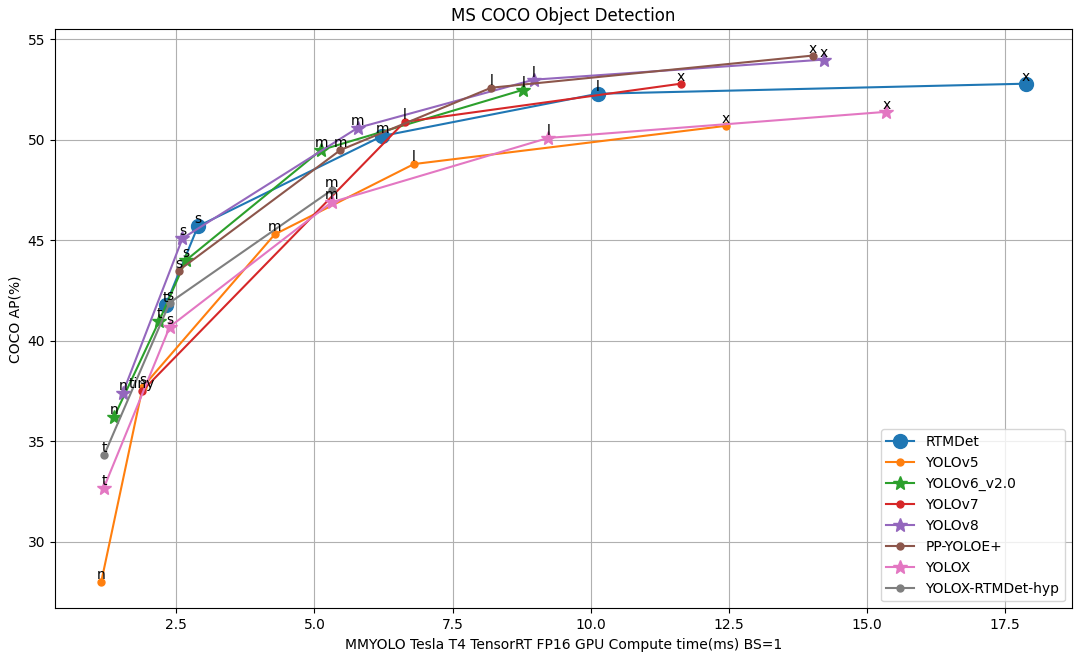
Prerequisite
🐞 Describe the bug
Hi there,
I have been trying to make YOLOV5 P6 custom training pipeline working for a while. Unfortunately, I could not make it working. I used the same setting for P5 models, it worked well. Here are the settings I put:
_base_ = '../yolov5_l-p6-v62_syncbn_fast_8xb16-300e_coco.py'
# _base_ = '../yolov5_l-v61_syncbn_fast_8xb16-300e_coco.py'
data_root = '/mnt/ssd/datasets-ml/COTS_GoPro_1080_v3/'
train_batch_size_per_gpu = 2
train_num_workers = 6
num_classes = 1
metainfo = {
'CLASSES': ('COTS', ),
'PALETTE': [
(220, 20, 60),
]
}
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
data_prefix=dict(img=''),
ann_file='mmdet_split_train.json'))
val_dataloader = dict(
dataset=dict(
data_root=data_root,
metainfo=metainfo,
data_prefix=dict(img=''),
ann_file='mmdet_split_val.json',))
val_dataloader = dict(
dataset=dict(
data_root=data_root,
metainfo=metainfo,
data_prefix=dict(img=''),
ann_file='mmdet_split_val.json'))
val_evaluator = dict(ann_file=data_root + 'mmdet_split_val.json')
test_evaluator = dict(ann_file=data_root + 'mmdet_split_test.json')
model = dict(bbox_head=dict(head_module=dict(num_classes=1)))
default_hooks = dict(logger=dict(interval=1))
With the base file: yolov5_l-v61_syncbn_fast_8xb16-300e_coco.py, the model can be trained. But with the base file: yolov5_l-p6-v62_syncbn_fast_8xb16-300e_coco.py, I got the following error messages:
11/09 19:05:34 - mmengine - WARNING - Failed to search registry with scope "mmyolo" in the "log_processor" registry tree. As a workaround, the current "log_processor" registry in "mmengine" is used to build instance. This may cause unexpected failure when running the built modules. Please check whether "mmyolo" is a correct scope, or whether the registry is initialized.
11/09 19:05:34 - mmengine - INFO -
System environment:
sys.platform: linux
Python: 3.8.13 (default, Oct 21 2022, 23:50:54) [GCC 11.2.0]
CUDA available: True
numpy_random_seed: 1934098022
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 2080 Ti
CUDA_HOME: /usr
NVCC: Cuda compilation tools, release 10.1, V10.1.24
GCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
PyTorch: 1.10.1
PyTorch compiling details: PyTorch built with:
-
GCC 7.3
-
C++ Version: 201402
-
Intel(R) oneAPI Math Kernel Library Version 2021.4-Product Build 20210904 for Intel(R) 64 architecture applications
-
Intel(R) MKL-DNN v2.2.3 (Git Hash 7336ca9f055cf1bfa13efb658fe15dc9b41f0740)
-
OpenMP 201511 (a.k.a. OpenMP 4.5)
-
LAPACK is enabled (usually provided by MKL)
-
NNPACK is enabled
-
CPU capability usage: AVX2
-
CUDA Runtime 11.3
-
NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_37,code=compute_37
-
CuDNN 8.2
-
Magma 2.5.2
-
Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.0, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.10.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,
TorchVision: 0.11.2
OpenCV: 4.6.0
MMEngine: 0.3.0
Runtime environment:
cudnn_benchmark: True
mp_cfg: {'mp_start_method': 'fork', 'opencv_num_threads': 0}
dist_cfg: {'backend': 'nccl'}
seed: None
Distributed launcher: none
Distributed training: False
GPU number: 1
11/09 19:05:35 - mmengine - INFO - Config:
default_scope = 'mmyolo'
default_hooks = dict(
timer=dict(type='IterTimerHook'),
logger=dict(type='LoggerHook', interval=50),
param_scheduler=dict(
type='YOLOv5ParamSchedulerHook',
scheduler_type='linear',
lr_factor=0.01,
max_epochs=200),
checkpoint=dict(
type='CheckpointHook', interval=5, save_best='auto', max_keep_ckpts=3),
sampler_seed=dict(type='DistSamplerSeedHook'),
visualization=dict(type='mmdet.DetVisualizationHook'))
env_cfg = dict(
cudnn_benchmark=True,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'))
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(
type='mmdet.DetLocalVisualizer',
vis_backends=[dict(type='LocalVisBackend')],
name='visualizer')
log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
log_level = 'INFO'
load_from = None
resume = False
file_client_args = dict(backend='disk')
data_root = 'data/coco/'
dataset_type = 'YOLOv5CocoDataset'
metainfo = dict(CLASSES=('COTS', ), PALETTE=[(220, 20, 60)])
num_classes = 1
img_scale = (1280, 1280)
deepen_factor = 1.0
widen_factor = 1.0
max_epochs = 200
save_epoch_intervals = 5
train_batch_size_per_gpu = 8
train_num_workers = 8
val_batch_size_per_gpu = 1
val_num_workers = 2
persistent_workers = True
batch_shapes_cfg = dict(
type='BatchShapePolicy',
batch_size=1,
img_size=1280,
size_divisor=32,
extra_pad_ratio=0.5)
anchors = [[(19, 27), (44, 40), (38, 94)], [(96, 68), (86, 152), (180, 137)],
[(140, 301), (303, 264), (238, 542)],
[(436, 615), (739, 380), (925, 792)]]
strides = [8, 16, 32, 64]
num_det_layers = 4
model = dict(
type='YOLODetector',
data_preprocessor=dict(
type='mmdet.DetDataPreprocessor',
mean=[0.0, 0.0, 0.0],
std=[255.0, 255.0, 255.0],
bgr_to_rgb=True),
backbone=dict(
type='YOLOv5CSPDarknet',
deepen_factor=1.0,
widen_factor=1.0,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True)),
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=1.0,
widen_factor=1.0,
in_channels=[256, 512, 768, 1024],
out_channels=[256, 512, 768, 1024],
num_csp_blocks=3,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True)),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
num_classes=1,
in_channels=[256, 512, 768, 1024],
widen_factor=1.0,
featmap_strides=[8, 16, 32, 64],
num_base_priors=3),
prior_generator=dict(
type='mmdet.YOLOAnchorGenerator',
base_sizes=[[(19, 27), (44, 40), (38, 94)],
[(96, 68), (86, 152), (180, 137)],
[(140, 301), (303, 264), (238, 542)],
[(436, 615), (739, 380), (925, 792)]],
strides=[8, 16, 32, 64]),
loss_cls=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=0.004687500000000001),
loss_bbox=dict(
type='IoULoss',
iou_mode='ciou',
bbox_format='xywh',
eps=1e-07,
reduction='mean',
loss_weight=0.037500000000000006,
return_iou=True),
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=3.0),
prior_match_thr=4.0,
obj_level_weights=[4.0, 1.0, 0.4]),
test_cfg=dict(
multi_label=True,
nms_pre=30000,
score_thr=0.001,
nms=dict(type='nms', iou_threshold=0.65),
max_per_img=300))
albu_train_transforms = [
dict(type='Blur', p=0.01),
dict(type='MedianBlur', p=0.01),
dict(type='ToGray', p=0.01),
dict(type='CLAHE', p=0.01)
]
pre_transform = [
dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
dict(type='LoadAnnotations', with_bbox=True)
]
train_pipeline = [
dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Mosaic',
img_scale=(1280, 1280),
pad_val=114.0,
pre_transform=[
dict(
type='LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(type='LoadAnnotations', with_bbox=True)
]),
dict(
type='YOLOv5RandomAffine',
max_rotate_degree=0.0,
max_shear_degree=0.0,
scaling_ratio_range=(0.5, 1.5),
border=(-640, -640),
border_val=(114, 114, 114)),
dict(
type='mmdet.Albu',
transforms=[
dict(type='Blur', p=0.01),
dict(type='MedianBlur', p=0.01),
dict(type='ToGray', p=0.01),
dict(type='CLAHE', p=0.01)
],
bbox_params=dict(
type='BboxParams',
format='pascal_voc',
label_fields=['gt_bboxes_labels', 'gt_ignore_flags']),
keymap=dict(img='image', gt_bboxes='bboxes')),
dict(type='YOLOv5HSVRandomAug'),
dict(type='mmdet.RandomFlip', prob=0.5),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
'flip_direction'))
]
train_dataloader = dict(
batch_size=8,
num_workers=8,
persistent_workers=True,
pin_memory=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(
type='YOLOv5CocoDataset',
data_root='data/coco/',
metainfo=dict(CLASSES=('COTS', ), PALETTE=[(220, 20, 60)]),
ann_file='mmdet_split_train.json',
data_prefix=dict(img=''),
filter_cfg=dict(filter_empty_gt=False, min_size=32),
pipeline=[
dict(
type='LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Mosaic',
img_scale=(1280, 1280),
pad_val=114.0,
pre_transform=[
dict(
type='LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(type='LoadAnnotations', with_bbox=True)
]),
dict(
type='YOLOv5RandomAffine',
max_rotate_degree=0.0,
max_shear_degree=0.0,
scaling_ratio_range=(0.5, 1.5),
border=(-640, -640),
border_val=(114, 114, 114)),
dict(
type='mmdet.Albu',
transforms=[
dict(type='Blur', p=0.01),
dict(type='MedianBlur', p=0.01),
dict(type='ToGray', p=0.01),
dict(type='CLAHE', p=0.01)
],
bbox_params=dict(
type='BboxParams',
format='pascal_voc',
label_fields=['gt_bboxes_labels', 'gt_ignore_flags']),
keymap=dict(img='image', gt_bboxes='bboxes')),
dict(type='YOLOv5HSVRandomAug'),
dict(type='mmdet.RandomFlip', prob=0.5),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'flip', 'flip_direction'))
]))
test_pipeline = [
dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
dict(type='YOLOv5KeepRatioResize', scale=(1280, 1280)),
dict(
type='LetterResize',
scale=(1280, 1280),
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, scope='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
val_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
pin_memory=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='YOLOv5CocoDataset',
data_root='data/coco/',
test_mode=True,
data_prefix=dict(img=''),
ann_file='mmdet_split_val.json',
pipeline=[
dict(
type='LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(type='YOLOv5KeepRatioResize', scale=(1280, 1280)),
dict(
type='LetterResize',
scale=(1280, 1280),
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, scope='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
],
batch_shapes_cfg=dict(
type='BatchShapePolicy',
batch_size=1,
img_size=1280,
size_divisor=32,
extra_pad_ratio=0.5)))
test_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
pin_memory=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='YOLOv5CocoDataset',
data_root='data/coco/',
test_mode=True,
data_prefix=dict(img=''),
ann_file='mmdet_split_test.json',
pipeline=[
dict(
type='LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(type='YOLOv5KeepRatioResize', scale=(1280, 1280)),
dict(
type='LetterResize',
scale=(1280, 1280),
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, scope='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
],
batch_shapes_cfg=dict(
type='BatchShapePolicy',
batch_size=1,
img_size=1280,
size_divisor=32,
extra_pad_ratio=0.5)))
param_scheduler = None
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(
type='SGD',
lr=0.01,
momentum=0.937,
weight_decay=0.0005,
nesterov=True,
batch_size_per_gpu=8),
constructor='YOLOv5OptimizerConstructor')
custom_hooks = [
dict(
type='EMAHook',
ema_type='ExpMomentumEMA',
momentum=0.0001,
update_buffers=True,
strict_load=False,
priority=49)
]
val_evaluator = dict(
type='mmdet.CocoMetric',
proposal_nums=(100, 1, 10),
ann_file='data/coco/mmdet_split_val.json',
metric='bbox')
test_evaluator = dict(
type='mmdet.CocoMetric',
proposal_nums=(100, 1, 10),
ann_file='data/coco/mmdet_split_test.json',
metric='bbox')
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=200, val_interval=5)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
launcher = 'none'
work_dir = './work_dirs/yolov5_l_cots'
Result has been saved to /mnt/ssd/code/CCIP/mmyolo/work_dirs/yolov5_l_cots/modules_statistic_results.json
Traceback (most recent call last):
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/build_functions.py", line 121, in build_from_cfg
obj = obj_cls(**args) # type: ignore
File "/mnt/ssd/code/CCIP/mmyolo/mmyolo/models/dense_heads/yolov5_head.py", line 197, in init
self.special_init()
File "/mnt/ssd/code/CCIP/mmyolo/mmyolo/models/dense_heads/yolov5_head.py", line 205, in special_init
assert len(self.obj_level_weights) == len(
AssertionError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/build_functions.py", line 121, in build_from_cfg
obj = obj_cls(**args) # type: ignore
File "/mnt/ssd/code/CCIP/mmyolo/mmyolo/models/detectors/yolo_detector.py", line 41, in init
super().init(
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmdet/models/detectors/single_stage.py", line 35, in init
self.bbox_head = MODELS.build(bbox_head)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/registry.py", line 454, in build
return self.build_func(cfg, *args, **kwargs, registry=self)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/build_functions.py", line 240, in build_model_from_cfg
return build_from_cfg(cfg, registry, default_args)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/build_functions.py", line 135, in build_from_cfg
raise type(e)(
AssertionError: class YOLOv5Head in mmyolo/models/dense_heads/yolov5_head.py:
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/aslab/code/CCIP/mmyolo/tools/train.py", line 106, in
main()
File "/home/aslab/code/CCIP/mmyolo/tools/train.py", line 95, in main
runner = Runner.from_cfg(cfg)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/runner/runner.py", line 434, in from_cfg
runner = cls(
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/runner/runner.py", line 404, in init
self.model = self.build_model(model)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/runner/runner.py", line 803, in build_model
model = MODELS.build(model)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/registry.py", line 454, in build
return self.build_func(cfg, *args, **kwargs, registry=self)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/build_functions.py", line 240, in build_model_from_cfg
return build_from_cfg(cfg, registry, default_args)
File "/home/aslab/anaconda3/envs/mmyolo/lib/python3.8/site-packages/mmengine/registry/build_functions.py", line 135, in build_from_cfg
raise type(e)(
AssertionError: class YOLODetector in mmyolo/models/detectors/yolo_detector.py: class YOLOv5Head in mmyolo/models/dense_heads/yolov5_head.py:
Process finished with exit code 1
I set $PYTHONPATH to be the root path of mmyolo. The error message is not clear to me for debugging...
Also, I would like to know how I can solve this warning from mmegine: Failed to search registry with scope "mmyolo" in the "log_processor" registry tree. As a workaround, the current "log_processor" registry in "mmengine" is used to build instance. This may cause unexpected failure when running the built modules. Please check whether "mmyolo" is a correct scope, or whether the registry is initialized. Any help would be greatly appreciated!
Best regards,
Yang
Environment
sys.platform: linux
Python: 3.8.13 (default, Oct 21 2022, 23:50:54) [GCC 11.2.0]
CUDA available: True
numpy_random_seed: 2147483648
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 2080 Ti
CUDA_HOME: /usr/local/cuda-11.2
NVCC: Cuda compilation tools, release 11.2, V11.2.152
GCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
PyTorch: 1.10.1
PyTorch compiling details: PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) oneAPI Math Kernel Library Version 2021.4-Product Build 20210904 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.2.3 (Git Hash 7336ca9f055cf1bfa13efb658fe15dc9b41f0740)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.3
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_37,code=compute_37
- CuDNN 8.2
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.0, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.10.1, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,
TorchVision: 0.11.2
OpenCV: 4.6.0
MMEngine: 0.3.0
MMCV: 2.0.0rc2
MMDetection: 3.0.0rc3
MMYOLO: 0.1.2+0b48313
Additional information
No response












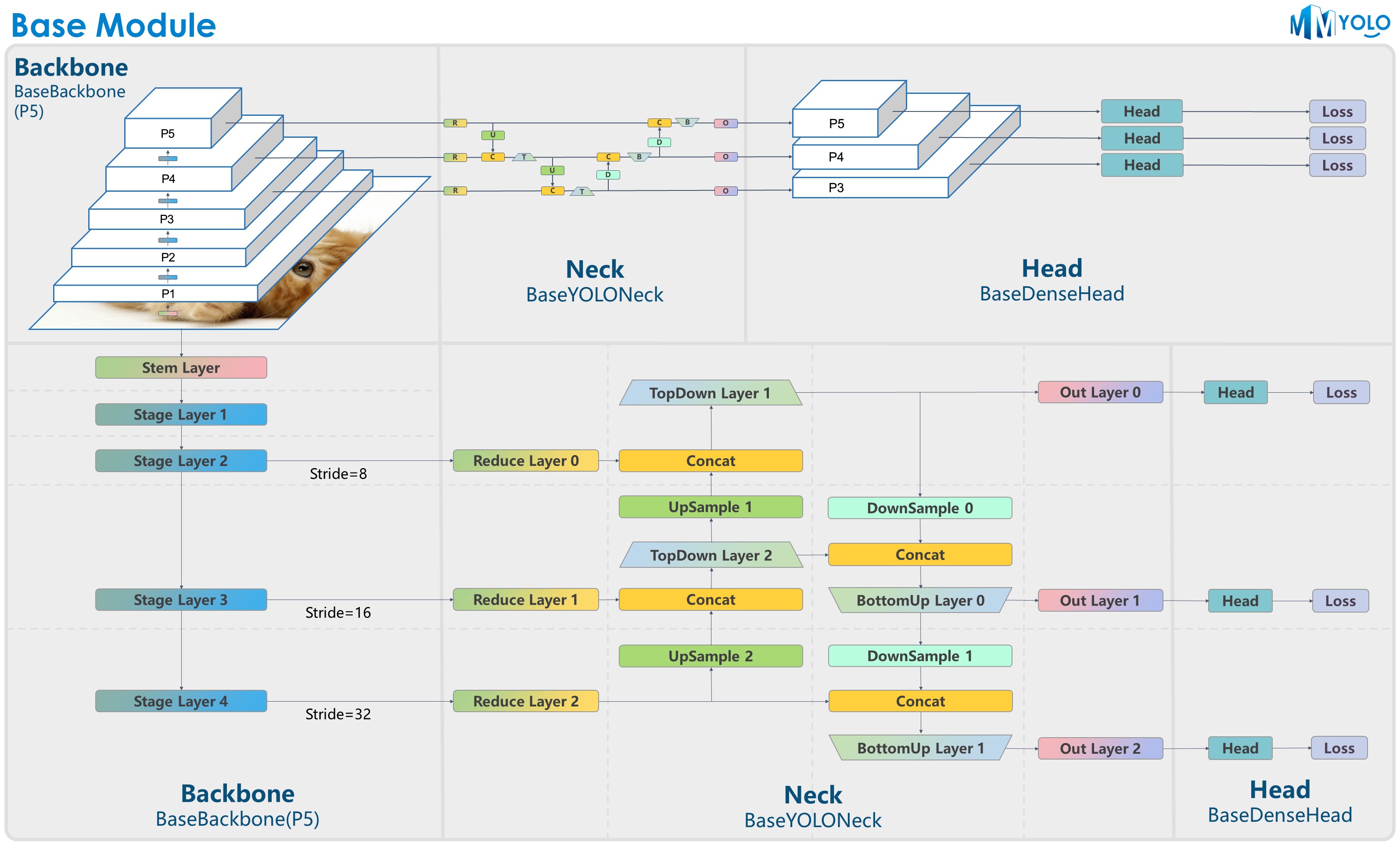 The figure above is contributed by RangeKing@GitHub, thank you very much!
The figure above is contributed by RangeKing@GitHub, thank you very much!