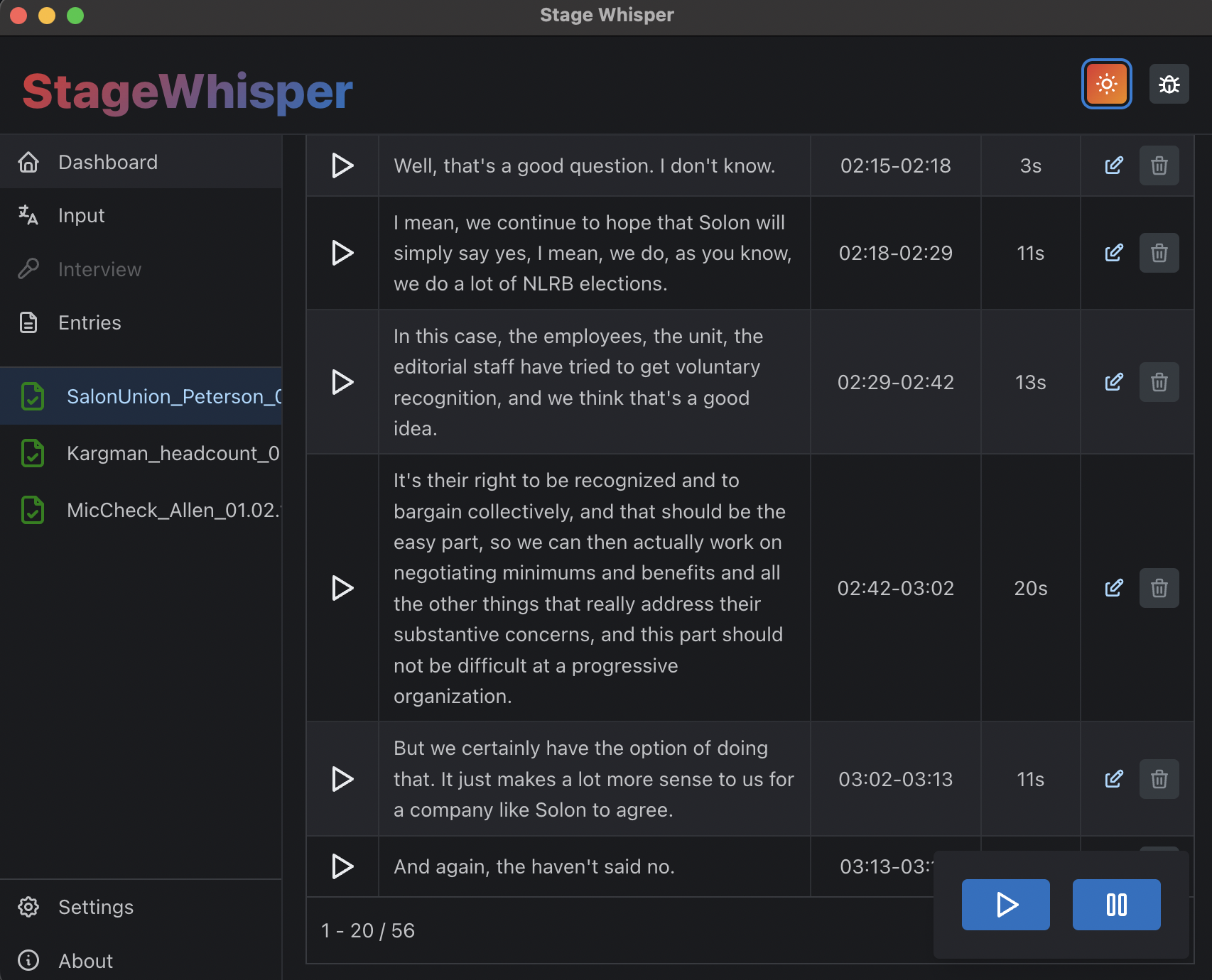
This is the main repo for Stage Whisper — a free, open-source, and easy-to-use audio transcription app. Stage Whisper uses OpenAI's Whisper machine learning model to produce very accurate transcriptions of audio files, and also allows users to store and edit transcriptions using a simple and intuitive graphical user interface.
Stage Whisper consists of two connected components:
- A Python backend that interfaces with OpenAI's Whisper library
- A Node/Electron-powered interface
The eventual 1.0 release of Stage Whisper will (ideally) not require any additional software. For now, though, you will need the following installed on your machine to develop Stage Whisper. It is currently possible to separately work on the Electron interface or the Python backend, so if you are planning to only work on one or the other, you only have to install the requirements specific to that component.
- Node (required for Electron)
- Yarn (required for Electron)
- Python 3.x (required for backend)
- Rust (required for backend)
- ffmpeg (required for backend)
- Poetry (required for backend)
There's any number of ways to get all these dependencies installed on your workstation, but here is one example of how you might install all of the above on a Mac (skip any step for something you have already installed):
# Install Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# Install Python, Node, Rust, ffmpeg, and Yarn
brew install python node rust ffmpeg yarn
# Install Poetry
curl -sSL https://install.python-poetry.org | POETRY_HOME=/etc/poetry python3 -Install dependencies:
cd backend
poetry installWhile the backend's primary purpose will be to run as a service for the Electron app to connect to, it can also be run as a standalone script. To do so, run:
poetry run python stagewhisper --input /path/to/audio/file.mp3cd electron
yarn
yarn devEarlier this year, OpenAI released Whisper, its automatic speech recognition (ASR) system that is trained on "680,000 hours of multilingual and multitask supervised data collected from the web." You can learn more by reading the paper [PDF] or looking at the examples on OpenAI's website.
As Dan Nguyen noted on Twitter, this could be a "godsend for newsrooms."
The only problem, as @PeterSterne pointed out, is that not all journalists (or others who could benefit from this type of transcription tool) are comfortable with the command line and installing the dependencies required to run Whisper.
Our goal is to package Whisper in an easier to use way so that less technical users can take advantage of this neural net.
Peter came up with the project name, Stage Whisper.
@PeterSterne and @filmgirl (Christina Warren) created the project, and @HarrisLapiroff and @Crazy4Pi314 (Sarah Kaiser) are leading the development with @oenu (Adam Newton-Blows) leading frontend development.
We'd love to collaborate with anyone who has ideas about how we could more easily package Whisper and make it easy to use for non-technical users.
The project is currently in the early stages of development. We have a working prototype that uses the Electron and Mantine frameworks to create an app that allows users to input audio files, transcribe them using Whisper, and then manage and edit the resulting transcriptions. The app will be available for MacOS, Windows, and Linux. We are currently working on implementing major improvements and hope to release a beta version soon.
- Request features or ask questions on the project discussions on GitHub.
- Find a bug? Open an issue so that we can see how we can fix it.
- Want to contribute? Check out our good first issues and our contributing guide.
- Join our Discord server to discuss the project's planning and development.
Any code that we distribute will be open sourced and follow the license terms of any of the projects that we are using. Whisper is MIT licensed, but some of its dependencies (FFmpeg) are licensed under different terms. We will be sure to adhere to any/all licensing terms and in the event that we cannot bundle ffmpeg with Stage Whisper, we will make it as easy to obtain as possible for the end-user. Any Stage Whisper-specific code will be licensed under the MIT license.