Comments (14)
 XavierXiao
commented on May 20, 2024
1
XavierXiao
commented on May 20, 2024
1
I found that by changing this line to attention_for_text = attention_maps[:, :, 1:8] improves the convergence a lot on SD2.1. This is just a stupid way to hard-code, ideally the 8 should be len(non_padded_token_ids). This makes sense because out of 77 tokens, there is a sot, a eot and the remaining ones are all padded, which should not be included in the computation. I think this should be done in SD v1 as well.
from attend-and-excite.
 AttendAndExcite
commented on May 20, 2024
AttendAndExcite
commented on May 20, 2024
Hi @Cococyh, thanks for your interest!
looks like the attention maps are not being saved by the controller.
we have a pending pull request to upgrade the version of diffusers that may help solve your issue.
if the issue persists after the PR is merged, we will try to help investigating this issue :)
from attend-and-excite.
 Cococyh
commented on May 20, 2024
Cococyh
commented on May 20, 2024
Hi @AttendAndExcite, thanks for your reply!
I update diffusers to 0.12.1, and I find out I was using the stabilityai/stable-diffusion-2-1-inpainting model, when I replace it to stabilityai/stable-diffusion-2-1, it works well! :)
When I set (width, height) as (256, 256), it still works, and the result picture is 256*256, but set (width, height) as (768, 768), I meet this error, it seems like a little different from the previously error.
Traceback (most recent call last):
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/run.py", line 90, in
main()
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/venv/lib/python3.10/site-packages/pyrallis/argparsing.py", line 158, in wrapper_inner
response = fn(cfg, *args, **kwargs)
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/run.py", line 73, in main
image = run_on_prompt(prompt=config.prompt,
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/run.py", line 44, in run_on_prompt
outputs = model(prompt=prompt,
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/pipeline_attend_and_excite.py", line 506, in call
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/pipeline_attend_and_excite.py", line 224, in _aggregate_and_get_max_attention_per_token
attention_maps = aggregate_attention(
File "/home/ubuntu/12T_1/szs/code/stable_diffusion/stable-diffusion-webui/Attend-and-Excite-diffusers/utils/ptp_utils.py", line 232, in aggregate_attention
out = torch.cat(out, dim=0)
RuntimeError: torch.cat(): expected a non-empty list of Tensors
from attend-and-excite.
XavierXiao
commented on May 20, 2024
I think this is because when you have 768-sized image, there is not an attention dimension 16, you need to adjust the attention dimension (to 24 I guess) correspondingly.
The forked codes is runnable for SDv2, but it seems like it is not effective. I found that the iterative refinement will always reach the max iter and the loss does not change much. I am trying to investigate what's wrong.
from attend-and-excite.
AttendAndExcite
commented on May 20, 2024
Hi @XavierXiao, and @Cococyh.
@Cococyh, as mentioned by @XavierXiao, if your model does not have 16x16 attention maps you would need to adjust to work on the most semantic attention resolution. I’d recommend visualizing all the attention resolutions separately and determining which gives the maps that correspond to the generated objects best.
@XavierXiao, which prompts did you work on? It could be an issue of expressiveness of Stable Diffusion, have you tried the prompts from the paper?
from attend-and-excite.
XavierXiao
commented on May 20, 2024
I am on a smaller GPU so I cannot run 768x768 generation. So I try stable diffusion 2-base which is a 512*512 model, with prompt A frog and a pink bench which is in the paper. But I found the gradient to be very small so the iterative refinement will always reach the max _iter, and the sample will look very similar to the original SD's sample.
Since it is still a 512 model, I use the default hyper parameters.
Here is a screenshot. As you can see, I print out the grad norm and it is small. The loss does not decrease much.

from attend-and-excite.
XavierXiao
commented on May 20, 2024
And the samples with (top) and without (bottom) A&E.
Maybe some configs need to be changed? You can have a try with the given SD version and prompt.


from attend-and-excite.
AttendAndExcite
commented on May 20, 2024
Thanks for the additional information, @XavierXiao!
We will do our best to investigate the issue as well but in the meantime, here are some tips that may be useful in case you’d like to explore a solution:
- Since this is a newly trained model, I’d take a look at the visualizations of the attention maps at different resolutions (to make sure the 16x16 maps are indeed still the most semantic ones).
- I see that the model uses a different text encoder. We perform an additional Softmax operation to discard the <sot> token, it could be that this is not necessary with the ViT-H text encoder (not sure but the attention visualization should answer this question).
- Related to the previous point- the attention normalization should result in generated subject tokens obtaining a maximal attention value close to 1, if this is not the case for successful generations, it could indicate that the attention normalization does not fit the model.
- This is less likely, but it could be that you need to tune the hyperparameters for this case separately (you can try increasing the scale factor).
from attend-and-excite.
Cococyh
commented on May 20, 2024
@AttendAndExcite @XavierXiao, As your say, I set attention dimension to 24 then it looks like I get a nice result, the result picture is 768*768.
The prompt is "a cat and a dog".
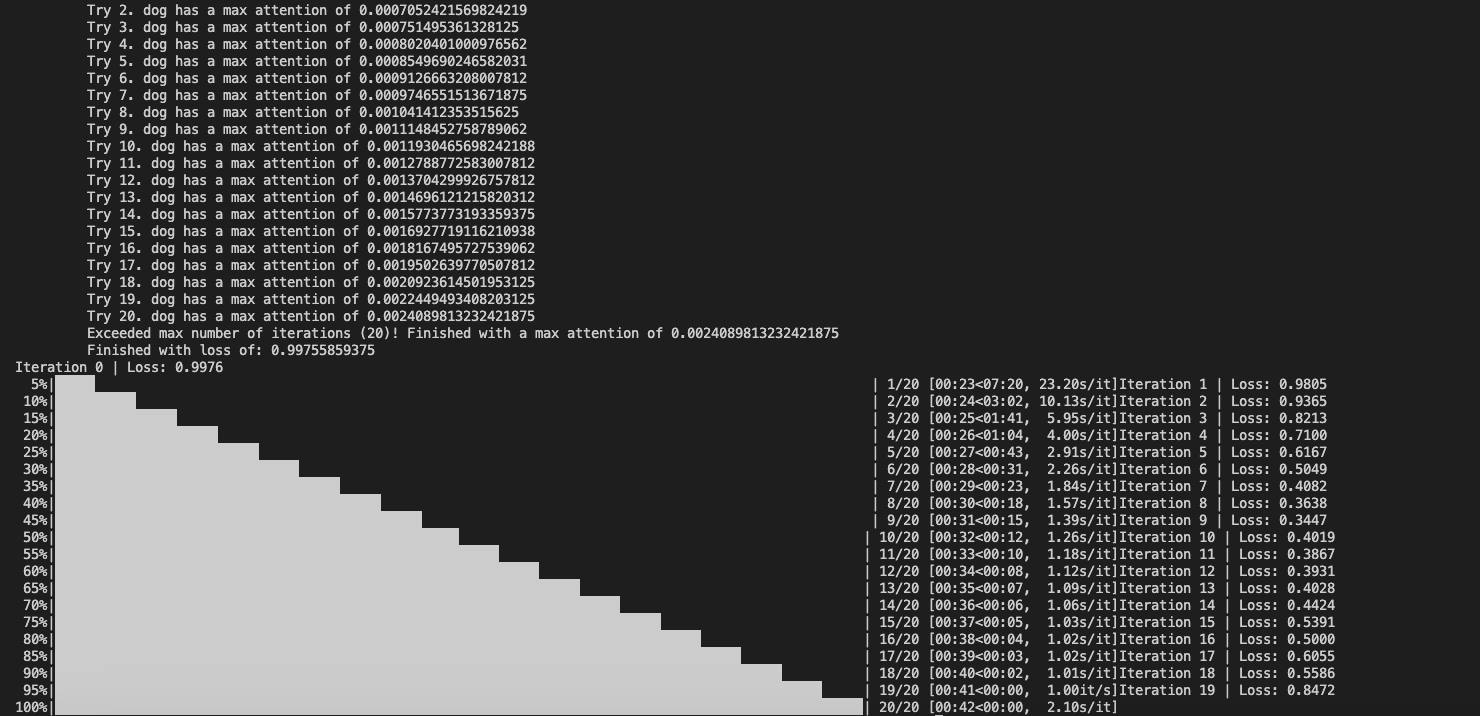

And this is the SD version result:

from attend-and-excite.
XavierXiao
commented on May 20, 2024
@Cococyh Can you try a more complicated example like "a frog and a pink bench"? As I say above the loss hardly decrease.
from attend-and-excite.
Cococyh
commented on May 20, 2024
@AttendAndExcite ,when use sd2.1-768, the token word such as frog's max attention is too small, but use sd1.5, the number is close to 1. Then I change the scale_factor to 100, it's not effective.


from attend-and-excite.
AttendAndExcite
commented on May 20, 2024
@XavierXiao @Cococyh the loss appears to be quite high for the cat and the dog too- this indicates that it may be an issue of the normalization of the probabilities. We will do our best to look into this ASAP :)
from attend-and-excite.
AttendAndExcite
commented on May 20, 2024
Thanks @XavierXiao, this actually makes a lot of sense, as I mentioned above, since the model uses a different text encoder the attention values may vary. It is entirely possible that the attention value of <eot> is high for SD 2.1 therefore removing it and normalizing without it helps the attention values be closer to 1 and then the optimization is easier.
This was not the case for SD 1.4, so it didn’t matter.
I’m leaving this issue open and we will modify the code accordingly once we officially add support for SD 2.1
from attend-and-excite.
AttendAndExcite
commented on May 20, 2024
Hi @Cococyh, and @XavierXiao, thanks for the discussion! Our code now officially supports SD 2.1 via the sd_2_1 parameter (see our README and generate_images.ipynb notebook for details).
from attend-and-excite.
Related Issues (20)
- Can this be used with the automatic1111 webui? HOT 6
- KeyError:'up' when generating images HOT 2
- Licensing? HOT 1
- How about global properties? HOT 2
- How do I give the token indices if I want to emphasize a group of words? HOT 2
- WebUI? HOT 1
- Explainabililty HOT 1
- Prompts for the quantitative results HOT 2
- "a spiky porcupine", what should I do for procupine, which contains three tokens HOT 1
- How to visualize the cross-attention map of each token HOT 2
- About the Memory usage HOT 2
- some issuses about stable-diffusion-2-1-base HOT 1
- perhaps you can be an add-in for sdwebui? HOT 1
- Did you release the evaluation dataset in your paper? HOT 2
- Comfyui HOT 3
- Intuition behind choosing step size HOT 2
- Latent not updated on first iteration of iterative refinement HOT 4
- KeyError: 'up_cross' HOT 2
- Are the datasets(Animal-Animal Animal-Object Object-Object) avaliable ? HOT 1
- Question about the attention score of <sot>
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from attend-and-excite.