Features
- multiple domain scanning with SQL injection dork by Bing, Google, or Yahoo
- targetted scanning by providing specific domain (with crawling)
- reverse domain scanning
both SQLi scanning and domain info checking are done in multiprocessing
so the script is super fast at scanning many urls
quick tutorial & screenshots are shown at the bottom
project contribution tips at the bottom
Installation
- git clone https://github.com/the-robot/sqliv.git
- sudo python2 setup.py -i
Dependencies
Pre-installed Systems
1. Multiple domain scanning with SQLi dork
- it simply search multiple websites from given dork and scan the results one by one
python sqliv.py -d <SQLI DORK> -e <SEARCH ENGINE>
python sqliv.py -d "inurl:index.php?id=" -e google 2. Targetted scanning
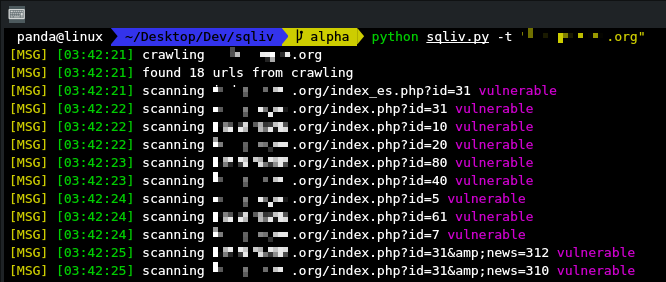
- can provide only domain name or specifc url with query params
- if only domain name is provided, it will crawl and get urls with query
- then scan the urls one by one
python sqliv.py -t <URL>
python sqliv.py -t www.example.com
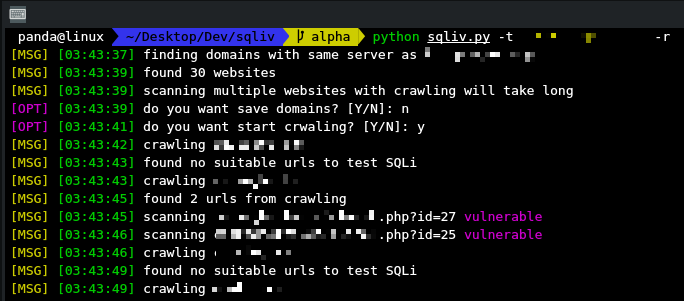
python sqliv.py -t www.example.com/index.php?id=1 3. Reverse domain and scanning
- do reverse domain and look for websites that hosted on same server as target url
python sqliv.py -t <URL> -r4. Dumping scanned result
- you can dump the scanned results as json by giving this argument
python sqliv.py -d <SQLI DORK> -e <SEARCH ENGINE> -o result.jsonView help
python sqliv.py --help
usage: sqliv.py [-h] [-d D] [-e E] [-p P] [-t T] [-r]
optional arguments:
-h, --help show this help message and exit
-d D SQL injection dork
-e E search engine [Google only for now]
-p P number of websites to look for in search engine
-t T scan target website
-r reverse domain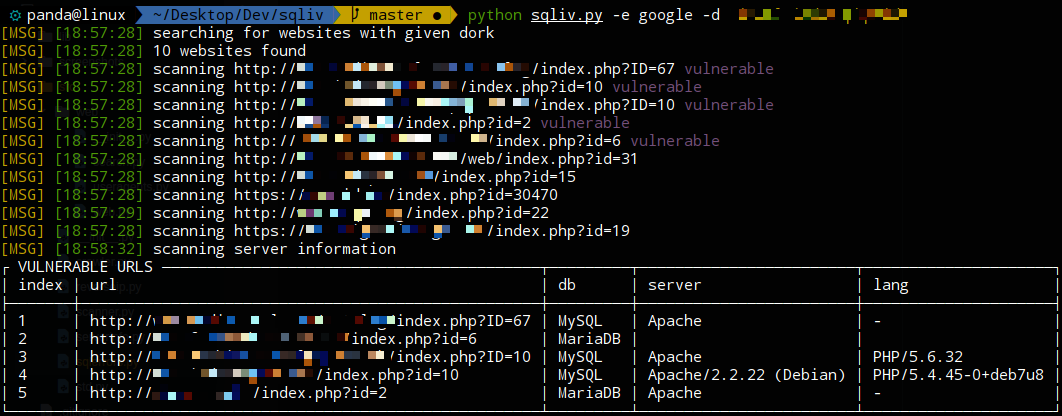

TODO
- POST form SQLi vulnerability testing

































































































































































