Comments (11)
 lukas-blecher
commented on May 9, 2024
lukas-blecher
commented on May 9, 2024
It should automatically use the GPU if available by setting the args.device to cuda here:
Line 55 in 3b930f0
I don't know about your own data set though.
from latex-ocr.
 LiuXiaoyang1111
commented on May 9, 2024
LiuXiaoyang1111
commented on May 9, 2024
Thank you!
For the train/validation/test data, i see that you only use one txt file. Now i want to train my data, what kind of txt file should I generate?Is there an order requirement for train/validation/test data in the txt file?
from latex-ocr.
lukas-blecher
commented on May 9, 2024
Yes the order is important.
You need to save all the images in a directory with increasing numbers as file name.
The txt file needs to have the same order of equations as the images are numerated, separated by a line break.
Next, you follow the instructions in the README under "Training the model" to generate a pkl file
Note there may be problems at the moment with loading the pkl file #37
from latex-ocr.
LiuXiaoyang1111
commented on May 9, 2024
Sorry to interrupt you again, although I am also a college student who is very interested in machine learning, I am a novice, so the question may be very simple.
About your data set, I have two questions:
1.The number of all your pictures is 195882, but your math.txt has 234884 lines. What is the reason for this? I guess you deleted some pictures, but kept the text content of these pictures in math.txt.
2.The name of your last picture is 0234884.png, but there is no corresponding text content in math.txt (normally line 234885 should be its text content). So the picture 0.234884.png didn't work during training?
Thanks again for your answer!
from latex-ocr.
lukas-blecher
commented on May 9, 2024
Ah yes you are right. I forgot about a small detail. The image title corresponds to the line in the txt file as you already deduced.
I was not able to render all the equations in math.txt because some will fail (my data extraction was not perfect. Some use packages that are not supported). So I rendered out as many as possible but there might still be working equations hidden in the dataset which is due to my rendering method which was not perfect.
The pairing is as follows:
0000.png - first line
0001.png - second line
and so on.
Hope this clears things up.
The data format is not very well thought out. It is better to store some uuid with the equation and name the image as the uuid. That way it is way easier to append more data.
from latex-ocr.
LiuXiaoyang1111
commented on May 9, 2024
Dear author, I'm really sorry, but I have to disturb you again:
When I am training on my own data set, I encounter the error in the following picture. The measure I took was to change the parameter in config.yaml: batchsize, but it still reported an error again. The only difference is that the size of the tensor changes.
Do you know how I should solve this problem? I did not find any help that was useful to me from the Internet. In addition, I used the jpg image format.

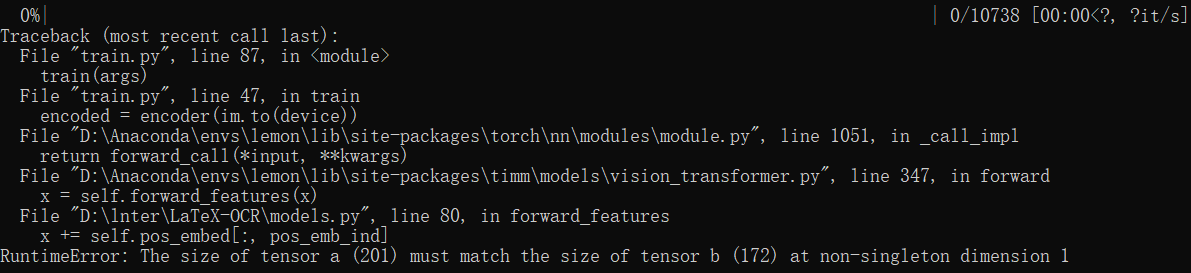
from latex-ocr.
lukas-blecher
commented on May 9, 2024
The images need to be padded as a multiple of your patch_size. If you don't want to do this you can just set pad to True in the config file.
from latex-ocr.
LiuXiaoyang1111
commented on May 9, 2024
Dear author, your project is of great significance to me and has provided me with a lot of help. Thanks again!
I changed the resolution of the picture to a multiple of patchsize as you said. Here I set patchsize=16, the resolution of the picture is 96*64, and epoch=10, but it doesn’t seem to be trained. (The result is in the first picture)
In addition, I tried to set the pad to true, but I got the same result. (The result is in the second picture)
Do you know the reason for this? I am sorry to bother you again, but any insights from you will be of great help to me.


from latex-ocr.
lukas-blecher
commented on May 9, 2024
Happy to help :)
Everything seems to be working. The loss is decreasing. But it seems like you only have two batches to train on. How many images do you have?
Also you can set pad to false again now, that you padded the images
from latex-ocr.
LiuXiaoyang1111
commented on May 9, 2024
Hello author, thank you for your help, I have successfully started training on my own data set, and the effect is good. I am currently studying how to improve the effect. I have three questions to consult with you, any of your suggestions are still very important to me.
- Where to check the score of the BLEU indicator?
- In my data, there are 24309 images in train, 4450 images in test, and 897 images in val. How much is more appropriate for batchsize and epoch? (when we set batchsize=9, epoch=50, the lowest loss Is 0.0225)
- When the --resume command is added during training, does it continue with the previous weight file or the best weight file training?
from latex-ocr.
lukas-blecher
commented on May 9, 2024
Sounds great!
- You can evaluate the model using the
eval.pyscript i.e.
python eval.py -m path/to/checkpoint.pth --config path/to/config.yaml --data path/to/test.pkl
You can also specify a temperature if you want to. Then you will see the progress bar with a running mean of the BLEU score and edit distance.
- Sounds good. More data is obviously always better. I trained on 160k images and I still want more.
- When you pass the resume flag it will look for the property
load_chkptin the config file (the one automatically generated and save in the checkpoint directory). I've opted for not saving the model based on the validation score because there is a high standard deviation with a small sample size. If you want to start form another checkpoint, simply edit the line in the config file
from latex-ocr.
Related Issues (20)
- Where is latex code stored and how do I capture it in a variable to post process it?
- Does the formula font have an effect when inserting an image?
- Screenshot doesn't work with grim on wayland HOT 1
- [bug] - Hugging Face Running Error
- AttributeError: module 'numpy' has no attribute 'float'. HOT 2
- Can similar methods be used to generate TikZ code from images?
- pdfs to latex HOT 1
- Issue with Qt6 on macOS: am I missing something?
- Error in batchsize.
- Convert model Latex-OCR to ONNX sucessfully !
- latexocr snip window opaque Ubuntu 23.10 HOT 2
- latexocr sagment error regarding qt HOT 1
- Training with limited memory HOT 1
- logging error
- Models trained on 110 million large-scale datasets
- Clarifications on loss definition
- How to get rid of the $ sign in latexocr GUI output? HOT 1
- LaTeX without style components
- Formula recognition error HOT 5
- requests.exceptions.SSLError: HTTPSConnectionPool(host='github.com', port=443): Max retries exceeded with url: /lukas-blecher/LaTeX-OCR/releases/download/v0.0.1/weights.pth (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)')))
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from latex-ocr.