
Phidata is a framework for building Autonomous Assistants (aka Agents) that have long-term memory, contextual knowledge and the ability to take actions using function calling.
Problem: LLMs have limited context and cannot take actions.
Solution: Add memory, knowledge and tools.
- Memory: Stores chat history in a database and enables LLMs to have long-term conversations.
- Knowledge: Stores information in a vector database and provides LLMs with business context.
- Tools: Enable LLMs to take actions like pulling data from an API, sending emails or querying a database.
- Step 1: Create an
Assistant - Step 2: Add Tools (functions), Knowledge (vectordb) and Storage (database)
- Step 3: Serve using Streamlit, FastApi or Django to build your AI application
pip install -U phidataCreate a file assistant.py
from phi.assistant import Assistant
from phi.tools.duckduckgo import DuckDuckGo
assistant = Assistant(tools=[DuckDuckGo()], show_tool_calls=True)
assistant.print_response("Whats happening in France?", markdown=True)Install libraries, export your OPENAI_API_KEY and run the Assistant
pip install openai duckduckgo-search
export OPENAI_API_KEY=sk-xxxx
python assistant.py- Read the docs at docs.phidata.com
- Chat with us on discord
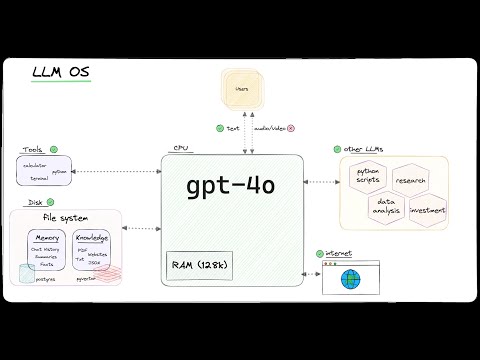
- LLM OS: Using LLMs as the CPU for an emerging Operating System.
- Autonomous RAG: Gives LLMs tools to search its knowledge, web or chat history.
- Local RAG: Fully local RAG with Ollama and PgVector.
- Investment Researcher: Generate investment reports on stocks using Llama3 and Groq.
- News Articles: Write News Articles using Llama3 and Groq.
- Video Summaries: YouTube video summaries using Llama3 and Groq.
- Research Assistant: Write research reports using Llama3 and Groq.
Show details
The PythonAssistant can achieve tasks by writing and running python code.
- Create a file
python_assistant.py
from phi.assistant.python import PythonAssistant
from phi.file.local.csv import CsvFile
python_assistant = PythonAssistant(
files=[
CsvFile(
path="https://phidata-public.s3.amazonaws.com/demo_data/IMDB-Movie-Data.csv",
description="Contains information about movies from IMDB.",
)
],
pip_install=True,
show_tool_calls=True,
)
python_assistant.print_response("What is the average rating of movies?", markdown=True)- Install pandas and run the
python_assistant.py
pip install pandas
python python_assistant.pyShow details
The DuckDbAssistant can perform data analysis using SQL.
- Create a file
data_assistant.py
import json
from phi.assistant.duckdb import DuckDbAssistant
duckdb_assistant = DuckDbAssistant(
semantic_model=json.dumps({
"tables": [
{
"name": "movies",
"description": "Contains information about movies from IMDB.",
"path": "https://phidata-public.s3.amazonaws.com/demo_data/IMDB-Movie-Data.csv",
}
]
}),
)
duckdb_assistant.print_response("What is the average rating of movies? Show me the SQL.", markdown=True)- Install duckdb and run the
data_assistant.pyfile
pip install duckdb
python data_assistant.pyShow details
One of our favorite LLM features is generating structured data (i.e. a pydantic model) from text. Use this feature to extract features, generate movie scripts, produce fake data etc.
Let's create an Movie Assistant to write a MovieScript for us.
- Create a file
movie_assistant.py
from typing import List
from pydantic import BaseModel, Field
from rich.pretty import pprint
from phi.assistant import Assistant
class MovieScript(BaseModel):
setting: str = Field(..., description="Provide a nice setting for a blockbuster movie.")
ending: str = Field(..., description="Ending of the movie. If not available, provide a happy ending.")
genre: str = Field(..., description="Genre of the movie. If not available, select action, thriller or romantic comedy.")
name: str = Field(..., description="Give a name to this movie")
characters: List[str] = Field(..., description="Name of characters for this movie.")
storyline: str = Field(..., description="3 sentence storyline for the movie. Make it exciting!")
movie_assistant = Assistant(
description="You help write movie scripts.",
output_model=MovieScript,
)
pprint(movie_assistant.run("New York"))- Run the
movie_assistant.pyfile
python movie_assistant.py- The output is an object of the
MovieScriptclass, here's how it looks:
MovieScript(
│ setting='A bustling and vibrant New York City',
│ ending='The protagonist saves the city and reconciles with their estranged family.',
│ genre='action',
│ name='City Pulse',
│ characters=['Alex Mercer', 'Nina Castillo', 'Detective Mike Johnson'],
│ storyline='In the heart of New York City, a former cop turned vigilante, Alex Mercer, teams up with a street-smart activist, Nina Castillo, to take down a corrupt political figure who threatens to destroy the city. As they navigate through the intricate web of power and deception, they uncover shocking truths that push them to the brink of their abilities. With time running out, they must race against the clock to save New York and confront their own demons.'
)Show details
Lets create a PDF Assistant that can answer questions from a PDF. We'll use PgVector for knowledge and storage.
Knowledge Base: information that the Assistant can search to improve its responses (uses a vector db).
Storage: provides long term memory for Assistants (uses a database).
- Run PgVector
Install docker desktop and run PgVector on port 5532 using:
docker run -d \
-e POSTGRES_DB=ai \
-e POSTGRES_USER=ai \
-e POSTGRES_PASSWORD=ai \
-e PGDATA=/var/lib/postgresql/data/pgdata \
-v pgvolume:/var/lib/postgresql/data \
-p 5532:5432 \
--name pgvector \
phidata/pgvector:16- Create PDF Assistant
- Create a file
pdf_assistant.py
import typer
from rich.prompt import Prompt
from typing import Optional, List
from phi.assistant import Assistant
from phi.storage.assistant.postgres import PgAssistantStorage
from phi.knowledge.pdf import PDFUrlKnowledgeBase
from phi.vectordb.pgvector import PgVector2
db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai"
knowledge_base = PDFUrlKnowledgeBase(
urls=["https://phi-public.s3.amazonaws.com/recipes/ThaiRecipes.pdf"],
vector_db=PgVector2(collection="recipes", db_url=db_url),
)
# Comment out after first run
knowledge_base.load()
storage = PgAssistantStorage(table_name="pdf_assistant", db_url=db_url)
def pdf_assistant(new: bool = False, user: str = "user"):
run_id: Optional[str] = None
if not new:
existing_run_ids: List[str] = storage.get_all_run_ids(user)
if len(existing_run_ids) > 0:
run_id = existing_run_ids[0]
assistant = Assistant(
run_id=run_id,
user_id=user,
knowledge_base=knowledge_base,
storage=storage,
# Show tool calls in the response
show_tool_calls=True,
# Enable the assistant to search the knowledge base
search_knowledge=True,
# Enable the assistant to read the chat history
read_chat_history=True,
)
if run_id is None:
run_id = assistant.run_id
print(f"Started Run: {run_id}\n")
else:
print(f"Continuing Run: {run_id}\n")
# Runs the assistant as a cli app
assistant.cli_app(markdown=True)
if __name__ == "__main__":
typer.run(pdf_assistant)- Install libraries
pip install -U pgvector pypdf "psycopg[binary]" sqlalchemy- Run PDF Assistant
python pdf_assistant.py- Ask a question:
How do I make pad thai?
-
See how the Assistant searches the knowledge base and returns a response.
-
Message
byeto exit, start the assistant again usingpython pdf_assistant.pyand ask:
What was my last message?
See how the assistant now maintains storage across sessions.
- Run the
pdf_assistant.pyfile with the--newflag to start a new run.
python pdf_assistant.py --newCheckout the cookbook for more examples.
- Read the basics to learn more about phidata.
- Read about Assistants and how to customize them.
- Checkout the cookbook for in-depth examples and code.
Checkout the following AI Applications built using phidata:
- PDF AI that summarizes and answers questions from PDFs.
- ArXiv AI that answers questions about ArXiv papers using the ArXiv API.
- HackerNews AI summarize stories, users and shares what's new on HackerNews.



We've helped many companies build AI products, the general workflow is:
- Build an Assistant with proprietary data to perform tasks specific to your product.
- Connect your product to the Assistant via an API.
- Monitor and Improve your AI product.
We also provide dedicated support and development, book a call to get started.
We're an open-source project and welcome contributions, please read the contributing guide for more information.
- If you have a feature request, please open an issue or make a pull request.
- If you have ideas on how we can improve, please create a discussion.
Our roadmap is available here. If you have a feature request, please open an issue/discussion.



























































































































































































