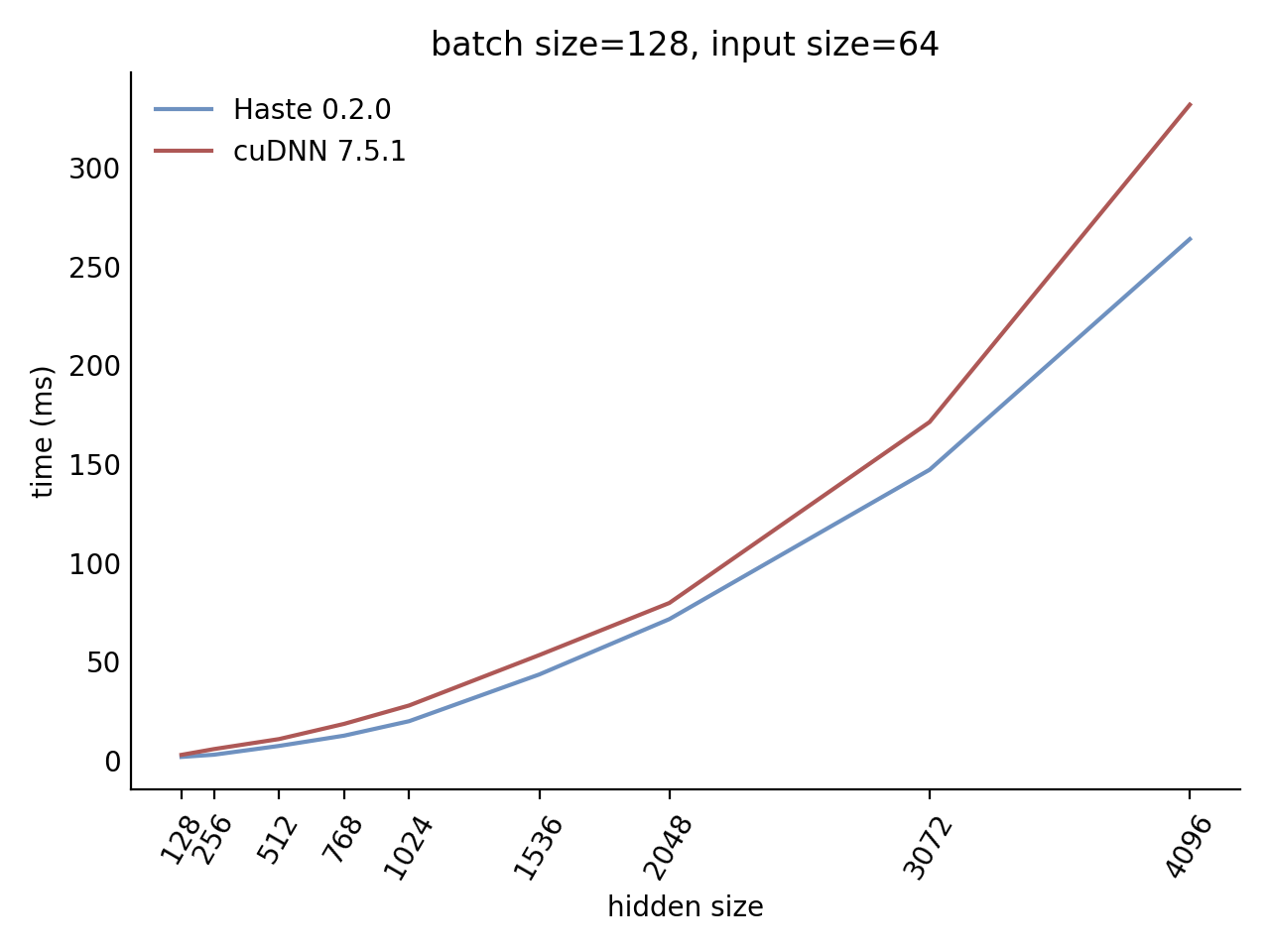
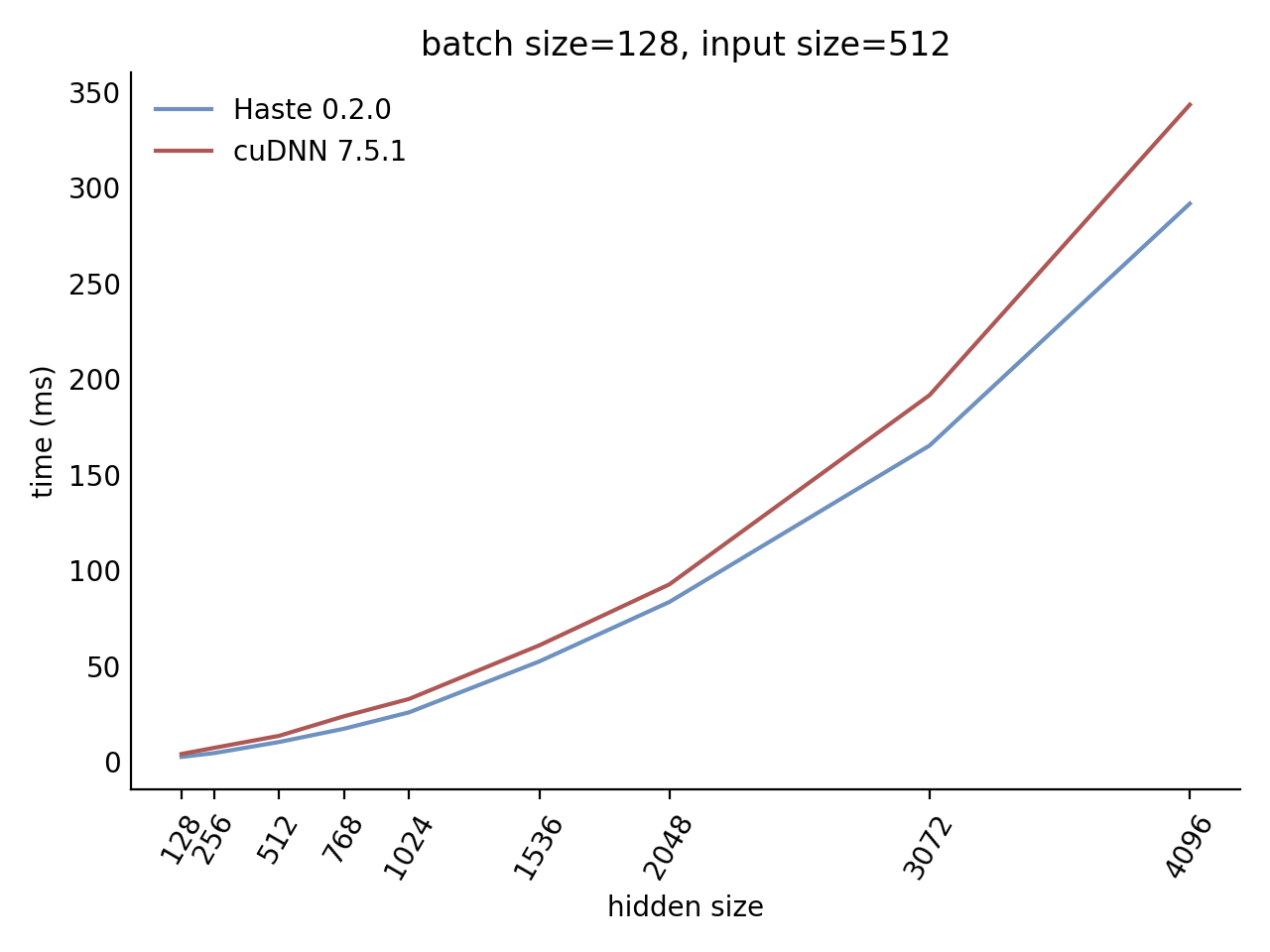
Our LSTM benchmark indicates that Haste has the fastest publicly available implementation for nearly all problem sizes.
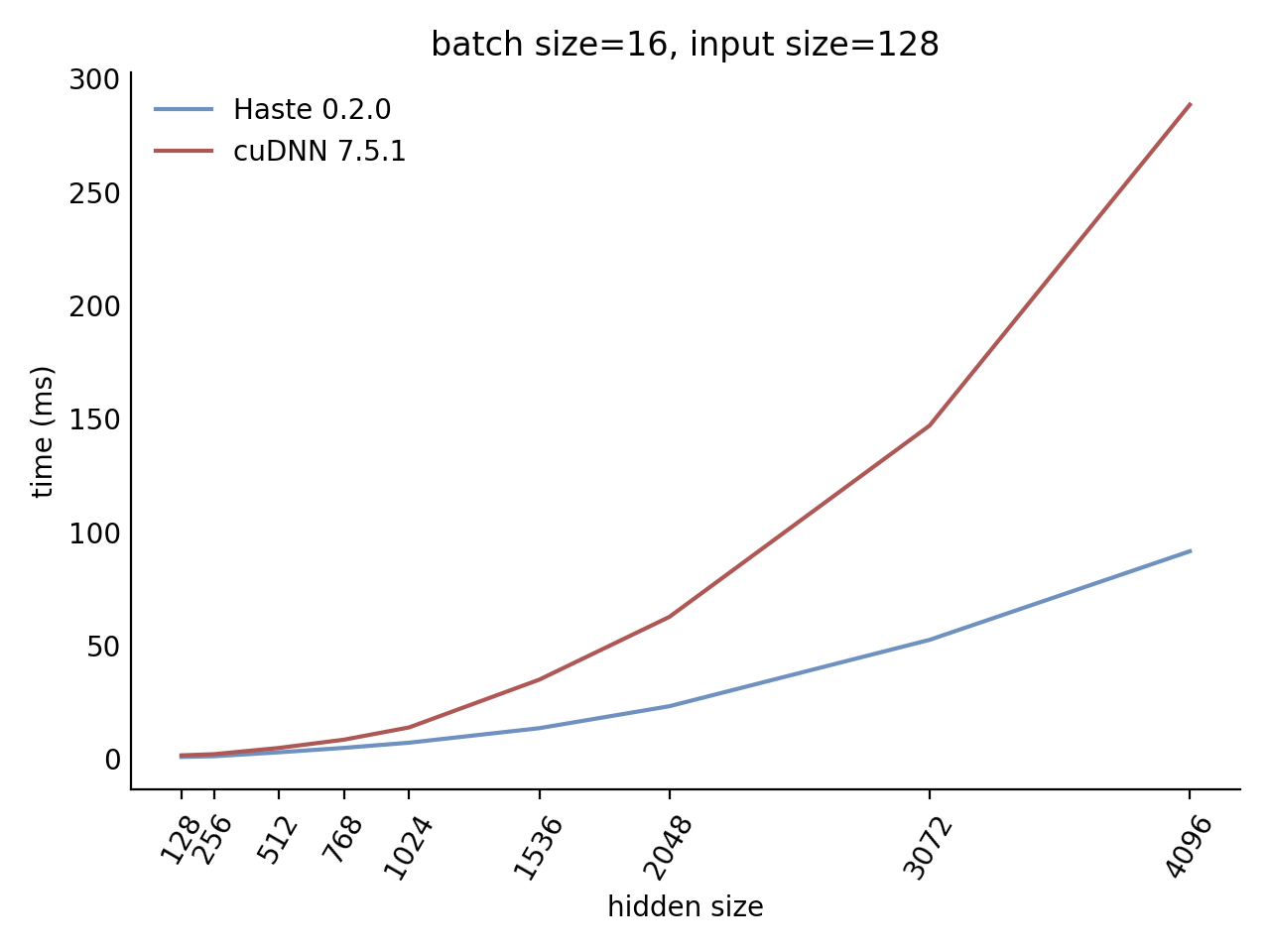 | 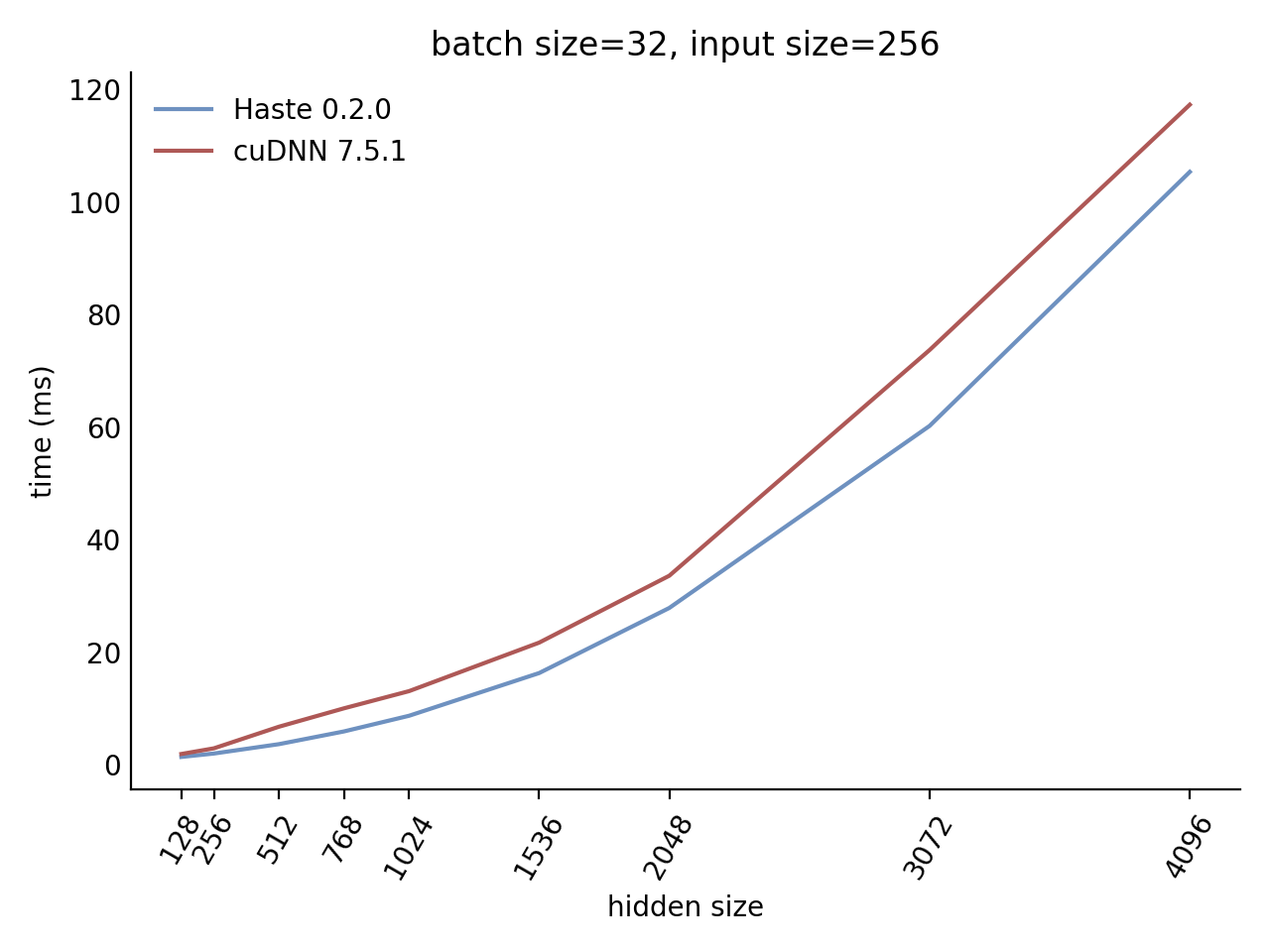 |
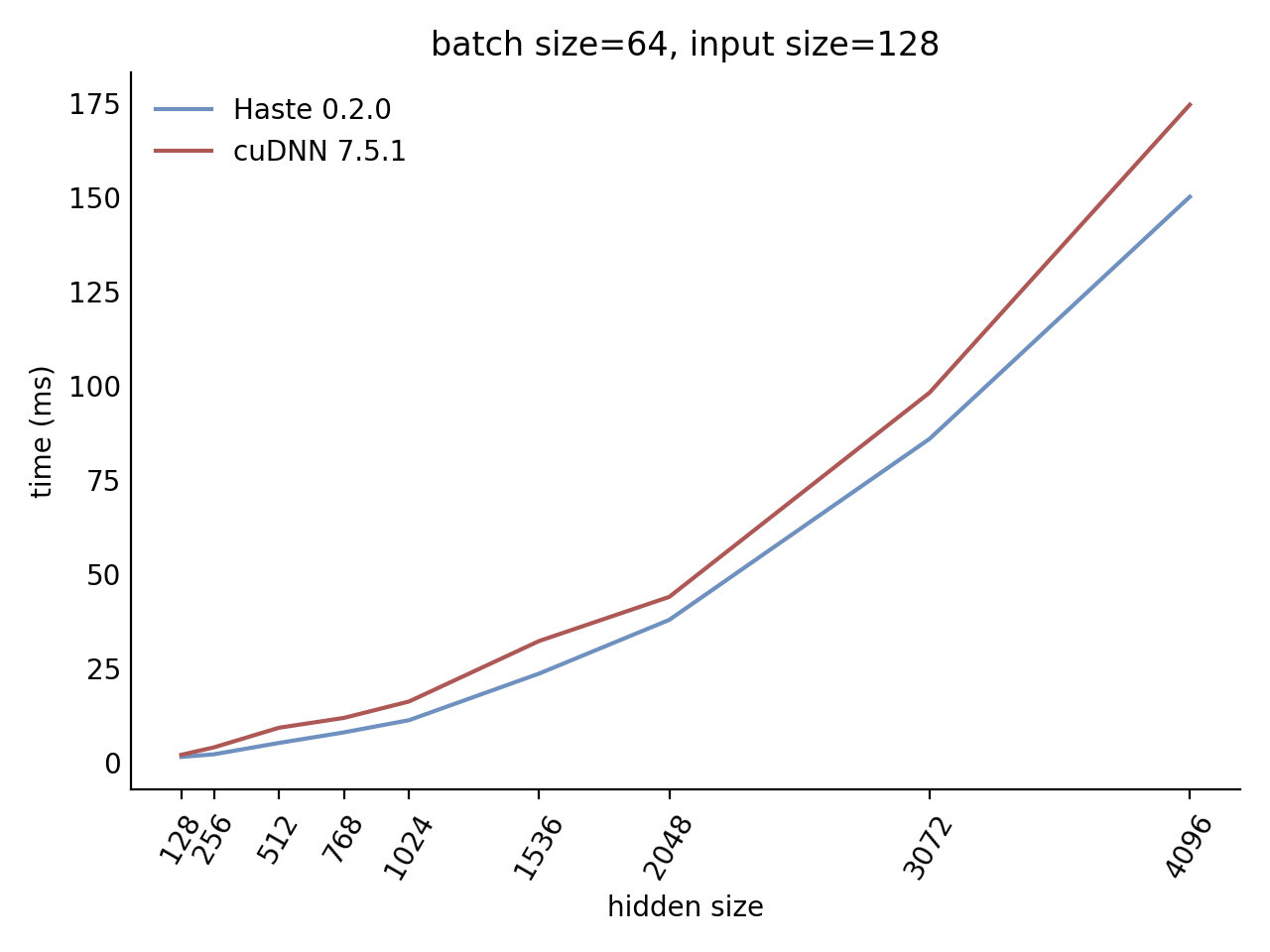 |  |
Here is our complete benchmark result grid:
N=1 C=64
N=1 C=128
N=1 C=256
N=1 C=512
N=32 C=64
N=32 C=128
N=32 C=256
N=32 C=512
N=64 C=64
N=64 C=128
N=64 C=256
N=64 C=512
N=128 C=64
N=128 C=128
N=128 C=256
N=128 C=512
Here's what you'll need to get started:
- a CUDA Compute Capability 6.0+ GPU (required)
- TensorFlow GPU 1.14+ or 2.0+ for TensorFlow integration (optional)
- PyTorch 1.2+ for PyTorch integration (optional)
- Eigen 3 to build the C++ examples (optional)
- cuDNN Developer Library to build benchmarking programs (optional)
Once you have the prerequisites, run one or more of the following to build the code:
make # Build everything
make haste # ;) Build C++ API
make haste_tf # Build TensorFlow API
make haste_pytorch # Build PyTorch API
make examples
make benchmarks
If you built the TensorFlow or PyTorch API, install it with pip:
pip install haste_tf-*.whl
pip install haste_pytorch-*.whl
import haste_tf as haste
norm_lstm_layer = haste.LayerNormLSTM(num_units=256, direction='bidirectional', zoneout=0.1, dropout=0.05)
lstm_layer = haste.LSTM(num_units=256, direction='bidirectional', zoneout=0.1, dropout=0.05)
gru_layer = haste.GRU(num_units=256, direction='bidirectional', zoneout=0.1, dropout=0.05)
# `x` is a tensor with shape [N,T,C]
x = tf.random.normal([5, 25, 128])
y, state = lstm_layer(x, training=True)
y, state = gru_layer(x, training=True)The TensorFlow Python API is documented in docs/tf/haste_tf.md.
import torch
import haste_pytorch as haste
norm_lstm_layer = haste.LayerNormLSTM(input_size=128, hidden_size=256, zoneout=0.1, dropout=0.05)
lstm_layer = haste.LSTM(input_size=128, hidden_size=256, zoneout=0.1, dropout=0.05)
gru_layer = haste.GRU(input_size=128, hidden_size=256, zoneout=0.1, dropout=0.05)
norm_lstm_layer.cuda()
lstm_layer.cuda()
gru_layer.cuda()
# `x` is a CUDA tensor with shape [T,N,C]
x = torch.rand([25, 5, 128]).cuda()
y, state = norm_lstm_layer(x)
y, state = lstm_layer(x)
y, state = gru_layer(x)The PyTorch API is documented in docs/pytorch/haste_pytorch.md.
The C++ API is documented in lib/haste/*.h and there are code samples in examples/.
benchmarks/: programs to evaluate performance of RNN implementationsdocs/tf/: API reference documentation forhaste_tfdocs/pytorch/: API reference documentation forhaste_pytorchexamples/: examples for writing your own C++ inference / training code usinglibhasteframeworks/tf/: TensorFlow Python API and custom op codeframeworks/pytorch/: PyTorch API and custom op codelib/: CUDA kernels and C++ APIvalidation/: scripts to validate output and gradients of RNN layers
- the GRU implementation is based on
1406.1078v1(same as cuDNN) rather than1406.1078v3 - Zoneout on LSTM cells is applied to the hidden state only, and not the cell state
- the layer normalized LSTM implementation uses these equations
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv:1406.1078 [cs, stat]. http://arxiv.org/abs/1406.1078.
- Wan, L., Zeiler, M., Zhang, S., Cun, Y. L., & Fergus, R. (2013). Regularization of Neural Networks using DropConnect. In International Conference on Machine Learning (pp. 1058–1066). Presented at the International Conference on Machine Learning. http://proceedings.mlr.press/v28/wan13.html.
- Krueger, D., Maharaj, T., Kramár, J., Pezeshki, M., Ballas, N., Ke, N. R., et al. (2017). Zoneout: Regularizing RNNs by Randomly Preserving Hidden Activations. arXiv:1606.01305 [cs]. http://arxiv.org/abs/1606.01305.
- Ba, J., Kiros, J.R., & Hinton, G.E. (2016). Layer Normalization. arXiv:1607.06450 [cs, stat]. https://arxiv.org/abs/1607.06450.
- Li, S., Li, W., Cook, C., Zhu, C., & Gao, Y. (2018). Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN. arXiv:1803.04831 [cs]. http://arxiv.org/abs/1803.04831.
To cite this work, please use the following BibTeX entry:
@misc{haste2020,
title = {Haste: a fast, simple, and open RNN library},
author = {Sharvil Nanavati},
year = 2020,
month = "Jan",
howpublished = {\url{https://github.com/lmnt-com/haste/}},
}


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}